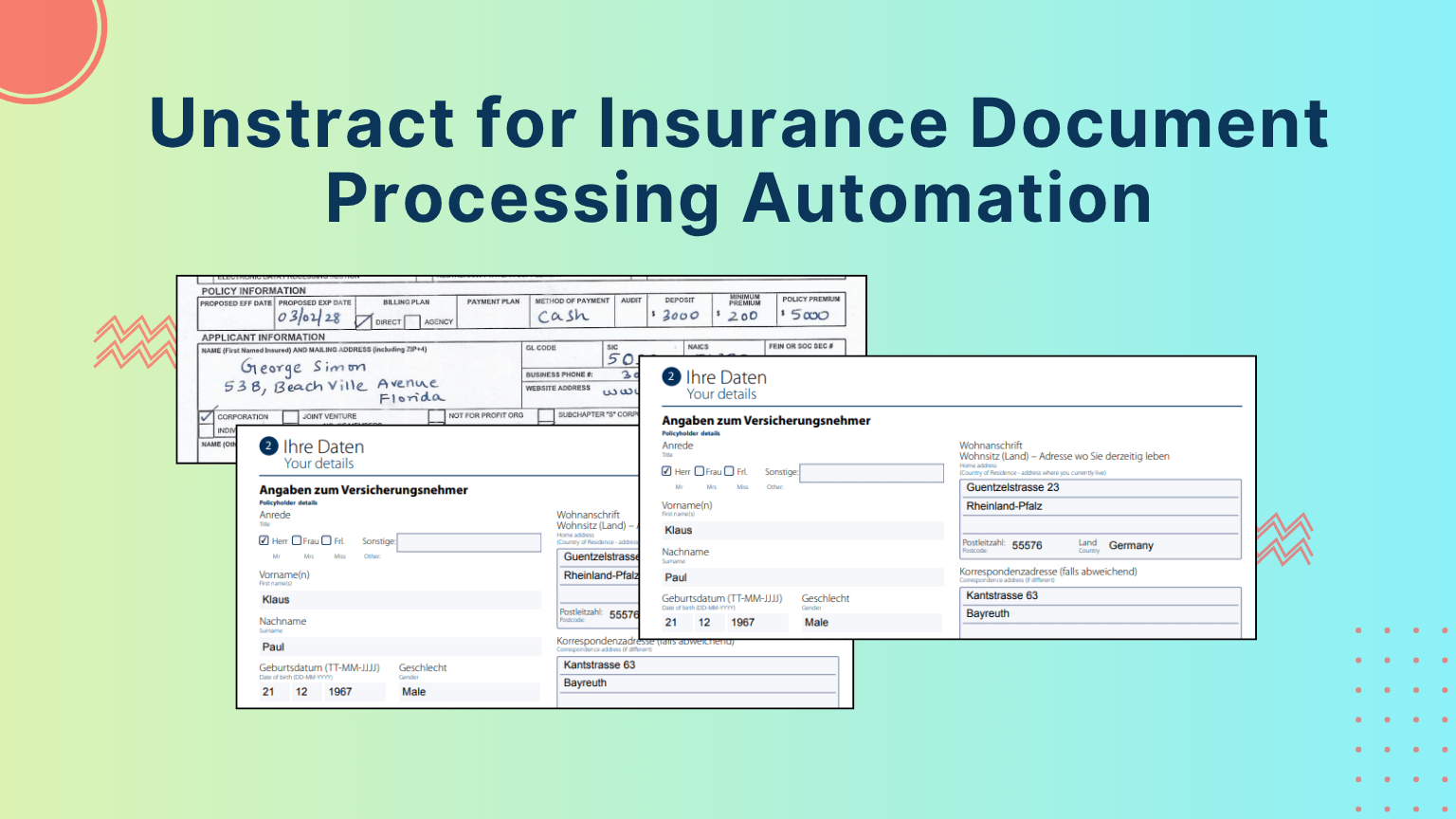
Insurance OCR: Parse Claims, ACORD & Policy Documents with LLMWhisperer
Table of Contents
Insurace OCR: An Introduction
Insurance runs on documents. Every claim form, policy application, underwriting report, and proof of coverage contains crucial data that determines whether a customer gets paid on time—or ends up stuck in a cycle of manual review. Yet, most of this information still lives inside scanned PDFs, handwritten forms, or old legacy systems.
That’s where OCR insurance automation changes the game. By converting these static, unsearchable documents into machine-readable data, insurers can streamline claims processing, accelerate policy approvals, and drastically reduce human error. Instead of teams re-keying data from claim forms or verifying customer details line by line, intelligent insurance OCR systems extract everything—names, policy numbers, coverage limits, amounts claimed, and even signatures—within seconds.
The impact is profound. Claims that once took days to validate can now move through straight-through processing in minutes. Underwriters can focus on risk decisions rather than data entry. Compliance officers can automatically verify whether documents meet regulatory standards.
In short, OCR in insurance isn’t just a technology upgrade—it’s the foundation of digital transformation across the insurance value chain. From claims to underwriting and compliance, it brings speed, accuracy, and trust to processes that once depended entirely on paper.
Modern insurance organizations now combine OCR with AI, using advanced document-understanding engines like LLMWhisperer to go beyond text recognition. They achieve a new level of automation: interpreting context, understanding layouts, and intelligently mapping unstructured data into usable formats. This is the evolution of ocr insurance—from text capture to true document intelligence.
TL;DR
If you wish to skip directly to the solution section, where you can see how LLMWhisperer OCR API handles insurance documents of any complexity — document scans, handwritten forms, skewed images, multi-language documents, click here.
Try LLMWhisperer Insurance OCR on the free demo playground. No signup required.
Insurance OCR (Optical Character Recognition for the insurance industry) is the technology that converts physical or digital documents—such as scanned claim forms, invoices, or handwritten applications—into structured, editable text that computers can understand. In simple terms, it’s how insurers “read” documents automatically.
Definition and Working Principle
OCR works by analyzing the shapes and patterns of printed or handwritten characters in an image or PDF and transforming them into digital text. In the context of ocr in insurance, this means converting everything from policy declarations to accident photos or claim receipts into structured, searchable data.
For example, when a customer uploads a claim form with sections like Policy Number, Date of Loss, and Amount Claimed, an insurance OCR system scans each line, recognizes the characters, and outputs digital text—often in JSON or CSV format. This data can then be pushed directly into claims-management systems, underwriting tools, or fraud-detection engines.
But traditional OCR stops at recognition. It doesn’t understand meaning. That’s why modern ocr insurance solutions now combine OCR with artificial intelligence (AI) and large language models (LLMs). This combination allows systems not just to read text but to interpret it—recognizing that “Sum Insured” and “Coverage Limit” refer to the same concept, or that a handwritten “Approved” stamp means the claim has cleared internal review.
OCR in Insurance and Its Relevance
In insurance, OCR stands for Optical Character Recognition, but in practice, it represents far more than character recognition. It’s a bridge between unstructured, paper-bound information and digital workflows. The relevance of OCR in the insurance sector can’t be overstated:
Speed: Instant data extraction from thousands of claim forms or policy applications.
Accuracy: Reduced manual errors in claim amounts, policy numbers, or personal details.
Compliance: Easier recordkeeping and audit trails for regulatory reporting.
Customer Experience: Faster turnaround times for claim settlements and renewals.
In an age where insurers compete on efficiency and trust, ocr in insurance gives them a tangible edge—turning paper into intelligence, delays into decisions, and disconnected processes into seamless automation.
Traditional OCR vs. AI-Powered OCR
Traditional OCR tools read static text; they work best with clean, typed documents. But real insurance data is messy: scanned forms, handwritten fields, checkboxes, stamps, watermarks, and multiple document layouts. AI-powered insurance OCR systems solve this by combining OCR with layout detection, semantic understanding, and contextual analysis.
By merging ocr insurance technology with AI and LLM-based understanding, insurers can automatically process claim documents, identify key entities, detect anomalies, and even validate extracted data against internal databases. This hybrid approach turns OCR from a back-office utility into a strategic enabler of end-to-end automation in OCR claims and policy processing.
Why Accurate OCR Matters in Insurance Processing
In the insurance world, accuracy isn’t just important — it’s everything. A single misplaced number in a policy document can delay a claim by weeks or even cost thousands of dollars in errors. That’s why OCR in insurance has become a cornerstone of modern insurance operations. It enables insurers to process documents faster, with fewer mistakes, while maintaining full compliance with regulations.
The Role of OCR in Claims, Underwriting, and Policy Management
Think about what happens when a customer files a claim after a car accident. They upload photos, fill out a handwritten claim form, and attach invoices from the repair shop. A claims team must review each document, check the policy number, verify coverage, and calculate reimbursement. Without automation, this takes hours.
Now imagine using insurance OCR — a system that reads each document, recognizes the policy number, extracts the repair costs, and cross-checks the customer’s name and date automatically. Within seconds, the claim can be verified and queued for approval. This is the power of ocr claims automation — fewer errors, faster processing, and happier customers.
Similarly, in underwriting, OCR extracts applicant details, income proofs, and prior insurance data from submitted forms. It ensures the underwriter sees only clean, validated information rather than scanning through dozens of pages.
And in policy management, OCR helps insurers manage renewals, identify expired policies, and extract key details (like coverage limits or premium amounts) from legacy documents that were never digitized.
Common Data Challenges in Insurance Documents
Despite its potential, insurance data is messy. That’s where intelligent OCR insurance tools like Unstract’s LLMWhisperer shine — they handle real-world complexity such as:
Handwritten fields: Older claim forms or medical statements often contain handwritten notes like “Approved,” “Pending,” or “See attached report.” Standard OCR tools may skip or misread these, but advanced OCR captures them accurately.
Scanned and low-quality copies: Many policies or claims are scanned from old files or photos taken on mobile phones. Blurry images, tilted pages, and stamps make extraction difficult. Smart ocr in insurance platforms deskew, enhance, and process such images for clean results.
Form checkboxes and radio buttons: Insurance forms often include options like “Yes / No” or “Accident / Theft / Fire.” Traditional OCR sees these as random marks, but modern insurance OCR systems identify checked boxes and return clear binary results for automation.
Impact on Compliance, Speed, and Customer Satisfaction
Accurate OCR directly influences three core insurance priorities:
Compliance: Insurers operate under strict data regulations. Missing a policyholder’s consent form or misplacing a claim date can result in audit failures. OCR ensures that every piece of information — from signatures to coverage amounts — is captured and traceable.
Speed: Faster document processing means faster claims settlement. Customers expect near-instant responses today. OCR claims automation helps insurers achieve that by cutting manual review time from hours to minutes.
Customer Satisfaction: Imagine a customer submitting a medical claim at night and getting an automated confirmation by morning — that’s the kind of experience OCR makes possible. Accuracy drives trust, and trust drives retention.
In short, precise OCR in insurance bridges the gap between paperwork and performance — turning every document into usable, auditable, and customer-ready data.
Key Insurance Processes Enhanced by OCR
Modern insurance OCR systems go far beyond reading text — they streamline almost every major workflow in the insurance lifecycle. Below are some of the most impactful examples of ocr insurance in action.
1. Claims Processing and Form Digitization
Filing claims is one of the most document-heavy processes in insurance. From motor accident claims to health reimbursements, every submission involves multiple forms, invoices, and receipts. With ocr claims technology, insurers can automatically:
Extract claim IDs, policyholder names, and amounts from scanned forms.
Match them to internal databases to prevent duplicates.
Flag incomplete claims for human review.
For example, a customer uploading a medical claim with a hospital bill in PDF format no longer needs to wait for manual validation. The OCR engine identifies hospital name, admission/discharge dates, and billed amount instantly.
2. Policy Application and Underwriting Automation
Underwriting often involves verifying hundreds of pages — identity proofs, income documents, health reports, and previous policy records. OCR in insurance underwriting automates these tasks:
Extracts applicant details like name, address, and date of birth.
Parses medical reports to identify pre-existing conditions.
Cross-references old policy numbers for continuity.
This helps underwriters focus on decision-making rather than data entry, reducing approval time from days to hours.
3. Insurance Verification and KYC
When a customer buys a policy or renews one, verification documents such as driver’s licenses, passports, and identity proofs must be validated. Insurance OCR automatically reads and matches these IDs to ensure authenticity. It detects tampered images, extracts expiry dates, and verifies that the policyholder’s name matches across all documents — making KYC faster and more secure.
4. Certificates of Liability and Proof of Insurance
Companies and individuals often need to share proof of coverage or certificates of liability with partners or clients. These documents contain policy limits, effective dates, and insurer details. OCR extracts all relevant fields, ensuring that compliance teams can validate certificates without manual inspection.
For example, a construction company renewing multiple liability certificates can upload them all at once. The ocr insurance platform reads and validates them automatically, flagging any missing endorsements or expired dates.
5. Health, Auto, and Life Insurance Documentation
Each category of insurance comes with its own unique documentation challenges:
Health Insurance: Extracts diagnosis codes, billing details, and patient information from medical claim forms.
Auto Insurance: Processes handwritten accident statements, repair invoices, and police reports.
Life Insurance: Parses policy schedules, beneficiary lists, and premium payment records.
By automating all of these, insurance OCR ensures that insurers spend less time reading PDFs and more time serving customers.
Accurate and intelligent ocr insurance transforms every aspect of insurance operations — from ocr claims handling to policy creation, underwriting, and verification. It not only cuts costs and errors but also empowers insurers to deliver what customers value most: speed, transparency, and trust.
Introducing LLMWhisperer for Insurance OCR
In the world of OCR insurance automation, accuracy and layout integrity are everything. Insurance documents—claims, ACORD forms, policy schedules, invoices—aren’t simple paragraphs of text. They include complex tables, checkboxes, handwritten endorsements, and even multi-language entries.
LLMWhisperer by Unstract is designed precisely for this world. It’s a layout-preserving OCR engine that transforms scanned PDFs, handwritten claim forms, and Excel-based statements into clean, structured text while preserving spatial context.
Unlike traditional OCR tools that flatten data, LLMWhisperer reproduces structure. Columns stay aligned, checkboxes remain checkboxes, and even tiny footnotes keep their place. The result is a readable, layout-true output that’s ready for downstream AI models or human validation.
Get started with LLMWhisperer: Best OCR API for AI Insurance Document Workfows
Try LLMWhisperer Insurance OCR for free on the demo Playground. No signup needed.
LLMWhisperer is not an AI or large language model itself — it’s the foundation that enables AI. Its job is to feed your LLM or automation engine with the cleanest, richest, and most structured text possible.
It doesn’t “guess” meaning. It preserves it.
That makes it AI-friendly: instead of raw, jumbled text, your downstream LLM receives clear, layout-preserving, token-efficient content — dramatically improving accuracy for insurance OCR, underwriting analytics, and ocr claims processing.
Think of it like this:
Traditional OCR gives your AI a messy desk full of papers. LLMWhisperer hands it a perfectly organized binder—indexed, labeled, and easy to read.
How It Improves Accuracy and Readability for Insurance Workflows
Better structured input → fewer LLM hallucinations and errors in downstream parsing.
Consistent layout cues → AI can understand “table rows” vs. “headings” vs. “signatures.”
Readable text extraction → ideal for human-in-the-loop reviews and audit trails.
Example: A rent roll or claims summary PDF with six columns, checkboxes for claim types, and handwritten notes (“approved”, “awaiting review”) is fully captured. The layout is maintained, text is clean, and coordinates are provided for precise review.
That’s why LLMWhisperer + Unstract has become the new standard for ocr in insurance—accuracy, structure, and AI readiness.
What Is LLMWhisperer?
LLMWhisperer is a general-purpose OCR and text parser optimized for unstructured and semi-structured insurance documents. It extracts not just text, but context—preserving the layout, spatial order, and document structure that AI needs to reason about meaning.
Whether it’s a handwritten health claim, a multi-page ACORD form, or an Excel-based loss report, LLMWhisperer ensures your extracted text is not just machine-readable, but also semantically ready for processing by AI and LLMs.
Features and Benefits of LLMWhispererOCR
Below is the most comprehensive feature overview—combining the official documentation (v2.0.0) with Unstract’s real-world insurance automation focus.
1. Layout Preservation and Output Modes
Key Feature: Keeps original document structure—columns, tables, checkboxes, headers, and footers.
Parameter
Description
output_mode
Layout-preserving mode keeps spacing and alignment for visual and semantic accuracy.
mark_vertical_lines
Marks column separators to help AI interpret table boundaries.
mark_horizontal_lines
Marks table rows and section dividers for better segmentation.
add_line_nos
Adds stable line numbers for traceability and review.
Why it matters: In insurance, layout defines meaning. For example, “Coverage Limit” and “Deductible” often sit side by side. Without layout retention, amounts can be mismatched. LLMWhisperer ensures every value stays where it belongs.
2. File Formats Supported (Comprehensive List)
LLMWhisperer supports virtually all file types used in insurance operations.
Category
Supported Formats
Word Processing
DOCX, DOC, ODT
Presentations
PPTX, PPT, ODP
Spreadsheets
XLSX, XLS, ODS
Documents & Text
PDF, TXT, CSV, JSON, TSV, XML, HTML
Images
BMP, GIF, JPEG, JPG, PNG, TIF, TIFF, WEBP
Insurance use case examples:
Extract data from Excel-based performance reports
Read scanned PDF claims or JPG inspection photos
Parse Word policy documents for clause analysis
3. Supported Document Types
LLMWhisperer is built to handle every document format the insurance industry uses:
Scanned or native PDFs
Photographed documents (mobile submissions)
PDF forms with checkboxes and radio buttons (ACORD, claim forms)
Handwritten documents
Complex tables like coverage matrices or loss runs
Example: A low-quality, scanned “Claim for Disability Benefits” form with faint ink and ticked checkboxes still extracts perfectly—with checkmark detection and correct field mapping.
4. LLMWhisperer Modes (API Parameters)
Different insurance documents need different OCR precision levels. LLMWhisperer provides five optimized modes:
Mode
Ideal Use Case
Handwriting
Checkboxes
Languages
Notes
Native Text
Clean digital PDFs, cost-sensitive apps
❌
❌
All (Unicode)
Fastest mode
Low Cost
High-quality scans/images
Basic
❌
120+
Good for standard PDFs
High Quality
Low-quality scans, handwritten claims
✅
✅
300+
Uses AI/ML enhancement
Form
ACORD forms, insurance applications
✅
✅
300+
Detects radio buttons
Table
Financial reports, loss runs, Excel extracts
✅
✅
300+
Best for structured data
Example:
Use Form mode for ACORD applications with multiple checkbox fields.
Use Table mode for financial statements and premium breakdowns.
Use High Quality mode for handwritten or faxed medical claim forms.
5. Multilingual OCR (300+ Languages)
Supports over 300 languages, including English, German, French, Spanish, Hindi, and Arabic—ideal for global insurers handling multilingual claim submissions.
Example: A German car insurance application can be processed without translation or data loss.
6. Advanced Preprocessing for Scanned Documents
LLMWhisperer includes built-in image repair and enhancement:
Rotation and skew compensation
Auto repair of corrupted PDFs
Median and Gaussian filtering for noise reduction
Contrast enhancement for faint scans
Insurance relevance: Faxed claim forms, photo captures from phones, or older scanned documents are processed cleanly without needing re-upload.
7. Table Extraction and Line Preservation
Financial and claims data often appear in tabular layouts. LLMWhisperer’s table mode reproduces lines, rows, and headers precisely, even when borders are missing.
Example: Extract “Premium,” “Coverage,” and “Deductible” columns from a PDF summary without manual template building.
8. Bounding Boxes and Spatial Context
Each text region includes x/y coordinates, enabling:
Visual overlays (highlight text regions)
Confidence visualization in dashboards
Integration into review UIs (click-to-view on PDF)
This feature is especially valuable for audit trails and compliance.
9. Form Element Extraction
Detects checkboxes and radio buttons and returns them as boolean fields.
LLMWhisperer uses intelligent handwriting support (in High Quality, Form, and Table modes) to read short annotations, notes, or numbers.
Example: Reads an adjuster’s handwritten “Approved” on a scanned claim or a doctor’s note on a medical reimbursement form.
11. Excel Sheet and Spreadsheet Extraction
Extracts structured data directly from Excel files — no copy-pasting or CSV conversion needed. Ideal for underwriting analytics or performance reports.
Example: “Premium by Product” or “Loss Ratio by Month” sheets are parsed cleanly into structured JSON.
12. Low-Fidelity Tolerance
Handles noisy, low-resolution, or stained documents—common in legacy archives or field submissions.
Example: A faded, crumpled photo of a health insurance claim still produces usable text output, reducing rejection rates.
13. Multilingual Data Extraction (End-to-End)
Maintains alignment between original and translated text even when multiple languages appear on a single page—critical for multinational insurers.
Helps insurers monitor SLA compliance and plan scaling efficiently.
15. Secure, Private, and Self-Hosted Option
LLMWhisperer can be self-hosted on-premise, offering:
Full control over infrastructure
Guaranteed data privacy for sensitive insurance information
Compliance with ISO, GDPR, and regional regulations
Ideal for: Carriers, TPAs, or reinsurers handling confidential customer data.
16. Simple, Transparent Pricing
No hidden costs, no complex licensing. LLMWhisperer follows a pay-per-page model with straightforward usage tiers—making it easy to predict OCR insurance costs per claim, policy, or monthly volume.
Summary: Why LLMWhisperer Stands Out in Insurance OCR
LLMWhisperer is not just another OCR. It’s the document foundation layer that makes every insurance OCR workflow—from ocr claims to underwriting—more accurate, faster, and enterprise-ready.
It reads, preserves, and prepares every document so that your AI or workflow automation tools can finally understand them—just like a trained insurance analyst would.
See How Unstract Handles End-to-End Insurance Document Processing
From ACORD forms and claim documents to policy PDFs and certificates of currency, Unstract automates structured data extraction across every insurance document your team processes — no custom templates, no per-document configuration.
Explore the full suite of insurance automation workflows Unstract supports.
How LLMWhisperer Differs from Traditional Insurance OCR Tools
Traditional OCR was built to read characters; LLMWhisperer is built to preserve meaning. That distinction is why it consistently outperforms legacy engines in ocr insurance and ocr claims workflows.
What legacy OCR does: Flattens pages into linear text. Columns bleed together, tables lose alignment, and labels drift away from values.
What LLMWhisperer does: Keeps the visual logic of the document intact.
Layout-preserving output_mode: Maintains columnar spacing so “Coverage Limit” stays aligned with its amount.
mark_vertical_lines / mark_horizontal_lines: Optional markers help LLMs infer table boundaries without converting to HTML.
add_line_nos: Stable line numbers for pinpoint reviews and audit references.
Why it matters for ocr in insurance: ACORD pages, EOBs, and coverage schedules often use tight tables and mixed fonts. Preserving layout prevents “Deductible” from being mistaken for “Copay” or “Limit.”
Everyday example: Think of sending a well-formatted spreadsheet vs. a copy-pasted wall of text. Your teammate (or LLM) will understand the spreadsheet faster and with fewer mistakes—same with LLMWhisperer’s layout-preserving output.
2) Support for multi-format & multi-lingual inputs
Document styles: Mixed content (text + images), multi-column pages, forms with checkboxes/radio buttons.
Languages:300+ languages supported out of the box.
Why it matters for insurance ocr: Carriers and TPAs see a flood of inputs—photos from mobile phones, spreadsheet-based performance reports, German application forms, etc. One engine handles all of it consistently.
Everyday example: A claimant snaps a picture of a hospital bill on their phone. It’s skewed, shadowed, and a bit blurry. LLMWhisperer still extracts the totals, dates, and provider name reliably—and in the right places.
3) Accuracy in mixed-content documents (images, tables, handwriting)
Preprocessing built-in:Deskew, denoise, contrast/levels—so low-fidelity scans become readable before text extraction starts.
Tables that stay usable: LLMWhisperer uses spacing and markers to keep columns aligned—even with merged headers or borderless tables.
Form elements: Extracts checkboxes and radio buttons as normalized values (true/false or explicit option names).
Handwriting recognition: Short notes, approvals (“Approved”), initials, or brief diagnosis remarks are captured.
Bounding boxes: Emits coordinates for each text region. Your review UI can highlight exactly where a value came from; your rules engine can cross-check positions for extra assurance.
Everyday example: An auto claim packet contains a photo of the paper ACORD, a scanned repair invoice, and a typed denial letter. LLMWhisperer treats all three correctly, keeping their layouts so your ocr insurance pipeline (and LLM prompts) don’t fall apart on the mix.
Common Insurance Documents Parsed with LLMWhisperer
Below are the everyday documents where ocr in insurance must be both accurate and context-aware. For each, LLMWhisperer’s features map directly to pain points in ocr claims and policy ops.
ACORD Insurance Forms
Why hard: Dense tables, small fonts, many checkboxes/radio buttons, and policy/coverage fields that look similar.
Coordinates let mobile apps highlight key fields (policy, VIN) to users.
If your goal is reliable ocr insurance at scale—across ocr claims, underwriting, and policy ops—LLMWhisperer provides the missing foundation: layout-true text, structured form signals, and spatial context. It’s not an AI; it’s the AI-ready substrate that lets your LLMs (or rules) deliver consistent accuracy in ocr in insurance scenarios where traditional tools struggle.
Practical Use Cases – Where LLMWhisperer Excels
Insurance documents come in every possible shape and format — scanned ACORD forms, Excel-based premium sheets, multilingual claim statements, and even handwritten policy applications. Traditional OCR tools struggle to handle this diversity, often flattening layouts, skipping checkboxes, or misreading handwriting.
LLMWhisperer was designed to solve exactly these pain points. It goes beyond basic text extraction to deliver layout-aware, form-intelligent OCR that preserves structure, recognizes handwriting, and captures even the smallest details from scanned or low-quality inputs.
In this section, we’ll explore real-world insurance scenarios where LLMWhisperer consistently outperforms traditional OCR — starting with one of the most common and complex document types: the handwritten and scanned ACORD form.
1) Handwritten & scanned ACORD form
A) Nature of the Document & Processing Challenges
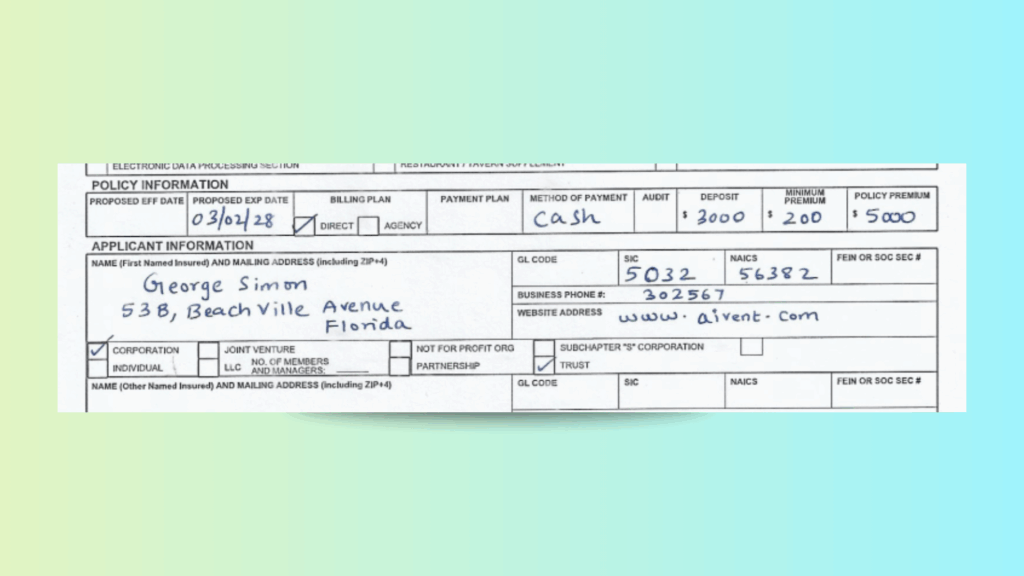
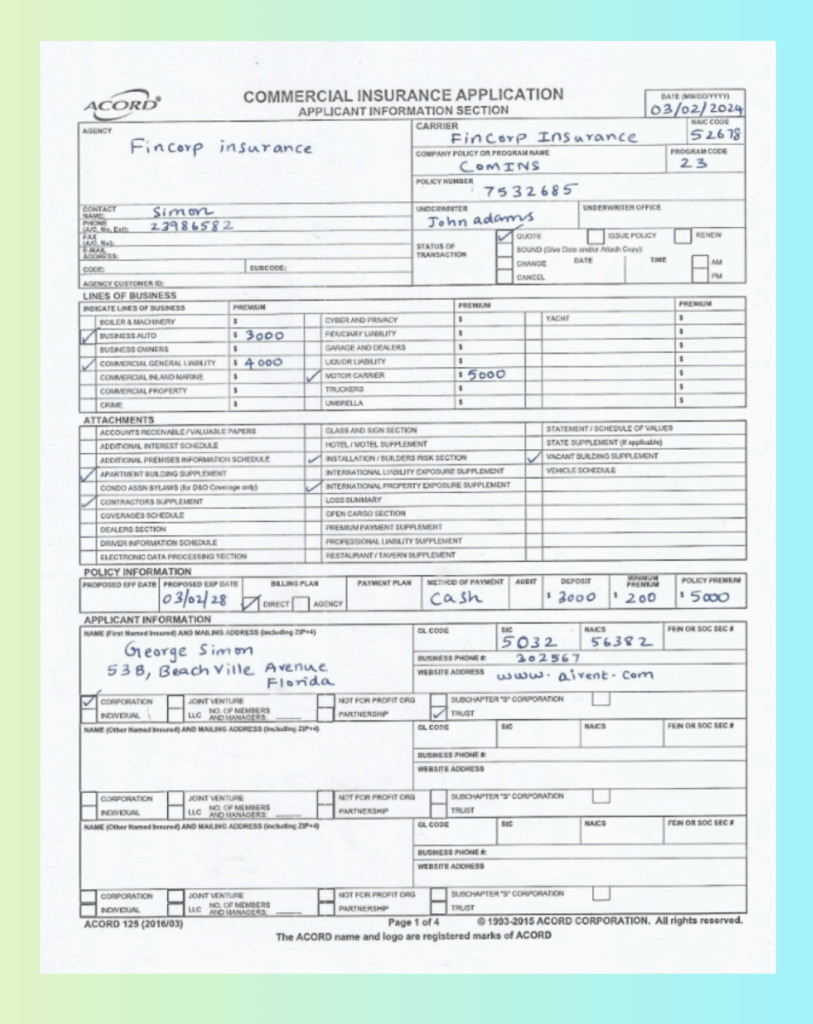
The ACORD 125 Commercial Insurance Application is a scanned, mixed-format form containing typed text, handwritten fields, and checkboxes — a nightmare for traditional OCR. Challenges include:
Together, these ensure every handwritten note, checkbox, and numeric value is extracted cleanly—making LLMWhisperer ideal for insurance OCR and claims automation.
Notes on Extraction Fidelity
Handwritten fields (names, address, premiums) are clearly captured.
Checkboxes (e.g., Corporation, Trust, Attachments) are normalized to true/false.
Layout is perfectly preserved — each premium aligns under its correct Line of Business with no column bleed.
TABLE L1 : LIFE INSURANCE PROFIT AND LOSS ACCOUNT : INCOME OF SINGAPORE LIFE INSURANCE FUNDS FOR THE YEAR ENDED 31ST DECEMBER 2021 (PART I)
DIRECT INSURERS
($'000)
SINGLE PREMIUMS OTHER PREMIUMS OUTWARD REINSURANCE PREMIUMS
COMPANIES
INVESTMENT- INVESTMENT-
NON-LINKED NON-LINKED INVESTMENT-LINKED NON-LINKED
LINKED LINKED
AIA SPORE 743,546 1,393,810 3,672,810 641,912 270,272 93,629
ALLIANZ SINGAPORE 0 0 0 0 0 0
AXA INSURANCE 6,219 127,946 417,655 296,107 60,184 3,516
CHINA LIFE 2,997 0 88,816 0 3,015 0
CHINA TAIPING 214,169 0 81,808 0 159,634 0
ETIQA PL 890,420 1,004 309,514 0 313,331 0
FRIENDS PROVIDENT 0 74,796 475 70,138 256 0
FWD SINGAPORE 20,909 18,713 14,406 17,132 5,443 0
GEG 0 0 0 0 0 0
GREAT EASTERN LIFE 9,103,959 853,369 4,347,403 467,983 236,495 11,325
HSBC INSURANCE 547,973 2,527 119,885 118,902 156,047 910
LIFE INSURANCE CORP 4,435 0 2 0 1 0
MANULIFE 3,961,337 739,592 1,916,647 1,160,659 627,973 0
NTUC INCOME 1,688,157 223,691 2,284,594 44,815 110,542 159
PRUDENTIAL 2,664,942 545,455 4,654,828 528,341 197,864 7,780
QUILTER INTERNATIONAL 0 287,586 0 0 0 233
RAFFLES HEALTH 0 0 100,952 0 51,533 0
SINGAPORE LIFE 360,029 818 2,268,381 20,868 369,569 87
SINGLIFE 1,074,961 0 -7,312 27,160 4,351 0
ST. JAMES'S PLACE 0 252,098 0 0 0 0
SUN LIFE 26,874 0 0 0 26,337 0
SWISS LIFE 0 34,444 0 0 0 1,260
TOKIO MARINE LIFE 17,880 46,538 663,022 74,335 122,894 52
TRANSAMERICA 84,874 0 10,261 0 6,306 0
UTMOST WORLDWIDE 0 56,861 0 22,466 0 0
ZURICH INTERNATIONAL 0 172 1,164 62,263 506 13
<<<
REINSURERS
($'000)
SINGLE PREMIUMS OTHER PREMIUMS OUTWARD REINSURANCE PREMIUMS
COMPANIES
INVESTMENT- INVESTMENT-
NON-LINKED NON-LINKED INVESTMENT-LINKED NON-LINKED
LINKED LINKED
ALLIANZ SE 0 0
ASIA CAPITAL RE 0 0
CHINA REINSURANCE 541,177 0
GENERAL RE 0 0
MAPFRE RE 0 0
MUNICH RE 0 0
PACIFIC LIFE INTERNATIONAL 0 0
PACIFIC LIFE LIMITED 0 0
PARTNER RE ASIA 7,667 0
RGA INTL 148,736 0
SCOR RE AP 0 0
SCOR SE 6 0
SWISS RE ASIA 227,338 0
TABLE L1 : LIFE INSURANCE PROFIT AND LOSS ACCOUNT : INCOME OF SINGAPORE LIFE INSURANCE FUNDS FOR THE YEAR ENDED 31ST DECEMBER 2021 (PART II)
DIRECT INSURERS
($'000)
INVESTMENT REVENUE
COMPANIES INVESTMENT EXPENSES OTHER INCOME
INTEREST / REALISED GAINS UNREALISED CHANGES
AIA SPORE 1,452,123 924,422 -1,174,377 208,519 92,334
ALLIANZ SINGAPORE 0 0 0 0 0
AXA INSURANCE 45,819 126,406 -132,948 17,737 100,040
CHINA LIFE 10,460 8,227 4,137 1,668 130
CHINA TAIPING 15,306 1,225 -31,533 1,207 720
ETIQA PL 60,684 18,450 -102,016 4,559 10,419
FRIENDS PROVIDENT 3,063 44,329 40,781 5,033 3,232
<<<
FWD SINGAPORE 239 -79 -175 1 2,157
GEG 0 0 0 0 0
GREAT EASTERN LIFE 1,540,512 1,337,586 -1,317,089 148,788 67,109
HSBC INSURANCE 225,231 67,739 -174,197 8,890 14,975
LIFE INSURANCE CORP 1,861 -367 -991 133 0
MANULIFE 531,773 124,885 -75,347 52,300 170,209
NTUC INCOME 1,162,962 1,189,788 -1,807,318 159,231 9,403
PRUDENTIAL 990,286 2,249,555 -1,462,115 143,634 30,044
QUILTER INTERNATIONAL 19,538 55,726 100,635 20,836 23,847
RAFFLES HEALTH 187 0 0 0 2,514
SINGAPORE LIFE 181,949 201,832 -270,474 27,596 5,510
SINGLIFE 13,737 -2,323 -4,525 746 1,138
ST. JAMES'S PLACE 9,242 26,673 57,609 917 11,378
SUN LIFE 751 -391 -670 246 64
SWISS LIFE 0 0 29,233 0 7,205
TOKIO MARINE LIFE 288,121 -5,975 -908,456 -31,498 20,116
TRANSAMERICA 80,034 2,481 -100,031 2,588 1
UTMOST WORLDWIDE 579 7,232 22,457 912 6,021
ZURICH INTERNATIONAL 575 0 75,638 367 6,280
REINSURERS
($'000)
INVESTMENT REVENUE
COMPANIES INVESTMENT EXPENSES OTHER INCOME
INTEREST / REALISED GAINS UNREALISED CHANGES
ALLIANZ SE 0 0 0 0 0
ASIA CAPITAL RE 2 0 -25 0 0
CHINA REINSURANCE 965 -498 132 111 1,026
GENERAL RE 114 0 13 26 50
MAPFRE RE 0 0 0 0 0
MUNICH RE 3,886 2,284 -35,298 276 11,148
PACIFIC LIFE INTERNATIONAL 0 0 0 0 0
PACIFIC LIFE LIMITED 2,058 339 -9,263 180 90
PARTNER RE ASIA 204 14 -207 26 0
RGA INTL 593 -6 -606 37 0
<<<
SCOR RE AP 0 0 0 0 0
SCOR SE 475 0 -383 42 1
SWISS RE ASIA 255 -710 -993 21 1,174
Why this helps
No column bleed: premiums, investment lines, and reinsurance outputs stay under the right headers.
Review-ready: line numbers + boxes enable cell-accurate QA.
LLM-friendly: stable, layout-true text lets downstream prompts compute totals, ratios (e.g., loss/expense), and compare Direct vs Reinsurer segments without re-engineering the table.
3) Photographed income-tax–style forms with checkboxes
1) Nature & Challenges
Photographed form-style document with printed fields, checkboxes, and dense numeric values.
Includes camera artifacts like skew, glare, and shadows.
Wrapped headers/columns make text extraction alignment tricky.
Common OCR risks:
Loss of checkbox states (checked/unchecked).
Column bleed in premium and amount grids.
Misreads in small numeric, date, and ID fields.
2) Features Used
Mode: form – Detects checkboxes/radio buttons and short handwritten or typed fields.
High-Quality Fallback (high_quality) – Corrects skew, glare, and noise from phone photos.
Bounding Boxes – Provides coordinates for visual validation and review.
Numeric/Date Normalization – Keeps symbols, decimals, and formats consistent for accurate processing.
Parsed text
®
COMMERCIAL INSURANCE APPLICATION DATE (MM/DD/YYYY)
APPLICANT INFORMATION SECTION 08/20/2023
AGENCY CARRIER NAIC CODE
Smith Insurance Agency AlphaSure Insurance A4S8F3G
123 Main Street, Anytown, NY, 10001 COMPANY POLICY OR PROGRAM NAME PROGRAM CODE
ShieldGuard SGK5H9P2
POLICY NUMBER
POL6D4J1NO
CONTACT UNDERWRITER UNDERWRITER OFFICE
NAME: John Smith
PHONE Veronica Lee New York, NY
(A/C, No, Ext); (555) 123-4567
FAX 123-4567
(A/C, No): (555) [ ] QUOTE [ ] ISSUE POLICY [ ] RENEW
E-MAIL STATUS OF
ADDRESS: [email protected] TRANSACTION [X] BOUND (Give Date and/or Attach Copy):
SIA123 SIA123-001 CHANGE DATE TIME AM
CODE: SUBCODE: [ ] [ ]
AGENCY CUSTOMER ID: [ ] CANCEL 08/19/2023 12:00 [X] PM
SECTIONS ATTACHED
INDICATE SECTIONS ATTACHED PREMIUM PREMIUM PREMIUM
ACCOUNTS RECEIVABLE / $ 873.05 ELECTRONIC DATA PROC $ TRANSPORTATION / $
[X] VALUABLE PAPERS [ ] [ ] MOTOR TRUCK CARGO
[X] BOILER & MACHINERY $ 364.03 [ ] EQUIPMENT FLOATER $ [X] TRUCKERS / MOTOR CARRIER $ 9.04
[ ] BUSINESS AUTO $ [X] GARAGE AND DEALERS $ 391.00 [ ] UMBRELLA $
[ ] BUSINESS OWNERS $ [ ] GLASS AND SIGN $ [X] YACHT $ 495.02
[ ] COMMERCIAL GENERAL LIABILITY $ [ ] INSTALLATION / BUILDERS RISK $ [ ] $
[X] CRIME / MISCELLANEOUS CRIME $ 3,394.00 [ ] OPEN CARGO $ [ ] $
[ ] DEALERS $ [ ] PROPERTY $ [ ] $
ATTACHMENTS
[ ] ADDITIONAL INTEREST [ ] PREMIUM PAYMENT SUPPLEMENT [ ]
[ ] ADDITIONAL PREMISES [X] PROFESSIONAL LIABILITY SUPPLEMENT [ ]
[ ] APARTMENT BUILDING SUPPLEMENT [ ] RESTAURANT / TAVERN SUPPLEMENT [ ]
[X] CONDO ASSN BYLAWS (for D&O Coverage only) [ ] STATEMENT / SCHEDULE OF VALUES [ ]
[ ] CONTRACTORS SUPPLEMENT [X] STATE SUPPLEMENT (If applicable) [ ]
[X] COVERAGES SCHEDULE [ ] VACANT BUILDING SUPPLEMENT [ ]
[X] DRIVER INFORMATION SCHEDULE [X] VEHICLE SCHEDULE [ ]
[ ] INTERNATIONAL LIABILITY EXPOSURE SUPPLEMENT [ ] [ ]
[ ] INTERNATIONAL PROPERTY EXPOSURE SUPPLEMENT [ ]
[ ] LOSS SUMMARY [ ] [ ]
POLICY INFORMATION
PROPOSED EFF DATE PROPOSED EXP DATE BILLING PLAN PAYMENT PLAN METHOD OF PAYMENT AUDIT DEPOSIT PREMIUM MINIMUM POLICY PREMIUM
08/10/2023 01/19/2024 MONTH CASH 1 $ 73,484.00 $ 634.00 $ 4,392.00
[ ] DIRECT [X] AGENCY
APPLICANT INFORMATION
NAME (First Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
Alex Johnson A7B2C8D5 3574 561730 12-3456789
P.O. Box 123, 123 Main Street, Anytown, NY, 10001 BUSINESS PHONE #: (555) 123-4567
WEBSITE ADDRESS
[ ] CORPORATION [X] JOINT VENTURE [ ] NOT FOR PROFIT ORG [ ] SUBCHAPTER "S" CORPORATION [ ]
NO. OF MEMBERS TRUST
[ ] INDIVIDUAL [ ] LLC AND MANAGERS: [ ] PARTNERSHIP [ ]
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
Emily Smith E3F8G6H1 8742 722513 98-7654321
P.O. Box 456, 456 Oak Avenue, Anothercity, NY, 20002 BUSINESS PHONE #: (555) 987-6543
WEBSITE ADDRESS
[ ] CORPORATION [ ] JOINT VENTURE [X] NOT FOR PROFIT ORG [ ] SUBCHAPTER "S" CORPORATION [ ]
NO. OF MEMBERS
[ ] INDIVIDUAL [X] LLC AND MANAGERS: 10 [ ] PARTNERSHIP [ ] TRUST
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
BUSINESS PHONE #:
WEBSITE ADDRESS
[ ] CORPORATION [ ] JOINT VENTURE [ ] NOT FOR PROFIT ORG [ ] SUBCHAPTER "S" CORPORATION [ ]
NO. OF MEMBERS
[ ] INDIVIDUAL [ ] LLC AND MANAGERS: [ ] PARTNERSHIP [ ] TRUST
ACORD 125 (2013/01) Page 1 of 4 1993-2013 ACORD CORPORATION. All rights reserved.
The ACORD name and logo are registered marks of ACORD
Why This Helps
Layout and data hierarchy remain fully preserved.
Checkboxes are converted to booleans (true/false) for automation.
Currency and dates remain accurate and machine-readable.
Enables reliable downstream automation for OCR insurance workflows such as:
Claims intake
Underwriting validation
Policy issuance
Eliminates manual verification, improving accuracy and turnaround time.
Test LLMWhisperer Insurance OCR Free — Instant Results, No Signup Required
If you want to skip straight to the tool, see how LLMWhisperer OCR API handles insurance documents of any complexity — scanned policy forms, handwritten claim notes, poorly photographed images, complex tables, and multi-language documents.
Try LLMWhisperer Insurance OCR for free on the Playground. No signup required.
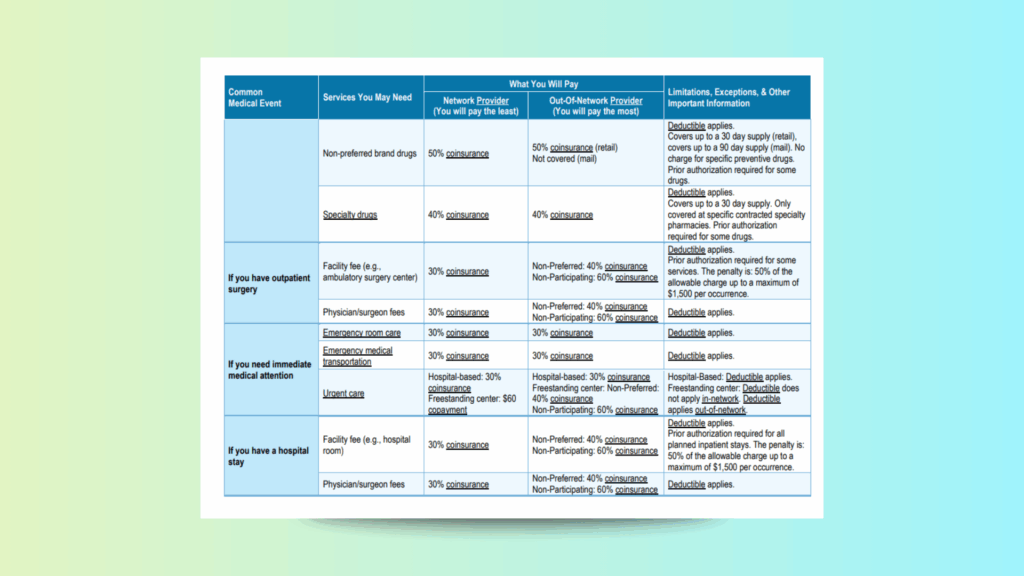
Table-heavy PDF: multi-row grid with merged headers (“What You Will Pay”), nested sections (e.g., “If you have outpatient surgery”), and two pricing columns (Network vs Out-of-Network).
Inline notes in the far-right column (“Limitations, Exceptions…”) with long wrapped sentences and policy conditions (deductibles, penalties).
Mixed typography (links/underlines like “coinsurance”), line breaks inside cells, and repeated phrases (“Deductible applies.”) that typical OCRs often fragment or reorder.
2) Features used
Mode: table → preserves grid structure; stabilizes row/column boundaries even for merged headers.
Layout-preserving output with mark_vertical_lines, mark_horizontal_lines, add_line_nos → keeps columns aligned for downstream parsing.
Bounding boxes → per-cell coordinates for UI highlighting or reviewer jump-to-cell.
Low-fidelity tolerance / repair → de-skew and denoise any scan artifacts; keeps small percentage symbols legible.
Line-splitting strategy + normalization → consistent rendering of “30% coinsurance”, “Not covered (mail)”, etc., while retaining original wording.
Parsed text
What You Will Pay
Common Limitations, Exceptions, & Other
Services You May Need Network Provider Out-Of-Network Provider
Medical Event Important Information
(You will pay the least) (You will pay the most)
Deductible applies.
Covers up to a 30 day supply (retail),
50% coinsurance (retail) covers up to a 90 day supply (mail). No
Non-preferred brand drugs 50% coinsurance
Not covered (mail) charge for specific preventive drugs.
Prior authorization required for some
drugs.
Deductible applies.
Covers up to a 30 day supply. Only
Specialty drugs 40% coinsurance 40% coinsurance covered at specific contracted specialty
pharmacies. Prior authorization
required for some drugs.
Deductible applies.
Prior authorization required for some
Facility fee (e.g., 30% Non-Preferred: 40% coinsurance
coinsurance services. The penalty is: 50% of the
If you have outpatient ambulatory surgery center) Non-Participating: 60% coinsurance allowable charge up to a maximum of
surgery $1,500 per occurrence.
Non-Preferred: 40% coinsurance
Physician/surgeon fees 30% coinsurance Deductible applies.
Non-Participating: 60% coinsurance
Emergency room care 30% coinsurance 30% coinsurance Deductible applies.
Emergency medical
30% coinsurance 30% coinsurance Deductible applies.
If you need immediate transportation
medical attention Hospital-based: 30% Hospital-based: 30% coinsurance Hospital-Based: Deductible applies.
coinsurance Freestanding center: Non-Preferred: Freestanding center: Deductible does
Urgent care
Freestanding center: $60 40% coinsurance not apply in-network. Deductible
copayment Non-Participating: 60% coinsurance applies out-of-network.
Deductible applies.
Prior authorization required for all
Facility fee (e.g., hospital 30% Non-Preferred: 40% coinsurance
coinsurance planned inpatient stays. The penalty is:
If you have a hospital room) Non-Participating: 60% coinsurance 50% of the allowable charge up to a
stay maximum of $1,500 per occurrence.
Non-Preferred: 40% coinsurance
Physician/surgeon fees 30% coinsurance Deductible applies.
Non-Participating: 60% coinsurance
3 of 8
Why this helps: The table structure is preserved (no column bleed), percentages and phrases like “coinsurance” remain intact, and policy notes stay bound to their originating rows—so downstream rules or LLM prompts can safely compute member liability, flag prior-auth requirements, or populate OCR insurance benefit summaries without manual clean-up.
5) Multilingual (e.g., German) application forms
1) Nature & challenges
Bilingual layout (German/English) with dense instructions, mixed currencies (GBP/EUR/USD), and many checkboxes/radio options.
Small numeric tokens (dates, postcodes, phones), diacritics (e.g., “Rheinland-Pfalz”), and multi-line addresses increase OCR error risk.
Typical camera/scan artifacts can skew boxes and break alignment between labels and chosen options.
2) Features used
Mode: form — checkbox/radio detection, short printed + handwritten fields.
Layout-preserving output — keep columns/option groups intact; optionally mark_vertical_lines, mark_horizontal_lines, add_line_nos for review.
High-quality fallback — deskew/denoise/auto-repair for photographed pages.
Handwriting + multilingual (300+ languages) — reliable capture of names with diacritics and German text.
Bounding boxes — precise field coordinates for audit UI.
Numeric/date normalization hooks — retain symbols; normalize downstream (ISO dates, E.164 phones) as needed.
Parsed text
In welcher Währung möchten Sie Ihre Prämie zahlen? Ihre Versicherungsleistungen werden ebenfalls in dieser Währung erfolgen.
In which currency would you like to pay your premium? Your policy benefits will also be in this currency.
[ ] GB£ [X] Euro€ [ ] US$
Wie viel Selbstbeteiligung möchten Sie übernehmen? Selbstbeteiligung gilt pro Person pro Versicherungsjahr und nicht für die Optionen Reguläre
Schwangerschaft und Entbindung, Zahnärztliche Behandlung, Evakuierung oder Repatriierung oder Leistungen für Wellness, Optik und Impfungen. Wählen Sie
eine höhere Selbstbeteiligung, um Ihre Versicherungsprämie zu reduzieren.
How much excess would you like to pay? Excess is per person per policy year and does not apply to Routine Pregnancy & Childbirth, Dental Treatment, Evacuation or Repatriation options or Well-being, Optical and
Vaccination benefits. To reduce your premium amount, choose a higher policy excess.
[ ] Nil [X] £ 50: € 60: US$ 75 [ ] £ 150: € 180: US$ 225 [ ] £ 300: € 360: US$ 450
[ ] £ 500: € 600: US$ 750 [X] £ 1,000: € 1,200: US$ 1,500 [ ] £ 2,500: € 3,000: US$ 3,750 [ ] £ 5,000: € 6,000: US$ 7,500
[ ] £ 7,500: € 9,000: US$ 11,250
Wie möchten Sie Ihre Prämie zahlen? Nachdem wir Ihren Antrag angenommen haben, werden wir Ihnen weitere Details zukommen lassen.
How would you like to pay your premium? We'll send details following acceptance of your application.
[X] Jährlich [X] Kredit-/Bankkarte [ ] SEPA-Lastschrift# [ ] Banküberweisung
Annually Credit / Debit Card SEPA Direct Debit Bank Transfer
[ ] Vierteljährlich [X] Kredit-/Bankkarte [ ] SEPA-Lastschrift# [ ] Banküberweisung
Quarterly Credit / Debit Card SEPA Direct Debit Bank Transfer
[ ] Monatlich [ ] Kredit-/Bankkarte [ ] SEPA-Lastschrift# [ ] Banküberweisung
Monthly Credit / Debit Card SEPA Direct Debit Bank Transfer
# SEPA-Lastschriftzahlungen nur von EU/EWR-Bankkonten.
#SEPA Direct Debit payments from EU/EEA bank accounts only
2
Ihre Daten
Your details
Angaben zum Versicherungsnehmer
Policyholder details
Anrede Wohnanschrift
Title
Wohnsitz (Land) - Adresse wo Sie derzeitig leben
Home address
[X] Herr [ ] Frau [ ] Frl. Sonstige: (Country of Residence - address where you currently live)
Mr Mrs Miss Other: Guentzelstrasse 23
Vorname(n) Rheinland-pfalz
First name(s)
Klaus
Postleitzahl: 55576 Land
Country Germany
Nachname Postcode:
Surname
Korrespondenzadresse (falls abweichend)
Paul Correspondence address (if different)
Kantstrasse 63
Geburtsdatum (TT-MM-JJJJ) Geschlecht
Date of birth (DD-MM-YYYY) Gender
Bayreuth
21 12 1967 Male
Höhe (cm/ft) Gewicht (kg/lbs)
Height (cm/ft) Weight (kg/lbs) PLZ: 95408 Land Germany
Postcode: Country
187 87
Telefonnummern
Branche Phone numbers
Industry
Privat: 06701 15 61 36
Home:
Software
Beruflich:
Work: 0921 10 29 84
Beruf (bitte vollständige Angaben machen)
Occupation (please give full details)
Mobil:
Mobile:
Engineer
Fax:
Nationalität Fax:
Nationality
England
E-Mail-Adresse
Email address
[email protected]
Soll der Versicherungsnehmer im Rahmen [X] Ja [ ] Nein
dieser Police versichert werden?
Is the Policyholder to be insured under this policy? Yes No
Seite 2 von 9 ALC Global Health Insurance ... wir sind anders, weil wir uns um Sie kümmern.
Insurance OCR: Conclusion
Why LLMWhisperer is the best choice for OCR insurance automation
In the insurance industry—where every checkbox, policy number, or handwritten field carries financial and legal weight—LLMWhisperer stands out as the most reliable OCR solution for document processing and automation. Its layout-preserving architecture, multi-format compatibility, and handwriting recognition capabilities make it ideal for transforming complex insurance documents—ACORD forms, claim reports, policy applications, and benefit tables—into clean, structured data.
Traditional OCR tools can read text, but they often lose context and structure. LLMWhisperer goes further—it retains the visual hierarchy, captures checkboxes and radio buttons as true data, and supports 300+ languages, ensuring insurers can handle multilingual and multi-region submissions without error. Whether it’s scanned claim forms or performance reports with merged tables, LLMWhisperer consistently delivers clarity, accuracy, and speed.
Scalability, accuracy, and compliance benefits
Scalable by design — Process thousands of PDFs, scans, and Excel sheets daily through APIs or self-hosted deployments.
Accuracy that adapts — Advanced layout modeling and noise tolerance ensure >99% text fidelity, even for low-quality scans or handwritten inputs.
Compliance-ready — Every output can include bounding boxes and line numbers, enabling precise audits and traceability for regulated workflows.
Data privacy — LLMWhisperer supports on-premise deployment, ensuring full control over infrastructure, storage, and sensitive customer data—vital for insurers bound by GDPR, HIPAA, or IRDAI guidelines.
Try LLMWhisperer Insurance OCR for free on the demo Playground.
How Unstract bridges the gap between OCR and intelligent insurance automation
While LLMWhisperer perfects text extraction, Unstract takes it a step further—transforming that raw text into meaningful, AI-driven insights. By connecting LLMWhisperer’s structured output to Prompt Studio, vector databases, and large language models, Unstract enables insurers to:
Parse policies, claims, and medical reports contextually (not just textually).
Build no-code, repeatable workflows that auto-classify documents, flag missing fields, or trigger claims validation.
Deploy intelligent APIs that integrate directly into underwriting, claims, and compliance systems.
Together, LLMWhisperer + Unstract deliver the full spectrum of OCR insurance automation—from accurate document digitization to contextual understanding and AI-led decision-making. It’s not just about reading insurance documents anymore—it’s about understanding them.
OCR Solutions for Specific Insurance Document Types
Insurance document processing covers hundreds of document types — claim forms, policy PDFs, ACORD submissions, medical records, certificates of currency and more. Rather than needing a separate tool for each, LLMWhisperer’s layout-agnostic insurance OCR engine accurately parses any document format, structure or layout without pre-configuration.
Unstract builds on this to deliver structured data extraction workflows specifically designed for insurance — so whether your team processes one document type or twenty, the same platform handles it all.
Explore OCR automation by document type:
• ACORD Form Data Extraction — Automate ACORD 125, 126 and 130 form processing for underwriting submissions across multiple carriers
• Health Insurance Claim Form OCR — Extract diagnosis codes, provider details and claim amounts from health insurance claim forms accurately
1. What is Insurance OCR and how does it work? Insurance OCR converts scanned claim forms, policy applications, and ACORD documents into machine-readable data. It works by analyzing character shapes, preserving layout, and detecting checkboxes — turning paper into structured JSON for automation.
2. Why is OCR in insurance critical for claims processing? OCR in insurance automates the extraction of policy numbers, claim amounts, dates, and handwritten notes from claim forms. This reduces manual review time from hours to minutes, accelerating FNOL (First Notice of Loss) and settlement cycles.
3. What makes LLMWhisperer the best OCR for insurance document types? LLMWhisperer is the best OCR for insurance because it preserves complex table structures, detects checkboxes as booleans, and recognizes handwriting on ACORD 125 forms, loss runs, and medical claim statements. It also supports 300+ languages for global carriers.
4. How does OCR for insurance documents handle handwritten fields and signatures? OCR for insurance documents using LLMWhisperer’s high_quality or form modes captures handwritten notes like “Approved,” adjuster initials, and physician comments. It also retains spatial context so signatures stay associated with the correct fields.
5. What types of insurance document OCR can LLMWhisperer process? Insurance document OCR with LLMWhisperer processes ACORD forms, certificates of liability, EOBs (Explanation of Benefits), disability claim forms, auto accident reports, life insurance applications, and Excel-based performance reports — all with layout preservation.
6. Can OCR insurance solutions be deployed on-premise for compliance? Yes — LLMWhisperer supports on-premise and self-hosted deployments, making OCR insurance workflows compliant with GDPR, HIPAA, and IRDAI. This ensures sensitive policyholder and claims data never leaves your infrastructure.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.