AI-Powered Legal Document Data Extraction with Unstract
Table of Contents
Millions of contracts, agreements, and compliance documents are being produced by law firms each year. Most of them are unstructured, dispersed, and not readable by conventional systems.
Manual document review isn’t just slow, it’s risky for any organization handling contracts, compliance records, or financial agreements. A single missed clause or incorrect entry can trigger penalties.
Automation eliminates the delays of manual review by processing, indexing, and validating documents in minutes. AI-powered legal document processing takes it further. It uses OCR, embeddings, and LLMs to read, understand, and extract insights from even the most complex legal text with speed and precision.
With platforms like Unstract and LLMWhisperer, firms are shifting from hours of manual work to minutes of automated, structured output. This article explores what legal document processing is, why automation is essential, the challenges AI solves, and how modern platforms are reshaping legal operations.
What is Legal Document Processing?
Legal document processing is the systematic process of managing documents by intake, review, data extraction, storage, and retrieval. It ensures that important facts concealed within lengthy texts are extracted, organized, and readily available.
Types of legal documents include:
Business Contracts: Vendor, employment, and NDA agreements that regulate obligations and risks.
Mergers/Acquisitions (M&A) Reports: Due diligence reports and purchase agreements crucial to deals.
Manual inefficiencies: Reviewing one contract can take hours, and M&A deals require analyzing thousands under strict deadlines. Manual processes slow progress and increase error risk. Automation accelerates review and boosts accuracy.
High costs: Manual review of legal documents consumes significant lawyer and paralegal hours. Automation reduces these costs by accelerating review and structuring data, freeing legal teams for higher-value tasks.
Error risks: Even the smallest error, such as the omission of an indemnity clause, may result in penalties or conflict. AI-based data extraction ensures consistency and minimizes human oversight errors. This helps improve accuracy and compliance across all legal documents.
Scalability: Legal departments can process increased volumes of contracts without requiring additional staff. With automation, firms can easily scale operations.
Compliance: Structured, searchable data simplifies audits and regulatory reporting. Automation ensures key fields are captured consistently, making it easier to meet compliance obligations and minimize the risk of non-adherence.
Challenges in Legal Document Processing
While automation streamlines document processing workflows, users may still face issues when implementing automated frameworks. The key is to recognize these challenges and pair them with the right solutions.
Format variability: Contracts often come in PDFs, scans, Word files, or even faxes, which makes consistent extraction a challenge. Modern automation seamlessly converts and interprets each format, ensuring every document is accurately read and processed.
OCR limitations: Scans of poor quality, handwriting, or multi-column layout reduce recognition accuracy and lead to missing out important information. OCR engines with advanced features save structure and context. This precision is even with the most complicated legal documents.
Complex legal language: Clauses tend to be vague, buried deep within, or full of jargon, and manual interpretation is highly prone to error. LLMs offer semantic insights, uncovering obligations, risks, and meaning beyond surface-level text or keywords.
Jurisdictional diversity: The legal terms, formats, and clauses vary across different regions, posing a major problem to international legal teams. With adaptive AI models, extractions are customized to geographical settings, which allows proper analysis in different jurisdictions.
Data security: Legal documents contain sensitive information about clients and corporations, and must be highly protected in terms of privacy and compliance. The contemporary systems provide encryption, control, and authorized access to secure confidential information throughout the process.
Human oversight: While sophisticated automation is highly effective, it can still overlook the nuances in complex legal or contractual language. Human-in-the-loop review bridges that gap by combining computational precision with human expertise to deliver reliable results.
Advent of AI & Role of LLMs in Unstructured Document Processing
For years, the legal industry relied on rule-based OCR to process documents. These systems could convert scanned pages into searchable text, but couldn’t interpret meaning. They couldn’t identify obligations, assess risks, or understand clause intent.
Artificial Intelligence (AI) and Large Language Models (LLMs) change that. They read and reason through legal language, extracting context, meaning, and relationships that rule-based systems could never reach.
What Modern AI/LLMs Can Do
Let’s look at how today’s AI and LLMs simplify and strengthen legal document processing:
Entity recognition: Automatically identifies key fields such as amounts, jurisdictions, governing law, and dates. For example, “TechNova Inc.” and “Orion Partners LLP” are recognized as counterparties, while “termination notice within 30 days” is flagged as a key obligation.
Semantic understanding: Goes beyond surface-level text to capture intent and potential risk. For example, it can identify that a confidentiality clause extends beyond the contract’s term, signaling possible compliance concerns.
Contextual summarization: Sums up hundreds of pages into readable summaries. For instance, an M&A contract can be distilled into five key points covering financial terms, indemnities, liabilities, and exit conditions.
Risk highlighting: Flags clauses or non-standard obligations. Evidence of a short notice or unlimited liability that is abnormally short.
LLM Strengths and Weaknesses
Understanding the strengths and weaknesses of LLMs helps set realistic expectations for their use in legal document processing.
Strengths
Weaknesses
Speed: Processes thousands of documents in minutes.
Expense: Token-based pricing can make long documents costly.
Precision: Delivers consistent accuracy in routine extractions.
Hallucinations: May generate content not present in the source.
Scalability: Handles workloads beyond traditional team capacity.
Domain Tuning: Requires fine-tuning for specific legal contexts.
AI/LLMs in Legal Document Use Cases
With these advantages in place, AI and LLMs are reshaping how legal teams manage documents.
Contract review: Extracts automatically clauses such as indemnities, governing law, and terms of payment. Cuts weeks of review to days in large-scale M&A deals.
Compliance monitoring: GDPR, HIPAA, or financial regulatory risks scans thousands of contracts. Sends real-time notifications in case of clauses being non-compliant.
Litigation support: Applies semantic search to display the most relevant documents, instead of just those that match keywords. Quickly eliminates review sets to save countless hours during the discovery.
Traditional contract digitization: Turns decades of scanned contracts into searchable repositories. Allows searching by clauses, finds all contracts in which the liability is unlimited.
Regulatory filings: Automates the process of obtaining necessary disclosures to submit to the SEC or FINRA. Minimizes the risk of errors in late filing.
Why Unstract? Beyond Raw LLM Extraction
Most organizations start with raw LLM extraction. They feed text into a model and use prompts to pull key data. While effective on clean text, it quickly breaks down with real-world legal documents like scans, handwritten notes, and complex layouts, often producing inconsistent or incomplete results.
Unstract directly addresses the growing need for reliable document extraction at scale. As a no-code, open-source system, it enables teams to move beyond brittle, ad-hoc prompting toward structured, production-ready workflows for unstructured documents.
Key Features of Unstract
Here’s what makes Unstract stand out:
LLMWhisperer OCR and Text Parsing
LLMWhisperer is a strong OCR and text parsing engine that does not rely on simple text extraction. It supports scanned PDFs, images, handwritten notes, and complex layout documents like tables and multi-column documents.
Unlike traditional OCR, which often distorts structure, LLMWhisperer preserves formatting and context hierarchy, enabling downstream LLMs to interpret content accurately. This can be especially useful in contracts and other compliance documents in which the positioning and structure of clauses are important.
Get started with LLMWhisperer: Best OCR for Legal Document Data Extraction
Prompt Studio
Prompt Studio is a no-code platform that allows users to develop, debug, and test extraction prompts without backend code. Teams can build repeatable schemas, compare outputs across multiple LLMs, and manage prompt versions instead of running one-off experiments.
Prompt Studio also enables result comparison to validate prompts before production use. This allows legal teams to iterate faster and extract diverse documents more efficiently.
Vector DB Integration
Unstract is compatible with vector databases like Qdrant and pgvector, allowing semantic search and embedding-based retrieval. This enables semantic search so users can find contracts with terms and conditions similar to a specific termination clause, even when the wording differs.
In the case of legal workflows, this feature is essential to due diligence, contract analytics, and scale-based compliance monitoring.
ETL Pipelines
A key strength of Unstract is its ability to integrate seamlessly into enterprise data pipelines. The platform not only extracts text but transforms unstructured data into structured formats like JSON, CSV, or direct database entries.
The extracted data can be ingested into case management systems, compliance dashboards, or data warehouses through ETL (Extract, Transform, Load) pipelines. This provides an end-to-end workflow that transforms legal documents into useful analytics and reporting information.
Human-in-the-Loop Validation
Although AI and LLMs are effective, high-stakes sectors such as the law still need to be regulated. Unstract has built-in support of human-in-the-loop (HITL) validation, which allows experts to review and approve extracted outputs before they move downstream.
This ensures high accuracy in sensitive areas such as indemnity clauses and compliance requirements, where even minor errors can lead to significant legal or financial risk.
Steps in Unstract for Legal Document Data Extraction
Unstract offers a structured, logical workflow for extracting data from legal documents. Every single step is optimized to be more accurate, scalable, and reflective of legal text subtleties.
Ingest Documents
The workflow starts with uploading or ingesting legal documents into Unstract. These can be contracts, business arrangements, compliance filings, credit applications, or legal reports.
Unstract is compatible with a diverse variety of file formats, including PDFs, Word documents, and even scanned images. All materials are processed in a single platform.
Parse Text
Once documents are ingested, LLMWhisperer performs text parsing and OCR. This powerful module processes both digital and scanned files. It converts them into structured text while preserving layouts, headers, and table structures.
Maintaining the contextual hierarchy ensures downstream LLMs can interpret clauses and legal definitions accurately. This helps preserve the logical meaning embedded in the document’s structure.
Generate Embeddings
After parsing, the extracted text is converted into embeddings. A numerical representation of its semantic meaning. These embeddings allow Unstract to identify similarities between clauses, uncover related concepts, and support context-aware retrieval.
For instance, a search for “termination clause” will return all clauses expressing the same intent, even if worded differently.
Store in Vector Database
The embeddings are finally kept in a vector database like the Qdrant or pgvector. This database drives semantic search, which enables users to locate contracts or clauses that are conceptually similar instead of using a strict match of keywords.
It represents a significant leap in the context of a traditional search where lawyers can search through thousands of documents and patterns, obligations, or risks.
Write Prompts
Users then transition to Prompt Studio, the no-code environment in Unstract, to create their own logic of extraction. In this case, you can write prompts to retrieve key fields such as parties involved, effective date, termination clause, jurisdiction, and terms of payment. The Studio makes it possible to version prompts and test on models before production deployment.
Validate Outputs
Next, the Human-in-the-Loop (HITL) step in Unstract allows experts to review and refine extracted data directly within the workflow.
This ensures greater accuracy and control, especially when processing complex or high-risk legal information, while maintaining reliability and compliance throughout the process.
Export Results
After validation, results can also be exported in structured formats, such as JSON or CSV, or imported into databases. This enables downstream integration with analytics dashboards, compliance applications, or contract lifecycle management systems.
Formatted data enables teams to derive insights quickly, such as all contracts that are set to expire within a quarter or those that contain risk clauses.
Deploy Workflow
Finally, the extraction workflow can be deployed as an API, making Unstract easy to integrate with existing case or document management systems. Through API endpoints, teams can auto-ingest contracts, run real-time extractions, and receive structured results in seconds.
Getting Started With Unstract: Best AI-Powered Legal Doucment Data Extractor
Demonstrations with LLMWhisperer & Unstract
With the groundwork in place, let’s see how these capabilities come together in action with LLMWhisperer and Unstract.
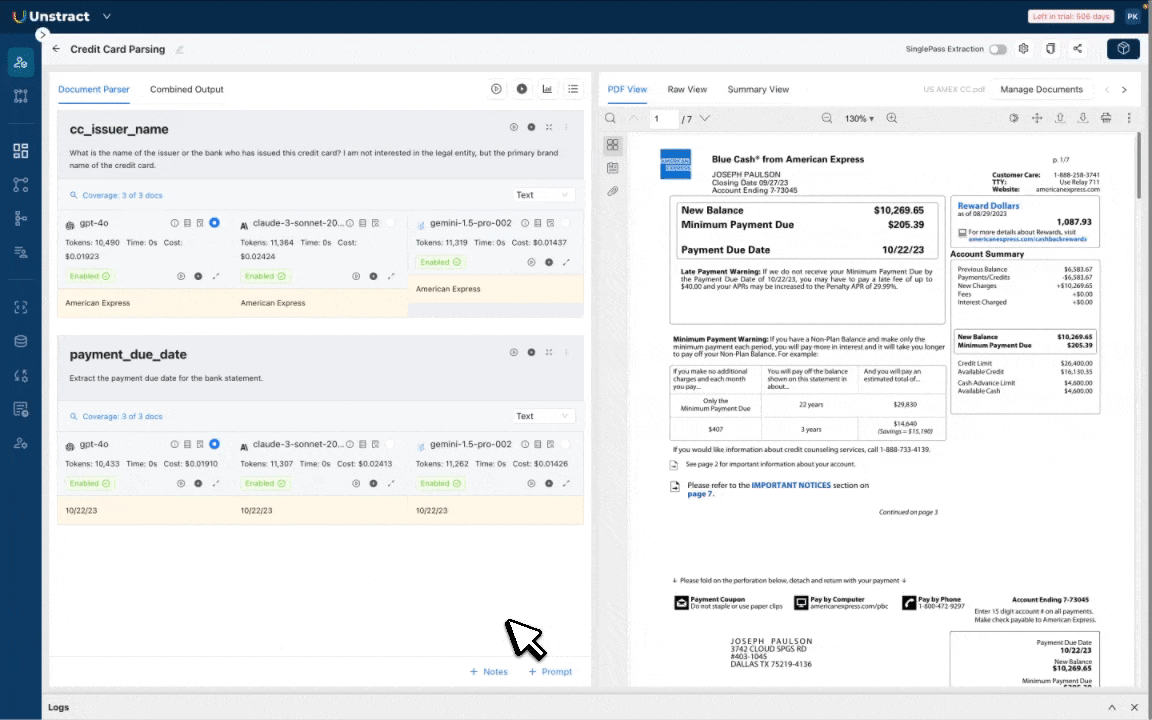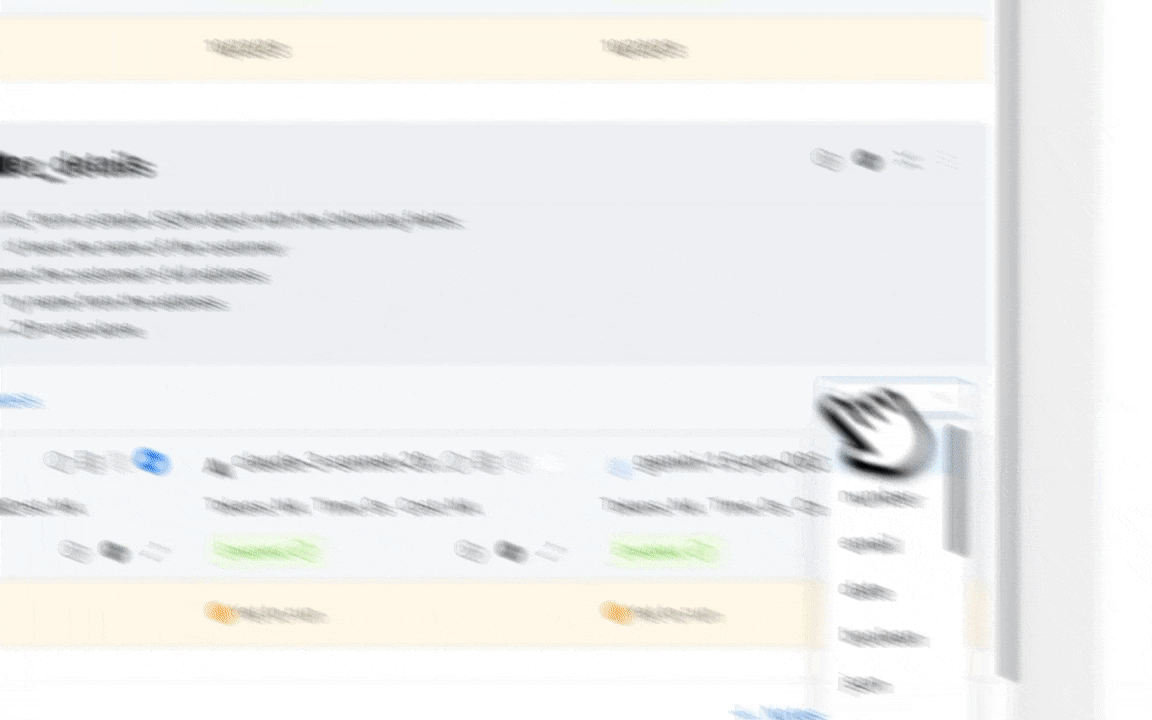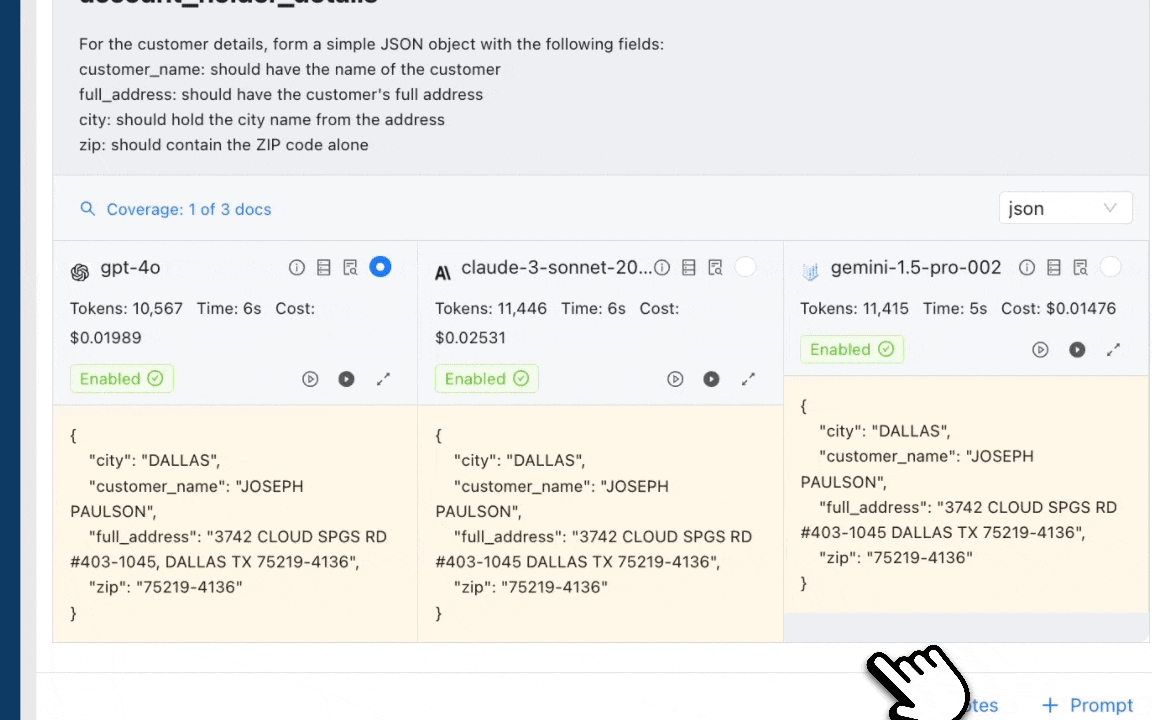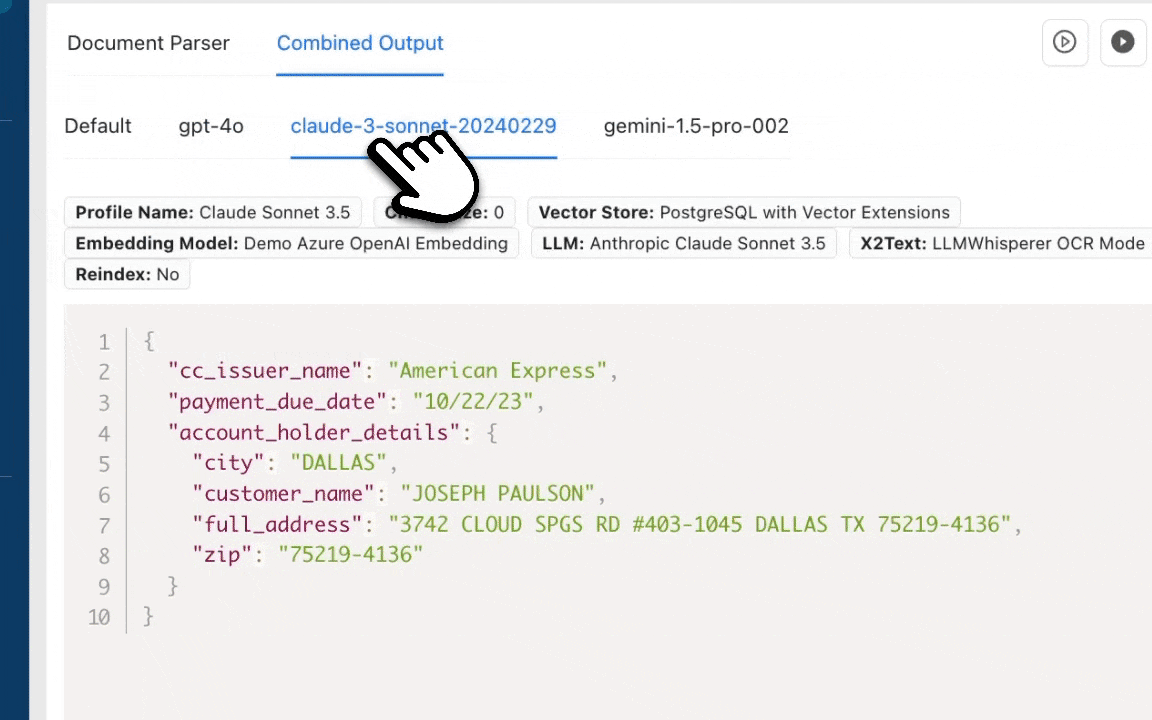
Contract Agreement (Playground Demo)
To show how AI can handle real legal documents, we tested a contract agreement inside the LLM Whisperer Playground.
This franchise disclosure document presented multiple extraction challenges:
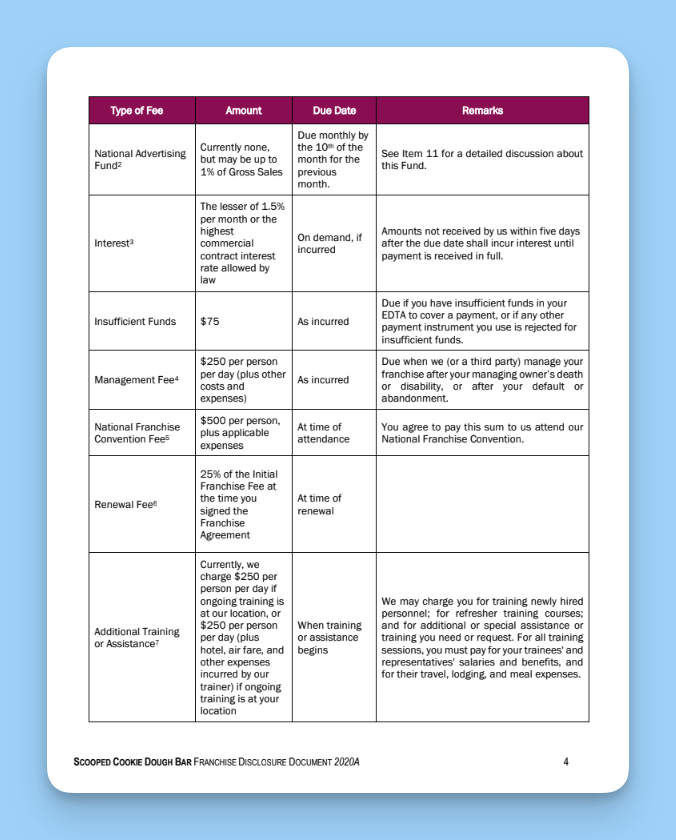
Figure 1: Challenges in the Franchise Contract Agreement
Dense tabular data: Sections like “Item 5: Initial Fees” and “Item 6: Other Fees” contain tables mixing numeric values, fee types, due dates, and remarks. Traditional OCR tools often lose these structures or merge cells incorrectly.
Multi-level formatting: The document uses bold headings, nested lists, and cross-references (e.g., “See Item 11”), which can easily confuse standard parsing models.
Legal definitions: Terms such as “Gross Sales,” “Development Fee,” and “Royalty Fee” carry specific contextual meaning that AI models must interpret precisely.
Scanned quality issues: Variations in spacing and alignment across pages add to the complexity.
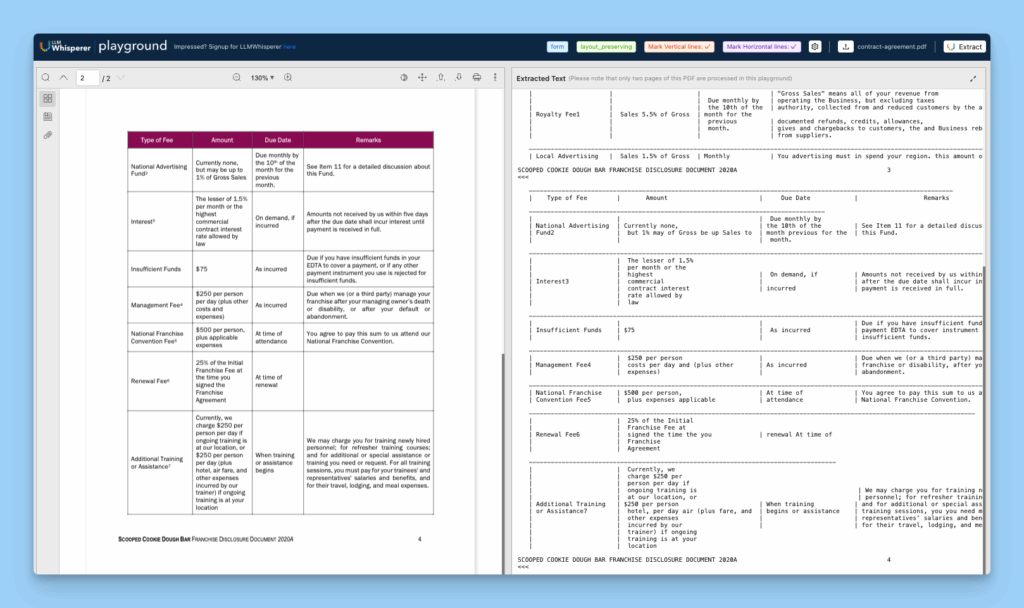
Here is the extracted data using the LLMWhisperer playground:
LLMWhisperer: Best OCR for Legal Document Processing
The Playground helps address these issues by combining layout-aware OCR with LLM-friendly text parsing. Instead of simply pulling raw text, it preserves the spatial arrangement and formatting of the original document, allowing downstream models to understand context.
For example, associating “Royalty Fee” correctly with 5.5% of Gross Sales” and “Due monthly by the 10th.
Credit Application (API + Postman Demo)
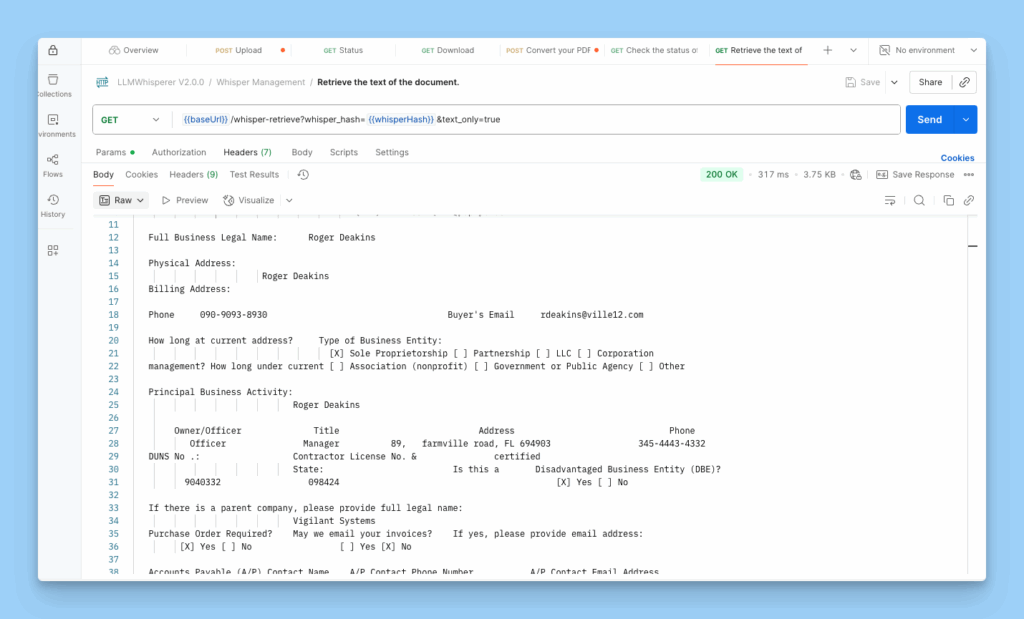
We start with LLMWhisperer to extract text and structure from the Credit Application document.
Its advanced OCR and layout-aware parsing ensure that every field, like company name, contact details, and compliance information, is captured accurately from the scanned form.
Next, we move to Prompt Studio to apply targeted extraction prompts that identify key details such as business name, officer information, and credit terms. These prompts convert the parsed document into structured fields, ready for validation and seamless API deployment.
Prompts we used for data extraction include:
Prompt 1
Extract the Business Name, Owner/Officer Name, and Phone Number from this credit application.
Prompt 1
Extract the Purchase Order Requirement (Yes/No), DBE Certification Status, and Signature Date from this document.
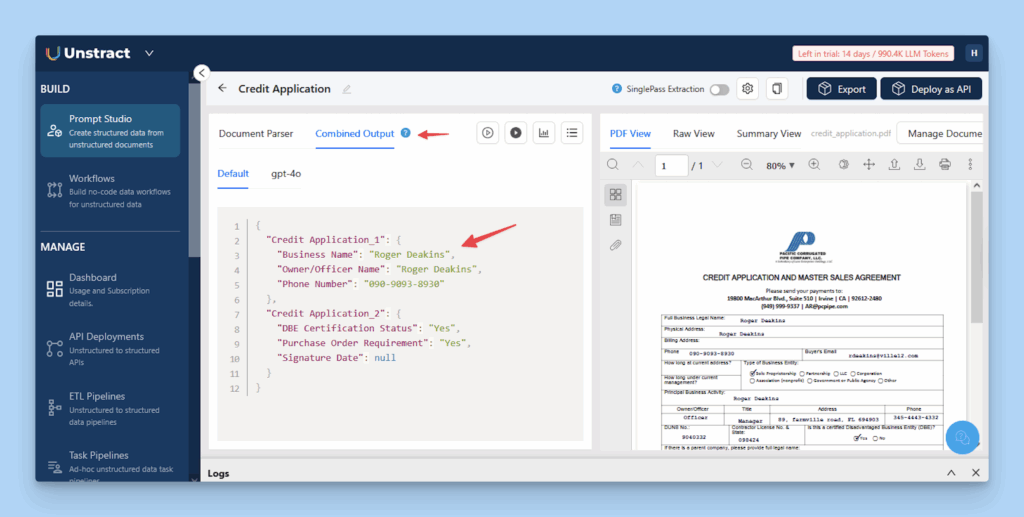
The combined result is shown below:
Prompt Studio Structured Extraction Output in Unstract
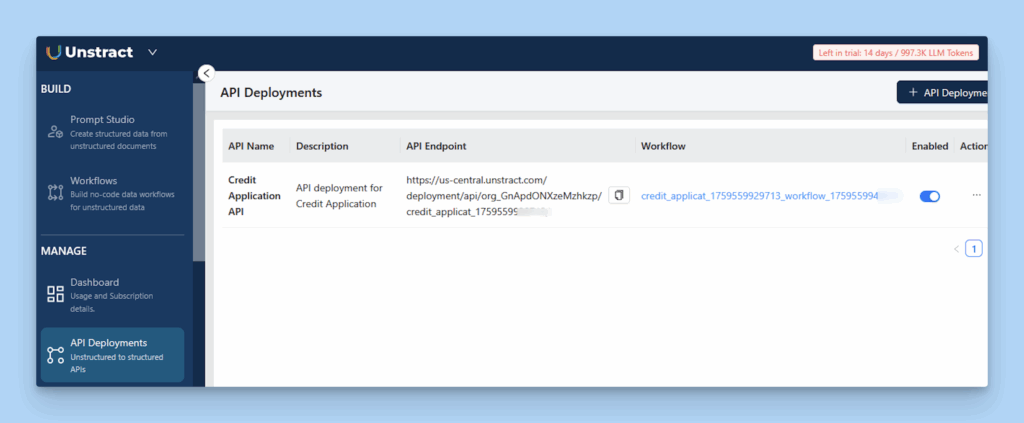
After validating the extracted data, you can directly deploy the workflow as an API within Unstract.
This allows users to send documents through Postman or other platforms and instantly receive structured JSON outputs, enabling seamless integration into existing automation pipelines.
Unstract Interface Showing an Active API Deployment for a Credit Application Workflow Enabling Real-Time Data Extraction.
Once the API is deployed from Unstract, a shareable API link is generated for external access.
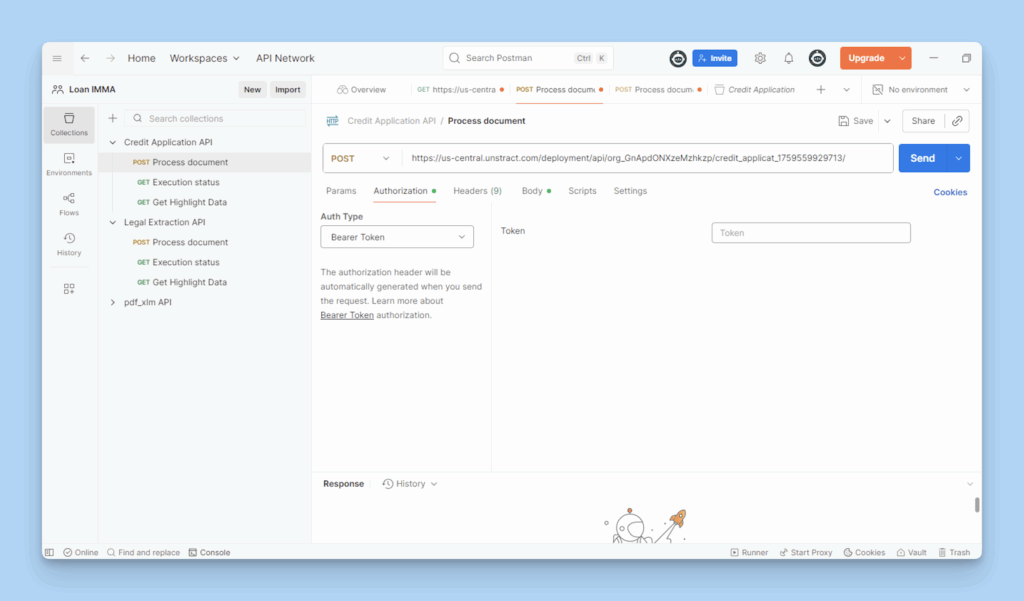
Open Postman and import the collection exported from Unstract, which automatically loads the API endpoints and request structure.
Next, navigate to the Authorization tab and select the Bearer Token type.
API KEY: Setting the Authorization as Bearer Token for Postman API
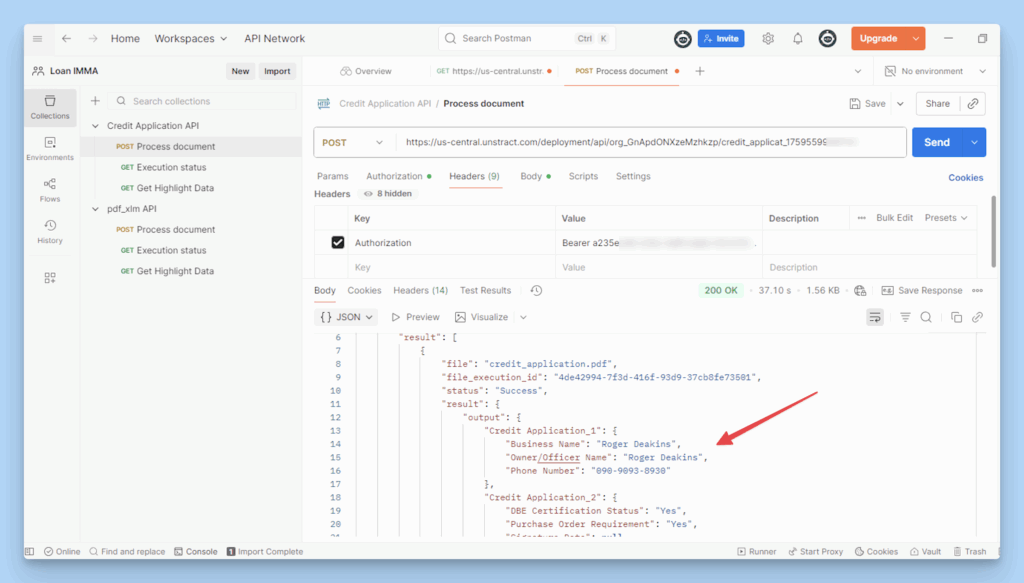
Finally, hit Send to trigger the request. Postman will return the extracted financial data in a clean, structured JSON format, verifying that your Unstract API workflow is live and functioning as expected.
Postman Interface Showing API Execution for a Credit Application Workflow Returning Structured JSON Output.
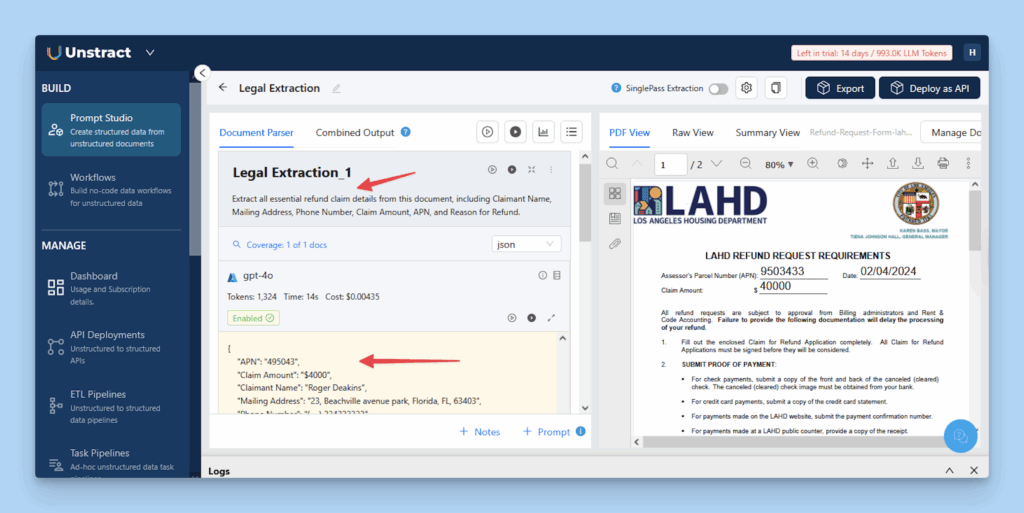
The LAHD Refund Request Form is a structured legal document used to claim refunds for overpayments or billing corrections. It contains key fields like APN, Claim Amount, and Reason for Refund, along with certification and signature details.
Accurate data extraction is crucial, as even minor errors, such as a missing APN or incorrect amount, can delay or invalidate the claim.
Next, we move into Prompt Studio to write and test custom prompts that define exactly what data needs to be extracted from legal documents.
Prompt 1
Extract all essential refund claim details from this document, including Claimant Name, Mailing Address, Phone Number, Claim Amount, APN, and Reason for Refund.
Prompt 2
Extract Date Paid, Payment Amount, Certification Statement, and Signature Details (Name and Date) from this refund request form.
The output on the prompt studio looks like this:
Refund Request Form Processed in Unstract, Displaying Extracted Claim Details Converted into Structured JSON Output.
Output of the first prompt in JSON format:
JSON
{
"APN": "495043",
"Claim Amount": "$4000",
"Claimant Name": "Roger Deakins",
"Mailing Address": "23, Beachville avenue park, Florida, FL, 63403",
"Phone Number": "( ) 234322323",
"Reason for Refund": [
"Overpayment or Billing Errors: Double billing or incorrect fee assessments",
"Security Deposit Disputes: Unfair deductions for damages you didn't cause",
"Failure to Provide Promised Amenities: Advertised facilities (Wi-Fi, laundry, security) were unavailable."
]
}
Output for second prompt:
JSON
{
"Certification Statement": "I hereby certify that the above statements are true.",
"Date Paid": "09/02/2023",
"Payment Amount": "20000",
"Signature Details": {
"Date": "02/09/2024",
"Name": "Roger Deakins"
}
}
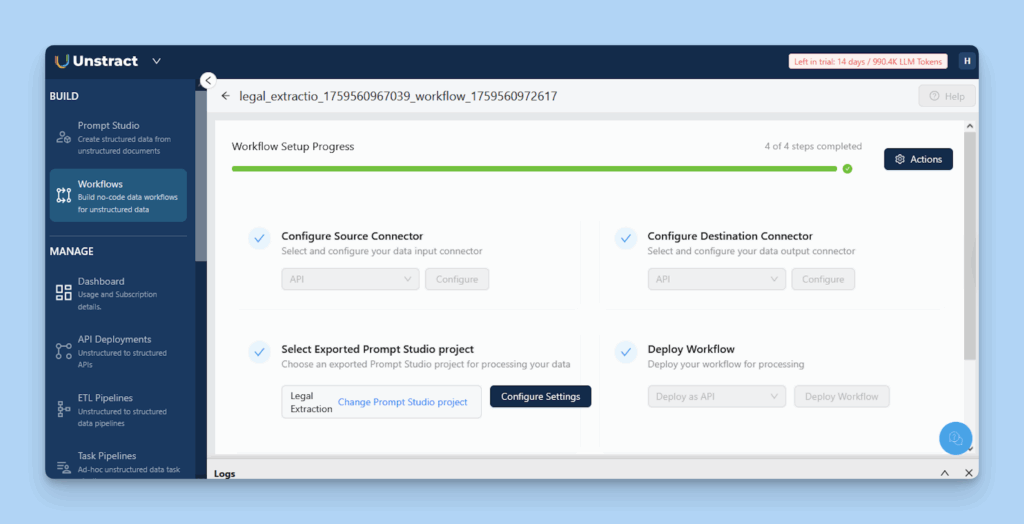
If you want to manually set up the API in Unstract, follow these steps:
Open Workflows and select your exported Prompt Studio project.
Set the Source Connector to API and the Destination to API/JSON.
Click Configure Settings to review the output schema and authentication.
Choose ‘Deploy as API’, and Unstract will generate the endpoint URL and access token automatically.
Workflow Setup Progress in Unstract, Showing Configuration of Source, Destination, and Prompt Studio Connectors for Deployment.
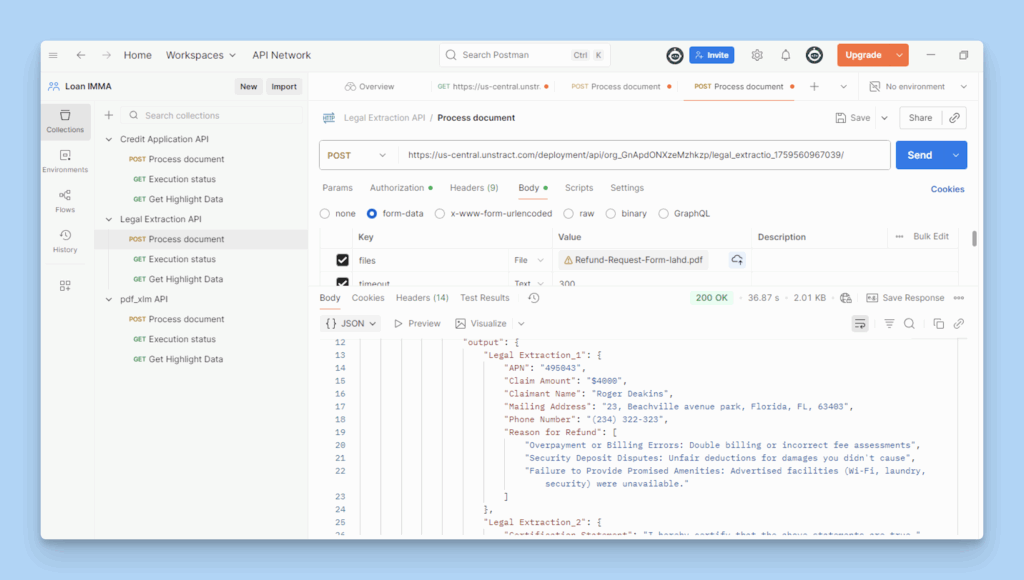
Once the API is deployed in Unstract, you can test it using Postman, a popular tool for sending and verifying API requests.
Postman allows you to easily connect to the Unstract endpoint, add authentication tokens, and upload legal documents to view how the extracted data is returned as structured JSON.
Postman Dashboard Executing Legal Extraction API and Returning Structured JSON Data for a Refund Request Document.
With the extracted JSON results now visible in Postman, the end-to-end workflow is complete. This shows how Unstract automates complex legal data extraction with precision, reducing manual effort and ensuring every clause, field, and value is captured accurately.
Such automation empowers legal and compliance teams to work faster, minimize errors, and make data-driven decisions with confidence.
Legal AI: What’s next?
Legal teams face mounting pressure to process vast volumes of contracts and compliance documents faster and with fewer errors. AI-powered platforms like Unstract and LLMWhisperer enable the transformation of unstructured text into structured, actionable data in minutes.
Ready to see AI transform legal work? Try it yourself by testing contracts in Playground, building smart prompts in Prompt Studio, or launching your own API with Postman.
AI-powered legal document data extraction: Related topics to explore
What do we mean by “AI legal document extraction,” and how does Unstract deliver it?
AI legal document analysis is the use of OCR, embeddings and large language models to read, interpret and cross-reference clauses, dates, amounts and obligations hidden in contracts, filings or scanned forms. Unstract combines LLMWhisperer OCR with prompt-driven extraction so the platform not only converts images to text but also highlights risks, summarizes key terms and sends the insights to downstream systems in minutes.
How does Unstract perform accurate legal document data extraction when files are PDFs, scans or handwritten?
Unstract’s pipeline starts with layout-aware OCR that keeps tables and multi-column text intact, then feeds the output to an LLM that is fine-tuned for legal document data extraction. Whether the source is a faxed credit application or a 300-page M&A agreement, the system pulls out parties, effective dates, termination clauses and more with high precision.
Can Unstract act as a stand-alone legal document processor inside my existing tech stack?
Yes. You can ingest documents via API, let Unstract parse and structure them, and then push the JSON to CLM, DMS or BI tools. Because the platform functions as a no-code legal document processor, legal teams can build, test and deploy extraction workflows without writing backend code.
Which stages of legal document processing are automated by Unstract?
Unstract automates the full legal document processing lifecycle: 1) intake and OCR, 2) layout-aware document parsing, 3) prompt-based extraction, 4) human-in-the-loop validation, and 5) export to data warehouses or vector databases for search and analytics. The result is faster review cycles, lower costs and higher accuracy.
Why use specialist legal contract extraction services instead of generic LLM APIs?
Generic models often hallucinate or lose table structure, leading to compliance risks. Purpose-built legal contract extraction services like Unstract add layout-aware OCR, prompt version control, vector search and human review. That domain focus yields consistent clause-level accuracy and audit trails demanded by legal and regulatory teams.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Salman Haider is a technical content writer focused on AI, machine learning, and data-driven innovation. He bridges the gap between complex technology and clear communication, using data storytelling to turn insights into compelling narratives. With a passion for simplifying advanced concepts, his work empowers businesses to make smarter, evidence-based decisions.