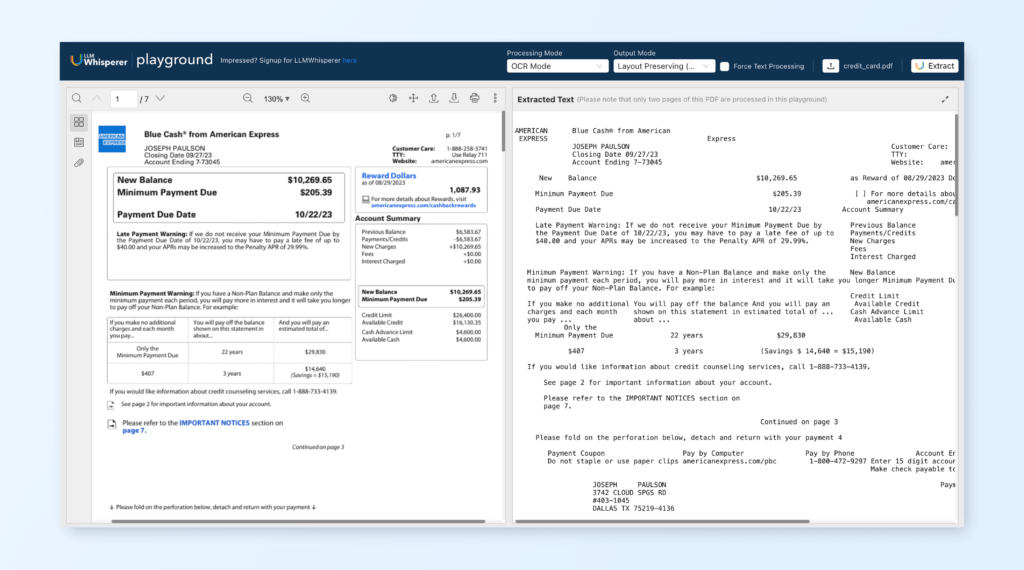
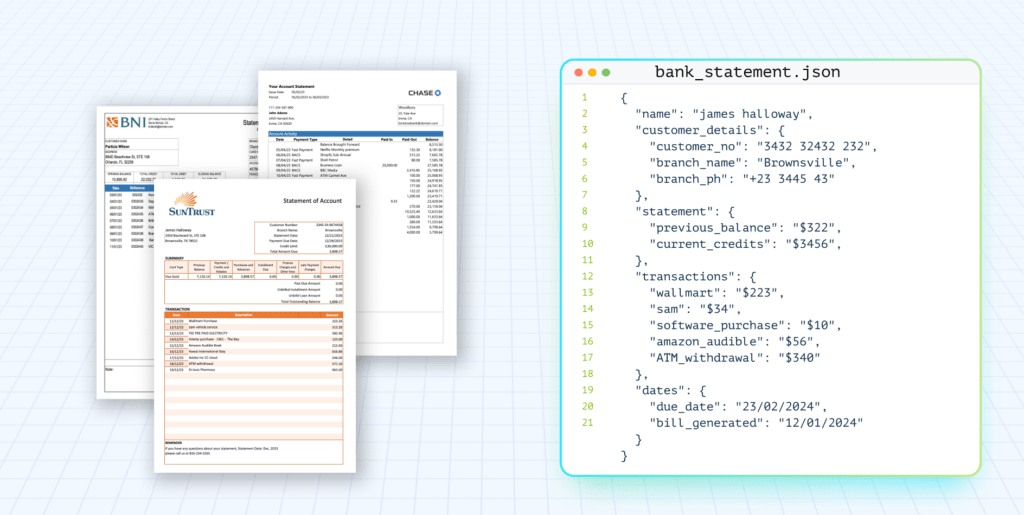
If you have tried to extract text from PDFs you would have come across a myriad of complications related to it. It is relatively easy to do a POC or experiment, but when it comes to handling PDFs from the real world on a consistent basis, it is a tremendously difficult problem to solve.
In this blog post, we explore the common but often difficult challenge: extracting text from PDFs for use in RAG, natural language processing and other applications of large language models (LLMs). While PDFs are a universal and ubiquitous format, valued for their ability to preserve the layout and integrity of content across different platforms, they were not originally designed for easy extraction of the text they contain. This presents a unique set of challenges for developers who need to repurpose content from PDF documents into dynamic, text-based applications.
Our experience stems from building LLMWhisperer, a Text Extraction service that extracts data from images and PDFs, preparing it and optimizing it for consumption by Large Language Models or LLMs.
Why is it difficult to extract meaningful text from PDFs?
PDFs are primarily designed to maintain the exact layout and presentation of content across varied devices and platforms. Also ensuring that documents look the same regardless of where they’re viewed or printed. This design goal is highly beneficial for document preservation, consistent printing, and sharing fully-formatted documents between users. Another popular use case is PDF forms that can be electronically and portably filled out.
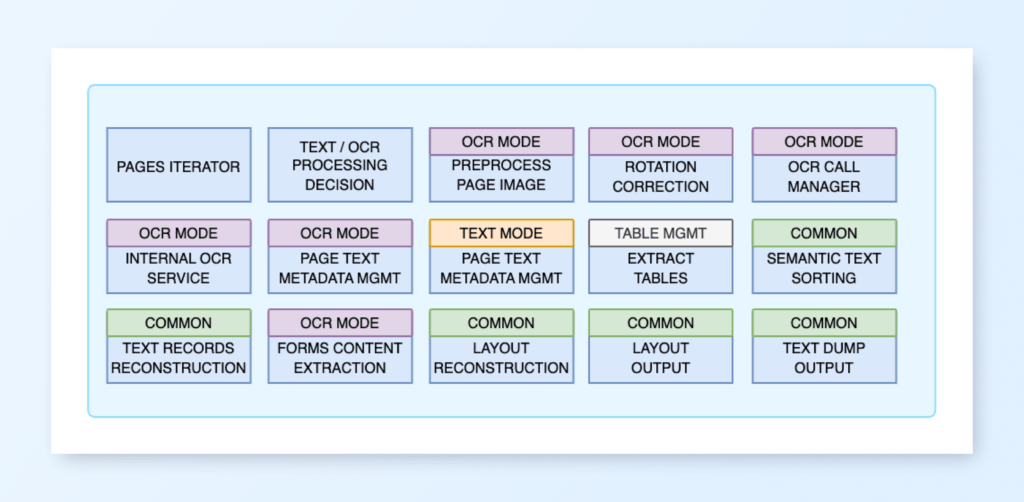
Advanced PDF Text Extractor Architecture
However, this very strength of the PDF format can become a challenge when extracting text for RAG or natural language processing (NLP) applications. Let’s delve a little deeper into how text is organized in PDFs. Refer to the figure below. Text in a PDF file is organized as text frames or records. It is based on a fixed layout and lacks any logical or semantic structure.
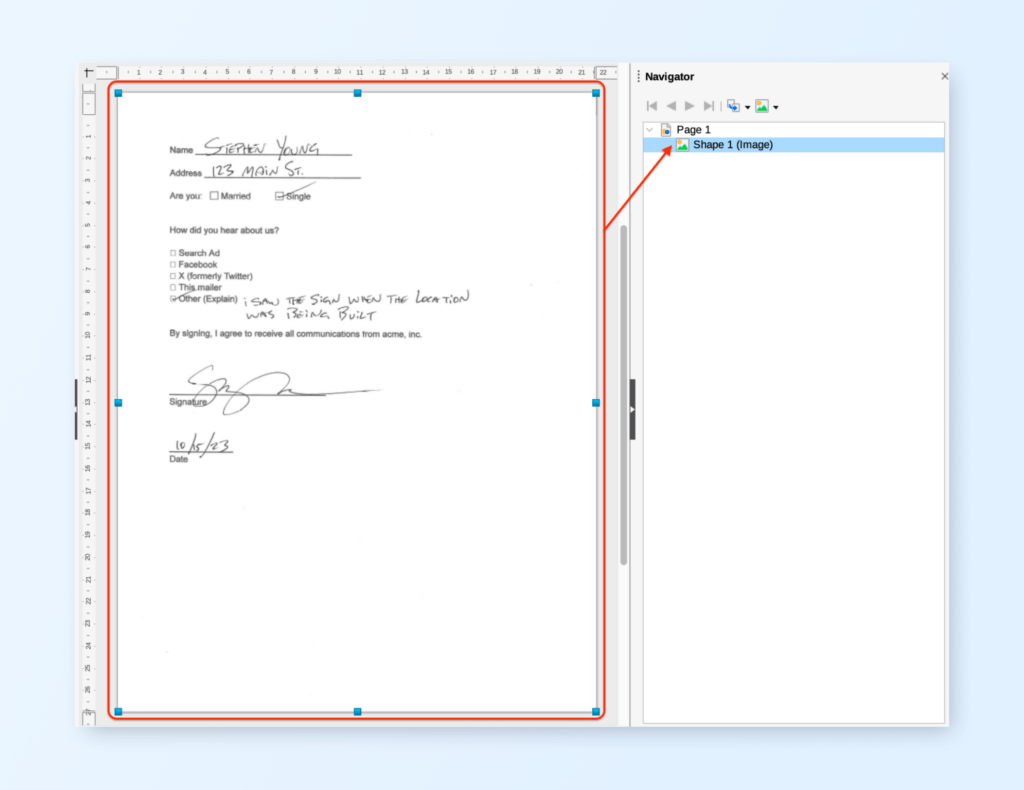
A sample PDF file opened in Libreoffice shows how a PDF file is organized
Note: Libreoffice is a good tool to open PDFs to understand how it is organized. It opens PDF documents in the drawing tool. You can make minor edits but it is not really designed for easy editing of PDFs.
Fixed Layout
The fixed layout of PDFs is essential for ensuring documents appear identical across different platforms and devices (unlike in say, HTML where text generally adapts to the device’s form factor it’s being displayed on). This fixed-layout feature is particularly valuable in contexts like legal documents, invoices, academic papers, and professional publications, where formatting is important. However, for NLP tasks, this fixed layout presents several issues:
Non-linear Text Flow: Text in PDFs might be visually organized in columns, sidebars, or around images. This makes intuitive sense to a human reader navigating the page visually, but when the text is extracted programmatically, the order can come out mixed up. For example, a text extraction tool might read across a two-column format from left to right, resulting in sentences that alternate between columns, completely breaking the text semantically.
Position-Based Text: Since text placement in PDFs is based on exact coordinates rather than relational structure, extracting text often yields strings of content without the contextual positioning that would inform a reader of headings, paragraph beginnings, or document sections. This spatial arrangement must be programmatically interpreted, which is not always straightforward and often requires advanced processing to deduce the structure from the raw coordinates.
Lack of Logical Structure
While theoretically the ability exists, in the wild, PDFs most often do not encode the semantic structure of their content. While a visually formatted document might appear to have a clear organization into headings, paragraphs, and sections, this structure is often not explicitly represented in the PDF’s internal data hierarchy.
Visual vs. Semantic Markup: Unlike HTML, which uses tags to denote headings, paragraphs, and other content blocks, PDFs typically lack these semantic markers. Text might be larger or in bold to indicate a heading to a human, but without proper tagging, a text extraction tool sees only a string of characters. This makes it difficult to programmatically distinguish between different types of content like titles, main text, or captions.
Absence of Standard Structure Tags: Although PDF/A (an ISO-standardized version of PDF specialized for archiving and long-term preservation) and tagged PDFs exist, most PDFs in the real world do not take advantage of these enhancements. Tagged PDFs include metadata about document structure, which aids in reflowing text and improving accessibility. Without these tags, automated tools must rely on heuristic methods to infer the document structure, such as analyzing font sizes and styles, indentation, or the relative position on the page.
To address these challenges in NLP use cases, we might have to write sophisticated and hybrid document analysis tools that combine optical character recognition (OCR) and machine learning models that can learn from large datasets of documents to better predict and reconstruct the logical ordering of text.
Tools/Libraries for PDF text extraction
A list of popular Python libraries for parsing text from PDFs:
pdfplumber (Our favorite, it is based on pdfminer.six)
Each library has its own pros and cons. Choosing the right one will be based on what type of PDF documents you are going to process and/or the eventual use of the text extracted.
Why is it even more difficult to parse text from PDFs?
Many PDFs are not “text” PDFs. They contain scanned or photographed images of pages. In these cases the only option is to either extract the image from the PDF or convert the PDF pages to images and then use an OCR application to extract the text from these images. Then the output from the OCR should be reconstructed as a page of text.
A sample PDF file opened in Libreoffice to show how a PDF file with scanned contents is organized
Preprocessing
Many scanned PDFs are not perfect. Scanned images might contain unwanted artifacts which will cause OCR output quality to degrade. If the PDF has a photo of some document page rather than a proper text — the issues you might face are potentially multiplied. Lighting conditions, rotation, skew, coverage and compression levels of the original photo might lead to even more degradation of OCR output quality.
Preprocessing is an important step which might need to be taken up before sending the image to OCR. Preprocessing typically involves noise reduction, rescaling, de-rotation, cropping, level adjustments and grayscale conversion. Note that some of the OCR providers have the preprocessing step built in. For example when you use LLMWhisperer, preprocessing is done automatically, which frees the user from worrying about it.
OCR
If you’ve read thus far, you probably already know OCR stands for Optical Character Recognition. It represents a family of technologies that convert images that contain text to machine-readable text (generally speaking, conversion of text in images to ASCII or Unicode). It is a technology that is incredibly useful in digitizing printed text or text images leading to the ability of editing, searching and storing the contents of the original document. In the context of this blog post, it helps us extract text from scanned documents or photographed pages.
Tools/Libraries to extract text from scanned/image PDFs
A small list of utilities for extracting text from images. Note that this list shown here is very small subset and there are a lot of tools out there:
Choosing a OCR is based on multiple factors and not the quality of extraction alone. OCR is a continuously evolving technology. Recent improvements in machine learning have made the quality of extraction reach new heights. But unfortunately not everyone has access to high end CPUs and GPUs to run the models. The cloud services from the big three have very high quality OCRs. But if there is a constraint on user privacy and secrecy, cloud-based services might not be an option for you.
And the other woes of PDF text extraction
Apart from the difficulties created by the actual format itself, functional requirements and the quality of PDFs can add to the complexities of extracting text from them. Samples from the real world can have a bewildering list of issues making it extremely challenging to extract text. Based on our experience developing and running LLMWhisperer, here are some functional and quality issues we commonly see in the wild.
Searchable PDFs
This format allows the document to maintain the visual nature of the original scanned image while also including searchable and selectable text thanks to the OCR’d layer. This makes it easy to search for specific words or phrases within the document, which would not be possible with a simple image-based PDF. Take a look at the image below. The top is how it appears in a PDF viewer. The bottom image has been adjusted to show the two layers. The gray layer is the original scanned image. The white text is the OCR’d text which has been added to the PDF and hidden behind the original scanned image. This is what is “selectable” when seen in a PDF viewer.
A sample searchable PDF file containing a scanned image layer and a searchable text layer which has been OCR’d and added.
This searchable feature is very useful when humans are interacting with the document. But when we want to extract the text programmatically it introduces a bunch of difficulties:
Detecting whether it is a searchable PDF
We could detect if there is a large image covering the entire page while also looking for text records in the PDF. But this does not work all the time because many PDFs like certificates or fancy brochures have a background image which can be mistaken for a scanned PDF. This is a difficult problem to solve.
Quality of the original OCR
Not all OCRs are great. The original OCR used to generate the searchable text might have created a low quality text base. This is not often easy to detect and objectively quantify especially when there is no human in the loop. In these cases, it is better to consider the document as a purely scanned PDF and take the OCR route and use your own OCR for text extraction, hoping yours is better than the one used to generate the original text.
Searchable PDFs are for searching and not full text extraction
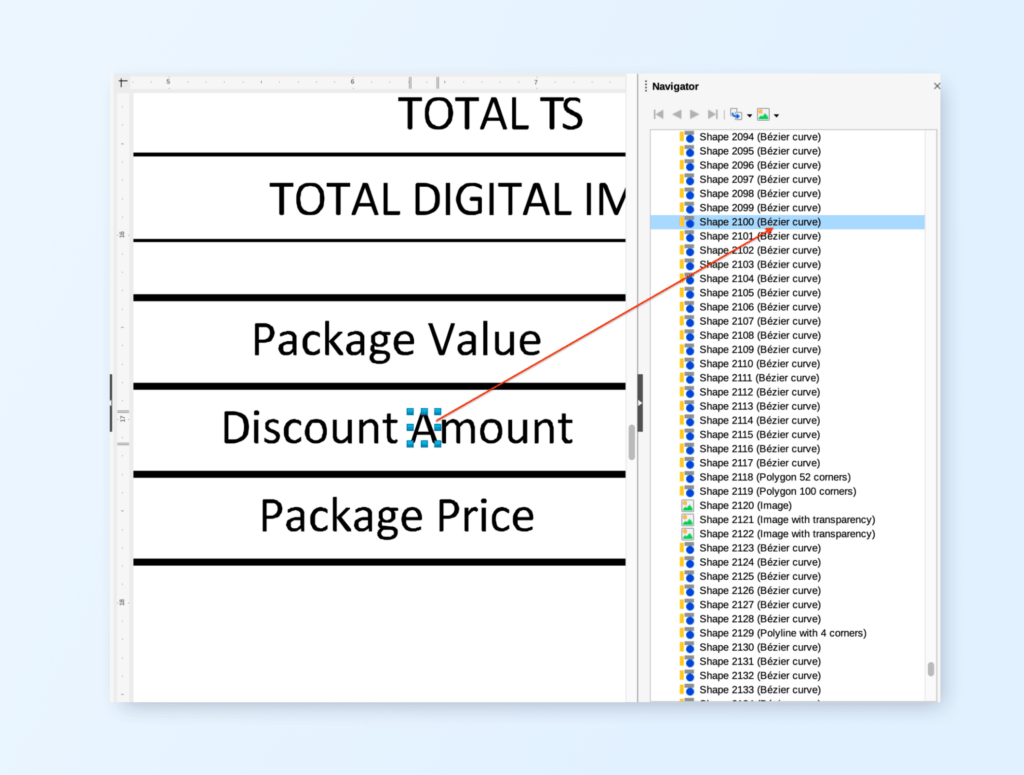
The text records which are available in these PDFs are not for extraction use cases. They can be split at random locations. Take a look at the example shown above, text frames/records “one” and “space-character-to…” are part of the same sentence but are split. When trying to rebuild text for NLP purposes it is difficult to merge them without using complex techniques.
Another example is the text “Learning Algorithms” in the figure above. This title text is not only split into two words but since the size of the text is large, the original OCR overlay system has double-spaced the characters (to match location of letters) in the result (take a look at the right pane). There are two records – “L e a r n i n g” and “A l g o r i t h m s”. Again a difficult problem to solve to de-double space the characters when we extract text. There is also a mistake in positions. “Algorithms” has backed into “Learning” creating an overlap. Just everyday difficulties extracting text from PDFs!
Extracting tables from PDFs
Unlike HTML or other document formats, PDF is a fixed layout format. This makes it very difficult to semantically understand where a table is and how it is organized. There are many approaches to extracting tables. Some of them try to understand the layout and some of them use computer vision based libraries to detect tables.
This approach defines a set of rules and tries to identify table data using the rules. The rules can be based on identifiable markers of cells or boundaries, keywords and other similar items. This is effective when the format of the PDF remains consistent. This works very well when all the documents we process are of the same format or variety. Unfortunately in the real world, PDFs come in so many different forms, a simple rule-based approach is not very reliable except for certain controlled use cases.
Computer vision
This approach uses computer vision models to detect lines that can be used to identify tables. The visual structure is analyzed to differentiate between rows, columns and cells. This can be used for identifying tables where traditional approaches fail. But keep in mind that this involves adding machine learning libraries and models which is going to bloat your application and will require some serious CPU (or GPU) horsepower to keep it quick.
While this provides good results in many use cases, many more PDFs in the real world have tables which do not have good visual differentiation (fancy tables with colors used to define cells etc). Also note that this requires converting even text PDFs to images for the CV libraries to work. This can get very resource-intensive, especially for longer documents.
Machine learning
Machine learning models can be trained to recognize structures and patterns that are typical of tables. Machine learning models can give better results than computer vision-based systems as they understand the context rather than depending only on visual cues.
Again, just like computer vision, machine learning also increases the footprint of your application and requires more resources to run. Also, training a model from scratch is a pretty involved process and getting training data might not be an easy task. It is best to depend on ready-made table extraction libraries, as mentioned earlier.
Hybrid approach
In the real world, no single approach works for a broad variety of document types. We most likely will have to settle for a combination of techniques to reliably extract tables from PDFs.
LLMWhisperer’s approach
We at Unstract, designed LLMWhisperer to extract and reproduce the table’s layout faithfully rather than trying to extract the table’s individual rows and columns while also extracting hints on where each cell is. Most of our customers use the extracted text from PDF to drive LLM/RAG/Search use cases and this approach works great.
From our experience, LLMs are able to comprehend tables when layout is preserved. There is no need to bend over backwards to recreate the whole table from the PDF as a HTML table or as a markdown table. LLMs are smart enough to figure out the contents of most tables when the layout of the table is preserved in the output with tabs or spaces separating columns.
Page orientation
A PDF file’s pages can be organized in:
Portrait mode
Landscape mode
Hybrid, portrait and landscape mode
Scanned pages in landscape mode which are rotated 90°, 180°, 270°
Scanned pages or photographed pages might be rotated arbitrarily by ±30°
Sample of a scanned PDF which has been rotated while photographing the original
Trying to extract text from portrait mode or landscape mode is relatively simple. The extraction becomes more difficult when we have a hybrid PDF in which some pages are in portrait mode and some are in landscape mode. If it is a text based PDF, it is relatively easier, but for scanned PDFs we need to detect this change using direct or indirect methods.
When dealing with pages that are arbitrarily rotated (especially PDFs created from photographed documents) detection and correction is never easy. We will have to use image processing libraries and probably machine learning to automatically correct such pages before sending them to an OCR.
LLMWhisperer: Best OCR to Extract Data from Handwritten Forms
Let’s see how to process challenging PDFs that contain hand-filled forms with elements like checkboxes and radiobuttons and also bad scan pages the unfriendly orientations with LLMWhisperer. LLMWhisperer is a text extraction service that specifically targets large language models (LLMs).
Bad (for extraction) PDF generators
Some PDF generators will consider every element inside the documents as “curves”. Even characters of the language are stored as “curve” representations. This has certain advantages as it can be reproduced in every medium without the requirement of having font information.
But it makes it very difficult to extract text from. The only way to extract text from these documents is to convert the pages to images and then use an OCR for extraction. Figuring out that the given PDF has curves instead of text is a step which needs to be performed before attempting to extract.
A zoomed-out portion of a PDF file with curves instead of text. Each character is represented as a Bezier curve
Multi-column page layout and fancy layouts
Multi-column page layout is very common in scientific publications and documents like invoices. The text is laid out as two columns as shown in the image below. As mentioned earlier, text in PDFs have a fixed layout. This makes it very difficult to semantically extract the text as paragraphs from these types of documents. We must use heuristics to intelligently extract text in a semantic order from these documents.
Some text based PDF generators are smart enough to arrange the text records following semantic ordering. But, as always, in the wild, we have to be prepared to encounter badly created PDFs which have absolutely no semantic ordering of text records. When we have scanned documents (with or without searchable content), we have no option but to use intelligent methods to understand multi-column layouts and extract text which makes semantic sense.
A two column PDF file. The lines and arrows indicate how text records are organized in a multi column PDF.
In the example shown above, text records can be organized in a semantically correct order as shown in the red lines. But in some PDFs (and all OCR’d documents) text records can be organized in a non-semantic order reading left to right over to the next column before moving to the next line. When text is collected this way, the final text will make no sense to downstream pipeline steps. We need smart ways to reorganize such text to make semantic sense.
Note that the problems described above are also applicable to pages with fancy layouts like invoices, receipts and test reports.
Background images and Watermarks
Background images in PDF files can be a problem for both text based PDFs and scanned PDFs. In text based PDFs, the extractor can confuse the background image to be indicating a scanned PDF and switch to an OCR based extraction which will be hundreds of times slower and cost way more.
When using such PDFs that feature background images in an OCR based extraction, it can confuse the OCR if it has contrasting colors or patterns. Especially if the background image and text in front of it have little contrast difference. For example black text on top of dark coloured background images. Human eyes can easily pick it up but for many OCR systems it is a challenge.
Sample PDF with a strong watermark which can interfere with text extraction
Some background images are watermarks and these watermarks can be text. When using OCR for extraction, these watermark texts can get added into the main body of texts. This is also the case for fancy backgrounds containing text in certificates etc.
In some cases, while using OCR for extracting text (which is the only way for scanned PDFs) background images with text can completely ruin text extraction, making it unextractable without human intervention.
Handwritten forms
PDFs with hand written text are scanned document PDFs. These are typically forms or documents with handwritten notes and then scanned. Not all OCRs are capable of handwriting recognition. Also, OCRs capable of recognising handwritten text might be prohibitively expensive, especially when processing larger volumes.
PDFs with form elements like checkboxes and radio buttons
A PDF form is a document that includes interactive fields where users can enter information. PDF forms can contain text fields, checkboxes, radio buttons, drop-down menus, and other interactive elements that allow users to input or select information.
Sample PDF with form elements
Many PDF libraries are not capable of extracting form elements from the PDF. Even less can extract the form elements’ contents which the user has filled in. Even if we decide to convert the form into an image for OCR use, there are a couple of issues:
The PDF to image conversion software or library should understand the form elements. Very few of them support this. PDF.js supports this, but that would sit well in a NodeJS stack. If you are using a Python based stack, your options are not many.
Not all OCR are capable of understanding form elements like checkboxes and radiobuttons. Your only option might be to train the OCR to recognize and render such elements if you are not willing to use 3rd party web services.
Large scanned PDFs
Scanned PDFs require OCR to extract the contents. OCR by its nature is a compute intensive process and takes time to convert a page into text. When we are dealing with very large documents (> 100 pages) the time to extract all pages can be significant. Apart from time latencies, high quality OCR services also involve a non-trivial cost factor.
Low level text extraction library bugs
PDF files are complicated and the sheer variety and generation variations are so many that writing libraries to process them is an inherently difficult task. There will always be some corner cases the authors of the library could have never anticipated. This will lead to runtime errors which need to be handled. And if a significant portion of your target use is affected by this, then there is no option to either write your own extractor to handle these cases or contribute to the library if it is open source.
Headers and Footers
Many PDFs have headers and footers. Headers typically contain information about the document and the owner (company name, address etc) and the footer contains copyright information and page numbers etc. These are repeated across all pages. This information is generally not required in most RAG and information extraction use cases.
These headers and footers simply add noise to the context when used with LLMs and other machine learning use cases. Though usually not a major issue, a good extraction tool should be able to ignore or even better, remove them from the final extracted text.
PDFs with both text and text as images
Some PDFs can have both native text and embedded images that in turn contain text in them. This requires special handling.
The simple solution is to send the entire page to an OCR to extract the text. But this method might be expensive for high volume use cases. This can also substantially increase the time latencies of extraction. If cost or time is important, a custom extraction library has to be used in these cases.
Tables spread out horizontally into many pages
This is not a regular use case. But we might encounter PDFs with wide tables which extend into the next page. It is a very difficult problem to solve. Detecting where the table’s horizontal direction extends into is very difficult. The next logical page may contain the following rows instead of the horizontal overflow. In some cases the next logical page may contain the horizontal overflow.These use cases should be considered special cases and custom logic has to be written.
It is easier when you know that all documents that will be processed have a similar structure. If that is the case custom extractors can be written. Unfortunately if these types of documents are not specially dealt with, it might be impossible to handle this case.
Privacy issues
As discussed above, writing a high quality PDF extraction library is a huge challenge. If you want to use 3rd party services to do extraction, there might be privacy and security issues. You will be sending information to a 3rd party service.
If your digital mandate or rules require strict privacy requirements, you will have to use 3rd party services which can provide on-premise services where your data does not leave your network. LLMWhisperer service is one of the services that can be run on-premise, protecting your data from leaving your network.
Layout Preservation
If the target use case is to use the extracted text with LLMs and RAG applications, preserving the layout of the original PDF document leads to better accuracy. Large Language Models do a good job of extracting complex data, especially repeating sections and line items when the layout of documents is preserved in the extracted text.
Most PDF extraction libraries or OCRs do not provide a layout preserving output mode. You will have to build the layout preserving output with the help of positional metadata provided for the text by either the PDF library or the OCR.
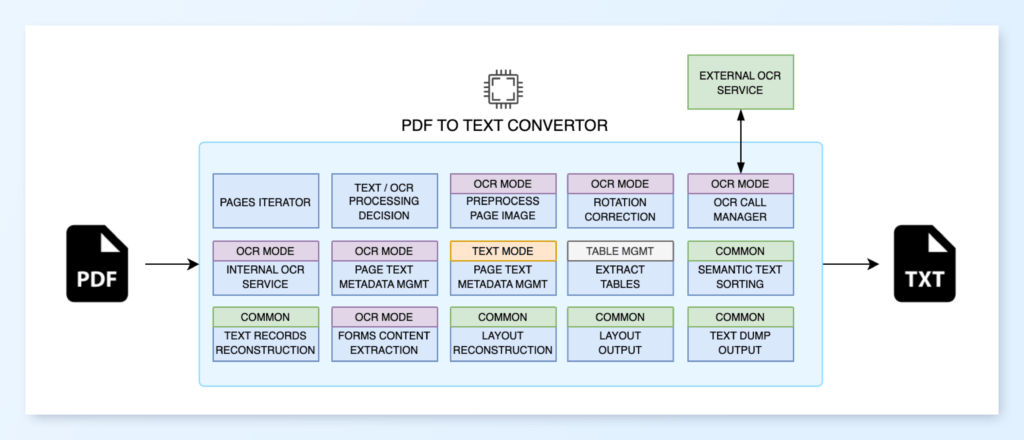
What a PDF-to-text converter architecture would look like
Considering all the cases described above, a block diagram of a high-quality PDF-to-text convertor would look like this:
Build vs Buy
Building a high-quality PDF extractor is a complex and massive exercise. Building your own tool allows for complete control over the functionality and integration with existing systems. However, this approach requires significant investment in time, expertise and ongoing maintenance.
On the other hand, purchasing a ready-made, pre-built solution can be quicker to deploy and often comes with continuous updates and professional support. The choice ultimately depends on your specific needs, strategic priorities, resources and budgets.
Introducing LLMWhisperer
LLMWhisperer is a general-purpose PDF-to-text converter service from Unstract.
LLMs are powerful, but their output is as good as the input you provide. LLMWhisperer is a technology that presents data from complex documents (different designs and formats) to LLMs in a way that they can best understand
Features of LLMWhisperer
Layout preserving modes Large Language Models do a good job of extracting complex data, especially repeating sections and line items when the layout of documents is preserved in the extracted text. LLMWhisperer’s Layout Preserving mode lets you realize maximum accuracy from LLMs.
Auto mode switching While processing documents, LLMWhisperer can switch automatically to OCR mode if text mode extraction fails to generate sufficient output. You don’t have to worry about the extraction mode when sending documents.
Auto-compaction The more tokens that go to the LLM, the more time it takes to process your prompts and the more expensive it becomes. With LLMWhisperer’s Auto-compaction, tokens that might not add value to the output are compacted—all while preserving layout.
Pre-processing To get the best of results, you can control how pre-processing of the scanned images is done. Parameters like Median Filter and Gaussian Blur can be influenced via the API, if needed.
Flexible deployment options
SaaS High-performance, fully managed SaaS offering. No more dealing with updates, security, or other maintenance tasks – we’ve got you covered.
On-Premise We offer a reliable way of deploying LLMwhisperer on your own servers to ensure the security of ultra-sensitive data.
And much more:
Support for PDFs and the most common image formats
High performance cloud for consistently low latency processing
Settable page demarcation
Three output modes: Layout preserving, Text, Text-Dump
Get started with LLMWhisperer: Best OCR for AI Document Processing
What’s next? Action items for the curious
Test drive LLMWhisperer with your own documents. No sign-up needed!
Even better, schedule a call with us. We’ll help you understand how Unstract leverages AI to help document processing automation and how it differs from traditional OCR and RPA solutions.
Document extraction at the cutting edge with LLMs vs LLMWhisperer
Discover how LLMWhisperer, Unstract’s dedicated text extraction service, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.