Product
PDF to Markdown: Best Tools, Comparison, Limitations (2026)
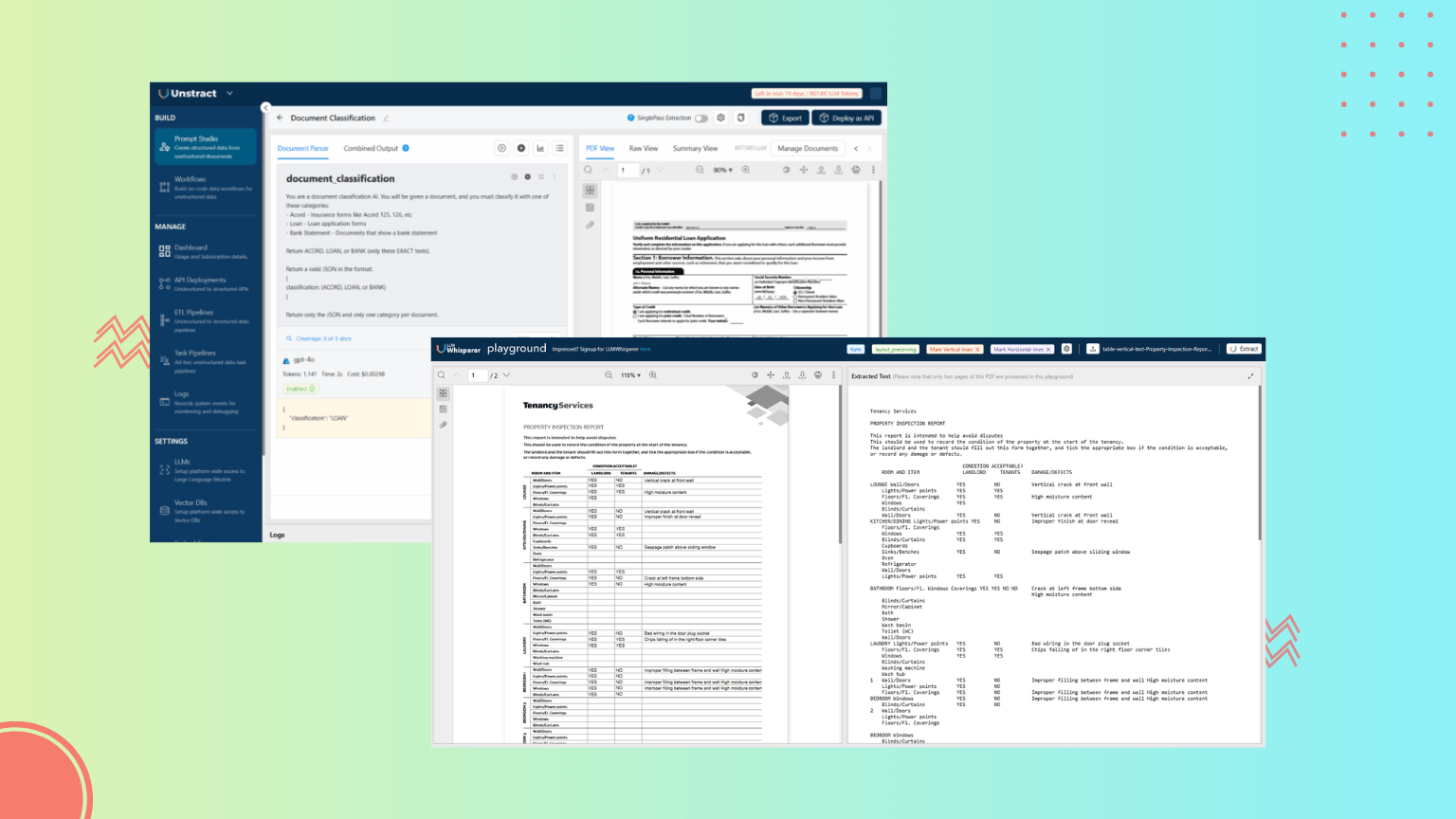
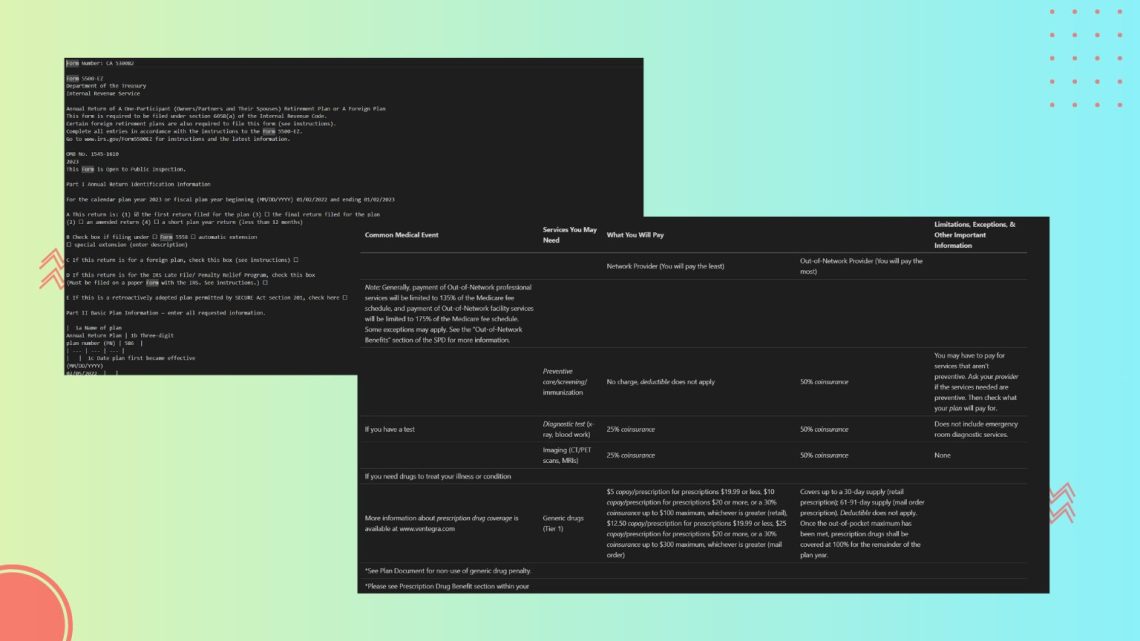
Markdown-based OCR falls short for LLM-driven structured data extraction. This article compares it with LLMWhisperer, a layout-preserving OCR built for LLM pre-processing, highlighting how retaining spatial structure and confidence scores enables more accurate downstream extraction.