

Engineers becoming product managers is a potentially dangerous idea. The reason behind this is simple—knowing too much about the tech, they might design products around the limitations of the available technology, potentially hampering innovation.
Good product managers care more about what users want, not what one can achieve with currently available technology. They will haggle with the engineering teams to push for features barely possible with current technology, fostering innovation.
Current IDP or Intelligent Document Processing platforms (we will call these IDP 1.0) are based on classical Machine Learning and Natural Language Processing (NLP) techniques. They have several very severely limiting disadvantages.
If you asked a product manager who works on IDP 1.0 systems to ignore the limitations of the current machine learning/NLP based systems and come up with a wishlist of sorts, a good product manager’s would look something like this:
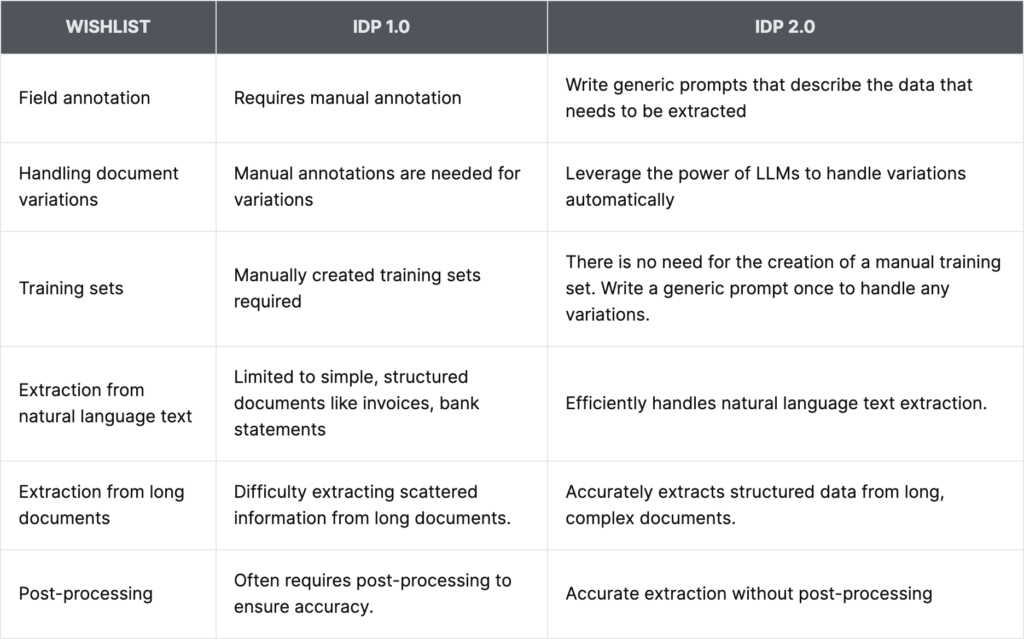
- Requirement #1: The most difficult part of IDP 1.0 systems is manually annotating fields for extraction. Let’s do away with it.
- Requirement #2: Somehow, magically handle variations within the same document type without more manual annotations—no matter how different the variations look from each other.
- Requirement #3: Do away with manually creating training sets for the classification of document variants.
- Requirement #4: Deal with the extraction of fields from documents that involve natural language text, not just from simple documents like invoices/passports/driver’s licenses/standard forms.
- Requirement #5: Accurately extract structured data from documents that may be dozens of pages long, with the information to be extracted present pretty much anywhere in the document.
- Requirement #6: Extract fields accurately without the need for post-processing.
Of course the engineering team would laugh the wishlist off. Luckily, making this dream product feature set a reality is already possible—with Large Language Models. However, there are challenges along the way. Let’s look at how LLMs take IDP into the 2.0 era.
In the next part of this series, we’ll also look at critical product components that enable this and in the 3rd part of this series, we’ll see how to deal with new challenges that pop up when applying Large Language Models to production use cases at scale.
By leveraging the power of Large Language Models, computers can deal with unstructured documents not unlike how humans deal with them—with natural language. This is a game changer. However, this also means that new product thinking around IDP has to be done from the ground up. Simply extending the old paradigm of IDP 1.0 won’t magically take us into the new IDP 2.0 era.
It is not often that a completely new toolset, that has completely new, powerful, disruptive capabilities and associated challenges becomes available to product leaders and engineers. It’s a great opportunity to rethink IDP systems in the light of this new technology.
Requirement #1: Doing away with annotations
IDP 1.0 systems currently use Natural Language Processing (NLP), Machine Learning and positional information in the documents to extract structured data out of them. If you have dealt with current IDP 1.0 systems, you know what I mean. You’ll have to quite literally “train” the system by manually annotating a training document set in order for the system to learn the physical structure of each of these documents.
This is required because unlike how humans deal with unstructured documents, NLP and machine learning based systems are pretty rigid. Using LLMs, on the other hand, we can process documents just like how a human would.
By using Large Language Models, we should be able to extract structured data from unstructured documents even if they have broad variations in the same document type by:
- Writing generic prompts that describe the data that needs to be extracted across different variants of the document type
- Describing the schema that the particular document type needs to be extracted into using simple language
What’s best is that prompts are written just like how one might describe the extraction and the structuring process to another human. In theory, one can do the needed prompt engineering for this using LLM-programming frameworks like Langchain or LlamaIndex, but doing it for the various document types that a business might need to process would be tedious.
Developing generic prompts means that one will have to refer between different document variants, the prompts and the LLM response back and forth. This requires an environment that is purpose built for structured data extraction from unstructured documents. This is the reason Prompt Studio exists. But, that’s a topic for the second part in this series.
A good analogy for using Large Language Models to process unstructured documents would be that of using a very smart intern to extract fields from them in a structured manner. Prompts to the LLM are like the instructions given to the intern describing the extraction process so there is no ambiguity with regards to what needs to be extracted and how it needs to be formatted. This “describe what you need with simple natural language” method to tackle unstructured documents was never possible before the advent of LLMs.
By moving from manually annotating which fields need to be extracted to simply prompting a Large Language Model using plain English not only allows us to extract fields more efficiently, but also has other advantages like dealing with variants of the same document type trivially. This is a huge step up from training a machine learning-based system so it can deal with document variants with yet more manual annotations!
Requirement #2: Magically handling document variants
Commonly found fields in bank statements are the bank name, branch, the customer’s name, customer’s address, account number, current balance and the list of transactions. It’s safe to assume that pretty much all regular bank statements will have this information in common.
Although all these statements contain the common information we need to pull out, when dealing with variants of the same document type in IDP 1.0 systems, you need to train the system, by manually annotating where the different fields are for each variant. This can get very unwieldy very quickly.
Let’s say you are a financial organization in the business of giving out loans to your customers. You’ll have to parse bank statements to determine their loan amount eligibility. Trouble is, you have no control over the different types of bank statements you might receive. Handling all those variants by training with manual annotations would be a huge drain on your resources.
Let’s say you were handed 10 bank statements from 10 different banks. As a human, you don’t really look at certain locations for the customer name and yet another location on the top right corner for her address.
We, as humans, use our ability to read and understand natural language and our knowledge of the world in general, to interpret and understand these different variations of bank statements without trouble. Amazingly, we can pretty much achieve the same effect with Large Language Models. This is what makes them so powerful and disruptive.

The fact that there can be many, many variations of a document type doesn’t matter. What matters is that all the variations have the same common information we seek to extract. Given the document, prompts that describe what fields to extract, how to format them and the schema to output the response in, we can indeed achieve structured data extraction from unstructured documents pretty much how a human would approach it. This was not possible before LLMs became commonplace. In essence, we’re relying on two powerful attributes Large Language Models have to achieve structured data extraction from unstructured documents:
- Their ability to reason
- Their ability to follow instructions
Customers often ask us in the context of some document: “Can an LLM extract this information”? We ask them back: “Given clear instructions, can an intern extract that information”? If the answer is yes, then yes—LLMs can indeed help. They are like a programmable intern. Never tiring—always eager to help. But, like we discussed before, there are challenges when they are deployed in production at scale. We discuss these challenges and solutions in part 3 of this series.
Requirement #3: Do away with manually creating training sets for the classification of document variants
This is related to the previous point of how we can easily deal with variants in IDP 2.0. The key to dealing with document variants is prompt engineering. It has to be generic enough to work across document variants. There is no need for manual annotation or classification.
Again, writing generic prompts becomes not just easy, but a lot of fun in an environment like Prompt Studio, which is purpose built for document data extraction with Large Language Models.
Features like Prompt Coverage and Output Analyzer gently guide you towards generic prompt engineering. Prompt Studio also allows side-by-side comparison of different LLMs, showing you extracted data, latency, tokens used up along with dollar value cost.
Like mentioned in the previous topic, since Large Language Models deal with documents with natural language just like humans do, variants are handled with just prompt engineering.
Requirement #4: Extract fields from long documents that involve natural language text
There are simple documents where information to be extracted is present as key-value pairs. For instance:
Customer name: John Appleseed
Address: 1024, Binary St, Beverly Hills 90210
Account number: #3141592653These kinds of documents lend themselves very well to extraction with manual annotations. Things get complicated when in IDP 1.0 when:
- There are multiple addresses, names, phone numbers, etc are present in the document
- There are wide ranging variations of the same document type
- The information to be extracted is spread across various segments of the document
This is in spite of IDP 1.0 systems having the ability to extract named entities (via Named Entity Recognition or NER). NER however is not very smart. It can only detect named entities. It can’t figure out if a particular named entity is indeed the actual entity you are looking for when there are several of them in the document. This is why features like Segmentation exist in IDP 1.0 systems so users can manually annotate which segment(s) the system should be looking into, to extract the entities they are interested in. Trouble is: more manual annotations and more training data sets need to be created!
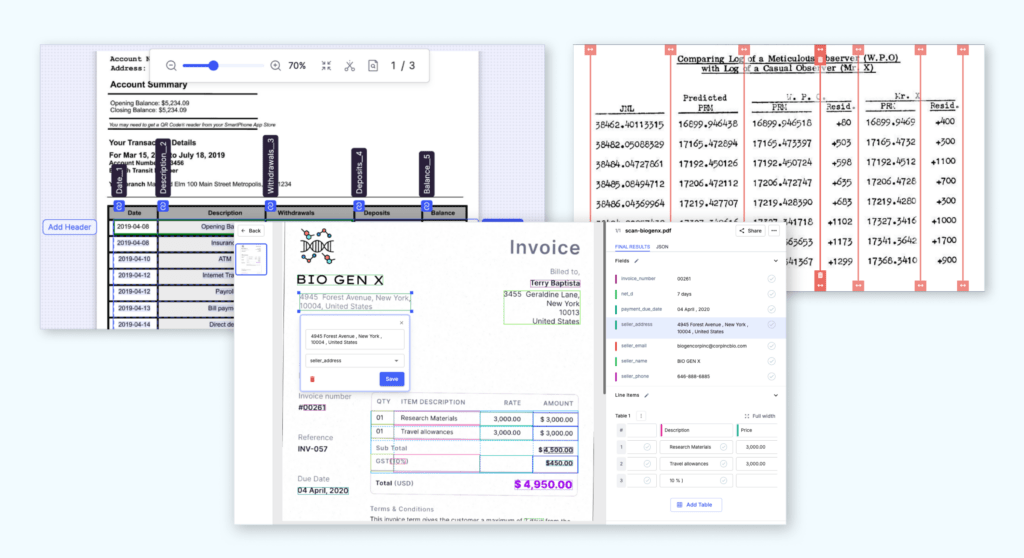
With LLM-powered IDP 2.0, you simply ask which address (business address vs residential address of the applicant) you want if there are multiple instances present and you just get it back as structured data. Just like you’d ask an intern. There is no need to do NER or Segmentation. It’s just a completely new and dramatically simple way to extract what you need.
Requirement #5: Easily extract from very long documents that are dozens of pages
We saw how LLMs make it possible to effortlessly extract the exact information you need without having to jump through the hoops of NER or manually training the system for Segmentation. LLMs can quite simply fetch you the exact data you need in the exact format you need even with prompts that are not all that sophisticated.
But, the fun part is that LLMs can go much further. They can deal with unstructured documents that are hundreds of pages long. There is one problem though. LLMs can take in information one context window at a time. Also, they are stateless. Meaning, when the next question is asked of them, they can’t really recall anything from the history of any conversations they might have had.
For structured data extraction, prompts that help extract and structure the data are sent along with the contents of the source document for structured data extraction. So, what happens if the document is too long to fit into the context window size of the LLM being used? Well, we can’t really send it to the LLM along with our prompts. This is where vector databases come in.
After storing the contents of the source document in a vector database divided as small, manageable chunks, we can ask the vector DB to return chunks that are likely to have the relevant information given any prompt. We can then send our prompts along with the relevant chunks (rather than contents of the whole document) returned by the vector database to the LLM. This technique is called Retrieval Augmented Generation or RAG. This is much like Segmentation used in IDP 1.0. However, this is fully automatic and does not need any manual annotations of the segments from various document variations.
This way, we can extract structured data from documents that are hundreds of pages long. Also, in IDP 2.0, as implemented by the Unstract Platform, the use of vector databases is completely transparent to the user. You hardly even realize they are employed. It is almost like an optimization technique that is used behind the scenes.
You can read more about the use of vector databases and chunking in IDP 2.0 in the article Vector DB Retrieval: To chunk or not to chunk on the Unstract blog.
Requirement #6: Extract fields accurately without the need for post-processing
This is again a time saving feature of IDP 2.0. When using IDP 1.0 for document data extraction, the extraction and the formatting of the extracted data happen in two separate steps. While it has its advantages and can also be done in IDP 2.0, in IDP 2.0 it can be done by simply setting the format of the extraction to one of the predefined types like String, Number, Date, Email, JSON, etc. For instance, irrespective of how a date was specified in the source document, in human readable format, it can always be output in the yyyy-mm-dd format that’s easy for computers to process.
More powerful is JSON format output. You can simply define the JSON structure you need in plain English, set the prompt output type to JSON and expect clean JSON output. For instance, you might want the address to be output as a simple JSON structure with the street address, city and ZIP code split out as separate subfields so that downstream processing is easy.
For this you simply prompt the LLM with something like “Extract the insured address as a JSON object with the following fields: street_address, city, zip”, while setting the output type to JSON. This will get the extraction done and validate that the output indeed is valid JSON.
When using IDP 1.0 and extracting fields, it’s common for surrounding characters to get extracted that later need to be culled in a post processing step. For instance, when we ask for the name to be pulled from a document that has something like the following:
Customer name: John Appleseed
It is not uncommon for the extraction to be “: John Appleseed”, leaving us to remove the “:” in a post-processing step. This never happens in IDP 2.0 due to how LLMs process data.
Ready for IDP 2.0?
LLMs present a very disruptive new way to do Intelligent Document Processing (IDP) and this new way is so fundamentally different from the current approach and is just leaps and bounds more productive compared to incumbent platforms.
Unstract is the leading open source IDP 2.0 platform that not only takes advantage of LLMs for structured document data extraction from unstructured documents but also has powerful features that ensure that you can actually use LLMs at scale for the document data extraction use case. This means countering hallucinations that LLMs are known for, but also tackling costs that can come with using LLMs at scale.
With API deployments you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically.
Sign up for our free trial if you want to quickly try it out. More information here.





















