Across finance, insurance, logistics, healthcare, and legal, teams live in PDFs. Invoices arrive as PDFs, auditors receive quarterly filings as PDFs, carriers email air waybills as PDFs, and HR stores contracts as—yet—PDFs. The result is a mountain of information locked in a format designed for human reading, not machine understanding. Manually copying values out of documents, or stitching together brittle macros, doesn’t scale. It burns analyst hours, introduces errors, and slows down processes that should be near-real-time.
That’s why PDF data scraping has moved from a “nice to have” to a core capability. A modern pdf scraper doesn’t just “scrape PDF” text; it captures context, tables, totals, line items, and labels—and turns that into structured data you can trust. Think of tasks like matching remittance advice to bank transactions, extracting “Total Current Assets” from a balance sheet, or pulling consignee details from a photographed bill of lading. When those jobs are automated, close cycles shrink, reconciliation speeds up, and compliance improves.
Manual scraping data from PDF documents fails for three reasons:
Volume & variety. You might process 10 vendor invoice templates today and 200 tomorrow—including scans, faxes, exports, and phone photos. Copy-paste breaks immediately.
Layout complexity. Multi-column statements, nested tables, footnotes, checkboxes, and stamps are common. Without layout awareness, values detach from their labels and lose meaning.
Audit & accuracy. Re-keyed numbers create audit trails nobody wants to defend. Accuracy and repeatability matter, especially in regulated workflows.
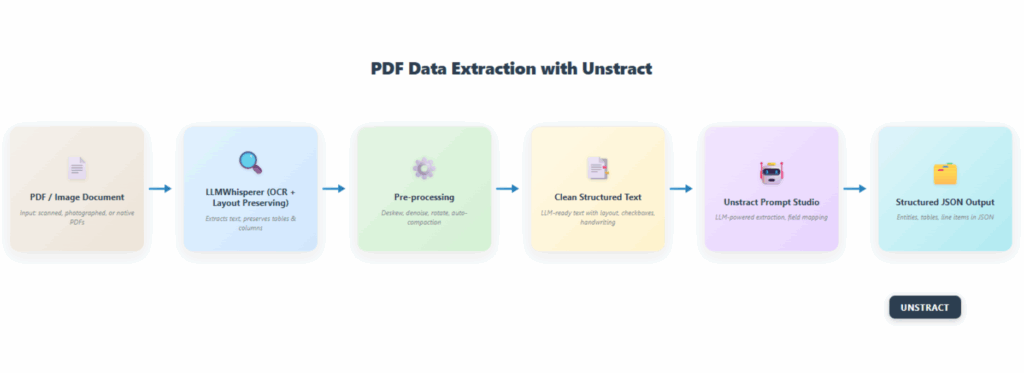
Modern document scraping replaces that grind with an API-first approach: ingest a file, extract the right fields, and deliver clean JSON to your database or app. This is where Unstract comes in: a no-code, enterprise platform that pairs layout-preserving text extraction (via LLMWhisperer) with LLM-driven field extraction, ETL connectors, and optional Human-in-the-Loop review. In short, it’s a practical path from “How to scrape data from a PDF?” to “We scrape data from PDF at scale, reliably.”
TL;DR
If you wish to skip directly to the solution section, where you can see how Unstract and LLMWhisperer handle document types of any complexity — document scans, PDFs with multi-column layouts, checkboxes, and handwriting etc, click here.
Quick glossary for this article’s SEO terms:
pdf scraping / pdf data scraping: The automated extraction of text and fields from PDFs.
pdf scraper / pdf data scraper: Software or pipelines that perform that extraction.
scrape pdf / scraping data from pdf: The act of programmatically capturing and structuring values out of PDF files.
What is PDF Document Scraping?
At its core, PDF document scraping is the automated process of converting the contents of a PDF—text, tables, labels, and sometimes marks like checkboxes—into a structured, machine-readable format (usually JSON) for downstream systems. A pdf scraper or pdf data scraper typically does some or all of the following:
Identifies content type: Is the PDF digital (selectable text) or an image scan/phone photo?
Extracts text reliably: For digital PDFs, parse the text layer; for scans, use OCR to “read” the image.
Preserves layout: Maintain relationships between labels and values, table rows and columns, multi-column flows, and section headers.
Understands intent (optional but powerful): Use rules or AI to turn raw strings into structured fields (e.g., “total_liabilities”: 352755).
Outputs clean data: Emit consistent JSON ready for analytics, RPA, or databases.
This is very different from basic copy-paste or “Ctrl+F” approaches. Let’s contrast simple copy-paste vs. intelligent scraping with realistic business scenarios:
Simple copy-paste (fragile and manual)
Scenario: An AP clerk opens a vendor invoice PDF, highlights the “Invoice Total,” and pastes it into ERP.
Problems:
Fonts, ligatures, and column breaks often mangle pasted values (e.g., 1,234.00 becomes 1 234.00).
Tables break: copying a row often loses column boundaries.
Human error sneaks in: one wrong digit cascades into payment misallocations.
Scenario: A pdf scraping pipeline ingests the same invoice.
What happens:
The system detects whether it’s a text-based or scanned PDF.
For scans, OCR converts it to text; for digital, it preserves the native text layer.
A layout-aware engine keeps line items and headers aligned.
A ruleset or LLM maps “Total Due,” “Balance Due,” or “Amount Payable” to a single total_due field—regardless of template.
Output is JSON with consistent keys and normalized values (currency, dates), and the process is logged for audit.
In other words, pdf data scraping is not just “getting the text out”—it’s retaining meaning. That means preserving table structure, associating a number with the correct label, and ensuring that complex formats (multi-column, footnotes, page breaks) remain coherent.
Types of PDFs you’ll encounter (and why they matter)
Digital, text-based PDFs
Generated by systems (ERPs, accounting tools, report writers).
Pros: crisp text, easy extraction.
Risk: embedded fonts and unusual encodings can still confuse naïve scrapers.
Scanned PDFs / images
Printers, faxes, phone photos of paper.
Require OCR; quality can vary wildly (skew, blur, shadows).
A good pdf scraper must deskew, denoise, and still preserve layout.
Hybrid PDFs
Mix of text layers and images (e.g., signatures, stamps, scanned pages in a digital file).
Robust pipelines must detect and process each page appropriately.
PDF Hell and Practical RAG Applications
While PDFs are a universal and ubiquitous format, valued for their ability to preserve the layout and integrity of content across different platforms, they were not originally designed for easy extraction of the text they contain. This presents a unique set of challenges for developers who need to repurpose content from PDF documents into dynamic, text-based applications.
“How to scrape data from a PDF?” — a practical, modern answer
If you’re evaluating how to scrape data from a PDF today, think in terms of a layered pipeline rather than a single script:
Ingest
Receive the file via API, upload, or connector (email, storage, EDI).
Pre-process
Decide: digital text or image? For images, run OCR with layout preservation.
Extract
Pull text, detect tables, keep columns/rows aligned, capture checkboxes and marks if present.
Understand
Map the extracted content to business fields (e.g., invoice_number, due_date, line_items[]) using rules or LLMs.
Validate
Optional Human-in-the-Loop for low-confidence fields or high-risk workflows.
Deliver
Emit JSON to your app, data warehouse, or queue; store lineage for audit.
This layered view is what separates a one-off script from an enterprise-ready document scraping solution.
Real business examples
Accounts Payable: Parse invoices from 200+ vendors, each with different layouts. A modern pdf scraper keeps line items intact, identifies taxes/fees, and posts structured data to your ERP—no templates required.
Financial Reporting: Extract “Total Assets,” “Total Liabilities,” and “Operating Cash Flow” from annual/quarterly statements. With layout-preserving extraction, values align with their correct sections, even in multi-column reports.
Logistics: From a photographed air waybill, capture shipper/consignee details, ports, charges, and item lists. A robust pdf data scraping flow handles skew, glare, and stamps while retaining table semantics.
Insurance: From an ACORD form, capture policyholder info, coverage limits, effective dates, and checkbox states. Intelligent parsing prevents mix-ups between similarly worded fields.
Where Unstract fits
Unstract operationalizes all of the above. It combines:
A layout-preserving text extraction layer (LLMWhisperer) that works on both digital and scanned PDFs.
LLM-driven prompts that transform raw text into structured fields you define.
Connectors and APIs so you can push results into apps, warehouses, or queues.
Optional Human-in-the-Loop for governance.
So if your team is searching for a dependable pdf scraper or evaluating pdf scraping strategies, the practical route is a platform that treats extraction and understanding as a single, auditable pipeline—not a collection of scripts. Unstract delivers exactly that, making it easy to scrape data from PDF documents at scale with the accuracy, speed, and control modern operations require.
Why automate PDF data scraping?
Modern teams deal with thousands of PDFs—statements, invoices, rent rolls, ACORD forms, air waybills, loan applications, test reports. Manually copying values into spreadsheets creates delays, inconsistent results, and compliance risk. A purpose-built PDF scraper (a.k.a. pdf data scraper) turns this into a reliable, trackable pipeline.
Benefits of automation (what you actually gain)
Speed & Throughput
Batch-process hundreds or thousands of files in parallel instead of page-by-page copy-paste.
Stable runtimes and predictable SLAs—great for end-of-month runs, due-diligence packets, or fund reporting.
Practical answer to “how to scrape data from a PDF” at scale: queue documents → run extraction → emit structured JSON.
Accuracy & Consistency
Deterministic parsing for structured PDFs; OCR + layout-preserving modes for scans/handwritten.
Eliminates “fat-finger” errors and inconsistent human interpretation of similar fields.
Automatic normalization (dates, currencies, totals) makes downstream validation trivial.
Scalability & Cost Control
Horizontal scale: add workers, not headcount.
Unified logs, retries, and dead-letter queues prevent silent data loss.
Auto-switch between text extraction and OCR to avoid paying OCR costs for native-text PDFs.
Compliance & Auditability
Enforced redaction and PII masking, policy-driven storage locations, immutable logs.
Repeatable runs with versioned prompts/configs and diffable outputs.
On-prem options when data sovereignty matters.
In short: automated pdf scraping converts “files” into “data products”—clean, structured, searchable, and governed.
Bulk underwriting: scrape PDF deal rooms into comps and models quickly.
Whether you label it pdf scraper, pdf scraping, document scraping, or “scrape data from pdf,” the business value is the same: faster decisions with higher confidence.
Challenges in PDF document scraping (and why they’re real)
Automating pdf data scraping isn’t “just run OCR.” PDFs were designed to preserve appearance, not to encode meaning. That core design choice produces the obstacles you hit in production.
1) Fixed layout, non-linear text flow
Symptoms: Two-column articles, sidebars, footnotes, and floating boxes cause sentence fragments to interleave (left column line 1 → right column line 1 → left column line 2…).
Impact: Downstream NLP/RAG sees garbled context; totals get separated from labels; headings merge with body text.
Mitigation: Layout-aware extraction, reading-order inference, and layout-preserving output modes so LLMs can reason with spatial cues.
2) Position-based text with little to no semantics
Symptoms: PDFs store glyphs with coordinates, not headings/paragraph tags. Font size ≠ <h1>. Bold ≠ <strong>.
Impact: “Total Payable” vs “Total Charges” may look identical to a naïve parser; section boundaries vanish.
Mitigation: Heuristics + ML on typography and spacing; embeddings to match semantic labels; persistent document structure hints.
3) “Searchable” PDFs with bad OCR overlays
Symptoms: A hidden OCR text layer sits behind a page image. It can be low-quality, split words oddly (“L e a r n i n g”), or overlap out of order.
Impact: Blindly trusting the overlay yields broken tokens, mis-spelled entities, and unreliable totals.
Mitigation: Detect searchable overlays; fall back to your own OCR when overlay quality is poor; stitch tokens carefully.
4) Scanned/photographed pages (true images)
Symptoms: Skew, rotation (±30°), lighting, moiré, compression artifacts; mobile photos instead of scans.
Impact: OCR quality drops; tables and stamps bleed into text; small fonts disappear.
Symptoms: Borderless tables, colored cells, merged headers, wrapped lines, and repeating line items.
Impact: Row/column boundaries are ambiguous; quantities and amounts misalign.
Mitigation (pragmatic): Prefer layout-preserving text (tabs/spacing) so LLMs can reason about columns; use CV/ML table detectors when needed; avoid over-engineering “perfect HTML tables” for every source.
9) Forms, checkboxes, radio buttons
Symptoms: Interactive fields often don’t serialize to simple text; scans flatten widgets into pixels.
Impact: Lost check states; missing selected options; “Yes/No” misreads.
Mitigation: PDF engines that understand AcroForms/XFA; for scans, vision models to detect tick marks and associate them to labels.
10) Hybrid pages (text + text-in-images)
Symptoms: A page has normal text plus embedded images containing more text.
Impact: If you OCR the whole page, cost/time spikes; if you skip OCR, you miss the image text.
Mitigation: Region classification to OCR only image zones; merge text layers carefully.
Symptoms: Many documents—loan applications, medical forms, Bills of Lading—still contain handwritten notes, signatures, or numeric entries. Standard OCR engines often misread cursive writing, faint ink, or overlapping strokes.
Impact: Critical details such as handwritten totals, initials, or checkmarks may be lost, misclassified, or incorrectly transcribed.
Mitigation: Use handwriting-capable OCR combined with LLM-driven post-processing. LLMs can cross-check context (“is this a number, a date, or a name?”) to improve accuracy. For enterprise use, always validate sensitive handwritten fields against secondary inputs.
How robust tools address these (tying it back to your stack)
Three output modes:
Layout-preserving (tabs/spaces maintain columns, best for LLM/RAG),
Text (cleaned, reading-order focus),
Text-Dump (raw, for debugging and fallbacks). These directly counter fixed layout issues and multi-column chaos.
Auto mode switching: Try native text first; only OCR when necessary (saves cost/time, improves stability on “searchable but poor-quality” PDFs).
Pre-processing baked in: Deskew/denoise/contrast/rotation fixes applied before OCR—critical for photographed forms and scrape pdf scenarios.
Layout fidelity for tables and forms: Preserve spacing, detect checkboxes/radios, and keep line items aligned so LLM prompts can reliably extract entities.
Deployment flexibility: SaaS for speed; on-prem for strict privacy. Both support API workflows so teams can operationalize “how to scrape data from a PDF” as a simple request/response service.
How AI and LLMs Transform PDF Scraping
Traditional OCR limitations
Classic OCR is great at turning pixels into characters, but it stops there. It doesn’t understand what those characters mean or how they relate on a page. That’s why pure OCR pipelines struggle with real-world pdf scraping:
No semantics, just glyphs. OCR extracts “what’s written,” not “what it is.” It can’t reliably tell a vendor address from a remit-to block, or a subtotal from a total payable figure.
Non-linear layouts. Two columns, sidebars, stamps, and floating boxes cause reading-order chaos. OCR will read across columns and jumble sentences, breaking downstream document scraping logic.
Scans, photos, and artifacts. Rotation, skew, blur, watermarks, and compression create misses and misreads—especially in tables, checkboxes, and handwritten notes.
“Searchable” PDFs with weak overlays. Many scanned PDFs include a hidden text layer created by an older OCR. Trusting that overlay can inject spaced-out tokens (“L e a r n i n g”), overlapping strings, and corrupted numbers.
Tables & forms. Borderless cells, merged headers, ticked checkboxes, and radio buttons rarely serialize cleanly through basic OCR, making it hard to scrape data from PDF tables at scale.
In short, traditional OCR answers how to get text out of a page, not how to scrape data from a PDF into high-quality, structured fields you can trust.
Role of AI/LLMs in semantic understanding and context-aware capture
Large Language Models change the game by adding meaning to the pixels:
Layout-aware comprehension. Feed LLMs layout-preserving text and they can track columns, line items, and headers—critical for pdf data scraping where totals, dates, and entities appear in repeated patterns.
Context + synonyms. LLMs can infer that “Net Amount Due,” “Amount Payable,” and “Total Payable” are the same business concept—even when labels vary across vendors, banks, or states.
Normalization & validation. Units, currencies, and dates can be standardized inline. Cross-field checks (sum of line items ≈ subtotal, taxes within expected ranges) catch bad parses early.
Reasoning across pages. Multi-page leases or statements keep meaning consistent over headers/footers, coping with scraping data from PDF packets compiled from different sources.
Confidence & guardrails. With the right orchestration, multiple prompts or models can agree (or disagree) before a value is accepted, cutting hallucinations out of your pdf scraper pipeline.
Example: differentiating “total payable” vs. “total charges”
Imagine a shipping invoice where a bold “Total Charges” appears mid-page and a small “Total Payable” sits near a stamp at the bottom.
A basic OCR parser might grab the first bolded number it sees (“Total Charges”), returning the wrong field.
A layout-aware, LLM-driven pdf data scraper reads the document structure: it knows “charges” is a component, while “payable” is the final amount after adjustments and credits.
With a challenge step, the system asks a second LLM to verify: “Is this the final amount due to be paid by the customer, considering credits and taxes?” If not, it returns NULL rather than a wrong value. This is how modern pdf scraping becomes reliable enough for finance, insurance, logistics, and real estate—where a single wrong number isn’t acceptable.
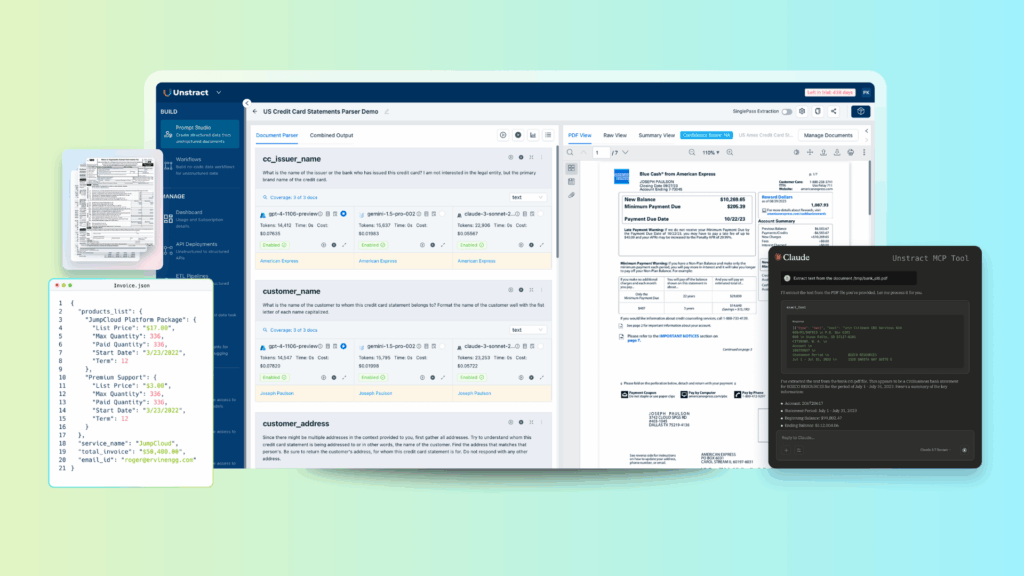
Introducing Unstract: AI-Powered PDF Scraper
Overview of Unstract
Unstract is a purpose-built, no-code platform for LLM-powered unstructured data extraction—open-source (AGPL-3.0) and designed to eliminate manual workflows around PDFs and other complex documents. Teams choose Unstract to go from “files” to clean, structured JSON with auditability and scale. It’s trusted by forward-thinking engineers and comes with a quick start, Slack community, GitHub, and a 3-minute demo to get you moving fast.
Capabilities you can assemble without code
Prompt Studio (no-code). Build generic prompts quickly from small, representative samples. Compare multiple LLMs side-by-side, track costs as you iterate, version prompts, and roll back safely.
LLM-driven extraction. Turn messy PDFs into structured fields using modern LLMs—exactly what you want from a production-grade pdf scraper.
Embeddings + Vector DBs. Add retrieval context for resilient document scraping across vendors, banks, states, or policy templates.
LLMWhisperer (companion extraction). Prepare documents for LLMs with layout-preserving text, robust OCR for scans/phone photos, handwriting detection, and checkbox/radio detection—so your LLM sees what a human sees.
APIs & ETL pipelines. Call Unstract from your apps, or point it at cloud storage and push structured data to warehouses and databases.
Agent & workflow integrations. Give your agents superpowers (e.g., n8n). Prefer MCP? Use Unstract MCP Server for consistent JSON, and LLMWhisperer MCP Server to prep documents for agents.
Flexible stack choices. You’re in control—pick the LLM, Vector DB, Embedding Model, and Text Extraction service that fit your cost, latency, and privacy needs.
Deployment options. Start for free in SaaS, or deploy on-prem for strict data residency and security.
Key differentiators (why Unstract is different)
Trust by design (LLMChallenge).NULL is better than wrong. Unstract runs two LLMs to extract and challenge a value. Only consensus passes; suspected hallucinations are discarded—vital for compliance-grade pdf data scraping.
Efficiency at scale. Reduce token usage by up to 7× with:
SinglePass Extraction: batch your field prompts into a single, optimized prompt; fewer round-trips, lower cost.
Summarized Extraction: automatically construct a compact representation of the document to minimize tokens while preserving meaning.
Zero templates, no training data. Handle variants (e.g., bank statements from 200 banks or forms that differ across 50 states) without brittle rules or months of labeling.
Production-ready operations. Versioned prompts, rollback, observability, retries, and a stable API surface—deployable as a scalable pdf scraper microservice.
Open-source foundation. Transparent, extensible, AGPL-3.0 licensed—aligns with modern engineering standards and avoids black-box lock-in.
What is LLMWhisperer?
When people hear “LLMWhisperer,” they sometimes assume it’s another Large Language Model. In reality, LLMWhisperer is not AI/LLM-powered—it’s a general-purpose text parser and OCR engine designed to prepare messy documents for downstream pdf scraping and document scraping workflows. Think of it as the pre-processor that ensures your LLM sees the document exactly the way a human would.
Why LLMWhisperer matters
Large Language Models are powerful, but their accuracy is only as good as the input text you feed them. PDFs, however, are notoriously tricky—multi-column layouts, handwritten notes, scanned pages, and interactive elements like checkboxes often confuse traditional pdf scrapers.
LLMWhisperer bridges this gap:
It extracts text from PDFs and images with high fidelity, even from poor scans or smartphone photos.
It outputs in layout-preserving modes so the positional relationships (columns, tables, headers, line items) remain intact.
It reads handwriting, checkboxes, and radio buttons, which are usually lost in basic OCR.
It offers auto mode switching: if a page has selectable text, it extracts it directly; if not, it falls back to OCR—saving cost and time while ensuring no data loss.
In short, LLMWhisperer transforms raw documents into LLM-ready text. That makes it the essential first step in any modern pdf data scraping pipeline.
Key capabilities for better PDF scraping
Layout-preserving OCR
Tables, invoices, and rent rolls keep their spacing so that line items stay aligned.
Multi-column scientific papers or financial statements don’t collapse into unreadable strings.
This ensures LLMs can correctly differentiate between “Total Payable” at the bottom and “Total Charges” mid-page—an important distinction in finance and logistics.
Handwritten notes & scanned PDFs
Many real-world documents—loan applications, delivery challans, medical forms—still have handwritten fields.
LLMWhisperer’s state-of-the-art handwriting detection makes them usable in automated pdf scraping workflows.
Checkboxes and radio buttons
Traditional pdf data scrapers ignore these interactive fields or flatten them into pixels.
LLMWhisperer captures whether a box is checked or unchecked, and which radio option was selected—critical in insurance claims, HR forms, and compliance documents.
Optimizations that reduce cost
Auto-compaction: removes low-value tokens while keeping layout, cutting LLM token usage by up to 7×.
Pre-processing: built-in deskew, denoise, blur handling, and rotation correction for better OCR accuracy.
Three output modes: Layout Preserving, Text, and Text-Dump—choose based on downstream needs.
Deployment flexibility
SaaS: fast, managed, low-latency cloud service.
On-Premise: run inside your network to meet strict privacy or data residency requirements.
The role of LLMWhisperer in Unstract’s ecosystem
Unstract positions LLMWhisperer as the front door of any pdf scraper pipeline. Before a Large Language Model applies prompts in Prompt Studio, the document passes through LLMWhisperer:
Scanned/handwritten pages become clean, structured text.
Layout is preserved for accurate scraping data from pdf tables and line items.
Tokens are compacted to keep LLM calls affordable.
That’s why Unstract calls it the perfect companion for LLMs: it doesn’t replace them, it prepares data so they can do their best work.
Testing LLMWhisperer in Real Scenarios
Real-world documents are rarely clean PDFs with selectable text. They are often scanned, handwritten, poorly aligned, or formatted in ways that confuse traditional pdf scrapers. To demonstrate how LLMWhisperer overcomes these issues, we tested it in two different scenarios—one using the Playground and the other using the API. Both tests highlight why Unstract’s approach is more reliable than conventional OCR-based pdf data scraping tools.
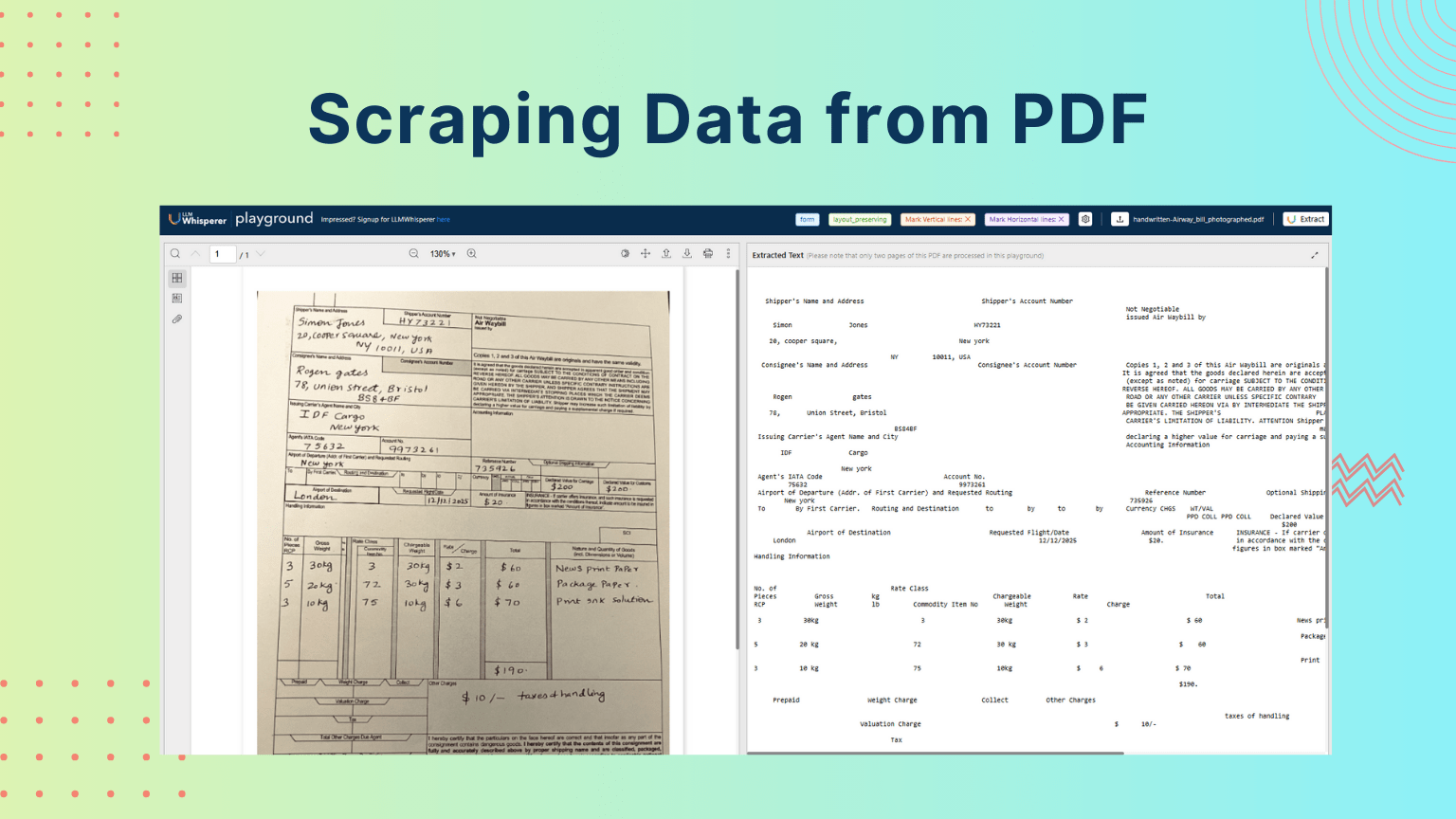
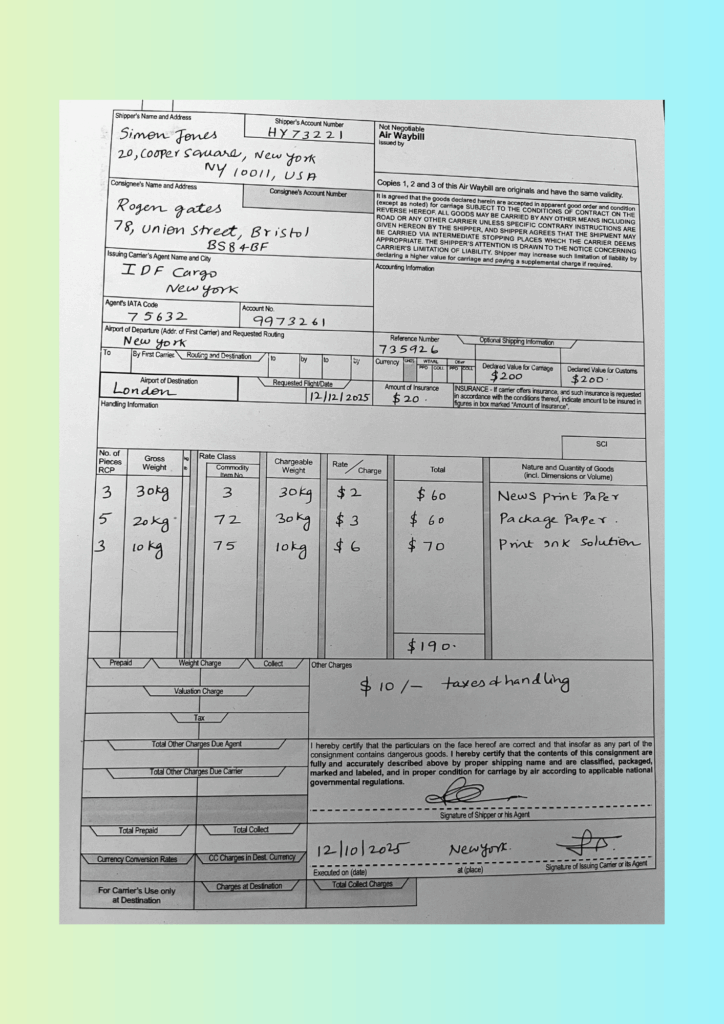
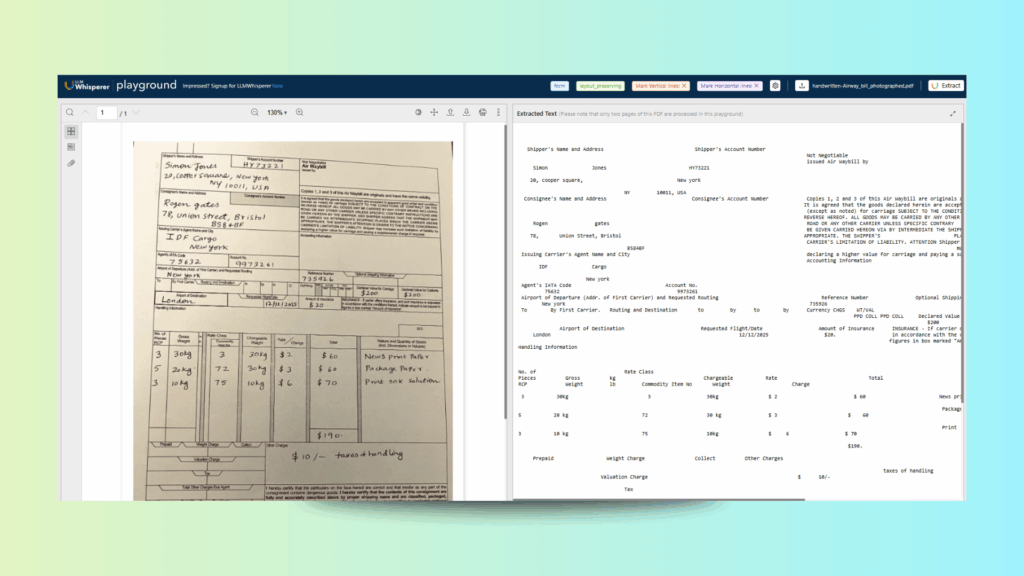
Playground Demo: Handwritten Air Waybill (photographed document)
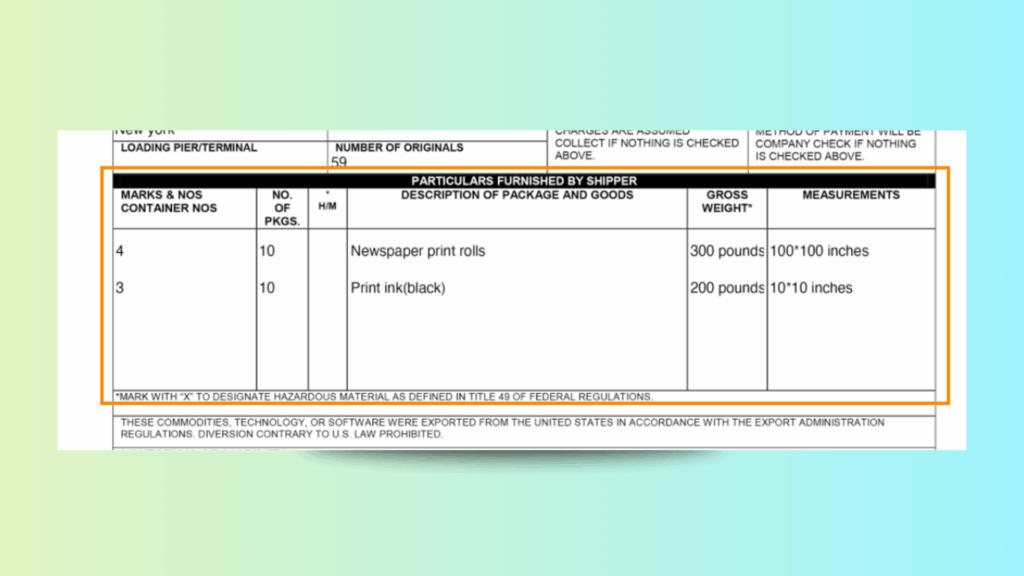
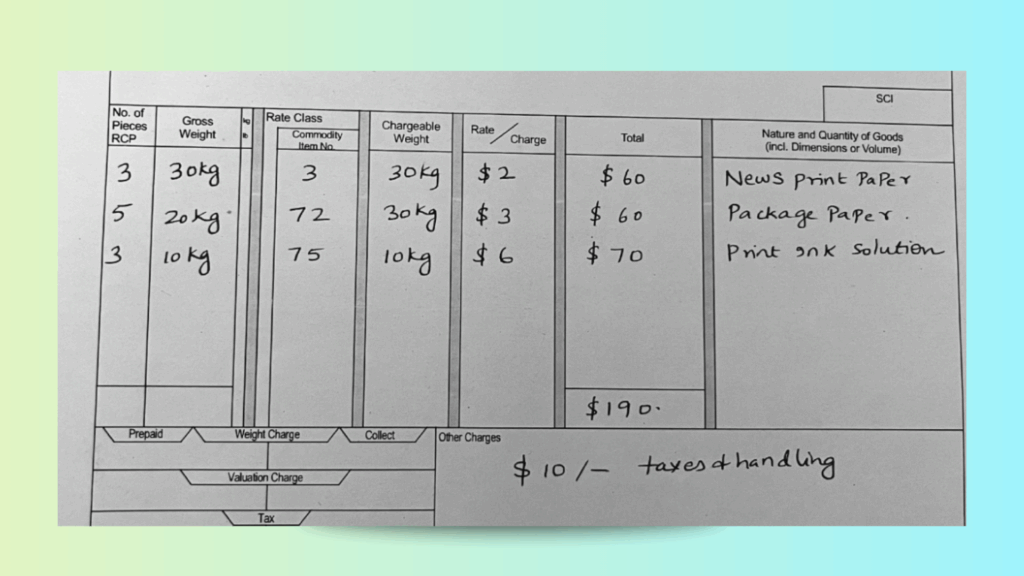
Test Case: An old, yellowish Air Waybill with handwritten and printed data. The document contained multiple data tables with merged headers, very small printed text, and handwritten numeric amounts with currency symbols.
Wait for the OCR process to complete and review the extracted text in the results panel.
Results:
Deskewing: The scanned page was corrected automatically, ensuring the text aligned properly.
Table alignment: Complex multi-column layouts with merged headers were preserved, allowing the data to remain structured.
Handwriting recognition: Numeric values written by hand (including currency symbols) were captured accurately.
Why this matters: Traditional OCR tools would return jumbled lines or lose critical handwritten details. In comparison, LLMWhisperer’s layout-preserving mode ensures that tables and handwritten entries remain in context, making the output usable directly for downstream document scraping and AI-driven extraction. This test shows how even difficult, low-quality scans can be transformed into structured, machine-readable text.
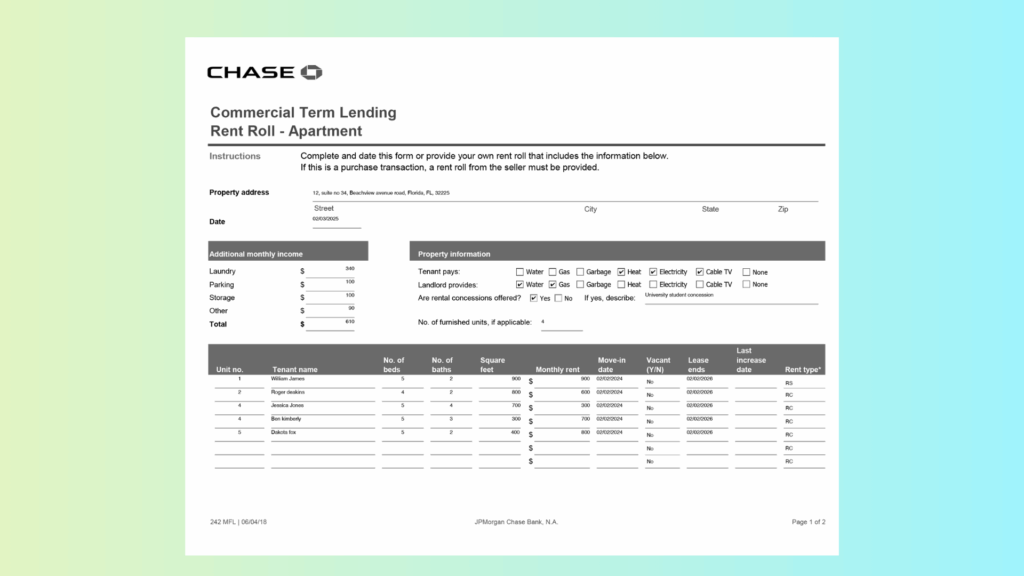
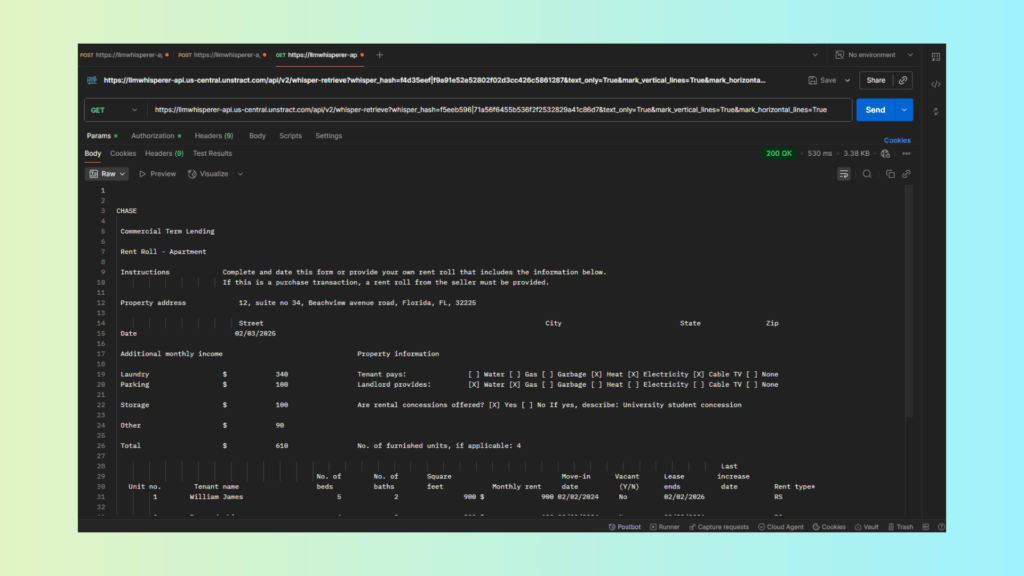
API Demo: Rent Roll Apartment PDF (Postman workflow)
Test Case: A rent roll document in PDF format. It contained small printed text, checkboxes, multiple fonts, and a multi-column layout with currency values.
The response will contain extracted text in layout-preserving mode.
Check the Output
Download or copy the response (for example, response-rent-roll.txt).
All sections—tenant names, checkboxes, addresses, amounts, and multi-column details—are extracted with proper alignment.
Results:
Checkbox detection: Selections were recognized correctly.
Multi-font and multi-column layout: Retained without collapsing into unreadable strings.
Currency formatting: Amounts and symbols were captured as they appeared in the original document.
Why this matters: Most pdf scrapers break down on multi-column layouts or fail to capture checkboxes. By contrast, LLMWhisperer produces consistent, structured text output that is ready for LLM-driven extraction in Unstract’s Prompt Studio. This makes the solution enterprise-ready for real estate, finance, and insurance workflows.
Results Analysis: Accuracy in Challenging Scenarios
Both tests highlight why Unstract’s LLMWhisperer is not just another OCR tool, but a specialized pre-processing engine built for AI pipelines:
Deskewing and pre-processing: Handles tilted scans and noisy backgrounds automatically.
Table alignment: Multi-column structures and merged headers remain intact for reliable downstream parsing.
Zero data loss: Handwritten notes, checkboxes, small fonts, and currency values are faithfully extracted.
Layout-preserving output: Essential for feeding LLMs with context-rich data, ensuring accurate field extraction later.
By combining Playground ease-of-use with API flexibility, LLMWhisperer proves it can handle both experimental trials and production-grade integrations. This makes it the foundation of any pdf data scraping workflow in Unstract—ensuring that complex, real-world documents are converted into high-quality text ready for LLM-driven analysis.
Using Unstract to Extract Data from a Multimodal Ocean Bill of Lading
One of the most powerful features of Unstract is its Prompt Studio—a no-code environment built to extract structured data from even the most complex business documents. A multimodal Ocean Bill of Lading is an excellent test case: it’s a dense, multi-column shipping document containing legal, financial, and cargo-related details scattered across multiple sections.
Unlike older approaches that rely on fixed templates or manual annotations, Prompt Studio lets you define extraction instructions in plain language. This makes it far easier to handle logistics and freight documents, where formats vary widely across carriers and regions.
Setting Up Unstract for Bill of Lading Document Processing
To automate the extraction of structured data from complex shipping documents such as Bills of Lading, Unstract provides a no-code interface to configure the complete workflow. A Bill of Lading often contains multi-column layouts, cargo descriptions, vessel and port details, and financial values scattered across the document. With Unstract, you can set up the essential components needed for accurate pdf data scraping and layout-aware parsing.
1. OpenAI LLM Profile
This profile powers the semantic-level field extraction from the Bill of Lading after preprocessing. It ensures the model can distinguish between fields like “Total Charges” and “Total Payable.”
Go to Settings > LLMs
Click New LLM Profile
Choose OpenAI
Enter your API Key and save
2. OpenAI Embedding Model
Embeddings help segment and index the Bill of Lading, so that entity-specific prompts (shipper, consignee, cargo list) retrieve the right context.
Navigate to Settings > Embedding
Click New Embedding Profile
Choose OpenAI
Enter your API Key and select a model (e.g., text-embedding-ada-002)
Save the profile
3. Vector Database (Postgres Free Trial)
A vector database is required for storing and retrieving the vectorized document chunks. This is particularly useful when processing large Bills of Lading or when integrating across multiple carriers and formats.
Go to Settings > Vector DBs
Create a new profile
Select Postgres Free Trial
Add a name, endpoint URL, and credentials (provided by Unstract)
4. Text Extractor: LLMWhisperer
Before sending data to the LLM, LLMWhisperer ensures the Bill of Lading is converted into clean, layout-preserving text. It handles scanned PDFs, complex cargo tables, checkboxes, and even handwritten values.
Go to Settings > Text Extractor
Click Create New
Choose LLMWhisperer
Paste your API key from the Unstract Whisperer dashboard
Set:
Processing Mode: OCR
Output Mode: Layout-preserving
With this setup, you’re ready to begin processing multimodal Bills of Lading using the Unstract platform. Shipper details, consignee information, vessel and port data, and complete cargo lists can now be automatically extracted, validated, and delivered in structured JSON—without templates, manual annotations, or repetitive rework.
Setting up Prompt Studio Project for Multimodal Ocean Bill of Lading
From the Unstract dashboard, navigate to Prompt Studio. This opens a visual, drag-and-drop workspace where you can design extraction rules without writing code.
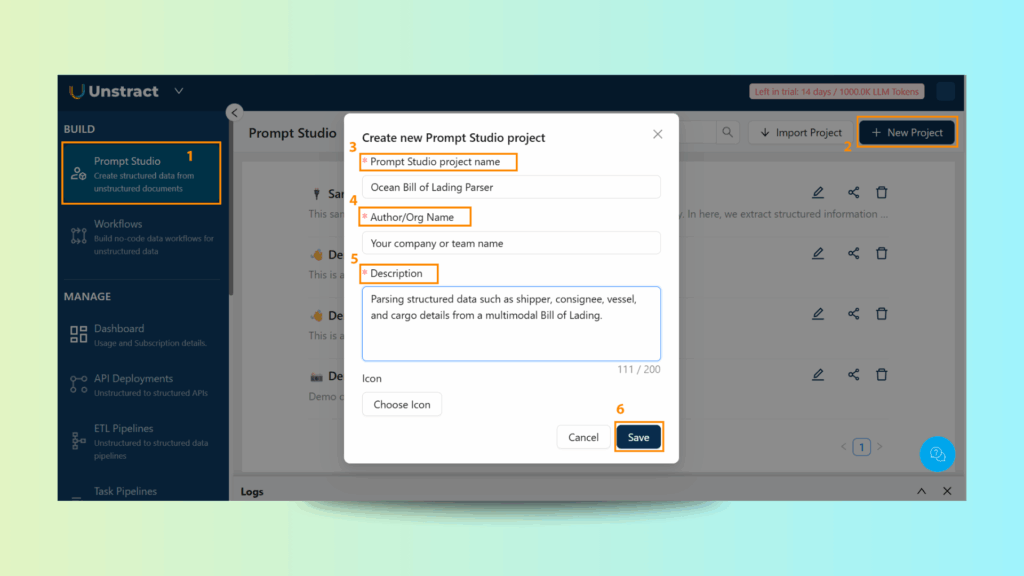
Step 2: Create a New Project
Click New Project.
Enter details such as:
Project Name: Ocean Bill of Lading Parser
Author: Your company or team name
Description: Parsing structured data such as shipper, consignee, vessel, and cargo details from a multimodal Bill of Lading.
Optionally, upload your logo for branding.
Save the project to continue.
Step 3: Upload the Sample Document
Upload ocean_bill_of_lading.pdf. This document typically contains:
Shipper and Consignee information
Notify party details
Vessel, voyage, and port information
Cargo list with weights, volumes, and measurements
Declared shipment value and payment terms
Step 4: Add Field-Level Prompts
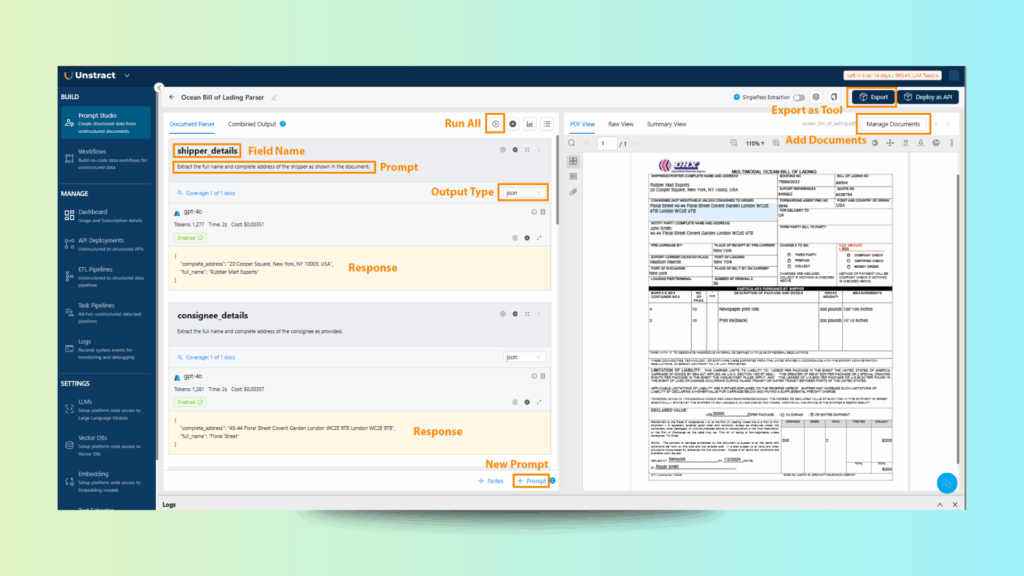
In Prompt Studio, click Add Prompts and define extraction rules in plain English. For example:
{
"shipper_details": "Extract the full name and complete address of the shipper as shown in the document.",
"consignee_details": "Extract the full name and complete address of the consignee as provided.",
"notify_party_details": "Extract the notify party name and address exactly as written.",
"vessel_and_ports": "Extract vessel name, voyage number, port of loading, and port of discharge.",
"cargo_details": "Extract each cargo item with quantity, gross weight, volume, and package description.",
"declared_value_and_cod": "Extract the declared value of the shipment and any Cash on Delivery (COD) amount mentioned.",
"issuer_and_date": "Extract the name of the issuer, place of issue, and date of issue."
}
These prompts allow you to target exactly what matters in the Bill of Lading, without needing rigid templates.
Step 5: Run and Validate the Extraction
Click Run.
Within seconds, Unstract produces structured JSON output for each field.
Currency and numeric values are captured accurately.
Names and addresses are returned in full without truncation.
Key benefit: This approach captures the right data even when the document layout or formatting differs between carriers—avoiding the pitfalls of static parsing methods.
Step 6: Export and Reuse
Once validated, click Export as Tool. Your Bill of Lading parser is now a reusable extraction component that can be integrated into larger workflows, APIs, or ETL pipelines.
Deploying Unstract as an API
Once you’ve built and validated the Bill of Lading extraction project in Prompt Studio, the next step is to make it usable in real-world systems. Unstract allows you to wrap your extraction logic into a workflow and expose it as a secure API. This makes integration seamless with ERP platforms, shipping management tools, or automation bots.
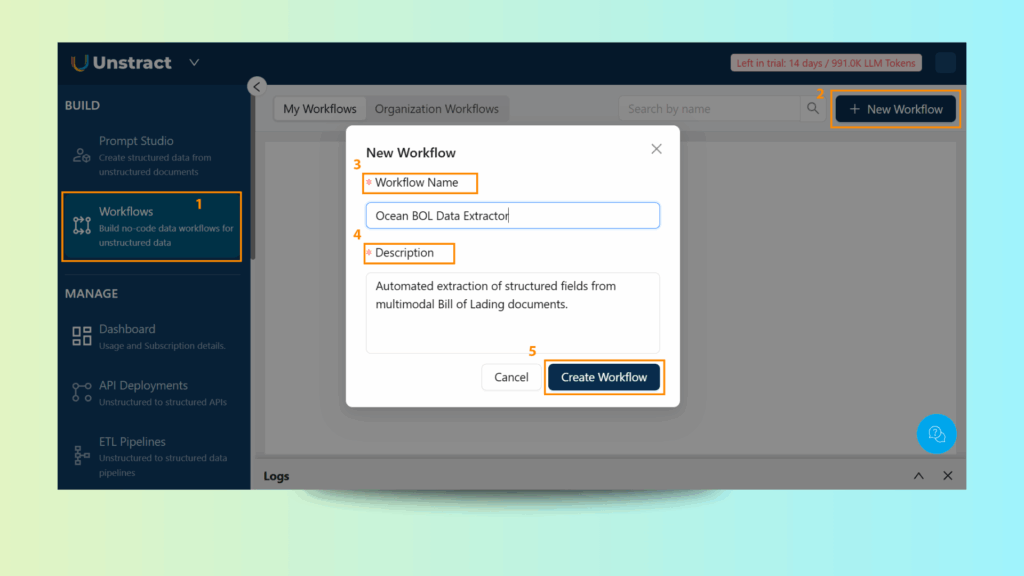
Step 1: Create a New Workflow
In the Unstract dashboard, go to Workflows.
Click New Workflow and fill in the details:
Workflow Name: Ocean BOL Data Extractor
Description: Automated extraction of structured fields from multimodal Bill of Lading documents.
Click Create Workflow to continue.
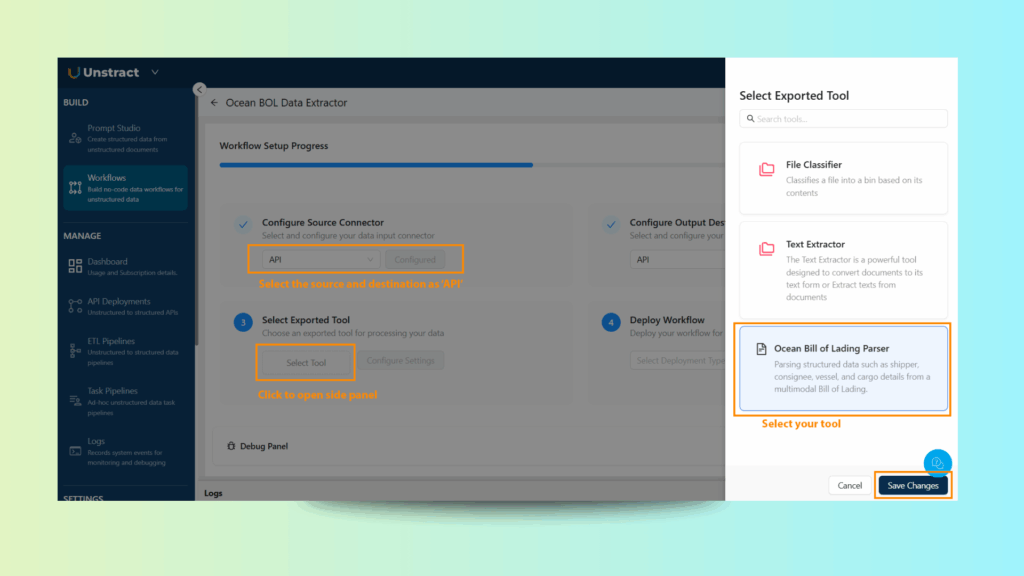
Step 2: Add Your Extraction Tool
From the workflow canvas, drag and drop the Bill of Lading Parser (the tool you exported from Prompt Studio).
This tool becomes the core logic of your workflow, responsible for parsing shipper, consignee, cargo, and vessel details.
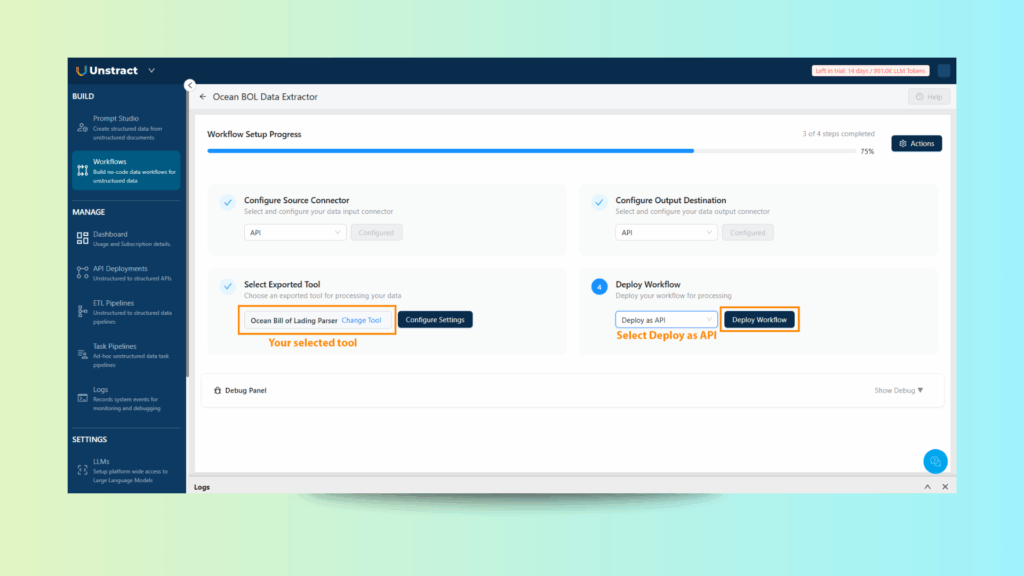
Step 3: Configure API Input and Output
Input Connector: Configure the workflow to accept PDF uploads via HTTP POST.
Output Connector: Set the workflow to return structured JSON with the extracted details.
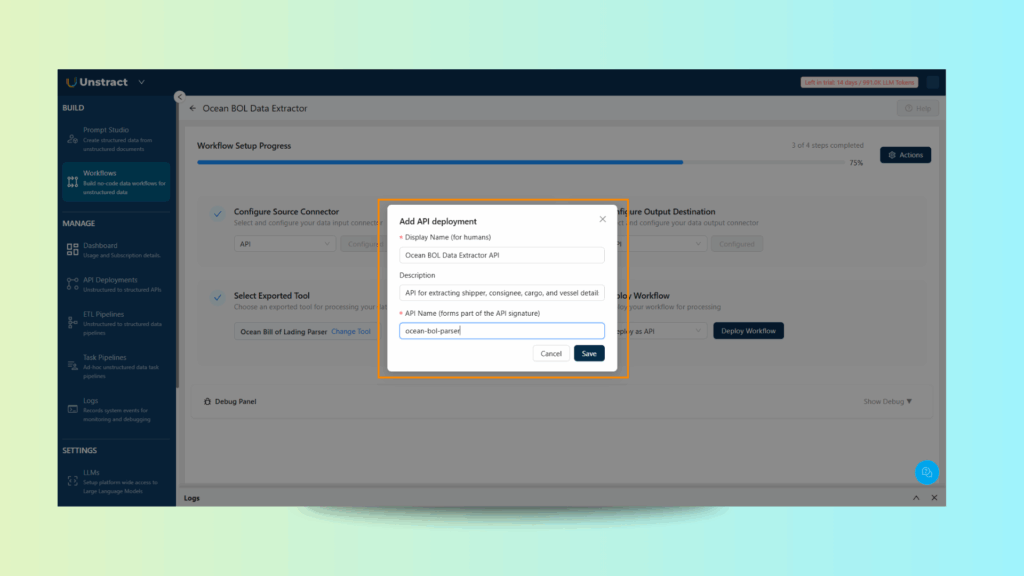
Click Save and then Deploy API.
At this point, your custom Bill of Lading parser is live as an API endpoint.
Step 4: Test the API with Postman
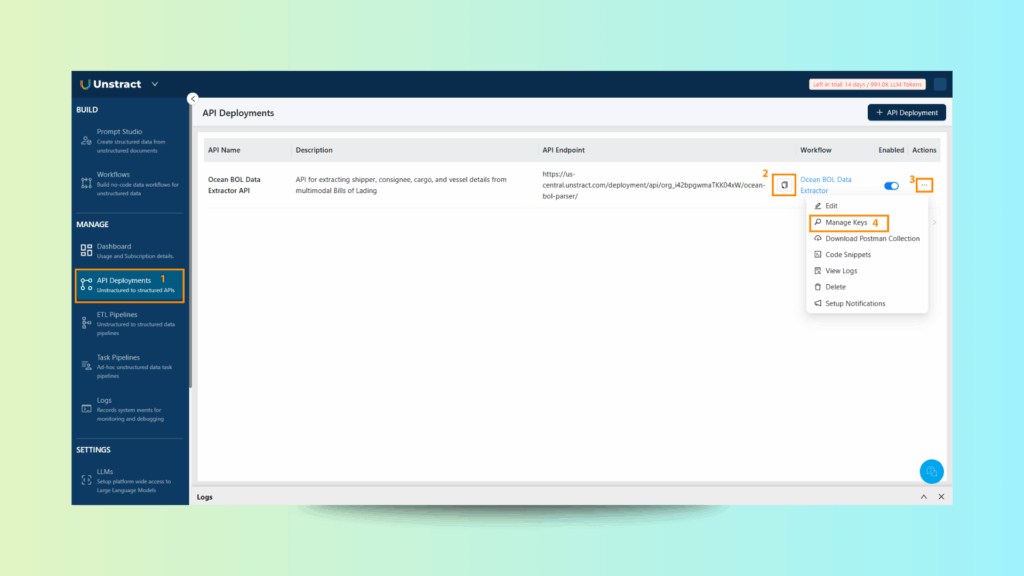
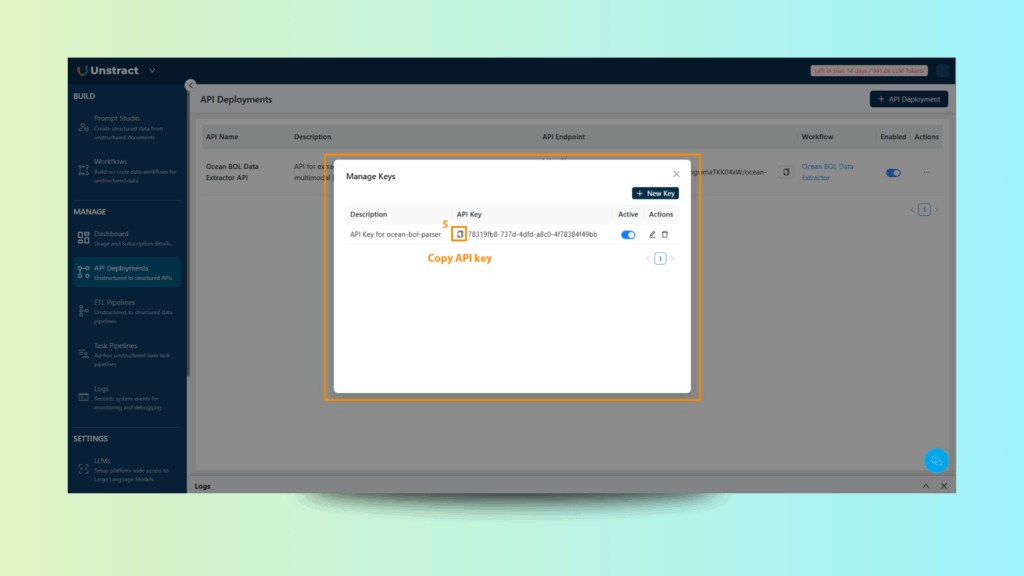
A. Get API Credentials
Navigate to the API deployment settings.
Copy the Endpoint URL and your API Key from the dashboard.
B. Configure Postman Request
Method: POST
URL: Paste your Endpoint URL
Headers:
Authorization: Bearer <YOUR API KEY>
Body: form-data
Key: files
Type: File
Value: Upload ocean_bill_of_lading.pdf
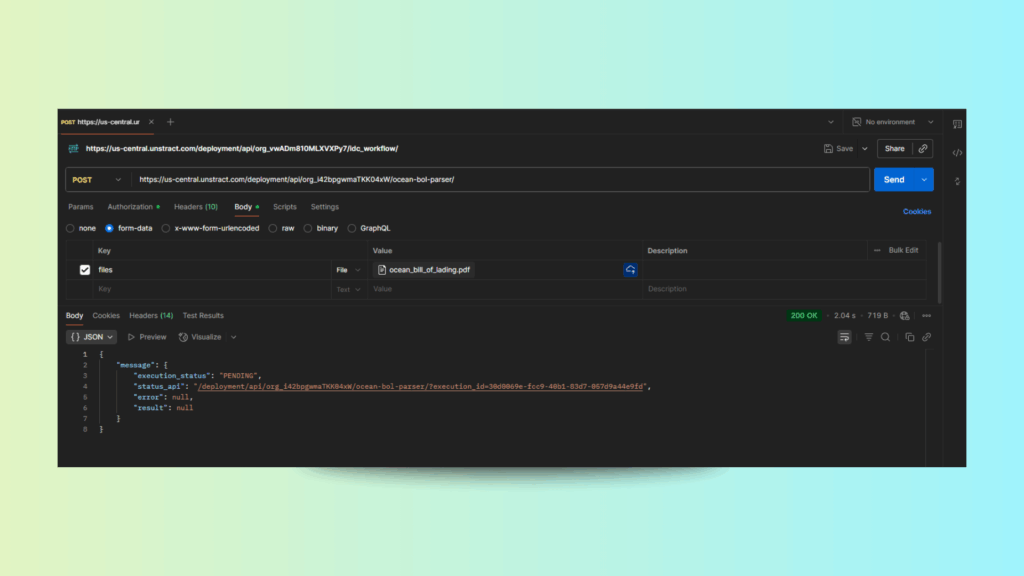
C. Send the Request
Click Send.
The first response will show a status update, typically { “status”: “executing”, “status_api”: “<status_url>” }.
D. Retrieve the Final JSON
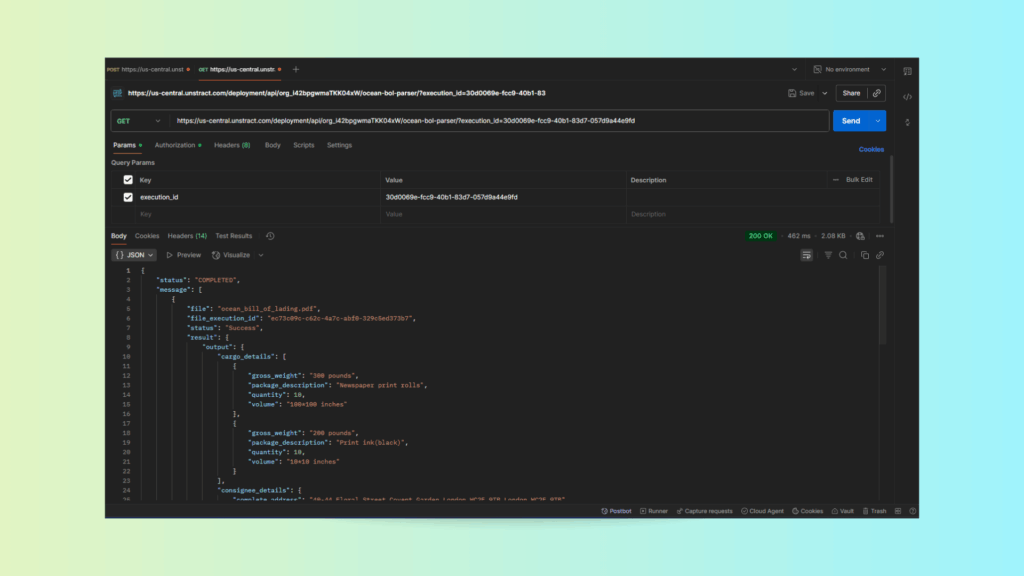
Use the provided status_api URL in a GET request.
Once the process completes, you’ll receive a structured JSON output containing:
Shipper details
Consignee details
Notify party information
Vessel and port data
Cargo items with weights and measurements
Declared value and COD information
Why This Approach Works
Most enterprises face a common challenge: every vendor, partner, or carrier produces documents in different layouts and formats. Traditional OCR solutions or rule-based extractors require rigid templates that break as soon as the layout changes. Unstract, combined with LLMWhisperer, removes that barrier and offers a practical answer to the question of how to scrape data from a PDF reliably.
Here is why this approach is different from conventional tools:
Zero manual annotation
No need to label hundreds of samples or build fragile templates.
You can configure plain-language prompts in Prompt Studio to capture exactly what you need—whether it’s shipper details from a Bill of Lading or line items from an invoice.
Works across all formats
Structured PDFs with selectable text.
Scanned or photographed documents that require OCR.
Handwritten forms, signatures, checkboxes, and multi-column layouts.
The same pipeline handles every case, ensuring consistency.
Layout-preserving extraction
LLMWhisperer maintains the visual structure—tables, columns, and line items—so the LLM can interpret the content correctly.
This ensures totals, dates, and amounts are not misplaced during extraction, which is vital for financial and logistics documents.
Enterprise-ready integration
Deploy as a workflow API and connect directly to ERP systems, shipping platforms, or RPA bots.
Scales to thousands of documents without human intervention.
Logging, retries, and versioning ensure compliance and auditability.
In short, this approach transforms Unstract into a truly intelligent pdf scraper—capable of scraping data from PDF files of any kind with accuracy, scalability, and speed.
Conclusion
The landscape of document scraping is changing. Businesses no longer want partial results or brittle template-based tools. Instead, they need AI-driven solutions that can reliably scrape PDF documents in all their forms—structured, scanned, and handwritten—without endless setup work.
With Unstract as the orchestration engine and LLMWhisperer as the layout-preserving text extractor, enterprises finally have a solution that delivers:
Accuracy: semantic extraction that differentiates between “total charges” and “total payable.”
Scalability: process hundreds or thousands of files per day without increasing headcount.
Compliance readiness: audit trails, PII masking, and the option to deploy on-premise.
If you are searching for the most efficient way to scrape data from PDF documents—whether bank statements, rent rolls, insurance forms, or Bills of Lading—Unstract offers the ideal balance of power and simplicity. It eliminates the guesswork of how to scrape data from a PDF by providing a proven, AI-powered workflow that works out of the box.
The future of pdf scraping lies in intelligent automation. With Unstract and LLMWhisperer, you’re not just adopting another pdf data scraper—you’re enabling a new standard in enterprise-ready document automation.
Unstract 101: Leveraging AI to Convert Unstructured Documents into Usable Data
Discover how Unstract(open-source) makes unstructured data extraction simple and powerful. In this webinar, we show you how to process complex documents—images, forms, and multi-layout tables—without any pre-training. See how Unstract improves accuracy, streamlines operations, and integrates seamlessly into your existing workflows.
Unstract PDF Scrapper: FAQs
What is a pdf scraper and how does Unstract improve on traditional tools?
A pdf scraper is software that automatically extracts text, tables, and other structured elements from PDF files. Unstract’s as a pdf scraper goes further by preserving layout(with LLMWhisperer OCR), using AI to understand context (e.g., “Total Payable” vs. “Total Charges”), and delivering clean JSON instead of raw, unstructured text.
What does pdf data scraping include beyond simply running OCR?
Pdf data scraping includes identifying whether a page is digital or scanned, applying OCR when necessary, preserving table structure, recognizing checkboxes, and mapping extracted strings to business fields like invoice_total or vessel_port. Unstract bundles all of these steps into a single, auditable pipeline.
Can I set up Unstract to automatically scrape data from pdf files without creating templates for every layout?
Yes. With Prompt Studio you write plain-language instructions (e.g., “extract shipper address” or “capture total_due”), and Unstract will scrape data from pdf documents of any format—digital, scanned, or hybrid—without the maintenance overhead of traditional template systems.
How to scrape data from a PDF using Unstract and LLMWhisperer?
To scrape data from a PDF with Unstract, upload your document to the platform, which uses LLMWhisperer for advanced OCR and layout extraction. Then, set up prompts in Prompt Studio to define which fields you want to extract (e.g., amounts, names, tables). The pdf scraper engine processes the document, returning structured data you can export or integrate via API—supporting both digital and scanned files.
How does AI improve pdf data scraping compared to traditional OCR methods?
Traditional OCR focuses on extracting text but often loses context and structure. AI-powered pdf data scraping leverages layout preservation, semantic understanding, and context-aware language models. This means a modern pdf scraper can reliably differentiate, for example, between “total charges” and “total payable,” handle synonyms, correct layouts, and validate extracted data for compliance.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.