Best OCR For Bookkeeping: LLMWhisperer, Accurate Accounting OCR API
Table of Contents
What is Bookkeeping and Accounting
Every successful business depends on an accurate financial picture, and that starts with bookkeeping and accounting. From small startups to global enterprises, financial records drive strategic decisions, ensure compliance, and unlock growth for the businesses. But to realize these benefits, it’s essential to understand how these two functions complement each other and where they differ.
Bookkeepers are the first line of defense in maintaining accurate financial records. They manage business’s daily inflow and outflow of money by recording transactions, reconciling accounts, and catching discrepancies early. Their work forms the backbone of a company’s financial infrastructure. Without it, accounting becomes reactive instead of strategic.
Accountants step in to interpret this financial data inserted by bookkeepers. They prepare financial statements, file tax returns, and ensure regulatory compliance. More importantly, they translate raw figures into insights that guide high-level decisions. Inaccurate or incomplete records can derail this process, leading to missed opportunities or costly risks.
It can be seen that both roles rely on a high volume of financial documents. These documents arrive in varied formats such as paper-based, scanned, PDFs, spreadsheets and must be processed either on daily, weekly, or monthly basis depending on workflow. Some of the most common documents include:
Journal Entries: Digital or handwritten documents recorded frequently to maintain the general ledger. They provide a chronological record of all business transactions and are the starting point for financial reporting.
Invoices and Bills: Typically PDFs or paper files received or issued on a periodic basis to track payables and receivables. These documents confirm sales or purchases and are essential for revenue recognition and cash flow tracking.
Expense Reports: Submitted monthly as spreadsheets or scanned forms for reimbursement and tracking. They detail employee spending on business activities and are used to update budgets and issue reimbursements.
Cash Receipts: Issued in digital or printed form upon payment and need to be logged immediately for accuracy. These serve as proof of payment and help reconcile incoming cash with recorded sales or receivables.
Financial Statements: Generated monthly or quarterly as PDFs or spreadsheet exports to summarize performance. These include income statements, balance sheets, and cash flow statements, giving a snapshot of financial health.
Tax Returns: Filed annually in digital formats and are vital for regulatory compliance. They compile taxable income and deductions to calculate liabilities and are submitted to government tax agencies.
Managing these documents isn’t just a matter of diligence, it requires consistency, speed, and precision across every entry and report. As businesses grow and volumes scale, this routine task can become a significant operational burden. It’s here that long-standing methods start to show their limitations.
Challenges of traditional bookkeeping and accounting
In most business operations, occasional errors are expected, sometimes due to technical glitches, other times simple human oversight. While some departments can absorb these mistakes without major consequences, finance isn’t one of them.
In bookkeeping and accounting, even a small error can have outsized consequences, whether it’s an incorrect tax calculation, a misclassified expense, or a missed payroll. These seemingly minor mistakes can distort financial reports, delay payments, and even affect a company’s legal standing.
Traditional bookkeeping processes are especially prone to such risks. Because much of the work is manual and repetitive, the likelihood of error increases as transaction volume grows. Some of the most common issues include:
Manual Entry Mistakes: Errors often occur when bookkeepers manually extract data from invoices or receipts to update customer or vendor records. These can range from typos in tax IDs and Purchase Order numbers to entering the wrong amounts or skipping entries entirely.
Misfiled or Lost Documents: Even when a transaction is recorded correctly, the original document may be stored improperly or mislabeled. With high transaction volumes, this can lead to lost paperwork, which becomes a liability during audits or when information is urgently needed.
Time-Heavy Workflows: Sorting, verifying, and reconciling financial data by hand consumes a significant portion of accounting teams’ time. This slows down monthly closings and increases the chances of duplicate entries, misclassifications, or missing data.
These issues not only reduce accuracy, but also strain internal resources and introduce avoidable compliance risks. As transaction volumes rise and expectations for real-time reporting increase, the pressure on traditional methods becomes even more apparent.
This is why many finance teams are now exploring ways to streamline and modernize their workflows, freeing up time, reducing errors, and allowing professionals to focus more on analysis over administration.
Benefits of automating the process of bookkeeping
This need resulted in various automations in bookkeeping and accounting which refer to the use of software systems that streamline manual, repetitive financial tasks. By digitizing and streamlining financial workflows, these automations replace these repetitive tasks with intelligent systems that perform them faster, more reliably, and with greater transparency. From day-to-day transaction entry to high-level financial reporting, both bookkeepers and accountants benefit from automation in distinct but connected ways.
Here’s how automated systems can reshape financial operations:
Improved Data Accuracy: Automation eliminates the inconsistencies of manual entry by applying best practices and real-time validation checks at the time of each entry. This ensures that the financial data feeding into a general ledger is clean, complete, and audit-ready.
Increased Productivity: Automating repetitive tasks like data extraction, reconciliation, and report generation frees up time for strategic thinking. Bookkeepers can spend less time chasing paperwork, while accountants can focus more on analysis, forecasting, and compliance planning.
Real-Time Financial Insights: Automated platforms update financial data continuously, giving businesses instant access to their financial status. Accountants can monitor performance metrics, detect anomalies early, and support decision-making with timely, accurate data.
Cost Efficiency: With fewer hours spent on manual processing and fewer errors to correct, businesses can significantly reduce labor costs and reallocate resources to higher-value initiatives.
Streamlined Document Management: Instead of filing cabinets and paper trails, automation enables digital document storage that’s searchable, shareable, and secure. This not only improves access but also helps maintain compliance and supports a more environmentally friendly approach to financial operations.
But before any of these benefits can be realized, there’s a crucial first step: transforming raw, unstructured documents, like printed invoices, scanned tax forms, or photographed receipts, into structured digital data. That’s where a foundational technology such as Optical Character Recognition, or OCR, comes into play.
Importance of accurate OCR in bookkeeping/accounting processing
Optical Character Recognition (OCR) is the technology that converts scanned documents, PDFs, and even photographed images into machine-readable text. In accounting and bookkeeping, OCR plays a critical role because it bridges the gap between physical documents and digital workflows.
By automating data extraction from sources like invoices, receipts, and bank statements, OCR reduces the need for manual entry, speeds up processing, and improves document accessibility. But for financial operations, accuracy isn’t optional. It’s essential.
Here are some common areas where OCR makes a measurable impact in these disciplines:
Invoice Processing: OCR extracts details like vendor names, invoice dates, and amounts, accelerating accounts payable cycles. This reduces turnaround time and lowers the risk of late payments or entry errors.
Payroll Processing: Timesheets and pay stubs can be digitized and parsed automatically, minimizing manual mistakes and helping payroll run on time even across large teams or multiple pay cycles.
Receipt Management: Employees can scan receipts for expense claims, and OCR handles the categorization and data entry. This supports faster approvals and improves fraud detection.
Bank Statement Reconciliation: OCR converts bank statements into structured data, making it easier to match transactions and spot inconsistencies. This ensures financial records stay accurate and up to date.
Expense Reporting and Auditing: When expense reports are digitized, auditors gain quick access to backup documents. This shortens audit timelines and improves the quality of financial oversight.
Despite these advantages, OCR’s effectiveness hinges on accuracy. In finance, even a small misreading( a transposed number or a misspelled account name) can trigger bigger problems such as unpaid vendors, unreconciled ledgers, or incorrect reports.
While many tools report accuracy rates around 95%, that still means 5 out of every 100 words could be wrong, a margin too wide for most financial workflows. In accounting, precision isn’t a luxury. It’s a requirement.
This is why selecting a high-accuracy OCR solution is not just a technical choice, but a strategic one. The right tool reduces manual correction, strengthens data integrity, and supports faster, more confident financial decisions.
What is LLMWhisperer?
LLMWhisperer is a high-performance PDF-to-text converter designed specifically for complex, real-world documents and optimized for downstream use with large language models (LLMs).
Unlike traditional OCR engines, which often struggle with complex layouts or mixed content types, LLMWhisperer is built from the ground up to handle real-world variability in financial documents. Without relying on any large language model during the extraction phase, it uses a specialized parsing engine to deliver clean, structured outputs that LLMs and other downstream systems can easily understand and act on.
Here’s what sets LLMWhisperer apart:
Layout Preservation: It maintains the original structure and formatting of documents during extraction, which is critical when accuracy depends on column order, headers, or alignment. This is common in financial statements and reports.
Checkbox and Radio Button Recognition: LLMWhisperer identifies and converts checkboxes and radio buttons into markdown-compatible formats, making form-based data easier for LLMs and other tools to process correctly.
Advanced Document Preprocessing: The tool includes filters and image correction features that enhance readability from poorly scanned or low-quality sources make it ideal for older tax forms or faded receipts.
Structured Output (JSON): Instead of flat text, LLMWhisperer can output structured data formats like JSON, enabling easy integration into accounting software, databases, or automated workflows.
Multi-Language Support: With coverage of over 300 languages, it’s a powerful solution for global businesses managing multilingual supplier invoices, payroll forms, or international tax records.
Broad Format Support: It handles a wide range of file types beyond PDFs, including:
Images: JPEG, PNG, BMP, GIF – often used for scanned receipts and invoices
Spreadsheets: XLSX, XLS, ODS – for balance sheets and financial statements
Presentations: PPTX, PPT, ODP – for internal or client-facing financial briefings
Documents: DOCX, DOC, ODT – for contracts or compliance reports
Plain Text: TXT – for logs, notes, or system-generated exports
Beyond its capabilities, LLMWhisperer is also accessible. Users can process up to 100 pages per day for free, with flexible, usage-based pricing available for higher volumes. This makes it a scalable solution, whether you’re automating bookkeeping in a small business or streamlining compliance for a finance team at scale.
Quickly take LLMWhisperer for a test drive, check out our free playground.
LMWhisperer can be used in two flexible ways, making it accessible for both technical and non-technical users:
Via the LLMWhisperer Playground: A user-friendly interface where you can upload documents, experiment with different parsing modes, and instantly view the parsed output.
Via the LLMWhisperer API: A programmatic option ideal for integrating LLMWhisperer into applications or automating document workflows at scale.
After registering, you’ll be redirected to the Playground where you can upload and test documents immediately, processing up to 100 pages per day for free.
Try a sample document or upload your own by clicking Upload.
Once uploaded, click See Results to view the parsed output.
Using the API
After account creation, your API key is automatically generated.
Navigate to the LLMWhisperer Dashboard and click the API Keys tab to access:
Base API URL – Click the LLMWhisperer API URL button to copy.
API Key – Found under the Keys column.
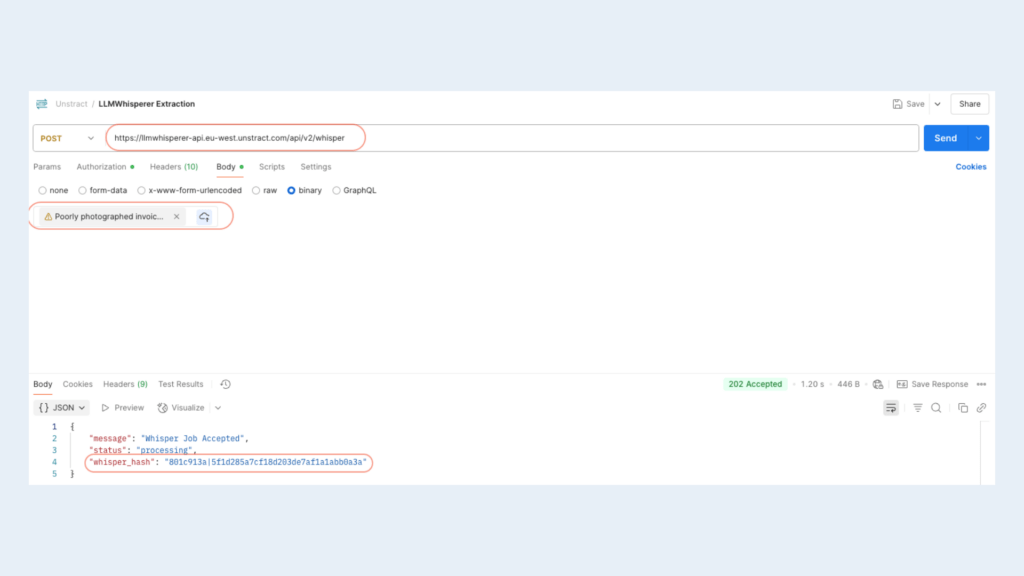
To integrate with tools like Postman:
Create a POST request:
URL: <Base API URL>/whisper
Headers: unstract-key: <YOUR API KEY>
Body: Set to application/octet-stream
Under Body, select Binary, then upload your document file. This returns a whisper_hash.
Once status is processed, retrieve the results via a GET request to the Retriever API:
URL: <Base API URL>/whisper-retrieve
Params: whisper_hash: <your_hash_id>
The above processes will now be applied to six common financial document types frequently encountered in accounting and bookkeeping operations.
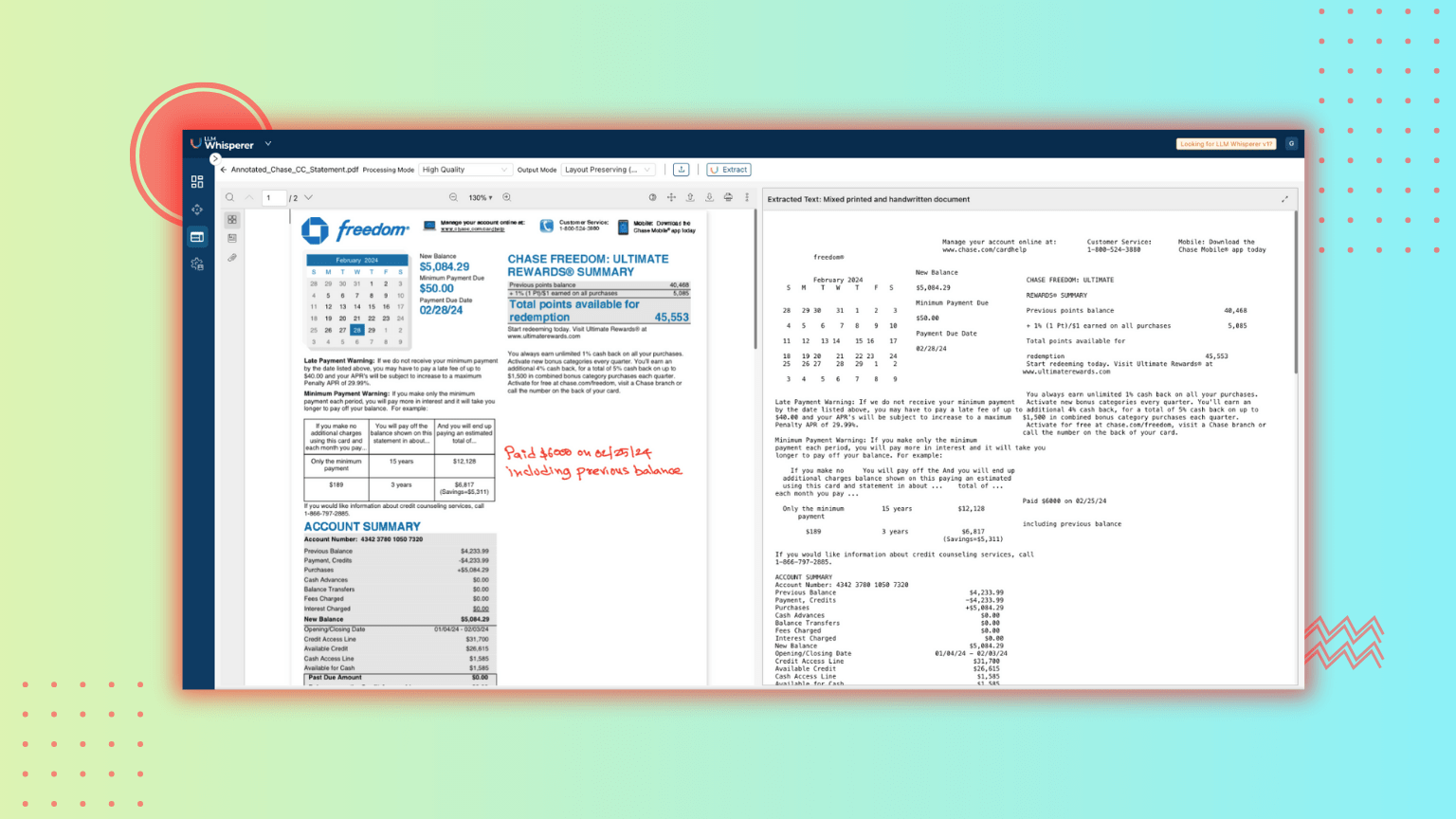
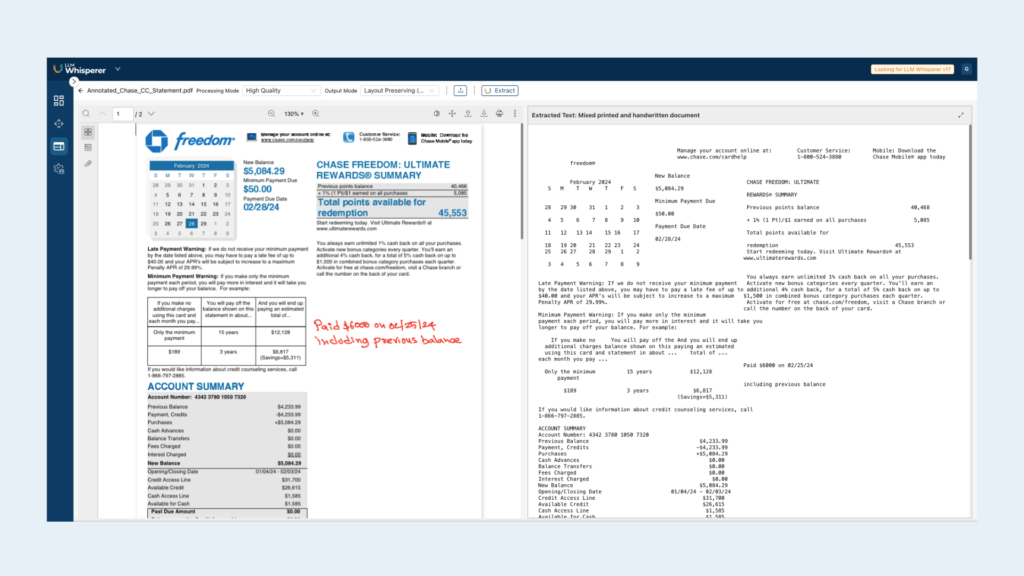
Use Case 1: Native PDF Bank Statement
Bank statements are essential financial documents used for account reconciliation and auditing. Issued periodically by banks and financial institutions, they often feature complex layouts such as multiple columns, tables, section headers, promotional banners, and embedded summaries that make them challenging to parse with traditional OCR tools.
Some common challenges in bank statement parsing:
Tabular and Multi-Column Layouts: Traditional OCR systems often struggle to accurately extract information from multi-column and tabular layouts, leading to misaligned or merged data fields.
Semantic Understanding of Key vs. Value Pairs: They typically extract raw text without preserving associations between labels (e.g., “New Balance”) and their corresponding values.
Handwritten Notes and Annotations: Handwritten notes, such as customer annotations or signatures, are often overlooked or misinterpreted.
Visual Separation of Sections: OCR tools may fail to distinguish structurally different sections (e.g., rewards summary vs. account balance), causing contextual blending of unrelated content.
Below, the result of this bank statement via LLMWhisperer playground is presented.
In this bank statement, which features a complex multi-column layout, the LLMWisperer excels in extracting structured financial data with high accuracy. Key-value pairs like “Minimum Payment Due: $50.00” and “New Balance: $5,084.29” are correctly linked, and tabular information in the Account Summary is preserved without loss of structure. Also the different content zones such as rewards summaries and account messages have been effectively separated, maintaining clarity and context. Notably, it also captures handwritten annotations (“Paid $6000 on 02/25/24”) and aligns them to the corresponding sections when needed, something that standard OCR tools often miss.
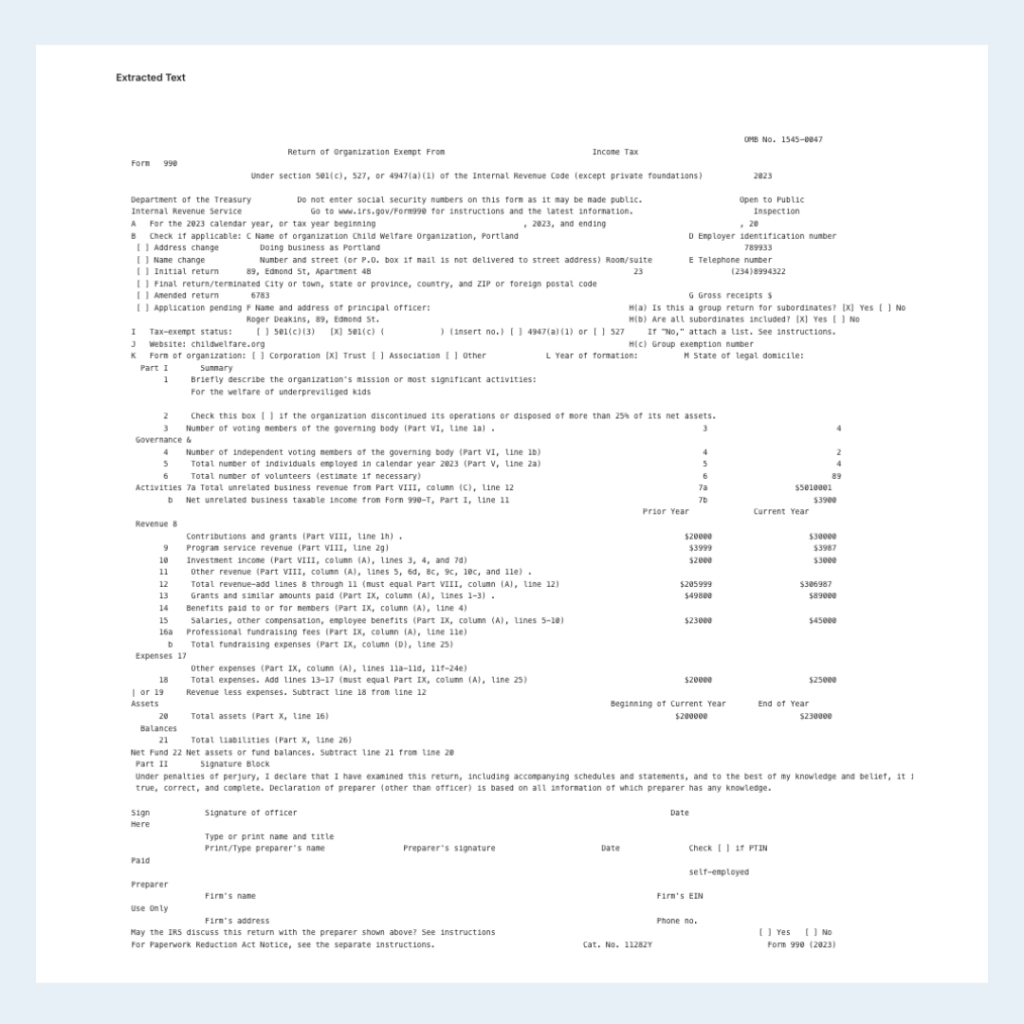
Use Case 2: Income Tax Documents (with Checkboxes)
Income tax documents are standardized government-issued forms used to report financial activity to tax authorities. They play a critical role in compliance, reconciliation, and audit preparation, particularly in accounting and bookkeeping workflows. These forms often contain checkboxes, dense tables, embedded labels, and segmented sections, making them notoriously difficult to process accurately with traditional OCR.
Some common challenges in tax document parsing:
Checkbox Detection: Many OCR tools fail to distinguish between checked and unchecked boxes, which can lead to incorrect interpretations of critical fields (e.g., filing status or return type).
Embedded Field Labels: Inline labels beside form fields (rather than above or below) disrupt conventional field-value pairing logic.
Dense Tabular Sections: Numeric fields in rows and columns (e.g., revenue or expense lines) are prone to misalignment or data shifts.
Sectional Segmentation: Accurately separating and labeling different areas (e.g., Assets, Revenue, Signatures) requires spatial and semantic awareness—something most OCR tools lack.
Below, the result of this tax document via LLMWhisperer playground is presented.
In this structured income tax document, the LLMWhisperer accurately extracts complex, form-based data while preserving checkbox selections, such as tax status and organization type, in a markdown format that traditional OCR systems often miss. Numeric fields across sections like Revenue and Expenses are clearly aligned and contextually linked to their labels, even when values appear inline. The tool also maintains the separation of distinct form sections (e.g., Assets, Balances, Signature) and handles structured tabular data with precision.
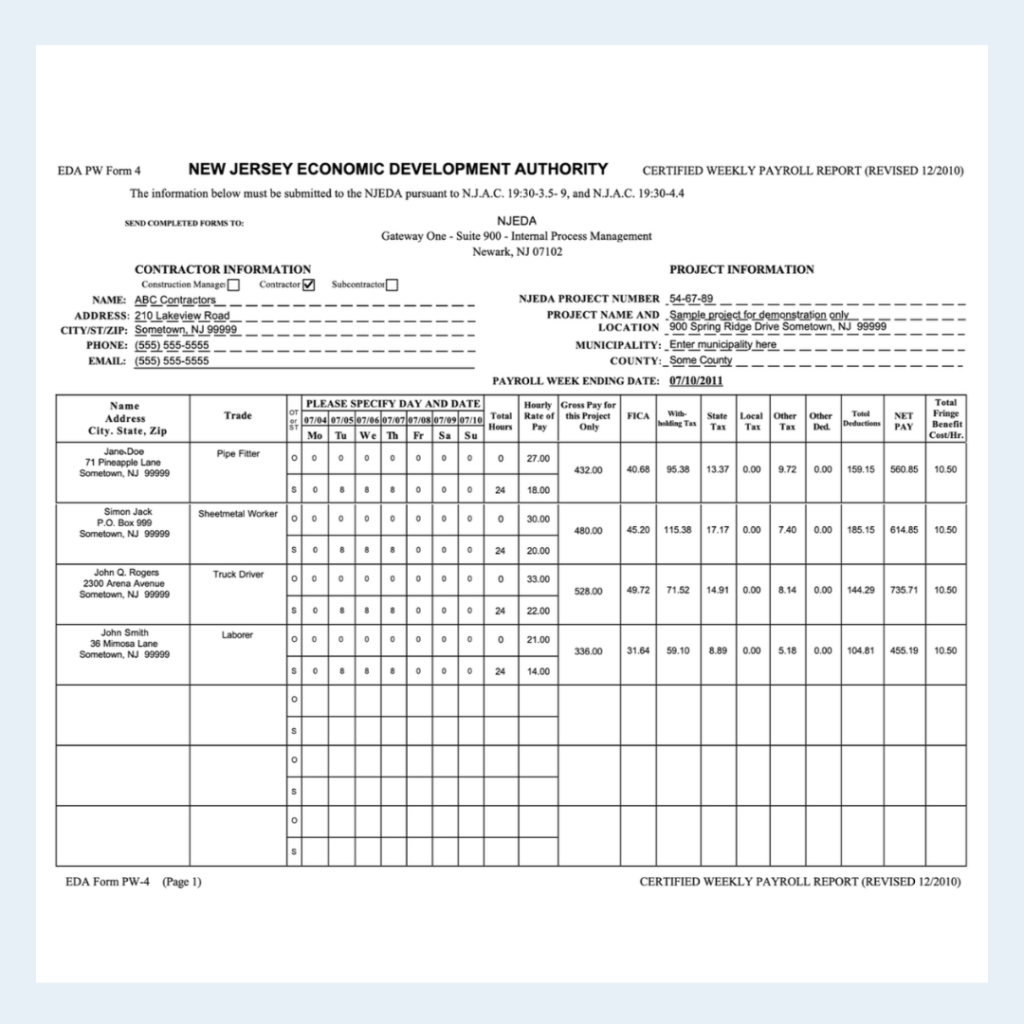
Use Case 3: Payroll and Wages Document (Complex Tables)
Payroll and wages documents, such as certified payroll reports, track hours worked, pay rates, taxes, and deductions across employees and time periods. These records are foundational in both accounting and HR for payroll processing, tax reporting, and compliance, particularly in regulated industries like construction or public works. Because they often include densely packed, multi-layered tables with mixed data types, they pose unique challenges for standard OCR systems.
Some common challenges in payroll document parsing:
Dense Tabular Layouts with Merged Headers: Tables often span multiple header levels, making it difficult to link headers to row values correctly.
Multi-Line Fields and Row Alignment: Employee names or trade descriptions that span multiple lines can throw off row associations, leading to mismatched data.
Precision-Dependent Numeric Data: Fields like tax deductions or hourly wages require accurate parsing to avoid costly rounding or decimal errors.
Grouped Columns and Subtotals: Column groups (e.g., “Tax Breakdown”) may be flattened or misread as separate tables, losing hierarchical meaning.
Sparse or Irregular Rows: Documents may contain optional fields, empty rows, or partial data that confuse traditional models and result in omissions or formatting errors.
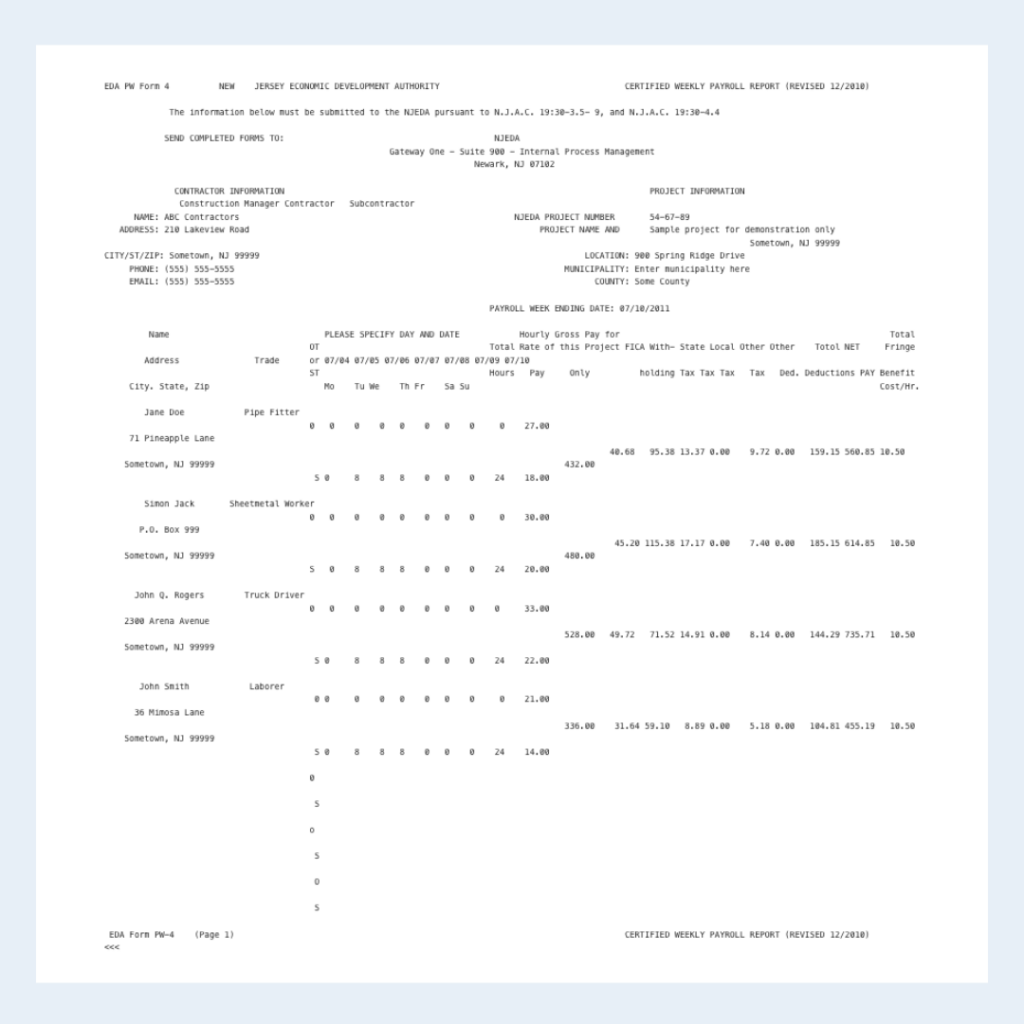
Below the result of this payroll document via LLMWhisperer API is presented.
In this payroll and wages document featuring complex multi-line tables, the LLMWhisperer accurately extracts structured data while preserving row alignment across employees, even with multi-line addresses and trade descriptions. It correctly associates header fields, such as hourly rate, taxes, and deductions, with the appropriate numeric values across all columns. Despite dense tabular formatting and repeated empty cells, the tool avoids misalignment and maintains table integrity throughout. These results show strong layout and table structure awareness, making it well-suited for high-volume payroll processing and labor compliance tasks in accounting workflows.
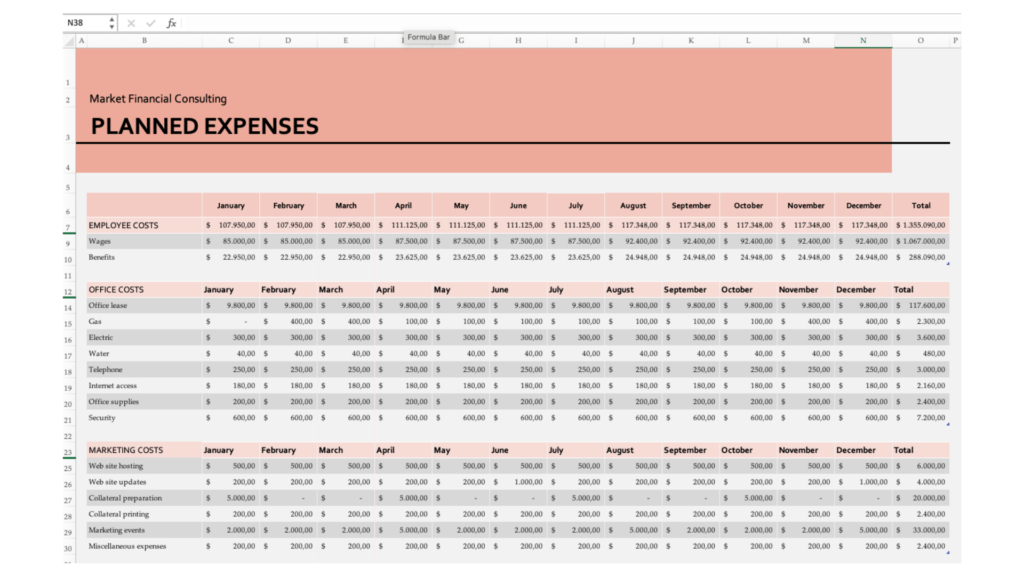
Use Case 4: Excel with Business Expenses Report Bank
Business expense reports, often prepared in spreadsheet formats like Excel, track and categorize operating costs across time periods and departments (e.g., employee, office, marketing). These reports are vital for budgeting, forecasting, and financial audits, but their structure makes them difficult to parse accurately. When exported to PDF or image format, or even handled as raw Excel files, their wide tables, layered headers, and precision-sensitive figures pose significant challenges for traditional OCR systems.
Some common challenges in expense report parsing:
Wide, Multi-Column Layouts: Horizontally spaced fields (e.g., monthly columns) are prone to header misalignment and column shifting.
Merged and Hierarchical Headers: Nested structures (like Category to Subcategory to Month) often lose their hierarchy during extraction.
Precision-Sensitive Numeric Data: Currency values with commas and decimals can be misread, truncated, or misformatted.
Section Context Preservation: Visually distinct blocks (e.g., Employee vs. Office Costs) may be flattened, mixing unrelated categories.
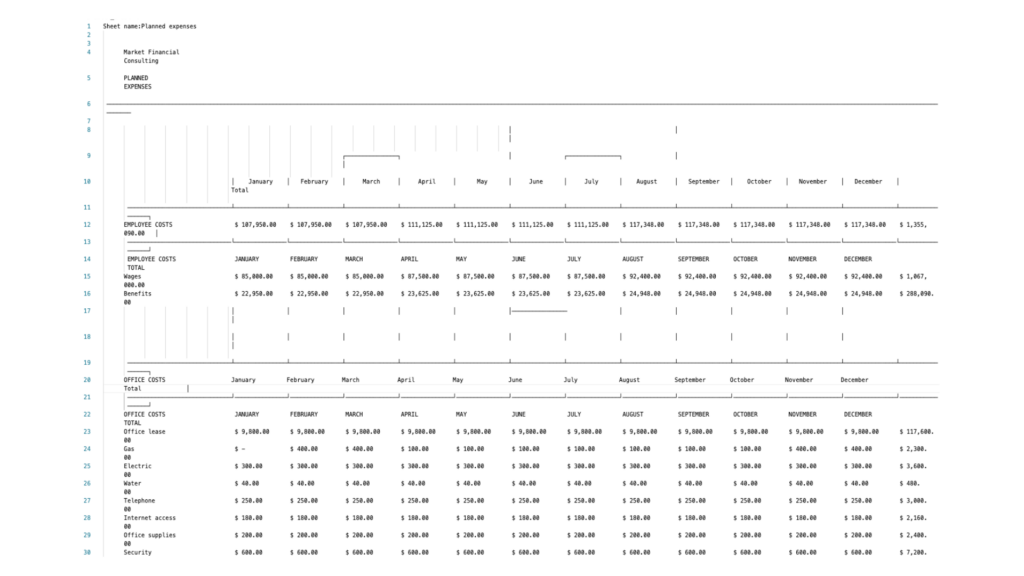
Below the result of this expenses report via LLMWhisperer API is presented.
In this structured Excel-based business expenses report, the LLMWhisperer demonstrates strong capabilities in extracting and interpreting dense tabular financial data. It accurately parsed wide tables across all twelve months, preserving the alignment between categories (e.g., Employee, Office, Marketing Costs) and their monthly values. Layered headers and hierarchical structures were maintained, and numeric values (particularly currency figures) were extracted with precision, including correct placement of decimals and thousands separators.
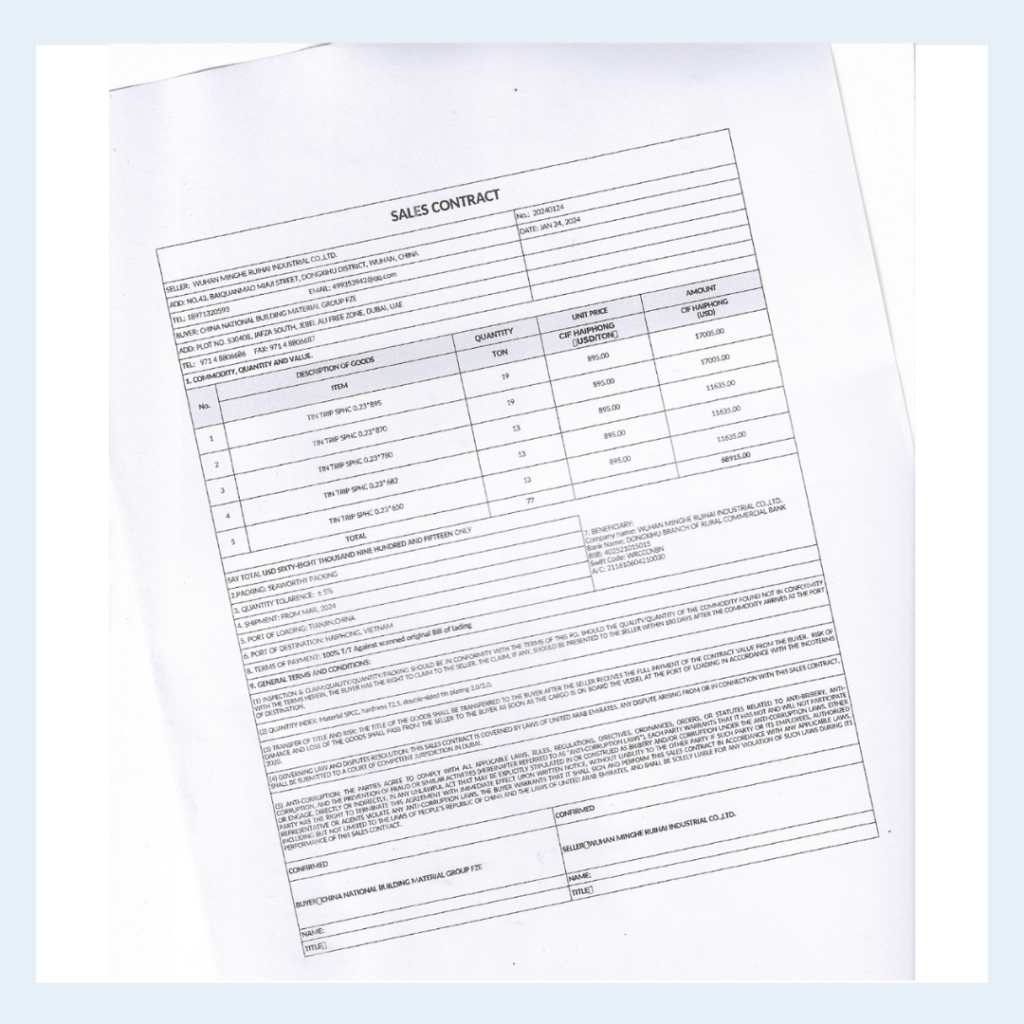
Use Case 5: Poorly Scanned Sales Contract
Sales contracts outline the terms of a transaction between a buyer and a seller, typically including item descriptions, pricing, quantities, delivery terms, and payment instructions. These documents are foundational in accounting and procurement workflows, supporting revenue recognition, audit trails, and order reconciliation. However, when contracts are scanned or photographed,often at awkward angles, with creases or shadows, they become difficult for traditional OCR systems to interpret accurately due to layout distortion and visual noise.
Some common challenges in poorly scanned contract parsing:
Skewed or Angled Geometry: Photos taken at an angle can warp text and disrupt table structures, leading to incorrect extraction or missing data.
Bordered and Merged Table Cells: Complex tables with boxed-in data (e.g., quantity, unit price, total) may be misread or lose their structure.
Small-Font Legal Clauses: Fine print is often degraded or omitted entirely in low-quality scans.
Signature and Confirmation Blocks: Buyer and seller signature sections can be detached or skipped during parsing.
Mixed Content Types: Contracts often include both structured (tables) and unstructured (terms and conditions) content, which many OCR tools fail to separate clearly.
Below the result of this sales contract via LLMWhisperer API is presented.
In this poorly aligned, photographed sales contract, the LLMWhisperer effectively corrected for image skew and successfully extracted structured table data such as item descriptions, quantities, unit prices, and totals without misalignment or value loss. It preserved the integrity of tabular headers and maintained the association between pricing and item rows. Despite small-font legal clauses and mixed content types, the tool captured full blocks of contract terms and beneficiary details with high accuracy. It also recognized confirmation sections and party information without dropping context.
Use Case 6: Badly Photographed Image of Invoice
Invoices and receipts are essential for recording transactions in retail, hospitality, and small business operations. When captured via mobile phone—often at odd angles, with glare, shadows, or creases—they become difficult for standard OCR systems to process cleanly. Yet these documents play a vital role in bookkeeping, expense tracking, and financial reconciliation making accurate digitization essential for accounting workflows.
Some common challenges in photographed invoices:
Angled Images and Skewed Text: Photos taken at a tilt distort text baselines, breaking row alignment and flow.
Low Print Quality or Faded Ink: Thermal printing and light ink can cause OCR to skip or misinterpret key details.
Compact, Tightly Spaced Text: Line-item names, tax values, and totals are often small and hard to segment.
Non-Standard Layouts: Receipts vary in design, making rigid template-based OCR tools unreliable.
Visual Noise and Background Artifacts: Folds, shadows, or nearby objects in the photo can interfere with recognition.
Below the result of this photographed invoices via LLMWhisperer API is presented.
In this poorly photographed restaurant invoice, the OCR tool accurately extracted structured data such as merchant details, order number, timestamp, itemized purchases, tax breakdowns, and total amount despite image skew and inconsistent text alignment. It successfully preserved line items like “Jack The Ripper” and “Coke 300 ML” with corresponding quantities and prices, while also capturing subtotals, GST components (CGST and SGST), and the final payable amount.
Conclusion
The diversity and complexity of financial documents,ranging from bank statements and tax forms to invoices and payroll reports, pose significant challenges for accounting and bookkeeping teams. Manual document processing is time-consuming, error-prone, and resource-intensive, often leading to compliance risks, delayed reporting, and inconsistent financial records.
Automating these workflows not only reduces manual effort but also improves data accuracy, ensures consistency, and accelerates financial operations. This shift allows professionals to focus more on analysis, planning, and decision-making rather than repetitive data entry.
In this context, Unstract offers a powerful solution through LLMWhisperer, a highly accurate and layout-aware document parsing tool designed to extract structured data from complex financial documents. LLMWhisperer significantly outperforms traditional OCR solutions, handling everything from tabular Excel data to photographed receipts and legal contracts, while outputting results in formats like JSON for seamless integration into accounting systems or LLM-powered workflows.
Ultimately, adopting LLMWhisperer enables finance teams to modernize their document processing pipelines, reduce operational costs, and scale more efficiently. It’s not just a tool for automation, it’s a foundation for smarter, faster, and more reliable accounting operations.
Document extraction at the cutting edge with LLMs vs LLMWhisperer
LLMs have become operational powerhouses, thanks in part to their ability to extract rich, meaningful information from documents. But even the best models, in real-world use cases, often depend heavily on the quality of the input they receive.
Discover how LLMWhisperer, Unstract’s dedicated text extraction service, prepares documents for peak LLM performance and sets standards for LLM-ready outputs.
Watch this webinar where we put top LLMs to the test—evaluating their performance across documents of varying complexity. We’ll dive into why directly parsing raw documents often leads to subpar results, and showcase the impact LLMWhisperer has on improving extraction outcomes.
Best Bookkeeping OCR in 2026:Related topics to explore
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.