
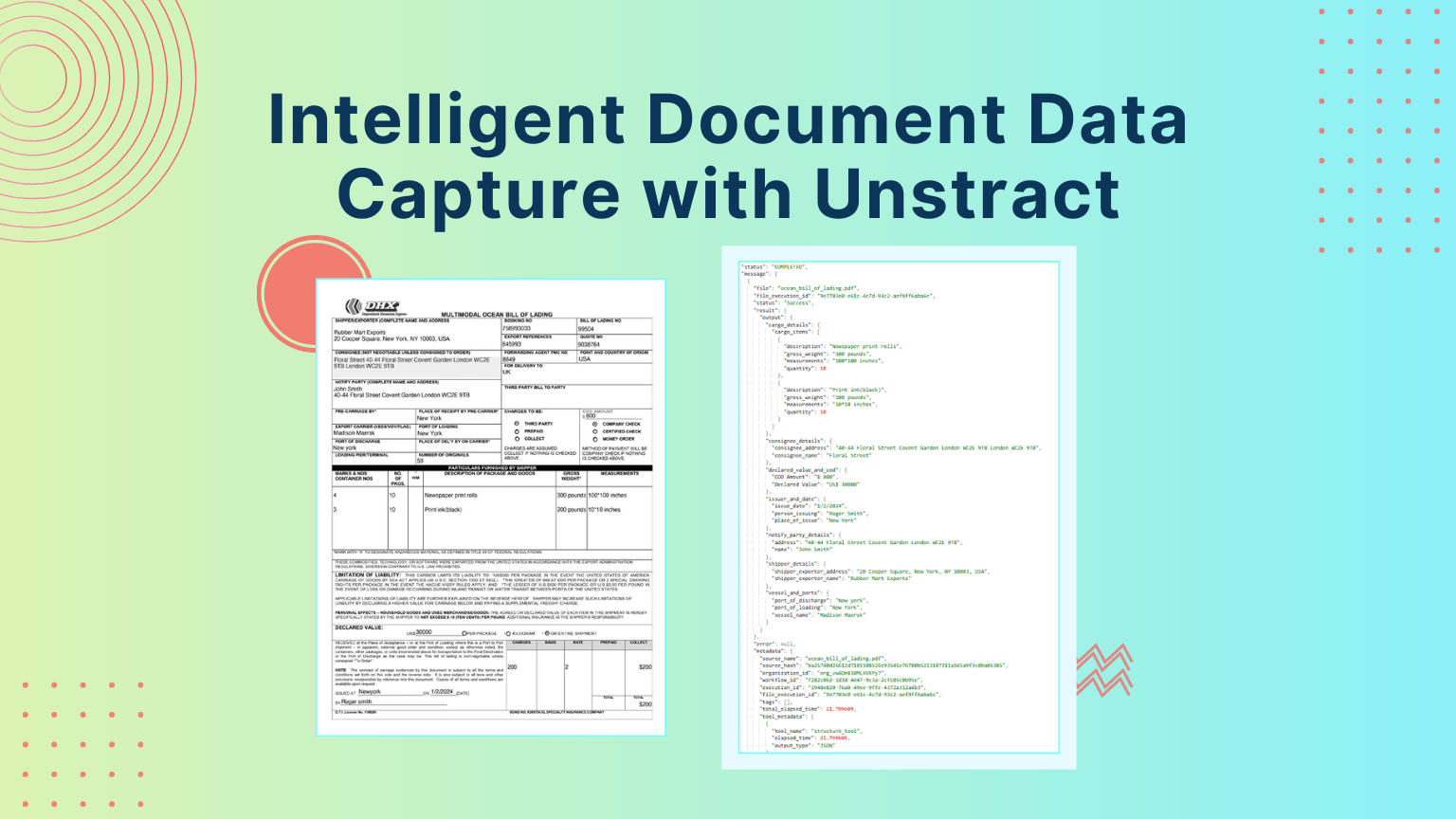
1. Introduction
In today’s fast-paced, data-driven world, businesses across industries are drowning in documents — invoices, contracts, forms, claims, bills of lading, financial reports, and countless others. For decades, teams have relied on manual review or outdated scanning tools to process these records, but these methods are slow, error-prone, and costly to scale. The growing volume and complexity of documents have created an urgent demand for automation in document-heavy industries.
This is where intelligent document capture (IDC) is transforming the game. Instead of simply digitizing paper into flat images, IDC goes several steps further — extracting structured, actionable data with high accuracy and context-awareness. IDC is no longer a “nice-to-have” but a crucial capability for modern businesses that want to boost productivity, reduce compliance risks, and make faster, data-backed decisions.
With IDC, organizations can process thousands of documents in minutes, ensure consistency across teams, and integrate extracted data directly into ERP, CRM, or analytics systems. The result? Lower costs, higher accuracy, and more agile business operations.
Unstract and LLMWhisperer are leading this transformation with a next-generation document capture software stack. Together, they offer a zero-code, enterprise-ready solution that can capture documents of any type — scanned, handwritten, tabular, or multi-format PDFs — and turn them into clean, structured data instantly. Unstract’s LLM-powered extraction engine understands the meaning behind the text, while LLMWhisperer ensures perfect OCR and layout preservation, making them one of the most advanced document capture solutions available today.
2. What is Intelligent Document Capture (IDC)?
Intelligent Document Capture refers to the process of automatically identifying, reading, and extracting relevant data from physical or digital documents, transforming them into structured formats ready for business use. Unlike traditional scanning tools that simply create a digital image of a document, IDC applies advanced technologies such as optical character recognition (OCR), machine learning (ML), and large language models (LLMs) to understand context, preserve layout, and ensure accuracy — even with complex, unstructured, or poorly formatted inputs.
The scope of document capture within IDC includes:
- Scanning and digitizing paper-based records.
- Extracting field-level data from forms, contracts, or reports.
- Handling multiple file types — PDFs, images, faxes, or emails.
- Preserving multi-column layouts, tables, and footnotes.
- Integrating the extracted data directly into business workflows.
How IDC Differs from Basic OCR and Traditional Scanning
Basic OCR tools simply read characters from an image and output plain text, often losing structure and misreading figures in complex tables. Traditional document capture software requires manual template creation or fixed rules to work effectively — meaning each new format requires reconfiguration.
In contrast, intelligent document capture solutions go beyond text recognition. They:
- Understand semantic context (e.g., distinguishing “Total Liabilities” from “Current Liabilities”).
- Adapt dynamically to new layouts without retraining.
- Extract only relevant data fields, not just raw text.
- Deliver results in structured formats like JSON or Excel for immediate integration.
TL;DR
If you’d like to jump straight to the solution section and see Unstract and LLMWhisperer’s intelligent document capture in action, click here.
IDC as Part of Digital Transformation
As organizations embrace digital transformation, capturing documents is no longer about archiving — it’s about unlocking the value hidden within unstructured data. IDC enables:
- Faster decision-making through instant access to accurate data.
- Operational efficiency by automating repetitive document handling.
- Regulatory compliance via accurate, traceable, and timestamped extractions.
Modern IDC powered by AI, like Unstract + LLMWhisperer, turns document processing from a manual bottleneck into a strategic advantage, empowering businesses to process information at scale and stay ahead in competitive markets.
3. Business Applications of Document Data Capture
While intelligent document capture (IDC) technology can be applied to virtually any industry that deals with unstructured or semi-structured documents, there are several sectors where the benefits are transformative. These are industries where document volume is high, formats are varied, regulatory oversight is strict, and speed + accuracy are critical for operations.
Below, we explore four major sectors — finance, insurance, logistics, and real estate — to understand how document capture solutions like Unstract + LLMWhisperer revolutionize their workflows.
3.1 Finance
Finance is one of the most document-intensive industries in the world. From loan processing to compliance reporting, financial institutions handle millions of pages of paperwork every month.
Types of Documents Processed
- Invoices – Vendor bills, supplier invoices, and internal purchase requests.
- Loan Documents – Loan applications, term sheets, mortgage agreements, credit reports.
- Receipts – Expense receipts for corporate cards, petty cash vouchers, and proof of payment slips.
- Regulatory Filings – Quarterly statements, tax forms, compliance disclosures.
Why Document Capture is Critical in Finance
- Speed in Financial Transactions: Delays in invoice processing or loan approvals directly impact cash flow and customer satisfaction.
- Regulatory Compliance: Financial regulators demand audit-ready records; errors in extraction can lead to fines or failed audits.
- Fraud Detection: Context-aware document capture software can flag suspicious inconsistencies, such as mismatched amounts between invoices and receipts.
Example Workflow: Invoice Processing with IDC
- Document Intake – Invoices are received via email, scanned from paper, or uploaded as PDFs.
- Preprocessing with LLMWhisperer – OCR ensures perfect text recognition while preserving the invoice’s tabular format (e.g., line items, totals, taxes).
- AI Extraction in Unstract – The LLM-powered engine identifies and extracts fields such as vendor name, invoice number, payment terms, and line-item details.
- Validation – Human-in-the-loop review for flagged anomalies.
- ERP Integration – Structured JSON is pushed to SAP, Oracle Financials, or QuickBooks automatically.
3.2 Insurance
Insurance is a paperwork-heavy business involving policies, claims, customer forms, and regulatory filings.
Types of Documents Processed
- ACORD Forms – Standardized forms for insurance applications, policy changes, and endorsements.
- Claim Summaries – Adjuster reports, damage estimates, settlement calculations.
- Underwriting Reports – Risk assessments, health declarations, inspection documents.
- Regulatory Compliance Forms – State-mandated filings, financial solvency reports.
Pain Points with Traditional Document Capture
- Variety of Formats: Even standardized ACORD forms can vary in layout depending on the insurance carrier’s systems.
- Manual Data Entry: Claims adjusters often retype information into claim management software, wasting hours daily.
- Error-Prone: Small mistakes can lead to claim disputes or payment delays.
How Intelligent Document Capture Solves This
- Form-Aware OCR: LLMWhisperer ensures that checkboxes, multi-section forms, and hand-filled data are accurately captured.
- Contextual Understanding: Unstract recognizes field meaning — it knows “Insured Name” is different from “Policyholder’s Agent Name” even if they appear close on the page.
- Direct Integration: Captured data flows into insurance CRM or claims management systems without manual rekeying.
3.3 Logistics
In logistics and supply chain management, speed is everything. Documents like bills of lading, customs declarations, and shipping manifests are mission-critical for moving goods across borders.
Types of Documents Processed
- Bills of Lading – Proof of cargo shipment with details of shipper, consignee, goods, and conditions.
- Shipping Documents – Airway bills, cargo manifests, and delivery receipts.
- Customs Documentation – Import/export declarations, duty payment receipts.
- Freight Invoices – Charges for transportation, warehousing, and handling.
Workflow Example: Bill of Lading Processing
- Capture Documents – Bills of lading received in paper or PDF format are scanned/uploaded.
- Pre-Capture OCR with LLMWhisperer – Extracts structured data while keeping table columns aligned.
- AI-Powered Field Extraction in Unstract – Prompts pull shipper/consignee names, port of loading, container numbers, HS codes, charges.
- ETL Process – Data is transformed into structured output for integration with supply chain management systems like SAP TM or Oracle SCM.
Impact
- Reduces customs clearance delays.
- Cuts data entry errors that can lead to misrouted shipments.
- Speeds up freight invoice reconciliation.
3.4 Real Estate
Real estate transactions involve large volumes of agreements, financial statements, and property records.
Types of Documents Processed
- Rent Rolls – Lists of tenants, rental amounts, and lease terms.
- Property Forms – Deed records, zoning compliance forms, building inspection reports.
- Mortgage Agreements – Loan terms, interest rates, repayment schedules.
- Appraisal Reports – Market value estimates, comparable sales data.
IDC Advantages in Real Estate
- Tenant Data Extraction: Quickly populate property management systems with rent roll information.
- Faster Closings: Automated extraction of loan and property details speeds up mortgage approvals.
- Regulatory Compliance: Ensures property-related filings are complete and accurate for municipal authorities.
4. Advantages of Intelligent Document Capture
IDC offers far more than just faster document scanning. It is a strategic enabler for businesses aiming to modernize workflows, cut costs, and improve compliance.
4.1 Faster Turnaround and Reduced Manual Effort
Manual document processing often involves printing, sorting, and retyping information — a labor-intensive cycle prone to bottlenecks. Intelligent document capture solutions streamline this by:
- Processing hundreds of pages per minute.
- Extracting data without human intervention.
- Automatically routing results to the right system.
For example, a bank using IDC for loan document capture reduced average processing time from 72 hours to under 4 hours.
4.2 Context-Aware and Layout-Preserving Extraction
Legacy OCR tools often flatten complex documents, making tables unreadable. In contrast, document capture software like Unstract + LLMWhisperer:
- Preserves Layout: Maintains the position of columns, headers, and footnotes.
- Understands Context: Knows the difference between “Billing Address” and “Shipping Address” even if they are formatted similarly.
This ensures higher accuracy for documents like ACORD insurance forms or bills of lading, where positional relationships are critical.
4.3 Cost Efficiency and Compliance Readiness
Cost Efficiency
- Reduces headcount needed for manual data entry.
- Lowers error-related rework costs.
- Scales without requiring additional infrastructure.
Compliance Readiness
- Automatically logs extraction metadata for audits.
- Ensures consistent data quality for regulatory reporting.
- Minimizes the risk of non-compliance penalties.
4.4 Why Businesses Choose Modern IDC Solutions
- No Templates Needed: Adapts to new formats without retraining.
- Integrates with Any System: From ERP to analytics platforms.
- Handles Any Document Type: From receipts to complex multi-page contracts.
- Global Scalability: Works across geographies, vendors, and languages.
5. Traditional IDC Approaches and Their Limitations
Before the arrival of AI-powered intelligent document capture, most organizations relied on traditional document capture solutions built on static rules, manual annotation, and template-driven OCR systems. These older methods offered basic digitization capabilities but were often rigid, costly, and slow to adapt to new document formats.
How Traditional IDC Worked
Historically, document capture software operated in a highly structured manner:
- Manual Annotation & Template Creation – A team of data entry operators or analysts would annotate sample documents line by line, mapping fields (e.g., “Invoice Number,” “Date,” “Total Amount”) to predefined locations on the page.
- ML/NLP Model Training – Machine Learning (ML) or Natural Language Processing (NLP) pipelines were then trained on these annotated datasets. Named Entity Recognition (NER) models were built to detect specific terms or values.
- Rule-Based Extraction – The trained models or scripts would extract data, but only if the incoming document matched the template or structure it was trained on.
- Post-Processing and Validation – Because template-based extraction was brittle, extracted data often required heavy manual verification and correction.
While this approach worked for static, high-volume, single-format documents (like utility bills or standardized forms), it struggled in dynamic, multi-format environments such as insurance claims, logistics reports, or global vendor invoices.
Limitations of the Traditional Document Capture Model
1. Scalability Challenges
- Every time a new document type was introduced, the capture system required new manual annotations and re-training of ML/NLP models.
- This made it nearly impossible to scale across multiple regions, vendors, or document variations.
2. High Resource Costs
- The labor involved in annotating documents line by line was expensive and time-consuming.
- Specialized teams were needed to maintain document capture software and keep rules/templates up to date.
3. Lack of Flexibility
- Even small changes in layout (e.g., an invoice where the “Total” field moved from bottom-right to top-right) could break extraction pipelines.
- The rigidity of templates meant organizations couldn’t easily capture documents from new vendors without downtime.
4. Slow Deployment
- Deploying a new extraction workflow could take weeks due to training, testing, and approval cycles.
- For industries like insurance or logistics, where documents change frequently, this delay could cause operational bottlenecks.
Example: Annotating Insurance Forms Line by Line
In the insurance sector, forms like ACORD claims reports often contain dozens of fields, checkboxes, and variable sections.
- In a traditional IDC setup, an insurance company might spend weeks annotating hundreds of forms just to build a model for one policy type.
- If the insurance provider updated its form layout, the entire model might need retraining — costing more time and money.
Traditional document capture solutions were a stepping stone in automation, but their dependence on manual annotation, static templates, and costly upkeep made them unsuitable for modern, fast-changing business environments.
6. The Modern Approach: AI-Powered Document Capture
The limitations of the legacy model gave rise to AI-powered intelligent document capture, where Large Language Models (LLMs) and context-aware extraction replace rigid templates and static training. Platforms like Unstract, paired with LLMWhisperer, are now redefining what’s possible in document capture software.
How LLMs Simplify Intelligent Document Capture
Unlike template-driven systems, AI-powered document capture solutions can process varied document formats without prior exposure to their layouts. This is possible because LLMs understand both the content and the context of the text, rather than relying solely on fixed positional rules.
Key Benefits of the Modern AI-Driven Model
1. No Training Data Required
- Businesses no longer need to collect and annotate hundreds of sample documents.
- A new document type (e.g., a different vendor’s invoice or a new bill of lading format) can be processed instantly by defining extraction prompts in natural language.
- This drastically reduces onboarding time for new document sources.
2. Works Across Varied Formats and Layouts
- Whether it’s a scanned ACORD form, a multi-page PDF bill of lading, or a handwritten rent roll, the intelligent document capture engine adapts instantly.
- LLMs can interpret different table structures, section headings, and even slightly distorted scans without retraining.
3. Context-Aware Intelligent Data Extraction
- Traditional OCR might capture “$1,500” without knowing if it’s a total invoice value or a partial payment amount.
- AI-powered document capture software uses semantic cues from surrounding text to determine meaning.
- For example, in a logistics document, it can distinguish between “Port of Discharge” and “Port of Loading” even if they are formatted similarly.
4. Scalable, Dynamic, and Highly Accurate
- AI-powered document capture solutions can scale to process millions of documents per month without manual intervention.
- Accuracy remains high even when handling multilingual documents or data with mixed formats (e.g., numeric + text fields).
Why This Modern Approach Outperforms Traditional Methods
| Factor | Traditional IDC | AI-Powered IDC |
| Setup Time | Weeks or months due to manual annotation | Minutes to hours with prompt-based setup |
| Adaptability | Limited to known layouts | Works on unseen formats instantly |
| Accuracy | Depends on template match | Context-aware, layout-preserving |
| Scalability | Costly and resource-heavy | Cloud-native, API-deployable |
| Maintenance | High (requires re-annotation) | Low (prompt edits only) |
Example in Action:
A logistics company previously using traditional OCR spent 3–4 weeks onboarding each new freight partner’s bill of lading format. With Unstract + LLMWhisperer, they now simply upload a sample, create prompts like “Extract shipper name, consignee name, port of loading, container number, and freight charges”, and deploy — all in under a day.
Modern intelligent document capture solutions free businesses from the rigid, costly constraints of the past. By combining LLMWhisperer’s accurate, layout-preserving OCR with Unstract’s LLM-driven extraction, companies can capture documents at scale, across formats, with unmatched speed and accuracy — all without the burden of manual annotation or retraining.
7. Introducing Unstract: A Modern LLM-Powered IDC Platform
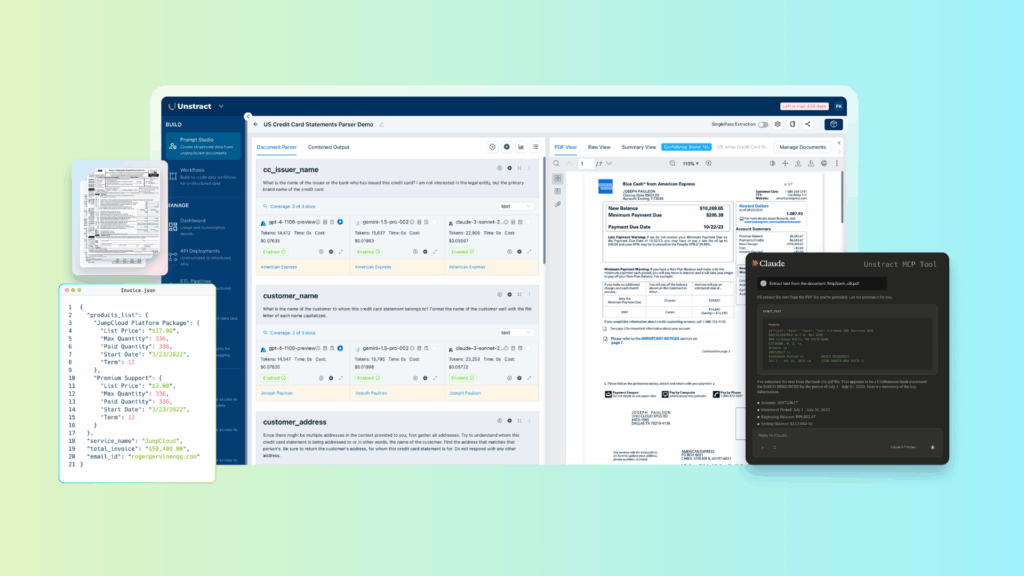
In today’s fast-moving, document-heavy industries, businesses need more than just basic scanning or template-based OCR — they need a platform that can capture documents from multiple sources, extract structured data in real time, and integrate seamlessly into existing enterprise workflows.
Unstract delivers exactly that. It’s a no-code, enterprise-ready intelligent document capture platform that combines Large Language Models (LLMs), embeddings, vector databases, and layout-preserving OCR through LLMWhisperer to redefine what’s possible in document processing.
Core Capabilities of Unstract
- No-Code Configuration
- Create, test, and deploy document capture workflows without writing a single line of code.
- Business analysts and operations teams can configure extraction logic directly through the UI.
- LLM-Driven Contextual Extraction
- LLMs are used to extract information from documents with an understanding of context, not just pattern matching.
- Works equally well for invoices, insurance forms, logistics documents, and real estate records — no retraining needed.
- Embeddings for Semantic Search & Matching
- Embedding models break down large documents into context-rich chunks for more accurate retrieval.
- Enables high-accuracy extractions even in multi-page, multi-section PDFs.
- Vector Database Integration
- Store and query vectorized document chunks for fast lookups and context preservation.
- Essential for scaling document capture solutions across hundreds of formats.
- OCR via LLMWhisperer
- Process scanned PDFs, faxes, and handwritten sections without losing layout or table structure.
- Ensures every downstream AI step starts with clean, structured, and complete text.
Key Differentiators
- Eliminates Manual Templates – No need for pre-designed form templates or field mapping.
- Handles Any Format – From neatly formatted Excel exports to scanned, skewed, or annotated PDFs, Unstract adapts instantly.
- No Training Data Required – Just load your document, write prompts in plain language, and extract.
- Natural Language Understanding – LLM-powered extraction identifies fields based on semantic meaning, not just position.
- High Accuracy & Layout Preservation – Retains table integrity, nested fields, and headings.
- Cost Efficiency at Scale – Lower operational costs compared to legacy document capture software because of minimal setup and maintenance overhead.
Why Businesses Choose Unstract for Intelligent Document Capture
For enterprises, Unstract is more than just a document capture solution — it’s a future-proof intelligent document capture system that integrates AI with practical business needs. Whether you need to process thousands of ACORD forms, extract cargo details from bills of lading, or digitize rent rolls, Unstract delivers speed, accuracy, and adaptability without the burden of heavy IT involvement.
8. Understanding LLMWhisperer

At the heart of Unstract’s preprocessing capabilities lies LLMWhisperer — a general-purpose text parser designed for layout-preserving OCR. Despite the name, it is not an LLM and does not use AI for parsing. Instead, it’s engineered to accurately extract text from complex, unstructured, or scanned documents while maintaining the original document’s structure.
Role of LLMWhisperer in IDC Workflows
When performing intelligent document capture, especially in industries like logistics, finance, or insurance, the first step is always the same: get clean, accurate text from the source file. This is where LLMWhisperer excels.
Its core functions include:
- Layout-Preserving OCR
- Retains the original arrangement of tables, columns, headings, and indents.
- Essential for extracting structured data from financial statements, bills of lading, or claims reports.
- Scanned Document Processing
- Reads skewed, rotated, or low-resolution scanned PDFs with minimal data loss.
- Useful for industries that still rely heavily on faxed or physical paperwork.
- Table & Grid Extraction
- Accurately identifies and retains multi-column tables — critical for invoices, rent rolls, and customs declarations.
- Handwritten Sections
- Can interpret printed handwriting for checkboxes, short notes, and form fields.
Why LLMWhisperer is Critical in IDC
Without accurate preprocessing, even the most advanced LLM-powered document capture software can produce incomplete or incorrect extractions.
- Garbage In, Garbage Out Principle – If an LLM receives distorted text, missing rows, or broken table structures, it cannot deliver accurate field extraction.
- Preserves Context for AI – LLMWhisperer ensures that every label, field, and number retains its spatial and logical relationship, giving LLMs richer context to work with.
- Universal Format Handling – It can capture documents from finance, insurance, logistics, and real estate without requiring different OCR engines.
Example in Practice:
When processing a bill of lading, LLMWhisperer will preserve:
- The full container list table with headers intact.
- Multi-page layouts without column merging errors.
- Notes and margin annotations from carriers or customs officials.
Only after this high-fidelity OCR step does Unstract’s LLM-based engine step in to extract structured, business-relevant data — ensuring accuracy, compliance, and minimal manual corrections.
In Summary:
- LLMWhisperer = Foundation Layer (accurate, layout-preserving OCR)
- Unstract = Intelligent Layer (context-aware LLM-powered extraction)
Together, they form a next-generation intelligent document capture solution that’s faster, more accurate, and more adaptable than any legacy document capture method on the market.
9. Testing LLMWhisperer
When evaluating any intelligent document capture solution, the first question is: Can it handle real-world imperfections?
Business documents are rarely perfect PDFs — they’re scanned at odd angles, contain handwriting, have overlapping lines, and sometimes use multi-column layouts that trip up traditional OCR engines.
LLMWhisperer was built to solve these problems at the OCR stage, before the extracted text even reaches an AI model. Below, we run two real-world tests:
Method 1: Playground Demo – Rent-Roll Scanned Document Extraction
The first test uses the LLMWhisperer Playground: https://pg.llmwhisperer.unstract.com/
Test Case: Rent-Roll Scan
- Source Document: Skewed by ~20°, printed and scanned
- Format: Multi-column property rent roll
- Challenges:
- Rotation & skew
- Multiple data tables with merged headers
- Small text in footers
- Numeric data closely packed with currency symbols
Steps:
- Open the LLMWhisperer Playground.
- Upload the Rent-roll scanned PDF.
- Wait for the OCR to complete, and view the output in the results panel.

Results:
| Test Case | Result |
| Rotated Scan | Successfully deskewed; content auto-aligned and fully readable |
| Table Extraction | Multi-column tables flattened logically with proper column order & alignment |
| Data Loss | 0% loss – Every table cell, label, and form field retained |
| Layout Preservation | Original structure maintained: columns, rows, headings, and sub-fields fully intact |
Why This Matters:
In intelligent document capture, even one missed invoice line item or a misread total can derail financial accuracy. LLMWhisperer ensures that every row, column, and field from scanned documents is preserved exactly, enabling flawless downstream AI extraction.
Method 2: API Demo (Postman) – ACORD Insurance Form Extraction
For development teams and automation workflows, LLMWhisperer is accessible as a REST API. This allows seamless integration into RPA bots, ERP systems, or custom pipelines.
Test Case: ACORD Insurance Form
- Source Document: Poorly aligned accord insurance form
- Challenges:
- Thick grid lines overlapping text
- Checkbox selections & multi-font formatting
- Nested address blocks
- Poor vertical/horizontal alignment
Setup Instructions:
- Sign Up & Get API Key
- Go to: https://unstract.com/start-for-free/
- Log in and navigate to API Keys in your dashboard.
- Copy your LLMWhisperer API Key.
- Open Postman
- Use either Postman Desktop or Web app.
- Configure Your API Request
- Method: POST
- URL: https://llmwhisperer-api.us-central.unstract.com/api/v2/whisper
- Headers: unstract-key: <YOUR API KEY>
- Body: Key: files
Type: File
Value: (Upload ACORD insurance form PDF)
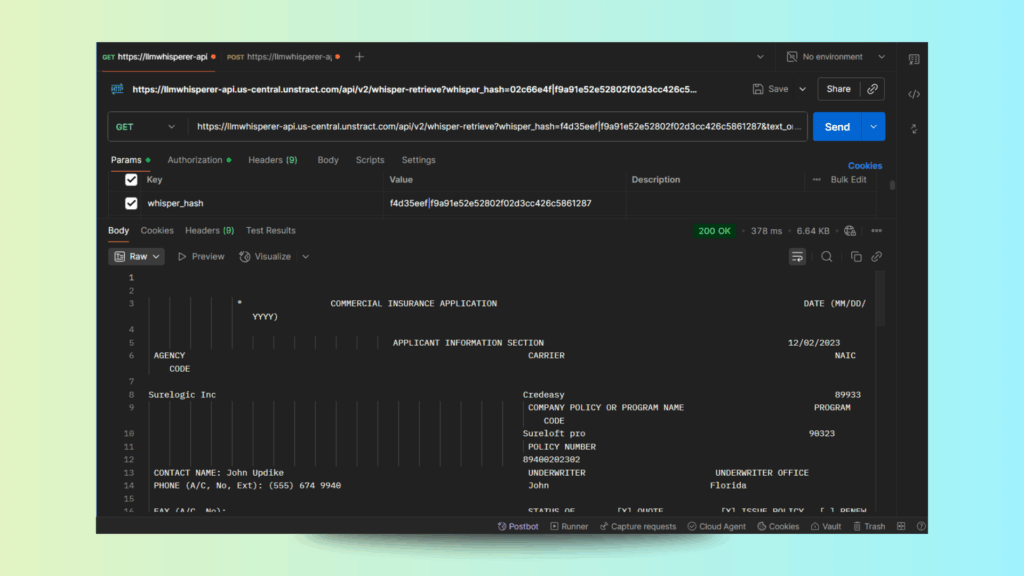
- Send the Request
- Click Send and wait for the OCR process to complete.
- The response will contain extracted text in layout-preserving mode.
- Check the Output
- Download or copy the output (example: response-acord-insurance-form.txt).
- You’ll see all sections — checkboxes, addresses, policy details, limits — perfectly captured despite grid lines and poor alignment.
® COMMERCIAL INSURANCE APPLICATION DATE (MM/DD/YYYY)
APPLICANT INFORMATION SECTION 12/02/2023
AGENCY CARRIER NAIC CODE
Surelogic Inc Credeasy 89933
COMPANY POLICY OR PROGRAM NAME PROGRAM CODE
Sureloft pro 90323
POLICY NUMBER
89400202302
CONTACT NAME: John Updike UNDERWRITER UNDERWRITER OFFICE
PHONE (A/C, No, Ext): (555) 674 9940 John Florida
FAX (A/C, No): STATUS OF [X] QUOTE [X] ISSUE POLICY [ ] RENEW
E-MAIL ADDRESS: [email protected] TRANSACTION [ ] BOUND (Give Date and/or Attach Copy):
CODE: 88499322 SUBCODE: [ ] CHANGE DATE TIME [X] AM
AGENCY CUSTOMER ID: [ ] CANCEL [ ] PM
LINES OF BUSINESS
INDICATE LINES OF BUSINESS PREMIUM PREMIUM PREMIUM
[ ] BOILER & MACHINERY $ $9000 [ ] CYBER AND PRIVACY $ [ ] YACHT $
[X] BUSINESS AUTO $ 89900 FIDUCIARY LIABILITY $ $
[ ] BUSINESS OWNERS $ GARAGE AND DEALERS $ $4000 $
[ ] COMMERCIAL GENERAL LIABILITY $ LIQUOR LIABILITY $ $
[ ] COMMERCIAL INLAND MARINE $ MOTOR CARRIER $ $
[ ] COMMERCIAL PROPERTY $ $900 TRUCKERS $ $3000 $
[ ] CRIME $ UMBRELLA $ $
ATTACHMENTS
[ ] ACCOUNTS RECEIVABLE / VALUABLE PAPERS GLASS AND SIGN SECTION STATEMENT / SCHEDULE OF VALUES
[ ] ADDITIONAL INTEREST SCHEDULE HOTEL / MOTEL SUPPLEMENT STATE SUPPLEMENT (If applicable)
[ ] ADDITIONAL PREMISES INFORMATION SCHEDULE INSTALLATION / BUILDERS RISK SECTION VACANT BUILDING SUPPLEMENT
[ ] APARTMENT BUILDING SUPPLEMENT INTERNATIONAL LIABILITY EXPOSURE SUPPLEMENT VEHICLE SCHEDULE
[ ] CONDO ASSN BYLAWS (for D&O Coverage only) INTERNATIONAL PROPERTY EXPOSURE SUPPLEMENT
[ ] CONTRACTORS SUPPLEMENT LOSS SUMMARY
[ ] COVERAGES SCHEDULE OPEN CARGO SECTION
[ ] DEALERS SECTION PREMIUM PAYMENT SUPPLEMENT
[ ] DRIVER INFORMATION SCHEDULE PROFESSIONAL LIABILITY SUPPLEMENT
[ ] ELECTRONIC DATA PROCESSING SECTION RESTAURANT / TAVERN SUPPLEMENT
POLICY INFORMATION
PROPOSED EFF DATE PROPOSED EXP DATE BILLING PLAN PAYMENT PLAN METHOD OF PAYMENT AUDIT DEPOSIT PREMIUM MINIMUM POLICY PREMIUM
DIRECT AGENCY Annual Credit card $ 10000 $1000 $500000
[X] [ ]
APPLICANT INFORMATION
NAME (First Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
Roger deakins 89933 7839232 898940 99403
345, Flower park avenue, Florida, FL 47873 BUSINESS PHONE #:
WEBSITE ADDRESS www.surelogic.com
[X] CORPORATION [X] JOINT VENTURE [ ] NOT FOR PROFIT ORG [X] SUBCHAPTER "S" CORPORATION [ ]
NO. OF MEMBERS PARTNERSHIP TRUST
[ ] INDIVIDUAL [ ] LLC AND MANAGERS: [ ] [ ]
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
BUSINESS PHONE #:
WEBSITE ADDRESS
[ ] CORPORATION [X] JOINT VENTURE [ ] NOT FOR PROFIT ORG [X] SUBCHAPTER "S" CORPORATION [ ]
NO. AND OF MEMBERS PARTNERSHIP TRUST
[ ] INDIVIDUAL [ ] LLC MANAGERS: [ ] [ ]
NAME (Other Named Insured) AND MAILING ADDRESS (including ZIP+4) GL CODE SIC NAICS FEIN OR SOC SEC #
BUSINESS PHONE #:
WEBSITE ADDRESS
[ ] CORPORATION [ ] JOINT VENTURE [ ] NOT FOR PROFIT ORG [ ] SUBCHAPTER "S" CORPORATION [ ]
[ ] INDIVIDUAL [ ] LLC AND NO. OF MANAGERS: MEMBERS [ ] PARTNERSHIP [ ] TRUST
ACORD 125 (2016/03) Page 1 of 4 1993-2015 ACORD CORPORATION. All rights reserved.
The ACORD name and logo are registered marks of ACORD
<<<
Why This Test Matters in Intelligent Document Capture
- No Missed Fields: Every policy number, date, and coverage limit appears exactly as in the original form.
- Robust Layout Handling: Complex tables and overlapping lines didn’t cause misreads or data shifts.
- AI-Ready Output: The clean, structured text can now be fed directly into Unstract’s LLM-based extraction without additional cleanup.
With this dual capability — Playground for quick visual testing and API for production integration — LLMWhisperer empowers teams to process scanned PDFs, faxes, and complex form layouts with enterprise-grade accuracy.
10. Using Unstract to Extract Data from a Bill of Lading
One of the standout capabilities of Unstract’s intelligent document capture software is its Prompt Studio—a completely no-code environment designed to extract structured data from even the most complex, multi-format business documents. For this walkthrough, we’ll use a Bill of Lading, which is known for having dense, multi-column layouts with shipping, financial, and cargo details scattered across sections.
Unlike traditional document capture solutions that require fixed templates or extensive manual annotation, Prompt Studio allows you to define semantic extraction rules in plain language. This makes it an ideal IDC workflow for logistics, freight forwarding, and supply chain automation.
Step-by-Step Setup for IDC Extraction in Prompt Studio
Step 1: Access Prompt Studio
- From the Unstract dashboard, select Prompt Studio from the left sidebar.
- This opens the drag-and-drop, visual prompt-building environment—your workspace for building an IDC pipeline without writing any code.
Step 2: Create a New Project
- Click New Project.
- Fill in the details:
- Tool Name: IDC Project – Bill of Lading
- Author: Your Name or Company Name
- Description: Extracting structured shipping, consignee, and cargo data from a Bill of Lading.
- (Optional) Upload an icon or company logo for branding.
- Click Save to create the project.
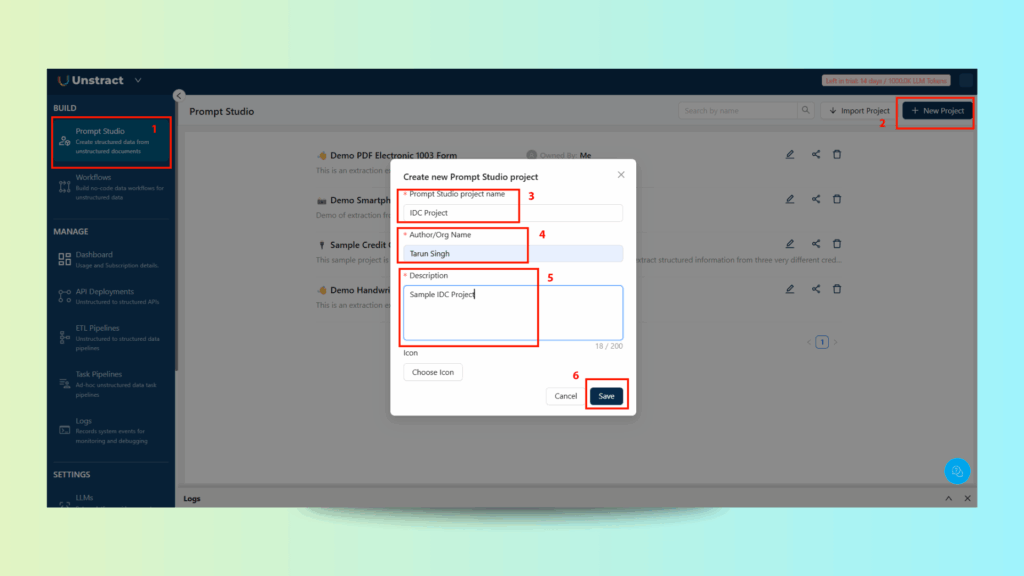
Step 3: Upload a Sample Bill of Lading
- Go to Manage Documents and upload ocean_bill_of_lading.pdf.
- This is a multi-column shipping document containing:
- Shipper and Consignee details
- Notify party information
- Vessel and port details
- Cargo list with weights and measurements
- Declared values and COD amounts
Step 4: Add Field-Level Prompts
In Prompt Studio, click Add Prompts and define your extraction fields in plain language.
Here’s an example list:
{
"shipper_details": "Extract the complete name and full address of the shipper/exporter exactly as mentioned in the document.",
"consignee_details": "Extract the complete name and full address of the consignee exactly as mentioned in the document.",
"notify_party_details": "Extract the complete name and full address of the notify party exactly as mentioned in the document.",
"vessel_and_ports": "Extract the vessel name, port of loading, and port of discharge from the document.",
"cargo_details": "Extract all listed cargo items along with their quantity, gross weight, and measurements.",
"declared_value_and_cod": "Extract the declared value for the shipment and any COD (Cash on Delivery) amount specified.",
"issuer_and_date": "Extract the name of the person issuing the Bill of Lading, the place of issue, and the issue date."
}
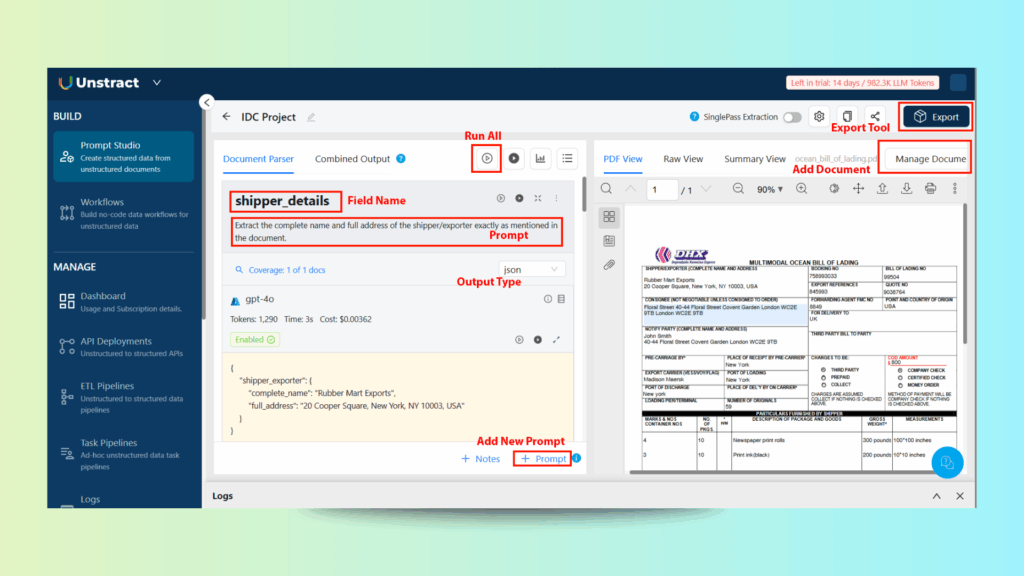
Step 5: Run & Validate
- Click Run.
- Within seconds, Prompt Studio returns structured JSON output with each field populated.
- Validate the extracted values against the PDF—ensuring zero data loss and layout preservation.
✅ Key Advantage: This method eliminates the need for manual templates while enabling context-aware extraction—capturing correct values even if they appear in varying formats or positions across documents.
Step 6: Export as a Reusable Tool
Once satisfied, click Export as Tool.
Your Bill of Lading extraction logic is now a reusable IDC engine that can be deployed to production workflows.
11. Deploying the Workflow as an API
Once the Bill of Lading extractor is ready, Unstract allows you to wrap it in a workflow and expose it as a secure API—making it easy to integrate with ERP systems, shipping management tools, or RPA bots.
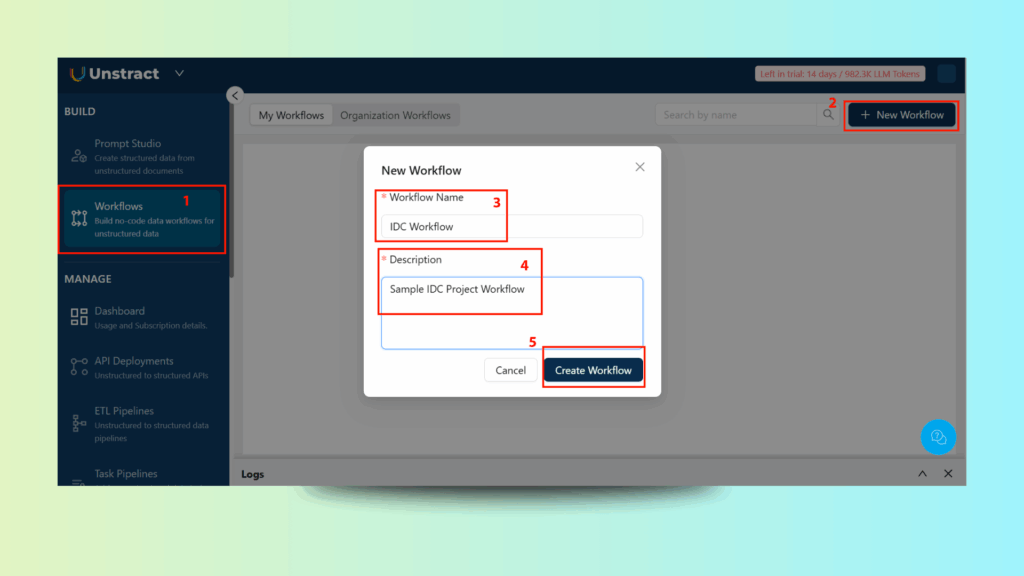
Step 1: Create the Workflow
- Go to Workflows in the dashboard.
- Click New Workflow and enter:
- Workflow Name: IDC Workflow – Bill of Lading
- Description: Automated Bill of Lading data extraction and JSON delivery.
- Click Create Workflow.
Step 2: Add Your Prompt Tool
- Drag and drop the Bill of Lading extraction tool (exported from Prompt Studio) into the workflow canvas.
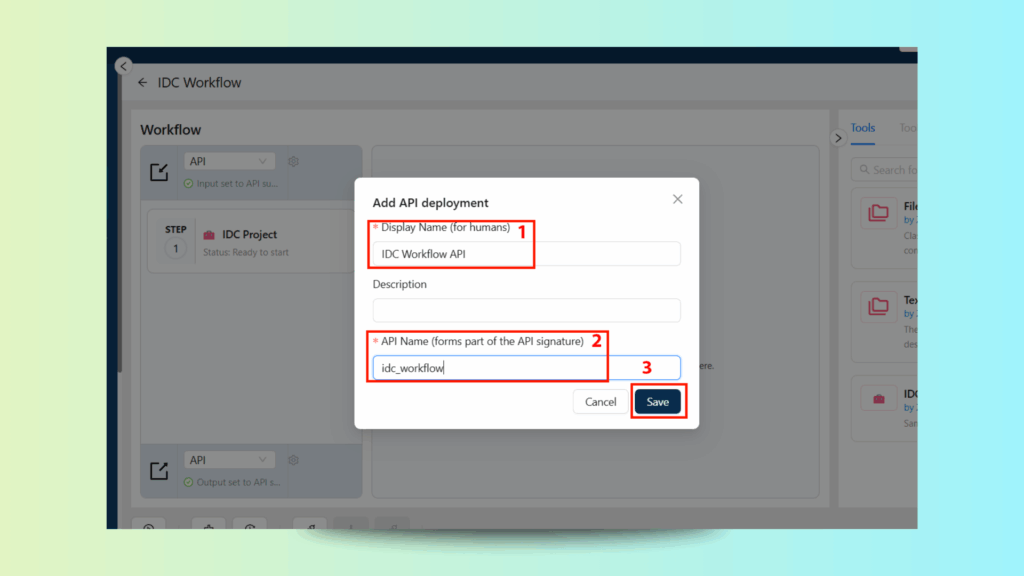
Step 3: Configure API Input & Output
- API Input Connector: Accepts PDFs via HTTP POST requests.
- API Output Connector: Returns clean, structured JSON for downstream processing.
- Click Save → Deploy API.
Step 4: Test the API via Postman
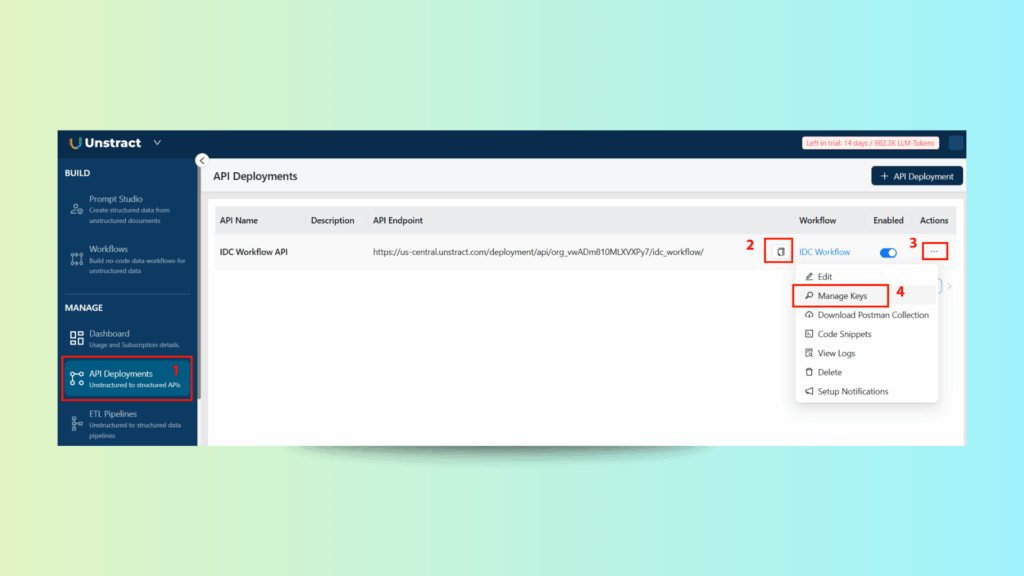
A. Get API Details
- In the API Deployment section, copy:
- Endpoint URL
- API Key (Manage Keys → Copy)
B. Configure the Postman Request
- Method: POST
- URL: (Paste API Endpoint)
- Authorization: Bearer Token → (Paste API Key)
- Body: form-data
- Key: files
- Type: File
- Value: (Upload ocean_bill_of_lading.pdf)
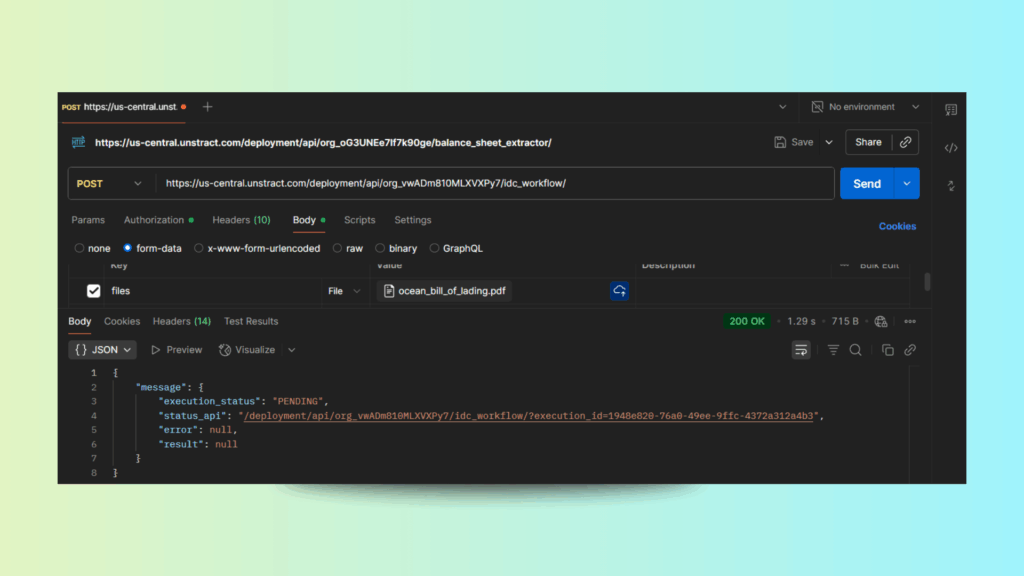
C. Send & Monitor
- Click Send.
- The initial response will show “status”: “executing” along with a status_api URL.
- Use this status URL in a GET request to check progress.
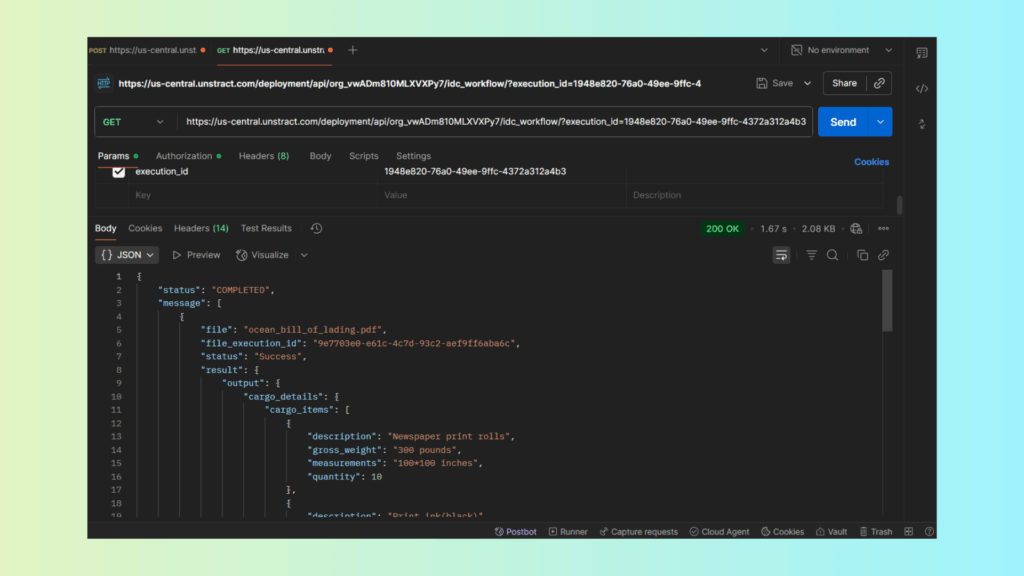
D. Retrieve Final JSON
- Once complete, the final response will include ocean_bill_of_lading.json with:
- Shipper details
- Consignee details
- Cargo list
- Ports and vessel info
- Declared value and COD
{
"status": "COMPLETED",
"message": [
{
"file": "ocean_bill_of_lading.pdf",
"file_execution_id": "9e7703e0-e61c-4c7d-93c2-aef9ff6aba6c",
"status": "Success",
"result": {
"output": {
"cargo_details": {
"cargo_items": [
{
"description": "Newspaper print rolls",
"gross_weight": "300 pounds",
"measurements": "100*100 inches",
"quantity": 10
},
{
"description": "Print ink(black)",
"gross_weight": "200 pounds",
"measurements": "10*10 inches",
"quantity": 10
}
]
},
"consignee_details": {
"consignee_address": "40-44 Floral Street Covent Garden London WC2E 9TB London WC2E 9TB",
"consignee_name": "Floral Street"
},
"declared_value_and_cod": {
"COD Amount": "$ 800",
"Declared Value": "US$ 30000"
},
"issuer_and_date": {
"issue_date": "1/2/2024",
"person_issuing": "Roger Smith",
"place_of_issue": "New York"
},
"notify_party_details": {
"address": "40-44 Floral Street Covent Garden London WC2E 9TB",
"name": "John Smith"
},
"shipper_details": {
"shipper_exporter_address": "20 Cooper Square, New York, NY 10003, USA",
"shipper_exporter_name": "Rubber Mart Exports"
},
"vessel_and_ports": {
"port_of_discharge": "New york",
"port_of_loading": "New York",
"vessel_name": "Madison Maersk"
}
}
},
"error": null,
"metadata": {
"source_name": "ocean_bill_of_lading.pdf",
"source_hash": "ba25740d26612d7181108526c93541e76780b5213107311a565a9f3c0ba06385",
"organization_id": "org_vwADm810MLXVXPy7",
"workflow_id": "f282c062-1d3d-4e47-9c3a-2cfc05c8b95e",
"execution_id": "1948e820-76a0-49ee-9ffc-4372a312a4b3",
"file_execution_id": "9e7703e0-e61c-4c7d-93c2-aef9ff6aba6c",
"tags": [],
"total_elapsed_time": 21.799609,
"tool_metadata": [
{
"tool_name": "structure_tool",
"elapsed_time": 21.799601,
"output_type": "JSON"
}
]
}
}
]
}
Result: You now have a fully functional document capture API for logistics workflows—zero code, 100% automation, and enterprise-grade accuracy.
12. Human-in-the-Loop in Unstract
In the world of intelligent document capture and document automation, speed and accuracy often go hand in hand—but in high-stakes industries like finance, insurance, logistics, and legal services, there’s a third equally critical factor: trust. This is where Human-in-the-Loop (HITL) in Unstract comes into play.
Unlike many document capture solutions that operate as black boxes, Unstract offers built-in HITL capabilities—ensuring that every automated workflow remains transparent, auditable, and fully controllable.
Why HITL Matters in Intelligent Document Capture
Even the most advanced AI systems face challenges with:
- Handwritten notes
- Low-quality scans
- Poorly formatted or tilted documents
- Unseen layouts and edge cases
In such situations, AI confidence scores drop, and automation without oversight can lead to costly errors. HITL ensures human reviewers step in precisely when needed, without slowing down the entire process.
Key Features of HITL in Unstract
- Built-in Review Controls
- Automatic routing of documents to human reviewers based on confidence scores, field-specific triggers, or business rules.
- Ability to create manual review checkpoints for critical fields such as names, account numbers, or financial amounts.
- Role-Based Access Management
- Assign roles like Reviewer, Supervisor, or Admin for controlled access.
- Enforce compliance by ensuring only authorized personnel can approve or modify extracted data.
- Flexible Workflow Routing
- Reviewed outputs can be:
- Sent to a secure database like NeonDB
- Pushed to processing queues
- Retrieved through secure API endpoints
- Reviewed outputs can be:
- Exception Handling for Low Confidence Outputs
- If the AI model flags uncertainty, HITL enables instant human validation—ensuring no incorrect data moves forward in the pipeline.
Benefits of HITL for Document Capture Workflows
- Accuracy Assurance: Manual validation catches errors before they impact financial records or compliance reporting.
- Compliance Readiness: Ensures extracted data meets legal and regulatory requirements, reducing audit risks.
- Adaptive Learning: Corrections from human reviewers can be logged to improve AI extraction accuracy over time.
- Business Decision Support: For workflows like loan approvals, insurance claims, and customs clearance, HITL allows humans to apply judgment that AI cannot replicate.
Example:
A blurry loan application comes in with a partially illegible Social Security Number. Unstract’s AI flags the field with low confidence. HITL routes it to a reviewer, who validates the correct number before the application moves to underwriting—avoiding delays, rejections, or compliance penalties.
HITL in Unstract is not just a fallback safety net—it’s an integrated trust mechanism that makes AI-powered document capture software truly enterprise-ready. It allows businesses to enjoy the speed and scalability of automation without sacrificing control, compliance, or quality.
13. Conclusion
The future of document automation belongs to platforms that combine AI-driven speed with human-level judgment—and Unstract + LLMWhisperer embody exactly that.
- Unstract delivers a no-code intelligent document capture platform that’s flexible, scalable, and capable of handling any document format—without templates, manual annotation, or training data.
- LLMWhisperer ensures layout-preserving OCR extraction that’s accurate even on scanned, rotated, or complex multi-column documents—providing a clean, structured base for AI to process.
- HITL workflows in Unstract guarantee that every piece of data is validated, compliant, and audit-ready, making it the most reliable document capture solution for modern enterprises.
Final Takeaway:
Intelligent Document Capture (IDC) is no longer just a tool for efficiency—it’s a strategic driver for business scalability, compliance readiness, and cost optimization. With Unstract + LLMWhisperer, companies can:
- Capture documents from any source
- Extract highly accurate, context-aware data
- Maintain full oversight with HITL
- Integrate seamlessly into ERP, finance, and operational systems
In an era where document capture software needs to be both fast and trustworthy, Unstract stands out as the complete AI-powered solution—turning unstructured data into business-ready intelligence.






















