LLMWhisperer OCR API – Extract Text & Data from Documents
Table of Contents
LLMWhisperer OCR API Introduction
In an age where businesses and applications are increasingly driven by automation, OCR (Optical Character Recognition) has become a cornerstone of digital transformation.
From scanning invoices to extracting text from scanned contracts, OCR enables machines to read and understand documents that were once locked in static formats like PDFs, images, or handwritten notes.
But as workflows evolve, so do the requirements, especially when Large Language Models (LLMs) are at the core of the stack.
Traditional OCR tools were never designed for the scale, structure, or complexity that modern AI workflows demand.
Developers building AI-native applications, from RAG pipelines and enterprise search systems to document Q&A bots and automated knowledge extraction tools, need more than just text output.
They need rich structure, flexible formats, and minimal pre-processing.
Enter LLMWhisperer OCR API: a next-gen, developer-friendly, AI-native solution that redefines what an OCR API for AI can be.
With support for multiple file formats, layout-aware structured output, and seamless integration into LLM-based systems, it’s built from the ground up for real-world document parsing problems.
TL;DR
If you wish to skip directly to the solution section, where you can see how LLMWhisperer OCR API handles document types of any complexity — document scans, handwritten forms, skewed images multi-language documents, click here.
What is an OCR API – And Why It Needs an Upgrade
An OCR API (Optical Character Recognition API) allows developers to programmatically extract text and structural information from visual files such as PDFs, scans, and images.
It serves as a critical bridge between raw documents and machine-usable data, powering use cases like:
Invoice and receipt scanning (line items, totals, tax info)
ID verification (passports, licenses)
Knowledge extraction (summarization, search, Q&A)
Traditional OCR APIs focus on raw text extraction, but they often break down when faced with complex layouts, multilingual content, or the structured output formats required by today’s LLM-powered workflows.
Developers are forced to spend hours on pre-processing, post-cleaning, and data normalization before results are usable.
With the rise of Large Language Models, a new generation of OCR is needed: one that understands not just what is written, but how it’s presented and returns results ready for downstream AI tasks.
LLMWhisperer OCR API: Document pre-processor for AI-based workflows
LLMWhisperer is purpose-built for the LLM-native era, where unstructured documents are transformed into structured, semantically-rich, and machine-actionable data with minimal developer effort.
AI-Native by Design
LLMWhisperer removes the friction of legacy OCR:
No pre-processing required: Send documents as they are.
Handles noisy scans, rotated text, and variable formats out of the box.
Built for real-world variability in documents.
From receipts and handwritten forms to multi-column research papers, the engine intelligently extracts meaningful content while preserving context.
LLM-Optimized Output
Unlike traditional tools that return plain blobs of text, LLMWhisperer provides well-tagged, structured output, which is ideal for:
Feeding into OpenAI, Claude, Mistral, or local LLMs
Retrieval-Augmented Generation (RAG)
Semantic search and summarization
Fine-grained field extraction and analysis
Optional modes like layout-preserving, add_line_nos, and mark_vertical_lines allow customization for downstream parsing or visualization.
Developer-Centric Tooling
Plug-and-play Python SDK (also JavaScript SDK) with async support, retries, and helper methods
Intuitive REST API with clear documentation and error handling
Seamless integration into AI stacks like LangChain, Haystack, or RAG pipelines
Get up and running in minutes, and scale to production with confidence.
Comprehensive File Format Support
LLMWhisperer supports a broad range of file types:
PDF (native and scanned)
Images: JPG, PNG, TIFF, BMP, WEBP
Office Docs: DOCX, XLSX, PPTX
Specialized logic ensures high fidelity for:
Scanned forms: Detects fields, checkboxes, radio buttons
Excel sheets: Preserves cell layout and merged cells
Multilingual documents: Supports 50+ languages (LTR + RTL)
Smart Layout & Form Understanding
Beyond basic text, LLMWhisperer extracts:
Visual structure: Lines, columns, paragraphs, and tables
Forms and fields: Key-value pairs, interactive PDF elements
On-premise deployment for full control over data privacy and compliance
Built-in support for scaling, observability, and integration with internal systems
Who Is the LLMWhisperer OCR API For?
LLMWhisperer OCR API is built for anyone turning unstructured documents into structured, AI-ready data:
LLM Product Teams – Need clean, structured inputs for chatbots, RAG, and summarization. LLMWhisperer delivers layout-aware, context-rich output ready for OpenAI, Claude, Mistral, and more.
Enterprise Automation Teams – Automate document-heavy workflows in legal, finance, and insurance with multilingual OCR, form extraction, and on-premise deployment options.
AI Copilot & Workflow Builders – Perfect for assistants that analyze contracts, reports, or forms. Preserve layout, extract fields, and skip complex preprocessing.
Data Scientists & Engineers – Feed your pipelines with structured data from PDFs, scans, and spreadsheets, ideal for embeddings, analytics, and model training.
Technical Guide to Getting Started with LLMWhisperer OCR API
When using the API, you can choose both processing modes and output modes to control how LLMWhisperer handles your document.
These settings let you balance speed, accuracy, and fidelity to layout.
All these settings are applicable to the /whisper API endpoint, more details about the API endpoints in the next section.
OCR API Processing Modes (mode parameter)
LLMWhisperer offers four primary processing modes to tailor OCR behaviour based on your document type and quality:
native_text: Skips OCR entirely and extracts embedded text directly, perfect for digital PDFs and documents with selectable text. It’s the fastest and cleanest option for software-generated files.
form (default): Optimized for forms and structured documents. It prioritizes layout fidelity, preserving field relationships, tables, and spacing for high-accuracy downstream use.
low_cost: A cost-efficient mode that balances performance and speed. Optional preprocessing filters help improve extraction without the overhead of full-quality OCR.
high_quality: Designed for difficult documents, scanned pages, noisy inputs, or skewed images. This mode uses advanced OCR techniques to ensure the most accurate extraction possible.
OCR API Output Modes (output_mode parameter)
LLMWhisperer supports two output modes to match your specific use case:
layout_preserving (default): Retains the document’s original visual structure, including line breaks, tables, columns, and spatial layout are preserved. Ideal for LLM pipelines that benefit from contextual fidelity. Whitespace and artifacts are intelligently cleaned for a polished result.
text: Produces clean, unstructured text with all formatting removed. Best for cases where layout is unnecessary or when dealing with documents that have inconsistent fonts or styles.
OCR API Customization Options
You can fine-tune extraction behavior using additional parameters:
mark_vertical_lines, mark_horizontal_lines: enable physical lines in layouts for better structure.
add_line_nos: include line numbers and metadata for debugging or data referencing.
median_filter_size, gaussian_blur_radius: apply filters in low_cost mode to reduce noise.
line_splitter_tolerance, line_splitter_strategy, horizontal_stretch_factor: adjust how lines are separated across varied fonts or columns.
By combining processing modes, output modes, and custom settings, LLMWhisperer gives you full control, from lightning-fast text extraction in native PDFs to pixel-perfect OCR of complex scanned documents with preserved structure and context.
Document extraction at the cutting edge with LLM models vs. LLMWhisperer OCR API
In this webinar, we put top LLMs to the test—evaluating their performance across documents of varying complexity. We’ll dive into why directly parsing raw documents often leads to subpar results, and showcase the impact LLMWhisperer has on improving extraction outcomes.
OCR API Endpoints
LLMWhisperer provides a robust and developer-friendly set of RESTful API endpoints that go far beyond traditional OCR.
These endpoints are designed to support the full lifecycle of document ingestion, conversion, enhancement, and monitoring by enabling seamless integration into AI pipelines, automation workflows, and enterprise applications.
The /whisper endpoint is the engine that powers LLMWhisperer’s document intelligence.
It’s where you send your files (PDFs, scanned images, Office docs, Excel sheets, and more) to be parsed, analyzed, and transformed into structured, LLM-optimized data.
Key Features:
Accepts a wide range of file formats: PDF, DOCX, XLSX, PNG, JPEG, TIFF, and others.
Requires zero pre-processing, just send raw files as-is.
Multiple output_mode options:
text – Plain text output.
layout_preserving – Includes bounding boxes, tables, and layout metadata.
Supports webhook integration for async workflows.
Works seamlessly for scanned documents, complex forms, and mixed-language text.
Use Cases: RAG pipelines, document Q&A, intelligent automation, data extraction from receipts/invoices/contracts.
Status API (/whisper-status)
This endpoint allows you to check the real-time status of a submitted extraction job.
It’s especially useful when operating in asynchronous mode.
Response: Includes per-page status, execution time, and overall job status.
Possible statuses:
accepted: Added to queue
processing: In progress
processed: Done, ready to retrieve
error: Failed with reason
retrieved: Already fetched
Use Case: Monitor job progress, handle retries, or show status to end users.
Retrieve API (/whisper-retrieve)
Once a document has been processed via the /whisper endpoint, the /whisper-retrieve endpoint allows you to retrieve the full output at any time.
Key Features:
Fetch previously processed document output, even after delays.
Returns the exact result_text and associated extraction metadata.
Ideal for batch processing and audit workflows.
Use Cases: Async pipelines, bulk document retrieval, fault-tolerant systems that fetch after queue processing.
Detail API (/whisper-detail)
The whisper-detail endpoint gives you in-depth metadata about your document’s processing.
It’s designed for advanced use cases that require visibility into processing metrics.
Key Features:
Shows timing, pages processed, file size, and more.
Ideal for auditing, debugging, quality checks, and layout-aware AI pipelines.
Use Cases: Use this endpoint to monitor, analyse, and fine-tune your OCR pipeline with full transparency.
Highlight API (/highlights)
The /highlights endpoint enables visual overlays of extracted content on top of the original document.
This is critical for building frontend experiences where users can see what was extracted and where.
Key Features:
Visual overlays for text blocks, lines, tables, and fields.
Support for highlighting confidence, form elements, and search matches.
Easy to integrate into PDF viewers and UI dashboards.
Use Cases: Document review tools, annotation systems, search interfaces, and form auditing.
Usage Metrics API (/get-usage-info)
This endpoint provides real-time insights into your current usage of the LLMWhisperer service.
It’s ideal for monitoring costs, enforcing rate limits, or optimizing workflows.
Key Features:
Tracks how many pages have been processed.
Breaks down usage by extraction mode (native_text, low_cost, high_quality, form), for paid plans.
See current plan limits and remaining quota.
Use Cases: Cost management, usage dashboards, billing automation, governance.
Usage Stats API (/usage-stats)
This endpoint enables users to track usage statistics filtered by tag over a specified time range.
It’s especially useful for analyzing historical usage by project, team, or customer if you’re tagging jobs with unique identifiers.
Key Features:
Historical breakdown by date, mode (e.g. form, low_cost), and tag (e.g. project, client).
Exportable JSON data for dashboards, audits, and internal reports.
Supports custom date ranges or defaults to the last 30 days.
Useful for identifying bottlenecks, usage spikes, or underutilized services.
Unstract offers official SDKs for popular programming languages like Python and JavaScript, making it easy to integrate LLMWhisperer into any workflow.
In this section, we’ll walk through an example using the Python SDK to demonstrate just how simple it is to get started with document processing.
First, install the required library:
pip install llmwhisperer-client python-dotenv
With that in place, you’re ready to start whispering to your documents.
But, before creating a script, make sure to also define a .envfile to place the API key:
LLMWHISPERER_API_KEY=<YOUR_LLMWHISPERER_API_KEY>
Now let’s see an example of a simple script that integrates with the SDK:
import os
from dotenv import load_dotenv
from unstract.llmwhisperer import LLMWhispererClientV2
from unstract.llmwhisperer.client_v2 import LLMWhispererClientException
import sys
# Load the API key from the .env file
load_dotenv()
# Function to process a document
def process_document(file_path):
# Initialize the client with your API key
client = LLMWhispererClientV2(base_url="https://llmwhisperer-api.us-central.unstract.com/api/v2",
api_key=os.getenv("LLMWHISPERER_API_KEY"))
# Call the sync method with the file path
try:
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
)
return result['extraction']['result_text']
except LLMWhispererClientException as e:
print(e)
return None
# Main function
if __name__ == "__main__":
# Get the path to the PDF file from the command line
pdf_path = sys.argv[1]
# Call the function to process the document
result = process_document(pdf_path)
# Print the result
print(result)
This script demonstrates how to use the LLMWhispererClientV2 from the unstract SDK to run OCR on a document file and extract text using the LLMWhisperer OCR API.
At the core of the script is the process_document() function, which takes a file path, initializes the OCR client with the proper base URL and API key, and sends the file to the LLMWhisperer API for processing.
It uses the whisper() method in synchronous mode (wait_for_completion=True) to ensure that the script pauses until the extraction is finished. This means the SDK handles the whisper, whisper-status and whisper-retrieve API calls for us.
Once processing is complete, it retrieves the plain extracted text from the API response and returns it.
Running the script, we can see the flow of API calls handled by the SDK:
In the next section, we’ll explore how changing these options affects the structure of the extracted output.
Running Examples
For simplicity, we’ll use the previously introduced Python script to interact with the LLMWhisperer API.
To demonstrate different output modes and customization options, we’ll modify this script as needed, any updates will be included alongside each example.
To be completed by the Lender:
Lender Loan No./Universal Loan Identifier Agency Case No.
Uniform Residential Loan Application
Verify and complete the information on this application. If you are applying for this loan with others, each additional Borrower must provide
information as directed by your Lender.
Section 1: Borrower Information. This section asks about your personal information and your income from
employment and other sources, such as retirement, that you want considered to qualify for this loan.
1a. Personal Information
Name (First, Middle, Last, Suffix) Social Security Number 175-678-910
IMA CARDHOLDER (or Individual Taxpayer Identification Number)
Alternate Names - List any names by which you are known or any names Date of Birth Citizenship
under which credit was previously received (First, Middle, Last, Suffix) (mm/dd/yyyy) [X] U.S. Citizen
08/31 /1977 [ ] Permanent Resident Alien
[ ] Non-Permanent Resident Alien
Type of Credit List Name(s) of Other Borrower(s) Applying for this Loan
[X] am applying for individual credit. (First, Middle, Last, Suffix) - Use a separator between names
[ ] I am applying for joint credit. Total Number of Borrowers:
Each Borrower intends to apply for joint credit. Your initials:
Marital Status Dependents (not listed by another Borrower) Contact Information
[X] Married Number -
- Home Phone ( )
[ ] Separated Ages Cell Phone
(408)123 4567
[ ] Unmarried Work Phone ( ) - Ext.
(Single, Divorced, Widowed, Civil Union, Domestic Partnership, Registered
Reciprocal Beneficiary Relationship) Email [email protected]
Current Address
Street 1024, SULLIVAN STREET Unit #
City LOS ANGELES State CA ZIP 90210 Country USA
How Long at Current Address? 3 Years 5 Months Housing [ ] No primary housing expense [ ] Own [X] Rent ($ 1,300 /month)
If at Current Address for LESS than 2 years, list Former Address [X] Does not apply
Street Unit #
City State ZIP Country
How Long at Former Address? Years Months Housing [ ] No primary housing expense [ ] Own [ ] Rent ($ /month)
Mailing Address - if different from Current Address [X] Does not apply
Street Unit #
City State ZIP Country
1b. Current Employment/Self-Employment and Income [ ] Does not apply
Gross Monthly Income
Employer or Business Name CAFFIENATED Phone (408) 109-8765
Base $ 8000 /month
Street 2048, MAIN STREET Unit #
Overtime $ /month
City LOS ANGELES State CA ZIP 90210 Country USA
Bonus $ /month
Position or Title CEO Check if this statement applies: Commission $
0.00 /month
Start Date [ ] I am employed by a family member,
02 / 04 / 2009 (mm/dd/yyyy)
property seller, real estate agent, or other Military
How long in this line of work? 15 Years 5 Months party to the transaction. Entitlements $ /month
Other $ /month
[X] Check if you are the Business [ ] I have an ownership share of less than 25%. Monthly Income (or Loss)
Owner or $ TOTAL $ 8000 /month
Self-Employed [X] I have an ownership share of 25% or more. 8000
Uniform Residential Loan Application
Freddie Mac Form 65 · Fannie Mae Form 1003
Effective 1/2021
<<<
USA DRIVER LICENSE
California
CLASS C
DL 11234568
EXP 08/31/2014 END NONE
LN CARDHOLDER
FNIMA
2570 24TH STREET
ANYTOWN. CA 35818
008 08/31/1977
RSTR NONE 08311977
VETERAN
SEX F HAIR BRN EYES BRN
Ima HGT 5-05 WGT 125 1b ISS
DD 08/31/2009
<<<
You can see that LLMWhisperer successfully processed even the scanned driver’s license.
By default, the API returns results in layout-preserving mode. If you’re only interested in the raw text without maintaining the original layout, you can simply switch to the text output mode like this:
...
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
output_mode="text",
)
...
Which gives this output:
To be completed by the Lender: Lender Loan No./Universal Loan Identifier
Agency Case No.
Uniform Residential Loan Application
Verify and complete the information on this application. If you are applying for this loan with others, each additional Borrower must provide information as directed by your Lender.
Section 1: Borrower Information. This section asks about your personal information and your income from employment and other sources, such as retirement, that you want considered to qualify for this loan.
1a. Personal Information
Name (First, Middle, Last, Suffix)
IMA CARDHOLDER
Alternate Names - List any names by which you are known or any names under which credit was previously received (First, Middle, Last, Suffix)
Date of Birth
(mm/dd/yyyy)
08/31 /1977
Citizenship [X] U.S. Citizen [ ] Permanent Resident Alien [ ] Non-Permanent Resident Alien
List Name(s) of Other Borrower(s) Applying for this Loan (First, Middle, Last, Suffix) - Use a separator between names
Marital Status
Dependents (not listed by another Borrower)
[X] Married
Number
[ ] Separated
Ages
-
[ ] Unmarried
Contact Information
Home Phone
(
-
Cell Phone
(408)123
4567
Work Phone
(
-
)
Ext.
Email
[email protected]
Current Address
Street
1024, SULLIVAN STREET
Unit #
City
LOS ANGELES
State CA
ZIP
90210
Country
USA
How Long at Current Address? 3 Years 5 Months Housing [ ] No primary housing expense [ ] Own [X] Rent ($ 1,300
/month)
If at Current Address for LESS than 2 years, list Former Address Street
[X] Does not apply
Unit #
City
State
ZIP
Country
How Long at Former Address? Years
Months Housing [ ] No primary housing expense [ ] Own [ ]
Rent ($ /month)
Mailing Address - if different from Current Address Street
Unit #
City
State
ZIP
Country
1b. Current Employment/Self-Employment and Income
[ ] Does not apply
Employer or Business Name
CAFFIENATED
Phone
(408) 109-8765
Street
2048, MAIN STREET
Unit #
City
LOS ANGELES
State
CA ZIP 90210
Country USA
Position or Title CEO
Start Date
02 / 04 / 2009
(mm/dd/yyyy)
How long in this line of work? 15 Years 5 Months
Check if this statement applies: [ ] I am employed by a family member, property seller, real estate agent, or other party to the transaction.
Gross Monthly Income
Base
$
8000
/month
Overtime $
/month
Bonus $ /month
Commission $ 0.00
/month
Military Entitlements $ /month
Other
$
/month
TOTAL $ 8000 /month
Uniform Residential Loan Application Freddie Mac Form 65 · Fannie Mae Form 1003 Effective 1/2021
[ ] I have an ownership share of less than 25%. Monthly Income (or Loss)
[X] Check if you are the Business Owner or Self-Employed [X] I have an ownership share of 25% or more. $ 8000
Social Security Number
175-678-910
(or Individual Taxpayer Identification Number)
Type of Credit [X] I am applying for individual credit. [ ] I am applying for joint credit. Total Number of Borrowers: Each Borrower intends to apply for joint credit. Your initials:
)
(Single, Divorced, Widowed, Civil Union, Domestic Partnership, Registered Reciprocal Beneficiary Relationship)
[X] Does not apply
<<<
California USA DRIVER LICENSE
OL 11234568 EXP 08/31/2014 LN CARDHOLDER FNIMA 2570 24TH STREET ANYTOWN. CA 95818 008 08/31/1977 RSTR NONE
CLASS C
END NONE
08311977
VETERAN
Ima Cardholder
SEX F HGT 5 -05
HAIR BRN WGT 125 1b
EYES BRN ISS 08/31/2009
DD 00/00/0000NNNANIANFDITY
<<<
We still retain all the form field identification, like checkboxes, but the output is now simplified to plain text, without any layout or structural formatting.
EWD1200-0
Only a matter of style?
For educational purposes we analyse the
opening pages of an 11-page article that
appeared in The American Mathematical
Monthly, Volume 102 Number 2/February 1995.
We have added line numbers in the right
margin.
line 4: Since in this article , squares don't get
alternating colours , it could be argued that
the term " chessboard " is misplaced .
line 4: The introduction of the name "B"
seems unnecessary: it is used - in the
combination " the board B" - in the text
for Figure and in line 71; in both cases
just " the board " would have done fine .
In line 77 occurs the last use of B ,
viz. in "X"B", which is dubious since
B was a board and not a set; in line
77, I would have preferred " Given a set X
of cells ".
line 7/8: The first move, being a move
like any other, does not deserve a separate
The term " step" is redundant.
line 8: Why not "a move consists of"?
line 10/ 11 : At this stage the italics are
puzzling, since a move is possible if,
1
<<<
Since this is a handwritten document, we can switch to the high_quality mode to see if it enhances recognition accuracy and improves the overall output quality.
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
mode="high_quality",
)
We get the following output:
EWD1200-0
Only a matter of style?
For educational purposes we analyse the
opening pages of an 11-page article that
appeared in The American Mathematical
Monthly, Volume 102 Number 2/ February 1995.
We have added line numbers in the right
margin.
line 4: Since in this article, squares don't get
alternating colours , it could be argued that
the term " chessboard " is misplaced .
line 4: The introduction of the name "B"
seems unnecessary : it is used - in the
combination " the board B" - in the text
for Figure 1 and in line 71; in both cases
just " the board " would have done fine .
In line 77 occurs the last use of B ,
viz. in "X"B", which is dubious since
B was a board and not a set; in line
77, I would have preferred " Given a set X
of cells ".
line 7/8: The first move, being a move
like any other, does not deserve a separate
. The term " step" is redundant.
line 8: Why not "a move consists of"?
line 10/11 : At this stage the italics are
puzzling, since a move is possible if,
1
<<<
As you can see, the default and high_quality modes produce very similar results, which is a testament to how well LLMWhisperer handles scanned (and written) documents out of the box.
Even without tuning, the default settings deliver impressive accuracy and structure.
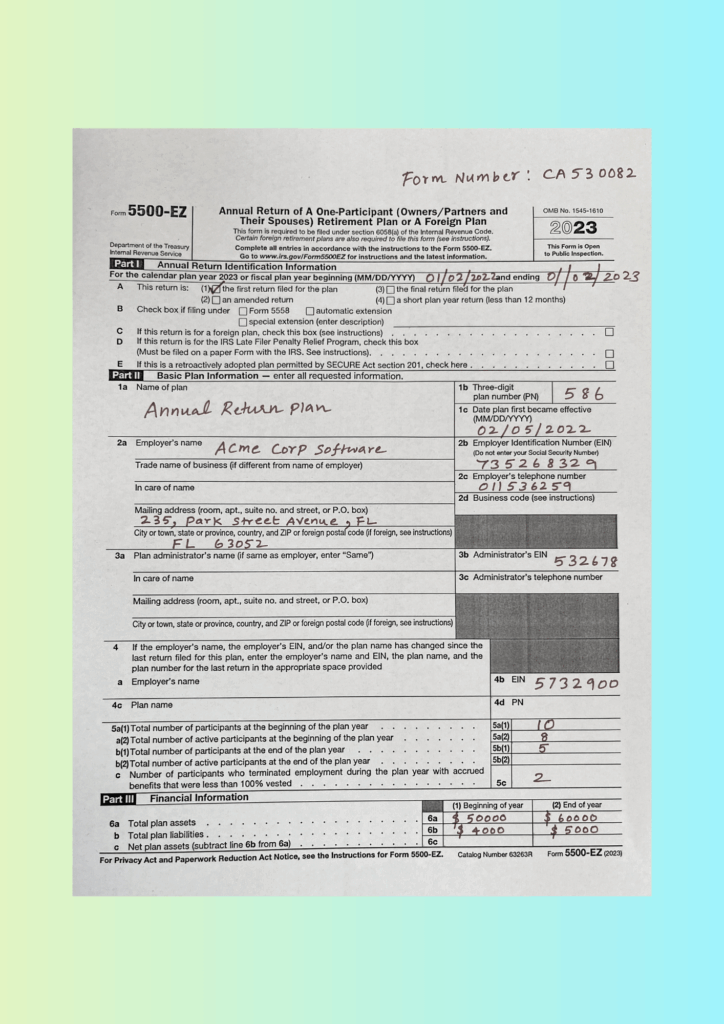
Form Number: CA530082
Form 5500-EZ Annual Return of A One-Participant (Owners/Partners and OMB No. 1545-1610
Their Spouses) Retirement Plan or A Foreign Plan
This form is required to be filed under section 6058(a) of the Internal Revenue Code. 2023
Certain foreign retirement plans are also required to file this form (see instructions).
Department of the Treasury Complete all entries in accordance with the instructions to the Form 5500-EZ. This Form is Open
Internal Revenue Service
Go to www.irs.gov/Form5500EZ for instructions and the latest information. to Public Inspection.
Part Annual Return Identification Information
For the calendar plan year 2023 or fiscal plan year beginning (MM/DD/YYYY) 01/02/202 Zand ending 01/02/2023
A This return is: (1) the first return filed for the
[X] plan (3) [ ] the final return filed for the plan
(2) [ ] an amended return (4) [ ] a short plan year return (less than 12 months)
B Check box if filing under [ ] Form 5558 [ ] automatic extension
[ ] special extension (enter description)
C If this return is for a foreign plan, check this box (see instructions) [ ]
D If this return is for the IRS Late Filer Penalty Relief Program, check this box
(Must be filed on a paper Form with the IRS. See instructions). [ ]
E If this is a retroactively adopted plan permitted by SECURE Act section 201, check here [ ]
Part II Basic Plan Information - enter all requested information.
1a Name of plan 1b Three-digit
plan number (PN) 586
1c Date plan first became effective
Annual Return Plan
(MM/DD/YYYY)
02/05/2022
2a Employer's name 2b Employer Identification Number (EIN)
Acme Corp Software (Do not enter your Social Security Number)
Trade name of business (if different from name of employer) 735268329
2c Employer's telephone number
In care of name 011536259
2d Business code (see instructions)
Mailing address (room, apt., suite no. and street, or P.O. box)
235, Park Street Avenue, FL
City or town, state or province, country, and ZIP or foreign postal code (if foreign, see instructions)
FL 63052
3a Plan administrator's name (if same as employer, enter "Same") 3b Administrator's EIN
532678
In care of name 3c Administrator's telephone number
Mailing address (room, apt., suite no. and street, or P.O. box)
City or town, state or province, country, and ZIP or foreign postal code (if foreign, see instructions)
4 If the employer's name, the employer's EIN, and/or the plan name has changed since the
last return filed for this plan, enter the employer's name and EIN, the plan name, and the
plan number for the last return in the appropriate space provided
a Employer's name 4b EIN 5732900
4c Plan name 4d PN
5a(1) 10
5a(1) Total number of participants at the beginning of the plan year
5a(2) 8
a(2) Total number of active participants at the beginning of the plan year
5b(1) 5
b(1) Total number of participants at the end of the plan year
b(2) Total number of active participants at the end of the plan year 5b(2)
with accrued
c Number of participants who terminated employment during the plan year
benefits that were less than 100% vested 5c 2
Part III Financial Information
(1) Beginning of year (2) End of year
6a $ 50000 $ 60000
6a Total plan assets
6b $ 4000 $ 5000
b Total plan liabilities
6a) 6c
c Net plan assets (subtract line 6b from
see the Instructions for Form 5500-EZ. Catalog Number 63263R Form 5500-EZ (2023)
For Privacy Act and Paperwork Reduction Act Notice,
<<<
Let’s now see how the output compares when we use the low_cost mode:
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
mode="low_cost",
)
We get the following output:
CA 5 3 0082
Number
Form
Annual Return of A and OMB No. 1545-1610
Form 5500 EZ One-Participant (Owners/Partners
Their Spouses) Retirement Plan or A Plan
Foreign
This form is required to be filed under section 6058(a) of the Internal Revenue Code. 2023
Certain foreign retirement plans are also required to file this form (see instructions).
Department of the all entries in accordance with the instructions to the Form 5500-EZ This Form is Open
Treasury Complete
Internal Revenue Service to Public Inspection.
Go to www.irs.gov/Form5500EZ for instructions and the latest information
Annual Return Identification Information
For the calendar plan year 2023 or fiscal D
plan year beginning (MM/DD/YYYY) O/]/0 2oz2and ending
A This return is
(1 the first return filed for the plan (3) [J the final return filed for the plan
(2) Jan amended return (4) [Ja short plan year return (less than 12 months)
B
Check box if filing under (J Form 5558 (_J automatic extension
(special extension (enter description)
Cc If this
return is for a foreign plan, check this box (see instructions) O
D If this return is for the IRS Late Filer Penalty Relief Program, check this box
(Must be filed on a paper Form with the IRS. See instructions). O
E If this
is a retroactively adopted plan permitted by SECURE Act section 201, chet iii O
Part Il Basic Plan Information -- enter all requested information
la Name of plan
|S
"mw 1c Date plan first became effective
Retrrn Plav
Annual
(MM/DD/YYYY)
02/05/2022
2a Employer's name 2b Employer Identification Number (EIN)
Acme Corp Software (Do not enter your Social Security Number)
Trade name of business (if different from name of employer) Wis. Gia 6 ESL iS
2c Employer's telephone number
In care of name
GAINS 3EZ2S4
2d Business code (see instructions)
address (room, apt., suite no. and street, or P.O. box)
oe 235 Park Street Avenue =
|
City or town, state or province, country, and ZIP or foreign postal code (if foreign, see instructions)
LL 63052
3a Plan administrator's name (if same as employer, enter "Same") 3b Administrator's EIN
532678
In care of name 3c Administrator's telephone number
street, or P.O. box)
Mailing address (room, apt., suite no. and
ZIP or foreign postal code see
City or town, state or province, country, and (if foreign, instructions)
EIN, and/or the name has since the
If the employer's name, the employer's plan changed
name and EIN, the and the
last return filed for this plan, enter the employer's plan name,
in the appropriate space
plan number for the last return provided
a_ Employer's name 4b EIN
5732400
PN
4c Planname 4d
at the of the
5a(1) Total number of participants beginning plan year
active at the of the year seo} _LC
a(2) Total number of participants beginning plan
at the end of the plan year
b(1) Total number of participants
of active participants at the end of the plan year
b(2) Total number
the with "accrued
c Number of participants who terminated employment plan year
ore y
benefits that were less than 100% vested a
Part Ill Financial Information
(2) End of year
$ 50000 60000
6a_ Total plan assets |éa| |
600
b Total plan liabilities .
line 6b fom 6a)
c Net plan assets (subtract
see the Instructions for Form 5500-EZ. Catalog Number 63263R Form 5500-EZ (2023)
Reduction Act Notice,
For Privacy Act and Pa) perwork
<<<
We can see that while some detail are lost compared to the default mode, low_cost still manages to recognize most of the handwritten text, making it a solid option when budget is a priority.
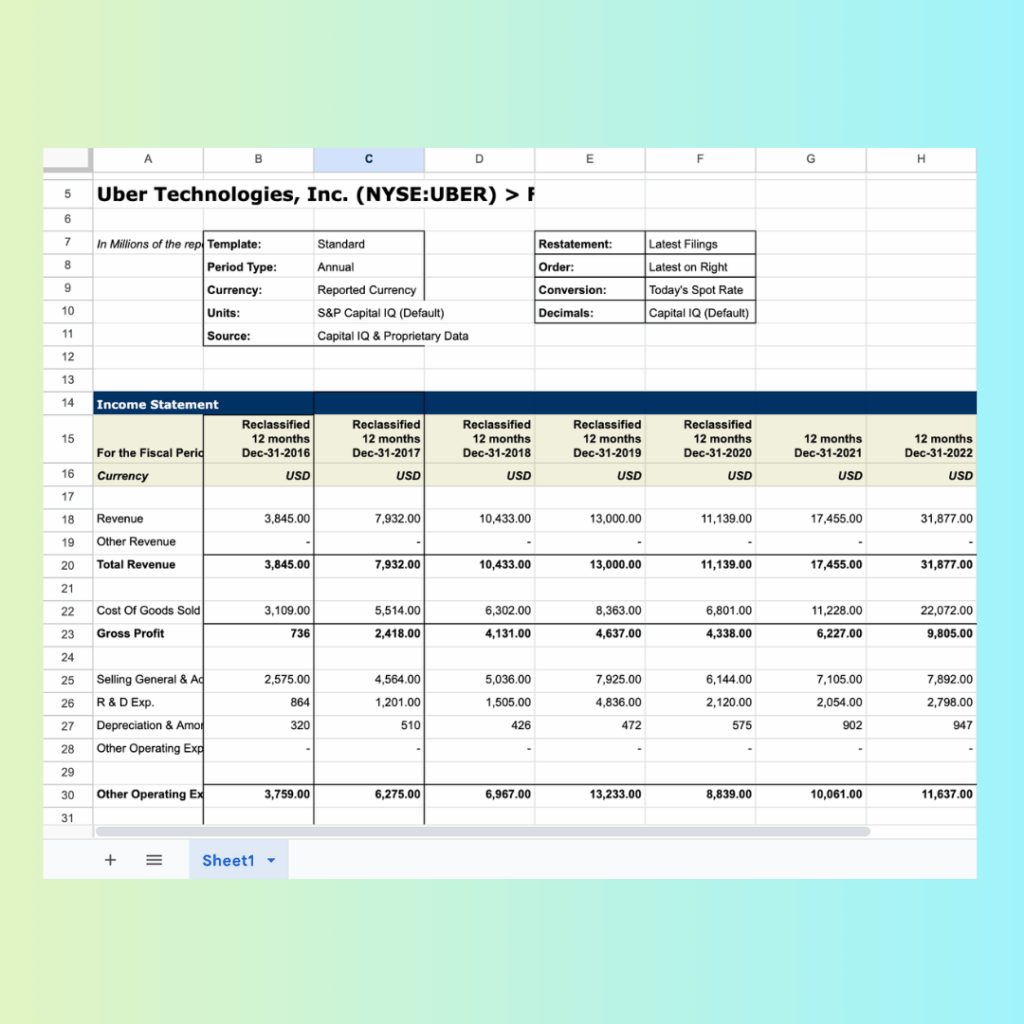
Sheet name:Income statements
Uber Technologies, Inc. (NYSE:UBER) > Financials > Income Statement
─────────────────────────────────────────── ──────────────────────────────────
In Millions of the reported currency, except per share items. Template: Standard Restatement: Latest Filings
──────────────────────────────────
Period Type: Annual Order: Latest on Right
──────────────────────────────────
Currency: Reported Currency Conversion: Today's Spot Rate
──────────────────────────────────
Units: S&P Capital IQ (Default) Decimals: Capital IQ (Default)
──────────────────────────────────
Source: Capital IQ & Proprietary Da
───────────────────────────────────────────
──────────────────────────
Income Statement
─────────────────
Reclassified Reclassified Reclassified Reclassified Reclassified
12 months 12 months 12 months 12 months 12 months 12 months 12 months
For the Fiscal Period Ending Dec-31-2016 Dec-31-2017 Dec-31-2018 Dec-31-2019 Dec-31-2020 Dec-31-2021 Dec-31-2022
Currency USD USD USD USD USD
USD USD
Revenue 3,845.0 7,932.0 10,433.0 13,000.0 11,139.0
17,455.0 31,877.0
Other Revenue - - - - -
- -
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Total Revenue 3,845.0 7,932.0 10,433.0 13,000.0 11,139.0
17,455.0 31,877.0
Cost Of Goods Sold 3,109.0 5,514.0 6,302.0 8,363.0 6,801.0
11,228.0 22,072.0
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Gross Profit 736.0 2,418.0 4,131.0 4,637.0 4,338.0
6,227.0 9,805.0
Selling General & Admin Exp. 2,575.0 4,564.0 5,036.0 7,925.0 6,144.0
7,105.0 7,892.0
R & D Exp. 864.0 1,201.0 1,505.0 4,836.0 2,120.0
2,054.0 2,798.0
Depreciation & Amort. 320.0 510.0 426.0 472.0 575.0
902.0 947.0
Other Operating Expense/(Income) - - - - -
- -
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Other Operating Exp., Total 3,759.0 6,275.0 6,967.0 13,233.0 8,839.0
10,061.0 11,637.0
Operating Income (3,023.0) (3,857.0) (2,836.0) (8,596.0) (4,501.0) (3,834.0) (1,832.0)
Interest Expense (334.0) (479.0) (648.0) (559.0) (458.0)
(483.0) (565.0)
Interest and Invest. Income 22.0 71.0 104.0 234.0 55.0
37.0 139.0
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Net Interest Exp. (312.0) (408.0) (544.0) (325.0) (403.0)
(446.0) (426.0)
Income/(Loss) from Affiliates - - (42.0) (34.0) (34.0)
(37.0) 107.0
Currency Exchange Gains (Loss) (91.0) 42.0 (45.0) (40.0) (128.0)
(67.0) (147.0)
Other Non-Operating Inc. (Exp.) 208.0 (129.0) (428.0) 82.0 59.0
(230.0) (213.0)
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
EBT Excl. Unusual Items (3,218.0) (4,352.0) (3,895.0) (8,913.0) (5,007.0) (4,614.0) (2,511.0)
Restructuring Charges - - - - (362.0)
- -
Impairment of Goodwill - - - - -
- -
Gain (Loss) On Sale Of Invest. - - 1,996.0 2.0 (1,815.0)
1,626.0 (6,822.0)
Gain (Loss) On Sale Of Assets - - 3,214.0 - 204.0
1,684.0 14.0
Asset Writedown - (223.0) (197.0) - -
- -
Other Unusual Items - - 152.0 444.0 -
242.0 -
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
EBT Incl. Unusual Items
You can see how LLMWhisperer not only processes Excel files but also extracts the content with impressive accuracy and detail, preserving cell structure, formatting, and data integrity.
And we’ll also demonstrate how to include line numbers in your output using the add_line_nos option:
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
add_line_nos=True,
)
Which produces this output:
0x01:
0x02:
0x03: OY. INTERNATIONAL BUSINESS MACHINES AB. 1705366 A
0x04: IBM
0x05: Helsinki - Kasarmikatu 44 - Puh. 10806 HUOLTOSOPIMUS
0x06:
0x07: IBM sitoutuu suorittamaan toiminimen Kudos Oy.SILO TURKU
0x08: toisella puolella mainittujen IBM- (International-) koneiden tarkistuksen, puhdistuksen ja voitelun
0x09: 3 kertaa tasaisin valiajoin, alkaen 6 mk :-
0x0A: suuruista vuotuista korvausta vastaan, joka summa laskutetaan 1/3 kerralta
0x0B: 1. Korvaukseen sisältyvät myös ylimääräiset tarkistuskäynnit mahdollisten vikojen ilmaantuessa,
0x0C: milloin näiden voidaan katsoa olevan IBM:n aiheuttamia. Kovakouraisesta tai huolimatto-
0x0D: masta käsittelystä, virtahäiriöistä, palosta, vedestä t.m.s. johtuvien vikojen korjauksesta veloi-
0x0E: tetaan erikseen.
0x0F: 2. Sopimukseen ei sisälly varaosien tai tarpeiden vapaa toimitus, ei myöskään täydellinen lait-
0x10: teiden purkaminen puhdistusta tai korjausta varten.
0x11: 3. Mekaanikon matka- ja ylläpitokustannuksista veloitetaan
0x12: 4. Tämä sopimus on jatkuvasti voimassa, alla mainitusta päivästä lukien. Irtisanomisaika on
0x13: 1 kuukausi jommaltakummalta puolelta ja on siitä tehtävä kirjallinen ilmoitus.
0x14: Huom.
0x15: Tämä kaksin kappalein laadittu ja vaihdettu sopimus hyväksytään kokonaisuudessaan.
0x16: Helsinki 25/6 1955
0x17: Huollonottaja: Huollonantaja:
0x18: KUDOS O.Y. SILO OY. INTERNATIONAL BUSINERS MACHINES AB.
0x19:
0x1A: Lomake: A Huollonottaja
As you can see, LLMWhisperer automatically detects and processes the correct language, preserving both accuracy and structural layout, even in complex, multilingual documents.
With line numbers added to each extracted line of text, it becomes much easier to reference specific sections and it also enables line-level metadata that maps each extracted line of text to its exact position in the original document.
The highlight data can be obtained with:
result = client.get_highlight_data(
whisper_hash="2d49adee|0c5315204d4cd84168e792aa3bd08bdf",
lines="1-10",
)
The whisper-hash is the hash from processing this document:
Each line of text includes bounding box data: [page_no, base_y, height, page_height].
This lets you highlight or align the extracted text precisely over the original document, making it ideal for audits, visual overlays, or review tools.
756 Orchard Street
Raynham, MA 02767
Bluestone 800.356.8622
bluestone.bank
BANK Let's get there, together.
ANNUAL RENT ROLL AND OPERATING STATEMENT
For period 02 /03 /24 to 02 /03 /25
Roger Deakins
Borrower's Name
23, Finance district, 23rd lane, FI, 32002 Number of Units 3 Units Occupied 3
Property Address
INCOME
Unit /
SQ. Footage Tenant Name Lease Term Lease Expiration Monthly Rent
Apt. No.
23 1200 Martha Stewart $ 3000
43 1400 Paul Cullinan $ 2000
45 1300 Vikram Sam $ 2000
$
$
$
$
$
Monthly Income $ 7000
Annual Income $ 70000
EXPENSE
Annual Expense
Real Estate Taxes $ 3000
Insurance $ 4000
Management Fees $ 1000
Repairs / Maintenance $
Utilities:
Electricity $ 4000
Water / Sewer $ 3000
Gas / Oil $
Other $ 1000
Landscape / Snow Removal $ 1000
Trash Removal $ 1000
Accounting / Legal $
Advertising $
Need Cleaning $
Miscellaneous $
Total Operating Expense $ 18000
Net Operating Income
$ 52000
(Rental Income Less Total Expense)
02/01/2005
Date
* INCLUDE COPIES OF LEASES
REVISED
Considering the skewed scan, we already get excellent results with all values and product rows correctly identified.
But if you want a more detailed reference of horizontal or vertical lines for better structure recognition, you can enable:
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
mark_horizontal_lines=True,
mark_vertical_lines=True,
)
Which gives this output:
| 756 Orchard Street
| Raynham, MA 02767
| Bluestone 800.356.8622
bluestone.bank
BANK Let's get there, together.
ANNUAL RENT ROLL AND OPERATING STATEMENT
For period 02 /03 /24 to 02 /03 /25
Roger Deakins
Borrower's Name
23, Finance district, 23rd lane, FI, 32002 Number of Units 3 Units Occupied 3
Property Address
| INCOME
Unit /
SQ. Footage Tenant Name Lease Term Lease Expiration Monthly Rent
Apt. No.
23 1200 Martha Stewart $ 3000
43 1400 Paul Cullinan $ 2000
45 1300 Vikram Sam $ 2000
$
$
$
$
$
Monthly Income | $ 7000
Annual Income $ 70000
EXPENSE
Annual Expense
Real Estate Taxes $ 3000
Insurance $ 4000
Management Fees $ 1000
Repairs / Maintenance $
Utilities:
Electricity $ 4000
Water / Sewer $ 3000
Gas / Oil $
Other $ 1000
Landscape / Snow Removal $ 1000
Trash Removal $ 1000
Accounting / Legal $
Advertising $
Need Cleaning $
Miscellaneous $
Total Operating Expense | $ 18000
Net Operating Income
$ 52000
(Rental Income Less Total Expense)
02/01/2005
Date
* INCLUDE COPIES OF LEASES
REVISED
<<<
As you can see, we get clear indications of horizontal lines represented with | characters.
Usage Info
You can retrieve the current usage data either via the API or the SDKs. For example, using this code:
LLMWhisperer is built with flexibility and scalability at its core, offering transparent, usage-based pricing that adapts to your operational needs, whether you’re an agile startup or a large-scale enterprise.
Usage-Based Pricing
Pricing is calculated primarily based on the number of pages processed, with further granularity based on the selected mode of extraction:
native_text – Ideal for extracting embedded text from digital PDFs.
low_cost – Optimized for affordability with lightweight image-based extraction.
high_quality – Designed for high-accuracy extraction from complex or noisy scans.
form – Specialized mode for structured form-like documents with layout preservation.
This tiered approach ensures you’re only paying for the level of fidelity and compute you need and nothing more. Full pricing details here.
LLMWhisperer also supports tagging-based usage tracking, allowing you to monitor resource consumption across different projects, teams, or clients.
On-Premise Deployment
For enterprises with sensitive data, strict regulatory environments, or air-gapped infrastructures, LLMWhisperer provides full support for on-premise deployments.
Key benefits include:
Full control over your data and document flow
Alignment with internal compliance and security policies
Seamless integration into internal pipelines and legacy systems
Ability to run the full stack behind firewalls or within private cloud environments
Deployment can be containerized and orchestrated with Kubernetes, ensuring scalability, monitoring, and update management remain enterprise-grade.
Operational Transparency
LLMWhisperer includes powerful Usage Metrics and Usage Stats APIs to give your team visibility into:
Total pages processed by mode, team, or project
Historical breakdowns by date for budget tracking
Bottlenecks or unexpected usage spikes
Exportable reports for billing and audits
With built-in observability and forecasting tools, you can maintain cost predictability, enforce quotas, and align usage with procurement policies.
Why LLMWhisperer OCR API Is the Best Choice for Both Developers and LLM-Powered Solutions
LLMWhisperer is purpose-built for the LLM-native era, bridging the gap between complex, real-world documents and clean, structured, LLM-ready outputs.
Unlike traditional OCR tools that require heavy pre-processing, format normalization, or template-based logic, LLMWhisperer removes the friction.
You can feed it PDFs, scans, spreadsheets, or even degraded images, without worrying about layout quirks, noise, or inconsistent structure.
It intelligently handles messy inputs like handwritten forms, multi-column reports, or skewed pages while preserving both layout and semantic meaning when needed.
With powerful APIs, intuitive defaults, and deep customization options, it strikes the perfect balance between ease of use and technical depth.
Designed for developers and backed by a team focused on modern AI-first workflows, LLMWhisperer evolves rapidly to meet the growing demands of LLM-based applications.
Its standout strengths include:
Extensive file support: PDFs, DOCX, XLSX, images, scans, and more.
Minimal code, fast results: Just upload and extract.
Structured output: Layout-preserving text that is ready for pipelines.
On-prem or cloud: Flexible deployment for any scale or sensitivity.
Whether you’re building internal tools, AI assistants, or document automation pipelines, LLMWhisperer gives you everything you need to go from raw input to actionable intelligence fast.
Get Started with LLMWhisperer OCR API
Try the API with our sample documents or bring your own.
Sign up, explore the playground, and start building smarter document workflows today with LLMWhisperer.
Get started with LLMWhisperer: Best OCR API for AI Document Workfows
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.