

Introduction
What if you could take one messy PDF packed with different documents, and instantly get back clean, perfectly labelled files?
Most PDF splitters today only handle simple, well-organized files, like splitting an eBook by chapters or breaking up a report every 10 pages. But real business documents aren’t that neat. Companies often deal with mixed PDFs, like a loan application that bundles a KYC form, salary slips, and tax documents all in one file. Traditional tools struggle because these files don’t follow a set pattern: the number of pages changes, the order shifts, and the formats are all over the place.
Now, imagine uploading that messy loan application and getting back separate, neatly labeled files, one for the loan form, one for the payslip, one for the tax proof, without lifting a finger. No manual page selection, no setting up keyword rules, no trial and error.
That’s what Unstract’s Document Splitter API does. It’s an AI-powered tool that works for any industry. Using smart language and image recognition, it automatically detects where one document ends and another begins, splitting mixed files into individual documents, no manual work, no templates, no complicated rules. Just upload, and let the API do the rest.
The Problem with Splitting Mixed-Document PDFs
For most companies, dealing with combined PDFs is just part of the daily routine. A single file might contain all kinds of unrelated documents, like a loan application packed with KYC forms, payslips, and tax records, or an insurance claim bundle with forms, medical reports, and policy copies. Industries like banking, insurance, healthcare, logistics, and outsourcing handle thousands of these files every day.
Splitting these PDFs manually is a slow, inconsistent, and expensive process. Workers have to go through each page, figure out where one document ends and another starts, and then save them one by one. It’s easy to make mistakes, and the process doesn’t scale well, especially when every document set looks different, with varying layouts, orders, and page counts.
Traditional PDF splitters weren’t designed for this. They work best with predictable, structured files, not messy, mixed-document batches. Most rely on fixed page numbers or keyword rules, which fail as soon as a document’s format changes.
Why Old-School, General Purpose PDF Splitters Don’t Work
- Manual Page Selection: Users have to pick exact page numbers to split files, impossible when every document is different.
- Header/Footer Detection: These tools look for repeating patterns in headers or footers, but those often change or disappear in scanned files.
- Keyword or Text Matching: Searching for specific words (like “Invoice” or “Tax Form”) fails when layouts, fonts, or scan quality vary.
- Template-Based Systems: These require predefined layouts or zones, which can’t adapt to new formats or messy scans.
The Fallout
The result? A slowdown in every workflow that relies on documents:
- Extra Work for Teams: Employees spend hours fixing mistakes and double-checking splits.
- Compliance Risks: Misplaced or incomplete documents can lead to missed deadlines or regulatory problems.
- Higher Costs: Manual splitting means hiring more people, not automating the process.
Old-school PDF splitters just can’t handle the complexity, variety, and sheer volume of real-world mixed-document PDFs.
Meet the Unstract Multi-Document PDF Splitter API
The Unstract Document Splitter API is an AI-powered tool designed to handle real-world PDFs, messy, mixed, and unpredictable.
Unlike traditional PDF splitters that rely on rigid rules or manual page selection, Unstract’s API actually understands what’s inside your documents. It uses advanced AI (Large Language Models + Vision AI) to analyse both the text and the visual layout of each page. This helps it accurately detect where one document ends and another begins, just like a human would.
How It Works
- Finds document breaks automatically, even in chaotic, unstructured files.
- Handles both digital and scanned PDFs, including faxes, phone photos, and image-based documents.
- Uses AI to classify and split documents based on content, layout, and meaning, not just keywords or page numbers.
Why It Stands Out
- No templates or manual setup needed, the AI adapts to each PDF’s unique structure on the fly.
- Works for any industry, banking, insurance, healthcare, logistics, government, legal, and more.
- Easy to integrate, just plug it into your workflow via a simple API, whether you’re processing 10 PDFs or 10,000.
The Unstract Document Splitter API takes the hassle out of splitting documents, making it faster, more accurate, and fully automated, so organizations can finally handle mixed PDFs without the manual grind.
How Different Industries Use Unstract’s PDF Splitter
Unstract’s Intelligent Document Splitter API works across all kinds of industries, handling any document format, order, or structure. Whether you’re dealing with insurance claims, loan applications, or medical records, the API automatically finds where one document ends and another begins. It sorts everything into the right files, so you can process them smoothly.
Here are some real-world examples of how businesses use it to save time and work more efficiently:
| Industry | PDF Splitter: Use cases | Example |
|---|---|---|
| Banking & Finance | Processing loans, splitting KYC files | Automatically pull out KYC forms, payslips, and tax documents from a single loan application. |
| Insurance | Handling claims submissions | Separate claim forms, policy documents, and attachments for faster processing and review. |
| Healthcare | Managing patient records | Split admission forms, test results, and lab reports from patient files for easier data entry. |
| Legal | Organizing case files | Break down large case files into individual documents, like contracts, filings, and evidence. |
| Outsourcing (BPO) | Processing bulk documents | Automatically sort through high volumes of contracts, onboarding forms, and compliance files. |
| Government | Processing citizen applications | Separate permits, ID documents, and application forms for quicker verification and filing. |
Why Accurate PDF Splitter Matters
These industries often deal with huge stacks of unstructured, scanned, or mixed documents. Manually sorting through them is slow and unreliable. Unstract’s API brings automation and intelligence to the process, so teams don’t have to waste time splitting files by hand. Everything stays organized, easy to search, and ready to use, making workflows faster and more efficient.
How to Split a Multi-Document, Mixed PDFs with Unstract?
Unstract’s Document Splitter API takes the hassle out of splitting messy, multi-document PDFs.
Just upload your file, and the API does the rest. It automatically figures out where each document starts and ends, then gives you back clean, organized files, no manual work required.
Everything happens on its own, so you get the results you need without the extra effort.
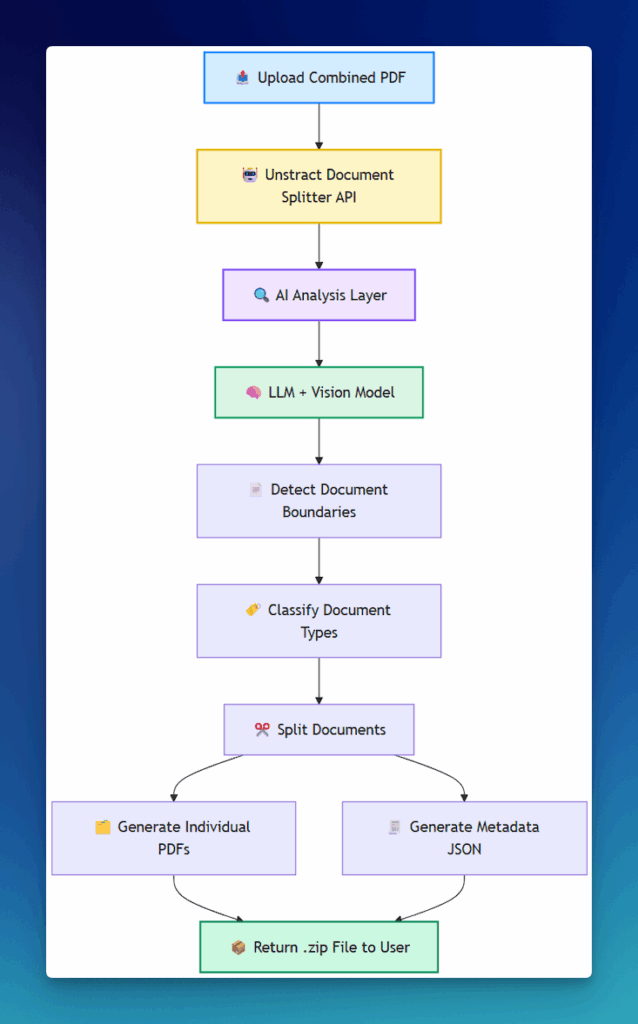
Upload & Process
1. Upload the PDF – Just send your combined PDF to the API, whether it’s 5 pages or 500, Unstract handles it all without any fuss.
2. AI Does the Work – Once uploaded, the API uses advanced AI (including language and vision models) to analyse each page. It:
- Finds where documents switch, detecting when one document ends and another begins.
- Splits files intelligently, using context, meaning, and visual clues, not just keywords.
- Labels each document, identifying what each section is (like a KYC form, tax proof, or payslip).
3. Get Your Results – The API sends back a .zip file with:
- Separate PDFs, each document split and saved individually, keeping the original look and quality.
- A JSON file, with helpful details like:
- Which pages belong to which document
- What type of document each one is
This makes it easy to plug the results into your existing systems, like document management tools, automation workflows, or compliance checks.
PDF Splitter Metadata:
Here’s a sample of what the JSON file might include for each document:
[
...
{
"file_name": "Multimodal_Ocean_Bill_of_Lading_20240102_Rubber_Mat_Exports_original_loc_1.pdf",
"start_page": 1,
"end_page": 1,
"document_type": "Multimodal Ocean Bill of Lading",
"header_info": "DHL (logo), Shipping document from Rubber Mat Exports, 20 Cooper Square, New York, NY 10003, USA",
"footer_info": "Issued by Roger smith on 1/2/2024, License No. 11862N",
"key_entities": [
"Rubber Mat Exports",
"Floral Street 40-44 Floral Street Covent Garden London WC2E 9TB",
"John Smith",
"New York",
"Madison Maersk",
"London"
],
"date_period": "1/2/2024",
"main_content": "Shipping document detailing export of newspaper print rolls and print ink from New York to London, UK, with shipping and cargo details including weight, measurements, and liability limitations"
},
...
]This structured information means every document is easy to find, sort, and use, helping your business run smoother and faster.
See the PDF Splitter API in Action
Let’s take a look at how the Unstract Document Splitter API works in real-life situations, especially for industries that deal with complicated PDFs packed with different types of documents. Each example shows:
- What the mixed PDF file looks like,
- The kinds of documents inside it, and
- What you get after the API splits it intelligently.
Pricing: You only pay for what you use, $0.03 per page. This makes it easy to start small and grow as you need.
You can sign up here: Unstract Document Splitter API.

Once you’re signed up:
- Download the Postman collection from the platform.
- Grab your API key, you’ll need it to log in.
In the examples below, we’ll use Postman to test the API. Just remember to swap out the example API key with your own before sending any requests:
Unstract PDF Splitter: Insurance Use Case
In the insurance world, a single PDF often contains an entire claim package, a mix of forms, policies, and extra documents all stuffed into one big file. This could include things like standard forms, policy details, claim descriptions, photos, and other evidence, all jumbled together in different orders.
Sorting through these manually is slow and easy to mess up, especially since no two claims look exactly the same.
With the Unstract Document Splitter API, the whole process is automatic. The AI figures out where each document starts and ends, labels everything correctly, and gives you clean, separate PDFs, ready to review, save, or process.
For this example, we’ll use this file:
![[Insurance-submission-intake-documents.pdf]]
Let’s try out the API using Postman. Here’s how it works.
Upload your file: Send your sample insurance PDF to the Upload endpoint. It’ll look something like this:
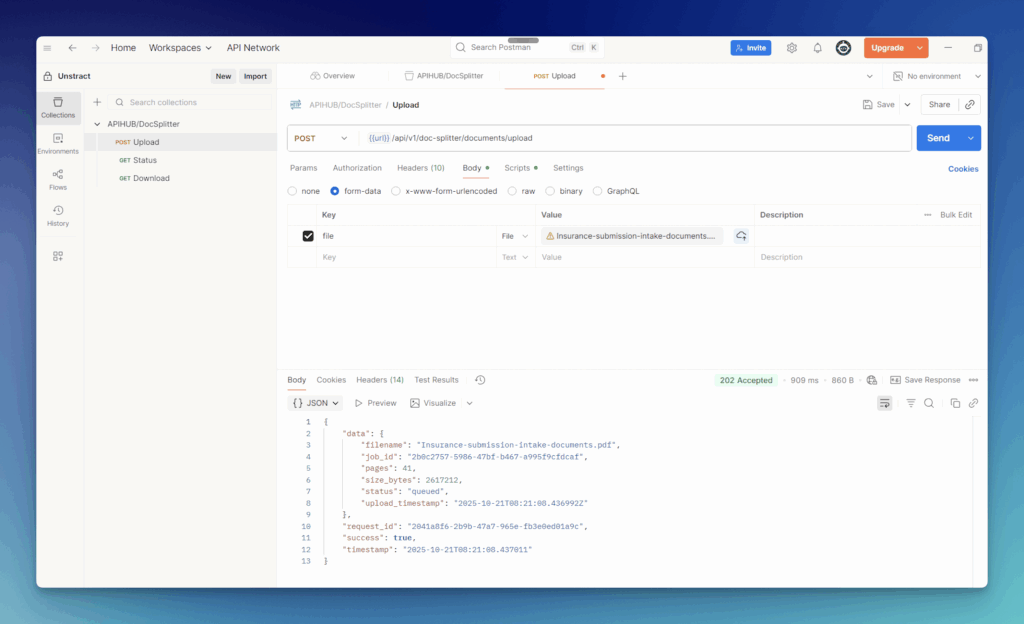
When you get a response, make sure to copy the job_id, you’ll need it for the next steps.
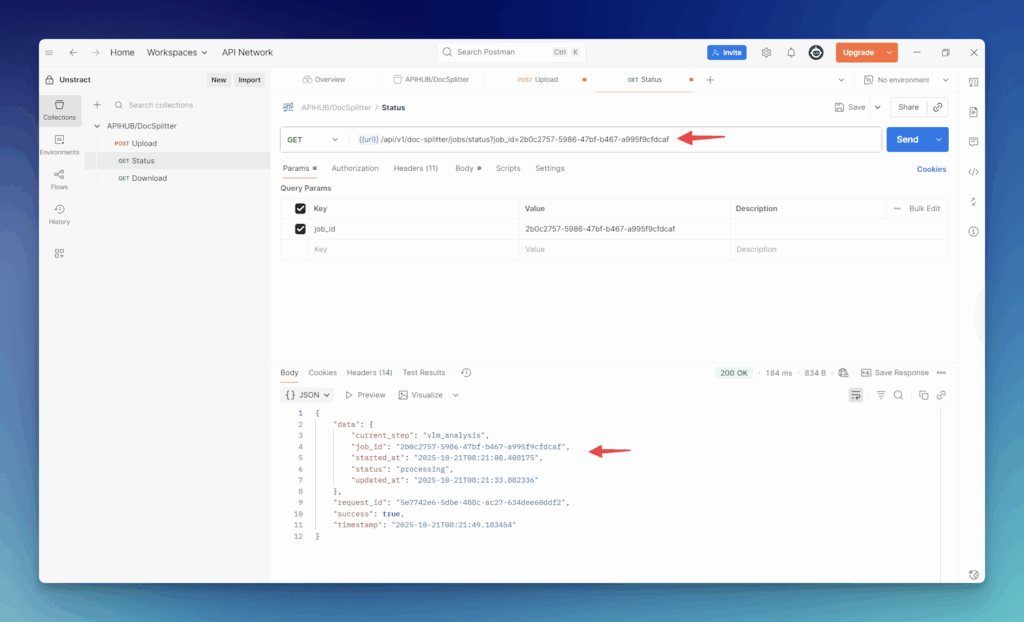
Check the progress: Use that job_id to ask the Status endpoint how the processing is going:
Download the results: Once it’s done, use the same job_id to call the Download endpoint. This will give you a ZIP file with:
- The split PDFs (each document separated out)
- A JSON file with extra details about each document
Now, let’s open that ZIP file and see what’s inside the JSON metadata.
{
"doc_id": "2b0c2757-5986-47bf-b467-a995f9cfdcaf",
"boundaries": [
{
"file_name": "Loss_Run_Summary_20190101-20231231_Zurich_original_loc_1.pdf",
"start_page": 1,
"end_page": 1,
"document_type": "Loss Run Summary",
"header_info": "Zurich Insurance Company Logo",
"footer_info": "Run Date: 8/8/24",
"key_entities": [
"Zurich"
],
"date_period": "Policy Years 2019-2023, Data valued as of: 08/07/2024",
"main_content": "Insurance claims summary showing claim counts, paid amounts, and incurred losses for multiple policy years, with a total of 32 claims across different years"
},
{
"file_name": "Loss_Detail_Report_20190101_Brody_Inc_original_loc_2.pdf",
"start_page": 2,
"end_page": 8,
"document_type": "Zurich North America Customer Loss Runs Loss Detail",
"header_info": "Zurich logo, Brody Inc.",
"footer_info": "Run Date: 8/8/24",
"key_entities": [
"Zurich North America",
"Brody Inc.",
"Nguyen, Lan N",
"Biddle, Kerry",
"Breen, Mallory"
],
"date_period": "Policy Year: 2019",
"main_content": "Insurance claims report detailing auto physical damage and liability claims for Brody Inc., showing claim numbers, dates, states, status, and financial details"
},
{
"file_name": "Glossary_of_Terms_Zurich_original_loc_9.pdf",
"start_page": 9,
"end_page": 9,
"document_type": "Glossary of Terms",
"header_info": null,
"footer_info": null,
"key_entities": [
"Zurich"
],
"date_period": null,
"main_content": "A detailed explanation of terminology used in insurance claim documentation, including definitions for terms like Claim Number, Claimant, Loss Type, Coverage Type, Date of Loss, Policy Symbol, and other key insurance claim-related terms"
},
{
"file_name": "Commercial_Insurance_App_20241115_Sea_Nagar_Condo_original_loc_10.pdf",
"start_page": 10,
"end_page": 13,
"document_type": "Commercial Insurance Application",
"header_info": "ACORD logo, Arthur J. Gallagher Risk Management Services, LLC, 1395 Panther Lane Ste 100, Naples, FL 34109",
"footer_info": "\u00a9 1993-2015 ACORD CORPORATION. All rights reserved. ACORD 125 (2016/03), Page 1 of 4",
"key_entities": [
"Arthur J. Gallagher Risk Management Services, LLC",
"Sea Nagar Condominium Association, Inc."
],
"date_period": "Proposed Policy Period: 11/15/2024 to 11/15/2025",
"main_content": "Commercial insurance application form for collecting applicant and business information, including lines of business, policy details, and contact information"
},
{
"file_name": "Property_Insurance_Cert_20241115_Sea_Nagar_Condo_original_loc_14.pdf",
"start_page": 14,
"end_page": 16,
"document_type": "ACORD Property Insurance Certificate/Declarations Page",
"header_info": "ACORD logo, Agency: Arthur J. Gallagher Risk Management Services, LLC",
"footer_info": "ACORD 140 (2014/12), Copyright notice for ACORD",
"key_entities": [
"Sea Nagar Condominium Association, Inc.",
"Arthur J. Gallagher Risk Management Services, LLC",
"1450 East Sea Blvd, Miami, FL 33132"
],
"date_period": {
"policy_effective_date": "11/15/2024",
"document_date": "09/30/2024"
},
"main_content": "Detailed property insurance policy declaration page for a residential condominium, listing property values, coverage amounts, and insurance details for building, contents, pool, and other property elements"
},
{
"file_name": "Insurance_Schedule_20240930_SEANCLO-0_original_loc_17.pdf",
"start_page": 17,
"end_page": 17,
"document_type": "Agency Customer Insurance Schedule",
"header_info": "SEANCLO-0 Agency",
"footer_info": "APPLIED 140SOI (2014/12)",
"key_entities": [
"SEANCLO-0",
"Miami, FL 33132",
"1450 East Sea Blvd"
],
"date_period": "09/30/2024",
"main_content": "Detailed insurance schedule for a residential condo property, listing multiple subjects of insurance with specific coverage amounts, deductibles, and loss causes for various property elements like storage, lighting, fencing, walls, signs, gates, equipment, and HVAC systems"
},
{
"file_name": "Commercial_Insurance_App_ACORD_Corporation_original_loc_18.pdf",
"start_page": 18,
"end_page": 21,
"document_type": "Commercial Insurance Application",
"header_info": "ACORD logo, Commercial Insurance Application form",
"footer_info": "\u00a9 1993-2015 ACORD CORPORATION. All rights reserved. ACORD 125 (2016/03)",
"key_entities": [
"ACORD Corporation"
],
"date_period": null,
"main_content": "Comprehensive commercial insurance application form for businesses to provide detailed information about their insurance needs, including lines of business, policy information, and applicant details"
},
{
"file_name": "Environmental_Service_App_20241101_Wonder_Corporation_original_loc_22.pdf",
"start_page": 22,
"end_page": 29,
"document_type": "Environmental Service Providers Application",
"header_info": "WONDER CORPORATION, 420 S. Oscar Best Road, Suite 350, Nashville, TN 37621-1546",
"footer_info": "FEI-300-ECC-0712",
"key_entities": [
"Wonder Corporation",
"Everest Indemnity Ins Co"
],
"date_period": "Proposed Effective Date: 11/01/2024, Retroactive Date: 11/01/2001",
"main_content": "Insurance application for environmental service providers, requesting renewal of commercial general liability, contractors pollution liability, and professional liability coverage with $1M/$2M limits and $1,000 deductible"
},
{
"file_name": "Contractor_Questionnaire_Brody_Inc_original_loc_30.pdf",
"start_page": 30,
"end_page": 40,
"document_type": "Contractor Questionnaire",
"header_info": "Zurich Insurance Company logo, Zurich branding",
"footer_info": "Toll-free number (866) 903-1192, Reference to ZurichAmerican Insurance Company",
"key_entities": [
"Brody Inc",
"David Young",
"Zurich"
],
"date_period": "Five-year historical financial data (4 years prior + current term + upcoming term)",
"main_content": "Detailed financial questionnaire for a contractor, capturing payroll, revenue, subcontract costs, and power units over multiple years. Includes sections for required attachments and desired supplementary documentation."
},
{
"file_name": "Insurance_Coverage_Request_general_original_loc_41.pdf",
"start_page": 41,
"end_page": 41,
"document_type": "Insurance Coverage Request Appendix",
"header_info": "APPENDIX",
"footer_info": null,
"key_entities": [],
"date_period": null,
"main_content": "Insurance coverage request form checking 'Yes' for Auto Liability, Workers' Compensation, and Commercial General Liability coverage"
}
],
"total_documents": 10
}The response gives you helpful details about each document it pulled out, like:
file_name– what each split document is calledstart_pageandend_page– which pages in the original PDF it coversmain_content– a quick summary of what’s inside the document- plus other useful info to help you organize and find things later
Now, let’s check out the list of files you get back:
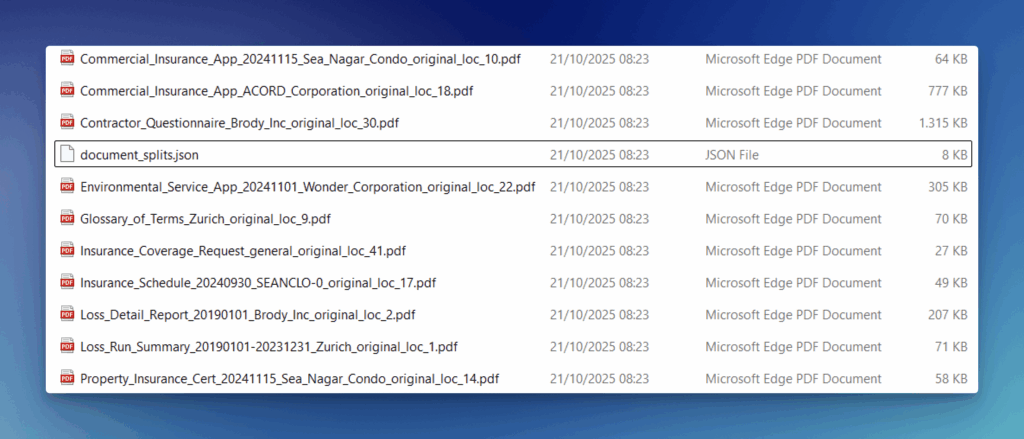
Let’s take a look at some of the split files to see how well the API picked out and separated each document:
![[Commercial_Insurance_App_20241115_Sea_Nagar_Condo_original_loc_10.pdf]]
![[Glossary_of_Terms_Zurich_original_loc_9.pdf]]
As you can see, the API did a great job splitting up the insurance documents—even with different layouts, formats, and types of content all mixed together.
Unstract PDF Splitter: Banking Use Case
In banking and lending, dealing with documents can be a mess. A single PDF from a customer might include a loan application, ID documents, pay stubs, and tax forms, all stuffed into one big file. Since every customer’s submission looks different, old-school splitting tools (that just go by page numbers) often get it wrong.
The Unstract Document Splitter API takes care of this automatically. It looks at what’s actually in the file, figures out where each document starts and ends, and sorts everything correctly, no manual rules or templates needed.
We’ll use Postman again to walk through the process: upload the file, check the progress, and download the results.
For this example, we’ll use this file:
![[loan-processing-documents.pdf]]
Let’s open the ZIP file and check out the details in the JSON file to see what we got:
{
"doc_id": "6b25e17e-457c-4784-9dc2-c36d995393dc",
"boundaries": [
{
"file_name": "Loan_Estimate_20130215_Michael_Jones_original_loc_1.pdf",
"start_page": 1,
"end_page": 3,
"document_type": "Loan Estimate",
"header_info": "Ficus Bank, 4321 Random Boulevard, Somecity, ST 12340",
"footer_info": "Visit www.consumerfinance.gov/mortgage-estimate for general information and tools, Loan ID # 12456789, Page 1 of 3",
"key_entities": [
"Michael Jones",
"Mary Stone",
"Ficus Bank"
],
"date_period": "2/15/2013 (Date Issued), Rate Lock until 4/16/2013",
"main_content": "Detailed mortgage loan estimate for a 30-year fixed-rate conventional home purchase, showing loan terms, projected payments, and closing costs for a $180,000 property with a $162,000 loan amount"
},
{
"file_name": "Uniform_Residential_Loan_App_Robert_Noah_original_loc_4.pdf",
"start_page": 4,
"end_page": 6,
"document_type": "Uniform Residential Loan Application",
"header_info": "Lender Loan No: Universal Loan Identifier, Agency Case No.",
"footer_info": "Uniform Residential Loan Application, Freddie Mac Form 65 - Fannie Mae Form 1003, Effective 1/2021",
"key_entities": [
"Robert Noah",
"Comp Corp Systems",
"Miami",
"FL",
"US"
],
"date_period": "05/02/1988 (Date of Birth)",
"main_content": "First section of a loan application collecting personal information, employment details, contact information, and income for an individual borrower applying for a residential loan"
},
{
"file_name": "Drivers_License_California_original_loc_7.pdf",
"start_page": 7,
"end_page": 7,
"document_type": "Driver's License",
"header_info": "California Driver License",
"footer_info": null,
"key_entities": [
"California"
],
"date_period": null,
"main_content": "Official state-issued identification document showing a driver's license with a portrait photo and key personal identification details",
"override_match": {
"matched": true,
"document_type": "Identification Documents (Driver's License, Passport, State ID)",
"confidence": 1.0
}
},
{
"file_name": "Payslip_202108_Sally_Harley_original_loc_8.pdf",
"start_page": 8,
"end_page": 8,
"document_type": "Payslip",
"header_info": "Zoodle Inc, 21023 Pearson Point Road Gate Avenue",
"footer_info": "This is system generated payslip",
"key_entities": [
"Sally Harley",
"Zoodle Inc",
"Marketing Department"
],
"date_period": "August 2021",
"main_content": "Monthly salary breakdown showing earnings and deductions for a Marketing Executive, with total earnings of $11600, total deductions of $2100, resulting in a net pay of $9500"
},
{
"file_name": "Chase_Freedom_Credit_Card_Stmt_202402_Larry_Page_original_loc_9.pdf",
"start_page": 9,
"end_page": 10,
"document_type": "Chase Freedom Credit Card Statement",
"header_info": "Chase Freedom, Customer Service: 1-800-524-3880, Manage account online at: www.chase.com/cardhelp",
"footer_info": "P.O. BOX 15123, WILMINGTON, DE 19850-5123, Cardmember Service PO BOX 6294, CAROL STREAM IL 60197-6294",
"key_entities": [
"Chase",
"Larry Page",
"Wilmington, DE",
"Carol Stream, IL"
],
"date_period": "February 2024, Billing Cycle: 01/04/24 - 02/03/24",
"main_content": "Monthly credit card statement showing account balance, payment due, rewards points, and account activity for Chase Freedom Ultimate Rewards credit card"
}
],
"total_documents": 5
}Now, let’s see the result, the list of files we got back:
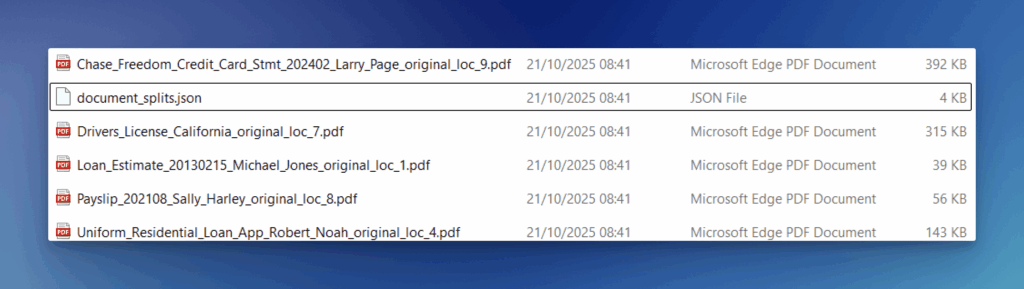
Let’s open a few of these split files to check how well the API picked out and separated each document:
![[Chase_Freedom_Credit_Card_Stmt_202402_Larry_Page_original_loc_9.pdf]]
![[Drivers_License_California_original_loc_7.pdf]]
As you can see, the API neatly separated all the banking documents, even tricky ones like a driver’s license, handling different formats and content types with great accuracy.
Unstract PDF Splitter: Logistics Use Case
In logistics and supply chain, dealing with documents often means working with long, messy PDFs that combine invoices, packing lists, shipping manifests, and delivery notes, all in one file. These documents can come from different systems, carriers, or suppliers, each with their own layout and style.
Sorting through them manually is slow and easy to mess up, especially when you’re handling thousands of shipments every day.
The Unstract Document Splitter API makes this process simple. The AI automatically finds where each document starts and ends, labels them correctly, and gives you clean, separate PDFs, keeping everything in order and just as it was originally formatted.
We’ll use Postman again to go through the steps: upload the file, check the progress, and download the results.
For this example, we’ll use this file:
![[combined-Logistics-documents.pdf]]
Let’s open the ZIP file and check out the details in the JSON file to see what we got:
{
"doc_id": "d79fd0d1-9de9-459c-9ada-a7909e830260",
"boundaries": [
{
"file_name": "Multimodal_Ocean_Bill_of_Lading_20240102_Rubber_Mat_Exports_original_loc_1.pdf",
"start_page": 1,
"end_page": 1,
"document_type": "Multimodal Ocean Bill of Lading",
"header_info": "DHL (logo), Shipping document from Rubber Mat Exports, 20 Cooper Square, New York, NY 10003, USA",
"footer_info": "Issued by Roger smith on 1/2/2024, License No. 11862N",
"key_entities": [
"Rubber Mat Exports",
"Floral Street 40-44 Floral Street Covent Garden London WC2E 9TB",
"John Smith",
"New York",
"Madison Maersk",
"London"
],
"date_period": "1/2/2024",
"main_content": "Shipping document detailing export of newspaper print rolls and print ink from New York to London, UK, with shipping and cargo details including weight, measurements, and liability limitations"
},
{
"file_name": "Air_Waybill_20251210_IDF_Cargo_original_loc_2.pdf",
"start_page": 2,
"end_page": 2,
"document_type": "Air Waybill (Shipping Document)",
"header_info": "IDF Cargo, New York - Shipping Carrier",
"footer_info": "Executed on date: 12/10/2025, Location: New York",
"key_entities": [
"Simon Jones",
"Rogen Gates",
"IDF Cargo",
"New York",
"London",
"Bristol"
],
"date_period": "12/10/2025",
"main_content": "International air shipping document for transporting goods from New York to London, including details of shipment weight, commodity, charges, and contents (News Print Paper, Package Paper, Print Ink Solution)"
},
{
"file_name": "Packing_List_20231212_Faculty_of_Arts_original_loc_3.pdf",
"start_page": 3,
"end_page": 3,
"document_type": "Packing List",
"header_info": "Faculty of Arts, 5 Washington Square S, New York, NY 10012, USA",
"footer_info": "Note about Export Administration Regulations, signature line",
"key_entities": [
"Faculty of Arts",
"Herald Corp",
"Air Cargo UPS"
],
"date_period": "12/12/2023 (Date of Shipment)",
"main_content": "Shipping document detailing print packaging and black ink cartridges being shipped, with total package and weight information"
},
{
"file_name": "Certificate_of_Origin_20251015_BlueSky_Apparel_Inc_original_loc_4.pdf",
"start_page": 4,
"end_page": 5,
"document_type": "Certificate of Origin",
"header_info": "Generalised System of Preferences Certificate of Origin (Form A)",
"footer_info": null,
"key_entities": [
"BlueSky Apparel Inc.",
"EuroFashion Retail GmbH",
"U.S. Chamber of Commerce",
"Port of Savannah (USA)",
"Port of Hamburg (Germany)"
],
"date_period": "October 15, 2025",
"main_content": "International shipping document certifying the origin of exported goods (20 cartons of cotton men's shirts) from USA to Germany, with details of exporter, consignee, transport route, and origin verification"
}
],
"total_documents": 4
}Now, let’s see the list of files we got back:
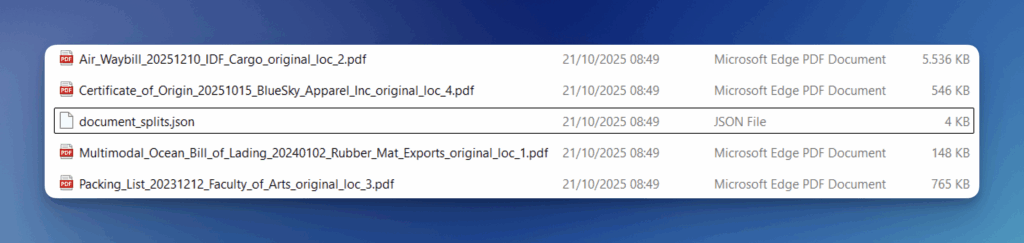
Let’s open a few of these split files to check how well the API picked out and separated each document:
![[Air_Waybill_20251210_IDF_Cargo_original_loc_2.pdf]]
![[Packing_List_20231212_Faculty_of_Arts_original_loc_3.pdf]]
As you can see, the API did a great job splitting the logistics documents, even with scanned or poor-quality files, keeping everything clearly separated and correctly labelled, no matter how messy or hard to read the originals were.
Why Accurate PDF Splitter Matters for Business Worflows
The Unstract Document Splitter API isn’t just a technical tool, it’s a game-changer for productivity. By automating tasks that used to take hours of manual work, it completely changes how companies handle piles of documents, saving time, reducing mistakes, and cutting costs.
Saves Time: It processes documents up to 10 times faster than doing it by hand. This means teams don’t have to waste time checking each page, and big batches of documents can be ready the same day.
Fewer Mistakes: It gets things right every time, no matter what documents you throw at it. No more human errors, just perfectly separated and labeled files.
Meets Regulations: Every document is clearly identified, easy to track, and ready for review, which helps businesses stay on top of rules and audits in industries like banking, insurance, and healthcare.
Cuts Costs: Instead of needing a whole team to sort documents, the API does the work automatically. This means lower labor costs, less hassle, and more getting done.
In short, Unstract’s Document Splitter API turns document handling from a slow, manual headache into a fast, reliable, and scalable process, helping businesses work smarter, stay compliant, and move forward faster.
Unstract PDF Splitter: Try Now, Get Instant Access to the API
Document processing just got a major upgrade, smarter, more flexible, and ready to grow with you. With the Unstract Document Splitter API, businesses can finally automate one of the most tedious and mistake-prone tasks: splitting combined PDFs into individual documents.
No matter what you’re working with, insurance claims, tax forms, loan applications, or ID checks, Unstract’s tool takes the hassle out of the process. No more manual sorting, no more setting up rules or templates. The API understands your files, finds where each document starts and ends, and gives you perfectly separated PDFs, fast and accurately.
Ready to make your document workflows smoother and smarter? Try it out for yourself with the Unstract Document Splitter API.
AI-Powered PDF Splitter: FAQs
What is a multi-document PDF splitter and how is it different from a regular PDF splitter?
A multi-document PDF splitter is an AI-driven tool that scans every page, recognises content and layout, and separates one file into many logically labelled documents. A standard PDF splitter usually cuts by fixed page numbers or bookmarks and fails when pages don’t follow a predictable pattern.
Why would a company choose a Combined Document splitter instead of doing the work manually or using legacy systems?
A Combined Document splitter eliminates manual page selection, reduces human error, and scales to thousands of files per day. Finance, insurance, healthcare, and logistics teams use it to turn one messy bundle into clean, compliant, ready-to-process documents in minutes.
How to split pdf files that bundle payslips, IDs and tax forms in random order?
Upload the file to a multi-document PDFs splitter like Unstract. The AI identifies where each document starts and ends, labels them (e.g., “Payslip – Aug 2025”), and returns individual PDFs plus a JSON index—no templates or keyword rules required.
What is the Combined PDF Splitter API and does it support bulk/batch processing of files?
The Combined PDF Splitter API is a REST service from Unstract. POST your combined file to the Upload endpoint; poll the Status endpoint with the job_id; then download a ZIP containing the split PDFs and structured metadata. You can call it from Postman, Python, Java, or any workflow tool.
How to automatically split combined PDFs with multiple document types?
Use an AI engine trained on both language and vision. Send the PDF to the API, let the model detect page boundaries, and receive separate, perfectly titled outputs. This is the fastest way to split combined PDFs automatically without pre-built templates.











