Tables in PDFs are very prevalent and for those of us who are intent on extracting information from PDFs, they often contain very useful information in a very dense format. Processing tables in PDFs, if not the top 10 priority for humanity, it certainly is an important one.
Once data from PDFs is extracted, it’s relatively easy to process it using Large Language Models (LLMs). We need to do this in two phases:
Extract the raw data from tables in PDFs
Then pass it to an LLM so that we can extract the data we need as structured JSON. Once we have JSON, it becomes super easy to process in almost any language.
PDF raw table extraction with LLMWhisperer
In this article, we’ll see how to use Unstract’s LLMWhisperer as the text extraction service for PDFs. As you’ll see in some examples we discuss, LLMWhisperer allows us to extract data from PDFs by page, so we can extract exactly what we need.
The key difference between various OCR systems and LLMWhisperer is that it outputs data in a manner that is easy for LLMs to process.
Also, we don’t have to worry about whether the PDF is a native text PDF or is made up of scanned images. LLMWhisperer can automatically switch between text and OCR mode as required by the input document.
Get started with LLMWhisperer: Best PDF Table Extraction Parser for LLMs
Getting started with PDF table extraction
Before you run the project
The source code for the project can be found here on Github. To successfully run the extraction script, you’ll need 2 API keys. One for LLMWhisperer and the other for OpenAI APIs. Please be sure to read the Github project’s README to fully understand OS and other dependency requirements. You can sign up for LLMWhisperer, get your
API key, and process up to 100 pages per day free of charge.
The input documents
Let’s take a look at the documents and the exact pages within the documents from which we need to extract the tables in question. First off, we have a credit card statement from which we’ll need to extract the table of spends, which is on page 2 as you can see in the screenshot below.
Extracting table from a PDF: credit card statement
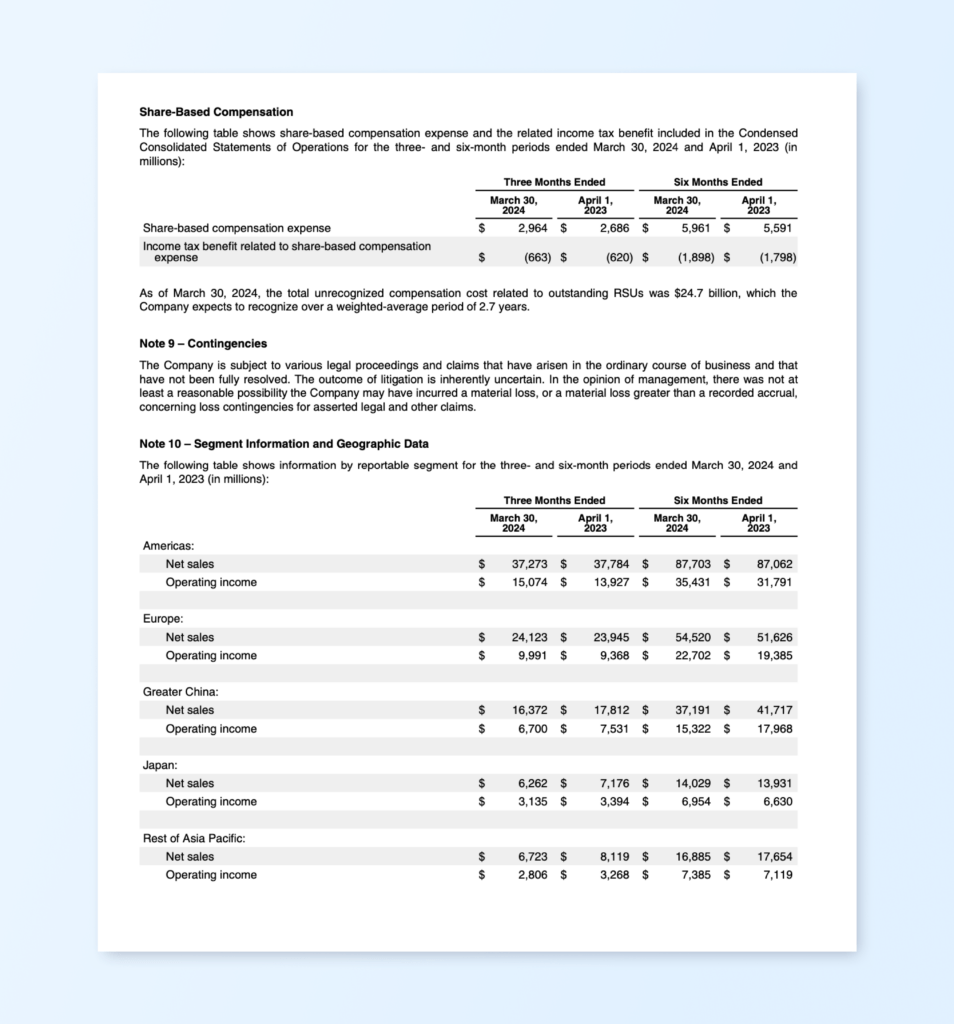
The other document we’ll use is one of Apple’s quarterly financial statements, also known as a 10-Q report. From this, we’ll extract Apple’s sales data by different regions in the world. We will extract a table that contains this information from page 14, a screenshot of which is provided below. You can find the sample 10-Q report in the companion Github repository.
Extracting table from a PDF: Apple financial statement
Unstract’s All Table Extraction API: Effortless Table Extraction
Unstract’s All Table Extraction API simplifies the process of extracting tables from PDFs, images, and other document formats.
With just an API key and endpoint, you can seamlessly integrate advanced AI-powered table detection into your workflow. Point your documents to the API, and receive structured, ready-to-use table data in return—no manual intervention required.
Using LLMWhisperer’s Python client, we can extract data from these documents as needed. LLMWhisperer is a cloud service and requires an API key, which you can get for free. LLMWhisperer’s free plan allows you to extract up to 100 pages of data per day, which is more than we need for this example.
Just calling the whisper() method on the client, we’re able to extract raw text from images, native text PDFs, scanned PDFs, smartphone photos of documents, etc.
Here’s the extracted data from page 2 of our credit card statement, which contains the list of spends.
Manage your account online at: Customer Service: Mobile: Download the
www.chase.com/cardhelp 1-800-524-3880 Chase Mobile ® app today
freedom
YOUR ACCOUNT MESSAGES (CONTINUED)
Your AutoPay amount will be reduced by any payments or merchant credits that post to your account before we
process your AutoPay payment. If the total of these payments and merchant credits is more than your set AutoPay
amount, your AutoPay payment for that month will be zero.
ACCOUNT ACTIVITY
Date of
Transaction Merchant Name or Transaction Description $ Amount
PAYMENTS AND OTHER CREDITS
01/28 AUTOMATIC PAYMENT - THANK YOU -4,233.99
PURCHASE
01/04 LARRY HOPKINS HONDA 7074304151 CA 265.40
01/04 CICEROS PIZZA SAN JOSE CA 28.18
01/05 USPS PO 0545640143 LOS ALTOS CA 15.60
01/07 TRINETHRA SUPER MARKET CUPERTINO CA 7.92
01/04 SPEEDWAY 5447 LOS ALTOS HIL CA 31.94
01/06 ATT*BILL PAYMENT 800-288-2020 TX 300.29
01/07 AMZN Mktp US*RT4G124P0 Amzn.com/bill WA 6.53
01/07 AMZN Mktp US*RT0Y474Q0 Amzn.com/bill WA 21.81
01/05 HALAL MEATS SAN JOSE CA 24.33
01/09 VIVINT INC/US 800-216-5232 UT 52.14
01/09 COSTCO WHSE #0143 MOUNTAIN VIEW CA 75.57
01/11 WALGREENS #689 MOUNTAIN VIEW CA 18.54
01/12 GOOGLE *YouTubePremium g.co/helppay# CA 22.99
01/13 FEDEX789226298200 Collierville TN 117.86
01/19 SHELL OIL 57444212500 FREMONT CA 7.16
01/19 LEXUS OF FREMONT FREMONT CA 936.10
01/19 STARBUCKS STORE 10885 CUPERTINO CA 11.30
01/22 TST* CHAAT BHAVAN MOUNTAI MOUNTAIN VIEW CA 28.95
01/23 AMZN Mktp US*R06VS6MNO Amzn.com/bill WA 7.67
01/23 UALR REMOTE PAY 501-569-3202 AR 2,163.19
01/23 UALR REMOTE PAY 501-569-3202 AR 50.00
01/24 AMZN Mktp US*R02SO5L22 Amzn.com/bill WA 8.61
01/24 TIRUPATHI BHIMAS MILPITAS CA 58.18
01/25 AMZN Mktp US*R09PP5NE2 Amzn.com/bill WA 28.36
01/26 COSTCO WHSE #0143 MOUNTAIN VIEW CA 313.61
01/29 AMZN Mktp US*R25221T90 Amzn.com/bill WA 8.72
01/29 COMCAST CALIFORNIA 800-COMCAST CA 97.00
01/29 TRADER JOE S #127 LOS ALTOS CA 20.75
01/30 Netflix 1 8445052993 CA 15.49
01/30 ATT*BILL PAYMENT 800-288-2020 TX 300.35
01/30 APNI MANDI FARMERS MARKE SUNNYVALE CA 36.76
02/01 APPLE.COM/BILL 866-712-7753 CA 2.99
2024 Totals Year-to-Date
Total fees charged in 2024 $0.00
Total interest charged in 2024 $0.00
Year-to-date totals do not reflect any fee or interest refunds
you may have received.
INTEREST CHARGES
Your Annual Percentage Rate (APR) is the annual interest rate on your account.
Annual Balance
Balance Type Percentage Subject To Interest
Rate (APR) Interest Rate Charges
PURCHASES
Purchases 19.99%(v)(d) - 0 - - 0 -
CASH ADVANCES
Cash Advances 29.99%(v)(d) - 0 - - 0 -
BALANCE TRANSFERS
Balance Transfers 19.99%(v)(d) - 0 - - 0 -
LARRY PAGE Page 2 of 3 Statement Date: 02/03/24
0000001 FIS33339 D 12 Y 9 03 24/02/03 Page 2 of 3 06610 MA MA 34942 03410000120003494202
<<<
This is the extracted text from page 14 of Apple’s 10-Q document, which contains the sales by geography table towards the end:
Share-Based Compensation
The following table shows share-based compensation expense and the related income tax benefit included in the Condensed
Consolidated Statements of Operations for the three- and six-month periods ended March 30, 2024 and April 1, 2023 (in
millions):
Three Months Ended Six Months Ended
March 30, April 1, March 30, April 1,
2024 2023 2024 2023
Share-based compensation expense $ 2,964 $ 2,686 $ 5,961 $ 5,591
Income tax benefit related to share-based compensation
expense $ (663) $ (620) (1,898) $ (1,798)
As of March 30, 2024, the total unrecognized compensation cost related to outstanding RSUs was $24.7 billion, which the
Company expects to recognize over a weighted-average period of 2.7 years.
Note 9 - Contingencies
The Company is subject to various legal proceedings and claims that have arisen in the ordinary course of business and that
have not been fully resolved. The outcome of litigation is inherently uncertain. In the opinion of management, there was not at
least a reasonable possibility the Company may have incurred a material loss, or a material loss greater than a recorded accrual,
concerning loss contingencies for asserted legal and other claims.
Note 10 - Segment Information and Geographic Data
The following table shows information by reportable segment for the three- and six-month periods ended March 30, 2024 and
April 1, 2023 (in millions):
Three Months Ended Six Months Ended
March 30, April 1, March 30, April 1,
2024 2023 2024 2023
Americas:
Net sales $ 37,273 $ 37,784 $ 87,703 $ 87,062
Operating income $ 15,074 $ 13,927 $ 35,431 $ 31,791
Europe:
Net sales $ 24,123 $ 23,945 $ 54,520 $ 51,626
Operating income $ 9,991 $ 9,368 $ 22,702 $ 19,385
Greater China:
Net sales $ 16,372 $ 17,812 $ 37,191 $ 41,717
Operating income $ 6,700 $ 7,531 $ 15,322 $ 17,968
Japan:
Net sales $ 6,262 $ 7,176 $ 14,029 $ 13,931
Operating income $ 3,135 $ 3,394 $ 6,954 $ 6,630
Rest of Asia Pacific:
Net sales $ 6,723 $ 8,119 $ 16,885 $ 17,654
Operating income $ 2,806 $ 3,268 $ 7,385 $ 7,119
Apple Inc. I Q2 2024 Form 10-Q | 11
<<<
Langchain+Pydantic to structure extracted raw tables from PDF
Langchain is a popular LLM programming library and Pydantic is one of the parsers it supports for structured data output. If you process a lot of documents of the same type, you might be better off using an open source platform like Unstract which allows you to more visually and interactively develop generic prompts.
But for one-off tasks like the example we’re working on, where the main goal is to demonstrate extraction and structuring, Langchain should do just fine. For a comparison of approaches in structuring unstructured documents, read this article: Comparing approaches for using LLMs for structured data extraction from PDFs.
Defining the schema for PDF table extraction
To use Pydantic with Langchain, we define the schema or structure of the data we want to extract from the unstructured source as Pydantic classes. For the credit card statement spend items, this is how it looks like:
class CreditCardSpend(BaseModel):
spend_date: datetime = Field(description="Date of purchase")
merchant_name: str = Field(description="Name of the merchant")
amount_spent: float = Field(description="Amount spent")
class CreditCardSpendItems(BaseModel):
spend_items: list[CreditCardSpend] = Field(description="List of spend items from the credit card statement")
Looking at the definitions, `CreditCardSpendItems` is just a list of `CreditCardSpend`, which defines the line item schema, which contains the spend date, merchant name and amount spent.
For the 10-Q regional sales details, the schema looks like the following:
class RegionalFinancialStatement(BaseModel):
quarter_ending: datetime = Field(description="Quarter ending date")
net_sales: float = Field(description="Net sales")
operating_income: float = Field(description="Operating income")
ending_type: str = Field(description="Type of ending. Set to either '6-month' or '3-month'")
class GeographicFinancialStatement(BaseModel):
americas: list[RegionalFinancialStatement] = Field(description="Financial statement for the Americas region, "
"sorted chronologically")
europe: list[RegionalFinancialStatement] = Field(description="Financial statement for the Europe region, sorted "
"chronologically")
greater_china: list[RegionalFinancialStatement] = Field(description="Financial statement for the Greater China "
"region, sorted chronologically")
japan: list[RegionalFinancialStatement] = Field(description="Financial statement for the Japan region, sorted "
"chronologically")
rest_of_asia_pacific: list[RegionalFinancialStatement] = Field(description="Financial statement for the Rest of "
"Asia Pacific region, sorted "
"chronologically")
Constructing the prompt and calling the LLM
The following code uses Langchain to let us define the prompts to structure data from the raw text like we need it. The compile_template_and_get_llm_response() function has all the logic to compile our final prompt from the preamble, the instructions from the Pydantic class definitions along with the extracted raw text. It then calls the LLM and returns the JSON response.
def compile_template_and_get_llm_response(preamble, extracted_text, pydantic_object):
postamble = "Do not include any explanation in the reply. Only include the extracted information in the reply."
system_template = "{preamble}"
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = "{format_instructions}\n\n{extracted_text}\n\n{postamble}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
parser = PydanticOutputParser(pydantic_object=pydantic_object)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
request = chat_prompt.format_prompt(preamble=preamble,
format_instructions=parser.get_format_instructions(),
extracted_text=extracted_text,
postamble=postamble).to_messages()
chat = ChatOpenAI()
response = chat(request, temperature=0.0)
print(f"Response from LLM:\n{response.content}")
return response.content
def extract_cc_spend_from_text(extracted_text):
preamble = ("You're seeing the list of spend items from a credit card statement and your job is to accurately "
"extract the spend date, merchant name and amount spent for each transaction.")
return compile_template_and_get_llm_response(preamble, extracted_text, CreditCardSpendItems)
def extract_financial_statement_from_text(extracted_text):
preamble = ("You're seeing the financial statement for a company and your job is to accurately extract the "
"revenue, cost of revenue, gross profit, operating income, net income and earnings per share.")
return compile_template_and_get_llm_response(preamble, extracted_text, GeographicFinancialStatement)
The output: PDF tables to JSON
Let’s examine the JSON output from the credit card statement table and the region-wise sales table. Here’s the structured JSON from the credit card spend items table first:
Excellent! We got exactly what we were looking for. Next, let’s look at the JSON output structured from the regional sales table from Apple’s 10-Q PDF.
This output is as we expected, too. With this kind of structured output, it becomes very easy for us to process complex information in these kinds of tables further. The key to easy extraction of structured information is the availability of cleanly formatted input tables and LLMWhisperer here plays a key role in that extraction even for scanned documents or documents that are just smartphone photos.
PDF table extraction with LLMs: Links to libraries, packages, and code
Pydantic: Use Pydantic to declare your data model. This output parser allows users to specify an arbitrary Pydantic Model and query LLMs for outputs that conform to that schema.
Live coding session on PDF table extraction with LLMs
You can also watch this live coding webinar where we explore all the challenges involved in PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
For the curious. Who are we and why are we writing about PDF table extraction?
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an Open Source software and is available at https://github.com/Zipstack/unstract.
If you want to quickly try it out, signup for our free trial. More information here.
LLMWhisperer is a document-to-text converter. Prep data from complex documents for use in Large Language Models. LLMs are powerful, but their output is as good as the input you provide. Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables.
Extracting data from these documents and blindly feeding them to LLMs is not a good recipe for reliable results. LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they’re able to best understand it.
If you want to quickly take it for test drive, you can checkout our free playground.
Document extraction at the cutting edge with LLMs vs LLMWhisperer
Discover how LLMWhisperer, Unstract’s dedicated text extraction service, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.
In this webinar, we put top LLMs to the test—evaluating their performance across documents of varying complexity. We’ll dive into why directly parsing raw documents often leads to subpar results, and showcase the impact LLMWhisperer has on improving extraction outcomes, especially extracting tables from PDFs.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Shuveb Hussain is the Co-founder and CEO of Unstract. Previously, he served as VP of Engineering at Freshworks, a NASDAQ-listed global SaaS company. With over two decades of experience, Shuveb has co-founded multiple internet startups and worked with companies operating at massive scale—handling petabytes of data and billions of requests per hour.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.