From PDFs to Structured Data: Convert PDFs to XML Using LLMWhisperer & Unstract
Table of Contents
Data powers all modern business workflows, but a lot of it remains trapped inside PDFs. What organizations need is not just document storage but document intelligence. This means having the ability to convert PDFs into structured formats that systems can easily process.
That’s where PDF to XML conversion becomes useful. XML is a structured data exchange standard for enterprise systems. With schema validation and broad compatibility, XML transforms unstructured PDFs into data pipelines for compliance, analytics and automation.
In this guide, we go beyond traditional parsing and learn how to use LLMWhisperer, Unstract and Python to convert PDF into XML. Together, these tools transform messy, inconsistent PDFs into clean, structured XML data that’s ready to integrate into any business system.
Why PDF to XML? Downstream Benefits & Use Cases
XML is still a foundational standard for structured data exchange. It drives compliance reporting, enterprise workflows and integrations in any industry where precision and validation are vital. Unlike JSON, XML can be bound to XSD schemas, which impose structure, eliminate the ability to leave out a field and ensure cross-system consistency.
This makes XML particularly useful to organizations that rely on legacy applications or must comply with regulations. Here are some use cases of XML:
Banking: XML standardizes loan applications, credit files, and mortgage disclosures, making them compliant and audit-ready. It facilitates automated validation, minimizes errors, and assists in long-term archives.
Real Estate: Rent rolls, leases, and property reports are fed directly into property management systems via XML. This simplifies the ingestion process, reduces manual entry, and provides uniform reporting.
Insurance: XML forms impose schema constraints that minimize claim rejections and manual re-entry. They also facilitate the easy transfer of policies and claims among insurers and reinsurers.
ERP and Supply Chain: Purchase orders, invoices, and shipment notices in XML allow seamless integration. It reduces conversion costs, accelerates workflows, and ensures traceability.
The PDF to XML file conversion transforms snapshots into validated data that are machine-ready and can be redirected into downstream business processes.
Why PDFs Are Hard to Parse?
PDFs do not store structured data. They were built to preserve visual consistency across screens and printers, rather than to maintain logical structures such as tables, fields or labels. This design makes information extraction difficult and introduces frequent errors during parsing.
When you attempt to convert a PDF to XML format, several issues arise that complicate the process to a level that is significantly more challenging than a simple file export. Some of them are:
Layout loss: PDFs can have multiple tables that can span more than one page. During extraction, row boundaries can be broken and column alignment can be lost. This complicates the ability to map values into structured XML tags reliably.
Fonts and encodings: Many PDFs contain embedded custom fonts or non-standard character encodings. Characters that cannot be decoded into Unicode appear as unreadable symbols. This corrupts the XML and makes critical data unusable.
Scanned documents: A large share of PDFs are image-only scans. Without OCR, characters remain invisible to parsers. The XML output in these cases is filled with empty or meaningless nodes that provide no usable information.
Checkboxes and handwritten notes: Forms often contain stamps, checkmarks or handwritten inputs. Without advanced OCR that can detect shapes and handwriting, the XML output omits vital fields, such as approvals or yes/no responses.
Mixed content: Real-world PDFs rarely contain a single content type. Each element requires a different extraction technique. Without specialized processing, XML output becomes inconsistent. Some elements appear as structured tags, while others remain unprocessed free text.
These challenges make PDF-to-XML conversion a true data extraction problem. It requires OCR to recognize text, layout preservation to maintain structure and intelligent parsing to generate validated XML that downstream systems can trust.
Read more about the common but often difficult challenge: Extracting text from PDFs for use in RAG, natural language processing and other applications of large language models (LLMs).
Conventional PDF parsers often rely on fixed rules and work best in situations where the layout of the document is predictable. These methods are ineffective when the structure changes. This limitation is overcome by Large Language Models (LLMs).
LLMs are capable of reading unstructured text, identifying semantic meaning and mapping values to data fields. In contrast to rule-based scripts, LLMs support various layouts. A single prompt can extract uniform fields across a wide range of PDF formats without retraining.
However, practical deployment often requires OCR for scanned PDFs, prompt engineering for consistency and validation layers to avoid errors or hallucinations. While less rigid than rule-based parsing, LLM approaches come with trade-offs in performance, cost and reliability.
Introducing Unstract for Structured Data Extraction (How LLMs Process and Convert PDFs to JSON?)
Unstract is a no-code intelligent document processing platform designed to simplify the complexity of unstructured data. It transforms PDFs, images and forms into structured, machine-readable formats.
The platform streamlines workflows by enabling users to ingest documents from various sources and categorize file types. It then extracts field-specific data and validates its accuracy before sending it downstream.
Unlike fixed rule-based systems, Unstract integrates LLMs, embeddings and vector databases with a user-friendly environment. This allows teams to create extraction logic and schemas without writing extensive code.
Prompt Studio, a key feature, offers a visual interface for creating and testing prompts. Teams can use natural language queries to define fields such as “Loan Amount” or “Tenant Name”.
Once configured, projects can be deployed as APIs or packaged as ETL pipelines. This supports automated, large-scale workflows integrated with enterprise systems and databases.
Explore Unstract’s Prompt Studio
Prompt Studio is a purpose-built prompt engineering environment for document data extraction
What Is LLMWhisperer?
LLMWhisperer is a layout-aware OCR and text extraction engine specifically designed to prepare documents for LLMs. Despite its name, it is not an LLM but rather a preparation layer for them.
The tool extracts text from PDFs, including scanned contracts and handwritten forms, while preserving the complex structures of tables, checkboxes and column layouts. Unlike typical OCR, it maintains the original document’s integrity for accurate data capture and processing.
LLMWhisperer features auto mode switching, which determines whether a document requires OCR or direct text extraction. This ensures optimal accuracy, regardless of the input format.
It includes auto-compaction technology that reduces token count while preserving structure, lowering LLM processing costs and improving workflow reliability.
The Need for Pre-processing with LLMWhisperer
LLMs can interpret unstructured text well, but they are sensitive to the quality of the input. If your PDF has a broken text layer, poorly aligned tables or is simply a scanned image, the model will struggle. In such instances, the LLM either hallucinates values, omits significant fields or fails to recognize document structure correctly.
Pre-processing offers clean and well-constructed input to downstream parsing. LLMWhisperer combines OCR, layout preservation and token optimization to preprocess documents. This allows LLMs to produce correct JSON or XML text from disorganized PDFs.
OCR on Scans: It applies high-accuracy OCR to convert PDFs and images into machine-readable text, enabling LLMs to read scanned or handwritten documents. The OCR pipeline uses prefilters, like Gaussian blur, despeckle and desaturate, to enhance recognition on noisy documents.
Layout Preservation: Spatial elements such as rows, columns, checkboxes, tables and multi-column layouts are reconstructed with awareness of their position. This ensures that relational context is not lost. Instead of outputting a flat text stream, it provides the LLM with a semantically structured representation of the document.
Consistency in Input: Normalization steps collapse redundant whitespace, remove irrelevant metadata and standardize field-label relationships. This reduces token overhead while preserving semantic precision.
Auto Mode Switching: PDFs vary widely in their internal structure. Some are machine-readable (text-based), while others are essentially scanned images requiring OCR. LLMWhisperer automatically classifies the input and switches between direct text extraction and OCR-based processing pipelines.
Cost and Accuracy Optimization: Extra tokens in an LLM increase latency and costs. LLMWhisperer streamlines text, cutting token counts and producing cleaner prompts. This reduces API costs and boosts model accuracy by eliminating irrelevant context.
Pre-processing with LLMWhisperer ensures that every downstream pipeline, from JSON extraction to XML conversion, operates with clean, accurate inputs. Consistently better inputs result in superior outputs and precision is vital in document automation.
Get started with LLMWhisperer: Best OCR for document parsing
LLMWhisperer is a technology that presents data from complex documents (different designs and formats) to LLMs in a way that they can best understand.
LLMWhisperer Playground
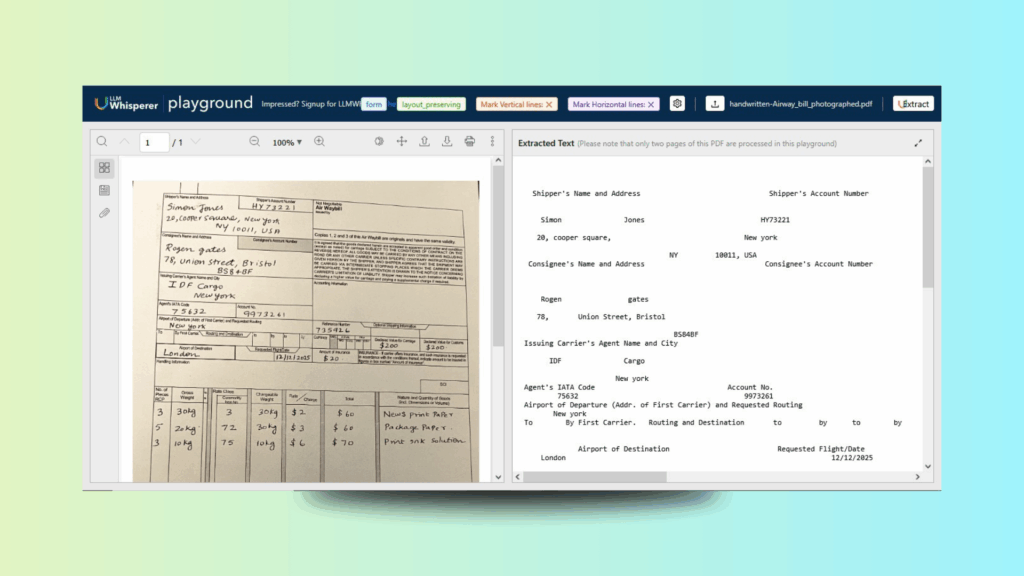
Extracting text from structured air waybills can flatten handwritten fields, tables and checkboxes. This results in fragmented text that loses the connection between labels and values. It makes details such as shipper information, cargo weight and insurance difficult to parse.
Within seconds, the LLMWhisperer Playground processes the document and returns structured text:
Figure 1: Processing Challenge: Variability in Handwritten and Scanned Forms
This helps businesses automate shipment processing, reduce manual errors and speed up customs or compliance workflows. This output is far more reliable than what a generic OCR would produce and is immediately ready for consumption by Unstract for structured extraction.
Setting Up Unstract — OpenAI, Embeddings, Vector DB, and LLMWhisperer
To use Unstract for structured data extraction, you first need to configure an LLM Profile. This profile acts as a logical bridge, integrating the language model, embeddings, vector storage and text extraction pipeline into a unified workflow.
LLM (OpenAI)
Navigate to settings, click on LLM Profiles in Unstract and click “Add New LLM Profile”.
Select OpenAI as the provider, enter your API key, choose your model (e.g., GPT‑4) and save the profile.
Unstract also offers a default sample profile that combines GPT-4, embeddings, vector database and LLMWhisperer for quick experimentation.
Choose a mode (Native Text, Low Cost, High Quality, Form),
Pick an output mode (layout_preserving or text) and tweak parameters like line splitter tolerance or blur filters.
Setting up a Prompt Studio Project
We will now set up and test a Prompt Studio Project, similar to how we extracted a text in LLMWhisperer. In this workflow, Prompt Studio provides a controlled environment to design, refine and evaluate prompts, ensuring they deliver consistent outputs before being integrated into automation pipelines.
This step is essential to move from raw extraction (LLMWhisperer) to meaningful transformation and reasoning with LLMs.
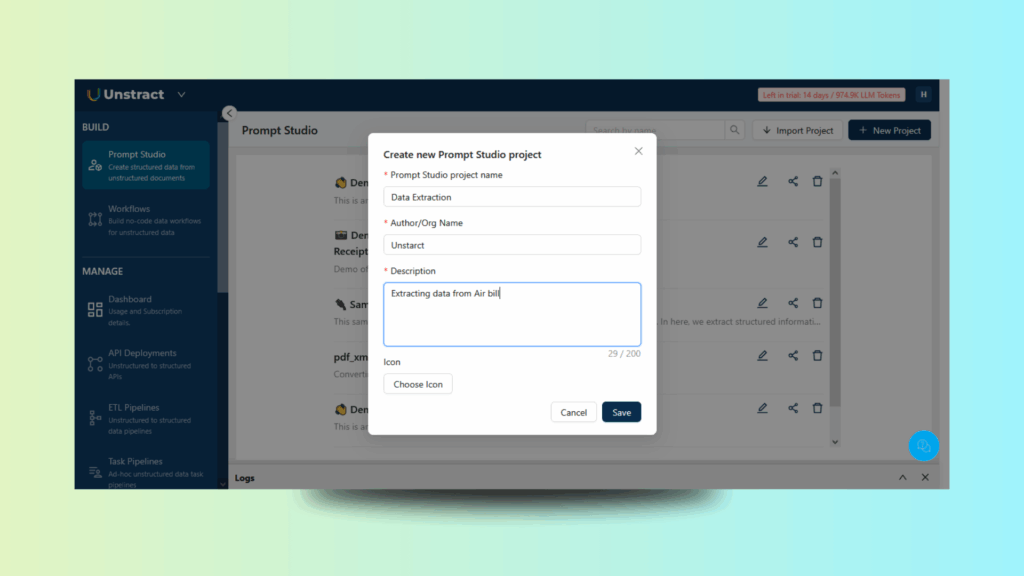
Create a Project and provide the name with a precise description.
Figure 2: Setting Up a New Project Workspace for Data Extraction
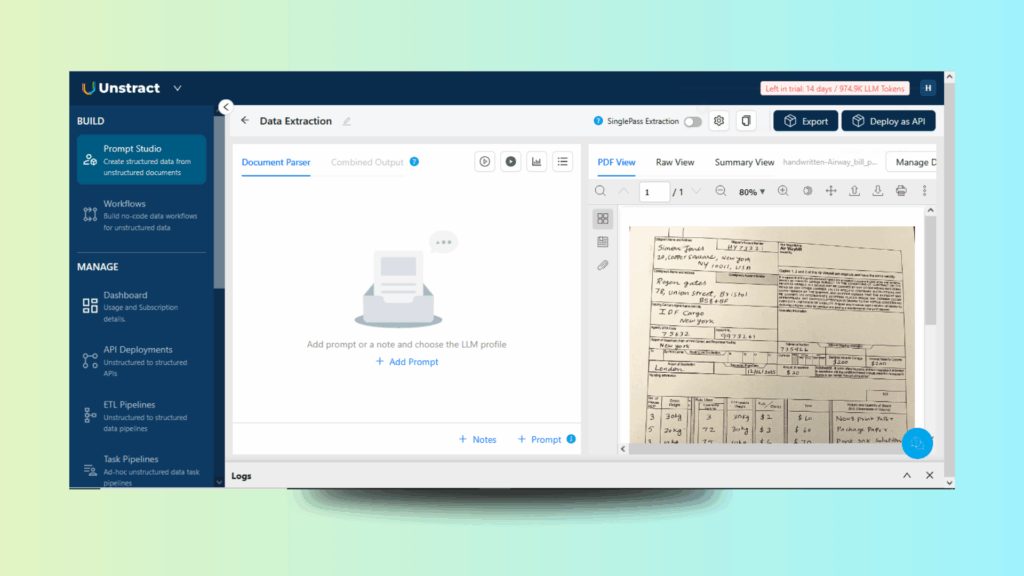
After the project framework is in place, navigate to the Document Manager to upload relevant files. These files serve as context for your prompts and enable prompt tuning via real examples. We will be using the same file we used in LLMWhisperer.
Figure 3: Uploading the File in the Prompt Studio
Now let’s write a simple prompt to extract the data from the file:
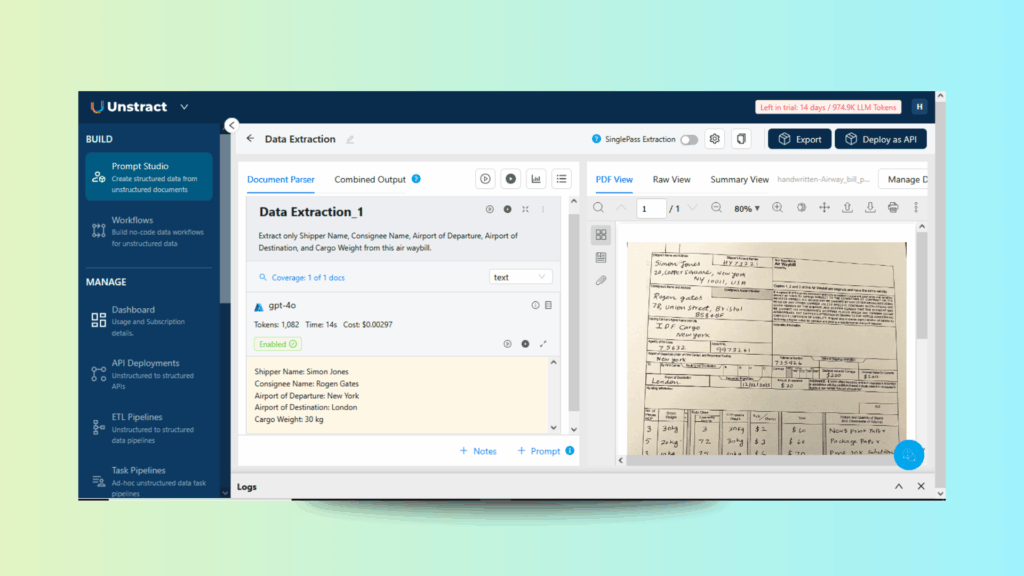
Extract only Shipper Name, Consignee Name, Airport of Departure, Airport of Destination and Cargo Weight from this air waybill.
Select the type of output you need. For example, you can select text, JSON or table format. Once selected, press Run and you will see the output like this:
Figure 4: Extracting Data with Prompt-Based Workflow
The following tuning tips will help maximize accuracy and efficiency in Prompt Studio. They can also optimize the use of prompts to produce high-quality outputs at reduced costs.
Use Prompt Coverage Analytics to identify underperforming prompts across your document set and spot gaps or inconsistencies in extraction coverage.
Use the Output Analyzer to compare the original document with the extracted results side by side.
Incorporate Preamble and Postamble templates to guide the LLM. Use a preamble for instructional context and a postamble to enforce output format and consistency.
Optimize for cost and speed using token-saving modes like SinglePass and Summarized Extraction.
Showcase: PDF to XML Data Extraction
We’ll demonstrate how a loan application PDF can be turned into structured XML. The process uses LLMWhisperer for layout-aware OCR, Prompt Studio for field-level extraction and Python for conversion.
Loan Application
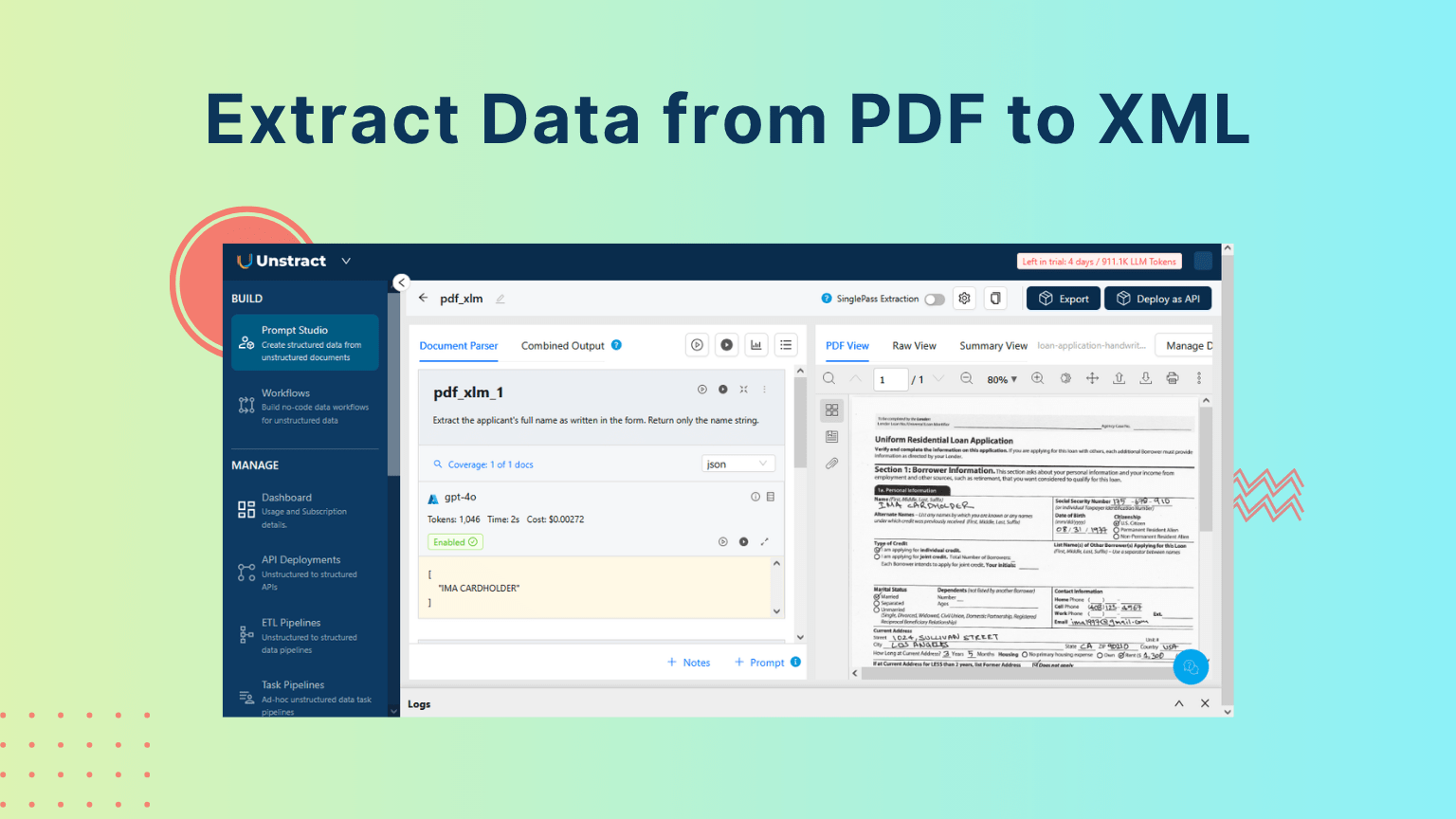
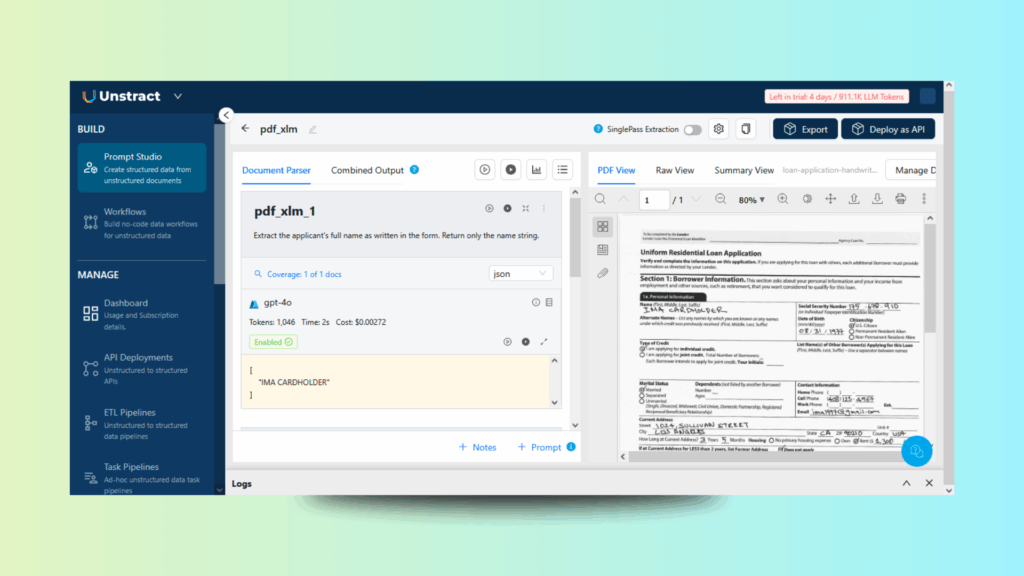
Upload the same file you used in the previous step and write a simple prompt in Prompt Studio to extract the applicant’s name.
Extract the applicant's full name as written in the form. Return only the name string.
Figure 5: Data Extraction: Extracting Applicant Name from Loan Application
Select the datatype as JSON and Run. The output will look like this:
JSON
[
"IMA CARDHOLDER"
]
Now, let’s write an advanced prompt for this to extract all of the important details of the borrower.
Extract all borrower details from this loan application, including name, SSN, DOB, citizenship, contact info and address.
Before XML conversion, extracted fields are represented as JSON. This structured intermediate layer allows for review, validation and downstream automation through APIs.
Rent Roll
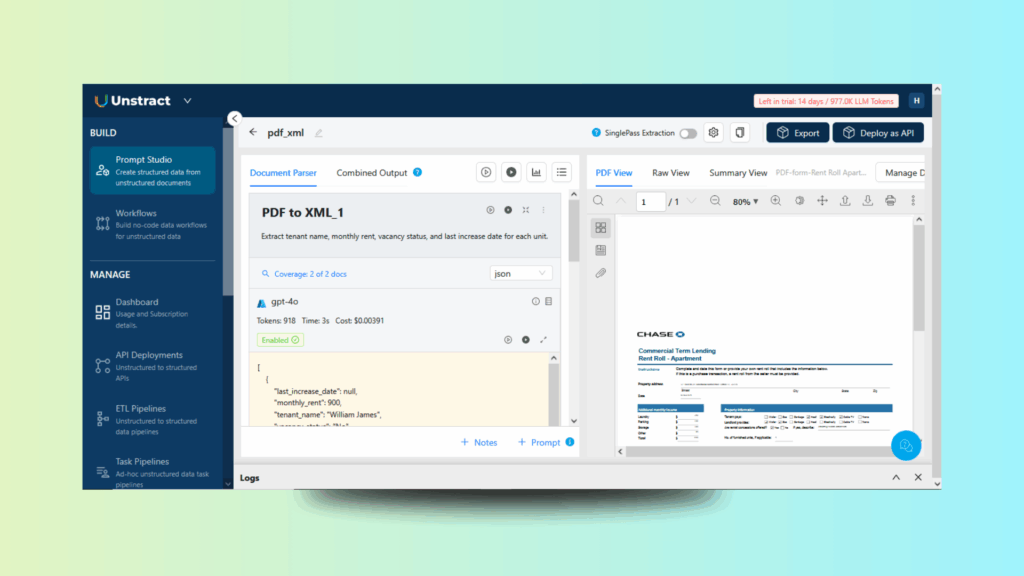
Now, let’s take a look at a rent roll, where extracting and structuring tabular data is essential. LLMWhisperer ensures Prompt Studio can reliably transform property data into XML for property-management systems by preserving rows and columns during OCR.
Prompt 1
Extract tenant name, monthly rent, vacancy status and last increase date for each unit.
Prompt 2
Extract property address, unit details (beds, baths, square feet), move-in date, lease end date and rent type.
Now run all of these once and you will see the results shown below. Another option is to click on the combined output to view both in one.
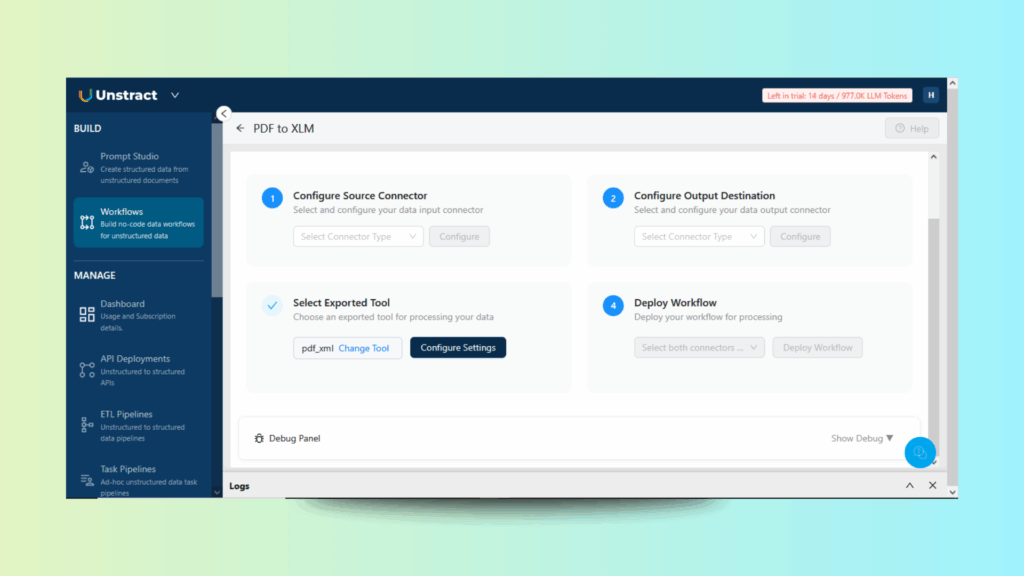
Start by packaging your Prompt Studio project so it can be reused. From the project dashboard, export it as a tool. This makes the extraction logic available for integration into workflows.
Next, design a workflow around the tool.
Figure 7: Workflow Creation for API: Exporting the Configured Workflow as a Reusable Tool for Integration
Go to the new workflow, create a new one and then drag your exported tool (e.g., PDF to XML) into the workflow canvas. This connects your extraction project into a repeatable process.
With the workflow ready, expose it as an API for external access. Under Manage in API deployments, add a new deployment. This instantly creates a REST endpoint that allows other systems to call your extractor, while also giving you options to configure authentication, keys, and client collections.
Figure 8: Configuring API Settings: Define Endpoint, Authentication, and Deployment Parameters
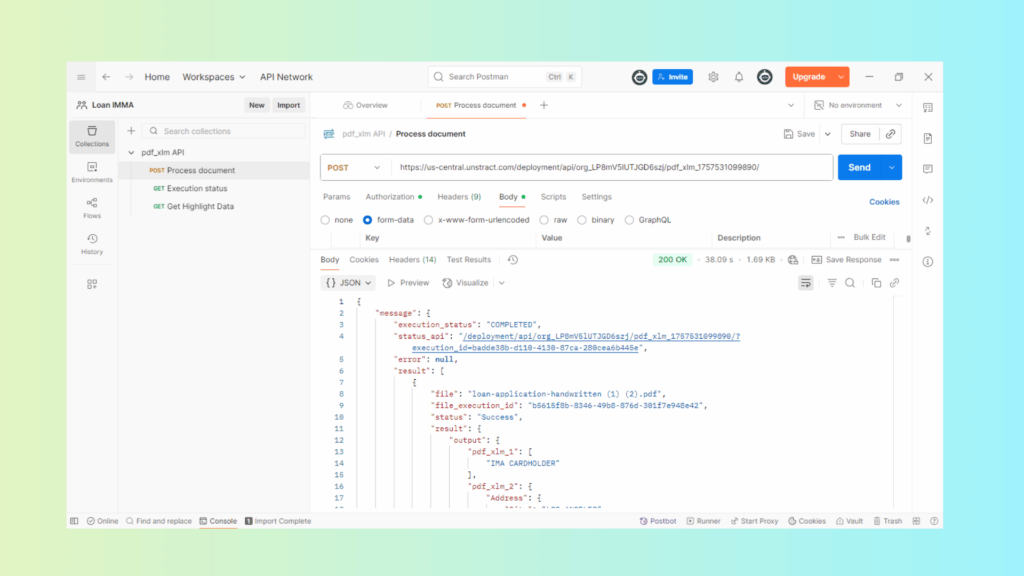
Access the API via Postman to Retrieve JSON
Finally, test the live API to confirm everything works end-to-end. Import the generated Postman collection, attach your API key (Bearer Token) and send a request with a sample PDF. You’ll receive structured results, proving the workflow is production-ready.
Figure 9: Live API Testing: Verifying End-to-End Workflow by Importing the Postman Collection, Adding the API Key and Sending a Sample PDF to Confirm Structured Results
Once you run, you will find the result for the Loan Application file like this: JSON
Repeat the same steps for the other files, just as we did with the Loan Application. Once you test and get JSON, it’s time to convert it into XML using Python.
Python: Convert the JSON to XML
Now that we’ve verified the deployment in Postman, let’s switch to Python to automate the workflow end-to-end. We’ll submit a PDF to the Unstract API, poll until extraction completes, then capture the JSON output, convert it to XML, print both, and save them.
Installing the necessary libraries
To run this script smoothly, you’ll first need to install the required Python libraries. These packages handle API requests, JSON/XML processing and time-based polling.
If you are using the command line, remove the !. This script was created in Jupyter Notebook, an interactive environment that combines code, text and visualizations for easy analysis and sharing.
!pip install requests xmltodict
In this script, the API key is defined using:
os.environ["UNSTRACT_API_KEY"] = "YOUR_API_KEY"
This Python script is designed to process PDF files using the Unstract API and convert the extracted data into JSON and XML formats. It automates job submission, progress tracking and result collection, delivering structured output ready for review or system integration.
import requests, time, json, os, xmltodict
from urllib.parse import urljoin
from typing import List, Dict, Optional
BASE_URL = "https://us-central.unstract.com"
The submit_job function sends a PDF file to the Unstract API and retrieves the initial response. Since the API runs asynchronously, the first response is often marked as PENDING and contains a status_api endpoint to check progress. This function uses the API key defined in the environment variables to authenticate requests.
The poll_status function continuously queries the status_api endpoint until the extraction job is either completed successfully or times out. This ensures the script only continues once the final output is available.
def poll_status(status_path_or_url: str, api_key: str, timeout: int = 240, interval: float = 2.0) -> dict:
headers = {"Authorization": f"Bearer {api_key}"}
status_url = status_path_or_url if status_path_or_url.startswith("http") else urljoin(BASE_URL, status_path_or_url)
start = time.time()
while True:
r = requests.get(status_url, headers=headers)
r.raise_for_status()
data = r.json()
msg = data.get("message", {})
state = msg.get("execution_status") or msg.get("status") or "UNKNOWN"
if state in {"SUCCESS", "COMPLETED"} and msg.get("result"):
return data
if state in {"FAILED", "ERROR"}:
raise RuntimeError(f"Job failed:\n{json.dumps(data, indent=2, ensure_ascii=False)}")
if time.time() - start > timeout:
raise TimeoutError(f"Polling timed out after {timeout}s; last state: {state}")
time.sleep(interval)
The extract_output_object function navigates the nested Unstract response to isolate the actual output payload (message.result[0].result.output), rather than returning the entire response wrapper. This makes downstream usage of the extracted data much cleaner.
def extract_output_object(final_json: dict):
msg = final_json.get("message", {})
result_list = msg.get("result") or []
if isinstance(result_list, list) and result_list:
inner = result_list[0].get("result", {})
if "output" in inner:
return inner["output"]
return msg # fallback for debugging
The json_to_xml function converts the extracted JSON payload into a well-structured XML string. It preserves the hierarchy of the original data by wrapping the output under a configurable root node.
Extracts the clean payload from the final response.
Prints the JSON output first, followed by the XML conversion.
Saves both results locally as output.json and output.xml.
def process_one(pdf_path: str, api_url: str, api_key: str, root_name: str = "root",
out_json: Optional[str] = None, out_xml: Optional[str] = None):
# 1) submit
initial = submit_job(pdf_path, api_url, api_key)
msg = initial.get("message", {})
# 2) poll if pending
if msg.get("result"):
final_json = initial
elif msg.get("execution_status") == "PENDING" and msg.get("status_api"):
final_json = poll_status(msg["status_api"], api_key, timeout=240, interval=2)
else:
print("Unexpected response; showing raw JSON:")
print(json.dumps(initial, indent=4, ensure_ascii=False))
final_json = initial
# 3) extract payload
payload = extract_output_object(final_json)
# 4) print JSON first
print(f"\n=== Extracted JSON ({os.path.basename(pdf_path)}) ===")
print(json.dumps(payload, indent=4, ensure_ascii=False))
# 5) convert & print XML second
xml_output = json_to_xml(payload, root_name=root_name)
print(f"\n=== Converted XML ({os.path.basename(pdf_path)}) ===")
print(xml_output)
# 6) save files if paths provided
if out_json:
with open(out_json, "w", encoding="utf-8") as jf:
json.dump(payload, jf, indent=4, ensure_ascii=False)
print(f"Saved JSON -> {out_json}")
if out_xml:
with open(out_xml, "w", encoding="utf-8") as xf:
xf.write(xml_output)
print(f"Saved XML -> {out_xml}")
This section defines multiple jobs (each with its own input PDF, API URL and output paths) and then runs them sequentially. For each file, the script produces both JSON and XML outputs, ready for analytics, reporting or system integration.
This approach provides a repeatable and automated pipeline for transforming unstructured PDF documents into structured machine-readable formats. The dual JSON/XML outputs make it flexible for analytics, reporting or integration into downstream systems.
PDF to XML: What’s next?
In this guide, we talked about how to convert a PDF to an XML file with LLMWhisperer, Unstract and Python. We began with OCR and layout preservation, then scraped clean text, wrote prompts in Prompt Studio and coded the pipeline in Python to convert JSON to XML.
Automation of PDF to XML conversion enables organizations to produce compliance-ready, validated output that can be seamlessly integrated into their existing workflows. This minimizes manual effort, prevents errors and provides access to essential business data.
With Unstract, messy PDFs no longer slow down operations. Loan applications, rent rolls, claims or medical forms can be converted into structured XML with accuracy and compliance built in.
AI-Powered PDF to XML Conversion: FAQs
What does “PDF to XML” conversion mean, and why is it important?
PDF to XML refers to the process of converting a PDF file into XML format, a structured markup language widely used for data exchange in enterprise systems. Using XML allows organizations to turn unstructured PDF data into machine-readable, validated information that’s ready for analytics, compliance, and automation.
Can I convert PDF to XML without writing thousands of lines of parsing code?
Yes. The article explains how LLMWhisperer handles OCR and layout, while Unstract’s Prompt Studio extracts the fields you need. When you click “Run,” the platform will automatically convert PDF to XML (via an intermediate JSON step) in just a few minutes.
What is the best PDF to XML converter if I have scanned documents with tables and handwriting?
For mixed or low-quality scans, a combination of LLMWhisperer (for intelligent OCR) and Unstract (for LLM-based extraction) is arguably the best PDF to XML converter because it keeps table structure, detects handwriting, and enforces XML schemas.
How can I convert PDF to XML using AI-powered tools?
You can convert PDF to XML by using platforms like Unstract in combination with LLMWhisperer. These tools utilize AI and OCR to extract structured data from complex or scanned PDFs. The general process involves extracting the data (usually in JSON format) and then transforming it into XML format using automated pipelines or scripts, such as those written in Python.
Is there a PDF to XML converter API so I can integrate this into my product?
A: Yes. After you package your Prompt Studio project, Unstract lets you deploy it as a PDF to JSON converter API. You’ll receive a REST endpoint; simply POST the PDF, poll the status URL, and the service returns structured JSON that can be programmatically(Python) converted to XML.
PDF to XML structured data extraction: Related topics to explore