Guide to Unstract’s Receipt OCR API for scanning line items
Table of Contents
Introduction
In today’s fast-paced business environment, efficiently processing and extracting information from receipts has become a crucial aspect of operational success.
Manual data entry from receipts is time-consuming, error-prone, and costly. This is where automated receipt OCR (Optical Character Recognition) solutions come into play, enabling businesses to streamline their workflows, reduce operational costs, and increase accuracy.
This guide explores how LLMWhisperer’s OCR and Unstract’s document extraction API simplify receipt parsing.
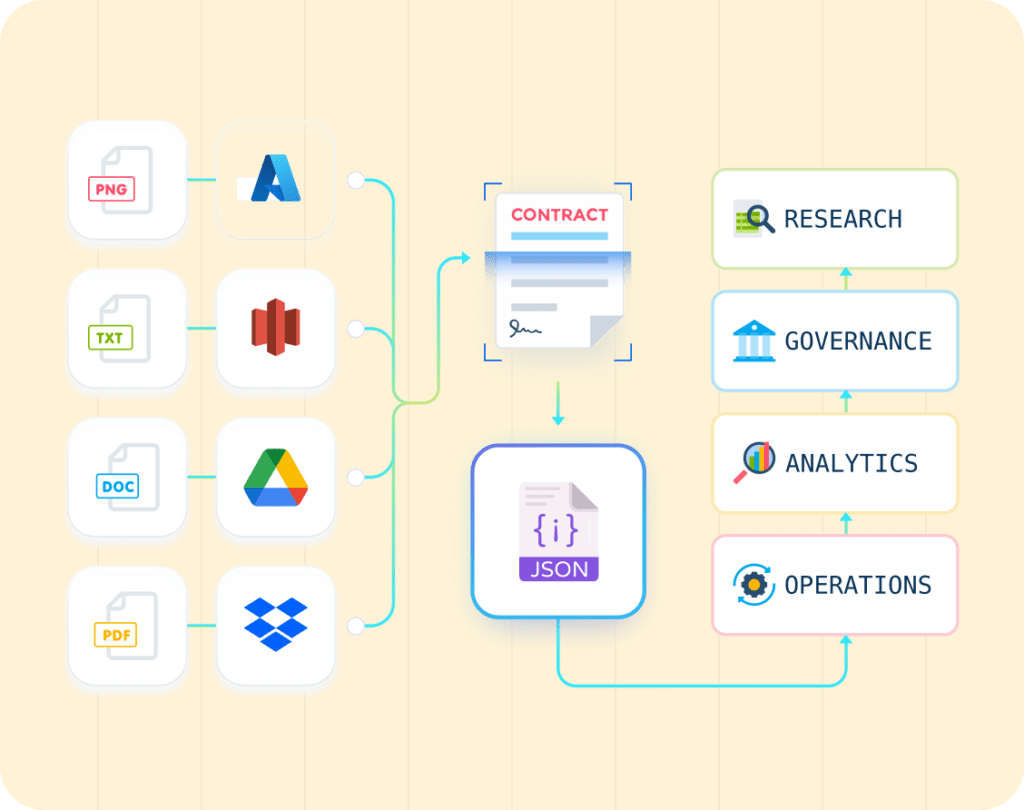
Businesses can achieve seamless, automated extraction of critical receipt details by leveraging LLMWhisperer’s text parsing capabilities and Unstract’s ability to structure unstructured data.
Key capabilities of LLMWhisperer’s OCR include extracting text from various receipt formats, such as scanned images, photographed receipts, and documents with complex table layouts. Paired with Unstract, users can transform this unstructured text into organized, actionable data.
This guide will use LLMWhisperer and Unstract to extract receipt data effectively and provide step-by-step instructions on integrating these tools into your workflow.
TL;DR
This article examines the challenges of processing receipts and demonstrates how using Large Language Models (LLMs) can enable new ways of handling receipt data extraction.
Receipt OCR (Optical Character Recognition) is the technology used to convert text from images, scanned documents, and photos of receipts into machine-readable data.
It allows businesses to automate the process of extracting information from receipts, such as purchase details, itemized lists, totals, and dates, eliminating the need for manual data entry.
OCR technology works by analyzing the visual elements of a receipt and identifying patterns that correspond to letters, numbers, and symbols. It can recognize printed text as well as certain types of handwritten text, depending on the quality of the image.
By processing this information, OCR tools can extract text from diverse receipt formats, including crumpled, skewed, or low-quality images. This capability makes it possible for businesses to process receipts in bulk, saving time and reducing errors.
Modern OCR solutions, like LLMWhisperer, further enhance the process by handling complex receipt layouts, such as tables, multi-line items, and irregular text alignment. This adaptability allows businesses to extract accurate, structured data from even the most challenging receipt images.
Why is Receipt OCR a Critical Business Process?
Automating receipt OCR is a vital component of modern business operations, offering numerous benefits that directly impact efficiency, cost savings, and data accuracy.
Automation Benefits:
Time Savings: Automated OCR significantly reduces the time required to process receipts compared to manual entry.
Cost Reduction: By minimizing manual labor, businesses can lower operational costs and allocate resources more effectively.
Improved Data Accuracy: Automated systems reduce human error, leading to more accurate data capture.
Elimination of Manual Data Entry: OCR eliminates the need for human input, allowing teams to focus on higher-value tasks.
Industries That Benefit:
Retail: Automate receipt processing for inventory tracking, expense management, and customer returns.
Hospitality: Extract and track expense data from hotel, restaurant, and travel receipts.
Finance: Streamline expense reporting, auditing, and reimbursement processes.
Healthcare: Simplify the processing of medical receipts for insurance claims and billing.
With the growing demand for automation, receipt OCR has become a key process for businesses aiming to increase efficiency and reduce operational costs.
Tools like LLMWhisperer and Unstract enable companies to achieve these benefits with minimal technical complexity.
Challenges in Parsing Receipts (Automation Obstacles)
While receipt OCR offers significant benefits, it also comes with its own set of challenges. These obstacles can affect the accuracy and efficiency of the data extraction process, especially when dealing with diverse receipt formats and image quality issues.
Key Challenges:
Handwritten vs. Printed vs. Scanned vs. Photographed Receipts:
Printed receipts are typically easier for OCR systems to recognize due to their consistent font and layout.
Handwritten receipts introduce variability in text style, size, and alignment, making them more difficult to parse.
Scanned receipts may have issues like noise, low resolution, or smudges that hinder text recognition.
Photographed receipts can be distorted due to perspective angles, lighting issues, and shadows.
Crumpled, Blurred, or Poorly Aligned Receipts:
Receipts that are crumpled or folded can result in text warping, making it difficult for OCR systems to recognize individual characters.
Blurred images, often caused by shaky cameras or low-quality photos, reduce the clarity of text and affect accuracy.
Poor alignment, such as skewed or rotated receipts, requires additional pre-processing to correct the orientation before OCR can be applied.
Extracting Structured Data from Receipt Tables:
Many receipts contain tabular information, such as itemized lists of products or services, along with quantities, prices, and taxes.
Extracting structured data from these tables is challenging due to inconsistent layouts, column alignment, and multi-line entries.
Advanced OCR solutions must recognize table boundaries and correctly assign the extracted text to relevant columns and rows.
By addressing these challenges, tools like LLMWhisperer and Unstract provide enhanced capabilities for parsing receipts with varying levels of complexity. Pre-processing techniques, such as image enhancement, de-skewing, and noise reduction, can play a vital role in overcoming these obstacles.
How AI and LLMs Are Transforming Receipt Parsing
The introduction of AI (Artificial Intelligence) and LLMs (Large Language Models) has revolutionized receipt parsing, enabling more accurate and efficient data extraction.
Traditional OCR systems rely on pre-defined templates and rigid rules, but AI and LLMs introduce a more adaptable, context-aware approach.
How LLMs Help Structure Unstructured Data:
LLMs can understand and interpret the context of extracted text, allowing them to identify key information, such as merchant names, dates, and itemized lists, without relying on strict templates.
Instead of treating all text as flat data, LLMs use natural language understanding to categorize and organize receipt information into structured formats.
This approach allows LLMs to handle variations in receipt formats, including layout changes, different fonts, and varying table structures.
Advantages Over Traditional Methods:
Template-Free Extraction: Unlike traditional OCR, which requires templates for each type of receipt, LLMs can generalize and adapt to new receipt formats without manual intervention.
Improved Accuracy: LLMs have a higher tolerance for imperfections, such as crumples, smudges, and poor alignment, leading to better recognition of text.
Context-Aware Parsing: By recognizing context, LLMs can identify and label essential information, such as line items, totals, and taxes, making it easier to convert unstructured text into usable data.
Reduced Maintenance: Since LLMs don’t rely on rigid templates, businesses save time and effort maintaining and updating OCR workflows as receipt designs change.
AI and LLMs enable businesses to process receipts more efficiently, reducing costs, improving accuracy, and providing greater flexibility in data extraction.
Tools like Unstract harness the power of LLMs to process the unstructured output of OCR systems like LLMWhisperer, making it possible to extract structured data from even the most complex receipt formats.
Overview of Unstract’s Capabilities
Unstract is an AI document extraction platform that transforms unstructured data, such as receipt text, into structured, actionable information.
By leveraging advanced AI techniques, including Large Language Models (LLMs), Unstract provides businesses with a robust, adaptable, and efficient solution for receipt data extraction.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
Key Capabilities of Unstract:
AI-Powered Data Structuring: Unstract utilizes AI and LLMs to process unstructured receipt text, automatically organizing it into a structured format. This includes categorizing key data points like merchant name, date, items, quantities, prices, taxes, and total amounts.
Dynamic Layout Adaptation: Unlike traditional OCR solutions that rely on rigid templates, Unstract can handle receipt layout changes without requiring re-training or re-modeling. This means that as receipt designs evolve — whether from different vendors, stores, or countries — Unstract continues to recognize and extract essential information without manual adjustments.
Template-Free Extraction: Traditional data extraction systems often require pre-defined templates for each receipt format, but Unstract’s LLM-based approach eliminates this need. It dynamically identifies patterns and relationships within the receipt text, allowing it to extract data from new or unseen receipt formats with ease.
Context-Aware Parsing: By leveraging natural language processing (NLP) capabilities, Unstract understands the context of text within a receipt. For example, it can distinguish between product names, prices, and totals, even if they are not explicitly labeled.
Automatic Adaptation to Receipt Changes: As receipt designs change over time, businesses traditionally face the burden of updating templates and reconfiguring OCR workflows. Unstract eliminates this problem. Its LLM-powered extraction process can automatically adapt to changes in receipt formats, ensuring seamless and uninterrupted data capture.
Simple Integration and API Support: Unstract offers API-based integration, allowing developers to connect it with existing business systems and workflows. The platform can be accessed using API calls, enabling real-time receipt processing and automated data extraction.
By streamlining the process of transforming unstructured receipt data into structured, usable information, Unstract saves businesses significant time and effort.
Its AI-driven adaptability and ease of integration make it a powerful tool for organizations dealing with high-volume receipt processing or diverse document formats.
Overview of LLMWhisperer’s Receipt Scanner Capabilities
LLMWhisperer is a general-purpose text parser designed to extract text from various document types, including images, scanned documents, and receipt photos.
Unlike AI-driven solutions, LLMWhisperer does not rely on machine learning, AI, or LLMs. Instead, it focuses on providing a straightforward, template-free method for extracting unstructured text.
Key Capabilities of LLMWhisperer:
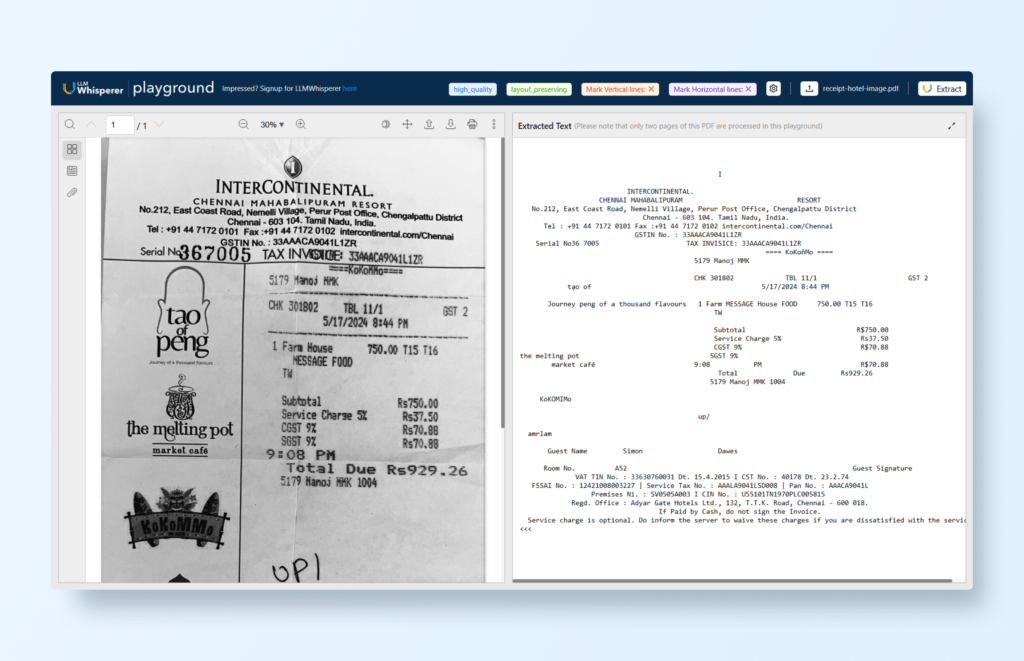
Versatile OCR Capabilities: LLMWhisperer can process and extract text from different receipt formats, such as printed, scanned, and photographed receipts. It handles text extraction from tables, itemized lists, and other complex receipt layouts.
General-Purpose Text Parsing: LLMWhisperer is not limited to OCR-specific tasks. It acts as a universal text extraction tool, making it suitable for a wide range of document parsing applications, including invoices, contracts, and multi-page PDFs.
No AI/ML/LLM Dependence: Unlike Unstract, which uses LLMs, LLMWhisperer focuses on parsing raw text without AI or machine learning. This makes it a more predictable and stable tool for text extraction, as it does not require training or model updates.
Easy-to-Use API: LLMWhisperer provides an easy-to-integrate API that allows developers to extract text from receipt images with minimal setup. The API accepts a variety of document types, enabling fast, scalable receipt OCR.
With its simple and direct approach, LLMWhisperer provides a fast, effective, and easy-to-use method for extracting text from receipts.
This makes it a reliable option for businesses seeking a no-frills solution for receipt OCR and text parsing.
Live coding session on data extraction from a scanned PDF form with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in scanned PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
Steps to Parse Receipt Line Items Using LLMWhisperer OCR
Unstract is a sophisticated document processing tool that leverages LLMs to extract structured data from PDFs. It is designed to handle the complexities of unstructured data and convert it into a usable format.
Unstract employs LLMs to analyze the text and data extracted by LLMWhisperer. These models can understand the context and structure of the document, enabling accurate data extraction.
The extracted data can be converted into JSON format, which is a structured and easily manageable format for further analysis and integration.
Key Features:
Data Extraction: Accurately extracts data from various types of documents, including tables, forms, and unstructured text.
Structuring Unstructured Data: Converts unstructured data into structured formats like JSON, making it easier to analyze and manage.
Integration: Can be integrated with other tools and platforms for seamless data flow and analysis.
Scalability: Designed to handle large volumes of documents, making it suitable for enterprise-level applications.
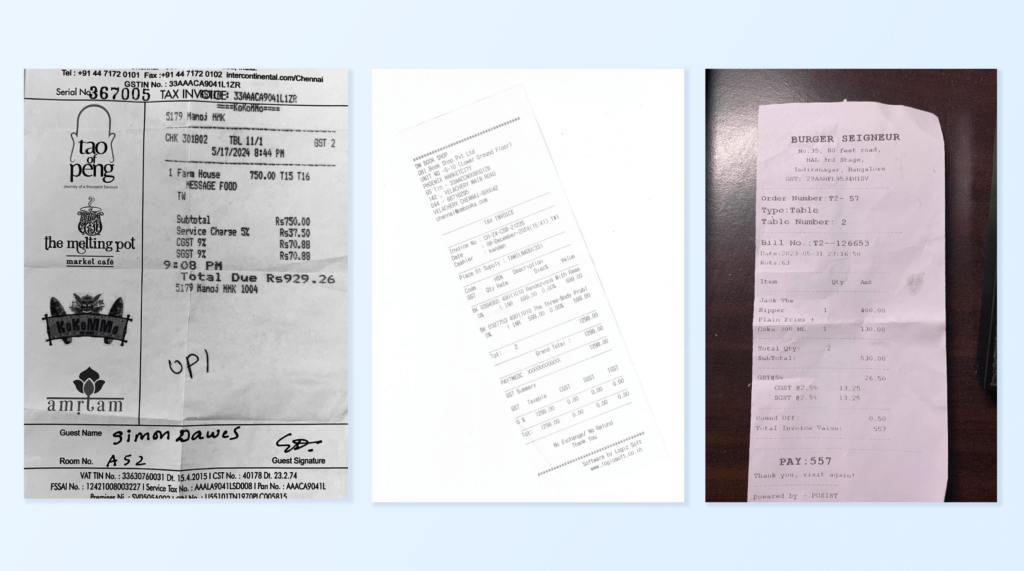
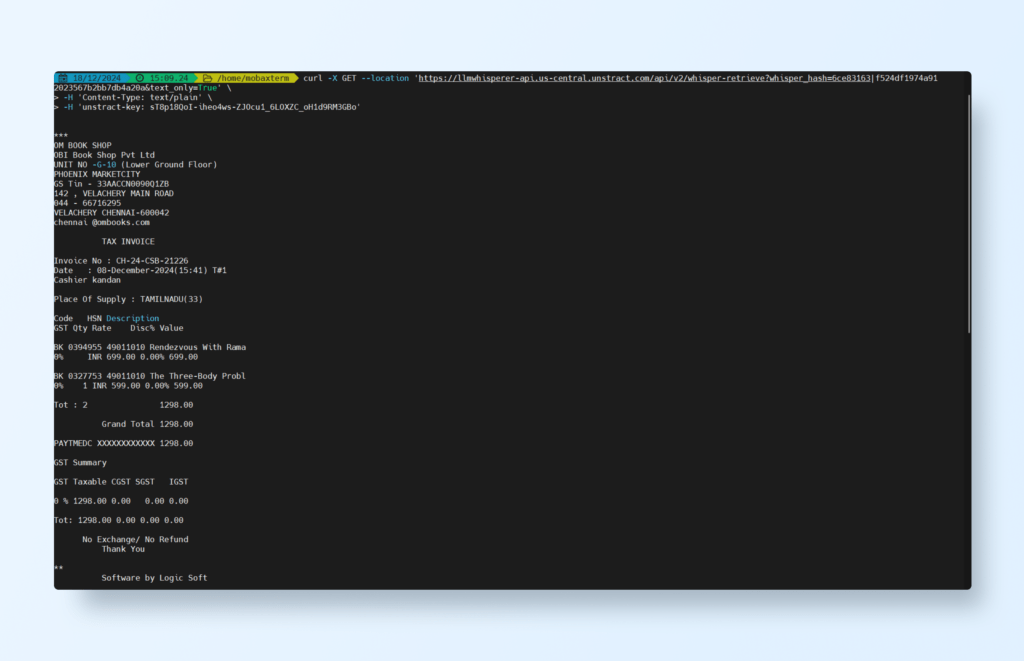
Let’s quickly see an example of Unstract’s extraction capabilities using the same photographed receipt
To extract the information, we need to write custom prompts:
The prompt used is:
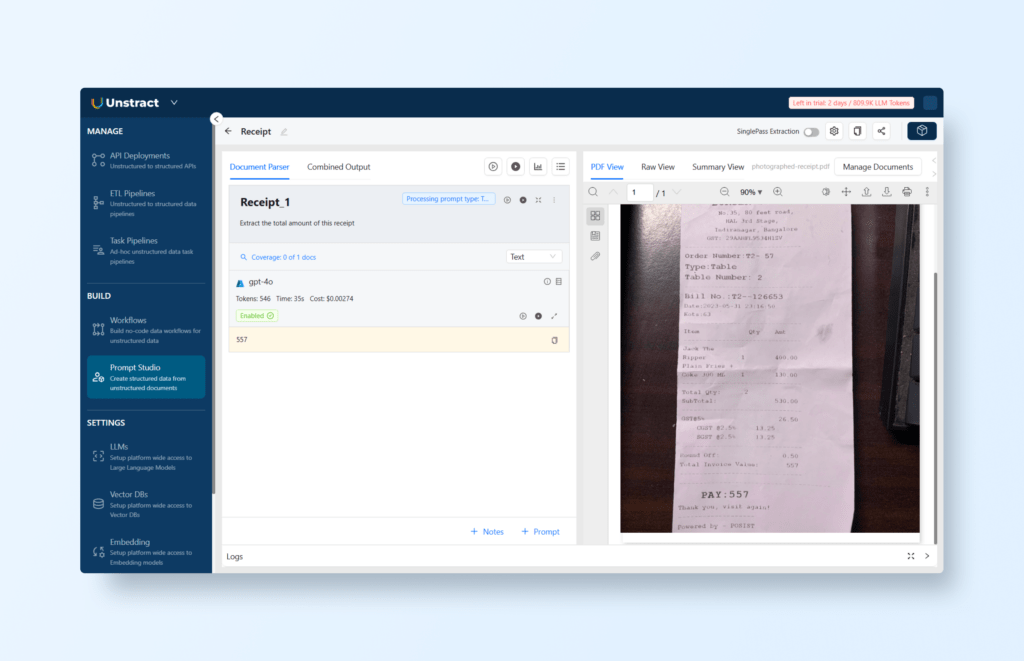
Extract the total amount of this receipt
The result is:
557
Setting Up a Prompt Studio Project
Before you start extracting data from PDF documents using Unstract, it’s necessary to set up the desired tools and accounts:
If you want to connect your own LLM go to SETTINGS → LLMs.
To add your embedding provider, go to SETTINGS → Embedding.
To add your vector database provider, navigate to SETTINGS → Vector DBs.
To add your text extractor, go to SETTINGS → Text Extractor.
Or you can use the default ones during the 14-day free trial.
Now you can create a new Prompt Studio project with ‘BUILD → Prompt Studio → New Project’.
Then upload your PDF to be processed, in this case, we will use the same photographed receipt as before.
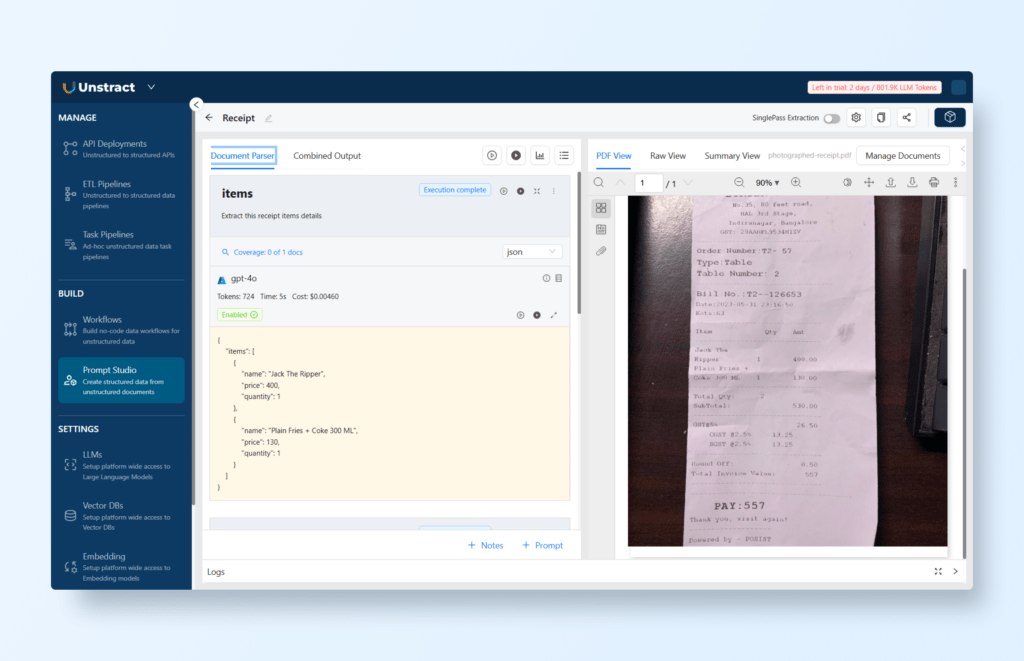
Then you can define the custom prompts to extract bill details, items, and total bill value:
The prompts used in this project are:
items -> Extract this receipt items details
bill_details -> Extract the bill details from the header
value -> Extract the bill value
All these combined prompts give the following JSON output:
After setting up your Prompt Studio project and perfecting your prompts for accurate data extraction, the next logical step is to deploy your Unstract solution as an API:
Begin by defining the existing project as a tool to be used in a workflow by clicking the ‘Export as tool’ icon in the top right corner.
The next step is to create a new workflow. In the Tools section on the right-hand side, inside a workflow, find the tool created from your project and drag and drop it into the workflow. Select an API as input and output.
Now, you can create an API from the newly created workflow. Click the ‘+ API Deployment’ button to create a new API deployment.
Once the API is created, you can use the Actions links to manage various aspects of the API. For instance, you can manage API keys or download a Postman collection for testing.
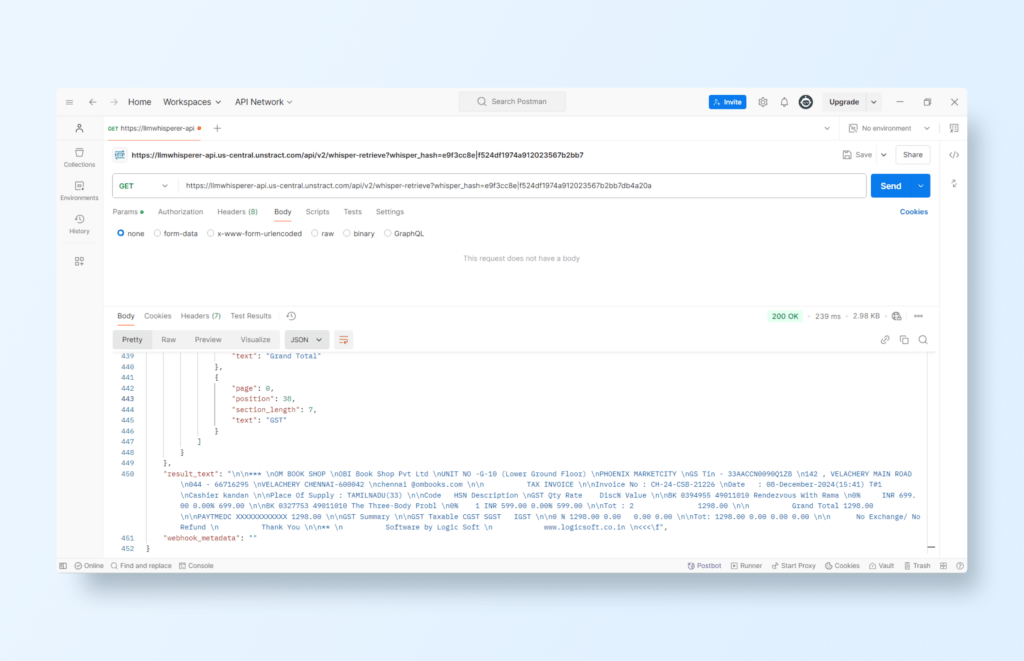
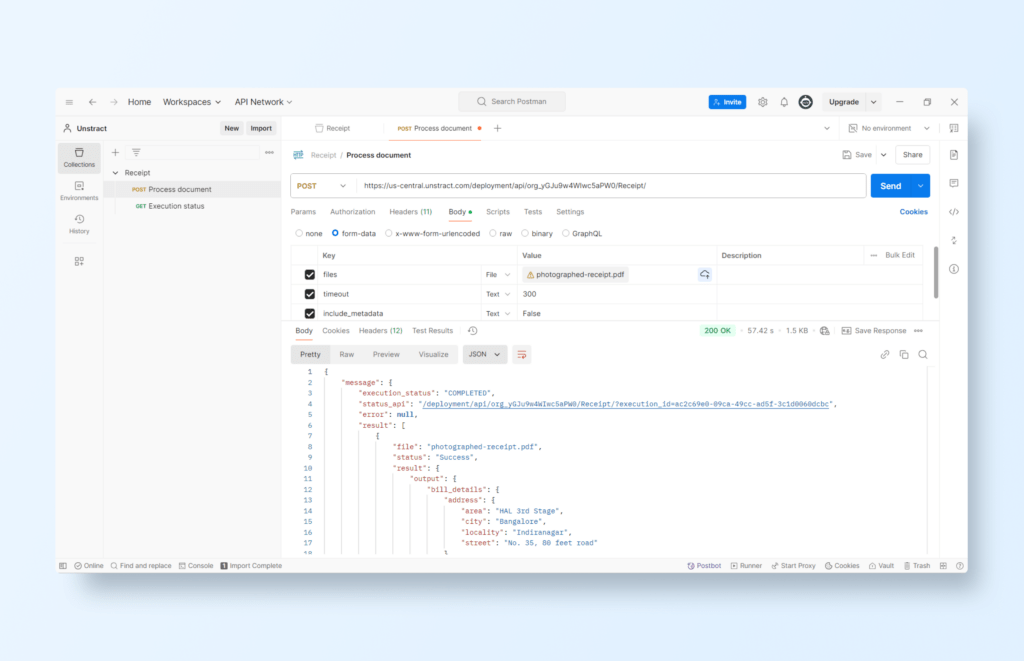
Then you can test the API with Postman:
Create a new workspace and import the Postman collection you downloaded previously.
Set the API authentication using an API key with the type ‘Bearer Token’.
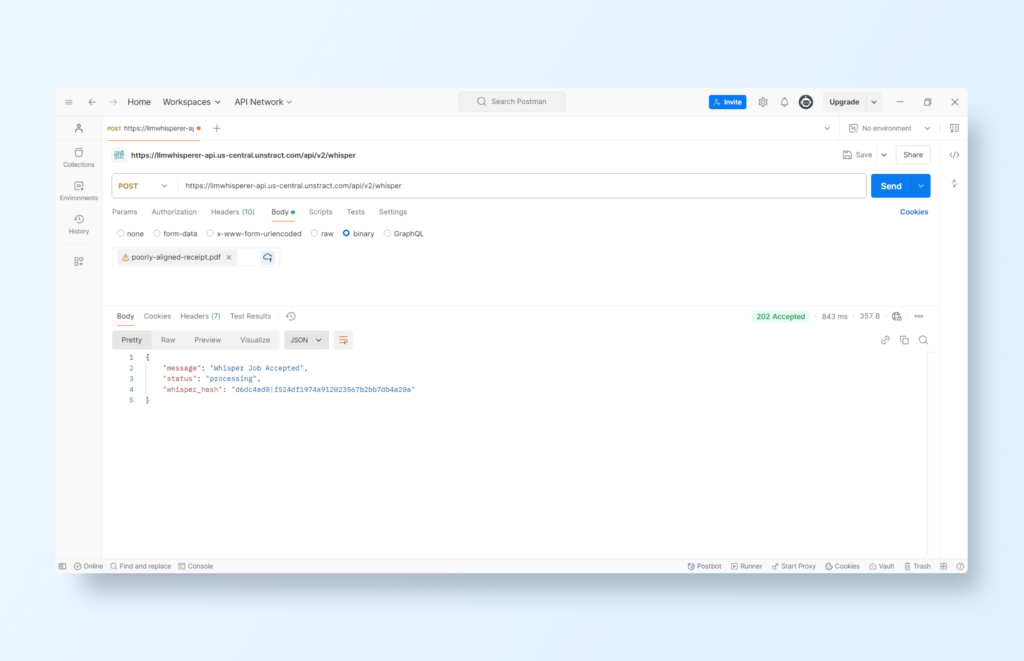
Select a PDF and run the request to test the API (we will use the same photographed receipt as before):
How LLMWhisperer and Unstract Work Together in Making Receipt Data Extraction Easier
The combined power of LLMWhisperer and Unstract offers a comprehensive and efficient solution for receipt parsing.
By leveraging their distinct capabilities, businesses can automate the process of converting unstructured receipt data into structured, actionable insights.
LLMWhisperer’s Role:
Initial OCR Extraction: LLMWhisperer acts as the first step in the process, converting receipt images, scanned files, or photographs into plain, unstructured text. Its ability to extract text from diverse receipt formats, including crumpled or misaligned receipts, makes it a reliable OCR solution.
Extracts Raw Text: It captures line items, prices, and totals as plain text. This raw text is essential for the next step, where Unstract processes and structures it into usable data.
Unstract’s Role:
Data Structuring and Categorization: Once LLMWhisperer extracts the raw text, Unstract processes it to identify key data points like merchant name, date, items, prices, and total amounts. It organizes this information into a clean, machine-readable format (like JSON), ready for use in financial systems, ERP software, or dashboards.
AI-Driven Contextual Understanding: Unstract recognizes patterns in the receipt data and distinguishes between different content types, such as product names, quantities, and total amounts.
The Power of the Duo:
Faster, More Accurate Receipt Parsing: LLMWhisperer handles raw text extraction, while Unstract structures it into usable information. This division of labor speeds up the receipt parsing process.
Template-Free Parsing: Unlike traditional OCR systems that rely on fixed templates, LLMWhisperer and Unstract adapt to new receipt formats automatically. This reduces the need for manual reformatting or template updates.
Comprehensive End-to-End Solution: From OCR to data structuring, LLMWhisperer and Unstract provide a complete, automated solution that minimizes manual effort and ensures consistent data extraction.
This combined approach offers businesses a reliable, cost-effective, and scalable method for receipt parsing, eliminating the challenges of manual data entry and enabling smarter financial processes.
If you want to take LLMWhisperer OCR API for a test drive quickly, you can check out our free playground.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.