Definitive Guide to pdfplumber Text and Table Extraction Capabilities
Table of Contents
Introduction
In today’s data-driven world, PDFs are one of the most common file formats used for sharing information. From business reports to financial statements and scanned forms, PDFs encapsulate crucial data in a compact and portable manner.
This is where PDF parsing tools come into play, enabling automated extraction of data from PDFs into formats that are easier to work with, such as plain text or structured tables.
PDF parsing is an essential process for businesses and developers looking to automate document processing, whether for financial auditing, legal document analysis, or extracting data from large-scale reports.
Manual extraction is often tedious, time-consuming, and prone to error, making automated solutions both efficient and scalable.
One of the leading Python-based tools for PDF parsing is pdfplumber. It is a powerful library that allows for precise extraction of text, tables, and metadata from PDFs.
This article aims to provide a comprehensive guide on how to set up and use PDFplumber to extract data from PDFs. We’ll explore the installation and basic setup, walk through key features like text and table extraction, and demonstrate these features using real-world examples.
Through this process, we’ll also evaluate the strengths and limitations of pdfplumber, highlighting when and where it shines.
Later in the post, we will also introduce LLMWhisperer API, a layout-preserving PDF-to-text extractor. LLMWhisperer handles document types of any complexity — document scans, images, PDFs with complex tables, checkboxes, and handwriting etc. If you are extracting documents to eventually pass to an LLM to analyze and extract info, this is the simplest and most effective solution. You do not have to worry or know about the document type, format, design and layout.
This command will install pdfplumber along with its dependencies, such as pdf2image, Pillow, and PyPDF2, which are required for processing PDFs.
If you encounter any issues related to pdf2image (a common one being missing dependencies on Linux or macOS), you might need to install additional libraries such as poppler-utils for proper image handling.
On Linux, you can install it using:
sudo apt-get install poppler-utils
On macOS, you can install it using Homebrew:
brew install poppler
Once pdfplumber is installed, you’re ready to begin working with PDF files.
pdfplumber initial setup
After installing pdfplumber, the next step is to import the library into your Python script and load a PDF file for processing.
pdfplumber works by opening a PDF file and then allowing you to extract data such as text, tables, and metadata from the document’s pages.
Here’s a basic code example that shows how to load and read the text from the first page of a PDF:
# Import pdfplumber
import pdfplumber
# Open the PDF file
with pdfplumber.open("Chase Freedom Bank Statement.pdf") as pdf:
# Access the first page of the PDF
first_page = pdf.pages[0]
# Extract the text from the first page
text = first_page.extract_text()
# Print the extracted text
print(text)
Explanation of Code:
pdfplumber.open("sample.pdf"): Opens the PDF file named sample.pdf. The file path can be adjusted to point to any PDF on your system.
pdf.pages[0]: Accesses the first page of the PDF (note that Python uses zero-based indexing, so 0 refers to the first page).
extract_text(): Extracts the raw text from the page. You can modify this method to extract other elements such as tables or specific data points.
The above code will print the raw text from the first page of the document.
If the page contains structured text like paragraphs, headings, or tables, this text will be extracted and displayed accordingly.
This provides a solid foundation for more complex PDF parsing tasks, such as extracting tables or handling multi-page documents, which will be covered in the next sections.
Key Features of pdfplumber
Text Extraction (Chase Bank Statement)
One of the most fundamental features of pdfplumber is its ability to extract text from PDF files, even when dealing with complex layouts that contain headers, footers, and varying sections of text.
In this section, we’ll walk through the process of extracting text from a Chase Bank Statement, a common document format that includes structured sections like headers, transaction lists, and footers:
We’ll use pdfplumber to load the Chase Bank Statement PDF and extract text from different sections of the document.
This is useful for extracting relevant information such as account numbers, balances, and transaction details, which can then be processed or stored in a structured format.
To begin, we will load the PDF file and extract the text from various pages of the statement. Here’s a step-by-step guide with code:
# Import pdfplumber
import pdfplumber
# Open the PDF file (Chase Bank Statement)
with pdfplumber.open("Chase Freedom Bank Statement.pdf") as pdf:
# Iterate over each page in the PDF
for page in pdf.pages:
# Extract the text from the page
page_text = page.extract_text()
# Print the extracted text
print(f"Page {page.page_number}:\\n{page_text}\\n")
Explanation:
pdfplumber.open("chase_bank_statement.pdf"): Opens the PDF file.
for page in pdf.pages: Loops through all the pages in the PDF document.
page.extract_text(): Extracts text from each page.
page.page_number: Retrieves the current page number, useful for displaying the page number in the output.
The extracted text will display content from various sections of each of the pages, including the header, account summary, and other structured data.
The output should show text similar to this:
Page 1:
SCENARIO-1D
New Balance
February 2024
S M T W T F S
Minimum Payment Due
28 29 30 31 1 2 3 Previous points balance 40,468
4 5 6 7 8 9 10 + 1% (1 Pt)/$1 earned on all purchases 5,085
Payment Due Date
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 1 2 Start redeeming today. Visit Ultimate Rewards(r) at
www.ultimaterewards.com
3 4 5 6 7 8 9
You always earn unlimited 1% cash back on all your purchases.
Late Payment Warning: If we do not receive your minimum payment Activate new bonus categories every quarter. You'll earn an
by the date listed above, you may have to pay a late fee of up to additional 4% cash back, for a total of 5% cash back on up to
$40.00 and your APR's will be subject to increase to a maximum $1,500 in combined bonus category purchases each quarter.
Penalty APR of 29.99%. Activate for free at chase.com/freedom, visit a Chase branch or
Minimum Payment Warning: If you make only the minimum call the number on the back of your card.
payment each period, you will pay more in interest and it will take you
longer to pay off your balance. For example:
If you make no You will pay off the And you will end up
additional charges balance shown on this paying an estimated
using this card and statement in about... total of...
each month you pay...
Only the minimum 15 years $12,128
payment
$189 3 years $6,817
(Savings=$5,311)
If you would like information about credit counseling services, call
1-866-797-2885.
Account Number: 4342 3780 1050 7320
Previous Balance $4,233.99
Payment, Credits -$4,233.99
Purchases +$5,084.29
Cash Advances $0.00
B`alance Transfers $0.00
Fees Charged $0.00
Interest Charged $0.00
New Balance $5,084.29
Opening/Closing Date 01/04/24 - 02/03/24
Credit Access Line $31,700
A`vailable Credit $26,615
Cash Access Line $1,585
Available for Cash $1,585
Past Due Amount $0.00
Balance over the Credit Access Line $0.00
Reminder: It is important to continue making your payments on time. Your APRs may increase if the minimum payment is not made on
time or payments are returned.
0000001 FIS33339 D 12 Y 9 03 24/02/03 Page 1 of 3 06610 MA MA34942 03410000120003494201
0404
P.O. BOX 15123
AUTOPAY IS ON
WILMINGTON, DE 19850-5123
See Your Account
For Undeliverable Mail Only
Messages for details.
Account number: 4342 3780 1050 7320
__________________________________________________..______________________ Amount Enclosed
34942 BEX 903424 D AUTOPAY IS ON
LARRY PAGE
C PAGE
24917 KEYSTONE AVE
LOS ANGELES CA 97015-5505
CARDMEMBER SERVICE
PO BOX 6294
CAROL STREAM IL 60197-6294
Page 2:
Date of
Transaction Merchant Name or Transaction Description $ Amount
01/28 AUTOMATIC PAYMENT - THANK YOU -4,233.99
01/04 LARRY HOPKINS HONDA 7074304151 CA 265.40
01/04 CICEROS PIZZA SAN JOSE CA 28.18
01/05 USPS PO 0545640143 LOS ALTOS CA 15.60
01/07 TRINETHRA SUPER MARKET CUPERTINO CA 7.92
01/04 SPEEDWAY 5447 LOS ALTOS HIL CA 31.94
01/06 ATT*BILL PAYMENT 800-288-2020 TX 300.29
01/07 AMZN Mktp US*RT4G124P0 Amzn.com/bill WA 6.53
01/07 AMZN Mktp US*RT0Y474Q0 Amzn.com/bill WA 21.81
01/05 HALAL MEATS SAN JOSE CA 24.33
01/09 VIVINT INC/US 800-216-5232 UT 52.14
01/09 COSTCO WHSE #0143 MOUNTAIN VIEW CA 75.57
01/11 WALGREENS #689 MOUNTAIN VIEW CA 18.54
01/12 GOOGLE *YouTubePremium g.co/helppay# CA 22.99
01/13 FEDEX789226298200 Collierville TN 117.86
01/19 SHELL OIL 57444212500 FREMONT CA 7.16
01/19 LEXUS OF FREMONT FREMONT CA 936.10
01/19 STARBUCKS STORE 10885 CUPERTINO CA 11.30
01/22 TST* CHAAT BHAVAN MOUNTAI MOUNTAIN VIEW CA 28.95
01/23 AMZN Mktp US*R06VS6MN0 Amzn.com/bill WA 7.67
01/23 UALR REMOTE PAY 501-569-3202 AR 2,163.19
01/23 UALR REMOTE PAY 501-569-3202 AR 50.00
01/24 AMZN Mktp US*R02SO5L22 Amzn.com/bill WA 8.61
01/24 TIRUPATHI BHIMAS MILPITAS CA 58.18
01/25 AMZN Mktp US*R09PP5NE2 Amzn.com/bill WA 28.36
01/26 COSTCO WHSE #0143 MOUNTAIN VIEW CA 313.61
01/29 AMZN Mktp US*R25221T90 Amzn.com/bill WA 8.72
01/29 COMCAST CALIFORNIA 800-COMCAST CA 97.00
01/29 TRADER JOE S #127 LOS ALTOS CA 20.75
01/30 Netflix 1 8445052993 CA 15.49
01/30 ATT*BILL PAYMENT 800-288-2020 TX 300.35
01/30 APNI MANDI FARMERS MARKE SUNNYVALE CA 36.76
02/01 APPLE.COM/BILL 866-712-7753 CA 2.99
2024 Totals Year-to-Date
Total fees charged in 2024 $0.00
Total interest charged in 2024 $0.00
YYeeaarr--ttoo--ddaattee ttoottaallss ddoo nnoott rreefflleecctt aannyy ffeeee oorr iinntteerreesstt rreeffuunnddss
yyoouu mmaayy hhaavvee rreecceeiivveedd..
Your Annual Percentage Rate (APR) is the annual interest rate on your account.
Annual Balance
Balance Type Percentage Subject To Interest
Rate (APR) Interest Rate Charges
PURCHASES
Purchases 19.99%(v)(d) - 0 - - 0 -
CASH ADVANCES
Cash Advances 29.99%(v)(d) - 0 - - 0 -
BALANCE TRANSFERS
Balance Transfers 19.99%(v)(d) - 0 - - 0 -
LARRY PAGE Page2 of 3 Statement Date: 02/03/24
0000001 FIS33339 D 12 Y 9 03 24/02/03 Page 2 of 3 06610 MA MA34942 03410000120003494202
Extracting Text from Specific Sections (Targeted Extraction)
Sometimes, you might want to extract text from specific areas of a page, such as only the transactions section in a bank statement, or avoid extracting headers and footers.
In this case, you can use pdfplumber’s ability to work with bounding boxes to target certain parts of the page.Here’s how to extract text from a specific region of the page, like the Transactions Table:
# Import pdfplumber
import pdfplumber
# Open the PDF file (Chase Bank Statement)
with pdfplumber.open("Chase Freedom Bank Statement.pdf") as pdf:
# Get the second page of the PDF
second_page = pdf.pages[1]
# Define a bounding box for the transactions area (x0, y0, x1, y1)
bbox = (50, 100, 550, 550)
# Extract text from the defined region
transactions_text = second_page.within_bbox(bbox).extract_text()
# Print the extracted transactions text
print(transactions_text)
Explanation:
bbox = (50, 100, 550, 550): Defines a bounding box for the area where the transactions are located. You may need to adjust these coordinates based on the structure of your PDF, these work for this sample.
within_bbox(): Limits the extraction to the defined region (bounding box) of the page.
extract_text(): Extracts the text within the specified bounding box.
This allows you to focus on specific sections of the document, making it easier to extract just the relevant information.
The output for the Transactions section should look like this:
Date of
Transaction Merchant Name or Transaction Description $ Amount
01/28 AUTOMATIC PAYMENT - THANK YOU -4,233.99
01/04 LARRY HOPKINS HONDA 7074304151 CA 265.40
01/04 CICEROS PIZZA SAN JOSE CA 28.18
01/05 USPS PO 0545640143 LOS ALTOS CA 15.60
01/07 TRINETHRA SUPER MARKET CUPERTINO CA 7.92
01/04 SPEEDWAY 5447 LOS ALTOS HIL CA 31.94
01/06 ATT*BILL PAYMENT 800-288-2020 TX 300.29
01/07 AMZN Mktp US*RT4G124P0 Amzn.com/bill WA 6.53
01/07 AMZN Mktp US*RT0Y474Q0 Amzn.com/bill WA 21.81
01/05 HALAL MEATS SAN JOSE CA 24.33
01/09 VIVINT INC/US 800-216-5232 UT 52.14
01/09 COSTCO WHSE #0143 MOUNTAIN VIEW CA 75.57
01/11 WALGREENS #689 MOUNTAIN VIEW CA 18.54
01/12 GOOGLE *YouTubePremium g.co/helppay# CA 22.99
01/13 FEDEX789226298200 Collierville TN 117.86
01/19 SHELL OIL 57444212500 FREMONT CA 7.16
01/19 LEXUS OF FREMONT FREMONT CA 936.10
01/19 STARBUCKS STORE 10885 CUPERTINO CA 11.30
01/22 TST* CHAAT BHAVAN MOUNTAI MOUNTAIN VIEW CA 28.95
01/23 AMZN Mktp US*R06VS6MN0 Amzn.com/bill WA 7.67
01/23 UALR REMOTE PAY 501-569-3202 AR 2,163.19
01/23 UALR REMOTE PAY 501-569-3202 AR 50.00
01/24 AMZN Mktp US*R02SO5L22 Amzn.com/bill WA 8.61
01/24 TIRUPATHI BHIMAS MILPITAS CA 58.18
01/25 AMZN Mktp US*R09PP5NE2 Amzn.com/bill WA 28.36
01/26 COSTCO WHSE #0143 MOUNTAIN VIEW CA 313.61
01/29 AMZN Mktp US*R25221T90 Amzn.com/bill WA 8.72
01/29 COMCAST CALIFORNIA 800-COMCAST CA 97.00
01/29 TRADER JOE S #127 LOS ALTOS CA 20.75
01/30 Netflix 1 8445052993 CA 15.49
01/30 ATT*BILL PAYMENT 800-288-2020 TX 300.35
01/30 APNI MANDI FARMERS MARKE SUNNYVALE CA 36.76
02/01 APPLE.COM/BILL 866-712-7753 CA 2.99
Key Takeaways
pdfplumber provides an efficient and easy way to extract text from PDFs, even with complex layouts like bank statements.
You can extract text from entire pages or target specific sections using bounding boxes.
The library can handle multi-page PDFs and allows for flexible, structured text extraction, which is essential when processing large or complex documents.
Table Extraction with pdfplumber
PDFs often contain tabular data, which can be challenging to extract accurately due to variations in layout and formatting.
In this section, we’ll walk through the process of extracting tables from a PDF using the Bank of England Financials as an example:
pdfplumber includes powerful features to detect and extract tables from PDFs.
It can handle a variety of table structures, such as those with visible borders or invisible separators, by analysing the position of characters and lines within the document.
One of the main challenges of table extraction in PDFs is that tables are not always explicitly marked in the document.
Instead, they may consist of text elements that are aligned in a way that makes them appear as a table to the human eye, but the underlying PDF structure may not contain actual table metadata.
This makes automatic detection more complex. pdfplumber tackles this by using geometric analysis of the page’s content, looking for rows and columns based on character positioning and whitespace.
Let’s extract a table from the Bank of England Financials. Here’s a basic Python script that demonstrates how to do this:
# Import pdfplumber
import pdfplumber
# Open the PDF file (Bank of England Financials)
with pdfplumber.open("bank-of-england-financials.pdf") as pdf:
# Access the first and only page of the PDF
page = pdf.pages[0]
# Extract tables from the page
tables = page.extract_tables()
# Iterate over tables and print them
for i, table in enumerate(tables):
print(f"Table {i + 1}:")
for row in table:
print(row)
print("\\\\n")
Explanation:
page.extract_tables(): This method analyses the page and extracts any table-like structures based on text alignment, cell positioning, and spacing.
enumerate(tables): Loops over the extracted tables and prints each table row-by-row.
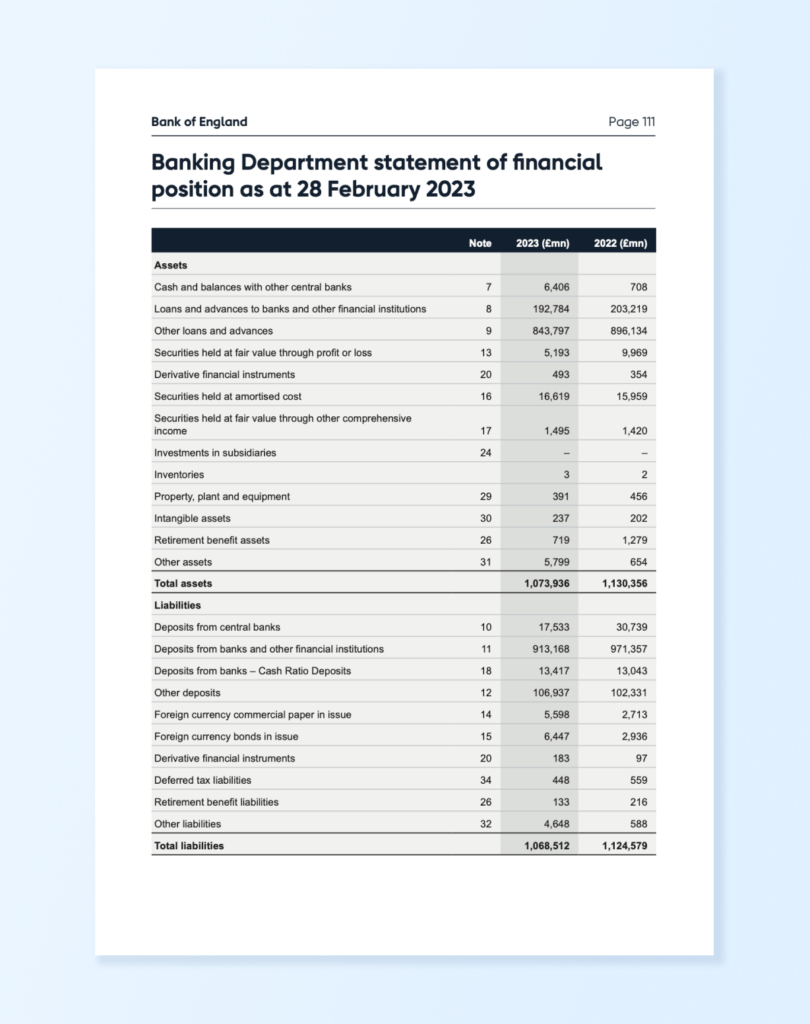
The extracted table might look something like this:
Table 1:
['', 'Note', '2023 (£mn)', '2022 (£mn)']
['Assets', '', '', '']
['Cash and balances with other central banks', '7', '6,406', '708']
['Loans and advances to banks and other financial institutions', '8', '192,784', '203,219']
['Other loans and advances', '9', '843,797', '896,134']
['Securities held at fair value through profit or loss', '13', '5,193', '9,969']
['Derivative financial instruments', '20', '493', '354']
['Securities held at amortised cost', '16', '16,619', '15,959']
['Securities held at fair value through other comprehensive\\nincome', '17', '1,495', '1,420']
['Investments in subsidiaries', '24', '-', '-']
['Inventories', '', '3', '2']
['Property, plant and equipment', '29', '391', '456']
['Intangible assets', '30', '237', '202']
['Retirement benefit assets', '26', '719', '1,279']
['Other assets', '31', '5,799', '654']
['Total assets', '', '1,073,936', '1,130,356']
['Liabilities', '', '', '']
['Deposits from central banks', '10', '17,533', '30,739']
['Deposits from banks and other financial institutions', '11', '913,168', '971,357']
['Deposits from banks - Cash Ratio Deposits', '18', '13,417', '13,043']
['Other deposits', '12', '106,937', '102,331']
['Foreign currency commercial paper in issue', '14', '5,598', '2,713']
['Foreign currency bonds in issue', '15', '6,447', '2,936']
['Derivative financial instruments', '20', '183', '97']
['Deferred tax liabilities', '34', '448', '559']
['Retirement benefit liabilities', '26', '133', '216']
['Other liabilities', '32', '4,648', '588']
['Total liabilities', '', '1,068,512', '1,124,579']
Extracting Tables with More Control (Improved Table Extraction)
Sometimes the default table extraction may miss certain elements or introduce inaccuracies, especially in more complex layouts.
You can use pdfplumber’s extract_table() method to get better control over the extraction process by specifying different strategies for extracting tables, such as accounting for the precise location of each cell.
# Import pdfplumber
import pdfplumber
# Open the PDF file (Bank of England Financials)
with pdfplumber.open("bank-of-england-financials.pdf") as pdf:
# Access the first and only page of the PDF
page = pdf.pages[0]
# Use improved table extraction with edge detection
table = page.extract_table({
"vertical_strategy": "lines", # Looks for vertical lines separating columns
"horizontal_strategy": "text", # Uses text positioning for rows
"intersection_tolerance": 5, # Adjusts for minor misalignment
})
# Print the extracted table
for row in table:
print(row)
Explanation:
vertical_strategy and horizontal_strategy: These options let you choose how to detect the boundaries of cells. The vertical strategy uses lines to detect columns, while the horizontal strategy uses text positioning to detect rows.
intersection_tolerance: A parameter that defines how strictly pdfplumber aligns text elements to form rows and columns. This can be tweaked to improve extraction accuracy for slightly misaligned content.
This method gives better results for tables that may have irregular row or column layouts.
The extracted table might look something like this:
['', 'Note', '2023 (£mn)', '2022 (£mn)']
['', '', '', '']
['Assets', '', '', '']
['', '', '', '']
['Cash and balances with other central banks', '7', '6,406', '708']
['', '', '', '']
['Loans and advances to banks and other financial institutions', '8', '192,784', '203,219']
['', '', '', '']
['Other loans and advances', '9', '843,797', '896,134']
['', '', '', '']
['Securities held at fair value through profit or loss', '13', '5,193', '9,969']
['', '', '', '']
['Derivative financial instruments', '20', '493', '354']
['', '', '', '']
['Securities held at amortised cost', '16', '16,619', '15,959']
['', '', '', '']
['Securities held at fair value through other comprehensive', '', '', '']
['income', '17', '1,495', '1,420']
['', '', '', '']
['Investments in subsidiaries', '24', '-', '-']
['', '', '', '']
['Inventories', '', '3', '2']
['', '', '', '']
['Property, plant and equipment', '29', '391', '456']
['', '', '', '']
['Intangible assets', '30', '237', '202']
['', '', '', '']
['Retirement benefit assets', '26', '719', '1,279']
['', '', '', '']
['Other assets', '31', '5,799', '654']
['', '', '', '']
['Total assets', '', '1,073,936', '1,130,356']
['', '', '', '']
['Liabilities', '', '', '']
['', '', '', '']
['Deposits from central banks', '10', '17,533', '30,739']
['', '', '', '']
['Deposits from banks and other financial institutions', '11', '913,168', '971,357']
['', '', '', '']
['Deposits from banks - Cash Ratio Deposits', '18', '13,417', '13,043']
['', '', '', '']
['Other deposits', '12', '106,937', '102,331']
['', '', '', '']
['Foreign currency commercial paper in issue', '14', '5,598', '2,713']
['', '', '', '']
['Foreign currency bonds in issue', '15', '6,447', '2,936']
['', '', '', '']
['Derivative financial instruments', '20', '183', '97']
['', '', '', '']
['Deferred tax liabilities', '34', '448', '559']
['', '', '', '']
['Retirement benefit liabilities', '26', '133', '216']
['', '', '', '']
['Other liabilities', '32', '4,648', '588']
['', '', '', '']
['Total liabilities', '', '1,068,512', '1,124,579']
Key Takeaways
pdfplumber effectively detects and extracts tables from PDFs by analysing the document’s layout, including text and lines.
It provides different strategies for table extraction, allowing users to customize how tables are detected and parsed, making it versatile for complex financial documents like the Bank of England Financials.
Table extraction can sometimes require fine-tuning depending on the document layout, but pdfplumber offers the flexibility needed for accurate parsing.
Form and Handwritten Data Extraction with pdfplumber
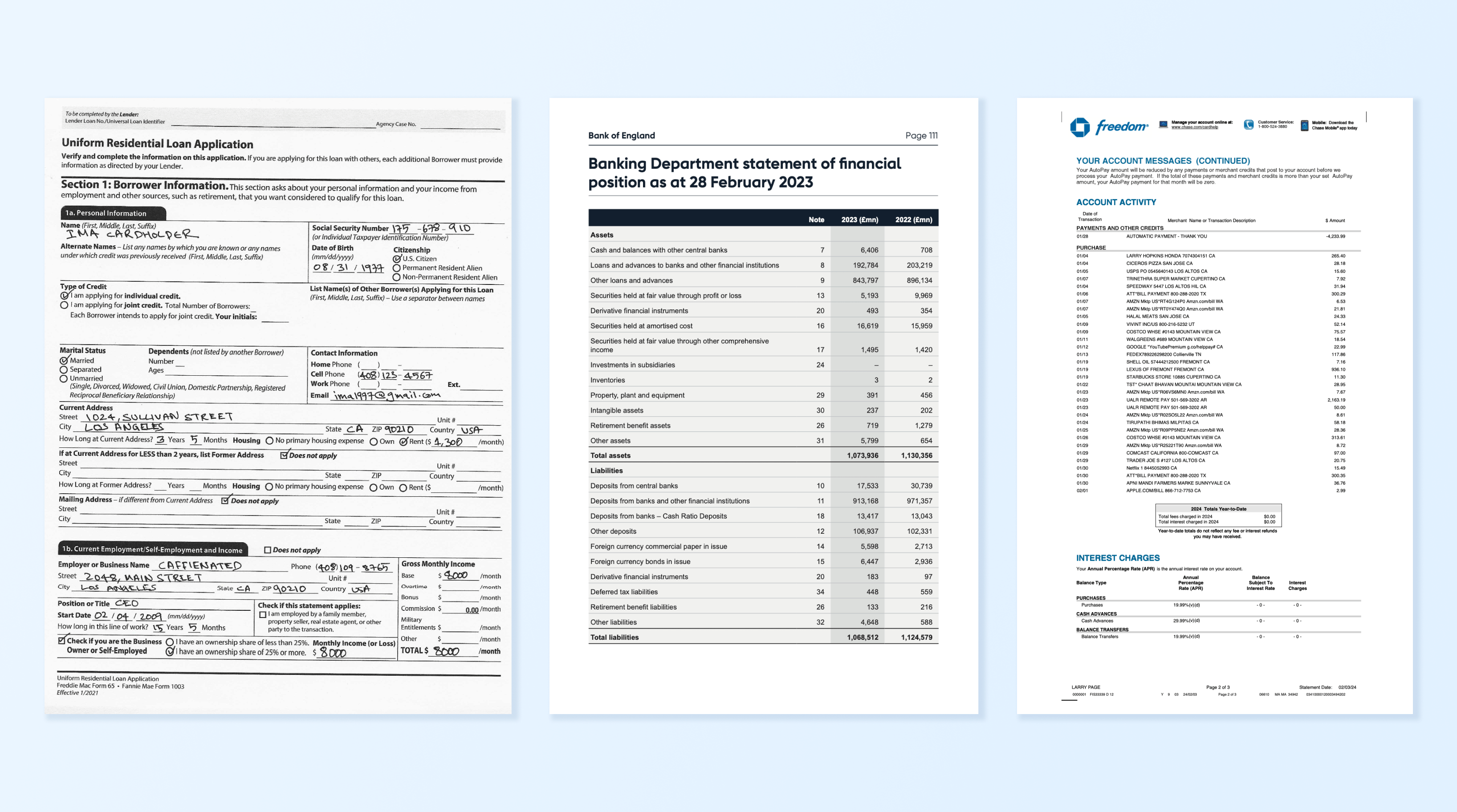
When dealing with scanned documents, such as a scanned loan application, extracting form data or handwritten text poses additional challenges compared to extracting regular text from digital PDFs.
Scanned PDFs are essentially images embedded within a PDF file, meaning there is no inherent text layer to extract:
Instead, Optical Character Recognition (OCR) needs to be applied to interpret the characters in the image and convert them into machine-readable text.
pdfplumber can handle this scenario by working in conjunction with OCR tools like Tesseract, which performs the heavy lifting of extracting text from scanned images.
However, handwritten text, in particular, can be difficult to extract accurately due to its irregularity, varying styles, and potential ambiguity.
Let’s walk through an example where we:
Extract the image of the scanned page using pdfplumber.
Apply OCR (using Tesseract) to extract text, including any handwritten text.
Handle form fields, where possible, by locating areas within the PDF where input data is likely to exist.
Step 1: Installing Tesseract OCR
To use Tesseract for OCR, you’ll need to install it on your system. Here’s how you can install it:
On Windows, you can download the installer from here.
Also, install the Python wrapper for Tesseract:
pip install pytesseract
Step 2: Extracting the Scanned Image from the PDF
First, we’ll extract the image of the scanned page (or pages) from the scanned loan application using pdfplumber:
import pdfplumber
from PIL import Image
import pytesseract
# Open the PDF file (scanned loan application)
with pdfplumber.open("scanned_loan_application.pdf") as pdf:
# Extract the first page (scanned document)
first_page = pdf.pages[0]
# Extract the page as an image
image = first_page.to_image()
# Save the image for OCR processing
image.save("loan_application_page.png")
Explanation:
to_image(): Converts the PDF page into an image, which can be further processed.
image.save("loan_application_page.png"): Saves the scanned page as a PNG image, which we’ll use in the next step for OCR.
Step 3: Applying OCR to Extract Text and Handwritten Data
Once the image is extracted from the scanned PDF, we can use Tesseract to apply OCR and extract both printed and handwritten text:
# Load the saved image of the loan application
image_path = "loan_application_page.png"
ocr_text = pytesseract.image_to_string(Image.open(image_path))
# Print the extracted text
print(ocr_text)
Explanation:
pytesseract.image_to_string(): This function runs Tesseract OCR on the image, extracting both printed and handwritten text, and returns it as a string.
Output Example:
Uniform Residential Loan Application
'ary and complete the Iformtin un hi.
Iefrtion as cise hy out Lender,
lation Fy are oping forth an wth lie wath vin Horner oust see
Sectlon 1: Borrawer Information. tris section cs about yor pursonal information and yourincare tram
femploymne nd other source sich as retirement, hol you vant canelaere to uaF tis oan,
'Soviai Security Number 12 AND
bob ere e
| Boek cence
Imevei| gen
28/3) / aay Qtrmmert adn
Non etraranliet on
((c) am apehjing ur oie ead ot unas once
Schroer intro py oro. e, Your iii
{tiamels}af other sowowers} Appling fortheLean
apa Sate Dependents a ity oetherSonaa)
sr Number
Q sepeatea ton
OD tinmeeond
'conte information
CallPhone ig08) G2 SECT
{ingle Ofewcen Widored, Cd! nan, Moinescie Mertens, Negiciad Work Mane ------- TM
Saret A O2t SOLUVAN STREET _aies
ee orn alae
'If at Current Adress for LESS than Zyears list Former Address [Over net apply ~
cy _ Ta ae. Tounty
Malling Address Fitivent ion Cammataniee RY Doeenet app
mon
Postion Tae CED = _ ams mee
Sturt Date OB 104 1 260A semencnss Oiimpeteietaceiawagentaratr | May
i Check Ifyou arene Business (| have an Generali sara 7] ne
nner orSelfEmployed havea
In this output, you can see that OCR successfully extracted printed text and some form data.
Step 4: Handling Form Data
For scanned documents that contain form fields, you may want to isolate specific parts of the document that are likely to contain important form data (such as names, signatures, or numbers).
This can be done by defining bounding boxes, similar to how you would extract specific sections of a PDF for text extraction.
Here’s how you can extract specific regions from the image that contain form fields:
import pdfplumber
import pytesseract
# Open the PDF file (scanned loan application)
with pdfplumber.open("Scanned Loan Application.pdf") as pdf:
# Extract the first page (scanned document)
first_page = pdf.pages[0]
# Define a bounding box around the form field (x0, y0, x1, y1)
bbox = (25, 150, 250, 200) # Coordinates for the name field
# Crop the image to focus on the form field
cropped_image = first_page.within_bbox(bbox).to_image()
cropped_image.save("cropped_name_field.png") # For debugging purposes
# Apply OCR on the cropped image
field_text = pytesseract.image_to_string(cropped_image.original)
print("Extracted Form Field Data:\\n", field_text)
The output should look like this:
Extracted Form Field Data:
Nave esas tet Sui
EMA ch@onnyeQ.
Explanation:
within_bbox(bbox): Isolates a specific region of the page (in this case, the name field) for OCR processing.
to_image(): Converts the cropped section into an image for OCR.
pytesseract.image_to_string(): Extracts the text from the cropped image.
Key Takeaways
pdfplumber combined with Tesseract OCR allows for effective extraction of text from scanned PDFs, even if they contain handwritten content.
While OCR works well for printed text, extracting handwritten data can still be prone to errors, particularly if the handwriting is unclear or inconsistent.
You can isolate specific regions of a scanned document to extract form data, making it easier to extract names, signatures, or financial data in a structured manner.
Unstract’s All Table Extraction API: Effortless Table Extraction
Unstract’s All Table Extraction API simplifies the process of extracting tables from PDFs, images, and other document formats.
With just an API key and endpoint, you can seamlessly integrate advanced AI-powered table detection into your workflow. Point your documents to the API, and receive structured, ready-to-use table data in return—no manual intervention required.
Extracting structured data from PDFs like the Chase Bank Statement requires not just text or table extraction but also the ability to interpret and preserve the overall layout of the document.
Bank statements often include elements such as headings, account summaries, transaction tables, and footers, which must be understood in context.
Using pdfplumber, we can extract this structured information while preserving the page’s layout, which is critical for accurate data representation.
In this section, we will explore how to use pdfplumber to extract and maintain layout elements from a Chase Bank Statement. We’ll cover how to:
Extract text and preserve structure (such as headers and sections).
Interpret page structure, including margins, text blocks, and spacing.
Extracting Text and Preserving Structure
When working with PDFs like bank statements, we often need to extract text in a way that maintains the original structure, such as separating headings, subheadings, and sections.
pdfplumber provides several tools to help preserve layout structure, including access to text coordinates (x, y positions) and page dimensions.
Here’s a basic example that shows how to extract text from the Chase Bank Statement while preserving layout context:
import pdfplumber
# Open the Chase Bank Statement PDF
with pdfplumber.open("Chase Freedom Bank Statement.pdf") as pdf:
# Access the pages
for page in pdf.pages:
# Extract all text from the page with detailed positional data
page_text = page.extract_text(layout=True)
# Print the extracted text with preserved structure
print(f"Page {page.page_number}:\\n{page_text}\\n")
Explanation:
extract_text(layout=True): This argument helps maintain the relative positioning of text elements as they appear in the PDF, preserving line breaks and spaces between sections.
The resulting text will more closely resemble how it is visually laid out in the document, ensuring that headers and different sections remain distinct, as you can see in the output example:
Page 1:
SCENARIO-1D
New Balance
February 2024
S M T W T F S
Minimum Payment Due
28 29 30 31 1 2 3 Previous points balance 40,468
4 5 6 7 8 9 10 + 1% (1 Pt)/$1 earned on all purchases 5,085
Payment Due Date
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 1 2 Start redeeming today. Visit Ultimate Rewards(r) at
www.ultimaterewards.com
3 4 5 6 7 8 9
You always earn unlimited 1% cash back on all your purchases.
Late Payment Warning: If we do not receive your minimum payment Activate new bonus categories every quarter. You'll earn an
by the date listed above, you may have to pay a late fee of up to additional 4% cash back, for a total of 5% cash back on up to
$40.00 and your APR's will be subject to increase to a maximum $1,500 in combined bonus category purchases each quarter.
Penalty APR of 29.99%. Activate for free at chase.com/freedom, visit a Chase branch or
Minimum Payment Warning: If you make only the minimum call the number on the back of your card.
payment each period, you will pay more in interest and it will take you
longer to pay off your balance. For example:
If you make no You will pay off the And you will end up
additional charges balance shown on this paying an estimated
using this card and statement in about... total of...
each month you pay...
Only the minimum 15 years $12,128
payment
$189 3 years $6,817
(Savings=$5,311)
If you would like information about credit counseling services, call
1-866-797-2885.
Account Number: 4342 3780 1050 7320
Previous Balance $4,233.99
Payment, Credits -$4,233.99
Purchases +$5,084.29
Cash Advances $0.00
B`alance Transfers $0.00
Fees Charged $0.00
Interest Charged $0.00
New Balance $5,084.29
Opening/Closing Date 01/04/24 - 02/03/24
Credit Access Line $31,700
A`vailable Credit $26,615
Cash Access Line $1,585
Available for Cash $1,585
Past Due Amount $0.00
Balance over the Credit Access Line $0.00
Reminder: It is important to continue making your payments on time. Your APRs may increase if the minimum payment is not made on
time or payments are returned.
0000001 FIS33339 D 12 Y 9 03 24/02/03 Page 1 of 3 06610 MA MA34942 03410000120003494201
0404
P.O. BOX 15123
AUTOPAY IS ON
WILMINGTON, DE 19850-5123
See Your Account
For Undeliverable Mail Only
Messages for details.
Account number: 4342 3780 1050 7320
__________________________________________________..______________________ Amount Enclosed
34942 BEX 903424 D AUTOPAY IS ON
LARRY PAGE
C PAGE
24917 KEYSTONE AVE
LOS ANGELES CA 97015-5505
CARDMEMBER SERVICE
PO BOX 6294
CAROL STREAM IL 60197-6294
Page 2:
Date of
Transaction Merchant Name or Transaction Description $ Amount
01/28 AUTOMATIC PAYMENT - THANK YOU -4,233.99
01/04 LARRY HOPKINS HONDA 7074304151 CA 265.40
01/04 CICEROS PIZZA SAN JOSE CA 28.18
01/05 USPS PO 0545640143 LOS ALTOS CA 15.60
01/07 TRINETHRA SUPER MARKET CUPERTINO CA 7.92
01/04 SPEEDWAY 5447 LOS ALTOS HIL CA 31.94
01/06 ATT*BILL PAYMENT 800-288-2020 TX 300.29
01/07 AMZN Mktp US*RT4G124P0 Amzn.com/bill WA 6.53
01/07 AMZN Mktp US*RT0Y474Q0 Amzn.com/bill WA 21.81
01/05 HALAL MEATS SAN JOSE CA 24.33
01/09 VIVINT INC/US 800-216-5232 UT 52.14
01/09 COSTCO WHSE #0143 MOUNTAIN VIEW CA 75.57
01/11 WALGREENS #689 MOUNTAIN VIEW CA 18.54
01/12 GOOGLE *YouTubePremium g.co/helppay# CA 22.99
01/13 FEDEX789226298200 Collierville TN 117.86
01/19 SHELL OIL 57444212500 FREMONT CA 7.16
01/19 LEXUS OF FREMONT FREMONT CA 936.10
01/19 STARBUCKS STORE 10885 CUPERTINO CA 11.30
01/22 TST* CHAAT BHAVAN MOUNTAI MOUNTAIN VIEW CA 28.95
01/23 AMZN Mktp US*R06VS6MN0 Amzn.com/bill WA 7.67
01/23 UALR REMOTE PAY 501-569-3202 AR 2,163.19
01/23 UALR REMOTE PAY 501-569-3202 AR 50.00
01/24 AMZN Mktp US*R02SO5L22 Amzn.com/bill WA 8.61
01/24 TIRUPATHI BHIMAS MILPITAS CA 58.18
01/25 AMZN Mktp US*R09PP5NE2 Amzn.com/bill WA 28.36
01/26 COSTCO WHSE #0143 MOUNTAIN VIEW CA 313.61
01/29 AMZN Mktp US*R25221T90 Amzn.com/bill WA 8.72
01/29 COMCAST CALIFORNIA 800-COMCAST CA 97.00
01/29 TRADER JOE S #127 LOS ALTOS CA 20.75
01/30 Netflix 1 8445052993 CA 15.49
01/30 ATT*BILL PAYMENT 800-288-2020 TX 300.35
01/30 APNI MANDI FARMERS MARKE SUNNYVALE CA 36.76
02/01 APPLE.COM/BILL 866-712-7753 CA 2.99
2024 Totals Year-to-Date
Total fees charged in 2024 $0.00
Total interest charged in 2024 $0.00
YYeeaarr--ttoo--ddaattee ttoottaallss ddoo nnoott rreefflleecctt aannyy ffeeee oorr iinntteerreesstt rreeffuunnddss
yyoouu mmaayy hhaavvee rreecceeiivveedd..
Your Annual Percentage Rate (APR) is the annual interest rate on your account.
Annual Balance
Balance Type Percentage Subject To Interest
Rate (APR) Interest Rate Charges
PURCHASES
Purchases 19.99%(v)(d) - 0 - - 0 -
CASH ADVANCES
Cash Advances 29.99%(v)(d) - 0 - - 0 -
BALANCE TRANSFERS
Balance Transfers 19.99%(v)(d) - 0 - - 0 -
LARRY PAGE Page2 of 3 Statement Date: 02/03/24
0000001 FIS33339 D 12 Y 9 03 24/02/03 Page 2 of 3 06610 MA MA34942 03410000120003494202
By using layout=True, the text output will reflect the bank statement’s structure, ensuring that sections like the account summary and transactions are logically separated.
Interpreting Page Structure
Beyond text and tables, pdfplumber can also help interpret the page layout by providing access to the geometric structure of the document.
This includes margins, spacing between text blocks, and the precise location of elements on the page.
Understanding these features can help when working with more complex layouts.
Here’s an example of how the output with the layout structure:
import pdfplumber
# Open the Chase Bank Statement PDF
with pdfplumber.open("Chase Freedom Bank Statement.pdf") as pdf:
# Access the first page
first_page = pdf.pages[0]
# Extract layout elements
page_layout = first_page.extract_words()
# Print each word with its positional data
for word in page_layout:
print(word)
Explanation:
extract_words(): Extracts individual words along with their positional data (e.g., x and y coordinates), font size, and width/height, allowing you to interpret the layout more precisely.
The output will provide detailed information about each word’s placement, which can be useful when reconstructing the page’s layout or when extracting specific regions, as show in the output example:
The output contains details about each word’s position on the page, including the coordinates (x0, x1, top, bottom). These coordinates can be used to recreate the layout or extract specific sections based on their location.
Key Takeaways
pdfplumber can effectively extract not just the content of a PDF but also maintain its layout, ensuring that structured documents like bank statements are parsed correctly.
By using options like layout=True, you can ensure that the text structure remains intact, preserving important divisions between sections.
By accessing word-level positional data, pdfplumber provides a detailed understanding of the page structure, which is useful for complex documents with varied layouts.
Strengths and Limitations of pdfplumber
Strengths
Granular Control Over PDF Parsing: pdfplumber offers fine-grained control over PDF parsing by allowing users to extract specific elements from a document, such as text, tables, and images, based on their exact location. This makes it particularly useful for documents with complex layouts, such as financial reports or invoices. Its ability to provide detailed positional data of text blocks and tables is a key advantage when precision is needed.
Table Extraction Capabilities: One of the standout features of pdfplumber is its ability to extract tables from PDFs with a high degree of accuracy. Whether the tables have visible borders or are simply structured text, pdfplumber detects the alignment of rows and columns to extract data in a structured format. This is especially useful for extracting data from financial reports or transaction tables.
Flexibility with Layout: pdfplumber can preserve the layout of text as it appears in the original PDF by providing positional information, which helps maintain the structural integrity of the document. For documents where the arrangement of information is crucial, like bank statements or official forms, this feature ensures that the extracted data mirrors the original document’s format.
Scalability: pdfplumber is capable of processing multi-page PDFs efficiently, making it suitable for large-scale document processing. It handles complex documents with multiple sections, tables, and images, allowing for the extraction of data across all pages in an organized manner.
Python Integration: As a Python library, pdfplumber is easily integrated into data pipelines and workflows, especially for developers familiar with Python. It works well with other libraries such as pandas and Tesseract for enhanced functionality (e.g., OCR for scanned PDFs), making it a versatile tool for different use cases.
Limitations
Limited OCR Capabilities: While pdfplumber excels at extracting data from digital PDFs, it struggles with scanned PDFs and handwritten documents because it does not natively include OCR functionality. Users need to rely on external tools like Tesseract for text extraction from images, which adds complexity and may lead to less accurate results, particularly with handwritten or poorly scanned documents.
Challenges with Complex or Ambiguous Layouts: Though pdfplumber is effective with well-structured documents, it can have difficulty interpreting PDFs with more complex or non-standard layouts. For example, PDFs with irregular tables, merged cells, or overlapping elements may require manual intervention to ensure correct data extraction. The bounding box method, while useful, may not always work seamlessly in every case, especially for documents with non-uniform designs.
Inconsistent Results Across PDFs: The accuracy and performance of pdfplumber can vary greatly depending on the quality and format of the PDF. For instance, PDFs generated from scans, with poor image quality or low-resolution content, can result in incomplete or incorrect extractions. Additionally, certain types of documents, such as forms with non-standard fields, may require more customization and tweaking to extract data properly.
Performance and Speed: While pdfplumber is highly effective, it can be slower when processing large PDFs or those with intricate layouts (e.g., PDFs with many images or complex tables). This may pose a challenge for users who need to process a large volume of documents quickly, as performance can degrade with more complex tasks.
Lack of Built-in Error Handling: In some cases, pdfplumber does not handle extraction errors or edge cases very gracefully. Users need to implement custom error handling, especially when working with documents that contain varying layouts across different pages. For instance, if one page contains a table while another has a free-form text layout, pdfplumber may not always differentiate or process both formats cleanly without manual adjustments.
Introduction to LLMWhisperer
LLMWhisperer is an advanced PDF parsing tool that leverages the power of large language models (LLMs) to extract data from PDFs in a more intuitive and context-aware manner.
Key Features and Strengths
Context-Aware Parsing: LLMWhisperer utilizes language models to interpret the context of text within the document, meaning it can distinguish between headings, body text, and footnotes even if the formatting is not consistent. It excels at extracting meaningful data from unstructured or semi-structured documents, such as legal contracts, business reports, and scanned forms.
Superior OCR Capabilities: One of LLMWhisperer’s strengths is its integration with cutting-edge OCR technology that works well with both printed and handwritten text. It can accurately extract text from scanned documents, including complex handwriting, making it particularly suitable for forms and applications that have both typed and handwritten elements.
Efficient Multi-Document Parsing: LLMWhisperer is designed to handle large volumes of PDFs at scale, making it ideal for batch processing of reports, statements, and forms. Its intelligent parsing capabilities allow for faster extraction while maintaining high accuracy, even across multi-page documents.
Natural Language Understanding: Leveraging LLMs enables LLMWhisperer to not only extract text but also infer the meaning behind certain text elements. For example, it can identify key financial metrics in a report or recognize sensitive information like signatures, dates, or legal clauses. This capability gives it an edge when parsing documents with nuanced content.
LLM Whisperer is specifically designed to convert documents in a way that LLMs can best understand.
Comparison with pdfplumber
LLMWhisperer and pdfplumber both serve the purpose of extracting data from PDFs, but they approach the task differently.
Feature
pdfplumber
LLMWhisperer
Handling of Complex Layouts
Excels with structured PDFs (clear tables, well-formatted sections). Struggles with irregular or ambiguous layouts.
Uses language models to infer structure in irregular or ambiguous layouts. More flexible for less structured documents.
OCR and Handwriting Recognition
Relies on external tools like Tesseract for OCR. Struggles with handwritten content.
Integrates advanced OCR that handles both printed and handwritten text. Superior for scanned documents with handwriting.
Context Awareness
Extracts raw text and tables without understanding context or meaning.
Parses text with context awareness, intelligently interpreting sections and key metrics (e.g., revenue, expenses).
pdfplumber vs. LLMWhisperer: Comparing Extraction Quality
We’ll now compare how LLMWhisperer performs on three key documents: the Bank of England Financials, the scanned loan application, and the Chase Bank Statement.
Bank of England Financials (Table Extraction)
LLMWhisperer handles financial reports like the Bank of England Financials with a strong focus on context-aware extraction.
LLMWhisperer Code Example:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>",
api_key='<your-api-key>',
api_timeout=300)
# Extract tables from the PDF
result = client.whisper(file_path="bank-of-england-financials.pdf", output_mode="line-printer")
extracted_text = result["extracted_text"]
# Print the extracted text
print(extracted_text)
LLMWhisperer Output:
Bank of England Page 111
Banking Department statement of financial
position as at 28 February 2023
Note 2023 (£mn) 2022 (£mn)
Assets
Cash and balances with other central banks 7 6,406 708
Loans and advances to banks and other financial institutions 8 192,784 203,219
Other loans and advances 9 843,797 896,134
Securities held at fair value through profit or loss 13 5,193 9,969
Derivative financial instruments 20 493 354
Securities held at amortised cost 16 16,619 15,959
Securities held at fair value through other comprehensive
income 17 1,495 1,420
Investments in subsidiaries 24 - -
Inventories 3 2
Property, plant and equipment 29 391 456
Intangible assets 30 237 202
Retirement benefit assets 26 719 1,279
Other assets 31 5,799 654
Total assets 1,073,936 1,130,356
Liabilities
Deposits from central banks 10 17,533 30,739
Deposits from banks and other financial institutions 11 913,168 971,357
Deposits from banks - Cash Ratio Deposits 18 13,417 13,043
Other deposits 12 106,937 102,331
Foreign currency commercial paper in issue 14 5,598 2,713
Foreign currency bonds in issue 15 6,447 2,936
Derivative financial instruments 20 183 97
Deferred tax liabilities 34 448 559
Retirement benefit liabilities 26 133 216
Other liabilities 32 4,648 588
Total liabilities 1,068,512 1,124,579
<<<
Scanned Loan Application (Handwriting and Form Data Extraction)
When extracting form and handwritten data, LLMWhisperer’s advanced OCR capabilities offer superior accuracy in identifying handwritten text.LLMWhisperer Code Example:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>",
api_key='<your-api-key>',
api_timeout=300)
# Extract tables from the PDF
result = client.whisper(file_path="Scanned Loan Application.pdf", output_mode="line-printer")
extracted_text = result["extracted_text"]
# Print the extracted text
print(extracted_text)
LLMWhisperer Output:
To be completed by the Lender:
Lender Loan No./Universal Loan Identifier Agency Case No.
Uniform Residential Loan Application
Verify and complete the information on this application. If you are applying for this loan with others, each additional Borrower must provide
information as directed by your Lender.
Section 1: Borrower Information. This section asks about your personal information and your income from
employment and other sources, such as retirement, that you want considered to qualify for this loan.
1a. Personal Information
Name (First, Middle, Last, Suffix) Social Security Number 175-678-910
IMA CARDHOLDER (or Individual Taxpayer Identification Number)
Alternate Names - List any names by which you are known or any names Date of Birth Citizenship
under which credit was previously received (First, Middle, Last, Suffix) (mm/dd/yyyy) [X] U.S. Citizen
08 /31 / 1977 [ ] Permanent Resident Alien
[ ] Non-Permanent Resident Alien
Type of Credit List Name(s) of Other Borrower(s) Applying for this Loan
[X] I am applying for individual credit. (First, Middle, Last, Suffix) - Use a separator between names
[ ] I am applying for joint credit. Total Number of Borrowers:
Each Borrower intends to apply for joint credit. Your initials:
Marital Status Dependents (not listed by another Borrower) Contact Information
[X] Married Number Home Phone ( )
[ ] Separated Ages Cell Phone (408) 123-4567
[ ] Unmarried Work Phone ( Ext.
(Single, Divorced, Widowed, Civil Union, Domestic Partnership, Registered
Reciprocal Beneficiary Relationship) Email ima1977@gmail.com
Current Address
Street 1024, SULLIVAN STREET Unit #
City LOS ANGELES State CA ZIP 90210 Country USA
How Long at Current Address? 3 Years 5 Months Housing [ ] No primary housing expense [ ] Own [X] Rent ($ 1,300 /month)
If at Current Address for LESS than 2 years, list Former Address [X] Does not apply
Street Unit #
City State ZIP Country
How Long at Former Address? Years Months Housing [ ] No primary housing expense [ ] Own [ ] Rent ($ /month)
Mailing Address - if different from Current Address [X] Does not apply
Street Unit #
City State ZIP Country
1b. Current Employment/Self-Employment and Income [ ] Does not apply
Gross Monthly Income
Employer or Business Name CAFFIENATED Phone (408) 109-8765
Base $ 8000 /month
Street 2048, MAIN STREET Unit #
Overtime $ /month
City LOS ANGELES State CA ZIP 90210 Country USA
Bonus $ /month
Position or Title CEO Check if this statement applies: Commission $ 0.00 /month
Start Date [ ] I am employed by a family member,
02/04/2009
property seller, real estate agent, or other Military
How long in this line of work? 15 Years 5 Months party to the transaction. Entitlements $ /month
Other $ /month
[X] Check if you are the Business [ ] I have an ownership share of less than 25%. Monthly Income (or Loss)
TOTAL $ 8000 /month
Owner or Self-Employed [X] I have an ownership share of 25% or more. $ 8000
Uniform Residential Loan Application
Freddie Mac Form 65 · Fannie Mae Form 1003
Effective 1/2021
<<<
DRIVER LICENSE
California
CLASS C
DL /1234568
EXP 08/31/2014 END NONE
LNCARDHOLDER
FNIMA
2570 24TH STREET
ANYTOWN. CA 35818
08/31/1977
RSTR NONE 08311977
VETERAN
SEX F HAIR BRN EYES BRN
Ima Cardholder HGT 5'-05" WGT 125 1b
08/31/2009
<<<
Chase Bank Statement (Text, Table, and Layout Extraction)
For structured documents like the Chase Bank Statement, LLMWhisperer goes further by understanding sections like account summaries and transaction categories.LLMWhisperer Code Example:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>",
api_key='<your-api-key>',
api_timeout=300)
# Extract tables from the PDF
result = client.whisper(file_path="Chase Freedom Bank Statement.pdf", output_mode="line-printer")
extracted_text = result["extracted_text"]
# Print the extracted text
print(extracted_text)
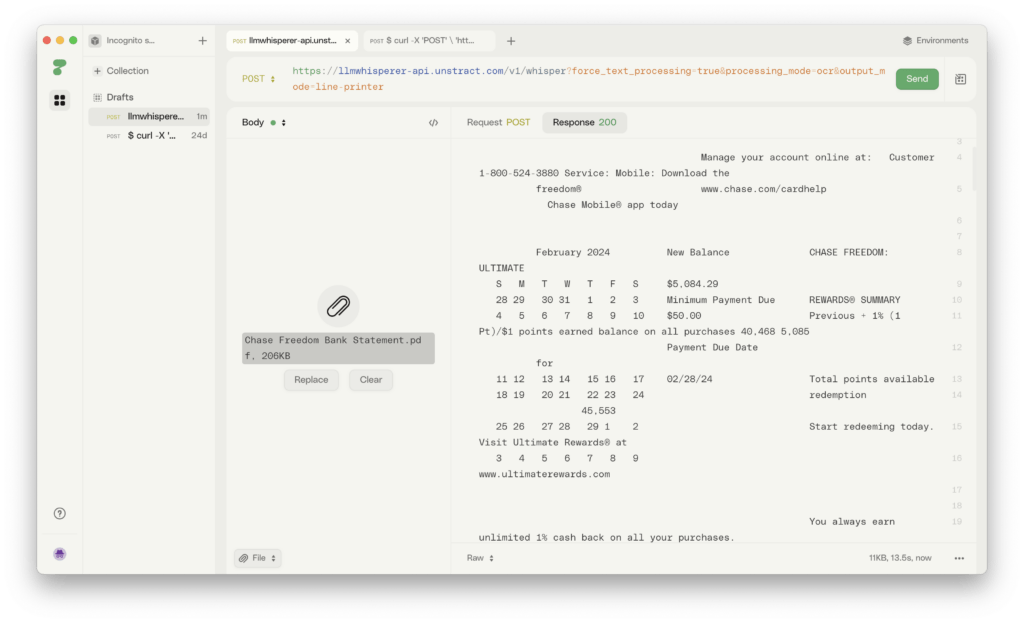
LLMWhisperer Output:
Manage your account online at: Customer Service: Mobile: Download the
1-800-524-3880 Chase MobileÂ(r)
freedomÂ(r) www.chase.com/cardhelp app today
New Balance
February 2024 CHASE FREEDOM: ULTIMATE
S M T W T F S $5,084.29 REWARDSÂ(r) SUMMARY
Minimum Payment Due
28 29 30 31 1 2 3 Previous points balance 40,468
$50.00
4 5 6 7 8 9 10 + 1% (1 Pt)/$1 earned on all purchases 5,085
Payment Due Date
11 12 13 14 15 16 17 Total points available for
02/28/24
18 19 20 21 22 23 24
redemption 45,553
25 26 27 28 29 1 2 Start redeeming today. Visit Ultimate RewardsÂ(r) at
www.ultimaterewards.com
3 4 5 6 7 8 9
You always earn unlimited 1% cash back on all your purchases.
Late Payment Warning: If we do not receive your minimum payment Activate new bonus categories every quarter. You'll earn an
by the date listed above, you may have to pay a late fee of up to additional 4% cash back, for a total of 5% cash back on up to
$40.00 and your APR's will be subject to increase to a maximum $1,500 in combined bonus category purchases each quarter.
Penalty APR of 29.99%. Activate for free at chase.com/freedom, visit a Chase branch or
call the number on the back of your card.
Minimum Payment Warning: If you make only the minimum
payment each period, you will pay more in interest and it will take you
longer to pay off your balance. For example:
If you make no You will pay off the And you will end up
additional charges balance shown on this paying an estimated
using this card and statement in about ... total of ...
each month you pay ...
Only the minimum 15 years $12,128
payment
$189 3 years $6,817
(Savings=$5,311)
If you would like information about credit counseling services, call
1-866-797-2885.
ACCOUNT SUMMARY
Account Number: 4342 3780 1050 7320
Previous Balance $4,233.99
Payment, Credits -$4,233.99
Purchases +$5,084.29
Cash Advances $0.00
Balance Transfers $0.00
Fees Charged $0.00
Interest Charged $0.00
New Balance $5,084.29
Opening/Closing Date 01/04/24 - 02/03/24
Credit Access Line $31,700
Available Credit $26,615
Cash Access Line $1,585
Available for Cash $1,585
Past Due Amount $0.00
Balance over the Credit Access Line $0.00
YOUR ACCOUNT MESSAGES
Reminder: It is important to continue making your payments on time. Your APRs may increase if the minimum payment is not made on
time or payments are returned.
Your next AutoPay payment for $5,084.29 will be deducted from your Pay From account and credited on your due
date. If your due date falls on a Saturday, we'll credit your payment the Friday before.
0000001 FIS33339 D 12 Y 9 03 24/02/03 Page 1 of 3 06610 MA MA 34942 03410000120003494201
0404
43323770106074170000500000508429000000002
freedomÂ(r)
P.O. BOX 15123
AUTOPAY IS ON Payment Due Date: 02/28/24
WILMINGTON, DE 19850-5123
See Your Account New Balance: $5,084.29
For Undeliverable Mail Only
Messages for details. Minimum Payment Due: $50.00
Account number: 4342 3780 1050 7320
$ Amount Enclosed
34942 BEX 9 03424 D AUTOPAY IS ON
LARRY PAGE
C PAGE
24917 KEYSTONE AVE
LOS ANGELES CA 97015-5505
CARDMEMBER SERVICE
PO BOX 6294
CAROL STREAM IL 60197-6294
â500016028â32370106074177â
<<<
1
Manage your account online at: Customer Service: Mobile: Download the
www.chase.com/cardhelp 1-800-524-3880 Chase MobileÂ(r) app today
freedom
YOUR ACCOUNT MESSAGES (CONTINUED)
Your AutoPay amount will be reduced by any payments or merchant credits that post to your account before we
process your AutoPay payment. If the total of these payments and merchant credits is more than your set AutoPay
amount, your AutoPay payment for that month will be zero.
ACCOUNT ACTIVITY
Date of
Transaction Merchant Name or Transaction Description $ Amount
PAYMENTS AND OTHER CREDITS
01/28 AUTOMATIC PAYMENT - THANK YOU -4,233.99
PURCHASE
01/04 LARRY HOPKINS HONDA 7074304151 CA 265.40
01/04 CICEROS PIZZA SAN JOSE CA 28.18
01/05 USPS PO 0545640143 LOS ALTOS CA 15.60
01/07 TRINETHRA SUPER MARKET CUPERTINO CA 7.92
01/04 SPEEDWAY 5447 LOS ALTOS HIL CA 31.94
01/06 ATT*BILL PAYMENT 800-288-2020 TX 300.29
01/07 AMZN Mktp US*RT4G124P0 Amzn.com/bill WA 6.53
01/07 AMZN Mktp US*RTOY474Q0 Amzn.com/bill WA 21.81
01/05 HALAL MEATS SAN JOSE CA 24.33
01/09 VIVINT INC/US 800-216-5232 UT 52.14
01/09 COSTCO WHSE #0143 MOUNTAIN VIEW CA 75.57
01/11 WALGREENS #689 MOUNTAIN VIEW CA 18.54
01/12 GOOGLE *YouTubePremium g.co/helppay# CA 22.99
01/13 FEDEX789226298200 Collierville TN 117.86
01/19 SHELL OIL 57444212500 FREMONT CA 7.16
01/19 LEXUS OF FREMONT FREMONT CA 936.10
01/19 STARBUCKS STORE 10885 CUPERTINO CA 11.30
01/22 TST* CHAAT BHAVAN MOUNTAI MOUNTAIN VIEW CA 28.95
01/23 AMZN Mktp US*R06VS6MNO Amzn.com/bill WA 7.67
01/23 UALR REMOTE PAY 501-569-3202 AR 2,163.19
01/23 UALR REMOTE PAY 501-569-3202 AR 50.00
01/24 AMZN Mktp US*R02SO5L22 Amzn.com/bill WA 8.61
01/24 TIRUPATHI BHIMAS MILPITAS CA 58.18
01/25 AMZN Mktp US*R09PP5NE2 Amzn.com/bill WA 28.36
01/26 COSTCO WHSE #0143 MOUNTAIN VIEW CA 313.61
01/29 AMZN Mktp US*R25221T90 Amzn.com/bill WA 8.72
01/29 COMCAST CALIFORNIA 800-COMCAST CA 97.00
01/29 TRADER JOE S #127 LOS ALTOS CA 20.75
01/30 Netflix 1 8445052993 CA 15.49
01/30 ATT*BILL PAYMENT 800-288-2020 TX 300.35
01/30 APNI MANDI FARMERS MARKE SUNNYVALE CA 36.76
02/01 APPLE.COM/BILL 866-712-7753 CA 2.99
2024 Totals Year-to-Date
Total fees charged in 2024 $0.00
Total interest charged in 2024 $0.00
Year-to-date totals do not reflect any fee or interest refunds
you may have received.
INTEREST CHARGES
Your Annual Percentage Rate (APR) is the annual interest rate on your account.
Annual Balance
Balance Type Percentage Subject To Interest
Rate (APR) Interest Rate Charges
PURCHASES
Purchases 19.99%(v) (d) - 0 - - 0 -
CASH ADVANCES
Cash Advances 29.99%(v) (d) - 0 - - 0 -
BALANCE TRANSFERS
Balance Transfers 19.99%(v)(d) - 0 - - 0 -
LARRY PAGE Page 2 of 3 Statement Date: 02/03/24
0000001 FIS33339 D 12 Y 9 03 24/02/03 Page 2 of 3 06610 MA MA 34942 03410000120003494202
<<<
Comparison Table
Use Case
pdfplumber
LLMWhisperer
Handling Scanned Documents
– Requires external OCR (e.g., Tesseract). – Struggles with handwriting and complex forms. – Requires manual adjustments.
– Built-in advanced OCR handles both printed and handwritten text. – Accurately extracts data from forms without manual intervention. – Superior for scanned forms.
Performance and Speed
– Effective for structured PDFs but slows down with large, complex documents. – Manual correction may be needed for irregular layouts.
– Fast and efficient for large-scale batch processing. – Optimized for complex layouts and high-volume document parsing. – Automates both extraction and interpretation.
Conclusion
pdfplumber is a powerful PDF parsing tool that excels at extracting structured data, particularly from well-formatted documents. Its key strengths lie in its ability to extract tables and text with fine control over the layout, making it ideal for digital PDFs with clear boundaries and sections, such as financial statements or reports.
pdfplumber also integrates well with Python workflows, providing developers with flexibility and precision in text and table extraction. However, it faces limitations when dealing with more complex or unstructured layouts, scanned documents, or handwritten content.
It also relies on external OCR tools like Tesseract for processing scanned PDFs, which can lead to less accurate results, especially for handwritten data.
In contrast, LLMWhisperer offers a more advanced solution for parsing PDFs, particularly in scenarios where the document includes mixed content like handwritten text or has ambiguous, unstructured layouts.
LLMWhisperer leverages natural language processing (NLP) and cutting-edge OCR technology, enabling it to understand the context behind the extracted text, intelligently interpret complex forms, and process large volumes of documents more efficiently.
Its ability to handle both printed and handwritten content in scanned documents makes it a superior choice for forms and applications. Additionally, LLMWhisperer excels at providing context-aware data extraction, offering insights into the extracted information that pdfplumber cannot provide.
Final Thoughts
When deciding between pdfplumber and LLMWhisperer, the choice largely depends on the type of document and the complexity of the content you need to extract:
Use pdfplumber if you are working with well-structured, digital PDFs where table extraction and precise control over layout are essential. It is ideal for processing documents like financial reports, invoices, or any PDF where the structure is clear and consistent.
Use LLMWhisperer if your document parsing needs involve scanned PDFs, handwritten forms, or complex layouts that require context-aware extraction. LLMWhisperer is the better option for documents with unstructured or mixed content, such as loan applications, legal contracts, or reports with ambiguous formatting. It also excels in large-scale document processing tasks where speed and accuracy are critical.
If you want to take it for a test drive quickly, you can check out our free playground.
In summary, while both tools have their strengths, LLMWhisperer offers a more versatile and intelligent solution for handling a wider range of PDF parsing challenges, particularly those involving complex or unstructured documents.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.