How to Extract Tables from PDF in Python — 5 Libraries Tested & Compared in 2026
Table of Contents
Python PDF Table Extraction : An Introduction
How to extract tables from PDF in Python is a problem that comes up constantly in data pipelines. PDFs were built for consistent printing and viewing, not for data extraction. Unlike a clean CSV or a well-structured JSON file, a table inside a PDF is just a collection of text fragments, lines, and coordinates arranged to look like a grid.
That’s why Python PDF table extraction is rarely as simple as it seems. The good news: the Python ecosystem has several libraries designed specifically for this job. Camelot, Tabula, and Pdfplumber each approach the problem differently — some use computer vision, others rely on coordinate analysis or layout heuristics. But no single tool handles every PDF.
Scanned documents break most libraries. Borderless tables confuse others. And tables that continue across multiple pages often get extracted as separate, disconnected pieces. In this guide, we benchmark three open-source libraries plus Pdftables and LLMWhisperer against real financial reports.
You’ll see exactly how each one performs when extracting tables from PDF in Python — from simple annual statements to messy, multi-page documents. By the end, you’ll know which tool works for your specific use case and when a managed solution makes more sense.
In this article, we’re going to look closely at these four Python libraries. We’ll compare what they can do, how well they work, and how to extract a table from a PDF accurately. To give a thorough evaluation, we’ll test each library with two sample documents and look at the results.
By the time you finish this article, you’ll understand the good and bad points of each library and be able to pick the best tool for your particular needs in getting tables out of PDFs.
Overview of Python parsers to Extract Table from PDF
When it comes to getting tables out of PDF files, Python has several strong libraries that can make the process easier. Each of these libraries has its own set of features, advantages, and limitations. In this section, we’ll introduce you to four well-known Python parsers for getting tables out of PDFs: Camelot, Tabula, Pdfplumber, and Pdftables.
Camelot
Camelot is a Python library made specifically for getting tables out of PDF files. It works great with simple table structures and has a user-friendly interface. Camelot’s main features include:
The ability to find tables using a straightforward API.
Options to save tables in various formats, including CSV and JSON.
Support for visual debugging, which helps make sure the table extraction is accurate.
The ability to handle multiple pages and get tables from all of them.
Support for saving tables in CSV, JSON, and TSV formats.
Pdfplumber
Pdfplumber is a versatile library that’s great at getting text and tables out of PDFs accurately. It’s particularly good with complex table structures. Key features of Pdfplumber include:
Detailed extraction capabilities for text and tables.
The ability to work with complex table layouts and nested tables.
Support for saving the extracted data in various formats.
Pdftables
Pdftables is an online service that provides an API for converting PDF tables to different formats. It’s known for its accuracy and ease of use. Pdftables’ notable features include:
Simple API integration for quick table extraction.
High accuracy in converting PDF tables to formats like CSV, Excel, and XML.
Requires an API key for access, making it a commercial service.
Unstract’s All Table Extraction API: Effortless Table Extraction
Unstract’s All Table Extraction API simplifies the process of extracting tables from PDFs, images, and other document formats.
With just an API key and endpoint, you can seamlessly integrate advanced AI-powered table detection into your workflow. Point your documents to the API, and receive structured, ready-to-use table data in return—no manual intervention required.
No prior knowledge of table structure, size and format is required before processing
Same code can work across many formats (example bank and credit card statements from different banks)
Can work across tables, rows and cells overflowing into next pages
Simple API, python and javascript client libraries
In the following sections, we’ll look more closely at each of these libraries, providing detailed comparisons and performance evaluations using two sample documents. By looking at their capabilities and limitations, we aim to help you determine the best tool for your specific needs in getting tables out of PDFs.
Camelot is a Python library created for getting tables out of PDF files. It’s known for being simple and effective, especially when working with PDFs that have basic table structures. Camelot uses computer vision algorithms to find and get tables from PDF documents, making it a reliable choice for many table extraction tasks.
Key features of Camelot include:
Table Parsing: Camelot can accurately get tables from PDF files, even those with complex structures.
Export Options: The tables you get can be saved in various formats, including CSV, JSON, Excel, and HTML.
Visual Debugging: Camelot lets you see and adjust the table extraction process.
Easy Integration: It works well with other Python tools and libraries, making it a versatile addition to any data processing pipeline.
Camelot Installation Steps
Before you can install Camelot, you need to make sure that the dependencies are installed, so make sure to have Ghostscript installed.
Then you can install Camelot using the following command:
pip install camelot-py[cv]
The cv part ensures that the necessary dependencies for computer vision, such as OpenCV, are also installed.
If you see this error message:
PyPDF2.errors.DeprecationError: PdfFileReader is deprecated and was removed in PyPDF2 3.0.0. Use PdfReader instead.
It is because there is currently an incompatibility of Camelot with PyPDF2 ≥ 3.0.0, so you might need to specify an older version of PyPDF2:
pip install PyPDF2==2.12.1
Code Example for Extracting Tables from a PDF
Here’s a simple example of how to use Camelot to get tables from a PDF file:
import camelot
# Extract tables from the PDF
tables = camelot.read_pdf('best-unicef-1.pdf')
# Print the number of tables extracted
print(f"Number of tables extracted: {len(tables)}")
# Print the first table
print(tables[0].df)
Here’s a step-by-step description of what the code does:
import camelot: This line imports the Camelot library.
tables = camelot.read_pdf('best-unicef-1.pdf'): The read_pdf function from the Camelot library is used to read the PDF file ‘best-unicef-1.pdf’ and extract tables from it. The extracted tables are stored in the tables variable as a list of table objects.
print(f"Number of tables extracted: {len(tables)}"): This line prints the number of tables that were extracted from the PDF file. It uses the len function to get the length of the tables list, which represents the number of tables extracted.
print(tables[0].df): This line prints the first table that was extracted from the PDF file. The tables[0] part accesses the first table object in the tables list, and the .df attribute converts the table object into a DataFrame. The DataFrame is then printed to the console.
Camelot’s ease of use and strong features make it an excellent choice for getting tables from PDFs, especially when dealing with simple to moderately complex table structures. In the next section, we will explore Tabula, another popular library for getting tables out of PDFs.
Tabula
Tabula is a popular tool for getting tables out of PDF files. It started as a web application but has a strong Python wrapper called tabula-py, which lets you use its features in Python. Tabula is known for handling multi-page PDFs well and having a user-friendly approach to table extraction.
Key features of Tabula include:
Java-Based Backend: Tabula uses a Java library for processing PDFs, which can handle many types of table structures.
Multiple Page Support: It can get tables from all pages in a PDF, making it good for large documents.
Export Options: The tables you get can be saved in various formats, including CSV, JSON, and TSV.
Ease of Use: The Python wrapper tabula-py provides a simple API for using Tabula’s capabilities in Python projects.
Tabula Installation Steps
To use Tabula in Python, you need to install the tabula-py package. Since Tabula relies on Java, you also need to have Java Runtime Environment (JRE) installed on your system. You can install tabula-py using the following command:
pip install tabula-py
Make sure that Java is properly installed and set up in your system’s PATH.
Code Example for Extracting Tables from a PDF
Here’s a simple example of how to use Tabula to get tables from a PDF file:
import tabula
# Extract tables from the PDF
tables = tabula.read_pdf('best-unicef-1.pdf', pages='all')
# Print the number of tables extracted
print(f"Number of tables extracted: {len(tables)}")
# Print the first table
print(tables[0])
Here’s a step-by-step description of what the code does:
import tabula: This line imports the tabula library.
tables = tabula.read_pdf('best-unicef-1.pdf', pages='all'): The read_pdf function from the tabula library is used to read the PDF file ‘best-unicef-1.pdf’ and extract tables from it. The pages=’all’ parameter ensures that tables from all pages of the PDF are extracted. The extracted tables are stored in the tables variable as a list, with each item representing a table.
print(f"Number of tables extracted: {len(tables)}"): This line prints the number of tables that were extracted from the PDF file. It uses the len function to get the length of the tables list, which represents the number of tables extracted.
print(tables[0]): This line prints the first table that was extracted from the PDF file. The tables[0] part accesses the first table in the tables list, and the print function displays the table’s content.
Tabula’s combination of ease of use and strong functionality makes it a popular choice for getting tables from PDFs, especially for documents with multiple pages. In the next section, we will explore Pdfplumber, another powerful library for getting tables out of PDFs.
Pdfplumber
Pdfplumber is a strong and flexible Python library designed to get text and tables from PDF files. It’s known for its accuracy and ability to handle complex table structures that other libraries may have trouble with. Pdfplumber gives you detailed control over the extraction process, making it great for users who need to work with complicated or non-standard table layouts.
Key features of Pdfplumber include:
High Precision: Can accurately extract complex table structures.
Detailed Control: Gives you fine-grained control over the extraction process, allowing you to handle specific table layouts.
Versatility: Supports getting both text and tables from PDFs.
Output Options: The data you get can be saved in various formats, including CSV and JSON.
Installation Steps
To install Pdfplumber, you can use pip, Python’s package installer. Run the following command in your terminal:
pip install pdfplumber
Pdfplumber also depends on pillow and pdf2image, which will be installed automatically with the above command.
Code Example for Extracting Tables from a PDF
Here’s an example of how to use Pdfplumber to get tables from a PDF file:
import pdfplumber
# Open the PDF file
with pdfplumber.open('best-unicef-1.pdf') as pdf:
# Go through each page
for page in pdf.pages:
# Get tables from the current page
tables = page.extract_table()
# Print the table data
print(tables)
Here’s a step-by-step description of what the code does:
import pdfplumber: This line imports the pdfplumber library.
with pdfplumber.open('best-unicef-1.pdf') as pdf:: This line opens the PDF file ‘best-unicef-1.pdf’ using the open function from the pdfplumber library. The opened file is assigned to the variable pdf.
The for loop iterates through each page in the PDF file:
page.extract_table(): This method extracts tables from the current page.
print(tables): This line prints the data of the tables.
Pdfplumber’s ability to handle complex tables and give you detailed control over the extraction process makes it a valuable tool for anyone needing to get structured data from PDFs. In the next section, we will explore Pdftables, a commercial service offering API-based PDF table extraction.
Pdftables
Pdftables is an online service that offers an API for converting PDF tables into various formats such as CSV, Excel, and XML. It is known for its accuracy and ease of use, making it a convenient option for users who need quick and reliable table extraction from PDFs. Pdftables provides a simple API interface, which allows developers to integrate its functionality into their applications seamlessly.
Key features of Pdftables include:
High Accuracy: Delivers precise table extraction, even for complex tables.
Multiple Output Formats: Supports conversion to CSV, Excel, XML, and more.
Ease of Use: Simple and straightforward API for quick integration.
API-Based Service: Requires an API key for access, making it suitable for automated workflows and large-scale extractions.
Installation Steps
To use Pdftables in Python, you need to install the pdftables package and obtain an API key from the Pdftables website. You can install the package using pip:
In order to use Pdftables, you will need to sign up for an account at PDFTables.com and create an API Key.
Here is an example of how to use Pdftables to extract tables from a PDF file:
import pdftables_api
# Create a Pdftables API client
c = pdftables_api.Client('<YOUR-API-KEY>')
# Convert PDF to HTML
c.html('best-unicef-1.pdf', 'best-unicef-1')
Here’s a step-by-step description of what the code does:
import pdftables_api: This line imports the pdftables_api library, which is a Python library for working with the Pdftables API service.
c = pdftables_api.Client('m5uo24we5v4s'): This line creates a client object c for the Pdftables API service. The placeholder ‘<YOUR-API-KEY>’ should be replaced with the actual API key required to access the service.
c.html('best-unicef-1.pdf', 'best-unicef-1'): This line uses the html method of the client object c to convert the PDF file ‘best-unicef-1.pdf’ into a HTML file named ‘best-unicef-1.html’.
Pdftables’ high accuracy and ease of use make it an excellent choice for users who need reliable and fast table extraction from PDFs. However, as a commercial service, it requires an API key and involves usage costs based on the volume of documents processed, you have initial to 40 free pages.
Introducing LLMWhisperer
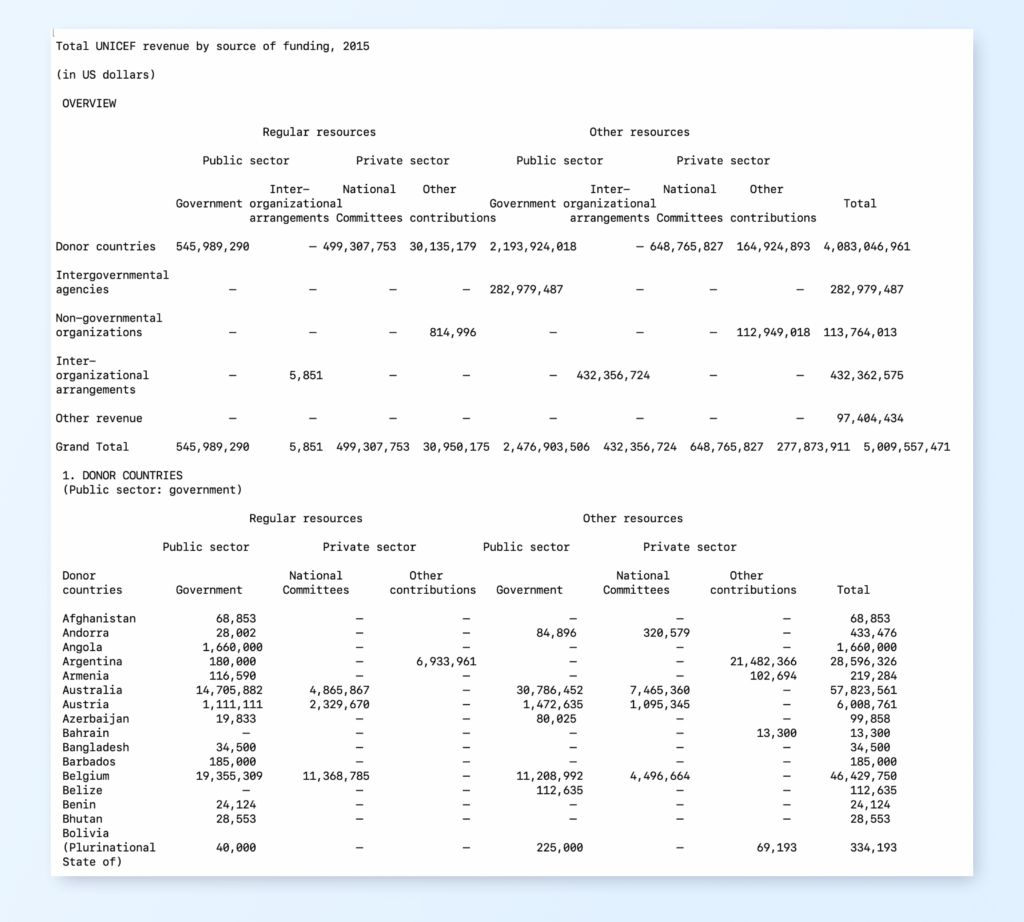
LLMWhisperer is an online service which converts PDFs to text. It is not a table extraction tool like per se like the other ones mentioned in this blog. But the output from LLMWhisperer can maintain the layout of tables as it is in the original document. As mentioned earlier, if you are going to use the extracted tables to extract information with an LLM, the layout preserved tables in text can provide rich context to the LLM. Unlike the other tools mentioned in this blog, LLMWhisperer can handle complex, irregular tables without any prior knowledge of its structure or format.
Key features of LLMWhisperer include:
Layout preserved text output for tables
No prior knowledge of table structure, size and format is required before processing
Same code can work across many formats (example bank and credit card statements from different banks)
Handles complex and irregular tables
Can work across tables, rows and cells overflowing into next pages
Simple API, python and javascript client libraries
Sign Up for an API Key: Visit the LLMWhisperer website and sign up for an account. You will receive an API key that you need to use in your code.
Install the LLMWhisperer Client: Use pip to install the llmwhisperer-client package.
pip install llmwhisperer-client
Code Example for Extracting Tables from a PDF
Here’s an example of how to use LLMWhisperer to extract tables from a PDF file:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>", api_key='<YOUR_API_KEY>')
# Extract tables from the PDF
result = client.whisper(file_path="best-unicef-1.pdf")
extracted_text = result["extracted_text"]
print(extracted_text)
Here’s a step-by-step description of what the code does:
from unstract.llmwhisperer.client import LLMWhispererClient: This line imports the LLMWhispererClient class from the unstract.llmwhisperer.client module. This class is used to interact with the LLMWhisperer API.
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>", api_key='<YOUR_API_KEY>'): This line initializes the LLMWhispererClient object with the base URL of the LLMWhisperer API and your API key. Replace <YOUR_API_KEY> with your actual API key.
result = client.whisper(file_path="best-unicef-1.pdf"): This line calls the whisper method of the LLMWhispererClient object to extract tables from the PDF file located at the path “best-unicef-1.pdf”. The extracted data is stored in the result dictionary.
extracted_text = result["extracted_text"]: This line retrieves the extracted text from the result dictionary and assigns it to the extracted_text variable.
print(extracted_text): This line prints the extracted text to the console.
Benchmark Comparison: Python parsers for PDF table extraction
To see how well the four Python libraries (Camelot, Tabula, Pdfplumber, and Pdftables) and LLMWhisperer work, we’ll use two sample documents:
apple.pdf: This document has financial statements from Apple Inc., including tables with different financial data like net sales, cost of sales, and operating income. The tables are well-organized but have a mix of text and numbers, making them a good test for accuracy and handling table structures.
best-unicef-1.pdf: This document has UNICEF’s annual report data, including tables with funding and revenue details from donor countries and other sources. The tables in this document have different structures and complexities, providing a good test for each library’s extraction capabilities.
Test documents to evaluate various Python libraries for PDF table extraction
Evaluation Criteria
To give a thorough comparison, we’ll evaluate each library based on the following criteria:
Ease of Use:
How easy it is to install and set up the library.
How simple and clear the API is for extracting tables from PDFs.
Accuracy:
How accurately does the library extract tables from the PDFs?
How well it handles both simple and complex table structures without losing data integrity.
Output Structure:
The quality and format of the extracted data.
How consistent it is in preserving the original table layout and structure in the output format (e.g., CSV).
Comparison
Using these criteria, we’ll assess each library’s strengths and weaknesses, providing a detailed comparison to help you choose the best tool for your PDF table extraction needs.
LLMWhisperer
Ease of Use: It’s very easy to use. It has a simple API and clear documentation. The installation process is straightforward, and you need an API key, which is easy to manage. It offers a generous free tier of 100 pages per day, which is enough for most users.
Accuracy: It has extremely high accuracy because of its advanced machine learning algorithms. It handles complex and irregular table layouts easily, maintaining data integrity across different types of tables.
Output Structure: It maintains the original table layout and structure precisely. The outputs are clean, well-organized, and require minimal post-processing.
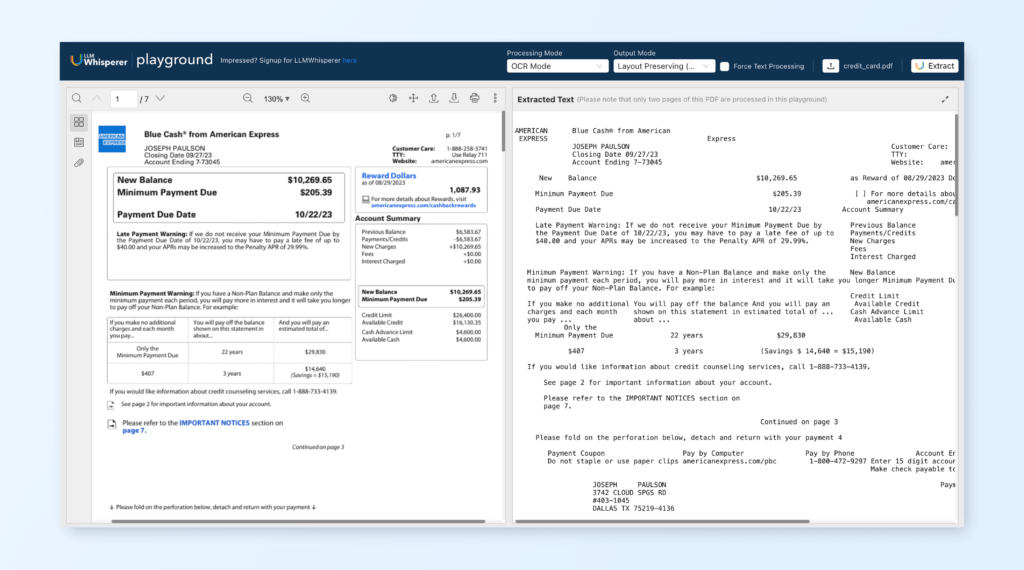
Screenshot from reading file best-unicef-1.pdf:
Results from PDF table extraction using LLMWhisperer
Camelot
Ease of Use: It’s easy to install and use. The documentation is clear.
Accuracy: It has high accuracy for simpler tables but struggles with more complex structures. You might need to make manual adjustments for the best results.
Could not read tables from file apple.pdf
Output Structure: It preserves the structure and formatting of simpler tables well. However, complex tables may require some post-processing to clean up the data.
Screenshot from reading file best-unicef-1.pdf:
Results from PDF table extraction using Camelot
Tabula
Ease of Use: It’s very user-friendly. The installation is simple, and it has a straightforward API. However, it requires Java, which can be an additional step for some users.
Accuracy: It has good accuracy for simple to moderately complex tables. However, it struggles with highly complex or irregular tables.
Output Structure: It maintains the table structure reasonably well for simpler tables. Some formatting issues can occur with more complex tables.
Screenshot from reading file best-unicef-1.pdf:
Results from PDF table extraction using Tabula
Pdfplumber
Ease of Use: The installation is straightforward. The API provides detailed control, but you might need some familiarity with PDF structures to get the best results.
Accuracy: It has very high accuracy, especially with complex and mixed data tables. It consistently extracts both simple and complex tables accurately.
Output Structure: It maintains the original table layout and structure precisely. The outputs are clean and well-organized.
Screenshot from reading file best-unicef-1.pdf:
Results from PDF table extraction using Pdfplumber
Pdftables
Ease of Use: It’s extremely easy to use. It has a simple API, but you need an API key. The process to get the key is quick and seamless. It offers 40 free pages.
Accuracy: It has high accuracy across different types of tables. It handles mixed data types and complex tables effectively.
Output Structure: It preserves the original table structure effectively. The outputs are clean and organized, with minimal need for additional formatting.
Screenshot from reading file best-unicef-1.pdf:
Results from PDF table extraction using pdftables
Extract Tables from PDF in Python: Library Comparison Table
Library
Ease of use
Accuracy
Output Structure
Notes
LLMWhisperer
Very high
Very high
Very high
Excellent for complex tables Built-in support for OCR Can directly provide output as input to an LLM
Camelot
High
Medium
Medium
Good for simpler tables
Tabula
High
Medium
Medium
Some formatting issues with complex tables
Pdfplumber
Medium
Very High
Very High
Excellent for complex tables; detailed control
Pdftables
Very High
High
High
Requires API key; very user-friendly
LLMWhisperer performed the best in terms of accuracy and output structure. It’s also extremely user-friendly with a simple API and a generous free tier.
Pdfplumber also performed exceptionally well, particularly with complex tables, offering detailed control over the extraction process. Camelot and Tabula are easier to use but may require adjustments for more complex tables, while Pdftables provides a highly accurate and user-friendly solution, ideal for users seeking quick and reliable results with minimal setup.
Each library has its strengths, and the choice depends on the specific requirements and complexity of your PDF table extraction tasks. For high accuracy and flexibility, LLMWhisperer and Pdfplumber are excellent choices, while Camelot, Tabula, and Pdftables offer strong performance for simpler extraction needs.
Live coding session on PDF Table extraction
You can also watch this live coding webinar where we explore all the challenges involved in PDF parsing and compare various PDF parsing tool’s capabilities.
For the curious. Who we are and why are we writing about PDF table extraction?
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an Open Source software and is available at https://github.com/Zipstack/unstract.
If you want to quickly try it out, signup for our free trial. More information here.
LLMWhisperer is a document-to-text converter. Prep data from complex documents for use in Large Language Models. LLMs are powerful, but their output is as good as the input you provide. Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables.
Extracting data from these documents and blindly feeding them to LLMs is not a good recipe for reliable results. LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they’re able to best understand it.
If you want to quickly take it for test drive, you can checkout our free playground.
How accurate are different libraries when it comes to how to extract tables from pdf using python on complex financial documents?
The blog tested all libraries against Apple’s financial statements. Camelot failed entirely on that document. Tabula extracted data but introduced formatting issues. Pdfplumber delivered very high accuracy. LLMWhisperer scored extremely well across both test documents. So if you regularly work with dense financial PDFs, Pdfplumber or LLMWhisperer are your safest bets for reliable python pdf table extraction.
Can I extract data from borderless or irregular tables using python pdf table extraction tools without manual tuning?
Camelot offers a “stream” mode for borderless tables, but it often needs parameter adjustments. Tabula generally struggles with irregular layouts. Pdfplumber gives you fine-grained control — you can manually define table regions if needed. If you want to avoid configuration entirely and just learn how to read tables from pdf using python without the hassle, LLMWhisperer preserves layout automatically regardless of borders or weird structures, making it the most hands-off option.
Which library for python extract table from pdf requires the least setup and system dependencies?
Tabula requires a working Java installation. Camelot needs Ghostscript and OpenCV. Pdfplumber has moderate dependencies (pillow, pdf2image). LLMWhisperer needs only pip install llmwhisperer-client plus an API key — no Java, no Ghostscript, no system-level headaches. If you want to minimize setup time while still learning how to extract tables from pdf using python, that matters.
What’s the fastest approach for python extract tables from pdf when processing hundreds of documents in bulk?
Avoid per-document overhead. Batch your PDFs and use multiprocessing with Camelot or Pdfplumber. Tabula is slower at scale because each call spins up a Java JVM. If you don’t want to manage infrastructure, LLMWhisperer’s API scales automatically — just send files and get back JSON, no server maintenance required. For teams that need to extract tables from pdf python at high volume, the API route saves significant engineering time.
How to extract tables from pdf using python when the document contains both text and images inside table cells?
Traditional libraries extract only text. Pdfplumber ignores images entirely. Camelot does the same. For mixed content, you need an OCR-aware approach. LLMWhisperer processes the full page layout, including any text embedded inside images, and preserves the table structure in the output. So if you’re wondering how to read tables from pdf using python for scanned or image-heavy documents, LLMWhisperer is the only tool in this comparison built for that scenario.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.