How to Extract Data from PDF to Database (Postgres)
Table of Contents
Introduction: Understanding Unstructured Data Processing
In the digital age, businesses generate and handle massive volumes of data every day. While some of this data is structured and easily stored in databases (like spreadsheets or transactional records), more than 80% of business data is unstructured—locked inside documents, PDFs, scanned forms, images, and handwritten notes.
What is Unstructured Data?
Unstructured data refers to information that doesn’t follow a predefined data model or format, making it difficult to search, analyze, or process using traditional databases or software. This includes:
PDFs and scanned documents
Photographed invoices and receipts
Forms with handwritten data
Contracts, insurance plans, and reports
Emails, ID cards, and multimedia content
Why It Matters for Businesses
Unstructured data often contains critical business information—customer details, financial figures, compliance records, or legal clauses. However, without a systematic way to extract and structure this information, businesses face:
Operational inefficiencies
Delayed decision-making
Compliance risks
Increased manual workloads
The ability to convert unstructured documents into structured, machine-readable formats unlocks immense value for industries such as banking, insurance, healthcare, and logistics.
TL;DR
This article explores how Unstract simplifies PDF data extraction and database import for faster, accurate workflows through AI and LLMs.
If you wish to skip directly to the solution section, where you can see a step-by-step walkthrough of extracting data from a PDF to a database, click here.
Challenges in Document Processing Using Traditional Methods
Despite technological advances, many organizations still rely on outdated methods to process documents. These traditional approaches—typically a mix of manual data entry and legacy OCR (Optical Character Recognition)—come with significant limitations.
Manual Processing: Labor-Intensive and Error-Prone
Time-Consuming: Employees manually extract information from documents, leading to bottlenecks in workflows.
Inconsistent Results: Human errors in typing, copying, or interpreting information lead to inaccuracies.
High Cost: Maintaining teams for data entry and validation adds overhead to operations.
OCR-Based Extraction: Limited Capabilities
Traditional OCR tools can convert scanned text into machine-readable text, but they struggle with complex document structures. Common issues include:
Broken formatting: Loss of tables, checkboxes, and multi-column data.
Poor recognition of handwriting: OCR engines fail with handwritten forms or signatures.
Inaccurate data mapping: Extracted text lacks context, making it hard to associate with fields like “Customer Name” or “Loan Amount”.
As document formats become more diverse and complex, these limitations create a pressing need for intelligent, scalable solutions.
The Role of AI in Document Processing & Extraction
Unstract 101: Leveraging AI to Convert Unstructured Documents into Usable Data
Watch this webinar/demo to explore Unstract, a platform for LLM-powered unstructured data extraction. Learn how to process complex documents—like those with images, forms, and multi-layout tables—without the need for pre-training.
AI has revolutionized how businesses handle unstructured data. Using techniques like natural language processing (NLP), machine learning, and document classification, AI-powered systems can now extract information with context, accuracy, and speed.
AI-Powered ETL for Document Processing
ETL (Extract, Transform, Load) is the process of:
Extracting data from source documents (PDFs, images, scanned forms)
Transforming it into structured formats (like JSON or CSV)
Loading it into a target system (such as a Postgres database)
AI enhances this pipeline by:
Understanding the context of data in paragraphs, tables, or forms.
Recognizing structured patterns, such as name-date-amount sequences.
Retaining layout and formatting, which is critical in business documents.
Structured vs. Unstructured Data Handling
AI bridges the gap between these two:
Unstructured input: PDFs with multi-column layouts, mixed fonts, handwritten notes.
Structured output: Clean, labeled data fields (e.g., “Customer_Name”: “Jane Doe”) ready for analysis.
Benefits for Businesses
Speed & Scalability: Automate the processing of thousands of documents in minutes.
Accuracy: Drastically reduce errors in data capture.
Compliance & Traceability: Extract and store key compliance data (SSNs, tax IDs, etc.) for audits and reports.
Operational Efficiency: Enable seamless data flow into CRMs, ERP systems, and cloud databases like Postgres or Snowflake.
What is ETL for Unstructured Data?
In the world of data engineering, ETL stands for Extract, Transform, and Load. It’s a foundational process used to move and manage data from various sources into a structured database or data warehouse. While ETL has traditionally been used for structured data (like from relational databases or CSV files), modern businesses now require ETL pipelines that can handle unstructured documents—especially PDFs, scanned forms, and images.
Breaking Down the ETL Process for Unstructured Data
Let’s explore how ETL applies to unstructured documents, such as bank statements, loan applications, or insurance forms.
1. Extract
This step involves reading data from unstructured formats:
PDF documents (scanned or digitally generated)
Handwritten forms and photographed receipts
Complex tabular documents like invoices or insurance summaries
The challenge is that the data is not machine-readable, so advanced tools like OCR engines (e.g., LLMWhisperer) are used to extract raw text. But simple text is not enough—you need to retain structure (tables, sections, checkboxes), which is where tools like Unstract come in.
2. Transform
The extracted text is then processed, cleaned, and structured using AI models, embeddings, and prompt-based NLP pipelines:
Parse and normalize formats (e.g., dates, phone numbers)
Organize content into structured JSON or tabular formats
This step adds meaning and schema to previously unstructured blobs of text.
3. Load
Finally, the structured output is loaded into a database, such as Postgres, where it can be:
Queried using SQL
Joined with other enterprise data
Visualized in BI dashboards
Used in automation or downstream processing pipelines
With Unstract + NeonDB, this entire flow can be built without code—allowing business teams to transform raw documents into usable data, ready for decision-making.
Why Converting Unstructured Data into Structured Data Matters
Modern businesses generate a wealth of information every day—but much of this data remains trapped inside unstructured formats. By converting this data into structured records and storing it in a database like Postgres, organizations unlock major operational and strategic benefits.
Key Business Benefits
1. Faster Decision-Making
With data neatly stored in tables and available through queries, decision-makers can:
Schema Flexibility: Can store raw JSON (in VARIANT or JSONB format) or expand it into normalized tables.
Free & Cloud-Hosted: NeonDB offers a modern, serverless Postgres environment—ideal for setting up test environments and workflows without DevOps friction.
Robust Ecosystem: Works well with Python, BI tools, ETL stacks, and cloud services.
By combining Unstract for extraction and Postgres (NeonDB) for structured storage, businesses build a reliable and intelligent pipeline for unstructured data processing.
Introduction to Unstract: How to Extract Data From PDF to Database
Unstract is a powerful, open-source platform purpose-built to automate the transformation of unstructured documents—like PDFs, images, and scanned forms—into structured, queryable formats. It simplifies the end-to-end ETL (Extract, Transform, Load) process using cutting-edge technologies such as OCR, embeddings, vector databases, and large language models (LLMs).
Why Use Unstract Over Traditional ML/NLP Tools?
Traditional ML and NLP tools for document extraction rely heavily on manual annotations and rigid pipelines. They struggle to handle diverse document formats, multi-page records, and natural language-heavy content like contracts. These approaches are not only time-consuming but also fail to scale reliably across document variations.
In contrast, Unstract eliminates the need for repetitive annotation through one-time prompt engineering—allowing it to adapt to multiple document types effortlessly.
Key Differentiators from ML/NLP Solutions:
Aspect/Challenge
ML+NLP Based Solutions
Unstract
Extraction method
Manual annotations
Prompt-based automation
Handling diverse document layouts
Requires re-annotation
Covered via prompt engineering
Natural language documents (contracts, etc.)
Unreliable
Efficiently parsed with layout-preserving OCR
Multi-page document support
Often fails
Handles large files seamlessly
Format transformation of extracted fields
Needs separate post-processing
Supported directly within the ETL pipeline
What Makes Unstract a Complete No-Code ETL Platform
Unstract comes with two powerful interfaces:
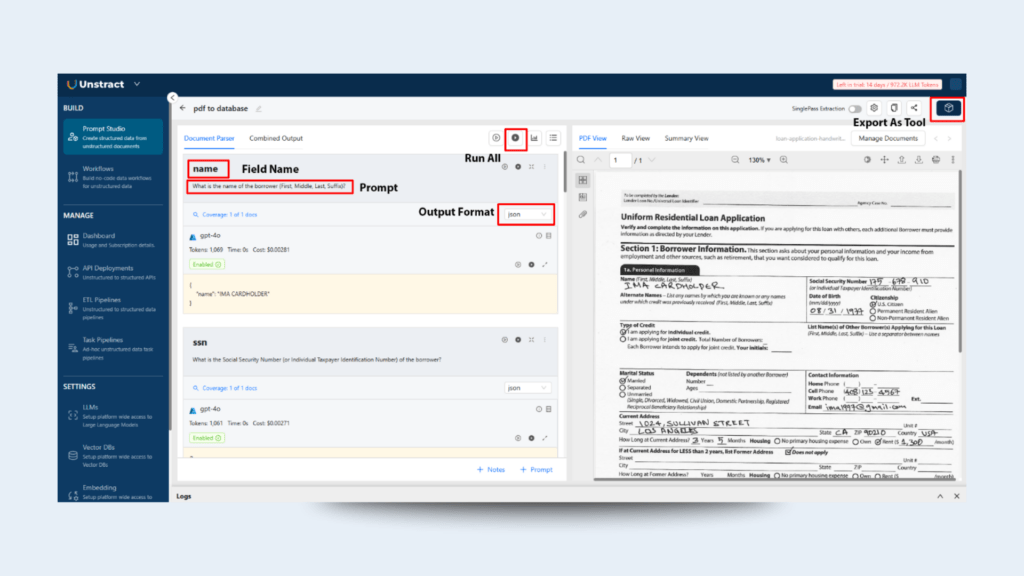
Prompt Studio: Enables users to build custom prompts without writing code, allowing precise extraction of fields like name, email, date of birth, etc., from unstructured documents.
Workflow Studio: A no-code interface to connect document sources like Dropbox, Google Drive, or APIs and direct outputs to destinations such as Postgres (via NeonDB), Snowflake, or other data warehouses.
With these two modules, even non-engineering teams can automate document pipelines using just configuration—not code.
Boosted Productivity for Engineering Teams
Engineers can build and run AI document extraction pipelines without worrying about the evolving LLM ecosystem.
Teams can focus on differentiated logic while Unstract takes care of document intake, processing, and output—saving time and reducing complexity.
Supports integration with APIs and databases for full automation of document workflows.
Seamless Integrations for Scalable Automation
Unstract is designed for flexible deployments and integrations:
Unstructured Data APIs – Convert unstructured data into usable APIs for custom apps.
ETL Pipelines – Build full document ingestion pipelines from sources like Dropbox to destinations like Postgres or Snowflake.
Data Warehousing – Structured data can be directly stored into data warehouses for reporting and analytics.
This modular design enables businesses to use Unstract for both real-time parsing and batch ETL operations—fitting perfectly into enterprise data ecosystems.
By combining layout-preserving OCR (via LLMWhisperer), prompt engineering, and ETL automation, Unstract redefines AI document processing. It empowers teams to extract structured insights from complex documents with speed, accuracy, and scale—without writing a single line of code.
What is LLMWhisperer? A High-Accuracy OCR Engine (Not AI-Based)
LLMWhisperer is a high-precision, layout-preserving OCR engine built to convert complex documents—like scanned PDFs, photographed forms, or handwritten files—into clean, structured text. Despite the name, LLMWhisperer is not a large language model or an AI-based tool. It doesn’t generate structured JSON, nor does it perform semantic analysis. Instead, it’s a document parser designed to accurately extract text while preserving layout, feeding this output to downstream tools like Unstract.
Core Capabilities of LLMWhisperer
Layout Preservation Keeps tables, columns, headers, and visual alignment intact for precise readability and downstream parsing.
OCR for Multi-Format Documents Supports scanned PDFs, image files (JPG, PNG, TIFF), Office docs (Word, Excel), and even poorly aligned or low-resolution files.
Form Element Recognition Accurately detects and extracts checkboxes, radio buttons, and form input values—critical for tax forms, contracts, and applications.
Handwriting Recognition Handles handwritten entries within forms or applications, improving data completeness from scanned physical documents.
Auto Mode Switching Automatically selects the appropriate mode (text or OCR) depending on the document type and quality—no manual input required.
Try It Yourself: Testing LLMWhisperer via Playground
You can experience LLMWhisperer’s capabilities in real time using the LLMWhisperer Playground:
Upload a sample: Try a loan application PDF that includes:
Section-wise structured data (e.g., personal details, income, contact info)
Checkboxes for options like marital status and citizenship
A mix of typed and prefilled information
The Result? Magic or Just LLMWhisperer at Work
Once uploaded, you’ll see the result instantly:
All content extracted with almost 0% data loss
Checkboxes and section labels are preserved and readable
Layout is fully maintained, including column alignment and form structure
Even pre-filled fields and label associations are retained accurately
It’s not magic—it’s the precision and engineering of LLMWhisperer. This pre-processing step enables AI models (via Unstract) to consume clean, layout-preserved text for advanced document intelligence workflows.
Project Setup: Processing PDFs and Loading Data into Postgres (NeonDB)
Unstract makes it easy to automate the ETL (Extract, Transform, Load) pipeline for unstructured PDF documents—like loan applications—into a structured Postgres database using a free cloud instance like NeonDB.
This extracted data is accurate, structured, and ready for integration into Neon DB or any other database system.
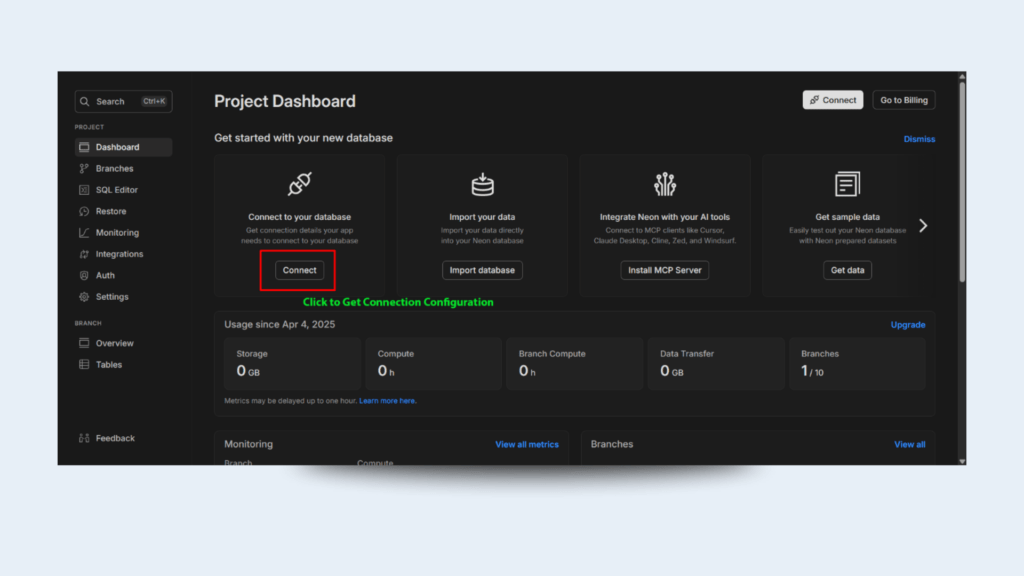
What is NeonDB?
NeonDB is a modern, fully managed, serverless PostgreSQL platform built for developers and data teams who want the flexibility and power of Postgres without the hassle of managing infrastructure. It’s especially useful when working with AI-powered ETL tools like Unstract, where structured data extracted from unstructured PDFs needs to be stored and queried efficiently.
Key Features of NeonDB:
Serverless and Scalable Neon automatically scales storage and compute independently. You only pay for what you use, making it perfect for both small projects and large-scale applications.
Built on PostgreSQL Neon uses standard PostgreSQL under the hood, so you get full compatibility with SQL, tools, libraries, and integrations you already know.
Branching and Versioning Just like Git for code, Neon allows you to create branches of your database for development, testing, and staging. You can experiment without affecting production data.
Instant Setup with Free Tier Neon offers a generous free plan that allows developers to quickly spin up a Postgres instance in the cloud. No credit card required.
Built-in Connection URLs for Easy Integration Once your database is created, Neon provides a connection string that you can directly paste into tools like Unstract, enabling fast and seamless data flow.
Secure and Cloud-Native Neon runs in the cloud with built-in TLS, storage snapshots, and auto backups, ensuring your data is safe and always available.
Why Use NeonDB with Unstract?
Simplifies cloud Postgres setup for storing extracted data.
Ideal for structured JSON ingestion from AI-based tools.
Works seamlessly with Unstract’s database connectors.
Enables quick data queries using SQL for dashboards, analytics, or reporting.
Example Use Case: You extract borrower details from a loan application PDF using Unstract and store the results in a NeonDB table to power a lending dashboard or audit workflow.
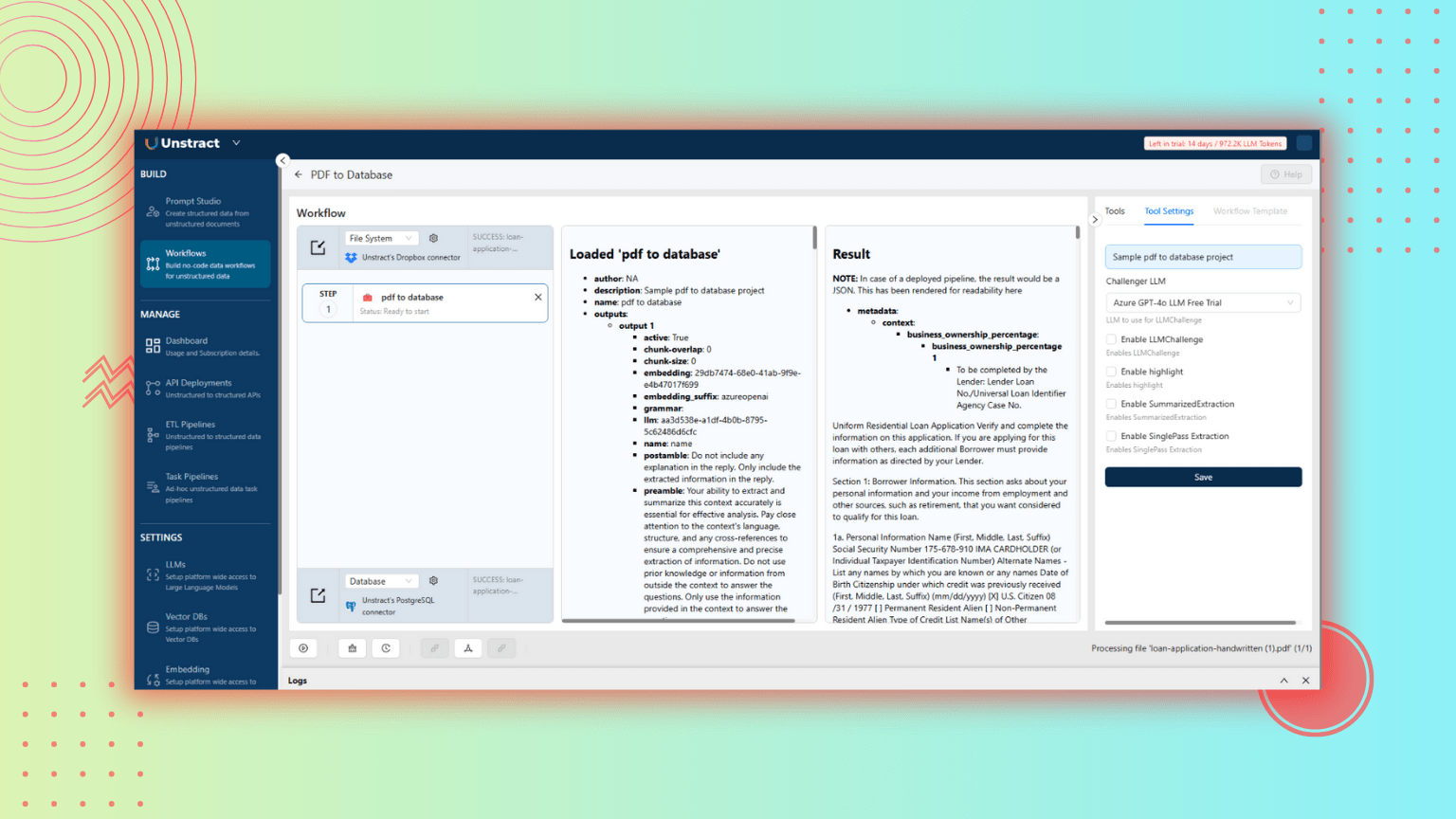
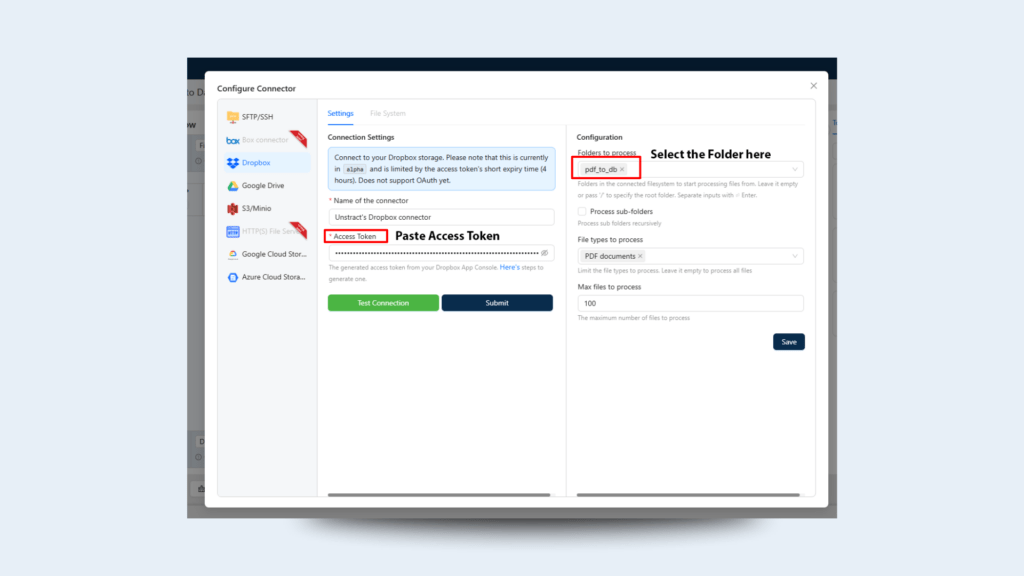
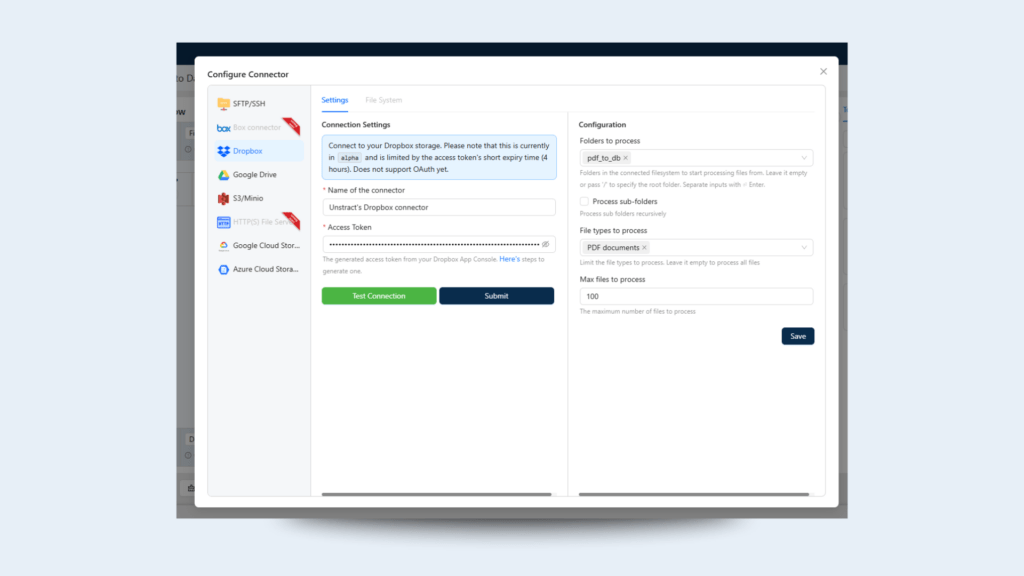
Step 3: Connect Dropbox as the Input Source
Now let’s link the Dropbox folder where loan applications are stored.
Steps:
Navigate to BUILD → Workflows
Click on + New Workflow
Name the workflow: pdf_to_database
In the Tools section, drag your previously exported pdf_to_database tool into the workflow editor
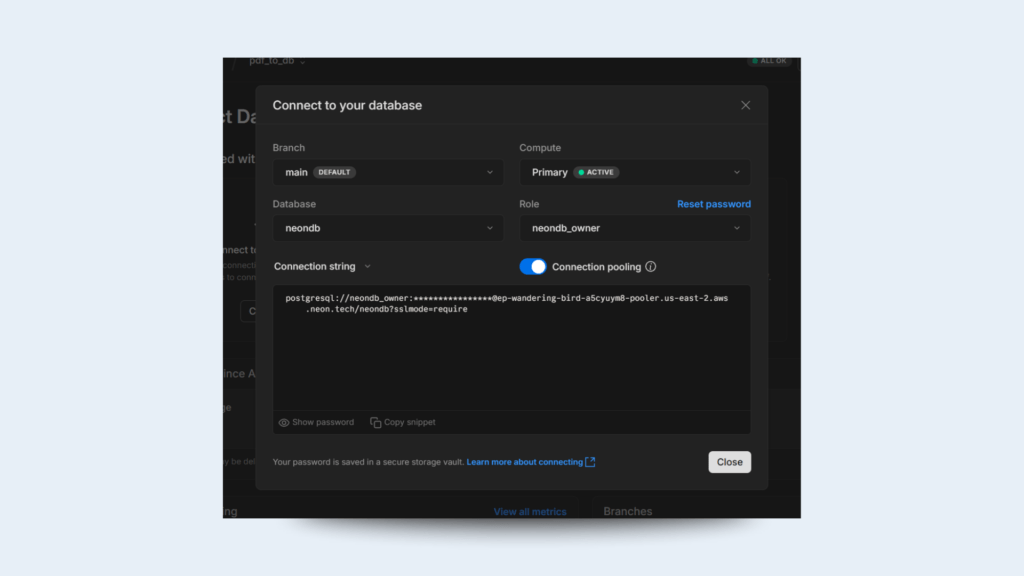
Click Connect Your Database → Copy the Connection String
In Unstract:
Select Database as the output
Click (settings gear icon)
Paste NeonDB Connection String
Enter:
Table Name: pdf_to_db_table
Column Name: data (JSON/variant type)
Click Test Connection → then Submit
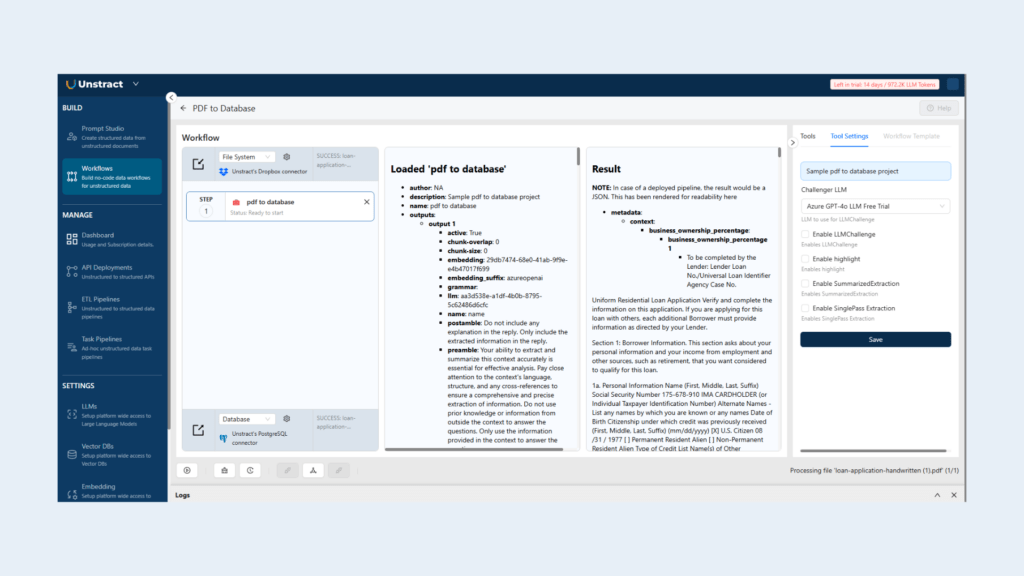
Step 5: Execute the Workflow
Now that Dropbox and NeonDB are connected:
Click Run Workflow
The workflow scans and processes all loan application PDFs from the selected Dropbox folder (pdf_to_db)
Extracted data will be pushed to pdf_to_db_table in NeonDB
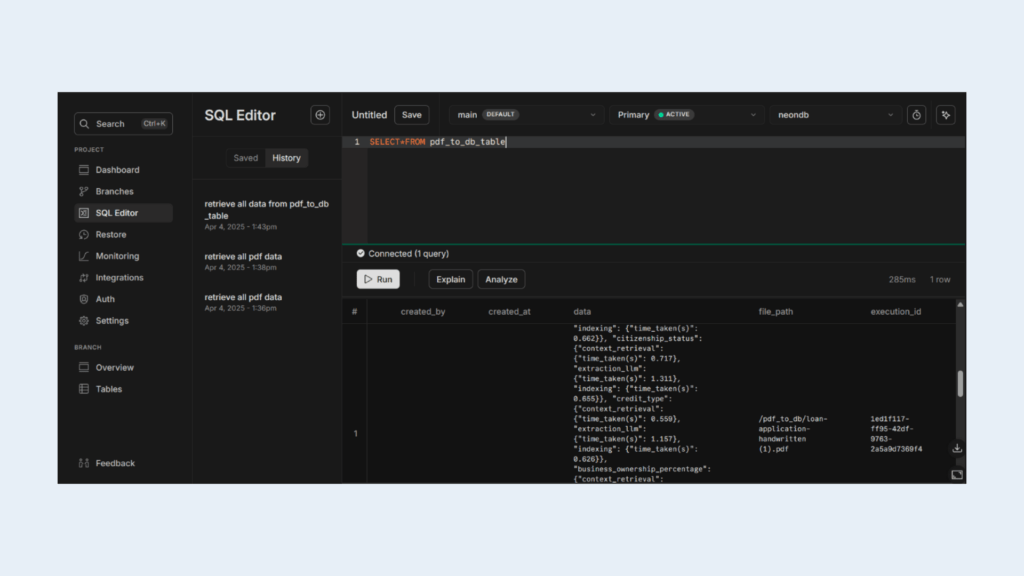
Verifying Data in NeonDB
Login to NeonDB SQL console and run:
SELECT * FROM pdf_to_db_table;
You’ll see structured JSON data for each processed loan application.
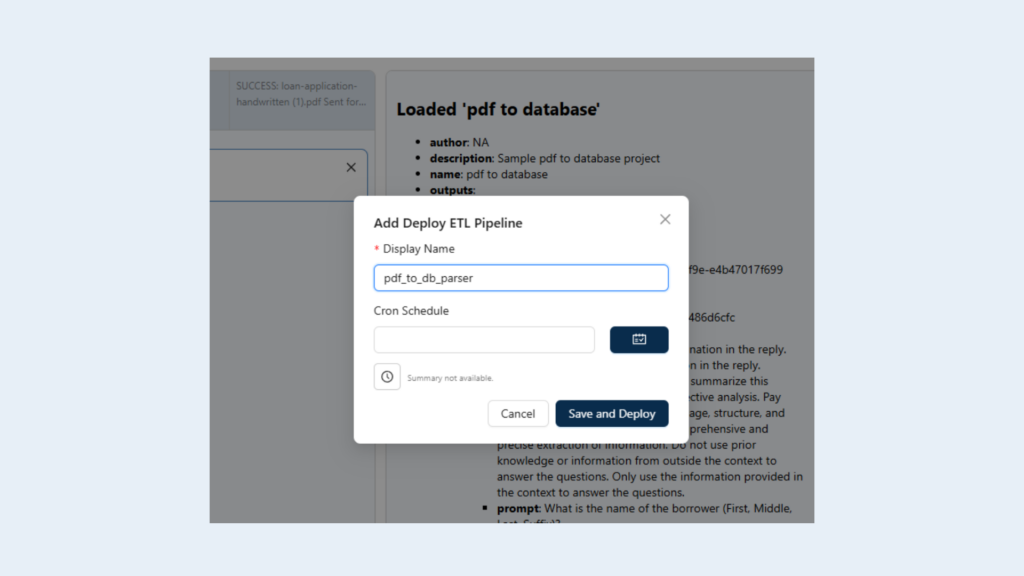
Step 6: Deploy the ETL Pipeline
After successful testing, make it a production-ready ETL pipeline.
Click Deploy as ETL Pipeline
Fill in:
Pipeline Name
Description
Trigger frequency (if scheduled)
Click Save and Deploy
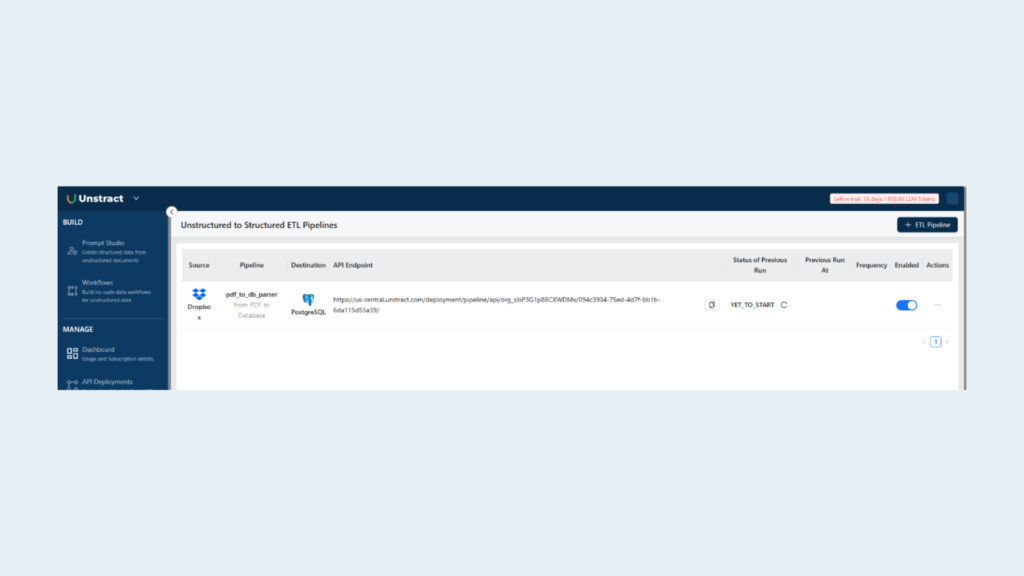
Manage all ETL jobs under ETL Pipelines in Unstract Dashboard. You can:
Monitor execution logs
Rerun or pause workflows
Audit extracted data flow end-to-end
This completes your project setup for Extracting PDF Data from Loan Applications → Processing with Unstract → Storing into NeonDB/Postgres.
Flattening JSON Data in Postgres for Easy Querying
When processing unstructured documents like loan applications, Unstract produces structured outputs in JSON format. These JSON records are typically stored in a single column of a Postgres table (e.g., on NeonDB), retaining the full data hierarchy.
While this is great for flexibility and nested data structures, querying or analyzing individual fields becomes complex when everything is stored in one column. To make the data easier to work with, Postgres allows us to flatten the JSON into individual columns using built-in JSON functions like ->, ->>, and jsonb_each.
Storing JSON Data in Postgres (NeonDB)
Assume your extracted data is saved in a table named pdf_to_db_table, where the structured JSON is in a column called data.
We’ll create a new table called pdf_data to hold this JSON using ::json casting:
CREATE TABLE pdf_data AS
SELECT data::json AS src
FROM pdf_to_db_table;
Querying and Flattening JSON Fields
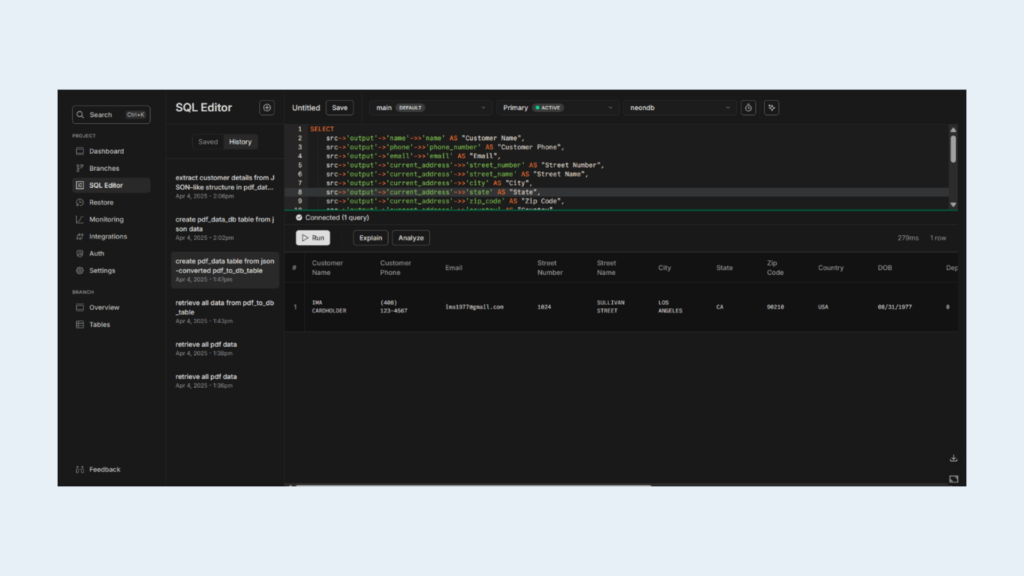
Now that your JSON is stored in a column (src), you can query individual fields using dot notation and flatten the values into readable columns:
SELECT
src->'output'->'name'->>'name' AS "Customer Name",
src->'output'->'phone'->>'phone_number' AS "Customer Phone",
src->'output'->'email'->>'email' AS "Email",
src->'output'->'current_address'->>'street_number' AS "Street Number",
src->'output'->'current_address'->>'street_name' AS "Street Name",
src->'output'->'current_address'->>'city' AS "City",
src->'output'->'current_address'->>'state' AS "State",
src->'output'->'current_address'->>'zip_code' AS "Zip Code",
src->'output'->'current_address'->>'country' AS "Country",
src->'output'->'dob'->>'date' AS "DOB",
src->'output'->>'dependents' AS "Dependents",
src->'output'->'citizenship_status'->>'status' AS "Citizenship Status",
src->'output'->'credit_type'->>'message' AS "Credit Type",
src->'output'->'business_ownership_percentage'->>'discount' AS "Business Ownership",
src->'output'->'income_details'->>'price' AS "Income",
src->'output'->'income_details'->>'period' AS "Income Period",
src->'output'->'employer_name'->>'company' AS "Employer Name",
src->'output'->'employer_phone'->>'phone_number' AS "Employer Phone",
src->'output'->'ssn'->>'number' AS "SSN"
FROM pdf_data;
Result: Tabular Format from JSON
The above query transforms deeply nested JSON into a flat, tabular format, making it easy to:
Run analytics
Join with other database tables
Generate reports or dashboards
Export to BI tools like Metabase or Power BI
This approach ensures high usability of AI-extracted data without losing the flexibility of JSON for storage.
Benefits of Using Unstract for PDF Data Extraction into Databases
Unstract simplifies and accelerates the process of extracting data from PDF to database, particularly for complex documents like loan applications, invoices, and insurance forms. Whether you’re dealing with scanned PDFs, multi-column tables, or handwritten fields, Unstract ensures the output is clean, structured, and ready for downstream use.
Here are the key advantages:
Speed & Efficiency AI-powered automation enables Unstract to process hundreds of PDFs in minutes—dramatically reducing manual processing time and improving operational efficiency.
High Accuracy Leveraging tools like LLMWhisperer, Unstract maintains the original layout, tables, checkboxes, and even extracts handwritten content—ensuring minimal data loss and preserving data fidelity.
Seamless Postgres Integration Unstract supports direct integration with Postgres databases such as NeonDB, making it easy to load structured data without custom code or manual data transfers.
Automation-Friendly Workflows in Unstract can be scheduled or triggered automatically, allowing businesses to implement real-time ETL pipelines for ongoing PDF to database document processing.
Cost-Effective & Compliant By reducing dependency on manual labor, Unstract cuts costs while maintaining audit trails and meeting data compliance requirements in regulated industries.
Conclusion: Making PDF-to-Database Seamless with Unstract
In today’s data-first environment, the ability to extract data from PDF to database is not just a technical requirement—it’s a strategic advantage. Traditional OCR and manual entry methods fall short when dealing with the complexity and scale of modern documents.
Unstract bridges this gap by offering an end-to-end, AI-driven solution to process unstructured PDFs and load clean, structured data directly into a Postgres database like NeonDB.
With powerful tools like:
LLMWhisperer for layout-preserving OCR
Prompt Studio for no-code data extraction
Built-in connectors for databases and file systems
Unstract allows you to move from static PDFs to dynamic, queryable data—automating document workflows and unlocking new insights.
Ready to transform your document extraction pipeline? Start using Unstract today to convert your PDF to database in minutes, not hours.
What is next? Explore Unstract’s capabilities
We are building Unstract. Unstract is a no-code platform that eliminates manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial to try it out quickly. More information here.
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.