A 2026 Guide to AI-Powered Logistics Document Processing
Table of Contents
Logistics operations often become overwhelmed by a constant flow of paperwork, resulting in significant delays and frequent errors. Every manual form, every misplaced signature, and every handwritten note risks shipments getting stuck at customs or warehouses. Unstract simplifies this by automatically processing bills of lading, packing lists, and customs forms, streamlining logistics document parsing, and boosting your bottom line.
This guide explores how advanced Logistics OCR (Optical Character Recognition) and AI solutions like Unstract, powered by LLMWhisperer, are transforming logistics document parsing.
What is Logistics Document Processing
Logistics document processing refers to the method of handling, extracting, organizing, and storing various documents essential for supply chain and logistics operations. This includes both hard-copy and digital documents, such as bills of lading, packing lists, and customs declarations. Efficient document processing is crucial for accurate tracking, compliance, and smooth logistics operations.
Documents in logistics can be categorized based on their format and structure:
Structured Documents: These have a fixed format with predefined fields, making them easy to process automatically, including tax returns and insurance applications.
Semi-Structured Documents: These contain some organizational elements but lack a strict format, such as invoices, receipts, and utility bills.
Unstructured Documents: These lack a predefined format and include free-form text, e.g., contracts, letters, and emails.
Handling documents manually often results in slow and inaccurate data extraction, increasing the risk of costly errors. However, techniques like OCR combined with large language models (LLMs) can automate workflows by scanning, interpreting, and organizing documents with minimal human intervention.
Why Automation is Critical in Logistics Document Processing
Modern supply chains require real-time visibility and rapid turnaround, as operations now span multiple countries, partners, and time zones. Traditional manual methods, such as entering order details from paper invoices or scanning PDFs for signatures, can’t keep up with the volume and speed that modern logistics demands.
For example, a freight company handling thousands of shipment documents daily across ports in Asia and Europe can’t afford delays or data entry errors that stall customs clearance and delivery.
Automated logistics document parsing addresses these challenges at scale. It enables systems to:
Extract structured data from unstructured documents like scanned PDFs, photos, or emails.
Automatically classify and route documents to the right workflow.
Trigger downstream actions such as delivery scheduling, invoice generation, or compliance checks.
This eliminates manual data entry, freeing teams to resolve exceptions and optimize operations..
Benefits of Logistics Document Automation
Here are some of the key advantages automation brings to document processing in logistics:
Faster Turnaround Times: Bottlenecks are removed from approval and validation workflows
Fewer Mistakes: Automation captures data more consistently than manual entry
Global Scalability: It handles multiple formats, languages, and sources at once
Regulatory Compliance: Digital trails make audits and inspections easier
Searchable and Connected Data: Clean and structured output integrates with WMS, ERP, or CRM
Challenges in Automating Logistics Document Processing
Automating logistics document processing is challenging due to the diversity of documents and the complexity of accurately extracting data from them. Below are some of the key obstacles:
Complex Formatting: Logistics documents often come in various formats, including multi-column layouts, tables, and forms. And multi-column documents and tables lose their formatting when processed by standard OCR tools.
Handwritten Text: Scanned or handwritten documents often have low image quality and varied writing styles.
Extraction Accuracy: Even AI-driven extraction faces variance in accuracy for complex documents, requiring some human review to correct errors, such as mistaking a comma for a period or the number 0 for the letter O.
Security and Regulatory Compliance: Regulations like GDPR or customs laws require invoices and delivery proofs to be securely archived. Automated systems must ensure the creation of audit trails, version control, and automated retention to avoid penalties.
Integration: Successful integration involves assessing document types and workflows, implementing in phases, and guaranteeing system compatibility.
The Role of AI and Large Language Models in Processing Unstructured Documents
Most enterprise data today comes in unstructured forms, such as text, images, emails, and sensor logs, and it continues to grow at a rapid pace every year. Traditional methods that rely on static rules or manual entry often fail to handle the volume, variability, and complexity of data, resulting in inefficiencies and errors.
LLMs are advanced AI systems trained on vast amounts of data that transform how businesses approach this challenge. These models are trained on extensive datasets and are designed to comprehend and generate human language with high accuracy. By doing so, they bring powerful capabilities to document processing:
Understanding Context: LLMs grasp syntax, semantics, and intent, enabling deeper comprehension of textual information.
Processing Multimedia: Computer vision interprets visual inputs like scanned forms, while natural language processing (NLP) handles free-form text.
Automating Extraction: Instead of relying on predefined rules, AI can detect patterns and extract data from complex formats such as handwritten invoices or varied document layouts.
LLMs are especially valuable in logistics, where critical documents often arrive in inconsistent formats. They can accurately process unstructured files, such as bills of lading, customs forms, shipping labels, and delivery notes, improving data quality and speed. Moreover, LLMs adapt to layout differences and recognize domain-specific fields to automate parsing tasks that would otherwise require manual review.
Understanding LLMWhisperer and Its Role in Pre-processing
LLMWhisperer is a preprocessing tool designed to prepare complex, unstructured documents such as scanned PDFs, images, and messy layouts for downstream analysis. It focuses on extracting and organizing text from these documents in a way that’s easier for LLMs to understand and analyze. It functions as a general-purpose text parser that can handle a wide range of document formats and layouts.
LLMWhisperer is neither an OCR engine nor an LLM itself; rather, it serves as a critical pre-processing layer that enhances OCR outputs before tools like Unstract consume them. LLMWhisperer does this by converting unstructured or semi-structured data into structured formats like JSON.
LLMWhisperer enhances OCR outputs by:
Removing noise such as smudges, watermarks, and skewed text
Preserving complex layouts (e.g., tables, columns, headers, and footers)
Standardizing formats for consistent parsing
These enhancements are essential when working with degraded scans, historical records, or low-quality forms. Tools like Unstract perform best when input data is clean and structured. LLMWhisperer handles that preprocessing step with precision, acting as the bridge between raw OCR outputs and intelligent AI models, ensuring the data passed forward is usable.
Document extraction at the cutting edge with LLMs vs LLMWhisperer
LLMs have become operational powerhouses, thanks in part to their ability to extract rich, meaningful information from documents. But even the best models, in real-world use cases, often depend heavily on the quality of the input they receive. Discover how LLMWhisperer, Unstract’s dedicated text extraction service, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.
How Unstract Uses AI to Structure Logistics Documents
Unstract is an AI-powered platform that transforms unstructured logistics documents into clean, structured outputs ready for downstream automation. It acts as a natural follow-up to LLMWhisperer, transforming raw text extraction into structured, meaningful data. It can adapt to various document formats, such as scanned PDFs, handwritten notes, or layout-heavy transport forms, without requiring repeated configuration or manual oversight.
For logistics use cases, Unstract can extract key details, including shipper and consignee information, bill of lading numbers, cargo weight and volume, delivery timelines, and customs declarations.
How Unstract Works
The process starts with LLMWhisperer, which extracts raw text from scanned or photographed documents using OCR and layout-aware preprocessing.
That raw text is passed to Unstract, where large language models interpret the content using Prompt Studio. Users first create a new Prompt Studio project, defining the document type and desired extraction fields. Prompt Studio then provides a visual interface for designing, testing, and refining field extraction prompts without code.
These prompts are then organized into prompt chains, breaking down complex extraction tasks into a sequence of interconnected prompts. This allows Unstract to extract related fields sequentially, for example, identifying headers before mapping dependent values, ensuring structured and accurate results.
Once the prompts are finalized, the project gets exported as a tool. This tool can then be integrated into workflows, which form the foundation for configuring data processing pipelines.
After a workflow is created, it can be deployed in various ways to automate document processing, such as API Deployments, ETL Pipeline Deployments, and Human-in-the-Loop Workflows.
Benefits of Using Unstract in Logistics Workflows
Unstract excels in high-volume logistics by reducing friction and automating messy, inconsistent document formats.
No Templates Required: It adapts to changing layouts and document types on the fly, reducing setup time and ongoing maintenance.
Context-Aware Extraction: AI models ensure that related information is grouped accurately, which is critical for compliance and downstream processing.
Semantic Relationship Mapping: Unstract understands and links related fields, like matching quantities with shipment references or associating costs with invoice IDs. This is effective even across documents with different structures or layouts.
Multi-Document Contextual Awareness: It recognizes field dependencies across multi-page or bundled documents, enabling intelligent data extraction even in complex logistics scenarios.
Output-Ready Data: Unstract delivers structured outputs optimized for automation, whether you need JSON, CSV, or direct integration with systems like ERPs or TMS platforms.
Future-Proof Learning: Instead of relying on rigid rules, Unstract identifies generalizable patterns, allowing it to evolve as your document types change over time.
Low Touch, High Accuracy: Designed for minimal human intervention while maintaining high precision, which is perfect for scaling document processing without adding headcount.
High Scalability: Unstract handles batch processing efficiently across logistics operations.
Compliance and Data Security: Unstract supports encrypted API deployments and access controls, helping ensure GDPR compliance and secure handling of sensitive logistics data.
Demonstrating OCR Capabilities with LLMWhisperer Playground and API
In this section, we walk through a practical demonstration of LLMWhisperer’s Logistics OCR capabilities using two real-world logistics documents, an Air Waybill and a Packing List. This test covers both the Playground and the API (via Postman). It shows how Airway bill OCR and Packing list OCR work on scanned or photographed files.
We’ve broken this demonstration into two parts:
Playground Demo (Air Waybill – photographed)
API Demo via Postman (Packing List – scanned)
Playground Demo: Photographed Air Waybill
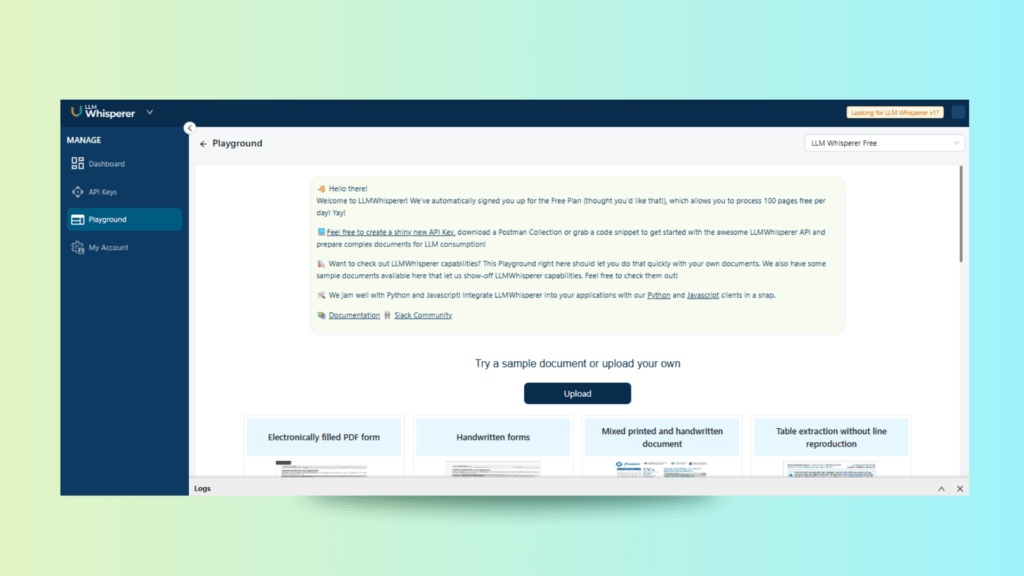
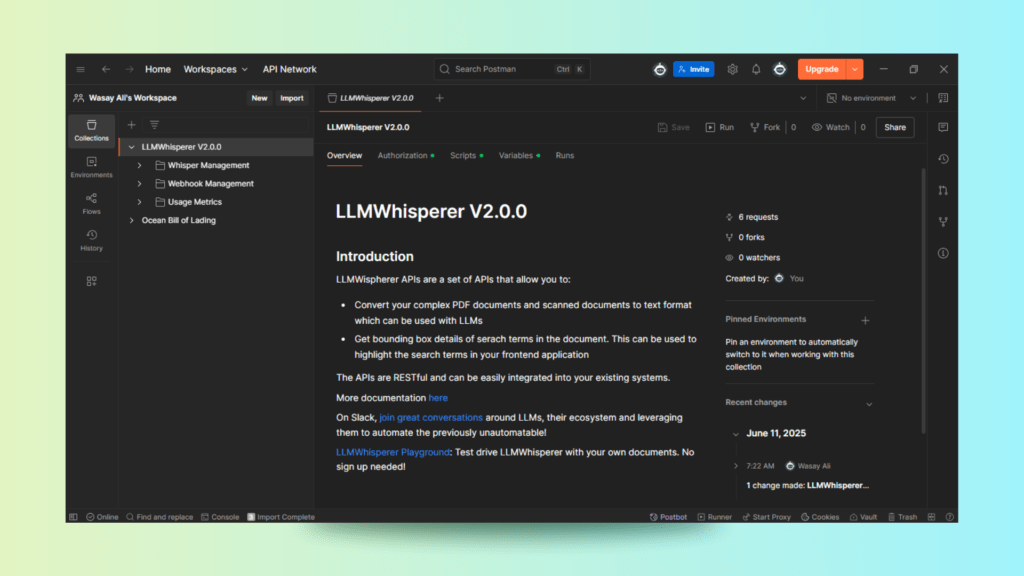
LLMWhisperer Playground Interface
We begin by navigating to the LLMWhisperer Playground. The interface offers a straightforward document upload option and form settings that enable layout-preserving text extraction. This is ideal for Logistics OCR scenarios where formatting matters.
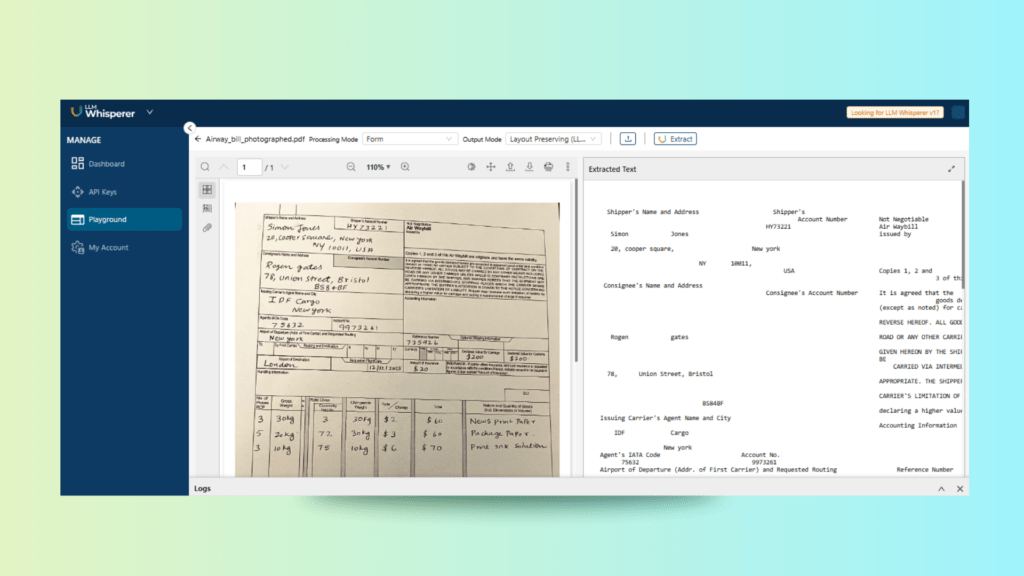
Uploaded Airway_bill_photographed.pdf
We upload a photographed version of an Air Waybill. Once uploaded, LLMWhisperer processes the file and returns structured text while maintaining the original layout. This is crucial for parsing tabular data or labeled sections effectively.
API Demo: Scanned Packing List Using Postman
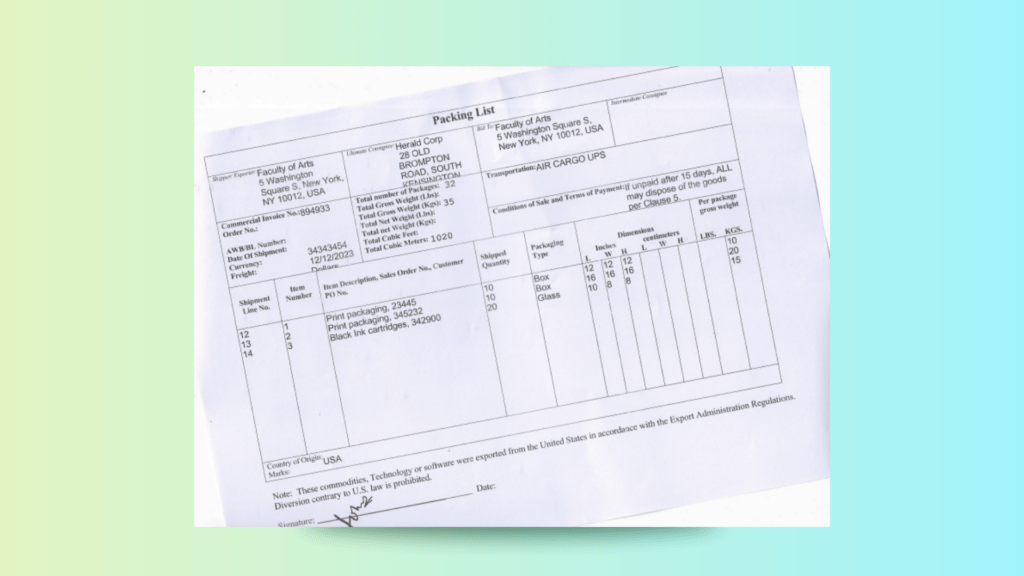
The second part of the demo showcases Packing list OCR using LLMWhisperer’s API, simulating a real-world integration scenario for automated logistics OCR pipelines.
Scanned Logistics Packing List used for API Demonstration
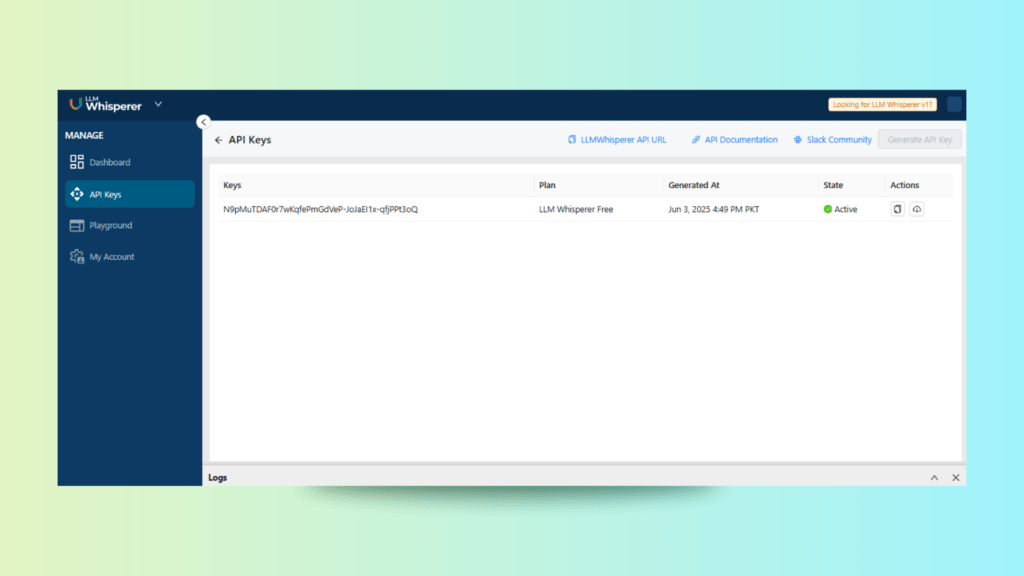
API Key and Postman Collection
API Key Section with Download Collection Option
From the LLMWhisperer dashboard, we head to the API Keys tab. There, we can generate and download a Postman Collection. The collection includes pre-configured endpoints for submitting OCR jobs and retrieving results. This makes it incredibly easy to get started without writing custom code.
Imported Collection
We import the collection into Postman Desktop. The collection includes:
A POST request for uploading documents
A GET request to check job status
A GET request to retrieve the processed output
Upload and Process the Scanned Packing List
POST Request with logistics_packing_list_scanned.pdf Uploaded
We initiate a POST request and upload a scanned packing list document. Once the request is submitted, the API responds with a message that the whisper job has been accepted. This Whisper Hash acts as a reference ID for subsequent requests and is passed as a query parameter when checking job status or retrieving results.
Track Job Status and Retrieve Results
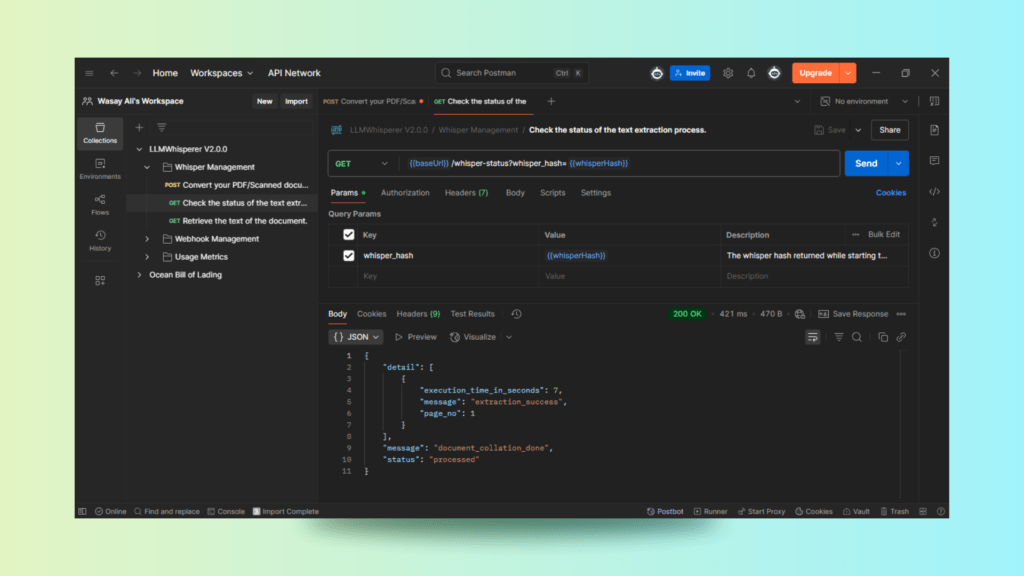
GET Request to Check OCR Job Status
Using the Whisper Hash, we perform a GET request to check the status. The response confirms that the job has been processed.
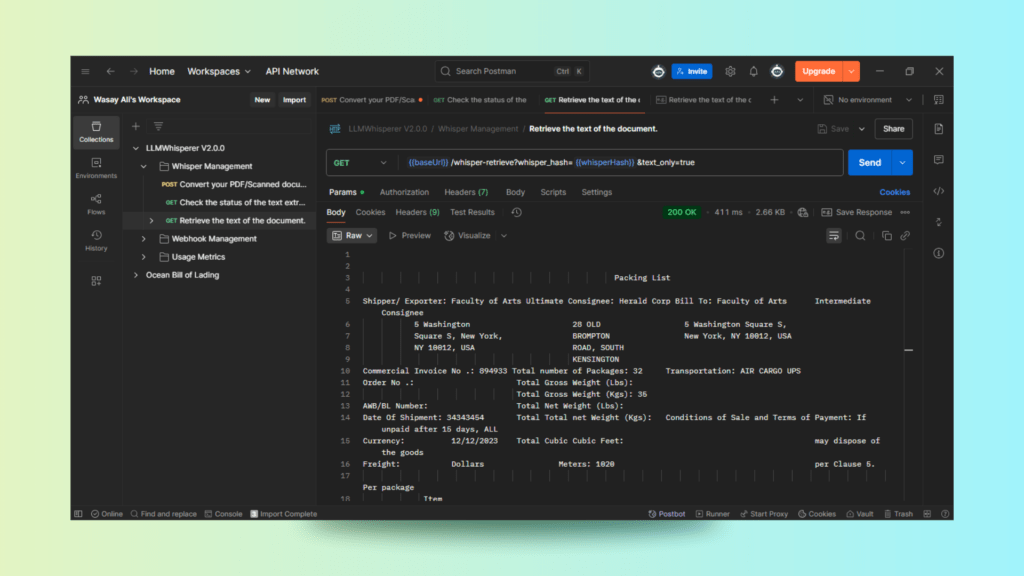
GET Request to Retrieve Extracted Text
We then retrieve the full packing list OCR output.
Setting Up Unstract and Creating Prompts for Logistics Document Extraction
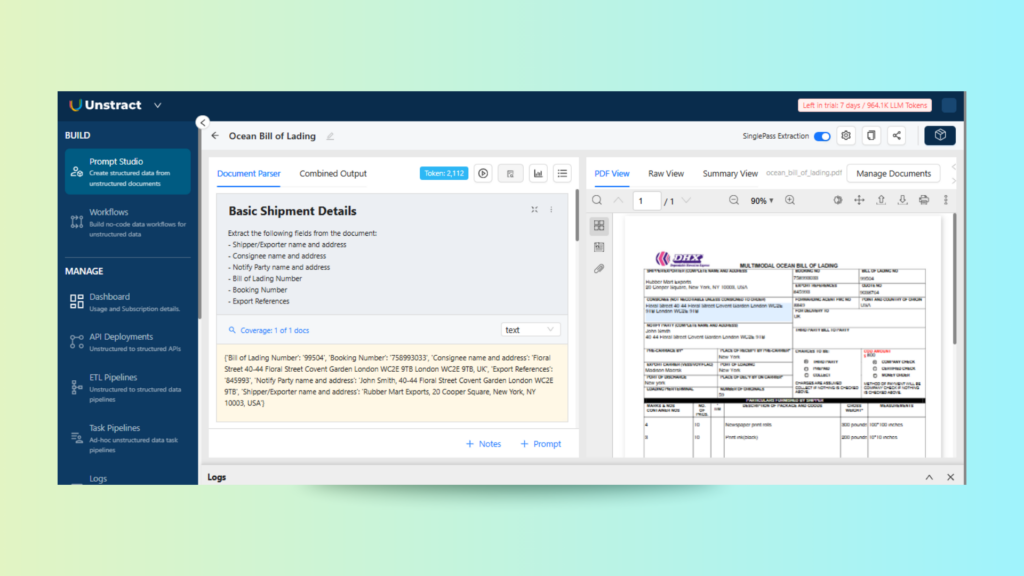
Unstract provides a powerful no-code and low-code interface for extracting structured data from documents using custom prompts. In this section, we demonstrate how to set up Unstract to extract key data from a logistics document like Bill of Lading, using a single-pass extraction approach. Our goal is to transform the raw text of the Bill of Lading into structured, actionable fields. This approach is optimized for both performance and cost.
Setting Up Our Project in Prompt Studio
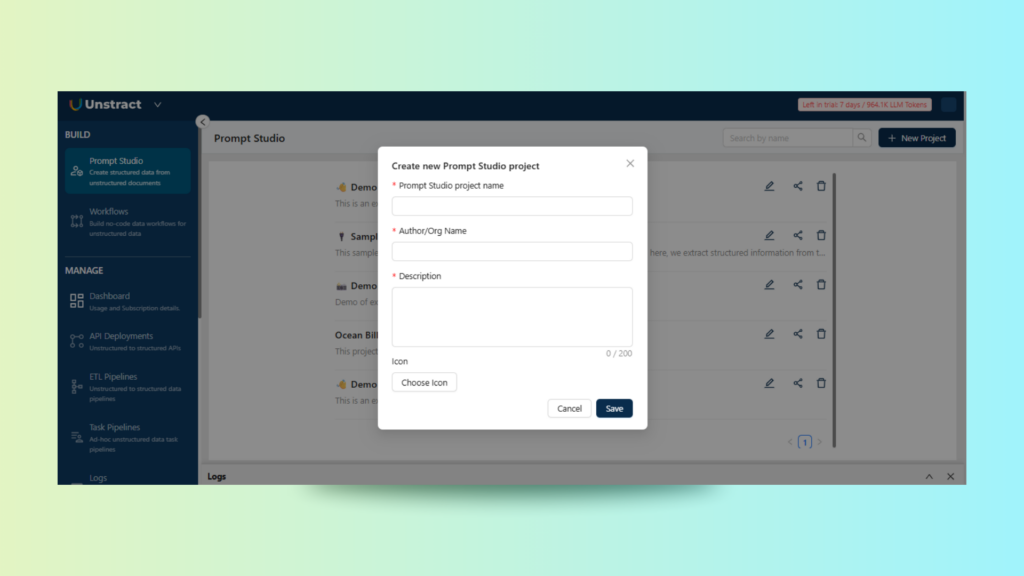
Creating a New Prompt Studio Project
We start by creating a new project inside Unstract’s Prompt Studio. Each project acts as a container where we can upload documents, extract raw or summarized text, and build reusable prompt-based workflows for structured extraction.
Uploading and Extracting Text from a Logistics Document
Uploaded Bill of Lading Document with Raw and Summarized Text Extraction
In our case, we upload a Bill of Lading. This critical logistics document typically contains sender and receiver details, goods descriptions, freight terms, and shipment identifiers.
Unstract provides two immediate extraction options:
Raw Text Extraction: The full plain-text version of the document.
Summarized Text: A compressed overview that highlights essential entities and facts.
Once the text is extracted, we can write prompts to extract specific fields, such as names, item quantities, ports of origin and destination, etc.
What makes Unstract particularly efficient is its single-pass extraction design. All prompts are concatenated and executed in a single LLM call, significantly reducing the number of tokens used and minimizing API costs while maintaining high throughput.
Writing Prompts to Extract Key Fields
Prompts in Unstract are modular, meaning each prompt is written to extract one or more specific fields. For instance:
“What is the consignee’s name?”
“List the item descriptions and quantities.”
“What is the estimated date of arrival?”
We add multiple prompts to the same run and can see the outputs instantly. This streamlines the process and eliminates the need for reprocessing documents multiple times for different queries.
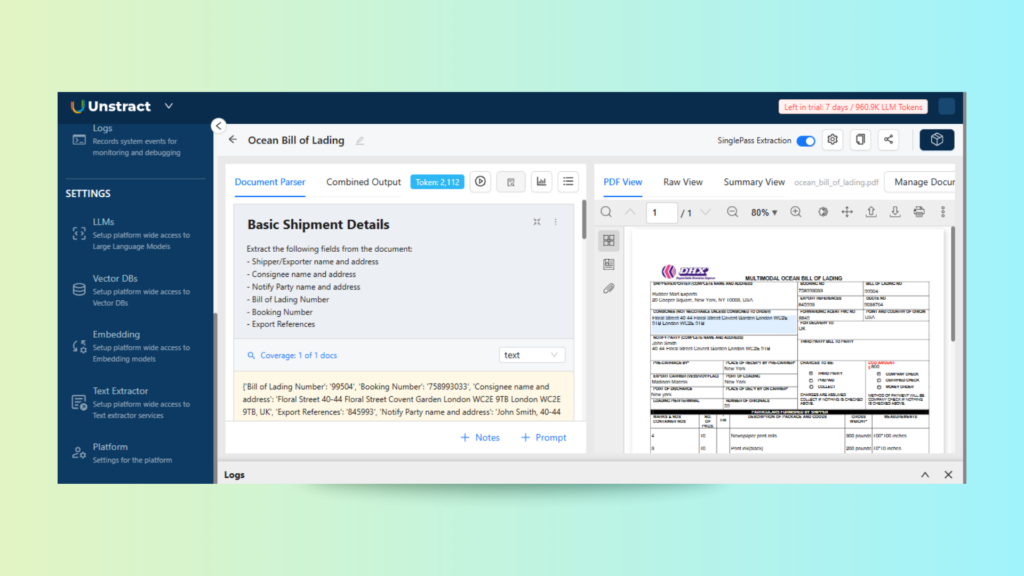
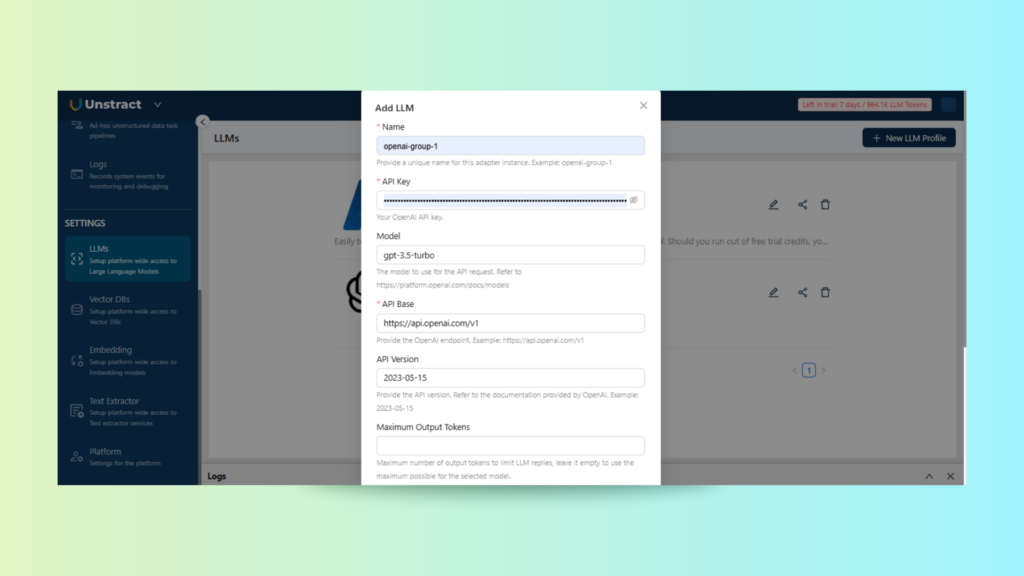
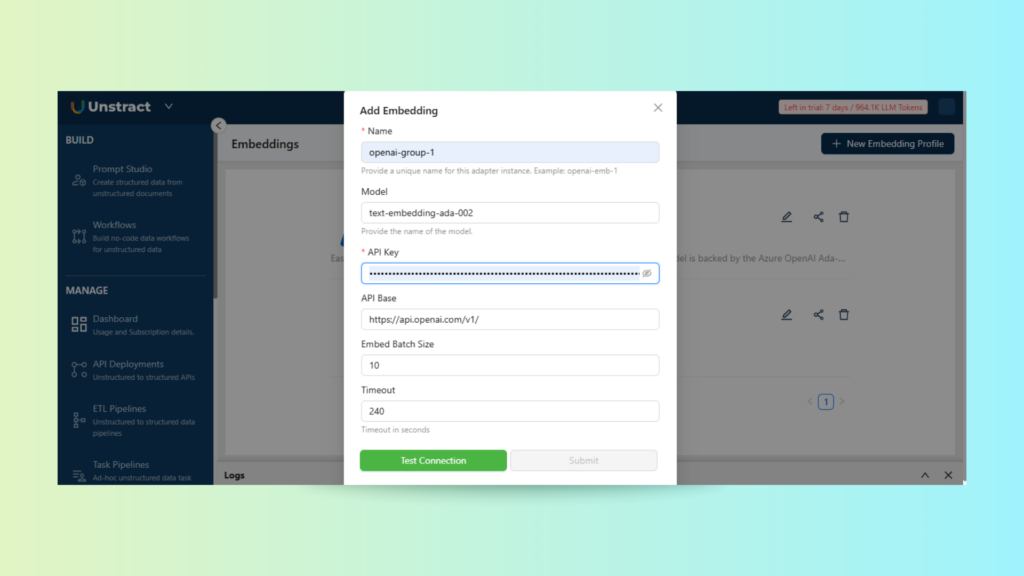
Configuring Models, Embeddings, and Extractors
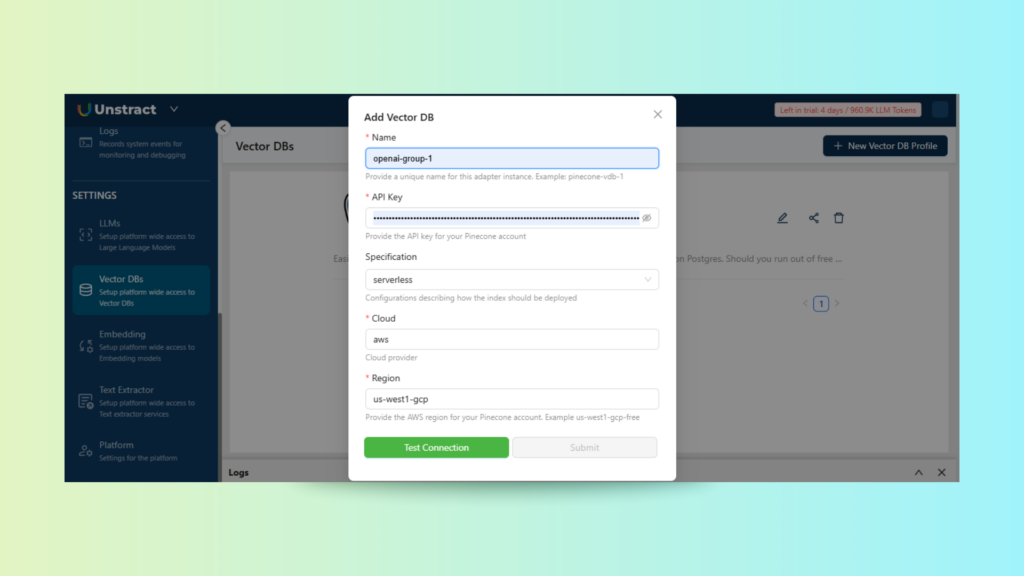
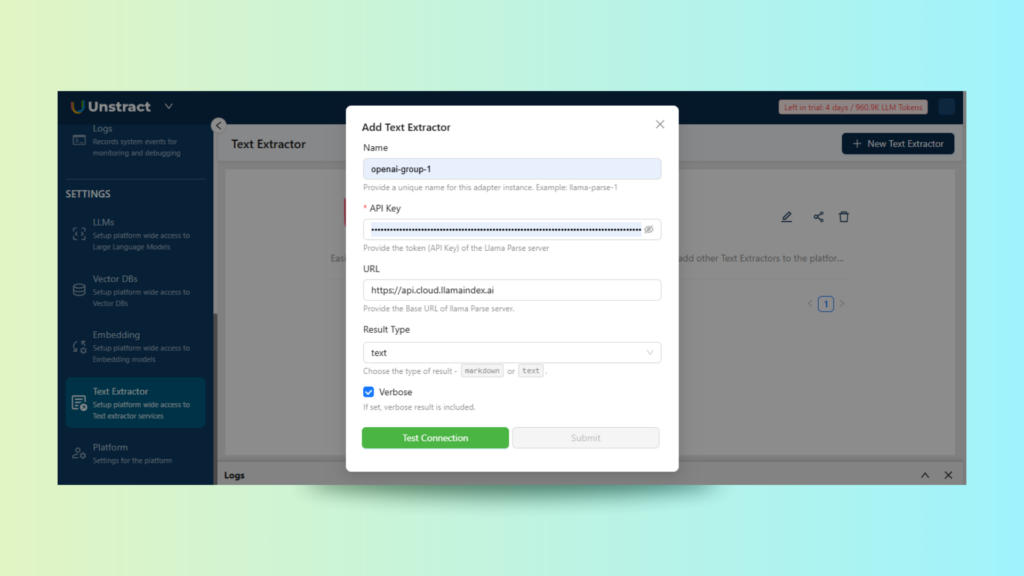
Managing LLMs, Embedding Models, Vector DB, and LLMWhisperer
Under Project Settings, we configure the technical backbone of the extraction pipeline. This includes:
LLMs: Choose from available models, such as OpenAI GPT, Gemini, or others.
Embeddings: Plug in your preferred embedding model to enhance search and indexing.
Vector DB: Set up your database (e.g., Qdrant, Pinecone) to store structured knowledge for long-term reference and retrieval.
Text Extractor: Connect external extractors, such as LLMWhisperer, to enable richer preprocessing for scanned or photographed document text.
This modular configuration ensures that your Unstract pipeline aligns with your preferred LLM stack and infrastructure, whether you’re prototyping or deploying at scale.
Deploying and Testing Logistics Document Processing as an API
Once our Unstract prompt project is tested, we can deploy it as a production-ready API. This enables seamless integration into larger logistics automation workflows such as shipment tracking systems, document management dashboards, or CRM pipelines.
This section walks through the process of building and deploying the API, integrating the tool with LLMWhisperer, and testing the complete workflow using Postman.
Creating the Workflow
The first step in deployment is setting up a workflow, which serves as the runtime environment for our prompt studio tool. In Unstract, a workflow connects various components like input parsers, extractors, LLMs, and output formatters to build an end-to-end document understanding pipeline.
Configuring Inputs, Outputs, and Tool
Inside the workflow:
Input Configuration: We define how documents are ingested, typically via file upload in the API body.
Output Configuration: Select the format in which you want the extracted data to be returned. We select the API in our case.
Next, we plug in the tool, the Prompt Studio project we previously created. This is where the extraction logic lives.
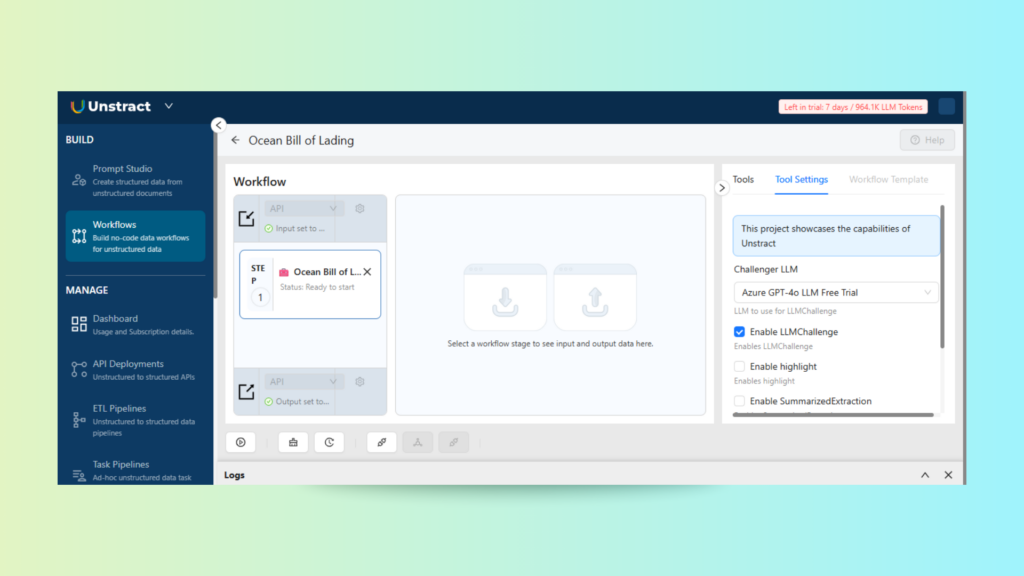
You can also enable advanced runtime behaviors. For instance:
LLM Challenger: This feature lets us run two different LLMs in parallel. The outputs are compared, and only the result that both agree on is accepted. This enhances confidence in the returned data and reduces the risk of hallucination.
Model Flexibility: You can assign your preferred LLMs, choose temperature and token limits, and even add fallback logic.
Once everything is configured, the workflow is deployed as an API service, making it ready for external consumption.
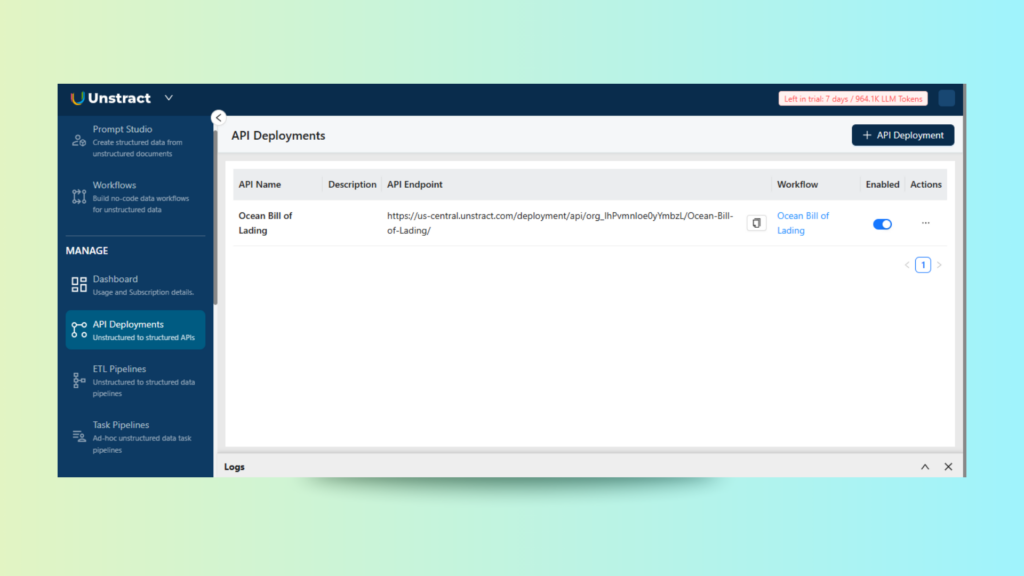
Exporting and Accessing the API
Once deployed, our workflow appears in the API Deployments dashboard. From here, we can:
View endpoint details
Check logs
Download a Postman Collection, a pre-configured collection of API requests that mirrors our deployed workflow
This is particularly useful for testing and integration. You don’t need to manually configure headers, endpoints, or request bodies; the collection has it all set up.
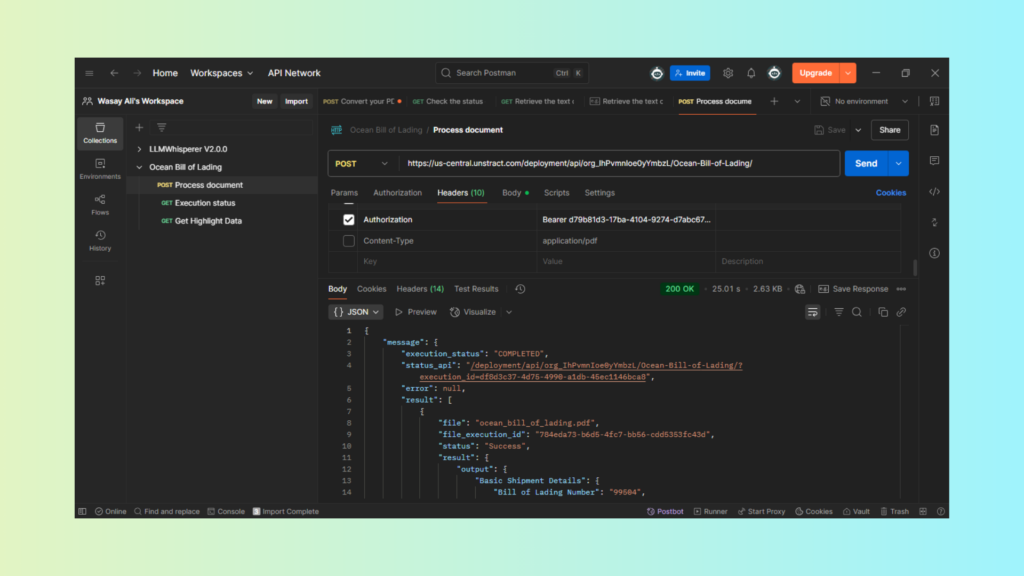
Testing the API with Postman
After importing the collection into Postman:
We select the POST request from the collection.
We upload the Bill of Lading in the body of the form data.
Hit Send, and the API responds with a clean, structured JSON output containing all the extracted fields from our Prompt Studio project.
Benefits of Using LLMWhisperer and Unstract for Document Automation
Together, LLMWhisperer and Unstract form a robust, low-code document automation pipeline. Here’s a quick summary of what makes this combination powerful for logistics document processing:
Visual Testing with Playground: The LLMWhisperer Playground allows for instant visual validation of OCR performance on any document. You can experiment with layout-preserving extraction, review results, and ensure document readiness before committing to automation.
Fast OCR-to-API Integration: The ability to download a ready-to-use Postman collection right from LLMWhisperer means you can switch from Playground testing to live API integration in minutes . No manual request crafting is needed.
Single-Pass Prompt Design in Unstract: Unstract’s Prompt Studio supports single-pass extraction, combining multiple prompts into one efficient LLM call. This helps:
Reduce token usage
Save costs
Speed up processing
All without sacrificing quality or flexibility.
Model-Agnostic Prompt Execution: You’re not locked into a single model. You can bring your own OpenAI, Gemini, or Claude keys, add your own embedding models, and connect to any vector database of choice. This makes the system highly modular.
Real-Time Workflow Deployment: Once you’re satisfied with your prompt logic, you can deploy it as an API with one click, allowing integration into:
Shipment tracking systems
ERP tools
Operations dashboards
Easy Testing with Postman: Postman collections exported from both LLMWhisperer and Unstract mean your team can validate the full workflow without needing engineering help. This is ideal for fast prototyping and stakeholder demos.
Conclusion
Automating logistics document processing is important to enhance the operational efficiency of modern supply chains. The combination of LLMWhisperer and Unstract directly addresses the industry’s critical need for efficient and accurate data extraction from a wide range of document types.
LLMWhisperer leads the way in Logistics OCR, preparing even the most complex documents by preserving layout integrity for optimal recognition accuracy. Unstract then leverages this pre-processed data with powerful AI, transforming raw text into structured, actionable insights. This synergy streamlines operations, reduces errors, and ensures compliance, driving significant gains in speed and cost-efficiency.
The future of logistics hinges on such intelligent automation, enabling businesses to navigate increasingly complex global demands with unparalleled agility. Ready to streamline your logistics document processing? Explore Unstract and sign up for a free trial to experience intelligent automation firsthand.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.