A Guide to Extracting Text from Scanned Handwritten PDFs
Table of Contents
Introduction: What is Handwriting OCR?
Handwriting OCR (Optical Character Recognition) refers to the technology that allows machines to read and convert handwritten text from scanned documents, PDFs, or images into machine-readable formats. While traditional OCR focuses on extracting printed text, handwriting OCR tackles the complexities associated with interpreting diverse handwriting styles, alignment, and formatting, making it more challenging yet incredibly useful.
This technology relies on advanced algorithms and AI models that can detect and interpret individual characters or complete words from handwritten documents. The extracted data can be stored as plain text, JSON, or CSV files, allowing seamless integration into various business processes.
How Does Handwriting OCR Work?
Scanning or Capturing the Document: The process begins with scanning or photographing a document containing handwritten text. This could be anything from tax forms to loan applications.
Image Pre-Processing: OCR systems often enhance the scanned document’s quality by applying filters, such as Gaussian blur or thresholding, to improve clarity for text recognition.
Segmentation and Recognition: The handwritten text is divided into characters, words, and lines using pattern recognition and machine learning models.
Feature Extraction: Handwriting OCR extracts key features (like pen strokes, spacing, and letter size) to distinguish between different characters, even when handwriting styles vary significantly.
Output Generation: Finally, the extracted data is converted into a machine-readable format, such as text, JSON, or structured fields, which can then be processed further.
Handwriting OCR finds relevance in both personal and professional settings, from digitizing personal notes to extracting critical data from government and financial forms. This technology paves the way for automated workflows, eliminating the need for time-consuming manual data entry.
TL;DR
This article examines the challenges involved in processing handwritten PDF documents with form fields and demonstrates how using Large Language Models (LLMs) can enable new ways of parsing documents.
If you wish to skip directly to the solution section, where you can see how Unstract uses AI to extract data from various types of handwritten documents with fillable form fields, click here.
Importance of Handwriting OCR
In today’s digital age, where automation is essential for efficiency, handwriting OCR plays a crucial role in transforming paper-based workflows into digital assets. Many industries still rely on handwritten forms — be it tax filings, medical prescriptions, or insurance claim forms. The ability to accurately extract and process data from these forms ensures operational efficiency, improves decision-making, and reduces manual effort.
Key Benefits of Handwriting OCR in Modern Workflows:
Accuracy in Data Entry: Handwritten forms are prone to human error during manual data entry. Handwriting OCR mitigates this risk by automatically extracting text with high precision, ensuring that the data is both reliable and consistent.
Faster Turnaround Times: Processing handwritten documents manually can be laborious and time-consuming. OCR accelerates this process, enabling faster loan approvals, medical claim settlements, or tax filings by extracting data instantly.
Improved Compliance and Audit-Readiness: Businesses, especially in finance and healthcare, must comply with strict regulations. Digitizing handwritten records with OCR ensures audit trails are maintained, and the data is easily accessible for compliance reviews.
Cost-Effective Operations: Automating handwritten data extraction eliminates the need for large data entry teams, resulting in lower operational costs for organizations.
Data Accessibility and Integration: Extracted text can be easily integrated into databases, CRM systems, and financial software, allowing businesses to make data-driven decisions in real time.
Scalability: Handwriting OCR technology allows organizations to scale their operations without additional labor costs, processing thousands of handwritten forms simultaneously.
By enabling faster, more reliable, and automated workflows, handwriting OCR ensures that businesses can focus on core activities, providing faster services to clients and customers without compromising on accuracy.
Business Use Cases of Handwriting OCR Across Various Industries
The use of handwritten forms persists across many sectors where official documentation, consent forms, or personalized information is essential. Below are the major industries where handwriting OCR plays a pivotal role, along with the specific types of forms it helps process.
1. Finance and Taxation:
Tax Documents: Tax forms often contain handwritten details, such as taxpayer names, addresses, or deductions. Automating the extraction of this information speeds up the filing and auditing processes, reducing human errors.
Loan and Mortgage Applications: Loan and mortgage providers use handwritten forms to collect borrower information. Handwriting OCR extracts critical data like income, credit history, and personal details, expediting the underwriting process.
Impact:
Faster loan approvals and real-time tax compliance.
Reduces reliance on manual data entry, ensuring accuracy during audits.
2. Healthcare and Medical Sector:
Medical Forms and Prescriptions: Doctors still issue prescriptions and medical notes by hand. OCR can extract drug names, dosages, and patient details from these forms for integration into electronic health record (EHR) systems.
Patient Intake Forms: Hospitals collect personal and medical history via handwritten forms. Automating this data extraction ensures faster patient onboarding and accurate medical records.
Impact:
Faster access to medical data during emergencies.
Improved pharmacy workflows, with prescriptions automatically verified and entered into systems.
3. Insurance Industry:
Insurance Claim Forms: Policyholders often submit claims with handwritten information. OCR helps insurers process claims faster by extracting key details like policy numbers, incident descriptions, and signatures from these forms.
Accident Reports and Medical Claims: When accidents or health emergencies occur, forms filled by hand need to be processed promptly to avoid delays in payouts. OCR ensures that these critical documents are handled efficiently.
Minimizes fraudulent claims through accurate data extraction and verification.
4. Legal Sector:
Legal Affidavits and Contracts: Legal documents often feature handwritten annotations, signatures, or clauses. OCR extracts and preserves these elements, making it easier to archive and reference them during legal proceedings.
Court Filings and Declarations: Court documents sometimes require handwritten input. Automating their processing ensures faster filing and case management.
Impact:
Streamlines legal documentation processes.
Facilitates the digital archiving of handwritten legal records.
5. Employment and HR Operations:
Employment Forms and Background Checks: Many organizations require candidates to fill out handwritten forms during onboarding. OCR automates the extraction of information like names, addresses, and employment history, speeding up the hiring process.
Performance Reviews and Feedback Forms: Handwritten feedback forms can be digitized using OCR, enabling HR departments to analyze employee performance trends more efficiently.
Improves record-keeping for audits and compliance.
6. Education Sector:
Examination Papers and Admission Forms: In educational institutions, students fill out admission forms or write exams by hand. OCR allows for the digital storage of handwritten submissions, ensuring easy access and faster evaluations.
Survey Forms: Schools often conduct surveys to collect feedback from students or parents. Automating the extraction of responses simplifies the analysis process.
Impact:
Facilitates faster data analysis in academic research.
Improves student record management and compliance.
Summary of Handwriting OCR Use Cases:
Finance: Tax documents, loan applications.
Healthcare: Prescriptions, patient intake forms.
Insurance: Claim forms, accident reports.
Legal: Affidavits, contracts.
HR and Employment: Background check forms, feedback forms.
Education: Examination papers, survey forms.
The widespread application of handwriting OCR across multiple industries highlights its importance in modern-day operations. It not only streamlines processes but also ensures data consistency and accuracy, transforming paper-based workflows into digital solutions.
Challenges in Processing Handwritten Files
The process of converting handwritten scanned documents to text presents a unique set of challenges. Unlike typed text, handwriting can vary widely from person to person, and additional factors—such as document quality and multilingual content—make the task even more complex. Below are some of the most significant hurdles faced in implementing handwriting OCR technology.
1. Variability in Handwriting Styles
Inconsistent Letter Formation: One of the biggest challenges in OCR handwriting is the inconsistency in letter formation. Handwriting styles differ dramatically based on personal writing habits, cultural influences, and even mood or speed of writing. Letters and numbers can look vastly different, causing confusion for OCR engines trying to recognize specific characters.
Example: Some individuals write the letter “s” in a cursive style that resembles a “5,” while others may write it in a distinct, separated form. These subtle variations require advanced algorithms to accurately identify each character, which can be particularly difficult when letters are joined in cursive.
Cursive Writing vs. Block Letters: Handwriting can be cursive (letters connected in a flowing style) or printed in block letters. Handwriting OCR systems must be able to handle both formats dynamically, without requiring separate settings for each type.
Example: Legal documents and signatures often include cursive handwriting, while forms like tax documents may include block letters. An OCR system needs to seamlessly process both formats within the same document or across multiple documents.
Personal Abbreviations and Symbols: Many people have a habit of using abbreviations, special symbols, or shorthand when filling out forms. This shorthand can be confusing for OCR engines, which are typically trained on full words and phrases rather than personalized or informal notations.
Example: “W/” is often used to denote “with,” and “&” is frequently used in place of “and.” While these may seem obvious to humans, they can lead to misinterpretations by OCR systems that are not specifically trained to handle shorthand or informal symbols.
2. Handling Noisy, Low-Quality Scanned Documents
Blurred or Faded Text: Documents that are old, frequently handled, or poorly scanned often suffer from faded or blurred text. This reduces the effectiveness of handwriting OCR, as the algorithms may struggle to distinguish faded characters from the background. Image enhancement techniques like contrast adjustment or noise reduction can be applied, but they’re not always enough to ensure accurate text extraction.
Example: Historical documents or archived medical records often contain faded handwritten notes, making them challenging to process accurately.
Skewed or Misaligned Pages: Misalignment occurs when a document is scanned or photographed at an angle, which can distort the text. OCR systems typically require straight, well-aligned text to function optimally, so skewed pages add an extra layer of difficulty to the text recognition process.
Example: A tax form scanned at an angle may present as a series of slanted lines, making it challenging for OCR to correctly segment and recognize individual fields.
Ink Bleeds and Smudges: Ink bleeds are common in handwritten documents, especially those filled out with fountain pens or gel pens. Smudges can also occur when documents are mishandled, particularly in the case of carbon-copied forms or older documents. These imperfections interfere with character recognition, complicating efforts to extract text from handwritten forms.
Example: Loan application forms that were filled out in ink and then photocopied multiple times may contain smudged areas, making it difficult for OCR systems to identify characters accurately.
3. Distinguishing Between Text, Symbols, and Annotations
Non-Textual Elements: Many handwritten documents include symbols, annotations, or other non-textual elements, which can confuse OCR systems. For example, a handwritten form might include stars or underlined text for emphasis, which can be mistakenly interpreted as part of the text.
Example: In medical forms, symbols such as “+” or “-” may be used to indicate specific test results, while asterisks might denote important sections. OCR systems need to be programmed to ignore these symbols when they are not relevant to the text.
Tables and Checkboxes: Tables, grids, and checkboxes are common in many document formats, particularly forms. Recognizing and preserving the structure of these tables is essential for meaningful data extraction, yet it’s challenging to maintain accuracy.
Example: In employment applications, tables often contain different data points such as name, contact information, and job history. OCR systems need to handle these tables without distorting their original format.
4. Managing Multilingual Handwritten Content
Multiple Languages in One Document: Handwritten documents can contain multiple languages, which can complicate text recognition. Different languages often have unique characters, diacritical marks, or scripts, which can be difficult for a standard OCR system to interpret accurately.
Example: In immigration forms, applicants may fill out information in multiple languages, especially if they are more comfortable using their native language for certain sections.
Language-Specific Nuances: Language-specific characters or accents need special handling. Many OCR systems are designed with a primary language in mind and may struggle with multilingual documents containing unique scripts or accents.
Example: Diacritical marks, such as accents or umlauts in German or French, may not be recognized by OCR systems that are not specifically trained to handle these nuances.
Benefits of Automating Handwritten OCR
Automating the OCR of handwritten files provides numerous advantages across various industries, from enhanced accuracy and scalability to significant cost reductions. Here’s a detailed look at the transformative benefits of this technology.
1. Improved Accuracy and Speed
Eliminate Manual Errors: Manual data entry is inherently prone to human errors, especially when interpreting and transcribing handwritten documents. Automated handwriting OCR systems minimize these errors by consistently applying the same recognition criteria across each document, ensuring data accuracy.
Example: Financial institutions processing loan applications rely on accurate data to assess creditworthiness. Automated OCR ensures that income details, personal information, and other critical data points are captured precisely.
Faster Processing Times: Manual transcription of handwritten files is time-consuming, especially for large volumes of documents. Automated OCR can process these documents within seconds or minutes, allowing businesses to streamline workflows and reduce the time needed for critical decision-making processes.
Example: In healthcare, automated OCR handwriting enables faster processing of patient intake forms, reducing wait times for appointments and ensuring that medical histories are immediately available to physicians.
2. Scalability: Process Large Volumes of Files Efficiently
High Throughput: Automated handwriting OCR tools are capable of processing thousands of handwritten files simultaneously. This high throughput makes it possible for businesses to scale operations without additional labor costs.
Example: Insurance companies can leverage automated OCR to handle the high volume of handwritten claims forms submitted after natural disasters, ensuring timely assistance for policyholders.
Batch Processing of Scanned PDFs: Businesses can easily extract data from large batches of scanned handwritten PDFs without losing accuracy. This capability is especially valuable for companies managing large-scale data entry projects or archival document digitization.
Example: Tax agencies digitizing archived tax records can use batch OCR to process files efficiently, making it easier to retrieve historical information when needed.
3. Cost Reduction: Lower Operational Costs
Minimize Human Involvement: By automating OCR handwriting to text, organizations can reduce their reliance on manual data entry teams, resulting in substantial labor cost savings. This reduction in human intervention not only saves money but also allows companies to reallocate resources to more strategic tasks.
Example: Banks can minimize the need for data entry staff by implementing OCR to handle loan application forms, freeing up personnel to focus on client services and loan assessments.
Streamline Operations: Automated handwriting OCR enables companies to process documents quickly, reducing bottlenecks in workflows and enhancing operational efficiency. This streamlined approach leads to faster response times, higher customer satisfaction, and a more agile organization.
Example: HR departments can automate the processing of handwritten feedback forms, reducing administrative load and enabling faster data analysis.
4. Compliance and Audit Trails: Maintain Proper Documentation
Audit-Ready Records: Automated OCR ensures that data extracted from handwritten files is stored in a structured format, making it easy to maintain audit trails. This capability is essential for organizations that need to adhere to strict regulatory standards and conduct regular audits.
Example: In healthcare, maintaining accurate patient records is critical for compliance with data privacy laws. Automated OCR helps healthcare providers keep accurate, organized records that are easily accessible for audits.
Regulatory Compliance: Industries such as healthcare, finance, and government have stringent data storage and record-keeping requirements. Automating handwritten document processing helps organizations ensure compliance with these standards by maintaining consistent, accurate records.
Example: Financial institutions must maintain compliance with KYC (Know Your Customer) regulations, which often require accurate records of handwritten documents. Automated OCR simplifies this process, ensuring that all documentation is correctly digitized and stored.
Real-Time Data Access: Extracted data from handwritten forms can be integrated into ERP or CRM systems, allowing businesses to access and analyze information immediately for audits or compliance checks. Real-time data integration ensures that organizations can quickly respond to compliance requests or regulatory inquiries.
Example: Insurance companies can access claim data in real time, providing faster responses to regulatory bodies that may require immediate information on claims activity.
Automated handwriting OCR offers a game-changing solution for businesses looking to streamline their operations, improve accuracy, and scale their data processing capabilities. With benefits that include enhanced accuracy, faster processing, scalability, cost efficiency, and better compliance, OCR handwriting to text technology is a powerful tool for modern enterprises seeking to transform traditional workflows into efficient digital processes. By adopting this technology, organizations can unlock greater productivity, reduce operational costs, and deliver faster, more reliable services to their customers.
Introduction to Unstract in PDF Form Processing
Unstract is a cutting-edge platform that automates the extraction of structured data from complex PDFs, including handwritten scanned documents to text. By combining advanced AI technologies and seamless API integration, Unstract simplifies the processing of various document types such as invoices, tax filings, and handwritten forms.
How Unstract Automates PDF Processing
Traditional document processing tools often struggle with unstructured or semi-structured PDFs, especially when dealing with handwritten OCR. Unstract overcomes these challenges by employing a blend of AI, Optical Character Recognition (OCR), and machine learning models to extract meaningful data from PDFs, including those containing both printed and handwritten content.
Unstract transforms handwritten forms into machine-readable formats like JSON, which can be seamlessly integrated into various business workflows. This automation eliminates manual data entry, ensuring that businesses can extract text from handwritten forms quickly and accurately.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
Key Features of Unstract for PDF Processing
AI-Powered Data Extraction
Uses machine learning models to handle unstructured data, ensuring high accuracy even with irregular layouts or handwritten scanned documents.
Recognizes tables, checkboxes, and multi-column content, making it suitable for OCR handwriting to text applications across industries.
Real-Time API Integration
Converts PDFs directly into JSON, enabling seamless integration with financial systems, ERPs, and CRMs.
Unstract’s API allows businesses to automate workflows by sending PDFs and receiving handwritten text from scanned PDFs in real-time.
Multi-Format Document Handling
Supports various file types, including scanned images, PDFs, and fillable forms.
Unstract processes diverse documents like handwritten tax forms, loan applications, and insurance claims without requiring additional configuration.
No-Code Environment
Unstract offers an intuitive no-code platform that allows non-technical users to set up document extraction workflows quickly.
It eliminates the need for constant reprogramming or retraining, making it easy to extract OCR handwriting across different document designs.
Unstract’s ability to handle both printed and handwritten content empowers businesses to streamline their PDF processing. Its adaptability ensures that the same setup can be applied to extract text from handwritten forms of varying formats, without requiring template adjustments for each new document type.
Introduction to LLMWhisperer
LLMWhisperer is an advanced, general-purpose text parser that is crucial for automating document extraction workflows. It does not directly perform OCR using large language models (LLMs); instead, it focuses on parsing the output of scanned documents, including handwritten files, and preparing the data for downstream processing by LLMs.
Role of LLMWhisperer in Document Parsing
LLMWhisperer is an intermediary text preprocessor that helps extract structured data from documents. It enables businesses to process complex PDFs like tax forms, invoices, and handwritten files.
Key Capabilities of LLMWhisperer
Extracts Structured Data from Handwritten Content
LLMWhisperer identifies and parses information from handwritten scanned documents.
Prepares Outputs for Downstream LLM Processing
LLMWhisperer optimizes document content for further processing by LLMs, such as GPT-based systems, ensuring enhanced accuracy during extraction.
Seamless OCR Integration
It automatically switches between OCR and text parsing modes, optimizing performance based on the document type.
Context-Aware Data Parsing
LLMWhisperer uses context-aware parsing to distinguish between text, symbols, and other elements within handwritten forms.
This capability ensures that critical elements, such as tables or annotations, are accurately represented in the extracted data.
Live coding session on data extraction from a handwritten PDF form with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in handwritten PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
Using LLMWhisperer Playground for Testing
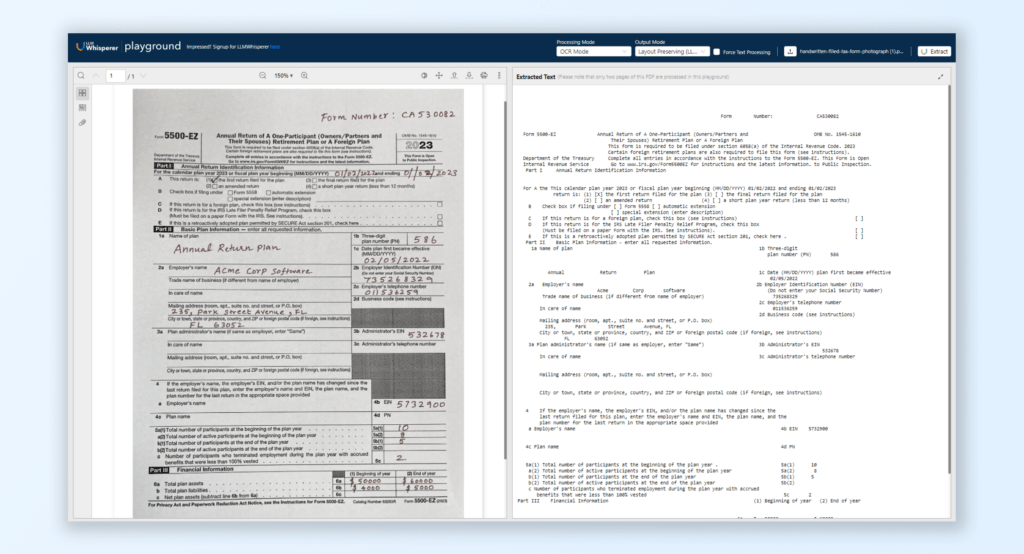
The LLMWhisperer Playground offers an interactive environment where users can test document parsing by uploading various PDFs, including handwritten forms. This testing platform showcases how LLMWhisperer can accurately extract text from handwritten forms while preserving the original layout and context of the document, allowing businesses to fine-tune and optimize their document extraction workflows confidently before deploying them.
To see this in action, head to the LLMWhisperer Playground, click “Upload Document,” and watch your handwritten text transform into LLM-readable data. Below, you’ll observe the results with examples of how LLMWhisperer extracts text from a simple handwritten document, maintaining critical layout details and preparing the data seamlessly for downstream analysis.
Below, you’ll also find the output for a handwritten tax form, showcasing how LLMWhisperer and Unstract together efficiently extract structured data from handwritten notes and content without any loss of information. This process maintains accuracy, organizing the extracted data into a clear, well-structured format ready for use.
The Integration of LLMWhisperer with Unstract for OCR Workflows
LLMWhisperer’s integration with Unstract creates a comprehensive solution for OCR handwriting workflows. Here’s how the combined process works:
The OCR engine initiates the extraction, converting handwritten content into digital text.
LLMWhisperer then processes this data, preserving the document’s structure and ensuring clarity, making it ready for further analysis, reporting, or use with LLM-based extraction.
This end-to-end process enables businesses to extract handwritten text from scanned PDFs efficiently and accurately, eliminating the need for manual adjustments.
With these powerful capabilities, Unstract and LLMWhisperer are invaluable tools for industries like finance, healthcare, and insurance, where automating handwritten OCR workflows is essential for managing high volumes of documents with accuracy. The integrated approach supports robust data extraction, requiring minimal human intervention, which significantly boosts efficiency across operations.
The combined platform preserves the fidelity of the data, ensuring no loss in accuracy or structure, even in highly detailed handwritten documents.
Learn how faithfully reproducing the structure of tables and other elements by preserving the original PDF layout is crucial for better performance in LLM and RAG applications.
To demonstrate Unstract’s capabilities, let’s walk through setting up Unstract with a handwritten scanned tax PDF as an example document. This will showcase how Unstract, in conjunction with LLMWhisperer, extracts and structures handwritten data with high accuracy.
Step 1: Configure Unstract Essentials
Before starting with the Prompt Studio, we need to ensure that Unstract is configured to process data efficiently.
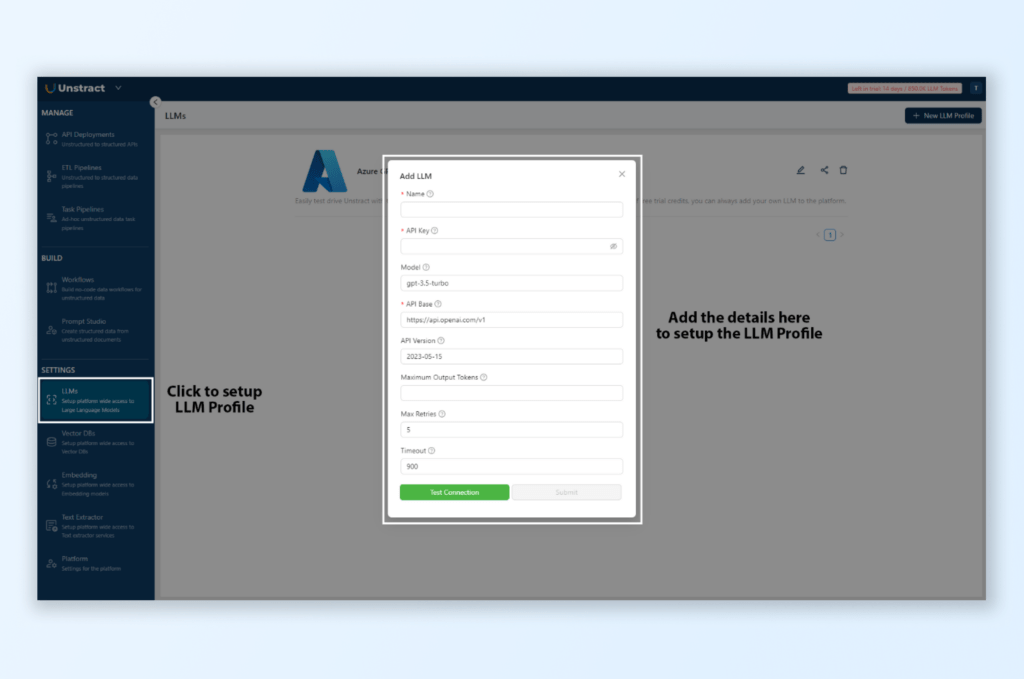
LLM Service:
Go to Settings > LLMs in Unstract.
Click on New LLM Profile and select OpenAI.
Enter the OpenAI API key, allowing Unstract to connect with the LLM for structured extraction.
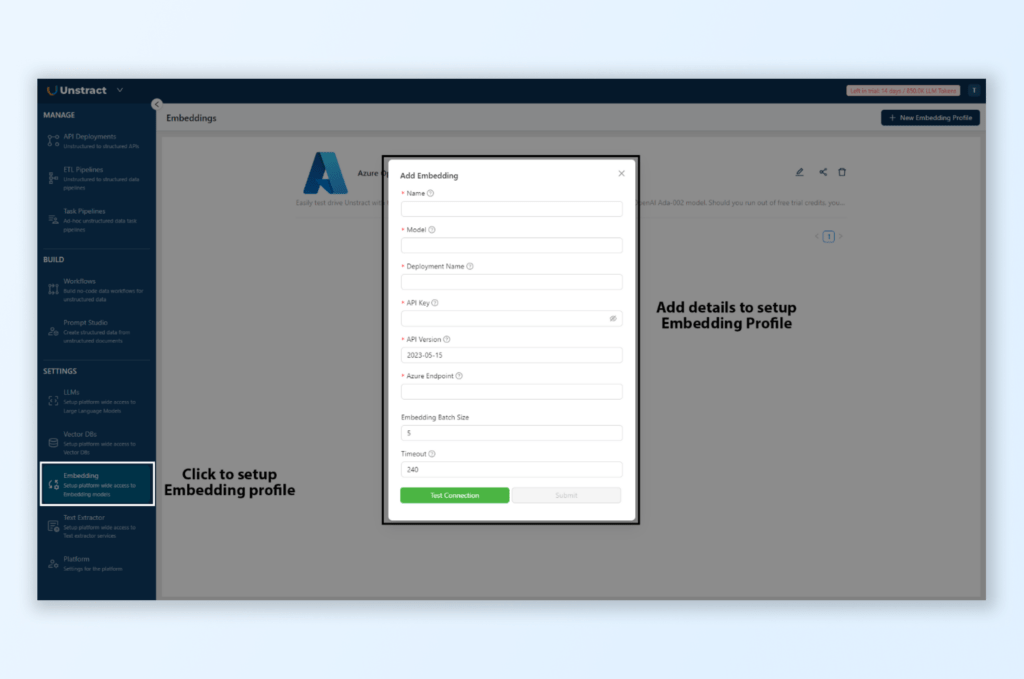
Embedding Model:
In Settings > Embeddings, create a new profile by selecting OpenAI embeddings.
Enter the required API details, which will help the system organize and structure extracted data.
Vector Database:
Access Settings > Vector DBs and create a New Vector DB Profile.
Choose Postgres Free Trial VectorDB, and input the necessary API key and URL.
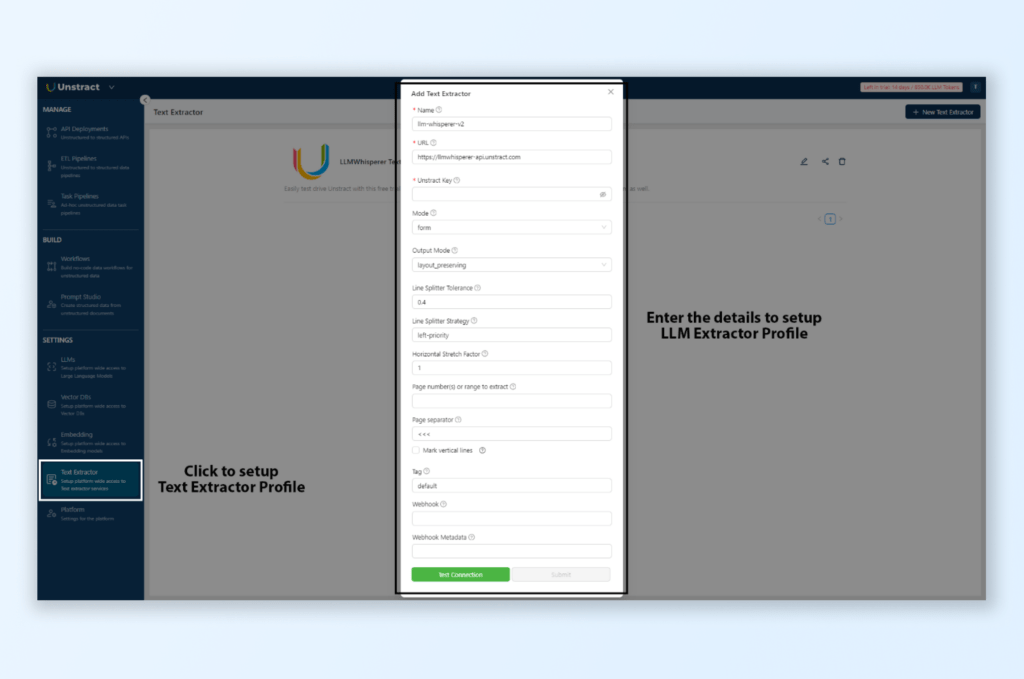
Text Extractor – LLMWhisperer:
Under Settings > Text Extractor, select LLMWhisperer V2 and configure OCR mode.
Set Processing Mode to OCR and Output Mode to line-printer to optimize for text extraction from scanned PDFs.
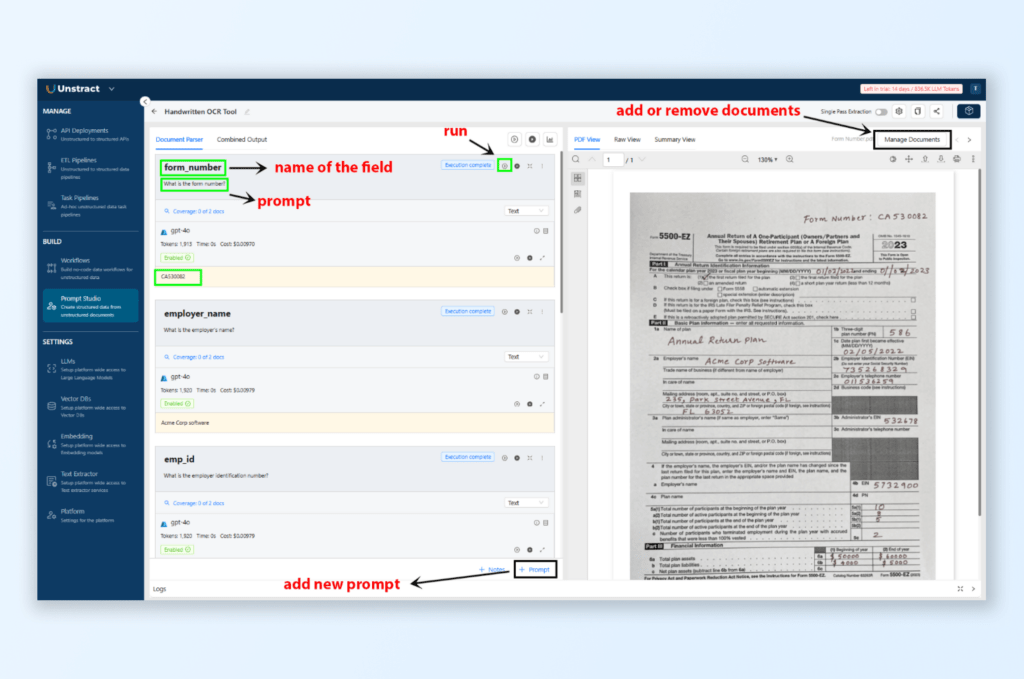
Step 2: Setting Up the Handwritten Tax Form in Prompt Studio
Access Prompt Studio:
Click on Prompt Studio in the left pane of Unstract’s interface to open the setup environment.
Create a New Project:
In Prompt Studio, select New Project in the top right.
Fill in the project details:
Tool Name: “Handwritten OCR Tool”
Author/Org Name: Your name or organization
Description: “Extracts key data fields from handwritten tax forms.”
Upload Document:
In the project interface, go to Manage Documents and click Upload Files.
Upload the handwritten tax form PDF to be used as the sample document for extraction.
Add Extraction Prompts:
To instruct the system on which data fields to extract, click Add Prompts and set prompts for each key field in the tax form.
Suggested prompts:
Field Name: Form Number, Prompt Text: “What is the form number?”
Field Name: Employer Name, Prompt Text: “What is the employer’s name?”
Field Name: Employer ID Number, Prompt Text: “What is the employer identification number?”
Field Name: Total Plan Asset, Prompt Text: “What is the total plan asset?”
Run and Test Prompts:
After creating the prompts, click Run to execute and view extracted data.
Check Output to see the extracted fields and their accuracy.
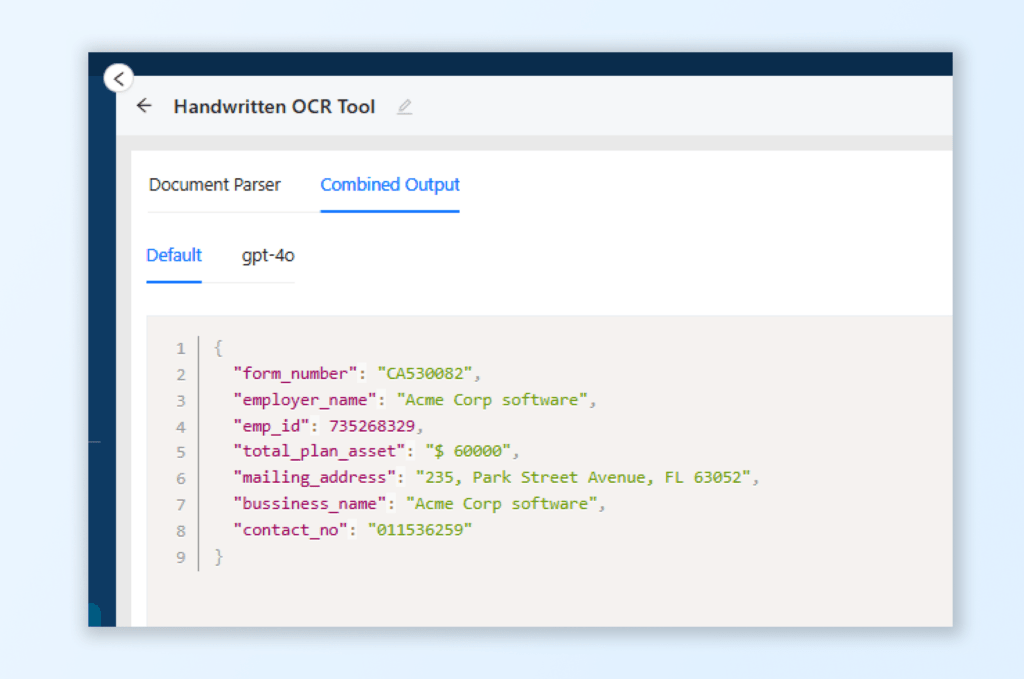
For structured JSON, switch to the Combined Output tab.
Export Tool as API:
Once satisfied with the setup, click on Export as Tool to finalize and export this tool.
The tool is now ready to be deployed as an API, making it accessible for other applications to fetch data in JSON format.
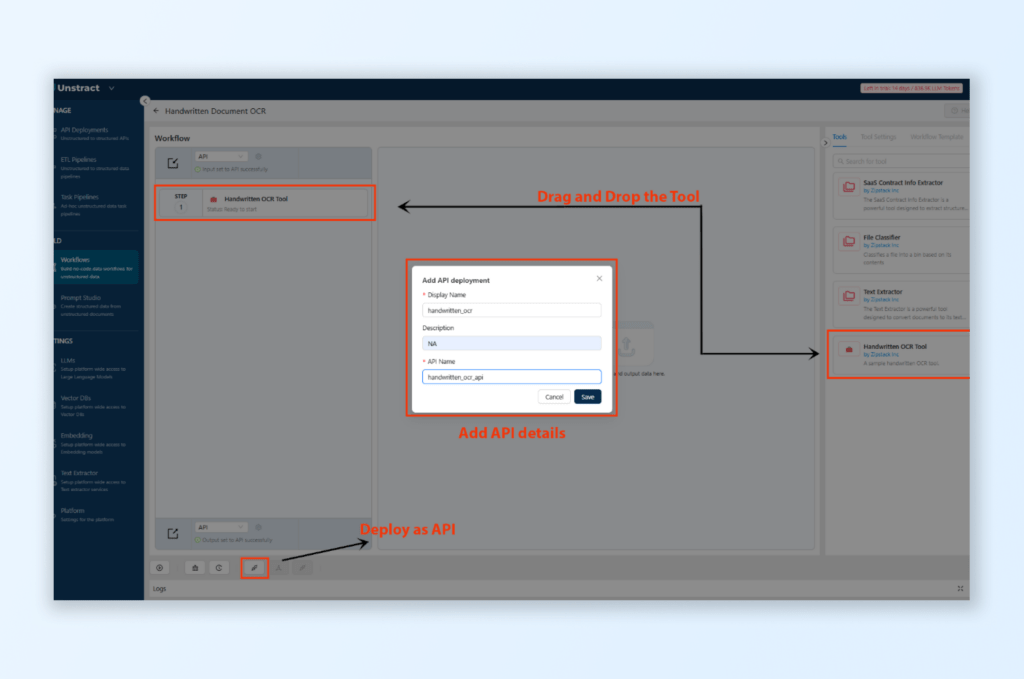
Deploy Workflow as an API:
Navigate to the Workflow Section in Unstract:
Click on Workflows from the left pane to access the workflow setup interface.
Create a New Workflow:
Click New Workflow and provide a name and description (e.g., “Handwritten Document OCR”).
Click Create Workflow to proceed.
Configure Workflow:
Drag and drop the previously exported tool (e.g., “Handwritten Form Parser”) into the workflow area.
Set API Input as the input connector and API Output as the output connector. This configuration allows Unstract to receive documents through the API and return structured JSON data.
Save and Deploy the API:
After configuring the workflow, add a display name, description, and API name.
Click Save and then Deploy API. You will see a confirmation message indicating successful deployment.
Accessing the API Using Postman
To test the deployed API, we will configure Postman to upload the handwritten document and access the extracted data in JSON format.
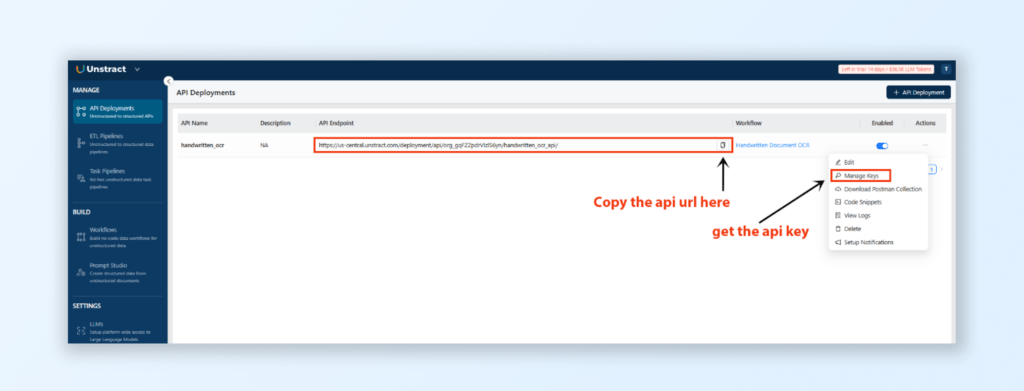
Step 1: Set Up API Access in Postman
Retrieve API URL and Key:
In Unstract’s API Deployment Section, locate the API URL and copy it.
Click on the three dots next to the deployed API, select Manage Keys, and copy the API Key.
Open Postman:
Open Postman and create a new POST request.
Paste the API URL into the URL field.
Set Authorization:
Go to the Authorization tab in Postman.
Select Bearer Token as the authorization type.
Paste the copied API Key into the Token field to authorize the request.
Prepare the Request Body:
Switch to the Body tab in Postman.
Select form-data as the format.
In the Key field, enter files.
Change the Type from Text to File using the dropdown.
Upload the handwritten document (either the tax form or simple content document).
Step 2: Send Request and View JSON Output
Send Request:
Click on Send to initiate the request.
You’ll receive an initial response with the status set as “executing.”
Check Status:
In the response, you’ll find a status_api link.
Create a new GET request in Postman with this link to check if the extraction process is complete.
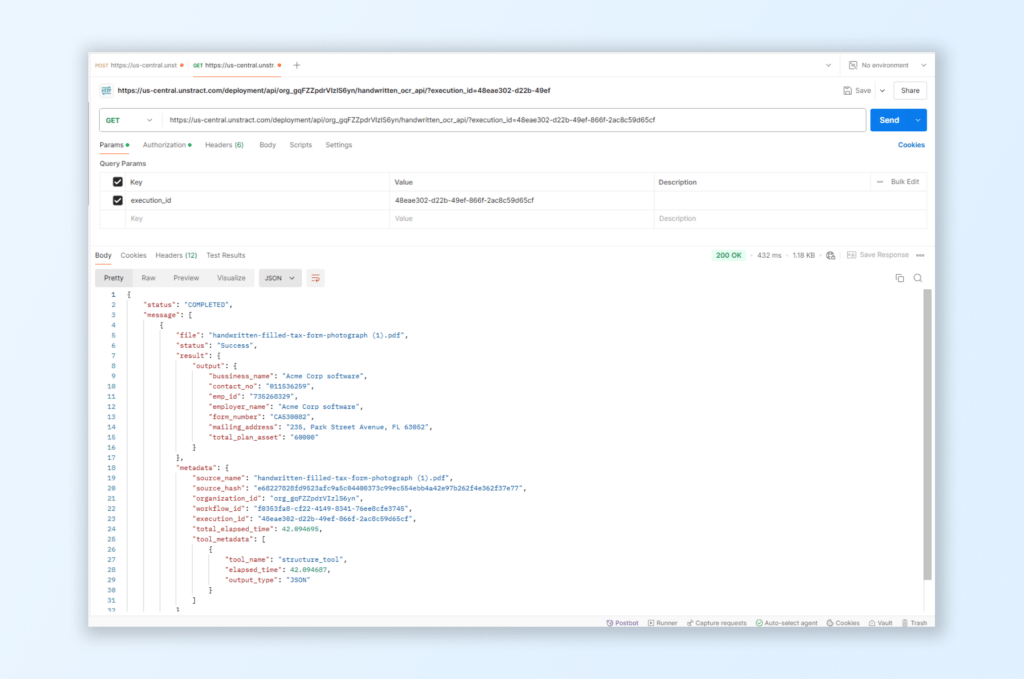
View Extracted JSON Data:
Once the status shows completion, you will receive a structured JSON response displaying extracted fields.
This JSON output includes data fields such as Form Number, Employer Name, Employer ID Number, and Total Plan Asset for the handwritten tax form.
The API is now verified to process and extract data from various handwritten documents, providing a flexible, high-accuracy solution that can be readily integrated into external workflows. This setup minimizes manual processing and ensures streamlined extraction of handwritten data.
Conclusion
Unstract and LLMWhisperer present a transformative approach to handwritten OCR, particularly for businesses and industries handling high volumes of handwritten data. Together, they offer a flexible, scalable solution that goes beyond traditional OCR, delivering structured, actionable data directly from complex handwritten forms and scanned PDFs. This eliminates the need for retraining models whenever document formats change, making it a truly adaptable tool for dynamic workflows.
Recap of Unstract’s Benefits
Unstract stands out with its ability to efficiently extract text from handwritten forms, convert handwriting OCR outputs into structured data, and deliver this data seamlessly to downstream systems:
Flexibility with Document Formats: Whether processing scanned tax documents, insurance claim forms, medical records, or legal affidavits, Unstract adapts without the need for reconfiguration or model retraining.
Streamlined Workflow with LLMWhisperer: LLMWhisperer’s powerful parsing capabilities enable Unstract to handle OCR handwriting with precision, ensuring high accuracy even in challenging, handwritten formats.
Seamless API Integration: With real-time API access, Unstract makes it easy for businesses to integrate handwriting OCR outputs into their existing systems, be it for tax filings, insurance claim verification, or data archiving.
Future of AI-powered OCR Solutions
The future of OCR handwriting to text lies in the continuous advancement of AI technologies. As AI and OCR capabilities progress, industries relying on handwritten data—such as finance, healthcare, and insurance—will benefit from faster processing times, greater accuracy, and reduced operational costs. AI-powered OCR solutions will redefine workflows by automating processes once heavily reliant on manual data entry, unlocking new efficiencies and allowing businesses to harness valuable insights from handwritten data.
As Unstract and LLMWhisperer continue to evolve, we will undoubtedly set a benchmark for handling the complex nature of handwritten OCR tasks, enabling companies to focus on data-driven decisions and strategic growth. The integration of these tools paves the way for a future where automated handwriting OCR will become an indispensable asset for any industry that relies on extracting data from handwritten scanned documents.
What is next? Explore Unstract’s capabilities
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
What is handwriting OCR and how does it work? Handwriting OCR (Optical Character Recognition for handwritten text) is a technology that scans handwritten documents—such as PDFs, photos, or forms—and converts the writing into machine-readable text. It generally follows five steps: image capture, image pre-processing, segmentation, feature extraction, and output generation in formats like JSON or CSV.
Why is handwriting OCR important for businesses and organizations? Handwriting OCR is crucial for modern businesses because it automates the extraction of handwritten data from forms like tax documents, medical prescriptions, and insurance claims. This reduces manual data entry, increases accuracy, speeds up processes, and enables seamless integration of handwritten information into databases and automated workflows.
How is handwriting OCR different from regular (printed-text) OCR? Traditional OCR is tuned for consistent, printed fonts, whereas handwriting OCR must interpret highly variable pen strokes, cursive scripts, and inconsistent spacing. This added complexity requires advanced OCR models that can interpret the nuances of individual handwriting styles.
How do Unstract and LLMWhisperer enhance handwriting OCR workflows? Unstract provides a no-code platform that converts handwriting OCR output into structured data via APIs. At the same time, LLMWhisperer is an OCR engine that preserves document context and readies it for downstream AI models. Together, they deliver scalable, accurate, and audit-ready extraction without the need for constant template re-engineering.
How can automation improve the accuracy and efficiency of handwriting OCR workflows? Automating handwriting OCR eliminates manual transcription errors, processes large volumes of scanned handwritten PDFs quickly, and lowers operational costs by reducing the need for manual data entry staff. Automation also ensures scalability, compliance, and real-time access to extracted data in structured formats.
How to Extract Text from Handwritten PDF in 2026: Related topics to explore
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.