Did you know data teams spend over 28% of their time just preparing spreadsheets? Extracting data from Excel files is tedious and time-consuming, especially when dealing with large datasets spread across multiple spreadsheets. Yet, businesses remain tied to manually extracting data from Excel documents, making operations slower and error-prone. Spreadsheets often become sources of inaccurate data due to human errors.
This is where AI-powered document processing can help. Tools like Unstract overcome these barriers by automating extraction with high accuracy. AI parses financial models, shipment trackers, and payroll sheets, transforming Excel’s static grids into real-time, queryable data. You get structured JSON in seconds, without complex formulas or cell collisions.
This article explores the need for automating Excel data extraction, industry use cases, and how Unstract and LLMWhisperer use AI to solve common challenges.
Why Automating Excel Document Extraction Is Crucial
Excel remains the backbone of everyday operations that support budgeting, financial planning, reporting, and data analysis across departments and industries. But as businesses grow, the manual handling of Excel files becomes increasingly inefficient. Tasks like data extraction, formatting, validation, and reporting are time-consuming, repetitive, and highly prone to human error.
Manual Excel operations can delay reporting, introduce inconsistencies, and compromise decision-making in data-intensive workflows. Automating Excel tasks emerges as a vital solution. It helps eliminate bottlenecks and improves the speed, accuracy, and reliability of data operations.
Excel automation helps businesses:
Save time by cutting down on repetitive tasks, so teams can focus on more important work.
Avoid mistakes by reducing manual data entry and improving accuracy in calculations and formatting.
Connect easily with other software and systems to automate the entire data process.
Get up-to-date insights by linking Excel with external tools for faster and clearer decisions.
Handle more data and complexity without needing extra manual effort.
However, not every part of Excel document processing can be automated. Automation can include structured tasks like extracting tables, cleaning layouts, or sending data to other systems. Human input is still needed to check unclear fields, review comments or notes, and work with messy spreadsheets that have mixed formats, charts, or macros.
Automation simplifies routine Excel tasks but doesn’t fully replace human review where decisions or judgment are involved.
Excel Document Extraction Use Cases Across Industries
Spreadsheets remain deeply ingrained in everyday operations. Despite the rise of specialized software, nearly 90% of modern companies continue using spreadsheets like Excel for essential tasks.
Below are industry-specific examples showing both Excel’s flexibility and the growing need for automating data extraction:
Finance
Businesses use Excel for financial planning, profit and loss reports, and budgeting. Banks and companies rely on spreadsheets to prepare quarterly forecasts, but manually combining files can create version mismatches and slow decision-making.
For example, Natixis uses Excel for enterprise content management, supporting financial modeling and reporting processes.
Insurance
Actuaries and claims teams track policies and claims through Excel. Yet reconciling data across multiple spreadsheets or extracting tables from semi-structured reports takes time and invites human error.
For instance, even major markets like Lloyd’s of London rely on Excel for underwriting and rating workbooks, underscoring both its widespread use and the need for automation.
Logistics
Logistics teams manage shipment tracking, freight cost breakdowns, and dispatch schedules using Excel. For example, Intel’s supply chain analysts and database administrators use Excel to manage supply chain data and logistics metrics. Automating these workflows improves efficiency and reduces manual effort.
Marketing and Sales
Lead lists, campaign trackers, and customer data often reside in spreadsheets. Sales managers track pipelines and forecast revenue in Excel by analyzing historical win/loss data and current deals. But manually aggregating data across sources slows down workflows and delays insights into campaign performance.
Human Resources (HR) and Admin
HR and administrative teams rely on Excel to manage employee databases, leave tracking, payroll, and shift schedules. For example, teams at JP Morgan Chase use Excel to handle HR data and reporting as part of their daily operations.
Challenges in extracting data from Excel
Given Excel’s widespread use, it’s critical to understand the structural and data quality challenges that make accurate extraction difficult.
Structural and Data Quality Issues
Extracting structured data from Excel is rarely straightforward. Here are a few common hurdles:
Inconsistent headers, merged cells, and mixed data types make manual extraction difficult and error-prone.
Hidden rows and unresolved formulas often break the structure, leading to corrupted output.
Sheets with mixed text, numbers, and formulas are harder to extract than clean, structured tables.
Multi-line text, comments, and notes often get flattened, losing important context.
Without version control, it’s difficult to tell which spreadsheet contains the correct or most recent data.
Challenges with Processing via PDF Conversion and Optical Character Recognition (OCR)
Extracting data from Excel files becomes especially unreliable when using PDF conversion and OCR-based methods. These approaches often introduce the following issues:
Excel files are not page-based, so converting them to PDFs often disrupts the original layout.
Wide spreadsheets are split across pages, which can reorder or misalign related columns.
Scaling down large tables to fit a page often makes text unreadable, causing OCR tools to misread or skip data.
Visual indicators like bold borders or highlighted cells often signal totals or exceptions, but standard parsers typically ignore them.
Misinterpreting even a single value during OCR can lead to significant data errors, especially in high-stakes documents.
Spreadsheets containing mixed languages confuse OCR tools, especially those using simpler character recognition algorithms, causing skipped or misread text.
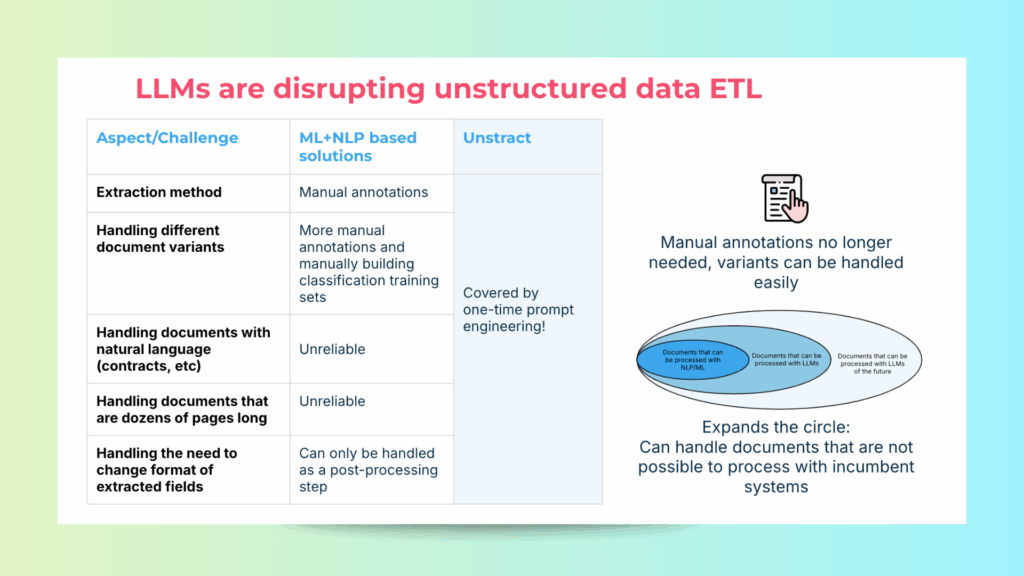
How AI and LLMs Enable Intelligent Excel Document Extraction
Large Language Models (LLMs) help extract data from Excel more accurately by understanding semi-structured tables without fixed templates. They can:
Detect Schemas and Headers: Automatically recognize column types, header rows, and table structures, even when formatting is inconsistent.
Extract Relationships: Understand how data points across rows and columns relate, even if connections aren’t explicitly defined.
Interpret Context: Grasp surrounding text, formulas, and formatting to accurately extract information from complex or irregular layouts.
However, LLMs are not designed to parse raw Excel files directly. They work best when the input is already cleaned, structured, and contextually clear.
Limitations of LLMs Compared with Unstract
Raw Excel files often contain layout complexities such as hidden rows, merged cells, inconsistent formatting, and visual cues like borders that carry meaning. These complexities can confuse LLMs and reduce extraction accuracy.
That’s where preprocessing tools like LLMWhisperer come in.
Understanding LLMWhisperer: Pre-processor for efficient excel data extraction
LLMWhisperer is a non-LLM text parsing tool built directly into Unstract’s processing stack. It plays a foundational role by preparing documents for further processing by LLMs or other systems within Unstract.
LLMWhisperer focuses on accurately extracting and structuring text from various document types, including PDFs, images, scanned documents, and Excel files, before they are fed into an LLM.
Unlike conventional approaches that rely on PDF conversion or OCR, LLMWhisperer reads Excel files natively. This means:
It extracts all values directly from the document without any form of conversion or rendering.
It preserves Excel’s original horizontal layout, no matter how many columns wide the sheet is.
It retains user-defined formatting like borders and emphasized cells, which often carry important contextual meaning.
This native parsing approach addresses common Excel extraction issues by avoiding column shifts during conversion, preserving data clarity without zoom-related OCR errors, and recognizing visual cues like borders and highlights.
LLMWhisperer provides LLMs with clean, layout-consistent, and structurally accurate input. This improves field extraction accuracy, enhances context understanding, and ensures higher-quality structured output. The result is more reliable performance in LLM-powered document processing workflows.
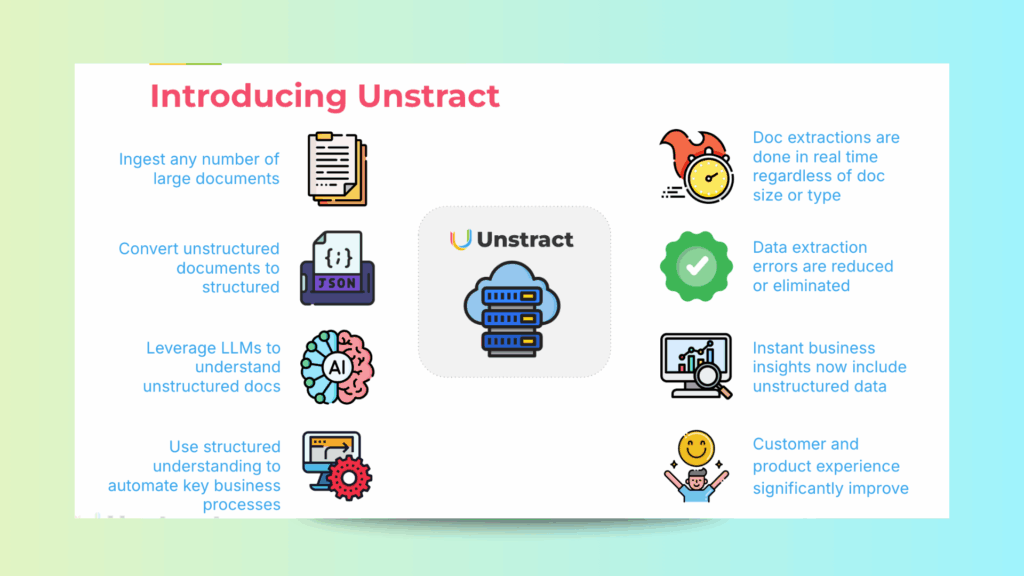
How Unstract Uses AI to Extract Data from Excel
Unstract is an open-source no-code platform purpose-built for automating document processing with AI.
Unstract Turns Unstructured Documents into Structured Insights
Unlike conventional Intelligent Document Processing (IDP) tools that rely on manual annotation and separate integration teams, Unstract allows engineers to handle everything from prompt engineering to ETL pipelines themselves.
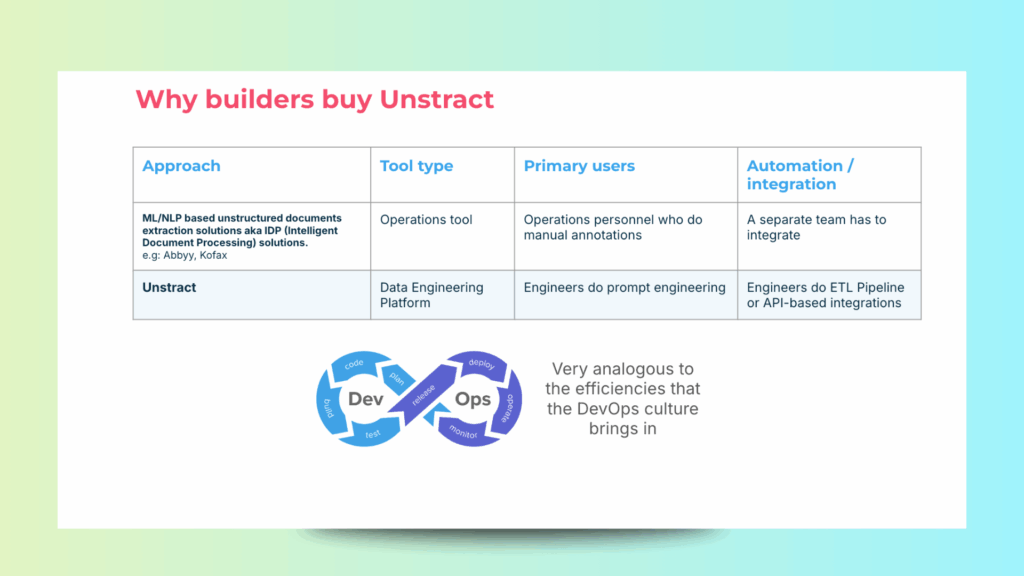
Why Teams Choose Unstract Over Traditional IDP Tools
It connects multiple components:
LLMs for context understanding.
Preprocessing tools like LLMWhisperer for layout-preserving text extraction.
Unstract uses AI to extract structured data from Excel without relying on fixed templates or fragile scripts.
When processing Excel files, Unstract combines:
LLMWhisperer: LLMWhisperer prepares raw Excel files by natively parsing their layout. It preserves tables, formatting, merged cells, and borders that traditional converters or OCR tools often miss.
LLMs: Once the Excel content is cleaned, LLMs handle schema detection, context interpretation, and relationship extraction across rows and columns.
This combination allows Unstract to enable businesses to:
Extract Actionable Insights From Excel Sheets: Capture data like financial summaries, transaction details, shipment breakdowns, or payroll reports, all structured as clean JSON.
Achieve High Data Fidelity: Preserve the original layout, formatting, and complex cell values to ensure the extracted output reflects the full context of the source data.
Automate Large-Scale Excel Processing Workflows: Use the workflow builder to connect sources like Dropbox and destinations like Snowflake, automating the entire Excel extraction process without manual effort.
Unstract converts Excel data into structured, machine-readable JSON, ready for use in downstream systems. This reduces manual effort, cuts operational costs, and speeds up decision-making through automation.
Extracting Excel Data Using LLMWhisperer
LLMWhisperer Playground provides a fast way to visually validate Excel text extraction before integrating it into larger workflows.
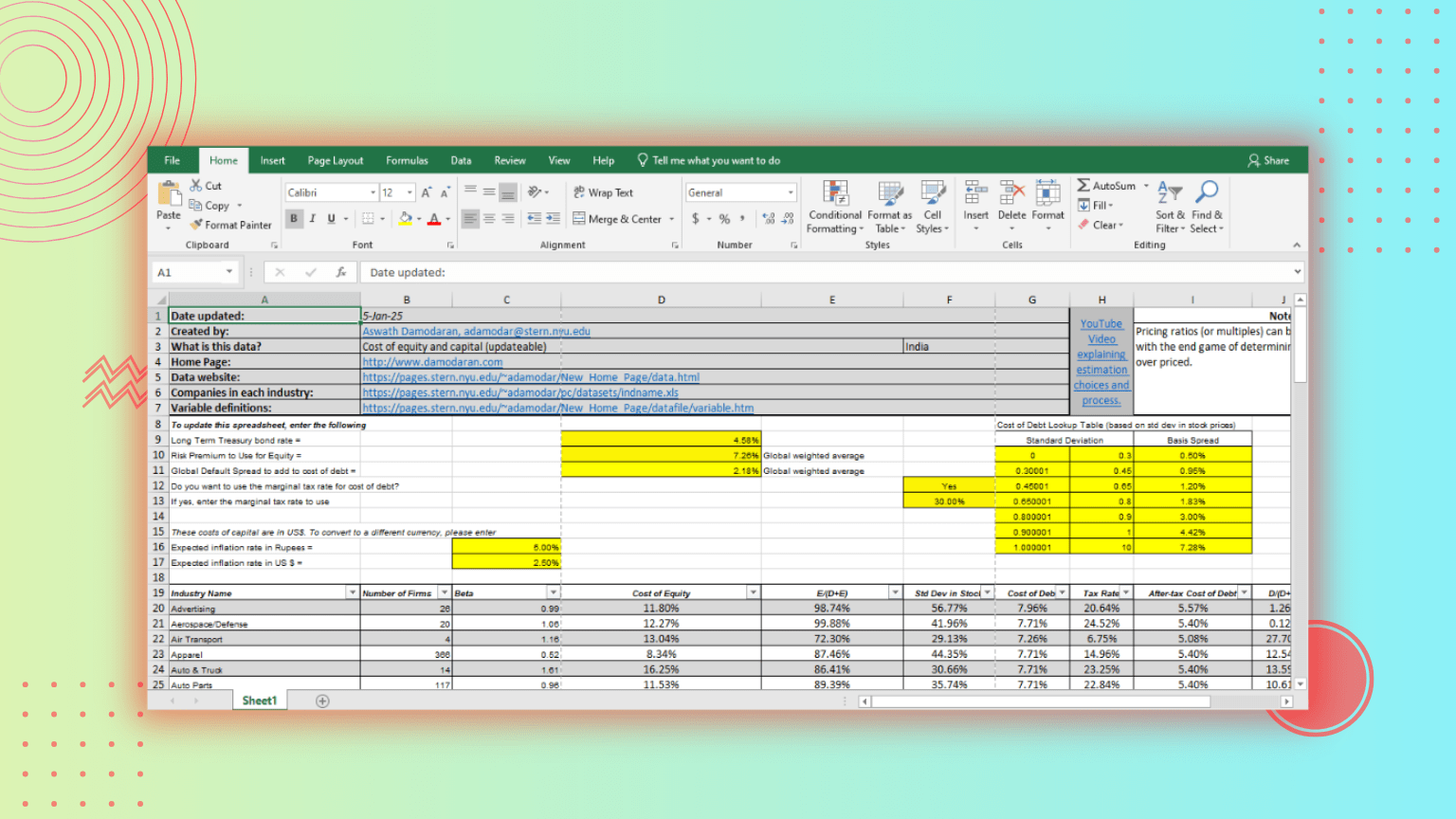
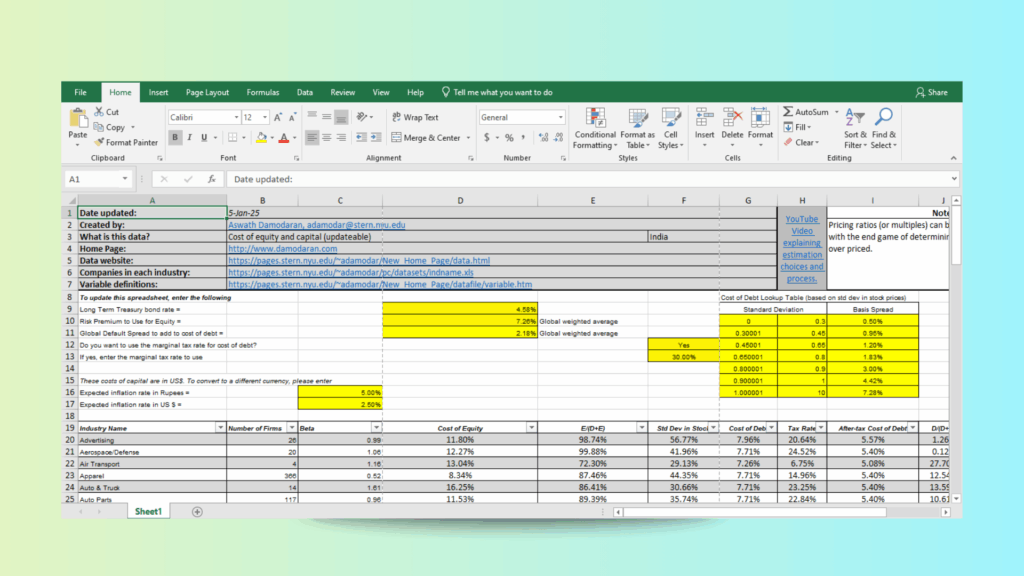
Parsing an Economics Spreadsheet Using the LLMWhisperer Playground
Economics Excel Sheet Featuring Merged Cells and Multi-Section Tables
The spreadsheet’s merged cells, multi-section tables, and overall layout are preserved as LLMWhisperer extracts the text in the next step.
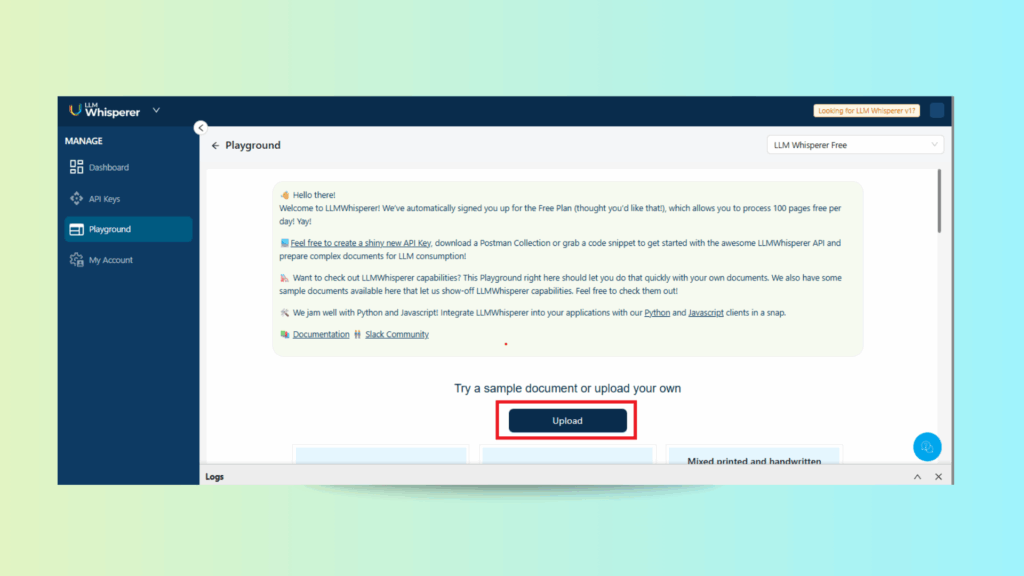
Uploading the Economics Excel Sheet in LLMWhisperer Playground
Upload an Excel sheet containing economic data into the LLMWhisperer Playground.
Extracted Text Result Displayed in the LLMWhisperer Playground
Once uploaded, LLMWhisperer instantly processes the file and outputs structured text while preserving the original layout, including column alignment and merged cells.
Extracting Data from a Financial Spreadsheet Using the API
The following steps show how to process Excel files using LLMWhisperer’s API through Postman.
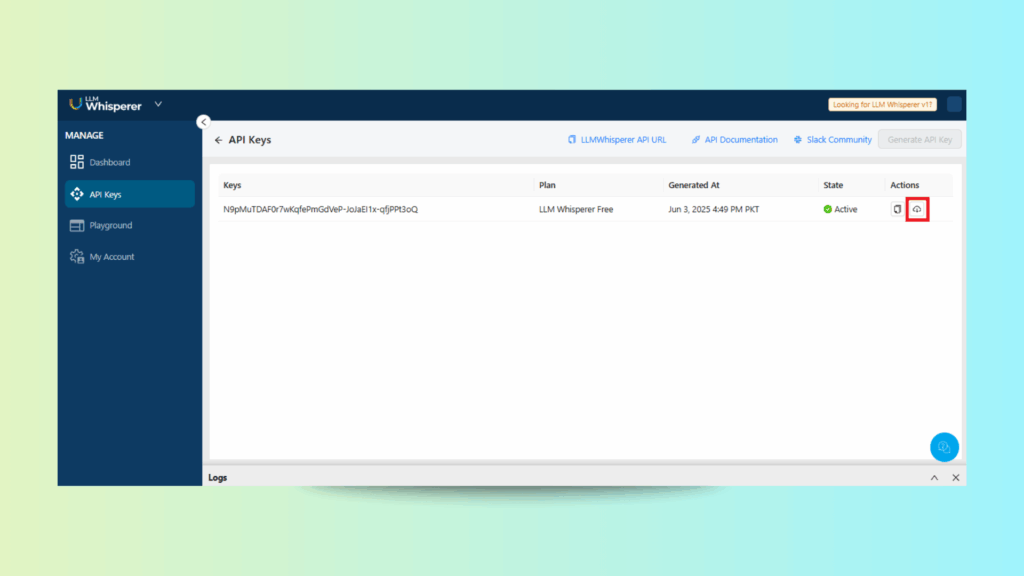
Step 1: Downloading the API Collection
Access the API Keys section in LLMWhisperer and download the pre-configured Postman collection.
Downloading the Postman Collection from the API Keys Section in LLMWhisperer
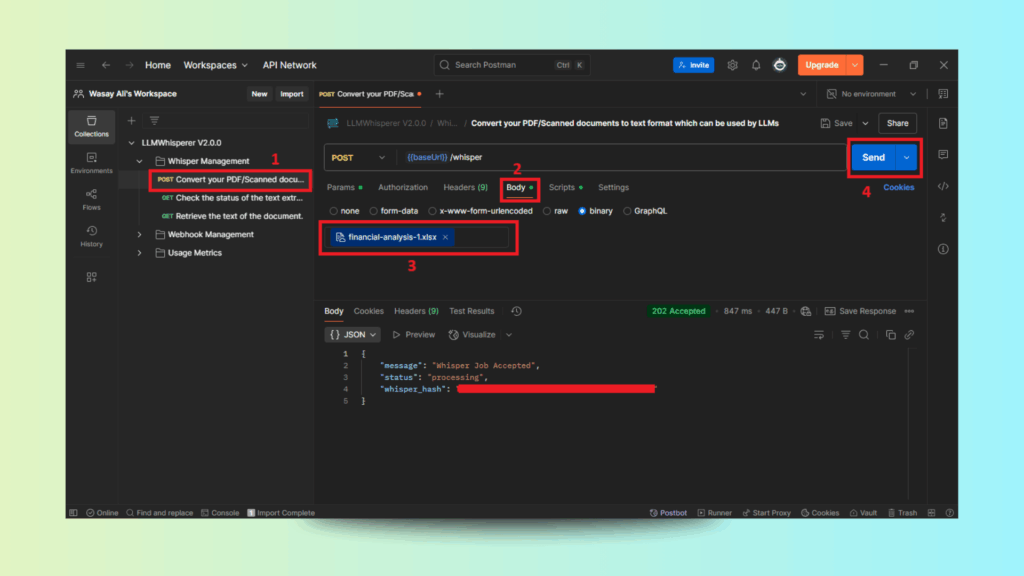
Step 2: Uploading the Financial Spreadsheet via POST Request
After importing the collection into Postman, use the POST request to upload a financial analysis Excel file.
Uploading the Financial Spreadsheet in Postman and Sending the POST Request
The API acknowledges the upload with a “processing” status.
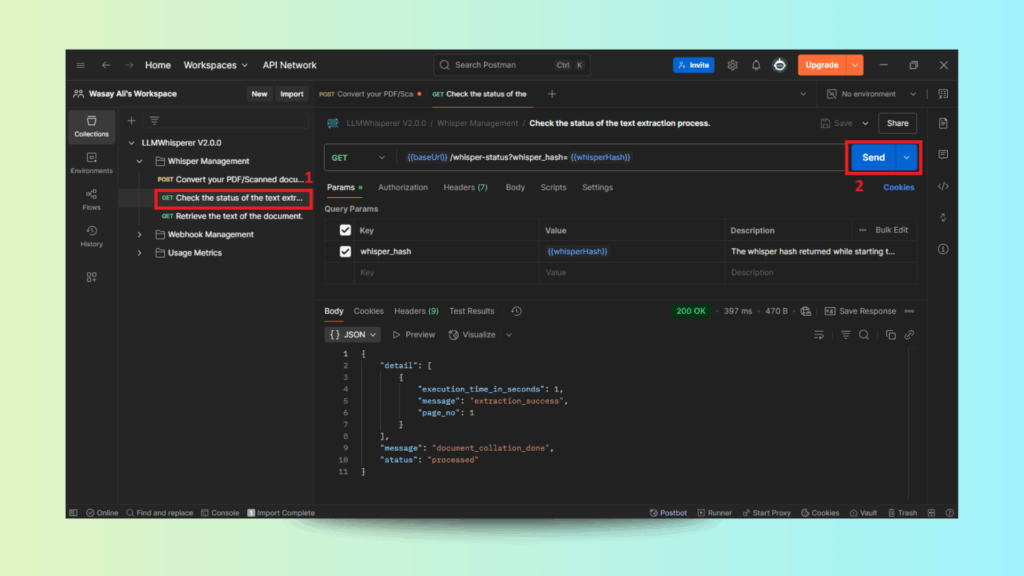
Step 3: Checking Processing Status
Monitor progress using the GET status request with the whisper hash ID.
Checking Document Processing Status in Postman
The system confirms when processing is complete.
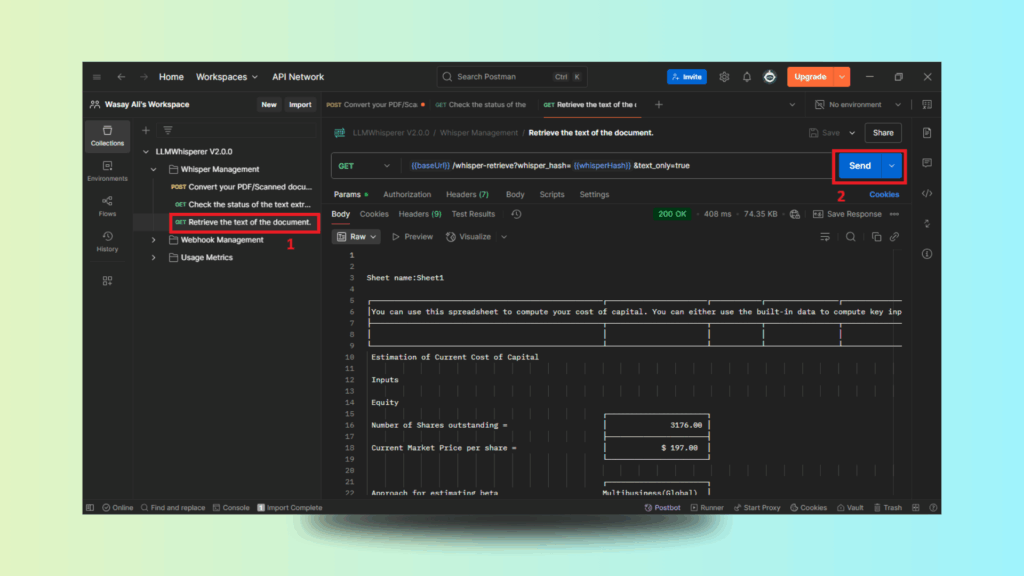
Step 4: Retrieving the Extracted Text
Perform a GET request to retrieve the extracted text.
Unstract Excel Data Extraction: Retrieving the Extracted Text From the Financial Spreadsheet
The response delivers structured, layout-consistent text ready for downstream processing.
Building an End-to-End AI-powered Excel Data Extraction Workflow in Unstract
LLMWhisperer manages document preprocessing, while Unstract powers end-to-end extraction workflows by integrating prompt logic, LLMs, vector databases, and embedding models into a deployable API.
This walkthrough outlines how to build an insurance performance extraction workflow using Unstract’s Prompt Studio and Workflow Builder.
Getting Started With Unstract: Best AI-Powered Excel Data Extractor
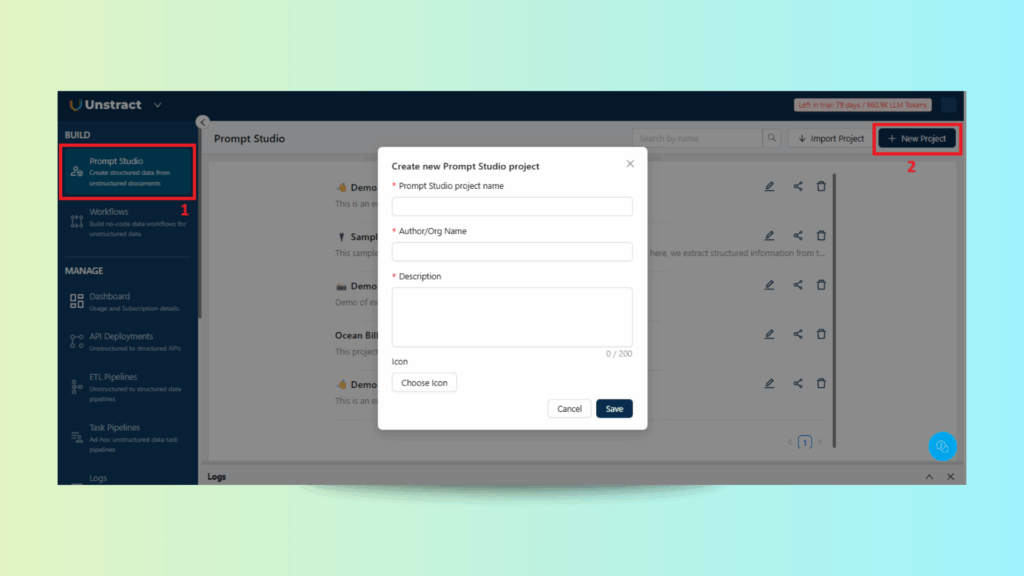
Step 1: Creating a New Prompt Studio Project
Unstract Excel Data Extraction: Creating a New Insurance Performance Project in Prompt Studio
Start by creating a new project in Prompt Studio specifically for insurance performance sheets.
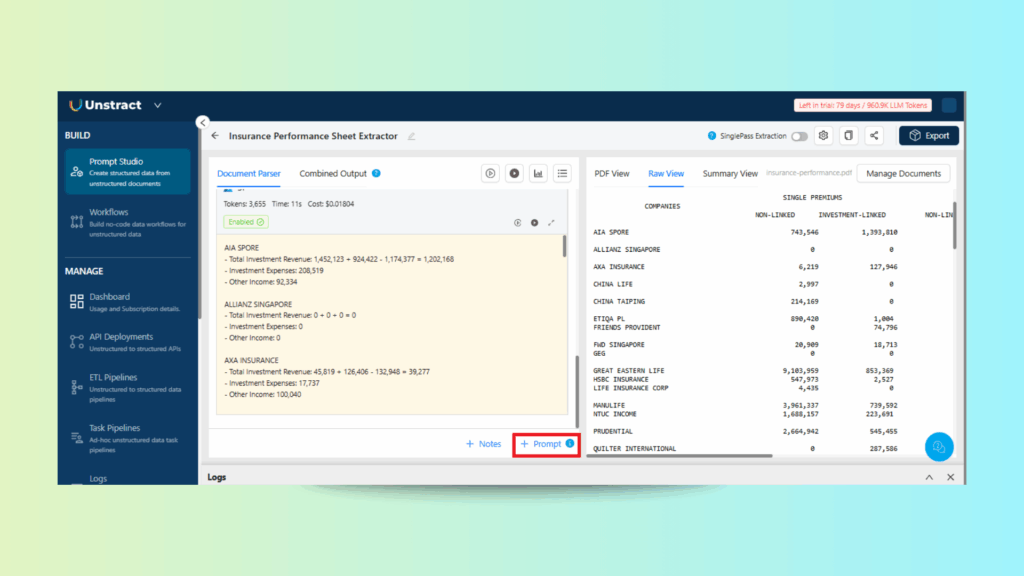
Step 2: Writing Extraction Prompts
Extract data from the Excel sheet in the Prompt Studio project.
Unstract Excel Data Extraction: Writing Prompts in Prompt Studio to Extract Key Insurance Performance Fields
Write prompts to identify specific insights, such as single premiums, other premiums, and investment revenue.
Step 3: Configuring Project Settings
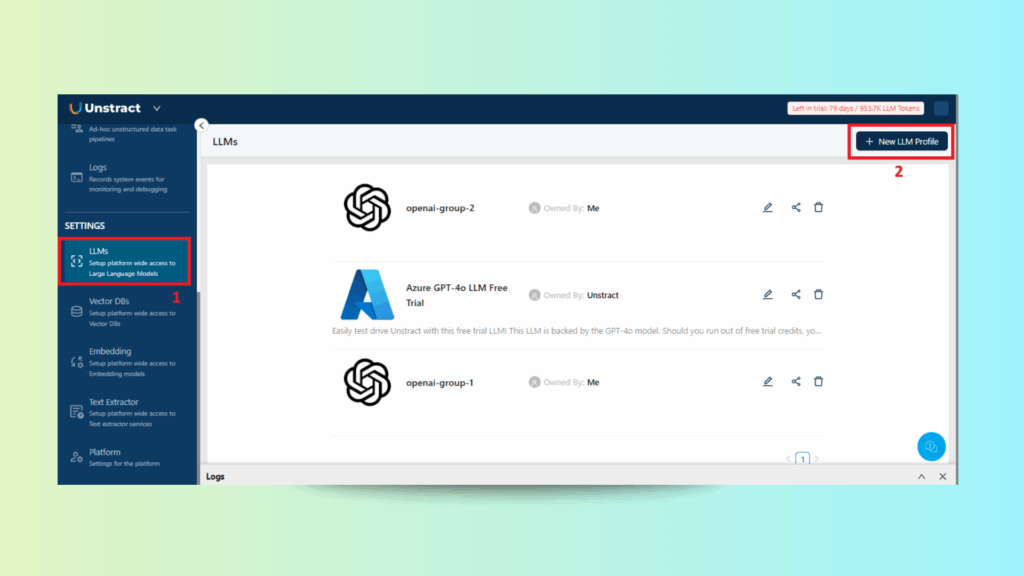
Choosing an LLM Model
Unstract Excel Data Extraction: Selecting the LLM Model Under Project Settings
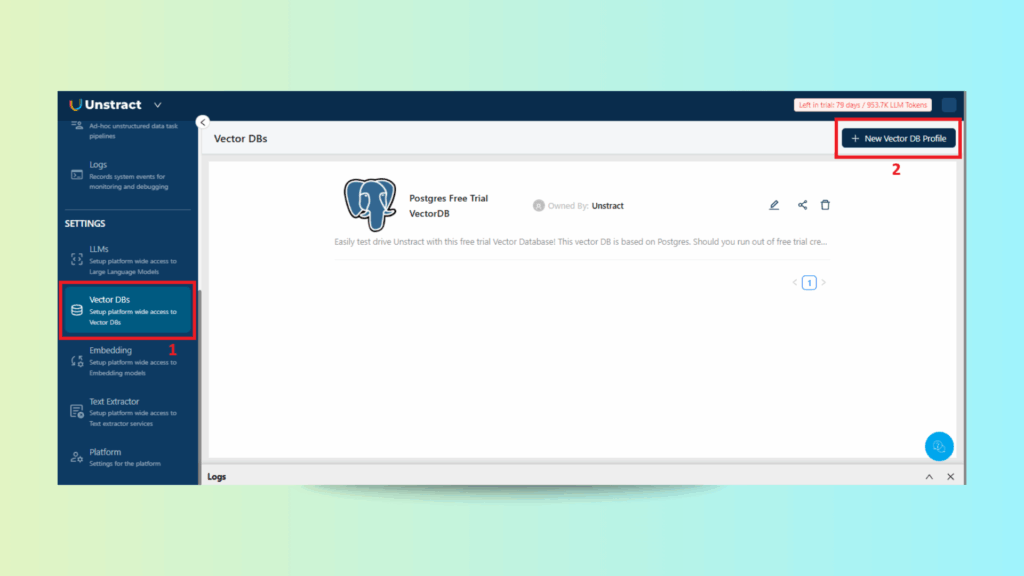
2. Adding Vector Database
Unstract Excel Data Extraction: Selecting a Vector Database for Structured Knowledge Storage
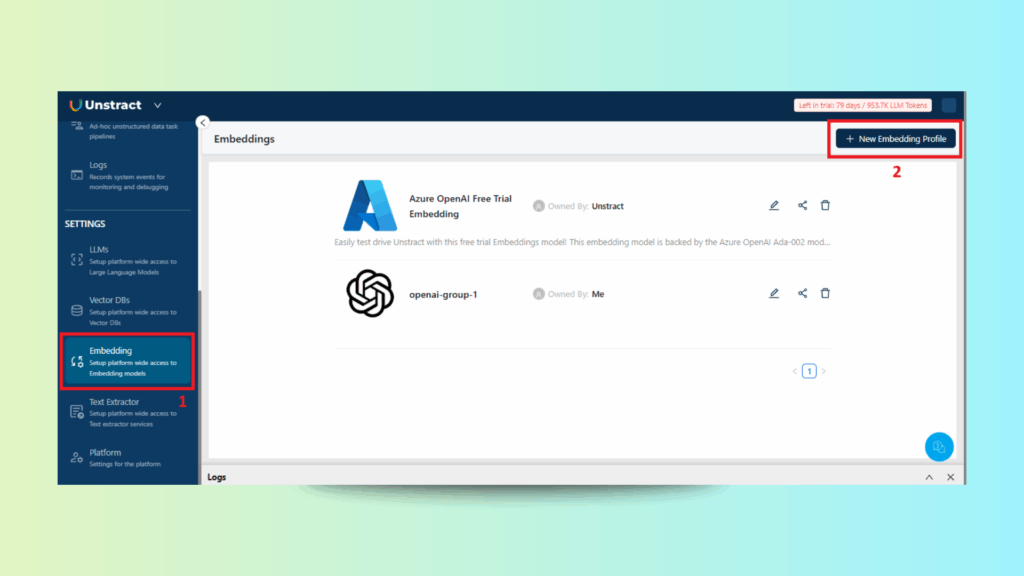
Choosing the Embedding Model
Unstract Excel Data Extraction: Adding an Embedding Model for Semantic Search and Indexing
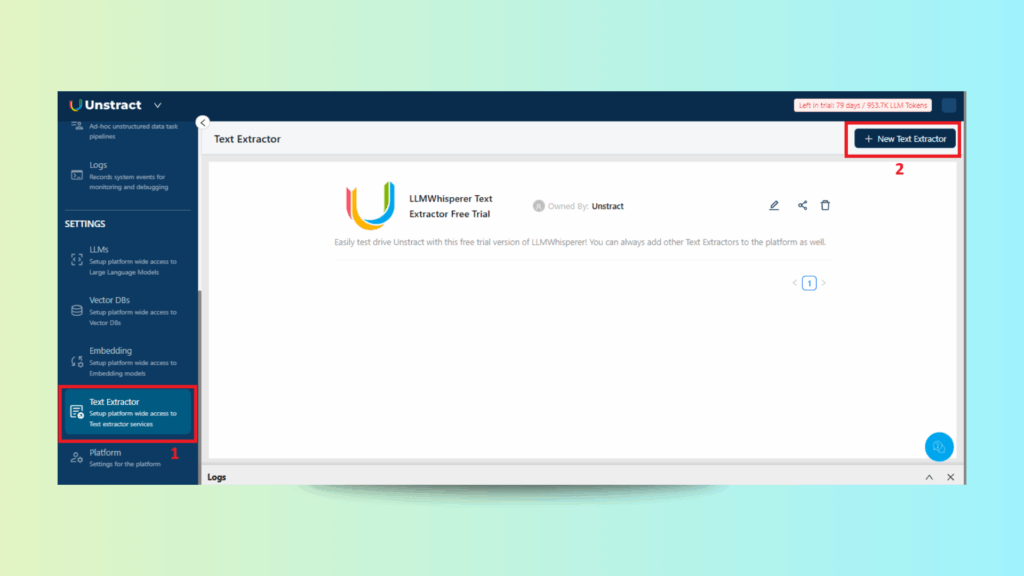
Connecting Text Extraction Tool
Choosing the Text Extraction Tool
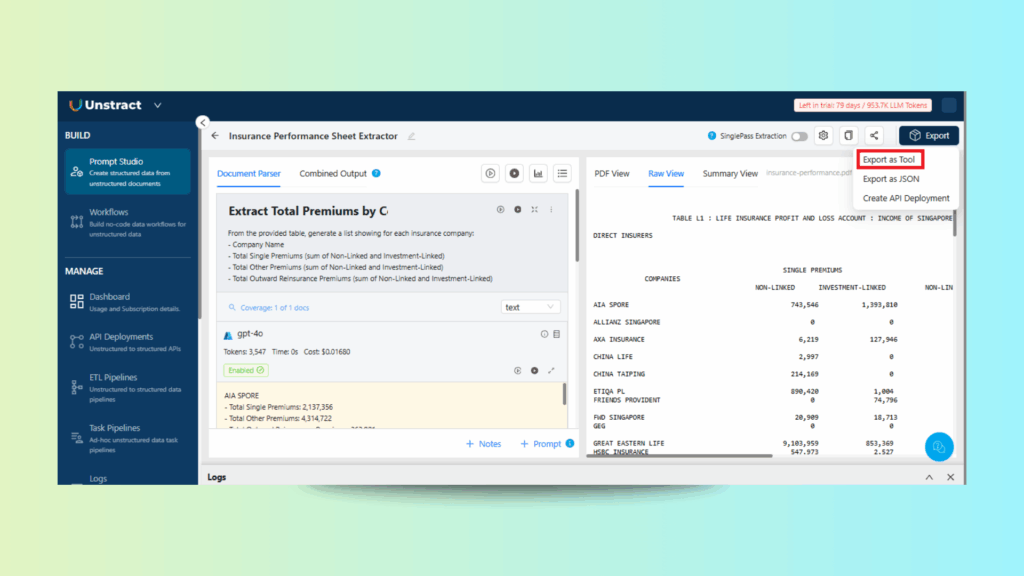
Step 4: Exporting the Prompt Project as a Tool
Unstract Excel Data Extraction: Exporting the Prompt Studio Project as a Tool for Workflow Integration
Once prompts and settings are finalized, export the project as a reusable tool that integrates into any Unstract workflow.
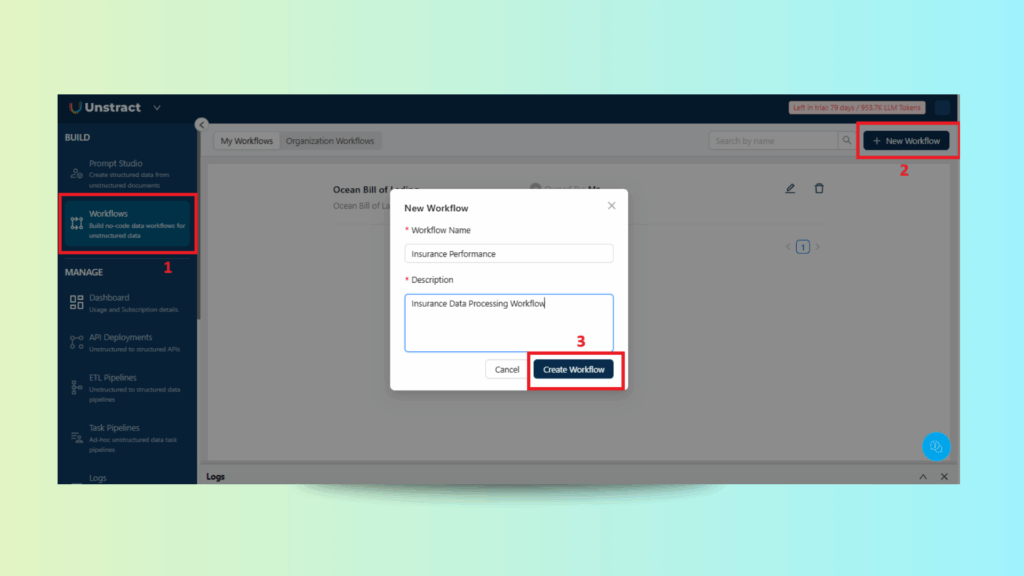
Step 5: Building and Deploying the Workflow
Create a new workflow in Unstract.
Creating the Workflow
Starting a New Workflow in Unstract
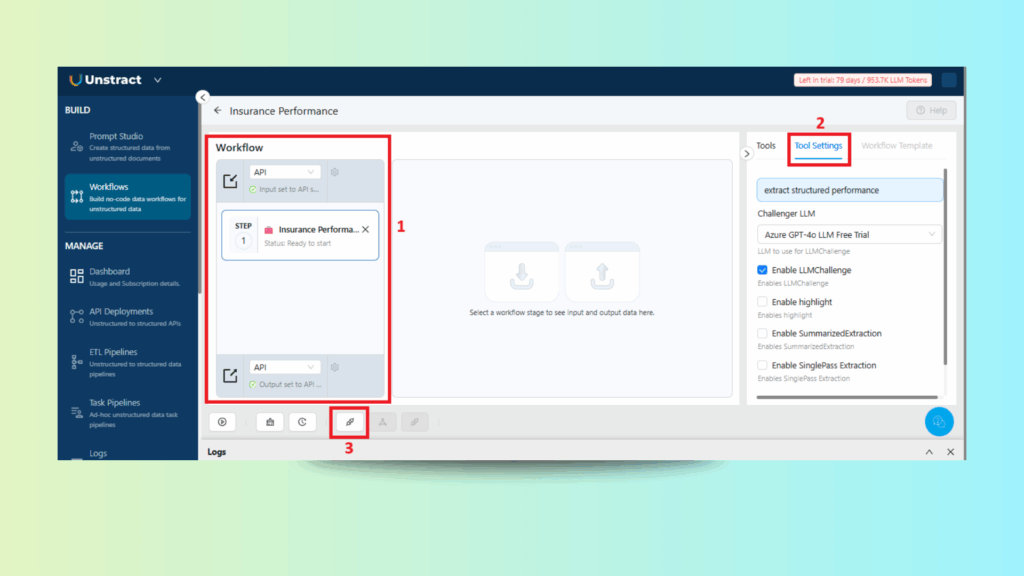
Configuring the Workflow
Configuring the Workflow with Input, Tool, and Output
Set the API file upload as the input, connect the insurance performance tool for data extraction, and define the API as the output.
Step 6: Deploying and Testing the Workflow API
After the workflow is configured, deploy it as an API service.
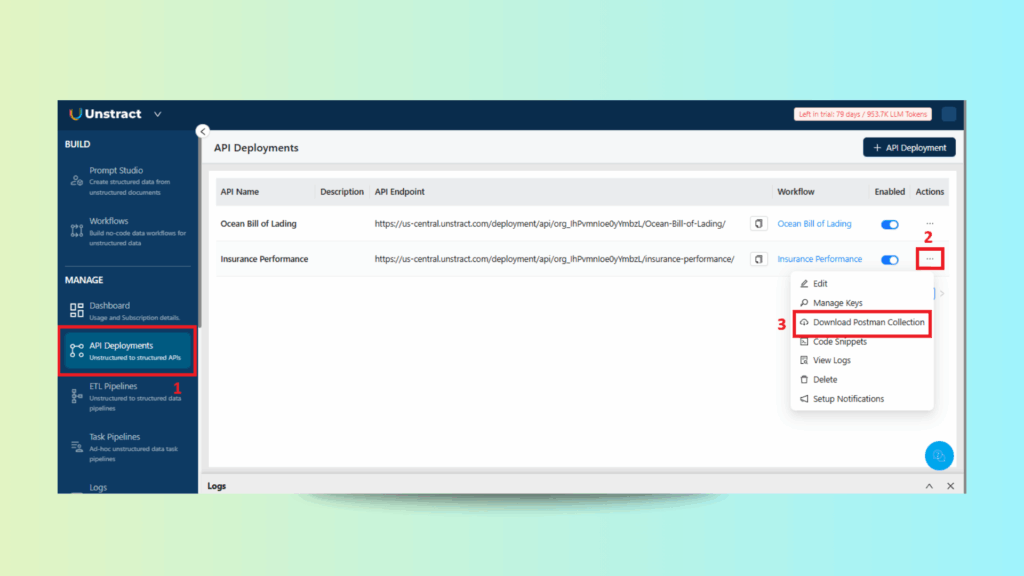
Downloading the Postman Collection
Downloading the Postman Collection for the Deployed Insurance Performance Workflow API
Testing the API with Postman
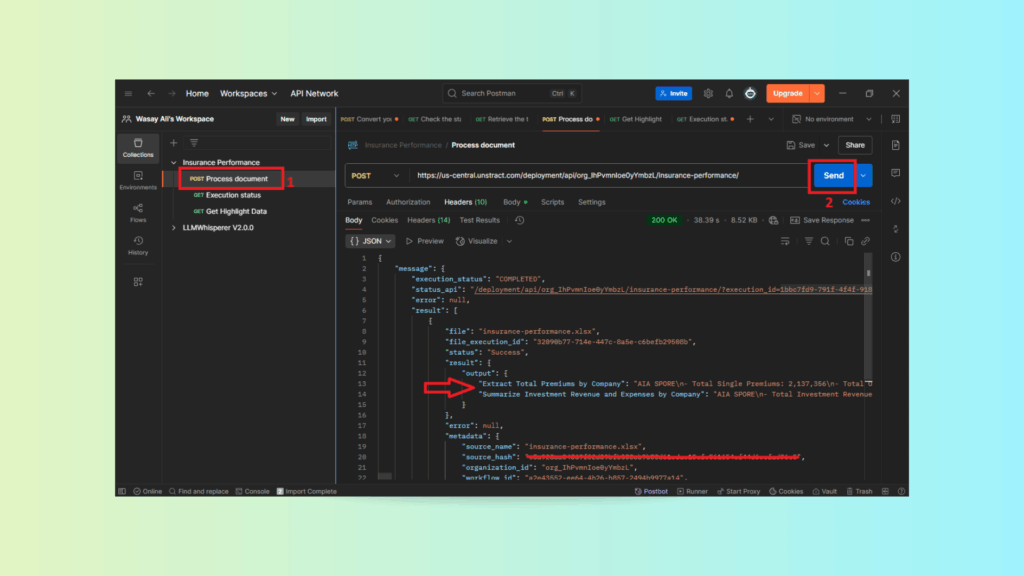
Upload the insurance performance Excel file in Postman and submit a POST request.
Unstract Excel Data Extraction: Sending the Insurance Excel File in Postman and Retrieving Structured JSON Results
The API returns structured insurance data as clean JSON output.
Benefits of Building End-to-End Workflows in Unstract
Once deployed, the insurance performance extraction workflow isn’t limited to a single use case. Unstract’s modular design connects Excel data extraction pipelines to various business systems, including dashboards, APIs, and data warehouses.
Transform Excel Extraction into API-Ready Workflows and ETL Pipelines
Here are the benefits of building end-to-end workflows in Unstract:
Automate Excel document processing without writing custom code.
Centralize data extraction, transformation, and loading (ETL) using no-code workflows.
Connect to your preferred LLMs, embedding models, and vector databases.
Seamlessly integrate outputs into business apps, analytics platforms, and storage systems.
This modular, integration-ready setup ensures your document extraction workflows stay flexible, secure, and scalable across industries.
How to extract data from Excel: What’s next?
Manually extracting data from Excel sheets slows down business work, whether it’s finance, insurance, or logistics. Errors creep in, reporting gets delayed, and teams end up spending more time cleaning spreadsheets than making decisions.
Automating Excel data extraction solves that, but most tools rely on clunky templates or break down with complex files.
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
LLMWhisperer is a document-to-text converter(best ocr). Prep data from complex documents for use in Large Language Models. LLMs are powerful, but their output is as good as the input you provide. Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables.
Extracting data from these documents and blindly feeding it to LLMs is not a good recipe for reliable results. LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they can best understand.
If you want to take it for a test drive quickly, you can check out our free playground.
How can I efficiently extract data from Excel files for business reporting?
Efficiently extract data from Excel by using AI-powered tools like Unstract. These platforms automate the extraction process and use technologies such as LLMWhisperer, which natively parses Excel files, preserves original formatting, and turns complex spreadsheets into structured, machine-readable data for downstream analytics.
How can I efficiently extract data from Excel files that have dozens of sheets and mixed formats?
To efficiently extract data from Excel, the article recommends pairing Unstract with its built-in LLMWhisperer pre-processor. LLMWhisperer reads the workbook natively, keeps the original layout intact, and hands clean text to an LLM, so you get reliable JSON in seconds instead of wrestling with templates or OCR.
Why does LLMWhisperer succeed when you need to parse data in Excel that includes hidden formulas or multiple languages?
LLMWhisperer can parse data in Excel natively, so it never loses context by converting to PDF. It captures every value, recognizes formatting that signals meaning, and even handles multilingual text—all problems that cause OCR or template-based parsers to fail.
How do you efficiently extract data from Excel for use in AI models or analytics pipelines?
To efficiently extract data from Excel for AI or analytics, use workflow automation platforms like Unstract. They preprocess and parse data in Excel with LLMWhisperer, convert it into structured formats like JSON, and easily feed it into LLMs, analytics tools, or data warehouses.
Why is it difficult to efficiently extract data from Excel manually?
Manually extracting data from Excel is difficult and error-prone due to structural and data quality issues like inconsistent headers, merged cells, hidden rows, and unresolved formulas. These complexities make the process slow and can lead to corrupted output and inaccurate data, especially when dealing with large datasets or multiple spreadsheets.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.