Evaluating Python Libraries for Converting PDF to Text — A 2026 Comparison and Evaluation Guide
Table of Contents
Introduction to PDF to text parsing
In the era of Large Language Models (LLMs), extracting accurate text from PDFs remains a surprisingly complex challenge. Whether you’re processing financial reports, analyzing legal documents, or automating form data extraction, the journey from PDF to usable text is often full of unexpected challenges, especially for LLM applications.
Consider these common scenarios:
A financial analyst needs to extract EBITDA tables from hundreds of 10-K reports
A legal team must process thousands of scanned contracts
A healthcare provider wants to automate insurance form processing
A research team needs to analyze text from academic PDFs
While PDFs excel at preserving document formatting across different platforms, this same feature makes them notoriously difficult to parse programmatically. The challenges multiply when dealing with complex table structures, multi-column layouts, scanned documents requiring OCR, form fields and annotations, and mixed content types including text, tables, and images.
Python offers several libraries for PDF text extraction, each with its own strengths and limitations. In this article, we’ll conduct an in-depth comparison of the two most popular tools: PyPDF, and PyMuPDF. We’ll evaluate these tools against real-world documents including Uber’s 10-K report (complex tables and formatting), IRS tax forms (structured form fields), and scanned invoices (OCR capabilities).
Finally, we’ll introduce LLMWhisperer, a modern solution designed specifically for preparing PDF data for LLM applications. We’ll see how it addresses common extraction challenges and compares with traditional tools.
LLMWhisperer: A modern, more advanced PDF-to-text parser built for LLMs.
By the end of this article, you’ll understand:
The strengths and limitations of each PDF extraction tool
How to implement each solution with practical code examples
Why traditional extraction methods might fall short for LLM applications
How modern tools like LLMWhisperer are changing the PDF extraction landscape
Here is the GitHub repository where you will find all the codes written for this article.
Now, let’s dive straight into the world of PDF text extraction and discover the right tool for your needs.
Python Libraries for PDF to Text Extraction
Several Python libraries have emerged to tackle PDF text extraction, each with its unique approach:
PyPDF is one of the oldest and most widely used PDF libraries in Python. It’s primarily designed for PDF file manipulations but also offers text extraction capabilities. While it’s lightweight and easy to start with, it often requires additional libraries for complex tasks like OCR or table extraction.
PyMuPDF is a more comprehensive solution that provides high-speed text extraction along with advanced features like table detection and OCR support. It is particularly good at handling complex layouts and preserving document structure.
LLMWhisperer is a cloud-based document processing API designed specifically for LLM applications. It combines advanced OCR, layout analysis, and text extraction capabilities in a simple API. Unlike traditional libraries that focus solely on text extraction, it processes documents to preserve structural context and relationships that LLMs need to understand the content effectively. The V2 version particularly excels at handling complex layouts, tables, and form fields with minimal code setup.
Benchmarking Documents
To provide a meaningful comparison of PDF extraction tools, we’ve selected three distinct types of documents that represent common real-world challenges. Each document type presents unique extraction challenges that will help us thoroughly evaluate the capabilities of different PDF processing tools.
Uber’s 10-K Report: Complex Financial Document
Financial reports like the Uber 10-K represent some of the most challenging documents for text extraction. This document combines sophisticated layouts with precise numerical data that must be extracted accurately.
The report features multiple sections with varying layouts, including dense paragraphs, financial tables, and footnotes. What makes this document particularly challenging is its mix of narrative text and structured financial data, all of which must maintain their relationships and context during extraction.
IRS Tax Form (Form 1098-E): Structured Form Document
The IRS 1098-E form represents a different kind of challenge. While it appears simple at first glance, structured forms like this are deceptively complex for automated extraction. The form combines pre-printed text with fillable fields, checkboxes, and specific positioning requirements.
The real challenge lies in distinguishing between the static form elements and the valuable data contained within the fields while maintaining the logical relationships between different form sections.
Scanned Invoice: Image-Based Document
Our third benchmark document is a scanned invoice, representing the challenges of processing image-based PDFs. Unlike digital PDFs where text is encoded as characters, scanned documents require OCR processing to convert image data into machine-readable text.
The invoice contains various elements including company letterhead, line items in tabular format, and payment details. The quality of extraction depends not only on the tool’s OCR capabilities but also its ability to maintain the document’s logical structure.
Evaluating PyPDF
When it comes to PDF processing in Python, PyPDF stands as one of the most established libraries in the ecosystem. Let’s dive into how it handles our scanned invoice document, combining it with OCR capabilities and LangChain for intelligent data extraction.
PyPDF Installation and Setup
Before we begin, we need to set up our environment with PyPDF and its supporting libraries. PyPDF alone isn’t enough for handling scanned documents – we’ll need additional tools for image processing and OCR:
Also, we will be using OpenAI API, so let’s import the key from the .env file.
import os
from dotenv import load_dotenv
# access the openai api
os.environ['OPENAI_API_KEY']=os.getenv("openai_api_key")
Scanned Invoice
Implementation Overview
First, we will try to extract text from the scanned invoice document. The implementation consists of three main components:
Text Extraction
First, we need to extract text from our scanned invoice. Since we’re dealing with a scanned document, we’ll need to convert the PDF to images and then use OCR:
def extract_text_from_scanned_pdf(pdf_path: str) -> str:
"""Extract text from scanned PDF using PyPDF2 + Tesseract"""
try:
images = pdf2image.convert_from_path(pdf_path)
text = ""
for i, image in enumerate(images):
print(f"Processing page {i+1}...")
text += pytesseract.image_to_string(image)
return text.strip()
except Exception as e:
print(f"Error processing PDF: {str(e)}")
return ""
# Process the invoice
pdf_path = "../raw-docs/scanned-invoice.pdf"
# Extract text
print("Extracting text from PDF...")
extracted_text = extract_text_from_scanned_pdf(pdf_path)
This is how the extracted text looks like:
American Railcorp
N2 78493 Invoice
Issued Due
01 Jan, 2022 07 Jan, 2022
From To
America Rail INC Simon Wilson
123 Godly St. 1234, Bouleward avenue st
Internet, 68493 Miami, 67833
United States United States
Item Cost Qty Total
eee
Travel expenses $2,000 1 $2,000
20% initial fee
Logistics expenses $5,000 1 $5,000
Weekly Rate
eee
Allowance expenses $1000 1 $1000
Weekly Rate
Subtotal $8,000
Discount (20%) $1,400
Total $6,600
Mise costs $1,100
Total $7,700
IBAN ABCD EFGH 0000 0000 0000
This invoice is to be paid by wire transfer only, unless
agreed otherwise and must be pald before the date
due specified above.
Dratins
As we can see it was able to preserve some basic layout but failed to preserve the table structure and column alignments.
Data Extraction with LangChain
Once we have the raw text, we use LangChain and Pydantic models to intelligently parse and structure the invoice data before feeding into the LLM. This is done to have more accurate answers and reduce hallucinations. Please follow the notebook code in the GitHub repository for exact details.
def extract_invoice_data(text: str) -> str:
"""Extract invoice data using LangChain"""
system_template = """You are an expert at extracting invoice information...
[template details]
"""
# LangChain setup and processing
llm = ChatOpenAI(temperature=0)
response = llm.invoke(prompt)
return response.content
# Extract data using LangChain
print("\nExtracting invoice data...")
invoice_data = extract_invoice_data(extracted_text)
Question Answering
With the extracted invoice data, we implement a Q&A system that can answer specific questions about the invoice:
def ask_invoice_question(question: str, parsed_data: dict) -> str:
prompt = f"""Based on the following invoice data:
{json.dumps(parsed_data, indent=2)}
Please answer this question: {question}
"""
llm = ChatOpenAI(temperature=0)
response = llm.invoke(prompt)
return response.content
Putting It All Together
Here’s how we combine these components into a complete workflow with a selected set of questions.
# Process the invoice
pdf_path = "../raw-docs/scanned-invoice.pdf"
# Extract text
print("Extracting text from PDF...")
extracted_text = extract_text_from_scanned_pdf(pdf_path)
# Extract data using LangChain
print("\nExtracting invoice data...")
invoice_data = extract_invoice_data(extracted_text)
try:
# Parse the response
parsed_data = json.loads(invoice_data)
# Save to file
output_file = "../saved-docs/pypdf_invoice_data.json"
with open(output_file, 'w') as f:
json.dump(parsed_data, f, indent=2)
print(f"\nData extracted and saved to {output_file}")
# Print key information
print("\nKey Invoice Details:")
print(f"Invoice Number: {parsed_data['invoice_number']}")
print(f"Total Amount: ${parsed_data['total']}")
print(f"Due Date: {parsed_data['due_date']}")
except Exception as e:
print(f"Error parsing invoice data: {str(e)}")
# Example questions
questions = [
"What is the total amount of this invoice?",
"Who is the sender of this invoice?",
"What items were purchased and what are their quantities?",
"When is the payment due?",
"Was any discount applied to this invoice?"
]
# Ask questions about the extracted data
if parsed_data:
print("\nAnswering Questions about Invoice:")
for question in questions:
print(f"\nQ: {question}")
answer = ask_invoice_question(question, parsed_data)
print(f"A: {answer}")
Here are the outputs:
Extracting text from PDF...
Processing page 1...
Extracting invoice data...
Data extracted and saved to ../saved-docs/pypdf_invoice_data.json
Key Invoice Details:
Invoice Number: N2 78493
Total Amount: $7700
Due Date: 2022-01-07
Answering Questions about Invoice:
Q: What is the total amount of this invoice?
A: The total amount of this invoice is $7700.
Q: Who is the sender of this invoice?
A: The sender of this invoice is "American Railcorp" with the address "123 Godly St., Internet, 68493 Miami, 67833, United States".
Q: What items were purchased and what are their quantities?
A: The items purchased were:
1. Travel expenses - Quantity: 1
2. Logistics expenses - Quantity: 1
3. Allowance expenses - Quantity: 1
Q: When is the payment due?
A: The payment is due on January 7, 2022.
Q: Was any discount applied to this invoice?
A: Yes, a discount of 20% was applied to this invoice. The discount amount was $1400, which was deducted from the subtotal of $8000 to get a total before miscellaneous costs of $6600.
Key Takeaway
As we can see from the responses, we are accurately able to extract specific information from the scanned document. However, the process requires additional packages for OCR and the layout cannot be maintained while extracting text.
IRS Tax Form
Implementation Overview
For the IRS 1098-E form, let’s try to extract specific structured information like recipient details, borrower information, and loan amounts. Our implementation builds upon the previous OCR approach with specialized form processing.
Text Extraction
The text can be extracted using the extract_text_from_scanned_pdf function as done previously for the scanned invoice document. Here is the raw extracted text:
7] CORRECTED (if checked)
RECIPIENT'S/LENDER'S name, street address, city or town, state or
province, country, ZIP or foreign postal code, and telephone number
OMB No. 1545-1576
Simon Williams Student
134, MarketView Avenue 2D ) 24 Loan Interest
Florida Statement
(545) 533-1234 Form 1098-E
RECIPIENT'S TIN BORROWER'S TIN 1 Student loan interest received by lender Copy B
273-43-4323 403-433-433 $ 3200} For Borrower
BORROWER'S name was
This is important tax
Jack Benny information and is being
Street address (including apt. no.)
893, Avenue express street
City or town, state or province, country, and ZIP or foreign postal code
Florida FL
'Account number (see instructions)
89493322
Form 1098-E
(keep for your records)
2 If checked, box 1 does not include loan origination
www.irs.gov/Form1098E
fees and/or capitalized interest for loans made before
September 1, 2004
furnished to the IRS. If
you are required to file a
return, a negligence
penalty or other
sanction may be
imposed on you if the
IRS determines that an
underpayment of tax
results because you
overstated a deduction
for student loan interest.
Department of the Treasury - Internal Revenue Service
This raw extraction demonstrates PyPDF’s limitations with structured forms – while it captures the text content, it fails to preserve the crucial layout elements that make IRS forms easily readable and understandable.
We will extract specific data using LangChain and create a specialized question-answering function.
Putting It All Together
# Process the form
pdf_path = "../raw-docs/IRS-1098e-form.pdf"
try:
# Extract and process form
form_text = extract_1098e_from_pdf(pdf_path)
parsed_data = json.loads(form_text)
# Example questions
questions = [
"What is the recipient's name and phone number?",
"What is the borrower's complete address?",
"What is the recipient's TIN?",
"What is the account number on the form?",
"How much student loan interest was received?",
"What is the borrower's TIN?"
]
# Ask questions about the extracted data
print("\nAnswering Questions about Form 1098-E:")
for question in questions:
answer = ask_1098e_question(question, parsed_data)
print(f"\nQ: {question}")
print(f"A: {answer}")
except Exception as e:
print(f"Error: {str(e)}")
Here are the outputs:
Answering Questions about Form 1098-E:
Q: What is the recipient's name and phone number?
A: The recipient's name is Simon Williams Student and their phone number is (545) 533-1234.
Q: What is the borrower's complete address?
A: The borrower's complete address is 893 Avenue Express Street, Florida, FL, 89493322.
Q: What is the recipient's TIN?
A: The recipient's TIN is 273-43-4323.
Q: What is the account number on the form?
A: The account number on the form is 89493322.
Q: How much student loan interest was received?
A: The amount of student loan interest received was $3,200.
Q: What is the borrower's TIN?
A: The borrower's TIN is 403-433-433.
Key Takeaway
The IRS form extraction demonstrates PyPDF’s ability to handle structured forms when combined with LangChain and Pydantic for intelligent parsing. However, it fails to preserve the crucial layout elements that help an LLM better understand such forms.
Uber 10-K Report
For financial reports with complex tables, we need additional libraries:
pip install tabula-py pandas
Implementation Overview
Our focus for the report would be to try and see if PyPDF is able to extract the EBITDA table and then build a question answering function to ask questions and validate if the responses are accurate.
Table Extraction
First, we use tabula-py to identify and extract tables from the PDF:
def extract_tables_from_pdf(pdf_path: str, pages: str = 'all', guess: bool = True) -> list:
"""Extract tables from PDF using tabula-py"""
try:
tables = tabula.read_pdf(
pdf_path,
pages=pages,
guess=guess,
multiple_tables=True,
pandas_options={'header': None}
)
print(f"Found {len(tables)} tables")
return tables
except Exception as e:
print(f"Error extracting tables: {str(e)}")
return []
def find_ebitda_tables(tables: list) -> list:
"""Find tables that look like EBITDA reconciliations"""
ebitda_tables = []
keywords = ['ebitda', 'earnings', 'reconciliation', 'adjusted']
for i, table in enumerate(tables):
table_str = table.to_string().lower()
if any(keyword in table_str for keyword in keywords):
print(f"Found potential EBITDA table (Table {i+1})")
ebitda_tables.append(table)
return ebitda_tables
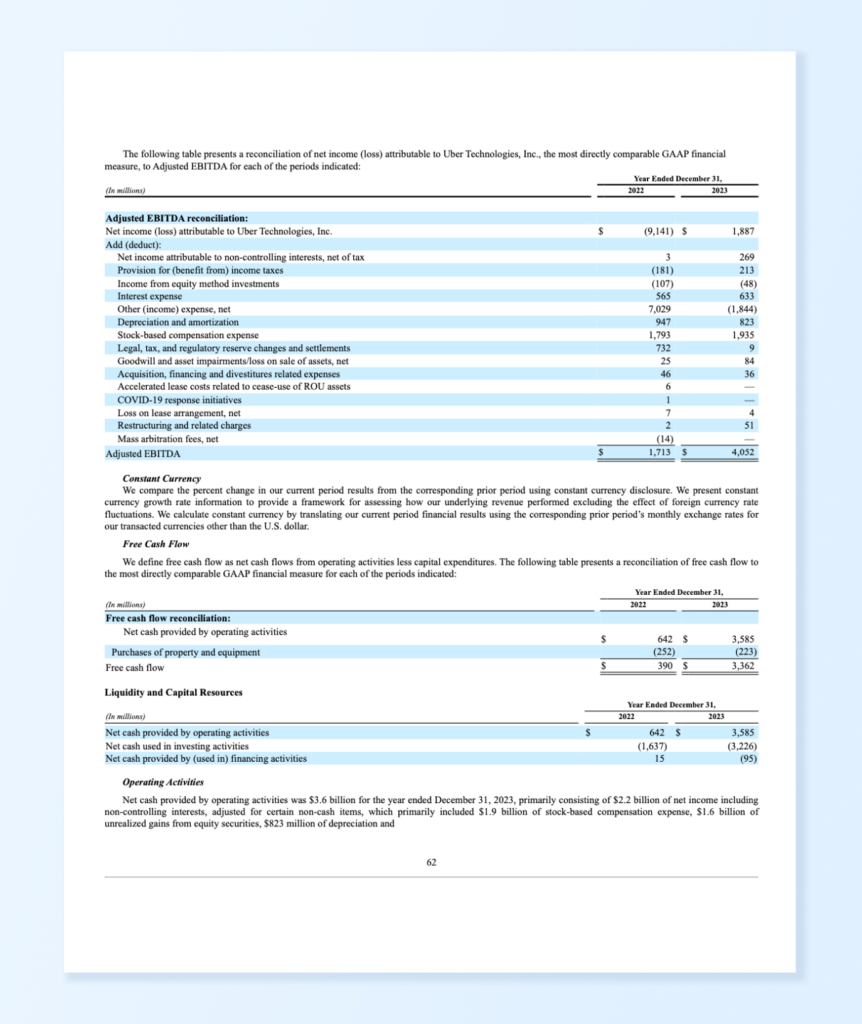
Here is the raw extracted table:
Found 1 tables
[ 0 1 2 3 \
0 (In millions) NaN 2022 NaN
1 Adjusted EBITDA reconciliation: NaN NaN NaN
2 Net income (loss) attributable to Uber Technol... $ (9,141) $
3 Add (deduct): NaN NaN NaN
4 Net income attributable to non-controlling int... NaN 3 NaN
5 Provision for (benefit from) income taxes NaN (181) NaN
6 Income from equity method investments NaN (107) NaN
7 Interest expense NaN 565 NaN
8 Other (income) expense, net NaN 7,029 NaN
9 Depreciation and amortization NaN 947 NaN
10 Stock-based compensation expense NaN 1,793 NaN
11 Legal, tax, and regulatory reserve changes and... NaN 732 NaN
12 Goodwill and asset impairments/loss on sale of... NaN 25 NaN
13 Acquisition, financing and divestitures relate... NaN 46 NaN
14 Accelerated lease costs related to cease-use o... NaN 6 NaN
15 COVID-19 response initiatives NaN 1 NaN
16 Loss on lease arrangement, net NaN 7 NaN
17 Restructuring and related charges NaN 2 NaN
18 Mass arbitration fees, net NaN (14) NaN
19 Adjusted EBITDA $ 1,713 $
4 5
0 2023.0 NaN
1 NaN NaN
2 NaN 1,887
3 NaN NaN
4 NaN 269
5 NaN 213
6 NaN (48)
7 NaN 633
8 NaN (1,844)
9 NaN 823
10 NaN 1,935
11 NaN 9
12 NaN 84
13 NaN 36
14 NaN --
15 NaN --
16 NaN 4
17 NaN 51
18 NaN --
19 NaN 4,052 ]
While the table was found and basic data was extracted, the output would need significant cleaning and restructuring to be useful for an LLM application. This demonstrates PyPDF’s limitations with complex financial tables.
Question Answering
We implement a Q&A system for analyzing the EBITDA data:
def ask_ebitda_question(question: str, parsed_data: dict) -> str:
"""Ask questions about the extracted EBITDA data"""
prompt = f"""Based on the following EBITDA data:
{json.dumps(parsed_data, indent=2)}
Please answer this question: {question}
"""
llm = ChatOpenAI(temperature=0)
response = llm.invoke(prompt)
return response.content
# Example questions and their responses
questions = [
"What was Uber's Adjusted EBITDA in 2023?",
"What was Uber's Adjusted EBITDA in 2022?",
"What was the year-over-year change in Adjusted EBITDA?"
]
for question in questions:
answer = ask_ebitda_question(question, parsed_data)
print(f"\nQ: {question}")
print(f"A: {answer}")
Here are the outputs:
Answering Questions about EBITDA:
Q: What was Uber's Adjusted EBITDA in 2023?
A: Uber's Adjusted EBITDA in 2023 was $4.052 billion.
Q: What was Uber's Adjusted EBITDA in 2022?
A: Uber's Adjusted EBITDA in 2022 was $1.713 billion.
Q: What was the year-over-year change in Adjusted EBITDA?
A: The year-over-year change in Adjusted EBITDA was an increase of $2.339 billion from 2022 to 2023.
Key Takeaway
While PyPDF with tabula-py can detect and extract tables from complex financial documents, it struggles with maintaining proper table structure, creating misaligned columns and formatting issues. This messy data structure, though readable, poses risks when used with LLMs as it could lead to incorrect interpretations or hallucinations, suggesting that additional data cleaning steps might be necessary for reliable analysis.
Conclusion
PyPDF serves as a robust foundation for PDF processing, particularly when enhanced with specialized libraries like Tesseract for OCR and tabula-py for table extraction. While these integrations significantly expand its capabilities, they also introduce additional complexity and dependencies that need to be carefully considered in your implementation strategy.
Evaluating PyMuPDF
When it comes to handling scanned documents, PyMuPDF (also known as fitz) offers a more streamlined approach than PyPDF.
PyMuPDF takes a notably different approach to handling scanned documents. While PyPDF required us to juggle multiple libraries for OCR processing, PyMuPDF provides an integrated solution through its native get_textpage_ocr() function:
def extract_text_with_ocr(pdf_path: str, dpi: int = 300) -> str:
"""Extract text from scanned document using PyMuPDF's OCR"""
doc = fitz.open(pdf_path)
text = ""
tessdata_dir = '/opt/homebrew/Cellar/tesseract/5.4.1_1/share/tessdata'
for page in doc:
tp = page.get_textpage_ocr(
dpi=dpi,
full=True,
tessdata=tessdata_dir
)
text += page.get_text(textpage=tp)
doc.close()
return text
While Tesseract is still required under the hood, PyMuPDF handles the PDF-to-text conversion more elegantly. There’s no need for intermediate image conversion steps – PyMuPDF manages this internally, resulting in cleaner, more maintainable code.
For the rest of our invoice processing pipeline – from structuring the data with LangChain to implementing the Q&A system – we follow the same approach we used with PyPDF. This consistency in the higher-level processing, combined with simpler OCR integration, makes PyMuPDF a more refined tool for handling scanned documents.
Here is the output from our LLM:
Example Questions and Answers:
--------------------------------------------------
Q: What is the total amount of this invoice?
A: The total amount of this invoice is $7700.
Q: Who is the sender of this invoice?
A: The sender of this invoice is "America Rall INC" as indicated in the "From Address" section.
Q: What items are listed in this invoice?
A: The items listed in this invoice are:
1. Travel expenses
2. Logistics expenses
3. Allowance expenses
Q: When is the due date for this invoice?
A: The due date for this invoice is January 7, 2022.
Q: What is the IBAN number for payment?
A: The IBAN number for payment is "ABCD EFGH 0000 0000 0000".
IRS Tax Form
After seeing PyMuPDF’s performance with our scanned invoice, let’s examine how it handles structured tax documents like the IRS Form 1098-E.
Text Extraction
First, let’s see how good the text extraction is using PyMuPDF’s in-built OCR capabilities.
CORRECTED (if checked)
RECIPIENT'S/LENDER'S name, street address, city or town, state or
OMB No. 1545-1576
province, country, ZIP or foreign postal code, and telephone number
a
Student
Simon Williams
134, MarketView Avenue
(r) @)24
Loan Interest
Florida
FL
Statement
(545) 533-1234
Form 1098-E
RECIPIENT'S TIN
BORROWER'S TIN
1 Student loan interest received by lender
Copy B
273-43-4323
403-433-433
$
3200
For Borrower
BORROWER'S name
oo
Jack B
This is important tax
ack
benny
information and is being
furnished to the IRS. If
you are required to file a
f
H
return, a negligence
Street
address (including apt. no.)
penalty or other
893, Avenue express street
sanction may be
.
|
;
imposed on you if the
City or town, state or province, country, and ZIP or foreign postal code
IRS determines that an
Florida FL
underpayment of tax
results because you
Account number (see instructions)
2 If checked, box 1 does not include loan origination
overstated a deduction
89493322
fees and/or capitalized interest for loans made before
for student loan interest.
September 1,2004.
.
.
.
.
....
Form 1098-E
(keep for your records)
www.irs.gov/Form1098E
Department of the Treasury - Internal Revenue Service
Key Observations
While the extracted text is generally readable and contains the necessary information, the loss of form structure and field relationships could pose challenges for automated data processing or when precise field mapping is required.
Uber 10-K Report
Next, let’s see how PyMuPDF performs with perhaps our most challenging test: extracting and analyzing complex financial tables from Uber’s 10-K report.
A Native Approach to Table Detection
PyMuPDF has built-in table detection capabilities, eliminating the need for external libraries like tabula-py:
import fitz
from typing import Dict, List
def extract_pdf_content(pdf_path: str, max_pages: int = None) -> Dict[int, Dict]:
doc = fitz.open(pdf_path)
content = {}
pages_to_process = min(len(doc), max_pages) if max_pages else len(doc)
for page_num in range(pages_to_process):
page = doc[page_num]
tables = page.find_tables()
content[page_num] = {
'text': page.get_text(),
'tables': [table.extract() for table in tables] if tables else []
}
doc.close()
return content
# Usage
content = extract_pdf_content("../raw-docs/uber-10k-report.pdf", max_pages=10) # Process first 10 pages
# Print results in a structured way
for page_num, data in content.items():
print(f"\n=== Page {page_num + 1} ===")
if data['tables']:
print(f"\nFound {len(data['tables'])} tables:")
for i, table in enumerate(data['tables']):
print(f"\nTable {i + 1}:")
for row in table:
print(row)
Let’s see the extracted tables:
=== Page 1 ===
=== Page 2 ===
Found 3 tables:
Table 1:
['Adjusted EBITDA reconciliation:', '', '', None]
['Net income (loss) attributable to Uber Technologies, Inc.', '$ (9,141)', '$', '1,887']
['Add (deduct):', '', '', None]
['Net income attributable to non-controlling interests, net of tax', '3', '269', None]
['Provision for (benefit from) income taxes', '(181)', '213', None]
['Income from equity method investments', '(107)', '(48)', None]
['Interest expense', '565', '633', None]
['Other (income) expense, net', '7,029', '(1,844)', None]
['Depreciation and amortization', '947', '823', None]
['Stock-based compensation expense', '1,793', '1,935', None]
['Legal, tax, and regulatory reserve changes and settlements', '732', '9', None]
['Goodwill and asset impairments/loss on sale of assets, net', '25', '84', None]
['Acquisition, financing and divestitures related expenses', '46', '36', None]
['Accelerated lease costs related to cease-use of ROU assets', '6', '--', None]
['COVID-19 response initiatives', '1', '--', None]
['Loss on lease arrangement, net', '7', '4', None]
['Restructuring and related charges', '2', '51', None]
['Mass arbitration fees, net', '(14)', '--', None]
['Adjusted EBITDA', '$ 1,713', '$', '4,052']
Table 2:
['(In millions) 2022', None, '2023', None]
['Free cash flow reconciliation:', '', '', None]
['Net cash provided by operating activities', '$ 642', '$', '3,585']
['Purchases of property and equipment', '(252)', '(223)', None]
['Free cash flow', '$ 390', '$', '3,362']
Table 3:
['Net cash provided by operating activities', '', '$', '642', '', '$ 3,585']
['Net cash used in investing activities', '', '(1,637)', None, '', '(3,226)']
['Net cash provided by (used in) financing activities', '', '15', None, '', '(95)']
Key Observations
PyMuPDF’s direct table extraction approach is better than PyPDF as it relies on external libraries like tabula-py. As you can see, all three tables were found while maintaining the structure, table boundaries, and numerical values. However, there are still inconsistencies in column handling between tables as well as empty cell representation (None vs ‘’).
Final Verdict
After putting PyMuPDF through its paces with three distinct document types – from a basic scanned invoice to complex financial tables in Uber’s 10-K report – it’s clear that this library offers a more integrated approach to PDF processing. While it still requires Tesseract for OCR tasks, PyMuPDF’s native table detection makes it a more robust solution than PyPDF.
LLMWhisperer: A New Approach to Document Processing
Traditional PDF processing libraries like PyPDF and PyMuPDF offer robust tools for text extraction and manipulation. However, LLMWhisperer introduces an innovative approach that leverages advanced AI capabilities from the ground up. It can extract text from text-based PDFs, perform OCR on image-based PDFs, and even extract text in a layout-preserving mode from any PDF, whether text-based or otherwise.
What Makes LLMWhisperer Different?
Unlike traditional PDF libraries that focus on text extraction first and interpretation second, LLMWhisperer takes an AI-first approach. It’s designed to understand documents the way humans do, combining OCR, layout analysis, and semantic understanding in a single integrated process.
This enables it to handle complex tables and difficult layouts with ease, making complex document data ready for large language models (LLMs) to understand and consume.
Setting Up LLMWhisperer
The setup is remarkably straightforward. First, we will install the LLMWhisperer library using pip:
pip install llmwhisperer-client
Then, we will need an API key to set up the python client which can be obtained by signing up for any of their plans. I obtained an API for their version 2 which is their latest model.
from unstract.llmwhisperer import LLMWhispererClientV2
import os
client = LLMWhispererClientV2(api_key=UNSTRACT_API_KEY)
Scanned Invoice
Let’s try to extract text from the scanned invoice document. For this, we will call the whisper method as shown by:
Notice how the process eliminates the need for setting up separate OCR engines, handling image conversions, or managing multiple library dependencies as we did for both PyPDF and PyMuPDF. This streamlined approach simplifies the workflow, allowing you to focus on extracting insights rather than managing complex integrations.
Here is the extracted text:
O=O American Railcorp
Nº 78493 Invoice
URGENT
Issued Due
01 Jan, 2022 07 Jan, 2022
From To
America Rall INC Simon Wilson
123 Godly St. 1234, Bouleward avenue st
Internet, 68493 Miami, 67833
United States United States
Item Cost Qty Total
Travel expenses $2,000 1 $2,000
20% initial fee
Logistics expenses $5,000 1 $5,000
Weekly Rate
Allowance expenses $1000 1 $1000
Weekly Rate
Subtotal $8,000
Discount (20%) $1,400
Total $6,600
Misc costs $1,100
Total $7,700
IBAN ABCD EFGH 0000 0000 0000
This invoice is to be paid by wire transfer only, unless
agreed otherwise and must be paid before the date
due specified above.
Thank you,
Deakins
<<<
As you can clearly see from the extracted text that using LLMWhisperer we are able to maintain the exact document layout while preserving formatting without artifacts.
This is in stark contrast to PyPDF and PyMuPDF, which struggled with random character artifacts, misaligned columns, and lost table structures. While both libraries successfully extracted the basic text content, they failed to maintain the document’s spatial relationships and formatting integrity that LLMWhisperer has achieved.
IRS Tax Form
Next, let’s examine how it handles the structured complexity of IRS Form 1098-E. We will set up the client the same way as before but now with the path pointing to the IRS form. There is no additional setup required, moving from one document to another.
[X] CORRECTED (if checked)
RECIPIENT'S/LENDER'S name, street address, city or town, state or OMB No. 1545-1576
province, country, ZIP or foreign postal code, and telephone number
Student
Simon Williams
134, MarketView Avenue 2024 Loan Interest
Florida
Statement
FL
(545) 533-1234 Form 1098-E
RECIPIENT'S TIN BORROWER'S TIN 1 Student loan interest received by lender Copy B
273-43-4323 403-433-433 $ 3200 For Borrower
BORROWER'S name
This is important tax
Jack Benny information and is being
furnished to the IRS. If
you are required to file a
Street address (including apt. no.) return, a negligence
penalty or other
893, Avenue express street sanction may be
imposed on you if the
City or town, state or province, country, and ZIP or foreign postal code IRS determines that an
Florida FL underpayment of tax
results because you
Account number (see instructions) 2 If checked, box 1 does not include loan origination overstated a deduction
fees and/or capitalized interest for loans made before for student loan interest.
89493322 September 1, 2004 [X]
Form 1098-E (keep for your records) www.irs.gov/Form1098E Department of the Treasury - Internal Revenue Service
<<<
Unlike PyPDF and PyMuPDF, which require separate OCR setup and form field detection, LLM Whisperer handles everything in a single API call. This isn’t just about fewer lines of code – it’s about a fundamentally different approach to form understanding.
Uber 10-K Report
Let’s now check how well tables can be extracted from the 10-K report:
<<<
The following table presents a reconciliation of net income (loss) attributable to Uber Technologies, Inc., the most directly comparable GAAP financial
measure, to Adjusted EBITDA for each of the periods indicated:
Year Ended December 31,
(In millions) 2022 2023
Adjusted EBITDA reconciliation:
Net income (loss) attributable to Uber Technologies, Inc. $ (9,141) $ 1,887
Add (deduct):
Net income attributable to non-controlling interests, net of tax 3 269
Provision for (benefit from) income taxes (181) 213
Income from equity method investments (107) (48)
Interest expense 565 633
Other (income) expense, net 7,029 (1,844)
Depreciation and amortization 947 823
Stock-based compensation expense 1,793 1,935
Legal, tax, and regulatory reserve changes and settlements 732 9
Goodwill and asset impairments/loss on sale of assets, net 25 84
Acquisition, financing and divestitures related expenses 46 36
Accelerated lease costs related to cease-use of ROU assets 6
COVID-19 response initiatives 1
Loss on lease arrangement, net 7 4
Restructuring and related charges 2 51
Mass arbitration fees, net (14)
Adjusted EBITDA $ 1,713 $ 4,052
LLMWhisperer demonstrates exceptional capability in handling complex financial tables from the 10-K report, maintaining precise column alignments, dollar sign placements, and hierarchical indentation that are crucial for financial data interpretation.
Unlike PyPDF and PyMuPDF, which struggled with misaligned columns and inconsistent formatting, LLMWhisperer preserves the exact visual structure of the EBITDA reconciliation table, making it significantly more readable and reliable for financial analysis. This accurate preservation of both content and format eliminates the need for extensive post-processing that would be required with the other libraries’ outputs.
Live coding session on data extraction from a scanned PDF form with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in scanned PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
Learn how faithfully reproducing the structure of tables and other elements by preserving the original PDF layout is crucial for better performance in LLM and RAG applications.
Our comparative analysis of PyPDF, PyMuPDF, and LLMWhisperer reveals distinct capabilities in PDF processing. While PyPDF and PyMuPDF require additional libraries for OCR and struggle with maintaining document structure, LLMWhisperer demonstrates superior accuracy in preserving document layouts and table formats.
This is evidenced in our tests with scanned invoices, IRS forms, and complex financial tables from the 10-K report. LLMWhisperer’s consistent performance across different document types, combined with its built-in OCR capabilities, offers a more streamlined approach to document processing, though it comes with the trade-off of less granular control compared to traditional libraries.
We’ve built a simple Gradio app for you to explore. Upload any PDF document, view the extracted text, and seamlessly ask questions about it—all within the app.
Here is how we implemented it:
import gradio as gr
from unstract.llmwhisperer import LLMWhispererClientV2
import os
from dotenv import load_dotenv
from langchain.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.schema import Document
from langchain import hub
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# Load environment variables
load_dotenv()
os.environ['OPENAI_API_KEY']=os.getenv("openai_api_key")
UNSTRACT_API_KEY = os.getenv("unstract_api_key")
BASE_URL = os.getenv("BASE_URL")
client = LLMWhispererClientV2(api_key=UNSTRACT_API_KEY)
# Global variable to store the current document's vector store
current_vectorstore = None
def process_pdf(pdf_path):
try:
# Process PDF with LLM Whisperer
whisper = client.whisper(
file_path=pdf_path.name,
wait_for_completion=True,
wait_timeout=200
)
extracted_text = whisper['extraction']['result_text']
# Create document for vector store
documents = [
Document(
page_content=extracted_text,
metadata={"source": pdf_path.name}
)
]
# Create vector store and store it globally
global current_vectorstore
embeddings = OpenAIEmbeddings()
current_vectorstore = FAISS.from_documents(documents, embeddings)
return extracted_text, "Document processed successfully. You can now ask questions."
except Exception as e:
return "", f"Error processing document: {str(e)}"
def answer_question(question):
try:
if current_vectorstore is None:
return "Please upload a document first."
# Set up QA chain
retriever = current_vectorstore.as_retriever()
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
retrieval_qa_chat_prompt = hub.pull("langchain-ai/retrieval-qa-chat")
combine_docs_chain = create_stuff_documents_chain(llm, retrieval_qa_chat_prompt)
retrieval_chain = create_retrieval_chain(retriever, combine_docs_chain)
# Get answer
response = retrieval_chain.invoke({"input": question})
return response['answer']
except Exception as e:
return f"Error answering question: {str(e)}"
# Create Gradio interface
with gr.Blocks() as demo:
gr.Markdown("# Document Q&A with LLM Whisperer")
gr.Markdown("Upload a PDF document and ask questions about its content.")
with gr.Row():
pdf_input = gr.File(label="Upload PDF", file_types=[".pdf"])
with gr.Row():
extracted_text = gr.Textbox(label="Extracted Text", interactive=False, lines=10)
status_output = gr.Textbox(label="Status", interactive=False)
with gr.Row():
question_input = gr.Textbox(label="Your Question", placeholder="Ask a question about the document...")
answer_output = gr.Textbox(label="Answer", interactive=False)
# Handle PDF upload
pdf_input.upload(
fn=process_pdf,
inputs=[pdf_input],
outputs=[extracted_text, status_output]
)
# Handle question submission
question_btn = gr.Button("Get Answer")
question_btn.click(
fn=answer_question,
inputs=[question_input],
outputs=[answer_output]
)
# Launch the app
demo.launch(server_name="127.0.0.1",
server_port=7860,
share=True)
PDF to Text Extraction: What’s next
LLMWhisperer is a pdf-to-text converter. Prep data from complex unstructured documents for use in Large Language Models. LLMs are powerful, but their output is as good as your input. Documents can be messy: widely varying formats and encodings, scans of images, numbered sections, and complex tables. Extracting data from these documents and blindly feeding them to LLMs is not a good recipe for reliable results. LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they’re able to understand it best.
If you want to quickly take it for test drive, you can checkout our free playground.
Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an Open Source software and is available at https://github.com/Zipstack/unstract.
If you want to quickly try it out, signup for our free trial. More information here.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.