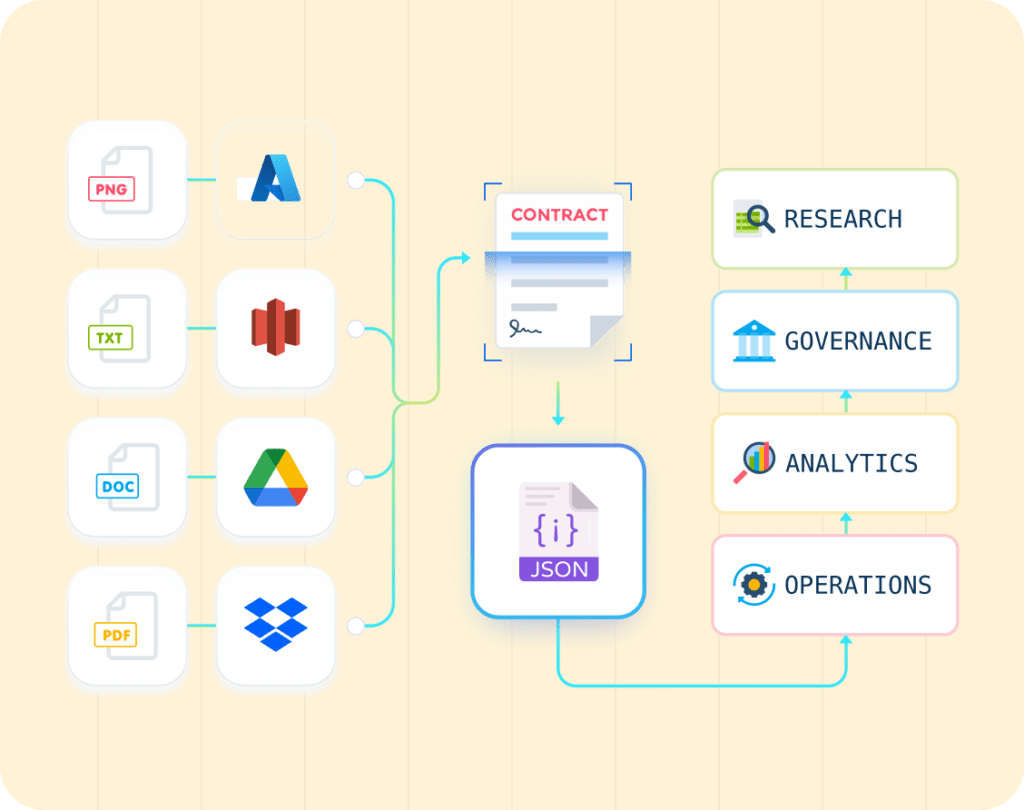
How to Extract Text from Scanned PDFs & Images — A 2026 Guide
Table of Contents
Scanned PDFs and images are everywhere in enterprise workflows — tax forms, invoices, purchase orders, logistics records, insurance claims. They look like documents. They are not. They are photographs of documents, and extracting usable data from them is one of the more stubborn problems in document processing.
The challenge is not just converting pixels to text. Standard scanned document OCR does that. The real problem is what gets lost in the process: table structures collapse, multi-column layouts merge into a single stream of characters, skewed or noisy scans return garbled output, and multi-language content breaks entirely. When that extracted text feeds into a downstream system — an LLM, a database, an ERP — garbage in means garbage out.
This article covers how to extract data from scanned PDFs, scanned images, and scanned documents reliably. We cover where standard OCR approaches fail, and demonstrate two tools built for exactly this problem:
LLMWhisperer is the OCR layer. It requires no image preprocessing, works across all file types and formats, and preserves the layout of complex documents — tables, multi-column text, forms with checkboxes, badly skewed scans. No configuration. No preprocessing pipeline. The highest accuracy on complex layouts of any tool we have tested.
Unstract is the structured data extraction layer. It is AI-powered, which means you can extract any specific data from any document and get it back as structured JSON — ready to route into an Excel file, a CSV, or directly into a database. You define what you want; Unstract handles the rest.
Both ship as APIs. For developers building document processing pipelines or integrating scanned image OCR into existing workflows, this means no new infrastructure — just endpoints you can call with a document and get structured data back.
Introduction: What is Scanned PDF/Image OCR?
Scanned PDF/Image OCR (Optical Character Recognition) is a transformative technology that allows machines to “read” text from scanned documents and image-based files, converting it into machine-readable formats such as plain text, JSON, or Excel.
This capability bridges the gap between physical, static documents and dynamic, digital workflows. Unlike text-based PDFs, scanned PDFs and images require OCR to extract meaningful data because they are essentially flat, pixel-based representations of information.
How Does Scanned Document OCR Work?
At its core, OCR mimics the human ability to recognize and interpret text. The process involves several stages, each powered by advanced algorithms and AI-driven techniques:
Image Pre-Processing
Prepares the scanned document or image for text recognition by enhancing its quality.
Common techniques include:
De-skewing: Corrects tilted or misaligned scans.
Noise Removal: Eliminates unwanted marks or background noise.
Contrast Adjustment: Enhances faint or low-quality text.
Example: A poorly scanned medical prescription with smudges is cleaned up to make the handwriting more legible for recognition.
Segmentation
Divides the document into zones such as text, images, and tables, isolating areas for focused recognition.
For text zones, segmentation identifies individual characters, words, and lines.
Example: On a scanned invoice, OCR identifies the vendor name in one section and the itemized table in another.
Feature Extraction
OCR systems analyze the patterns of each character, using features like shape, size, and spacing.
This step is crucial for recognizing diverse handwriting styles and printed fonts.
Example: Recognizing a handwritten “7” that might otherwise look like a “1” depending on the stroke style.
Recognition and Post-Processing
Converts the recognized characters into digital text and applies linguistic rules to enhance accuracy.
Includes error correction mechanisms to validate results using pre-trained dictionaries or models.
Example: Correcting “INVIOC” to “INVOICE” by referencing a business glossary.
TL;DR
How to use AI to extract text from a scanned document?
This article examines the challenges involved in processing scanned PDF documents and images. The article also demonstrates how using Large Language Models (LLMs) can enable new ways of parsing documents.
If you wish to skip directly to the solution section, where you can see how Unstract uses AI to extract data from various types of scanned documents with complex tables and fillable form fields, click here.
Try Unstract on the free demo playground. No signup required.
Scanned PDFs and images are prevalent in sectors like finance, healthcare, and government, where critical information is stored in static formats. Organizations that need to extract data from scanned pdfs at scale rely on OCR to unlock this data, enabling automated workflows, faster decision-making, and enhanced data accessibility.
Documents Suitable for OCR Processing
OCR technology supports a wide array of document types:
Invoices: Automates expense tracking by extracting totals, dates, and vendor names.
Tax Forms: Extracts taxpayer IDs and financial summaries for compliance reporting.
Contracts: Digitizes legal agreements for easy archiving and retrieval.
Medical Records: Converts prescriptions and forms into electronic health records.
OCR transforms unstructured data into actionable intelligence, laying the foundation for digital transformation.
Why Extracting Data from Scanned Documents Is a Critical Business Process
In today’s data-driven world, businesses handle vast amounts of information, much of which is trapped in scanned PDFs and images. When teams attempt to extract data from scanned documents manually, the process is not only labor-intensive but also fraught with inefficiencies.
The Problem with Manual Data Extraction
Time-Consuming
Employees spend hours manually transcribing data from scanned documents into digital systems.
Example: A bank processes thousands of scanned loan applications monthly, delaying approvals due to manual transcription bottlenecks.
Error-Prone
Human errors in transcription can lead to costly mistakes, such as incorrect financial entries or misfiled records.
Example: A mistyped account number on a bank statement results in a failed reconciliation process.
Lack of Scalability
Manual methods cannot keep pace with growing data volumes, especially during peak periods like tax season.
The Benefits of Automating Scanned PDF Data Extraction
Improved Accuracy and Consistency
OCR eliminates inconsistencies and errors inherent in manual transcription.
Example: Insurance companies extract accurate claim details, minimizing the risk of processing fraudulent claims.
Accelerated Processing Times
OCR processes documents within seconds, enabling faster workflows and quicker decision-making.
Example: Retail chains process scanned invoices in real time, ensuring timely supplier payments.
Enhanced Audit Readiness and Compliance
Digitized data ensures accurate record-keeping and a clear audit trail, critical for compliance with industry regulations.
Example: Healthcare providers digitize patient forms to comply with HIPAA requirements.
Seamless Integration with Business Systems
Extracted data flows directly into ERPs, CRMs, or databases, enabling real-time analytics and reporting.
Example: A logistics company integrates OCR outputs with its inventory management system to optimize stock levels.
Cost Efficiency
Automating data extraction reduces dependency on manual labor, lowering operational costs.
Example: A tax consultancy saves on payroll expenses by digitizing scanned tax forms using OCR.
OCR not only addresses the inefficiencies of manual data extraction but also unlocks new opportunities for operational excellence.
Business Use Cases for Scanned PDF Processing Across Various Industries
OCR technology is a versatile tool that serves diverse industries by enabling teams to extract data from scanned documents efficiently — whether those are tax forms, insurance claims, or logistics records.
Example: A fintech startup automates the extraction of financial details from 1,000 scanned loan applications daily, reducing processing times from weeks to hours.
2. Healthcare
Documents: Medical prescriptions, patient intake forms.
How OCR Helps:
Converts handwritten prescriptions into digital formats, integrating with pharmacy systems.
Extracts medical history from patient forms, populating electronic health records.
Example: A hospital uses OCR to digitize 500 patient intake forms daily, ensuring faster access to critical medical data during emergencies.
3. Insurance
Documents: Claim forms, accident reports.
How OCR Helps:
Extracts policy details and claim amounts, automating the claims processing workflow.
Extracts taxpayer IDs and income details from scanned forms, speeding up processing.
Digitizes legacy archives for searchable public records.
Example: A tax agency automates the processing of 10,000 scanned tax returns, improving turnaround times by 80%.
5. Retail and E-Commerce
Documents: Purchase orders, delivery receipts.
How OCR Helps:
Extracts item details and quantities from scanned receipts, streamlining inventory management.
Automates expense tracking from scanned invoices.
Example: An online retailer integrates OCR with its supply chain system, automating the processing of 5,000 scanned delivery receipts monthly.
6. Legal Sector
Documents: Contracts, affidavits.
How OCR Helps:
Extracts key clauses, signatures, and dates, digitizing legal documents for easier searchability.
Converts scanned affidavits into editable text for case preparation.
Example: A law firm digitizes its archive of scanned contracts, reducing document retrieval times by 70%.
By automating the extraction of data from scanned PDFs, OCR empowers businesses to operate more efficiently, deliver better services, and remain competitive in a fast-paced digital landscape.
Challenges in Extracting Data from Scanned Documents
Extracting data from scanned PDFs presents unique obstacles that require sophisticated technological solutions. These challenges stem from the inherent complexity of scanned documents, which often lack structure, vary in quality, and incorporate elements like symbols, annotations, or multilingual content. Below, we delve into these issues and their impact on efforts to extract data from scanned PDFs effectively.
1. Variability in Document Formats and Layouts
One of the primary hurdles in processing scanned PDFs is the lack of standardization in formats and layouts. Unlike digital documents, which are often structured and uniform, scanned PDFs can include diverse layouts depending on the source, purpose, or industry. This variability poses a significant challenge when attempting to extract data from scanned documents consistently.
Real-World Example: Consider two scanned invoices: one from a retail supplier that lists itemized charges in a simple table and another from a contractor that uses paragraphs and subheadings to describe services. An OCR system might excel with the tabular format but fail to identify critical data points in the second layout.
Impact: Without advanced AI algorithms, systems cannot adapt to new or irregular layouts, leading to inaccurate or incomplete data extraction from scanned images.
2. Low-Quality Scans or Noisy Images
Scanned PDFs frequently suffer from poor quality due to outdated scanners, improper scanning techniques, or degraded original documents. This issue directly affects the ability of OCR systems to extract text from PDF images accurately.
Challenges:
Blurry or Faded Text: OCR struggles to interpret characters correctly, especially if the scan is out of focus or the text has faded due to age.
Background Noise: Marks like water stains, stamps, or digital noise introduced during scanning can interfere with text recognition.
Crooked or Skewed Documents: Misaligned scans can distort the text, making it difficult for OCR to segment and process data effectively.
Example: A scanned bank statement with faded transaction details and a visible watermark over the text may result in inaccurate OCR scanned PDF outputs, leading to errors in downstream processing.
3. Multi-Language Document Handling
In global enterprises, it’s common to encounter documents written in multiple languages or featuring non-Latin scripts. For example, a scanned insurance form from an international customer might include both English and Cyrillic content, requiring OCR systems to switch seamlessly between languages while preserving context.
Key Challenges:
Diacritical Marks: Languages like French or Spanish include accents that OCR systems may misinterpret.
Non-Latin Scripts: Arabic, Mandarin, or Hindi scripts introduce entirely different character sets that demand specialized OCR training.
Example: A multinational logistics company processes scanned purchase orders in various languages. Errors in recognizing language-specific terms can lead to misinterpretation of critical data points, affecting logistics and inventory decisions.
4. Distinguishing Between Text, Symbols, and Annotations
Scanned PDFs often include elements beyond plain text, such as handwritten notes, checkboxes, logos, or annotations. OCR systems must distinguish between these components to ensure accurate extraction of tables from images or extraction of structured data.
Structured Forms:
Tax documents and loan applications frequently feature checkboxes or grids. OCR must not only recognize the text but also interpret whether checkboxes are selected.
Example: A scanned tax form with a checkbox indicating “Single” filing status must differentiate the ticked box from surrounding text.
Non-Structured Annotations:
Handwritten notes in the margins or symbols (e.g., “+” or “*”) add complexity.
Example: A medical record with a handwritten prescription alongside a printed patient summary can confuse OCR systems, leading to incomplete text extraction from image PDFs.
5. Complex Layouts and Overlapping Elements
Many scanned PDFs feature complex designs, such as multi-column formats, overlapping tables, or embedded charts. OCR systems must analyze and preserve the structure while extracting the underlying data.
Challenges:
Tables spanning multiple pages or mixing numeric and textual data.
Overlapping graphical elements, such as promotional banners or company logos.
Example: A retailer’s scanned receipt includes overlapping columns for item descriptions, prices, and discounts alongside a promotional logo. OCR systems often fail to segment and extract tables from images accurately under such circumstances.
Introduction to Unstract and How It Leverages AI for Extracting Data from a Scanned PDF
Unstract is a cutting-edge platform designed to revolutionize how organizations extract and structure data from scanned PDFs and image-based documents. With its focus on automation and intelligent processing, Unstract eliminates the traditional challenges associated with data extraction from scanned images and unstructured formats, empowering businesses to streamline workflows and improve operational efficiency.
Unstract: A No-code LLM Platform to launch APIs and ETL Pipelines to structure unstructured documents
Overview of Unstract’s Scanned Document Extraction Capabilities
Unstract excels at converting complex, unstructured documents into structured, actionable data. Its AI-driven approach and seamless integration with existing systems make it a versatile solution across industries such as finance, healthcare, insurance, and government. The platform ensures that data extraction from even the most challenging documents, such as handwritten forms or noisy scanned PDFs, is both accurate and scalable.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
How to use LLMs to extract data from a scanned document using Unstract:
AI-Powered Structuring: Using LLMs, the platform organizes extracted data into structured formats like JSON or CSV, making it suitable for database entry or analytics.
No-Code Environment: With an intuitive interface, users can set up document processing workflows without the need for programming expertise.
Key Features of Unstract for scanned document text extraction
Unstract stands out for its robust feature set, designed to address the diverse needs of businesses that rely on OCR-scanned PDFs and other document types:
No-Code Environment:
Allows non-technical users to create and manage document workflows effortlessly.
Reduces the dependency on developers for setting up or modifying workflows.
Example: A healthcare organization can quickly configure a workflow to extract patient information from scanned medical forms without hiring specialized IT staff.
Multi-Format Document Support:
Handles various file types, including scanned PDFs, handwritten forms, and images.
Capable of extracting text from image PDFs, structured tables, and freeform notes, ensuring adaptability to different document types.
Example: Retailers can process purchase orders in multiple formats, from clean PDFs to scanned receipts, with equal efficiency.
API Integrations:
Converts extracted data into real-time outputs such as JSON, enabling seamless integration with CRM, ERP, and analytics platforms.
Ensures a continuous data flow for businesses relying on automated decision-making.
Example: Financial institutions can connect Unstract to their core systems to process loan applications directly from scanned forms, improving speed and accuracy.
Unstract: A no-code Intelligent Document Processing 2.0 (IDP 2.0) platform powered by Large Language Models.
Unstract’s Use of AI for Flexible and Accurate Scanned Document Extraction
One of Unstract’s most transformative features is its ability to adapt to various document types and layouts without requiring constant retraining or reconfiguration. This flexibility is achieved through AI-based processing, which allows the platform to handle unstructured data dynamically.
Advantages of AI-Based Processing:
Layout Recognition: Identifies and preserves the structure of tables, headers, and fields, even in scanned PDFs with complex layouts.
Adaptability: Automatically adjusts to new document formats, eliminating the need for frequent updates or rule changes.
Consistency: Maintains high accuracy across a wide range of document types, reducing errors and manual intervention.
Example: An insurance company using Unstract can process scanned claim forms from multiple providers, each with its own layout, without requiring separate configurations for each template.
By leveraging AI, Unstract empowers businesses to efficiently extract data from scanned documents, improve data accuracy, and scale operations without being bogged down by document variability.
LLMWhisperer: The Best Scanned Document OCR purpose-built for AI Processing
LLMWhisperer is a specialized text parser that bridges the gap between raw OCR outputs and advanced Large Language Model (LLM) processing. Unlike traditional OCR engines, which often struggle to organize unstructured data, LLMWhisperer focuses on helping developers extract data from scanned image files and prepare it in a structured manner, enabling smoother integration with downstream systems powered by LLMs.
Introduction to LLMWhisperer
At its core, LLMWhisperer serves as a pre-processing layer that enhances the usability of data extracted from scanned or image-based documents. By intelligently parsing text outputs, it transforms noisy, unorganized data into structured fields suitable for analysis or further refinement by LLMs. This capability is particularly valuable in handling low-quality scans, handwritten forms, and documents with intricate layouts.
What It Is Not:
LLMWhisperer does not directly perform OCR using AI or LLMs.
Instead, it prepares OCR outputs for downstream LLM processing, ensuring contextual and structural accuracy.
Key Scanned PDF OCR Capabilities of LLMWhisperer
Structured Data Extraction:
LLMWhisperer helps prepare documents for LLMs to best understand
Handles both printed and handwritten text effectively, ensuring no loss of critical information during processing.
Low-Quality Document Handling:
Enhances noisy or blurry scans to improve OCR recognition, ensuring accurate text extraction from problematic scanned PDFs.
Example: Processing an aged, faded insurance policy document to recover key policyholder details.
Multi-Language Support:
Capable of parsing documents in multiple languages, accommodating global business operations.
Example: A logistics firm processes multilingual invoices from international suppliers using LLMWhisperer.
Live coding session: How to extract data from scanned documents with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in scanned PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
Pre-Processing with LLMWhisperer: How It Supports Scanned PDF/Image OCR
The role of LLMWhisperer in pre-processing scanned PDFs and image-based documents is crucial to achieving high-quality OCR results. By addressing challenges like noise, layout preservation, and contextual accuracy, it ensures that data extraction workflows deliver actionable outputs with minimal errors.
How LLMWhisperer Enhances Scanned PDF OCR Processing
Improves OCR Recognition for Noisy or Low-Quality Scans:
Applies filters and enhancements, such as de-skewing, noise reduction, and contrast adjustment, to prepare scanned documents for OCR processing.
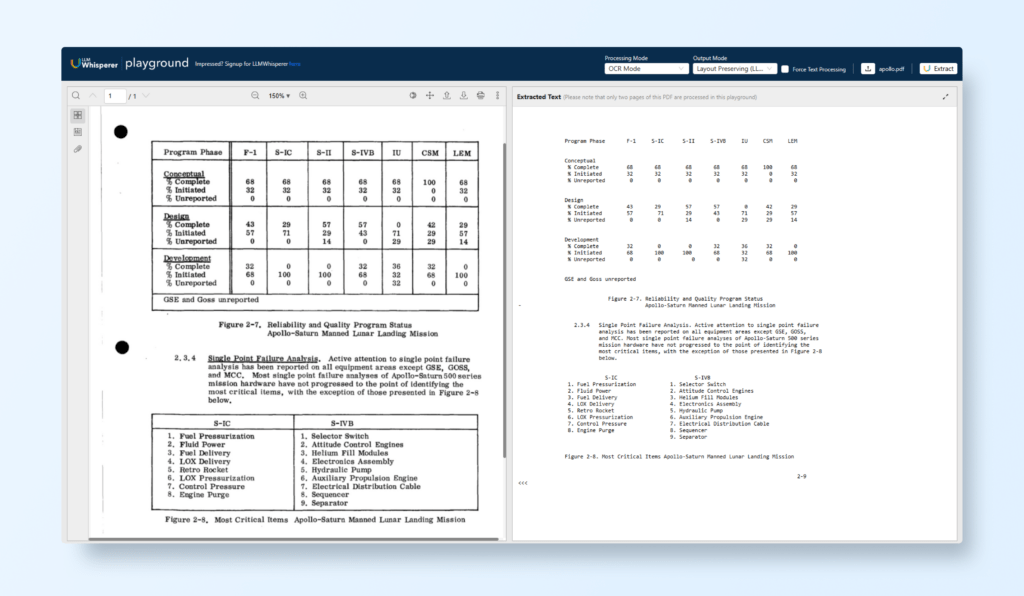
Example: A historical scanned document, such as the Apollo Space Mission Manual, is cleaned and clarified to ensure accurate text recognition.
Preserves Document Layout:
Maintains the integrity of the original document structure, including tables, multi-column layouts, and annotations, enabling reliable data extraction.
Example: In a scanned bank statement, LLMWhisperer ensures that transaction data remains aligned with corresponding dates and balances.
Contextual Pre-Processing:
Organizes text outputs into logical groupings, ensuring key sections like headers, footers, and tables are properly categorized for downstream analysis.
Example: A scanned invoice is parsed to separate billing details, itemized charges, and payment terms into distinct fields.
Test LLMWhisperer scanned document OCR API for free — Instant Results, No Signup Required
If you want to skip straight to the tool, see how LLMWhisperer OCR API handles scanned pdfs of any complexity — handwritten receipts, poorly photographed images, multi-column layouts, and multi-language invoices.
Try LLMWhisperer scanned document OCR for free on the Playground. No signup required.
Scenario: A historical document like the Apollo Space Mission Manual is scanned and uploaded to the LLMWhisperer Playground.
Steps:
Upload the document to the playground.
Observe how LLMWhisperer pre-processes the data, enhancing text clarity and preserving the manual’s intricate layout.
Extract the structured text, showcasing how even complex technical documents can be digitized effectively.
LLMWhisperer: Best OCR for processing document scans and images
This demonstration highlights LLMWhisperer’s ability to handle diverse document types, ensuring that businesses can reliably scan and OCR PDFs for actionable insights.By integrating LLMWhisperer with platforms like Unstract, organizations can tackle the most challenging aspects of OCR-scanned PDF processing, from noisy images to multilingual content, with unparalleled efficiency.
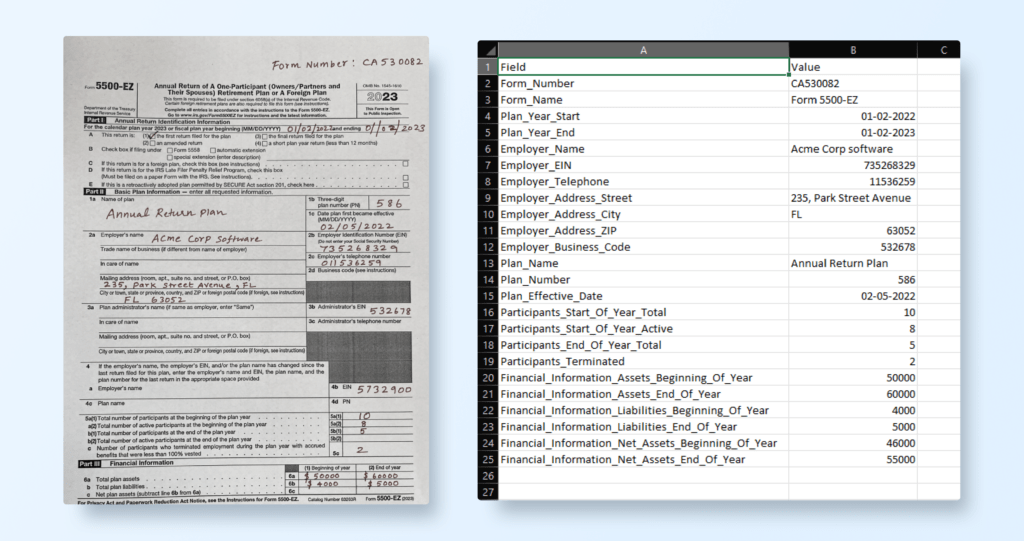
Setting Up Unstract for Data Extraction from a Scanned Tax Form PDF
Unstract provides a streamlined approach to extract structured data from scanned tax forms using AI-based processing and LLMWhisperer for pre-processing. Below is a step-by-step guide to set up Unstract to extract critical fields such as Form Number, Employer Name, Employer Identification Number, and Total Plan Asset from scanned tax form PDFs.
Step 1: Configuring Unstract Essentials
This integration allows Unstract to leverage advanced language models for understanding and structuring the document content.
Connecting OpenAI for LLMs:
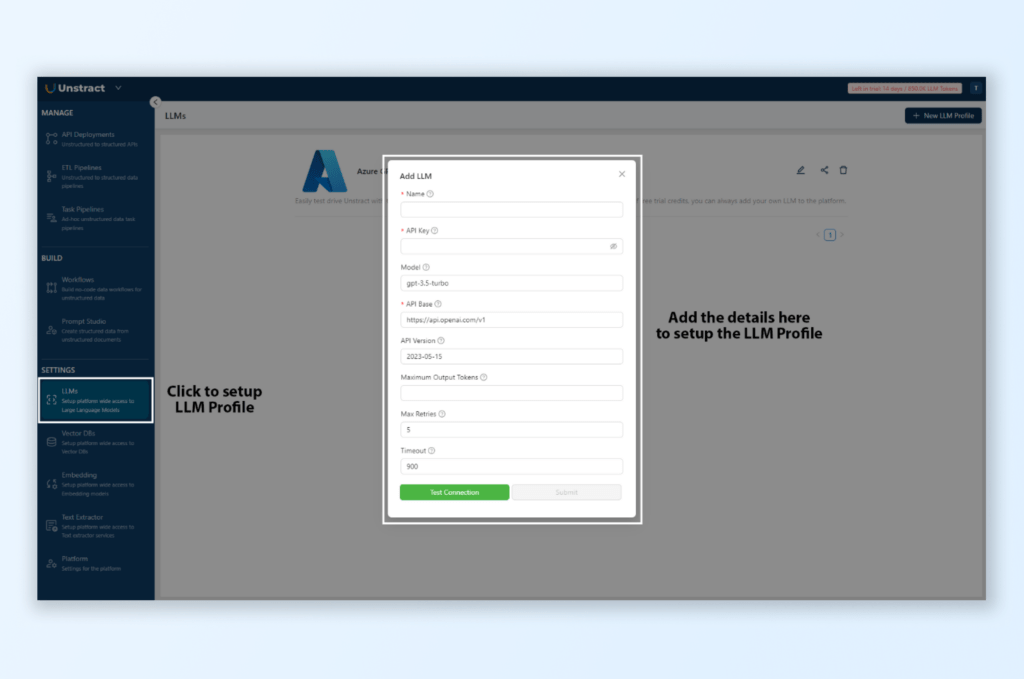
Go to Settings > LLMs in the Unstract dashboard.
Click on New LLM Profile, select OpenAI, and input your API key.
This integration allows Unstract to leverage advanced language models for understanding and structuring the document content.
Scanned document data extraction: Add LLM model for document understanding
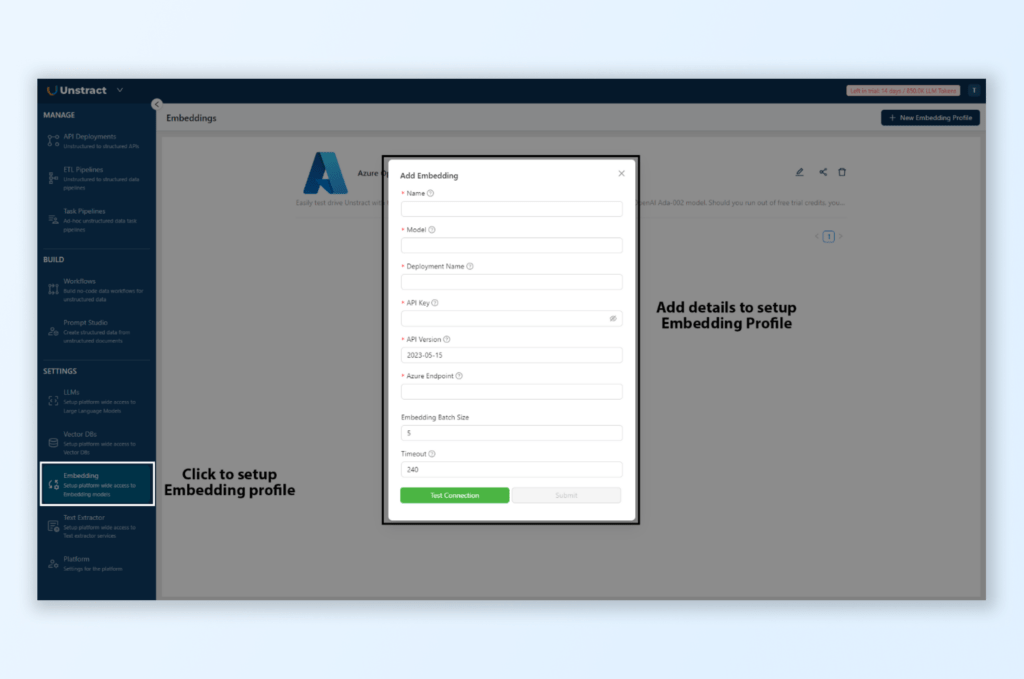
Setting Up Embeddings:
Navigate to Settings > Embeddings and create a new profile.
Select OpenAI embeddings and input the necessary API details.
Embeddings help Unstract identify relationships within the document, such as connecting labels (e.g., “Employer Name”) with their respective values.
Vector Database Configuration:
Access Settings > Vector DBs and click on New Vector DB Profile.
Choose Postgres Free Trial VectorDB and provide the required API key and database URL.
The vector database enables efficient storage and retrieval of extracted data for further processing.
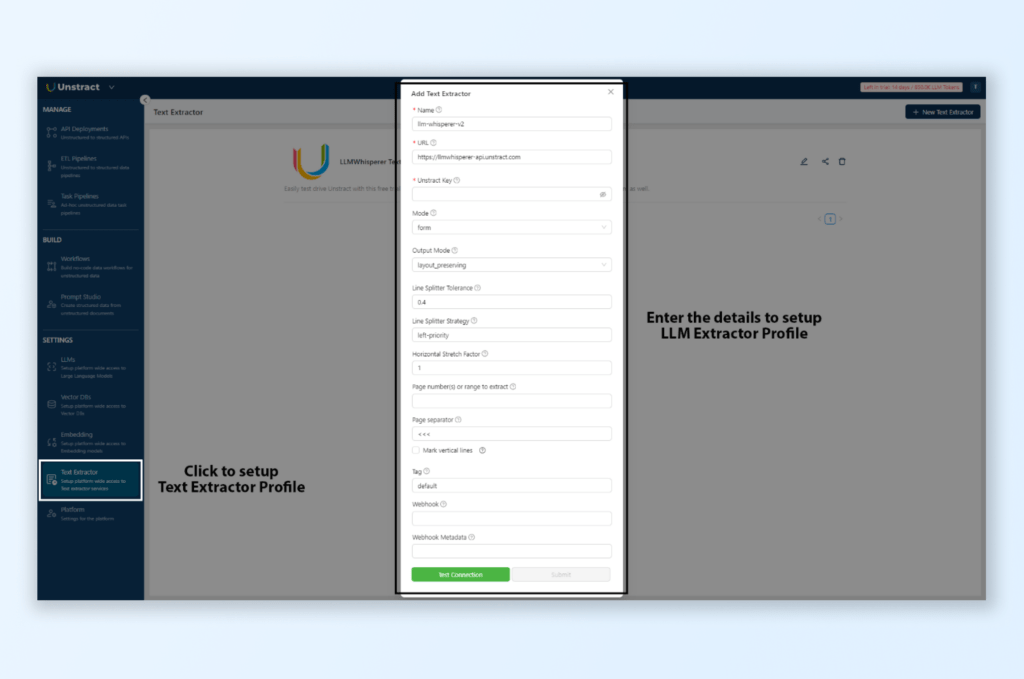
Text Extractor – LLMWhisperer:
Under Settings > Text Extractor, select LLMWhisperer V2 and configure it for OCR mode.
Set the Processing Mode to OCR and the Output Mode to line-printer to optimize text extraction from scanned PDFs.
Step 2: Setting Up the Tax Form in Prompt Studio
Access Prompt Studio:
Open Prompt Studio from the left pane of the Unstract interface.
Create a New Project:
Click on New Project and fill in the following details:
Tool Name: Handwritten OCR Tool
Author/Org Name: Your name or organization.
Description: Extracts key data fields from handwritten tax forms.
Upload Document:
In the project interface, click on Manage Documents and select Upload Files.
Upload the scanned tax form PDF for testing and configuration.
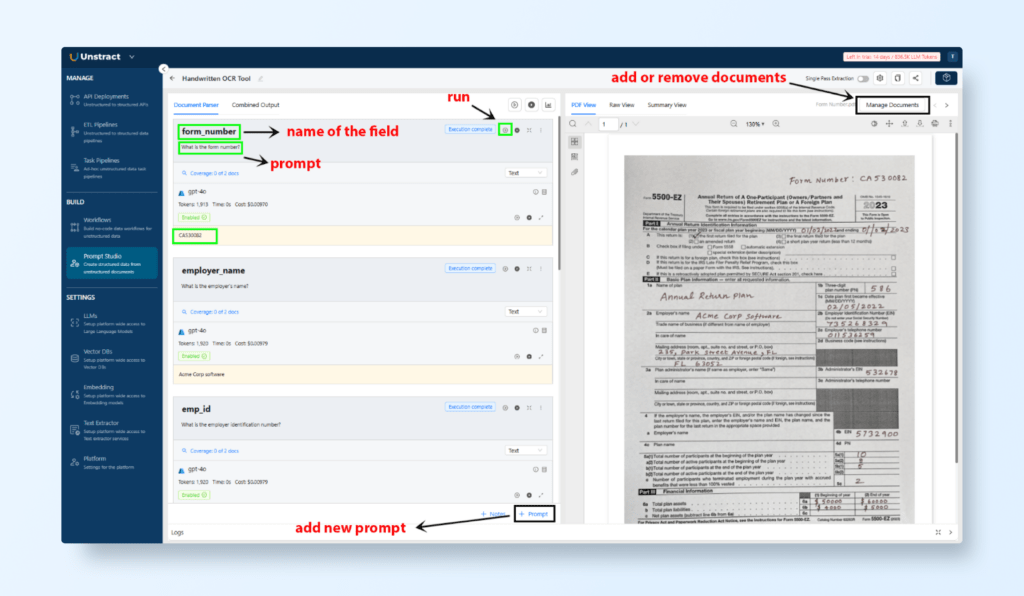
Add Prompts for Key Fields:
Create specific prompts for the fields to be extracted. For example:
Field Name: Form Number | Prompt Text: “What is the form number?”
Field Name: Employer Name | Prompt Text: “What is the employer’s name?”
Field Name: Employer ID Number | Prompt Text: “What is the employer identification number?”
Field Name: Total Plan Asset | Prompt Text: “What is the total plan asset?”
Run and Test Prompts:
Click Run to execute the prompts and view the extracted data.
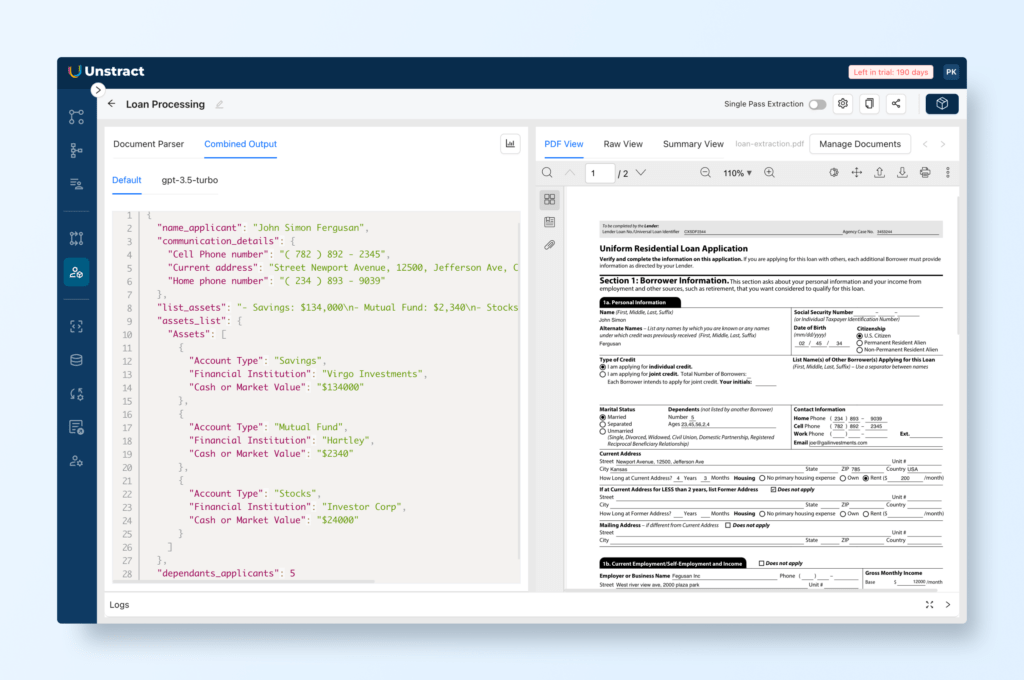
Check the Output Tab for individual field results or the Combined Output Tab for structured JSON output.
Scanned PDF data extraction: Write natural language prompts to extract data in a structured format (JSON)
Step 3: Exporting and Deploying the Tool as an API
Export the Tool:
Once the prompts are verified, click on Export as Tool to make the tool accessible for workflow integration.
Name the tool appropriately (e.g., “Tax Form Parser API”).
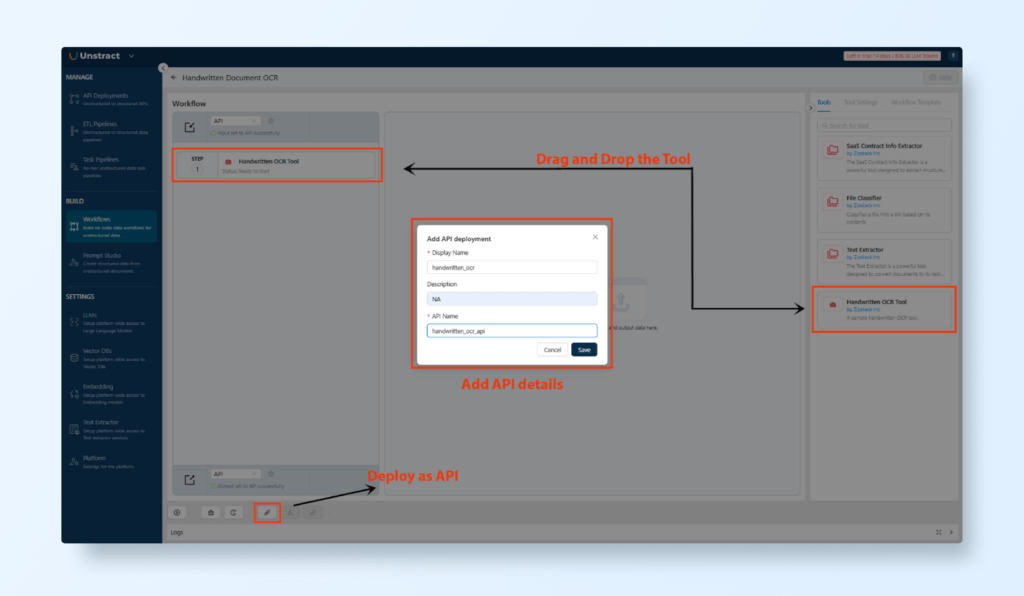
Deploy Workflow as an API:
Go to Workflows in the left pane and click New Workflow.
Name the workflow (e.g., “Tax Form Extraction Workflow”) and provide a brief description.
Drag and drop the exported tool into the workflow area.
Configure the API Input to accept scanned PDFs and the API Output to return extracted data in JSON format.
Click Save and then Deploy API. A confirmation message will appear upon successful deployment.
Unstract scanned document data extraction API
10. Setting Up Unstract Workflow as an API
After setting up the extraction tool, deploying it as an API allows external systems to integrate seamlessly with Unstract for processing scanned tax forms.
Step 1: Configuring the API
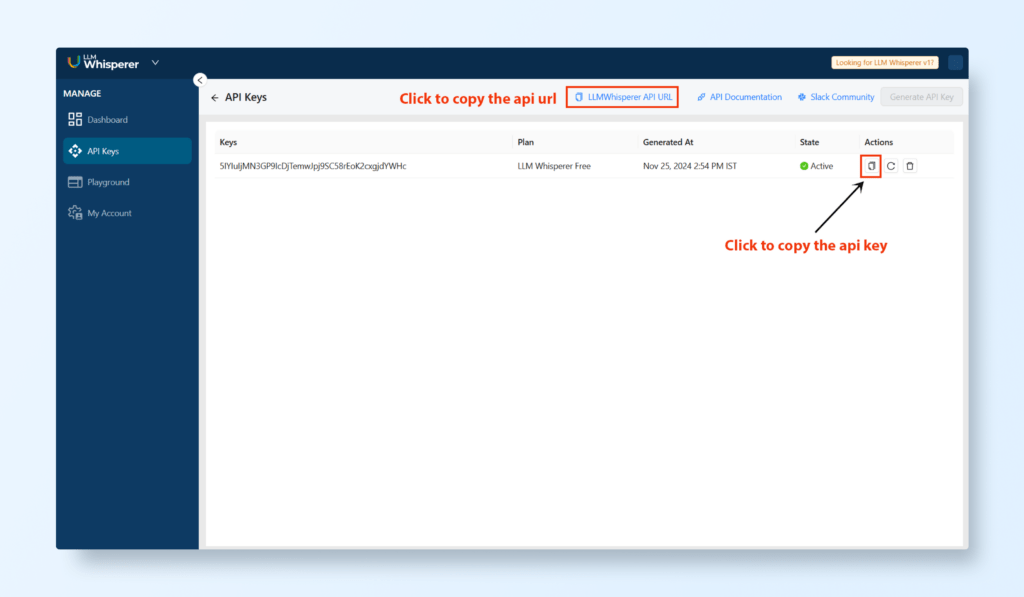
Retrieve API Details:
Navigate to the API Deployment Section in Unstract.
Copy the API URL and generate an API Key by clicking on Manage Keys.
Prepare API Input/Output Connectors:
Ensure the workflow’s API Input is set to accept file uploads (PDFs).
Configure the API Output to deliver structured JSON data.
Step 2: Accessing the API via Postman
Set Up Postman:
Open Postman and create a new POST Request.
Paste the API URL into the URL Field.
Authorize the Request:
Go to the Authorization Tab in Postman.
Select Bearer Token as the authorization type.
Paste the copied API Key into the Token Field.
Prepare the Request Body:
Navigate to the Body Tab in Postman.
Select form-data as the format.
Add a key field named files and change its type to File.
Upload the scanned tax form PDF from your local system.
Send the Request:
Click Send to submit the request.
The initial response will include a status field set to “executing.”
Check the Status and Extract JSON Output:
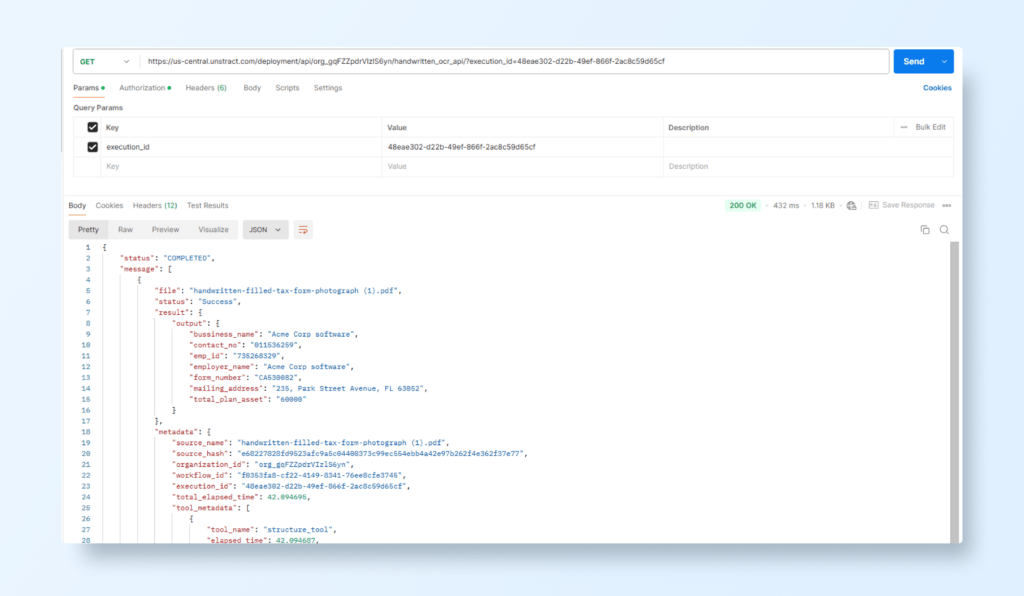
Use the status_api link from the response to create a new GET Request.
Once the process is complete, view the returned JSON data, including fields such as:
Form Number
Employer Name
Employer Identification Number
Total Plan Asset
Unstract scanned PDF data extraction API
Convert JSON Output to Excel
To enhance usability, you can convert the JSON response into an Excel file using Python. Below is a code snippet for this process:
import json
import pandas as pd
# Function to convert JSON to CSV
def json_to_csv(json_path, csv_output_path):
# Load JSON data
with open(json_path, "r") as file:
data = json.load(file)
# Flatten the JSON structure
flat_data = pd.json_normalize(data, sep="_")
# Save to CSV
flat_data.to_csv(csv_output_path, index=False)
return csv_output_path
# Define file paths
json_path = "/mnt/data/tax_form_data.json" # Input JSON file
csv_output_path = "/mnt/data/tax_form_data.csv" # Output CSV file
After execution of this code, you will get the Excel file below as output.
Learn how faithfully reproducing the structure of tables and other elements by preserving the original PDF layout is crucial for better performance in LLM and RAG applications.
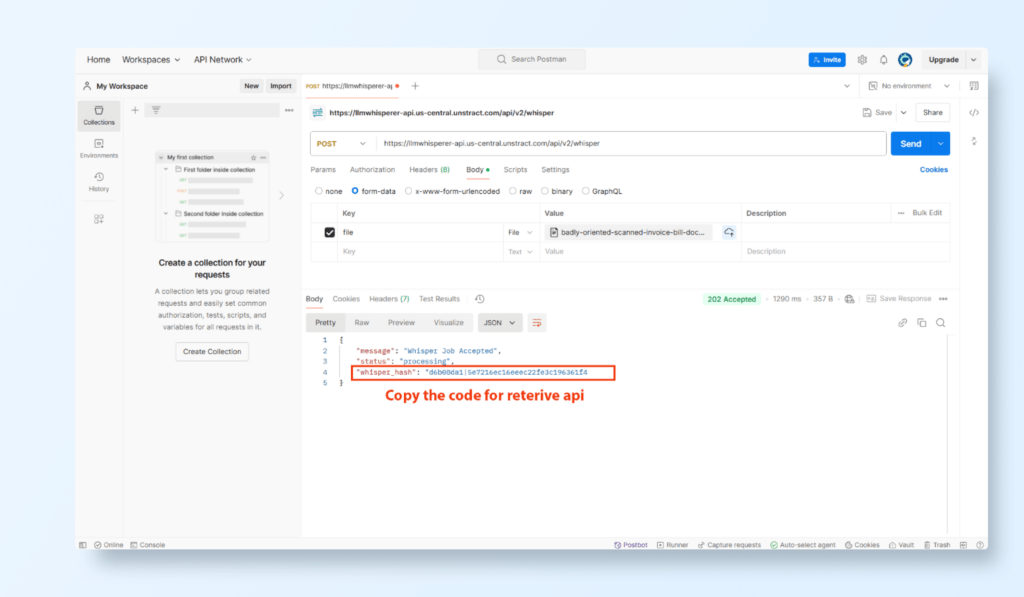
Using LLMWhisperer API for Parsing a Scanned and Badly Skewed Invoice
For processing badly oriented or skewed scanned documents such as invoices or bills, LLMWhisperer provides an API-based solution to extract structured data with high accuracy. Below is a detailed walkthrough of the process:
Step 1: Retrieve API Key and Endpoint
Navigate to the LLMWhisperer API Key Management Portal: Visit LLMWhisperer API Keys.
Generate API Key:
Click on Generate Key and copy the API Key.
Note the API endpoint URL for processing:
POST Endpoint: https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper
GET Endpoint: https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper-retrieve
Value: (paste the whisper_hash value copied from the POST request response).
Send Request:
Click on Send.
The API will return a JSON response containing the extracted text and data fields from the skewed invoice or bill.
Sample Output
Here’s an example of what the output might look like:
LLMWhisperer: Best scanned PDF OCR API
AI-Powered Scanned Document Data Extraction: What is next?
Unstract stands out for its flexibility, adaptability, and precision, offering a no-code environment, multi-format support, and seamless API integrations. Its AI-driven processing ensures high accuracy, even when handling complex or poorly structured documents like handwritten tax forms and skewed invoices. On the other hand, LLMWhisperer complements this by pre-processing low-quality scans, preserving layout integrity, and preparing data for downstream analysis. Together, they deliver unmatched efficiency, scalability, and consistency, empowering businesses to unlock valuable insights from previously inaccessible data.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
Explore scanned document text extraction by document type
Individual Tax Returns Data Extraction — Extract text from scanned tax returns, capturing filer details, income sources, deductions and tax liabilities across all IRS forms and layouts
ACORD Insurance Document Data Extraction — Extract text from scanned ACORD forms, pulling policyholder details, coverage limits, premiums and endorsements accurately regardless of format
Loan Data Verification — Extract text from scanned loan agreements, capturing borrower details, principal amounts, interest rates and repayment terms for faster verification workflows
Purchase Orders Data Extraction — Extract text from scanned purchase orders, pulling vendor details, line items, quantities and pricing regardless of layout or template
Receipt Data Extraction — Extract text from scanned receipts and handwritten invoices, capturing merchant names, dates, line items and totals for automated expense processing
Invoice Data Extraction — Extract text from scanned invoices across formats and languages, pulling vendor details, line items, taxes and totals into structured, LLM-ready output
What is Scanned PDF OCR, and how is it different from normal PDF text extraction? Scanned PDF OCR is the process of running optical character recognition on image-only PDFs, so the text becomes machine-readable. Because the original file is just pixels, scanned PDF OCR is the essential first step before you can index, search, or analyze the document.
Why do some tools fail to OCR scanned PDF statements that have tables or multiple languages? OCR-scanned PDF files are challenging because of low resolution, skew, and multilingual fonts that can confuse rule-based engines. Unstract couples advanced image pre-processing(LLMWhisperer) with LLMs to recognize layout, language, and context, delivering highly accurate structured output.
What’s the fastest way for developers to automate scanned PDF OCR in bulk? Deploy the Unstract API, loop through your folder of images, and call the endpoint; each request performs scanned PDF OCR, returns a job hash, and lets you pull the finished JSON when ready—ideal for nightly batches of thousands of pages.
What are the main challenges when trying to extract data from scanned PDFs or images? The challenges of extracting data from scanned PDF or images include variable formats, low quality or noisy scans, multi-language content, and complex layouts with tables or annotations. Effective OCR scanned PDF solutions, often enhanced by AI, are required to address these issues and reliably extract structured data from scanned documents.
What is LLMWhisperer and how does it assist with Scanned PDF OCR? LLMWhisperer is a specialized pre-processing tool designed to enhance Scanned PDF OCR. It cleans up OCR scanned documents by performing tasks like de-skewing, noise reduction, and contrast adjustment. It also preserves the original document layout and organizes text logically, ensuring higher quality input for downstream AI processing and data extraction.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.