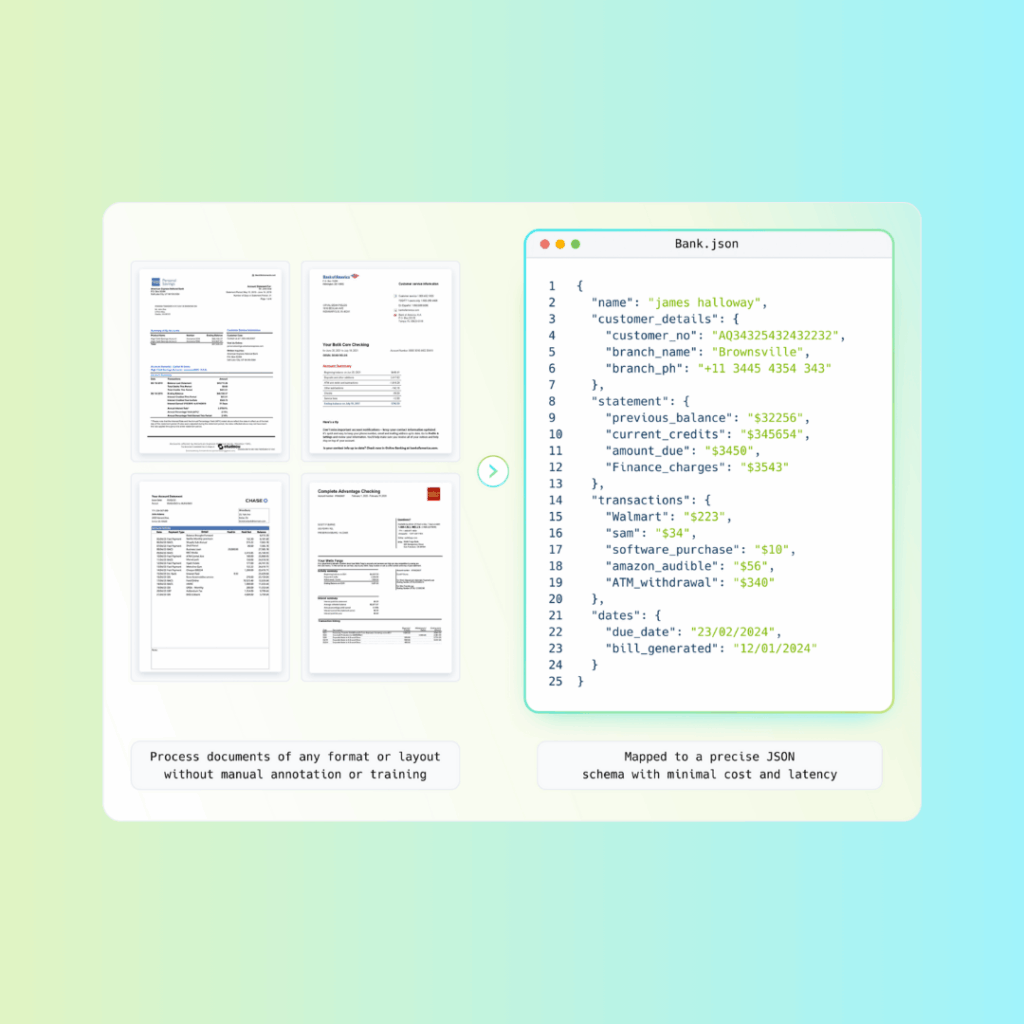
1. Introduction: The Need for Financial Statement Automation
In the world of corporate finance, financial statements are the bedrock of strategic decision-making, regulatory compliance, and investor communication. These documents—ranging from annual reports to balance sheets, income statements, and cash flow statements—capture the health and trajectory of a business in numbers and narrative. However, despite their importance, the process of extracting data from financial statements remains surprisingly manual and inefficient for many organizations.
Financial analysts, controllers, auditors, and CFOs often find themselves sifting through scanned PDFs of financial documents, struggling to copy-paste relevant figures, interpret handwritten notes, or reformat multi-column tables that don’t preserve alignment. This tedious process isn’t just time-consuming—it’s prone to errors, non-compliance risks, and data silos. When financial teams must process dozens—or hundreds—of quarterly reports, Form 10-Qs, or multi-entity income statements, the operational drag becomes massive.
This is where the need for financial document scanning and OCR in finance becomes critical. In this 2026 guide, we’ll show you how leading finance teams have replaced manual extraction with intelligent, AI-powered Unstract.
What is Financial Statement Processing?
Financial statement processing refers to the collection, parsing, and analysis of key values from financial reports. This includes extracting structured data from documents such as:
Annual Reports: Comprehensive overviews of a company’s financial activity and performance.
Quarterly Reports & Form 10-Q: Regulatory filings that provide periodic snapshots of financial position.
Balance Sheets: Highlighting assets, liabilities, and shareholder equity.
Income Statements: Detailing revenue, expenses, and net income.
Cash Flow Statements: Explaining the movement of cash into and out of the business.
These reports come from varied sources—internal systems, vendor documents, or third-party scanned forms—each with unique formats and layouts.
Why Manual Processing Is Not Scalable
Traditional financial data extraction methods rely on manual review or basic tools like spreadsheets and keyword searches. These methods fall short for several reasons:
Problem
Description
Slow Turnaround
Manually processing dozens of financial PDFs may take hours or even days.
Inconsistent Accuracy
Copy-paste errors, missed line items, and layout shifts can compromise critical data.
Poor Scalability
When a company grows or expands to new geographies, the volume of financial documents to scan increases exponentially.
Compliance Risks
Delayed or inaccurate data capture can lead to reporting discrepancies or audit issues.
Manual data handling simply cannot keep pace with modern reporting cycles or regulatory expectations. In a landscape where speed and precision are non-negotiable, businesses need smarter solutions to manage their financial documentation.
The Shift Toward Intelligent Automation in Finance
This rising challenge has sparked a revolution in how companies approach financial data extraction. Today, modern finance teams are turning to OCR financial statements tools and AI-driven platforms to automate the end-to-end processing pipeline. Unlike outdated scanning solutions, these modern systems go beyond surface-level text recognition.
They can extract values from financial statement documents with layout awareness, understand financial context, and deliver structured outputs—ready for integration into ERP, accounting, or analytics systems.
From scanning financial documents to transforming them into usable insights, the future of finance lies in intelligent automation. As we explore deeper in this article, you’ll see how innovations like LLMWhisperer and Unstract’s intelligent document processing platform are changing the way financial data is extracted, structured, and operationalized—with zero code and 100% accuracy.
In today’s fast-paced financial landscape, organizations handle hundreds of financial documents each month—from income statements and balance sheets to cash flow reports and quarterly filings. These documents often arrive in varied formats: digitally generated PDFs, printed scans, photographed pages, or even faxed statements. Processing them manually is no longer sustainable for companies aiming to stay agile, compliant, and competitive.
This is where automating financial document processing becomes not just a convenience—but a necessity.
Guide to Unstract’s Receipt OCR API for scanning line items
Learn how to use LLMWhisperer and Unstract to extract receipt data effectively and provide step-by-step instructions on integrating these tools into your workflow.
Financial reporting is time-sensitive. Month-end closings, board meetings, tax filings, and investor updates all depend on quick and accurate financial data. Manual entry slows things down, introduces bottlenecks, and increases the risk of error.
By using OCR in finance workflows, businesses can automatically extract key values—such as total revenue, current liabilities, or operating expenses—from scanned PDFs of financial statements. This allows finance teams to work faster, freeing up time to focus on analysis and strategy instead of administrative tasks.
Accuracy Reduces Risk and Improves Compliance
Manual data entry is prone to human error. A misplaced decimal or misread figure can cascade into major accounting mistakes or compliance issues. Errors in extracting data from financial statements can result in misreported earnings, failed audits, or penalties from regulators.
Automating the extraction process using financial data extraction software significantly reduces such risks. Tools powered by reliable OCR for financial statements ensure that the data pulled from even the most complex reports—like Form 10-Q or multi-page annual statements—is precise and layout-faithful. By preserving context and structure, these tools support cleaner records, accurate filings, and robust internal controls.
Audit-Ready from Day One
Regulatory audits are no longer annual surprises—they’re continuous expectations. Auditors demand full transparency into the financial document lifecycle. By automating data capture from financial statements, companies can maintain detailed, timestamped logs of what data was extracted, when, and how.
Using financial data extraction tools, finance teams can:
Automatically generate standardized audit trails.
Ensure data integrity from document upload to final report.
Maintain full visibility into scanned financial documents without manual cross-verification.
Cost Savings and Operational Efficiency
Beyond accuracy and speed, automation translates directly to bottom-line savings. Replacing full-time equivalents (FTEs) dedicated to document processing with OCR financial statement software allows finance departments to scale without hiring or increasing headcount.
Manual Workflow
Automated OCR Workflow
Manual data entry from PDFs
Instant value extraction from uploaded PDFs
Double-checking for errors
AI-powered accuracy and consistency
High labor costs and turnaround time
Low cost-per-document and 10x faster results
Automation pays off quickly—especially for enterprises dealing with large volumes of vendor statements, consolidated reports, or multi-entity financial filings.
Structured Output for Downstream Use
The ultimate benefit? With automation, you don’t just scan financial documents—you convert them into structured, machine-readable data formats (like JSON or Excel) that are ready for ingestion by accounting platforms, BI tools, or ERPs. This makes your financial data not only cleaner, but also more actionable.
Platforms like Unstract, powered by LLMWhisperer, take this a step further by combining OCR with prompt-based AI extraction—offering layout-preserving OCR and intelligent field recognition without writing a single line of code.
3. Challenges in Financial Statement Processing
Despite the critical importance of financial data, extracting structured insights from financial statements remains complex due to several persistent challenges.
1. Format Variability
There’s no universal template for financial reports. A balance sheet from one company may differ drastically in layout and structure from another—especially across geographies or industries. This inconsistency makes traditional OCR tools struggle with reliable extraction.
2. Scanned and Faxed Document Issues
Many financial statements are still shared as scanned PDFs or faxed copies, leading to problems like low resolution, skewed alignment, or handwritten notations. These make standard OCR in finance workflows error-prone and unreliable without advanced preprocessing.
3. Complex Structures and Tables
Financial documents often contain multi-column layouts, nested tables, footnotes, and dense figures. Extracting information like total liabilities or net income from such layouts requires more than basic parsing—it demands layout awareness and semantic understanding.
4. Integration Limitations
Most legacy ERP or finance platforms aren’t designed to natively ingest unstructured or semi-structured PDF data. Without an intelligent financial data extraction tool, bridging the gap between scanned documents and structured digital systems becomes a major bottleneck.
4. The Role of AI & LLMs in Financial Document Processing
Processing financial documents accurately is not just about reading text—it’s about understanding meaning and structure. Traditional OCR tools, while useful for basic digitization, often fall short when faced with the complexity of financial statements. This is where AI and Large Language Models (LLMs) offer a transformative leap forward.
Why Traditional OCR Falls Short
Conventional OCR in finance workflows focus on converting images or scanned documents into text. They perform well on clean, well-formatted inputs but struggle with:
Layout preservation: Complex tables with nested rows and columns often lose structure.
Context comprehension: OCR might extract “Liabilities” and “$50,000” from a balance sheet, but can’t determine if it refers to total, current, or long-term liabilities.
Ambiguity resolution: OCR lacks the ability to differentiate similarly worded fields unless they are in fixed positions.
As a result, teams often resort to post-processing, manual validation, or hardcoded rules to fix OCR outputs—adding inefficiencies to what’s supposed to be an automated pipeline.
AI & LLMs Bring Context and Intelligence
LLMs change the game by understanding the semantics behind text. Instead of just recognizing the word “liabilities,” an LLM-powered system understands what “total liabilities” means in the context of financial reporting, where to look for it, and how to extract it—even if it appears in varied formats across different companies’ statements.
Benefits of AI and LLMs in financial data extraction include:
Contextual Accuracy: AI identifies whether “net income” refers to current year, previous year, or consolidated figures—based on context.
Semantic Extraction: Rather than grabbing arbitrary text, LLMs extract meaningful fields like “total assets,” “revenue,” “cash equivalents,” or “operating cash flow.”
Flexibility Across Layouts: LLMs are trained on diverse data and handle format variability far better than traditional rule-based systems.
Real-World Example:
Imagine a scenario where a finance team is reviewing an annual report PDF from Apple. A traditional OCR tool might capture a line like:
“Total liabilities and shareholders’ equity ………………………………………….. $352,755”
However, it won’t distinguish whether this is a summary total or a duplicate figure from a different section. An LLM, on the other hand, can accurately identify and extract only the total liabilities, based on surrounding headings and its understanding of financial structures.
Unstract: AI-Driven Financial Data Extraction Tool
In today’s digital finance landscape, organizations are handling thousands of unstructured financial documents—ranging from annual reports to quarterly cash flow statements. Manual extraction of these values is no longer viable. This is where Unstract, a cutting-edge AI-powered financial data extraction tool, offers a transformative solution.
What is Unstract?
Unstract is a no-code intelligent document processing (IDP) platform designed specifically to automate and simplify the extraction of structured data from unstructured financial documents. Whether you’re dealing with scanned PDFs, digital 10-Qs, or tabular balance sheets, Unstract ensures clean, contextual data extraction at scale.
Core Capabilities of Unstract
Unstract combines several advanced technologies to streamline financial document processing:
Feature
Description
LLM-Powered Extraction
Uses Large Language Models (LLMs) to extract semantically rich fields like total assets, current liabilities, net income, etc., even when formats vary across companies.
Vector Database Integration
Supports vector DBs to enable context-aware document chunking and retrieval, allowing high accuracy even in multi-page financial statements.
LLMWhisperer OCR
Leverages layout-preserving OCR via LLMWhisperer, ideal for scanned or tilted documents, retaining tabular structure and preserving key metadata.
Why Unstract is Different from Other Financial Data Extraction Software
Unlike traditional financial data extraction tools or legacy OCR systems, Unstract offers:
No training data required: Unlike IDP 1.0 platforms, there’s no need to annotate datasets or create templates.
Scalable architecture: Built for enterprise use, it scales from dozens to millions of documents with consistent accuracy.
API deployment: Convert any Prompt Studio project into a production-ready API, making it easy to integrate into existing finance and ERP systems.
If your team is searching for a financial document scanning tool that can extract structured data from financial statements—Unstract stands out as one of the most powerful AI-based IDP platforms available today.
See How Unstract Handles End-to-End Finance Document Processing
From balance sheets and income statements to investment portfolio reports, business credit reports and FP&A documents, Unstract automates structured data extraction across every financial document your team processes — no custom templates, no per-document configuration.
Explore the full suite of finance document processing workflows Unstract supports.
6. Deep Dive: What is LLMWhisperer & Why It Matters
When it comes to financial statement OCR, accuracy isn’t just nice to have—it’s mandatory. From footnotes to multi-line financial tables, any missed value can create reconciliation issues or audit discrepancies. Enter LLMWhisperer: the foundation for reliable OCR in finance workflows.
What is LLMWhisperer OCR?
Despite the name, LLMWhisperer is not a Large Language Model. It is a general-purpose, layout-preserving OCR engine designed specifically to prepare unstructured or scanned documents for downstream AI/LLM extraction.
Think of it as the “pre-processing lens” that prepares raw documents for intelligent data extraction—ensuring nothing important is lost, no matter how cluttered or misaligned the document.
Key Capabilities of LLMWhisperer
Capability
Benefit in Financial OCR Workflows
Layout Preservation
Retains original document structure—critical for balance sheets and income statements.
Table Extraction
Extracts multi-column financial tables without breaking structure.
Checkbox & Handwriting Support
Recognizes checkboxes and handwritten notes common in remittance forms or annotated audits.
Rotated / Scanned PDF Handling
Parses documents scanned at odd angles (30-40 degrees) with 0% data loss.
Document extraction at the cutting edge with LLMs vs LLMWhisperer
LLMs have become operational powerhouses, thanks in part to their ability to extract rich, meaningful information from documents. But even the best models, in real-world use cases, often depend heavily on the quality of the input they receive.
Discover how LLMWhisperer, Unstract’s dedicated text extraction service, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.
Why It Matters for Financial Document Scanning
Financial documents often contain:
Dense tabular data with sub-headings, roll-ups, and footnotes.
Visual cues, such as indentation or font styling, that hint at hierarchy and categorization.
Non-standard layouts, like multi-section cash flow summaries or variance explanations in margins.
Traditional OCR tools struggle with these nuances. LLMWhisperer, however, excels by:
Delivering clean, structured plain text while preserving layout fidelity.
Ensuring all necessary data points reach the LLM layer intact, enabling high-quality downstream extraction.
Whether you are scanning annual reports or parsing financial statements for audit workflows, LLMWhisperer is an indispensable component of modern financial OCR pipelines.
7. Testing LLMWhisperer on Real Financial Statements
When it comes to automating financial document scanning—especially complex documents like cash flow statements or 10-K filings—maintaining layout, numerical accuracy, and context is everything. This is why LLMWhisperer’s precision-focused OCR capabilities are a foundational step in any financial data extraction pipeline.
Let’s walk through a real-world test case using the APPLE Cash Flow Statement, showcasing how to use the LLMWhisperer API to extract layout-preserved, structured data ready for downstream processing.
Test LLMWhisperer Financial Statement OCR Free — Instant Results, No Signup Required
If you want to skip straight to the tool, see how LLMWhisperer OCR API handles financial statements of any complexity — scanned annual reports, multi-column balance sheets, complex income statement tables, poorly photographed documents, and multi-language filings.
Try LLMWhisperer Financial Statement OCR for free on the Playground. No signup required.
Test Case 1: Extracting Data from APPLE Cash Flow Statement Using LLMWhisperer API
The Apple Cash Flow Statement is a dense, machine-generated document featuring three-column tables, totals, subtotals, and nested sections. Parsing this accurately is essential to maintain data fidelity before any semantic LLM-based field extraction.
Send the request and you’ll get a response like: FILE – Attached Apple Inc Cashflow Response.txt
Key Observations from the Test
Metric
Result
Layout Preservation
✅ Tables, columns, rows, and indentation retained perfectly
Data Accuracy
✅ 100% of values, including nested totals and footnotes, extracted
Handling of Complex Tables
✅ No merging or misalignment of columns
No Data Loss
✅ All monetary and label fields were present in the output
Why This Extraction Step Is Crucial Before LLMs
Before an LLM can semantically understand and extract values like total liabilities, net income, or operating cash flow, the raw data must be accurate, complete, and well-structured. Any noise, formatting error, or missed value in this pre-processing phase will cascade into inaccuracies downstream.
This is why LLMWhisperer is not just useful—it is necessary. It ensures the LLM receives clean, layout-preserved, context-rich data, especially for:
ocr financial statements
financial data extraction
scanning financial documents
financial data extraction software pipelines
8. Setting Up Unstract for Financial Document Processing
To automate financial document processing using OCR and AI, Unstract provides a no-code interface to configure the complete IDP (Intelligent Document Processing) workflow. For financial statement parsing, these are the core components to set up:
OpenAI LLM Profile
Used to power semantic-level field extraction from unstructured financial documents.
Go to Settings > LLMs
Click New LLM Profile
Choose OpenAI
Enter your API Key and save.
OpenAI Embedding Model
Helps with semantic chunking and document indexing for contextual understanding.
Navigate to Settings > Embedding
Click New Embedding Profile
Choose OpenAI
Enter the API Key and model (e.g., text-embedding-ada-002) and save.
Vector DB (Postgres Free Trial)
This allows storing and retrieving vectorized representations of financial statement chunks efficiently.
Go to Settings > Vector DBs
Create a new Vector DB profile
Select Postgres Free Trial
Add name, endpoint URL, and credentials (provided by Unstract)
Text Extractor: LLMWhisperer
This is the layout-preserving OCR engine that handles scanned, tabular financial PDFs.
Go to Settings > Text Extractor
Create New
Choose LLMWhisperer
Paste your API key from the Unstract Whisperer dashboard
Set:
Processing Mode: OCR
Output Mode: line-printer
With this setup, you’re ready to begin processing structured and semi-structured documents like balance sheets and cash flow statements using the Unstract platform.
9. Creating a Prompt Studio Project for Financial Fields
Once preprocessing is configured, head to Prompt Studio to build the extraction logic—no code needed.
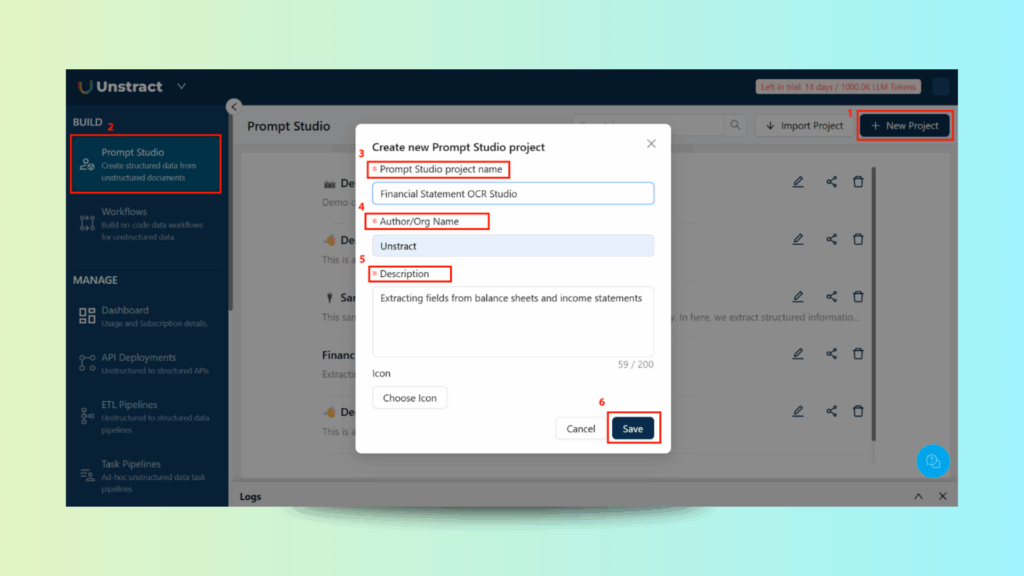
Step 1: Create the Project
Go to Prompt Studio
Click New Project
Fill in:
Tool Name: Financial Statement OCR Studio
Description: Extracting fields from balance sheets and income statements
Author: Your name or org
Click Save
Step 2: Upload APPLE Balance Sheet
Inside the project, click Manage Documents
Upload the APPLE Balance Sheet PDF
This document includes values such as:
Assets
Liabilities
Shareholders’ Equity
Notes and Comments
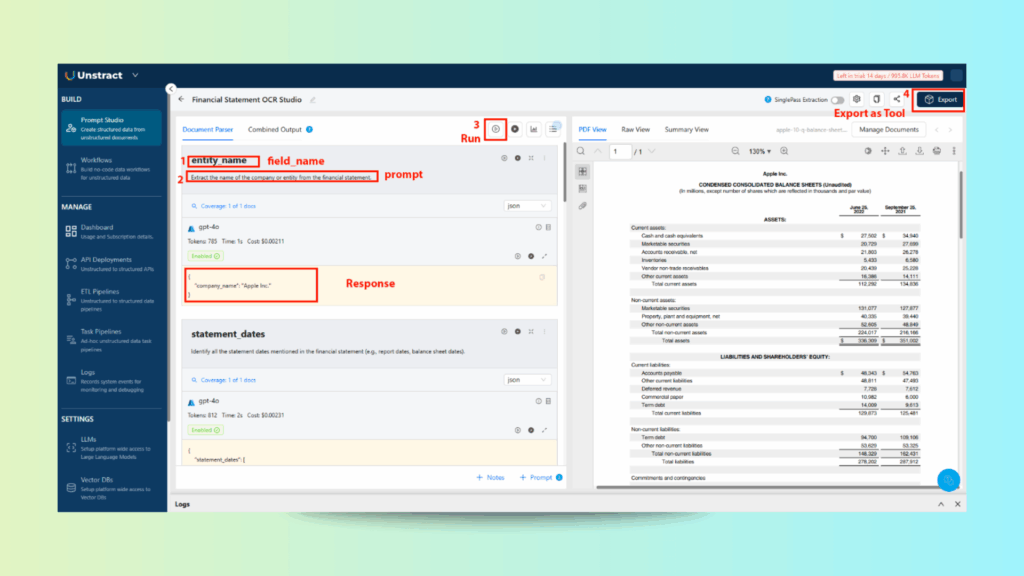
Step 3: Add Extraction Prompts
Click Add Prompts and input your financial field definitions. Sample prompts:
entity_name: Extract the name of the company or entity from the financial statement.
statement_dates: Identify all the statement dates mentioned in the financial statement.
current_assets: Extract all line items and their values listed under “Current assets” along with the total current assets.
non_current_assets: Extract all line items and their values listed under “Non-current assets” along with the total non-current assets.
current_liabilities: Extract all line items and their values listed under “Current liabilities” along with the total current liabilities.
non_current_liabilities: Extract all line items and their values listed under “Non-current liabilities” along with the total non-current liabilities.
shareholders_equity: Extract all line items and their values listed under “Shareholders’ equity”.
additional_notes: Extract any additional notes or comments such as “Commitments and contingencies”.
Click Run to generate the output. You’ll see each field populated with structured, layout-preserving results extracted directly from the PDF.
This proves how effective Prompt Studio is at enabling financial data extraction using a no-code, LLM-powered intelligent document processing platform.
Step 4: Export as Tool
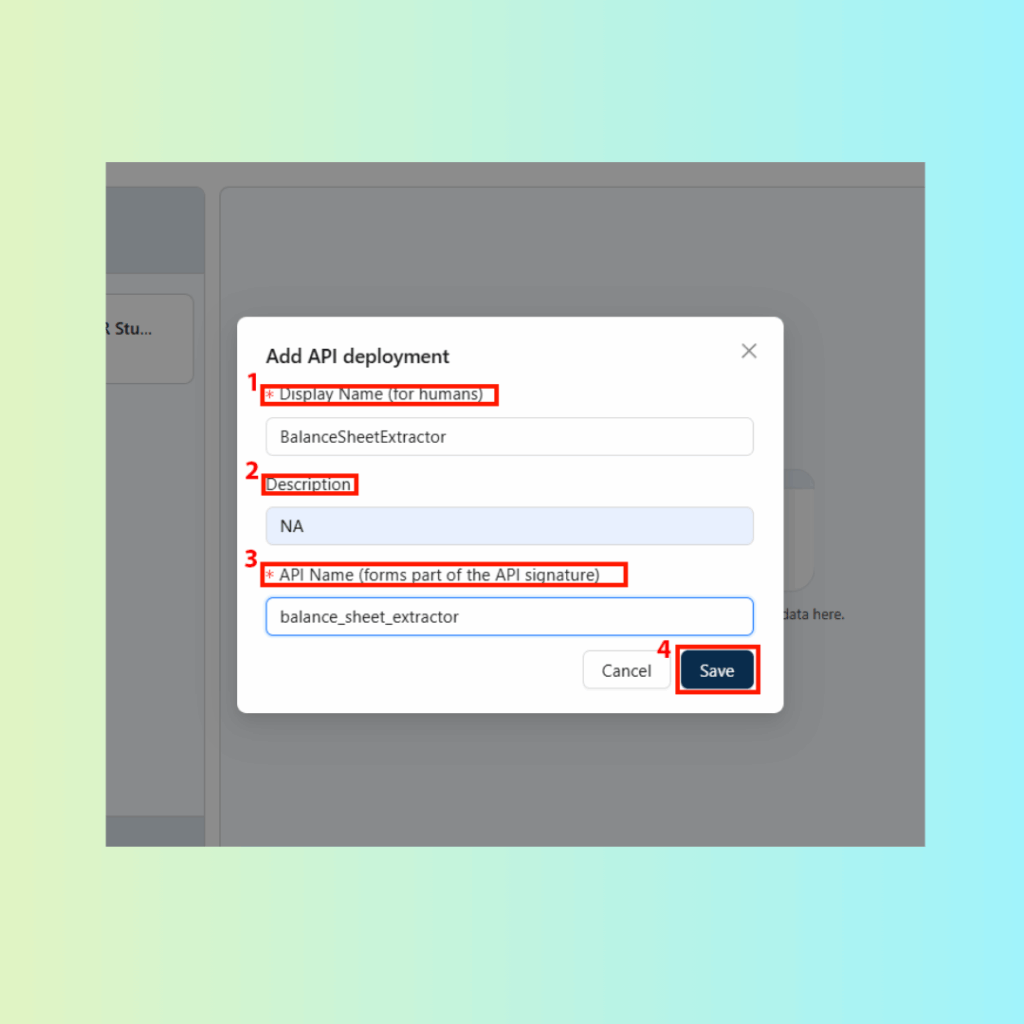
Once validated:
Click Export as Tool
Name your tool (e.g., BalanceSheetExtractor)
This makes it available for use in workflows and API deployment.
10. Deploying the Project as an API Workflow
Now let’s publish the prompt tool as an API so you or your clients can upload financial documents and receive structured data.
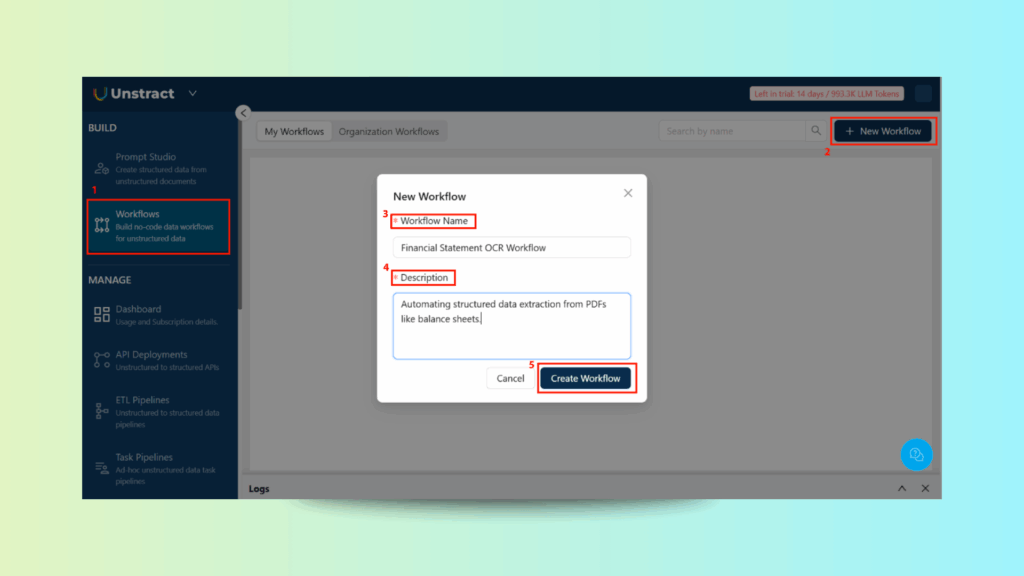
Step 1: Navigate to Workflows
Go to Workflows
Click New Workflow
Fill in:
Name: Financial Statement OCR Workflow
Description: Automating structured data extraction from PDFs like balance sheets
Click Create Workflow
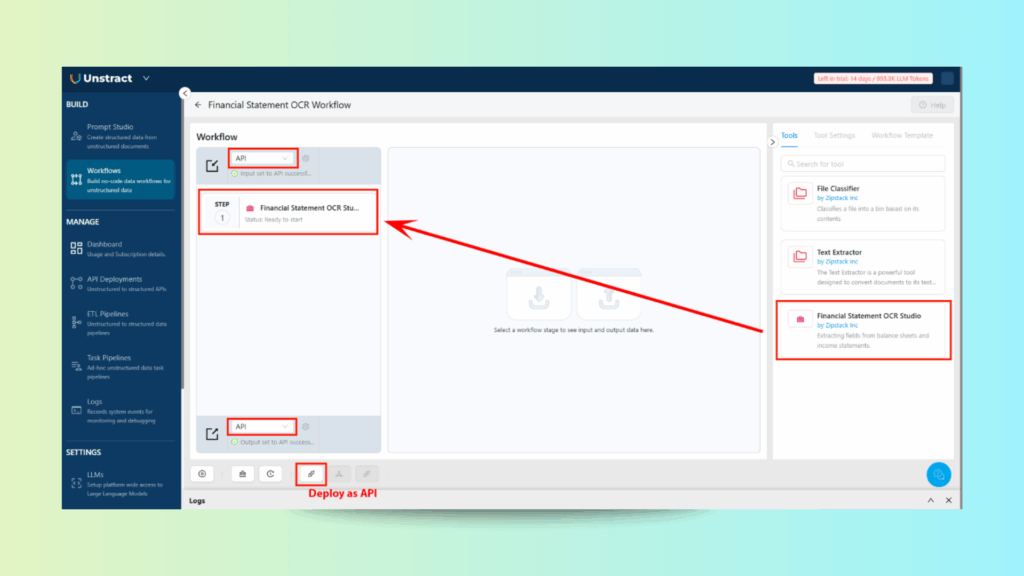
Step 2: Build the Workflow
Drag your exported tool (BalanceSheetExtractor) onto the workflow builder
Configure:
API Input: Accepts PDF files
API Output: Returns structured JSON data
Add metadata like Display Name and API ID
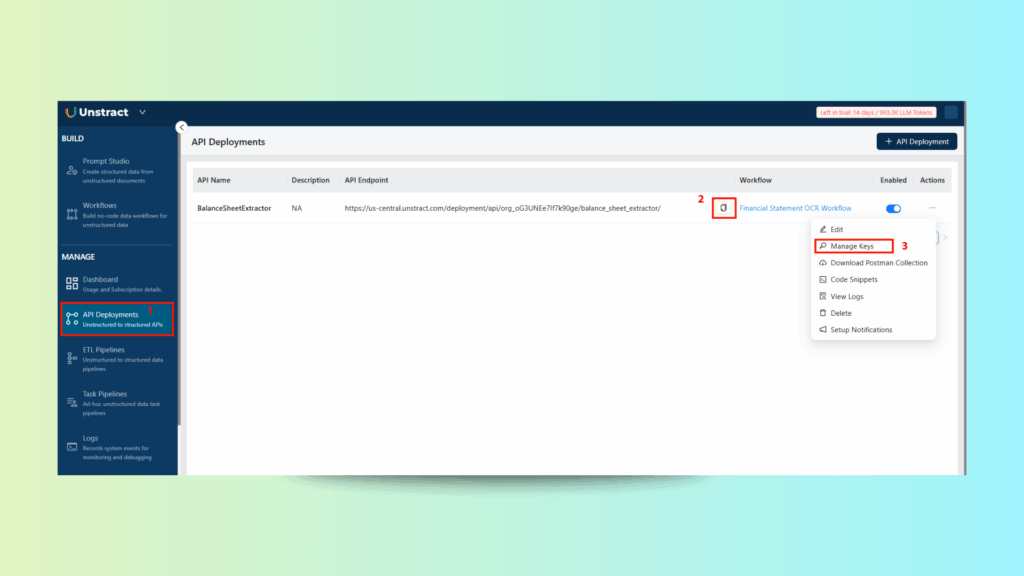
Step 3: Deploy API
Click Save
Click Deploy API
You will see:
The API Endpoint URL
The Status and Manage Keys option
This is now a fully functional, production-ready financial data extraction tool that clients or systems can call via REST API.
11. API Testing in Postman: End-to-End Use Case
Let’s test this deployed API using Postman for a complete, real-world financial document workflow.
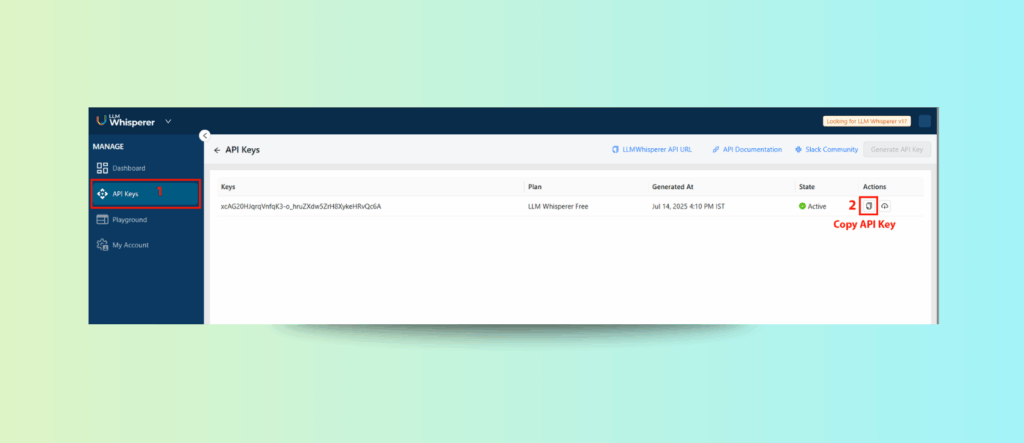
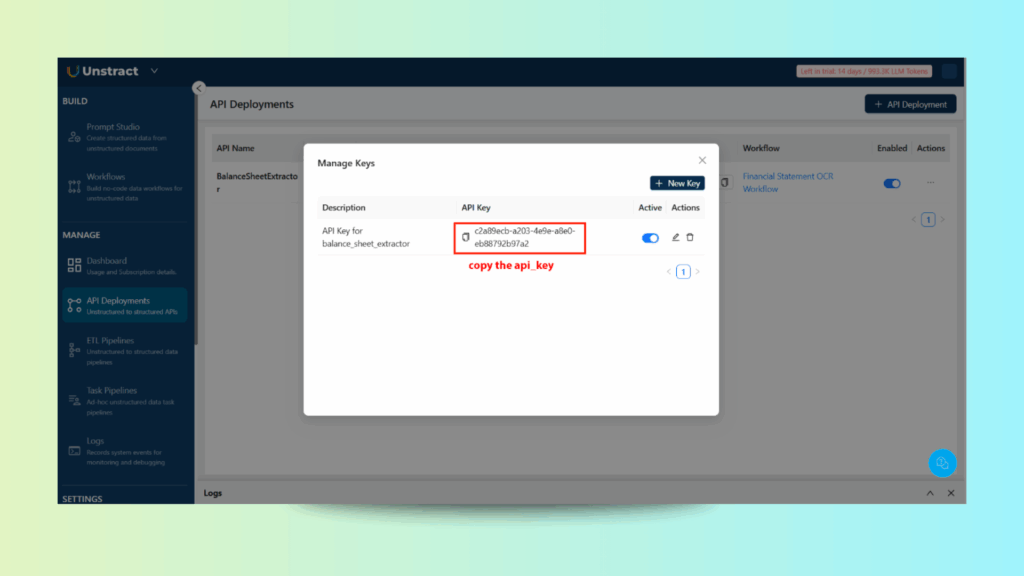
Step 1: Gather API Credentials
From API Deployment, copy:
The Endpoint URL
The API Key via “Manage Keys”
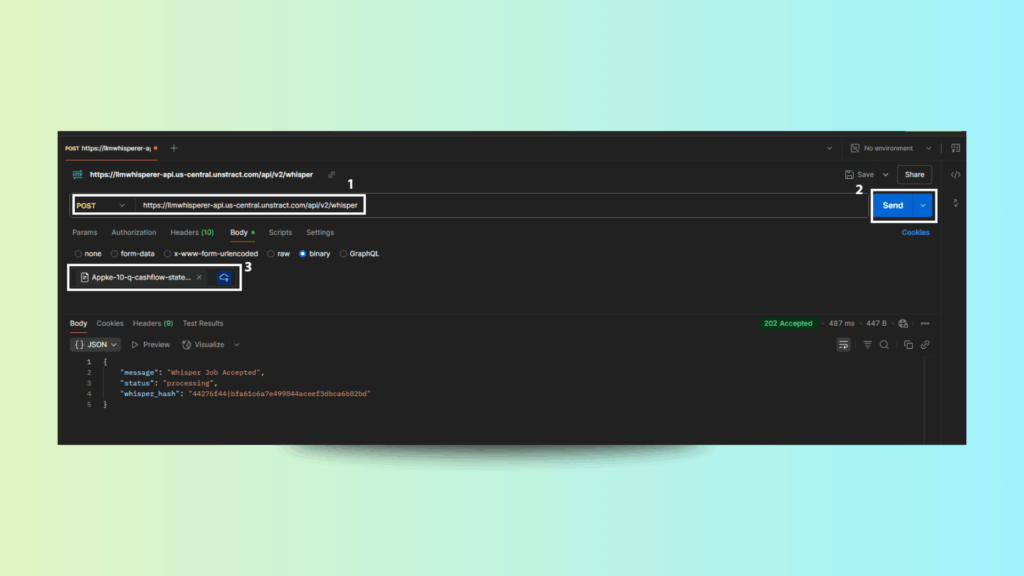
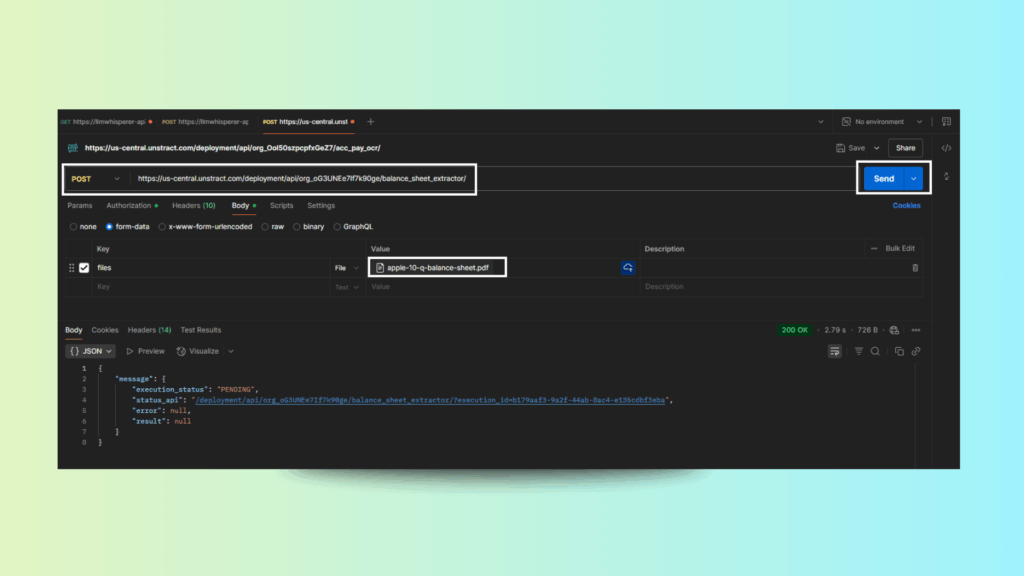
Step 2: Configure Postman Request
Method: POST
URL: Paste your copied endpoint
Authorization: Bearer Token → Paste your API Key
Body:
Type: form-data
Key: files
Type: File
Upload the APPLE Balance Sheet PDF
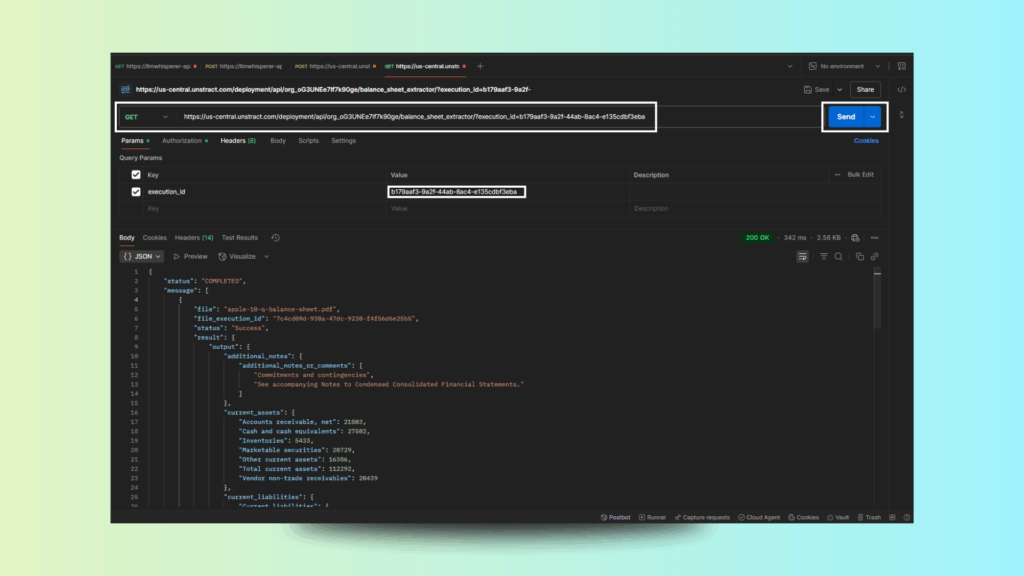
Step 3: Send the Request
Click Send. The initial response will show:
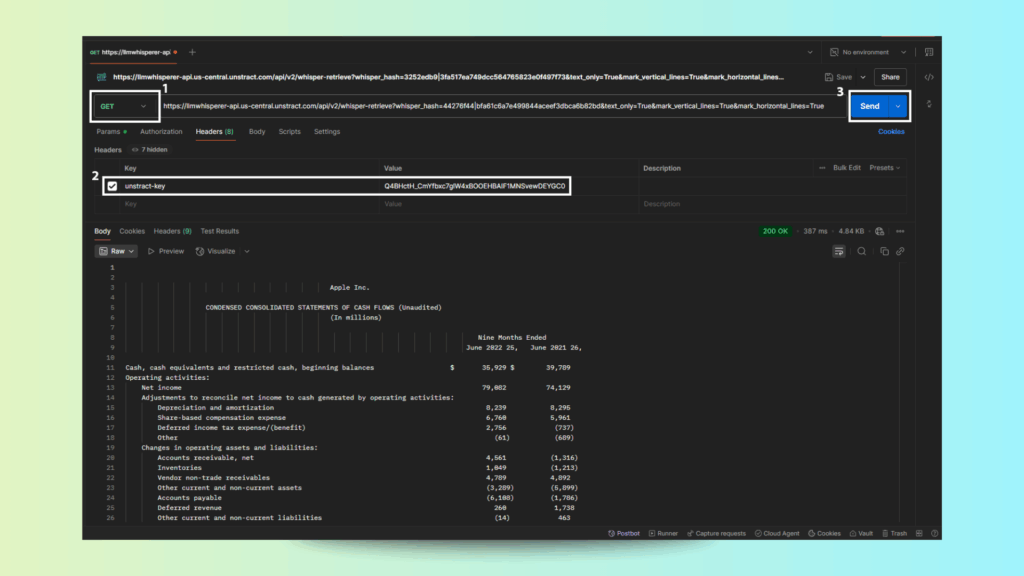
Copy the status_api URL and make a GET request to check completion.
Step 4: Retrieve the Results
Once complete, a JSON response will be returned with fields like:
You’ve just built and tested a real-time financial data extraction pipeline — from document upload to accurate structured output — without writing a single line of code.
12. Why This Approach Works for Finance Teams
In the fast-paced world of finance, agility, compliance, and precision are non-negotiable. Traditional document processing workflows are often rigid, dependent on manual templates, and ill-equipped to handle the ever-growing influx of complex financial documents. This is where intelligent document automation, powered by financial data extraction software like Unstract, becomes a critical enabler.
Zero-Code, Instant Deployment
Finance teams no longer need to rely on development cycles or external IT support to configure OCR pipelines. With Unstract’s no-code document processing platform, users can set up data extraction workflows using intuitive interfaces—simply upload documents, define field prompts, and deploy APIs in minutes.
No Templates or Manual Annotation Required
Unlike legacy OCR in finance systems that depend on fixed-format templates or labeled training data, Unstract uses LLM-powered extraction to identify and understand the structure of financial statements dynamically. It adapts to variations in layout, language, and formatting—whether it’s an income statement from Tokyo, a Form 10-Q from New York, or a European cash flow sheet.
Works Across Vendors, Regions, and Formats
Financial statements often differ drastically between vendors, jurisdictions, and time periods. Unstract’s OCR financial statement processing handles scanned PDFs, multi-column layouts, and even documents with handwritten annotations or footnotes. Thanks to LLMWhisperer, the system accurately preserves layouts, reads tabular data, and ensures zero information loss.
ERP/Finance System Integration Ready
Unstract’s APIs can be integrated seamlessly into finance stacks—whether you’re using SAP, Oracle, QuickBooks, or a custom ERP. This allows real-time data flows between your financial document scanning software and downstream analytics, payment, or audit tools.
Scalable for Global Teams
From startups to enterprises, this solution scales effortlessly—no server provisioning, no manual configuration, and no model retraining required. Just upload, extract, and integrate.
13. Unstract: Best APIs to Extract Data from Balance Sheets & Reports
The future of financial document scanning and analysis lies not in traditional OCR engines, but in adaptive, AI-driven systems that understand context, preserve structure, and extract meaning—not just characters.
With Unstract and LLMWhisperer, businesses now have access to a robust financial data extraction tool that is:
Highly accurate — thanks to layout-preserving parsing and LLM-based extraction.
Effortlessly scalable — deployable as an API, ready to handle thousands of financial documents per day.
Truly plug-and-play — requiring no code, no templates, and no pre-annotation.
From OCR financial statements to automating compliance checks, this stack is more than software—it’s a strategic advantage for modern finance operations. Whether you’re digitizing quarterly reports, parsing 10-Ks, or extracting liabilities from balance sheets, Unstract turns financial document processing into a streamlined, intelligent, and future-ready experience.
It’s not just OCR in finance. It’s intelligent financial automation.
Explore finance document processing by document type:
Investment Portfolio Report Data Extraction — Extract holdings, asset allocation, performance metrics and returns from investment portfolio reports across formats and custodians
Balance Sheet Data Extraction — Pull assets, liabilities and equity figures from balance sheets accurately, regardless of layout or accounting standard
Financial Report Data Extraction — Process annual and quarterly financial reports to extract revenue, expenses and key financial metrics at scale
FP&A Report Data Extraction — Extract budget vs actuals, forecasts and variance data from financial planning and analysis documents
Loan Data Verification — Capture loan amounts, interest rates, borrower details and repayment terms from loan documents for faster verification workflows
What is OCR financial statements and why does it matter for finance teams?
OCR financial statements convert scanned PDFs of balance sheets, income statements, and cash flow statements into machine-readable text. This replaces manual data entry, reducing errors and accelerating month-end closing and audit preparation.
How does cash flow statement OCR handle complex tables with nested totals?
Cash flow statement OCR powered by LLMWhisperer preserves three-column layouts, subtotals, and footnotes without merging or misaligning data. This ensures operating, investing, and financing activities are extracted accurately for downstream analysis.
Can balance sheet OCR distinguish between current and non-current assets automatically?
Yes — balance sheet OCR with LLMWhisperer retains indentation, section headers, and hierarchical structure. This allows systems to separate current assets (e.g., cash, receivables) from non-current assets (e.g., property, equipment) without manual rules.
How do you extract data from financial statements using LLMWhisperer and Unstract?
To extract data from financial statements, use LLMWhisperer API for layout-preserving OCR, then build prompts in Unstract Prompt Studio for fields like total assets, current liabilities, and net income. Deploy as an API with zero code.
What is the difference between basic OCR and financial statement data extraction for compliance?
Basic OCR extracts raw text; financial statement data extraction preserves table relationships, footnotes, and monetary precision. This is critical for audit trails, regulator filings (10-Q, 10-K), and ERP integration without manual reconciliation.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.