A Document OCR API (document scanner API) is a tool that converts text from scanned documents, PDFs, or images into machine-readable formats like JSON or text. It bridges the gap between static documents and dynamic workflows by enabling seamless text extraction across diverse document types.
Purpose and Advantages
Scalability: Handles varying workloads, from a few documents to thousands, easily.
Ease of Integration: Integrates directly into existing systems like CRMs and ERPs.
Flexibility: Processes various document types, including scanned forms, handwritten notes, and tables, ensuring compatibility with multiple layouts.
By offering OCR functionality as an API, organizations eliminate the need for standalone tools and automate text extraction, making document data instantly usable.
Why Extracting Data from Documents is a Critical Business Process
Extracting data from documents like scanned PDFs and images is crucial for businesses managing unstructured data. Many operations depend on extracting details like invoice totals, tax IDs, or customer information, which is often locked in static formats.
Challenges with Manual Extraction
Manual methods are time-intensive, error-prone, and lack scalability. Employees may spend hours transcribing scanned forms, introducing inaccuracies, and delaying workflows. Example: A logistics company may struggle with manually extracting data from thousands of delivery receipts, leading to delays.
TL;DR
If you wish to skip directly to the solution section, where you can see how LLMWhisperer OCR API handles document types of any complexity — document scans, images, PDFs with complex tables, checkboxes, and handwriting etc, click here.
Benefits of Automation
Time Savings: Automating OCR drastically reduces processing time. Example: Retailers process invoices in minutes, ensuring prompt supplier payments.
Accuracy: APIs reduce human error by standardizing data extraction. Example: An insurance company extracts claim details with near-perfect accuracy.
Seamless Integration: Extracted data flows into systems for real-time analysis, boosting operational efficiency.
Automation makes static data actionable, saving time, reducing costs, and enhancing decision-making.
Challenges in Document PDF Processing and How OCR Solves Them
Processing scanned PDFs and images presents unique challenges, including variability in document formats, low-quality scans, and complex layouts. OCR APIs address these hurdles with precision.
Key Challenges
Variability in Layouts: Scanned documents often lack uniformity, with each having distinct fonts, tables, or annotations. Example: Vendor invoices with different formats require dynamic adaptation.
Low-Quality Scans: Blurry or faded text and noisy images hinder recognition. Example: A smudged tax form still yields accurate results after pre-processing by OCR.
Complex Tables: Extracting data from multi-page tables or overlapping elements is challenging. Example: A bank statement’s mixed columns for debits and credits is parsed correctly with OCR.
How OCR Solves These Issues
Pattern Recognition: Identifies and categorizes text elements, ensuring accurate extraction.
Error Correction: Post-processing algorithms refine OCR outputs for precision.
Layout Preservation: Maintains document structure for downstream analysis.
OCR APIs overcome these obstacles, enabling organizations to extract accurate, structured data efficiently from even the most challenging document types.
Brief Introduction to LLMWhisperer and Its Document OCR API Capabilities
Overview of LLMWhisperer
LLMWhisperer is an advanced text parser that prepares complex documents, including scanned PDFs, images, and tables, for downstream processing by large language models (LLMs). It focuses on converting unstructured or semi-structured data into organized, actionable formats like JSON. LLMWhisperer shines in handling intricate layouts, noisy scans, and handwritten text, enabling organizations to streamline document parsing workflows.
LLMWhisperer is not powered by AI or LLMs for the OCR process. Instead, it enhances OCR outputs by applying intelligent parsing mechanisms that make the data more comprehensible for LLMs and other systems.
LLMWhisperer: The best document OCR API for AI workflows
Modern Document OCR API: Key Features and Capabilities
Structured Data Extraction
LLMWhisperer excels at extracting structured text from scanned or image-based documents. It identifies key elements such as text zones, tables, and annotations, organizing them into usable formats.
Complex Layout Handling
It preserves the structure of intricate document layouts, such as multi-column designs, nested tables, and checkboxes. This ensures accurate parsing while maintaining the context of the original document. Example: Processing a multi-page bank statement with overlapping tables and transaction details without losing alignment or context.
Pre-Processing for Noisy or Low-Quality Scans
LLMWhisperer improves the quality of noisy scans by applying filters, de-skewing, and contrast adjustments. This pre-processing enhances the accuracy of OCR outputs. Example: Extracting policyholder details from a faded, watermarked insurance document with precision.
Multilingual Document Parsing
It supports multiple languages, allowing global enterprises to parse documents containing diverse scripts and mixed-language content. Example: Parsing an international invoice containing English, German, and French sections.
OCR reader API that talks to your systems
Available as an API, LLMWhisperer integrates effortlessly into existing workflows, enabling organizations to preprocess documents on the fly. This flexibility ensures scalability and adaptability across various document types.
LLMWhisperer’s Role in OCR Workflows
Not Just an OCR Tool
LLMWhisperer is not a standalone OCR engine; it acts as a bridge between raw OCR outputs and advanced LLM-powered systems. By parsing and structuring the data, it ensures the input is optimized for downstream processing by LLMs, enhancing contextual understanding and overall accuracy.
Example: Preparing OCR-extracted text from a scanned academic thesis for further semantic analysis by an LLM.
Comparison with Traditional OCR
Traditional OCR engines, such as Tesseract, rely on static models and predefined patterns, which struggle with non-standard or complex layouts. In contrast, LLMWhisperer uses advanced algorithms to adapt dynamically, preserving document context while ensuring accuracy in text parsing.
Real-World Applications
Form-Based Data Parsing LLMWhisperer identifies checkboxes, radio buttons, and handwritten notes in scanned forms, converting them into structured data formats. Example: Digitizing a tax form by extracting selected filing statuses, amounts, and notes.
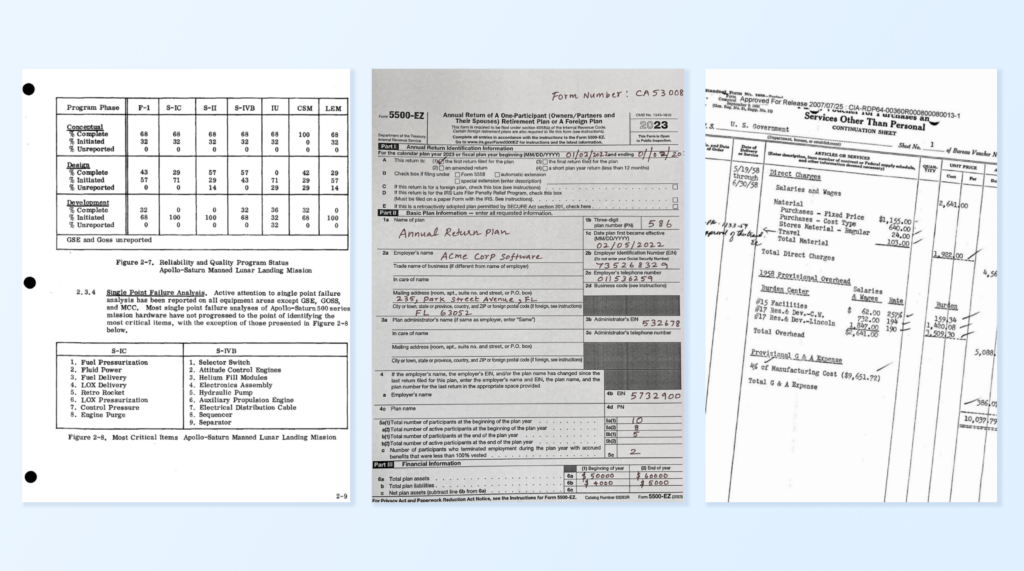
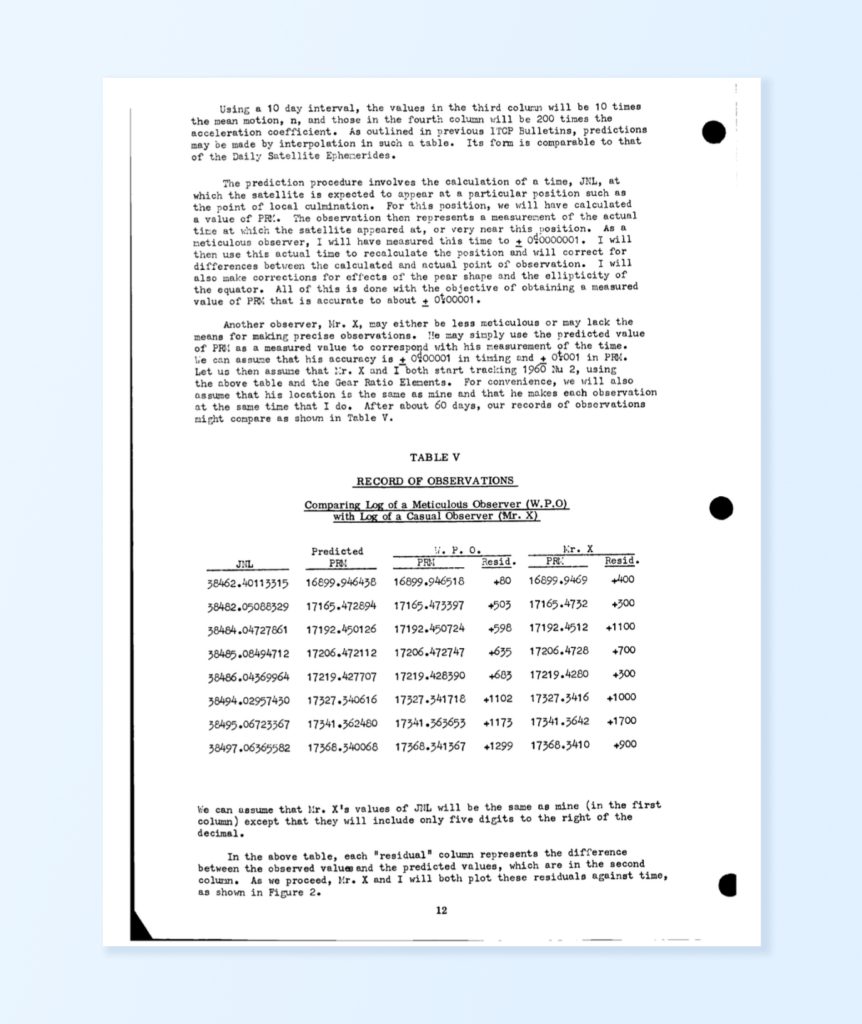
Historical Document Processing It processes low-quality historical documents like manuals or old reports, cleaning up noisy scans and extracting text accurately. Example: Extracting structured text from a scanned page of the Apollo Space Mission Manual.
Global Invoice Management LLMWhisperer handles multi-language invoices with varying layouts, extracting consistent data fields for payment processing. Example: Parsing invoices from suppliers across different countries and consolidating the data for analytics.
Why choose LLMWhisperer for the document reader API?
Adaptability Across Document Types LLMWhisperer handles printed, handwritten, and mixed-layout documents, making it ideal for businesses that process diverse data sources.
Ease of Integration Its API-based architecture allows seamless integration into existing systems, ensuring smooth data processing pipelines without overhauling infrastructure.
Foundational Parsing for LLMs By enhancing and structuring OCR outputs, LLMWhisperer maximizes the potential of LLMs, ensuring accurate and context-aware insights from complex document data.
With its robust capabilities, LLMWhisperer transforms how businesses process scanned documents and prepare data for AI-driven applications, delivering efficiency, accuracy, and scalability.
Pre-Processing with LLMWhisperer: How It Helps Scanned PDF/Image OCR
Pre-processing is a critical step in ensuring accurate and efficient Optical Character Recognition (OCR) for scanned PDFs and image-based documents. LLMWhisperer stands out as a powerful text parser by employing advanced pre-processing techniques to address common challenges such as noisy scans, complex layouts, and unstructured formats. These enhancements not only improve OCR accuracy but also prepare the extracted data for seamless downstream analysis.
Key Pre-Processing Techniques in LLMWhisperer
Noise Removal Noise, such as smudges, watermarks, stains, or digital artifacts, can significantly impact OCR performance. LLMWhisperer’s noise removal techniques enhance document clarity, ensuring that irrelevant marks do not interfere with text recognition.
How It Works:
Filters out unwanted artifacts, such as background patterns or faint text shadows.
Enhances text contrast for better recognition of faint or degraded text.
Layout Preservation Many scanned PDFs and image-based documents have complex layouts, including multi-column text, tables, or overlapping sections. LLMWhisperer preserves the original structure of these documents during pre-processing, enabling accurate text parsing without distorting the context or relationships between data points.
How It Works:
Recognizes document zones (headers, footers, tables, and text blocks) and maintains their spatial arrangement.
Prepares tabular data and column-based layouts for structured extraction.
Format Optimization Scanned documents often suffer from issues like skewed alignment, uneven text spacing, or non-standard formats. LLMWhisperer applies format optimization techniques to align and structure the content for maximum OCR accuracy.
How It Works:
De-skewing: Corrects tilted or misaligned pages, ensuring text is horizontal for proper segmentation.
Standardization: Adjusts inconsistent spacing, line breaks, and margins to create a uniform layout.
Pre-OCR Splitting: Breaks large blocks of text into manageable segments for more precise recognition.
Live coding session on data extraction from a scanned PDF form with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in scanned PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
Benefits of LLMWhisperer’s Pre-Processing Techniques
Enhanced OCR Accuracy Pre-processing directly improves the quality of the input data, enabling OCR engines to identify characters, words, and layouts more precisely.
Impact: Reduces errors caused by poor scan quality, such as misreading “O” as “0” or skipping faded text.
Preservation of Document Context Maintaining the document’s original layout ensures that the relationships between data points remain intact, which is crucial for downstream analysis.
Impact: Data extracted from tables, forms, and columns is contextually accurate and ready for further processing.
Support for Diverse Document Types LLMWhisperer’s pre-processing techniques work seamlessly across a variety of documents, including handwritten forms, scanned PDFs, and image-based text.
Impact: Expands the range of documents that businesses can process automatically, minimizing the need for manual intervention.
Improved Downstream Analysis Pre-processed and structured data ensures smooth integration with analytics platforms, databases, or AI models, enabling real-time insights and decision-making.
Impact: Eliminates the need for manual corrections or additional formatting steps.
Let’s take the example of processing a scanned document, such as a page from the Apollo Space Mission Manual. Using LLMWhisperer, this process becomes seamless and efficient:
Noise Removal LLMWhisperer eliminates age-related degradation like faded text, stains, or handwritten annotations in the margins, ensuring the document is clean and readable for OCR extraction.
Layout Preservation The structured format of the manual, including diagrams, tables, and text, is preserved. This ensures that critical information such as captions, headers, and content flows remain in their original context.
Format Optimization Any misaligned text or uneven spacing caused by outdated scanning methods is corrected. This results in a clear, professionally aligned document ready for accurate data parsing.
Why LLMWhisperer’s Pre-Processing Is Essential
LLMWhisperer’s robust pre-processing ensures that OCR systems perform optimally, even under challenging conditions like noisy, low-quality scans or complex layouts. By preserving the integrity of the document while enhancing its quality, LLMWhisperer enables businesses to unlock valuable insights from scanned PDFs and image-based text with unparalleled accuracy and efficiency.
Two Practical Examples Using LLMWhisperer
LLMWhisperer is a powerful tool for extracting text and structured data from scanned documents and images. Below, we showcase two practical examples to demonstrate its capabilities:
Example 1: Using LLMWhisperer Playground to Extract Text from the Apollo Space Mission Manual
The Apollo Space Mission Manual is a historical document with a mix of structured tables, illustrations, and descriptive text. By using the LLMWhisperer Playground, we can see how effectively it processes such a complex document.
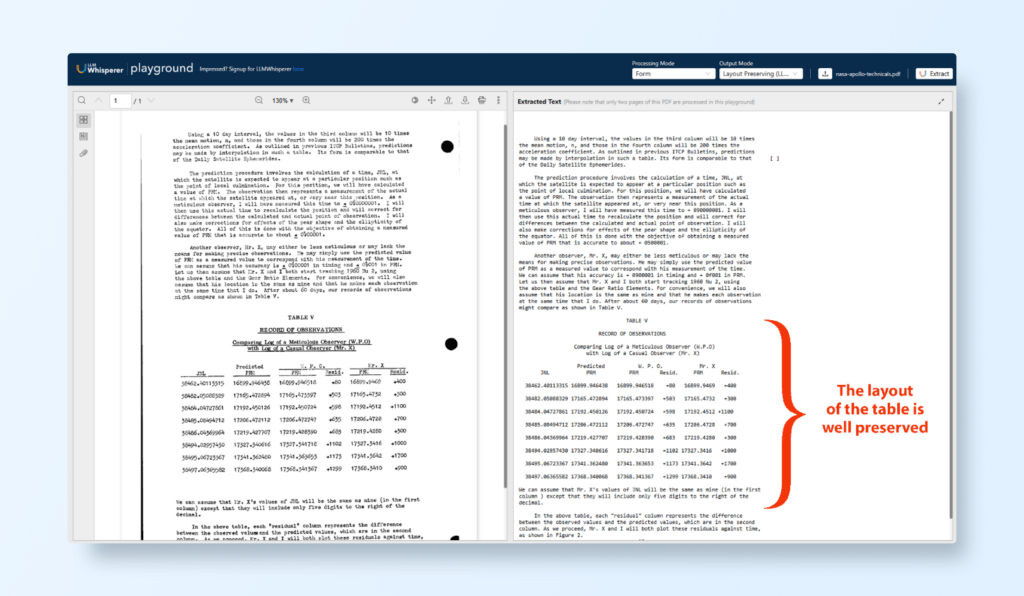
Upload the Document Drag and drop a scanned Apollo Space Mission Manual page or upload the file manually.
Initiate Processing Once uploaded, click the Process Document button. LLMWhisperer begins analyzing the document.
Observe the Magic In just seconds, the extracted text and data appear on your screen.
Preserved Layout: LLMWhisperer retains the document’s original structure, keeping sections like headers, tables, and diagrams intact.
Clean Text Extraction: Even faded or poorly scanned text is accurately recognized and digitized.
Tables and Diagrams: Complex tables are extracted precisely, with rows and columns preserved in a structured format, ready for downstream processing.
Benefits Demonstrated
Effortlessly handles scanned documents with mixed content.
Ensures no loss of context or structure, making the document ready for archival or analysis.
Whether digitizing scanned data or processing technical manuals, LLMWhisperer Playground shows how easily it bridges the gap between scanned documents and machine-readable data.
Get started with LLMWhisperer: Best Document OCR API for AI Document Worklfows
Example 2: Using LLMWhisperer Document OCR API in Postman to Extract Text from a Handwritten Scanned Image (PNG)
For this example, let’s demonstrate the capabilities of the LLMWhisperer API to process a handwritten scanned image (e.g., a PNG file of notes or forms).
Step-by-Step Workflow Using Postman
Sign Up and Get Document OCR API Key
Visit the LLMWhisperer signup page and create an account.
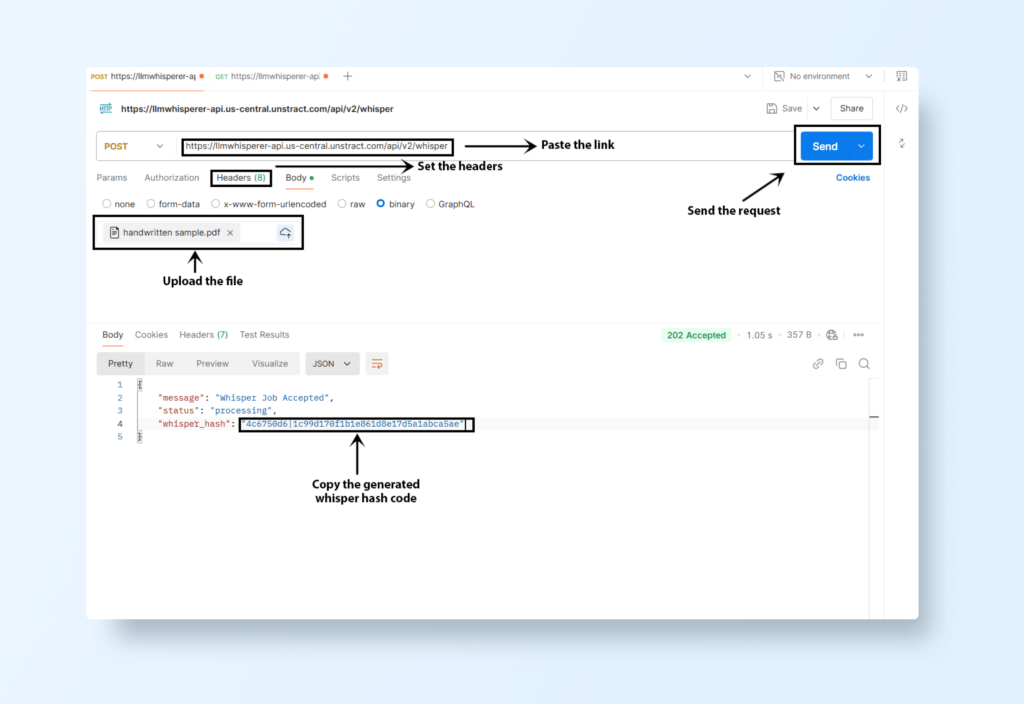
Add the key files, set its type to File, and upload the handwritten scanned image (PNG).
LLMWhisperer Document OCR API Request
Example cURL Command:
curl -X POST 'https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper' \
-H 'unstract-key: <Your API Key>' \
-F 'files=@handwritten_sample.png'
Submit the request, and you’ll receive a response containing the whisper_hash, which you’ll use to retrieve the results.
Check Conversion Status
Create a GET request using the /whisper-status endpoint to check if processing is complete: https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper-status
Example cURL Command:
curl -X GET 'https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper-status' \
-H 'unstract-key: <Your API Key>'
The response will indicate the status (processing or completed).
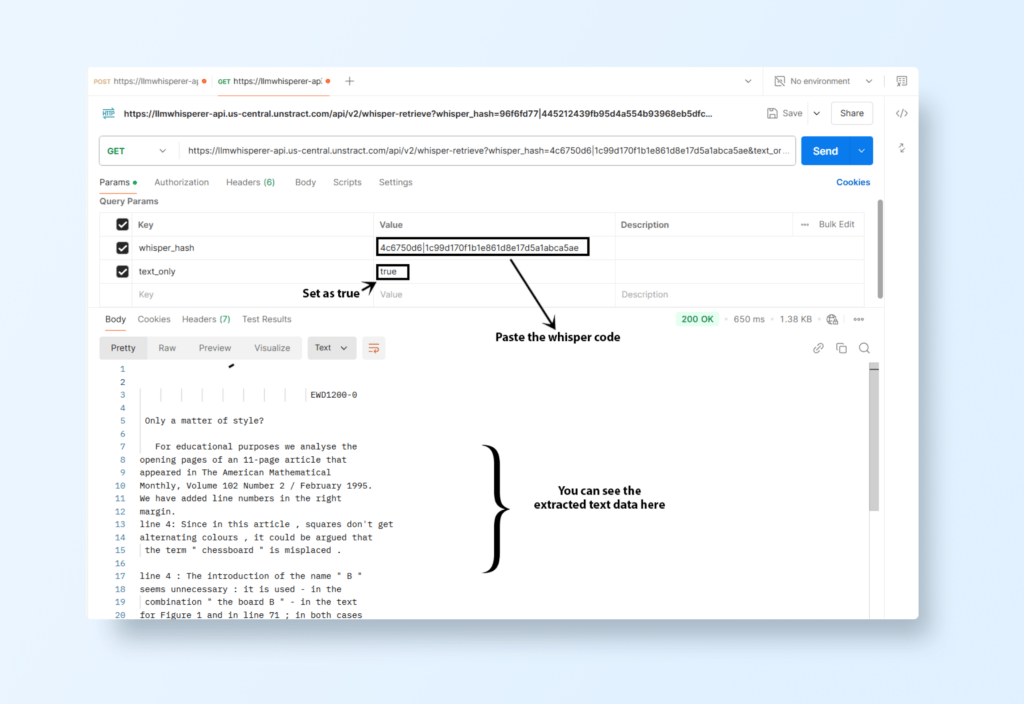
Retrieve the Extracted Text
Once processing is complete, use the /whisper-retrieve endpoint to fetch the extracted text: https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper-retrieve
GET Request Parameters:
Add whisper_hash as a query parameter.
Use text_only=true for a clean, nearly formatted text output.
LLMWhisperer Document OCR API Response
Example cURL Command:
curl -X GET 'https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper-retrieve?whisper_hash=<whisper_hash>&text_only=true' \
-H 'unstract-key: <Your API Key>'
The response will include an object containing the structured text extracted from the handwritten scanned image.
The outcome of the OCR extraction:
EWD1200-0
Only a matter of style?
For educational purposes we analyse the
opening pages of an 11-page article that
appeared in The American Mathematical
Monthly, Volume 102 Number 2 / February 1995.
We have added line numbers in the right
margin.
line 4: Since in this article, squares don't get
alternating colours , it could be argued that
the term " chessboard " is misplaced .
line 4 : The introduction of the name " B "
seems unnecessary : it is used - in the
combination " the board B " - in the text
for Figure 1 and in line 71 ; in both cases
just " the board " would have done fine .
In line 77 occurs the last use of B,
viz . in " X CB " , which is dubious since
B was a board and not a set ; in line
77 . I would have preferred " Given a set X [X]
of cells ".
line 7/8: The first move, being a move
like any other , does not deserve a separate
discription . The term " step " is redundant .
line 8: Why not "a move consists of"?
line 10/11: At this stage the italics are
puzzling, since a move is possible if,
<<<
Key Highlights of the PDF OCR API
Accurately extracts handwritten content, even from noisy scans.
Outputs structured data that can be seamlessly integrated into your workflows.
LLMWhisperer Document OCR API: Final Thoughts
By showcasing these two practical examples, LLMWhisperer demonstrates its versatility in handling diverse document types, whether historical or handwritten. Its Playground provides an intuitive testing environment, while its API allows seamless integration into enterprise workflows. Together, these tools redefine how we process and extract value from scanned PDFs and images.
Learn how faithfully reproducing the structure of tables and other elements by preserving the original PDF layout is crucial for better performance in LLM and RAG applications.
Unstract is a transformative platform designed to simplify the processing of unstructured documents by converting them into actionable, structured data. As a powerful companion to LLMWhisperer, Unstract leverages advanced AI and LLMs to refine and organize outputs from diverse document types such as invoices, tax forms, resumes, and handwritten notes. Its robust capabilities eliminate the complexities of manual data extraction, enabling seamless workflows across industries.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
How Unstract Complements LLMWhisperer
LLMWhisperer excels at extracting text and context from scanned PDFs, images, and other unstructured files. Unstract builds upon this foundation by further structuring and enhancing the extracted data, ensuring it is ready for use in downstream applications such as analytics, compliance, or CRM integration.
Seamless Integration: Outputs from LLMWhisperer are fed into Unstract for advanced processing, including context-aware data structuring and organization.
AI-Driven Refinement: While LLMWhisperer parses data, Unstract employs AI and LLMs to interpret relationships between document elements, preserving context and ensuring accuracy.
Adaptability to Document Variability: Unstract accommodates various layouts, designs, and content formats without requiring constant reconfiguration, making it highly efficient for dynamic workflows.
Key Features of Unstract
Dynamic Data Structuring
Unstract converts unstructured data, such as raw outputs from LLMWhisperer, into structured formats like JSON, CSV, or databases.
It uses machine learning algorithms to detect patterns, relationships, and hierarchies within documents.
Example: For a scanned tax form, Unstract organizes extracted fields such as “Employer Name,” “Tax Year,” and “Form ID” into structured JSON, ready for integration with financial systems.
No Need for Constant Retraining
Unlike traditional systems, Unstract adapts to changes in document formats and layouts without requiring retraining or remodelling.
This flexibility reduces maintenance overhead and ensures consistent performance even as documents evolve.
Example: A recruitment agency can process resumes with varying designs and fonts without modifying the tool each time a new style is encountered.
Multi-Format Document Support
Unstract handles outputs from diverse sources, including handwritten forms, scanned PDFs, and image-based data.
It manages complex layouts like multi-column formats, tables, or embedded diagrams.
Example: In an insurance claims process, Unstract can handle scanned accident reports, structured forms, and handwritten notes simultaneously, delivering consistent results.
AI-Enhanced Context Understanding
Unstract uses AI to understand the context of the extracted data, ensuring that important relationships—like linking totals to invoice numbers or matching candidates’ skills to job descriptions—are preserved.
The AI/LLM Advantage for Document Processing
Unstract integrates with powerful AI/LLMs to enhance its processing capabilities:
Contextual Awareness: AI algorithms allow Unstract to interpret nuanced relationships between extracted fields, ensuring greater accuracy.
Scalable Automation: Whether processing thousands of resumes or extracting data from a batch of handwritten tax forms, Unstract scales effortlessly to meet enterprise demands.
Minimal Human Intervention: With intelligent pre-configuration and adaptability, Unstract reduces the need for manual oversight, improving operational efficiency.
Why Choose Unstract for Document Processing Automation?
Efficiency and Speed: Automates time-consuming tasks like manual data entry and document parsing, delivering results in minutes.
Reliability Across Formats: Adapts to document changes without requiring constant reprogramming or updates.
Seamless Workflow Integration: Outputs can be directly integrated into downstream systems, such as ERPs, CRMs, or analytics platforms.
By complementing the text parsing capabilities of LLMWhisperer with advanced data structuring powered by AI, Unstract transforms the way organizations handle unstructured data. Its adaptability and intelligence make it an indispensable tool for any business seeking to optimize document processing workflows.
Data Extraction from a Scanned Handwritten Tax Form Using Unstract
Extracting structured data from scanned handwritten tax forms is a crucial step in automating tax reporting and compliance workflows. Using Unstract’s Prompt Studio, organizations can tailor prompts to extract critical information such as the taxpayer’s name, total assets, and employer details. Here’s a detailed guide to setting up Unstract to process a scanned handwritten tax form, complete with API integration via Postman.
Step 1: Setting Up the Project in Prompt Studio
Access Prompt Studio
Log into your Unstract account and navigate to the Prompt Studio page from the dashboard.
Click New Project to create a project tailored for tax form processing.
Provide details:
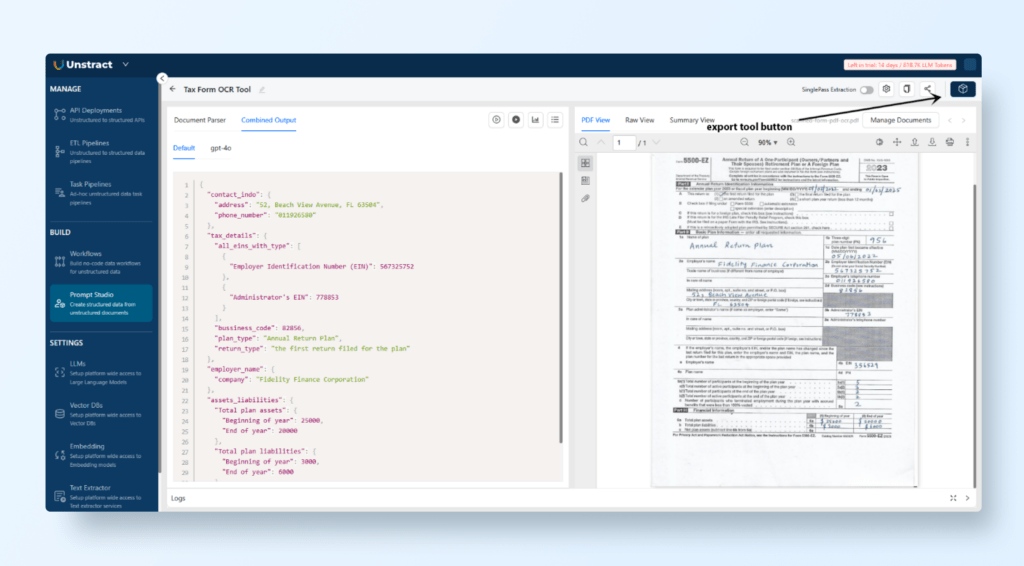
Tool Name: “Tax Form OCR Tool”
Description: “Extracts critical fields such as taxpayer details and financial information from tax forms.”
Upload the Handwritten Tax Form
Go to the Manage Documents section and click Upload Files.
Upload the scanned tax form PDF provided.
Write Tailored Prompts for Key Data Fields: Craft prompts to extract specific fields from the tax form. Here are examples:
Set the output type as ‘json’.
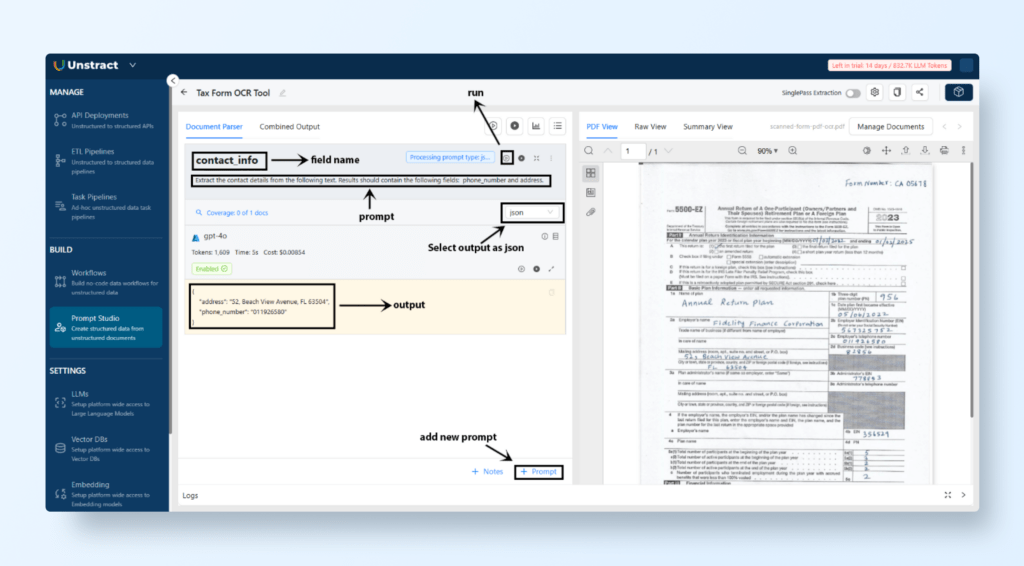
Field Name: contact_info
Prompt Text: “Extract the contact details from the following text. Results should contain the following fields: phone_number and address.”
We can add more prompts per the requirements to extract the desired info.
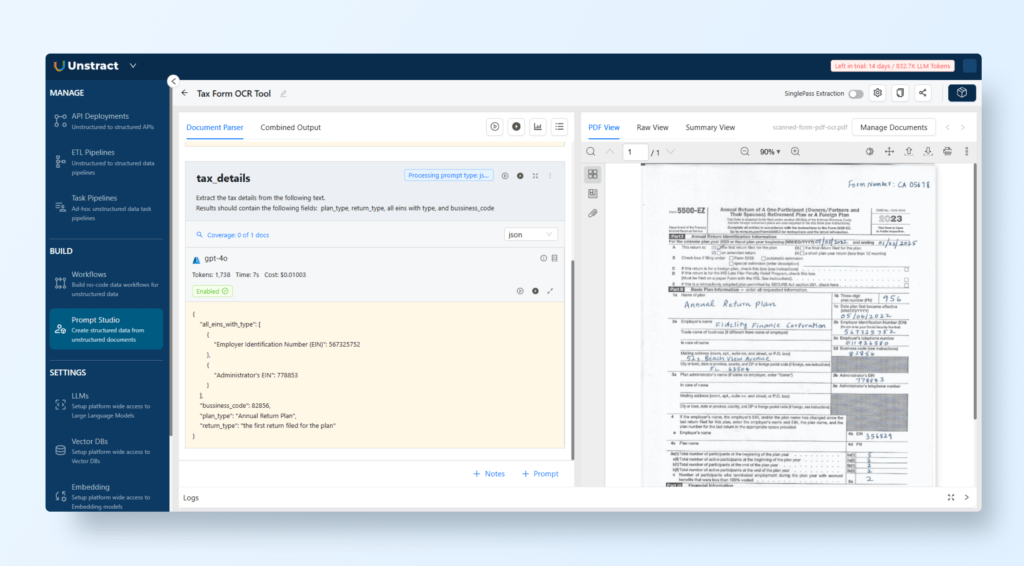
Let’s extract the Tax Details.
Field Name: tax_details
Prompt Text: ” Extract the tax details from the following text. Results should contain the following fields: plan_type, return_type, all eins with type, and bussiness_code.”
Below is the output:
{
"all_eins_with_type": [
{
"Employer Identification Number (EIN)": 567325752
},
{
"Administrator's EIN": 778853
}
],
"bussiness_code": 82856,
"plan_type": "Annual Return Plan",
"return_type": "the first return filed for the plan"
}
Run and Test Prompts
After creating the prompts, click Run to execute them and check the extracted data.
Verify the output in the Combined Output tab, which displays the results in structured JSON format.
Step 2: Export and Deploy the Tool as an API
Export as Tool
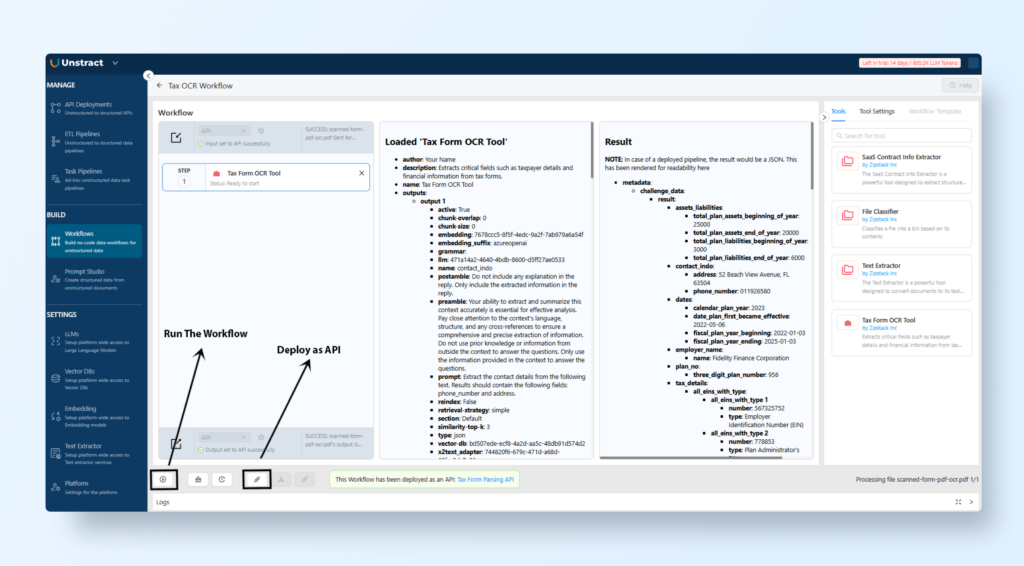
Once the prompts have been validated, click on Export as Tool to convert the project into a usable tool.
Assign a name like “Handwritten Tax Form Parser API.”
Create a Workflow
Navigate to Build → Workflows and click New Workflow.
Drag and drop the exported tool into the workflow area.
Define:
Input: Accept file uploads (PDFs).
Output: Return extracted data in JSON format.
Test the Workflow
Run the workflow
Upload the document
Click on continue
You will see the output on the screen of the loaded tool and the result of the tool.
Deploy as an API
Go to Manage → API Deployments and click + API Deployment.
Provide a name, such as “Tax Form Parsing API.”
Retrieve the API URL and generate an API key for integration.
Step 3: Testing the API via Postman
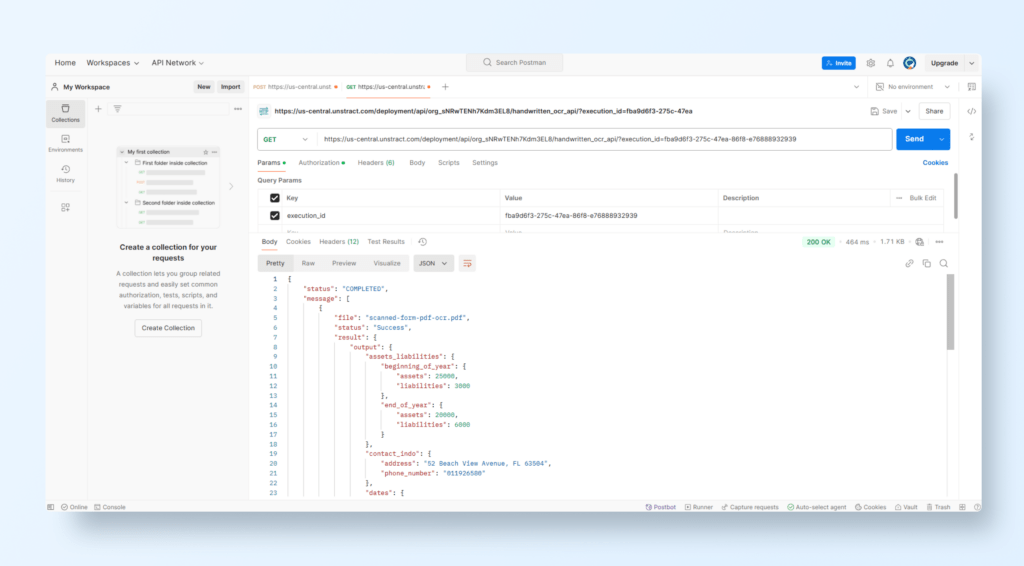
Configure POST Request
Open Postman and create a POST Request.
API URL: Paste the deployment URL from Unstract.
Authorization:
Go to the Headers tab.
Add:
Key: Authorization
Value: unstract-key YOUR_API_KEY (replace with the generated API key).
Body:
Switch to the Body tab.
Select form-data format.
Add:
Key: files
Type: File
Value: Upload the scanned tax form.
Send the Request
Click Send.
Below is the output
View JSON Output
Below is the JSON output of the uploaded handwritten tax form.
Key Advantages of Using Unstract for Tax Form Processing
Efficiency: Automates the extraction of detailed data fields without manual effort.
Scalability: Handles multiple tax forms simultaneously with high accuracy.
Integration Ready: Outputs are available in structured JSON and can be integrated with tax software or databases.
Flexibility: Prompts can be customized for other financial forms or compliance documents.
By leveraging Unstract and its seamless integration with LLMWhisperer, organizations can extract meaningful data from even the most complex handwritten tax forms with unparalleled ease and precision.
Conclusion
The synergy between LLMWhisperer and Unstract represents a groundbreaking approach to transforming unstructured documents into actionable data. LLMWhisperer, with its robust text parsing capabilities, serves as a reliable pre-processing layer, ensuring that even the most complex or degraded scanned documents are converted into structured text.
Unstract complements this by leveraging advanced AI and LLM-powered workflows to extract, organize, and present the data in meaningful formats such as JSON, empowering businesses to streamline processes and make data-driven decisions.
OCR APIs, such as those offered by LLMWhisperer, are revolutionizing how organizations handle document-heavy workflows.
If you want to take LLMWhisperer OCR API for a test drive quickly, you can check out our free playground.
By automating data extraction, these tools eliminate manual inefficiencies, reduce human error, and enhance scalability across industries. Whether dealing with handwritten tax forms, complex tables, or multi-language documents, the ability to seamlessly integrate OCR APIs into existing systems enables businesses to unlock the value hidden within their unstructured data repositories.
In an era driven by digital transformation, the integration of solutions like LLMWhisperer and Unstract into business workflows underscores the potential of technology to simplify, accelerate, and optimize operations.
Sign up for our free trial of Unstract if you want to try it out quickly. More information here.
As document processing demands grow, these tools pave the way for a future where unstructured data is no longer a bottleneck but a competitive advantage, enabling enterprises to operate with precision and agility in a fast-paced digital landscape.
Get started with LLMWhisperer: Best OCR API for AI Document Worklfows
Discover how LLMWhisperer, Unstract’s dedicated OCR API, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.