Extract and Convert PDF Data to Excel Spreadsheet with Unstract
Table of Contents
In today’s data-driven world, the need for automated solutions to convert PDFs into structured formats like Excel has become increasingly important.
PDFs are widely used for storing and sharing documents, but they often need a more structured format for efficient data analysis and management. Manually extracting data from PDFs can be time-consuming, error-prone, and not scalable for large volumes of documents.
This is where automated solutions come into play, offering significant benefits such as time savings, accuracy, and scalability.
This article explores how the combination of LLMWhisperer and Unstract simplifies converting PDFs to Excel.
LLMWhisperer serves as a powerful OCR (Optical Character Recognition) and text parsing tool, preparing documents for further processing. Unstract, on the other hand, leverages Large Language Models (LLMs) to extract structured data from the parsed text, ensuring that the information is accurately converted into a usable format.
Unstract: No-code LLM Platform to launch APIs and ETL Pipelines to structure unstructured documents.
By the end of this article, you will understand the step-by-step process of using these tools to extract data from PDFs and convert it into Excel, along with practical examples.
Excel has long been the standard in the world of data analysis and management, and for good reason. Converting PDFs into Excel offers a multitude of benefits that make it a preferred format for various applications.
Benefits of Parsing PDF into Excel
Excel organizes data into rows and columns, making it easy to sort, filter, and analyze. This structured format is crucial for performing complex data operations and generating insights.
Its user-friendly interface allows users to perform a wide range of tasks without requiring extensive technical knowledge. Its intuitive design makes it accessible to both beginners and advanced users.
It also comes equipped with a variety of built-in functions and tools, such as pivot tables, charts, and formulas, which enable users to perform in-depth data analysis and visualization.
The compatibility with numerous other software applications and the ease of integrating with databases and other data sources make it a versatile tool for data management and reporting.
Downstream Benefits and Applications
Converting PDFs to Excel opens up a world of downstream benefits and applications.
Excel’s analytical capabilities allow users to perform detailed data analysis, identify trends, and make data-driven decisions. This is particularly useful in fields like finance, marketing, and research.
The reporting features enable users to create comprehensive reports and dashboards that can be easily shared with stakeholders. This ensures that everyone has access to the same data and insights.
It supports automation through macros and VBA (Visual Basic for Applications), allowing users to automate repetitive tasks and streamline workflows.
The collaboration features, such as co-authoring and sharing, make it easy for teams to work together on data projects. This fosters a collaborative environment and ensures that everyone is on the same page.
Use Cases for Converting PDF to Excel
Converting PDFs to Excel is beneficial for a number of use cases.
Converting financial statements and reports from PDF to Excel allows for detailed financial analysis, budgeting, and forecasting. This is essential for financial professionals who need to make informed decisions based on accurate data.
Market research reports often come in PDF format. Converting these reports to Excel enables researchers to analyze market trends, consumer behavior, and competitive landscapes more effectively.
Inventory lists and reports in PDF format can be converted to Excel for better inventory management. This helps in tracking stock levels, managing orders, and optimizing inventory processes.
Research papers and datasets in PDF format can be converted to Excel for data analysis and visualization. This aids researchers in drawing meaningful conclusions from their data.
Why Excel is a Preferred Format
Excel’s popularity as a preferred format for data analysis and management can be attributed to several factors.
Many professionals are already familiar with Excel, making it a go-to tool for data-related tasks. Its widespread use ensures that there is a large community of users and resources available for support.
Excel’s flexibility allows users to perform a wide range of tasks, from simple data entry to complex data analysis and visualization. This versatility makes it suitable for various industries and applications.
It can handle large datasets and perform complex calculations, making it a scalable solution for data management. Its ability to integrate with other tools and platforms further enhances its scalability.
The powerful visualization tools enable users to create charts, graphs, and dashboards that make data more understandable and presentable. This is crucial for communicating insights effectively.
Challenges in Parsing PDF to Excel
Parsing PDFs to extract data and convert it into structured formats like Excel presents several challenges. Understanding these obstacles is crucial for developing effective solutions and leveraging the right tools to overcome them.
Diverse PDF Formats
Structured PDFs: These are digitally created documents where the text and layout are embedded in a structured format. Extracting data from these PDFs is relatively straightforward, as the text can be easily copied and pasted.
Scanned PDFs: These are essentially images of documents, where the text is not embedded but rather appears as part of the image. Extracting data from scanned PDFs requires Optical Character Recognition (OCR) to convert the image into text.
Variability in Table Layouts and Content Structure: PDFs often contain tables with varying layouts and structures, making it difficult to extract data consistently. Tables may have merged cells, different column widths, or irregular formatting, which complicates the extraction process.
The content structure within PDFs can also vary significantly. Documents may include headers, footers, images, and other elements that need to be distinguished from the main content during extraction.
PDF Challenge: Variability in Table Layouts and Content Structure
OCR Limitations
OCR technology, while advanced, is not perfect. It can struggle with low-quality scans, handwritten text, or complex layouts. Ensuring accurate extraction of text and tables from scanned images requires high-quality OCR tools and often manual verification.
Tables in scanned PDFs pose a particular challenge. OCR may misinterpret table borders, merge cells incorrectly, or fail to recognize the structure altogether, leading to inaccurate data extraction.
Manual Processes: Time-Consuming and Error-Prone
Manually extracting data from PDFs is a labor-intensive process. It involves opening each PDF, copying the relevant data, and pasting it into Excel. This process can be extremely time-consuming, especially for large volumes of documents.
Manual data entry is susceptible to human error. Typos, missed entries, and incorrect data placement can lead to inaccuracies in the extracted data. These errors can compound over time, affecting the reliability of the data analysis and decision-making processes.
Addressing these challenges requires a combination of advanced OCR tools, intelligent data extraction techniques, and automated workflows.Tools like LLMWhisperer for OCR and text parsing, and Unstract for structured data extraction using LLMs, provide robust solutions to overcome these obstacles.
AI and LLMs for Document Extraction
The advent of Artificial Intelligence (AI) and Large Language Models (LLMs) has indeed revolutionized the field of document extraction and processing, among others. These technologies offer powerful solutions to the challenges associated with parsing PDFs and converting them into structured formats like Excel.
How AI and LLMs are Used in Document Extraction and Processing
AI and LLMs can analyze and understand the content of documents, identifying patterns, structures, and relevant information. This capability is crucial for extracting data accurately from diverse PDF formats.
LLMs, in particular, can interpret natural language, making them effective at understanding and extracting meaningful data from unstructured text.
Advantages of Using AI for Document Processing:
Accuracy: AI-driven tools can achieve high levels of accuracy in data extraction, reducing the risk of errors compared to manual processes.
Efficiency: AI automates the extraction process, significantly reducing the time required to process large volumes of documents.
Scalability: AI solutions can handle vast amounts of data, making them suitable for enterprise-level applications.
Consistency: AI ensures consistent extraction results, regardless of the variability in document formats and structures.
Introduction to LLMWhisperer
LLMWhisperer is a general-purpose OCR and text parsing tool designed to prepare documents for further processing. It is not powered by AI or LLMs but serves as a crucial pre-processing step.
Pre-processing is essential for ensuring that the text and data within PDFs are accurately recognized and structured. This step lays the foundation for effective data extraction.
LLMWhisperer uses advanced OCR technology to convert scanned images into text. It can handle various document formats and layouts, making it a versatile tool for parsing PDFs.
By accurately recognizing and structuring the text, LLMWhisperer prepares the document for further processing with tools like Unstract.
Live coding session on data extraction from a scanned PDF form with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in scanned PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
Introducing Unstract for Document Processing
Unstract is a sophisticated document processing tool that leverages LLMs to extract structured data from PDFs. It is designed to handle the complexities of unstructured data and convert it into a usable format.
Unstract employs LLMs to analyze the text and data extracted by LLMWhisperer. These models can understand the context and structure of the document, enabling accurate data extraction.
The extracted data can be converted into JSON format, which is a structured and easily manageable format for further analysis and integration.
Brief Introduction to Unstract and Its Capabilities:
Data Extraction: Accurately extracts data from various types of documents, including tables, forms, and unstructured text.
Structuring Unstructured Data: Converts unstructured data into structured formats like JSON, making it easier to analyze and manage.
Integration: Can be integrated with other tools and platforms for seamless data flow and analysis.
Scalability: Designed to handle large volumes of documents, making it suitable for enterprise-level applications.
By combining the strengths of LLMWhisperer for pre-processing and OCR with Unstract for structured data extraction, organizations can achieve efficient, accurate, and scalable PDF-to-Excel conversions.
Steps for Unstract to extract PDF to JSON
Before you start extracting data from PDF documents using Unstract, it’s necessary to set up the desired tools and accounts.
First, visit the Unstract website and create an account. The registration process is simple and grants you access to the platform’s features, including the Prompt Studio and LLMWhisperer tools.
You have two options for using Unstract: you can utilize the Unstract cloud platform (with Prompt Studio), which we will explore in this article, or opt to use LLMWhisperer independently.
When you first sign up, you will receive a 14-day trial that includes $10 in LLM tokens, allowing you to start using the account immediately:
You are now ready to start exploring the Unstract cloud platform. By default, you will land on the Prompt Studio page.If you run out of credits or wish to add your own LLM, embeddings, vector database, or text extractor providers, you can use the various options available in the SETTINGS menu.
Configuring OpenAI LLM
If you want to connect your OpenAI account, you can do so by providing your API key. Navigate to SETTINGS → LLMs.
From here, choose ‘+ New LLM Profile’ and then OpenAI. Input the necessary OpenAI API key and your desired configuration:
Embeddings
To add your own embedding provider, go to SETTINGS → Embedding. From there, you can add a new embedding provider by selecting ‘+ New Embedding Profile’:
Vector Database
To add your vector database provider, navigate to SETTINGS → Vector DBs. Then, add your vector database provider by selecting ‘+ New Vector DB Profile’:
Text Extractor
To add your own text extractor, go to SETTINGS → Text Extractor. Here, you can add a new text extractor by selecting ‘+ New Text Extractor’:
Preparing Data for LLMs
A key component of Unstract’s technology is LLMWhisperer, a general-purpose Optical Character Recognition (OCR) tool designed to pre-process documents for consumption by Large Language Models (LLMs).
LLMWhisperer functions as an efficient OCR engine that converts various document formats into machine-readable text. Although it is not powered by AI or LLMs itself, it is engineered to accurately extract text from unstructured documents, preparing them for advanced processing.
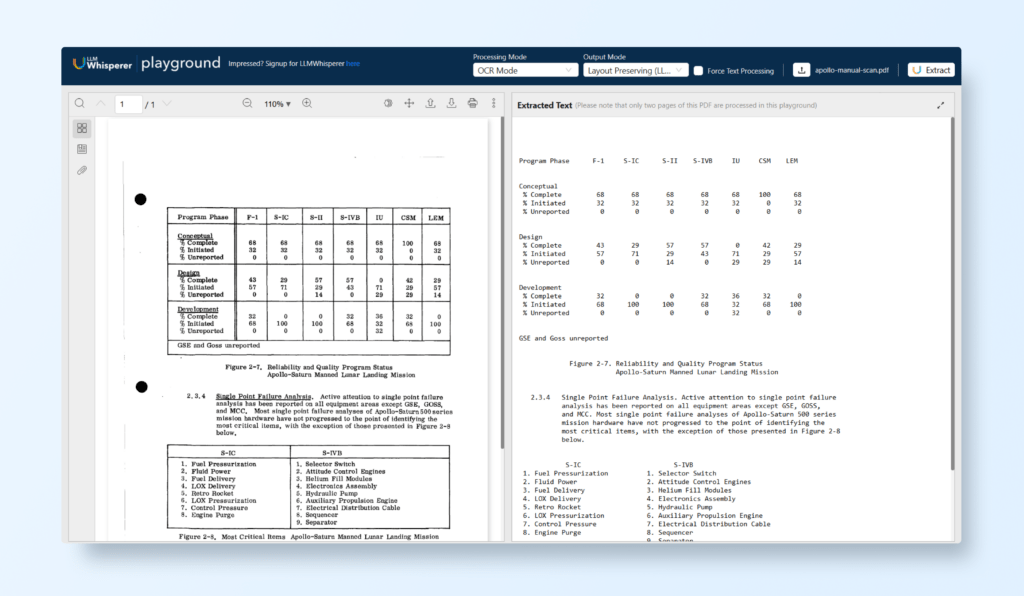
Before LLMs can analyze a document, the textual content must be clean and well-structured. Let’s explore an example from the LLMWhisperer Playground:
LLMWhisperer employs proprietary OCR techniques to accurately capture text from documents, ensuring that all relevant text is extracted and correctly formatted. This process removes noise and irrelevant data that could otherwise hinder the performance of LLMs, as demonstrated in the example.
Setting Up a Prompt Studio Project
Prompt Studio is the central feature within Unstract that empowers users to create, test, and refine prompts for extracting structured data from unstructured documents like PDFs.
It serves as an interactive environment where you can tailor prompts to meet specific data extraction needs, ensuring high accuracy and efficiency in the parsing process.
Features and Benefits:
Integration with LLMWhisperer: Prompt Studio works seamlessly with LLMWhisperer, Unstract’s OCR tool, ensuring that pre-processed data is optimally prepared for extraction.
Customization: It allows for the creation of highly customized prompts that can adapt to various resume formats and designs.
Efficiency: By enabling prompt testing and refinement within the studio, it reduces the time spent on trial and error during the extraction process.
Scalability: Once a prompt is perfected, it can be applied to numerous PDFs without further adjustments, thanks to Unstract’s adaptability.
User-Friendly Interface: Prompt Studio offers an intuitive platform that doesn’t require advanced technical skills, making it accessible to a wide range of users.
Writing Effective Prompts:
Crafting effective prompts is crucial for accurately extracting the desired information from PDFs or any other unstructured data source.
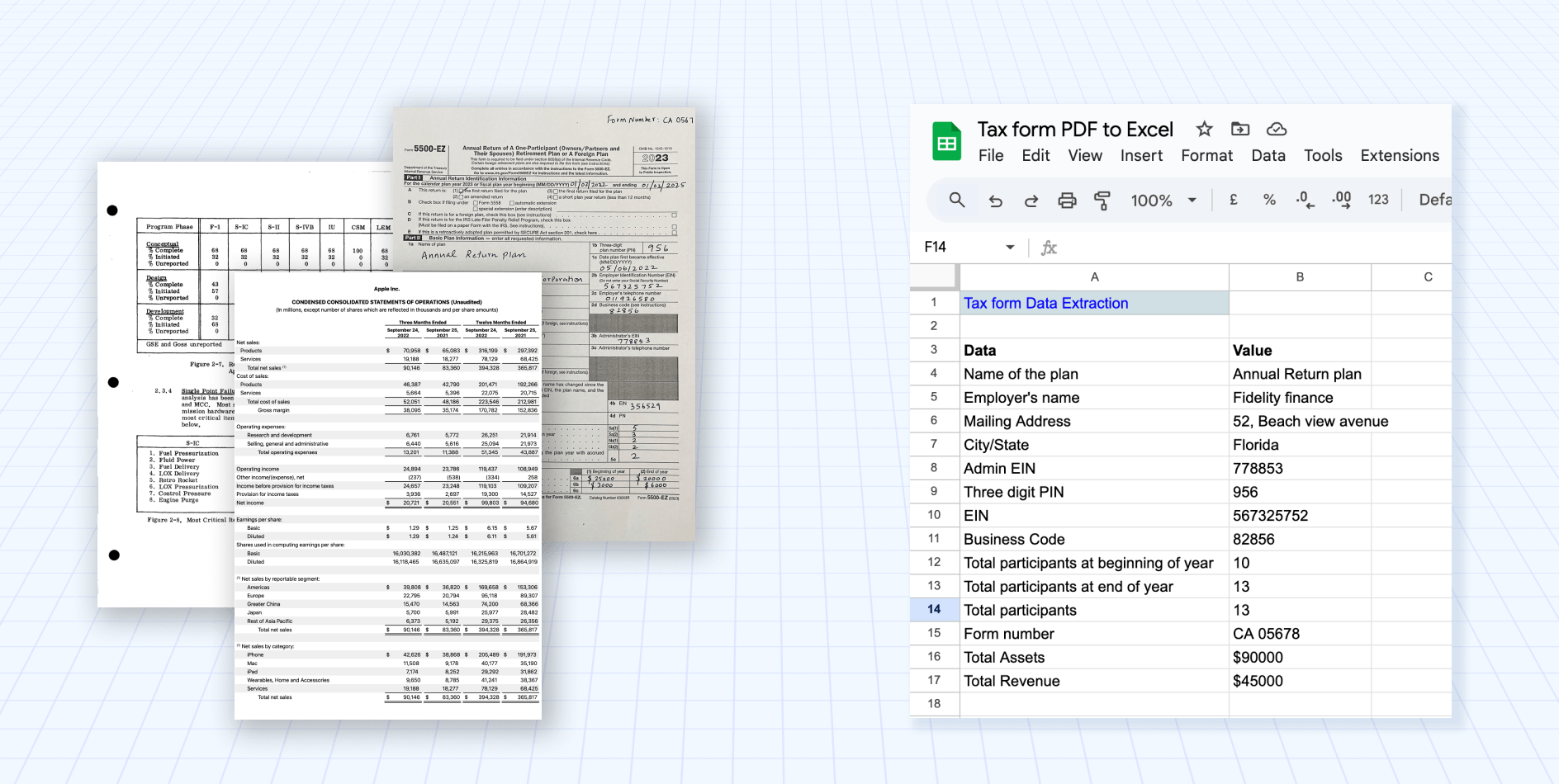
The PDF document we will use for this example is: IRS-tax-form.pdf
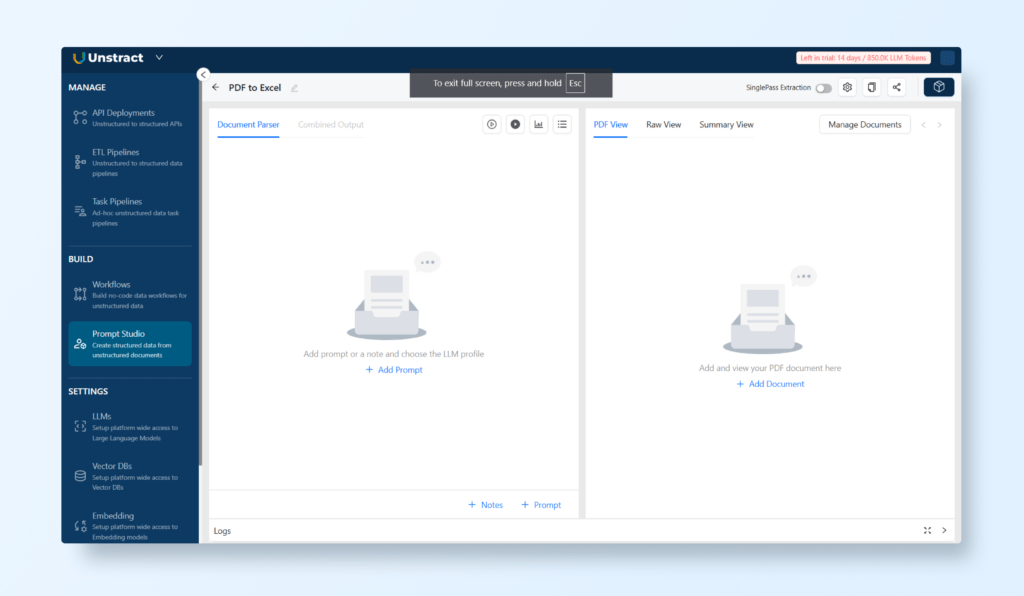
To begin, navigate to SETTINGS → Prompt Studio and create a new project by selecting ‘+ New Project’. Once the project is created, you can start crafting prompts and uploading documents:
First, we upload a new document with ‘+ Add Document’.
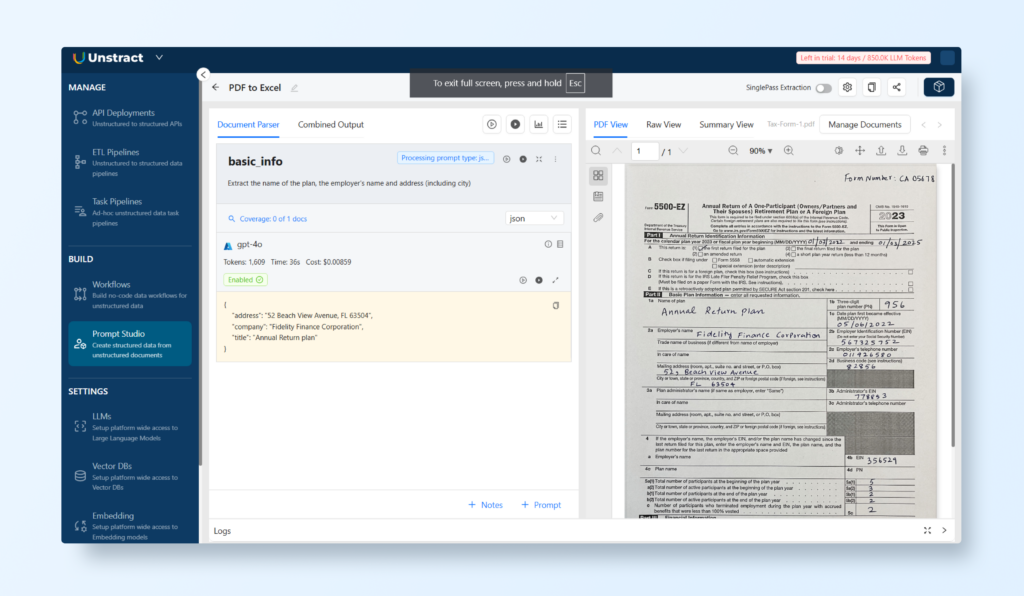
Now let’s take a look at how to craft a prompt to extract the basic information from a tax form:
Here we added a new prompt with the name basic_info. The prompt used was:
Extract the name of the plan, the employer's name and address (including city)
Since we will be exporting this information as a JSON (notice the type defined), the name will also be the key name for this block of information in the JSON.
We can test the prompt by using the run button and we get the following results:
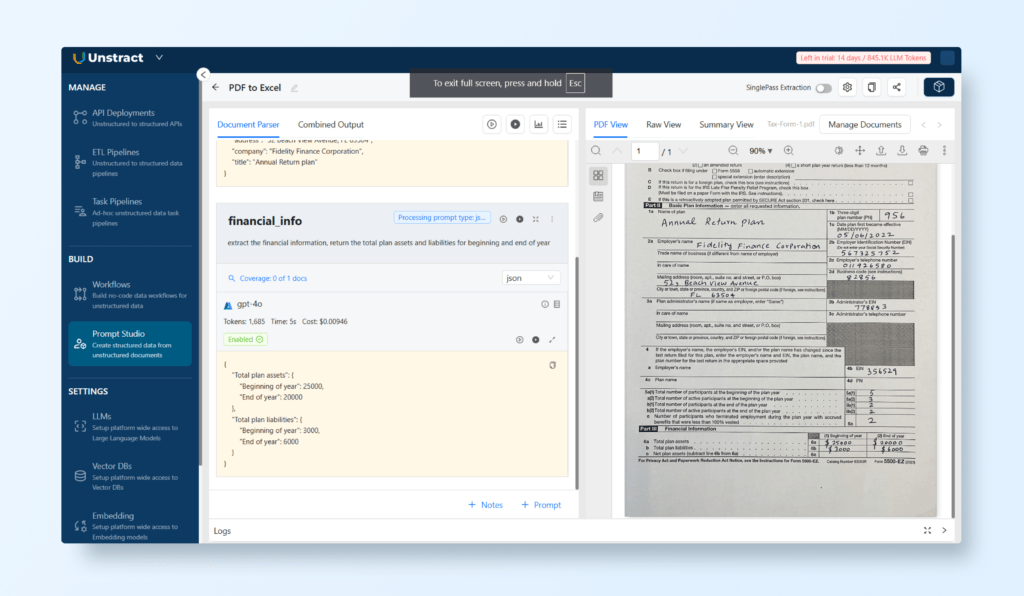
We can add more prompts to extract the desired information from other sections of the tax form. For instance for financial_info:
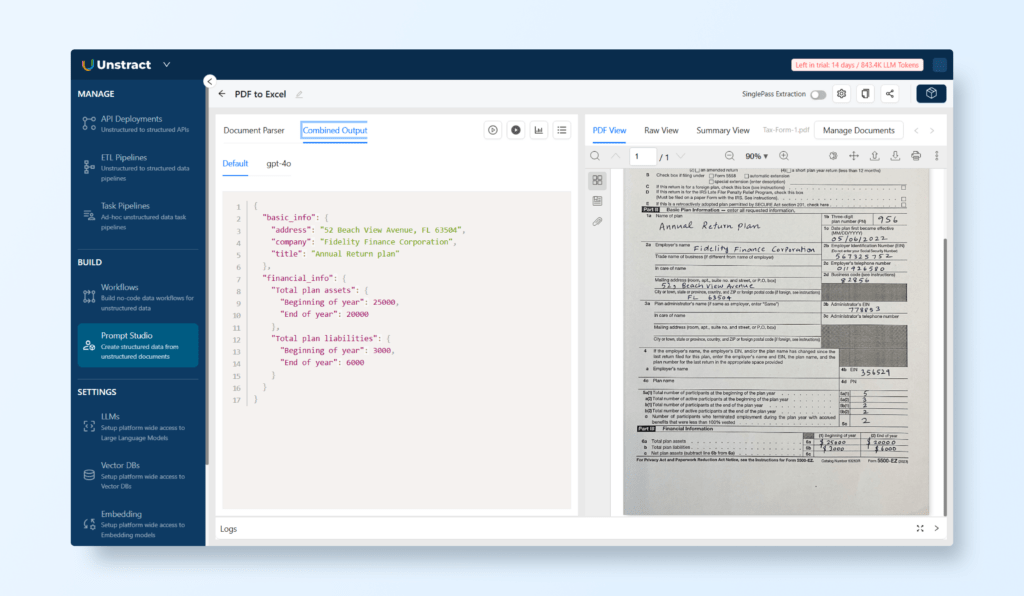
All these prompts work together to extract all the desired information from the document. We can see the combined output in one tab:
For crafting the best prompts, make sure to be clear on the intended output and also make sure to export the information as JSON (when more than one field would be returned from the prompt).
Deploying as an API
After setting up your Prompt Studio project and perfecting your prompts for accurate data extraction, the next logical step is to deploy your Unstract solution as an API.
Creating a Tool
Begin by defining the existing project as a tool to be used in a workflow.
In the Prompt Studio project, click the ‘Export as tool’ icon in the top right corner. This action will create a usable tool from your project.
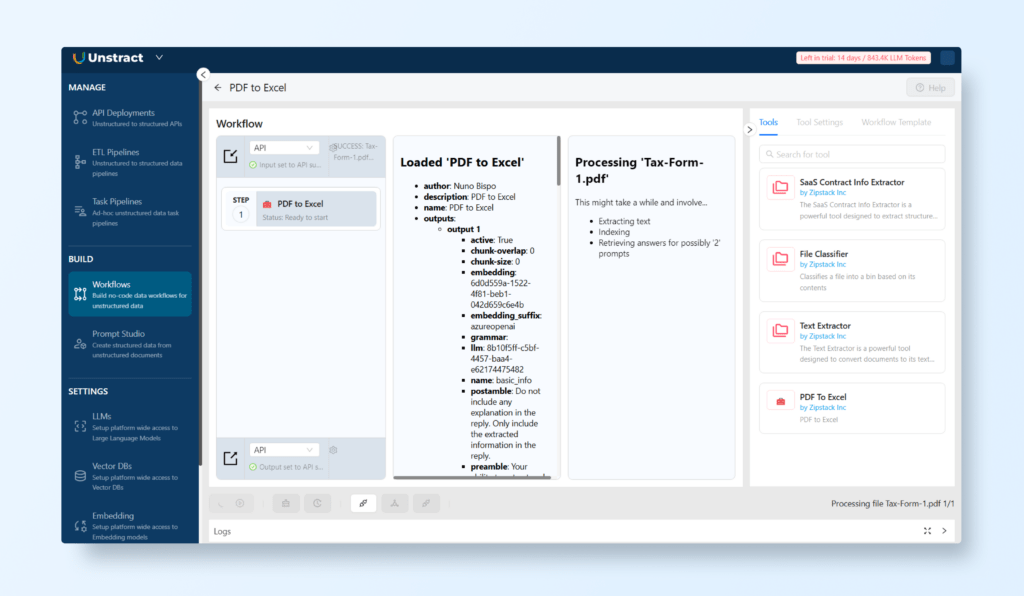
Creating a Workflow
The next step is to create a new workflow.
Navigate to BUILD → Workflows.
Click on ‘+ New Workflow’ to add a new workflow.
In the Tools section on the right-hand side, find the tool created from your project (e.g., ‘PDF to Excel’) and drag and drop it into the workflow settings on the left-hand side.
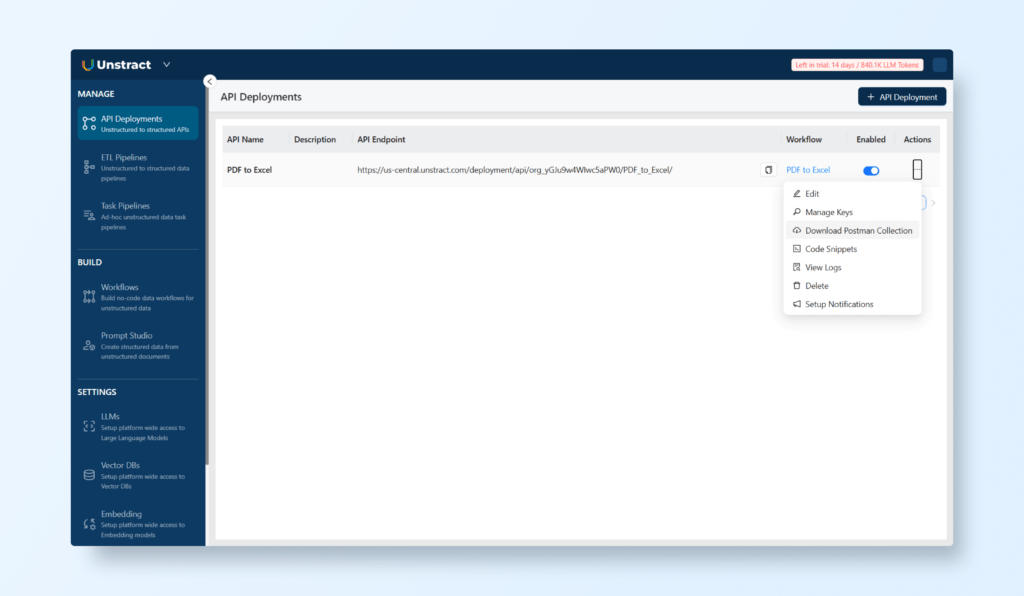
Creating an API
Now, you can create an API from the newly created workflow.
Navigate to MANAGE → API Deployments.
Click the ‘+ API Deployment’ button to create a new API deployment.
Once the API is created, you can use the Actions links to manage various aspects of the API. For instance, you can manage API keys or download a Postman collection for testing.
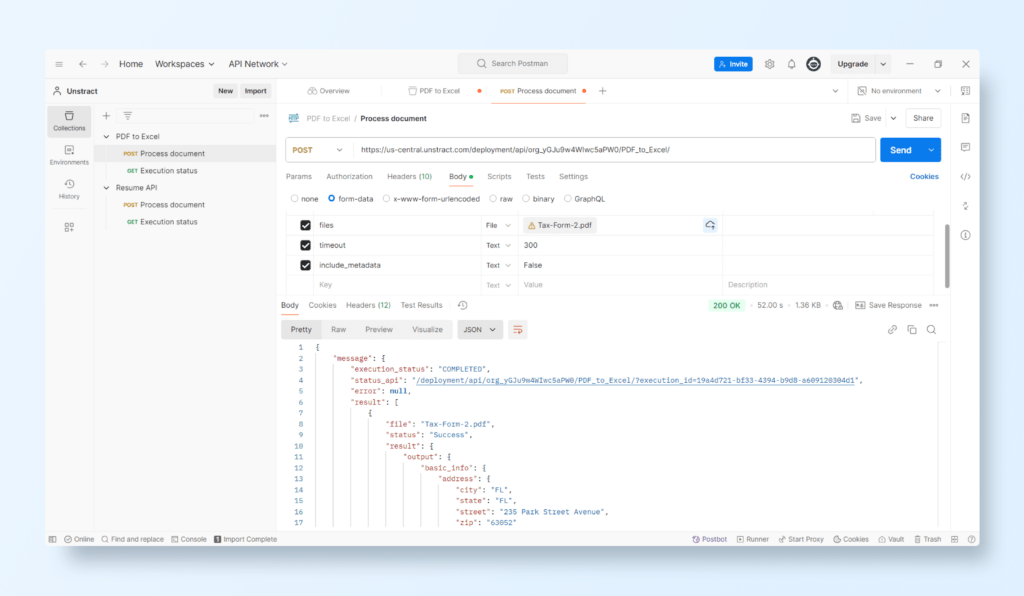
Testing with Postman
After deploying your Unstract parsing workflow as an API, it’s crucial to test it to ensure it functions correctly and accurately extracts data from resumes.
Postman is a widely used API development and testing tool that allows you to send requests to your API and inspect the responses.
Here’s how you can use Postman to test your Unstract API:
Create a new workspace and import the Postman collection you downloaded previously.
Set the API authentication using an API key with the type ‘Bearer Token’.
Converting JSON data into Excel format is a common requirement for data analysis and reporting.
Python provides powerful libraries that make this conversion straightforward and efficient.
Below, we’ll walk you through the steps to convert JSON data into an Excel file using Python by building a command line application (with Click) that can process a PDF and return a JSON or XLSX file.
Installing the necessary libraries
First, we start by installing the necessary libraries. Since we will build the command line application with Click, that is one of the requirements, the others are related to processing data:
We define the API Key to the Unstract’s API that we deployed previously with a .env file:
UNSTRACT_API_KEY=<YOUR_UNSTRACT_API_KEY>
Now we can write the command line application, in the file main.py:
import requests
from decouple import config
import click
import json
import pandas as pd
import os
# Process the PDF file using the Unstract API and return the output in JSON format
def process_pdf(file):
# Get the API key from the environment variables
api_key = config('UNSTRACT_API_KEY')
# API endpoint
api_url = '<https://us-central.unstract.com/deployment/api/org_yGJu9w4WIwc5aPW0/PDF_to_Excel/>'
# Headers and payload
headers = {
'Authorization': f'Bearer {api_key}',
}
payload = {'timeout': 300, 'include_metadata': False}
# Files
files = [('files', ('file', open(file, 'rb'), 'application/octet-stream'))]
# Send the request
response = requests.request("POST", api_url, headers=headers, data=payload, files=files)
# Return the response
return response.json()['message']['result'][0]['result']['output']
# Flatten the JSON data
def flatten_json(data):
# Output dictionary
out = {}
# Function to flatten the JSON data
def flatten(x, name=''):
if type(x) is dict:
for a in x:
flatten(x[a], name + a + '_')
elif type(x) is list:
i = 0
for a in x:
flatten(a, name + str(i) + '_')
i += 1
else:
out[name[:-1]] = x
# Call the function to flatten the data and return the output
flatten(data)
return out
# Define a Click command to process the PDF file
@click.command()
@click.argument('input_file', type=click.Path(exists=True))
@click.option('--output', '-o', type=click.Path(), help='Output filename.')
@click.option('--file_format', '-f', type=click.Choice(['json', 'xlsx']), default='json', help='Output format (json or xlsx).')
def process_file(input_file, output, file_format):
# If the output filename is not provided, use the input filename with the specified format
if not output:
output = os.path.splitext(input_file)[0] + f'.{file_format}'
# Process the PDF file
data = process_pdf(input_file)
# Write the output to a file in the specified format
if file_format == 'json':
write_json(data, output)
elif file_format == 'xlsx':
write_xlsx(data, output)
click.echo(f'File processed successfully. Output saved to {output}')
def write_json(data, output):
"""Write the data to a JSON file."""
with open(output, 'w') as file:
json.dump(data, file, indent=4)
def write_xlsx(data, output):
"""Write the data to a XLSX file."""
flattened_data = flatten_json(data)
df = pd.DataFrame([flattened_data])
df.to_excel(output, index=False)
if __name__ == '__main__':
process_file()
This Python script is designed to process PDF files using the Unstract API and convert the extracted data into either JSON or XLSX format.
The process_pdf function sends a PDF file to the Unstract API and retrieves the extracted data in JSON format. This function uses the API key stored in the environment variables to authenticate the request.
The flatten_json function is responsible for converting nested JSON data into a flat structure, making it easier to convert into a tabular format like XLSX.
The process_file function is the main command-line interface that takes an input PDF file, processes it, and writes the output to a specified file in either JSON or XLSX format. This function uses the click library to handle command-line arguments and options.
Additionally, the script includes helper functions write_json and write_xlsx to handle writing the data to JSON and XLSX files, respectively.
The write_xlsx function utilizes the flatten_json function to ensure that the JSON data is properly flattened before being converted into a DataFrame and written to a XLSX file.
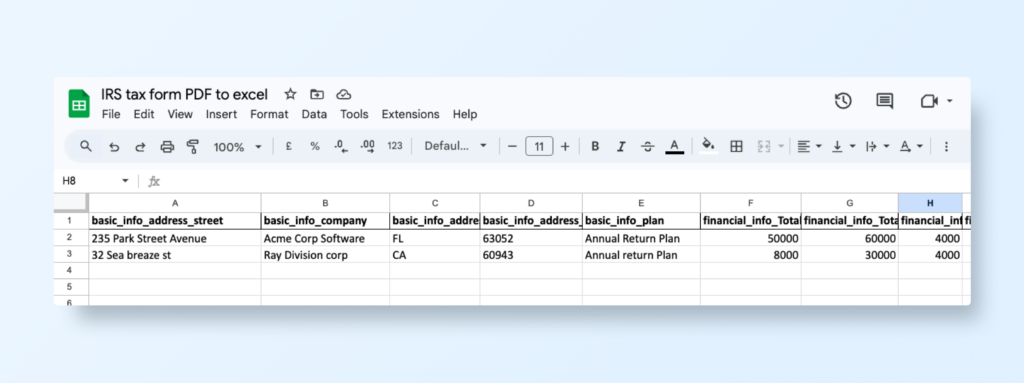
Let’s see the outputs, using this file as an example: IRS-Tax-Form.pdf
The script is executed as a command-line application, allowing users to specify the input PDF file, output file name, and desired output format via command-line arguments:
In this article, we explored a comprehensive solution for converting PDFs to Excel using Python, leveraging the powerful capabilities of LLMWhisperer for OCR and text parsing, and Unstract for structured data extraction with LLMs.
This approach not only simplifies but also automates the PDF-to-Excel workflow, making it more efficient and accurate.
By integrating LLMWhisperer and Unstract, the process of extracting data from PDFs and converting it into structured formats like Excel becomes more streamlined. This solution eliminates the need for manual data entry, reducing the risk of errors and significantly saving time.
The automated workflow ensures consistency and scalability, making it suitable for handling large volumes of documents.
If you want to take it for a test drive LLMWhisperer quickly, you can check out our free playground.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
What is the best way to convert a scanned PDF to Excel? The most effective method for PDF to Excel conversion of scanned documents is a two-step process. First, use an advanced OCR tool like LLMWhisperer to extract text from the scanned image. Then, leverage a no-code LLM platform like Unstract to understand, structure, and output the parsed data into a format like JSON, which can easily be converted to Excel.
Can I convert PDF to Excel in bulk and serve the results from an API? Yes. After refining your prompts, you can export the project as a “Tool,” wrap it in an Unstract Workflow, and then deploy it as an API. The API accepts multiple PDFs and returns structured JSON that can be instantly converted to Excel files by writing custom Python scripts.
What is the final step to convert the extracted JSON data to Excel? The final step to convert PDF to Excel is to transform the structured JSON output from Unstract into an Excel (.xlsx) file. This can be done using a Python script with libraries like pandas and openpyxl. The script flattens the nested JSON structure into a tabular format and writes it directly to an Excel spreadsheet, completing the PDF to Excel data extraction pipeline.
Why should I use AI for PDF to Excel data extraction instead of manual methods? Using LLMs for PDF to Excel data extraction offers significant advantages over manual processes. It provides greater accuracy, higher efficiency by automating the task, and superior scalability to handle large volumes of documents. It also ensures consistency in extraction, overcoming the challenges of variable PDF formats and layouts that make manual extraction time-consuming and error-prone.
What role does LLMWhisperer play in the overall PDF to Excel pipeline? LLMWhisperer is the pre-processing layer. It performs OCR, removes noise, and structures raw text so that Unstract’s LLMs can focus purely on PDF to Excel data extraction logic—dramatically boosting accuracy for complex layouts.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.