Product
Unstract: Best Automated Document Processing Software in 2026
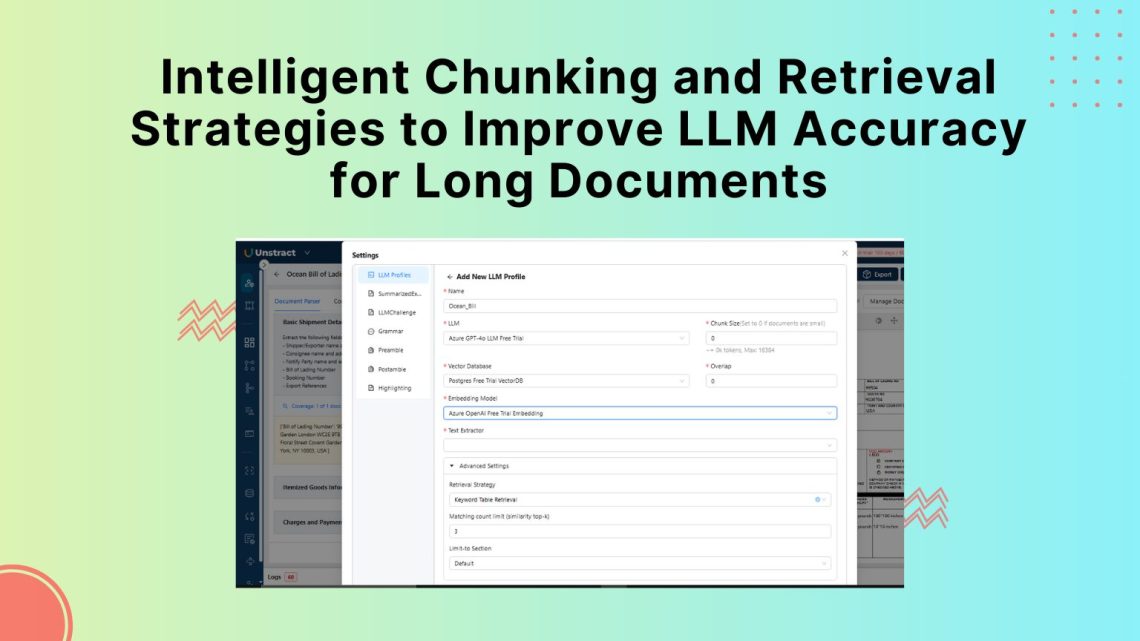
Explore automated document processing software built for variability. Handle scanned PDFs, handwritten forms, and complex layouts with built-in accuracy scoring and API-first deployment.