Comparing approaches of using LLMs for Structured Data Extraction from Unstructured PDFs
Table of Contents
Organizations have to deal with a lot of data in PDF form, and those unstructured PDFs can come in a variety of structural formats as well. There can be native text PDFs, PDFs that are made up of scanned images and more recently, users uploading photos of various documents clicked on their smartphones are fairly common as well.
It is a common need for structured data in a well-defined schema to be extracted from these documents so that it can be processed predictably in downstream systems.
Unstructured to structured data processing: A challenge on many levels
When structured data needs to be created from various document sources, there are multiple challenges involved.
Wide-ranging input formats: Raw data from native text PDF, scanned PDFs and images needs to be extracted
Well-defined schema: We should be able to take that raw extracted data and prompt a Large Language Model (LLM) to give us the data we need in a well-defined schema so that downstream systems can predictably process that data.
Automated Evaluation: Since LLMs can hallucinate or extract the wrong data, we need to ensure that there are automated evaluations in place so that we can trust the data that the LLM is responding with. If a human is involved in this evaluation, it can become slow, laborious and not to mention, error prone.
Structural variations of the same document type: There can be a large number of variations in the same document type of class. For example each invoice, NDA, contract or resume might look very different from the other. We need to create prompts that are generic enough, so that they can successfully extract structured data from widely varying structural or semantic formats.
Generic prompts: One needs to ensure that developed prompts are good for a particular type or class of document irrespective of different forms that document presents itself in. One also has to think about how we can quickly do the required prompt engineering for new types of unstructured documents from which we need to extract structured data from.
Strict output formats for machine consumption: Humans are very tolerant of different styles of outputs from LLMs. For instance, while extracting a date, the same date could be returned by an LLM as: 2024-06-03, July 3rd, 2024, 3rd July, 2024 or 06/03/2024. To a human, these are easily interpreted. Structured data extraction needs to be in an exact format so that it can be processed by downstream systems. Variations in formatting are not tolerated easily. The easiest format for machine processing is JSON and we’ll stick to that in this article.
In the first one, we’ll employ Langchain, the popular Python-based LLM framework in combination with the Pydantic library to use an LLM to create structured output.
In the second approach, we’ll use an open source platform, Unstract, which is purpose built for structured document data extraction. Unstract features Prompt Studio, a prompt engineering environment specialized for what we’re trying to achieve—document data extraction with LLMs.
Later in the article, once we look in detail into our two approaches of using a regular IDE to do prompt engineering vs. using a specialized environment to do the same, we’ll look at these challenges in light of each of those approaches to evaluate how we fared in either case.
Let’s settle on an extraction use case
Let’s consider that you want to extract structured data from a bunch of credit card statements from different issuers. We’re taking credit card statements as an example since no matter what your background, it’s safe to assume that you’ll know what a typical credit card statement looks like and what key points of information it might contain, since credit cards are a fairly common part of our lives.
At the same time, we know that every issuer has their own statement format and even for the same issuer, the format of the statement can keep changing from time to time. So, it’s a pretty decent challenge to use such statements to build our project.
The aim is to extract structured data from diverse credit card statements in PDF format and convert it into a consistent JSON format using OpenAI’s GPT-4 Turbo.
Credit card statements are typically emailed to users as PDF documents. Like most unstructured documents, these statements, although most of them consist of the same bits of key information (customer name, customer address, issuer name, statement date, list of spends, etc.), they come in wildly different formatting and lengths.
It has never been easy to get data from these varied types of statements into a database or into an application in structured form for easy querying, analysis or visualization.
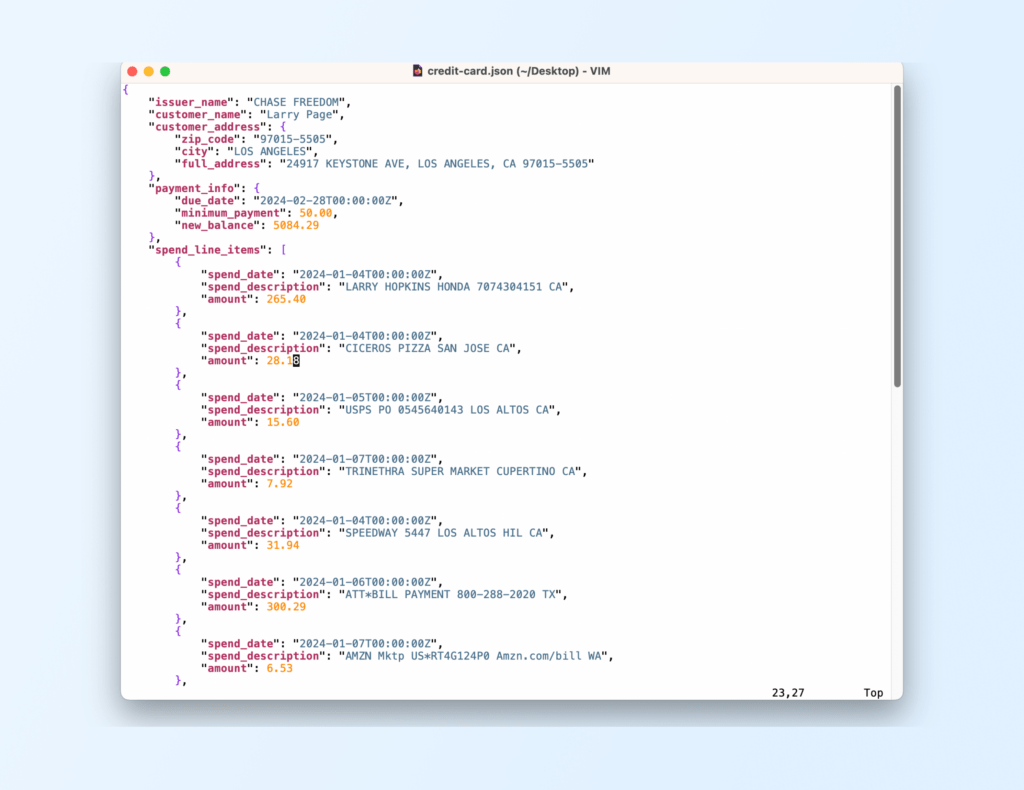
With either approach, we want the end result to be similar: each of the PDF credit card statements need to be converted into JSON output to the one shown above. We will use OpenAI’s GPT4-Turbo LLM to achieve this.
Downloading sample documents
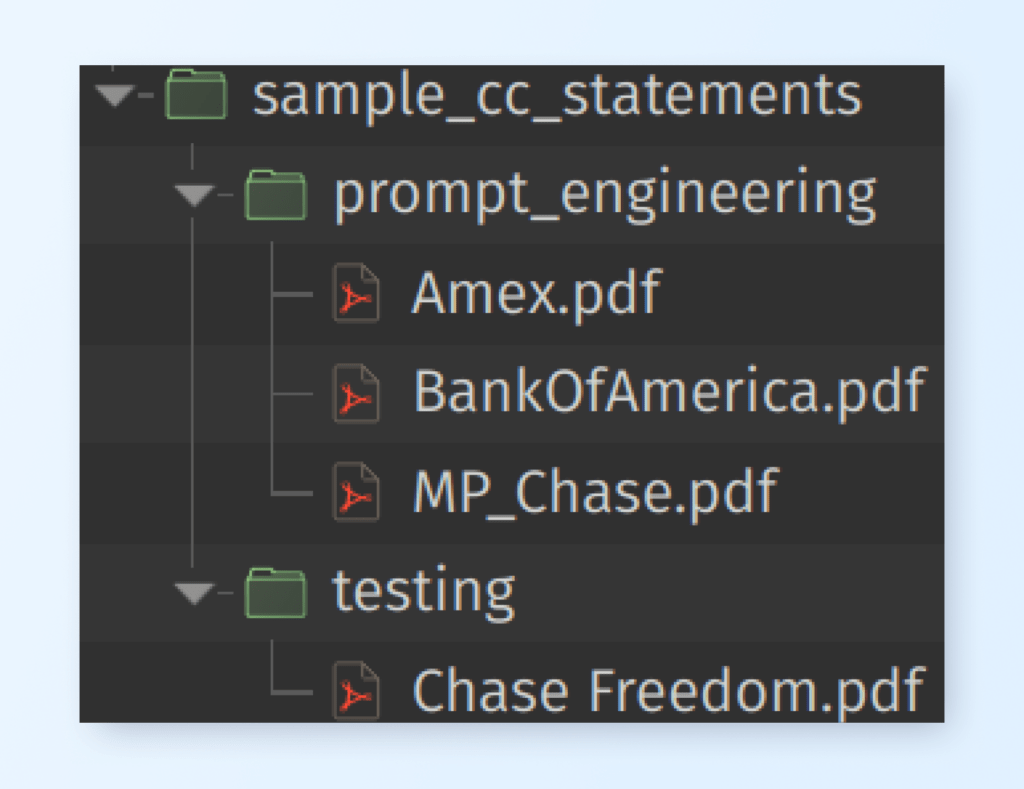
So you can get started quickly, we’ve put together a zip file consisting of a set of sample credit card statements. Download the sample set of credit card statements from here. There are a total of 4 sample statements in the provided zip file.
Once you unzip the files, you’ll find two folders inside the parent folder. One named prompt_engineering and the other named testing. We will use 3 statements inside the prompt engineering folder to prompt engineer structuring of the documents and then we’ll use the statement inside the testing folder later in our second approach when we use Unstract, to see how well our project works on new files not seen by the system. To create generic structuring APIs, you’ll probably need dozens of documents, but this simple project should help you wet your feet.
Now that you’ve downloaded the statements, let’s go ahead, structure them and look at how to automate the processing of credit card statements.
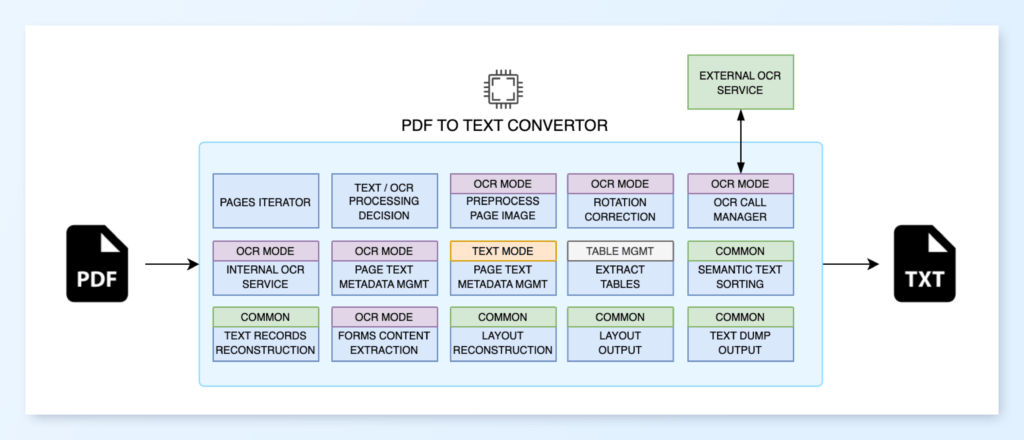
Extracting text from the PDFs
Irrespective of the type of approach we’ll take to structure our credit card statements, we’ll first need to extract text from the statement PDFs. Since we want to concentrate on the heavy lift of structuring the unstructured data effectively, we do not want to be dealing with the low-level raw text extraction from the PDFs themselves, since they could be native text documents, scanned image PDFs or smartphone-clicked pictures of statements.
For this purpose, we’ll go with LLMWhisperer, which is a text extraction service designed to output text for processing by LLMs. It has the ability to extract text from most real-world PDFs, including pretty bad scans or pictures. Also, LLMWhisperer is free to use for up to 100 pages per day, which should be plenty enough for our exercise here.
Prompting goal: making them generic
It’s very important for us to develop prompts that are generic since the input documents—in this case, credit card statements—can come from any bank or issuer and can be in a wide variety of formats or structures. So, the idea is to start with a set of sample documents that are from different banks and so naturally, they will be differently structured.
We will then ensure that the developed prompts work as expected for all 3 sample input documents. This will ensure that when new documents are processed with the same prompts, structured extraction succeeds for those documents that the system has not seen before. While for the purpose of this exercise we use 3 sample unstructured documents to develop our prompts, in practice you might want to use at least a dozen.
The sample document zip file also comes with a test document from another bank to verify if our prompts are indeed fairly generic. We will use this later once we develop our prompts.
Approach 1: Full code with Langchain and Pydantic
Langchain is a popular Python-based LLM programming framework. Since the creation of structured data is an important LLM use case, Langchain integrates Python’s popular Pydantic library in order to achieve this. In this approach, we’ll define the output schema we need as Pydantic models or classes.
The really good thing about this approach is that we just mostly need to annotate the Pydantic classes with the format we’re expecting as the output and these annotations will then be turned into prompts to instruct whatever LLM we use. Parsers are available in Langchain that can then be used to create native Python objects from the LLMs output, thus in effect converting an unstructured PDF credit card statement into a Python object, which is great!
This is how we define our schema with Pydantic:
class CustomerAddress(BaseModel):
zip_code: str = Field(description="Should contain the zip code alone")
city: str = Field(description="Should hold the city name from the address")
full_address: str = Field(description="Should hold the full address of the customer")
class PaymentInfo(BaseModel):
due_date: datetime = Field(description="The due date of the credit card statement. Also known as the payment due "
"date")
minimum_payment: float = Field(description="the minimum amount that is due")
new_balance: float = Field(description="the total new balance amount that can be paid")
class SpendLineItem(BaseModel):
spend_date: datetime = Field(description="The date of the transaction. If the year part isn't mentioned in the "
"line item explicitly, pick up the year from the statement date and use "
"it instead.")
spend_description: str = Field(description="The description of the spend")
amount: float = Field(description="The amount of the transaction")
class ParsedCreditCardStatement(BaseModel):
issuer_name: str = Field(description="What is the name of the issuer or the bank who has issued this credit card? "
"I am not interested in the legal entity, but the primary brand name of the "
"credit card.")
customer_name: str = Field(description="What is the name of the customer to whom this credit card statement "
"belongs to? Format the name of the customer well with the first letter of "
"each name capitalized.")
customer_address: CustomerAddress = Field(description="Since there might be multiple addresses in the context "
"provided to you, first gather all addresses. Try to "
"understand whom this credit card statement is being "
"addressed to or in other words, the name of the customer. "
"Find the address that matches that person's. Be sure to "
"return the customer's address, for whom this credit card "
"statement is for. Do not respond with any other address.")
payment_info: PaymentInfo = Field(description="Payment information is important part of any credit card statement "
"and it consists of the new balance or the full amount due for the "
"current statement, the minimum payment due and the payment due "
"date.")
spend_line_items: list[SpendLineItem] = Field(description="This credit card statement contains spending details "
"line items. Spend details can be split across the "
"provided context. Respond with details of all the "
"spend items by looking at the whole context always.")
The ParsedCreditCardStatement class defines the main schema, while other class definitions are nested objects under it.
Before you run the project
The source code for the project can be found here on Github. To successfully run the extraction script, you’ll need 2 API keys. One for LLMWhisperer and the other for OpenAI APIs. Please be sure to read the Github project’s README to fully understand OS and other dependency requirements. You can sign up for LLMWhisperer, get your API key, and process up to 100 pages free of charge per day.
Step 1: Extracting raw text with LLMWhisperer
When you run the extract.py script, you need to either pass the path to a credit card statement PDF file or point to a folder that has multiple PDFs, which will all be processed one after the other.
The function enumerate_pdf_files() is dedicated to enumerating the files and creating a list of one or more files that will need to be processed.
Since the script can be run multiple times, especially when you experiment with tweaking the prompts or the extraction schema, we don’t want to keep invoking the LLMWhisperer raw text extraction service. Our PDFs are read only and the raw text from them isn’t going to change. We cache the raw text we extract from our PDFs with LLMWhisperer in the /tmp directory based on the file’s hash. Every time raw text needs to be extracted from a PDF, we’ll always check if the file is cached and if it is, we’ll return the cached data.
The extraction script is peppered with a bunch of print statements so that you can see what’s going on. You should also see the extracted text returned by LLMWhisperer scroll by as the script runs. You can see that LLMWhisperer preserves the format of the input PDF in the raw text output, which is really good for LLMs since with this, they are able to detect columns and tables. Also, feel free to inspect the cached .txt files under the /tmp directory after you run the script. Below is a sample extraction of raw text from one of the sample credit card PDF statements.
AMERICAN Blue Cash ® from American p. 1/7
EXPRESS Express
JOSEPH PAULSON Customer Care: 1-888-258-3741
Closing Date 09/27/23 TTY: Use Relay 711
Account Ending 7-73045 Website: americanexpress.com
New Balance $10,269.65 as Reward of 08/29/2023 Dollars
Minimum Payment Due $205.39 [ ] For more details about Rewards, 1,087.93 visit
americanexpress.com/cashbackrewards
Payment Due Date 10/22/23 Account Summary
Late Payment Warning: If we do not receive your Minimum Payment Due by Previous Balance $6,583.67
the Payment Due Date of 10/22/23, you may have to pay a late fee of up to Payments/Credits -$6,583.67
$40.00 and your APRs may be increased to the Penalty APR of 29.99%. New Charges +$10,269.65
Fees +$0.00
Interest Charged +$0.00
Minimum Payment Warning: If you have a Non-Plan Balance and make only the New Balance $10,269.65
minimum payment each period, you will pay more in interest and it will take you longer Minimum Payment Due $205.39
to pay off your Non-Plan Balance. For example:
Credit Limit $26,400.00
If you make no additional You will pay off the balance And you will pay an Available Credit $16,130.35
charges and each month shown on this statement in estimated total of ... Cash Advance Limit $4,600.00
you pay ... about ... Available Cash $4,600.00
Only the
Minimum Payment Due 22 years $29,830
$407 3 years (Savings $ 14,640 = $15,190)
If you would like information about credit counseling services, call 1-888-733-4139.
See page 2 for important information about your account.
Please refer to the IMPORTANT NOTICES section on
page 7.
Continued on page 3
Please fold on the perforation below, detach and return with your payment 4
Payment Coupon Pay by Computer Pay by Phone Account Ending 7-73045
Do not staple or use paper clips americanexpress.com/pbc 1-800-472-9297 Enter 15 digit account # on all payments.
Make check payable to American Express.
JOSEPH PAULSON Payment Due Date
3742 CLOUD SPGS RD 10/22/23
#403-1045
DALLAS TX 75219-4136 $10,269.65 New Balance
Minimum Payment Due
$205.39
See reverse side for instructions AMERICAN EXPRESS $
on how to update your address, PO BOX 6031 Amount Enclosed
phone number, or email. CAROL STREAM IL 60197-6031
0000349991822708152 001026965000020539 24 H
<<<
Step 2: Invoking the LLM
Langchain makes it easy for us to define the prompts needed. Langchain’s Pydantic integration allows us to specify the exact output schema we need from the LLM with Pydantic-defined objects.
Much of the prompting logic is in the extract_values_from_file() function:
def extract_values_from_file(raw_file_data):
preamble = ("\n"
"Your ability to extract and summarize this information accurately is essential for effective "
"credit card statement analysis. Pay close attention to the credit card statement's language, "
"structure, and any cross-references to ensure a comprehensive and precise extraction of "
"information. Do not use prior knowledge or information from outside the context to answer the "
"questions. Only use the information provided in the context to answer the questions.\n")
postamble = "Do not include any explanation in the reply. Only include the extracted information in the reply."
system_template = "{preamble}"
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = "{format_instructions}\n{raw_file_data}\n{postamble}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
parser = PydanticOutputParser(pydantic_object=ParsedCreditCardStatement)
print(parser.get_format_instructions())
# compile chat template
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
request = chat_prompt.format_prompt(preamble=preamble,
format_instructions=parser.get_format_instructions(),
raw_file_data=raw_file_data,
postamble=postamble).to_messages()
model = ChatOpenAI()
print("Querying model...")
result = model(request, temperature=0)
print("Response from model:")
print(result.content)
return result.content
The preamble and postamble provide general instructions to the LLM. The AI’s system prompt is set to the `preamble`.
We create a Pydantic parser instance from PydanticOutputParser passing in our top-level schema definition of ParsedCreditCardStatement and use the get_format_instructions() method to generate the required prompts to pass to the LLM so it can create the structured output we need.
The human prompt consists of the following:
The formatting instructions created from our description of the schema with Pydantic
The PDF’s extracted raw text is included as a whole
The postamble
Sidenote
You might be wondering if it’s a good idea to be sending the whole extracted raw text from the PDF as part of the LLM’s input context. In this particular case, we do have to, and for a very good reason. A common technique with RAG or Retrieval-Augmented Generation is to use a vector DB to find chunks of text from the raw input text that is relevant for each prompt.
In this case, however, we have two problems with that approach. First off, we’re sending our instructions to extract a bunch of fields as a single prompt, but we’re trying to extract a variety of data from name to address to payment info. When we try to extract a relatively large number of fields that can be spread across multiple locations in the document, any vector DB’s performance dramatically comes down.
Next, we have a practical issue: let’s assume we have a separate prompt to extract just the customer name from the raw text. We’d first ask the vector DB to give us relevant chunks containing the customer’s name. However, there is no “customer name” label in the input raw text that points to the customer name which the vector DB will be able to find relevant chunks.
If you look at the sample raw extracted text above, you’ll see that the credit card statement mentions “Joseph Paulson” in a couple of random places with no “Customer name:” label that might help the vector DB narrow down on the chunk. The vector DB isn’t smart enough to know that the bit of text “Joseph Paulson” is the name of the customer. It quite literally is looking for anything related to “customer name”. In this case, we send the LLM the full context and depend on its smarts to pull out the customer’s name. And for all the sample documents we have, it just works reliably!
We invoke the LLM with the final prompt we’ve assembled and we’ve turned our input PDF statements into beautifully structured JSON data! We now have managed to create a set of fairly generic prompts that should be able to extract structured information from a wide variety of credit card statements.
Let’s evaluate the Langchain+Pydantic approach
In the beginning of this article, we enumerated some challenges one must face when dealing with the task of gleaning structured data out of unstructured documents. Let’s look at those challenges in the light of the code we’ve written so far.
Aspect
How we fared
Wide-ranging input formats
Out of the 3 PDFs we dealt with, one (Bank of America) statement has mostly text-based pages, but page 2 is an image. One giveaway is that you can’t select text from it once it’s opened in a PDF viewer.
But, we didn’t have to bother about any of this since we simply used a raw text extraction service, LLMWhisperer, to take care of this for us. Else, we might have had to deal with PDF extraction libraries, OCR libraries, etc.
Things can quickly become way more difficult when having to deal with smartphone pictures of documents or handwritten text. It is always a good idea to use a raw text extraction service like LLMWhisperer.
Well-defined schema
We did define a clean, simple schema which was also a bit nested for some groupings by defining various Pydantic objects.
Automated Evaluation
This would’ve been a heavy lift for us. One common technique would’ve been to use another LLM to evaluate the output of the first to detect hallucinations and also see if the LLMs also come to a consensus. This would mean a non-trivial amount of development.
Structural variations among the same document type
Although all 4 sample documents we had were credit card statements and contained the same core information, they each had very different structures and layouts.
It would be very difficult to process them with regular programming and processing techniques. Since we leveraged an LLM to process them, we were able to get really good results.
Generic prompts
Writing generic prompts is where development was very challenging. Between the IDE, the terminal and the input documents, as each prompt evolved and got tweaked, there was a need to constantly switch between the IDE to write prompts, the terminal to see the output and the documents themselves to verify that the extraction is indeed correct.
Also, now the code is a mix of prompts, which are instructions to the LLM and our Python code, which are instructions to the computer. Tweaking a prompt, adding more prompts to extract newer fields, is going to be laborious. Even a single word change in a prompt can mean regressions. This means checking the output with all sample documents. This means constantly switching between the IDE, the terminal and the PDFs.
Structured output for machine consumption
Once we defined our schema, we employed Pydantic and Langchain’s ability to work with it to obtain structured output from the LLM. While this approach works, it splits the prompts into various bits between some of the code and the Pydantic class definitions.
Prompt engineering is a new type of development. While leveraging existing tools you can indeed develop systems that achieve what we need, we had to constantly switch between the IDE, PDFs and the terminal to ensure we had generic enough prompts that will work for new documents the system will see in the future.
Approach 2: Using a purpose-built platform like Unstract
Unstract’s Prompt Studio is a prompt engineering environment purpose-built for document data extraction use cases. It uses a similar approach where we develop generic prompts using a set of sample documents which can then be used to extract structured data from other documents of the same type.
There are a lot of advantages when using a purpose-built prompt engineering environment like Prompt Studio. We will look at what those advantages are as we describe the prompt engineering process using Prompt Studio.
Unstract’s Prompt Studio is purpose-built to get prompt engineering done for structured data extraction use cases
While Unstract is open source and you can set it up locally to run on your machine, for this exercise, we’ll be using Unstract’s Cloud Edition, which comes with a 14-day free trial. As part of the free trial, you get free access to the GPT4-Turbo LLM along with access to other essential services like a vector DB, an embedding model and also to LLMWhisperer to extract raw text from the unstructured documents.
Setting up Prompt Studio
Unstract has very detailed documentation available. Once you’ve signed up, you are ready to recreate the credit card statement processing project on the Unstract platform.
Before we look into the various features, it’s a good idea to become a bit familiar with the Unstract platform via the platform documentation. Let’s set your Prompt Studio project up with the following steps:
Read the Getting Started section for a general overview of the credit card structuring example we’ll be undertaking.
Set up the Prompt Studio project by creating an LLM profile, a preamble and postamble, much like the preamble and postamble we create in our full code approach.
Add our sample credit card statements to the Document Manager, which as the name suggests, help manage sample documents in your Prompt Studio project.
You are now ready to start creating prompts to extract structured data.
Creating and running prompts
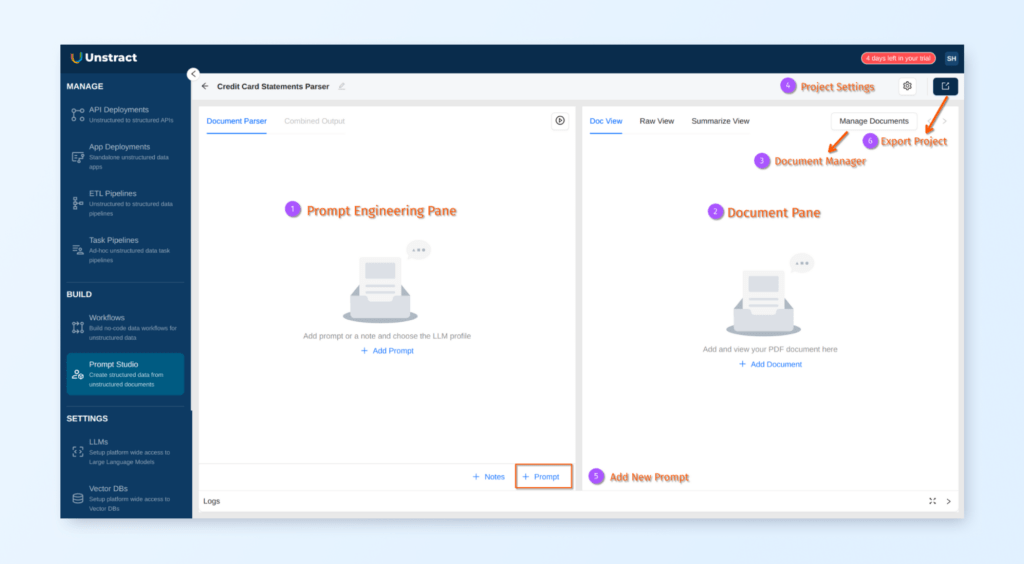
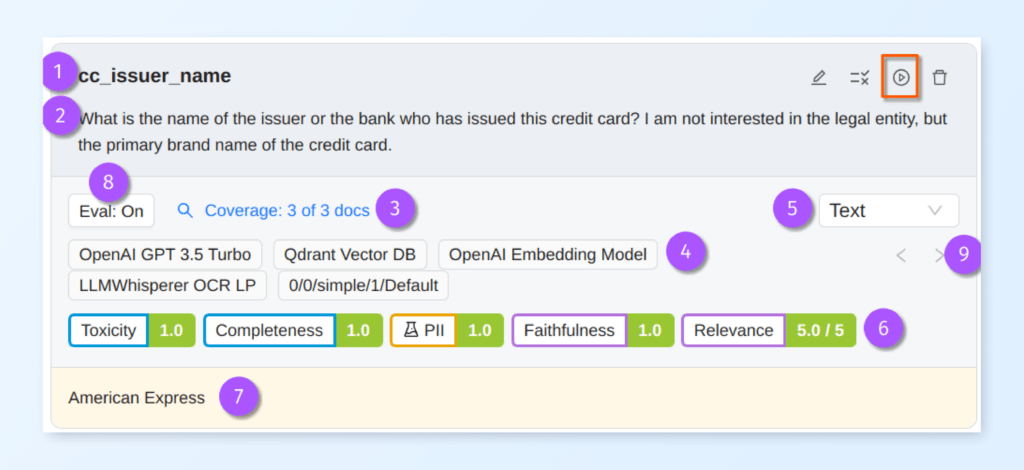
Let’s create our very first Unstract prompt in Prompt Studio to fetch the name of the credit card issuer. Click on the + Prompt button to add a new prompt cell
Let’s understand the different components that make up a prompt cell:
Field Name: This is the field name of the prompt. This will be the field name used in the JSON output. You’ll need to make sure this is JSON key syntax compatible.
Field Prompt: Prompt used to extract the field.
Coverage Info: We have 3 documents loaded into this Prompt Studio project. Coverage Info shows you the number of documents for which this prompt created any output. In this screenshot, we see that our prompt returned some output for all 3 documents, making our coverage 100%. Coverage only checks for null. You’ll need to manually check if the values themselves make sense.
LLM Profile Settings: Shows the currently selected LLM Profile for this prompt. You can use the LLM Profile Switcher (highlighted by 9) to switch profiles and then re-run the prompt.
Output type selector: You can switch between types of output you need. Prompt Studio takes care of adding the prompts required to generate that type of output behind the scenes automatically for you. You can choose between text, data, number, JSON object, etc. When a new prompt is created, the default is always set to Text.
Eval Output: Shows you various parameters determined by output evaluation. You can optionally use this metadata to further process this output. You can set Evaluation parameters in the panel which is brought up by the Eval button highlighted by 8.
LLM Response: This is the area which shows you the response from the LLM.
The Run Prompt button is highlighted in red. As you enter the field name and field prompt, they’re auto-saved. You can then click on the Run button to run the prompt.
For this example prompt, here’s what we enter:
Prompt Field:cc_issuer_name
Field Prompt:What is the name of the issuer or the bank who has issued this credit card? I am not interested in the legal entity, but the primary brand name of the credit card.
Click on the Run button
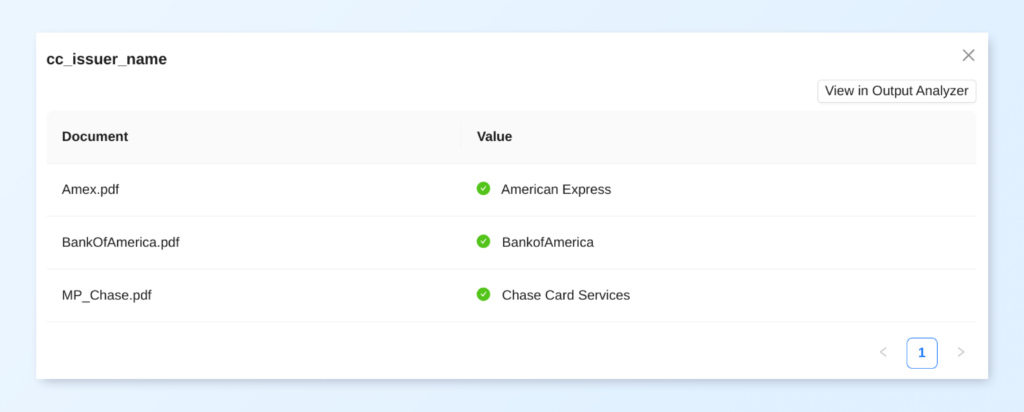
Understanding Prompt Coverage
One thing we struggled with when developing prompts for document data extraction in our IDE is to understand if our prompts were generic enough to extract data out of documents that were in different formats. In Prompt Studio, with just the click of a button, you can see what data was extracted for each of the 3 sample documents in the Prompt Studio project for any prompt you’re developing.
Clicking on the Coverage link brings up the Coverage Panel, which shows the output against the document’s file name.
Adding the rest of the prompts
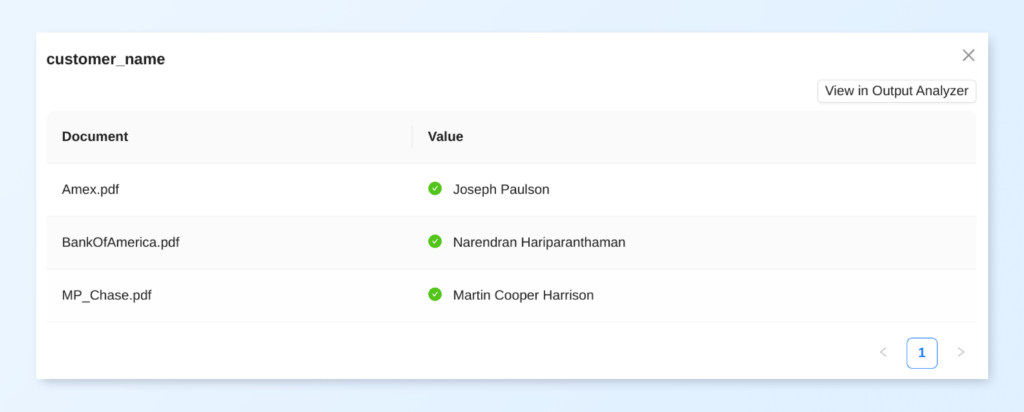
Now that you know how each of your prompts is working for all 3 sample documents in your Prompt Studio project, it’s time to add the rest of the prompts to extract the other fields we’re interested in.
Field prompt: What is the name of the customer to whom this credit card statement belongs to? Format the name of the customer well with the first letter of each name capitalized.
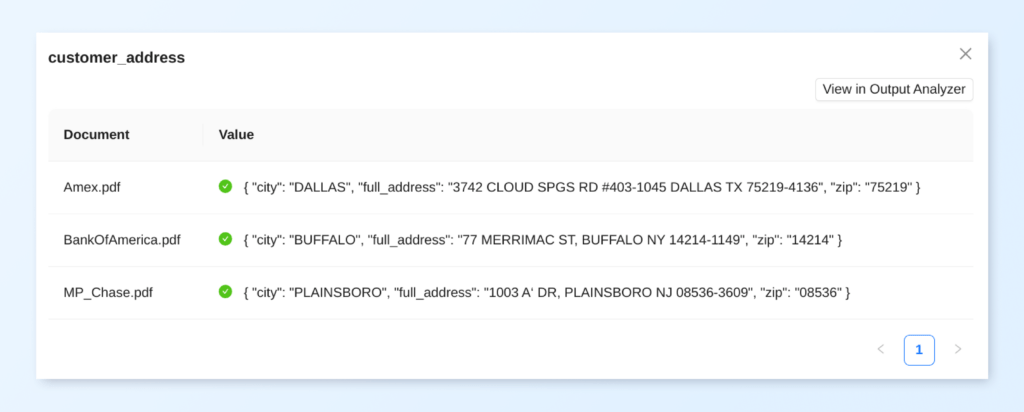
Since there might be multiple addresses in the context provided to you, first gather all addresses. Try to understand whom this credit card statement is being addressed to or in other words, the name of the customer. Find the address that matches that person's. Be sure to return the customer's address, for whom this credit card statement is for. Do not respond with any other address.
For the customer's address, form a simple JSON object with the following fields:
- full_address: should have the customer's full address
-city: should hold's the city name from the address
- zip: should contain the zip alone
Payment Info
Field name: payment_info
Field type: JSON
Field prompt:
Payment information is an important part of any credit card statement and it consists of the new balance or the full amount due for the current statement, the minimum payment due and the payment due date.
Respond with a JSON object with the following fields:
new_balance: the total new balance amount that can be paid
minimum_payment: the minimum amount that is due
due_date: the payment due date in yyyy-mm-dd format
Spend line items
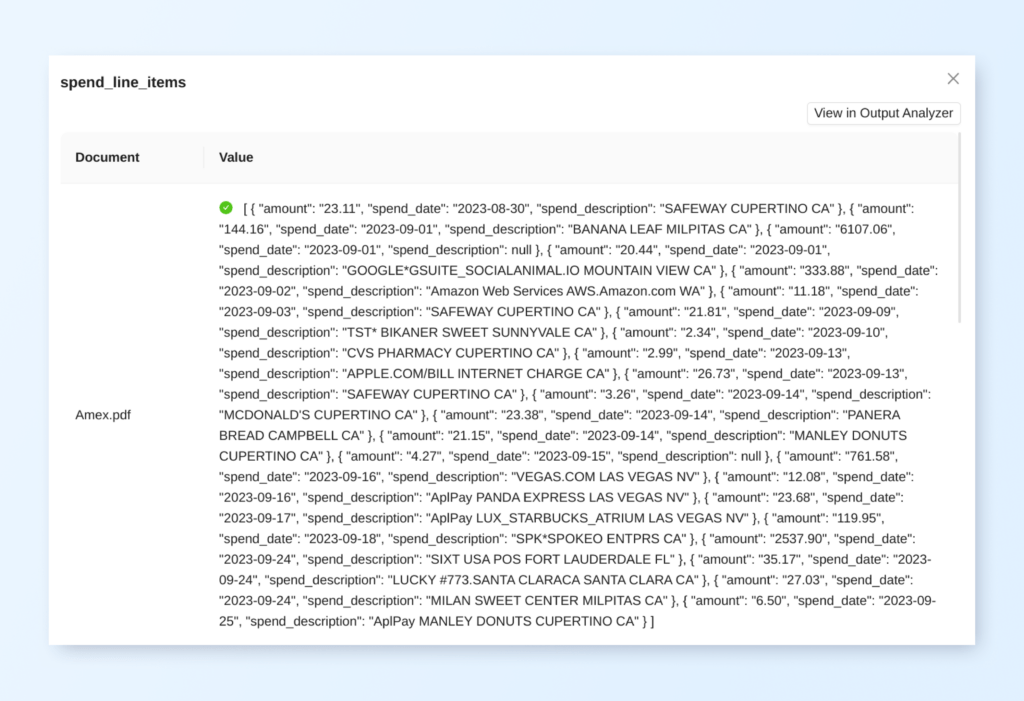
Field name: spend_line_items
Field type: JSON
Field prompt:
This credit card statement contains spending details line items. Spend details can be split across the provided context. Respond with details of all the spend items by looking at the whole context always. For each of these spend details line items, form a simple JSON object with the following fields:
-spend_date: date of the spend in yyyy-mm-dd format. If the year part isn't mentioned in the line item explicitly, pick up the year from the statement date and use it instead.
- spend_description: description of the spend
- amount: amount of the spend without the dollar sign formatted to 2 decimal points Put all of these items into a JSON array and return that.
Viewing Response JSON
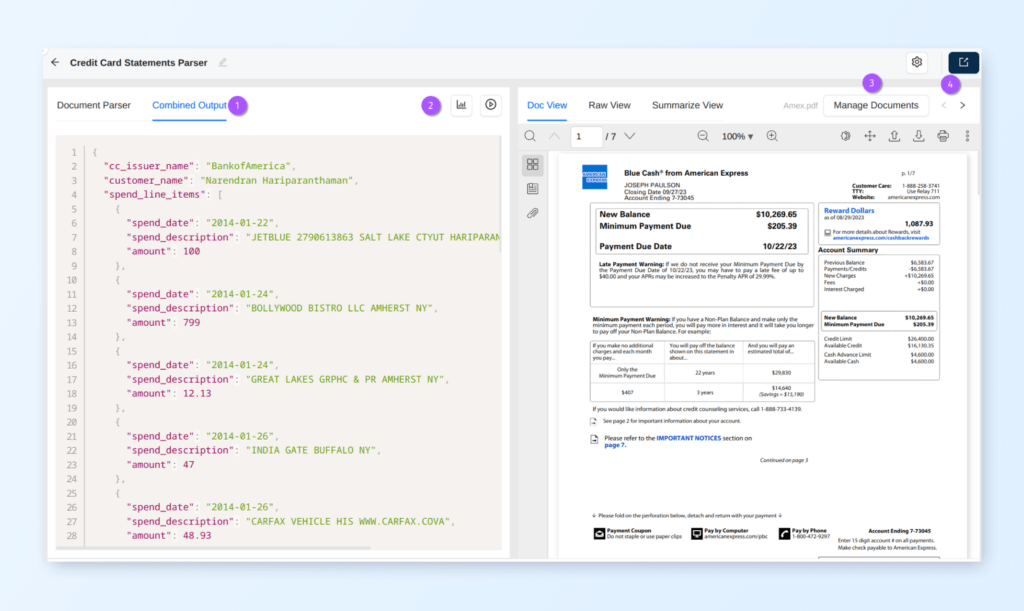
Now that we’ve added prompts to extract multiple fields, let’s see how to view response JSON in its entirety. Prompt Studio has two separate features that allow you to examine JSON from a single document and also JSON outputs from all documents in the Prompt Studio project side-by-side.
Combined Output
This option can be used to examine the response JSON per document. Let’s look at the various options we have in Prompt Studio for this purpose:
Legend:
Combined Output tab: switch to this tab to see the combined output for the currently loaded document.
Show Output Analyzer: this button brings up the Output Analyzer (see next section for a description of what it is)
Documents Manager: this button brings up the Documents Manager, which you can use to switch from one document to the other
Document Switcher: this option lets you easily switch from one project document to the next
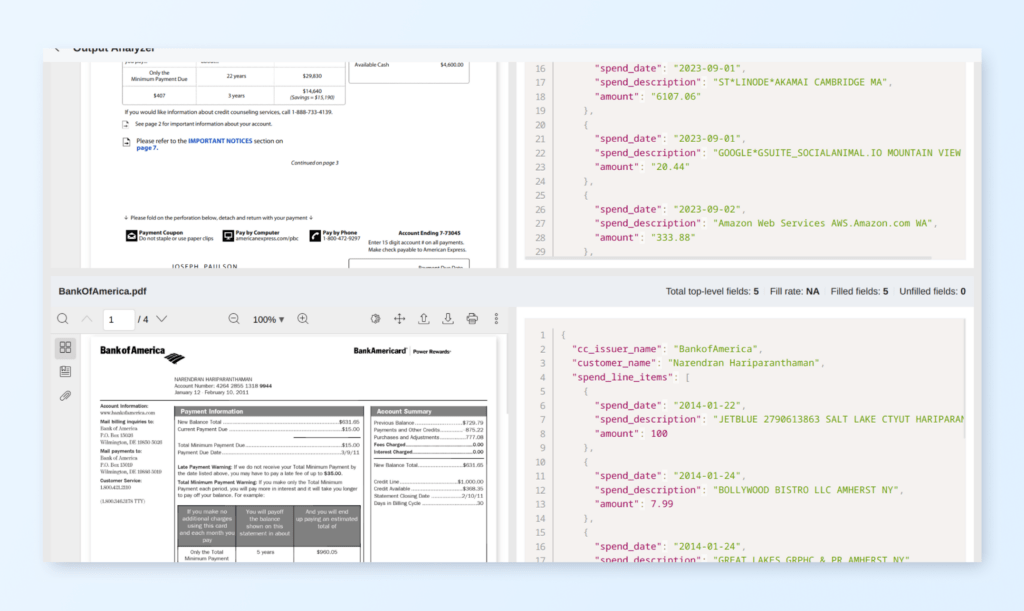
Output Analyzer
The Output Analyzer makes it easy to view documents and their full JSON output side-by-side for easy referencing, examination and debugging.
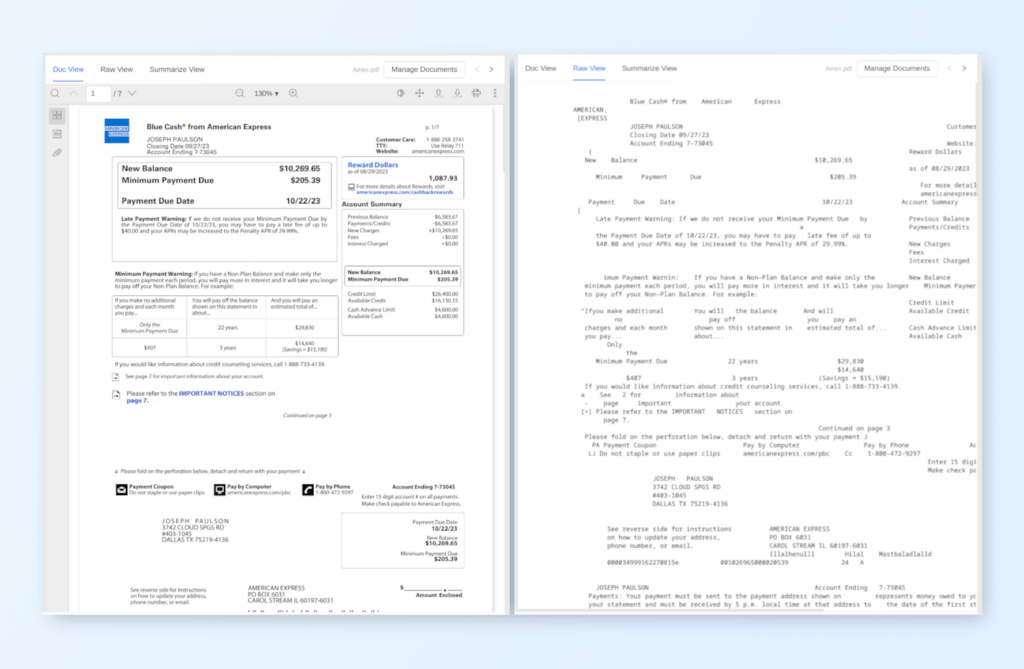
Viewing Text Extractor Output
The original PDF document is viewable in the Doc View and the extracted text from LLMWhisperer is available for inspection in the Raw View.Below is a side-by-side comparison of Doc View and Raw View.
If a prompt response is wrong, one of the very first places you should check is the Raw View to ensure that the output to the LLM is indeed correct. Switch to Raw View and check portions of the input document to see why a prompt response might be the way it is. Especially in OCR mode, a lot of mistakes can be made with text extraction even in the cleanest looking documents.
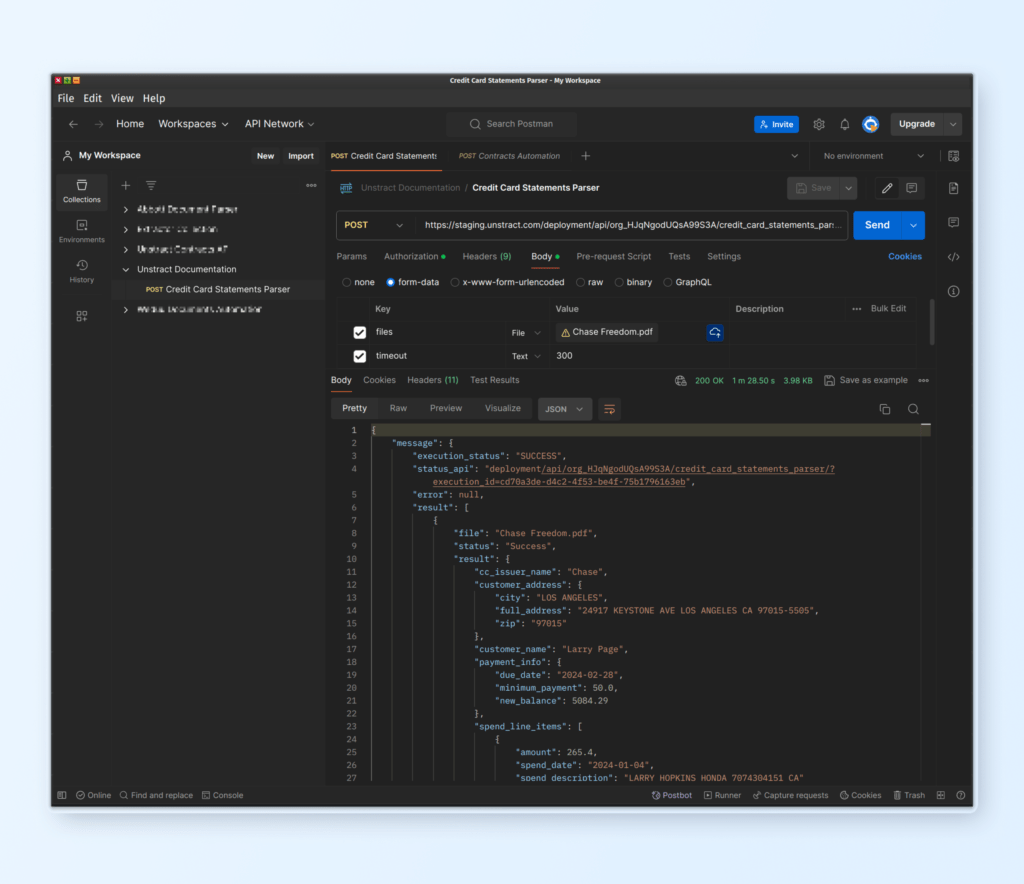
Launch an API to process credit card statements
From the JSON data you see for each of the 3 sample credit card statements, it’s clear that the prompts are generic enough to extract structured data out of all of them successfully. It’s also likely that these prompts work well even for a new statement from a new bank we’ve never encountered before. In the “testing” folder from the sample documents list, there’s a fourth credit card statement from Chase that we should be able to use to verify this.
The great thing about using a platform like Unstract, that is purpose-built for prompt engineering, especially for document data extraction, is that you can now launch APIs from the Prompt Studio project you just created. This allows you to simply send a document to the API and get structured JSON data back! Follow these steps to launch an API and test it with the 4th document:
Unstract’s Prompt Studio has a very powerful feature that is turned on with just 2 clicks. LLMChallenge uses a second LLM to challenge the response of the first. Unless they both come to a consensus, any field you’re trying to extract is set to null rather than with a potentially wrong value. Of course, to enable LLMChallenge, you’d first need to add another LLM to the Unstract Platform.
It is also important to understand that you should never set the challenger LLM to the same LLM as the extractor LLM or even an LLM from the same provider. Choosing an extractor LLM which is generally considered to have similar or better abilities as the extractor LLM is important to have LLMChallenge work successfully. It’s ideal to choose LLMs from different providers as the extractor and challenger LLMs—for instance: OpenAI GPT4-Turbo for extraction and Google Gemini Pro 1.5 for challenging is a good combination.
Simply choosing a Challenger LLM and Enabling Challenge should arm LLMChallenge and ensure that no field is set unless both the LLMs can agree on a particular output value.
Let’s evaluate our Unstract approach
Our previous approach was to use Langchain with Pydantic to solve the problem at hand. Our second approach was to use Unstract to do the prompt engineering. So, how easy or difficult was it compared to the previous approach?
Aspect
How we fared
Wide-ranging input formats
Out of the 3 PDFs we dealt with, one (Bank of America) statement has mostly text-based pages, but page 2 is an image. One giveaway is that you can’t select text from it once it’s opened in a PDF viewer.
But, we didn’t have to bother about any of this since we simply used a raw text extraction service, LLMWhisperer, to take care of this for us. Else, we might have had to deal with PDF extraction libraries, OCR libraries, etc.
Things can quickly become way more difficult when having to deal with smartphone pictures of documents or handwritten text. It is always a good idea to use a raw text extraction service like LLMWhisperer.
Well-defined schema
We simply defined the schema as part of developing the prompts. We could set each prompt to a specific type. In the course of our development so far, we set our output types to either text or JSON. When it came to JSON, we simply described the JSON we needed as part of the prompt, while setting the type of the prompt cell to JSON.
Automated Evaluation
For this project, we used GPT4-Turbo for extraction and Gemini Pro 1.5 for Evaluation. For every field that is extracted, Gemini would challenge GPT4-Turbo. If they did not come to a consensus, that field would be set to null. Remember, in LLM applications, a null value is always better than a wrong value.
Structural variations of the same document type
Although all 3 documents we dealt with were credit card statements and contained the same core information, they had very different structures and layouts.
It would be very difficult to process them with regular programming and processing techniques. Since we leveraged an LLM to process them, we were able to get really good results.
Generic prompts
This is where Unstract shines compared to our previous, full-code approach. One has to realize that prompt engineering is “English” programming and we need the right tools for this.
With Prompt Studio, we were able to see the LLM outputs then and there, we were able to easily see the per prompt output for all sample documents with the Prompt Coverage feature, the document and the outputs were there side-by-side for easy verification.
The Output Analyzer let us see all the output and all the sample documents in one view. Even the extracted raw text from LLMWhisperer was available for ready inspection any time. This made developing prompts super easy compared to wranging various individual tools that are not purpose built for document data extraction.
Structured output for machine consumption
Not only were we able to easily develop generic prompts and verify the JSON they produced, we were also able to launch the Prompt Studio project as an API for further, easy document processing.
Final thoughts on prompt engineering for document extraction use cases
Although extracting key pieces of information for documents is a very prevalent problem, until we had LLMs, this was a very tough problem to crack. Even with LLMs, there are many challenges that need to be addressed. There are two distinct phases and their associated challenges:
Design phase
In the design phase is when prompt engineers try to create generic prompts with a few sample documents as reference extraction docs. They’ll need to ensure that these sample documents are representative of the variety that one can expect to see in the wild for this type of document in the future.
One can also expect the design phase to extend a bit into production since prompt engineers might find that the prompts they’ve developed are not that generic after all and might not be getting the LLM to respond with the right output for some new document layouts that are encountered.
Changing even a word in any prompt is a dangerous undertaking since this can introduce regressions. For this reason, a specialized prompt engineering environment like Unstract’s Prompt Studio shines. It brings the ability to easily specify the schema, the output type for each field, see the “coverage” of each prompt, or how generic it is with ease without the prompt engineer having to switch between the IDE, the terminal and various sample PDFs.
Production phase
Putting LLMs into production without solving for their shortcomings is asking for trouble. LLMs can hallucinate or just be plain wrong. This is where features like LLMChallenge help by using a second LLM to challenge the extractor LLM. Arriving at a consensus before agreeing on what a field’s value should be set to makes the system as a whole more reliable and trustworthy.
LLMs can also be expensive. When dealing with a large number of documents, even a small number of tokens here and there can add up very quickly into expensive LLM bills. This is where features like SinglePass Extraction and Summarized Extraction come in handy, keeping LLM costs and latency in check.
Unstract: A robust, specialized platform for document data extraction
Unstract is a robust, specialized platform for document data extraction use cases powered by large language models. It helps with both the design and production phase of the deployment lifecycle. It also helps that Unstract makes it super easy to take any Prompt Studio project and launch it as an API or as an ETL pipeline with dozens of integrations included out of the box.
Workshop: Live coding session on preparing documents for LLMs.
If you are going to leverage LLMs for structured data extraction, then one of the top problems you’ll face is going to be presenting the LLM with good input data. Good LLM responses need good input data.
In this practical workshop, we explore all the challenges involved in document parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
LLMs for Structured Data Extraction from PDFs in 2026:Related topics to explore
Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an Open Source software and is available at https://github.com/Zipstack/unstract.
If you want to quickly try it out, signup for our free trial. More information here.
LLMWhisperer is a document-to-text converter. Prep data from complex unstructured documents for use in Large Language Models. LLMs are powerful, but their output is as good as the input you provide. Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables. Extracting data from these documents and blindly feeding them to LLMs is not a good recipe for reliable results. LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they’re able to best understand it.
If you want to quickly take it for test drive, you can checkout our free playground.
FAQs on extracting structured data from PDF documents:
What are the main challenges of LLM PDF extraction from real-world documents?
The primary challenges for Document extraction using LLMs include handling wide-ranging input formats (like native text PDFs, scanned images, and photos), creating generic prompts that work across structural variations of the same document type (e.g., different credit card statement layouts), and ensuring strict, machine-readable output formats. The article also highlights that LLM document extraction requires robust automated evaluation to prevent hallucinations and ensure data accuracy for downstream systems.
How does the Langchain and Pydantic approach work for PDF to structured data extraction?
This approach involves using the Langchain framework to integrate with Pydantic, a Python library. You define the desired output schema (e.g., for a credit card statement) as Pydantic models. Langchain then uses these model definitions to automatically generate the prompts instructing the LLM. A parser converts the LLM’s response into a native Python object, effectively achieving structured data extraction. This method is a powerful way of using LLMs to extract structured data directly within a code-centric environment.
What are the advantages of using a purpose-built platform like Unstract for LLM document extraction?
A platform like Unstract, with its Prompt Studio environment, is specifically designed for Document extraction using LLMs. Key advantages include streamlined prompt engineering with features like instant coverage checks across multiple sample documents, an integrated output analyzer for side-by-side verification, and built-in tools for automated evaluation (like LLM challenger systems). This eliminates the need to constantly switch between an IDE, a terminal, and PDF viewers, making the process of LLM for PDF extraction more efficient and reliable.
Why is it important to have automated evaluation when you extract structured data from PDF using an LLM?
Because LLMs can hallucinate or extract incorrect data, automated evaluation is critical for building trust in the extraction pipeline. The article discusses a feature called “LLMChallenge,” where a second LLM challenges the output of the primary extraction LLM. If they don’t agree, the field value is set to null. This ensures that only verified data passes through, making the Structured data extraction process more robust and production-ready, as a null value is preferable to a wrong value for machine consumption.
What is the role of a text extraction service like LLMWhisperer in an LLM PDF extraction pipeline?
Before any LLM PDF extraction can occur, raw text must be reliably extracted from the PDFs. LLMWhisperer is a service designed to handle this first step, processing everything from native text documents to poor-quality scans and images. It outputs clean, structured text that preserves layout cues like columns and tables, which is essential for the LLM to understand the document’s context. This allows developers to focus on the Structured data extraction logic without dealing with the complexities of low-level PDF parsing and OCR libraries.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Shuveb Hussain is the Co-founder and CEO of Unstract. Previously, he served as VP of Engineering at Freshworks, a NASDAQ-listed global SaaS company. With over two decades of experience, Shuveb has co-founded multiple internet startups and worked with companies operating at massive scale—handling petabytes of data and billions of requests per hour.