Convert Unstructured PDF Documents to Structured JSON using Unstract.
Table of Contents
Introduction: Why JSON? Why Convert PDFs to JSON?
In today’s digital-first business environment, efficiently handling large volumes of data is critical. Documents in PDF format are widely used for various purposes, from contracts and invoices to reports and forms. While PDFs are perfect for preserving the look and layout of a document, they are not the most convenient format for extracting and manipulating data. This is where converting PDFs to JSON becomes essential.
Why JSON is a Preferred Format for Structured Data
JSON (JavaScript Object Notation) is one of the most commonly used formats for structuring and exchanging data between systems. It has become a standard due to its flexibility, lightweight nature, and ease of use, especially when compared to other formats like XML. Here’s why JSON is the go-to format for handling structured data:
Human-Readable and Machine-Friendly: JSON is easy to understand for both humans and machines. Its clean, organized structure of key-value pairs allows developers to quickly identify and extract relevant data from any dataset, making it ideal for document processing.
Universally Supported: JSON is supported by virtually all programming languages, including Python, JavaScript, and PHP. This means data stored in JSON can be easily integrated into a wide variety of applications and systems without compatibility issues.
Lightweight and Fast: JSON is a minimalistic format, containing only the necessary data without extraneous information. This makes it an efficient choice for transmitting and storing data, especially in high-performance environments where speed and bandwidth usage are concerns.
Scalable and Flexible: Whether dealing with simple data points or complex datasets, JSON is highly scalable. It can represent everything from a single item of data to deeply nested structures. This scalability is particularly useful when extracting information from complex PDF documents that may contain tables, images, and forms.
TL;DR
In this article, we will explore why JSON is a preferred format for structured data, its benefits, and how to use Unstract to leverage Large Language Models (LLMs) to convert PDF documents into JSON.
If you want to skip directly to the solutions section, click here.
Why Convert PDFs to JSON?
JSON has become one of the most widely used standards for data interchange, valued for its human-readable format and lightweight structure
PDF to JSON conversion transforms unstructured data trapped in PDF documents into a structured, machine-readable format. Once the data is structured in JSON format, it opens up numerous opportunities for automation, analysis, and integration into various business processes.
Key Use Cases for Converting PDFs to JSON:
Data Analysis: Converting a PDF to JSON allows businesses to extract critical information from documents like contracts, financial statements, or invoices and perform in-depth data analysis. For example, an organization can extract invoice details like amounts, dates, and customer information from PDFs, then analyze payment patterns, forecast cash flow, or identify anomalies in billing.
Automation and Integration: By using PDF to JSON converters, businesses can automate document workflows. For instance, extracted invoice data can automatically be fed into accounting software or CRM systems, eliminating manual data entry and reducing the chances of errors.
Streamlining Business Operations: JSON’s structured format makes it easy to integrate data into backend systems. Once a PDF is converted to JSON, businesses can automate routine tasks like filling out forms, generating reports, or sending automated responses based on the extracted data.
Database Storage: JSON is natively supported by most modern databases, like MongoDB and PostgreSQL. Converting a PDF to JSON makes it easy to store document information directly into a database, allowing for easy querying and retrieval in the future.
API Integration: JSON is the format of choice for APIs, making it simple to transmit data between different systems. Once a PDF document is converted to JSON, the structured data can be easily shared via APIs with other services or platforms, such as financial reporting tools or ERP systems.
A Primer on Invoice Data Extraction and Processing with LLMs. Read it here.
Benefits of Structured JSON Data for Downstream Applications
The primary advantage of converting PDF to JSON is the ability to unlock the full potential of the data stored within the document. Here’s how structured JSON data benefits various applications:
Enhanced Data Extraction: Converting PDFs to JSON allows for precise and detailed extraction of data from tables, text fields, and other document elements. This structured format allows for the automation of tasks like populating fields in software applications or filling out forms.
Efficient Storage: JSON is lightweight and easy to store, making it an ideal choice for archiving large datasets. Businesses can convert massive volumes of PDFs into JSON, reducing the storage burden while retaining the ability to retrieve and analyze data whenever needed.
Improved Accuracy and Consistency: JSON ensures that extracted data follows a consistent structure, making it easier to process automatically. For instance, data extracted from multiple invoices or contracts can be standardized, ensuring that all critical fields are present and properly formatted.
Integration with APIs: Many modern systems and applications use APIs for data exchange, and JSON is the preferred format for API communication. By converting PDFs to JSON, businesses can effortlessly integrate document data into external systems, such as sending financial data to an accounting platform or uploading contract details to a CRM system.
Faster Processing: With structured JSON data, systems can process and analyze documents much faster than with unstructured PDF files. JSON’s simple structure allows quick lookups, searches, and modifications, saving time and computational resources.
Automation-Friendly: Once data from a PDF is in JSON format, automation tools can easily work with it to trigger workflows, generate reports, or send notifications based on the data. This is particularly useful for repetitive tasks that would otherwise require manual intervention, such as extracting and processing data from hundreds of invoices.
Examples of JSON Use Cases in Different Sectors
Finance: Extracting data from invoices, balance sheets, and bank statements from PDFs to JSON allows for easier integration with financial software, automating payment processing, and creating financial reports.
Healthcare: Converting medical reports or patient information stored in PDFs into JSON makes it easier for healthcare organizations to integrate data into electronic health records (EHR) systems, perform analysis, and ensure compliance with regulatory standards.
E-Commerce: PDF to JSON conversions allow e-commerce platforms to extract order details, shipping information, and product catalogs, which can then be integrated into order management systems, inventory tracking, and customer support tools.
By converting PDFs to JSON, businesses can unlock a range of opportunities for automation, data integration, and improved decision-making. It’s a foundational step toward creating smarter, more efficient workflows that reduce manual effort and enhance accuracy across various business operations.
Challenges in Parsing PDFs (and Converting to JSON)
Converting PDFs to JSON can unlock valuable insights and streamline business operations, but the process is far from straightforward. PDFs come in a wide variety of formats, layouts, and structures, making it challenging to extract data in a clean, structured format like JSON. Let’s dive into the key challenges businesses face when trying to convert PDFs to JSON.
Variety in PDF Formats
One of the biggest challenges in parsing PDFs is the sheer variety of formats they can come in. PDFs are designed to preserve the layout and appearance of documents across different devices and platforms. However, this flexibility in layout becomes a hurdle when trying to extract data for structured use.
Diverse Layouts: PDFs may contain single-column text, multi-column layouts, complex tables, or a combination of these. For instance, a financial report might have text in one section and a table summarizing financial data in another, each with its own format.
Different Types of PDFs: Some PDFs are text-based, while others are scanned images of documents. Text-based PDFs can be easier to parse, but scanned documents add another layer of complexity. Extracting data from scanned PDFs requires optical character recognition (OCR) to first convert the images to text.
Document-Specific Variations: Businesses receive invoices, contracts, and reports from multiple vendors, clients, and stakeholders. Each of these documents may use a different template or format, even if they convey the same information. This lack of standardization can make it difficult to create a PDF to JSON converter that handles all possible variations seamlessly.
The variety in PDF formats requires specialized tools that can adapt to different document structures, accurately extracting data without losing context or format.
Unstructured Nature of PDFs
PDFs were primarily designed for human readability, not for automated data extraction. They are often unstructured, meaning that the data doesn’t follow a clear or standardized pattern that can be easily parsed by machines. This unstructured nature makes it challenging to extract the relevant information, especially when converting it to JSON.
Text-Heavy PDFs: Many PDFs contain large blocks of text with minimal formatting, making it hard to identify key pieces of information like names, dates, or amounts. For example, legal contracts or research papers may span several pages, with key data points buried within paragraphs of text. Extracting structured data from such documents often requires the use of AI or Natural Language Processing (NLP) to understand the context.
Scanned Documents: When dealing with scanned documents, the problem becomes even more complex. Scanned PDFs are essentially images, and the data must be extracted using OCR. Even with advanced OCR techniques, the quality of the scanned image (blurriness, skewed text, or poor contrast) can affect the accuracy of the data extraction process.
The unstructured nature of PDFs means that specialized tools, like Unstract’s PDF to JSON converter, are essential for interpreting the context and extracting the necessary information for downstream applications.
Complex Data Elements
PDFs often contain a mix of simple text and more complex elements such as tables, multi-column layouts, forms, checkboxes, radio buttons, and images. Handling these complex data elements can be particularly challenging when trying to convert PDFs to JSON.
Tables and Multi-Column Layouts: Tables are a common feature in PDFs, especially in invoices, financial reports, or spreadsheets. However, extracting data from tables isn’t as simple as copying text. The layout of rows and columns needs to be preserved, and the relationships between data points (such as totals, quantities, or prices) must be accurately represented in the JSON output. Similarly, multi-column layouts can confuse traditional parsers, which may read the text out of order.
Forms, Checkboxes, and Radio Buttons: Many PDFs contain interactive elements like forms, checkboxes, and radio buttons. For instance, in surveys or application forms, these elements hold crucial data. Extracting and representing these in JSON requires advanced parsing techniques that can differentiate between filled and unfilled checkboxes, or between selected and unselected radio buttons.
Images and Logos: Some PDFs also contain images, logos, and other visual elements that are not easily represented in JSON format. While the images themselves may not need to be extracted as data, their placement or context can affect the interpretation of nearby text, especially in documents like invoices where logos or signatures may be present next to crucial information.
Handling these complex data elements requires sophisticated algorithms that can understand and retain the relationships between different parts of the document, ensuring that no information is lost when converting a PDF to JSON.
OCR Limitations
OCR (Optical Character Recognition) is a key technology used to extract text from scanned PDFs, but it comes with its own set of limitations. While modern OCR tools have significantly improved, they still face challenges in accurately parsing text from scanned or handwritten documents, especially when converting them into structured formats like JSON.
Scanned Documents: As mentioned earlier, scanned documents are essentially images, and OCR is needed to convert them into machine-readable text. The quality of the scan can greatly impact the OCR’s accuracy. Low-resolution scans, skewed or tilted text, and faded prints can lead to errors in text recognition.
Handwritten Text: Handwritten PDFs present an even greater challenge. OCR technology struggles to accurately recognize and convert handwritten text into digital form, especially when the handwriting is cursive or uneven. This can result in misinterpretations or missing data during the conversion process.
Formatting Loss: Another issue with OCR is the potential loss of formatting. Scanned documents often have carefully structured layouts, with tables, columns, or forms. OCR can extract the text, but it may lose the structure, making it difficult to organize the data properly when converting it to JSON.
Overcoming These Challenges with AI and Unstract
Given these challenges, converting PDFs to JSON requires more than basic parsing techniques. AI-powered tools like Unstract are designed to address these issues by using LLMs (Large Language Models) and advanced OCR technology. Unstract’s PDF to JSON converter not only handles different PDF formats but also tackles complex layouts and unstructured data, making it easier to extract and organize information in JSON format.
With AI at its core, Unstract can parse complex elements such as tables, forms, and multi-column layouts, while advanced OCR ensures accurate extraction from scanned or handwritten documents. This makes Unstract an ideal solution for businesses looking to automate the conversion of PDFs to JSON, regardless of the document’s complexity.
The Role of AI/LLMs in Document Processing
The advent of AI (Artificial Intelligence) and LLMs (Large Language Models) has revolutionized how businesses handle document parsing and extraction, especially when converting PDFs to JSON. Traditional methods of processing PDFs often struggle with the variety and complexity of formats, but AI-driven PDF parsing introduces a new level of efficiency, accuracy, and adaptability. Let’s explore how AI and LLMs are reshaping the landscape of document processing.
The Advent of AI and LLMs: Revolutionizing Document Parsing
With the rise of AI and LLMs, document parsing has evolved from simple rule-based systems to highly intelligent models that can understand and process unstructured data. PDFs are inherently complex, as they can contain diverse layouts, images, forms, and tables. Traditional parsing tools struggle with this variability, but AI-powered models bring the ability to adapt and learn from different formats.
For instance, AI models can identify key patterns and relationships within a document, such as recognizing that a certain section of a PDF contains a table with invoice details, while another section may have a legal disclaimer in free text. This capability allows AI to parse documents that were previously too complex for conventional tools. LLMs, trained on vast amounts of text data, have the ability to understand context, making them particularly effective in extracting meaningful data from PDFs.
By leveraging LLMs, businesses can now automate the extraction of structured data from PDFs with high accuracy. Whether it’s invoices, legal contracts, or scanned documents, AI-driven tools like Unstract can handle the entire process, ensuring that businesses can easily convert PDFs to JSON without manual intervention.
AI-Driven PDF Parsing: Interpreting Unstructured Data in PDFs
One of the biggest challenges in converting PDFs to JSON is the unstructured nature of many PDFs. Traditional parsing tools often fail when it comes to extracting meaningful data from complex documents, but AI-driven PDF parsing overcomes this by applying machine learning techniques to understand the document’s structure.
Here’s how LLM models improve PDF parsing:
Contextual Understanding: AI models, especially LLMs, are trained to understand the context within a document. This means they can differentiate between important data (e.g., invoice amounts, dates) and irrelevant information (e.g., footnotes or disclaimers). For instance, when processing a multi-page PDF with a mix of text, tables, and images, AI can accurately identify which sections of the document hold key data and which can be ignored in the JSON conversion.
Handling Complex Layouts: PDF documents often come with complex layouts such as multi-column text, tables, and embedded images. Basic parsers struggle to maintain the integrity of these layouts when extracting data. AI, on the other hand, can intelligently analyze and preserve these structures, ensuring that the JSON output reflects the original document accurately. This makes AI-driven PDF parsing particularly effective for financial reports, contracts, and forms where layout integrity is crucial.
Adaptability to Different Formats: AI models are not bound by rigid rules. They can adapt to various PDF formats, whether it’s a neatly typed invoice or a scanned handwritten note. This adaptability is what makes AI-powered tools like Unstract capable of processing PDFs that vary greatly in complexity and structure, enabling businesses to convert PDFs to JSON with confidence.
Benefits of Using AI/LLMs for Document Processing
The introduction of AI and LLMs into document processing provides significant benefits, especially when it comes to converting PDFs to JSON. Here are the key advantages:
Enhanced Accuracy: Traditional PDF parsers are prone to errors, especially when handling complex documents or scanned files. AI-driven solutions significantly enhance accuracy by using machine learning to detect patterns and make intelligent decisions about the content being processed. For instance, LLM models can differentiate between header information and body content, ensuring the correct extraction of data.
Handling Complex Layouts: One of the most significant advantages of AI/LLMs is their ability to handle documents with complex layouts. Whether it’s multi-column text, tables, or forms with checkboxes and radio buttons, LLM models can interpret these structures accurately, ensuring that the extracted data is well-organized in the JSON output. This ability is crucial for industries dealing with documents like invoices, medical records, or financial statements, where layout preservation is essential.
Improved OCR Performance: AI enhances the capabilities of OCR (Optical Character Recognition), especially when dealing with scanned PDFs or handwritten documents. Traditional OCR struggles with low-quality scans or distorted text, but AI-driven OCR models improve text recognition by learning from vast datasets. This means businesses can now convert scanned PDFs to JSON with higher accuracy, even when dealing with poor-quality documents.
Faster Processing: AI models are not only more accurate but also faster at processing large volumes of documents. Instead of manually parsing through PDFs or relying on slow traditional methods, AI-driven PDF parsing can handle thousands of documents in a fraction of the time. This speed is especially valuable for businesses dealing with high volumes of paperwork, such as legal firms or financial institutions.
Cost Efficiency: By automating the process of converting PDFs to JSON, businesses can reduce the need for manual labor, thereby cutting costs. LLM models handle the bulk of the work, from parsing to data extraction, allowing teams to focus on more strategic tasks. Moreover, tools like Unstract can scale with business needs, providing flexibility without increasing costs.
In summary, the integration of AI and LLMs in document processing marks a significant shift in how businesses approach PDF parsing and extraction. The ability of AI to adapt to complex layouts, understand context, and improve OCR accuracy makes it an invaluable tool for converting PDFs to JSON. By leveraging AI-driven tools like Unstract, businesses can automate and streamline document workflows, ensuring data accuracy, speed, and cost-efficiency.
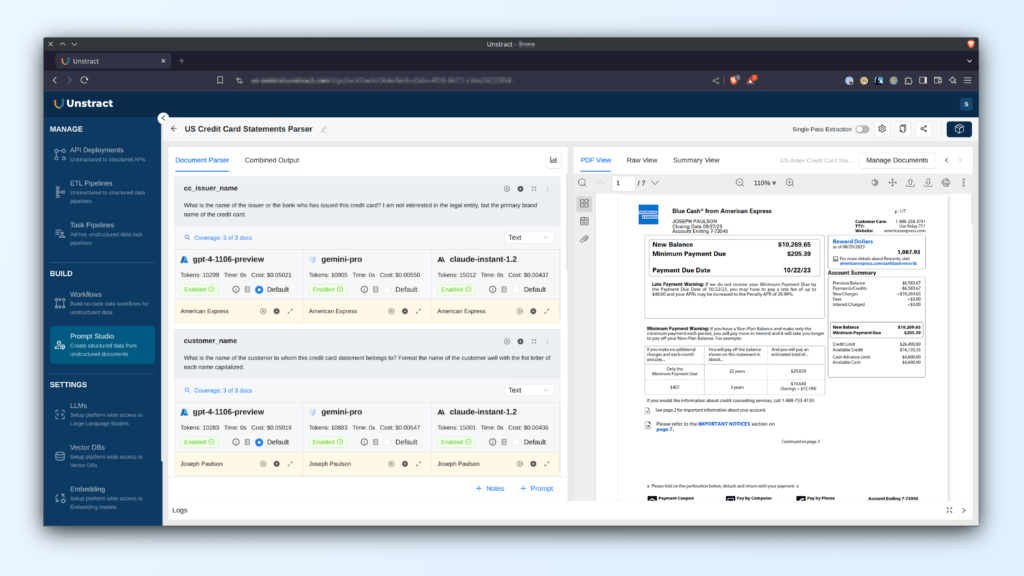
Introducing Unstract for Structured Data Extraction (PDF to JSON)
Unstract is an open-source, no-code platform designed to extract structured data from unstructured documents, with a primary focus on simplifying the process of converting PDFs to JSON. The platform leverages advanced AI and LLMs (Large Language Models) to automate document processing tasks that would otherwise require significant manual effort.
By offering an easy-to-use interface and API integrations, Unstract has become an essential tool for businesses looking to streamline their document workflows and achieve higher accuracy in data extraction.
Unstract: An open-source PDF document data extraction tool powered by LLMs
Learn how faithfully reproducing the structure of tables and other elements by preserving the original PDF layout is crucial for better performance in LLM and RAG applications.
Unstract is built to handle a wide variety of document formats, including PDFs, scanned documents, and images, converting them into structured data formats like JSON. The platform is ideal for processing complex, unstructured documents such as invoices, bank statements, contracts, and legal forms, which often present challenges due to their varied layouts and embedded elements like tables, forms, and images.
With Unstract, users can upload or integrate PDFs via API, and the platform uses LLMs to automatically extract key information and output it in JSON format. This not only simplifies the data extraction process but also ensures consistency and accuracy, making it easier to integrate the extracted data into APIs, databases, or other downstream applications.
How Unstract Uses LLMs to convert PDF to JSON
One of Unstract’s standout features is its use of LLMs to enhance the document processing experience. Traditional PDF parsers struggle with documents that have complex layouts or contain unstructured text. However, Unstract’s LLM-powered platform goes beyond basic parsing, enabling users to accurately convert PDFs to JSON even when dealing with multi-column layouts, tables, images, or handwritten notes.
Here’s how Unstract leverages LLMs for seamless PDF to JSON conversion:
Contextual Understanding: LLMs used in Unstract can interpret the context of the document, allowing for the accurate extraction of key data points such as dates, totals, and line items in invoices or contracts. This ensures that even documents with irregular formatting or complex structures are parsed correctly.
Handling Complex Layouts: Whether it’s a table-heavy document or a form with checkboxes and radio buttons, Unstract’s LLMs can break down these elements and map them into a structured JSON format. This feature is particularly useful for industries that rely on data-rich documents, such as finance or healthcare.
Enhanced OCR Integration: For scanned or photographed PDFs, Unstract integrates OCR (Optical Character Recognition) with its LLM-based processing to extract text from images and convert it into usable JSON data. This means even low-quality or handwritten documents can be processed with high accuracy.
API-Ready Output: Once Unstract processes a document, it outputs the structured data in JSON format, making it easy to integrate into other systems. Whether it’s an invoice, a contract, or a scanned document, Unstract provides clean, structured data that’s ready for further use in databases, analytics, or automation workflows.
Get started with Unstract: Best PDF to JSON Converter API
Unstract is an open-source, no-code Agentic Document Intelligence platform that helps you automate document-heavy workflows, without needing manual effort or writing any code.
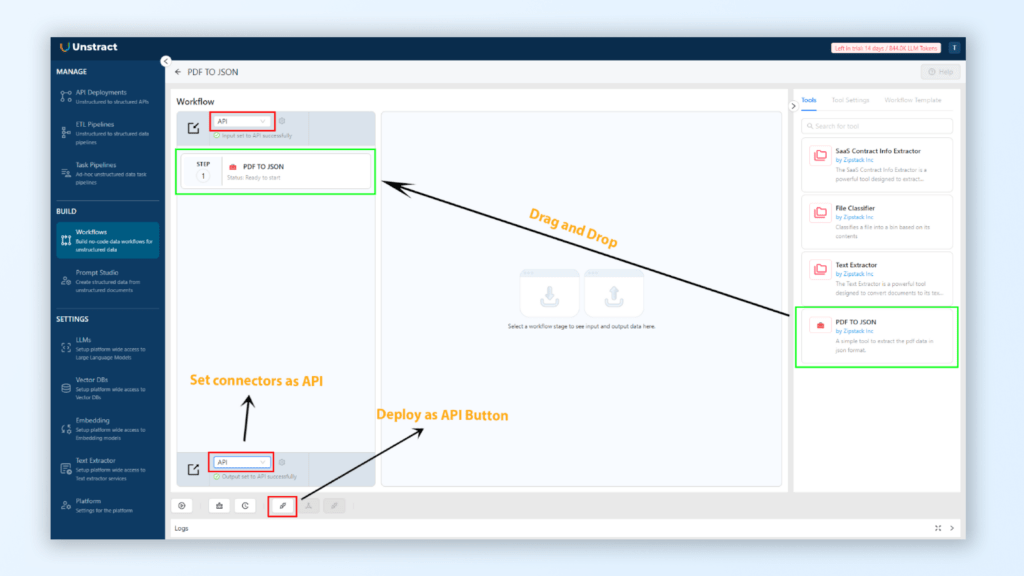
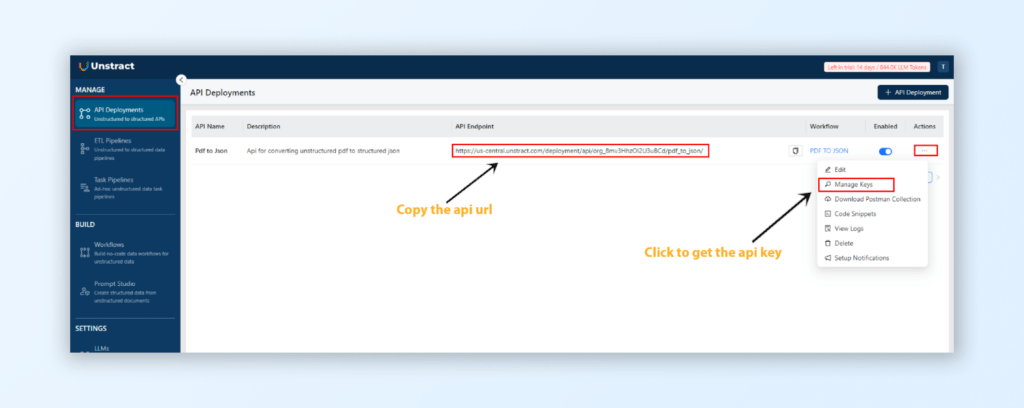
Steps to Extract Data from PDFs and Convert to JSON Using Unstract
In this section, we’ll walk through the process of extracting data from PDFs and converting it into JSON using Unstract. We will follow several key steps, from setting up Unstract to configuring a Prompt Studio project, and finally, deploying the workflow as an API. Let’s begin.
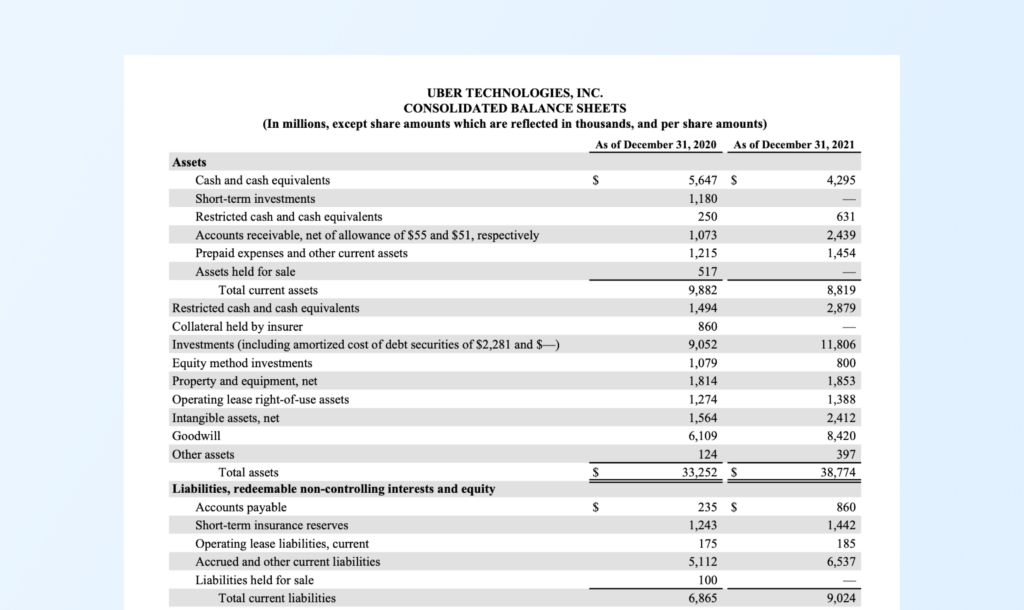
We will use UBER’s financial report as a use case to covert PDF data into JSON with Unstract
Select Bearer Token from the Auth Type dropdown menu.
Paste the copied API key into the Token field.
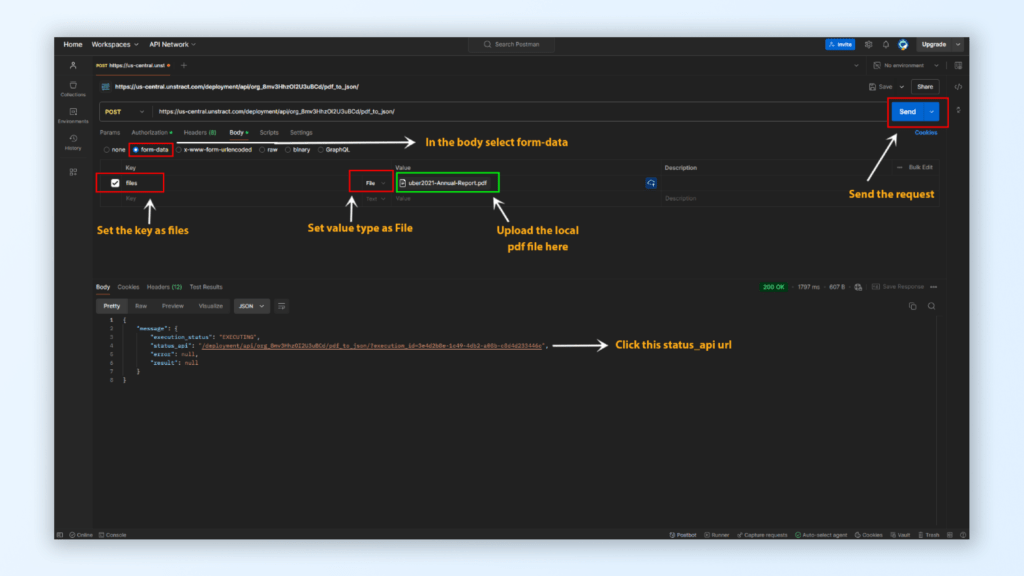
Prepare the Request Body:
Navigate to the Body tab in Postman.
Choose form-data as the format.
In the key field, enter files.
Change the format from Text to File using the dropdown next to the key field.
Upload the PDF File:
Click on the Value field and select New File from Local Machine.
Upload one of the sample PDF documents.
Send the Request:
Click on the Send button at the top right corner of Postman.
You will receive a response indicating the status as “executing”.
Check the Status of the Request:
In the response, there will be a status_api link. Click this link and create another GET request to check the status.
Once the request is complete, you will receive the JSON response with the structured data extracted from the PDF.
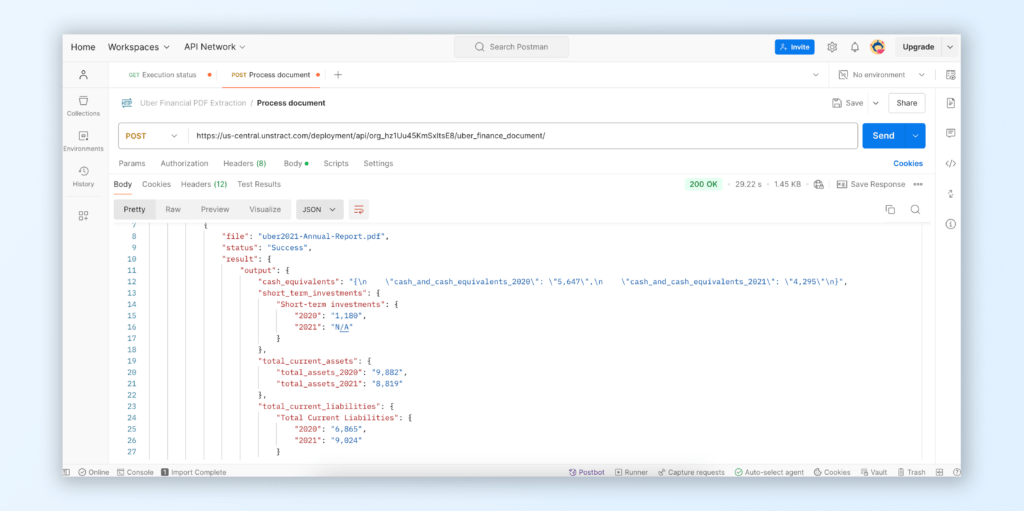
RESULT: PDF to JSON extraction of Uber’s Annual Report pdf file
Unstract PDF to JSON converter API
Benefits of Using Unstract for Parsing PDF to JSON
Unstract offers a comprehensive solution for converting unstructured PDF documents into structured JSON data, providing several unique advantages that make it a standout choice for businesses looking to automate their document processing workflows.
Supports Any Document Type or Layout
One of the biggest challenges in document processing is handling the vast variety of document types and layouts. Unstract’s PDF to JSON conversion capabilities extend beyond simple text extraction. It works seamlessly with scanned documents, handwritten notes, and complex multi-column layouts. Whether you have PDFs generated from software, scanned documents, or photographed files, Unstract can convert them into structured JSON with unparalleled accuracy.
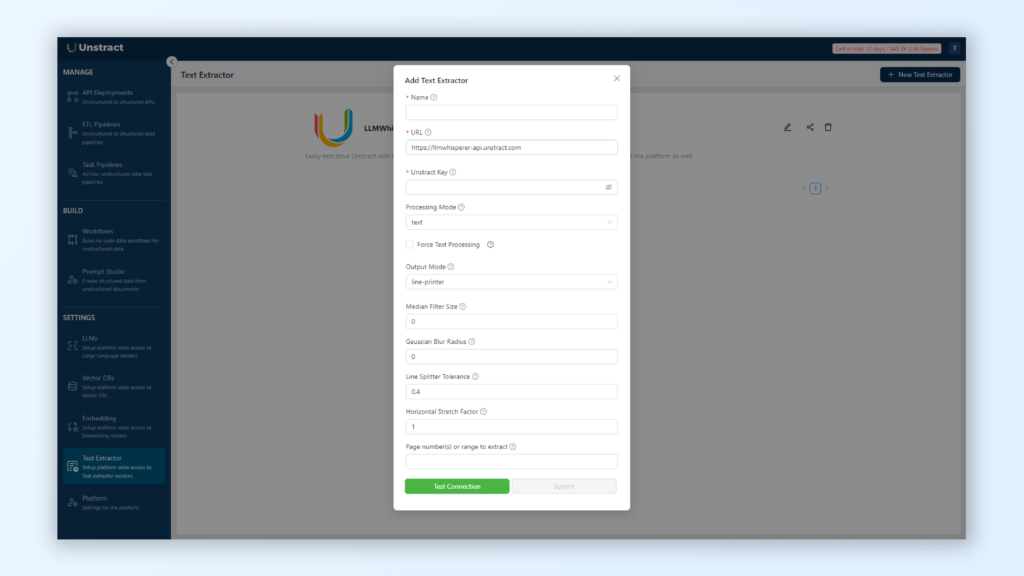
LLMWhisperer: Document pre-preprocessor for LLMs
Unstract’s LLMWhisperer is a text extraction service for PDFs. LLMWhisperer allows us to extract data from PDFs by page to extract exactly what we need. The key difference between various OCR systems and LLMWhisperer is that it outputs data in a manner that is easy for LLMs to process.
Also, we don’t have to worry about whether the PDF is a native text PDF or is made up of scanned images. LLMWhisperer can automatically switch between text and OCR mode as required by the input document.
Handles Complex Layouts
Parsing complex layouts like tables, multi-column formats, forms, checkboxes, and radio buttons is another area where Unstract excels. Traditional PDF to JSON converters often struggle with such elements, leading to inaccurate or incomplete data extraction. However, Unstract’s AI capabilities ensure that even the most complex document layouts are accurately parsed and converted into JSON, preserving the integrity of the original data.
End-to-End Solution
Unstract is more than just a PDF to JSON converter. It provides an end-to-end solution for document processing, including connectors for various document sources and destinations. Whether you’re pulling documents from cloud storage, APIs, or local databases, Unstract integrates smoothly into your existing workflows. The structured JSON output can then be seamlessly integrated into downstream systems like databases, ERP software, or business analytics tools.
Scalability
Once you build and deploy your workflow using Unstract, the API can be scaled across any platform or application. This means that whether you’re processing a few dozen documents or hundreds of thousands, Unstract can handle the load without compromising performance. This scalability is particularly beneficial for businesses that deal with large volumes of documents and require a robust, scalable solution for PDF to JSON conversion.
With these comprehensive features, Unstract proves to be an ideal tool for businesses looking to automate their document processing and convert PDF to JSON efficiently and accurately. Whether you’re dealing with standard invoices or complex multi-page forms, Unstract’s AI-driven technology ensures reliable and precise data extraction, making it a valuable asset for any organization.
Unstract PDF to JSON API: Conclusion
Unstract offers a robust solution for businesses looking to convert PDF documents into structured JSON data. Its advanced AI and LLM capabilities make it a powerful tool for handling various document types and complex layouts with high accuracy. From supporting scanned and handwritten documents to managing multi-column layouts and forms, Unstract simplifies the process of transforming unstructured data into actionable insights.
As AI-powered document processing continues to evolve, tools like Unstract will become indispensable for organizations aiming to automate and streamline their workflows. The ability to convert PDFs to JSON not only enhances data accessibility and usability but also opens up new possibilities for automation, analytics, and integration into broader business processes. By leveraging Unstract’s capabilities, businesses can stay ahead of the curve, transforming the way they manage and process documents.
Get started with Unstract: Unstract 101: Leveraging AI to Convert PDF to JSON
Unstract is an open-source, no-code Agentic Document Intelligence platform that helps you automate document-heavy workflows, without needing manual effort or writing any code.
Best PDF to JSON API in 2026: Related topics to explore
Why should I convert PDF to JSON instead of working with the PDF directly? Converting a PDF to JSON transforms unstructured, layout-locked information into a lightweight, machine-readable format. JSON is easy for both humans and software to parse, integrates natively with modern databases and APIs, speeds up downstream automation, and enables accurate analytics on data that would otherwise be trapped inside static PDFs.
What challenges do teams face when they try to convert PDF to JSON?
Loss of context or table structure when copy-pasting text.
High error-rates and poor scalability when relying on rule-based scripts or manual re-typing.
How does Unstract’s PDF to JSON converter handle complex document layouts like tables and forms? Unstract combines advanced OCR with Large Language Models (LLMs). The OCR (LLMWhisperer) converts scans to text, while the LLM understands context, identifies key fields, preserves table relationships, and outputs clean, structured JSON. This AI-first approach handles multi-column layouts, tables, forms, and even low-quality scans with far greater precision than traditional parsers.
What are the most common business use-cases for PDF to JSON conversion?
Data analysis on invoices, contracts, financial statements, purchase orders and more.
Automation—feeding extracted fields straight into ERPs, CRMs, or accounting platforms without manual key-entry.
Real-time API integration, allowing services to exchange structured data instantly.
Add your OpenAI API key (LLM) and embedding model in Settings.
Configure the free Postgres Vector DB and the LLMWhisperer text extractor.
Create a Prompt Studio project, upload a sample PDF, define the fields you want, and test the JSON output.
Export the project as a tool, drop it into a new Workflow, set API Input/Output connectors, and hit “Deploy.” You’ll receive an endpoint where any PDF you POST is automatically parsed and returned as structured JSON—ready for immediate integration into your apps or data pipelines.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.