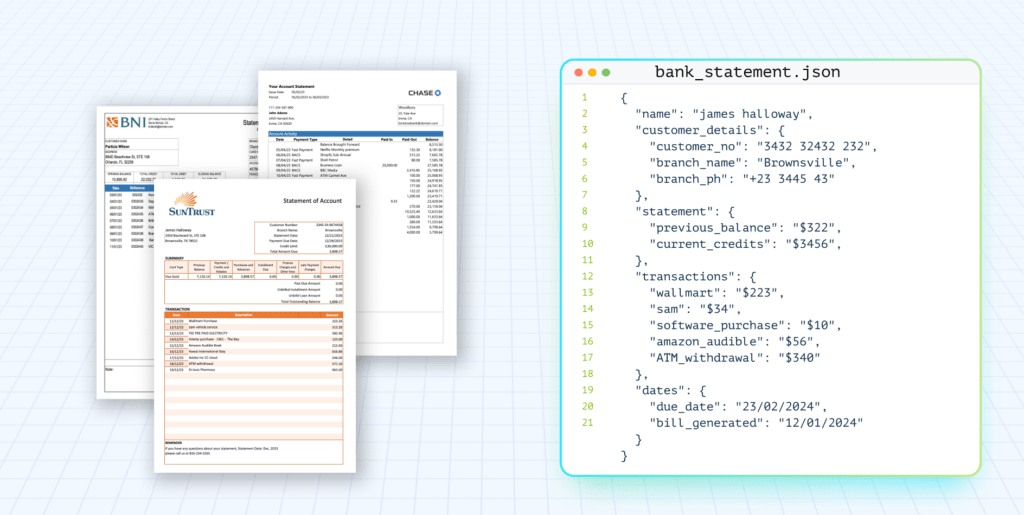
Three agents analyze every document variant, identify the fields, normalize the inconsistencies, and produce a complete JSON Schema. All in minutes.
Summarizer Agent
Analyzes each document on its own. Identifies field names, data types, descriptions, and example values. No field gets overlooked, because it processes each variant separately.
Uniformer Agent
Takes the summaries and finds commonalities. Recognizes that similar, but differently-named fields are the same. Merges duplicates, picks consistent names, consolidates descriptions.
Finalizer Agent
Converts everything into a standardcompliant JSON schema with proper data types, required fields, nested structures, and validation rules. The output is ready to use. Edit it freely, if you want.
We know how difficult prompt engineering can be. A prompt that works on one document can fail on another.
Agentic Prompt Studio uses an additional 3-agent pipeline to generate a comprehensive extraction prompt from your schema and document patterns.
Pattern Miner Agent
Digs through your samples to find extraction clues. It identifies the labels that precede fields, discovers formatting patterns, and maps where fields tend to appear in each layout.
Prompt Architect Agent
Constructs a detailed extraction prompt. Get a structured set of instructions, field-level guidance, disambiguation rules, edge case handling, and output format.
Critic Dry-Runner Agent
Stress-tests the prompt before you ever run it. The agent simulates an extraction, validates the output against the schema and identifies potential failure points. Safe to say, that you get a vetted final prompt.
Know if your prompt change made things better. Or worse.
When handling many document variants, a single prompt change may fix one extraction but break others. Regressions can reach production unnoticed.
The Verification Set compares new results with baselines and shows what improved, regressed, and by how much.
Track prompt versions and rollback in 1 click
Every prompt version provides an instant document accuracy score. Track trends over time and identify which edit caused a regression.
Drill-down, track and fix errors
See which fields matched and which didn't for each document. Find the source location of any value with Highlighting. Plus, get an overview of extraction quality with a Project Accuracy score.
Get a bird’s-eye view of extraction accuracy
Get a unified view of every field across every document, color-coded by result. View matches, partials, complete mismatches, or filter just the errors. Export for further analysis.
Today, prompt tuning is the one step that still requires your input. We're building multi-agent pipelines that will analyze extraction accuracy as feedback and fine-tune prompts on their own.
No more manual schema definitions or prompt engineering
Agentic Prompt Studio is available in beta on all Unstract Cloud and OnPrem plans. Upload your documents and start extracting in minutes