Tesseract OCR: Features, Capabilities & Python Setup with Pytesseract (2026)
Table of Contents
Tesseract OCR: An Introduction
Tesseract OCR started at HP Labs in 1985, was open-sourced in 2005, and picked up by Google in 2006. Four decades later, it is still the most-used open source OCR engine in the world — and the default starting point for any developer building a document processing pipeline. That staying power means something.
This guide covers Tesseract OCR from setup to production limits. You will learn what Tesseract is, why it has stayed the open source default for decades, how to install it on Linux, macOS, and Windows, and how to use it in Python through Pytesseract. We cover Page Segmentation Modes, image preprocessing with OpenCV, multilingual document handling, and the configuration options that determine whether your OCR output is usable or garbage.
Then we test it honestly. We run Tesseract OCR in Python against three real document types: a typewritten scientific manual, Dijkstra’s handwritten notes, and a German multilingual product catalog with tables. You will see exactly where Tesseract performs reliably and where it breaks down — complex layouts, handwriting, structured tables, low-quality scans.
For the cases where Tesseract reaches its ceiling, we introduce LLMWhisperer. If your document pipeline feeds into an LLM or an AI workflow, layout fidelity in the extracted text directly affects output quality.
LLMWhisperer is built for that layer: it handles the document types Tesseract struggles with — complex tables, multi-column layouts, handwritten content, regulatory documents — and delivers layout-preserved text through a simple REST API, with both SaaS and on-premise deployment options.
Later in the post, we will also introduce LLMWhisperer API, a layout-preserving OCR-to-text extractor. LLMWhisperer handles document types of any complexity — document scans, images, PDFs with complex tables, checkboxes, and handwriting etc.
If you are extracting documents to eventually pass to an LLM to analyze and extract info, this is the simplest and most effective solution. You do not have to worry or know about the document type, format, design and layout.
Try LLMWhisperer OCR on the free demo playground. No signup required.
It was originally developed by Hewlett-Packard (HP) between 1985 and 1995 but was not actively maintained for several years until it was open-sourced in 2005.
In 2006, Google took over the project and has since significantly improved it.
Over the years, Tesseract OCR has become a highly reliable solution for text extraction from various document types and languages.
Tesseract’s main strength is its adaptability and open-source nature, allowing developers to modify and extend its capabilities to meet their specific needs.
It supports over 100 languages, including complex scripts, and can be trained to recognize new fonts and languages.
Since Google’s involvement, Tesseract OCR has seen improvements in recognition accuracy, making it suitable for a wide range of document processing tasks.
Key Features of Tesseract OCR
Multilingual Support: Tesseract OCR supports over 100 languages out of the box and can be trained to recognize additional languages or custom fonts.
Configurable Page Segmentation Modes: Tesseract offers several page segmentation modes (PSMs) that let users control how text is segmented for recognition, making it versatile for handling complex layouts.
Custom Training: Tesseract allows users to train the OCR engine on custom datasets, enabling higher accuracy for specialized document types, custom fonts, or languages not natively supported.
Structured Output: Tesseract OCR can output text along with formatting information, making it easier to work with tables, forms, or other structured documents.
Tesseract OCR Python library (via Pytesseract): With the help of the Python wrapper Pytesseract, Tesseract can be easily integrated into Python projects, allowing developers to automate OCR tasks with just a few lines of code.
Key Use Cases for Tesseract OCR in Document Processing
Document Digitization: Converting printed or scanned documents into searchable, editable text, making them easier to store, retrieve, and process.
Invoice and Receipt Processing: Automating the extraction of key details from receipts, invoices, and financial documents.
Multilingual Text Extraction: Extracting text from documents written in multiple languages or from multilingual archives.
Accessibility Enhancement: Converting printed documents into digital formats that can be read by screen readers or other assistive technologies.
Data Extraction from Forms and Tables: Processing documents that contain structured data such as forms, tables, or catalogs, with potential for post-processing to improve accuracy.
Tesseract OCR Installation
Step-by-Step Instructions for Installing Tesseract OCR
Tesseract OCR can be installed on various operating systems.
Below are instructions for installing it on Windows, macOS, and Linux.
Windows Installation:
Download the Tesseract installer for Windows from GitHub or a precompiled binary.
Run the installer and follow the on-screen instructions.
Add Tesseract to the system path:
Open “System Properties” → “Environment Variables” → “Path.”
Add the directory where Tesseract is installed (usually C:\Program Files\Tesseract-OCR).
Verify the installation by opening the command prompt and running: tesseract --version
MacOS Installation:
Open the terminal.
Install Tesseract using Homebrew: brew install tesseract
If you don’t have Homebrew installed, you can run the following command to install it:
Once Tesseract is installed, you can set up Pytesseract, a Python OCR wrapper that allows seamless interaction with Tesseract in Python projects. Install Pytesseract: In the terminal or command prompt, install Pytesseract using pip:
pip install pytesseract
Install the Python Imaging Library (PIL or Pillow): Pytesseract works with images, so you need to install the Pillow library, which provides support for opening, manipulating, and saving images:
pip install Pillow
Set Up Pytesseract in Python: Once installed, you can easily use Pytesseract in your Python code. See this simple example:
from PIL import Image
import pytesseract
# Open an image file
img = Image.open('example_image.png')
# Use Pytesseract to convert the image to text
text = pytesseract.image_to_string(img)
# Print the extracted text
print(text)
Exploring Tesseract’s Key Features
Text Extraction from a Typewritten Scanned Document
Tesseract OCR is particularly good at handling typewritten and printed documents.
Its recognition algorithm is excellent at extracting clear, readable text from high-quality scans or digital images of typewritten material.
This makes Tesseract a popular choice for digitizing books, documents, contracts, and other text-heavy resources.
To show Tesseract’s text extraction capabilities, we’ll use a simple scanned document that contains clear, typewritten text:
Tesseract processes the document by analysing the shapes of the characters and converting them into digital text.
The general process involves:
Loading the scanned document or image file.
Using Pytesseract to extract the text from the image.
Displaying the extracted text and reviewing the output for accuracy.
Since Tesseract OCR cannot directly read a PDF file, you will need to install an additional library:
pip install pdf2image
Here’s a Python code example using Pytesseract OCR to extract text from a typewritten scanned document:
import pytesseract
from pdf2image import convert_from_path
# Convert PDF pages to images
pdf_path = 'Dirac-language-manual-for-tesseract-feature-analysis.pdf'
pages = convert_from_path(pdf_path, 300) # 300 is the resolution (dpi)
# Extract text from each page
extracted_text = ""
for page_number, page_image in enumerate(pages, start=1):
# Perform OCR on the page image
text = pytesseract.image_to_string(page_image)
extracted_text += f"--- Page {page_number} ---\\n"
extracted_text += text + "\\n"
# Print or process the extracted text
print(extracted_text)
The convert_from_path(pdf_path, dpi) function from the pdf2image library converts each page of the PDF into an image. The DPI (dots per inch) is set to 300 for better OCR accuracy, but you can adjust it based on your needs.
Once each page is converted into an image, the pytesseract.image_to_string(page_image) function extracts the text from the image.
The text extracted from each page is stored in the extracted_text variable and labelled by page:
--- Page 1 ---
Vallee pare 3
1. THE DERAC LANGUAGE FAHILY.
Activities and levels of users
The language used tn the current interactive experiments, DERACH1,
is the first prototype in the family of information-ariented lansuaces
we have designed. The objective of this project is to facilitate
flexihle interaction with larce files of scientific data. The languare is
of the non-procedural type and denands no previous computer experience
on the part of the user. {[t allows creation, undatinr, bookkeeping and
validating operations as well as the querying of data filas;
these activities take place in conversational mode axclusively. Ta the
more sopbisticated user, the DIRAC languages offer a simple interface with
the Stanford text editor (WYLBUR) and to the systems propramner, they
Make available a straightforward interface with FORTRAN that dons not
require intermediate storage of the extracted information outside of
the direct-access memory, (2)
The name BDIRAC (NIRect ACcess) is intended to renind tre user of
this fact. It also summarizes the five data types handled ty the
language, respectively: Date, Interer, Real, Alphanumeric, Code,
Four operation modes
The user of DIRAC can apply to any file (that Fe Is authorized to access
any command within one of the four sets grouped under the modes:
CREATE, UPDATE, STATUS and QUERY. The first of these nodes is a
privileged one, but this privilere can be extended to any user by the
data-base administrator at the time of file creation: it consists in
the definition of a file or a series of inter-related files, accordinr
GC a terminology to be defined helow, in both nomenclature and
ERIC
Fait Text Proved by ERIC
Improving Tesseract’s OCR Accuracy Through Pre-processing
To improve the accuracy of Tesseract OCR, particularly when dealing with challenging images such as low-quality scans, skewed text, or noisy images, you can apply several pre-processing techniques before using Tesseract to extract text.
Common pre-processing steps include converting the image to grayscale, binarization (thresholding), deskewing, and noise reduction.
Let’s implement these steps using Python, with the help of libraries such as OpenCV and Pillow for image pre-processing:
Grayscale Conversion: Converting an image to grayscale simplifies it, making the text stand out more clearly from the background. This is especially useful for images with varying colours or patterns.
Binarization (Thresholding): Binarization converts the grayscale image into a black-and-white format, which further improves text recognition by removing any unnecessary color noise.
Noise Reduction: Noise reduction helps to eliminate small imperfections or unwanted artifacts in the image, improving the quality of the text extraction.
Deskewing: If the text is slightly tilted, Tesseract might struggle to recognize it correctly. Deskewing realigns the text, making it horizontal and easier to read.
Make sure you have installed OpenCV before running the next example:
pip install opencv-python
Below is the code that incorporates these pre-processing techniques to improve the accuracy of text extraction using Tesseract:
import cv2
import numpy as np
import pytesseract
from PIL import Image
from pdf2image import convert_from_path
# Function to preprocess the image for better OCR results
def preprocess_image(image):
# Read the image using OpenCV
img = cv2.imread(image)
# Convert the image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Apply Gaussian Blur to reduce noise
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# Apply adaptive thresholding to binarize the image
binary_img = cv2.adaptiveThreshold(blurred, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
# Deskew the image by calculating the rotation angle and rotating it back
coords = np.column_stack(np.where(binary_img > 0))
angle = cv2.minAreaRect(coords)[-1]
if angle < -45:
angle = -(90 + angle)
else:
angle = -angle
(h, w) = binary_img.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
deskewed_img = cv2.warpAffine(binary_img, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
# Save the preprocessed image for inspection
cv2.imwrite('preprocessed_image.png', deskewed_img)
return deskewed_img
# Convert PDF pages to images
pdf_path = 'Dirac-language-manual-for-tesseract-feature-analysis.pdf'
pages = convert_from_path(pdf_path, 300) # 300 is the resolution (dpi)
# Extract text from each page
extracted_text = ""
for page_number, page_image in enumerate(pages, start=1):
# Save the page image to disk
page_image.save(f'page_{page_number}.png', 'PNG')
# Preprocess the image
processed_image = preprocess_image(f'page_{page_number}.png')
# Convert the processed image back to PIL format for Tesseract
pil_img = Image.fromarray(processed_image)
# Perform OCR on the page image
text = pytesseract.image_to_string(pil_img)
extracted_text += f"--- Page {page_number} ---\\n"
extracted_text += text + "\\n"
# Print or process the extracted text
print(extracted_text)
The preprocess_image function is designed to enhance the quality of the images before they are passed to Tesseract for text extraction:
Reading the Image: The image is read using OpenCV.
Grayscale Conversion: The image is converted to grayscale to simplify it and make the text stand out more clearly.
Gaussian Blur: A Gaussian blur is applied to reduce noise and smooth the image, which helps in improving text recognition.
Adaptive Thresholding: Adaptive thresholding is used to convert the grayscale image to a binary image, further enhancing the contrast between the text and the background.
Deskewing: The image is deskewed by calculating the rotation angle of the text and rotating the image back to horizontal. This step is crucial for aligning the text properly and improving OCR accuracy.
Saving the Pre-processed Image: The pre-processed image is saved to disk for inspection.
The resulting improved output:
--- Page 1 ---
Vallee pare 3
1. THE DERAC LANGUAGE FAMILY.
Activities and levels of users
The language used tn' the current interactive experiments, DERAC=1,
is the first prototype in the family of information-oriented languaces
we have designed, The objective of this project is to facilitate
_
yn
flexible interaction with large files of scientific data, The languare
of the non-procedural type and denands no previous computer experionce
on the part of the user. {t allows creation, updating, bookkeeping and
validating operations as well as the querying, of data files;
these activities take place in conversational mode axclusively. To tha
more sophisticated user, the DIRAC languages offer a simpin interface with
the Stanford text editor (WYLBUR) and to the systems programmer, they
Make available a straightforward interface with FORTRAN that dons not
require intermediate storage of the extracted information outside of
the direct-access memory. (2)
The name DIRAC (DIRect ACcess) is tntended to remind tke user of
this fact. I!t also summarizes the five data types handled ky the
language, respectively: Date, Interer, Real, Alphanumeric, Code.
Four operation modes
The user of DIRAC can apply to any file (that Fe fs authorized to access
any command withtn one of the four sets grouped under the modes:
CREATE, UPDATE, STATUS and QUERY. The first of these modes is a '
privileged one, but this privilege can be extended to any user by the
By applying these pre-processing techniques, you will notice a significant improvement in Tesseract’s ability to accurately recognize and extract text, even from images that are less than ideal (e.g., noisy, low-quality, or slightly skewed).
Evaluating Tesseract OCR Handwriting Accuracy
Tesseract OCR is very effective for printed and typewritten text, but it faces significant challenges when it comes to recognizing handwritten text.
Unlike printed text, handwriting varies greatly in style, size, and consistency, which makes accurate recognition difficult for standard OCR engines like Tesseract.
Tesseract’s underlying models are primarily trained on printed fonts, so its performance with handwritten text is often less reliable and more prone to errors.
Despite these limitations, Tesseract can still be used for handwriting ocr, especially when the handwriting is clear, consistent, and similar to typewritten text.
However, the accuracy will typically be lower than that for printed text, and additional steps may be needed to enhance the results.
Testing Tesseract with a Handwritten Document
To evaluate Tesseract’s ability to parse handwritten text, we can test it with a scanned image of a handwritten document:
The process is similar to extracting text from printed documents, but the results are often more variable.
Here’s an example to extract text from a handwritten document:
import cv2
import numpy as np
import pytesseract
from PIL import Image
from pdf2image import convert_from_path
# Function to preprocess the image for better OCR results
def preprocess_image(image):
# Read the image using OpenCV
img = cv2.imread(image)
# Convert the image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Apply Gaussian Blur to reduce noise
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# Apply adaptive thresholding to binarize the image
binary_img = cv2.adaptiveThreshold(blurred, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
# Deskew the image by calculating the rotation angle and rotating it back
coords = np.column_stack(np.where(binary_img > 0))
angle = cv2.minAreaRect(coords)[-1]
if angle < -45:
angle = -(90 + angle)
else:
angle = -angle
(h, w) = binary_img.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
deskewed_img = cv2.warpAffine(binary_img, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
# Save the preprocessed image for inspection
cv2.imwrite('preprocessed_image.png', deskewed_img)
return deskewed_img
# Convert PDF pages to images
pdf_path = 'Edsger-Dijkstra-Notes-handwriting.pdf'
pages = convert_from_path(pdf_path, 500) # 500 is the resolution (dpi)
# Extract text from each page
extracted_text = ""
for page_number, page_image in enumerate(pages, start=1):
# Save the page image to disk
page_image.save(f'page_{page_number}.png', 'PNG')
# Preprocess the image
processed_image = preprocess_image(f'page_{page_number}.png')
# Convert the processed image back to PIL format for Tesseract
pil_img = Image.fromarray(processed_image)
# Perform OCR on the page image
text = pytesseract.image_to_string(pil_img)
extracted_text += f"--- Page {page_number} ---\\n"
extracted_text += text + "\\n"
# Print or process the extracted text
print(extracted_text)
As you can see, here we are using the image improvements from the previous section.
Here is the resulting output:
--- Page 1 ---
tlhe erpuaA rd Ge
Net FT
For eclucational purposes Le analy se the
opening pages of an Il-page arkicle that
appeared in The American Mathemahical
Monthl,, Volume 102 Number 2/ February 1995.
We have added line numbers in the right
Margin.
line Gi Since in this arti cle, SQuares don't get
alter nating colours, it could be argued thet
the term "ehessboard is misplaced.
line 4. The introduction of the name "B"
seems Unnecessary: it is usec --in the
combination "the board B" ~ Wn the tex}
fr 'tigure 1 and in line 7; in both cases
just "the board would have done (ine.
In line 77 occurs the las} use of 3B )
mz. in "Xe B', which is dubious since
B WAS CG board ane not on ser. im line
77, T weuld have preferred " Given a set X
of cells -_
line 7/8: The first Move ,
like anu other, does not deserve oa separate
discription The term "step" is redundant.
being O move
line a: Why not "oO Move consists of "9
line 10/11. At Vhis slage the italics are
wmiravolina a ea ro Wes oe Leo wn om ee? Ila (7
--- Page 2 ---
and cells Ci+t, j and Ce, jr) are empty .
line iO. "lwice the term "pesitions" for
whet everywhere else §s called "cells".
board has 4 oa pebbles on it." 7
line 12/14 : In the One sentence, k counts
moves , in the other k counts pebbles,
Since the pro se does not indicate the
| Scope of dummies, this double use of
the same kis ao litte bil untorgivalle.
line 14: "ancl we set We: Uh ROK) " de
remark
o the use of the verb "to set " when defining
Che set!) "Rk can be considered unlErtunake
o since Ris nok used on the next two
pages, the name seems to be introduced
+00 carly
o the introduction of? the name "RK seems
AO NESE SS AY 5 iv the rest of? the Po per al
saw it used once in Tang C eR", where
Hoy reachable configuration " would have
dure. CNote. In the context in question
-P [16 ~ the reachable com text Can remarn
ANTIOAYYVLOUS: the quoted MmCIUrren ce uF
C is) the ony occurrence of the idenki-~
Fier Cin that cantexk. My conclusisn is
dan nb dhe meacheahie awe (en ae | ecwTM Ln a
While Tesseract can be used to recognize handwritten text, the results are often inconsistent and require careful handling.
Tesseract handwriting recognition limitations:
Variability in Handwriting Styles: Handwriting differs greatly from person to person, with variations in letter shapes, spacing, and size. This makes it difficult for Tesseract to reliably recognize all characters.
Connected or Cursive Writing: When letters are connected, as in cursive handwriting, Tesseract may struggle to distinguish individual characters, leading to incorrect or garbled text output.
Noise and Irregularities: Handwritten documents often have additional noise, such as smudges, variable ink thickness, or uneven paper, which can confuse the OCR process.
Lack of Handwriting-Specific Training Data: Tesseract is primarily trained on printed text, so it lacks the extensive training data required to accurately parse the wide range of handwritten styles.
Multilingual Text Recognition and Structured Data Parsing with Tesseract OCR
One of Tesseract’s standout features is its robust support for over 100 languages, making it an excellent choice for applications that require multilingual OCR.
Whether dealing with documents that contain multiple languages or those in non-Latin scripts, Tesseract can recognize and extract text across various languages with relative ease.
This capability is particularly valuable for international applications, such as translating documents, processing multilingual legal texts, or digitizing global archives.
Adding German language
To add the German language (deu) to Tesseract, you need to download and install the appropriate language data file.
Here’s how you can do it:
Step 1: Download the German Language Data
Tesseract uses language data files to recognize text in different languages.
These files typically have a .traineddata extension and are stored in the tessdata directory.
Visit the Official Tesseract GitHub Repository for Language Data Files:
After downloading the deu.traineddata file, you need to place it in the appropriate tessdata directory that Tesseract uses.
Locate the Tesseract Installation Directory:
On Windows: The default installation directory might be C:\Program Files\Tesseract-OCR\tessdata.
On macOS or Linux: If you installed Tesseract using a package manager like Homebrew or APT, the directory might be /usr/local/share/tessdata/ or /usr/share/tesseract-ocr/5.4/tessdata/.
Copy the deu.traineddata file:
Copy the downloaded deu.traineddata file into the tessdata directory you located in the previous step.
Recognizing German Text in a Multilingual Document
To utilize Tesseract’s multilingual OCR capabilities, you can specify the languages you want to recognize by using the lang parameter in Pytesseract.
For example, if you are processing a document that contains both German text, you can configure Tesseract to recognize it:
Here’s how you can set up Tesseract OCR to recognize German text:
import cv2
import numpy as np
import pytesseract
from PIL import Image
from pdf2image import convert_from_path
# Convert PDF pages to images
pdf_path = 'catalog-german-multilingual.pdf'
pages = convert_from_path(pdf_path, 300) # 300 is the resolution (dpi)
# Extract text from each page
extracted_text = ""
for page_number, page_image in enumerate(pages, start=1):
# Perform OCR on the page image
text = pytesseract.image_to_string(page_image , lang='deu')
extracted_text += f"--- Page {page_number} ---\\n"
extracted_text += text + "\\n"
# Print or process the extracted text
print(extracted_text)
This is the extracted text:
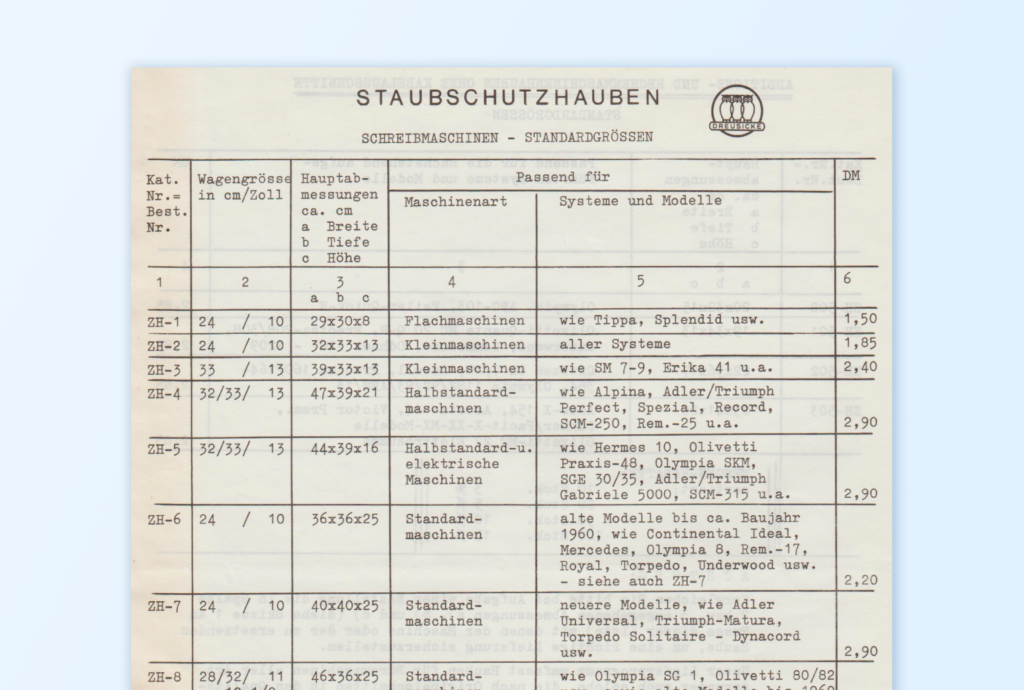
--- Page 1 ---
STAUBSCHUTZHAUBEN
SCHREIBMASCHINEN - STANDARDGRÖSSEN
Kat. |Wagengrössd Hauptab- Passend für DM
Nr.= |in cm/Zoll | messungen Maschinenart Systeme und Modelle
Best. ca. cm
Nr. a Breite
b Tiefe
c Höhe
-- UE E S
2
ZH-1 | 24 A 2053058 Flachmaschinen wie Tippa, Splendid usw. F7 50
" zH825|21 /2°010]- 30x33x4% aller Systeme 1,85
ZH-3 |[33 /4313d3r39x33=13 wie SM 7-9, Erika 41 u.a. 240
3
ä 66
3
ZH-4 |32/33/ 13 | 47x39x21 | Halbstandard- wie Alpina, Adler/Triumph
maschinen Perfect, Spezial, Record,
ZB-5=-50/33/--93-|---44x=39x= 16
wie Hermes 10, Olivetti
Praxis-48, O0Olympia SKM,
SGE 30/35, Adler/Triumph
H6 21 -- 101 26x36725
24 Y O 40x40x25
uSW. 2,90
ZH-8 |28/32/ -11 | 46x36x25 | Standard- wie Olympia SG 1, Olivetti 80/82
T maschinen usw. sowie alte Modelle bis 1960
teils bis 45 cm Wagengrösse 2,65
ZH-9 |28/30/. 12 | 47x40x25 | Standard- Modelle wie ZH-6 3,50
maschinen
Gabriele 5000, SCM-515 u.a.
ZH-10| 33 52425
290
Halbstandard-u,.
elektrische
Maschinen
2,90
Standard-
maschinen
alte Modelle bis ca. Baujahr
1960, wie Continental Ideal,
Mercedes, 0lympia 8, Rem.-17,
Royal, Torpedo, Underwood usw.
- siehe auch ZH-7
220
Standard-
maschinen
neuere Modelle, wie Adler
Universal, Triumph-Matura,
Torpedo Solitaire - Dynacord
neuere Modelle wie Adler/Triumph
nın & S, 11-151, Matura -
Universal 30-500, IBM: Executive
E OLEr : " Draspron,
Linea-88, Tekne & Editor,
0lympia: SG 1-3, SGE 40-51,
Rem.-713, SCM-410 u.a.
Modelle wie ZH-8. -Passt auch
für alte Modelle mit 45 cm
Wagen
Modelle wie ZH-6, ZH-8,
u.a.
Standard-u.
elektrische
Maschinen
-passt _zum Teil auch für
35 _& 38 _cm _ Wagen der
angegebenen _ Modelle
ZH-11 35/38/ 15 52x36x25
ZH-12|45/46/ 18 | 60x36x25
elektrische
Maschinen
ZH-13 60/62 76x36x25 Standard-u. Modelle wie ZH-6, ZH-8, ZH-10
elektrische u.8a.
Maschinen ; 4,70
3,30
Standard-u.
elektrische
Maschinen
2,90
Standard-u.
--- Page 2 ---
ADDITIONS- UND RECHENMASCHINENHAUBEN OHNE KABELAUSSCHNITTE
W
STANDARDGRÖSSEN
Kat.Nr.= Haupt- Passend für die nachstehend aufge- DM
Best.Nr. abmessungen führten Systeme und Modelle
cE,: OE
a Breite
b Tiefe
6 Höhe
1 2 3 4
&- D: 6
ZH-500 20x32x15 0lympia, ABC-103, Feiler-Quick-E 285
ZH-501 19234213 Olivetti-Quanta MC 20 Q-R, Precisa-208/308,
Underwood, Commodore, Odhner 1207 - 1209 2785
ZH-502 22x36x17 Citizen CA 7/10, Adwell, Precisa 160/164-
364, Olympia 1182/92/93/4AE8/13 2,85
ZH-503 23x41x20 Addo-X 154, Ascota-114, Victor Prem.,
Odhner/Facit-X-XX-MX-Modelle
Olivetti-MC 22 Elettrosumma
MENGEN-RABATTE:
sortiert: 10 _SteXK. 3 %
20 Stek. 5 %
50 Stek. 10 %
100 Stck. 15 %
KC-HrI-U - G:
Vergleichen Sie bitte bei Aufgabe einer Bestellung die in Spalte
2 bzw. 3 angegebenen Abmessungen a), b) und c) (siehe Skizze 1 am
Fusse dieser Liste) mit denen der Maschine oder der zu ersetzenden
Haube, um eine richtige Lieferung sicherzustellen.
Unser Lieferprogramm umfasst Hauben für Büromaschinen aller Art,
darunter auch solche, die nach Originalschnitten in den Qualitä-
ten und Farben der Fabriken mit deren Firmenzeichen- oder Namen-
Aufdruck angefertigt werden.
Für Staubhauben, die nicht in dieser Liste aufgeführt sind benö-
tigen wir folgende Angaben: System und Modell der Maschine, sowie
Wagengrösse und die gewünschte Farbe.
Zur Anfertigung von Staubhauben in Spezialgrössen erbitten wir die
Einsendung einer Skizze mit Maßangaben entsprechend Zeichnung
1,o0der 2.
S Skizze 1 x Skizze 2
d v
WILHELM DREUSICKE & CO. KG. - 1 BERLIN 42 - ROHDESTRASSE 17
SEB
Some aspects to take into consideration with multi-language:
Strengths: Tesseract is generally accurate in recognizing multiple languages within a single document, especially when the text is clearly printed and the languages use distinct scripts.
Challenges: However, accuracy may decrease if the languages use similar alphabets (e.g., English and German), especially with words that have similar spelling but different meanings. Additionally, mixed content, such as Latin characters interspersed with non-Latin scripts, may require careful preprocessing to ensure accurate recognition.
Table and Structured Data Parsing
While Tesseract OCR excels at extracting text from plain documents, it faces challenges when dealing with structured data, such as tables, forms, or documents with complex layouts.
By default, Tesseract treats the document as unstructured text, which can result in the loss of important structural information like column boundaries, row alignment, or table headers.
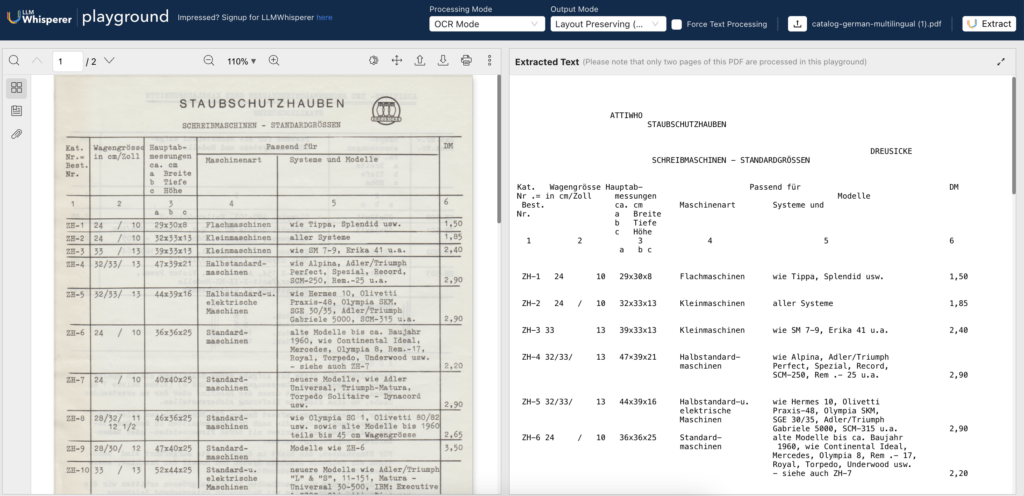
To evaluate Tesseract’s ability to handle structured data, let’s consider a table from a German catalog (the same file as in the previous example).
Configuring Tesseract OCR for Table Extraction
Tesseract has several page segmentation modes (PSMs) that influence how it processes the document.
For tables, certain modes may work better than others.
You can experiment with these modes to see which one works best for your specific document.
PSM 6: Assume a single uniform block of text.
PSM 11: Sparse text with a table-like structure.
PSM 12: Sparse text, in a columnar format.
PSM 3: Fully automatic page segmentation, but no OSD (orientation and script detection).
By trying out these different modes, you can find the one that best suits your document and helps Tesseract accurately recognize and extract the table data.
We will use PSM 3 to extract the table and observe how well it retains the structure:
import cv2
import numpy as np
import pytesseract
from PIL import Image
from pdf2image import convert_from_path
# Convert PDF pages to images
pdf_path = 'catalog-german-multilingual.pdf'
pages = convert_from_path(pdf_path, 300) # 300 is the resolution (dpi)
# Extract text from each page
extracted_text = ""
for page_number, page_image in enumerate(pages, start=1):
# Perform OCR on the page image
text = pytesseract.image_to_string(page_image, lang='deu', config='--psm 3')
extracted_text += f"--- Page {page_number} ---\\n"
extracted_text += text + "\\n"
# Print or process the extracted text
print(extracted_text)
This is the output:
--- Page 1 ---
STAUBSCHUTZHAUBEN
SCHREIBMASCHINEN - STANDARDGRÖSSEN
Kat. |Wagengrössd Hauptab- Passend für DM
Nr.= |in cm/Zoll | messungen Maschinenart Systeme und Modelle
Best. ca. cm
Nr. a Breite
b Tiefe
c Höhe
-- UE E S
2
ZH-1 | 24 A 2053058 Flachmaschinen wie Tippa, Splendid usw. F7 50
" zH825|21 /2°010]- 30x33x4% aller Systeme 1,85
ZH-3 |[33 /4313d3r39x33=13 wie SM 7-9, Erika 41 u.a. 240
3
ä 66
3
ZH-4 |32/33/ 13 | 47x39x21 | Halbstandard- wie Alpina, Adler/Triumph
maschinen Perfect, Spezial, Record,
ZB-5=-50/33/--93-|---44x=39x= 16
wie Hermes 10, Olivetti
Praxis-48, O0Olympia SKM,
SGE 30/35, Adler/Triumph
H6 21 -- 101 26x36725
24 Y O 40x40x25
uSW. 2,90
ZH-8 |28/32/ -11 | 46x36x25 | Standard- wie Olympia SG 1, Olivetti 80/82
T maschinen usw. sowie alte Modelle bis 1960
teils bis 45 cm Wagengrösse 2,65
ZH-9 |28/30/. 12 | 47x40x25 | Standard- Modelle wie ZH-6 3,50
maschinen
Gabriele 5000, SCM-515 u.a.
ZH-10| 33 52425
290
Halbstandard-u,.
elektrische
Maschinen
2,90
Standard-
maschinen
alte Modelle bis ca. Baujahr
1960, wie Continental Ideal,
Mercedes, 0lympia 8, Rem.-17,
Royal, Torpedo, Underwood usw.
- siehe auch ZH-7
220
Standard-
maschinen
neuere Modelle, wie Adler
Universal, Triumph-Matura,
Torpedo Solitaire - Dynacord
neuere Modelle wie Adler/Triumph
nın & S, 11-151, Matura -
Universal 30-500, IBM: Executive
E OLEr : " Draspron,
Linea-88, Tekne & Editor,
0lympia: SG 1-3, SGE 40-51,
Rem.-713, SCM-410 u.a.
Modelle wie ZH-8. -Passt auch
für alte Modelle mit 45 cm
Wagen
Modelle wie ZH-6, ZH-8,
u.a.
Standard-u.
elektrische
Maschinen
-passt _zum Teil auch für
35 _& 38 _cm _ Wagen der
angegebenen _ Modelle
ZH-11 35/38/ 15 52x36x25
ZH-12|45/46/ 18 | 60x36x25
elektrische
Maschinen
ZH-13 60/62 76x36x25 Standard-u. Modelle wie ZH-6, ZH-8, ZH-10
elektrische u.8a.
Maschinen ; 4,70
3,30
Standard-u.
elektrische
Maschinen
2,90
Standard-u.
--- Page 2 ---
ADDITIONS- UND RECHENMASCHINENHAUBEN OHNE KABELAUSSCHNITTE
W
STANDARDGRÖSSEN
Kat.Nr.= Haupt- Passend für die nachstehend aufge- DM
Best.Nr. abmessungen führten Systeme und Modelle
cE,: OE
a Breite
b Tiefe
6 Höhe
1 2 3 4
&- D: 6
ZH-500 20x32x15 0lympia, ABC-103, Feiler-Quick-E 285
ZH-501 19234213 Olivetti-Quanta MC 20 Q-R, Precisa-208/308,
Underwood, Commodore, Odhner 1207 - 1209 2785
ZH-502 22x36x17 Citizen CA 7/10, Adwell, Precisa 160/164-
364, Olympia 1182/92/93/4AE8/13 2,85
ZH-503 23x41x20 Addo-X 154, Ascota-114, Victor Prem.,
Odhner/Facit-X-XX-MX-Modelle
Olivetti-MC 22 Elettrosumma
MENGEN-RABATTE:
sortiert: 10 _SteXK. 3 %
20 Stek. 5 %
50 Stek. 10 %
100 Stck. 15 %
KC-HrI-U - G:
Vergleichen Sie bitte bei Aufgabe einer Bestellung die in Spalte
2 bzw. 3 angegebenen Abmessungen a), b) und c) (siehe Skizze 1 am
Fusse dieser Liste) mit denen der Maschine oder der zu ersetzenden
Haube, um eine richtige Lieferung sicherzustellen.
Unser Lieferprogramm umfasst Hauben für Büromaschinen aller Art,
darunter auch solche, die nach Originalschnitten in den Qualitä-
ten und Farben der Fabriken mit deren Firmenzeichen- oder Namen-
Aufdruck angefertigt werden.
Für Staubhauben, die nicht in dieser Liste aufgeführt sind benö-
tigen wir folgende Angaben: System und Modell der Maschine, sowie
Wagengrösse und die gewünschte Farbe.
Zur Anfertigung von Staubhauben in Spezialgrössen erbitten wir die
Einsendung einer Skizze mit Maßangaben entsprechend Zeichnung
1,o0der 2.
S Skizze 1 x Skizze 2
d v
WILHELM DREUSICKE & CO. KG. - 1 BERLIN 42 - ROHDESTRASSE 17
SEB,
Some aspects to take into consideration with table extraction:
Loss of Structure: The primary challenge with Tesseract’s handling of tables is the potential loss of structure. The text might be extracted correctly, but the alignment and organization (e.g., columns, rows) are often lost, making it difficult to use the data directly in its intended format.
Overlapping Text: In cases where the table lines are too close to the text or the image quality is low, Tesseract might misinterpret the boundaries, leading to text overlapping or incorrect alignment.
Tesseract OCR for Simple Text. LLMWhisperer for Complex Documents.
Tesseract works well on clean, printed, single-column documents. But when you throw it complex tables, multi-column layouts, or batch processing at scale, accuracy drops and preprocessing time explodes.
LLMWhisperer is built for that gap. It preserves table structure, parses nested layouts without custom rules, and processes documents in parallel — so you get structured output at speed, not just raw text.
Try LLMWhisperer Invoice OCR for free on the Playground. No signup required.
Evaluating Tesseract OCR: Strengths and Weaknesses
Strengths
Open Source and Free: Tesseract is completely open-source, so it is freely available for both personal and commercial use. This makes it an attractive option for developers and organizations looking for a cost-effective OCR solution.
Multilingual Support: Tesseract supports over 100 languages out of the box, making it a versatile tool for global applications. It also allows for easy addition of custom language training, making it adaptable to specific needs.
High Accuracy for Printed Text: Tesseract performs exceptionally well with clean, high-quality scans of printed and typewritten text. Its recognition accuracy for these types of documents is very high, making it a reliable choice for digitizing standard documents.
Customizable and Extensible: As an open-source tool, Tesseract can be customized and extended to fit specific use cases. Users can train Tesseract on custom datasets, adjust OCR settings, or integrate it with other tools and frameworks to enhance its functionality.
Wide Platform Support: Tesseract is cross-platform, running on Windows, macOS, and Linux. Additionally, it has strong integration with Python through the Pytesseract library, making it accessible for a wide range of development environments.
Structured Data Output: Tesseract can output not just plain text but also more structured formats like hOCR, which includes information about text formatting, making it easier to retain the layout of the original document.
Weaknesses
Limited Handwriting Recognition: Tesseract struggles with handwritten text due to its primary training on printed fonts. The recognition of handwriting is often inaccurate, especially when dealing with cursive or highly stylized writing.
Challenges with Complex Layouts: Documents with complex layouts, such as forms, tables, or multi-column text, can pose difficulties for Tesseract. The OCR engine might misinterpret the structure of the document, leading to incorrect text extraction.
Quality Dependence: Tesseract’s performance is highly dependent on the quality of the input image. Low-resolution scans, skewed text, or images with significant noise can result in poor OCR accuracy. Pre-processing steps are often required to enhance the image before processing.
Steep Learning Curve for Customization: Although Tesseract is highly customizable, configuring it for specific needs (like custom training for new languages or fonts) can be complex and requires a deep understanding of the tool. This can be a barrier for users who need to quickly deploy OCR solutions.
Basic Out-of-the-Box Capabilities: While Tesseract is capable, its default configuration might not meet the needs of more advanced use cases without significant customization. For example, it lacks built-in support for recognizing structured data like tables or forms without additional tools or preprocessing.
Use-Cases for Tesseract OCR
Document Digitization: Tesseract is ideal for converting large volumes of printed or typewritten documents into digital, searchable text. This makes it a valuable tool for digitizing archives, books, contracts, and other textual resources.
Automating Data Extraction: Businesses can use Tesseract to automate the extraction of information from standard documents like invoices, receipts, or reports. This helps in reducing manual data entry and improving workflow efficiency.
Multilingual OCR Applications: Due to its extensive language support, Tesseract is well-suited for applications that require text extraction from documents in multiple languages, such as international legal documents or multilingual archives.
Accessibility Enhancement: Tesseract can be used to convert printed materials into digital formats that are accessible to visually impaired individuals. This supports the creation of accessible content that can be read by screen readers or other assistive technologies.
Integration in Software and Web Applications: Tesseract’s open-source nature and Python integration make it an excellent choice for embedding OCR capabilities into custom software, web applications, or mobile apps. Developers can leverage Tesseract to add text recognition features to a wide range of applications.
Research and Development: Tesseract’s customizability makes it a valuable tool in research environments, where OCR needs may vary greatly. Researchers can use it as a baseline OCR engine for experiments, training it on specialized datasets to suit specific project requirements.
Introduction to LLMWhisperer: OCR for LLMs
What is LLMWhisperer?
LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they can best understand it.
Unlike traditional OCR engines like Tesseract, which rely primarily on pattern recognition and predefined datasets, LLMWhisperer uses a combination of deep learning techniques and natural language processing to understand and interpret text in a more context-aware manner.
LLMWhisperer is designed to handle a wide range of document types, including those with complex layouts, handwritten notes, and multilingual content.
Comparison of LLMWhisperer’s Approach to OCR Versus Tesseract
While Tesseract is an excellent tool for basic OCR tasks, it relies heavily on traditional image processing techniques and pre-trained models that may not perform well with non-standard or complex documents.
LLMWhisperer, on the other hand, uses deep learning models that can adapt to the nuances of different writing styles, languages, and document structures.
Contextual Understanding: LLMWhisperer’s use of LLMs allows it to understand the context of the text it is recognizing, making it more effective at interpreting ambiguous or unclear characters, especially in handwritten documents or when dealing with multiple languages.
Versatility in Document Types: LLMWhisperer excels at processing documents with complex layouts, such as tables, forms, and multi-column text, where Tesseract might struggle without extensive preprocessing or post-processing.
Key Features of LLMWhisperer OCR
Key features of LLMWhisperer include:
Automatic Mode Switching: It can easily switch between extracting text and using OCR based on the type of document, making sure it gets the best results from both digital text and scanned images.
Layout Preservation: LLMWhisperer keeps the original layout of documents when it extracts text. This is important for keeping the context and accuracy when the data is used by large language models.
Checkbox and Radio Button Recognition: It accurately identifies and converts checkboxes and radio buttons from forms into a text format that language models can easily understand, making it better for processing form-based data.
Document Preprocessing: The tool has advanced options for preprocessing documents, like applying filters and adjusting image settings. This helps improve the quality of text extraction, especially from poorly scanned documents.
Structured Data Output: LLMWhisperer can produce structured data outputs, like JSON, making it easier to use the extracted information in other systems and workflows.
SaaS and On-Premise Deployment: It offers flexible deployment options, including a fully managed online service and an on-premise version for handling sensitive data securely.
Advanced Handwriting Recognition: One of the standout features of LLMWhisperer is its superior ability to recognize and interpret handwritten text. Traditional OCR engines often falter when faced with handwriting due to the variability in individual writing styles. LLMWhisperer overcomes this challenge by using deep learning models that have been trained on vast datasets of handwritten text from diverse sources.
Superior Multilingual and Table Parsing Capabilities: LLMWhisperer’s multilingual support goes beyond simple text recognition in different languages. It is designed to handle documents that contain multiple languages within the same page or even within the same sentence. This is particularly useful in global applications where documents might include a mix of languages, such as legal contracts, academic papers, or international correspondence.
Machine Learning Integration for Improved Accuracy Over Time: LLMWhisperer is built on a foundation of machine learning, which allows it to continuously improve as it processes more data. This continuous learning capability sets it apart from traditional OCR tools that rely on static models.
Get started with LLMWhisperer: Best OCR for AI Document Processing
Demonstrating LLMWhisperer for OCR Use-Cases
To show how LLMWhisperer works, we’ll walk through the process of setting it up and using it to process different types of documents, including those with handwriting, multilingual text, and tables.
First, make sure to install the necessary package:
pip install llmwhisperer-client
Testing the Same Test Documents (Handwriting, Multilingual, Table) with LLMWhisperer
Now, let’s apply LLMWhisperer to the same types of documents we previously tested with Tesseract:
Typewritten Recognition:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>",
api_key='<api_key>',
api_timeout=300)
# Extract tables from the PDF
result = client.whisper(file_path="Dirac-language-manual-for-tesseract-feature-analysis.pdf", output_mode='line-printer')
extracted_text = result["extracted_text"]
print(extracted_text)
Vallee page 3
1. THE DIRAC LANGUAGE FAMILY.
Activities and levels of users
The language used in the current interactive experiments, DIRAC-1,
is the first prototype in the family of information-oriented languages
we have designed. The objective of this project is to facilitate
flexible interaction with large files of scientific data. The language is
of the non-procedural type and demands no previous computer experience
on the part of the user. It allows creation, updating, bookkeeping and
validating operations as well as the querying of data files;
these activities take place in conversational mode exclusively. To the
more sophisticated user, the DIRAC languages offer a simple interface with
the Stanford text editor (WYLBUR) and to the systems programmer, they
make available a straightforward interface with FORTRAN that does not
require intermediate storage of the extracted information outside of
the direct-access memory. (2)
The name DIRAC (DIRect Access) is intended to remind the user of
this fact. It also summarizes the five data types handled by the
language, respectively: Date, Integer, Real, Alphanumeric, Code.
Four operation modes
The user of DIRAC can apply to any file (that he is authorized to access
any command within one of the four sets grouped under the modes:
CREATE, UPDATE, STATUS and QUERY. The first of these modes is a
privileged one, but this privilege can be extended to any user by the
data-base administrator at the time of file creation: it consists in
the definition of a file or a series of inter-related files, according
a terminology to be defined below, in both nomenclature and
ERIC
Full Text Provided by ERIC
6
<<<
Handwriting Recognition:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>",
api_key='<api_key>',
api_timeout=300)
# Extract tables from the PDF
result = client.whisper(file_path="Edsger-Dijkstra-Notes-handwriting.pdf", output_mode='line-printer')
extracted_text = result["extracted_text"]
print(extracted_text)
EWD1200-0
Only a matter of style?
For educational purposes we analyse the
opening pages of an 11-page article that
appeared in The American Mathematical
Monthly, Volume 102 Number 2 / February 1995.
We have added line numbers in the right
margin.
line 4 : Since in this article , squares don't get
alternating colours , it could be argued that
the term " chessboard " is misplaced .
line 4 : The introduction of the name " B "
seems unnecessary : it is used - in the
combination " the board B " - in the text
for Figure and in line 71 ; in both cases
just " the board " would have done fine .
In line 77 occurs the last use of B ,
viz . in " X "B " , which is dubious since
B was a board and not a set ; in line
77 . I would have preferred " Given a set [X]
of cells " .
line 7 /8 : The first move , being a move
like any other , does not deserve a separate
discription . The term " step " is redundant .
line 8: Why not "a move consists of"?
line 10/11: At this stage the italics are
puzzling , since a move is possible if ,
1
<<<
EWD1200-1
for some i, j, cell (i,j) contains a pebble
and cells ( 1 , j ) and ( i , j + 1 ) are empty .
line 10 : Twice the term " positions " for
what everywhere else is called " cells " .
line 12: Why not " After k moves the
board has pebbles on it . " ?
line 12/ 14: In the one sentence, counts
moves , in the other k counts pebbles .
Since the prose does not indicate
scope of dummies , this double use of
the same k is a little bit unforgivable .
line 14: " and we set R := R(K) ". We
remark
. the use of the verb " to set " when defining
( the set ! ) R can be considered unfortunate
. since is not used on the next two
pages , the name seems to be introduced
too early
. the introduction of the name R seems
unnecessary ; in the rest of the paper I
saw it used once in " any " , where
" any reachable configuration " would have
done . ( Note . In the context in question
- p 116 - the reachable context can remain
anonymous : the quoted occurrence of
is the only occurrence of the identi-
fier C in that context . My conclusion is
that the reachable configuration has been
2
<<<
Multilingual Text Recognition and Table Parsing:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>",
api_key='<api_key>',
api_timeout=300)
# Extract tables from the PDF
result = client.whisper(file_path="catalog-german-multilingual.pdf", output_mode='line-printer')
extracted_text = result["extracted_text"]
print(extracted_text)
ATTIWHO
STAUBSCHUTZHAUBEN
DREUSICKE
SCHREIBMASCHINEN - STANDARDGRÃSSEN
Kat. Wagengrösse Hauptab- Passend fÃ1/4r DM
Nr .= in cm/Zoll messungen
Maschinenart Systeme und Modelle
Best. ca. cm
Nr. a Breite
b Tiefe
c Höhe
1 2 3 4 5 6
a b c
ZH-1 24 10 29x30x8 Flachmaschinen wie Tippa, Splendid usw. 1,50
ZH-2 24 / 10 32x33x13 Kleinmaschinen aller Systeme 1,85
ZH-3 33 13 39x33x13 Kleinmaschinen wie SM 7-9, Erika 41 u.a. 2,40
ZH-4 32/33/ 13 47Ã39x21 Halbstandard- wie Alpina, Adler/Triumph
maschinen Perfect, Spezial, Record,
SCM-250, Rem .- 25 u.a. 2,90
ZH-5 32/33/ 13 44x39x16 Halbstandard-u. wie Hermes 10, Olivetti
elektrische Praxis-48, Olympia SKM,
Maschinen SGE 30/35, Adler/Triumph
Gabriele 5000, SCM-315 u.a. 2,90
ZH-6 24 / 10 36x36x25 Standard- alte Modelle bis ca. Baujahr
maschinen 1960, wie Continental Ideal,
Mercedes, Olympia 8, Rem .- 17,
Royal, Torpedo, Underwood usw.
- siehe auch ZH-7 2,20
ZH-7 24 / 10 40x40x25 Standard- neuere Modelle, wie Adler
maschinen Universal, Triumph-Matura,
Torpedo Solitaire - Dynacord
usw. 2,90
ZH-8 28/32/ 11 46x36x25 Standard- wie Olympia SG 1, Olivetti 80/82
12 1/2 maschinen usw. sowie alte Modelle bis 1960
teils bis 45 cm Wagengrösse 2,65
ZH-9 28/30/ 12 47x40x25 Standard- Modelle wie ZH-6 3,50
maschinen
ZH-10 33 / 13 52Ã44x25 Standard-u. neuere Modelle wie Adler/Triumph
elektrische "L" & "S", 11-151, Matura -
Maschinen Universal 30-500, IBM: Executive
& "72", Olivetti: Diaspron,
-passt zum Teil auch fÃ1/4r
Linea-88, Tekne & Editor,
35 & 38 cm Wagen der
Olympia: SG 1-3, SGE 40-51,
angegebenen Modelle
Rem. - 713, u.a. 3,30
ZH-11 35/38/ 15 52x36x25 Standard-u. Modelle wie ZH-8. - Passt auch
elektrische fÃ1/4r alte Modelle mit 45 cm
Maschinen Wagen 2,90
ZH-12 45/46/ 18 60x36x25 Standard-u. Modelle wie ZH-6, ZH-8, ZH-10
elektrische u. a.
Maschinen 3,30
ZH-13 60/62 76x36x25 Standard-u. Modelle wie ZH-6, ZH-8, ZH-10
elektrische u. a.
Maschinen 4,70
Tr 388ARTEBOHOR SP WISH.JIW
ET - IIIV
<<<
ADDITIONS- UND RECHENMASCHINENHAUBEN OHNE KABELAUSSCHNITTE
(OUD) STANDARDGRÃSSEN
OCHACMATE
Kat. Nr .= Haupt- Passend fÃ1/4r die nachstehend aufge- DM
Best.Nr. abmessungen fÃ1/4hrten Systeme und Modelle
ca. cm lebo 186
a Breite
b Tiefe
c Höhe
1 2 3 4
a b c
ZH-500 20x32x15 Olympia, ABC-103, Feiler-Quick-E 2,85
ZH-501 19x34x13 Olivetti-Quanta MC 20 Q-R, Precisa-208/308,
8
Underwood, Commodore, Odhner 1207 - 1209 2,85
ZH-502 22x36x17 Citizen CA 7/10, Adwell, Precisa 160/164-
364, Olympia 1182/92/93/AE8/13 2,85
ZH-503 23x41Ã20 Addo-X 154, Ascota-114, Victor Prem.,
Odhner /Facit-X-XX-MX-Modelle
Olivetti-MC 22 Elettrosumma 2,85
MENGEN-RABATTE:
sortiert: 10 Stck. 3 %
20 Stck. 5 %
50 Stck. 10 %
100 Stck. 15 %
OS , S ACHTUNG:
Vergleichen Sie bitte bei Aufgabe einer Bestellung die in Spalte
2 bzw. 3 angegebenen Abmessungen a), b) und c) (siehe Skizze 1 am
Fusse dieser Liste) mit denen der Maschine oder der zu ersetzenden
Haube, um eine richtige Lieferung sicherzustellen.
pe,s
$8\\08 Unser Lieferprogramm umfasst Hauben fÃ1/4r BÃ1/4romaschinen aller Art,
darunter auch solche, die nach Originalschnitten in den Qualita-
ten und Farben der Fabriken mit deren Firmenzeichen- oder Namen-
Aufdruck angefertigt werden.
FÃ1/4r Staubhauben, die nicht in dieser Liste aufgefÃ1/4hrt sind benö-
tigen wir folgende Angaben: System und Modell der Maschine, sowie
Wagengrösse und die gewÃ1/4nschte Farbe.
Zur Anfertigung von Staubhauben in Spezialgrössen erbitten wir die
Einsendung einer Skizze mit MaÃangaben entsprechend Zeichnung
1 oder 2.
-06
Skizze 1 Skizze 2
doxre
a-
CA Aim elleb
---
pe,s
!
LIeboM 81 ST-HS
1 1
1 -
C c e 9
0 1 8-1
1
oals
- b- b
WILHELM DREUSICKE & CO. KG. · 1 BERLIN 42 · ROHDESTRASSE 17
VIII - 73
<<<
After testing these use cases, the key takeaways are:
Accuracy: LLMWhisperer demonstrates higher accuracy in recognizing complex handwriting and multiple languages, significantly outperforming traditional OCR tools like Tesseract.
Efficiency: By integrating advanced machine learning models, LLMWhisperer is able to handle complex document layouts, such as tables, with minimal need for preprocessing or manual correction.
Versatility: The ability to seamlessly switch between languages and accurately interpret structured data makes LLMWhisperer an invaluable tool for a wide range of applications, from document digitization to data analysis.
Tesseract has a hard time with handwriting, especially cursive or irregular styles. It needs a lot of preprocessing to get good results.
LLMWhisperer is excellent at recognizing handwriting using deep learning models trained on different handwriting styles. It needs minimal preprocessing and handles context better.
Multilingual Text Recognition
Tesseract supports over 100 languages but may have trouble with similar languages like English and German. Users must specify languages for the best accuracy.
LLMWhisperer automatically detects and switches between languages within a document, maintaining high accuracy even with closely related languages.
Structured Data Extraction (Tables)
Tesseract can extract text from tables but often loses the structure, requiring a lot of post-processing to correctly reconstruct tables, rows, and columns.
LLMWhisperer accurately detects and preserves table structures, outputting data in usable formats like CSV or JSON, reducing the need for additional processing.
Strengths and Weaknesses of Each Tool
Aspect
Tesseract
LLMWhisperer
When to Use
Ideal for simple OCR tasks with high-quality printed documents in a single language. Free, open-source, and easy to integrate across platforms for basic needs.
Best for complex OCR tasks, including handwriting recognition, multilingual text extraction, and table parsing. Continuously improves through machine learning adaptation.
Weaknesses
Struggles with complex scenarios like handwriting, multilingual documents, and structured data. Requires a lot of pre-processing and manual correction.
More expensive and complex to set up. Its advanced features may be unnecessary for simpler OCR tasks, making it potentially excessive for basic projects.
Scenarios Where LLMWhisperer Outperforms Tesseract
Scenario
Why LLMWhisperer Outperforms
Handwritten Document Digitization
Advanced handwriting recognition makes LLMWhisperer the better choice for digitizing handwritten notes, forms, and historical documents.
Multilingual Document Processing
Superior at processing documents with multiple languages, especially where high accuracy in language detection and complex linguistic content is required.
Structured Data Extraction (Tables)
Maintains the integrity of rows and columns in tables and structured data, significantly reducing the need for extensive post-processing.
Which OCR Tool Should You Choose?
Tesseract is still a very useful tool for basic OCR tasks, especially when cost is important and the documents are simple, like high-quality scans of printed text. It’s particularly good for projects where simplicity and ease of use matter more than dealing with complex document structures or multiple languages.
For engineers and developers, the choice between Tesseract and LLMWhisperer should depend on the specific needs of your project. Tesseract is the best choice if your project mostly involves high-quality printed documents and you need a free, open-source OCR solution. It’s also the right tool if your documents are in a single language and don’t require complex layout parsing, especially when budget is a major concern.
On the other hand, LLMWhisperer is the better choice if you need high accuracy for tasks like recognizing handwriting, processing multilingual text, or extracting structured data. It works well for projects that involve complex documents, like forms with tables, mixed-language texts, or handwritten notes.
If your OCR tasks require continuous learning and adaptability, particularly in dynamic environments where document types vary, LLMWhisperer’s machine learning approach will be very beneficial. Additionally, if you need a strong OCR tool that reduces the need for a lot of pre-processing and post-processing, saving time and effort, LLMWhisperer is the tool to choose.
Tesseract OCR Conclusion
In this article, we looked at the abilities of two OCR tools, Tesseract and LLMWhisperer, and how they deal with different text recognition tasks. We checked their performance in reading handwritten text, handling documents with multiple languages, and getting structured data from tables.
While Tesseract has been a good choice for simple OCR tasks, especially with printed text, LLMWhisperer performs better because it uses advanced machine learning, giving it better accuracy and flexibility, especially in complicated situations.
Choosing the right OCR tool is very important for any text recognition project. The decision should be based on the specific types of documents you need to process and the level of accuracy you need. For simple, high-quality printed documents, Tesseract offers a cost-effective solution that is easy to use and integrate.
However, if your project involves more complex document types—like handwritten notes, multilingual texts, or structured data such as tables—LLMWhisperer is likely the better choice, offering higher accuracy and the ability to handle complicated OCR tasks with less manual work.
Both Tesseract and LLMWhisperer have their strengths and are important in modern OCR applications. Tesseract is a powerful, open-source tool that has been proven to work well in many projects over the years, especially for straightforward text extraction.
On the other hand, LLMWhisperer represents the next generation of OCR technology, with its advanced features and machine learning integration, making it a preferred choice for more demanding and varied OCR tasks.
For the curious. Who are we, and why are we writing about OCR?
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
LLMWhisperer is a document-to-text converter. Prep data from complex documents for use in Large Language Models. LLMs are powerful, but their output is as good as the input you provide. Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables.
Extracting data from these documents and blindly feeding it to LLMs is not a good recipe for reliable results. LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they can best understand.
For AI-driven automation, LLMWhisperer redefines OCR, offering a smarter alternative to Tesseract. If you want to take it for a test drive quickly, you can check out our free playground.
When your workflow is AI-first, LLMWhisperer is the smarter alternative to Tesseract for OCR.
Let’s see how to process challenging PDFs that contain hand-filled forms with elements like checkboxes and radiobuttons and also bad scan pages the unfriendly orientations with LLMWhisperer. LLMWhisperer is a text extraction service that specifically targets large language models (LLMs).
What are the main features of Tesseract OCR, and how does it handle different document types?
Tesseract OCR is a powerful open-source tool that supports over 100 languages, configurable page segmentation, and custom training for new fonts or languages. It excels at extracting text from high-quality, printed documents but can face challenges with handwritten text, complex layouts like forms or tables, and noisy or low-resolution images. Preprocessing routines (such as grayscale conversion, binarization, and noise reduction) can help improve its accuracy.
What kinds of documents does Tesseract OCR handle best?
Tesseract OCR excels with clean, high-resolution scans of printed or typewritten text. It performs reliably on single-language pages that have simple layouts, such as books, contracts, or standard letters. Complex tables, heavy noise, or handwriting often require additional pre-processing or a different engine.
What pre-processing steps can improve Tesseract OCR’s accuracy?
To improve Tesseract OCR’s accuracy, especially with low-quality or skewed images, you can apply several pre-processing techniques using libraries like OpenCV. Key steps include converting the image to grayscale, applying a Gaussian blur to reduce noise, using adaptive thresholding for binarization, and deskewing the image to correct text alignment before performing OCR.
When should I choose the LLMWhisperer — a Tesseract alternative — over Tesseract?
Tesseract alternative (LLMWhisperer) is a next-generation OCR tool designed to work seamlessly with large language models (LLMs). Unlike Tesseract OCR, which relies on traditional image processing and static datasets, LLMWhisperer leverages deep learning to understand context, accurately extract handwritten text, preserve document layouts, and handle complex, multilingual, and structured documents (like tables and forms) with minimal preprocessing and higher accuracy.
Can the Tesseract alternative (LLMWhisperer) be integrated into existing Python or API workflows?
Absolutely. LLMWhisperer offers a REST API and a Python client (pip install llmwhisperer-client). After initializing the client with your API key, a single whisper() call returns the layout-preserved text that downstream applications, ETL pipelines, or LLM prompts can consume.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.