LLMWhisperer, the best OCR text recognition software for AI-based Document extraction workflows
Table of Contents
Introduction
Modern business data mostly exists in digital format such as PDF invoices, scanned receipts, contracts, reports and presentations. However, much of it are not machine readable i.e., we cannot search the text as it only exist in the form of pixels. This means in order to process them one has to manually type in the information. This is not possible in today’s era where businesses need to process documents in the order of thousands or even millions. Optical Character Recognition (OCR) solves this bottleneck
Optical Character Recognition (OCR) solves this bottleneck by converting an input image that has text into a machine-readable and editable data. OCR has helped companies digitize scanned invoices, contracts, medical records and helped businesses to process millions of documents with far fewer errors than what manual entry is ever capable. OCR works by taking the input image that contains text, analyzing the pixels, and identifying the shapes of the characters. It then matches them with numbers, letters, and symbols, and outputs the recognized characters as extractable text.
OCR Landscape
Traditional OCR engines such as earlier versions of Tesseract followed rule-based framework and hand-crafted features to extract text. It worked really well in digitizing clean, high-resolution printed documents such as scanned books without images or simple archival materials. However, these traditional engines perform poorly on low-quality scans, complex layouts, and handwritten documents. Also, extracting structured elements such as images and tables from within those documents required significant post-processing. While in practice, we could recognize text but the semantic understanding was often lost.
To address these limitations, modern OCR engines such as PaddleOCR started to utilize deep learning architectures like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). PaddleOCR employs a two-stage architecture that separates the text detection from text recognition. First, a CNN-based architecture is used as the detection model that identifies the bounding boxes around the text. It basically answers where the text is located. In the second attempt, an LSTM architecture is used to identify the text sequences in those boxes and answers what does the text say. This two-stage approach allows PaddleOCR to handle documents with diverse layouts, and correctly identify different regions within the document (paragraph, charts, tables, headers and footers) making it significantly better than rule-based approaches.
With the advent of large language models (LLM), we have entered into a new era where LLMs and agentic workflows are capable of near-human level semantic understanding of text. However the problem has now shifted from “can we recognize text?” to “can we structure it in a way that LLMs can understand it?”. While LLMs and vision-language models can extract fields, and reason over documents, their accuracy relies heavily on receiving well-structured and layout preserved inputs. This is where intelligent document processing tools like LLMWhisperer comes into the picture.
What is LLMWhisperer?
In the world of LLM-driven document processing, the quality of output is only as good as the input you feed into the LLM. If the model do not have the right context, it will most likely provide inaccurate results or worse produce hallucinated outputs. The document processing pipeline is critical to the success of AI applications that is meant to take real-world documents as inputs. Otherwise, what the LLM sees is text without any layout preservation, tables without any structure, form elements completely missing and handwritten text and characters from other languages that never gets picked up. This is exactly the problem LLMWhisperer is trying to solve.
LLMWhisperer is an advanced document preprocessing and text extraction API tool designed specifically for LLMs and agentic workflows. It sits in between raw, messy real-world documents and the AI that need to reason over them. It handles the full complexity of preprocessing out-of-the-box i.e., noise removal, de-skewing, rotation correction, and most importantly layout preservation.
Layout Preservation
Layout preservation might be the single most consequential feature needed for LLM-based document processing. At the time of extraction, if the document loses its structure, the model loses its ability to reason. Consider a multi-column article that you want to feed into your LLM. Without layout preservation, all text will end up together as one stream with text from one column ending up with another one, thereby losing its meaning.
LLMWhisperer’s default output mode of layout_preserving retains the visual structure of the document. As a result, the spatial relationship between different parts remain intact, and an LLM can easily distinguish section headers from body content, correctly parse multi-column layouts, and understand table relationships.
To provide a more granular control to developers, LLMWhisperer exposes additional output parameters such as mark_vertical_lines and mark_horizontal_lines for denoting table and section boundaries, as well as add_line_nos to attach line numbers for positional reference and traceability. Even though layout_preserving is the default, LLMWhisperer also provides many processing mode options, and the user can pick based on their use case.
Here is an image from LLMWhisperer’s documentation site showing the different processing modes:
To use it in Python, you can simply define the client with the API key and call the whisper module with a file path:
If you want more information, you can follow the extraction API documentation and check out the different parameters that LLMWhisperer provides. Note that there is also Javascript and N8N clients available.
Let’s use LLMWhisperer to extract text from a real-world document. We will consider a scanned copy of an ACCORD commercial insurance application with checkboxes.
Here is the extracted text using the default output mode of layout_preserving and processing mode of form which is suitable for this document with a structured form-like layout and includes checkboxes.
®
COMMERCIAL INSURANCE APPLICATION DATE (MM/DD/YYYY)
APPLICANT INFORMATION SECTION 08/20/2023
AGENCY CARRIER NAIC CODE
Smith Insurance Agency AlphaSure Insurance A4S8F3G
123 Main Street, Anytown, NY, 10001 COMPANY POLICY OR PROGRAM NAME PROGRAM CODE
ShieldGuard SGK5H9P2
POLICY NUMBER
POL6D4J1NO
CONTACT UNDERWRITER UNDERWRITER OFFICE
NAME: John Smith
PHONE Veronica Lee New York, NY
(A/C, No, Ext); (555) 123-4567
FAX 123-4567
(A/C, No): (555) [ ] QUOTE [ ] ISSUE POLICY [ ] RENEW
E-MAIL STATUS OF
ADDRESS: john.smith@example.com TRANSACTION [X] BOUND (Give Date and/or Attach Copy):
SIA123 SIA123-001 CHANGE DATE TIME AM
CODE: SUBCODE: [ ] [ ]
AGENCY CUSTOMER ID: [ ] CANCEL 08/19/2023 12:00 [X] PM
SECTIONS ATTACHED
INDICATE SECTIONS ATTACHED PREMIUM PREMIUM PREMIUM
ACCOUNTS RECEIVABLE / $ 873.05 ELECTRONIC DATA PROC $ TRANSPORTATION / $
[X] VALUABLE PAPERS [ ] [ ] MOTOR TRUCK CARGO
[X] BOILER & MACHINERY $ 364.03 [ ] EQUIPMENT FLOATER $ [X] TRUCKERS / MOTOR CARRIER $ 9.04
[ ] BUSINESS AUTO $ [X] GARAGE AND DEALERS $ 391.00 [ ] UMBRELLA $
[ ] BUSINESS OWNERS $ [ ] GLASS AND SIGN $ [X] YACHT $ 495.02
[ ] COMMERCIAL GENERAL LIABILITY $ [ ] INSTALLATION / BUILDERS RISK $ [ ] $
[X] CRIME / MISCELLANEOUS CRIME $ 3,394.00 [ ] OPEN CARGO $ [ ] $
[ ] DEALERS $ [ ] PROPERTY $ [ ] $
ATTACHMENTS
[ ] ADDITIONAL INTEREST [ ] PREMIUM PAYMENT SUPPLEMENT [ ]
[ ] ADDITIONAL PREMISES [X] PROFESSIONAL LIABILITY SUPPLEMENT [ ]
[ ] APARTMENT BUILDING SUPPLEMENT [ ] RESTAURANT / TAVERN SUPPLEMENT [ ]
[X] CONDO ASSN BYLAWS (for D&O Coverage only) [ ] STATEMENT / SCHEDULE OF VALUES [ ]
[ ] CONTRACTORS SUPPLEMENT [X] STATE SUPPLEMENT (If applicable) [ ]
[X] COVERAGES SCHEDULE [ ] VACANT BUILDING SUPPLEMENT [ ]
[X] DRIVER INFORMATION SCHEDULE [X] VEHICLE SCHEDULE [ ]
[ ] INTERNATIONAL LIABILITY EXPOSURE SUPPLEMENT [ ] [ ]
[ ] INTERNATIONAL PROPERTY EXPOSURE SUPPLEMENT [ ]
[ ] LOSS SUMMARY [ ] [ ]
POLICY INFORMATION
PROPOSED EFF DATE PROPOSED EXP DATE BILLING PLAN PAYMENT PLAN METHOD OF PAYMENT AUDIT DEPOSIT PREMIUM MINIMUM POLICY PREMIUM
08/10/2023 01/19/2024 MONTH CASH 1 $ 73,484.00 $ 634.00 $ 4,392.00
[ ] DIRECT [X] AGENCY
APPLICANT INFORMATION
NAME (First Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
Alex Johnson A7B2C8D5 3574 561730 12-3456789
P.O. Box 123, 123 Main Street, Anytown, NY, 10001 BUSINESS PHONE #: (555) 123-4567
WEBSITE ADDRESS
[ ] CORPORATION [X] JOINT VENTURE [ ] NOT FOR PROFIT ORG [ ] SUBCHAPTER "S" CORPORATION [ ]
NO. OF MEMBERS TRUST
[ ] INDIVIDUAL [ ] LLC AND MANAGERS: [ ] PARTNERSHIP [ ]
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
Emily Smith E3F8G6H1 8742 722513 98-7654321
P.O. Box 456, 456 Oak Avenue, Anothercity, NY, 20002 BUSINESS PHONE #: (555) 987-6543
WEBSITE ADDRESS
[ ] CORPORATION [ ] JOINT VENTURE [X] NOT FOR PROFIT ORG [ ] SUBCHAPTER "S" CORPORATION [ ]
NO. OF MEMBERS
[ ] INDIVIDUAL [X] LLC AND MANAGERS: 10 [ ] PARTNERSHIP [ ] TRUST
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
BUSINESS PHONE #:
WEBSITE ADDRESS
[ ] CORPORATION [ ] JOINT VENTURE [ ] NOT FOR PROFIT ORG [ ] SUBCHAPTER "S" CORPORATION [ ]
NO. OF MEMBERS
[ ] INDIVIDUAL [ ] LLC AND MANAGERS: [ ] PARTNERSHIP [ ] TRUST
ACORD 125 (2013/01) Page 1 of 4 1993-2013 ACORD CORPORATION. All rights reserved.
The ACORD name and logo are registered marks of ACORD
<<<
Accurate Table Extraction
Most documents present results in tables as they summarize information. However, they are also notoriously difficult to extract information from as the spatial relationship between the different columns has to be maintained. A medical diagnosis depends on accurately extracting multi-row table results. Otherwise, there will be a mismatch between the column header and its value, which can have severe consequences. LLMWhisperer provides a Table processing mode, which is optimized to extract dense structured data from documents like financial reports, statements, Excel sheets, etc., by keeping the layout and the cell groupings preserved.
Handling Different Documents Types
Enterprise document types are never uniform. They are messy and will come in various types and conditions. Your document processing pipeline has to be ready regardless of the situation. LLMWhisperer has the capability to handle multiple document types in a real-world scenario. A contractor might take a photograph of a paper form, a planning team might be involved with multi-sheet Excel files, or a risk analysis team might receive scanned copies of insurance forms. These are real-world documents that a production-grade pipeline will encounter. LLMWhisperer handles all such cases, whether it’s a scanned image, PDF, Excel sheet, or handwritten forms; it can reliably process all of them.
Scanned Document and Handwriting Recognition
Many real-world documents are scanned copies of physical files and most often they can be of low-quality having blurry image, or tilted pages. Many of them might include handwritten fields, which are usually skipped by traditional OCR tools. As seen in the insurance document I had presented earlier, documents can have checkboxes, radio buttons, and signature fields, which need to be identified correctly. A checkbox marked with a tick but not identified in processing can have critical implications.
LLMWhisperer has built-in correction tools using which it can deskew images, auto-repair corrupted files, as well as enhance contrast for low-quality images. Hence, even if you upload a blurry image, LLMWhisperer will automatically clean the image and accurately process it without a second attempt at clicking a better photo. Similarly, it excels at recognizing handwritten elements while preserving the spatial relationship with its associated field, as well as in detecting interactive elements and their state in an LLM-ready format.
Bounding Box Output
Most AI workflows are not fully automated. Right now, we are in a human + AI workflow setup where AI does the heavy-lifting while humans can evaluate its quality. Similarly, for document processing pipelines, text extraction should not be considered a black-box but should be precisely evaluated using a human-in-the-loop approach. But human review only works if the reviewer can quickly locate the text and compare it to the original source. To aid this scenario, LLMWhisperer provides spatial coordinates or bounding boxes for every text it extracts from the document. This is super useful for a reviewer who can now directly compare the text in a particular location and flag discrepancies. For more information, you can follow the documentation for the highlight API.
Multilingual OCR: 300+ Languages and One API
Enterprise documents are not monolingual; they might come in multiple languages. Especially in countries that have more than one official language, it is common to have forms and other documents in more than one language. The documents can also come in regional languages. Such a scenario becomes an edge case for OCR engines that can handle only English or a handful of popular languages.
LLMWhisperer supports multilingual OCR across 300+ languages, enabling consistent and high-quality extraction regardless of the document’s origin. With a single API, it can handle documents of different languages without the need to route documents to different tools based on language. For global companies, this is not a nice-to-have but a business-as-usual situation, and LLMWhisperer simplifies this seamlessly.
Real-World Use Cases
In this section, we will be showcasing LLMWhisperer’s OCR capability with real-world use cases. We will test its performance in text extraction for five different documents — scanned handwritten PDF, performance report in Excel format, photographed tax form with checkboxes as well as a receipt, document with complex tables, multi-lingual form, and scanned copy of a misaligned logistics packing list.
Case Study #1: Handwritten and Scanned Application Form
In this first case study, we analyze a scanned insurance application form that combines several elements that makes accurate text extraction difficult for traditional OCR engines. The main challenges that this document presents include:
recognizing diverse handwriting styles
extracting both printed and handwritten fields
detecting checkboxes and their states
preserving the original layout and table structure
identifying text from low-quality, skewed, or noisy scans
We will first showcase the extracted text using a Pytesseract, a traditional OCR engine. Here is a sample code and the extracted text.
# Traditional OCR approach with Pytesseract
from pdf2image import convert_from_path
import pytesseract
# Convert PDF to images
images = convert_from_path("accord-insurance-handwritten-scanned-copy.pdf")
# Extract text
pytesseract_text = ""
for image in images:
pytesseract_text += pytesseract.image_to_string(image)
As you can clearly see, the layout was not preserved and it extracted as one text blob. Also, many of the handwritten words are misread (Simon → Simove, George Simon → George Simm)
We will now use LLMWhisperer and pass this document as is and compare the extracted text with the one from Pytesseract. We will be using the layout_preserving as the output mode as it is perfect for forms that needs spatial relationships between elements to be preserved.
from unstract.llmwhisperer import LLMWhispererClientV2
client = LLMWhispererClientV2(api_key=api_key)
result = client.whisper(
file_path="accord-insurance-handwritten-scanned-copy.pdf",
wait_for_completion=True,
wait_timeout=300,
output_mode="layout_preserving",
)
Here is the extracted text:
® COMMERCIAL INSURANCE APPLICATION DATE (MM/DD/YYYY)
APPLICANT INFORMATION SECTION 03/02/2024
NAIC CODE
AGENCY CARRIER
Fincorp Insurance 52678
Fincorp insurance COMPANY POLICY OR PROGRAM NAME PROGRAM CODE
COMINS 23
POLICY NUMBER
7532685
CONTACT UNDERWRITER UNDERWRITER OFFICE
NAME: Simon
PHONE John adams
(A/C, No. Ext): 23986582
FAX QUOTE ISSUE POLICY RENEW
(A/C, No); [X] [ ] [ ]
E-MAIL STATUS OF BOUND (Give Date and/or Attach Copy):
ADDRESS: TRANSACTION [ ]
DATE TIME AM
CODE: SUBCODE: [ ] CHANGE [ ]
AGENCY CUSTOMER ID: [ ] CANCEL [ ] PM
LINES OF BUSINESS
INDICATE LINES OF BUSINESS PREMIUM PREMIUM PREMIUM
$ CYBER AND PRIVACY $ YACHT $
[ ] BOILER & MACHINERY [ ] [ ]
BUSINESS AUTO $ 3000 FIDUCIARY LIABILITY $ $
[X] [ ] [ ]
BUSINESS OWNERS $ GARAGE AND DEALERS $ $
[ ] [ ]
LIQUOR LIABILITY $ $
[X] COMMERCIAL GENERAL LIABILITY $ 4000 [ ]
$ MOTOR CARRIER $ 5000 $
[ ] COMMERCIAL INLAND MARINE [X]
$ TRUCKERS $ $
[ ] COMMERCIAL PROPERTY [ ] [ ]
CRIME $ UMBRELLA $ $
[ ] [ ] [ ]
ATTACHMENTS
PAPERS GLASS AND SIGN SECTION STATEMENT / SCHEDULE OF VALUES
[ ] ACCOUNTS RECEIVABLE / VALUABLE [ ] [ ]
HOTEL / MOTEL SUPPLEMENT STATE SUPPLEMENT (If applicable)
[ ] ADDITIONAL INTEREST SCHEDULE [ ] [ ]
SCHEDULE INSTALLATION / BUILDERS RISK SECTION VACANT BUILDING SUPPLEMENT
[ ] ADDITIONAL PREMISES INFORMATION [X] [X]
INTERNATIONAL LIABILITY EXPOSURE SUPPLEMENT VEHICLE SCHEDULE
[X] APARTMENT BUILDING SUPPLEMENT [ ] [ ]
EXPOSURE SUPPLEMENT
[ ] CONDO ASSN BYLAWS (for D&O Coverage only) [X] INTERNATIONAL PROPERTY [ ]
[X] CONTRACTORS SUPPLEMENT [ ] LOSS SUMMARY [ ]
OPEN CARGO SECTION
[ ] COVERAGES SCHEDULE [ ]
PREMIUM PAYMENT SUPPLEMENT
[ ] DEALERS SECTION [ ]
[ ] DRIVER INFORMATION SCHEDULE [ ] PROFESSIONAL LIABILITY SUPPLEMENT [ ]
ELECTRONIC DATA PROCESSING SECTION RESTAURANT / TAVERN SUPPLEMENT
[ ] [ ] [ ]
POLICY INFORMATION
MINIMUM PREMIUM
PROPOSED EFF DATE PROPOSED EXP DATE BILLING PLAN PAYMENT PLAN METHOD OF PAYMENT AUDIT DEPOSIT PREMIUM POLICY
$ $
cash 3000 200 $ 5000
03/02/28 [X] DIRECT [ ] AGENCY
APPLICANT INFORMATION
NAME (First Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
5032 56382
George Simon
BUSINESS PHONE #: 302567
53B, Beach Ville Avenue WEBSITE ADDRESS
www.aivent.com
Florida
SUBCHAPTER "S" CORPORATION
[X] CORPORATION [ ] JOINT VENTURE [ ] NOT FOR PROFIT ORG [ ] [ ]
NO. OF MEMBERS
INDIVIDUAL LLC AND MANAGERS: PARTNERSHIP TRUST
[ ] [ ] [ ] [X]
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
BUSINESS PHONE #:
WEBSITE ADDRESS
JOINT VENTURE NOT FOR PROFIT ORG SUBCHAPTER "S" CORPORATION
[ ] CORPORATION [ ] [ ] [ ] [ ]
NO. OF MEMBERS TRUST
INDIVIDUAL LLC AND MANAGERS: PARTNERSHIP
[ ] [ ] [ ] [ ]
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
BUSINESS PHONE #:
WEBSITE ADDRESS
JOINT VENTURE NOT FOR PROFIT ORG SUBCHAPTER "S" CORPORATION
[ ] CORPORATION [ ] [ ] [ ] [ ]
NO. OF MEMBERS
INDIVIDUAL LLC AND MANAGERS: PARTNERSHIP TRUST
[ ] [ ] [ ] [ ]
ACORD 125 (2016/03) Page 1 of 4 1993-2015 ACORD CORPORATION. All rights reserved.
The ACORD name and logo are registered marks of ACORD
<<<
We can see the layout is preserved for the entire document including the multi-column table structures. The checkboxes as well as their states (checked/unchecked) are captured and the extracted handwritten values are also accurate and are next to the corresponding printed fields.
Let’s go one step further and analyze the extracted text using LLM. We will use LangChain and OpenAI model for this test where we will try and extract particular information by prompting.
# Use LangChain + OpenAI to analyze the extracted text
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Initialize OpenAI model
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Create a prompt for analyzing the insurance document
analysis_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert at analyzing insurance documents.
Extract key information from the document text provided and structure it clearly.
Focus on: policy holder details, policy numbers, coverage amounts, dates, and any other important information."""),
("user", "Please analyze this insurance document text and extract all key information:\n\n{text}")
])
# Create chain
chain = analysis_prompt | llm
# Analyze the document
print("Analyzing document with GPT-4o...")
analysis = chain.invoke({"text": extracted_text})
print("\n" + "="*80)
print("DOCUMENT ANALYSIS")
print("="*80)
print(analysis.content)
Here is the output:
Analyzing document with GPT-4o...
================================================================================
DOCUMENT ANALYSIS
================================================================================
Here is the extracted key information from the provided insurance document:
**Policy Holder Details:**
- **Name (First Named Insured):** George Simon
- **Mailing Address:** 53B, Beach Ville Avenue, Florida
- **Business Phone:** 302567
- **Website Address:** www.aivent.com
- **Business Type:** Corporation
- **Subchapter:** "S" Corporation
**Policy Information:**
- **Agency:** Fincorp Insurance
- **Carrier:** Fincorp Insurance
- **NAIC Code:** 52678
- **Company Policy or Program Name:** COMINS
- **Program Code:** 23
- **Policy Number:** 7532685
- **Contact Name:** Simon
- **Contact Phone:** 23986582
- **Underwriter:** John Adams
- **Quote Status:** Issued
**Coverage Details:**
- **Business Auto Premium:** $3,000
- **Commercial General Liability Premium:** $4,000
- **Motor Carrier Premium:** $5,000
**Policy Dates:**
- **Proposed Effective Date:** 03/02/2028
- **Proposed Expiration Date:** Not specified
**Payment Information:**
- **Billing Plan:** Direct
- **Payment Plan:** Cash
- **Deposit:** $3,000
- **Minimum Premium:** $200
- **Total Policy Premium:** $5,000
**Attachments and Supplements:**
- **International Liability Exposure Supplement**
- **Apartment Building Supplement**
- **Contractors Supplement**
- **Vacant Building Supplement**
This structured information provides a clear overview of the insurance policy details, including the policy holder, coverage, and financial aspects.
LLMWhisperer perfectly extracted all critical information from the handwritten ACCORD form including the handwritten values and their association with the corresponding printed fields. Its layout preserving mode maintained the form’s complex structure, and reliably identified the checkboxes and their states. Together, these results highlight LLMWhisperer’s effectiveness for processing scanned, handwritten insurance forms end to end.
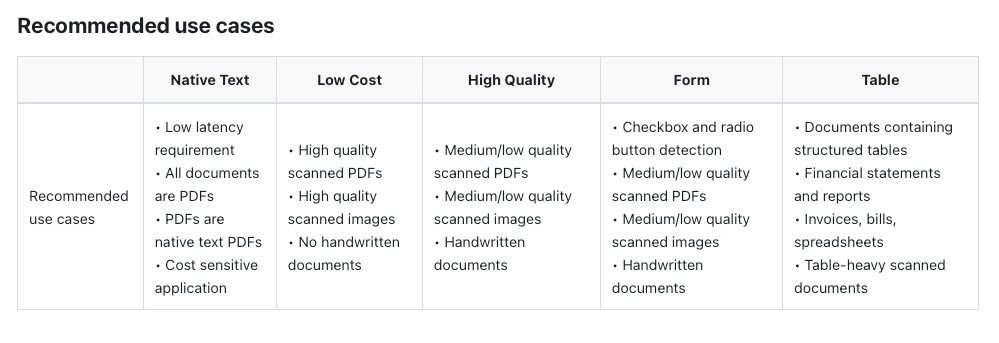
Case Study #2: Insurance Performance Report in Excel Format
In this second case study, we analyze a complex insurance performance report stored as an Excel spreadsheet containing multi-part financial tables with merged headers and multiple nested column groups having numerical data for various companies. The challenges that this document presents are:
preserving the hierarchical structure of the merged column headers
maintaining alignment between the company and their financial figures across multiple columns
correctly handling empty cells and blank rows
accurately distinguishing between the two major sections (DIRECT INSURERS and REINSURERS) along with their sub-tables (PART I and PART II)
Here are the images of the tables in the Excel sheet:
As we can see LLMWhisperer accurately extracted all critical elements of the complex insurance performance report while preserving the full table structure. It maintained the three‑level headers, kept every company name correctly aligned with its financial figures, and handled thousands separators, negatives, and decimals without errors. Sections for DIRECT INSURERS and REINSURERS (including PART I and PART II) remained clearly separated, resulting in database‑ready structured data that required no manual cleanup.
Case Study #3: Income Tax Form with Checkboxes and Photographed Receipt
In this third case study, we look at two challenging document types: an image version of an income tax form with multiple checkboxes and a photographed hotel receipt. The challenges these documents presents are:
The photographed receipt presents another kind of difficulty as it is a noisy image with uneven lighting and many key-value pairs including some handwritten values also.
First, here is an image of the actual income tax form:
Using the default form mode, here is the extracted text:
Form Number: CA530082
Form 5500-EZ Annual Return of A One-Participant (Owners/Partners and OMB No. 1545-1610
Their Spouses) Retirement Plan or A Foreign Plan
This form is required to be filed under section 6058(a) of the Internal Revenue Code. 2023
Certain foreign retirement plans are also required to file this form (see instructions).
Department of the Treasury Complete all entries in accordance with the instructions to the Form 5500-EZ. This Form is Open
Internal Revenue Service
Go to www.irs.gov/Form5500EZ for instructions and the latest information. to Public Inspection.
Part Annual Return Identification Information
For the calendar plan year 2023 or fiscal plan year beginning (MM/DD/YYYY) 01/02/202 Zand ending 01/02/2023
A This return is: (1) the first return filed for the
[X] plan (3) [ ] the final return filed for the plan
(2) [ ] an amended return (4) [ ] a short plan year return (less than 12 months)
B Check box if filing under [ ] Form 5558 [ ] automatic extension
[ ] special extension (enter description)
C If this return is for a foreign plan, check this box (see instructions) [ ]
D If this return is for the IRS Late Filer Penalty Relief Program, check this box
(Must be filed on a paper Form with the IRS. See instructions). [ ]
E If this is a retroactively adopted plan permitted by SECURE Act section 201, check here [ ]
Part II Basic Plan Information - enter all requested information.
1a Name of plan 1b Three-digit
plan number (PN) 586
1c Date plan first became effective
Annual Return Plan
(MM/DD/YYYY)
02/05/2022
2a Employer's name 2b Employer Identification Number (EIN)
Acme Corp Software (Do not enter your Social Security Number)
Trade name of business (if different from name of employer) 735268329
2c Employer's telephone number
In care of name 011536259
2d Business code (see instructions)
Mailing address (room, apt., suite no. and street, or P.O. box)
235, Park Street Avenue, FL
City or town, state or province, country, and ZIP or foreign postal code (if foreign, see instructions)
FL 63052
3a Plan administrator's name (if same as employer, enter "Same") 3b Administrator's EIN
532678
In care of name 3c Administrator's telephone number
Mailing address (room, apt., suite no. and street, or P.O. box)
City or town, state or province, country, and ZIP or foreign postal code (if foreign, see instructions)
4 If the employer's name, the employer's EIN, and/or the plan name has changed since the
last return filed for this plan, enter the employer's name and EIN, the plan name, and the
plan number for the last return in the appropriate space provided
a Employer's name 4b EIN 5732900
4c Plan name 4d PN
5a(1) 10
5a(1) Total number of participants at the beginning of the plan year
5a(2) 8
a(2) Total number of active participants at the beginning of the plan year
5b(1) 5
b(1) Total number of participants at the end of the plan year
b(2) Total number of active participants at the end of the plan year 5b(2)
with accrued
c Number of participants who terminated employment during the plan year
benefits that were less than 100% vested 5c 2
Part III Financial Information
(1) Beginning of year (2) End of year
6a $ 50000 $ 60000
6a Total plan assets
6b $ 4000 $ 5000
b Total plan liabilities .
6a) 6c
c Net plan assets (subtract line 6b from
see the Instructions for Form 5500-EZ. Catalog Number 63263R Form 5500-EZ (2023)
For Privacy Act and Paperwork Reduction Act Notice,
<<<
As we can see, LLMWhisperer maintains the layout while correctly capturing the checkbox markers.
Next we move on to the other use case which is a picture of a hotel receipt shown by:
INTERCONTINENTAL.
CHENNAI MAHABALIPURAM RESORT
No.212, East Coast Road, Nemelli Village, Perur Post Office, Chengalpattu
District
Chennai - 603 104. Tamil Nadu, India.
Tel : +91 44 7172 0101 Fax :+91 44 7172 0102 intercontinental.com/Chennai
GSTIN No. : 33AAACA9041L1ZR
Serial N 367005 TAX INVOICE: 33AAACA9041L1ZR
==== Kokoffo ====
5179 Manoj MMK
CHK 301802 TBL 11/1 GST 2
tao 5/17/2024 8:44 PM
of S
1 Farm House 750.00 T15 T16
peng
Journey of a thousand flavours MESSAGE FOOD
TW
Subtotal R$750.00
Service Charge 5% Rs37.50
CGST 9% Rs70.88
the melting pot SGST 9% R$70.88
market café
9:08 PM
Total Due Rs929.26
5179 Manoj MMK 1004
KoKoMM.
UP/
amrtam
Guest Name
Simon Dawes
Room No. AS2 Guest Signature
VAT TIN No. : 33630760031 Dt. 15.4.2015 CST No. : 40178 Dt. 23.2.74
FSSAI No. : 12421008003227 Service Tax No. : AAALA9041LSD008 Pan No. : AAACA9041L
Premises Ni. : SV0505A003 CIN No. : U55101TN1970PLC005815
Regd. Office : Adyar Gate Hotels Ltd., 132, T.T.K. Road, Chennai - 600 018.
If Paid by Cash, do not sign the Invoice.
dissatisfied with the service.
Service charge is optional. Do inform the server to waive these charges if you are
<<<
ven for the photographed receipt, we can see that the amounts were correctly extracted including the handwritten guest name, room no. and the signature.
Ready-to-Use APIs for Instant, Domain-Specific Document Automation
Watch this webinar as we introduce API Hub—a new service within Unstract that delivers ready-to-use, domain-specific APIs for all your key documents.
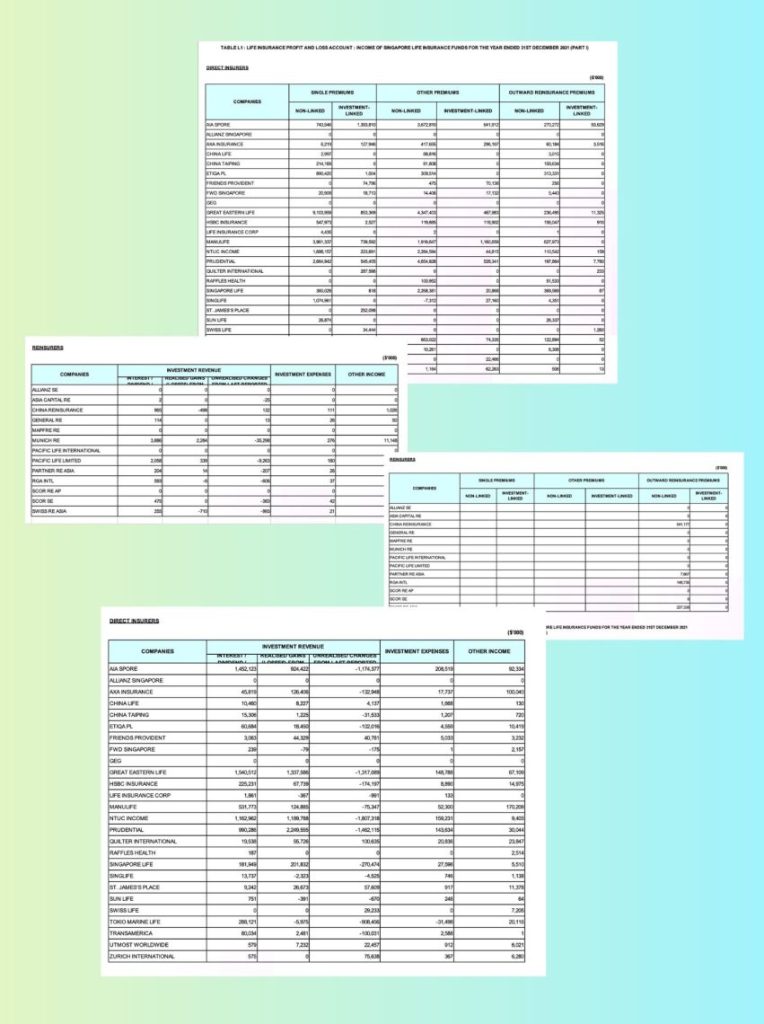
Case Study #4: Multilingual (German–English) Insurance Application Form
In this case study, we analyze a multilingual health insurance application form that mixes German and English labels, dual-language instructions, currency options, and structured policyholder details. The main challenges this document presents are:
correctly handling mixed languages and special characters
preserving the association between English and German label pairs
keeping the layout of the sections intact
accurately capturing numerical fields
Here is the actual insurance application form in German:
In welcher Währung möchten Sie Ihre Prämie zahlen? Ihre Versicherungsleistungen werden ebenfalls in dieser Währung erfolgen.
In which currency would you like to pay your premium? Your policy benefits will also be in this currency.
[ ] GB£ [X] Euro€ [ ] US$
Wie viel Selbstbeteiligung möchten Sie übernehmen? Selbstbeteiligung gilt pro Person pro Versicherungsjahr und nicht für die Optionen Reguläre
Schwangerschaft und Entbindung, Zahnärztliche Behandlung, Evakuierung oder Repatriierung oder Leistungen für Wellness, Optik und Impfungen. Wählen Sie
eine höhere Selbstbeteiligung, um Ihre Versicherungsprämie zu reduzieren.
How much excess would you like to pay? Excess is per person per policy year and does not apply to Routine Pregnancy & Childbirth, Dental Treatment, Evacuation or Repatriation options or Well-being, Optical and
Vaccination benefits. To reduce your premium amount, choose a higher policy excess.
[ ] Nil [X] £ 50: € 60: US$ 75 [ ] £ 150: € 180: US$ 225 [ ] £ 300: € 360: US$ 450
[ ] £ 500: € 600: US$ 750 [X] £ 1,000: € 1,200: US$ 1,500 [ ] £ 2,500: € 3,000: US$ 3,750 [ ] £ 5,000: € 6,000: US$ 7,500
[ ] £ 7,500: € 9,000: US$ 11,250
Wie möchten Sie Ihre Prämie zahlen? Nachdem wir Ihren Antrag angenommen haben, werden wir Ihnen weitere Details zukommen lassen.
How would you like to pay your premium? We'll send details following acceptance of your application.
[X] Jährlich [X] Kredit-/Bankkarte [ ] SEPA-Lastschrift# [ ] Banküberweisung
Annually Credit / Debit Card SEPA Direct Debit Bank Transfer
[ ] Vierteljährlich [X] Kredit-/Bankkarte [ ] SEPA-Lastschrift# [ ] Banküberweisung
Quarterly Credit / Debit Card SEPA Direct Debit Bank Transfer
[ ] Monatlich [ ] Kredit-/Bankkarte [ ] SEPA-Lastschrift# [ ] Banküberweisung
Monthly Credit / Debit Card SEPA Direct Debit Bank Transfer
# SEPA-Lastschriftzahlungen nur von EU/EWR-Bankkonten.
#SEPA Direct Debit payments from EU/EEA bank accounts only
2
Ihre Daten
Your details
Angaben zum Versicherungsnehmer
Policyholder details
Anrede Wohnanschrift
Title
Wohnsitz (Land) - Adresse wo Sie derzeitig leben
Home address
[X] Herr [ ] Frau [ ] Frl. Sonstige: (Country of Residence - address where you currently live)
Mr Mrs Miss Other: Guentzelstrasse 23
Vorname(n) Rheinland-pfalz
First name(s)
Klaus
Postleitzahl: 55576 Land
Country Germany
Nachname Postcode:
Surname
Korrespondenzadresse (falls abweichend)
Paul Correspondence address (if different)
Kantstrasse 63
Geburtsdatum (TT-MM-JJJJ) Geschlecht
Date of birth (DD-MM-YYYY) Gender
Bayreuth
21 12 1967 Male
Höhe (cm/ft) Gewicht (kg/lbs)
Height (cm/ft) Weight (kg/lbs) PLZ: 95408 Land Germany
Postcode: Country
187 87
Telefonnummern
Branche Phone numbers
Industry
Privat: 06701 15 61 36
Home:
Software
Beruflich:
Work: 0921 10 29 84
Beruf (bitte vollständige Angaben machen)
Occupation (please give full details)
Mobil:
Mobile:
Engineer
Fax:
Nationalität Fax:
Nationality
England
E-Mail-Adresse
Email address
pklaus@protomail.de
Soll der Versicherungsnehmer im Rahmen [X] Ja [ ] Nein
dieser Police versichert werden?
Is the Policyholder to be insured under this policy? Yes No
Seite 2 von 9 ALC Global Health Insurance ... wir sind anders, weil wir uns um Sie kümmern.
<<<
LLMWhisperer can perfectly capture German words including special characters (ä, ö, ü) without any specific configuration, unlike Pytesseract that requires manual setup. Also, the English-German label pairs and the currency values were correctly identified.
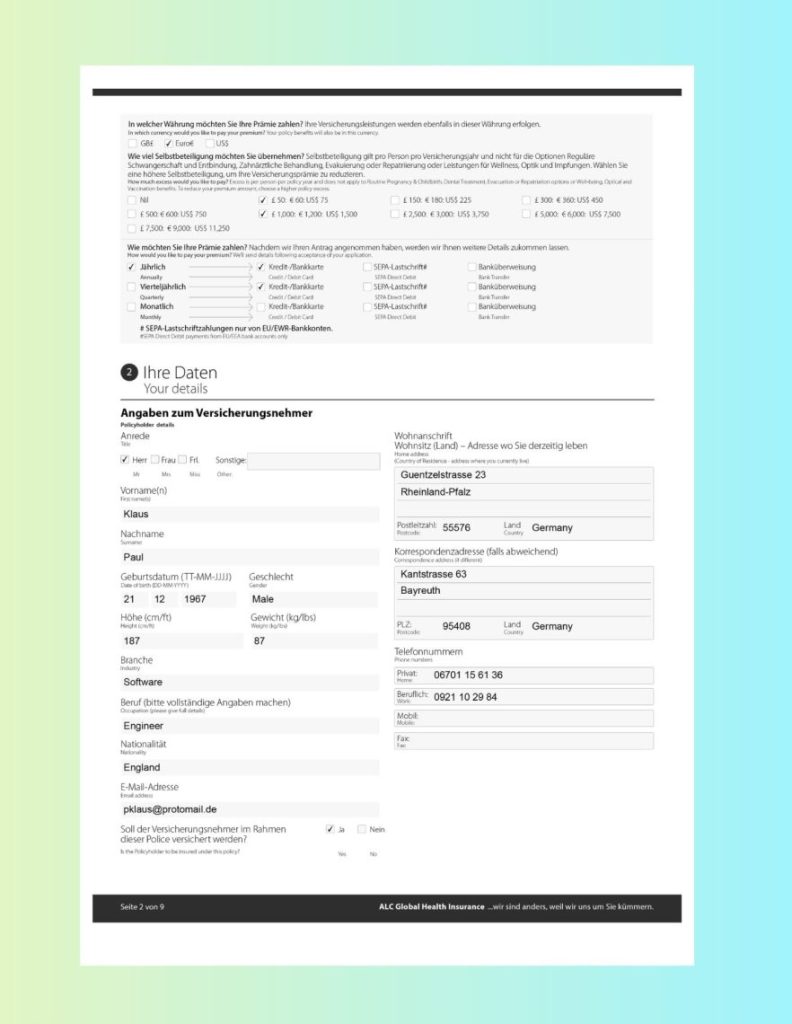
Case Study #5: Scanned, Misaligned Logistics Packing List
In this case study, we work with a scanned packing list that is slightly misaligned and contains dense tabular shipping data. The main challenges here are:
correcting page skew and misalignment from scanning
preserving the structure of the shipment table so each item’s quantities and dimensions stay aligned
accurately identifying the text in shipper, consignee, and bill‑to sections
Packing List
Shipper/ Exporter: Faculty of Arts Ultimate Consignee: Herald Corp Bill To: Faculty of Arts Intermediate Consignee
5 Washington 28 OLD 5 Washington Square S,
Square S, New York, BROMPTON New York, NY 10012, USA
NY 10012, USA ROAD, SOUTH
KENSINGTON
Commercial Invoice No .: 894933 Total number of Packages: 32 Transportation: AIR CARGO UPS
Order No .: Total Gross Weight (Lbs):
Total Gross Weight (Kgs): 35
AWB/BL Number: Total Net Weight (Lbs):
Date Of Shipment:
Total net Weight (Kgs): Conditions of Sale and Terms of Payment: If unpaid after 15 days, ALL
Currency: 34343454 Total Cubic Feet:
Freight: 12/12/2023 Total Cubic Meters: 1020 may dispose of the goods
Dollars per Clause 5.
Per package
Item gross weight
Shipment Item Description, Sales Order No., Customer Shipped Packaging
Number Dimensions
Line No. PO No. Quantity Type Inches centimeters
L W H L W H LBS. KGS.
12 1 Print packaging, 23445 10 Box 12 12 12 10
13 2 Print packaging, 345232 10 Box 16 16 16 20
14 3 Black Ink cartridges, 342900 20 Glass 10 8 8 15
Country of Origin:
Marks: USA
Note: These commodities, Technology or software were exported from the United States in accordance with the Export Administration Regulations.
Diversion contrary to U.S. law is prohibited.
Signature: Date:
<<<
As we can see from the extracted text, LLMWhisperer can automatically handles misaligned documents. It properly captures the different sections including the row-column alignment in each of these sections.
Conclusion
LLMWhisperer stands out as one of the best OCR solution for AI-driven workflows, delivering layout-preserved, LLM-ready text from even the toughest real-world documents like handwritten forms and complex tables. You can use it via API call and integrate it directly with a RAG pipeline for direct LLM Q&A applications.
Key Takeaways
Surpasses traditional tools like Pytesseract on most real-world documents
preserves layout for complex multi-column tables
accurately detect both printed and handwritten words
Here is the Github repository where you will find all the notebooks used for the experiments in this article and more.
Feel free to use your sample docs with the code presented in the notebooks. You will also need an API key. For this, please go to Unstract’s official website and create an API key by first signing up.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.