Unstract: A Better Reducto Alternative for Document Processing Automation
Table of Contents
Introduction
In the ever-evolving landscape of AI-powered document processing, businesses are increasingly turning to automation tools to extract structured data from PDFs, scanned documents, and handwritten forms. The goal is simple: to reduce manual effort while improving accuracy, efficiency, and data usability across workflows.
Among the new players in this space is Reducto AI, a Y Combinator–backed startup that has quickly gained visibility for its use of vision-language models (VLMs) to extract data from unstructured documents. While its approach emphasizes simplicity and quick onboarding, Reducto represents just one step in the broader evolution of intelligent document understanding.
On the other end of the spectrum is Unstract, an open-source, enterprise-ready platform built for complete end-to-end ETL (Extract, Transform, Load) workflows. Unlike black-box systems, Unstract offers full transparency and modularity, allowing users to choose their own OCR engines, LLMs, and data pipelines. It’s designed not just to extract data but to integrate, transform, and validate it at scale, making it ideal for teams that need flexibility, accuracy, and control.
This article takes a practical, hands-on look at both tools in action. We’ll start by walking through Reducto’s setup and testing a few sample documents, then explore how Unstract approaches the same challenges, comparing their performance, flexibility, and readiness for real-world enterprise use.
About Reducto
Reducto AI is an advanced, AI-powered document processing platform built to help businesses automatically extract structured data from PDFs, images, and scanned documents. It aims to remove the manual effort involved in data entry, form parsing, and text extraction by leveraging vision-language models (VLMs), deep learning systems trained to understand both the textual content and the visual structure of documents.
Reducto can interpret both the content and layout of documents—detecting tables, headers, signatures, and multi-column formats—allowing it to handle structured, semi-structured, and fully unstructured files. But ultimately, accuracy is what determines the value of any extraction system, and this post examines how reliably Reducto performs in real-world scenarios.
Platform Overview
Reducto offers two primary ways for users to interact with its capabilities:
No-Code Web Application: A browser-based interface designed for non-technical users.
Users can upload PDFs or images directly, review extracted data in real-time, and export results as JSON or CSV.
The interface provides automatic field detection and labelling, allowing quick validation of extracted information
It’s particularly useful for teams wanting to experiment or run smaller-scale extractions without any coding knowledge.
Developer-Focused API: Built for developers who want to integrate Reducto’s extraction engine into their own systems or products.
The REST API supports asynchronous document uploads and result retrieval.
Developers can embed Reducto in internal dashboards, CRM systems, or ETL pipelines.
The API documentation is well-organized, with example requests and prebuilt SDKs in Python and JavaScript for faster integration.
This dual-interface approach makes Reducto accessible to both technical and non-technical audiences.
Features
Reducto’s feature set focuses on simplicity, automation, and speed to deployment. Some of its standout functionalities include:
Automatic Schema Generation: Reducto automatically identifies fields and data types (e.g., “invoice number,” “total,” “date”) by analysing the uploaded document. This helps users get quick results without defining field templates manually.
Built-in OCR: The platform includes integrated Optical Character Recognition, allowing it to extract text even from scanned or low-quality images. Users don’t need to connect third-party OCR tools, which simplifies the workflow.
Batch Document Processing: Reducto supports multi-file uploads, enabling parallel document processing. This is useful for organizations processing large volumes of similar files, such as receipts or purchase orders.
Adaptive Vision-Language Models: The system uses large vision-language models that can understand the context and visual structure of a document simultaneously. This makes it capable of extracting meaningful data even from unstructured layouts.
Simple Pricing Model: Reducto follows a transparent pay-as-you-go model, typically based on document or page count, making it accessible for small teams and startups experimenting with AI-based document extraction.
Limitations and Design Philosophy
While Reducto offers impressive out-of-the-box automation, it’s built as a closed, managed platform, meaning users do not have visibility into or control over the following:
This “black-box” approach prioritizes ease of use and quick setup but limits the flexibility needed for custom integrations, data governance, or enterprise-grade ETL pipelines. Teams looking for fine-grained control over prompts, models, or intermediate steps may find the platform restrictive.
Trying Out Reducto
Before diving into feature comparisons, it’s important to experience Reducto firsthand. In this section, we’ll walk through the process of getting started with the platform, from registration to testing a few sample documents.
This hands-on approach helps illustrate how Reducto’s vision-language model–based extraction works in practice and what kind of results users can expect.
After verifying your email, you’ll gain access to the dashboard, where you can explore several available options and workflows:
In this article, we’ll focus specifically on the Parse and Extract features.
Parsing Documents
This functionality is designed to simulate how a human would interpret and extract information from a real-world form.
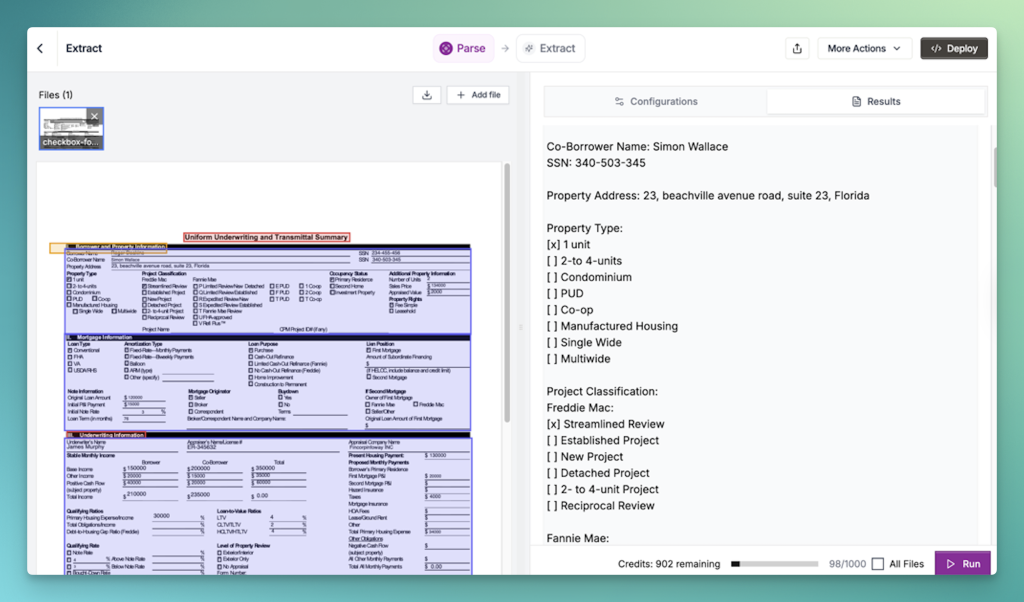
To evaluate the Parse feature, we’ll begin with a PDF of a commercial insurance application containing handwritten text, checkboxes, and various field types:
Uniform Underwriting and Transmittal Summary (Form 1008)
In the Reducto Studio dashboard, click on “Parse” and give your pipeline a name.
Next, upload a test document, in this case, the PDF of the Universal Underwriting and Transmittal Summary:
Clicking Run will process the document and return the following results:
Results of parsing:
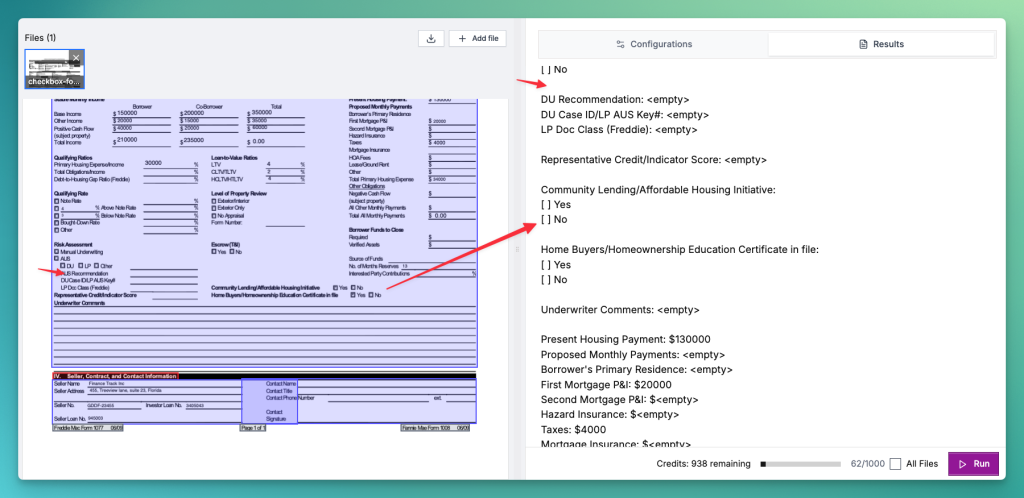
This document has a highly complex layout — it spans three to four columns and includes tables, text fields, and multiple checkboxes. Reducto performs fairly well in parsing this structure: it accurately recognizes most text elements and identifies checkboxes across different layout sections.
However, recognition alone isn’t enough. The real question is accuracy. In this case, Reducto misses certain fields. For example:
The “AUS Recommendation” text field was not detected.
Two checkbox fields — “Community Lending/Affordable Housing Initiative:” and “Home Buyers/Homeownership Education Certificate in file:” — were incorrectly identified, with the system failing to mark the checked boxes correctly.
Overall, while Reducto handles complex layouts competently, its accuracy is not perfect in this particular complex extraction use case.
Reducto clearly missed certain fields and could not parse checkboxes in certain instances
Parsing with Unstract’s LLMWhisperer Pre-processor
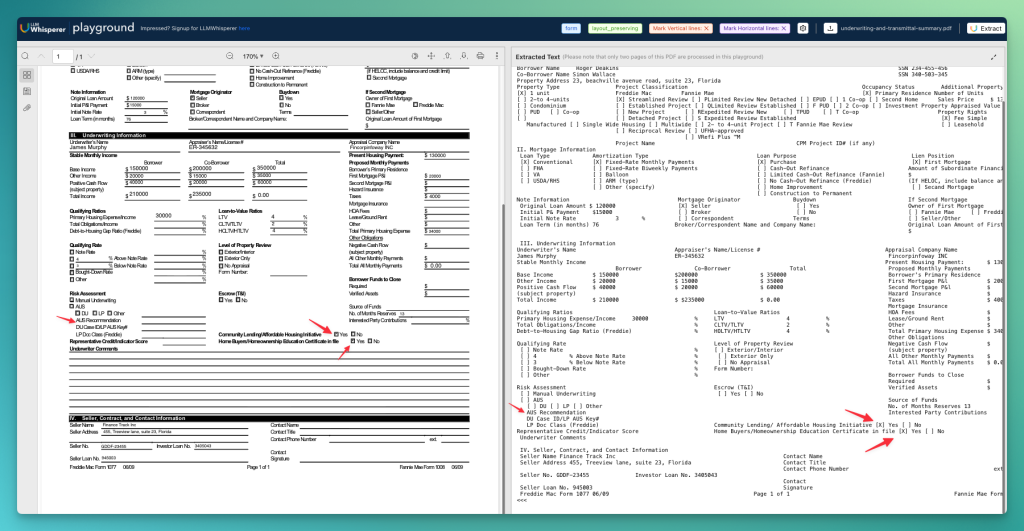
When you compare the same document’s extraction with Unstract’s LLMWhisperer, it captures every element—text, checkboxes, tables—with 100% accuracy, including fields that Reducto misses.
The key advantage is its layout-preserving OCR: LLMWhisperer retains the original structure of complex, multi-layout documents, where meaning often depends on how information is arranged. By preserving layout, it preserves context, which leads to consistently higher accuracy and far more reliable outputs for any LLM-based downstream task.
LLMWhisperer accurately parses the complex document without any omission.
Extracting Data From Documents using Reducto
The Extract feature allows you to define a schema either manually or automatically from a text description, enabling the extraction of more structured data.
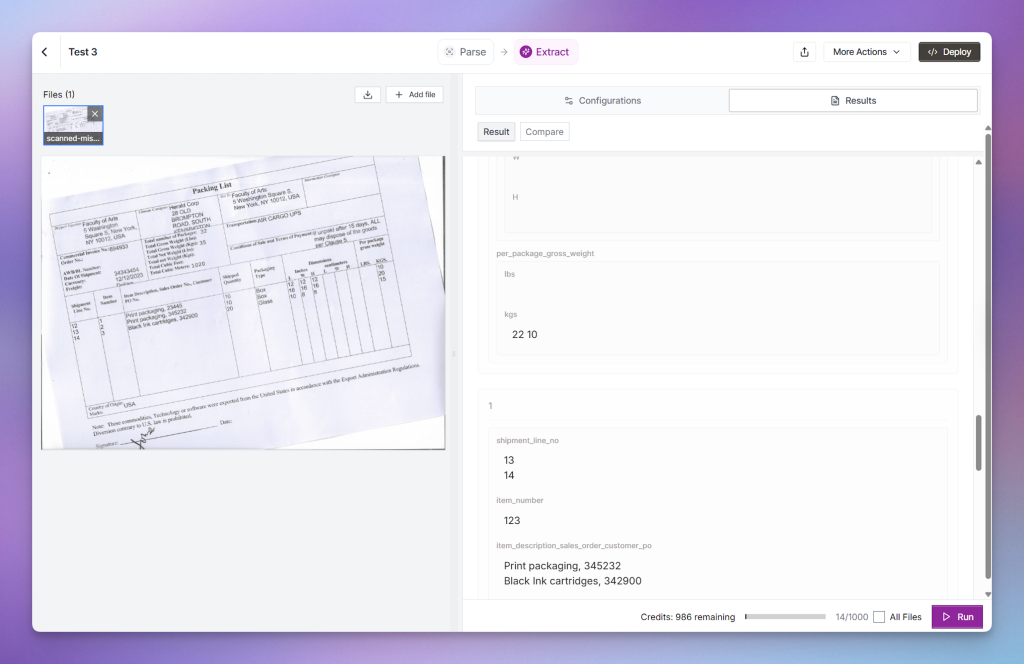
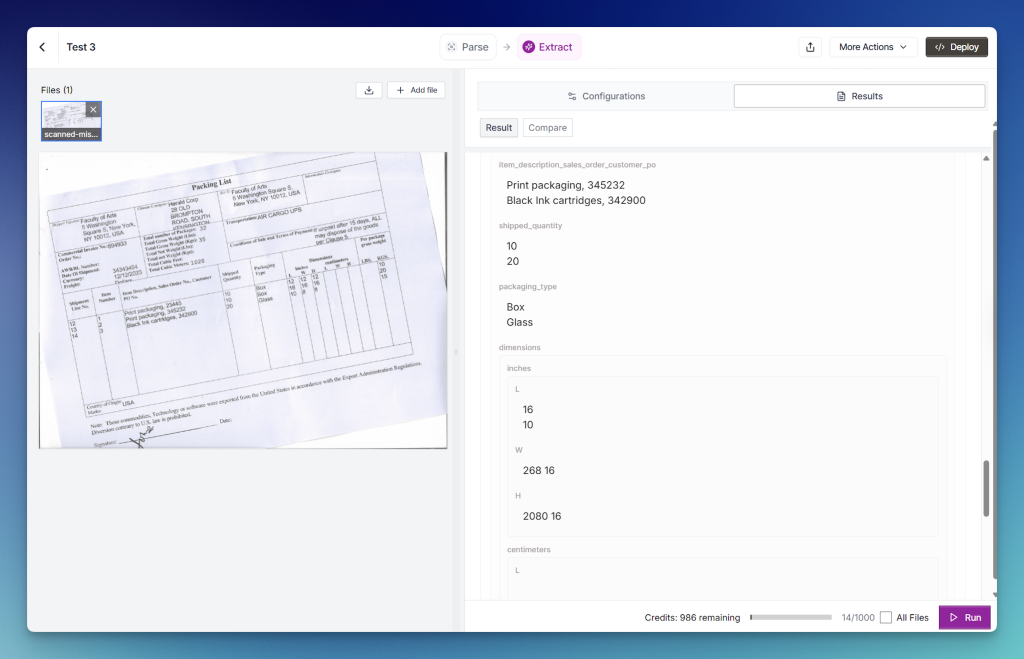
Example 1: Skewed Packing List Scan
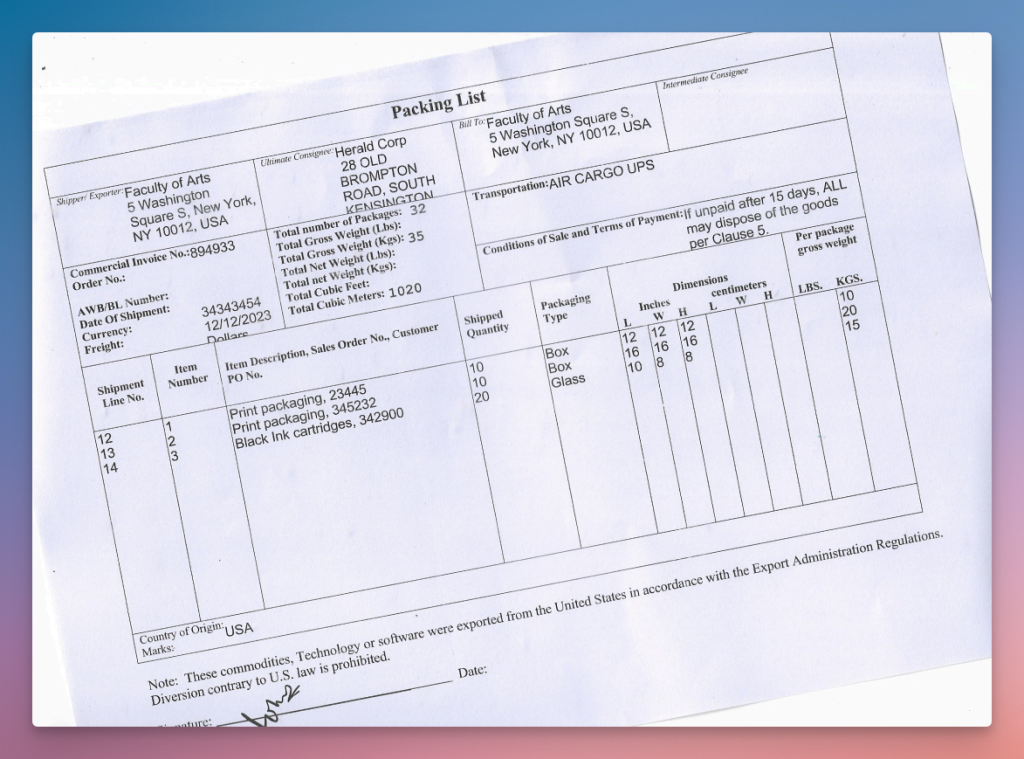
Let’s now test the Extraction feature with additional examples, starting with a skewed scan of a packing list document:
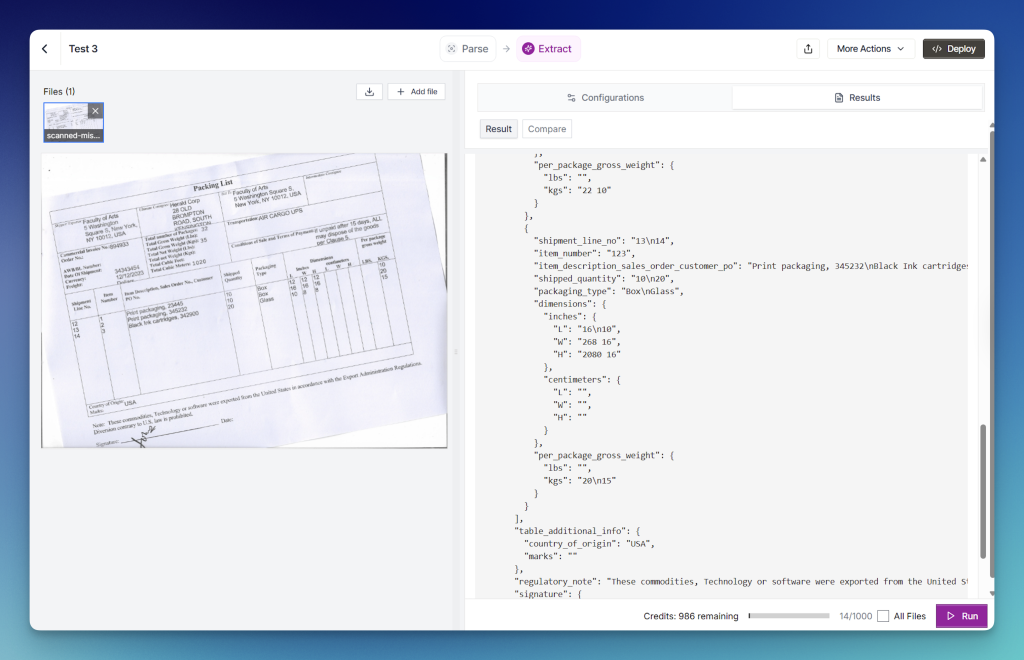
We can see that it becomes confused, merging shipping line values, introducing inconsistencies, and producing entirely incorrect results:
This issue occurs across multiple records and several columns:
You can also observe these inconsistencies reflected in the JSON output:
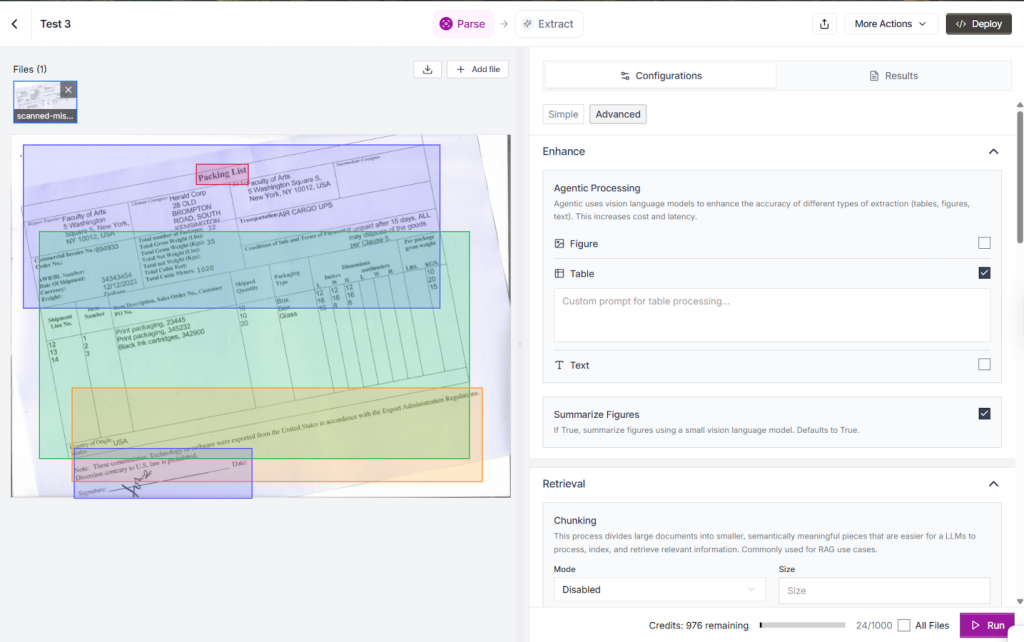
When checking for ways to adjust or improve output quality, the available options are quite limited, mainly focused on processing figures and tables, and they require custom, highly specific prompts:
Example 2: Product datasheet with complex nested table
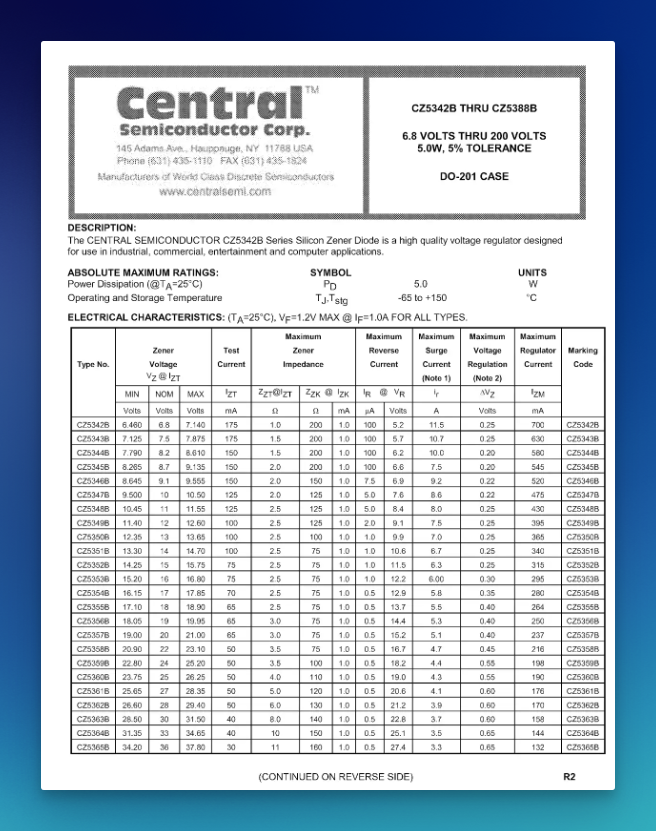
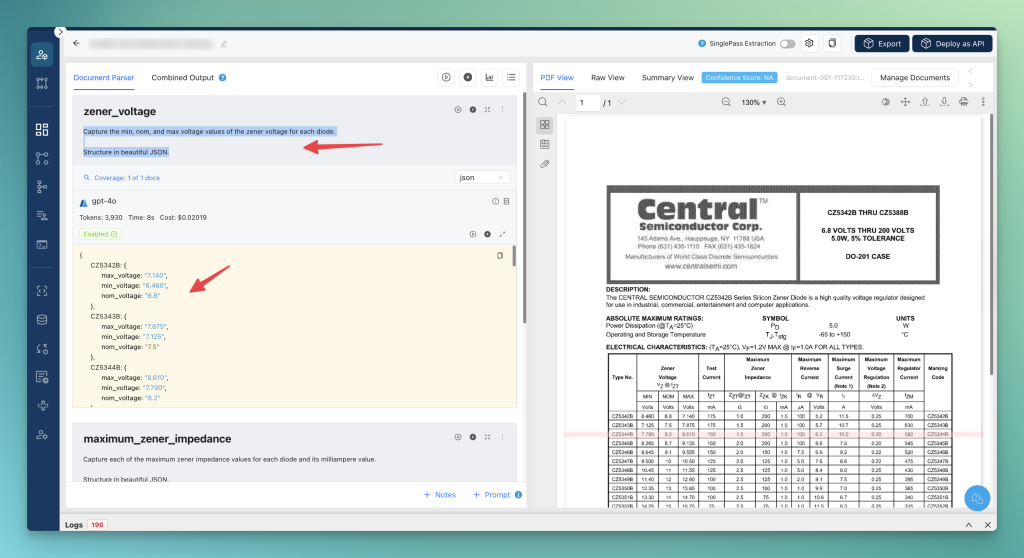
This document is a datasheet from Central Semiconductor Corporation for a series of Zener diodes.
Prompt Used:
“Capture the min, nom, and max voltage values of the zener voltage for each diode.
Structure in beautiful JSON.”
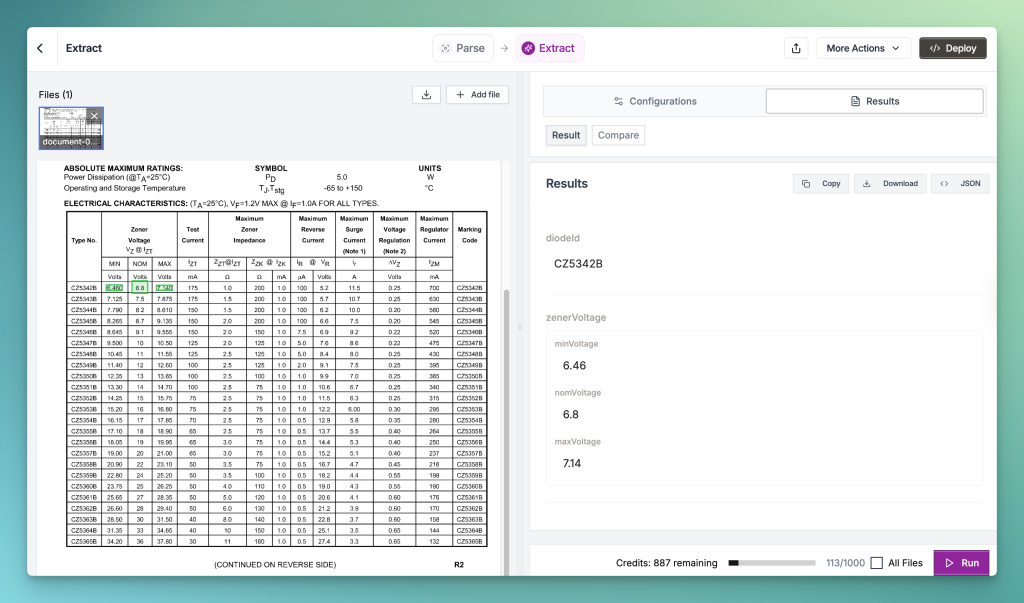
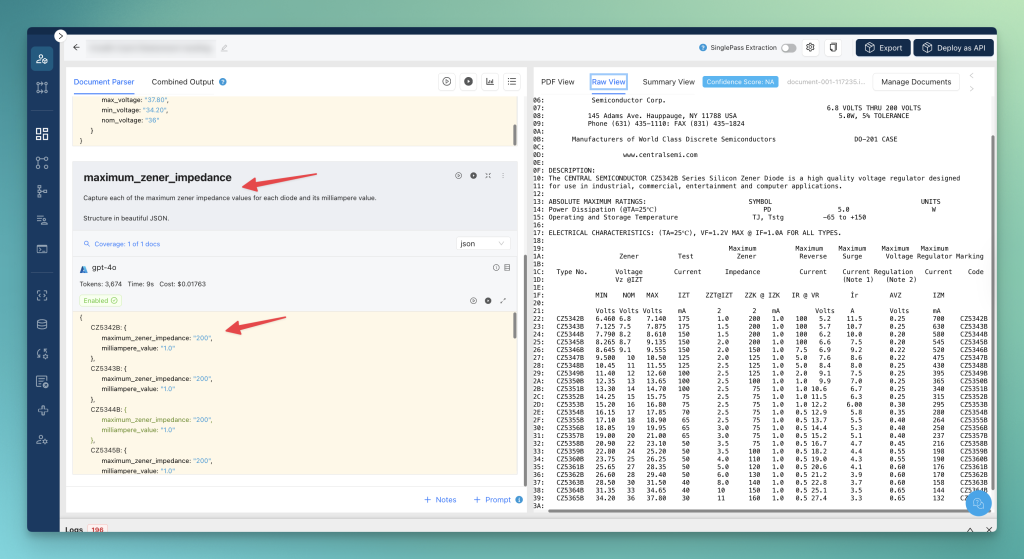
“Capture each of the maximum zener impedance values for each diode and its milliampere value.
Structure in beautiful JSON.”
Extraction results from Reducto:
Output for the first prompt: Reducto captured only the first 3 values.
Reducto: Incomplete extraction from complex tables
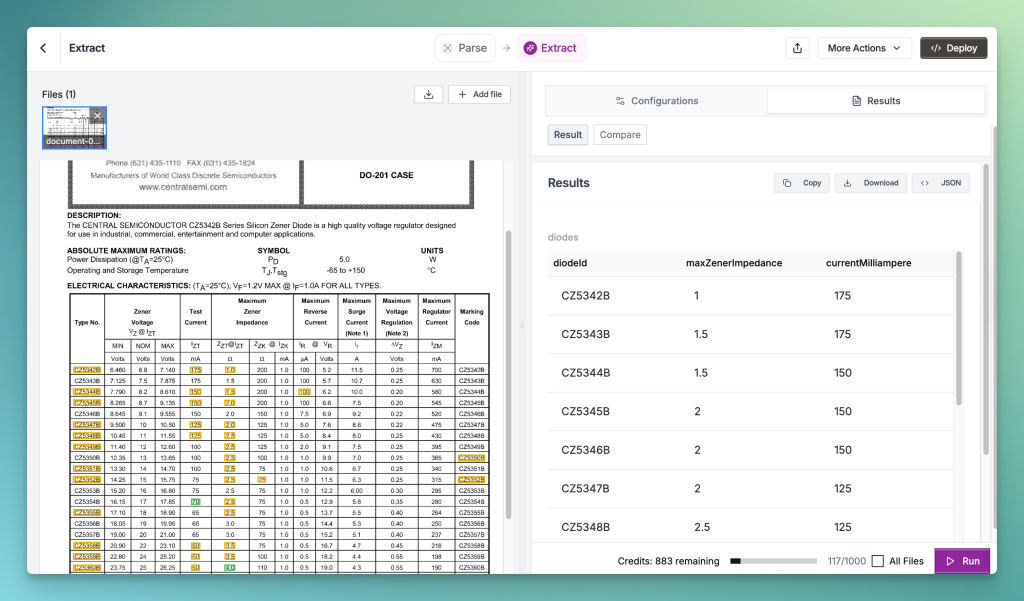
The output for the second prompt incorrectly identifies the maximum impedance and corresponding mA values by looking in the wrong places.
Reducto: Fails to perform complex table extraction
Example: Uniform Underwriting and Transmittal SummaryDocument
Prompts used:
Capture the borrower full name, co-borrower full name, property address, SSN of each of the borrowers, property type selected, project classification selected, occupancy status selected, and property rights selected. Also important are the number of units. The sales price. And the appraised value.
Extraction results:
Reducto is reencountering issues; the values it extracts for property type, project classification, and occupancy status are incorrect. It also indicates the sources of its information, but can cite only 5 to 10 references from the entire document.
Reducto successfully “parsed” the document, but it failed to extract data accurately during the extraction stage.
Summary Analysis of Reducto’s Document Processing Capabilities
After testing multiple document types, including a commercial insurance application, a packing list, and a mortgage form, several consistent patterns emerged in Reducto’s processing performance:
Ease of Use: The platform is intuitive and simple to get started with. Uploading documents and triggering extractions require minimal setup, making it ideal for quick trials or demonstrations.
Automatic Structuring: Reducto automatically classifies and segments documents into sections, tables, and fields without requiring user configuration. However, this classification is rigid, users cannot modify or influence how sections are defined.
Accuracy and Consistency: While Reducto performs reasonably well on straightforward, typed documents, it struggles with:
Handwritten text or non-standard layouts.
Tables containing merged or multi-line entries.
Checkbox fields, which are often misread or ignored.
JSON Output Quality: The resulting JSON output lacks consistency. Fields are scattered and unstructured, and there’s no way to define a custom schema for name–value pairing. This limits its usefulness for integration into structured databases or downstream systems.
Customization Limitations: Aside from a few prompt-based adjustments for tables or figures, there are no substantial options to improve output quality or guide the model toward more accurate extractions.
Overall, Reducto delivers a streamlined experience for simple extraction tasks but demonstrates notable limitations in field accuracy, schema flexibility, and data consistency. It’s a solid starting point for quick document parsing but not yet suitable for complex or enterprise-grade ETL workflows where precision, control, and customization are essential.
Introducing Unstract
Unstract is an open-source, enterprise-ready platform designed to help organizations extract, transform, and load (ETL) data from all types of unstructured documents, including PDFs, images, scanned files, and multi-format archives. Unlike closed or single-model systems, Unstract is built on a modular, transparent, and LLM-agnostic architecture, giving users full control over every part of the document processing pipeline.
At its core, Unstract’s mission is to democratize document intelligence, enabling developers, analysts, and enterprises to design highly customized extraction workflows without being tied to a single model or vendor. Every stage in the pipeline, from ingestion and OCR to schema creation and validation, is configurable, auditable, and extendable.
Getting Started With Unstract: Best AI-Powered Document Data Extractor
Modular Architecture
Unstract’s plug-and-play architecture allows users to mix and match components to fit their needs:
OCR Providers: LLMWhisperer, Unstructured.io, LlamaParse, Tesseract, or custom engines.
Large Language Models (LLMs): OpenAI, Anthropic, Mistral, Claude, or local models via Ollama.
Vector Databases: Pinecone, Milvus, FAISS, and others for semantic search or RAG pipelines.
Connectors: AWS S3, PostgreSQL, BigQuery, Snowflake, Redshift, and REST APIs for data ingestion and export.
This modularity empowers teams to create precise, cost-efficient pipelines for use cases ranging from invoice extraction and contract analysis to large-scale document ETL workflows.
Deployment Flexibility
Unstract supports a variety of deployment modes, making it adaptable for teams of any size and compliance level:
Cloud (SaaS): Fully managed, ideal for quick setup and experimentation.
Local (Desktop): Perfect for developers running small extractions or local testing.
Self-Hosted (Enterprise): Deployable on private clouds, Kubernetes, or on-prem environments, providing maximum control, security, and compliance.
MCP server and N8N nodes
This flexibility makes Unstract equally suitable for startups building fast prototypes and for large enterprises in finance, healthcare, or government that require strict data governance.
Unified Interface
Unstract offers a cohesive, intuitive interface that combines simplicity and power:
A dashboard for monitoring jobs, datasets, and performance metrics.
A visual pipeline builder to connect OCR, LLM, and transformation steps.
The Prompt Studio, where users can define and test custom extraction schemas.
This design bridges no-code convenience with developer-level configurability, allowing teams to iterate quickly without writing boilerplate code.
Key Features and Advantages
Unstract is more than a document parser, it’s a complete, modular ETL platform that transforms unstructured content into structured, actionable data. It combines flexibility, transparency, and enterprise-grade capabilities in one ecosystem.
End-to-End ETL Pipelines: Unstract handles the full data journey, from ingestion and extraction to validation and export. With pre-built connectors for databases, warehouses, and cloud storage (like S3 and Snowflake), it easily integrates into existing workflows. Pipelines can be orchestrated visually or automated via n8n nodes and MCP servers.
Infinite Customizability: Built to be LLM-agnostic, Unstract lets users mix and match models, OCR tools, and vector databases. Whether using OpenAI, Mistral, or local LLMs via Ollama, teams can design pipelines optimized for their cost, accuracy, and privacy needs.
Prompt Studio: The Prompt Studio allows teams to design custom extraction schemas with field-level rules. This ensures deterministic, structured outputs, a major improvement over automatically generated, less flexible schemas.
Multi-Service Text Extraction: By combining multiple tool, such as LLMWhisperer for OCR, Unstract reduces hallucinations and improves accuracy across complex layouts and scanned documents.
Enterprise-Grade Features: Designed for scale and compliance, Unstract includes human-in-the-loop validation, single-pass extraction for cost efficiency, and LLM Challenge tools to enhance precision. These make it ideal for regulated industries like finance, insurance, and healthcare.
Open Source and Community Trust: With over 6,000 GitHub stars, Unstract’s open-source foundation ensures transparency, auditability, and continuous innovation. Its active community and public roadmap make it a trustworthy long-term choice for developers and enterprises alike.
Trying out Unstract
Registration
To get started, visit the Unstract website and sign up for a free account. The registration process is quick and gives you immediate access to Unstract’s core tools, including Prompt Studio and LLMWhisperer.
Each new account includes a 14-day free trial and 1 million LLM tokens, providing everything you need to start building and testing your own document extraction pipelines right away.
Extracting Data From Documents
Once logged in, open Prompt Studio and create a new project for your document(s).
Then, go to the Manage Documents section to upload the file you want to process and extract the data from. After uploading, you can begin defining prompts that describe the exact data fields you want to extract, such as names, dates, totals, or checkbox selections.
In Unstract, prompts act as instructions for the AI; they define what to extract and how to structure the output, ensuring the results align with your schema.
This schema-driven approach contrasts sharply with Reducto’s static extraction, where the system automatically guesses fields based on its internal model and doesn’t allow users to fully adjust or refine them. With Unstract, you’re in full control, able to guide the extraction logic, enforce data types, and ensure consistency across documents.
Example: Skewed Packing List Scan
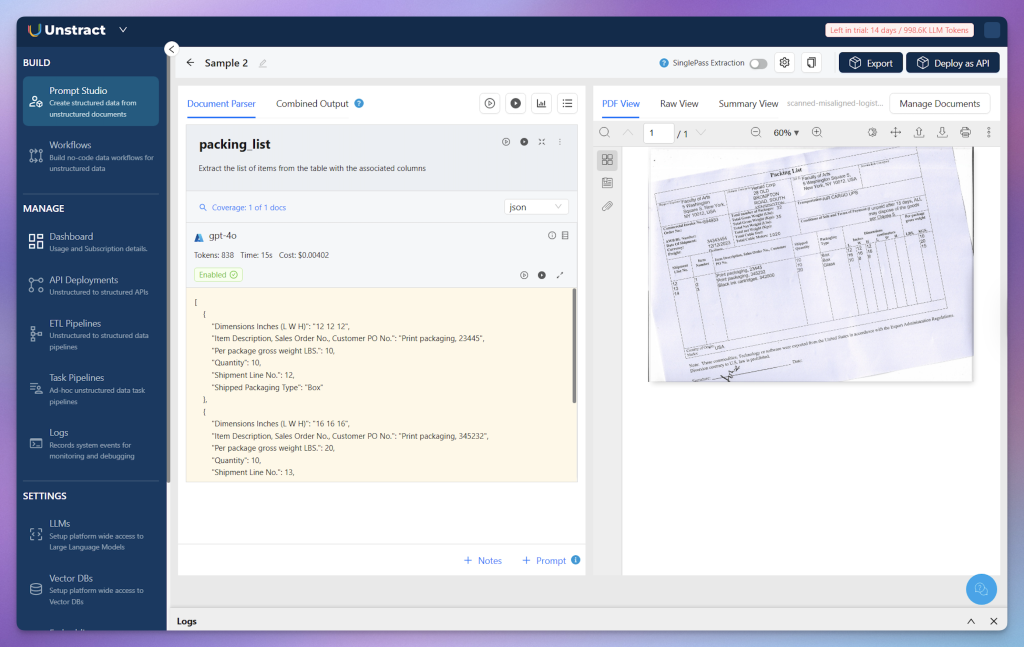
For the skewed scan of a packing list document, let’s define a simple yet generic prompt designed to generate detailed and structured extraction results.
Extract the list of items from the table with the associated columns
This produces the following output:
Unstract: Returning a clean, well-structured, and accurate dataset.
And the formatted JSON:
[
{
"Dimensions Inches (L W H)": "12 12 12",
"Item Description, Sales Order No., Customer PO No.": "Print packaging, 23445",
"Per package gross weight LBS.": 10,
"Quantity": 10,
"Shipment Line No.": 12,
"Shipped Packaging Type": "Box"
},
{
"Dimensions Inches (L W H)": "16 16 16",
"Item Description, Sales Order No., Customer PO No.": "Print packaging, 345232",
"Per package gross weight LBS.": 20,
"Quantity": 10,
"Shipment Line No.": 13,
"Shipped Packaging Type": "Box"
},
{
"Dimensions Inches (L W H)": "10 8 8",
"Item Description, Sales Order No., Customer PO No.": "Black Ink cartridges, 342900",
"Per package gross weight LBS.": 15,
"Quantity": 20,
"Shipment Line No.": 14,
"Shipped Packaging Type": "Glass"
}
]
Incredible, even without a detailed prompt, Unstract not only extracted the data accurately (avoiding the missing columns and overlapping rows seen with Reducto) but also interpreted the content intelligently, returning a clean, well-structured dataset.
Example 2: Product datasheet with complex nested table
This document is a datasheet from Central Semiconductor Corporation for a series of Zener diodes.
Prompt Used:
“Capture the min, nom, and max voltage values of the zener voltage for each diode.
Structure in beautiful JSON.”
“Capture each of the maximum zener impedance values for each diode and its milliampere value.
Structure in beautiful JSON.”
Extraction results from Unstract:
Output for the first prompt: Unstract accurately captures all voltage values and sorts them by type number.
Output for the 2nd prompt – Unstract is again able to capture all the data by looking at it in the right column group called “Maximum Zener Impedance”.
Unstract: Accurate structured data extraction from documents with complex tables
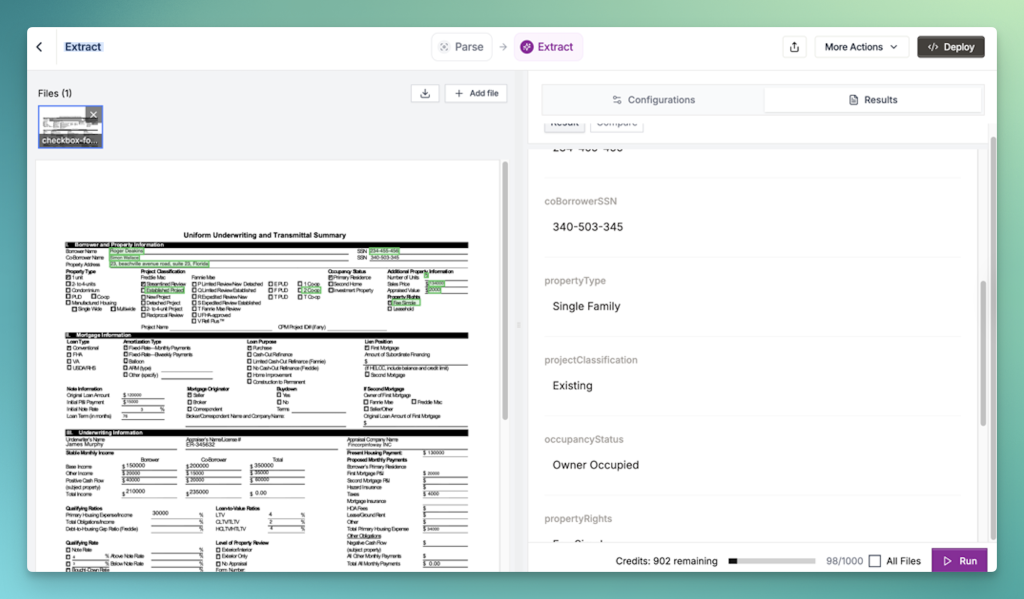
Example: Uniform Underwriting and Transmittal SummaryDocument
Next, we’ll test another document, the mortgage application that includes multiple checkbox options spread across its pages.
Let’s design a simple prompt to extract the key mortgage information:
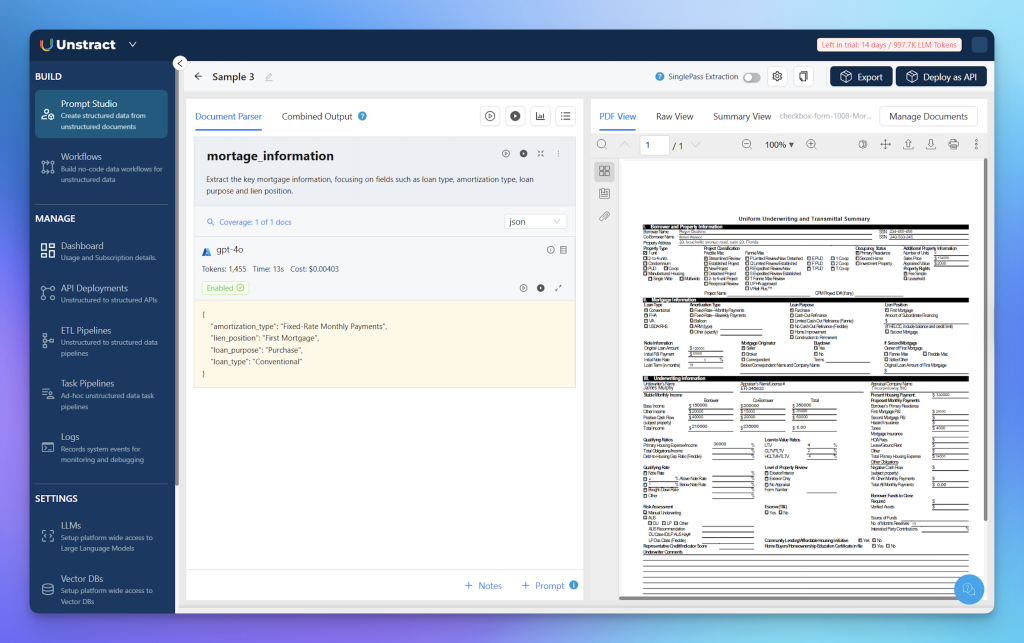
Extract the key mortgage information, focusing on fields such as loan type, amortization type, loan purpose and lien position.
This produces the following output:
Once again, Unstract delivers outstanding results; it accurately recognizes the checkbox selections and correctly associates them with their corresponding information.
In contrast, Reducto often misidentifies or mismatches values for several of these fields.
Summary Analysis of Unstract’s Processing
After testing Unstract with the same set of documents, the results demonstrate clear improvements in accuracy, structure, and interpretability compared to Reducto.
Accuracy and Completeness: Unstract consistently captured all relevant data fields, including those previously missed by Reducto (such as expirationDate in the insurance form and checkbox selections in the mortgage document). Its ability to interpret handwritten text, identify layout variations, and handle skewed or low-quality scans shows a more reliable understanding of document structure.
Structured and Consistent Output: Even with simple or generic prompts, Unstract produced clean and logically organized JSON outputs. Data was properly aligned under field names and grouped within the correct sections. This level of consistency reduces the need for post-processing or manual data cleaning, a major advantage for large-scale ETL pipelines.
Prompt Flexibility and Control: The use of Prompt Studio proved to be a key differentiator. Instead of relying on automatic schema generation, users can explicitly define what information to extract and how it should be represented. This schema-driven approach not only improves reliability but also allows easy adaptation to new document types without retraining or extensive setup.
Interpretation and Context Awareness: Unstract’s underlying architecture demonstrates contextual understanding, it doesn’t just extract text, but interprets the relationship between fields. For example, it successfully linked checkbox selections with their corresponding options and grouped related values in structured arrays, resulting in a more semantically accurate dataset.
Ease of Use and Efficiency: Despite its flexibility, the platform remains accessible. Setting up a pipeline, defining prompts, and obtaining structured output required minimal effort. The system’s ability to achieve high accuracy with simple prompt definitions makes it practical for both technical and non-technical users.
Unstract stands out as a robust and adaptable document processing solution. It combines high extraction accuracy, schema-level control, and contextual understanding with the transparency of an open-source platform. Whether dealing with handwritten forms, structured tables, or checkbox-heavy applications, Unstract consistently delivers precise and interpretable results, a clear step ahead of Reducto’s more limited, black-box approach.
Reducto vs. Unstract: Unstract Captures What Reducto Misses
Using Prompt Studio, we processed the same three documents to compare results and evaluate Unstract’s performance against Reducto’s. The difference was immediately clear, Unstract successfully captured key data fields that Reducto had previously missed.
By defining a precise schema and guiding the extraction through structured prompts, Unstract produced consistent and accurate outputs across all files. This highlights the advantage of a schema-driven, transparent extraction approach over fully automated, black-box systems.
Here’s a clear comparison table summarizing the extraction results between Reducto and Unstract for the same three test documents:
Reducto vs. Unstract
Document Type
Challenges
Reducto
Unstract
Scanned Skewed Packing List
Very dense, complex table
Inconsistent and incorrect extraction
100% accurate extraction
Product datasheet
Very dense complex table
Incomplete and incorrect extraction
100% accurate extraction
Form 1008 Mortgage document
Complex layout with checkboxes
Inaccurate extraction
100% accurate extraction
Across all test cases, Unstract’s Prompt Studio demonstrated greater precision, schema control, and data consistency. By allowing users to define field names, types, and validation logic, it avoided the common issues of missing, merged, or misclassified data observed with Reducto’s automatic extraction.
Unstract: A better Reducto alternative for document processing
Both Reducto and Unstract represent important steps forward in the evolution of AI-powered document understanding, but they serve very different needs.
Reducto shines in its simplicity. It’s a great choice for teams that want to get started quickly without worrying about setup or infrastructure. Startups, small businesses, and developers who need a plug-and-play OCR or document extraction tool will appreciate its minimal learning curve and intuitive interface. For quick trials, prototypes, or smaller workloads, Reducto offers a fast path to automation.
Unstract, on the other hand, is built for depth and control. It’s an enterprise-grade, open-source, and highly customizable platform designed for organizations that need scalable, reliable, and auditable ETL pipelines. With its modular design, Prompt Studio, and multi-service extraction capabilities, Unstract allows teams to fine-tune every layer of their data pipeline, from OCR to LLM orchestration and downstream integration. Whether the goal is compliance, cost optimization, or accuracy, Unstract provides the tools and transparency needed to operate at scale.
Reducto vs. Unstract Comparison: Related topics to explore
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.