Introduction: The Urgent Need for Intelligent Document Processing
In a world where data is the lifeblood of decision-making, document-heavy industries like finance, insurance, logistics, healthcare, and legal are constantly flooded with paperwork—contracts, forms, reports, bills, and statements. These documents, often unstructured, pose a significant challenge for traditional IT systems that rely on rigid templates or manual data entry. The process is slow, error-prone, and lacks the flexibility to scale.
This growing digital chaos is creating an urgent need for transformation. Organizations are not just looking for speed; they demand intelligent document automation—solutions that can comprehend, extract, and structure data with human-like intelligence. Enter Intelligent Document Processing (IDP)—a technological leap that combines OCR, AI, machine learning, and natural language processing (NLP) to extract structured insights from raw, unstructured documents.
IDP isn’t just digitization. It’s intelligent data extraction with context-awareness, making decisions on the fly and learning over time.
Over the past few years, the rise of LLMs (Large Language Models) has further pushed the boundaries of what IDP solutions can do. Traditional OCR-based pipelines are giving way to context-driven, prompt-based AI workflows that not only identify data but also understand it.
This article unpacks the evolution of intelligent document processing, explores the new era of IDP AI, and dives deep into how Unstract, a next-generation intelligent document processing platform, is revolutionizing the space by eliminating the need for training data or annotation and bringing real-time human oversight into AI workflows.
What to Expect in This Article:
A clear IDP definition and how it works.
The limitations of traditional IDP software.
The modern, LLM-powered approach to intelligent document automation.
A deep dive into Unstract, showcasing how it uses OCR IDP, LLMWhisperer, and ETL pipelines.
Practical examples: extracting data from rent rolls, ACORD forms, and bills of lading.
A quick overview of Human-in-the-loop (HITL) integration for compliance and control.
Whether you’re an enterprise looking to reduce operational costs or a data engineer building automation pipelines, understanding the future of IDP intelligent document processing is now mission-critical.
What is Intelligent Document Processing (IDP)?
Intelligent Document Processing (IDP) refers to the use of advanced technologies like OCR, artificial intelligence, machine learning, and NLP to extract, understand, classify, and structure data from both digital and scanned documents.
Let’s break it down:
Traditional vs Intelligent Document Handling
In legacy systems:
Data entry was manual.
OCR could recognize text but failed at understanding context.
Rule-based systems broke down when faced with new document formats.
With intelligent document processing software, however:
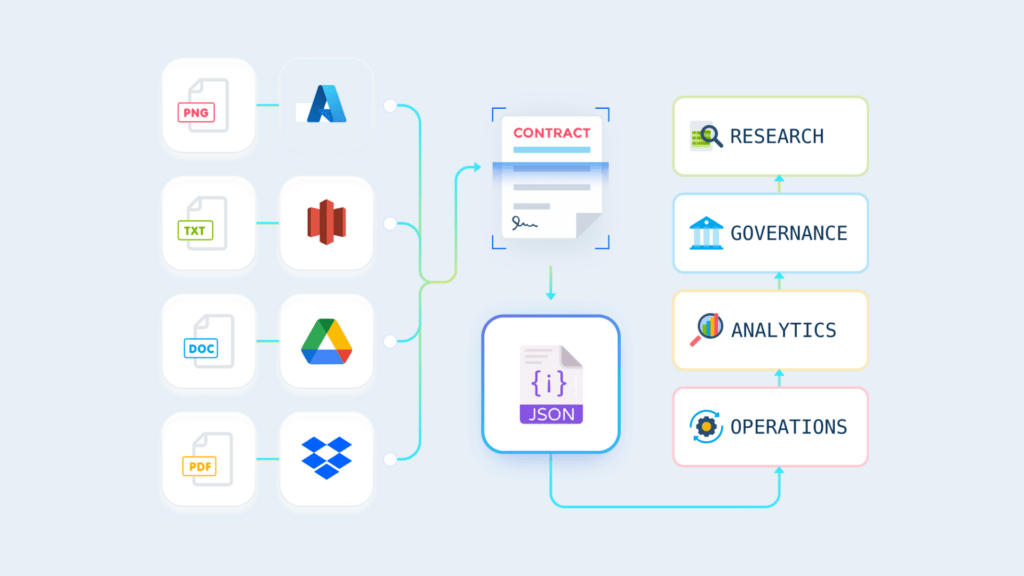
The document is scanned or ingested.
OCR (like LLMWhisperer) extracts raw text and layout data.
NLP and ML models understand context, classify fields, and extract structured values.
Results are converted into machine-readable structured formats (e.g., JSON).
Final data is stored in databases like Postgres or Snowflake, ready for analytics.
How IDP Works: The Core Components
Here’s how a typical intelligent document processing platform operates:
Document Ingestion
Supports formats like PDF, scanned images, Word documents, etc.
Files can be uploaded via APIs, Google Drive, Dropbox, or enterprise systems.
OCR & Layout Detection
OCR systems like LLMWhisperer identify printed or handwritten characters.
Table structures, headers, footers, and layout elements are preserved.
Context-aware prompts extract fine-grained data: name, SSN, invoice total, etc.
Validation & Human-in-the-Loop (HITL)
Rules check extraction confidence.
Low-confidence or flagged documents are routed to humans for review.
Structured Output & Integration
Extracted data is stored in relational or document-based databases.
It powers workflows, analytics, dashboards, and downstream automation.
Core Benefits of IDP Intelligent Document Processing
Benefit
Description
Intelligent Data Extraction
Understands and extracts context-rich information across formats
No Need for Training Data
LLM-based systems like Unstract require no upfront ML training
Human Oversight
With HITL, the system is never a black box
Ready for Analytics
Extracted data can be stored in systems like NeonDB or visualized in BI dashboards
Reduces Manual Effort
Saves cost and time on manual data entry and QA
Supports Complex Documents
Invoices, rent rolls, contracts, and bills of lading are handled out of the box
The Role of AI and NLP in IDP
Modern IDP AI systems use transformers and deep learning to make sense of unstructured data.
AI understands semantics — distinguishing between “Total Due” and “Paid Amount.”
NLP parses paragraphs — turning narrative sections into structured tags.
ML models detect anomalies — flagging when a field seems unusual (e.g., an SSN format error).
Unlike legacy intelligent document processing solutions, which are template-based and static, today’s LLM-powered systems like Unstract are dynamic, prompt-driven, and context-aware.
To summarize:
Intelligent Document Processing (IDP) is the practice of using OCR, AI, ML, and NLP to extract structured information from unstructured documents at scale. It’s a smarter, faster, and more flexible way to handle documents in the digital era.
Business Applications of Intelligent Document Processing (IDP)
The versatility of intelligent document processing solutions makes them invaluable across industries where unstructured and semi-structured documents are a part of daily operations. Below, we explore how IDP software is transforming core document workflows in key sectors.
Invoices and Receipts: Data like invoice number, due dates, line items, and totals can be auto-extracted using OCR IDP combined with LLMs. The structured output can directly feed into accounting systems like QuickBooks or SAP.
Loan Applications: Complex multi-section forms with borrower information, employment details, and financial declarations are parsed into JSON using Unstract.
Expense Reports: Hundreds of scanned receipts can be processed into standardized formats with intelligent data extraction, enabling faster reimbursement and audit readiness.
Example: A bank processes 1,000 loan applications daily. With an intelligent document processing platform, those forms are scanned, parsed, validated, and ingested into a Postgres (NeonDB) database—no manual typing needed.
Insurance: Extracting Data from ACORD Forms & Claim Documents
Insurance providers often deal with high-volume, multi-format documents—most of them coming from customers, partners, or internal systems.
Common uses of IDP in insurance:
ACORD Forms: Standardized forms like ACORD 25 (certificates of insurance) and ACORD 80 (homeowners applications) contain detailed customer, policy, and coverage data. IDP AI can parse these without training on each layout.
Claims Processing: Extracting claim numbers, insured details, descriptions of loss, and amount claimed is seamless with AI-driven IDP software.
Policy Documents: Intelligent document automation can classify and extract clauses, endorsements, and coverage limits.
Example: Using Unstract, an insurer digitized 10,000 legacy ACORD forms in a week, storing them as structured rows in a relational database for analytics.
Logistics: Digitizing Bills of Lading, Invoices & Shipping Records
In logistics and supply chain, time-sensitive documents like Bills of Lading (BOLs) and shipping manifests drive operational continuity.
Key applications of IDP in logistics:
Bills of Lading: Extract shipper, consignee, container info, and cargo description into structured formats.
Delivery Receipts: Automate data entry for PoD (proof of delivery) documents.
Example: A logistics firm integrated Unstract’s intelligent document processing platform to extract cargo details from BOLs and sync them with internal ERP systems—cutting manual workload by 80%.
Real Estate: Processing Rent Rolls & Property Records
Property Tax Forms: Digitize and classify tax ID, parcel numbers, and owner details.
Property Valuations: Use IDP AI to extract appraiser details, valuation metrics, and comparable property data.
Example: A property management firm used IDP to convert scanned rent roll PDFs into tabular data for investment analysis in Google Sheets.
Advantages of Intelligent Document Processing
Adopting intelligent document automation isn’t just about saving time—it’s about enabling smarter, more reliable operations that scale. Here’s why businesses are embracing IDP solutions:
1. Faster Turnaround with Automation
Manual processing of hundreds of documents could take hours—or even days. With IDP intelligent document processing software, documents are parsed, validated, and transformed into structured formats within seconds.
Speed reduces processing time by up to 90%.
Documents can be processed in real-time, even at scale.
Example: A lender uses Unstract to process mortgage applications in real-time with near-zero delay between upload and structured data extraction.
2. Reduced Manual Workload
One of the biggest benefits of intelligent document processing is reducing repetitive manual effort, especially for BPOs, data entry teams, and operations managers.
Fewer errors due to misreading or mistyping.
Resources can be redirected to more strategic, value-adding tasks.
“A 5-person team that once spent 8 hours a day on invoice entries now oversees automated workflows requiring just 30 minutes of validation.”
3. Higher Accuracy & Consistency
Modern IDP platforms like Unstract use prompt-based LLMs that understand context and intent—achieving extraction accuracies as high as 99%, especially when paired with OCR tools like LLMWhisperer.
Minimizes data mismatches or missing fields.
Great for compliance-critical documents (e.g., KYC, insurance claims).
4. Context-Aware Extraction
What sets modern IDP AI apart from legacy systems is the ability to understand context:
Recognizes whether “Total” refers to subtotal, grand total, or tax-inclusive amount.
Identifies hidden relationships like co-borrower vs. primary borrower.
This intelligent understanding comes from LLMs like GPT-4, which are leveraged inside platforms like Unstract via prompt engineering.
5. Works Across Document Types
An ideal intelligent document processing solution supports structured, semi-structured, and unstructured formats:
Format
Example
Can IDP Handle?
Structured
Web forms, XML exports
✅
Semi-structured
Invoices, BOLs, Rent Rolls
✅
Unstructured
Handwritten forms, Scanned PDFs
✅ (via OCR + NLP)
With Unstract’s layered approach—LLMWhisperer for parsing + LLMs for understanding—even challenging documents become manageable.
Traditional IDP Approach: Limitations
Before the rise of LLM-powered platforms, most intelligent document processing solutions relied heavily on rule-based engines, traditional OCR, and classical machine learning models. These systems were powerful in specific use cases—but brittle and inefficient when scaled across real-world business document variety.
Manual Annotation and Training Overhead
One of the core bottlenecks in the traditional IDP intelligent document processing model is the need for extensive training data:
Each document layout required manual annotation of entities—highlighting every name, address, date, amount, etc.
For example, if you were automating insurance claims, a team had to annotate 1,000+ forms line by line, teaching the model where each key data point lives.
This meant the system wasn’t just expensive—it was also time-consuming to build, tune, and validate.
Multiple Disjointed ML/NLP Pipelines
Legacy intelligent document processing software depended on stacking components like:
Optical Character Recognition (OCR)
Named Entity Recognition (NER)
Regex or rule-based post-processing
Data formatting and database mapping
Each of these pipelines was trained and maintained separately, increasing operational complexity. A small change—like adding a new document format—often broke the pipeline or required costly retraining.
Lack of Scalability and Adaptability
Traditional IDP solutions often failed when a new document type was introduced.
Systems trained on one document layout could not generalize to others.
Businesses had to build custom workflows for every new vendor, form, or geography.
Example: A US insurance company used an IDP system trained on ACORD 25. When switching to ACORD 80, the system failed entirely because fields were placed differently—and the old model couldn’t adapt.
Slow Time-to-Value
The ramp-up for traditional intelligent document automation could span weeks or months—from data collection to model training, evaluation, and deployment.
As a result:
Small and mid-sized businesses were priced out of IDP adoption.
Enterprises faced project delays and constant maintenance overhead.
These limitations paved the way for a new paradigm in document automation: LLM-powered intelligent document processing platforms.
Modern IDP Approach Using LLMs
Enter the era of Large Language Models (LLMs)—transforming intelligent document processing (IDP) from a rigid, rule-based system into a flexible, context-aware platform. LLMs power platforms like Unstract, bringing natural language understanding, adaptability, and speed to the forefront of document automation.
No Training Data Required
Unlike traditional systems that rely on hundreds of labeled documents, LLM-powered IDP platforms don’t need annotated data to start working.
You can define what you want to extract using plain language prompts.
No need for annotation tools or manual bounding boxes.
Example: In Unstract’s Prompt Studio, you can ask: “What is the borrower’s email address?” …and the system intelligently finds it across varying document layouts.
Understands Natural Language Context
LLMs excel at reading like humans. That means intelligent data extraction isn’t limited to keyword matches—it uses semantic understanding.
Knows that “Total Due,” “Amount Payable,” and “Final Balance” may all refer to the same entity.
Handles synonyms, rewordings, and layout differences with ease.
This makes modern IDP software highly resilient and layout-agnostic.
Handles Diverse Document Types
Whether it’s a scanned insurance claim, a digital rent roll, or a hand-filled shipping document, modern IDP solutions like Unstract can process:
Structured documents: Online forms or XML exports
Semi-structured documents: Invoices, BOLs, ACORD forms
LLMs remove the need to build separate extractors for each type.
Scalable & Dynamic Extraction
With LLM-powered IDP platforms, scaling is seamless:
Add new document types? Just update or add prompts.
Need to extract 50 fields instead of 10? No need to re-train—just extend your prompt set.
Unstract’s prompt studio and ETL pipeline lets you deploy new extraction logic with zero downtime and full version control.
Improved Accuracy & Time-to-Value
Thanks to pre-trained knowledge and context comprehension, LLMs reduce both false positives and missing fields.
Higher initial accuracy than traditional OCR + NER stacks.
Drastically reduced go-live timelines (hours instead of weeks).
A logistics firm using Unstract reduced their data entry team from 6 people to 1 validator—within 3 days of setup.
Why It Matters: Unified Pipeline, Real Results
Modern IDP AI doesn’t need to stitch together OCR, NER, ML, and validation—it’s a unified, intelligent pipeline. This reduces:
Engineering effort
Latency in extraction
Failures during deployment
With Unstract, documents are parsed (via LLMWhisperer), passed to LLMs for understanding, and output as structured JSON—all in a single, no-code flow.
Unstract 101: Leveraging AI to Convert Unstructured Documents into Usable Data
Watch this webinar/demo to explore Unstract, a platform for LLM-powered unstructured data extraction. Learn how to process complex documents—like those with images, forms, and multi-layout tables—without the need for pre-training.
Overview of Unstract: A Modern LLM-Powered IDP Platform
In a world flooded with paperwork, PDF forms, scanned documents, and endless compliance files, the need for smarter document automation has never been greater. This is where Unstract enters the picture—not just as another intelligent document processing platform, but as a revolutionary no-code LLM-powered IDP solution built for the AI era.
Unstract simplifies what used to be a months-long manual process involving OCR tools, annotation frameworks, training pipelines, and rigid ML models—and replaces it with a no-code interface, powered by large language models (LLMs), that extracts structured data intelligently and scalably.
What Is Unstract?
At its core, Unstract is an AI-powered intelligent document automation platform designed to help businesses extract structured data from documents of any kind—be it invoices, rent rolls, insurance forms, logistics bills, contracts, or identity papers.
Think of it as a smart intern that reads your documents, understands the context, and gives you structured outputs—without ever needing manual instructions or re-training.
Unstract integrates the latest in AI tooling:
LLMs (OpenAI, DeepSeek, Claude) for context-aware data extraction
Embeddings + Vector DBs for handling long or complex documents
LLMWhisperer for OCR & text parsing from scanned files
Prompt Studio for guiding extractions via natural language
ETL Pipelines to deploy workflows into production
Human-in-the-Loop (HITL) for manual validation and quality assurance
How Unstract Differs from Traditional IDP Solutions
Most legacy IDP intelligent document processing software systems (also referred to as IDP 1.0) suffer from critical bottlenecks:
Require manual field-level annotation on hundreds of documents
Need dedicated training datasets for each variation of a document
Involve rigid pipelines with separate OCR, NER, and rule-based steps
Struggle with unstructured text or documents spanning multiple pages
Require frequent retraining and engineering effort when document formats evolve
Unstract discards this old paradigm.
Instead of making users train models, it asks users to simply describe what they want extracted, in natural language. These instructions—called prompts—guide powerful LLMs to extract fields directly from the documents. No annotations. No training sets. Just intelligent parsing and structuring.
Key Features That Make Unstract a Modern IDP 2.0 Solution
1. No More Manual Annotation
The single biggest pain point of traditional IDP systems is gone.
Instead of asking you to draw boxes or annotate documents line by line, Unstract lets you write prompts like:
“What is the borrower’s full name from the loan application?” “Extract the monthly rent from this rent roll in USD format.”
Unstract then returns a clean, structured JSON or string response—instantly.
2. Supports Document Variants Out of the Box
One invoice from Vendor A might say “Total Amount,” while Vendor B says “Amount Due.” Traditional IDP software would require training for both.
Unstract? It just understands.
Using LLMs’ natural language capabilities, Unstract handles document variants with zero manual effort. Just write a generic prompt, and let the model do the rest.
3. Works Across Any Document Format
Scanned PDFs
Digitally generated forms
Hand-filled insurance papers
Multi-page legal contracts
Tabular reports and summaries
With LLMWhisperer as the OCR engine and LLMs for understanding, Unstract processes structured, semi-structured, and unstructured data without needing format-specific templates.
This means no more custom workflows for each form. Just upload the document and write a prompt.
4. Vector DBs for Long Document Parsing
Some documents are too long to fit into a single model prompt window. Here’s where Unstract’s seamless RAG (Retrieval-Augmented Generation) strategy comes in.
It breaks the document into chunks and uses vector embeddings to fetch only the relevant portions based on the prompt. This allows it to process:
Long shipping manifests
Property lease agreements
Legal disclosures
… all while returning the exact data you asked for.
5. Prompt Studio: The Natural Language IDE
Unstract includes Prompt Studio, a purpose-built interface for designing, testing, and refining prompt-based extraction workflows.
It lets you:
Upload sample documents
Write prompts for each field
Preview responses from different LLMs
Compare latency, cost, and output quality
Visualize output in JSON, tables, or custom formats
It even includes coverage tools and output analyzers to validate prompt effectiveness and improve your extraction strategies iteratively.
6. Built-in ETL Pipelines for Deployment
Once your prompts are tested, you can export them as a Tool and deploy them via the ETL Pipelines tab.
Choose Google Drive, Dropbox, or S3 as input source
Choose NeonDB, Snowflake, or BigQuery as the output
Configure Human-in-the-Loop review, logging, and error handling
Run and monitor your document pipeline in real-time
No need to integrate dozens of tools. It’s all in one platform.
7. Human-in-the-Loop (HITL) Built Right In
Sometimes AI needs human judgment. That’s where Unstract’s HITL interface shines.
You can:
Route low-confidence documents to reviewers
Add rules like “Review 50% of all ACORD forms”
Assign roles (Reviewer, Supervisor, Admin)
Review, approve, or reject extractions from a clean UI
Publish reviewed data to your final database or queue
This HITL integration ensures transparency, quality control, and regulatory compliance in even the most sensitive document workflows.
8. API-Ready for Automation
Unstract lets you expose your extraction workflows as REST APIs.
Test with Postman
Integrate with web apps
You can build fully automated document ingestion pipelines in a day—no engineering team required.
Why Unstract Is a Game-Changer for Intelligent Document Automation
Feature
Traditional IDP 1.0
Unstract (IDP 2.0)
Manual Annotation
✅ Required
❌ Not Needed
ML/NLP Training
✅ Required
❌ Zero Training
Document Variant Handling
❌ Breaks Easily
✅ Works Out of the Box
Long Document Support
❌ Manual Segmentation
✅ Vector DB + RAG
Output Format
❌ Often Needs Post-processing
✅ JSON/Structured Formats
Deployment Time
Weeks/Months
Hours
User Skills Needed
Engineers/Data Scientists
Anyone with prompt writing
Cost of Ownership
High
Low
Time to Value
Long
Instant
Is Unstract the Best Intelligent Document Processing Software?
Yes, for modern businesses looking for:
A low-code/no-code intelligent document automation tool
That can handle any type of document
Without training data or annotations
While maintaining accuracy, transparency, and control
Unstract isn’t just another IDP vendor. It’s a next-generation platform that combines the power of LLMs, OCR, embeddings, and review workflows into one seamless user experience.
This makes it the leading intelligent document processing platform for enterprises seeking to scale document understanding at speed—without hiring a machine learning team.
Understanding LLMWhisperer
In the world of Intelligent Document Processing (IDP), one of the biggest hurdles lies at the very first step: parsing scanned documents, PDF forms, and images that contain vital business data. Whether it’s rent rolls, ACORD insurance forms, or bills of lading, most documents come in non-editable, visually complex formats. This is where LLMWhisperer plays a foundational role.
First, What Is LLMWhisperer?
Despite the name, LLMWhisperer is not a large language model (LLM).
Let’s clarify that upfront:
It is not powered by OpenAI, Claude, or Gemini.
It does not perform reasoning or prompt-based extraction.
It does one thing exceptionally well — extract raw text from scanned PDFs and image-based documents while preserving layout structure.
It’s a general-purpose OCR (Optical Character Recognition) engine built specifically to retain the original formatting and structural fidelity of documents. This makes it a pre-processing step in the Unstract pipeline, right before LLMs are used for understanding and structured extraction.
Why Pre-Processing with LLMWhisperer Matters
AI and LLMs are powerful—but they can’t do anything without clean, accessible input data.
Scanned documents present several challenges:
Rotated or tilted pages (even by 30° or more)
Overlapping tables and checkboxes
Handwritten elements mixed with printed text
Multiple columns, stamps, or logos interfering with OCR
Text embedded inside images (especially in old forms)
These need to be parsed before any structured extraction begins.
This is the exact role of LLMWhisperer:
OCR the document
Preserve structure and layout
Convert checkboxes, tables, and even rotated text into usable raw text
Output clean pre-processed data for downstream LLMs in Unstract
What Makes LLMWhisperer Stand Out?
Unlike traditional OCR libraries (Tesseract, Adobe, or online converters), LLMWhisperer is optimized for document intelligence use cases:
Feature
Traditional OCR
LLMWhisperer
Handles scanned + rotated inputs
❌ Limited
✅ Yes
Layout preservation
❌ Partial
✅ Full
Table structure parsing
❌ Poor
✅ Accurate
Handwriting detection
❌ Poor
✅ Basic
Checkbox & multi-column layout
❌ Breaks
✅ Preserved
Designed for IDP pre-processing
❌ No
✅ Yes
This precise pre-processing is what allows Unstract to handle complex unstructured documents with near-perfect fidelity.
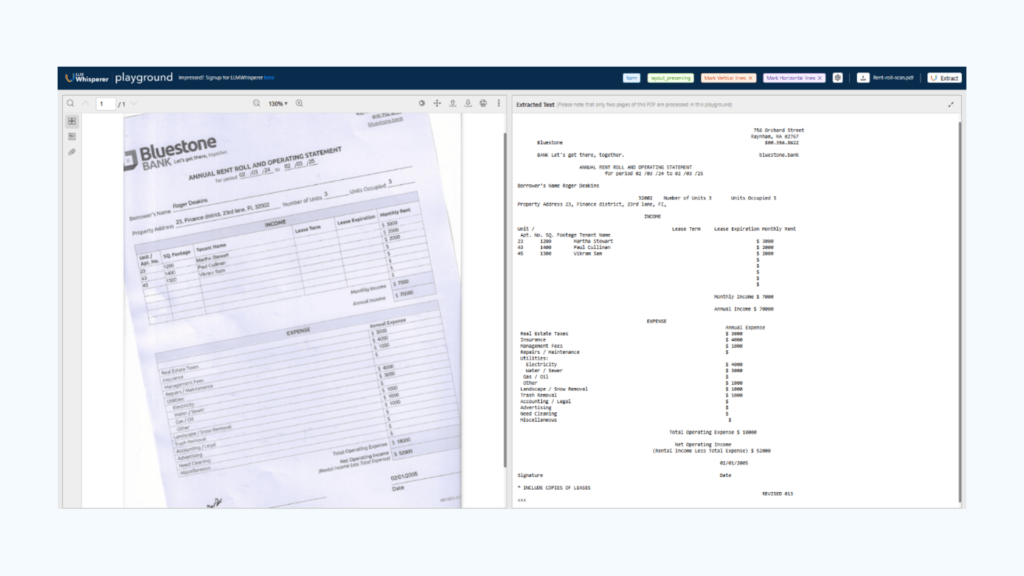
Testing LLMWhisperer in Action
You can experience the power of LLMWhisperer firsthand using either the web-based playground or a direct API integration via Postman. Let’s walk through both methods with real-world examples.
All fields extracted perfectly, despite noisy layout.
Lines overlapping text did not affect OCR quality.
No content was lost—even section titles and policy limits were readable.
Output was plain text and preserved the logical flow of the form.
This makes LLMWhisperer a top-tier option for insurance workflows, especially for companies automating claim processing, policy reviews, and risk assessments.
Summary: Why LLMWhisperer Is Critical
Capability
Benefit
Rotated Scanned PDFs
Accurately corrected and parsed
Dense Form Layouts
Preserves visual logic
Tables, Checkboxes, and Multi-columns
Extracted with structure
Noise-Tolerant
Lines, stamps, watermarks handled gracefully
Integration Ready
Playground for testing and API for automation
Whether you’re processing real estate, logistics, or insurance documents, LLMWhisperer ensures your data reaches the LLM layer in perfect form—with no noise, no data loss, and no structural corruption.
Setting Up Prompt Studio, deploying as an API, & Accessing via Postman
Once you’ve configured the LLM, embeddings, OCR tool (LLMWhisperer), and vector database inside Unstract, the next step is to set up a Prompt Studio project. This is where the magic of AI-powered intelligent document processing (IDP) begins—converting raw, unstructured data from documents like ocean bills of lading into clean, structured outputs in JSON format.
Step-by-Step Guide to Creating the Prompt Studio Project
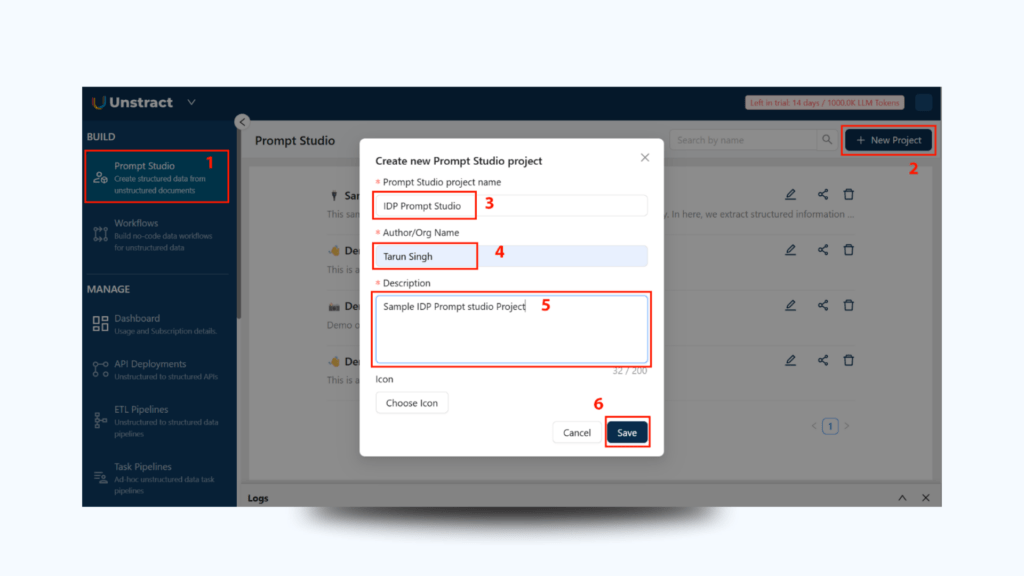
1. Access Prompt Studio
From the left sidebar on the Unstract dashboard, click on Prompt Studio to open the document prompt-building environment.
2. Create a New Prompt Project
Click New Project and fill in these fields:
Tool Name: e.g., IDP Prompt Studio
Author / Org Name: Your name or organization
Description: e.g., Extracting structured data from logistics documents like bills of lading
(Optional) Add an icon for branding.
Click Save to create your prompt project.
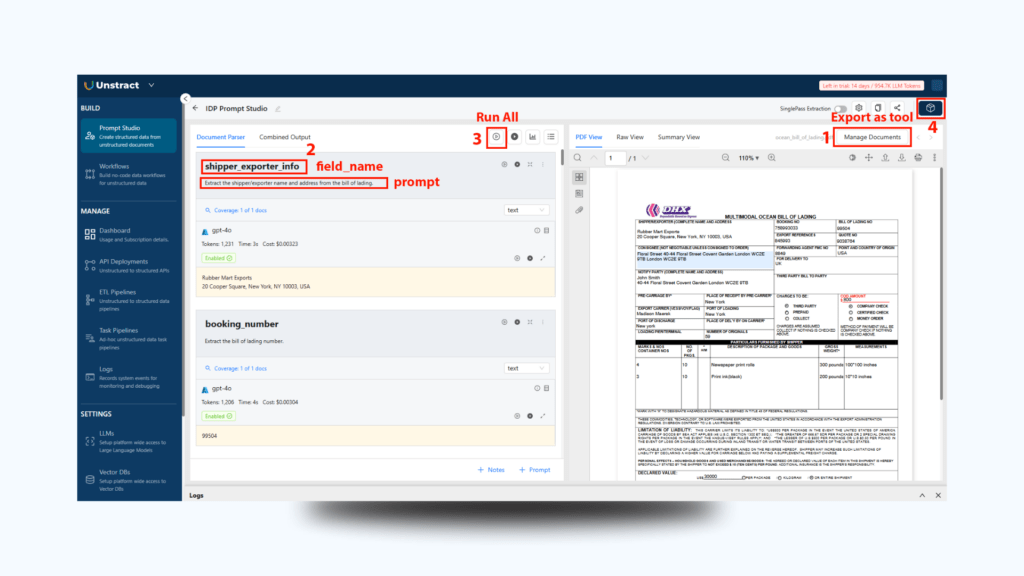
3. Upload Sample Document – Ocean Bill of Lading
Click Manage Documents and upload the test file (ocean_bill_of_lading.pdf). This document will be used to create field-specific prompts.
Tip: This sample PDF contains complex shipping data, making it a perfect example for showcasing AI-based intelligent document processing solutions.
4. Add Prompts for Field-Level Intelligent Data Extraction
Click Add Prompts and enter your extraction fields. Some recommended prompts with field name:
shipper_exporter_info: Extract the shipper/exporter complete name and address from the bill of lading.
booking_number: Extract the booking number.
bill_of_lading_number: Extract the bill of lading number.
export_references: Extract any export references mentioned.
quote_number: Extract the quote number.
consignee_info: Extract the consignee’s full name and address.
forwarding_agent_info: Extract the forwarding agent name and FMC number.
notify_party_info: Extract the notify party details.
for_delivery_to: Extract the final delivery destination.
third_party_bill_to_party: Extract third-party billing info, if available.
pre_carriage_by: Extract pre-carriage transport information.
Click Run to extract data from the uploaded file. The results appear in the Output panel, in fully structured format.
This showcases the true potential of LLM-powered intelligent document automation—accurate, context-aware, and completely code-free.
5. Export as a Tool
Once satisfied with the results, click Export as Tool. This turns your prompt project into a reusable extraction engine that can be deployed in workflows.
Deploying the Prompt Project as an API (IDP-as-a-Service)
Now that the tool is ready, let’s deploy it using Unstract’s Workflow Builder to expose it as a production-ready API.
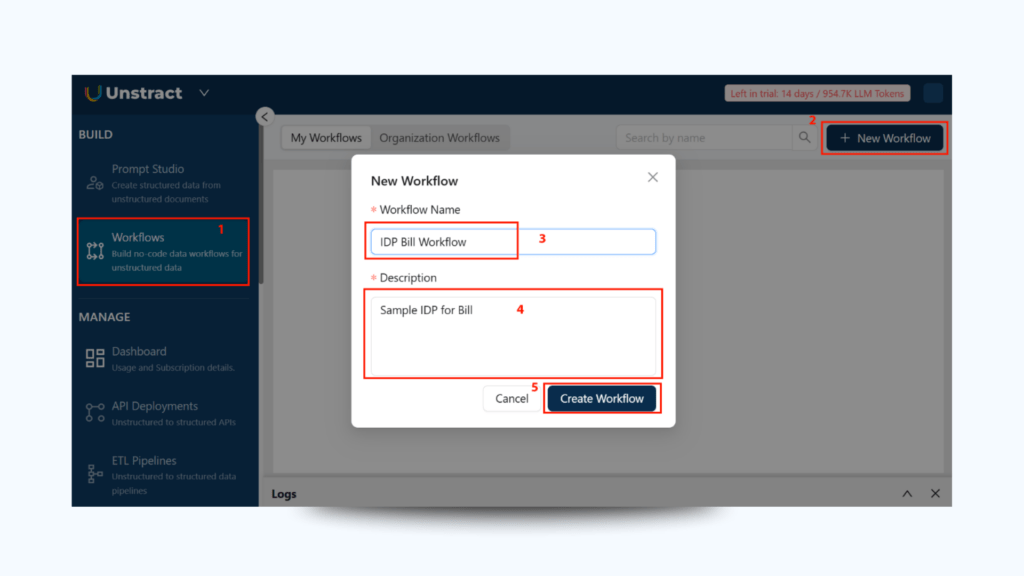
1. Navigate to Workflows
From the dashboard, go to Workflows and click New Workflow.
Name: IDP Bill Workflow
Description: Extracting structured logistics data from- bills of lading
Click Create Workflow.
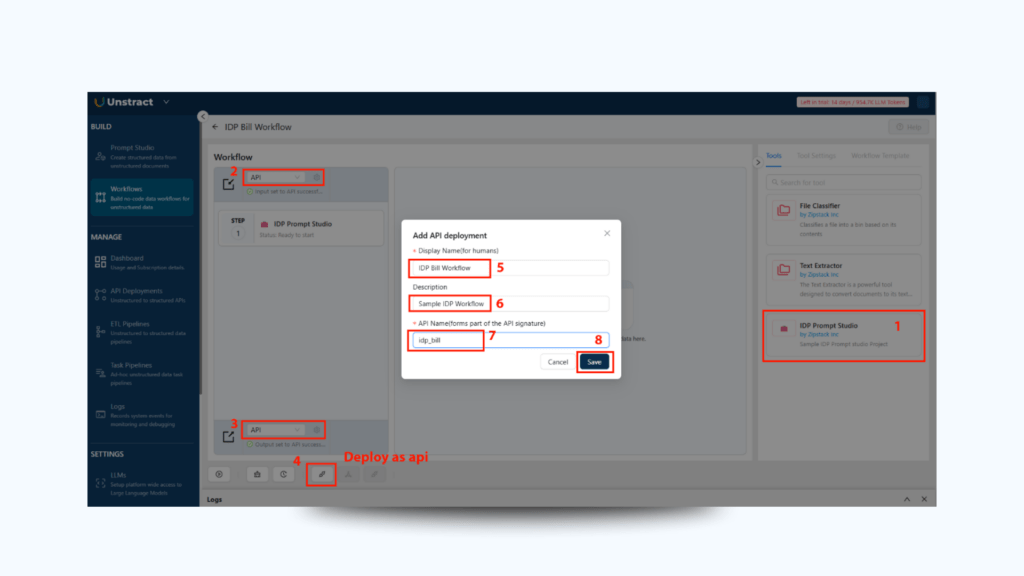
2. Add Your Tool
Drag and drop your previously exported tool into the workflow builder canvas.
3. Configure Input & Output API Connectors
API Input: Accepts uploaded PDFs (bills of lading)
API Output: Returns structured JSON to the client
Click Save, and then Deploy API to publish the endpoint.
This API can now serve as your own intelligent document processing platform for logistics use cases.
Accessing the API via Postman for Real-Time IDP
Let’s now test this deployed API and experience the power of Unstract’s intelligent document processing software in action.
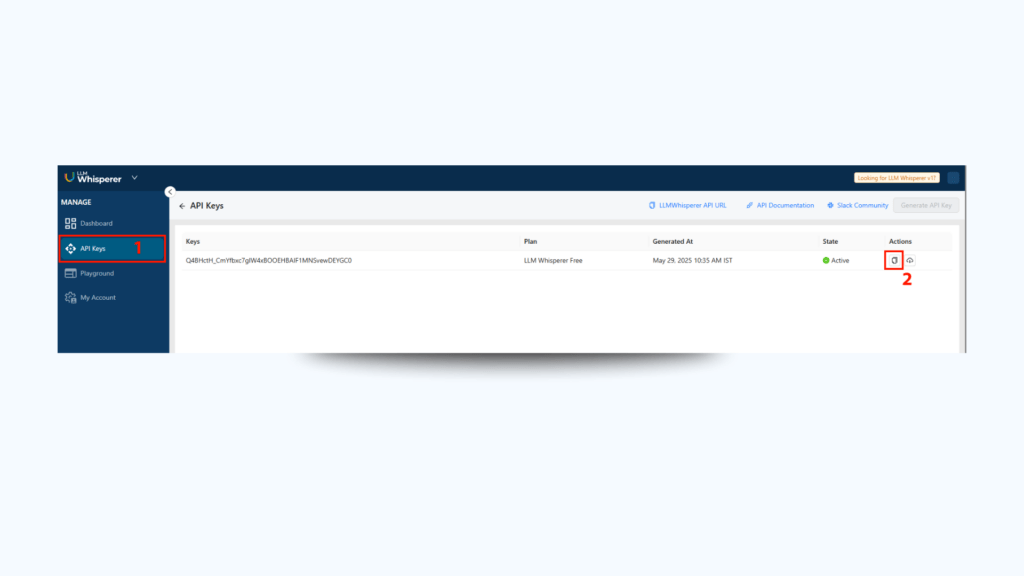
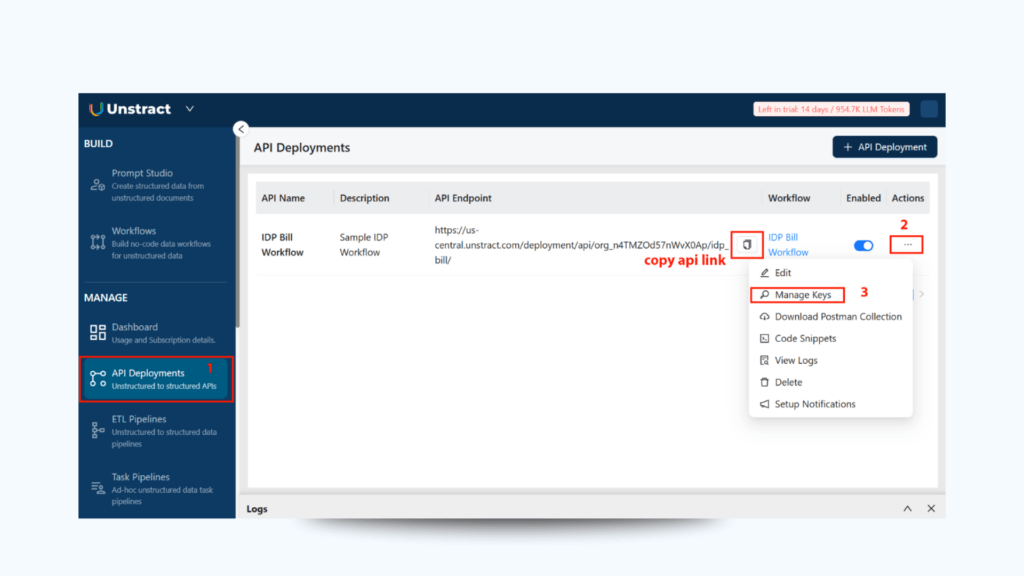
Step 1: Locate Your API Details
In API Deployment section on the sidebar:
Copy the API Endpoint URL
Click on the three dots → Manage Keys → Copy the API Key
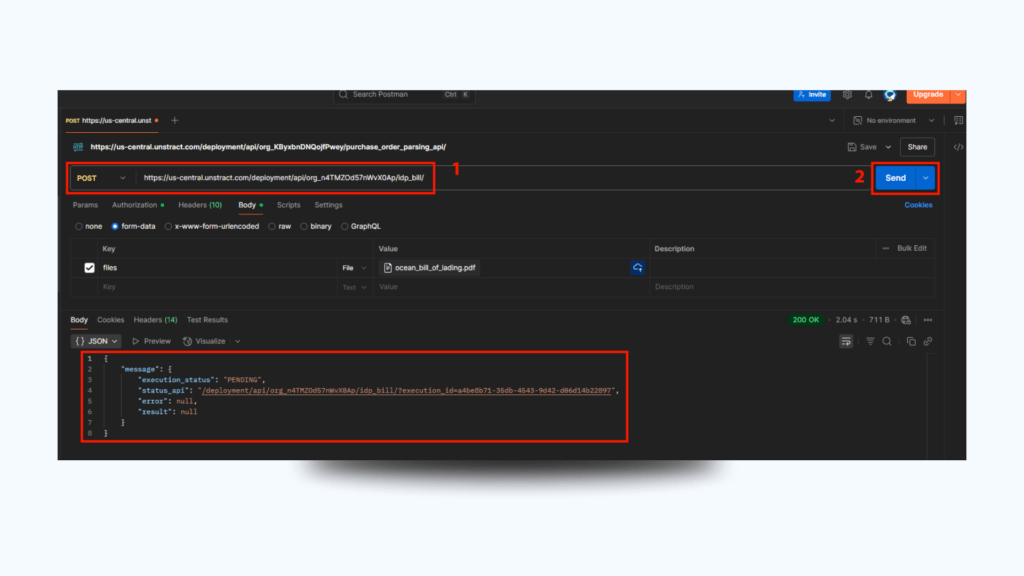
Step 2: Open Postman & Set Up Request
Method: POST
URL: Paste the copied API endpoint
Authorization: Choose Bearer Token, paste the API key
Body:
Set format to form-data
Key = files, Type = File, Value = Upload ocean_bill_of_lading.pdf
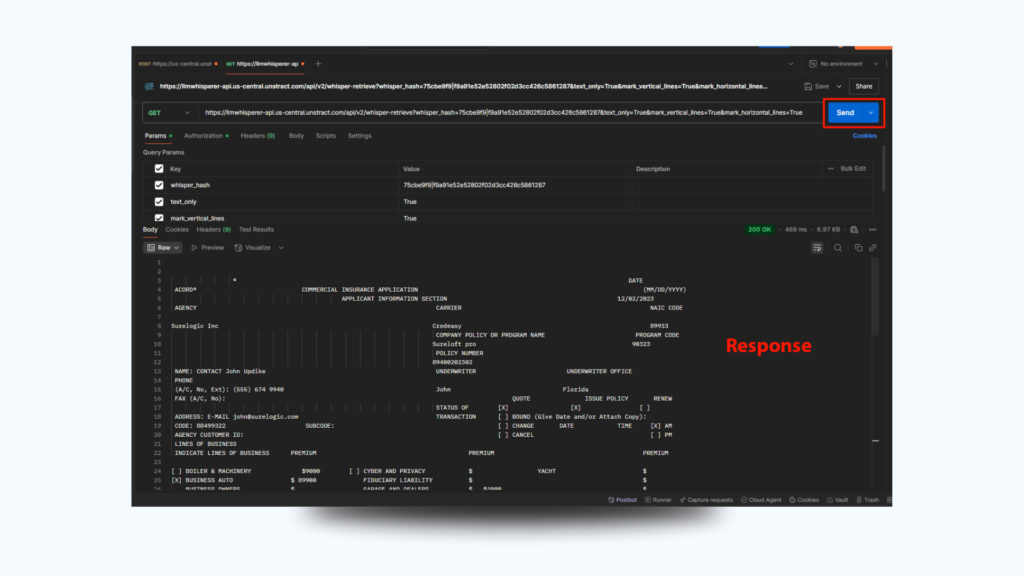
Step 3: Submit & Monitor
Click Send.
Initially, the response will say “status”: “executing”.
You’ll also get a status_api link. Use this to make a GET request in Postman to retrieve final results.
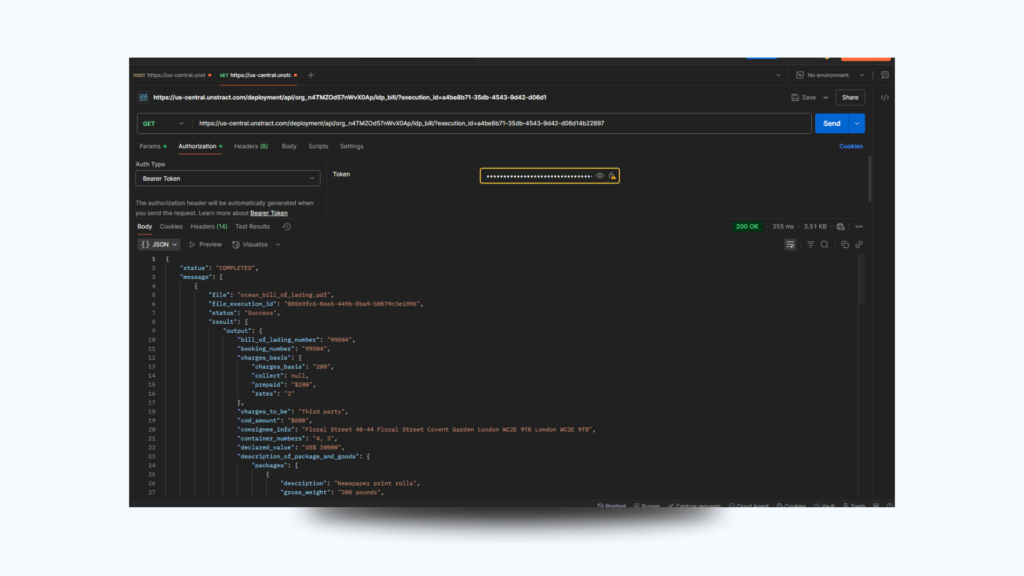
Step 4: Retrieve JSON Response
Once completed, the JSON will include all key-value pairs extracted—such as shipper name, booking number, consignee info, charges, item list, etc.
Output: ocean_bill_of_lading-response.json
Why This Matters for IDP Users
By following the steps above, businesses can build and deploy a real-time IDP solution without writing a single line of code. This is a breakthrough for:
Logistics companies processing large volumes of shipping documents
Finance teams that need automated invoice ingestion
Insurance providers parsing ACORD forms
Real estate extracting data from rent rolls or scanned contracts
Unstract acts as a full-stack intelligent document processing platform that seamlessly combines OCR, LLMs, embeddings, and APIs for high-accuracy, scalable document automation.
Human-in-the-Loop in Unstract: Merging AI with Human Judgment
While intelligent document processing (IDP) has dramatically advanced through LLMs, real-world enterprise workflows still require a layer of human validation. That’s where the Human-in-the-Loop (HITL) system comes in—bridging the gap between AI automation and human oversight to ensure quality, compliance, and control.
Discover how Unstract’s Human-in-the-Loop (HITL) feature empowers you to review, verify, and refine extraction results for greater accuracy and control.
Human-in-the-Loop (HITL) is a methodology where human reviewers validate, correct, or approve AI-generated outputs before they are finalized or pushed downstream. In the domain of IDP solutions, HITL ensures the extracted document data is not just machine-processed—but human-verified, making it reliable for critical business processes.
Think of HITL as your internal QA checkpoint, embedded inside your automated AI document processing pipeline.
Enabling HITL in Unstract
Unstract offers built-in support for HITL AI capabilities directly within its no-code workflow builder:
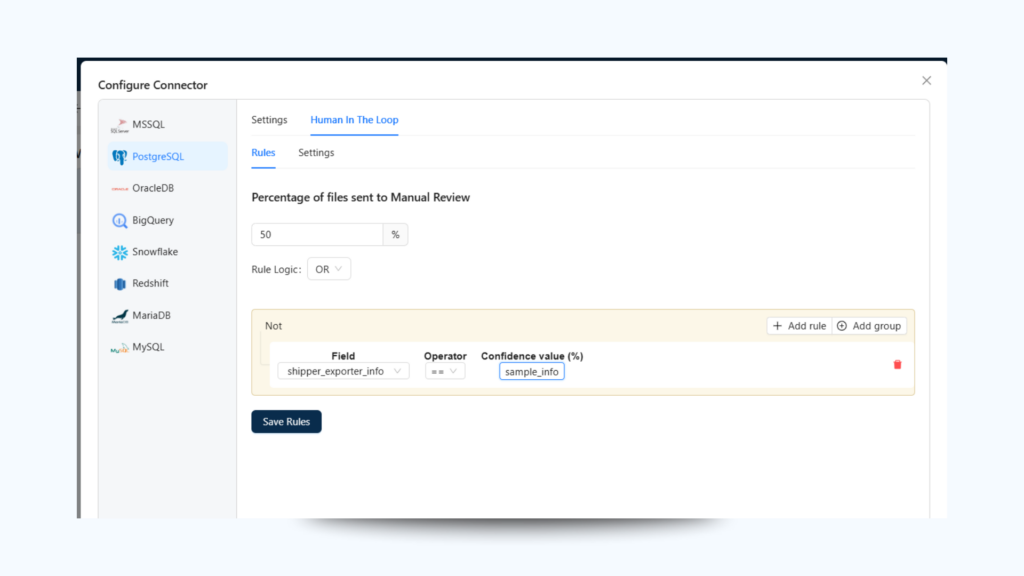
1. Enable HITL in the ETL Pipeline
In Unstract’s Workflow editor:
Navigate to the ETL (Extract, Transform, Load) section.
Toggle the Human-in-the-Loop option to enabled.
2. Set Review Thresholds
You can define specific confidence thresholds (e.g., 50% confidence):
If the LLM output for a data field falls below this threshold, it will be flagged for human review.
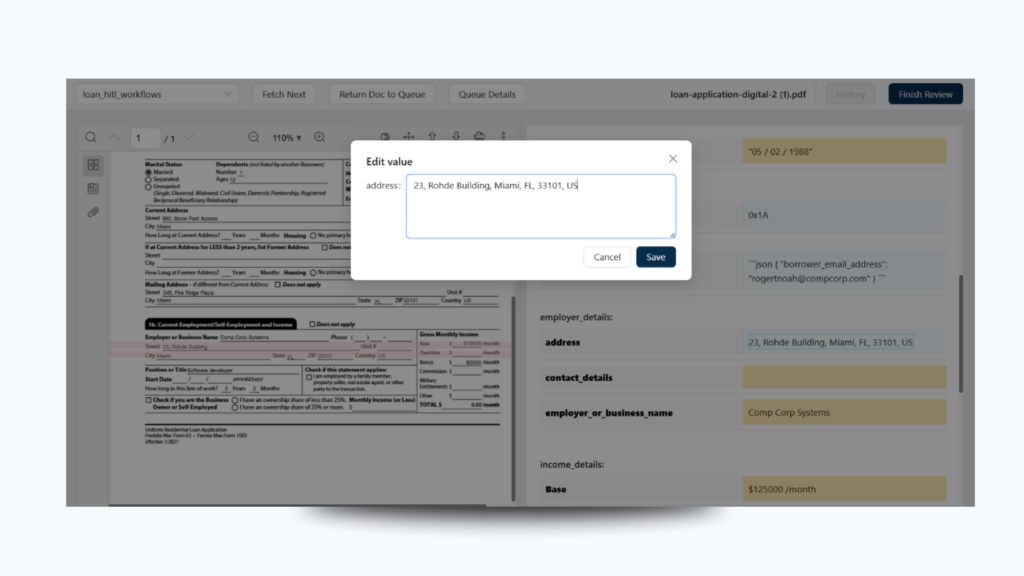
You can also configure rules for fields that must always be reviewed, regardless of confidence (e.g., Social Security Numbers or Address fields in loan documents).
3. Approve or Edit Before Final Output
When flagged, these fields will appear in a review dashboard where human agents can:
Accept the AI-suggested extraction.
Edit it if partially correct.
Reject or escalate fields with errors.
Once confirmed, the data is passed forward to the output connector (e.g., Postgres, Snowflake, or your API endpoint).
Why HITL is Essential in IDP AI Workflows
The integration of Human-in-the-Loop AI within IDP platforms like Unstract ensures:
Accuracy: Every critical field is double-checked before ingestion.
Transparency: You can trace every correction made to the AI output.
Compliance: HITL workflows meet regulatory requirements for data-sensitive industries like insurance, finance, and healthcare.
In essence, HITL transforms IDP from a black-box AI process into a trustworthy, transparent, and auditable solution.
Conclusion: The Future of Document Processing is Here
The evolution of Intelligent Document Processing (IDP) has shifted from rule-based systems and rigid ML models to context-aware, LLM-powered platforms like Unstract.
This transformation is more than just technical—it’s strategic.
Why Unstract’s LLM-Powered IDP is the Future
Let’s summarize what sets Unstract apart as a cutting-edge IDP solution:
Platforms like Unstract embody the modern vision of intelligent document automation—where AI, OCR, LLMs, embeddings, and vector search come together to automate even the most complex document workflows with scalability, precision, and speed.
Whether you’re in finance, logistics, insurance, or real estate, Unstract delivers a future-proof intelligent document processing platform that:
Processes data in real time
Reduces operational costs
Eliminates human error
Keeps humans in the loop when needed
If you’re still relying on legacy tools or semi-automated IDP software, now is the time to upgrade. Explore the next generation of document automation powered by LLMs, and make your business future-ready with Unstract.
???? Unstract Intelligent Document Processing(IDP): Related topics to explore
How does AI-intelligent document processing differ from manual template-based approaches?
AI intelligent document processing uses a context-aware, prompt-driven method powered by large language models (LLMs), while template-based approaches depend on fixed layouts and require frequent re-training for new document types. AI document parsing can handle document variants and different structures out-of-the-box, making it far more flexible for real-world scenarios.
Can intelligent document processing be done without a template?
Yes! Modern platforms like Unstract enable document processing without a template. No template intelligent document processing means you simply provide prompts (instructions), and the AI extracts the needed data regardless of the document’s structure—removing the need for manual template setup or extensive training data.
What are the advantages of no template intelligent document processing over template-based systems?
No template intelligent document processing adapts instantly to new or changing formats, requires no manual template creation, and dramatically reduces setup time. Unlike template-based systems, which break easily when the layout changes, AI solutions can extract information from new document types right away, enabling faster, more scalable automation.
How does Unstract’s AI document parsing work with unstructured data?
Unstract uses an advanced combination of LLMs and an OCR engine called LLMWhisperer to perform AI document parsing. It can process unstructured data such as scanned PDFs, handwritten notes, and mixed-layout forms—all without manual annotation or pre-defined templates, delivering structured results ready for analytics and automation.
How does intelligent OCR compare in template-based vs. intelligent OCR solutions?
In template-based intelligent OCR systems, you must define exact locations and rules for extraction, which is rigid and time-consuming. In contrast, intelligent OCR within modern platforms uses AI to understand the context and content dynamically, supporting unstructured data processing and eliminating the need for a manual template—enabling higher accuracy and broader document coverage.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.