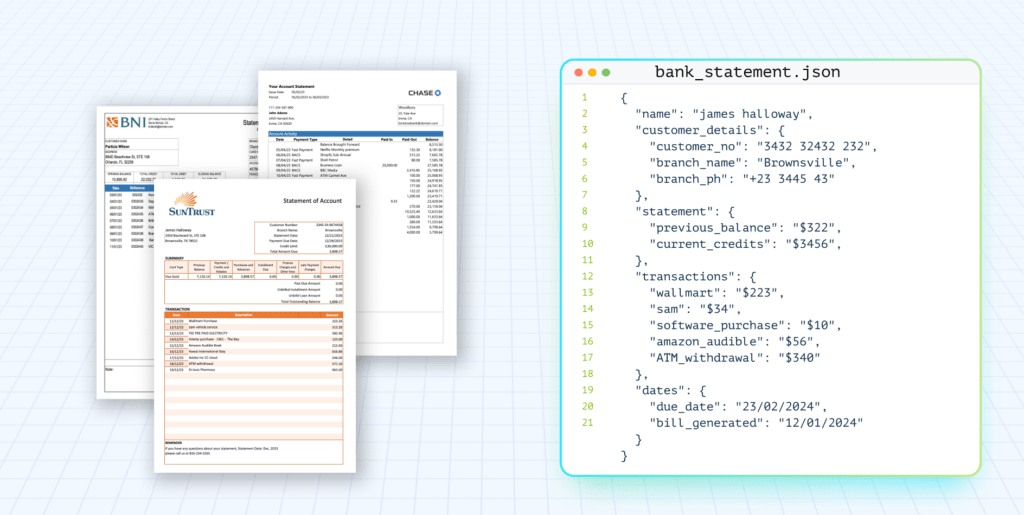
A 300-page report. Tables buried on pages 187 and 234. Merged cells, multi-row headers, and columns that don’t behave. You run extraction and get garbage output. Or worse, output that looks right but isn’t. Works in demo, breaks in production.
This is the single-model extraction problem. One model, one pass, no fallback when document tables get complex.
Unstract’s Agentic Table Extractor is built to solve this. A multi-agent pipeline powers specialized agents to detect, scope, extract, and validate results, from complex real-world tables.
In this webinar, we deep-dive into the Agentic Table Extractor with multiple example tables and show you why agentic extraction is the way forward.
What we’ll cover:
- How the multi-agent pipeline works and what each specialized agent does
- Text and vision models working together for accurate structural extraction
- Pre-scan and sliding window techniques that keep costs reasonable on large documents
- The prompt-readiness checklist that helps you write extraction prompts that get results
If you work with documents where table data is critical and errors have real consequences, this webinar is for you.
This session includes an expert Q&A segment. Bring your questions.
Can’t make it live? Register anyway and we’ll send you the recording.
BONUS: Claim a free extended Unstract trial, upon request.