Businesses today handle a constant flow of documents that can range from invoices and contracts to tax forms and compliance reports. Efficiently classifying these documents is essential for streamlined operations, faster retrieval, regulatory compliance, and accurate data analysis. Without a proper system in place, teams can quickly become bogged down by manual sorting, leading to wasted time, missed deadlines, and costly errors.
The challenge becomes even greater when organizations deal with diverse document types at scale. Files can arrive as PDFs, scanned images, or mixed formats, often with inconsistent layouts and varying levels of readability. Traditional rule-based systems and basic OCR pipelines struggle to keep up, especially when documents have complex structures or lack consistent keywords.
While Unstract isn’t directly designed as a dedicated document classification software, it can handle around 80% of the heavy lifting. By combining Unstract’s Prompt Studio for content understanding with LLMWhisperer for OCR preprocessing, businesses can create a powerful classification pipeline that works across broad and granular categories, integrates seamlessly via API, and feeds into automated folder sorting workflows.
In this article, we’ll walk through a practical approach to AI-powered document classification using:
Unstract’s Prompt Studio to identify document types.
LLMWhisperer to preprocess scanned and unstructured files.
API integration to export classification results in JSON format.
Custom automation demo example to sort documents into the right storage locations.
By the end, you’ll see how this setup can transform document organization from a manual, error-prone process into an intelligent, largely automated workflow.
Here is the Github repository where you will find all the codes written for this article.
Challenges in Document Classification
Document classification may sound straightforward: just look at a file, decide what it is, and put it in the right place. But at scale, it becomes a complex problem with multiple points of failure.
Here are some of the main challenges organizations face:
Variety of Document Formats: Business documents don’t arrive in a single neat format. You might receive PDFs from vendors, scanned images from legacy archives, HTML emails from clients, or structured forms from online submissions. And all of which need to be categorized accurately. Each format requires a different handling approach, and traditional systems often can’t process them all equally well.
OCR Errors in Scanned Files: When working with scanned documents, Optical Character Recognition (OCR) is essential for converting images into machine-readable text. However, OCR isn’t perfect; poor scan quality, unusual fonts, handwritten notes, or skewed pages can lead to inaccurate text extraction, which in turn reduces classification accuracy.
Inconsistent Layouts Across Sources: Even documents of the same type can look vastly different depending on the sender. An invoice from Vendor A might have its invoice number at the top-right corner, while Vendor B hides it at the bottom. This layout inconsistency makes it difficult for rule-based systems to identify key information reliably.
Time Costs and Human Error: Manual classification requires significant human effort, especially in high-volume environments like finance, insurance, and legal sectors. This not only slows down workflows but also introduces the risk of human error, potentially leading to misplaced files or compliance breaches.
Compliance and Audit Requirements: Certain industries, especially banking, healthcare, and government, must adhere to strict regulatory standards for document retention and retrieval. Incorrect classification can make audits painful, regulatory checks slow, and compliance failures costly.
These challenges reinforce the need for a more flexible, intelligent approach to document classification, one that can adapt to multiple formats, understand content context, and scale effortlessly without sacrificing accuracy.
This is where AI-powered tools like Unstract, combined with LLMs, start to show their value.
Traditional Methods of Document Classification
Before the rise of AI-driven workflows, organizations relied on a mix of manual processes and rigid automation to classify documents. While these methods still have their place in certain scenarios, they come with significant limitations when applied at scale.
Manual Tagging:
Pros: When performed by trained staff, manual tagging can be extremely accurate. Human reviewers can interpret ambiguous layouts, catch subtle details, and make informed judgments about document type.
Cons: The process is slow, labor-intensive, and costly. In high-volume environments, the turnaround time can quickly become a bottleneck. Human fatigue and inconsistency also introduce risks of misclassification.
Rule-Based Systems:
Pros: These systems classify documents by looking for specific keywords, patterns, or positions in the text. They are fast, predictable, and easy to explain to stakeholders.
Cons: They are brittle; if a document format changes or a new vendor uses different wording, the rules must be updated. Maintaining these rules over time becomes a significant burden, especially when dealing with hundreds of document variations.
Basic OCR Pipelines:
Pros: OCR (Optical Character Recognition) converts scanned images or printed documents into machine-readable text, making it possible to apply classification logic. It’s a critical first step for digitizing paper records.
Cons: While OCR enables digitization, it does not understand context or meaning. It can extract words but can’t determine whether “Account Summary” appears on a bank statement or a utility bill without additional logic or human intervention.
Traditional methods either lean on humans (who are accurate but slow), or on rigid systems (fast but inflexible). Neither approach scales effectively when faced with the diversity and complexity of modern business documents.
This is where AI-powered classification offers a compelling alternative, bridging the gap between speed and accuracy.
How LLMs are Changing Document Classification
Large Language Models (LLMs) represent a major leap forward in how organizations can approach document classification. Unlike traditional systems that rely on rigid rules or keyword matching, LLMs bring contextual understanding to the process by interpreting a document much like a human would.
Context-Aware Understanding: LLMs don’t just search for isolated keywords; they interpret the meaning and relationships between words in the broader context of the document. For example, they can distinguish between “Invoice Date” on a financial invoice and the same phrase appearing in an unrelated sample invoice within a training guide.
Broad and Granular Classification: With the right prompt design, LLMs can operate at different classification levels:
Broad classification: Grouping documents into general categories such as invoices, bank statements, or tax forms.
Granular classification: Identifying specific subtypes, like tax form 586 vs. tax form 2, or accord form 5 vs. accord form 7.
This flexibility makes them adaptable to industries where precise categorization is critical, such as law, healthcare, and finance.
Rapid Adaptation to New Document Types: Traditional rule-based systems require constant updates when a new document layout appears. LLMs, however, can adapt with minimal retraining or even none at all. Often requiring only a revised prompt or a few examples to handle a new format.
Reasoning Over Text + Layout: While OCR extracts raw text, it lacks an understanding of document structure. LLMs can reason over both the extracted content and the layout cues, such as headers, tables, and labels, to accurately infer a document’s purpose. This helps overcome the classic OCR problem of “words without meaning”.
By combining OCR pre-processing with LLM-based reasoning, businesses can build classification pipelines that are smarter, more resilient, and easier to maintain which sets the foundation for an automation that scales without sacrificing accuracy.
Unstract’s Role in AI Document Classification
While many AI tools require complex machine learning pipelines and extensive training datasets, Unstract offers a more accessible, flexible approach to document classification. It leverages Large Language Models (LLMs) through its Prompt Studio, making it possible to design classification workflows without building a dedicated AI system from scratch.
Why Unstract is a Game-Changer
Seamless LLM Integration via Prompt Studio: Unstract’s Prompt Studio lets you directly connect to LLMs and craft classification prompts tailored to your needs. You can start with a simple instruction, something like “Identify whether this is an invoice, bank statement, or accord form”, and expand it to handle more complex, granular categories.
No Need for a Full ML Pipeline: Instead of setting up your own model training, preprocessing layers, and deployment infrastructure, Unstract handles the heavy lifting. This enables rapid prototyping and deployment without deep AI engineering resources.
API-Friendly for Automation: Once classification logic is working, results can be exported as JSON through Unstract’s API. This means any document sent to the API can instantly return a structured classification output, making it perfect for integrating into existing automation workflows like sorting documents in Google Drive, AWS S3, or enterprise content management systems.
LLMWhisperer’s Role in Preprocessing
OCR with Intelligence: LLMWhisperer functions like an advanced OCR engine, but with better context handling. Instead of simply pulling out raw text, it extracts clean, structured, and logically ordered content, making it far easier for LLMs to interpret.
Handles Scanned and Unstructured Files: Whether it’s a low-quality scan, a complex multi-column document, or a form with embedded tables, LLMWhisperer organizes the text into a format that preserves meaning and relationships between elements.
Improved Accuracy for LLM Processing: Clean input equals better classification. By preprocessing with LLMWhisperer, the LLM receives context-rich, accurate text, greatly reducing the risk of misclassification caused by OCR errors or missing information.
Together, Unstract + LLMWhisperer form a very streamlined classification stack: one tool prepares the document content for understanding, and the other applies intelligent categorization through flexible, API-driven workflows.
This pairing eliminates much of the complexity found in traditional AI deployments, while still delivering enterprise-grade results.
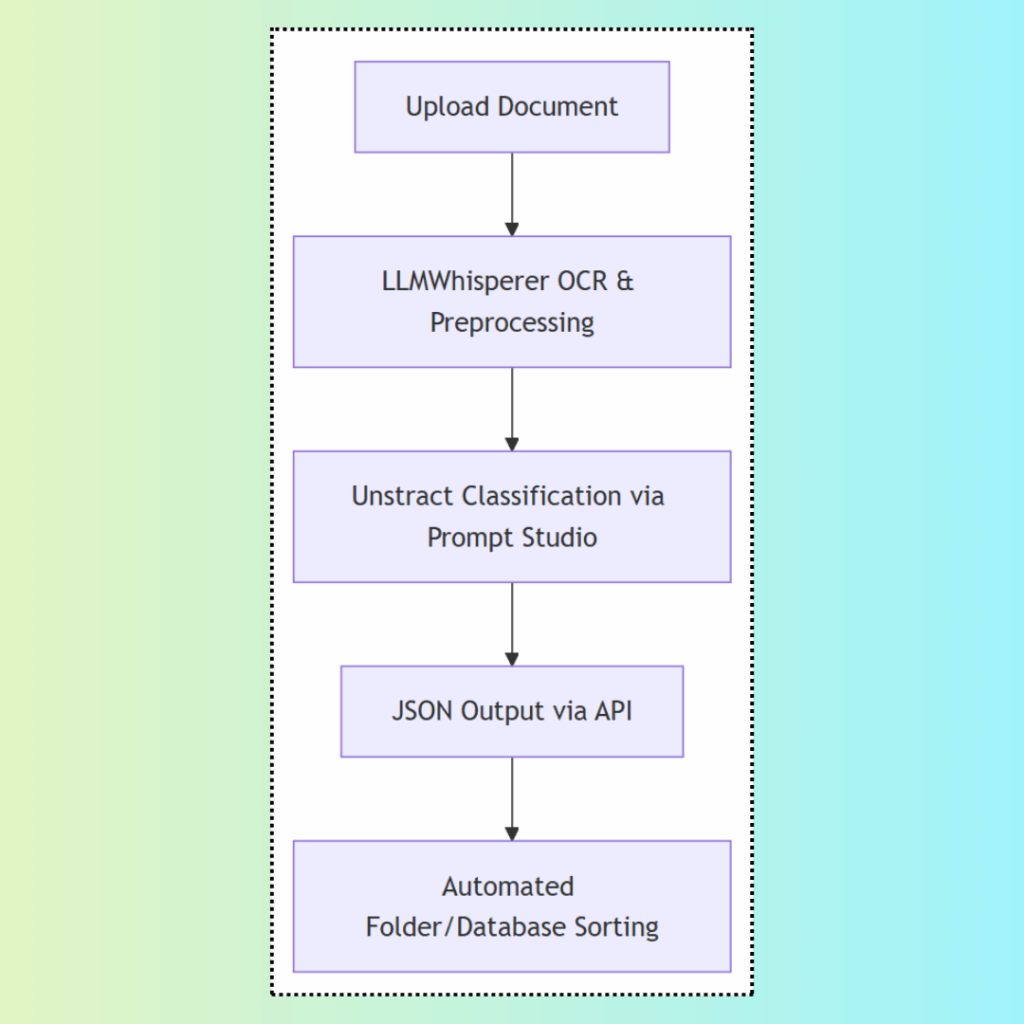
Step-by-Step Workflow
To bring AI-powered document classification to life, it helps to break the process down into clear, actionable steps. The workflow combines LLMWhisperer for intelligent text extraction, Unstract for context-aware classification, and its API for automation.
Below is a visual overview of the process, showing how documents can move from raw input to fully classified and sorted output:
Step 0 – Sign Up to Unstract
Before you can start classifying documents, you need access to Unstract.
Here’s how to get started:
Create an Account: Visit the Unstract website and sign up using your email or a supported SSO (Google, Microsoft, etc.).
Verify Your Email: Confirm your email address to activate your account.
Access Prompt Studio: Once logged in, navigate to Prompt Studio, the workspace where you’ll create classification prompts and manage your document projects.
All new accounts include a 14-day trial and $10 worth of LLM tokens, so you can start building and testing your document classification pipeline immediately.
Step 1 – Set up Classification Prompts in Prompt Studio
With the account created and ready, you can now create a new project in Prompt Studio, let’s call it ‘Document Classification’.
You can upload the files you want to test the prompts with by clicking on ‘Manage Documents’.
For these examples, we will be using three different files to test the prompts:
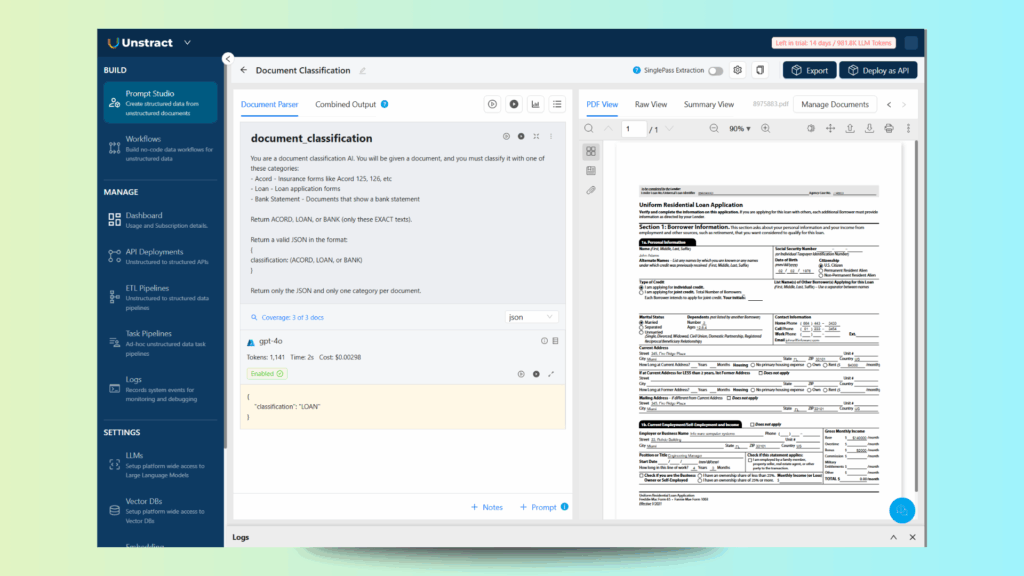
Let’s now write the prompt to classify the documents and export the classification:
The prompt used:
You are a document classification AI. You will be given a document, and you must classify it with one of these categories:
- Acord - Insurance forms like Acord 125, 126, etc
- Loan - Loan application forms
- Bank Statement - Documents that show a bank statement
Return ACORD, LOAN, or BANK (only these EXACT texts).
Return a valid JSON in the format:
{
classification: (ACORD, LOAN, or BANK)
}
Return only the JSON and only one category per document.
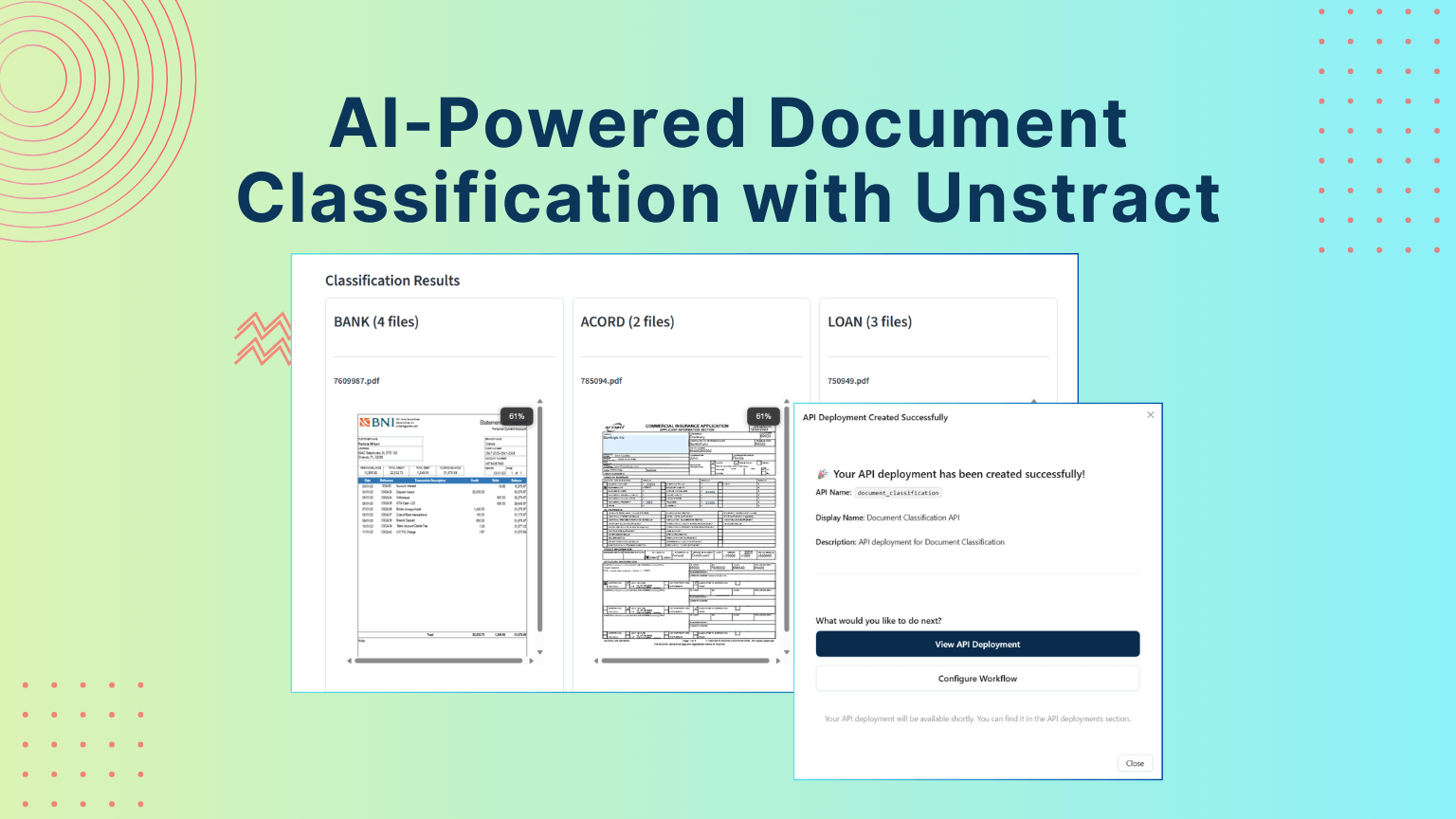
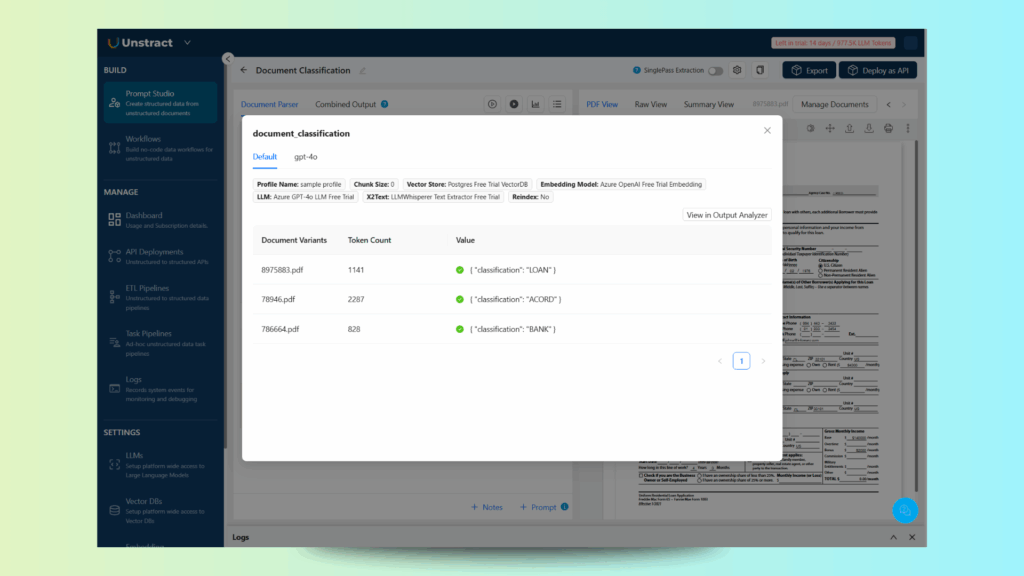
You can also test the prompt against all uploaded documents, which, for our examples, returns:
As you can see, all documents are classified correctly with the correct type.
Step 2 – Deploy the API
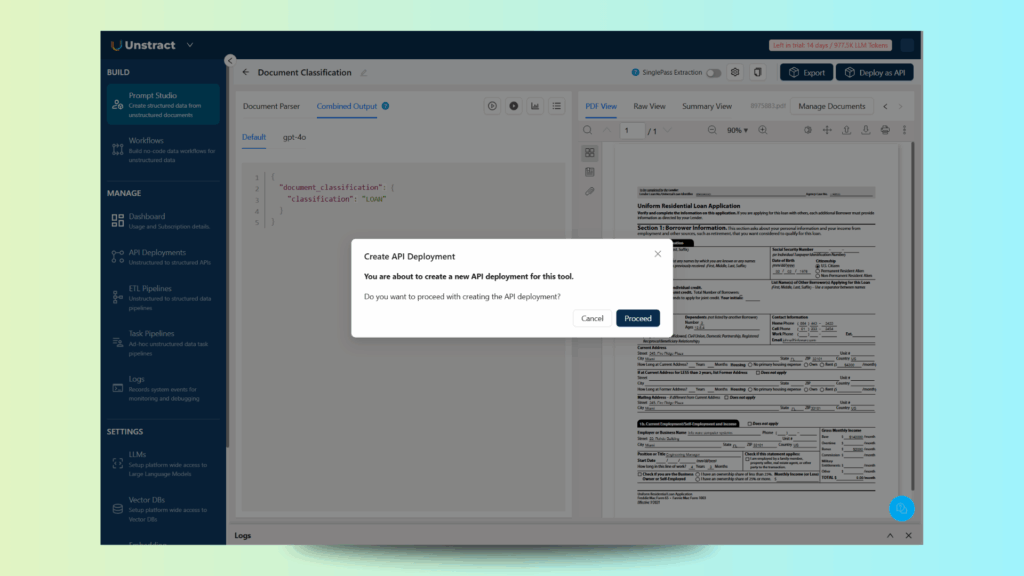
With the prompt defined and tested, you can now deploy it as an API so it can be used in your workflow or simply for testing it with Postman, for example.
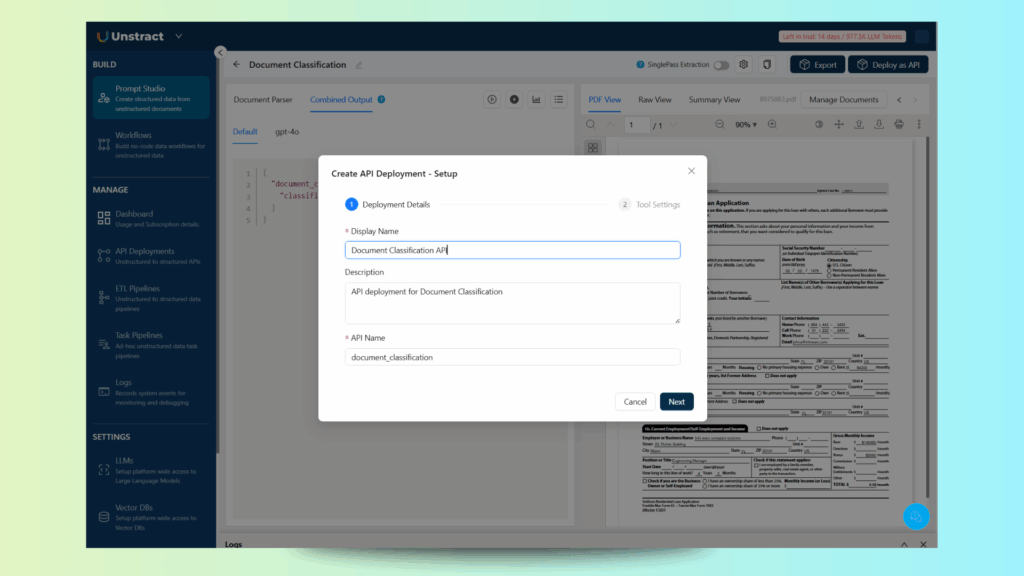
To deploy as an API, all you need to do is click on the top-right button ‘Deploy as API’, which will take you into the following flow:
Let’s proceed and define a name for the API, in this case, document_classification:
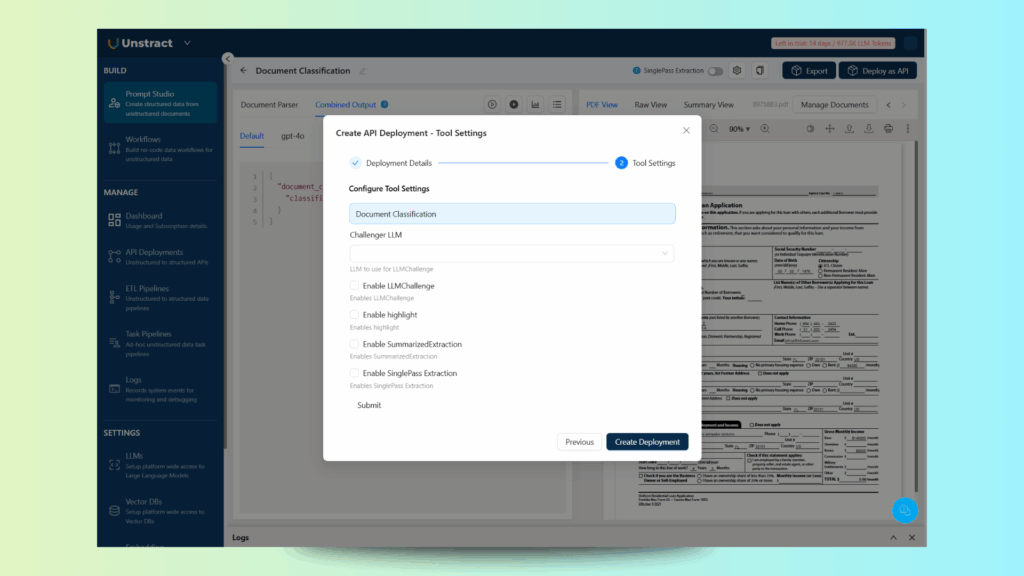
On the tool settings, you can leave the default values:
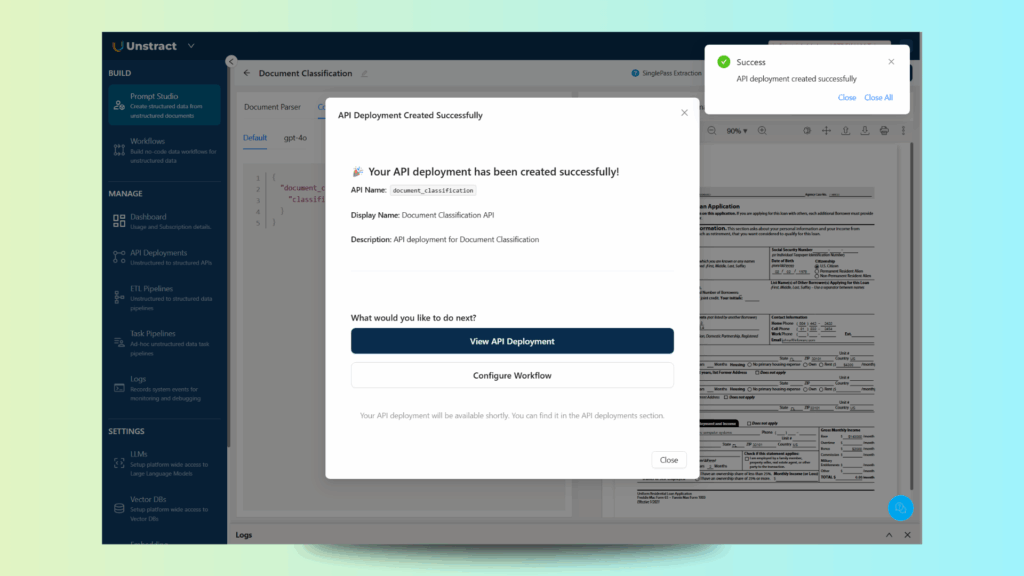
And after a few seconds, your API is deployed:
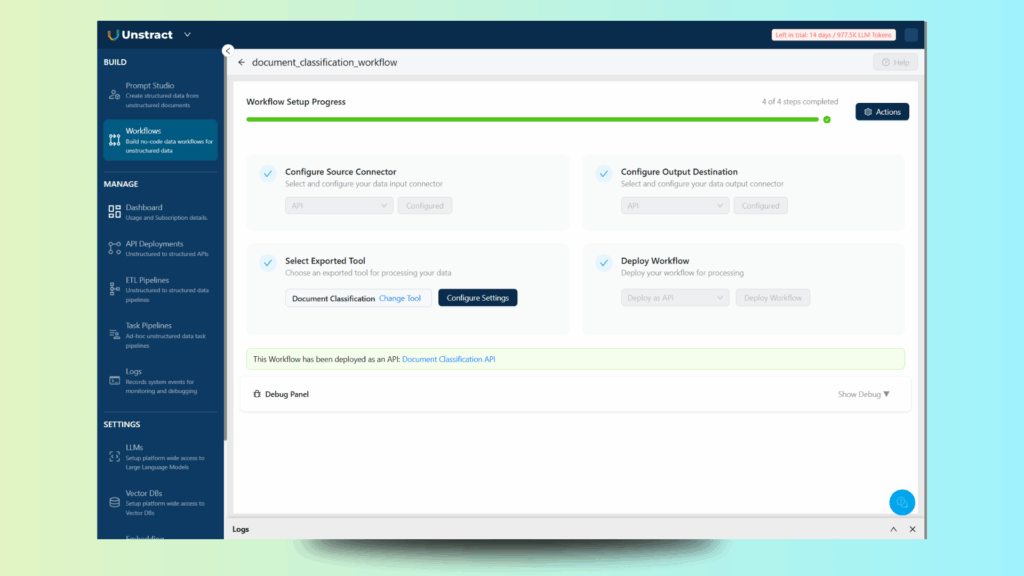
As you can see, Unstract has automatically defined a workflow, document_classification_workflow:
If you want to check the details of the workflow, you can click on the workflow link:
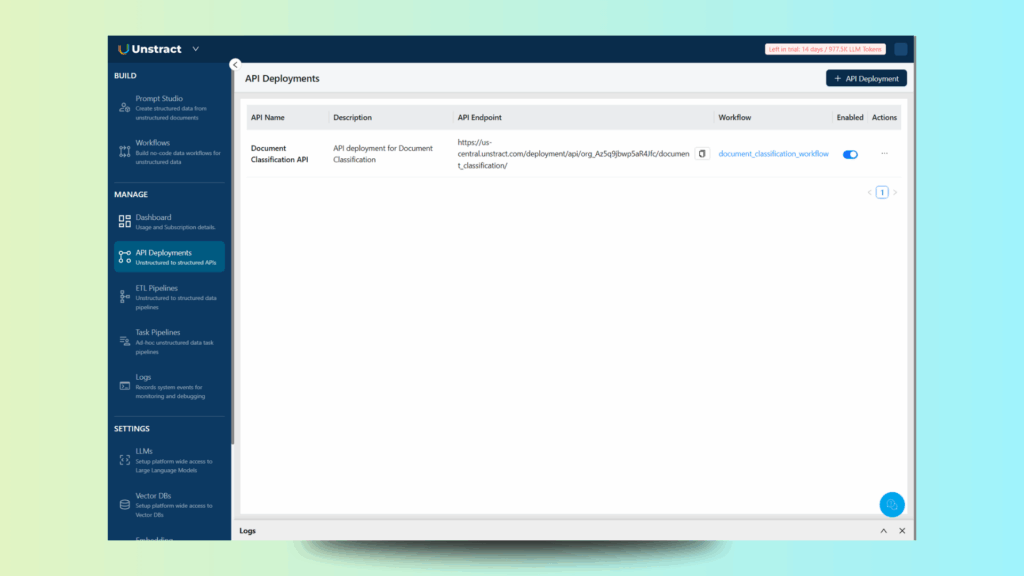
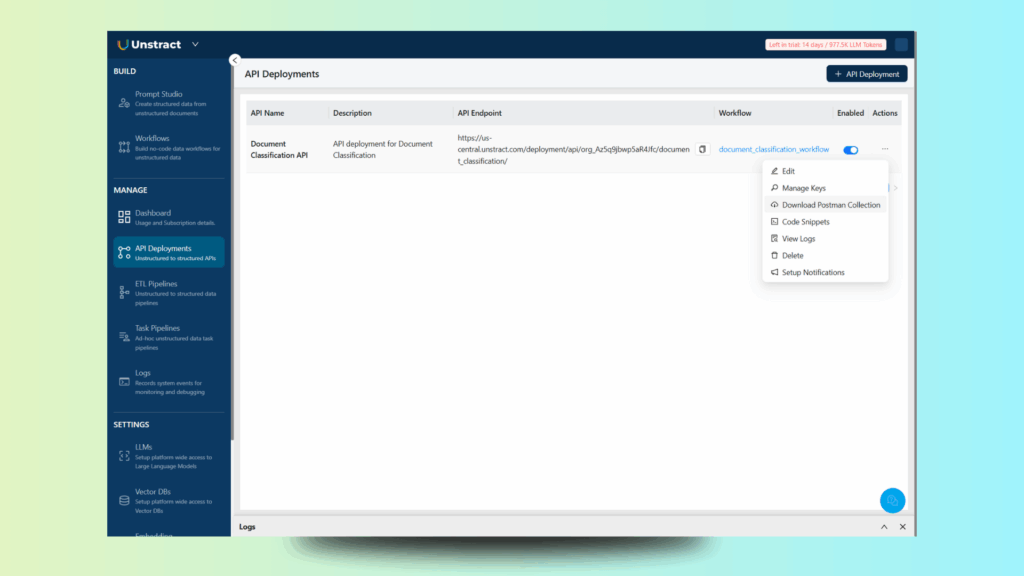
Back in the API deployment list, you can access the actions menu and download a Postman collection for testing and/or manage the API keys:
Retrieve the API key with ‘Manage Keys’ and write it down, as well as the API endpoint shown. You will need them to run the example application later on.
Step 3 – Example Streamlit Application
Process showing document upload, app run, and classification results.
With the API deployed, you can now use it inside your desired workflows. As an example, we will now create a small Streamlit application where several files can be uploaded and classified.
The Python requirements that are required to install are:
We will use the requests library to call the Unstract API, streamlit-pdf-viewer for showing the actual classified PDFs in the Streamlit application, and python-dotenv for keeping the API key safe with environment variables.
Let’s now create a .env file:
API_URL=<YOUR_API_URL>
API_KEY=<YOUR_API_KEY>
Replace with the values obtained previously.
Next, we create the main application file, app.py:
import base64
import os
import tempfile
from dotenv import load_dotenv
import streamlit as st
import requests
from io import BytesIO
from streamlit_pdf_viewer import pdf_viewer
# ----------------------------
# Configuration
# ----------------------------
load_dotenv()
API_URL = os.getenv("API_URL")
API_KEY = os.getenv("API_KEY")
# ----------------------------
# Streamlit App
# ----------------------------
st.set_page_config(layout="wide")
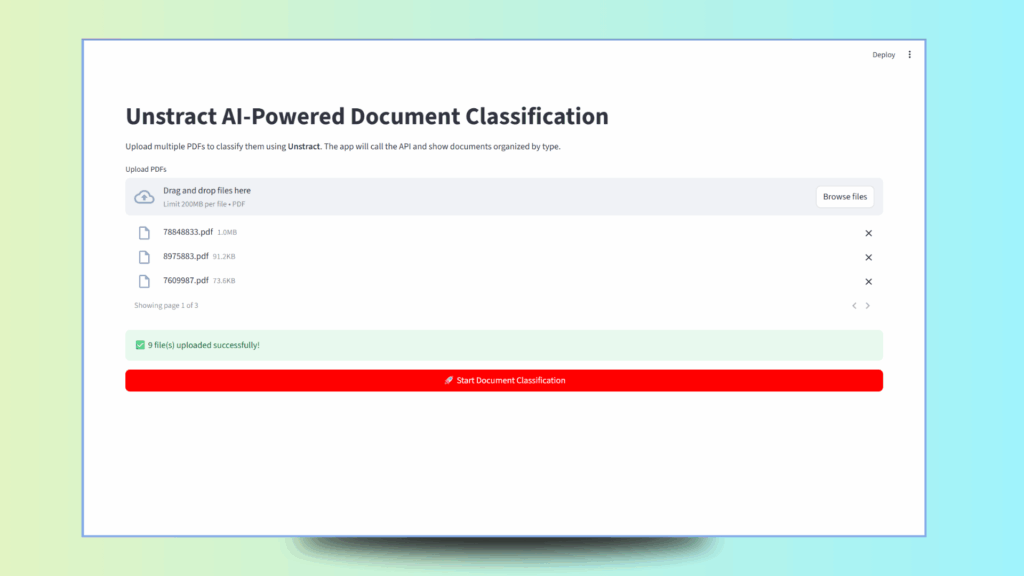
st.title("Unstract AI-Powered Document Classification")
st.markdown("""
Upload multiple PDFs to classify them using **Unstract**.
The app will call the API and show documents organized by type.
""")
# Add a file uploader
uploaded_files = st.file_uploader(
"Upload PDFs",
type=["pdf"],
accept_multiple_files=True
)
# If files are uploaded, process them
if uploaded_files:
st.success(f"✅ {len(uploaded_files)} file(s) uploaded successfully!")
# Process button
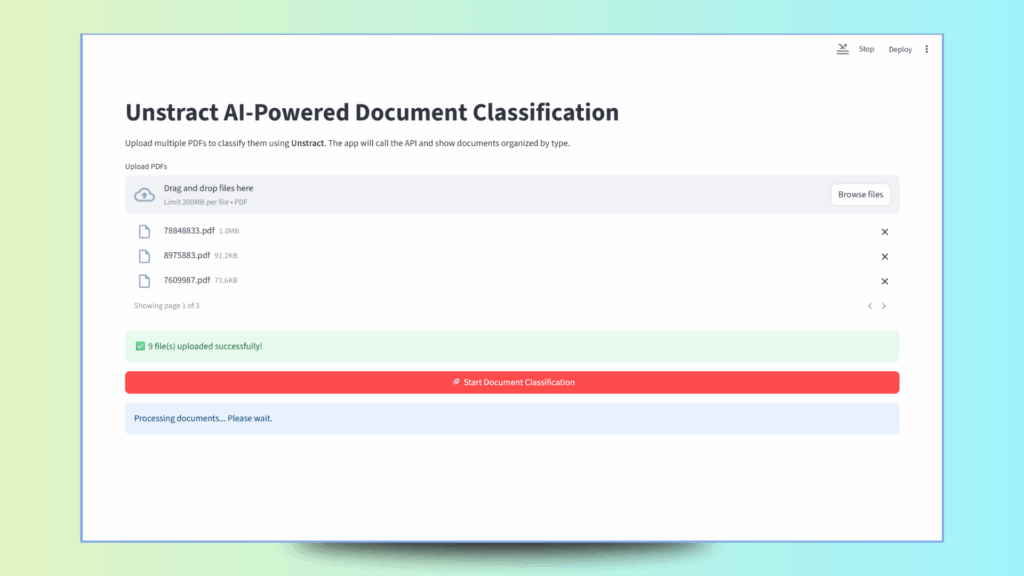
if st.button("Start Document Classification", type="primary", use_container_width=True):
st.info("Processing documents... Please wait.")
# Remove duplicate files based on name
unique_files = {}
for pdf_file in uploaded_files:
if pdf_file.name not in unique_files:
unique_files[pdf_file.name] = pdf_file
else:
st.warning(f"Skipping duplicate file: {pdf_file.name}")
# Display the number of unique files
if len(unique_files) != len(uploaded_files):
st.info(f"Removed {len(uploaded_files) - len(unique_files)} duplicate files. Processing {len(unique_files)} unique files.")
# If there are unique files, process them
if unique_files:
# Initialize the dictionary to store PDFs by type
organized_docs = {}
# Prepare the API call with all files at once
headers = {
'Authorization': f'Bearer {API_KEY}'
}
payload = {'timeout': 300, 'include_metadata': False}
# Create file objects for all files in a single API call
files = []
for pdf_file in unique_files.values():
file_bytes = pdf_file.read()
files.append(('files', (pdf_file.name, BytesIO(file_bytes), 'application/octet-stream')))
# Call the API with all files
response = requests.request("POST", API_URL, headers=headers, data=payload, files=files)
# Check if the API call was successful
if response.status_code == 200:
# Get the result from the API call
result = response.json()
# Check if the execution is completed
if result.get("message", {}).get("execution_status") == "COMPLETED":
# Extract results from the new response structure
results_list = result.get("message", {}).get("result", [])
# Check if there are any results
if results_list and len(results_list) > 0:
# Process all results
for file_result in results_list:
file_name = file_result.get("file", "Unknown")
pdf_file = unique_files.get(file_name)
# Check if the file was processed successfully
if pdf_file and file_result.get("status") == "Success":
# Extract classification from the successful result
try:
doc_type = file_result.get("result", {}).get("output", {}).get("document_classification", {}).get("classification", "Unknown")
except (KeyError, AttributeError):
doc_type = "Unknown"
# Add the file to the organized_docs dictionary
if doc_type not in organized_docs:
organized_docs[doc_type] = []
organized_docs[doc_type].append(pdf_file)
elif pdf_file:
st.error(f"File processing failed for {file_name}: {file_result.get('error', 'Unknown error')}")
else:
# If no results are found, display an error message
st.error("No results found in the API response")
else:
# If the execution is not completed, display an error message
st.error(f"Execution not completed. Status: {result.get('message', {}).get('execution_status', 'Unknown')}")
st.json(result)
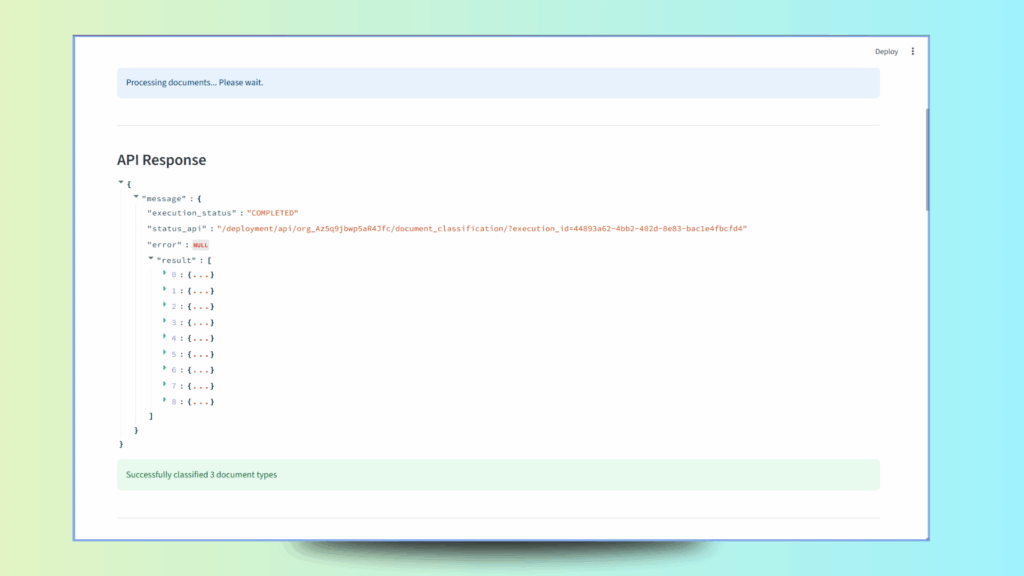
# Display the full API response for debugging
st.divider()
st.subheader("API Response")
st.json(result, expanded=False)
else:
# If the API call fails, display an error message
st.error(f"Failed to classify files: {response.text}")
# Display organized PDFs
if organized_docs:
# Display success message and divider
st.success(f"Successfully classified {len(organized_docs)} document types")
st.divider()
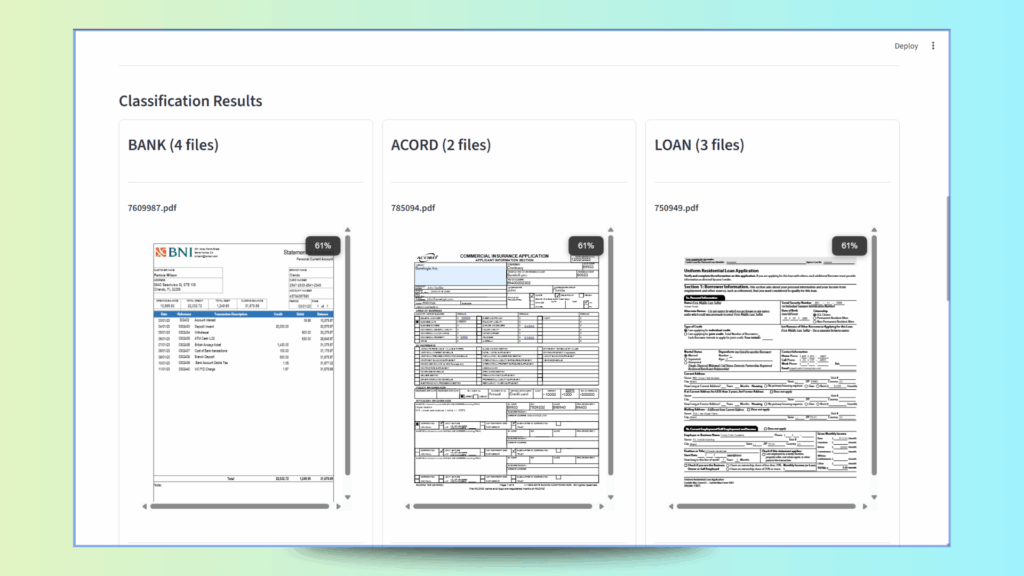
st.subheader("Classification Results")
# Create columns for better layout
cols = st.columns(len(organized_docs), border=True)
# Display each document type in a column
for idx, (doc_type, files) in enumerate(organized_docs.items()):
# Display the document type in a column
with cols[idx]:
st.subheader(f"{doc_type} ({len(files)} files)")
st.divider()
# Display each file in the column
for f in files:
# Display the file name
st.markdown(f"**{f.name}**")
# Display PDF in a container for better organization
with st.container():
# Save uploaded file to a temporary file
temp_file = tempfile.NamedTemporaryFile(delete=False)
temp_file.write(f.getvalue())
temp_file.close()
# Display PDF using the temporary file
pdf_viewer(temp_file.name, width="90%", height=500, zoom_level="auto")
st.divider()
else:
# If no documents were successfully classified, display a warning message
st.warning("No documents were successfully classified.")
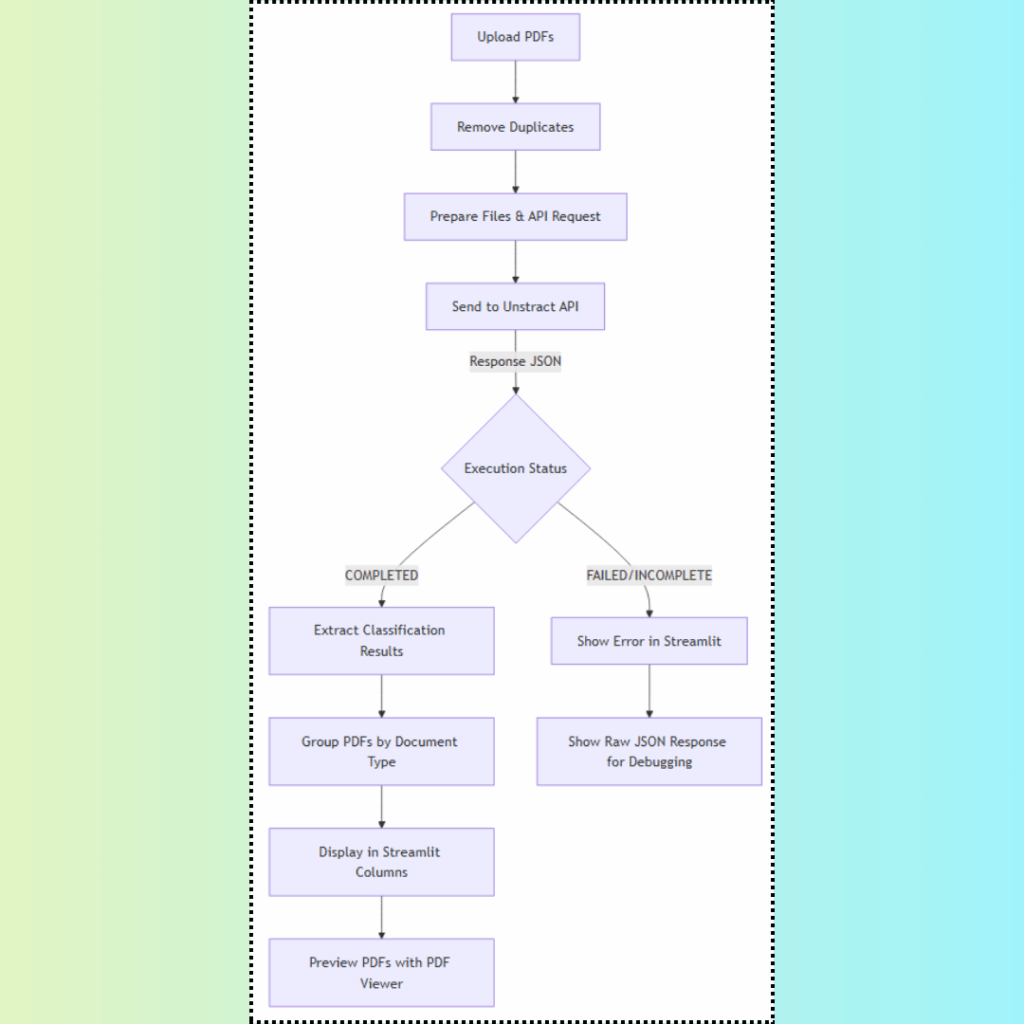
The app provides an AI-powered document classification tool built on top of Unstract’s API.
It allows users to upload multiple PDFs, send them to the API for classification, and then view the results organized by document type directly in the app. The workflow ensures duplicate files are removed, documents are processed in bulk, and results are neatly displayed with previews of the classified PDFs.
To better understand the flow of the application, refer to this diagram:
Step 4 – Running and Testing the Streamlit Application
Let’s run the application with a set of 9 example files.
We run the application with:
streamlit run app.py
First, we start by uploading the files:
Clicking on ‘Start Document Classification’ will invoke the deployed Unstract API:
After a couple of seconds, we get a response, which we can debug with the JSON output:
And the full classified documents, where each column shows a specific document type that was classified:
The next set of documents:
Continuing to scroll through the documents:
Finally, the last classified document:
With just a few clicks, any unstructured PDFs are transformed into organized, business-ready documents.
Instead of manually sorting, tagging, or building complex ML pipelines, Unstract + LLMWhisperer and a small Streamlit application do the heavy lifting for you:
AI-powered classification that adapts to any document type.
Clean, organized results displayed instantly in your dashboard.
Seamless preview of each file, grouped by category.
Enterprise-ready automation without costly setup or training data.
This isn’t just a demo application, it’s a glimpse into how your organization can cut hours of manual work down to minutes and unlock faster, smarter operations at scale.
Use Cases for Enterprises
AI-powered document classification with Unstract isn’t just a technical showcase, it solves a real and high-value problems across industries. By automating the identification and categorization of documents, organizations can save time, reduce errors, and improve compliance.
Here are some practical examples:
Invoice and Billing Document Management: Finance departments often receive invoices in multiple formats from dozens (or even hundreds) of vendors. With Unstract, invoices can be automatically identified, tagged, and routed to the right accounts payable workflow, regardless of layout or file type. This reduces manual handling and speeds up payment cycles.
Tax Form Sorting for Accounting Firms: During tax season, firms handle a flood of documents ranging from generic “tax forms” to highly specific ones like Form 1040, Form 941, or Form W-2. LLM-powered classification can distinguish between these at both the broad and granular level, ensuring each form goes to the correct processing team.
Compliance Document Tagging for Legal Teams: Legal and compliance teams must often track contracts, NDAs, certifications, and regulatory filings. Misplacing these documents or failing to tag them properly, can lead to costly compliance violations. Automated classification ensures that sensitive or time-critical documents are properly labelled and easy to retrieve during audits.
Insurance Claim Categorization: Insurance providers receive claims in various formats, often bundled with supporting documents like police reports, repair estimates, and medical records. Unstract can automatically separate and classify these, enabling faster triage, routing to specialized teams, and improved response times for customers.
From finance to legal to insurance, the ability to automatically sort and tag documents translates to operational efficiency, lower costs, and improved service delivery.
All without building and maintaining a full-scale machine learning infrastructure in-house.
Benefits of Using Unstract as a Document Classification Software
Unstract offers a practical, low-friction way for organizations to implement AI-powered document classification without the heavy engineering investment typically required for machine learning projects.
Some of the key advantages include:
Faster Setup Compared to Custom ML Pipelines: Building a classification model from scratch often involves data collection, labelling, model training, evaluation, and deployment. This process can take weeks or months. With Unstract, you can start classifying documents in hours, not weeks, by leveraging Prompt Studio and ready-to-use LLM integrations.
No Need for Extensive Training Datasets: Traditional ML approaches require thousands of labelled examples to achieve reasonable accuracy. Unstract’s prompt-driven model works zero-shot or few-shot, meaning you can achieve meaningful results with just a handful of representative examples. This makes it ideal for organizations without large, curated datasets.
Scales Easily with API-Based Automation: Once your classification workflow is set up, Unstract can export results in structured formats (like JSON) via API. This allows seamless integration into your existing automation systems, no matter whether you’re sorting files in Google Drive, moving them into AWS S3 buckets, or updating records in an ERP system. Scaling to process hundreds or thousands of documents becomes a matter of running more API calls, not re-engineering your system.
Unstract brings speed, flexibility, and scalability to document classification, which makes it a strong choice for enterprises that need automation without the complexity of traditional AI deployments.
Document Classification with Unstract: Conclusion
Document classification has long been a challenge for organizations dealing with diverse formats, inconsistent layouts, and strict compliance requirements. While no tool can make the problem vanish entirely, Unstract + LLMWhisperer comes very close by handling roughly 80% of the heavy lifting through intelligent pre-processing and context-aware classification.
By combining LLMWhisperer’s ability to produce clean, structured text from even the messiest scanned files with Unstract’s prompt-driven classification and API integration, enterprises can build workflows that are faster, more accurate, and far less reliant on manual effort. The final 20%, such as sorting into storage systems, can be addressed with straightforward scripting or integration into existing automation tools.
For businesses, the potential is clear: automate repetitive classification tasks, reduce human error, improve compliance readiness, and free up teams to focus on higher-value work.
If you’re ready to streamline your document workflows, start small by running Unstract on a sample set of documents, integrating the classification API into your pipeline, and watch the time savings compound as you scale. The sooner you start, the sooner your organization can move from manual document chaos to intelligent, automated order.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.