AI Document Processing and Extraction with Unstract
Table of Contents
Introduction to AI Document Processing
You have a pile of PDFs – invoices, contracts, forms, and millions of pages of data locked inside documents your systems can’t read.
What if you didn’t have to manually build templates, write rules, craft prompts, or define schemas?
What if an AI agent could handle all of that for you in one click?
That’s not a hypothetical. That’s where AI document processing is in 2026.
For decades, extracting structured data from documents meant one of two things: hiring people to do it manually, or building brittle rule-based systems that broke every time a vendor changed their layout. Both approaches are expensive, slow, and don’t scale.
AI document processing changes the equation entirely. Instead of configuring templates or writing extraction rules, you feed documents into an AI pipeline and get clean, structured data out – automatically, at scale, across any document type.
As LLMs have matured, so has the ability to understand documents the way humans do: reading context, inferring structure, and handling variability without needing to be reprogrammed for every new format.
The mental model is simple – one API endpoint. Send in any document, a scanned bank statement, a multi-page contract, a handwritten form, and get structured JSON back. No manual setup. No schema definition. No prompt engineering. Just data.
Let’s see that in action before we get into how it works.
Seeing It Work – A Live Demo in AI Document Processing
LLMWhisperer – The OCR Layer
Before any LLM can extract structured data from a document, someone has to solve a deceptively hard problem: getting the text off the page in a form the LLM can actually use.
LLMWhisperer is a document parsing engine built specifically for LLM-based extraction pipelines. Its job is the step before extraction, converting PDFs, scanned images, and complex documents into text output that preserves enough of the original structure for a language model to reason over correctly. It sits at the entry point of the pipeline, and the quality of everything downstream depends on what it produces.
The Layout Preservation Problem
Standard OCR tools were built to extract text, not to preserve meaning. They read a page left to right, top to bottom, and produce a stream of characters. That works well for simple single-column documents. It fails badly for anything more complex.
Consider a bank statement. It contains a header block with account details, a multi-column transaction table with dates, descriptions, and amounts running across the page, a running balance column, and a summary section at the bottom. A conventional OCR tool flattens all of that into a single text stream. The date from column one ends up adjacent to the description from column two, which runs into the amount from column three, with no reliable way to tell which values belong to which transaction. The spatial relationships that give the numbers their meaning are gone.
An LLM trying to extract structured data from that output isn’t working with a document, it’s actually working with noise. It may produce plausible-looking results, but accuracy will be inconsistent and unpredictable, especially across statements from different banks with different layouts.
LLMWhisperer solves this through layout-aware parsing. Rather than flattening the page, it analyses the spatial structure and reconstructs the text in a way that preserves the relationships between elements. Table rows stay intact. Multi-column sections are handled correctly. Headers, footers, and summary blocks are separated from transaction data. The output reads like the document, not like a scrambled approximation of it. That’s what makes reliable LLM-based extraction possible.
Seeing It in Action
The quickest way to understand what LLMWhisperer produces is to call it directly via the API and inspect the output.
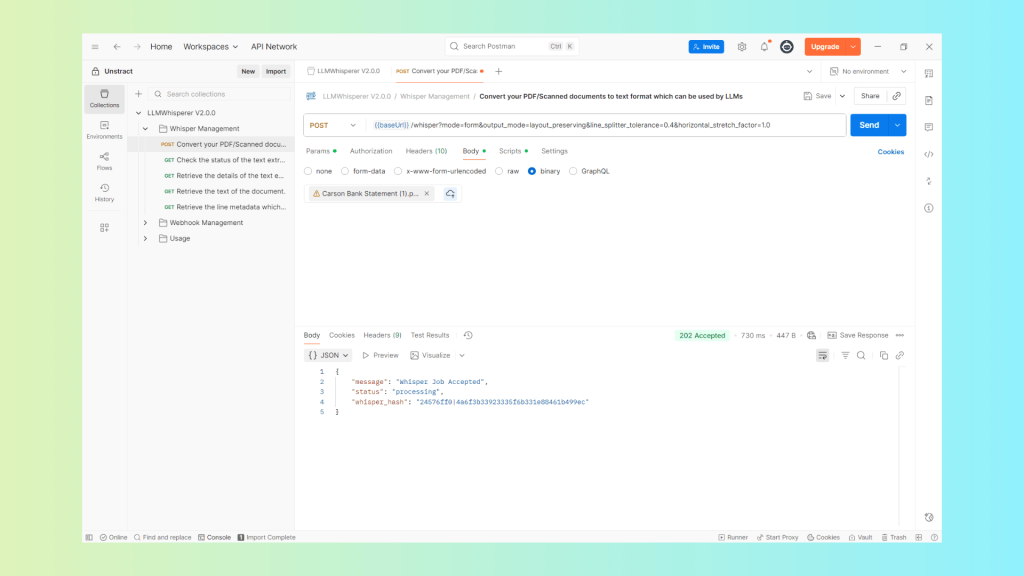
In Postman, the request is straightforward: set the endpoint for the Extraction API, the authorization header, then attach the document, and send it to the whisper endpoint:
This will return a whisper_hash that you can use to call the whisper-retrieve endpoint:
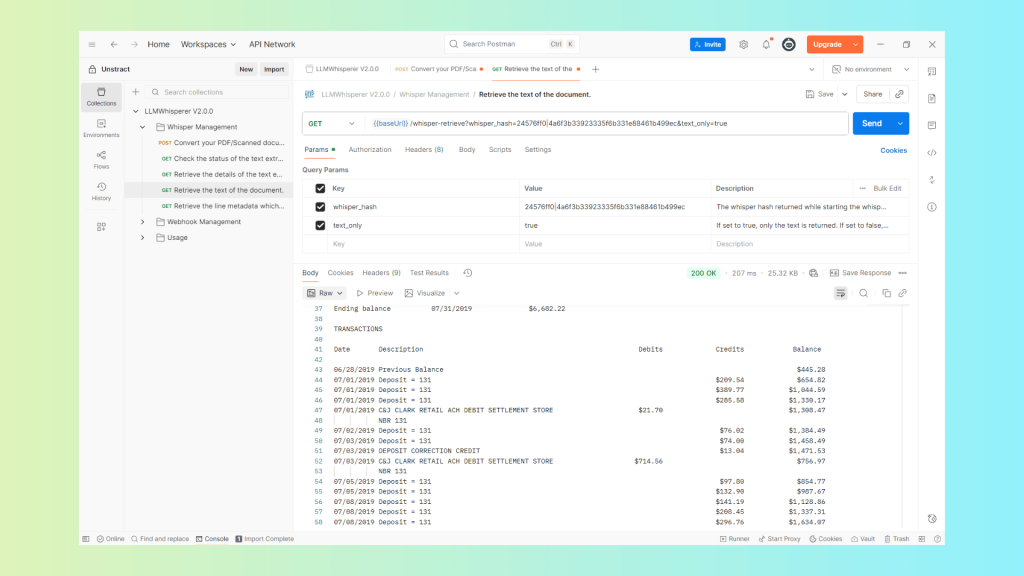
The response comes back with the extracted text laid out in a way that mirrors the original document structure, transaction rows aligned, column relationships intact, header and summary sections clearly separated from the transaction body:
Contact us: MEMBER
(316)777-1171 FDIC
EQUAL HOUSING
LENDER
CARSON BANK Branch:
EST. 1886 Carson Bank
122 W Main
Mulvane, KS 67110
Visit our web site at:
www.carsonbank.com
JOHN TEST
123 TEST
YOUR CITY, KS 03087
Page 1 of 6
Statement Date: July 31, 20XX Account Number: 6547
TRUE CHECKING
ACCOUNT ACTIVITY SUMMARY
Statement period number of days 33
Average balance $5,032.20
Total service charge today $6.00
Year to date interest $8.15
Debits
Previous balance 06/28/2019 $3,005.93 $14,365.21
Credits
Deposits/credits 10 $18,041.50 $18,041.50
Checks/withdrawals 54 $14,365.21
Ending balance 07/31/2019 $6,682.22
TRANSACTIONS
Date Description Debits Credits Balance
06/28/2019 Previous Balance $445.28
07/01/2019 Deposit = 131 $209.54 $654.82
07/01/2019 Deposit = 131 $389.77 $1,044.59
07/01/2019 Deposit = 131 $285.58 $1,330.17
07/01/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $21.70 $1,308.47
NBR 131
07/02/2019 Deposit = 131 $76.02 $1,384.49
07/03/2019 Deposit = 131 $74.00 $1,458.49
07/03/2019 DEPOSIT CORRECTION CREDIT $13.04 $1,471.53
07/03/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $714.56 $756.97
NBR 131
07/05/2019 Deposit = 131 $97.80 $854.77
07/05/2019 Deposit = 131 $132.90 $987.67
07/08/2019 Deposit = 131 $141.19 $1,128.86
07/08/2019 Deposit = 131 $208.45 $1,337.31
07/08/2019 Deposit = 131 $296.76 $1,634.07
<<<
CARSON BANK
EST. 1886
Page 2 of 6
JOHN TEST Account Number: 6547
TRANSACTIONS (continued)
Date Description Debits Credits Balance
07/09/2019 Deposit = 131 $130.28 $1,764.35
07/10/2019 Deposit = 131 $238.74 $2,003.09
07/11/2019 Deposit = 131 $305.73 $2,308.82
07/12/2019 Deposit = 131 $86.96 $2,395.78
07/12/2019 DEPOSIT CORRECTION CREDIT $1.00 $2,396.78
07/15/2019 Deposit = 131 $406.35 $2,803.13
07/15/2019 Deposit = 131 $547.09 $3,350.22
07/15/2019 Deposit = 131 $536.59 $3,886.81
07/15/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $1,845.80 $2,041.01
NBR 131
07/16/2019 Deposit = 131 $94.48 $2,135.49
07/17/2019 Deposit = 131 $228.08 $2,363.57
07/17/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $950.82 $1,412.75
NBR 131
07/18/2019 Deposit = 131 $108.62 $1,521.37
07/18/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $547.09 $974.28
NBR 131
07/19/2019 Deposit = 131 $456.09 $1,430.37
07/19/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $536.59 $893.78
NBR 131
07/22/2019 Deposit = 131 $280.22 $1,174.00
07/22/2019 Deposit = 131 $108.59 $1,282.59
07/22/2019 Deposit = 131 $213.69 $1,496.28
07/23/2019 Deposit = 131 $43.40 $1,539.68
07/24/2019 Deposit = 131 $250.82 $1,790.50
07/24/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $94.48 $1,696.02
NBR 131
07/25/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $108.59 $1,587.43
NBR 131
07/25/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $1,073.01 $514.42
NBR 131
07/26/2019 Deposit = 131 $162.89 $677.31
07/29/2019 Deposit = 131 $538.79 $1,216.10
07/29/2019 Deposit = 131 $515.31 $1,731.41
07/29/2019 Deposit = 131 $170.55 $1,901.96
07/29/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $213.69 $1,688.27
NBR 131
07/30/2019 Deposit = 131 $21.70 $1,709.97
07/31/2019 Deposit = 131 $241.75 $1,951.72
07/31/2019 C&J CLARK RETAIL ACH DEBIT SETTLEMENT STORE $995.90 $955.82
NBR 131
07/31/2019 SERVICE CHARGE $10.00 $945.82
07/31/2019 PAPER STATEMENT CHARGE $3.00 $942.82
CHECKS
Number Date Amount Number Date Amount Number Date Amount
4416 07/08/19 $100.00 4419 * 07/08/19 $266.00 4420 07/08/19 $69.13
<<<
CARSON BANK
EST. 1886
Page 3 of 6
JOHN TEST Account Number: 6547
CHECKS (continued)
Number Date Amount Number Date Amount Number Date Amount
4421 07/12/19 $12.53 4423 07/19/19 $114.00 4451 * 07/25/19 $150.00
4422 07/12/19 $25.00 4424 07/16/19 $1,046.66
* Indicates Break In Sequence
Number of Checks 8 Total Amount of Checks $1,783.32
DAILY BALANCE SUMMARY
Date Amount Date Amount Date Amount
07/01/2019 $2,860.22 07/15/2019 $11,373.85 07/24/2019 $7,285.72
07/03/2019 $2,918.99 07/16/2019 $10,120.07 07/25/2019 $9,428.29
07/05/2019 $2,888.81 07/17/2019 $7,079.35 07/26/2019 $8,428.29
07/08/2019 $2,200.49 07/18/2019 $7,108.96 07/29/2019 $7,187.52
07/10/2019 $509.97 07/19/2019 $7,935.34 07/30/2019 $6,687.52
07/11/2019 $2,998.76 07/22/2019 $7,318.61 07/31/2019 $6,682.22
07/12/2019 $2,886.23 07/23/2019 $7,292.22
<<<
CARSON BANK
EST. 1886
Page 4 of 6
JOHN TEST Account Number: 6547
READY RESERVE Account Number: 3216
Closing Date 07/31/2019 Statement Date 07/31/2019
Last Closing Date 06/30/2019 Last Statement Date 06/28/2019
Summary Of Account Activity Payment Information
Principal Summary: New Balance 913.01
Previous Balance 926.18 Current Payment Due Date 08/26/2019
Advances & Debits 0.00
Payments & Credits 13.17 Current payment due 0.00
New Balance 913.01 Amount Past Due 0.00
Late Charges Due 0.54
Interest Summary:
Paid This Period 12.91 Total Due 26.29
Paid Year-To-Date 100.60
Charged This Period 14.09 Your Payment Will Be Debited On 08/26/2019
Fee Summary: Loan Is Past Maturity
Fees Financed 0.00
Other Fees 0.00
A&H/Credit Life Insurance 0.00
Credit Limit 1,000.00
Available Credit 86.99
Average Daily Balance 921.93
Days In Billing Cycle 31
TRANSACTIONS
Tran Date Transaction Principal Fees Credit Life
Post Date Amount Interest Late Fees Accident & Health
OVB LOAN PAYMENT
07/22/2019 26.08 - 13.17 - 0.00 0.00
07/22/2019 12.91 - 0.00 0.00
Fees
Tran Date Post Date Amount Description
No Fees This Period ***
Interest Charged
Interest Charge On Outstanding Balance: 14.09
Total Interest For This Period: 14.09
2019 Totals Year-to-date
Total Fees Charged In 2019 $0.54
Total Interest Charged In 2019 $99.90
<<<
CARSON BANK
EST. 1886
Page 5 of 6
JOHN TEST Account Number: 6547
INTEREST CHARGE CALCULATION
Your Annual Percentage Rate (APR) is the annual interest rate on your account.
Annual # of Balance Subject Interest
Date Percentage Rate Days to Interest Rate Charge
07/01/2019 18.00000% 21 926.18 9.59
07/22/2019 18.00000% 10 913.01 4.50
Total: 31 14.09
On variable rate plans, the annual percentage rate may vary
<<<
Page 6 of 6
Account Reconciliation Form
A. The ending balance shown on H. The ending balance in your check
statement $ register $
B. List deposits not shown on $ I. List deposits, transfers or interest $
statement $ credited not already listed in your $
$ check register $
$ $
$ $
C. Total of lines B $ J. Total of lines I $
D. Add line C to line A $ K. Add line J to line H $
E. List below all checks written and any L. List below all checks and charges not
withdrawals not posted on statement already reflected in your check register
Check # $ Amount Check # $ Amount Check # $ Amount Check # $ Amount
$ $ $ $
$ $ $ $
$ $ $ $
$ $ $ $
$ $ $ $
F. Total of Column E $ M. Total of Column L $
G. Subtract line F from line D $ N. Subtract line M from line K $
The balances (Line "G" and Line "N" above) should agree. If not, recheck your entries from this
statement and your check register. All deposits and credits are subject to final collection.
The following pertains to accounts established for personal, family or household purposes only.
For information regarding business and custodial accounts please refer to your account disclosure. Contact us if you have a specific question pertaining to
your account.
In Case of Errors or Questions About Your Electronic Transfers may have to pay the amount in question. While we investigate whether or not
there has been an error, the following are true:
Direct inquiries to us at our address or telephone number printed on the front
page of this statement if you think your statement or receipt is wrong or if you . We cannot try to collect the amount in question, or report you as
need more information about a transfer on the statement or receipt. We must delinquent on that amount.
hear from you no later than 60 days after we sent you the FIRST statement on · The charge in question may remain on your statement, and we may
which the error or problem appeared. continue to charge you interest on that amount. But, if we determine that
1. . Tell us your name and account number (if any). we made a mistake, you will not have to pay the amount in question or any
interest or other fees related to that amount.
2. Describe the error or the transfer you are unsure about, and explain as
· While you do not have to pay the amount in question, you are responsible
clearly as you can why you believe there is an error or why you need more
information. for the remainder of your balance.
3. Tell us the dollar amount of the suspected error. · We can apply any unpaid amount against your credit limit.
If you tell us orally, we may require that you send us your complaint or question PAYMENT INFORMATION - Please mail or deliver your payment to the
in writing within 10 business days. financial institution at the address indicated on the reverse side hereof.
Payments received on weekends and holidays will be credited the next
We will determine whether an error occurred within 10 business days after we business day. Payments received after your closing date will appear on your
hear from you and will correct any error promptly. If we need more time, next statement. If the financial institution has been authorized to deduct the
however, we may take up to 45 days to investigate your complaint or question. minimum payment from your Account, it will be deducted and credited to your
If we decide to do this, we will credit your account within 10 business days for Account as of the date shown on the reverse side hereof. To avoid additional
the amount you think is in error, so that you will have the use of the money INTEREST CHARGES, pay your balance in full. Please call the financial
during the time it takes us to complete our investigation. If we ask you to put institution for the exact balance as the balance changes daily.
your complaint or question in writing and we do not receive it within 10 business
days, we may not credit your account. INTEREST CHARGE - The INTEREST CHARGE on your account is calculated
by applying the different PERIODIC RATES to the appropriate range of the
For errors involving new accounts, point-of-sale, or foreign-initiated transactions, outstanding daily balance of your account. The outstanding daily balance is
we may take up to 90 days to investigate your complaint or question. For new calculated by using the beginning balance of your account each day, adding any
accounts, we may take up to 20 business days to credit your account for the new advances or debits, and subtracting any payments or credits. The
amount you think is in error. INTEREST CHARGE may be determined as follows:
We will tell you the results within 3 business days after completing our 1. . Using the rate ranges, separate the outstanding daily balance into
investigation. If we decide that there was no error, we will send you a written appropriate range amounts.
explanation. You may ask for copies of the documents that we used in our 2. Multiply each outstanding daily balance by the applicable periodic rate.
investigation. 3.
Multiply each of these results by the number of days the applicable rate
The information below is applicable to those Accounts which may be was in effect.
subject to an Interest Charge. 4. Add the results of step #3 together.
What To Do If You Think You Find A Mistake On Your Statement USE OF THE AVERAGE DAILY BALANCE - If the daily balances are not
shown on your statement, the average daily balance may be used. The
If you think there is an error on your statement, write to us (on a separate sheet) average daily balance is or can be multiplied by the number of days in the
at our address shown on the front page of this statement as soon as possible. In billing cycle and the periodic rate applied to the product to determine the
your letter, give us the following information: amount of the interest charge. To calculate the average daily balance, all of
the daily balances for the billing cycle are added up, and the total is divided by
Account information: Your name and account number.
the number of days in the billing cycle. The INTEREST CHARGE is or may be
Dollar amount: The dollar amount of the suspected error. determined as follows:
Description of Problem: If you think there is an error on your bill, describe
what you believe is wrong and why you believe it is a mistake. 1. Multiplying each of the average balances by the number of days in the
billing cycle (or if the daily rate varied during the cycle, by multiplying by
You must contact us within 60 days after the error appeared on your statement. the number of days the applicable rate was in effect).
You must notify us of any potential errors in writing [or electronically]. You may 2. . Multiplying each of the results by the applicable periodic rate, and adding
call us, but if you do we are not required to investigate any potential errors, and these products together.
you
<<<
What you’re looking at in that output isn’t raw OCR text, it’s a structured representation of the document that an LLM can parse the way a human would read the original. Spatial relationships are intact: account number near account holder name, transaction amounts adjacent to their descriptions.
Feed that to an LLM, and you get accurate, consistent extraction. Feed it flattened OCR text and you get variance, results that look right sometimes, and fail silently the rest of the time.
Legacy OCR destroys layout. LLMWhisperer keeps it intact. That’s the difference between an extraction pipeline that works in production and one that works only on the documents you tested it with.
Unstract – AI Document Processing Tool That Turns Raw Text into Structured Data
LLMWhisperer gets the text off the page with its structure intact. Unstract takes it from there.
Unstract is an open-source intelligent document processing platform that handles everything involved in turning raw extracted text into structured, usable data – schema management, accuracy evaluation, workflow automation, and production deployment.
Four components make up the core of the platform:
Agentic Prompt Studio is where extraction projects are built. Agents handle schema creation, prompt generation, and accuracy validation automatically, removing the manual iteration loop that made this work slow.
Workflow Builder connects extraction pipelines to the rest of your systems, defining where documents come in, what processing steps they pass through, and where output goes.
ETL pipelines handle data movement at scale, ingesting documents from source systems and loading structured outputs into databases, data warehouses, or APIs.
APIs are the production interface: every Prompt Studio project can be deployed as an endpoint. Send a document, get structured JSON back.
The key question all of this exists to answer is: how do you go from raw extracted text to clean JSON output without manually writing prompts and schemas? Let’s walk through exactly how Unstract does it.
Agentic Prompt Studio Walkthrough
The Old Way
The original approach to building an extraction pipeline required you to own every step of the configuration manually.
Start by uploading a sample document, study its layout, and define a schema – every field you wanted to extract, named and typed by hand. Then write a prompt for each field, calibrated to find that specific value in that specific document’s layout. Run an extraction, compare the output against what you expected, identify what was wrong, adjust the prompt, and run it again. Repeat until the results looked acceptable, then move on to the next document.
Validation was manual too. There was no automated accuracy scoring, no mismatch matrix, no field-level comparison against ground truth. You eyeballed the output, spot-checked values, and made judgment calls about whether the extraction was good enough to ship. If you later discovered the pipeline was failing on a class of documents it hadn’t been tested against, you found out the hard way, through errors downstream, not through the tool alerting you.
The result was a configuration process that scaled badly. One document type with a stable, predictable layout was manageable. Three document types from different vendors with different layouts meant three full cycles of manual schema definition, prompt writing, and validation. Ten meant ten. Every new document source added to the maintenance burden, and there was no systematic way to know whether changes you made to fix one case were quietly breaking another.
The bottleneck wasn’t capability – the LLMs could extract accurately when given the right prompts. The bottleneck was everything around the LLM: the human time required to define what to extract, write how to extract it, and verify that extraction was actually working across the full range of documents the pipeline would encounter in production.
The New Way: Agentic AI Document Processing
The Agentic Prompt Studio replaces that manual loop with an AI agent-driven pipeline. You bring the documents. The agents handle the rest: analyzing structure, inferring schema, generating extraction prompts, running extractions, and scoring accuracy against verified outputs – automatically, in sequence, without manual input at each step.
The result is a production-ready extraction configuration that would have taken hours of manual iteration, produced in minutes.
For this walkthrough, we’re using three bank statements from different banks with different layouts, deliberately chosen to test how the agents handle variability.
Watch Free Demo: How to build modern AI-powered document processing workflows with Unstract’s agentic prompt studio
Step 1 – Upload Documents and Extract Raw Text
Navigate to Agentic Prompt Studio in the Unstract sidebar, you’ll find it listed below the original Prompt Studio.
Create a new project and upload your documents:
Make sure that in the project settings, all the default connectors are properly configured:
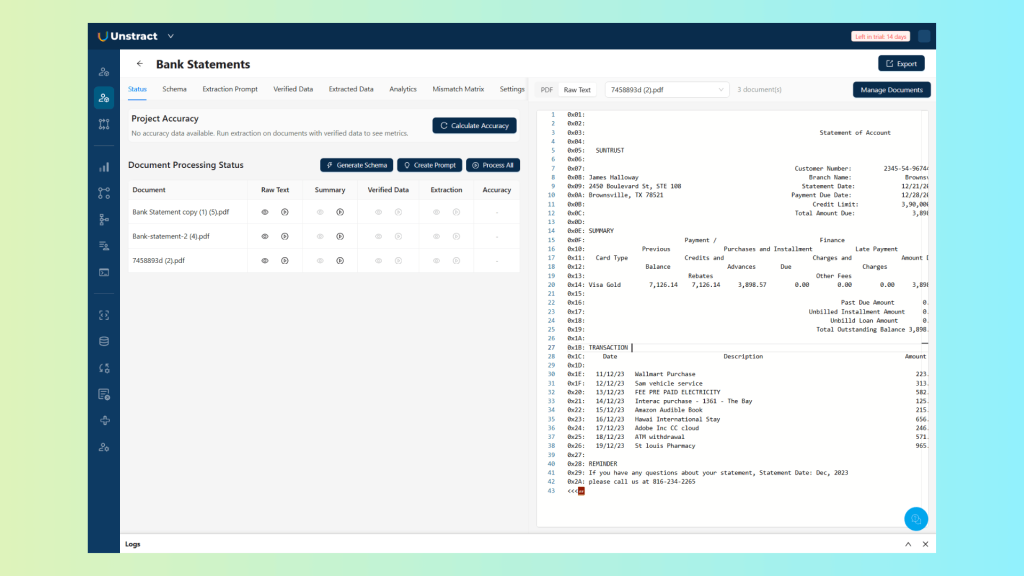
Once uploaded, Unstract passes each document through LLMWhisperer to extract the raw text with layout preserved, by clicking on the ‘play’ button in the ‘Raw Text’ column.
You can inspect this output directly in the interface, the transaction tables, header blocks, and summary sections are all intact and readable, structured the way the original document was structured:
Step 2 – Summarize and Generate Schema
With the raw text extracted, the next step for the agent is the first analytical pass: summarizing the document class and inferring a schema from what it finds.
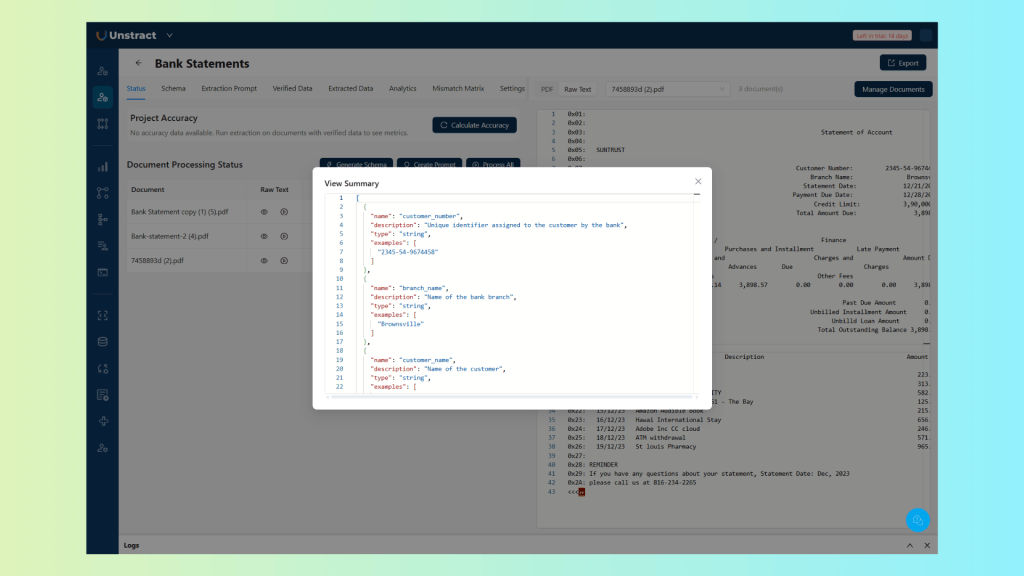
Click on the ‘play’ button in the ‘Summaries’ column and then the preview button once the summaries are generated:
This is where the agentic approach earns its name. Let’s move on to generate the schemas.
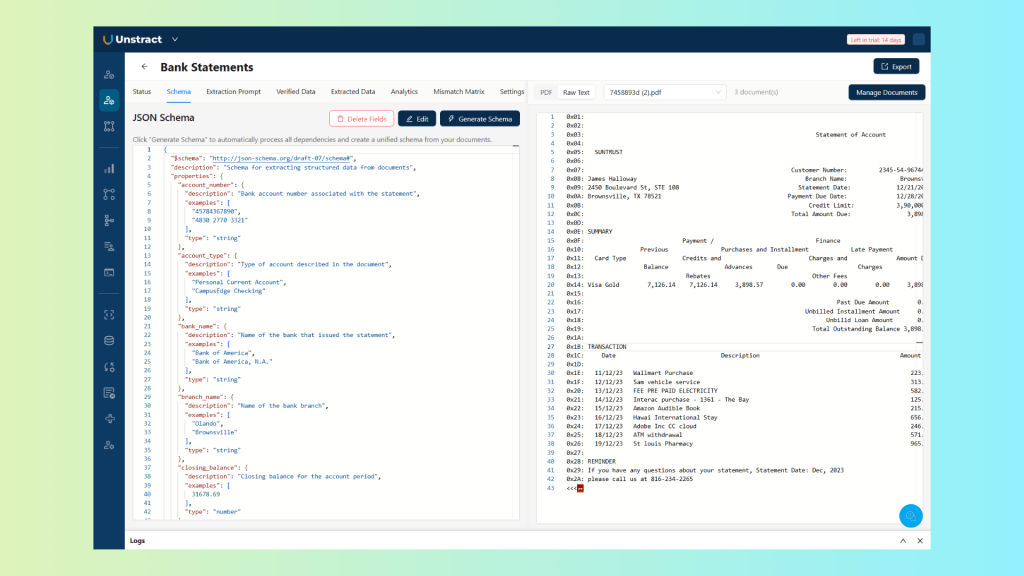
Rather than you defining which fields exist, the agent reads across all three documents, identifies the fields that appear consistently, account number, account holder name, transaction date, description, debit amount, credit amount, closing balance, and builds a schema that reflects the actual structure of the document class. Fields that appear in only some documents are flagged rather than silently omitted.
Click on the ‘Generate Schema’ button to automatically generate the schema from the documents. Once it is complete, you can move over to the ‘Schema’ tab to examine the generated schema:
The schema is editable. If the agent missed a field or named something differently than your downstream system expects, you can adjust it here before moving on. But for most standard document types, the generated schema requires little or no modification.
Step 3 – Generate Prompts
With the schema confirmed, next step for the agent is the prompt generation. For each field in the schema, it writes an extraction prompt calibrated to find that field reliably across the range of layouts it observed in your document set.
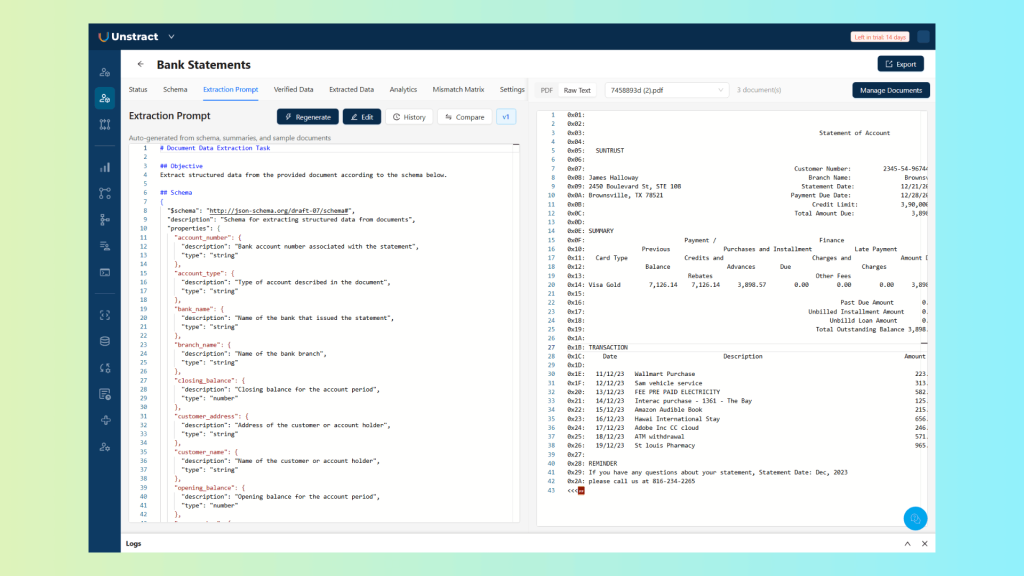
Click on the ‘Create Prompt’ button in the ‘Status’ tab to generate the extraction prompt. Once it is created, you can check it on the ‘Extraction Prompt’ tab:
This step replaces what was previously the most time-consuming part of building an extraction project. Writing prompts that work well on one document is straightforward.
Writing prompts that work across multiple vendors, formats, and edge cases – and that continue working when new variants arrive – requires the kind of systematic testing that’s difficult to do manually at scale.
The agent handles this by generating prompts informed by everything it observed across all three uploaded documents, not just one.
Step 4 – Run Extraction
With schema and prompts in place, run the extraction across all three documents. Unstract processes each one using the generated prompts and returns field-level results for every document in the project.
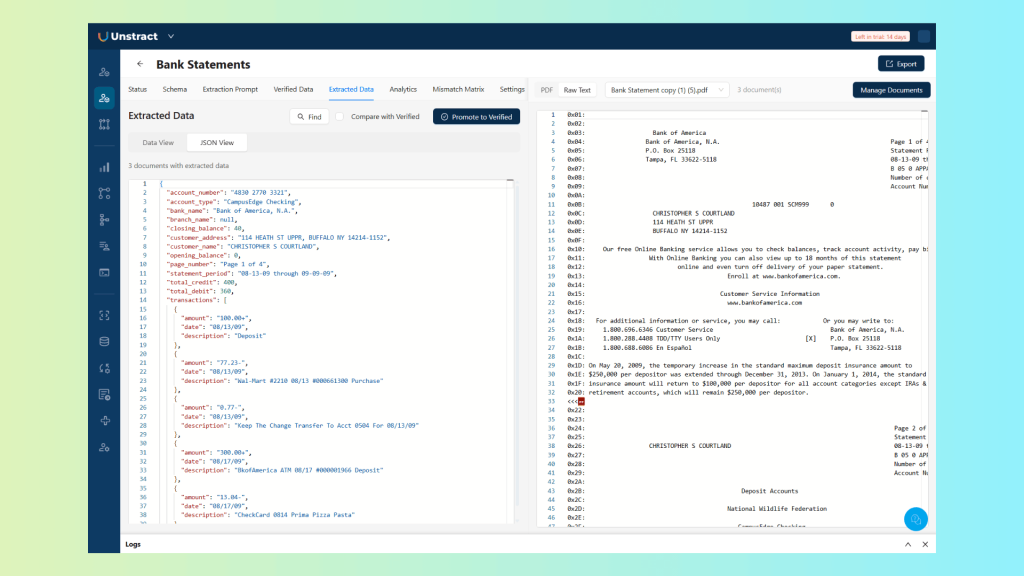
Click on the ‘Process All’ button in the ‘Status’ tab to process and extract data from all the documents. Once completed you can check the extracted data in the ‘Extracted Data’ tab:
The extraction view shows each document alongside its extracted values, every field, every document, in a single consolidated view. At this stage you can already see the pipeline working: structured JSON output from three different bank statement layouts, using prompts and a schema that were generated without any manual configuration.
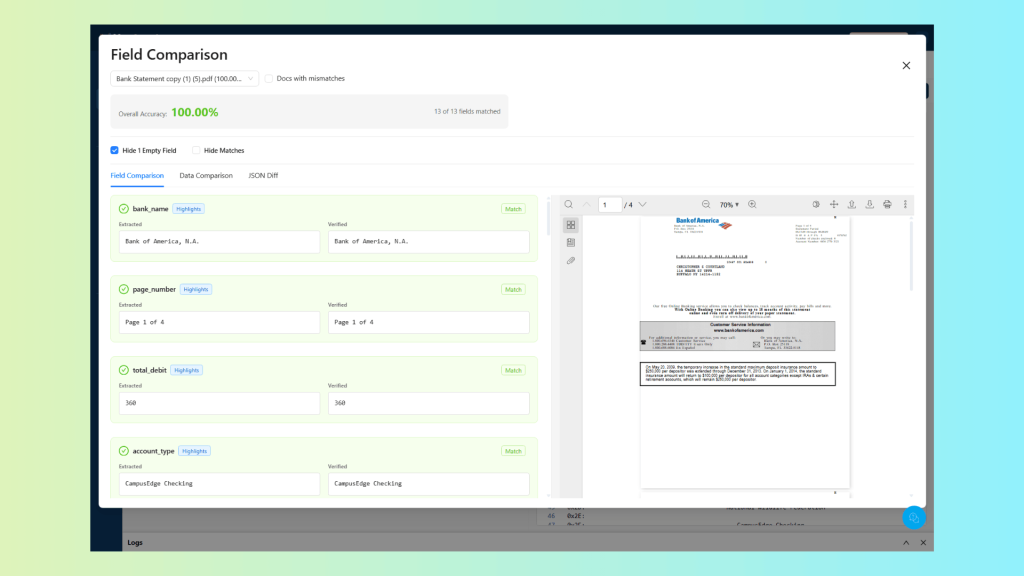
Step 5 – Verified vs. Extracted Comparison and Accuracy Score
Extraction results alone don’t tell you how accurate the pipeline is. To measure accuracy, Unstract compares extracted values against verified ground truth, the correct values for each field, confirmed by a human reviewer.
To verify the data, click on the ‘play’ button on the ‘Verified Data’ column in the ‘Status’ tab:
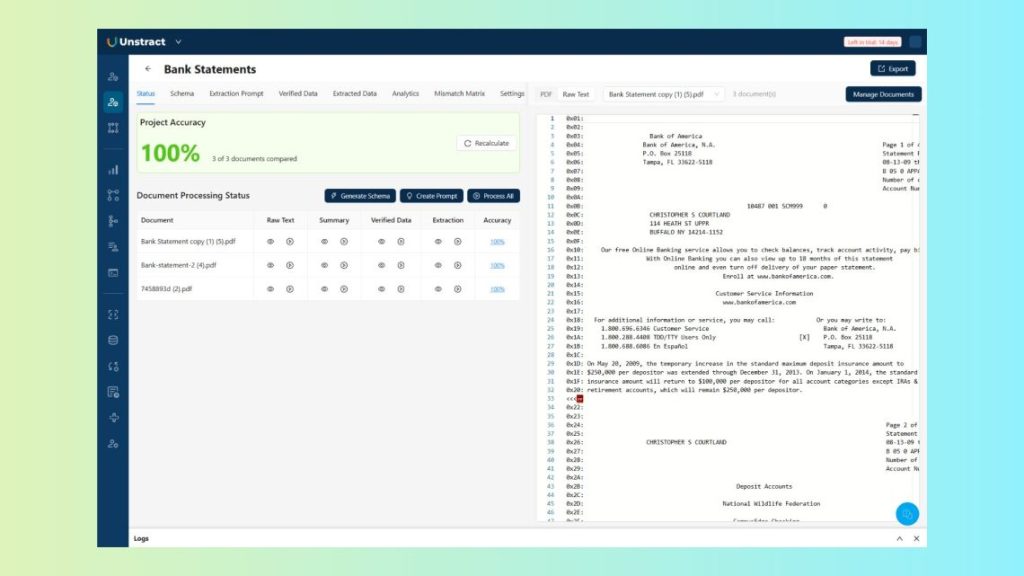
Unstract runs the comparison automatically, producing a field-level accuracy score for the entire project, which you can check by click on the percentage link in the ‘Accuracy’ column:
You can see immediately which fields are extracting reliably, which are inconsistent, and which are failing outright.
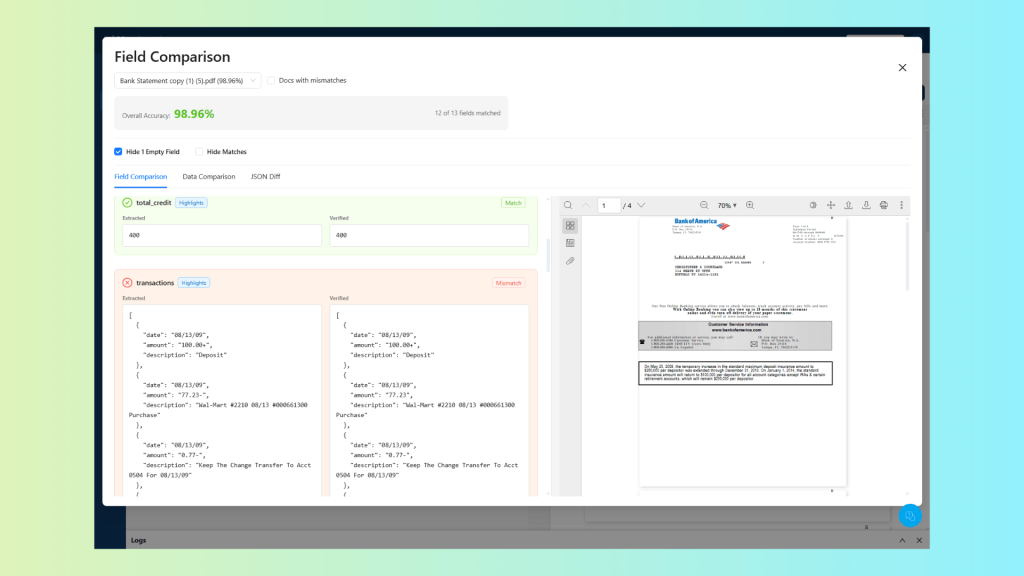
For instance, if there is a field mismatch:
The accuracy score is a single number you can track over time and report to stakeholders, not a subjective assessment, but a measured outcome.
Step 6 – Mismatch Matrix
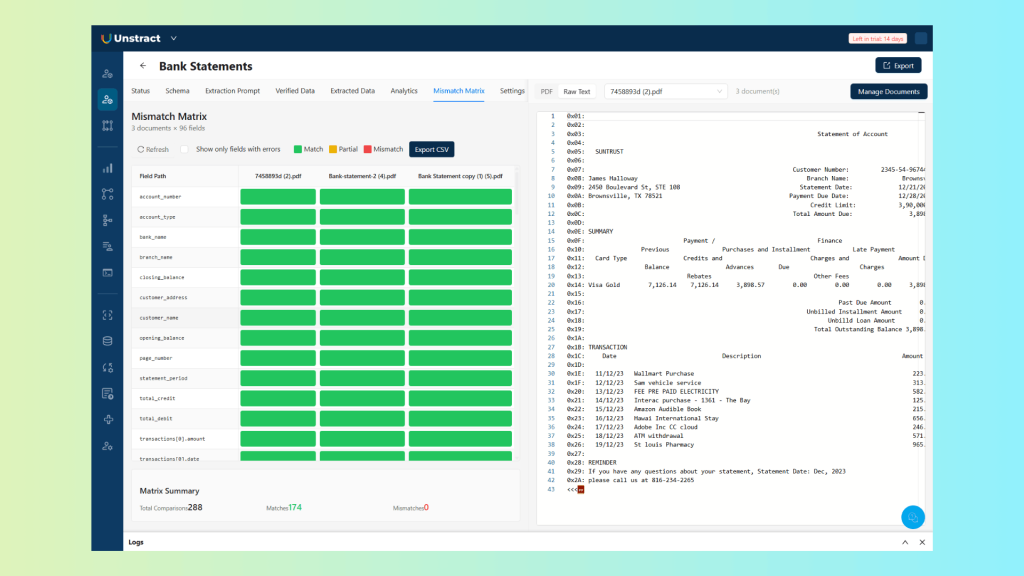
Where the accuracy score tells you how well the pipeline is performing overall, the mismatch matrix tells you exactly where it’s failing.
You can check it on the ‘Mismatch Matrix’ tab:
Each mismatch is logged with the document it occurred in, the field that was wrong, the extracted value, and the verified value, giving you precise, actionable information rather than a general sense that something isn’t working.
Example of a mismatch:
This is the feedback loop that drives improvement. Identify the pattern behind a cluster of mismatches, a particular date format, an edge case in how one bank formats transaction descriptions, adjust the relevant prompt, re-run extraction, and measure the delta. The cycle is fast because the problem is always precisely located.
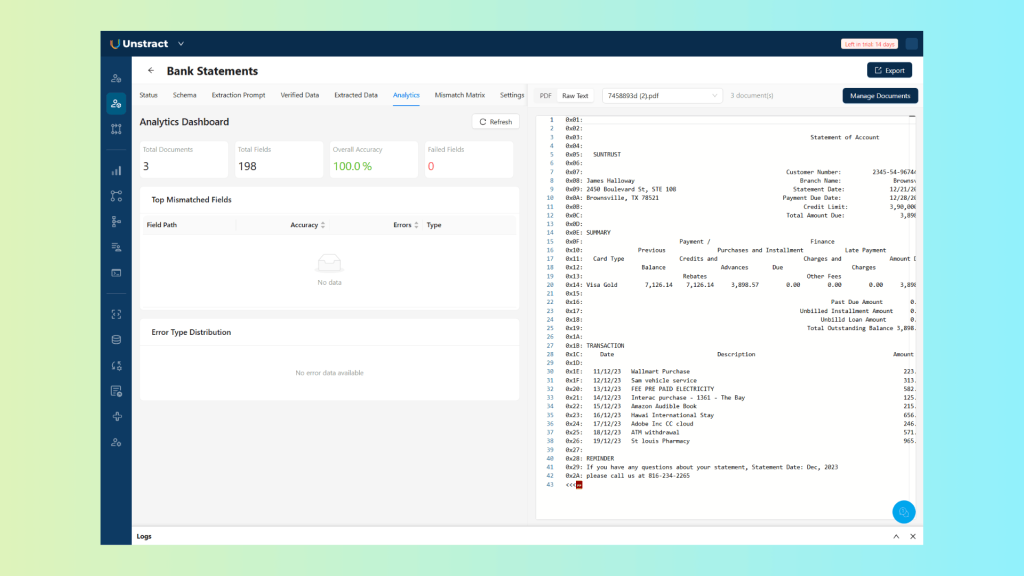
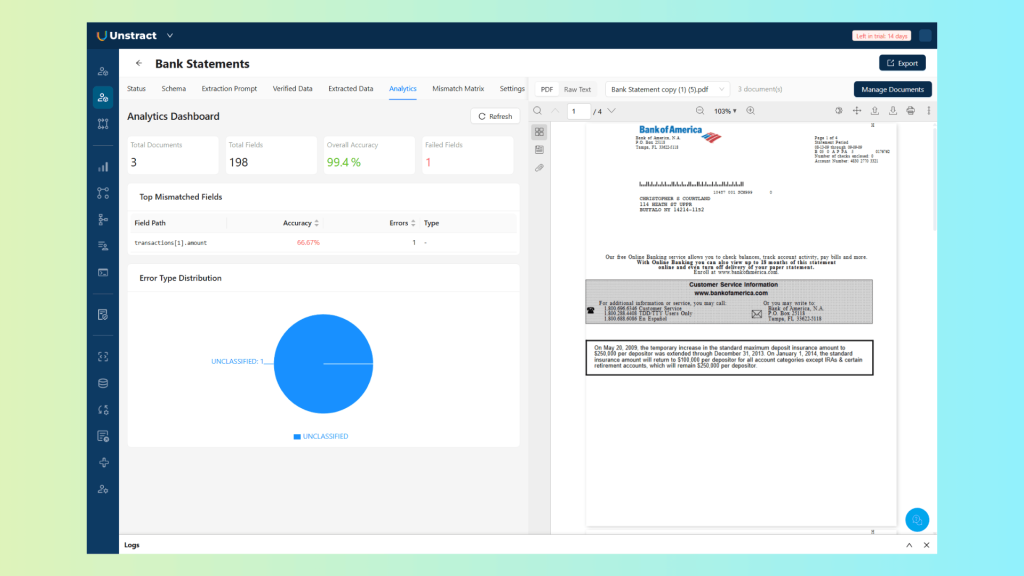
Step 7 – Analytics View
The analytics view surfaces aggregate patterns across the project: accuracy by field, accuracy by document, extraction performance over time as prompts are refined.
Access it on the ‘Analytics’ tab:
In case there is some mismatch, more information is provided:
This is the operational dashboard for anyone responsible for maintaining extraction quality, it makes the state of the pipeline visible without requiring a manual audit of individual results.
Export as a Tool
Once the extraction project is performing at the accuracy level you need, it is time to export it as a Tool.
This packages the schema, prompts, and configuration into a deployable unit that can be connected to a workflow or exposed directly as an API endpoint.
The export step is what moves the project from a configuration environment into production.
Everything built and validated in Agentic Prompt Studio travels with it, the schema, the prompts, the accuracy baseline. You’re not rebuilding anything for deployment. You’re shipping exactly what you tested.
To export the tool, click on the ‘Export’ button on the top right:
In the next section, we’ll take that Tool and deploy it as a live API endpoint, the final step from document in to structured JSON out.
Deploy as an API
The extraction project is built, validated, and exported as a Tool. Now it goes to production.
Set Up the Workflow
In Unstract’s Workflow Builder, create a new workflow and connect the Tool you just exported as the processing step.
The workflow defines the full pipeline: where documents come in, which Tool processes them, and where the structured output goes.
Configure the workflow with your exported Tool as the active processing step:
For API deployment, the input source is the API endpoint itself, documents arrive via POST request and results are returned in the response.
Then deploy the workflow:
Unstract handles the infrastructure: the endpoint is live, authenticated, and ready to receive documents.
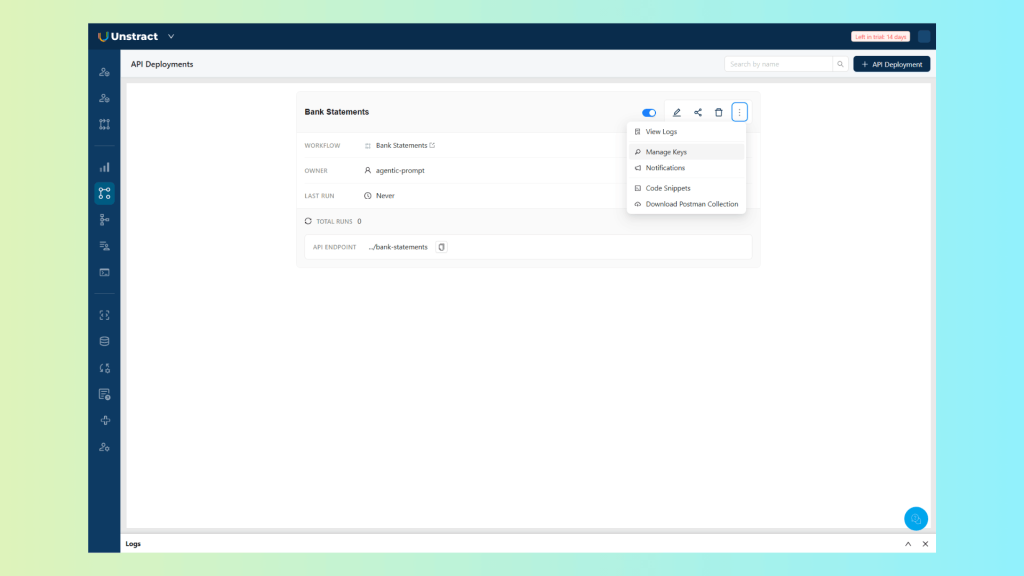
Deployed Endpoint
With the workflow active, Unstract generates an API endpoint and authentication credentials.
You can manage the API endpoint by clicking the three dots icon:
You can for instance, download the Postman collection to test the API endpoint, as we will see next.
Test the AI document processing API with Postman
Open Postman and import the downloaded collection.
Add the API key to the authorization header, attach a bank statement in the request body, and send.
The response comes back with the extracted data as a structured JSON object.
Every field defined in the schema is present: account number, account holder name, transaction rows with dates, descriptions, debit and credit amounts, closing balance.
Clean, structured, ready to be consumed by any downstream system, a database, an ERP, a data warehouse, a custom application.
A document that arrived as a PDF, a format no database can query, no system can parse, no pipeline can act on, comes out the other side as structured data in under a second.
No template was built for this specific bank. No rules were written for its layout. No prompt was manually crafted for its fields. The pipeline generalized from the three training documents to a fourth it had never seen, and extracted correctly.
This is what AI document processing looks like at the API layer: a single endpoint that accepts any document in the class it was trained on and returns structured JSON, every time, at whatever volume you need to throw at it.
The workflow runs 24/7. The endpoint scales horizontally. New documents process the moment they arrive. And if accuracy drifts as new document variants appear, you go back to Agentic Prompt Studio, add examples, regenerate prompts, re-export the Tool, and redeploy – the entire iteration cycle in minutes, not days.
Unstract vs. The Alternatives
The case for AI-based document processing is clear in theory. Here is how it stacks up against every alternative in practice:
Manual Processing
Template-Based Tools (ABBYY, Rossum)
Cloud APIs (AWS Textract, Azure Form Recognizer)
Unstract + LLMWhisperer
Setup time
None upfront, but ongoing data entry labor is the cost.
Days to weeks per document type. Each new format requires a custom template built and tested manually.
Hours to days. Requires field mapping and configuration per document type. Retraining needed for new layouts.
Minutes to hours. Agentic Prompt Studio generates schema and prompts automatically from sample documents.
Accuracy
Dependent on individual attention and fatigue. Typically 96–99% under normal conditions, lower under pressure.
High on documents that match the template exactly. Degrades immediately when layout shifts or new vendors are added.
Good on standard document types. Struggles with complex layouts, handwriting, and documents outside the training distribution.
Consistently high across document variants. Accuracy is measured, tracked, and improves iteratively through the mismatch feedback loop.
Cost
High and scales linearly with volume. Labor cost per document never decreases.
Low licensing cost upfront, but high ongoing operations cost: template maintenance, exception handling, and re-engineering every time a format changes.
Pay-per-page pricing that compounds at scale. Vendor lock-in limits negotiating leverage over time.
Higher capability investment, lower total cost of ownership. Reduced manual review, fewer downstream errors, and no template maintenance treadmill.
Scalability
Does not scale. Volume increases require proportional headcount increases.
Scales poorly with variety. Adding new document types multiplies template maintenance burden linearly.
Scales with volume but not variety. New document types require reconfiguration and retraining.
Scales with both volume and variety. New document types are onboarded through the same agent-driven process without compounding overhead.
Maintenance overhead
Continuous human attention required for every document processed.
Continuous. Every vendor layout change or new document source requires manual intervention.
Moderate. Model updates from the provider can shift accuracy unexpectedly. Custom configurations require ongoing management.
Minimal. Prompt updates are targeted, impact is immediately measurable through accuracy scoring, and redeployment is fast.
Data control
Full control. Data stays internal.
Depends on deployment model. Cloud-hosted options introduce data residency concerns.
Data processed by third-party cloud infrastructure. Limited control over retention and usage policies.
Full control with open-source and on-premises options. No data sent to external vendors unless explicitly configured.
The pattern across every dimension is the same: every alternative to Unstract’s Agentic-based document processing front-loads simplicity and back-loads cost.
Manual processing requires no setup but scales only with headcount. Template-based tools are fast to start with a single stable document type but become progressively more expensive to maintain as the variety grows. Cloud APIs reduce configuration effort but introduce per-page costs that compound at scale, vendor dependency, and limited control over how your data is handled.
Unstract inverts that curve. The setup is faster than it looks, thanks to agent-driven configuration, the operational burden decreases over time rather than compounding, and the open-source and on-premises options mean you’re never trading control for capability.
For organizations processing documents from a single source in a fixed format, the differences between approaches are manageable. For anyone dealing with multiple vendors, multiple document types, or any meaningful degree of layout variability – which is to say, most organizations running document processing at scale – the gap is significant and widens with time.
How AI Document Processing Works
AI document processing is the practice of using machine learning and large language models to automatically extract, structure, and route data from unstructured documents, without manual configuration for each document type.
The inputs can be almost anything: native PDFs, scanned images, photographs of physical documents, email attachments, multi-page mixed-format files. In production environments, documents rarely arrive clean. You get low-resolution scans, two-column bank statements, handwritten annotations on top of printed forms, and PDFs generated by a dozen different accounting systems. A robust AI document processing pipeline handles all of it.
The processing chain has four stages:
Ingestion is where the document enters the pipeline. The system accepts the file, identifies its type, and prepares it for parsing. This sounds trivial but matters, a scanned PDF and a native PDF look the same from the outside but require different handling internally.
Layout understanding is where most legacy systems fall apart, and where modern AI earns its value. A document isn’t just text, it’s text with spatial meaning. A number in a table cell means something different from the same number in a footer. Layout understanding maps the document’s structure: columns, rows, headers, key-value pairs, sections. Without this step, extracted text is noise.
Extraction is where the actual data pull happens. The system reads the structured layout and identifies the fields you care about, invoice number, total amount, account holder, transaction date, based on context and semantics, not fixed coordinates.
Structured output is the end result: clean JSON, CSV, or database-ready records that downstream systems can consume directly.
On the question of OCR versus LLM-based extraction: they’re not competing approaches, they’re complementary layers. OCR converts pixels to text, it’s the prerequisite step for any scanned or image-based document. LLMs then operate on that text to understand meaning, infer schema, and extract specific fields. The key is that the OCR output needs to preserve layout for the LLM to reason correctly. If the OCR layer flattens a table into a stream of disconnected words, the LLM has nothing useful to work with. That’s why the parsing layer is as important as the extraction layer.
Beyond basic extraction, production-grade AI document processing also includes schema inference (the system determines what fields exist in a document class without you defining them manually), confidence scoring (each extracted value gets a reliability score so low-confidence results can be flagged), and human-in-the-loop review (exceptions route to a human reviewer rather than silently propagating errors downstream).
Why Older Approaches Break Down
The traditional approach to document processing is template-based: you define exactly where on the page each field lives, and the system reads that coordinate. It works, until it doesn’t.
The fundamental problem is that templates are brittle by design. They encode assumptions about document structure that hold only as long as nothing changes. The moment a supplier updates their invoice layout, moves the PO number two columns to the right, or switches from one accounting platform to another, your template breaks. Extractions fail silently or return garbage, and someone has to go fix the template before processing can resume.
In practice, this creates a permanent maintenance treadmill. Large enterprises processing documents from hundreds of vendors end up maintaining hundreds of templates. Every new vendor relationship requires a new template. Every layout change requires a template update. The engineering and operations cost compounds over time, and the system never gets easier to run, it only gets more fragile.
AI document processing breaks this pattern at the root. Instead of encoding where a field is, the model understands what a field means. It can read an invoice it has never seen before, infer that a number preceded by “Total Due” is the amount payable, and extract it correctly, even if the layout is completely different from any previous document. New vendors don’t require new templates. Layout changes don’t require maintenance windows.
The practical advantages stack up quickly: less manual configuration upfront, lower ongoing operations overhead, faster on-boarding of new document sources, and an accuracy curve that improves over time as the system processes more documents and feedback loops are applied. With legacy systems, accuracy degrades as document variety increases. With AI-based extraction, the relationship inverts, more variety produces more signals, and the system gets better.
The paradigm shift is this: legacy document processing is a maintenance problem disguised as a technology solution. AI document processing is a feedback loop. You measure accuracy, identify mismatches, improve prompts or models, and re-evaluate – continuously, systematically, without rebuilding from scratch every time the world changes.
With Agentic Prompt Studio, you can turn documents into reliable extraction pipelines in minutes. Simply upload a sample file—Unstract will handle schema generation, create prompts you can fine-tune, and validate outputs for trusted results.
Watch this webinar to learn how agentic workflows improve accuracy while reducing manual review:
Business Value of AI Document Processing and Use Cases
Operational Impact
The most immediate impact of AI document processing is throughput. A manual data entry operation processing a few hundred documents per day can scale to tens of thousands with the same headcount, or the same volume with a fraction of the staff. Turnaround time compresses from days to minutes. Documents that arrived at the end of the business day and sat in a queue until morning now get processed the moment they land. The pipeline runs 24/7 without shift changes, sick days, or bottlenecks caused by volume spikes.
The labour story isn’t about elimination, it’s about reallocation. The people who were manually keying invoice data into ERP systems are expensive, skilled employees doing work far below their capability. Automating extraction frees them for exception handling, vendor relationship management, analysis, and judgment calls that actually require a human. Organizations that have made this shift consistently report that the work is more engaging and the output is higher quality.
Error rates are where the downstream cost argument becomes concrete. Manual data entry operates at roughly 1–4% error rates under normal conditions, higher under time pressure or with complex documents. Those errors don’t just affect one record. They propagate: a wrong invoice total flows into accounts payable, distorts cash flow reporting, triggers incorrect payments, and creates reconciliation work weeks later. The cost of a single upstream error multiplies by the time it surfaces. AI document processing, with confidence scoring and exception routing, catches mismatches before they enter downstream systems.
For industries like insurance and financial services, the ultimate operational metric is straight-through processing rate – the percentage of documents that move from intake to completed workflow without any human intervention. Every percentage point gained in straight-through processing directly reduces cost per document and increases throughput capacity. AI document processing, with its confidence scoring and exception routing, is the primary lever for moving that number.
Accuracy, Compliance, and Data Quality
Unlike template-based systems where accuracy is static, the template either works or it doesn’t, AI-based extraction improves interactively. Every mismatch identified in review is a signal. Adjust the prompt, update the validation logic, re-run the evaluation set, measure the delta. Accuracy compounds over time rather than plateauing at whatever the template could achieve on day one.
This iteration loop also produces something legacy systems never could: a traceable record of how extraction quality changed over time, which documents caused problems, and what was done to fix them. That audit trail is increasingly valuable not just operationally, but for compliance. Regulators in financial services, healthcare, and government contracting want to know not just what data you have, but where it came from, how it was processed, and who reviewed it. A well-implemented AI document processing pipeline answers all of those questions by design.
For data quality more broadly, structured output from a consistent pipeline is far more reliable as an analytical foundation than data that passed through human hands at varying levels of attention. Consistent field names, consistent formats, consistent validation rules, the downstream reporting and analytics stack gets cleaner inputs, and the insights built on top of them are more trustworthy.
Competitive Advantage and Transformation
The operational and compliance gains are measurable quickly. The strategic impact takes longer to see but tends to be larger.
Most organizations are sitting on significant amounts of trapped data, information locked inside documents that no system can query, no analyst can aggregate, and no workflow can act on. Contracts that contain pricing commitments no one can search. Financial statements that inform decisions only after someone has manually keyed the numbers somewhere. Inspection reports that feed into compliance tracking only if someone remembered to file them correctly.
AI document processing unlocks that data systematically, turning a static document archive into a queryable, actionable information layer.
The speed advantage compounds across the customer experience. Loan applications that took days to process because someone had to manually review supporting documents now complete in minutes. Insurance claims that sat in a queue waiting for data entry now trigger automated workflows the moment they arrive. On-boarding processes that required back-and-forth document collection now resolve faster because extraction and validation happen in real time.
Customers notice the difference, and so do the competitors who haven’t made the switch yet.
For organizations with broader automation ambitions, document processing is typically the enabling layer. Robotic process automation, agentic workflows, and AI-driven decision systems all depend on structured data inputs. Most of the data those systems need lives in documents. Solving document processing at scale isn’t just an efficiency project, it’s the foundation that makes the rest of the automation road map executable.
Common Use Cases by Document Type
Finance is the highest-volume application for most organizations. Invoices, bank statements, and credit applications are processed in enormous quantities, follow recognizable patterns, and have clear structured output requirements. The ROI case is straightforward: reduce processing cost per document, accelerate payment cycles, improve cash flow visibility.
Legal documents, like contracts, NDAs, amendments, and agreements, present a different challenge. Volume is lower but stakes are higher, and the extraction requirements are more nuanced: clause identification, obligation extraction, date and party recognition, risk flagging. AI document processing makes contract review faster and more consistent, reducing the time lawyers spend on routine document analysis.
Healthcare involves records, claims, referral forms, and prior authorization documents, often scanned, often handwritten, always sensitive. Extraction here feeds billing systems, clinical workflows, and compliance reporting. Speed matters: a faster claims processing pipeline means faster reimbursement and less administrative burden on providers.
HR teams process resumes, onboarding documents, policy acknowledgments, and benefits forms at scale, especially during hiring surges. Automated extraction feeds HRIS systems and reduces the manual work of building candidate profiles or tracking document completion.
Government agencies handle permits, applications, citizen services forms, and compliance filings, often in high volume with strict processing timelines. AI document processing reduces backlogs, accelerates approvals, and frees staff from data entry to focus on case assessment and public-facing work.
Industry Verticals
Banking and financial services sit at the center of document processing demand. Loan origination, KYC onboarding, trade finance, and regulatory reporting all depend on extracting structured data from high volumes of complex documents quickly and accurately.
Insurance companies process claims, policies, inspection reports, and medical records continuously. Improving straight-through processing rates is the central operational goal, and AI document processing is the primary lever for getting there.
Healthcare providers and payers deal with a document burden unlike almost any other industry: clinical notes, EOBs, prior authorizations, lab results, and referrals flowing between dozens of incompatible systems. Automation here directly affects patient outcomes by reducing administrative delays.
Legal firms and corporate legal departments are adopting AI document processing to handle due diligence, contract lifecycle management, and litigation support, areas where the document volumes are large and the cost of missed information is high.
Supply chain and logistics operations process bills of lading, customs declarations, delivery confirmations, and supplier invoices across global networks and multiple languages. Automation reduces clearance delays and improves inventory visibility.
Real estate transactions generate title documents, appraisals, inspection reports, mortgage applications, and closing disclosures, all of which need to be reviewed, verified, and filed. AI document processing compresses transaction timelines and reduces closing errors.
Accounting and taxation firms process financial statements, receipts, payroll records, and tax documents at scale, with strict accuracy requirements and hard deadlines. Automated extraction feeds directly into compliance workflows and reduces the manual burden during peak filing periods.
Strategic Guidance for AI Document Processing Adoption
Knowing that AI document processing works is one thing. Knowing how to adopt it successfully inside your organization is another.
The pilot you choose determines whether AI document processing gets adopted broadly or dies in a proof-of-concept. Pick the wrong use case and you’ll spend months on a problem that doesn’t move the needle. Pick the right one and you’ll have a clear win to build on.
Three criteria matter most:
Volume comes first: you need enough document throughput to measure accuracy meaningfully and to make the efficiency gains visible. A use case processing twenty documents a month won’t generate enough signals to evaluate extraction quality or justify the integration work. A use case processing thousands will show results quickly and build internal confidence.
Variability comes second: start with documents that have recognizable structure but enough variation to stress-test a template-based approach. Invoices from multiple vendors are ideal, they all contain the same fields but no two look alike. Highly irregular documents like free-form correspondence are better left for later, once the system is proven.
Business impact comes third: choose a process where faster or more accurate extraction has a measurable downstream effect, payment cycle time, claims turnaround, onboarding speed. If no one can tell the difference when the process improves, it’s the wrong pilot.
Once you’ve chosen the use case, define success before you start:
Accuracy targets should be specific: not “high accuracy” but “95% field-level accuracy on the top ten extraction fields.”
Cycle time gives you an operational baseline to beat.
Cost per document, including human review time, establishes the economic case.
Exception rate, the percentage of documents that require human intervention, tells you how well the system handles real-world variability.
Set these numbers upfront, measure them consistently, and use them to make the case for expanding to the next use case.
Operating Model
One of the most common failure modes in AI document processing adoption isn’t technical, it’s organizational. The question of who owns the system after deployment is often left unanswered until something breaks.
Operations and engineering have different relationships with the system. Engineering builds and integrates it. Operations runs it daily, understands where it struggles, and feels the impact of extraction errors. The healthiest model gives operations ownership of the outcome, accuracy targets, exception rates, business metrics, while engineering owns the infrastructure, integrations, and model updates. Neither team can own it alone. Operations without engineering support can’t iterate. Engineering without operations input doesn’t know what to fix.
Review workflows need to be designed explicitly, not retrofitted. Every AI document processing pipeline produces exceptions, documents where confidence is low, fields are missing, or outputs don’t pass validation. Those exceptions need a defined path: who reviews them, in what timeframe, using what interface, and how corrections feed back into the system. If the exception workflow is clunky or slow, reviewers work around it, corrections don’t get captured, and the system doesn’t improve.
Change management is the part organizations consistently underestimate. The people whose jobs currently involve manual document handling need to understand what’s changing and why.
Framing matters: this is not a headcount reduction exercise, it’s a reallocation of effort toward higher-value work. Involve them early, use their domain knowledge to validate extraction outputs, and make them stakeholders in accuracy improvement. Adoption fails when the people closest to the documents feel like the system is being done to them rather than built with them.
AI Document Processing Tools: Build vs. Buy
The build vs. buy question in AI document processing is less binary than it used to be, but it still deserves honest analysis before you commit either way.
Building from scratch, assembling your own OCR layer, prompt engineering stack, schema management, and evaluation framework, gives you maximum control and no vendor dependency.
It also requires significant engineering investment upfront, ongoing maintenance as models evolve, and internal expertise that most organizations don’t have sitting idle. For companies with genuinely unique document processing requirements and strong ML engineering teams, building makes sense. For everyone else, the total cost of ownership calculation rarely favors it.
Buying a platform accelerates time to value but introduces integration and lock-in risks that need to be managed deliberately. On integration: your document processing pipeline doesn’t exist in isolation. Outputs need to flow into ERP systems, CRMs, data warehouses, or case management tools. Evaluate platforms on the quality of their integration story, native connectors, API flexibility, webhook support, not just extraction accuracy. A system that produces perfect JSON but can’t deliver it anywhere useful solves half the problem.
On vendor lock-in: the risk isn’t just that switching is expensive, it’s that proprietary data formats, closed model architectures, and opaque accuracy scoring make it hard to evaluate whether you’re getting better over time or to migrate if you need to. Protect yourself by maintaining your own evaluation sets, insisting on exportable outputs in standard formats, and choosing platforms with open APIs. Open-source options like Unstract give you the extraction capability without surrendering control of your data or your pipeline.
Total cost of ownership is rarely just the platform fee. Factor in integration development time, ongoing prompt and schema maintenance, human review labor, the cost of errors that slip through, and the engineering time required to handle model updates or API changes. A cheaper platform that requires more maintenance often costs more in practice than a more capable one that runs with minimal intervention. Run the numbers over a two-year horizon, not just the first quarter.
The Future of AI Document Processing
The capability curve in AI document processing is steep, and most organizations are still on the early part of it. The foundational technology, LLM-based extraction, schema inference, confidence scoring, is proven and in production. What’s coming next will expand what’s possible significantly, and the organizations building operational capability now will be positioned to absorb those advances without starting over.
Emerging Capabilities
Multi-modal models are changing what “reading a document” means. Current pipelines treat documents as text after OCR, the visual information is converted to characters, and the LLM reasons over those characters. Multi-modal models reason directly over the visual representation: they see the table as a table, the signature block as a signature block, the stamp as a stamp. This removes a layer of translation and with it a class of errors that stem from OCR misrepresenting visual structure. Table extraction in particular, long one of the hardest problems in document processing, improves substantially when the model can see the grid rather than reconstruct it from flattened text.
Cross-document reasoning is the next frontier for complex use cases. Today, most extraction pipelines process one document at a time. But many real-world workflows require understanding relationships across documents: matching a purchase order to an invoice to a delivery confirmation, reconciling a contract against an amendment against a statement of work, flagging discrepancies between a loan application and supporting financial statements. Models that can hold multiple documents in context simultaneously and reason across them will unlock automation in areas that currently require skilled human reviewers precisely because the information is distributed.
Real-time and streaming workflows are becoming viable as inference costs drop and latency improves. Batch processing, accumulate documents, run extraction overnight, deliver results in the morning, is giving way to event-driven pipelines where a document is processed the moment it arrives and the structured output is available in seconds. For time-sensitive workflows like claims triage, trade finance, or customer onboarding, that latency difference is operationally significant.
Market and Technology Dynamics
Hyperautomation, the practice of automating not just individual tasks but entire end-to-end workflows, is driving document processing up the priority stack for most large organizations. Documents are the connective tissue of business processes, and automating their extraction is often the prerequisite for automating everything downstream.
GenAI expands what automation can cover: not just extraction but summarization, classification, anomaly detection, draft generation, and decision support. The scope of what a document processing pipeline can produce is widening from structured data to actionable intelligence.
The open-source versus commercial dynamic is also shifting. A year ago, serious document processing automation required commercial platforms with significant licensing costs. Today, capable open-source tooling, including Unstract, makes production-grade extraction accessible without that overhead.
This is compressing the market toward platforms that win on integration quality, evaluation tooling, and operational support rather than proprietary model access. For buyers, it means more leverage and less lock-in risk than the market offered even recently.
Preparing your Organization for AI-powered Document Processing
The organizations that will benefit most from the next wave of AI document processing capabilities are the ones building foundational capability now, before they need it.
Process comes first. Document the workflows that depend on manual extraction today: where documents enter, what fields matter, where errors cause problems, how exceptions are handled. This mapping exercise serves two purposes: it identifies the best automation candidates, and it creates the process baseline you’ll need to measure improvement against.
Data and evaluation are the unglamorous work that determines whether your AI document processing investment compounds or stagnates. Build ground truth sets early, collections of documents with verified, human-validated extraction outputs. These sets are what you use to evaluate new models, test prompt changes, catch regressions, and demonstrate accuracy to stakeholders. Organizations that skip this step end up unable to tell whether things are getting better or worse.
Governance needs to be established before scale, not after. Define data handling policies for the documents flowing through your pipeline, retention, access control, PII handling, audit logging. Establish who is accountable for extraction accuracy and what the escalation path is when something goes wrong. These aren’t bureaucratic exercises; they’re the controls that make it safe to process sensitive documents at volume.
Tool selection should prioritize extensibility and integration-friendliness over feature count. The specific capabilities that matter most today will shift as models improve. What won’t change is the need to connect your document processing pipeline to the rest of your systems, to swap components as better options emerge, and to maintain visibility into how the system is performing. Choose platforms with open APIs, standard output formats, and active development communities. Lock-in is the risk that compounds quietly and expensively, extensibility is how you stay ahead of it.
Conclusion: Next Steps in AI Document Processing for Enterprises
Document processing has been a solved problem for decades, solved badly, with templates that broke, rules that needed constant maintenance, and operations teams spending enormous effort on work that should have been automated. The shift to AI-driven extraction isn’t an incremental improvement on that model. It’s a replacement for it.
What the demo in this article proved is straightforward: take three bank statements, feed them into Unstract’s Agentic Prompt Studio, and walk away with a production-ready extraction pipeline, with generated schema, prompts written, accuracy scored, mismatches flagged, all without writing a single rule or defining a single field manually. Then deploy it as an API endpoint and process new documents in seconds. That’s not a prototype capability. That’s what production looks like now.
LLMWhisperer handles the layer that makes everything else possible: converting complex, layout-heavy documents into text that LLMs can actually reason over, preserving the spatial structure that gives extracted values their meaning. Unstract handles everything above that, schema inference, prompt generation, accuracy evaluation, workflow automation, and API deployment. Together they cover the full path from raw document to structured data, from first pilot to scaled production.
If you’re ready to see it work on your own documents, the fastest path is the demo. If you want to understand the architecture before committing, the documentation covers every component in detail. If you have a specific use case and want to evaluate fit, run a pilot, the scope is small, the feedback is immediate, and the business case either holds up or it doesn’t.
Unstract is available in three editions to match where your organization is: open-source for teams that want full control and self-hosted deployment, cloud for teams that want to move fast without infrastructure overhead, and on-premises enterprise for organizations with strict data residency or compliance requirements.
The future of document processing is here, and it’s more accessible than you think.
FAQs for Developers: Unstract’s AI Document Processing Architecture
1. How does Unstract’s architecture separate layout preservation from semantic extraction in AI document processing? Unstract uses a two-stage pipeline that cleanly separates concerns. The first stage is LLMWhisperer, a dedicated OCR and parsing engine that handles the challenge of layout preservation—converting complex documents like multi-column bank statements or scanned forms into text that retains spatial relationships.
The second stage is Unstract’s Agentic Prompt Studio, which performs AI document extraction by using LLMs to interpret that structured text and pull specific fields. This separation ensures that the LLM receives clean, context-rich input, which is critical for reliable production deployments.
2. What are the key components required to build an end-to-end AI document extraction workflow using Unstract? To build a complete AI document processing pipeline, you need five core components: (1) LLMWhisperer for layout-preserving text extraction from PDFs and images; (2) Unstract’s Agentic Prompt Studio for schema inference and prompt generation; (3) an LLM provider (such as OpenAI or open-source models) for semantic extraction; (4) an embedding engine and vector database for retrieval-augmented workflows; and (5) a destination system like Snowflake, a data warehouse, or an API endpoint to consume the structured JSON output.
3. How does the Agentic Prompt Studio automate the manual work typically required in AI document extraction projects? The Agentic Prompt Studio replaces the traditional manual loop of schema definition, prompt writing, and validation with AI agents. Developers simply upload sample documents—the agents then automatically analyze structure, infer a schema, generate extraction prompts, run extractions, and score accuracy against verified ground truth.
This transforms what used to take hours of manual configuration into a process that completes in minutes, enabling developers to rapidly deploy production-ready AI document processing pipelines without ongoing template maintenance.
4. What optimization techniques does Unstract use to reduce token costs when scaling AI document processing? Unstract incorporates several optimizations to make AI document extraction cost-effective at scale. SinglePass Extraction batches multiple field prompts into a single LLM call, reducing round-trip overhead.
Summarized Extraction creates compact document representations that preserve meaning while minimizing token count. Additionally, auto-compaction in LLMWhisperer removes low-value tokens like repetitive headers and footers before text reaches the LLM. These techniques can reduce token usage by up to 7x, which is significant when processing thousands of documents.
5. How does Unstract handle the layout preservation problem that breaks traditional OCR in AI document processing? Traditional OCR flattens complex layouts like multi-column bank statements into a single text stream, destroying the spatial relationships that give data its meaning. For AI document processing to work reliably, layout must be preserved.
LLMWhisperer solves this through layout-aware parsing: it analyzes spatial structure, keeps table rows intact, correctly handles multi-column sections, and separates headers and footers from transaction data. The output reads like the original document, not a scrambled approximation, giving the LLM the context it needs for accurate extraction.
6. As an open-source platform (AGPL-3.0), what control do developers have over the AI document processing stack? Unstract’s open-source foundation gives developers complete flexibility over their AI document extraction stack. You can choose and configure your own LLM (OpenAI, Anthropic, or local open-source models), vector database, embedding model, and text extraction service. This allows you to tailor the pipeline to your specific cost, latency, privacy, and data residency requirements.
For strict compliance needs, on-premises deployment is available, ensuring no data is sent to external vendors. This extensibility prevents vendor lock-in and allows teams to evolve their AI document processing infrastructure as new models and techniques emerge.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.