In today’s competitive job market, organizations are often inundated with many resumes for each open position.
Efficiently managing this influx is crucial for promptly identifying and securing top talent.
Traditional methods of manually reviewing and processing resumes are labor-intensive and prone to human error, leading to potential oversights of qualified candidates and delays in the hiring process.
Handling large volumes of resumes presents multifaceted challenges.
Human resources professionals must sift through documents that vary widely in format, style, and organization, complicating the extraction of essential information like contact details, educational background, work experience, and skills.
This manual data entry into recruitment systems is time-consuming and diverts valuable resources away from strategic activities such as candidate engagement and employer branding.
Recognizing these challenges, Unstract has created a powerful solution that enables resume parsing by fully leveraging the latest advancements in AI.
It also effortlessly integrates with existing Applicant Tracking Systems (ATS) and HR platforms, reducing administrative burdens, minimizing errors, and accelerating the recruitment timeline. This enables organizations to focus on engaging with the most suitable candidates and enhance their overall talent acquisition strategies.
TL;DR
This article examines the challenges of processing resumes and demonstrates how using Large Language Models (LLMs) can enable new ways of handling resume parsing.
At the end of the article, we’ll create a demo resume parser app in Streamlit to showcase how Unstract handles extracting data from resumes, no matter how they’re formatted.
What Is Resume Parsing/Processing/Extraction?
Resume parsing, also known as resume processing or extraction, is the automated method of converting unstructured resume data into a structured format that can be easily stored, analyzed, and retrieved.
Resumes come in various formats and designs, containing rich information about a candidate’s qualifications, experience, and skills.
The primary purpose of resume parsing is to streamline the recruitment process by transforming diverse and unstructured data from resumes into a consistent, structured format, enabling recruiters and hiring managers to search, sort, and filter candidate information more effectively.
Resume parsing works by following several key steps to convert unstructured data into structured, actionable information:
Data Acquisition: Collecting resumes in various formats such as PDFs, Word documents, or plain text files.
Optical Character Recognition (OCR): Using OCR technology to convert visual text from scanned images or non-editable PDFs into machine-readable text.
Text Pre-processing: Cleaning and normalizing the extracted text by removing irrelevant content and correcting errors.
Data Extraction: Employing advanced algorithms to identify and extract relevant information like personal details, education history, work experience, and skills.
Data Structuring: Organizing the extracted data into predefined fields within a structured format such as JSON or XML.
Validation and Formatting: Validating the structured data for accuracy and consistency.
Storage and Integration: Storing the final structured data in a database or integrating it into Applicant Tracking Systems (ATS) or other HR tools.
By automating these steps, resume parsing significantly reduces the time and effort required to process each resume manually, allowing recruiters to focus on engaging with candidates rather than administrative tasks.
Common use cases for resume parsing include applications in HR departments and recruitment agencies, where it is essential for handling large volumes of applications efficiently.
Key applications are:
Bulk Processing of Applications: Rapidly processing hundreds or thousands of resumes to ensure no potential candidate is overlooked.
Candidate Database Creation: Building comprehensive databases to search for specific skills or qualifications across a talent pool.
Streamlined Screening: Applying filters and criteria to quickly identify candidates who meet job requirements.
Integration with ATS: Enhancing functionalities like automated data entry, and advanced search capabilities, and improving the candidate experience by speeding up the recruitment process.
By integrating resume parsing with ATS and other HR technologies, organizations can optimize their recruitment workflows, improve data accuracy, and make more informed hiring decisions.
Why Is Resume Parsing a Critical Business Process That Needs Automation?
In today’s competitive job market, organizations often face many applications for each open position.
Managing this influx manually places a significant burden on HR departments, especially in large organizations.
The task of manually entering data from countless resumes is not only time-consuming but also diverts valuable resources away from strategic initiatives such as talent engagement and recruitment planning.
Automating resume parsing offers several key benefits that enhance the efficiency and effectiveness of the hiring process:
Time-Saving and Efficiency: Automated systems can process large numbers of resumes quickly, accelerating the hiring timeline and allowing recruiters to focus on connecting with qualified candidates.
Reduction of Human Error: Automation ensures consistent and accurate data extraction, minimizing mistakes that can occur with manual data entry.
Improved Candidate Experience: A faster, more streamlined recruitment process leads to timely communication with applicants, enhancing the organization’s reputation and attractiveness to potential hires.
Embracing automation in resume parsing also provides a competitive advantage. Faster hiring processes enable organizations to secure top talent before competitors do.
Additionally, with administrative tasks reduced, HR professionals can develop better talent acquisition strategies, such as sourcing high-quality candidates and strengthening employer branding.
This strategic focus not only improves the quality of hires but also positions the organization as a leader in the talent market.
Challenges in Resume Parsing
Despite the benefits of automating resume parsing, several challenges can impede its effectiveness.
Candidates submit resumes in a variety of designs, layouts, and file types, ranging from simple text documents to complex PDFs with graphics and unconventional structures.
This diversity makes it difficult for parsing software to extract information consistently, as traditional algorithms may struggle to interpret non-standard formats.
Another challenge is the unstructured data complexity inherent in resumes.
Extracting accurate information from free-form text is a complex task.
Candidates often use varied phrasing and organization to describe their experiences, skills, and qualifications.
This lack of uniformity can lead to inconsistencies in data extraction, as parsing tools may misinterpret or overlook critical information embedded in the text.
Traditional parsing limitations also pose significant obstacles.
Many parsing tools rely on predefined templates or rule-based systems, which makes them inflexible when encountering new or unique resume formats.
This inflexibility necessitates constant retraining or re-templating to adapt to different designs, which can be time-consuming and resource-intensive.
Additionally, integration issues arise when connecting parsing tools with existing systems like Applicant Tracking Systems (ATS).
These challenges include compatibility problems and the need for custom configurations, which can hinder seamless data flow and reduce overall efficiency.
AI and LLMs in Resume Parsing
The rise of Artificial Intelligence (AI) and Large Language Models (LLMs) has revolutionized resume parsing by significantly enhancing its capabilities.
AI introduces advanced machine learning algorithms that improve the accuracy and efficiency of data extraction from resumes.
These algorithms learn from vast amounts of data, enabling the parsing system to recognize patterns and interpret information more effectively than traditional methods.
LLMs, such as OpenAI’s GPT-4, play a crucial role in understanding the context within resumes.
They are designed to comprehend natural language with a high degree of sophistication, allowing them to interpret the nuances and variations in how candidates present their information.
This contextual understanding means that LLMs can accurately extract relevant details even when the resume content is complex or unconventional.
By incorporating AI and LLMs, resume parsing tools achieve improved accuracy and efficiency.
AI’s ability to handle diverse resume formats reduces the need for constant retraining or re-templating when encountering new designs or layouts.
This adaptability not only streamlines the parsing process but also ensures consistent data extraction across a wide range of resume styles, ultimately enhancing the recruitment workflow and enabling organizations to process applications more effectively.
It leverages cutting-edge technology to convert diverse document formats into actionable data without the need for manual intervention or constant reconfiguration.
Unstract provides a suite of tools that streamline data processing workflows, making it an invaluable asset for organizations seeking efficiency and accuracy in handling large volumes of documents.
Key Advantages
No Need for Retraining or Remodelling with Document Changes: Unlike traditional parsing tools that require constant updates or retraining when faced with new document formats, Unstract adapts seamlessly to changes in document design. This adaptability eliminates the need for ongoing maintenance and ensures consistent performance even as resume styles and layouts evolve.
Flexibility in Handling Various Resume Designs and Formats: Unstract tools can be configured to handle a wide array of resume formats and designs. Whether dealing with different layouts, fonts, or graphical elements, the platform consistently extracts accurate data. This flexibility ensures that HR departments and recruiters can process resumes from diverse candidates without compromising on data quality.
AI Integration
Unstract harnesses the power of Artificial Intelligence to enhance its data extraction capabilities.
By integrating AI algorithms, the platform can intelligently interpret and extract information from unstructured data with high precision.
This AI-driven approach allows Unstract to understand the context within documents, ensuring that relevant information is accurately identified and organized for further use.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
LLMWhisperer: Preparing Data for LLMs
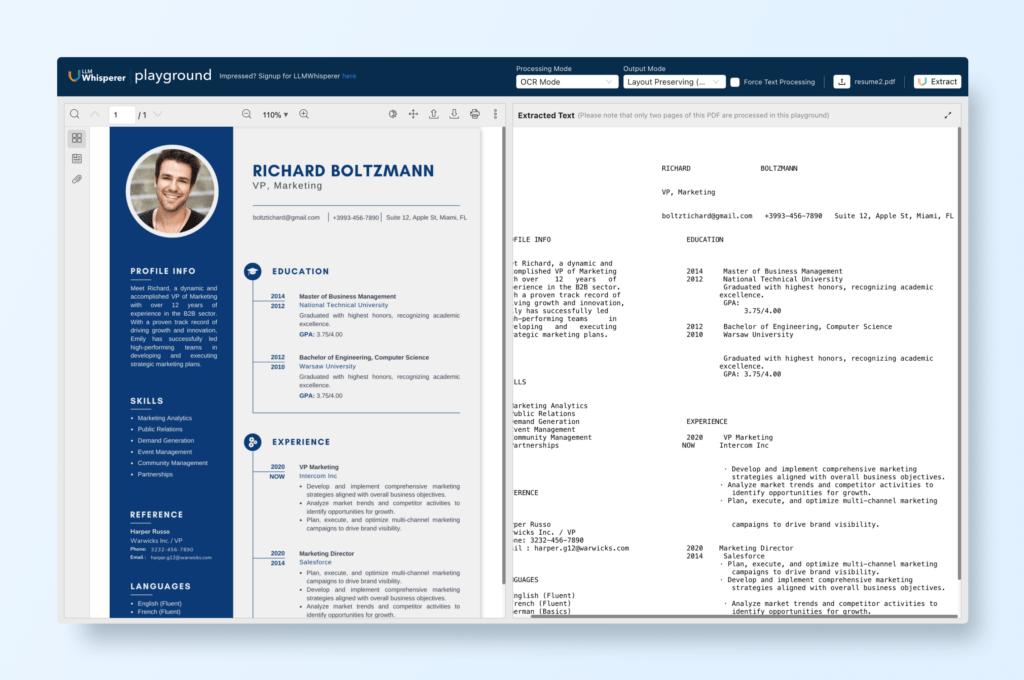
A key component of Unstract’s technology is the LLMWhisperer, a general-purpose Optical Character Recognition (OCR) tool designed to pre-process documents for consumption by Large Language Models (LLMs).
LLMWhisperer operates as an efficient OCR engine that converts various document formats into machine-readable text. It is not powered by AI or LLMs itself but is engineered to accurately extract text from unstructured documents, preparing them for advanced processing.
Before LLMs can analyze a document, the textual content must be clean and well-structured. Let’s see an example from the LLM Whisperer Playground:
LLMWhisperer uses proprietary OCR techniques to capture text from documents to ensure that all relevant text is extracted and formatted correctly, removing noise and irrelevant data that could hinder the performance of LLMs, as you can see from the example.
By focusing on high-quality text extraction without the use of AI or LLMs, it provides a reliable foundation for subsequent AI-driven analysis.
This separation of duties ensures that the pre-processing is efficient and does not introduce additional complexities or dependencies.
It enables LLMs to perform at their best by providing them with well-prepared input, which in turn leads to more precise and reliable data extraction outcomes.
Unstract’s combination of AI integration and the specialized capabilities of LLMWhisperer positions it as a powerful tool for organizations looking to automate resume parsing and overcome the challenges associated with unstructured data.
Its ability to adapt to various document formats without retraining makes it a cost-effective and efficient solution for modern recruitment needs.
Before you begin extracting data from resumes using Unstract, it’s essential to set up the necessary tools and accounts.
Visit the Unstract website and create an account. Registration is straightforward and gives you access to the platform’s features, including the Prompt Studio and LLMWhisperer.
You have the option of using the Unstract cloud platform (with Prompt Studio), which we will see in this article, or using LLM Whisperer:
When you first sign up, you will have a 14-day trial which also includes $10 credits of LLM tokens, so you can start using the account immediately
You are now ready to start exploring the Unstract cloud platform, by default you will land on the Prompt Studio page:
In case you run out of credits, or if you want to add your own LLM, Embeddings, Vector Database, or Text Extractor provider(s), you can use the different options in the SETTINGS menu.
Configuring OpenAI LLM
In case you want to connect your OpenAI account by providing your API Key, you can go to SETTINGS → LLMs:
From here, choose ‘+ New LLM Profile’ and then OpenAI. Input the necessary OpenAI API key and your desired configuration.
Embeddings
For adding your own embeddings provider, you can navigate to SETTINGS → Embedding. And add a new embedding provider with ‘+ New Embedding Profile’
Vector Database
For adding your vector database provider, navigate to SETTINGS → Vector DBs. And add your vector database provider with ‘+ New Vector DB Profile’
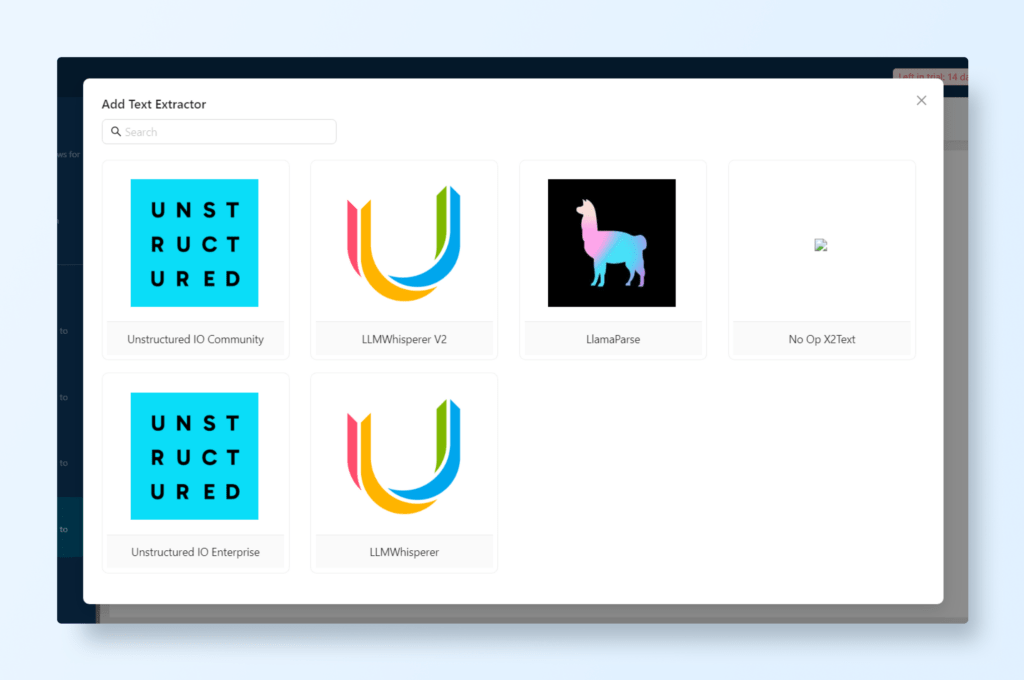
Text Extractor
For adding your own Text Extractor, navigate to SETTINGS → Text Extractor. Here you can add a new Text Extractor with ‘+ New Text Extractor’.
In the next section, we’ll delve into creating a Prompt Studio project and crafting prompts to extract critical information from resumes, preparing the steps to deploy your solution as an API.
Setting Up a Prompt Studio Project
Prompt Studio is the central feature within Unstract that empowers users to create, test, and refine prompts for extracting structured data from unstructured documents like resumes.
It serves as an interactive environment where you can tailor prompts to meet specific data extraction needs, ensuring high accuracy and efficiency in the parsing process.
Features and Benefits:
Integration with LLMWhisperer: Prompt Studio works seamlessly with LLMWhisperer, Unstract’s OCR tool, ensuring that pre-processed data is optimally prepared for extraction.
Customization: It allows for the creation of highly customized prompts that can adapt to various resume formats and designs.
Efficiency: By enabling prompt testing and refinement within the studio, it reduces the time spent on trial and error during the extraction process.
Scalability: Once a prompt is perfected, it can be applied to numerous resumes without further adjustments, thanks to Unstract’s adaptability.
User-Friendly Interface: Prompt Studio offers an intuitive platform that doesn’t require advanced technical skills, making it accessible to a wide range of users.
Writing Effective Prompts for resume parsing
Crafting effective prompts is essential for accurately extracting the desired information from resumes or any other unstructured data source.
We start by navigating into SETTINGS → Prompt Studio. And we create a new project with ‘+ New Project’. After the project is created we can start crafting prompts and upload documents.
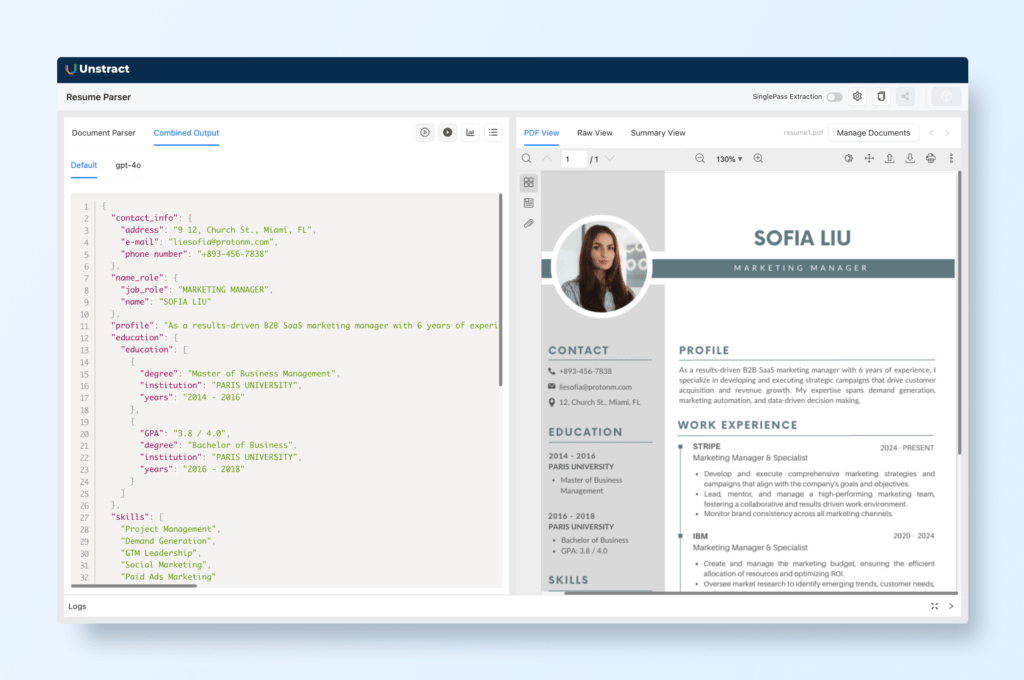
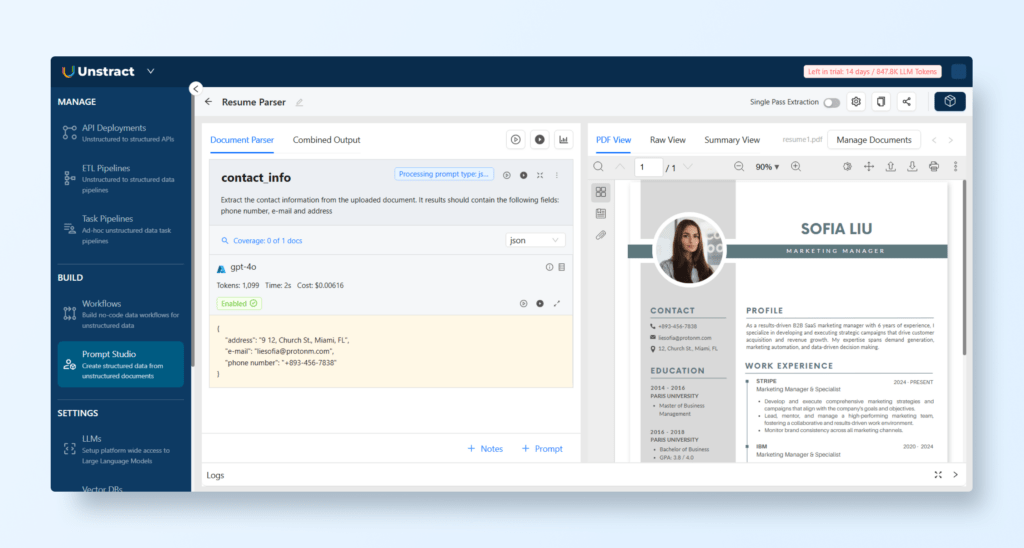
First, we upload a new document with ‘+ Add Document’. Let’s take a look at how to craft a prompt to extract the contact information from a resume.
Here we added a new prompt with the name contact_info. Since we will be exporting this information as a JSON (notice the type defined), this name will also the the key name for this block of information in the JSON. As for the prompt, we define it as:
Extract the contact information from the uploaded document.
It results should contain the following fields: phone number, e-mail and address
We can test the prompt by using the run button and we get the following results:
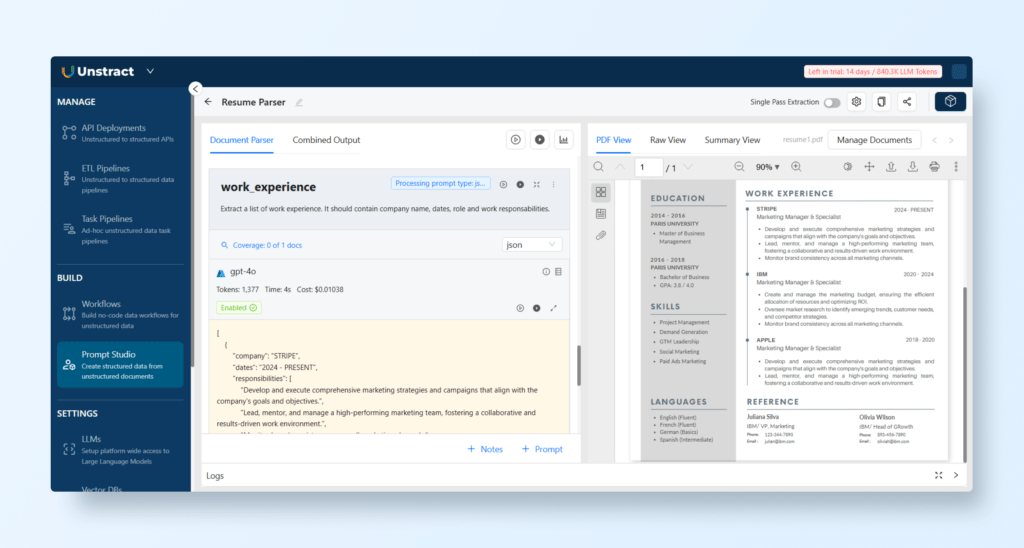
We can add more prompts to extract the desired information from other sections of the resume.
For instance for work_experience:
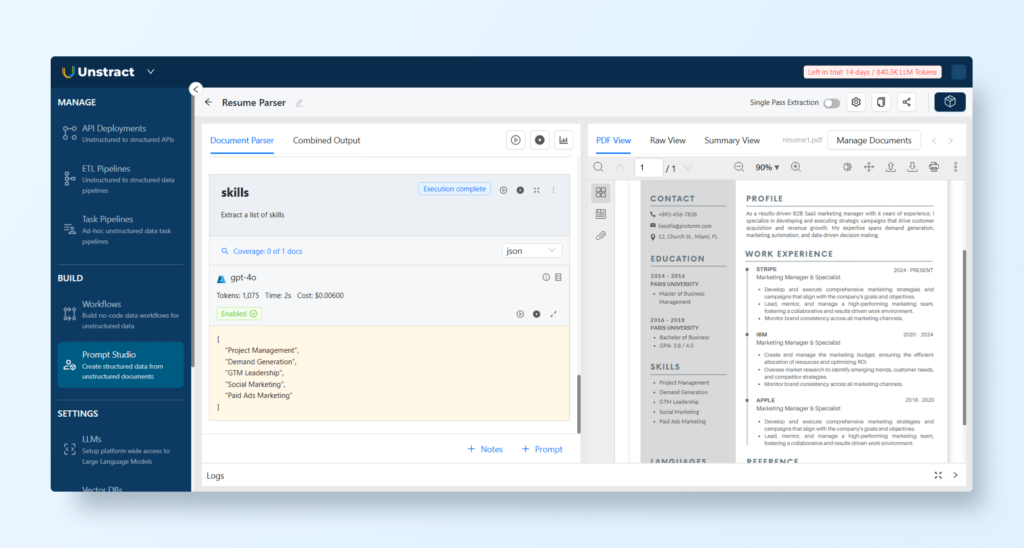
Example of skills:
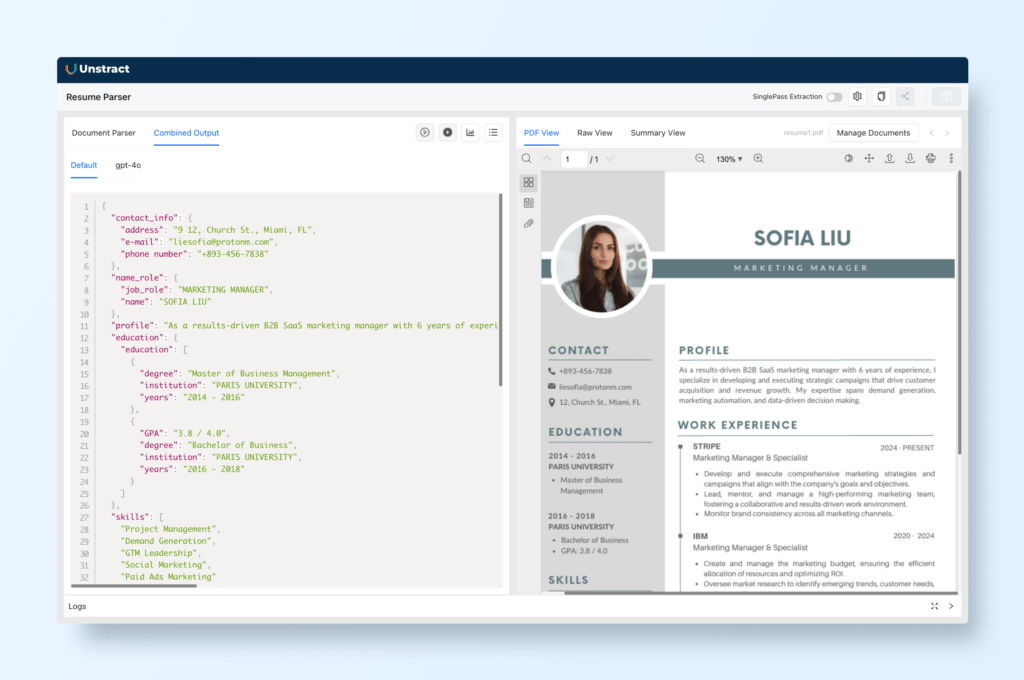
All these prompts work together to extract all the desired information from a resume. We can see the combined output in one tab. For crafting the best prompts, make sure to be clear on the intended output and also make sure to export the information as JSON (when more than one field would be returned from the prompt) or as a text (if there is only one text output).
Deploying as an API
After setting up your Prompt Studio project and perfecting your prompts for accurate data extraction, the next logical step is to deploy your Unstract solution as an API.
This deployment allows you to integrate the resume parsing functionality directly into your applications or systems, enabling real-time processing and scalability.
Creating a Tool
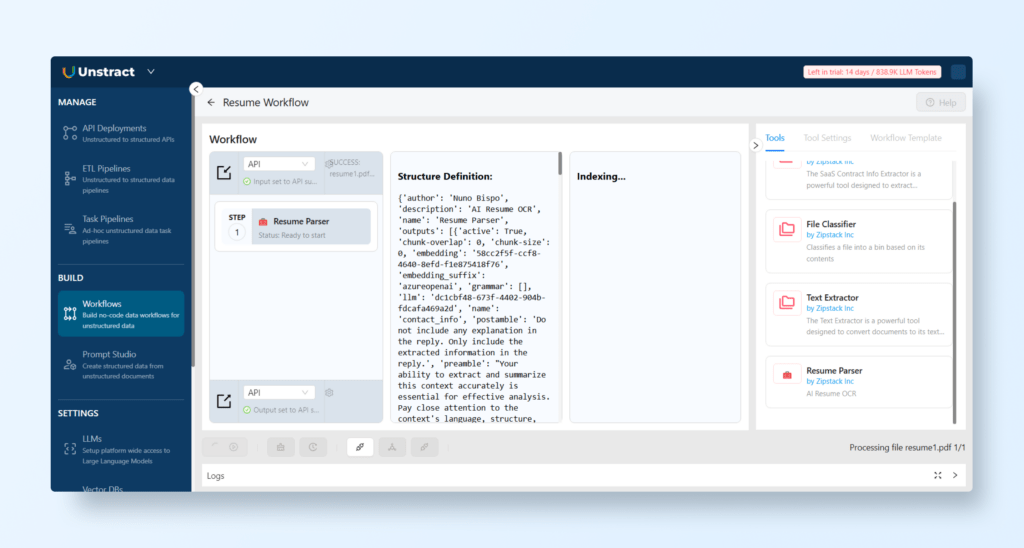
We first start by defining the existing project as a tool to be used in a workflow.
In the Prompt Studio project, click the ‘Export as tool’ icon on the top right corner. This will create a usable tool from this project.
Creating a Workflow
The next step is to create a new workflow. First navigate to BUILD → Workflows. And click on `+ New Workflow’ to add a new workflow.
Then, on the Tools section on the right hand side, find the tool created from the project, in this case ‘Resume Parser’, and drag and drop it to the workflow setting on the left hand side:
Since we intend to expose this workflow as an API, make sure that the input and output formats are defined as ‘API’.
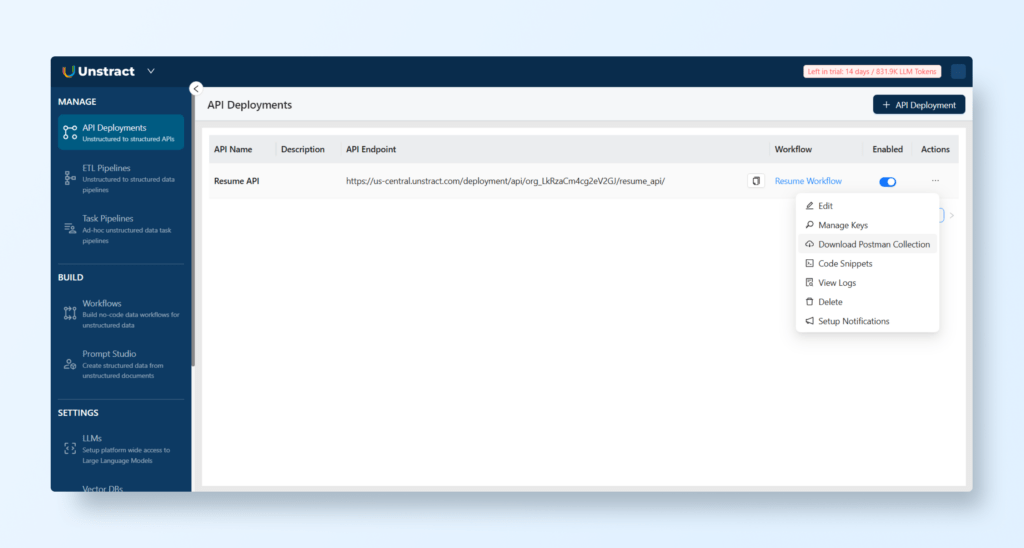
Creating an API
Now you can create an API from the newly created workflow. First navigate to MANAGE → API Deployments. And create a new API deployment with ‘+ API Deployment’ button. Once the API is created you can use the Actions links to manage aspects of the API. For instance you can manage the API keys or download a Postman collection for testing.
Accessing the API via Postman
After deploying your Unstract resume parsing workflow as an API, it’s crucial to test it to ensure it functions correctly and accurately extracts data from resumes.
Postman is a widely used API development and testing tool that allows you to send requests to your API and inspect the responses.
Here’s how you can use Postman to test your Unstract API.
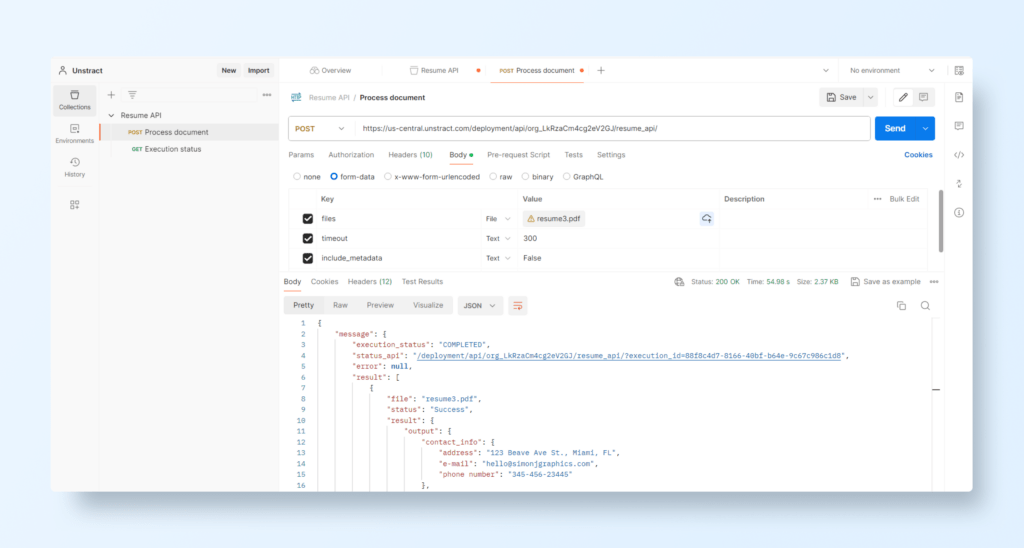
Create a new workspace an import the Postman collection downloaded previously. Don’t forget to set the API authentication with an API key with type ‘Bearer Token’. Select a resume and run the request.
And the resulting JSON is:
{
"message": {
"execution_status": "COMPLETED",
"status_api": "/deployment/api/org_LkRzaCm4cg2eV2GJ/resume_api/?execution_id=88f8c4d7-8166-40bf-b64e-9c67c986c1d8",
"error": null,
"result": [
{
"file": "resume3.pdf",
"status": "Success",
"result": {
"output": {
"contact_info": {
"address": "123 Beave Ave St., Miami, FL",
"e-mail": "hello@simonjgraphics.com",
"phone number": "345-456-23445"
},
"education": [
{
"end_year": 2014,
"institution": "Rome University",
"start_year": 2012,
"study": "Masters in Art and Illustration"
},
{
"end_year": 2012,
"institution": "Rome University",
"start_year": 2009,
"study": "BA in Art and Illustration"
}
],
"name_role": {
"job_role": "Graphic Designer",
"name": "Simon Jack"
},
"profile": "Meet Simon, a seasoned Graphic Designer with over Nine years of experience specializing in web design. With a keen eye for detail and a passion for creating captivating visuals, Alex has consistently delivered innovative design solutions that elevate user experiences. Proficient in industry-standard tools and always up-to-date with the latest design trends, Alex brings a blend of creativity and technical expertise to every project.",
"skills": [
"Web Design",
"Illustrator",
"UI/UX",
"User research"
],
"work_experience": [
{
"company_name": "Salford & Co.",
"dates": "Mar 2018 - Present",
"role": "Creative Director",
"work_responsibilities": "Works closely with the marketing team regarding advertisements and promotions."
},
{
"company_name": "Netfly Telecom",
"dates": "Dec 2015 - Jan 2018",
"role": "Project Manager",
"work_responsibilities": "Handled multiple digital accounts and works with reputed organizations to provide unique graphic designs."
}
]
}
},
"metadata": {
"source_name": "resume3.pdf",
"source_hash": "46196dcd1124b2a6670e83fa45481875e0271e7d8f1daffc69342d6be67cacfe",
"organization_id": "org_LkRzaCm4cg2eV2GJ",
"workflow_id": "40c055c4-0263-4ebd-bbdc-5777fe80302e",
"execution_id": "88f8c4d7-8166-40bf-b64e-9c67c986c1d8",
"total_elapsed_time": 46.778645,
"tool_metadata": [
{
"tool_name": "structure_tool",
"elapsed_time": 46.778641,
"output_type": "JSON"
}
]
}
}
]
}
}
As you can see, the prompts were designed and tested on a completely different resume, but executing the API with another resume still allows you to extract all the defined data fully.
Integrating resume parsing API with your ATS Systems
Integrating Unstract’s API with Applicant Tracking Systems (ATS) significantly enhances recruitment workflows by creating a seamless connection between resume parsing and candidate management platforms.
Unstract’s API is designed for seamless integration, allowing it to connect effortlessly with popular ATS platforms such as Greenhouse, Lever, Taleo, and others. This integration ensures that the structured data extracted from resumes flows directly into the ATS without the need for manual intervention.
By automating data entry into ATS systems, Unstract eliminates the tedious and error-prone task of manually inputting candidate information. When a resume is processed through Unstract, the API transforms unstructured resume data into structured formats compatible with the ATS.
This automated transfer includes critical candidate details such as personal information, education history, work experience, skills, and certifications. The immediate availability of this data within the ATS enables recruiters to quickly search, filter, and assess candidates based on specific criteria, thereby accelerating the hiring process.
The benefits of integrating Unstract with ATS systems are substantial. Firstly, it streamlines hiring processes by reducing administrative workload, allowing HR professionals to focus on strategic tasks like engaging with candidates and improving talent acquisition strategies. Secondly, it leads to improved data management by ensuring that all candidate information is accurate, consistent, and easily accessible within a single platform.
This enhanced data integrity facilitates better reporting, analytics, and compliance with data protection regulations. Ultimately, the integration empowers organizations to make more informed hiring decisions, reduces time-to-hire, and provides a competitive edge in attracting top talent.
Advantages of Using Unstract for Resume Parsing
Unstract offers a range of benefits that set it apart from traditional resume parsing tools.
Its innovative approach leverages AI and specialized technologies to provide a flexible, efficient, and accurate solution for organizations looking to optimize their recruitment processes.
No Need for Retraining or Remodelling
One of the standout features of Unstract is its ability to handle a wide variety of resume formats without the need for constant retraining or remodelling.
Traditional parsing software often relies on predefined templates or rules, which means that any deviation in resume design can lead to errors or require manual intervention to update the system.
Unstract overcomes this limitation through its advanced AI algorithms and the use of tools like LLMWhisperer.
Seamless Adaptation: Unstract automatically adapts to different layouts, fonts, and structures found in resumes. Whether it’s a creative design with unconventional formatting or a standard professional template, Unstract can accurately extract the necessary information.
Reduced Maintenance Effort: Without the need for ongoing adjustments or template creation, organizations save time and resources. This allows HR teams to focus on strategic tasks rather than managing the technical aspects of the parsing tool.
Scalability
Unstract is designed to scale effortlessly with the needs of an organization, making it suitable for both small businesses and large enterprises.
High-Volume Processing: The platform can process large batches of resumes quickly, ensuring that even during peak recruitment periods, there are no bottlenecks in data extraction.
Versatile Application: Unstract’s ability to manage different types of resumes—including various file formats like PDF, Word documents, and images—means that it can accommodate a diverse applicant pool without compromising performance.
Cloud-Based Infrastructure: Leveraging cloud technology, Unstract provides scalable computing power that adjusts based on workload, ensuring consistent performance regardless of demand.
Cost and Time Efficiency
Implementing and maintaining traditional resume parsing software can be costly and time-consuming.
Unstract addresses these concerns by offering a more efficient alternative.
Lower Operational Costs: By eliminating the need for constant retraining and reducing manual intervention, Unstract lowers the operational expenses associated with resume parsing.
Faster Deployment: The platform’s user-friendly interface and out-of-the-box functionality mean that organizations can get up and running quickly without extensive training or setup periods.
Resource Optimization: Automation of repetitive tasks frees up HR personnel to focus on higher-value activities, such as candidate engagement and strategic planning, leading to better use of human resources.
Improved Data Accuracy
Accurate data extraction is critical for effective recruitment decisions.
Unstract’s integration of AI technologies significantly enhances the precision of resume parsing.
Contextual Understanding: Utilizing AI and Large Language Models (LLMs), Unstract can understand the context in which information is presented within a resume. This means it can accurately extract data even when candidates use varied terminology or unconventional formats.
Error Reduction: Advanced algorithms minimize the risk of misinterpretation or omission of important details, ensuring that the data fed into Applicant Tracking Systems (ATS) or databases is reliable.
Continuous Improvement: Unstract’s AI components can learn and improve over time, further increasing accuracy as they process more data.
By combining these advantages, Unstract provides a powerful solution for organizations seeking to modernize their resume parsing capabilities.
Its adaptability, scalability, cost-effectiveness, and accuracy not only streamline the recruitment process but also contribute to better hiring outcomes by ensuring that critical candidate information is captured and utilized effectively.
Case Study: Testing Unstract with Different Resumes
To demonstrate Unstract’s capability to consistently extract information from resumes of varying formats, we will develop a simple Streamlit Python application.
This application allows users to upload a CV, which then calls the Unstract API created previously to parse the resume and display the extracted information in organized sections.
Building the Streamlit Application with Python
First we start by installing all the necessary packages with pip:
pip install streamlit requests python-decouple
We define the API Key to the Unstract’s API that we deployed previously with a .env file:
UNSTRACT_API_KEY=<YOUR_UNSTRACT_API_KEY>
Now we can write the Streamlit application, main.py:
import streamlit as st
import requests
from decouple import config
# Function to process the resume using the Unstract API
def process_resume(file):
# Get the API key from the environment variables
api_key = config('UNSTRACT_API_KEY')
# API endpoint
api_url = 'https://us-central.unstract.com/deployment/api/org_LkRzaCm4cg2eV2GJ/resume_api/'
# Headers and payload
headers = {
'Authorization': f'Bearer {api_key}',
}
payload = {'timeout': 300, 'include_metadata': False}
# Files
files = [('files', ('file', open(file, 'rb'), 'application/octet-stream'))]
# Send the request
response = requests.request("POST", api_url, headers=headers, data=payload, files=files)
# Print (for debugging) and return the response
print('Response:', response.json())
return response.json()['message']['result'][0]['result']['output']
# Streamlit app setup
st.set_page_config(page_title='Resume Parser', page_icon=':page_with_curl:', layout='centered')
st.header('Resume Parser')
st.subheader('Upload your resume and receive a JSON output')
st.divider()
# File uploader
uploaded_file = st.file_uploader("Choose a file")
if uploaded_file:
# Show a status message
with st.status('Processing your resume...'):
# Save the uploaded file to a temporary location
with open('temp.pdf', 'wb') as f:
f.write(uploaded_file.getbuffer())
# Process the resume
json_response = process_resume('temp.pdf')
st.write('Resume processed successfully!')
# Show the name and role extracted from the resume
st.divider()
st.title('Name and Role')
st.write(f'Name: {json_response['name_role']['name']}')
st.write(f'Role: {json_response['name_role']['job_role']}')
# Show the profile summary extracted from the resume
st.divider()
st.title('Profile Summary')
st.write(json_response['profile'])
# Show the contact information extracted from the resume
st.divider()
st.title('Contact Information')
st.write(f'Email: {json_response['contact_info']['e-mail']}')
st.write(f'Phone: {json_response['contact_info']['phone number']}')
st.write(f'Address: {json_response['contact_info']['address']}')
# Show the education information extracted from the resume
st.divider()
st.title('Education')
for education in json_response['education']['education']:
st.write(f'{education["degree"]} from {education["institution"]} between {education["start_year"]} and '
f'{education["end_year"]}')
# Show the skills extracted from the resume
st.divider()
st.title('Skills')
st.write(', '.join(json_response['skills']))
# Show the work experience extracted from the resume
st.divider()
st.title('Work Experience')
for experience in json_response['work_experience']:
st.write(f'{experience["role"]} at {experience["company_name"]} between {experience["dates"]}')
st.write(', '.join(experience['work_responsibilities']))
The code defines a function process_resume that handles the communication with the Unstract API by sending the uploaded resume file and retrieving the parsed data. The extracted information includes personal details, education history, work experience, skills, and contact information.
The Streamlit app sets up a user-friendly web interface where users can upload their resumes. Upon uploading, the app calls the process_resume function to process the resume and then displays the extracted data in organized sections on the web page.
Uploading that file to the Streamlit application we get the following result, starting with the name, role, profile summary, contact information, and work experience.
The extracted data is well-organized, matching the corresponding sections in the original resume.
For instance, even when resumes presented work experience in unconventional layouts, Unstract correctly identified and parsed job titles, company names, employment dates, and responsibilities.
This demonstration highlights Unstract’s ability to consistently extract information from resumes of various formats without additional configuration, showcasing how its API can be integrated into custom applications for automated resume parsing.
Conclusion
In summary, Unstract provides a ground-breaking solution for automating resume parsing, addressing the key challenges that organizations face with unstructured resume data.
By harnessing advanced AI technologies and tools like LLMWhisperer, Unstract eliminates the need for constant retraining or remodelling when document formats change.
Its flexibility allows it to adapt seamlessly to various resume designs and layouts, ensuring accurate and efficient data extraction across a diverse range of resumes.
This adaptability not only streamlines the recruitment process but also significantly reduces the time and resources required for manual data entry and template adjustments.
The key advantages of using Unstract in resume parsing automation are multifaceted:
No Need for Retraining or Remodelling: Unstract adapts to different document formats without additional setup, saving time and reducing maintenance efforts.
Scalability: It efficiently handles varying volumes and types of resumes, making it suitable for organizations of all sizes.
Cost and Time Efficiency: By reducing overhead associated with traditional parsing software, Unstract lowers operational costs and accelerates the hiring timeline.
Improved Data Accuracy: Enhanced extraction precision due to AI integration ensures that critical candidate information is accurately captured and utilized.
By integrating Unstract into their recruitment and HR workflows, organizations can significantly enhance their business processes.
Unstract automates time-consuming tasks, allowing HR professionals to focus on strategic activities such as engaging with candidates and developing effective talent acquisition strategies.
The improved accuracy and speed of data extraction lead to faster hiring processes, giving organizations a competitive advantage in attracting and securing top talent.
Ultimately, Unstract not only optimizes operational efficiency but also contributes to better hiring outcomes, strengthening the organization’s ability to compete in today’s dynamic job market.
What is next? Explore Unstract’s capabilities
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.