Open-Source Unstructured Data ETL with Unstract, Ollama, DeepSeek, and PostgreSQL
Table of Contents
Introduction to open-source AI document extraction
This article focuses on creating an open-source document extraction environment using Unstract Open Source.
Unlike the cloud version, this approach requires manually installing and configuring each component of the AI tech stack, including:
Unstract Open Source – the core document processing engine.
Ollama – An open-source framework for running local LLMs.
Ollama Embeddings – to generate vector representations of extracted text.
Unstructured.io – an open-source text extractor/OCR parser.
PostgreSQL with PGVector – Open source vector database storage.
By the end of this guide, you will have a fully open-source, locally hosted document extraction pipeline that integrates AI-driven processing with zero reliance on proprietary cloud services. This setup provides complete flexibility in choosing models, databases, and processing techniques while ensuring data privacy and cost efficiency.
What is Unstract?
Unstract is an open-source document processing tool designed to extract structured data from unstructured documents such as PDFs, images, and scanned files.
It provides a modular and flexible framework, allowing users to customize their document processing pipeline based on their specific needs.
AI Stack Agnostic
One of Unstract’s key advantages is its AI stack agnostic design, meaning users can integrate:
Any Large Language Model (LLM) – Choose from open-source models like DeepSeek R1, Mistral, or Llama, depending on performance and resource constraints.
Any Vector Database – Supports PGVector (PostgreSQL), ChromaDB, Weaviate, and more to store and retrieve embeddings efficiently.
Any Embedding Model – Works with embedding models from Ollama, Hugging Face, or custom-built ones.
Any Text Extractor – Can be configured with LLMWhisperer, Unstructured.io, and LlamaParse
This flexibility ensures that organizations are not locked into a single AI vendor and can build an optimal tech stack based on their requirements.
Cloud vs. Open-Source Self-Hosted Version
Unstract is available in two deployment models:
Unstract Cloud App (Managed)
Fully hosted solution, accessible via a web interface.
Pre-configured AI stack with automatic updates.
Quick and easy setup with a free trial option.
Ideal for users who need a hassle-free document processing solution.
Unstract Open Source (Self-Hosted)
Requires manual installation and setup.
Complete control over data privacy, security, and AI model selection.
Fully customizable pipeline, ideal for developers and enterprises with specific compliance or infrastructure requirements.
Runs locally or on private cloud infrastructure.
This article focuses on the self-hosted version, guiding you through setting up Unstract Open Source with an entirely open-source AI tech stack.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
Why Open-Source for Document Processing?
Open-source document processing solutions provide organizations with greater flexibility, transparency, and control over their data and AI stack.
Unlike proprietary software, which often comes with restrictions and licensing fees, open-source tools allow for customization and integration based on specific use cases.
Here’s why open-source is a strong choice for document processing:
Transparency & Flexibility – Users can inspect and modify the code, ensuring that the software behaves exactly as needed. It also allows for seamless integration with various AI models, databases, and extractors.
Avoiding Vendor Lock-In – With open-source solutions, there’s no dependency on a single provider’s technology, pricing, or updates. You can switch out LLMs, vector databases, or text extractors without being tied to a proprietary ecosystem.
Full Control Over Data Privacy & Security – Since all processing happens locally or on self-hosted infrastructure, sensitive documents never leave your environment. This is crucial for businesses with strict compliance requirements (e.g., healthcare, finance, legal).
Cost-Effectiveness – No recurring licensing fees or pay-per-use costs make open-source a long-term, budget-friendly solution. Organizations can scale their document processing without worrying about escalating expenses.
Pros and Cons of Open-Source Solutions
Pros
Cons
Highly Customizable – Modify, extend, or integrate tools based on your needs.
Requires Manual Setup – Unlike cloud-based solutions, installation and configuration need to be done manually.
Community-Driven Improvements – Open-source projects evolve quickly with contributions from developers worldwide.
Potential Need for Technical Expertise – Deploying and maintaining an open-source solution often requires some knowledge of Docker, databases, and AI models.
No Recurring Licensing Costs – Run as many processes as needed without worrying about subscription fees.
Ongoing Maintenance – Unlike managed services, users are responsible for keeping their system up to date.
Despite these challenges, open-source solutions provide unmatched flexibility and control, making them an excellent choice for organizations that require scalable, secure, and customizable document processing workflows.
Setting Up Unstract on a Local Machine
To build a fully open-source document processing environment, we first need to install and run Unstract Open Source on a local machine using Docker.
This section provides a step-by-step guide to setting up Unstract and verifying that it runs correctly.
Prerequisites
Before starting, ensure you have the following installed on your system:
Docker (for running Unstract in containers)
Git (for cloning the Unstract repository)
Installation Steps
Clone the Unstract repository from GitHub:
git clone https://github.com/Zipstack/unstract
cd unstract
Start Docker if it isn’t already running. Run the setup script to launch Unstract:
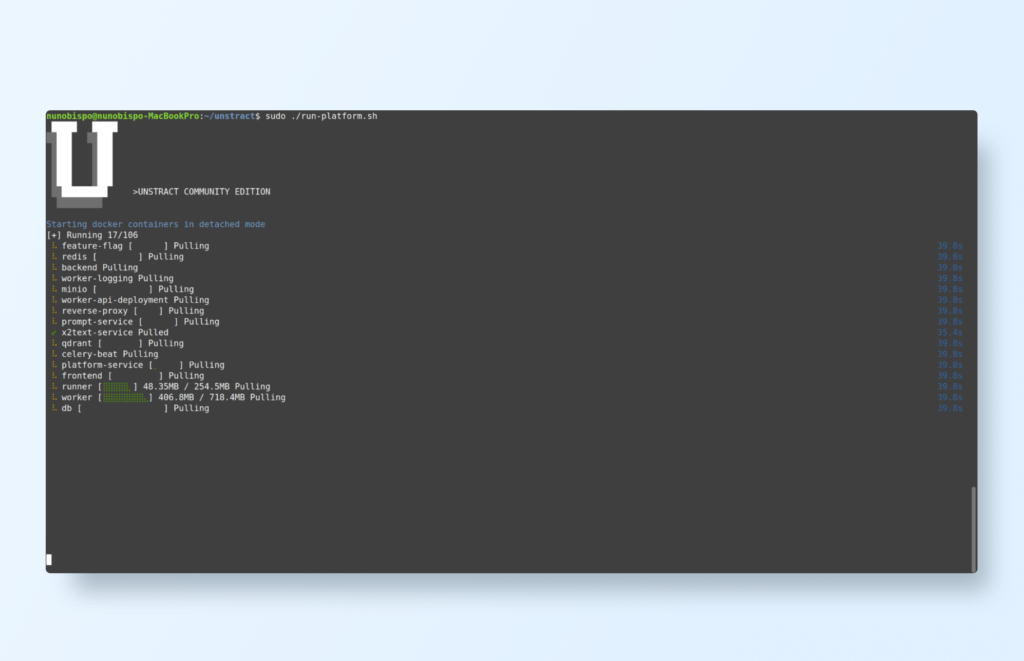
./run-platform.sh
Note: Depending on your user permissions, you might need to run this and the other commands in this article using sudo.
This script initializes the required services and containers for Unstract:
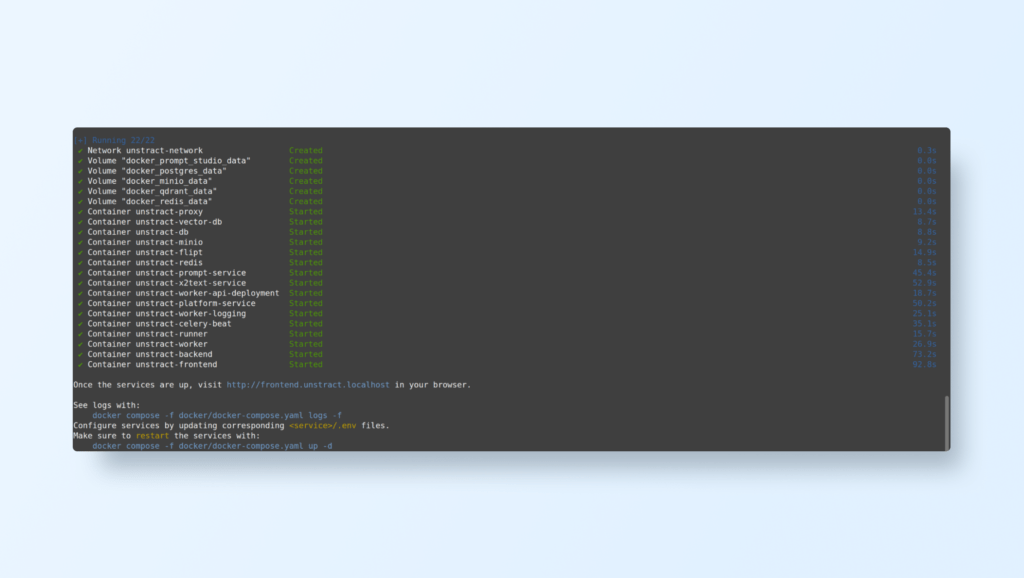
After a while, you should see all the containers running:
You can verify the setup by navigating to http://frontend.unstract.localhost.
If the installation is successful, you should see the Unstract web interface:
You can log in with username and password unstract.
Verifying the Setup
After installation, confirm that all components are running correctly:
Open your terminal and run:
docker ps
Ensure the backend container is up and running in Docker.
You should see Unstract services running in active containers.
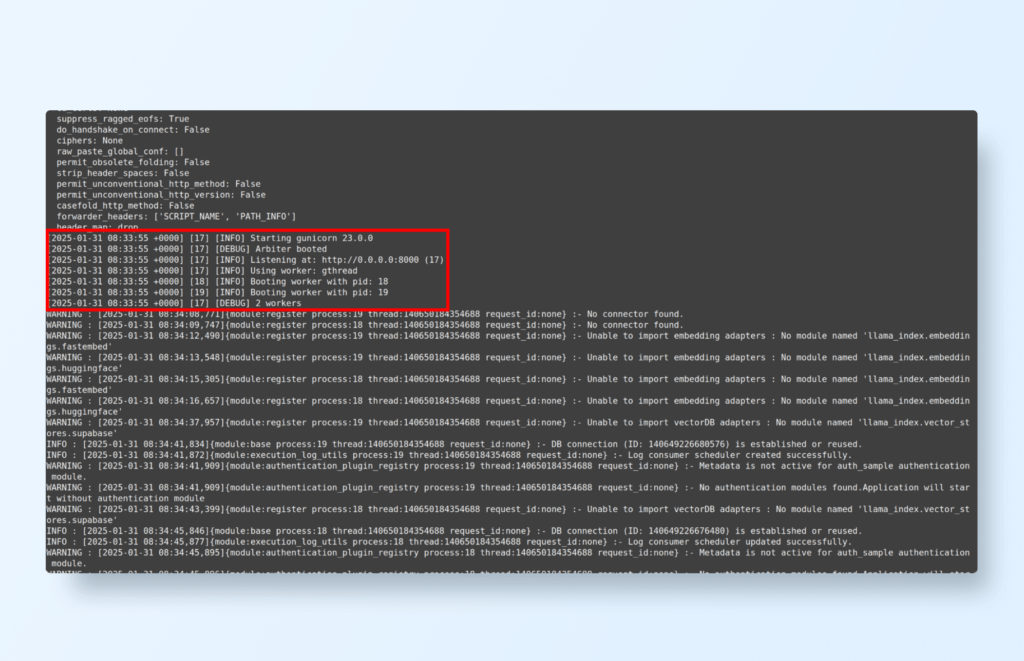
Check if the workers started successfully:
The logs should show two worker processes successfully started.
To check the logs, run:
docker logs <container_id>
(Replace <container_id> with the actual Unstract backend container ID from docker ps.)
You should see the indication that 2 workers have started:
Next Steps
Once Unstract is running, the next step is to integrate additional open-source AI components, such as Ollama for local models, Unstructured.io for text extraction, and PGVector for vector storage.
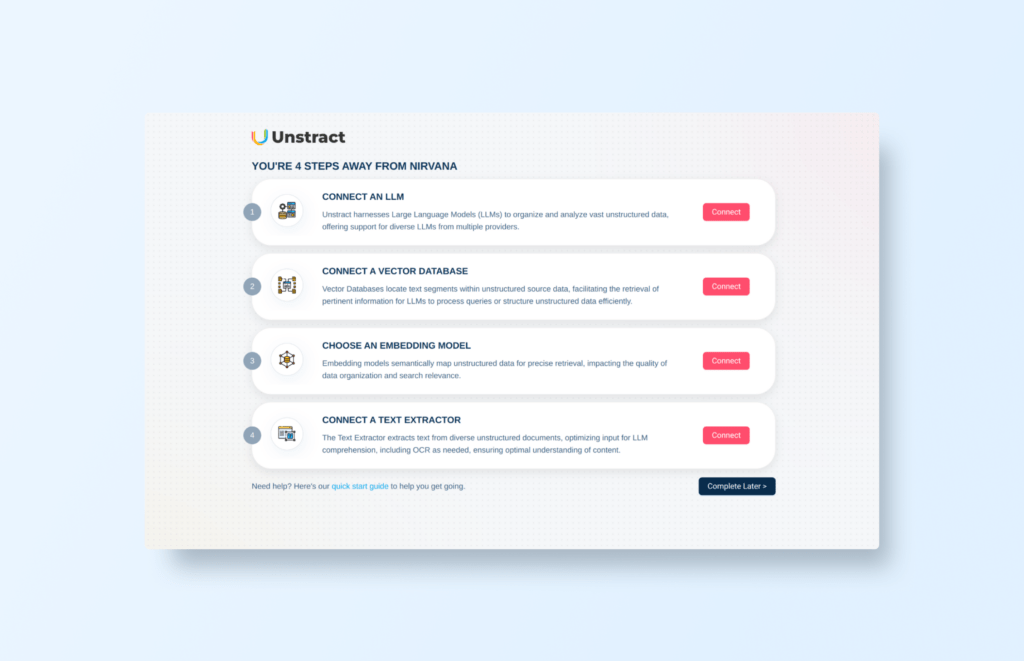
This is the onboarding page when you first log in:
We will cover these steps in the following sections.
Unstract: Best Open-Source Document Processing Tool
Unstract is a No-code LLM Platform to launch APIs and ETL Pipelines to structure unstructured documents
Installing the Open-Source AI Tech Stack for Document Processing
Installing Ollama for Local Models
To enable local AI model processing within Unstract, we will use Ollama, an open-source framework for running LLMs on local machines.
This section walks through installing and running Ollama with Docker, selecting a lightweight model from the popular DeepSeek R1, and connecting Ollama to Unstract.
1. Running Ollama with Docker
Run the Ollama container:
docker run -d --name ollama --network=unstract-network -p 11434:11434 ollama/ollama
This starts Ollama as a background process, exposing it on port 11434. It also connects it to the unstract-network so that the container is accessible by the Unstract internal containers.
2. Choosing and Pulling a Distilled Model (DeepSeek R1)
Since LLMs can be resource-intensive, we will use DeepSeek R1 – 7B, a lightweight, distilled model that balances performance and efficiency.
Pull the DeepSeek R1 – 7B model:
docker exec -it ollama ollama pull deepseek-r1:7B
You can use other versions of the model depending on your hardware capabilities. You can check other DeepSeek models here and a full list of models is available here.
3. Connecting Ollama to Unstract
Once Ollama is running, we need to connect it to Unstract so it can be used for document processing tasks.
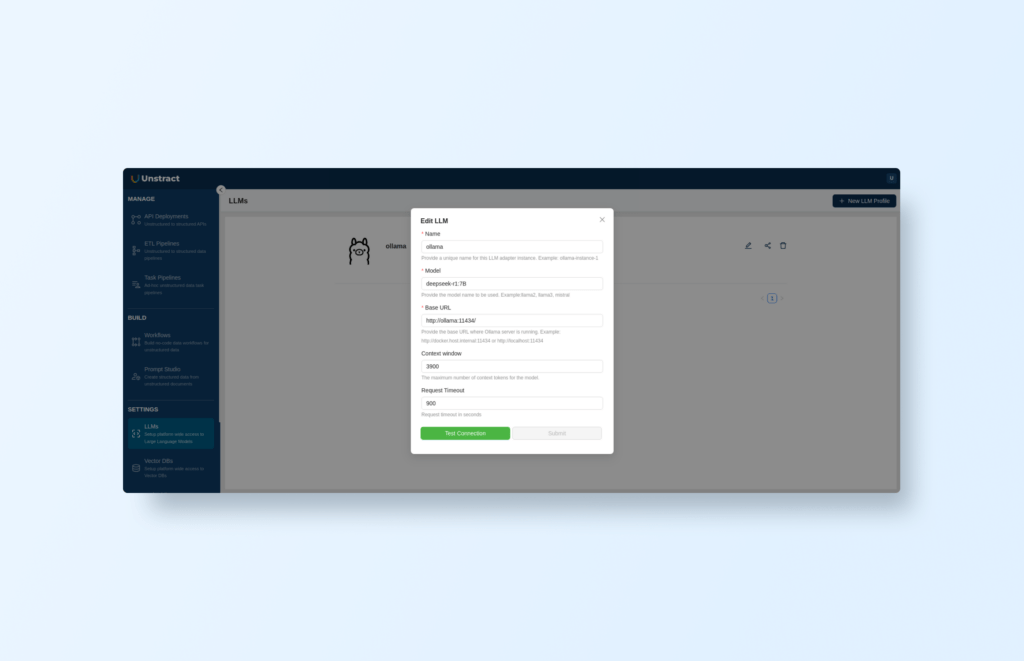
In Unstract’s configuration, go to ‘SETTINGS->LLMs’ and add a new LLM, select Ollama and then set the URL:
It should be the container’s DNS name, like this:
http://ollama:11434/
With Ollama installed and connected, the next step is to set up an embedding model to generate vector representations for processed documents. We will cover this in the following section.
Note: While DeepSeek OCR demonstrates strong capabilities, OCR remains a challenging task, and large language models (LLMs) are prone to hallucinations or omitting text. Despite DeepSeek’s OCR functionality, the risk of inaccuracies makes enterprise adoption potentially risky. And that is why you’ll need tools like Unstructured.io or LLMWhisperer to pre-process the document before sending it to LLMs.
Installing Ollama Embeddings
To enable semantic search and document retrieval in Unstract, we need to install an embedding model.
Ollama provides several embedding models, and in this guide, we will use nomic-embed-text, a lightweight model optimized for generating vector representations of text.
This downloads and installs nomic-embed-text inside the Ollama container.
2. Connecting Ollama Embeddings to Unstract
Once the embedding model is running, we need to configure Unstract to use it for vector-based document search.
In Unstract’s configuration, go to ‘SETTINGS->Embedding’, and add a new embedding. select Ollama and set the URL:
As before, since the embedding is also in Ollama, the address should be:
http://ollama:11434/
With embeddings set up, the next step is to install a text extraction tool to convert unstructured documents into raw text. We will cover this in the next section.
To process unstructured documents and extract raw text, we will use Unstructured.io’s open-source text extractor.
This tool efficiently handles various document formats, including PDFs, DOCX, HTML, and images, making it a powerful alternative to proprietary solutions.
1. Using Unstructured.io’s Text Extractor
Why use Unstructured.io?
Open-source and customizable.
OCR support for multiple document formats.
Works seamlessly with AI-powered processing pipelines.
Provides structured outputs for downstream analysis.
Unstructured.io extracts raw text, tables, and metadata, which can then be processed by an LLM, embeddings model, or vector database for further insights.
LLMWhisperer: A general-purpose PDF-to-text converter service from Unstract.
LLMs are powerful, but their output is as good as the input you provide. LLMWhisperer is a technology that presents data from complex documents (different designs and formats) to LLMs in a way that they can best understand.
If you want to quickly test LLMWhisperer with your own documents, you can check our free playground. Alternatively, you can sign up for our free trial which allows you to process up to 100 pages a day for free.
This launches the extractor on port 8010, making it accessible via API. Again, it is also connected to the Unstract internal container network, unstract-network.
3. Connecting Unstructured.io to Unstract
To integrate the text extractor with Unstract, configure its connection settings:
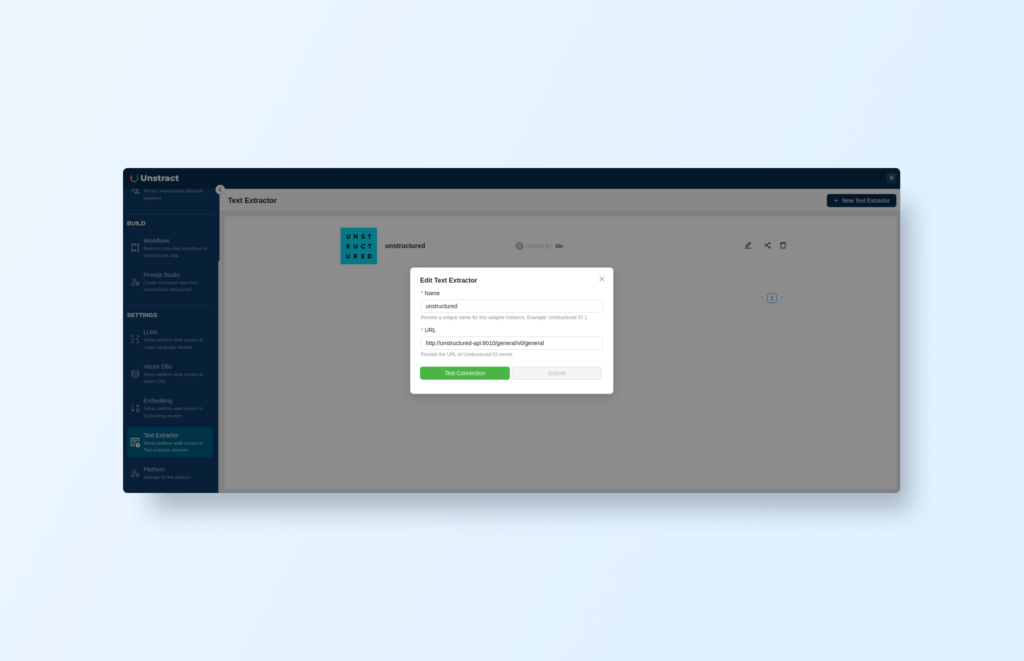
In Unstract’s configuration, go to ‘SETTINGS->Text Extractor’, add a new text extractor, select Unstructured community, and set the URL:
It should be the container’s DNS name:
http://unstructured-api:8010/general/v0/general
With text extraction in place, the next step is to set up a vector database (Postgres + PGVector) for efficient document search and retrieval. We will cover this in the following section.
Setting Up PGVector for Vector Database
To store and efficiently search vector embeddings generated from document data, we will use PostgreSQL with the PGVector plugin.
PGVector allows storing and querying embeddings using similarity search, making it a great open-source alternative to proprietary vector databases like Pinecone or Weaviate.
1. Running PostgreSQL with PGVector
Since Unstract is already running a Postgres database, we can use that database to set up PGVector.
Once inside the PostgreSQL shell, enable PGVector with:
CREATE EXTENSION IF NOT EXISTS vector;
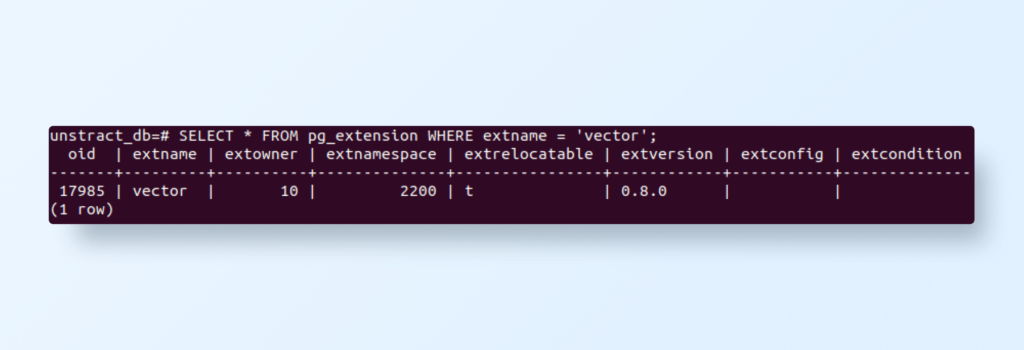
To verify that PGVector is installed correctly, run:
SELECT * FROM pg_extension WHERE extname = 'vector';
This should return details about the installed extension.
3. Connecting PGVector to Unstract
To integrate Unstract with PGVector:
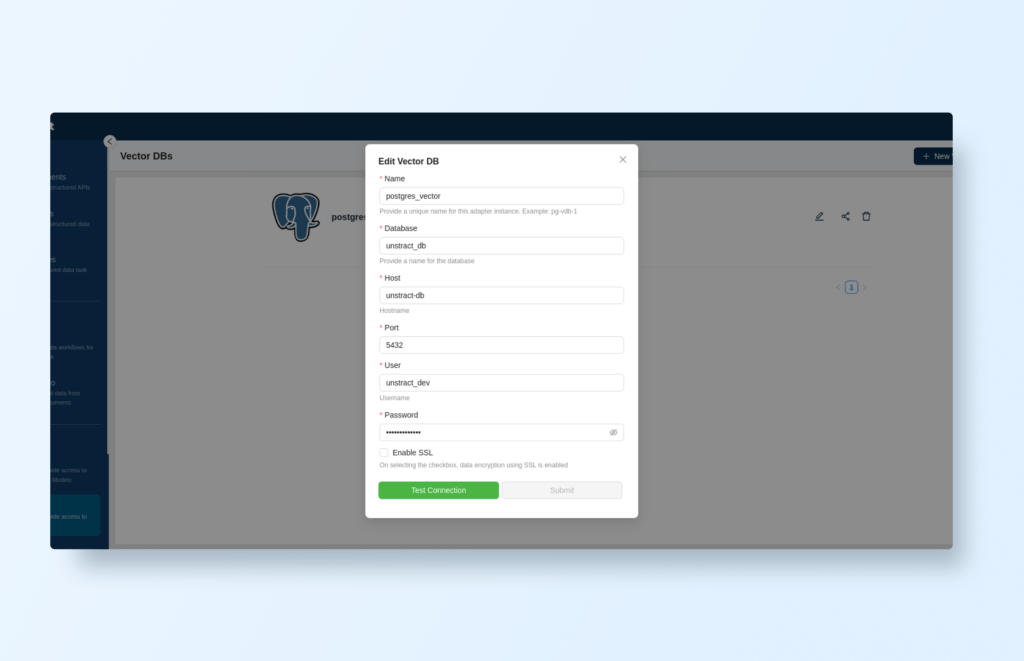
In Unstract’s configuration, go to ‘SETTINGS->Vector DBs’, add a new vector database, select Postgres and fill in the information:
The default password is unstract_pass.
Now that we have a vector database for storing and searching document embeddings, the next step is to extract data from invoices using Unstract’s prompt studio.
Setting Up the Prompt Studio for Invoice PDF Data Extraction
Begin by creating a new project in Prompt Studio and naming it something descriptive, like “Invoice Extraction”.
This project will serve as your dedicated workspace for developing prompts that cater specifically to your invoice data extraction needs.
Next, upload sample invoice PDFs that cover the various formats you expect to handle.
These samples will be invaluable for testing and fine-tuning your prompts, ensuring that key data points are accurately captured.
For this example, we will use the following pdf document:
By setting up and rigorously testing your prompts, you’ll establish a robust workflow that transforms unstructured invoice data into structured formats, making it ready for further processing or analysis.
Note: Ensure that you configure the output format as JSON in your prompts. Also since we will be using DeepSeek, which is a reasoning model, it is advised to mention in the prompt to not return any reasoning, just the JSON.
Configure Default LLM Profile
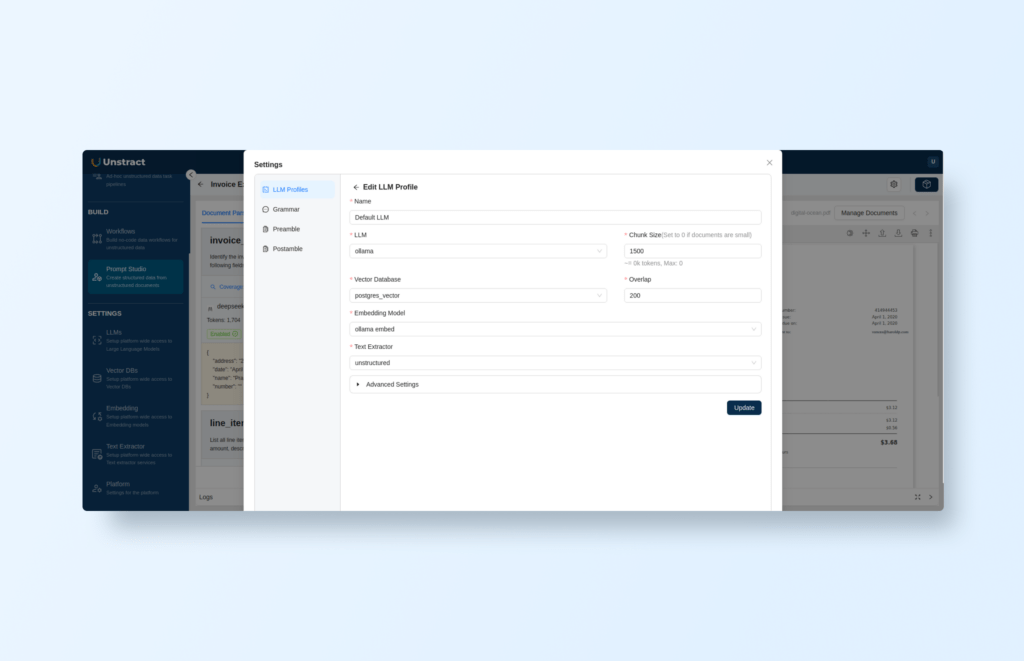
Before adding any documents, you need to configure the default LLM profile by clicking on the gear icon in your Prompt Studio project to open the settings and select ‘LLM Profiles’:
Open source AI document extraction: Configure LLM models for extraction
Here you just need to select the connectors that were defined previously for the LLM, Vector Database, Embedding Model, and Text Extractor.
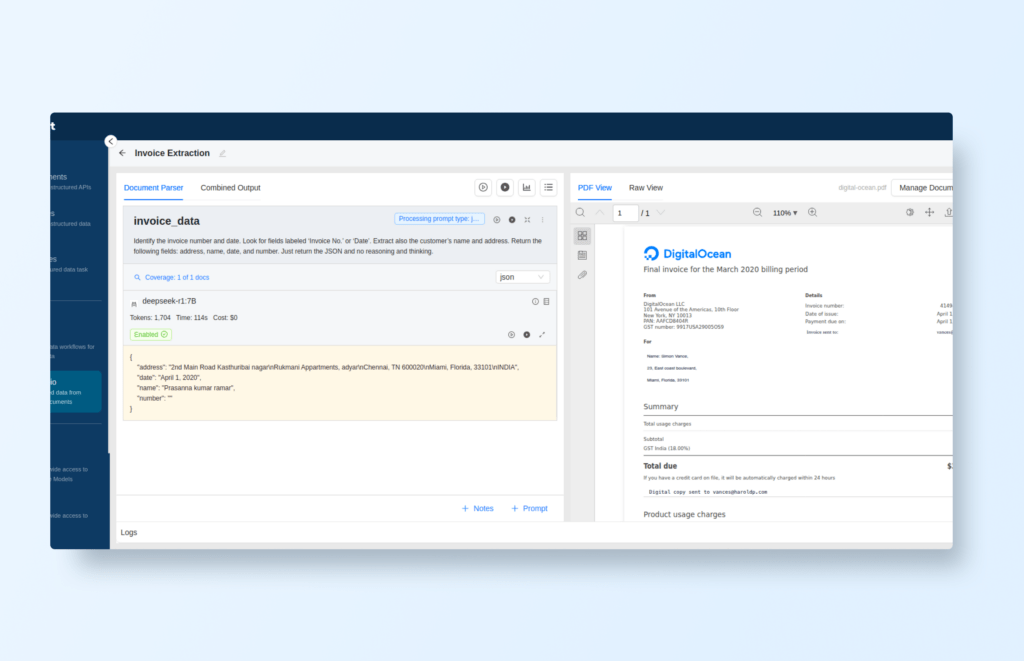
Extract Invoice Data
Prompt: "Identify the invoice number and date. Look for fields labeled ‘Invoice No.’ or ‘Date’. Extract also the customer’s name and address. Return the following fields: address, name, date, and number. Just return the JSON and no reasoning and thinking."
Open source AI document extraction: Write prompts to extract data from documents
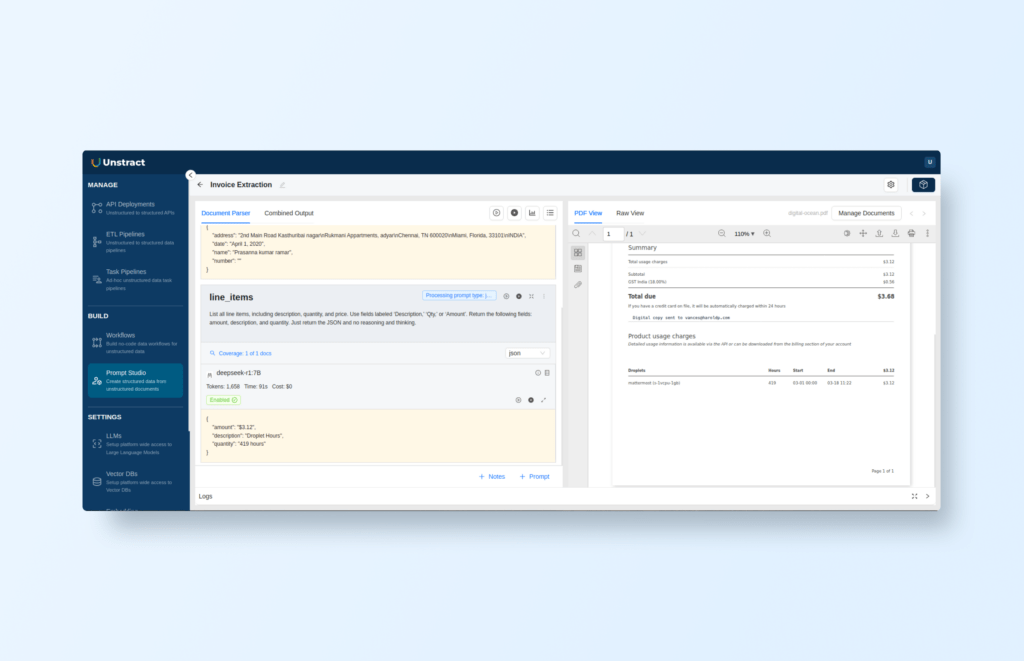
Extract Line Items
Prompt: "List all line items, including description, quantity, and price. Use fields labeled ‘Description,’ ‘Qty,’ or ‘Amount’. Return the following fields: amount, description, and quantity. Just return the JSON and no reasoning and thinking."
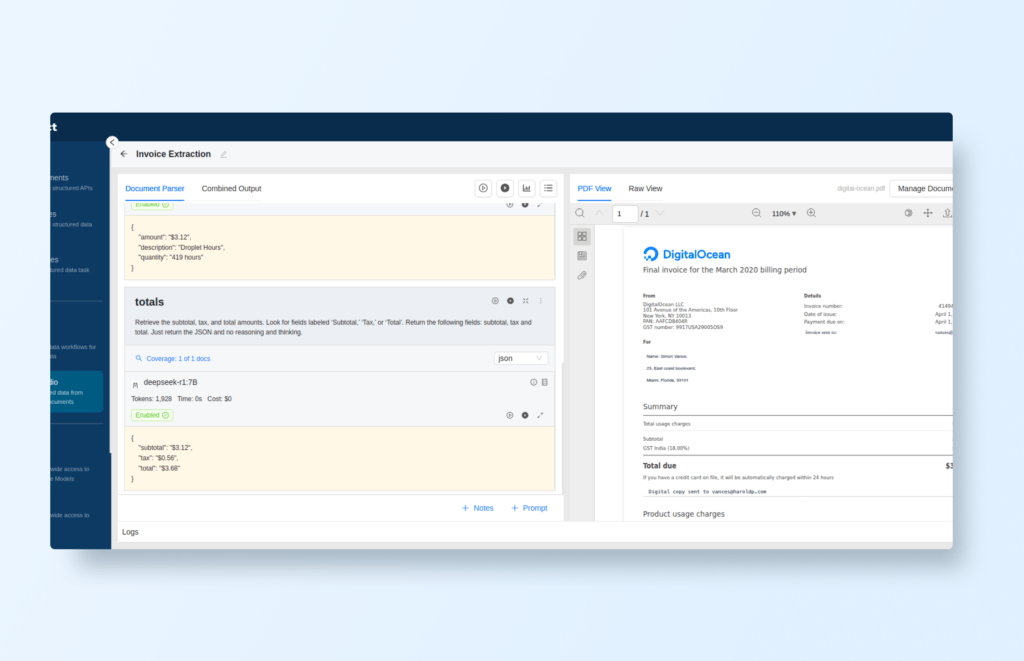
Extract Totals
Prompt: "Retrieve the subtotal, tax, and total amounts. Look for fields labeled ‘Subtotal,’ ‘Tax,’ or ‘Total’. Return the following fields: subtotal, tax, and total. Just return the JSON and no reasoning and thinking."
Run these prompts to extract the structured JSON outputs. The combined output of the different prompts is for example:
Once you’ve set up your Prompt Studio project and fine-tuned your prompts for precise data extraction, the next step is to deploy your Unstract solution as an API.
This deployment enables you to integrate the parsing functionality directly into your applications or systems, supporting real-time processing and scalable operations.
Creating a Tool
Begin by converting your project into a tool that can be incorporated into a workflow. In your Prompt Studio project, click the Export as tool icon located at the top right corner.
This action will transform your project into a ready-to-use tool.
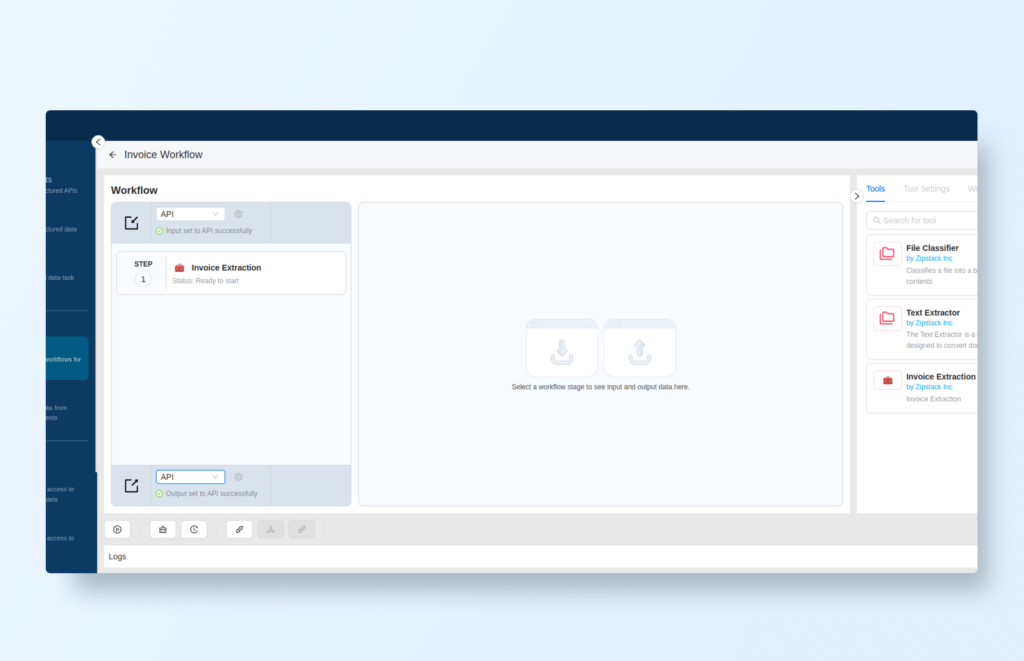
Creating a Workflow
Next, create a new workflow:
Navigate to BUILD → Workflows.
Click on + New Workflow to start a new workflow.
Then, in the Tools section on the right, locate the tool you just created (e.g., “Invoice Extraction”) and drag and drop it into the workflow editor on the left side:
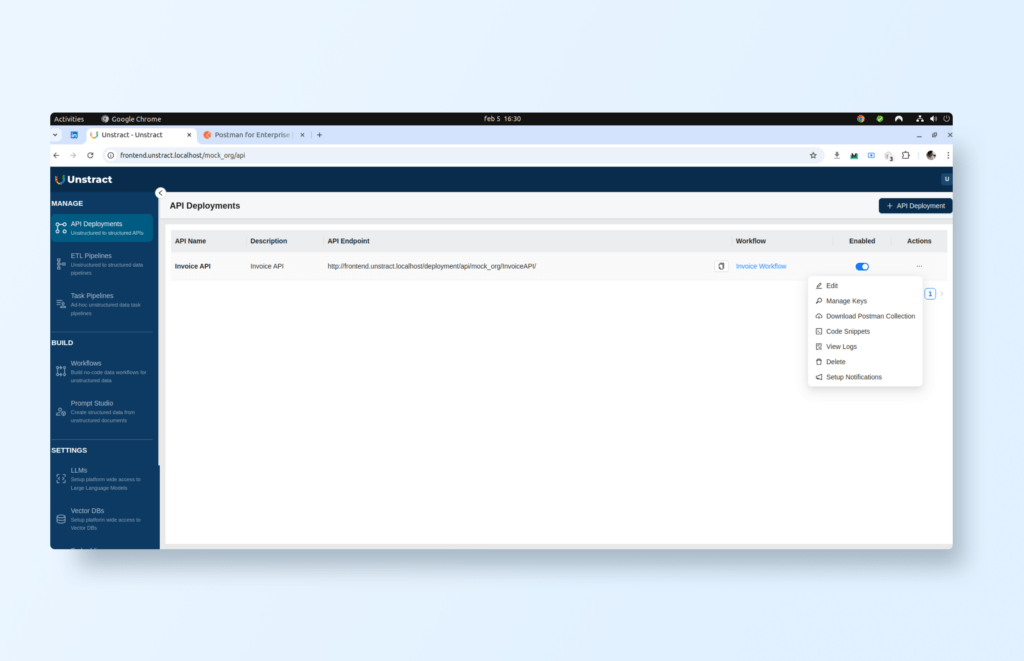
Creating an API
Now that your workflow is ready, you can transform it into an API. Begin by navigating to MANAGE → API Deployments and clicking on the + API Deployment button to create a new API deployment by selecting the created workflow. Once the API is set up, you can use the Actions links to manage different aspects of the API. For example, you can configure API keys or download a Postman collection for testing:
Building an Open source AI document extraction API
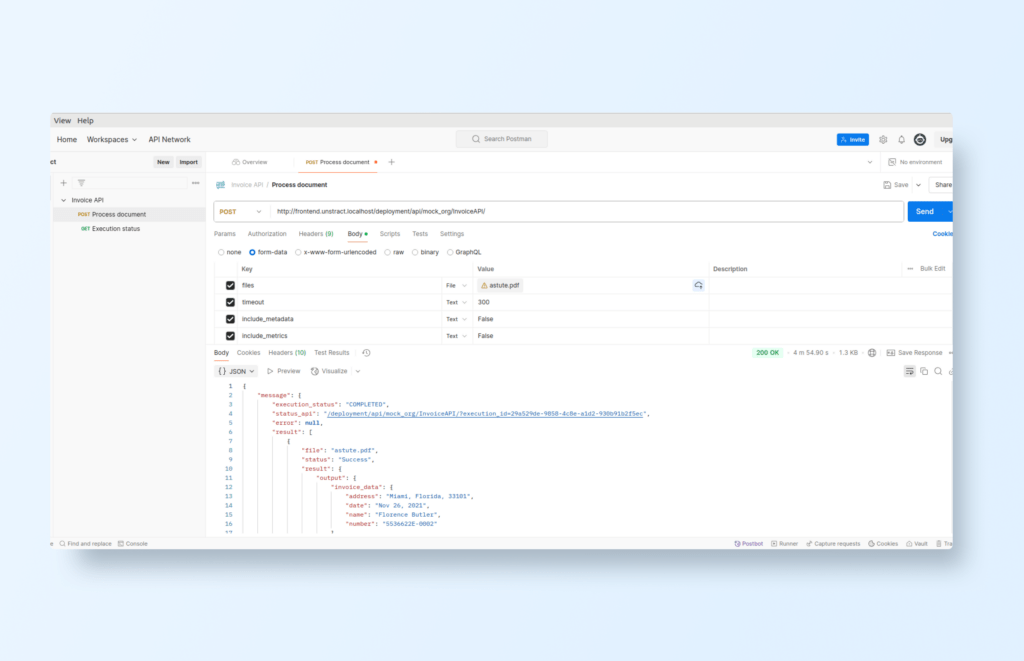
Testing API Extraction with Postman
Once your Unstract workflow is deployed as an API, testing it ensures it functions correctly and extracts data accurately.
Postman, a popular API development and testing tool, allows you to send requests and inspect responses easily.
Steps to Test Your Unstract API in Postman:
Create a New Workspace – Open Postman and set up a new workspace.
Import the Postman Collection – Use the previously downloaded collection.
Set API Authentication – Configure authentication by selecting Bearer Token and entering your API key.
Send a Request – Choose an invoice file, run the request, and review the extracted data.
For example:
Open source AI document extraction: Processing unstructured documents to structured(JSON) output
Demo of Unstract for processing unstrucutred documents
In this webinar, we’ll dive deep into all the features of Unstract and guide you through setting up an ETL pipeline tailored for unstructured data extraction.
Open source document data extraction: Conclusion
In this guide, we explored a fully open-source document processing setup, demonstrating how to extract structured data from unstructured documents efficiently.
By leveraging open-source tools, users gain flexibility, transparency, and cost-effectiveness—key advantages over proprietary solutions that often come with limitations on customization and high licensing fees.
With this foundation in place, the next steps could involve expanding the pipeline to handle additional document types, improving accuracy with fine-tuned models, or integrating the API into existing business workflows.
Whether you’re scaling up or refining your setup, the open-source approach ensures adaptability and long-term sustainability.
Even better, schedule a call with us. We’ll help you understand how Unstract leverages AI to help document processing automation and how it differs from traditional OCR and RPA solutions.
LLMWhisperer: Best OCR to Extract Data from Handwritten Forms
Let’s see how to process challenging PDFs that contain hand-filled forms with elements like checkboxes and radiobuttons and also bad scan pages the unfriendly orientations with LLMWhisperer. LLMWhisperer is a text extraction service that specifically targets large language models (LLMs).
Open-source Unstructured Data ETL:Related topics to explore
What is Unstract, and how does it serve as document data extraction software? Unstract is an open-source document processing tool designed for data extraction from documents. As document data extraction software, it allows users to build custom pipelines for extracting structured data from unstructured sources using various open-source AI models, embedding tools, and text extractors.
What makes up the “open source ai document processing” stack in the article?
The stack consists of five core pieces:
Unstract (document processing engine, workflow orchestrator, and UI)
Ollama (runs local LLMs such as DeepSeek or Mistral)
Ollama-Embeddings (e.g., nomic-embed-text for vector creation)
Unstructured.io or LLMWhisperer or LlamaParse (OCR/Text extractor)
PostgreSQL with the PGVector extension (vector database)
Together, they create a 100 % open source AI document processing pipeline with no reliance on cloud APIs.
What are the main benefits of using open source AI document processing for enterprises?
Complete data privacy (all data stays on-premises)
No recurring licensing or usage fees
Ability to inspect, modify, and extend the code
Avoidance of vendor lock-in
Seamless integration with a wide variety of AI, database, and text extraction tools
How can someone get started with an open-source document data extraction setup using Unstract? To begin with, set up open source document data extraction using Unstract by installing the Unstract open source platform on your local machine through Docker. Configure it with Ollama (LLM engine), Unstructured.io/LlamaParse (OCR), and connect to an open-source vector database, such as PostgreSQL, using PGVector. Step-by-step guides make it easy to establish an efficient document data extraction pipeline, eliminating the need for cloud services.
Unstract be integrated with other tools to improve accuracy and scalability? Because it’s open-source, Unstract lets you plug in alternative OCR engines, custom embedding models, or different vector databases, such as ChromaDB or Weaviate. You can also export Prompt-Studio projects as tools, chain them in workflows, and expose them as REST APIs—making large-scale, high-accuracy document data extraction easy to embed in any system.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.