Data Entry OCR: Best OCR Software for Automated Data Entry (2026)
Table of Contents
Enterprises today face a critical data paradox. According to IDC, about 90% of enterprise data is unstructured, and research indicates that only 18% of organizations effectively utilize this type of data. Most of this data is stored in image-based documents such as invoices, receipts, and reports. Processing them manually is slow, prone to human error, and costly to scale.
Businesses turn to OCR (Optical Character Recognition) software to automate data entry, but even the latest tools often fall short. They struggle with noisy images, cursive handwriting, or highly unstructured layouts.
This is where LLMWhisperer comes in. It is an LLM-optimized OCR pipeline, audit-ready, and built to handle complex documents.
In this article, we will walk through the challenges, explore the solution, and show why LLMWhisperer is the most reliable OCR platform for data entry in 2026.
TL;DR
If you wish to skip directly to the solution section, where you can see how LLMWhisperer data entry OCR API handles document types of any complexity — document scans, handwritten forms, skewed images multi-language documents, click here.
What is Document OCR?
Document OCR is a transformative technology that extracts text from scanned documents, images, and PDFs into a machine-readable and editable format. In the context of data entry, OCR is the foundational technology that enables the process to shift from manual human transcription to automated, scalable digital data acquisition.
One of the most familiar examples of OCR is Google Lens. This app uses OCR to extract text from images such as documents, street signs, or menus in real time, allowing users to instantly translate the text or search for related information.
Why Automating Data Entry with OCR is Crucial
Manual data entry imposes significant limitations on modern business operations, primarily compromising accuracy, consuming unacceptable amounts of time, and lacking scalability.
According to a recent survey by analyst firm IDC, about 22% of IT decision-makers admit their organizations unnecessarily replicate unstructured data because they don’t know what they have or where to find it. That kind of chaos drives up storage costs and creates risks for audits, security, and decision-making.
OCR eliminates the need for manual data entry, automating text extraction to streamline workflows across industries. It directly solves these issues by improving accuracy, accelerating processing speed, and enabling teams to process far more documents in a fraction of the time.
Here are some common sectors that depend on OCR technology to handle large volumes of documents:
Finance & Banking: Banking and finance sector accounted for 26% of the global OCR market in 2024, reflecting strong adoption of OCR tools to extract information from invoices, receipts, contracts, and financial statements. These tools cut down reconciliation time and help financial teams stay audit-ready.
Logistics & Shipping: Documents like Airway bills, invoices, and shipment manifests often contain handwritten notes, faded stamps, and inconsistent layouts. OCR turns these messy details into searchable fields like IDs, addresses, and tariff codes for smoother tracking.
Healthcare: Patient intake forms and insurance claims often include handwritten entries, checkboxes, and medical codes. OCR extracts this data quickly and accurately, improving billing efficiency and patient record management.
Why LLM OCR Struggles Without Preprocessing
Traditional OCR systems primarily rely on rule-based text extraction; they were never designed for the scale, structure, or complexity that modern AI workflows demand. LLM-based OCR bridges this gap as it understands context, adapts to new formats, and captures structural relationships within documents.
However, like any AI model, its performance is directly tied to the quality of the input text and structure. Without preprocessing, LLM-based OCR is limited by the “garbage in, garbage out” principle. Raw documents present multiple points of failure that cause LLM-based OCR to fail in production due to the following factors:
Scanned PDFs and Image Quality: Poor lighting or low-resolution images introduce noise that corrupts the underlying text recognition and reduces recognition accuracy.
Complex Layouts: Multi-column text, tabular data, and forms with numerous checkboxes often break the logical flow required for accurate LLM parsing.
Handwritten or Semi-Structured Data: The variability inherent in non-standardized or human-written forms presents a structural challenge that basic text extraction cannot resolve.
Multilingual Documents: Many business documents contain content in multiple languages, requiring adaptive OCR intelligence and language-aware preprocessing to maintain accuracy.
Get started with LLMWhisperer: Best OCR API for AI Document Workfows
Introducing LLMWhisperer OCR Capabilities
LLMWhisperer is an advanced OCR and document parsing tool designed to extract text from PDFs and scanned images while preserving the document’s original structure. Unlike traditional OCR, LLMWhisperer focuses on layout preservation and enhances parsing accuracy by using advanced algorithms that make the data more comprehensible for LLMs and other systems.
LLMWhisperer uses a specialized parsing engine to clean noisy scans, correct skewed images, and adjust contrast for better clarity. This results in a clean, structured output that large language models (LLMs) and other downstream systems can easily understand and use.
Core Strengths
Layout Understanding: Preserves structure from multi-column documents, tables, and checkboxes instead of flattening into plain text.
Scanned PDFs & Images: Processes low-quality scans, handwritten notes, and multi-format documents with high precision.
Flexible Integration: Available via API and automation workflows, making it easy to plug into existing enterprise systems.
Extracting Data with LLMWhisperer
Businesses can use LLMWhisperer in two ways, depending on their requirements: through the Playground for quick testing or via the API for direct integration.
Using the LLMWhisperer Playground
The LLMWhisperer Playground provides a no-code environment to test document parsing. You can upload scanned PDFs, images, or forms and immediately view how the parser extracts structured data.
Visit the LLMWhisperer Starter Page, select your region, and sign up for a free account. Open the Playground and simply upload scanned PDFs, images, or forms, and test how the parser extracts data.
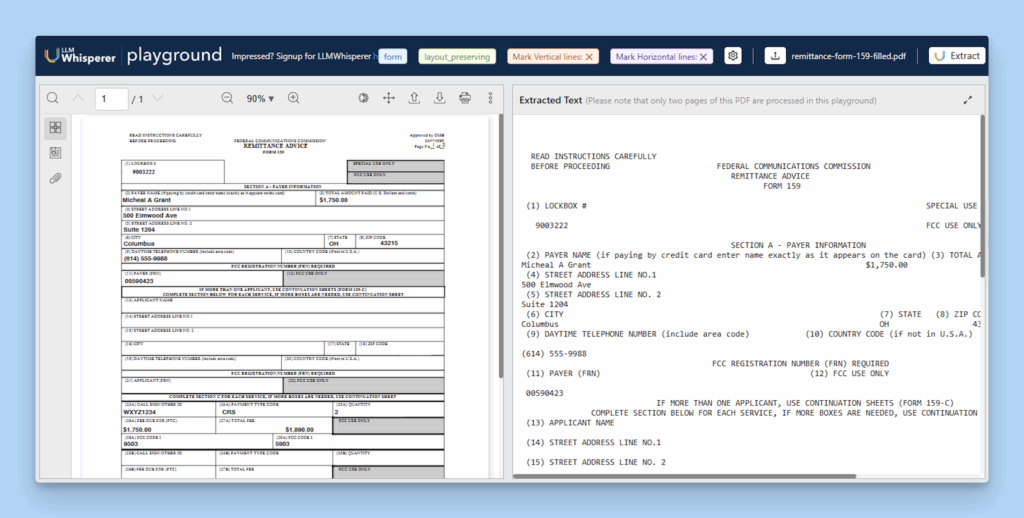
Let’s walk through a Federal Remittance Form example:
Data Entry OCR: Extracted text from the Federal Remittance form displayed LLMWhisperer Playground
After uploading the document to LLMWhispherer Playground, the parser extracts fields with high accuracy, such as borrower’s name (Michael A. Grant), loan reference numbers, and payment amounts, cleanly captured.
Test LLMWhisperer data entry OCR API for free — Instant results, no signup required
If you want to skip straight to the tool, see how LLMWhisperer OCR API handles invoices of any complexity — scanned PDFs, handwritten receipts, poorly photographed images, multi-column layouts, and multi-language invoices.
Try LLMWhisperer data entry OCR for free on the Playground. No signup required.
The LLMWhisperer OCR API is best suited for enterprise automation, batch document processing, and direct integration with Enterprise Resource Planning (ERP), Customer Relationship Management (CRM), or document management systems. It provides developers with full control while ensuring accuracy and scalability.
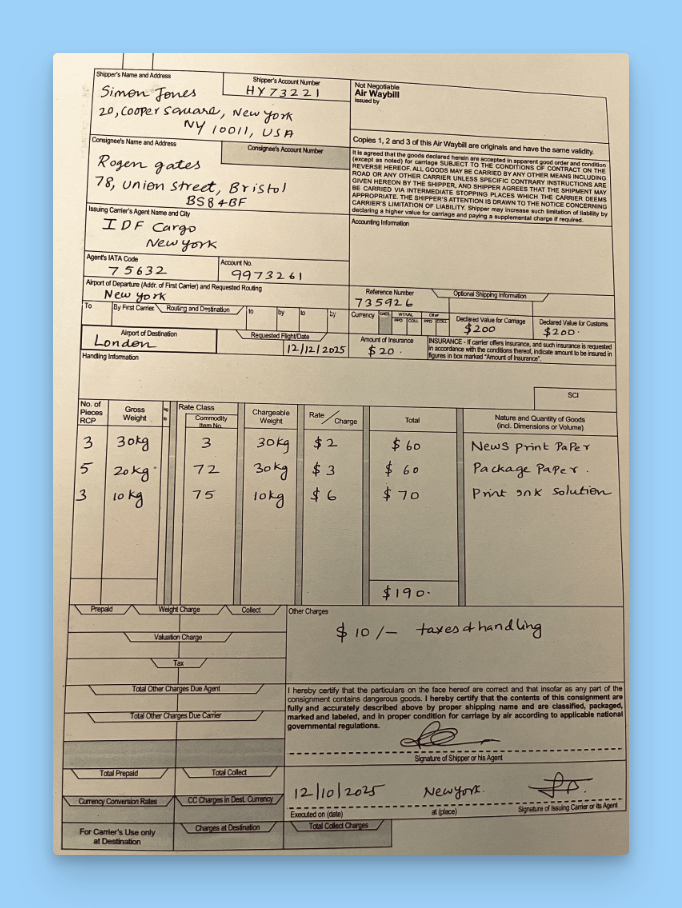
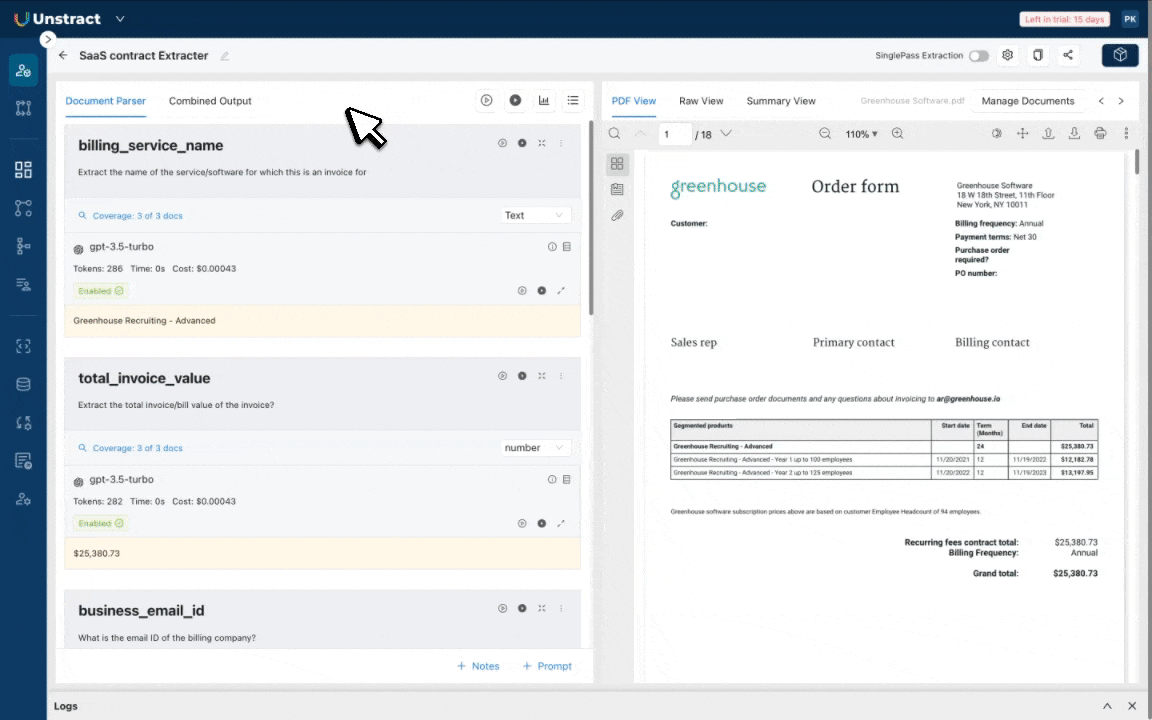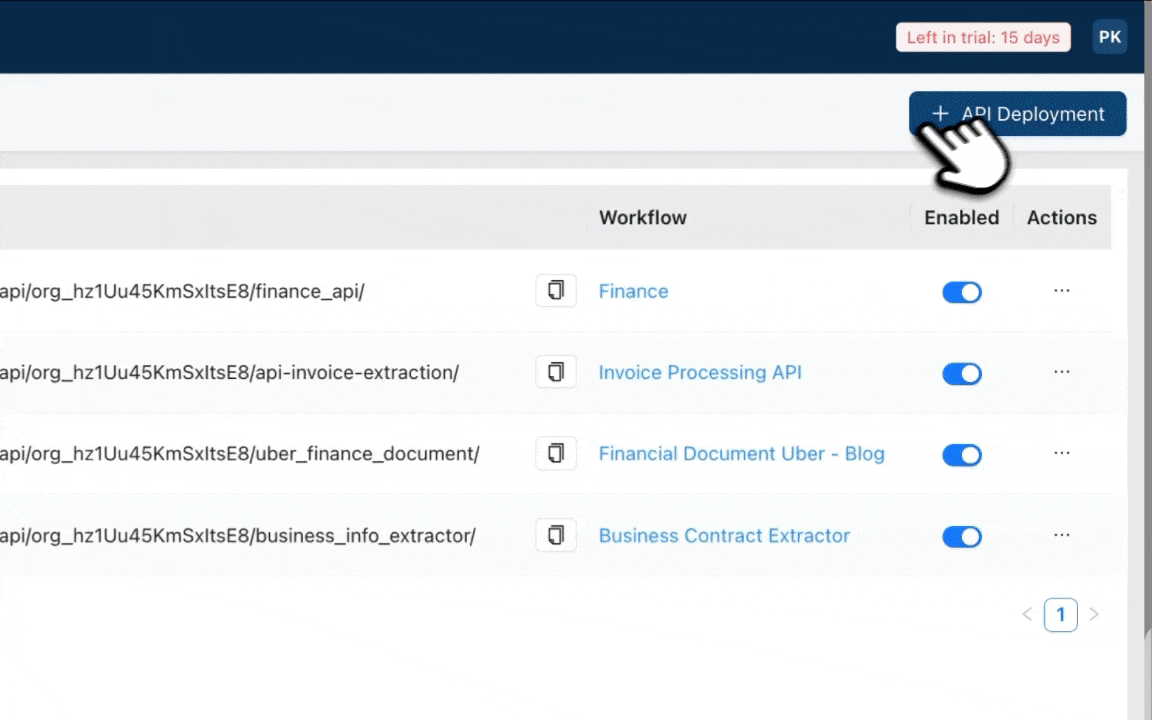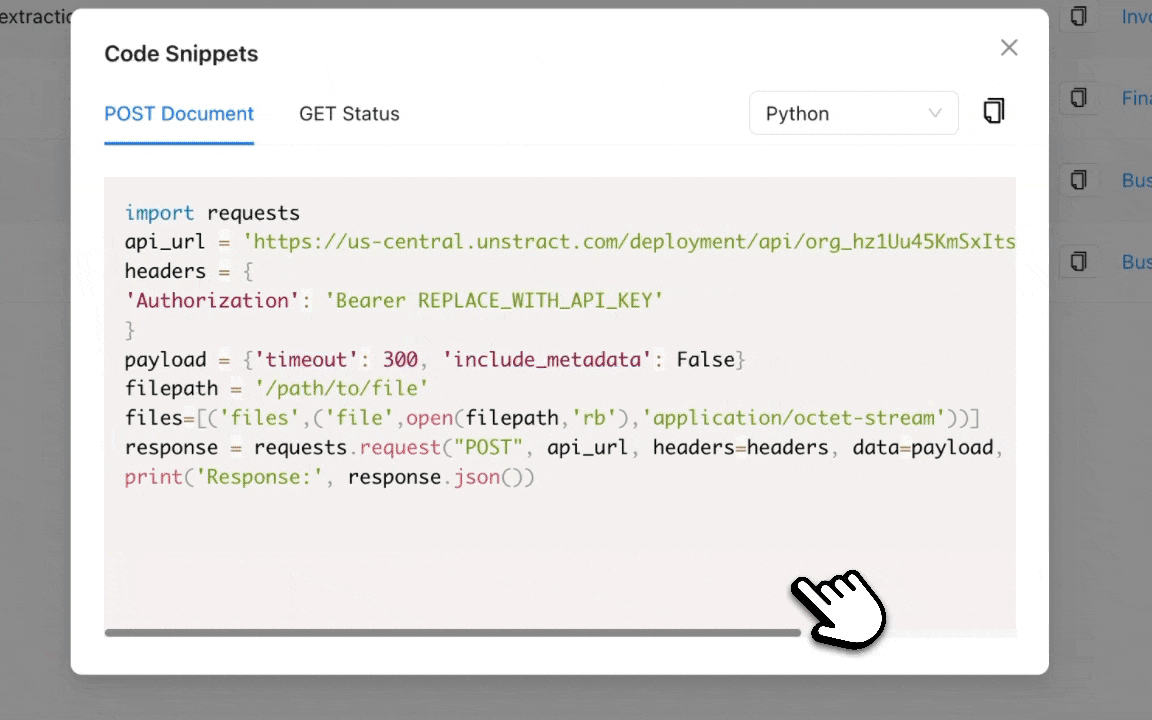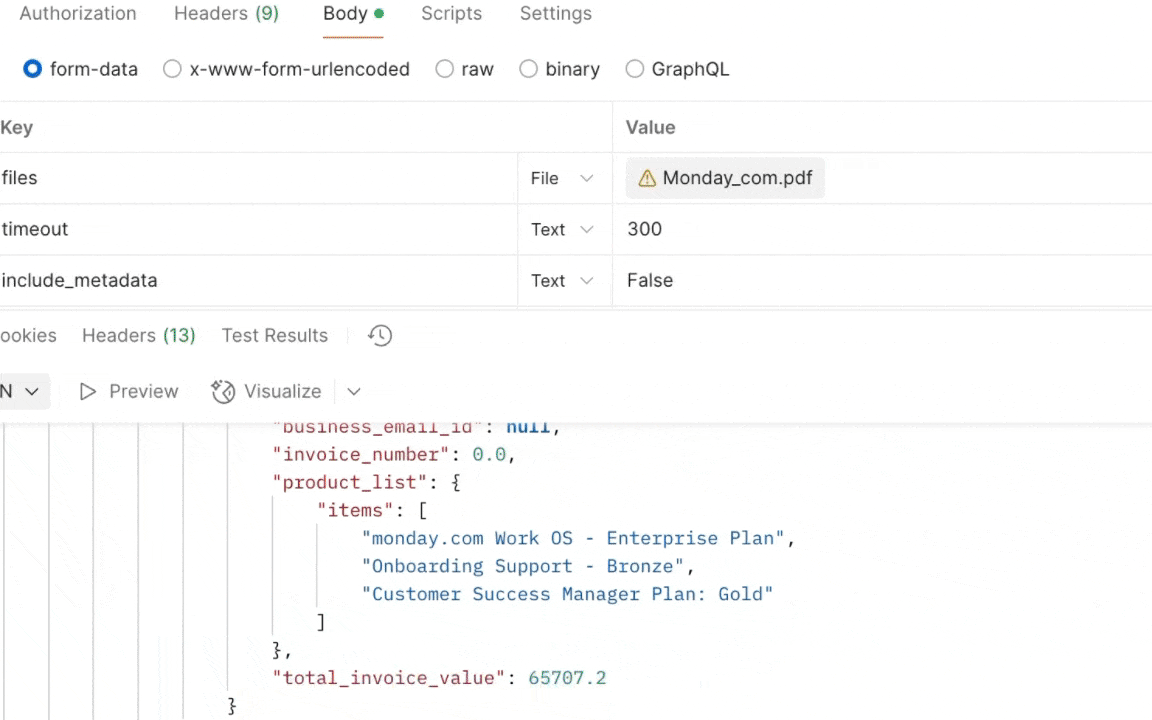
For this walkthrough, we’ll use the LLMWhisperer API to extract data from a photographed Airway Bill (PNG).
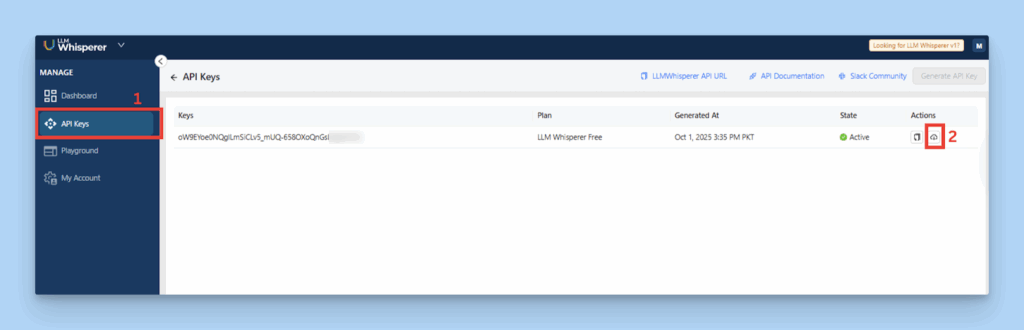
Get an API key from the ‘API Keys’ section and download the pre-configured Postman collection.
Downloading the Postman collection from the API keys section
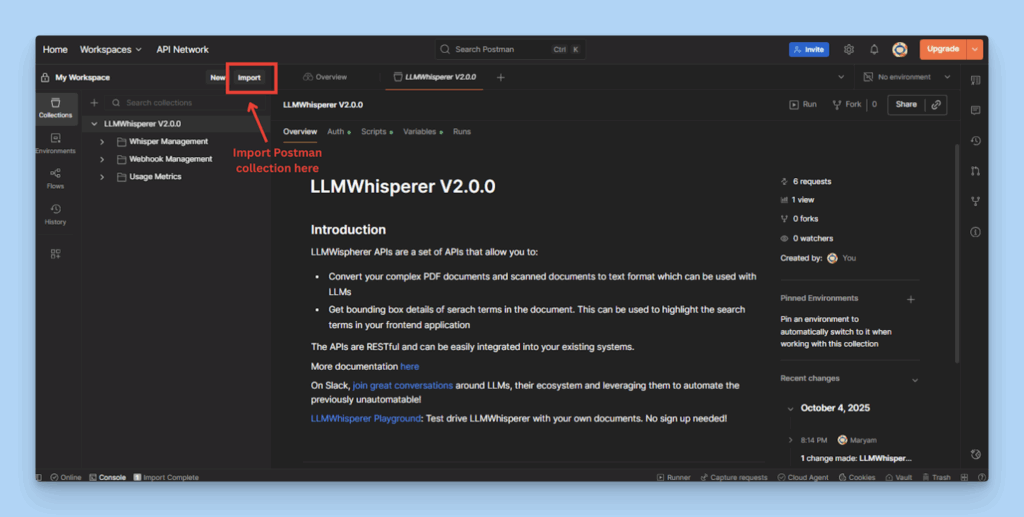
Open Postman and import the downloaded collection (postman_collection.json).
This will load all available API requests (whisper, whisper-status, whisper-retrieve).
Importing the collection into Postman
Step 2: Upload a Document
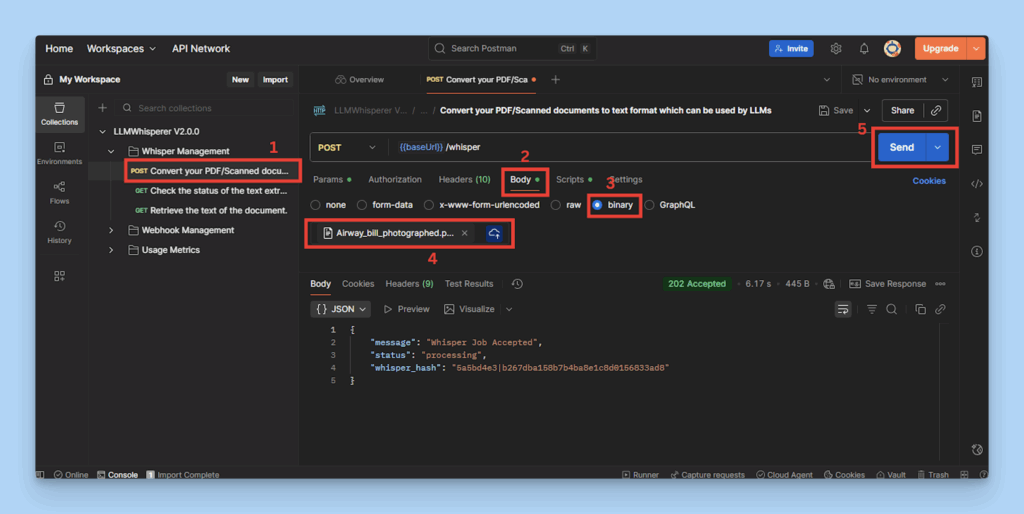
Open the Whisper (POST) request.
Go to the Body tab
Select binary and upload your Airway Bill image
Click Send, and you’ll receive a whisper_hash in the response.
Uploading the Photographed Airway Bill in Postman and sending the POST request
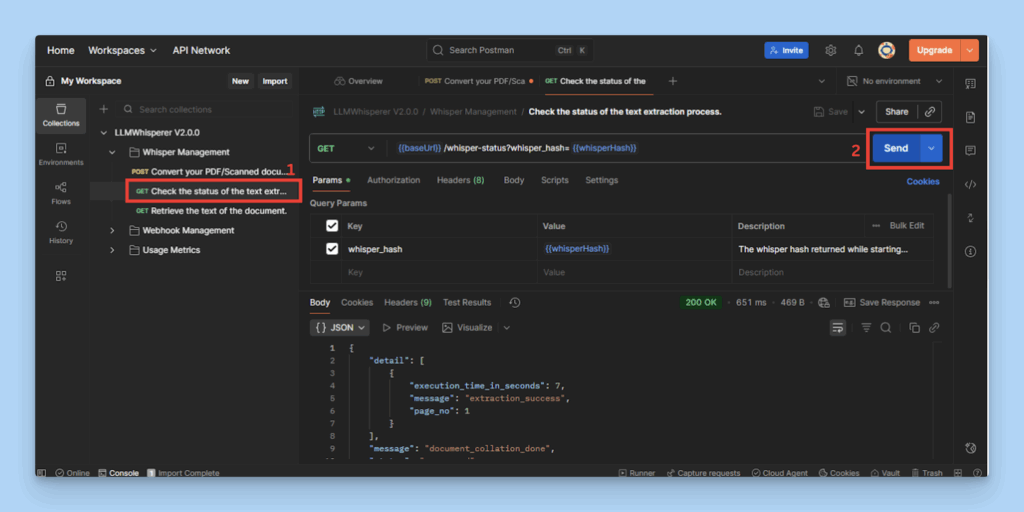
Step 3: Track and Retrieve Results
Use the Whisper Status (GET) request to check if processing is complete.
Checking document processing status
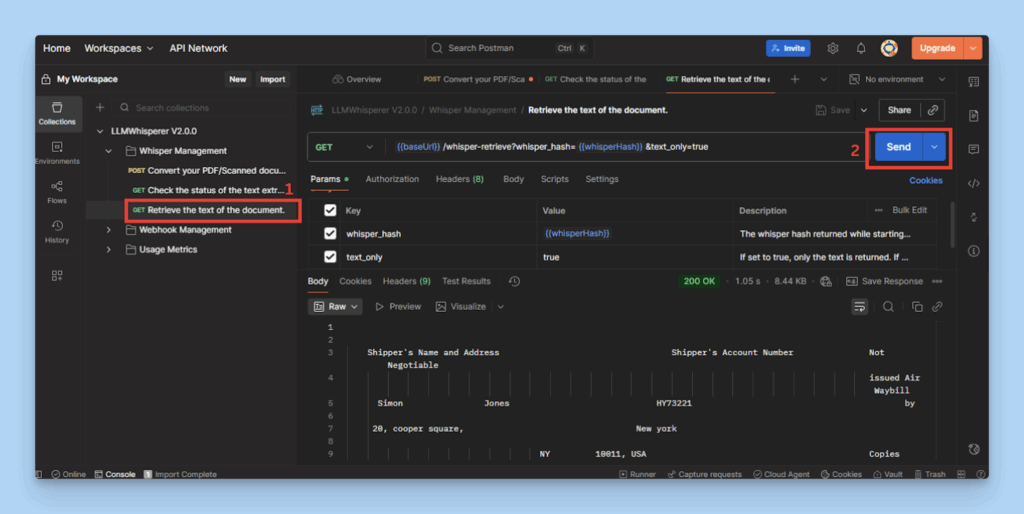
Once ready, run the Whisper Retrieve (GET) request.
The response delivers structured text ready for downstream processing.
Data Entry OCR: Retrieving the extracted text from the Photographed Airway Bill
Handling Complex Layouts with LLMWhisperer
Complex layouts are one of the main reasons why OCR data entry projects often fail. Standard OCR software for data entry may capture plain text, but it usually breaks when dealing with tables, checkboxes, multi-column pages, or handwritten inputs. This leads to messy outputs and forces teams to revert to manual correction.
LLMWhisperer takes a different approach. Its preprocessing ensures that the structure is preserved during extraction. Businesses using LLMWhisperer for OCR automated data entry can:
Extract tables and line items without losing rows or columns.
Retain form elements such as checkboxes and radio buttons.
Preserve multi-column formatting in financial statements, invoices, and contracts.
Process photographed or scanned documents without distortions affecting accuracy.
Supported Document Types
LLMWhisperer supports a wide range of document formats, including:
PDFs (native, scanned, forms)
Image files (JPG, PNG, TIFF, GIF, WEBP)
Microsoft Office files (Word, Excel, PowerPoint)
OpenDocument files (ODT, ODS, ODP)
Plain text (TXT)
Integrating LLMWhisperer into Workflows
LLMWhisperer is designed to plug directly into existing OCR data entry workflows. Depending on your setup, you can integrate it in three ways:
1. Direct API
The LLMWhisperer API gives developers full control. Document files can be sent via API calls, returning structured outputs such as JSON that connect seamlessly into downstream systems. This approach is ideal for teams embedding OCR into custom apps, such as ERPs or analytics platforms.
2. N8n Nodes
For users building automation workflows without heavy coding, LLMWhisperer offers custom N8n nodes. These nodes enable you to visually design document parsing pipelines within N8n and connect results directly to hundreds of supported integrations.
3. MCP Server
For advanced orchestration,Model Context Protocol (MCP) allows seamless integration with agent-driven document pipelines. The LLMWhisperer MCP server converts prompts into executable workflows, making this option ideal for enterprises managing large-scale, automated OCR data entry.
With these three integration methods, LLMWhisperer adapts to both developer-led deployments and no-code environments, making it one of the most flexible OCR for data entry solutions in 2026.
Advanced Use Cases of Data Entry OCR
In this section, we explore three real-world scenarios that demonstrate how LLMWhisperer significantly enhances accuracy, preserves layout integrity, and adapts to complex document structures.
Use Case 1: Native PDF Bank Statement (Complex Layouts)
Bank statements are essential documents used for account reconciliation and auditing, but they often feature complex layouts that include multiple columns, tables, section headers, promotional banners, and embedded summaries.
Traditional OCR tools struggle to maintain alignment, while LLMWhisperer preserves structure and delivers clean, analyzable outputs.
Sample bank statement PDF with complex tabular layout
Below is the result of this bank statement in the LLMWhisperer Playground. It accurately extracts and structures the financial data with high precision.
Data Entry OCR: Extracted data using LLMWhisperer playground
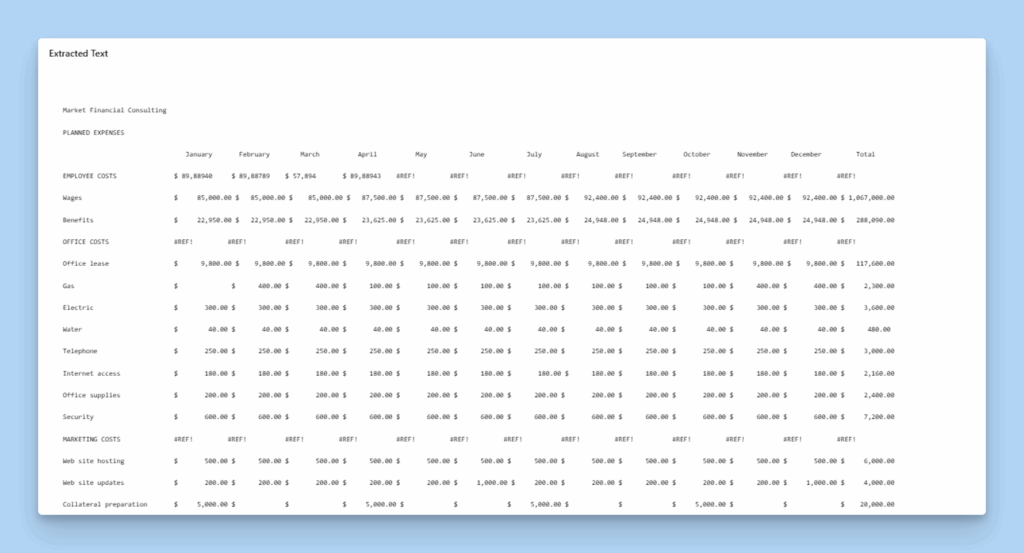
Use Case 2: Business Expenses Report (Semi-Structured Excel Data)
Business expense reports exported from spreadsheets often lack consistent formatting. When exported to PDF or image format, rows may be merged, notes misplaced, or categories misaligned, which makes automated processing difficult.
LLMWhisperer preserves these semi-structured files and delivers clean, analyzable outputs.
Business expenses report in Excel format
Below is the result of this expenses report via LLMWhisperer, demonstrating strong capabilities in extracting and interpreting dense tabular financial data.
Data Entry OCR: Extracted text from expenses report
Use Case 3: Income Tax Forms (Checkboxes & Non-Standard Inputs)
Income tax documents are standardized government-issued forms used to report financial activity for compliance and audit purposes. They often contain checkboxes, dense tables, embedded labels, and segmented sections that traditional OCR struggles to process reliably.
LLMWhisperer detects checkbox states, preserves layout, and extracts structured values for accurate downstream use.
Scanned income tax form with checkboxes
Below, LLMWhisperer accurately captures all key details. It handles structured tabular data with precision, including Assets, Balances, and Signature.
OCR for data entry: Extracted text from tax form
Beyond OCR: LLMWhisperer with Unstract
LLMWhisperer excels at extracting text and preserving context from scanned PDFs, images, and other unstructured files. However, the resulting output often requires field mapping, validation, and orchestration before it can be used in analytics, compliance, or CRM workflows.
As a powerful companion to LLMWhisperer, Unstract is an AI-powered document processing automation system that helps transform unstructured text into structured data using prompts, workflows, and APIs. It adds a layer of logic and orchestration that converts extracted text into structured, field-specific outputs that businesses can use directly.
Getting Started With Unstract: Best AI-Powered Document Data Extractor
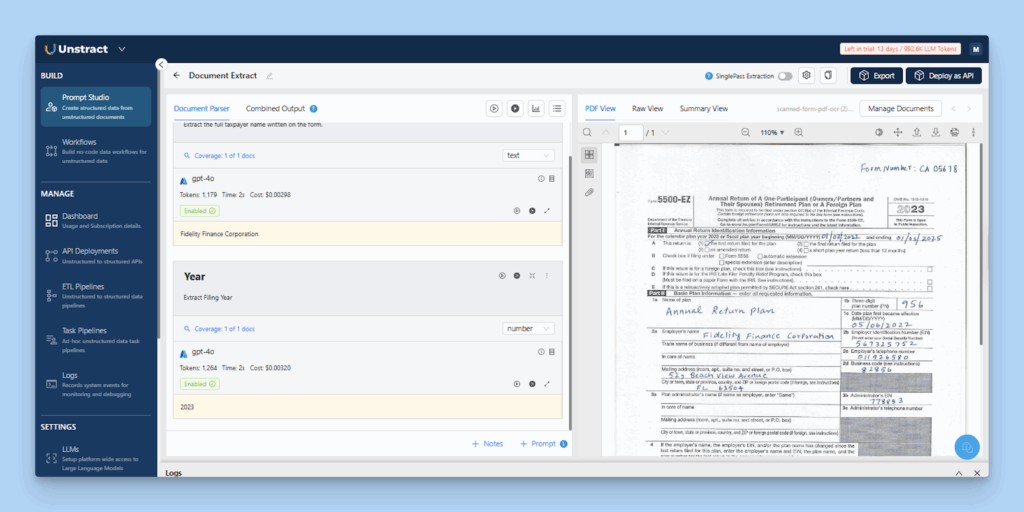
For this demo, let’s use Unstract’s Prompt Studio to extract data from a scanned handwritten tax form.
Scanned handwritten tax form
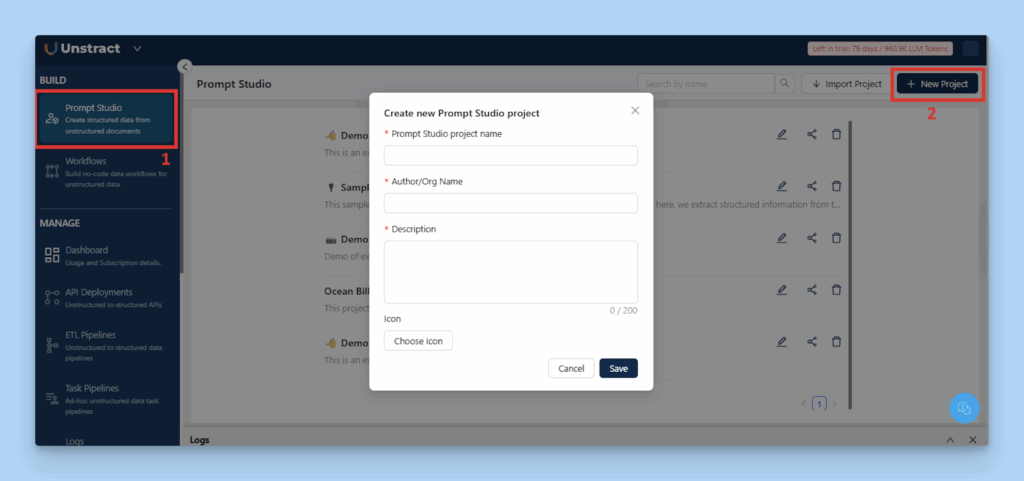
Step 1: Create a Prompt Studio Project
In Unstract’s Prompt Studio, start a new project for the tax form.
Setting Up a New Project Workspace in Prompt Studio
Step 2: Write Extraction Prompts
Define prompts to capture key fields such as taxpayer name, deductions, and total tax payable.
Extracting data with custom prompts in Unstract’s Prompt Studio
Step 3: Test via API in Postman
Deploy the project as an API, attach your API key (Bearer Token), and send a request with a scanned tax document. You’ll receive structured results, clean extracted fields ready for accounting or compliance workflows.
Unstract: AI-Powered Unstructured Data Extraction Tool
Why LLMWhisperer is the Best OCR for Data Entry in 2026
Enterprises have plenty of OCR software options, but most fail under real-world complexity. Traditional OCR struggles with accuracy, while LLM OCR often breaks on poor-quality scans or complex layouts. LLMWhisperer bridges this gap as it fits the needs of enterprises that demand accuracy, scalability, and security in their OCR data entry workflows.
The table below highlights how LLMWhisperer compares with traditional and LLM-based OCR across key dimensions.
Feature
Traditional OCR
LLM OCR
LLMWhisperer OCR
Accuracy
Good for clean text only
Higher, but often fails on noisy scans and layouts
Higher across complex layouts, tables, forms
Layout Handling
Strips formatting, plain text only
Struggles with tables & checkboxes
Preserves complex structure like multi-column designs and nested tables
Scalability
Batch only, rigid setup
Limited due to token costs and model size
Scales across millions of docs efficiently
Integration
Standalone apps are not flexible
Integrates with AI pipelines, but is less auditable
Works with APIs, n8n, MCP, existing tools
Multilingual Support
Limited language support
Support multi-language, but it depends on the model
Supports over 300 languages
The real measure of the best OCR software for data entry is not just text recognition, but how well the system integrates into workflows, scales across industries, and adapts to document diversity. LLMWhisperer is not just a standalone OCR engine; it is the enterprise standard for reliable, automated data entry at scale.
Data Entry OCR: Conclusion
In today’s data-driven economy, businesses depend on accurate document processing for various operations, but most of the critical data exists in unstructured formats. Traditional OCR solutions struggle with complex layouts, multi-column reports, and handwritten forms, often resulting in inaccurate outputs and manual rework.
LLMWhisperer provides a scalable alternative. As an advanced OCR-based document parsing tool, it ensures high accuracy in text recognition and maintains layout integrity, making it ideal for processing diverse documents.
LLMWhisperer fits seamlessly into modern enterprise workflows, available both as a SaaS platform and on-premise deployment for organizations prioritizing scalability, security, and compliance.
Get started with LLMWhisperer by signing up for a free trial. Process up to 100 pages a day completely free! No credit card required.
Document extraction at the cutting edge with LLM models vs. LLMWhisperer OCR API
In this webinar, we put top LLMs to the test—evaluating their performance across documents of varying complexity. We’ll dive into why directly parsing raw documents often leads to subpar results, and showcase the impact LLMWhisperer has on improving extraction outcomes.
How does data entry OCR differ from traditional manual data entry?
Data entry OCR automates the process of capturing and converting printed or handwritten text from paper or image files into structured, machine-readable data. Unlike manual data entry, which is slow and error-prone, data entry OCR enables organizations to handle higher volumes of documents faster and with greater precision, thus boosting productivity and scalability.
What are the common challenges when using OCR for data entry in complex documents?
Challenges with OCR for data entry often arise from poor image quality, complex layouts (like tables and checkboxes), and handwritten or semi-structured data. Standard OCR tools may struggle to maintain document structure or accurately interpret varied inputs, often requiring manual correction. Advanced solutions like LLMWhisperer overcome these challenges by using preprocessing and layout-aware extraction.
Why should enterprises invest in advanced OCR software for data entry like LLMWhisperer?
OCR software for data entry, such as LLMWhisperer, offers features that go beyond basic text extraction. It preserves complex formatting, processes low-quality scans, and integrates seamlessly with enterprise systems via APIs or automation tools. By investing in advanced OCR software for data entry, businesses can improve accuracy, ensure compliance, and scale their operations efficiently.
What are the benefits of integrating OCR data entry solutions into existing business systems?
Integrating OCR data entry solutions—especially modern platforms like LLMWhisperer—into existing business systems brings multiple benefits: streamlined workflows, reduced operational costs, higher data accuracy, support for multilingual and complex document formats, and the ability to scale as data volumes grow. This integration ensures businesses remain competitive and compliant in a data-driven market.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.