AI OCR: How It Works, Enterprise Readiness & When to Use It
Table of Contents
AI OCR — AI-powered OCR — is rewriting what document processing can do. Where traditional optical character recognition matches visual patterns rule by rule, AI OCR uses deep learning, transformer models, and language understanding to extract text from scanned PDFs, handwritten forms, degraded faxes, and complex multi-column layouts with a level of accuracy that fixed pipelines cannot reach. But the honest picture is more complicated.
Most AI-powered OCR systems in production today suffer from hallucinations, non-deterministic outputs, poor layout traceability, and compliance gaps that make them difficult to deploy in regulated industries like finance, healthcare, and insurance. According to IDC, 90% of enterprise data is unstructured — much of it in scanned or photographed formats. The extraction bottleneck is real. But swapping traditional OCR for an AI model does not automatically solve it.
This article examines both approaches with technical depth. You will find a breakdown of how AI OCR works at the model level, an honest look at where it falls short in enterprise environments, a comparison of traditional and AI-based OCR tools, and four hands-on extraction examples across loan applications, IRS compliance forms, insurance tables, and receipts.
It also introduces LLMWhisperer — a hybrid pipeline that combines deterministic layout parsing with LLM-optimized structured output, built specifically for teams that need audit-ready extraction without the hallucination risk of pure AI OCR.
TL;DR
This article covers how AI OCR works, where it breaks down in production, and why most tools aren’t enterprise-ready yet. If you’d rather skip to the solution,see how LLMWhisperer OCR handles it — scanned PDFs, handwritten forms, complex tables, multi-column layouts, 300+ languages.
What is OCR?
Optical Character Recognition (OCR) is a technology that converts text from images into machine-readable characters. Modern OCR systems have pipelines that include modules of image acquisition, preprocessing, segmentation, feature extraction, classification and post-processing.
Here is the working flow of the OCR system:
Preprocessing: Improves contrast, reduces noise and corrects skew or rotation in scanned inputs.
Segmentation: Breaks scanned content into lines, words and characters before further analysis. This step ensures each unit is processed with maximum recognition accuracy.
Feature Extraction: Applies techniques like contour analysis, zoning and projection profiles to create numerical representations of character shapes.
Classification: Identifies characters through methods like template matching, support vector machines and deep convolutional neural networks. Handwriting recognition uses sequence models, such as recurrent neural networks (RNNs) combined with connectionist temporal classification (CTC).
Post-processing: Uses language models or lexicon constraints to correct misrecognitions. This final step refines output and significantly improves overall OCR accuracy.
End-to-end OCR systems merge the detection and recognition modules into a single neural network for efficiency. OCR uses statistical learning for recognizing language patterns to automate the extraction of text in a wide variety of industrial uses. Multilingual OCR systems need specialized script recognition and language-specific model training to perform well.
These engines use dictionary-based language models in post-recognition correction. However, they rely on hand-designed features and rule sets that constrain their ability to adapt to new fonts or noisy inputs.
They are highly accurate with clean, printed documents. Performance is decreased with skewed layouts, low-resolution scans and cursive handwriting.
OCR engines, such as Tesseract, identify text lines and use word lists or dictionaries in post-processing to improve accuracy. You can train custom LSTM models using labeled line-level data (images paired with text transcriptions), either from scratch or by fine-tuning existing models.
Comparison of LLMWhisperer’s Approach to OCR Versus Tesseract
While Tesseract is an excellent tool for basic OCR tasks, it relies heavily on traditional image processing techniques and pre-trained models that may not perform well with non-standard or complex documents.
LLMWhisperer, on the other hand, uses deep learning models that can adapt to the nuances of different writing styles, languages, and document structures.
Traditional OCR offers several clear advantages when applied to clean, well-structured documents. Let’s have a look:
Deterministic Output: It provides exact glyph-level bounding boxes that align with the input image. You can use these boxes to pinpoint the text with pixel accuracy. This mapping facilitates ROI cropping, annotation and the accurate overlay of results for verification.
Low Resource Footprint: Traditional OCR is designed to run on modest hardware, with low compute requirements. It works well without GPUs, which reduces the infrastructure demands. This performance allows low-cost deployment on desktop computers, embedded systems or local servers.
Tooling and Language Support: Well-established OCR engines provide mature APIs, developer tools and integration libraries. This versatility helps in easy adoption across diverse industries and geographies.
Cost-Effective: Most conventional OCR engines are either open-source or have permissive licensing. They can be installed on a large scale without recurrent charges. This low cost makes them appealing to large-scale digitization and archiving projects.
The performance is predictable with variable batch sizes, which helps in capacity planning and resource allocation.
Disadvantages
The strengths of traditional OCR fade quickly outside controlled conditions. Here’s how:
Accuracy Limitations: LSTM-based models struggle with cursive handwriting and low-resolution scans. This leads to a higher character error rate in these cases. To address this, we may need to preprocess the inputs. This involves de-skewing, denoising and enhancing the resolution.
Context-Free: Conventional OCR focuses on matching visual patterns. It doesn’t interpret the meaning of the text. External dictionaries can boost accuracy in specific domains. However, they make processing more complex and add maintenance costs.
Fixed Output: Traditional OCR engines typically produce plain Unicode text with little layout metadata and have no native table or form reconstruction. As a result, extracting structured data often requires custom post-processing using third-party tools or parsers.
Clean, high-quality scans with custom LSTM training
Moderate
Local / On-Prem
Free (Apache 2.0)
PaddleOCR
Multi-language documents, standard layouts
High
Local / On-Prem
Free (Apache 2.0)
Surya OCR
Printed documents where Tesseract falls short
High
Local / On-Prem
Free* (GPL-3.0)
Introduction to AI OCR
AI OCR turns text recognition into document comprehension. It uses convolutional backbones to detect text-regions (e.g., CRAFT or EAST) and transformer-based decoders to transcribe the sequence.
Graph neural networks or spatial transformers model inter-block relationships through layout analysis. Semantic modules use multimodal transformers to correlate text spans with context, which allows for extracting entities and linking relations.
End-to-end pipelines combine detection, recognition and post-processing in a single neural network, which decreases the error propagation. Some AI scanning software like Donut, LayoutLMv3 and TrOCR are self-supervised and pretrained to reduce domain adaptation and labeled data needs. However, not all OCR systems work this way.
AI-Based OCR Solutions
OCR AI models uses deep learning to improve recognition accuracy and interpret complex, real-world documents. Let’s have a look at some of the best AI OCR models:
Mistral OCR: A vision-language transformer pretrained on millions of annotated pages. It uses cross-attention between text tokens and image patches to segment table cells and parse multi-language text. Fine-tuning tasks include form understanding and key-value pair extraction.
OpenAI GPT Plugins: GPT-4o and GPT Actions can work with OCR outputs to extract fields, summarize content and classify documents. These workflows replace the old “Plugins” approach and allow programmatic orchestration of parsing and layout-aware prompts.
Llamaparse: A layout-aware document parser that outputs structured JSON with bounding boxes, semantic tags and object links. It also supports schema-style extraction controls.
Qwen2.5-VL: A multimodal vision-language model handles high-resolution image input, extracts OCR-level text, and understands complex layouts including tables and charts. The model supports multi-turn interactions for iterative document comprehension and excels in visual question answering benchmarks, making it a powerful document intelligence tool.
Tool
Accuracy
Layout Handling
Hallucination Risk
Best For
LLMWhisperer
Superior
Superior
✅ None
Handling complex layouts and tables with built-in compliance for enterprise workflows
Mistral OCR
High, not accurate with tables
Medium
⚠️ High
Fast prototyping, digital docs
Qwen2.5-VL
Medium, not accurate with tables
High
⚠️ High
Multilingual, complex layouts
olmOCR
High, limited language support
Poor
⚠️ High
Self-hosted experimentation
LLMWhisperer vs. Mistral AI OCR
We compared Mistral AI OCR and LLMWhisperer through hands-on tests with real-world, complex documents. Beyond raw text extraction, we evaluated each tool’s ability to preserve structure, process non-text elements, and minimize LLM pitfalls like hallucination.
Noise Resistance: Deep convolutional denoising networks and large data augmentation allow strong recognition of blurred, low-contrast or folded documents. This eliminates the need to have custom preprocessing pipelines to deal with variable scan conditions.
Contextual Corrections: Transformer-based language models apply attention over full sentences to disambiguate similar glyphs (e.g., “1” vs. “I”). Context-aware decoding improves character error rates by fixing plausible misclassifications.
Semantic Structuring: Graph-based relation extractors can identify key-value pairs without needing strict templates. End-to-end neural parsers create structured JSON. They link text spans with semantic tags and spatial data.
Multi-language, Multi-format: Byte Pair Encoding (BPE) tokenizers and multi-lingual vision-language models can be used across scripts and fonts. Unified architectures do not have different engines to handle printed text, tables and mixed-layout documents.
Disadvantages of AI OCR
Despite its strengths, AI OCR introduces its own set of challenges. These include:
Hallucinations: When generative LLM decoders encounter low confidence scores, they may insert plausible but non-existent content, leading to inaccuracies. A Reddit user shared their experience with multimodal LLM-based OCR, explaining that it doesn’t actually “read” the page. Instead, it attempts to predict a likely version after embedding the image.
Latency: Deep transformers often take hundreds of milliseconds per page for GPU-bound inference. Latency can slow down real-time or high-throughput pipelines, especially if they lack special hardware. Use model-optimized inference runtimes to reduce GPU load and cut per-page latency.
Cost: Cloud-hosted OCR APIs are typically priced per API call or token, making large-scale operations costly. On-premise setups are expensive due to GPU provisioning and maintenance. Use batch processing and lightweight or open-source OCR models to help reduce GPU usage and lower API costs.
Human-in-the-Loop: Many services provide optional human-review features, like review queues and feedback loops. But these can increase complexity, cost and latency. Custom annotation layers are needed to collect feedback and retrain models.
Poor Traceability: End-to-end neural pipelines do not always accurately map extracted entities back to their exact locations in the original image. Provenance tracking modules are essential for auditing and compliance workflows.
Privacy Risks: Posting sensitive files to cloud APIs creates GDPR, HIPAA and other compliance issues. On-premise secure alternatives reduce risks at the cost of complexity in infrastructure.
Poor Layout Parsing: In real-world scenarios, AI OCR can misinterpret document structure, which can lead to major usability issues. On Hacker News, one user described an AI OCR service that mistook 80% of the text for images. As a result, the system replaced most of the text with whitespace, leaving the document largely blank and rendering it unusable.
Why AI OCR Software Isn’t Enterprise-Ready Yet?
Weak transparency and governance controls limit AI OCR adoption in enterprises. Most pipelines don’t log model versions, parameters or data provenance in a tamper-proof way. Without this, teams can’t maintain a verifiable record of how outputs were produced. This makes GDPR, HIPAA and SOX compliance difficult.
Transformer-based models are nondeterministic. This means that even small changes in prompts or updates to the model can result in different text extractions from the same document.
That unpredictability makes it difficult to enforce SLAs or keep downstream automations stable. Field positions may shift and accuracy can vary without clear warning.
Enterprises often build custom MLOps layers with tools like MLflow or data version control to track changes and monitor model drift. This slows deployment and reduces the operational efficiency of AI OCR.
Where AI OCR Solution Works Well
Although traditional OCR has its advantages, AI-powered OCR is best used in situations where you need more than simple text recognition:
Standardized Documents: Neural parsers work well with template-based documents with slight variations, such as invoices, receipts and tax forms. They learn the fixed layouts of these fields and can adjust to small changes or imperfections. This delivers low character-error rates with consistent and reliable field positioning.
Fast Prototyping: Composable prebuilt OCR+LLM stacks using APIs can speed up proof-of-concept development. Minimal template logic allows engineers to iterate in days instead of weeks.
Low-Risk Applications: Applications like search-indexing and metadata tagging can handle some misreads without major issues. In this case, throughput and flexibility are more important than absolute precision.
Digitizing Archives: Bulk conversion of historical or scanned collections is typically optimized for speed rather than perfect accuracy. Any remaining errors can be fixed by subsequent manual review or enrichment.
What Is LLMWhisperer? The Missing Link in OCR for LLMs
Modern LLMs work best with structured and detailed inputs. Raw documents usually lack this organization. It’s important to change these into a format that keeps the meaning, context and structure.
A tool like LLMWhisperer can help streamline such processes and help create dependable AI-driven workflows. It is a high-precision document parsing tool that formats OCR outputs into clean, LLM-compatible formats.
It uses deterministic computer-vision methods, including adaptive thresholding and layout analysis, to identify zones of text, tables and annotations.
LLMWhisperer Explained: Quick Intro Video
AI-Powered Document Extraction: How LLMWhisperer OCR Fits In
LLMWhisperer is a hybrid between OCR and AI OCR. It uses pixel-perfect layout parsing and schema-based structuring to maintain document context. It is compatible with mixed-layout documents, scanned PDFs and images. Preprocessing modules carry out adaptive thresholding, de-skewing and semantic zone detection to assure spatial fidelity.
Its output includes token-level bounding boxes, element semantics, and confidence scores in JSON, HTML, Markdown, or CSV format. Embedded metadata enables full auditability and traceability from the source image to the extracted text.
Structured output streamlines LLM workflows by reducing prompt complexity and minimizing unnecessary token usage. Optional compaction removes whitespace and unnecessary tokens to regulate the cost of inference. Integration is available through REST API, on-premise server or cloud, which makes it scalable and provides stable performance.
Key Benefits
Here are the key benefits that make LLMWhisperer a powerful choice for precise, context-rich text extraction.
Auditability & Layout Fidelity: LLMWhisperer’s layout preserving mode maintains visual and positional context, including checkboxes, radio buttons and raw text for full traceability. This ensures that extracted data remains auditable against the original document layout.
Cost Efficiency: Auto-compaction removes whitespace and unnecessary tokens without changing the layout. This decreases LLM input size, reducing inference costs and increasing throughput.
Future-Proofing: Schema-driven and layout-preserving JSON decouples data formatting from changing LLM prompt needs. This keeps it compatible with LLM architectures and prompt engineering practices.
No AI in OCR Stage: Extraction uses median filtering and Gaussian blur before OCR to ensure consistent results and reduce variability. This lowers the chances of layout mistakes, drift and model hallucination issues.
Deterministic Preprocessing: The Python client offers fine-grained control over preprocessing parameters such as line_splitter_tolerance. These parameters make it possible to reproduce identical image enhancement results in both edge deployments and on-premise environments.
LLM-Optimized Structuring: Layout-preserving output mode maintains reading order and block alignment, reduces noise and ensures coherent text flows. This reduces downstream error rates and lowers prompt complexity when feeding LLMs.
Use-Cases
From OCR order entry systems in retail to complex image-based PDF data extraction from legal notices, LLMWhisperer can streamline OCR pipelines efficiently. The following examples demonstrate how LLMWhisperer turns complex documents into clean, structured data.
Document: Universal Loan Application Extraction PDF
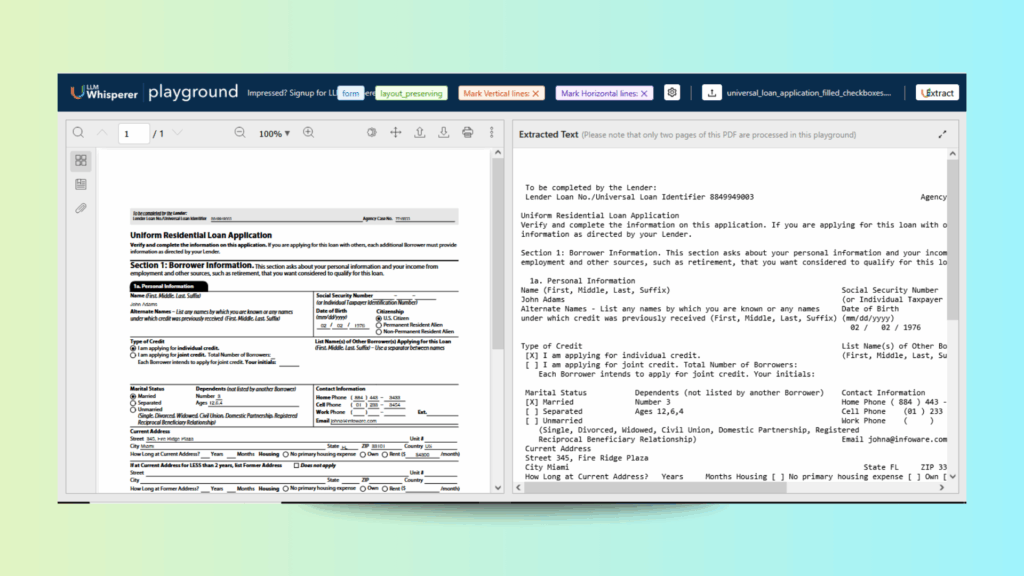
The URLA (Form 1003/65) is a standardized mortgage industry form used in the U.S. It gathers detailed information about the borrower, including identity, income, employment, assets, debts, and housing history.
Business Use Case
Parsing the URLA allows mortgage lenders, banks, and fintech platforms to automate their loan origination processes. With structured data out of this form, businesses can:
Pre-Fill Systems: Structured data can pre-fill underwriting systems.
Verification: Compare the information of the borrower with the supporting documents
Risk & Compliance: Accelerate credit risk analysis and compliance reporting.
This automation streamlines data entry, accelerates the approval process, and improves the customer experience.
Problems in Parsing
Complex Structure: The form has numerous sections (borrower, co-borrower, income, employment, housing, etc.), with checkboxes, dates, and multi-field tables to map.
Differences in Filled Forms: Handwritten entries, scanned PDFs, checkmarks, or digital vs. paper variations can make OCR and data extraction more difficult.
Sensitive Data: Parsing should be able to meet stringent privacy and regulatory standards (e.g., GLBA, CFPB, GDPR for some users).
Contextual Fields: Some fields are conditional (e.g., less than 2 years at the current address), requiring intelligent parsing rather than simple text extraction.
Result: Complete Borrower Profiles Extracted Without Omissions
After uploading the document to LLMWhispherer Playground, the results are clear and accurate. Borrower details, income, and housing data are extracted into structured fields instantly, eliminating manual entry. This ensures faster loan processing, higher accuracy, and compliance-ready records.
LLMs have become operational powerhouses, thanks in part to their ability to extract rich, meaningful information from documents. But even the best models, in real-world use cases, often depend heavily on the quality of the input they receive.
Discover how LLMWhisperer, Unstract’s dedicated text extraction service, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.
Document: Scanned Document form with Handwriting
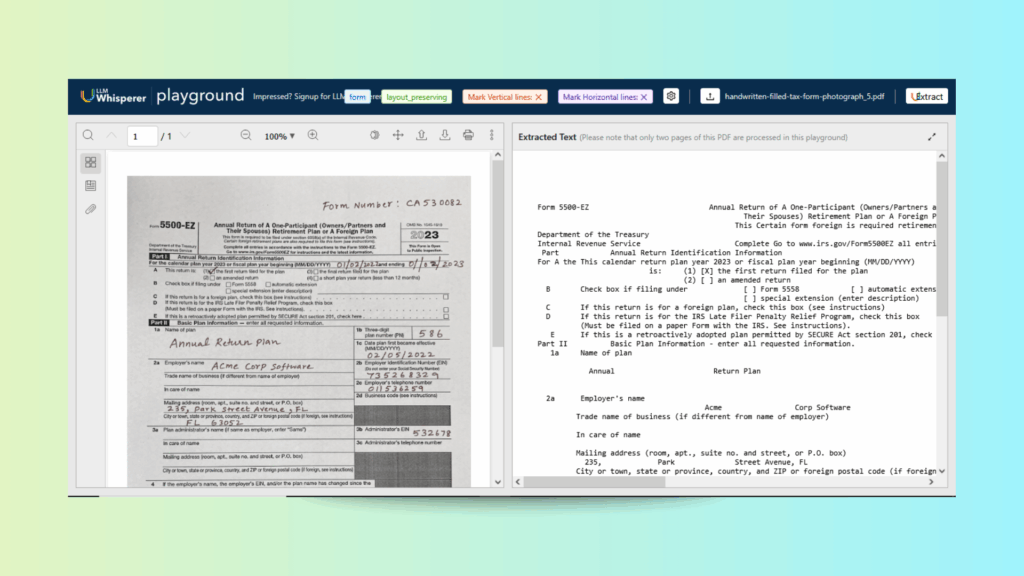
The IRS Form 5500-EZ is a mandatory compliance document for one-participant retirement plans. It records plan identifiers, employer information, administrator details, and contribution timelines, often combining typed fields with handwritten updates.
Business Use Case
Compliance Reporting: Automates IRS compliance reporting by extracting structured plan data.
Monitoring: Supports year-over-year tracking of contributions and plan changes.
Audit Readiness: Enables audit preparation and reduces manual processing effort.
Penalty Prevention: Minimizes risk of penalties from late or incorrect filing.
Parsing Challenges
Mixed Fields: A combination of handwritten and typed fields complicates OCR.
Date Rules: Multiple date fields must align with IRS compliance rules.
Layout Rigidness: Checkboxes and rigid layout create parsing complexity.
High Precision: Sensitive financial and personal data demands compliance-level accuracy.
Result: Error-Free Compliance Digitization
LLMWishperer accurately captures all key details. It handles different handwriting styles and recognizes both printed and handwritten text. The preserved structure keeps the extracted content ready. It’s set for review, storage or further processing.
See How LLMWhisperer Handles What AI OCR Gets Wrong
You’ve read about the hallucinations, the layout collapse, the compliance gaps. Now test the hybrid approach yourself — no theory, no signup, no credit card.
Drop in a scanned PDF, a handwritten form, a multi-column insurance table, or a faded bank statement. Get structured, audit-ready output instantly.
Try LLMWhisperer free on the Playground — 100 pages/day, no account required.
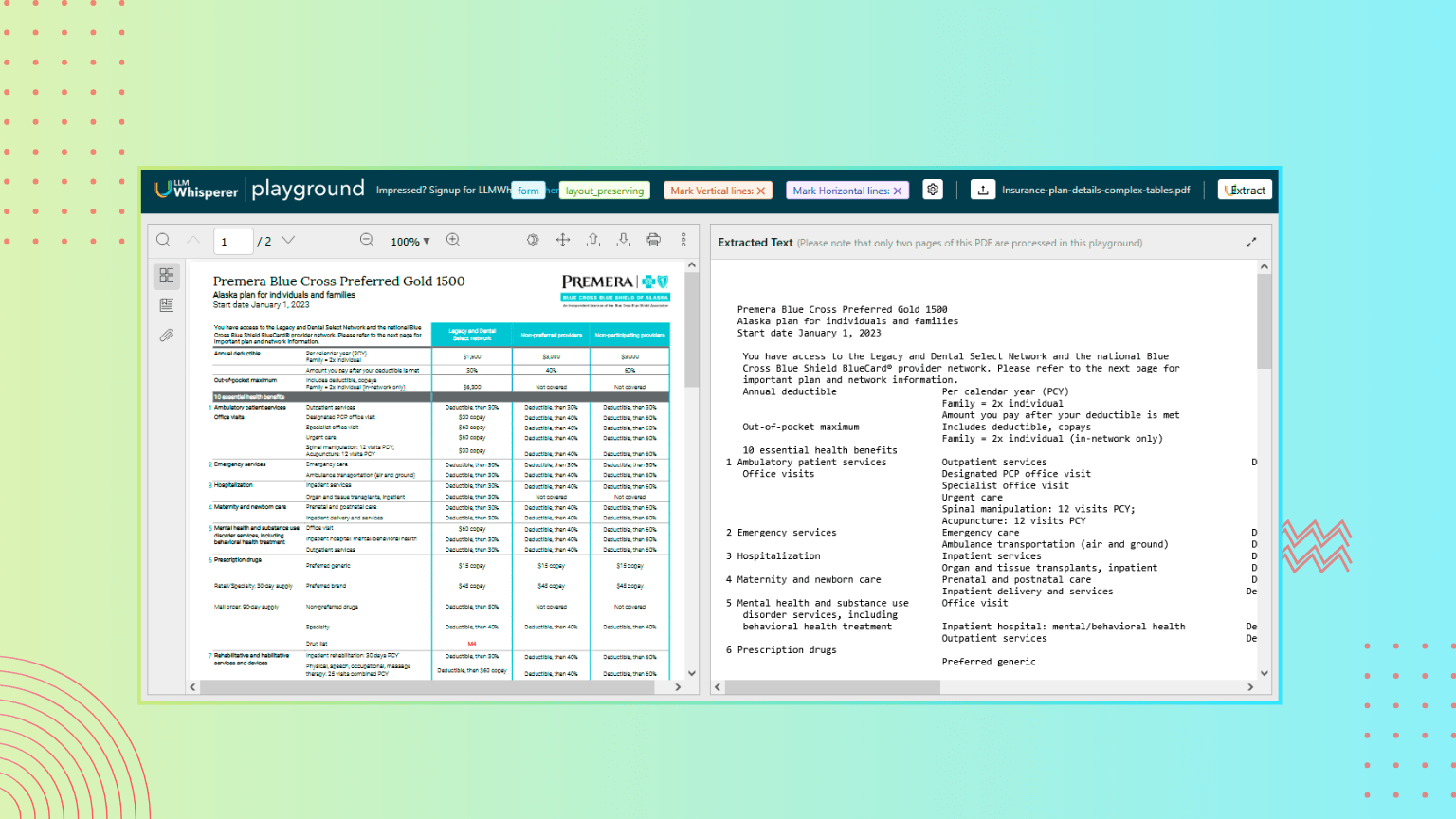
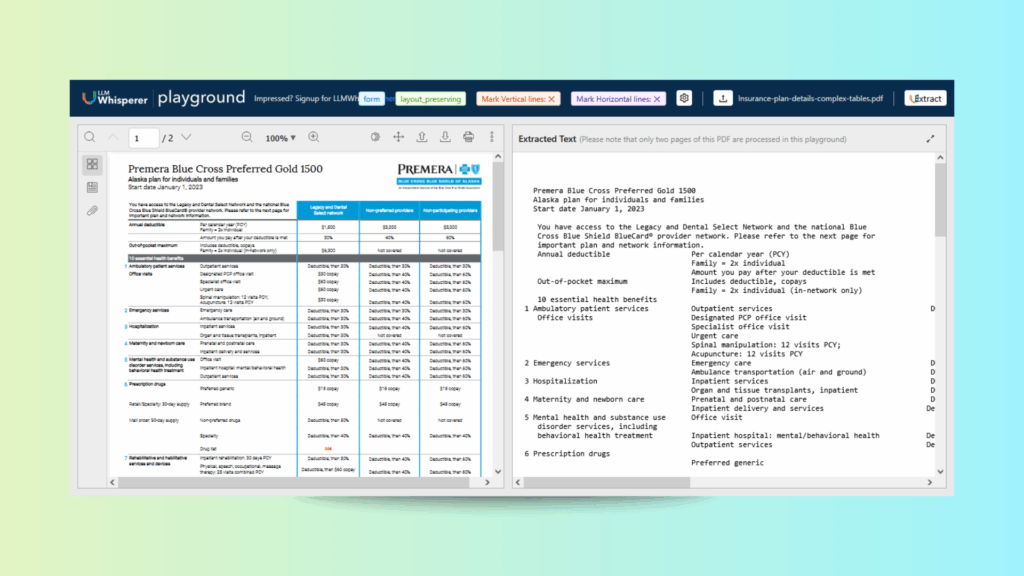
Health insurance coverage table detailing deductibles, co-pays, coverage levels, and cost-sharing between in-network and out-of-network providers.
Business Use Case
Benefit Comparison: Automates plan comparison and eligibility checks to insurers, brokers, and HR platforms.
Cost Estimating: Provides patients with accurate calculations, eliminating misunderstandings about co-pays and coverage.
Process Automation: It supports digital onboarding, claims pre-validation, and plan recommendation engines.
Parsing Challenges
Complex Layout: It is hard to parse the multi-column tabular layout.
Terminology Variance: There are different terms (copay, deductible, coinsurance) that will need to be standardized.
Conditional Coverage: In-network vs. non-preferred vs. out-of-network rules have to be pinpointed with precision
Accuracy Requirement: Misinterpretation can cause financial mistakes and compliance problems.
Result: From Pages of Tables to Ready-to-Use Digital Data
The system accurately extracts and keeps the structure, even with dense formatting. This makes it easy to review benefits, costs, and provider tiers in plain text.
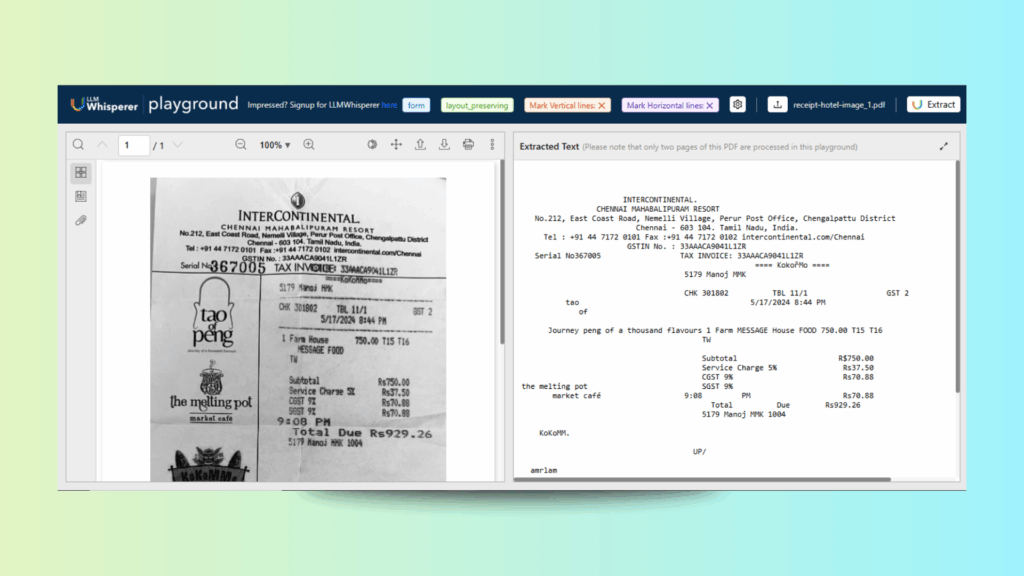
Document: Poorly Aligned Receipt
Itemized hotel/restaurant invoice showing guest name, room number, charges (food, service, GST/SGST), payment mode, and signatures. Mix of printed, stamped, and handwritten fields (e.g., guest name, payment type).
Business Use Case
Expense Reporting: Automates reporting for corporate travelers and finance teams.
Reconciliation: Matches hotel/restaurant charges with bookings and payments.
Compliance: Ensures audit trails and adherence to T&E policies.
Parsing Challenges
Mixed Data Types: Printed, stamped, and handwritten text require hybrid OCR/NLP techniques.
Unstructured Layout: Branding, logos, and varied formatting can confuse parsing models.
Abbreviations & Codes: Tax fields (CGST, SGST, GSTIN) must be recognized and normalized.
Handwriting Variability: Guest name and payment method (e.g., “UPI”) must be correctly captured.
Result: Seamless Receipt Digitization for Smarter Expense Management
Complete digitization of hotel receipts with line-item accuracy, enabling seamless expense automation and compliance-ready reporting.
Finding the right AI OCR Solution: What’s next
Choosing the right OCR approach requires balancing accuracy, transparency, and risk tolerance. Traditional OCR performs well with clean, structured documents. However, it struggles with messy handwriting, complex tables, and unstructured layouts.
AI for OCR uses deep learning to boost accuracy in complex cases. It can interpret context, handle irregular layouts, and extract text from poor-quality inputs.
LLMWhisperer offers a balanced alternative. It combines deterministic processing with layout-aware extraction to produce structured, LLM-ready JSON outputs. Results are consistent, verifiable, and preserve complete contextual integrity.
Get started with LLMWhisperer for free, process up to 100 pages a day, and experience precise, LLM-ready extraction.
AI OCR – FAQ
1. Why is ai OCR not yet fully enterprise‑ready according to the blog?
AI OCR suffers from non‑deterministic outputs, hallucinations, poor traceability, and high compliance risk. Most ai ocr software does not log model versions or data provenance in a tamper‑proof way, making it difficult to meet GDPR, HIPAA, or SOX requirements in production environments.
2. What business value does ai OCR software bring compared to traditional OCR?
AI OCR software excels at handling messy documents – cursive handwriting, low‑resolution scans, and unstructured layouts. It reduces manual data entry for invoices, tax forms, and contracts, speeding up back‑office workflows when absolute precision is not critical.
3. Where do ai OCR tools work best in real‑world business scenarios?
AI powered OCR tools work well for standardized documents like invoices and receipts, fast prototyping, low‑risk applications (search indexing, metadata tagging), and bulk digitization of historical archives where occasional errors can be fixed by human review.
4. How does LLMWhisperer address the governance gaps of ai powered OCR for enterprises?
LLMWhisperer uses deterministic computer‑vision methods (adaptive thresholding, layout analysis) with no AI in the OCR stage. It outputs confidence scores, bounding boxes, and audit‑ready JSON, giving full traceability – a hybrid model that combines the strengths of ai powered ocr with enterprise governance.
5. What are the hidden costs of deploying ai OCR at scale for a finance or healthcare company?
AI powered OCR incurs high inference latency (hundreds of milliseconds per page on GPUs), per‑API‑call pricing, and expensive on‑premise GPU maintenance. Hallucinations and layout errors also require human‑in‑the‑loop review, adding operational complexity and cost.
6. How can a business identify the best ai OCR solution for its document types?
To find the best ai OCR, verify that the engine produces deterministic layout metadata, supports human‑in‑the‑loop review, and logs model provenance for audits. Hybrid platforms like Unstract with LLMWhisperer offer greater governance and stability than pure end‑to‑end LLM‑based APIs.