
Product
Processing Sensitive Unstructured Data with Sovereign AI
If your organization handles sensitive documents at scale, you’ve probably hit a wall that has nothing to do with model

If your organization handles sensitive documents at scale, you’ve probably hit a wall that has nothing to do with model
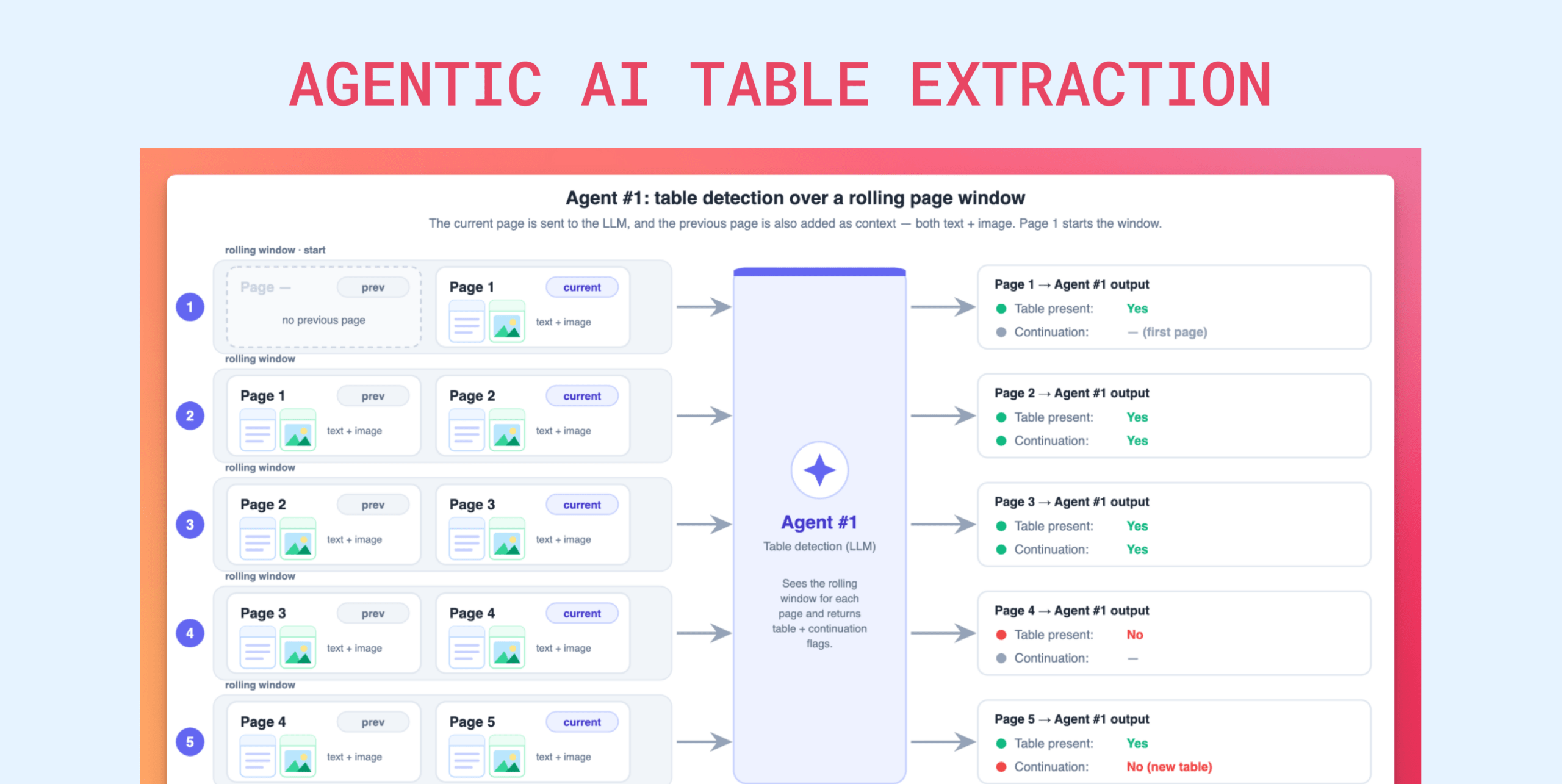
Extraction demos are easy. We can build one in an afternoon, and so can anyone. Clean document in, clean JSON

Explore automated document processing software built for variability. Handle scanned PDFs, handwritten forms, and complex layouts with built-in accuracy scoring and API-first deployment.

Learn how LLMWhisperer delivers high-accuracy OCR for forms across tax, banking, KYC, insurance, logistics, and government workflows.

Most RAG failures start with a broken ocr pipeline in rag. LLMWhisperer delivers the best ocr for rag—preserving tables, handwriting, and layout so your rag workflow returns accurate, auditable answers.

LLMs and vision-language models depend on clean, structured inputs for accurate results. Discover how OCR text recognition with LLMWhisperer preserves layout and improves document understanding for reliable data extraction.



















