In today’s digital landscape, the demand for accurate OCR and document parsing has never been higher. Businesses and organizations rely on accurate data extraction from complex documents, forms, and tables to automate workflows, reduce manual errors, and increase efficiency.
Several popular solutions exist to address these needs, including established tools like Tesseract, Google Cloud Vision, and Amazon Textract. While these platforms offer robust features and integration capabilities, they sometimes fall short when it comes to preserving document layouts, which is an essential factor for workflows that leverage large language models (LLMs) for data extraction.
This is where LLMWhisperer becomes a compelling Textract alternative. Designed to excel in layout preservation, cost efficiency, and nuanced parsing (especially for challenging formats like vertical text or intricate tables), LLMWhisperer offers a fresh perspective on document processing that can be a game-changer for many applications.
In this article, we will:
Walk through the setup processes for both Amazon Textract and LLMWhisperer.
Explore and evaluate key features using sample documents such as an OSHA form, a Loan Estimate form, and an Apollo Space Program document.
Compare the performance and pricing of each solution to help you determine the best fit for your OCR and data extraction needs.
Let’s dive in and explore how each tool performs, and why LLMWhisperer might just be the superior choice for your next OCR project.
Here is the GitHub repository where you will find all the codes written for this article.
Amazon Textract
Amazon Textract is a powerful machine learning service provided by AWS that automates the process of extracting text and data from scanned documents and images.
Designed for OCR and document parsing, Textract goes beyond simple optical character recognition by not only reading printed text but also intelligently identifying and capturing key elements such as forms and tables.
Key functionalities of Amazon Textract include:
Key-Value Pair Extraction: Textract efficiently locates and extracts information from structured documents by identifying key-value pairs, which is essential for automating data entry and processing workflows.
Table to CSV API: For documents containing tabular data, Textract offers a specialized API that converts tables into CSV format, simplifying data analysis and integration with other systems.
These features, along with its seamless integration within the AWS ecosystem, make Textract a robust solution for organizations aiming to streamline their document processing and data extraction tasks.
Textract Setup Guide
Setting up Amazon Textract is a straightforward process that involves configuring your AWS account, preparing your documents, and integrating the service into your workflow.
Follow these steps to get started.
Create an AWS Account:
If you don’t already have one, sign up for an AWS account at AWS Signup.
Access the AWS Management Console:
Log in to the AWS Management Console and search for “Textract” in the services menu.
To assess the performance of Amazon Textract, we applied it to several sample documents that represent common challenges in document parsing.
Key-Value Pairs (Form data)
First, let’s start by taking a look at the Python code used to extract data as key-value pairs:
# textract_kv.py
import boto3
import sys
from collections import defaultdict
def get_kv_map(file_name):
# Read the PDF file as bytes
with open(file_name, 'rb') as file:
document_bytes = file.read()
print("Document loaded:", file_name)
# Initialize a boto3 client
client = boto3.Session(aws_access_key_id="",
aws_secret_access_key="",
region_name='eu-central-1').client('textract')
# Call analyze_document API; per AWS docs, PDFs are supported here if within limits
response = client.analyze_document(
Document={'Bytes': document_bytes},
FeatureTypes=['FORMS']
)
blocks = response['Blocks']
key_map = {}
value_map = {}
block_map = {}
for block in blocks:
block_id = block['Id']
block_map[block_id] = block
if block['BlockType'] == "KEY_VALUE_SET":
# Distinguish keys from values based on the 'EntityTypes' field
if 'KEY' in block.get('EntityTypes', []):
key_map[block_id] = block
else:
value_map[block_id] = block
return key_map, value_map, block_map
def get_text(block, block_map):
"""Extracts text from a block by concatenating text from its child relationships."""
text = ""
if block and 'Relationships' in block:
for relationship in block['Relationships']:
if relationship['Type'] == 'CHILD':
for child_id in relationship['Ids']:
child = block_map.get(child_id)
if child and child['BlockType'] == 'WORD':
text += child['Text'] + ' '
elif child and child['BlockType'] == 'SELECTION_ELEMENT' and child.get(
'SelectionStatus') == 'SELECTED':
text += 'X ' # Marking selected checkboxes
return text.strip()
def find_value_block(key_block, value_map):
"""Finds the value block associated with a given key block."""
if 'Relationships' in key_block:
for relationship in key_block['Relationships']:
if relationship['Type'] == 'VALUE':
for value_id in relationship['Ids']:
return value_map.get(value_id)
return None
def get_kv_relationship(key_map, value_map, block_map):
"""Builds the key-value pairs from the key and value maps."""
kvs = defaultdict(list)
for key_id, key_block in key_map.items():
key_text = get_text(key_block, block_map)
value_block = find_value_block(key_block, value_map)
value_text = get_text(value_block, block_map) if value_block else ""
kvs[key_text].append(value_text)
return kvs
def print_kv_pairs(kvs):
"""Prints the key-value pairs to the console."""
for key, values in kvs.items():
print(f"{key}: {', '.join(values)}")
def main(file_name):
key_map, value_map, block_map = get_kv_map(file_name)
kvs = get_kv_relationship(key_map, value_map, block_map)
print("\nExtracted Key-Value Pairs:\n")
print_kv_pairs(kvs)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <PDF file>")
sys.exit(1)
main(sys.argv[1])
Don’t forget to fill in your aws_access_key_id and aws_secret_access_key.
Here’s a breakdown of the code:
get_kv_map(file_name):
Reads a PDF file and initializes a boto3 client for Amazon Textract.
Calls the analyze_document API to extract blocks of text from the PDF.
Separates blocks into key and value maps based on their types.
Returns three maps: key_map, value_map, and block_map.
get_text(block, block_map):
Extracts text from a block by concatenating text from its child relationships.
Handles both text and selection elements (e.g., checkboxes).
find_value_block(key_block, value_map):
Finds the value block associated with a given key block using relationships.
Builds key-value pairs from the key and value maps.
Uses defaultdict to handle multiple values for a single key.
print_kv_pairs(kvs):
Prints the extracted key-value pairs to the console.
main(file_name):
Orchestrates the extraction process by calling the above functions.
Prints the extracted key-value pairs.
You can execute the script with:
python textract_kv.py my-document.pdf
Tables to CSV
Now, let’s look at the Python code used to extract tables to a CSV file:
# textract_csv.py
import os
import sys
import json
import boto3
from io import BytesIO
from pprint import pprint
def get_text(result, blocks_map):
"""Extracts text from a block by combining its child words and selection elements."""
text = ''
if 'Relationships' in result:
for relationship in result['Relationships']:
if relationship['Type'] == 'CHILD':
for child_id in relationship['Ids']:
word = blocks_map.get(child_id)
if word and word['BlockType'] == 'WORD':
# If the word contains a comma and is numeric when commas are removed, wrap it in quotes
if "," in word['Text'] and word['Text'].replace(",", "").isnumeric():
text += f'"{word["Text"]}" '
else:
text += word['Text'] + ' '
elif word and word['BlockType'] == 'SELECTION_ELEMENT':
if word.get('SelectionStatus') == 'SELECTED':
text += 'X '
return text.strip()
def get_rows_columns_map(table_result, blocks_map):
"""
Creates a mapping of rows and columns for a table block. Returns a dictionary of rows with their corresponding cells' text and a list of confidence scores.
"""
rows = {}
scores = []
for relationship in table_result.get('Relationships', []):
if relationship['Type'] == 'CHILD':
for child_id in relationship['Ids']:
cell = blocks_map.get(child_id)
if cell and cell['BlockType'] == 'CELL':
row_index = cell['RowIndex']
col_index = cell['ColumnIndex']
if row_index not in rows:
rows[row_index] = {}
scores.append(str(cell.get('Confidence', 0)))
rows[row_index][col_index] = get_text(cell, blocks_map)
return rows, scores
def generate_table_csv(table_result, blocks_map, table_index):
"""
Generates a CSV string for the table block.
"""
rows, scores = get_rows_columns_map(table_result, blocks_map)
table_id = f'Table_{table_index}'
csv_output = f'Table: {table_id}\n\n'
# Create CSV rows
for row_index in sorted(rows.keys()):
row_data = rows[row_index]
# Sort columns by their index
row_text = ",".join(row_data[col_index] for col_index in sorted(row_data.keys()))
csv_output += row_text + "\n"
# Append confidence scores at the end
csv_output += "\nConfidence Scores (per cell):\n"
# Assuming each row has same number of columns, get the number of columns from the first row
if rows:
col_count = len(next(iter(rows.values())))
for i, score in enumerate(scores, start=1):
csv_output += score + ","
if i % col_count == 0:
csv_output += "\n"
csv_output += "\n\n"
return csv_output
def get_table_csv_results(file_name):
"""
Reads a PDF file, sends it to Textract to extract tables, and returns a CSV string with the extracted table data.
"""
# Read PDF file bytes
with open(file_name, 'rb') as file:
pdf_bytes = file.read()
print('PDF loaded:', file_name)
# Initialize a boto3 client
client = boto3.Session(aws_access_key_id="",
aws_secret_access_key="",
region_name='eu-central-1').client('textract')
# Call analyze_document API (PDFs are supported if within size limits)
response = client.analyze_document(
Document={'Bytes': pdf_bytes},
FeatureTypes=['TABLES']
)
# Optionally, print all the blocks for debugging
# pprint(response['Blocks'])
blocks = response['Blocks']
blocks_map = {}
table_blocks = []
for block in blocks:
blocks_map[block['Id']] = block
if block['BlockType'] == "TABLE":
table_blocks.append(block)
if not table_blocks:
return "<b>No table found in the document.</b>"
csv_output = ''
for index, table in enumerate(table_blocks, start=1):
csv_output += generate_table_csv(table, blocks_map, index)
csv_output += "\n"
return csv_output
def main(file_name):
# Get CSV output from the PDF file
table_csv = get_table_csv_results(file_name)
# Write the CSV output to a file
output_file = 'output.csv'
with open(output_file, "w", encoding='utf-8') as fout:
fout.write(table_csv)
# Print a confirmation and the CSV output
print('CSV OUTPUT FILE:', output_file)
print('\nExtracted CSV Content:\n')
print(table_csv)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <PDF file>")
sys.exit(1)
main(sys.argv[1])
Don’t forget to fill in your aws_access_key_id and aws_secret_access_key.
Here’s a detailed breakdown of the code:
get_text(result, blocks_map):
Extracts text from a block by combining its child words and selection elements.
Handles numeric values with commas by wrapping them in quotes.
Marks selected checkboxes with an “X”.
get_rows_columns_map(table_result, blocks_map):
Creates a mapping of rows and columns for a table block.
Returns a dictionary of rows with their corresponding cells’ text and a list of confidence scores.
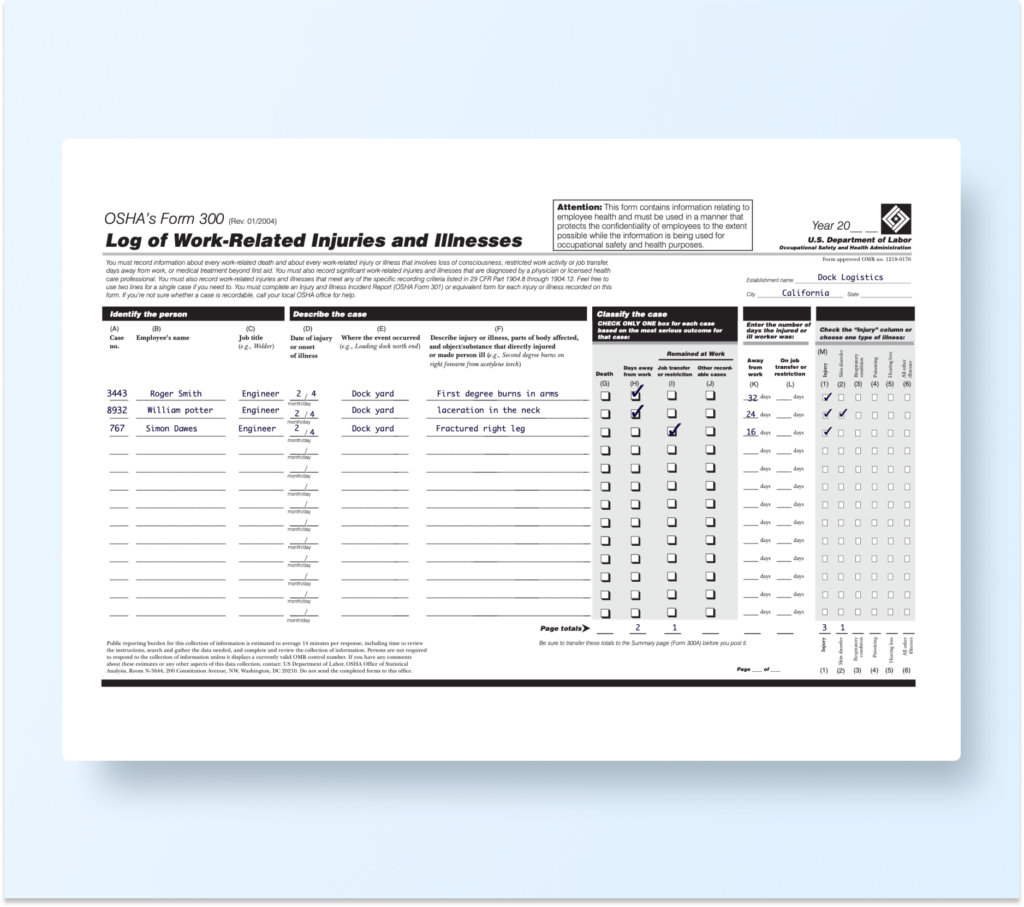
Identify,the person,,Describe,the case,,Classify,the,case,,,,,,,,,
(A) Case,(B) Employee's name,(C) Job title,(D) Date of injury,X (E) Where the event occurred,(F) Describe injury or illness, parts of body affected,,CHECK based
that,ONLY ONE on the most case:,box for each serious,case outcome for,Enter the days the ill worker,number of injured or was:,Check choose,the,"Injury" one type,of,column illness:,or
no.,,(e.g., Welder),or onset of illness,(e.g., Loading dock north end),and object/substance that directly injured or made person ill (e.g., Second degree burns on,,,Remained,at Work,,,(M),,,,,
,,,,,right forearm from acetylene torch),Death,Days away from work,Job transfer or restriction,Other record- able cases,Away from work,On job transfer or restriction,,Stain,,,,
,,,,,,(G),(H),(I),(J),(K),(L),(1),(2),(3),(4),(5),(6)
3443,Roger Smith,Engineer,2 / 4,Dock yard,First degree burns in arms,,X,,,32 days,days,X,,,,,
8932,William potter,Engineer,month/day 2 4,Dock yard,laceration in the neck,,X,,,24 days,days,X,X,,,,
767,Simon Dawes,Engineer,month/day 2 / 4,Dock yard,Fractured right leg,,,X,,16 days,days,X,,,,,
,,,month/day,,,,,,,days,days,,,,,,
,,,month/day /,,,,,,,days,days,,,,,,
,,,month/day,,,,,,,,,,,,,,
,,,/,,,,,,,days,days,,,,,,
,,,month/day /,,,,,,,days,days,,,,,,
,,,month/day,,,,,,,,,,,,,,
,,,/,,,,,,,days,days,,,,,,
,,,month/day /,,,,,,,days,days,,,,,,
,,,month/day,,,,,,,,,,,,,,
,,,/,,,,,,,days,days,,,,,,
,,,month/day,,,,,,,,,,,,,,
,,,/,,,,,,,days,days,,,,,,
,,,month/day,,,,,,,,,,,,,,
,,,/,,,,,,,days,days,,,,,,
,,,month/day,,,,,,,,,,,,,,
,,,/,,,,,,,days,days,,,,,,
,,,month/day,,,,,,,,,,,,,,
Issues Encountered with Textract
Orientation Issues: Textract appears to struggle when processing documents with vertical text. In the provided output, notice how the data under certain keys (e.g., “days:” and “month/day:”) is misaligned, with characters and numbers appearing in an unexpected order. This is indicative of Textract reorienting vertical text into a horizontal flow, which disrupts the original document layout.
Fragmented Data Extraction: The output shows several commas and disjointed numerical entries under the “days:” field. This suggests that the tool is not consistently capturing entire columns or lines of vertical text, leading to fragmented outputs. Such misalignment can cause serious issues when the extracted data is used for downstream processing or decision-making, as it may no longer accurately reflect the intended values or structure.
Loss of Context: Vertical text often provides contextual or structural information that is vital in forms and tables. When Textract fails to maintain the correct orientation, the relationship between different data elements can be lost, making it difficult to determine which numbers or words belong together.
Inconsistent Detection: The output reveals that checkboxes are not being reliably distinguished. Textract sometimes fails to clearly mark whether a checkbox is selected or not. For instance, while a selected checkbox should ideally be represented by a distinct symbol (such as an “X”), the output may simply show extraneous commas or blank spaces, leading to ambiguity.
Test Document: Loan Estimate Form
The file to analyze:
You run the script with:
python textract_kv.py loan-estimate-filled.pdf
or
python textract_csv.py loan-estimate-filled.pdf
This is the key-value output:
Document loaded: .\loan-estimate-filled.pdf
Extracted Key-Value Pairs:
Mortgage Insurance:
YES,: X
Monthly Principal & Interest See Projected Payments below for: $761.78
Estimated Taxes, Insurance & Assessments: $206 a month
PRODUCT: Fixed Rate
SALE PRICE: $180,000
NO:
Conventional: X
DATE ISSUED: 2/15/2013
FHA:
VA:
APPLICANTS: Michael Jones and Mary Stone 123 Anywhere Street Anytown, ST 12345
PROPERTY: 456 Somewhere Avenue Anytown, ST 12345
LOAN ID #: 123456789, 123456789
Homeowner's Insurance: X
Estimated Cash to Close: $16,054 Includes Closing Costs. See Calculating Cash to Close on page 2 for details.
LOAN TERM: 30 years
PURPOSE: Purchase
Property Taxes: X
Estimated Closing Costs: $8,054 Includes $5,672 in Loan Costs + $2,382 in Other Costs - $0 in Lender Credits. See page 2 for details.
Prepayment Penalty:
Loan Amount: $162,000
Does the loan have these features?: YES As high as $3,240 if you pay off the loan during the first 2 years
In escrow?: YES YES
Interest Rate: 3.875%
Balloon Payment: NO
PAGE: 1 OF 3
Estimated Total Monthly Payment: $1,050 $968
Visit: www.consumerfinance.gov/mortgage-estimate
Other::
This is the CSV output:
LOAN TERM,30 years
PURPOSE,Purchase
PRODUCT,Fixed Rate
LOAN TYPE,X Conventional FHA VA
LOAN ID #,123456789
RATE LOCK,X NO YES, until 4/16/2013 at 5:00 p.m. EDT Before closing, your interest rate, points, and lender credits can change unless you lock the interest rate. All other estimated closing costs expire on 3/4/2013 at 5:00 p.m. EDT
DATE ISSUED,2/15/2013
APPLICANTS,Michael Jones and Mary Stone 123 Anywhere Street Anytown, ST 12345
PROPERTY,456 Somewhere Avenue Anytown, ST 12345
SALE PRICE,$180,000
Loan Terms,,Can this amount increase after closing?
Loan Amount,$162,000,NO
Interest Rate,3.875%,NO
Monthly Principal & Interest See Projected Payments below for your Estimated Total Monthly Payment,$761.78,NO
Prepayment Penalty,,Does the loan have these features? YES As high as $3,240 if you pay off the loan during the first 2 years
Balloon Payment,,NO
Payment Calculation,Years 1-7,Years 8-30
Principal & Interest,$761.78,$761.78
Mortgage Insurance,+ 82,+ -
Estimated Escrow Amount can increase over time,+ 206,+ 206
Estimated Total Monthly Payment,$1,050,$968
Estimated Closing Costs,$8,054 Includes $5,672 in Loan Costs + $2,382 in Other Costs - $0 in Lender Credits. See page 2 for details.
Estimated Cash to Close,$16,054 Includes Closing Costs. See Calculating Cash to Close on page 2 for details.
Issues Encountered with Textract
Omitted Data: Some critical fields are either completely missing or only partially extracted. For instance, fields such as “FHA:” and “VA:” appear in the output without any associated values—even if they were meant to be part of the form’s complete data set.
Empty or Blank Fields: The key-value output shows entries like “Prepayment Penalty:” with no value, and other fields like “NO:” are extracted as stand-alone keys without clear context, indicating that certain portions of the form are not being captured.
Misalignment Between Labels and Values: In an ideal scenario, each form label should directly correspond to its value. However, the output shows that elements such as “Mortgage Insurance:” are followed by “YES,: X” where the additional symbols or characters (like the extra comma or “X”) cause confusion regarding the intended response.
Discrepancies in CSV Output: The CSV output, which is supposed to provide a clear and organized representation of the table data, contains fields where critical details are missing or not clearly separated. For example, the “RATE LOCK” row appears to merge multiple pieces of information into one entry, making it unclear how the values should be interpreted.
Fragmented Data Across Multiple Columns: Some rows in the CSV output include extra columns with ambiguous or misplaced values. This fragmentation indicates that Textract is having difficulty recognizing the boundaries between different form elements, resulting in a disjointed data structure.
Document loaded: .\apollo-documents-vertical-text.pdf
Extracted Key-Value Pairs:
Phase: ,
Figure:
- Status Unknown:
I - Initiated:
U:
C: Complete
3-4.: Apollo-Saturn 201 Vehicle Reliability and Quality Program Status
This is the CSV output:
NPC-500-5,,Engines,,,Booster,,CSM
Program Elements,,H-1,J-2,S-IB,S-IVB,IU,SLA
Reliability Goals R&QA Plan Reliability Predictions,Conceptual Phase,C U C,C I I,C I C,C I C,C I C,C C I
Apportionments FMEA's Specification Reliability Req. Mission Profile Human Eng. and Maint. Parts and Materials Test Requirements,Design Phase,U C C C I I C,U C C C C I C,I C C C C I C,C C C I I I C,I I I C I I C,C C C C U U C
Change Control Critical Items FR's and Corrective Action,Development Phase,C C U,C C I,C C C,C C I,C I I,C I I
Reliability Assessments MRB Configuration Control Program Reviews Contractor Audits by Center,Fabrication Phase,I C C U I,I I C U I,U C C I I,U C C I I,U I C I I,I I C I I
Qualification Tests Qual. Status List Reliability Demo. Test EI Accept. Tests Checkout Equipment Logs Buy-Off,Ground Test Phase,C U I C C I I,I I I C I I I,I C I C I U U,I U U I I U U,I I U I I U U,I I U I U U U
Issues Encountered
Loss of Original Formatting: In the Apollo Space Program Document, the table was originally designed with vertical text intended to serve as headers or labels. Textract reorients this vertical text into a horizontal format, thereby disrupting the intended structure of the table. As a result, what were clearly distinct headings in the original layout became jumbled with the rest of the data, causing misalignment and fragmentation of information.
Ambiguity and Misinterpretation of Data: The reorientation of vertical text leads to ambiguity in the extracted output. For example, key headings such as “Phase,” “Figure,” and various status indicators become misaligned. In the key-value output, we see incomplete or misplaced values (e.g., “Phase: ,” and “I – Initiated:”), while the CSV output shows rows of data that no longer clearly correspond to their original headers. This misinterpretation can confuse downstream applications or human reviewers who depend on the precise mapping of headers to their associated data.
Loss of Spatial Context: Vertical text in tables often conveys crucial spatial context by delineating different sections or columns. When Textract rotates this text horizontally, it loses this spatial cue, leading to difficulties in distinguishing between different categories. The reoriented data, as seen in the CSV output, can result in merged or misplaced column headers and values, ultimately undermining the integrity of the dataset.
Key Features of Amazon Textract Explored via Sample Documents
These were the key features that we checked in analyzing the sample documents:
Forms: Textract’s ability to extract key-value pairs is evident, though layout nuances can sometimes be lost.
Tables: While the Table to CSV API is effective, orientation issues (as seen in the Apollo document) reveal limitations in handling complex layouts.
General Text: Basic text extraction works reliably; however, formatting details (such as vertical text) may require additional processing or post-extraction adjustments.
These evaluations demonstrate that while Amazon Textract offers robust OCR capabilities, certain document types—especially those with unique formatting challenges—can lead to extraction inaccuracies.
Strengths and Weaknesses of Amazon Textract
Amazon Textract is a robust and scalable solution for OCR and document parsing, but like any tool, it comes with its unique advantages and limitations.
Understanding these is key to determining when and how to best use Textract for your document processing needs.
Strength of Textract
Weakness of Textract
Robust APIs and Seamless AWS Integration: Textract offers well-documented and powerful APIs that integrate effortlessly with other AWS services. This seamless integration streamlines the development process and makes it easier to incorporate Textract into existing AWS-centric infrastructures.
Layout Preservation Challenges: Despite its strong OCR capabilities, Textract sometimes struggles to maintain the original document layout—especially with complex formatting—leading to inaccuracies that can disrupt workflows reliant on precise layout information.
Scalability for Enterprise Needs: Built to handle high volumes of documents, Textract scales efficiently for enterprise environments, ensuring reliable performance whether processing hundreds or millions of documents.
Cost Implications: Textract’s pricing structure, particularly when dealing with forms and tables, can add up quickly, making it a significant consideration for organizations with large-scale or highly detailed document processing needs.
Specific Use-Cases Where Textract Underperforms: Certain document formats, such as those with vertical text or intertwined forms and tables, can lead to extraction errors that require additional manual adjustments or supplemental processing.
When to Use Textract
These are some situations where using Textract can be recommended:
Ideal for AWS-Centric Environments: If your infrastructure is built on AWS, Textract’s seamless integration makes it a natural choice for automating document processing workflows.
Standard Document Formats and High-Volume Processing: Textract works best with documents that have conventional layouts. For large-scale processing of standard documents, its scalability and robust API offerings provide significant advantages.
Scenarios Requiring Enterprise-Level Automation: When your organization needs to automate document parsing at scale, Textract’s enterprise-grade performance and reliability can be a strong asset.
While Amazon Textract is a powerful tool with impressive scalability and integration capabilities, it may face challenges with layout preservation and certain specialized document formats.
It excels in environments with standard documents and robust AWS integration, but if you need precise layout retention or are dealing with complex document structures, you might need to consider alternative solutions or additional processing steps.
The next section will explore how LLMWhisperer addresses these challenges to offer a more refined solution.
Introducing LLMWhisperer as the Amazon Textract Alternative
LLMWhisperer is an innovative document parsing tool designed with a modern approach to handling OCR challenges, particularly in environments that rely on large language models (LLMs) for data extraction.
Here’s what sets it apart.
Core Philosophy and Capabilities: LLMWhisperer is built on the idea of maximizing layout preservation and enhancing parsing accuracy by leveraging advanced LLM techniques. Unlike traditional OCR tools, it focuses on understanding the context and structure of documents, ensuring that even complex layouts—such as vertical text or intertwined forms and tables—are maintained accurately in the extracted data.
Development Motivation: LLMWhisperer was developed as an alternative to solutions like Amazon Textract to address specific shortcomings. While Textract offers robust OCR capabilities, it often struggles with preserving document layouts and managing cost-intensive tasks such as form and table extraction.
LLMWhisperer’s Document Layout Preservation
Key Features and Advantages
LLMWhisperer is engineered to tackle the shortcomings found in traditional OCR solutions, making it particularly effective in modern, LLM-driven workflows.
Its standout features include:
Layout Preservation: LLMWhisperer excels at maintaining the original document structure, which is crucial for downstream LLM-based extraction workflows. This superior layout retention ensures that the context, formatting, and hierarchy of the document remain intact, leading to more accurate and meaningful data extraction.
Cost Efficiency: One of the key advantages of LLMWhisperer is its cost-effectiveness, particularly when dealing with forms and tables. By offering a more affordable solution compared to alternatives like Textract, LLMWhisperer makes it economically viable to process large volumes of complex documents without compromising on quality.
Enhanced Parsing: LLMWhisperer offers advanced parsing capabilities that handle challenging scenarios with ease. It is adept at processing vertical text and making a clear distinction between forms and tables, areas where traditional OCR tools often struggle. This enhanced parsing ability minimizes errors and reduces the need for post-processing corrections, streamlining your AI document extraction workflows.
Together, these features make LLMWhisperer a compelling choice for businesses looking to optimize their document processing, ensuring that both accuracy and cost-effectiveness are achieved in every workflow.
Targeted Use-Cases of LLMWhisperer
LLMWhisperer is specifically designed to address the challenges that traditional OCR solutions like Amazon Textract face, making it ideal in several scenarios:
LLM-Based Extraction Workflows: When downstream processes rely on large language models, maintaining the exact layout and structure of the original document is critical. LLMWhisperer preserves contextual and formatting details, ensuring that LLMs have a reliable foundation to work from.
Complex Document Formats: For documents featuring vertical text, intertwined forms and tables, or non-standard layouts, LLMWhisperer excels in accurately parsing and preserving the intended format. This capability minimizes errors that often arise when these elements are misinterpreted by conventional OCR tools.
Cost-Sensitive Environments: In situations where processing large volumes of forms and tables is necessary, costs can quickly escalate. LLMWhisperer’s cost efficiency makes it a compelling choice, offering high-quality extraction without the premium price tag associated with some traditional solutions.
Specialized Business Documents: Industries that deal with specialized or regulatory documents—such as healthcare, finance, or government forms—often require meticulous layout preservation to ensure data accuracy and compliance. LLMWhisperer’s enhanced parsing capabilities are particularly well-suited for these use cases, providing clear differentiation between similar-looking elements like forms versus tables.
Scenarios Requiring Minimal Post-Processing: When extracted data needs to be immediately actionable, reducing the need for extensive post-processing is crucial. By delivering more precise and well-structured outputs, LLMWhisperer reduces the time and effort required to clean and reformat data after extraction.
In these targeted use cases, LLMWhisperer not only addresses the shortcomings of existing tools but also enhances overall efficiency and reliability, making it a superior choice for modern OCR and document parsing needs.
LLMWhisperer Setup Process
Getting started with LLMWhisperer is straightforward, whether you’re integrating it into an existing application or using it as a standalone tool.
Follow these steps to set up LLMWhisperer and begin processing your documents.
Sign Up and Obtain API Credentials:
Register: Visit the LLMWhisperer website and create an account.
API Key: Once registered, navigate to your dashboard to generate and retrieve your API key. This key will be required to authenticate all API calls.
Install the LLMWhisperer Python SDK:
pip install llmwhisperer-client
By following these steps, you can quickly set up and integrate LLMWhisperer into your document processing workflow, allowing you to take full advantage of its superior layout preservation, cost efficiency, and enhanced parsing capabilities.
Evaluating LLMWhisperer Using Sample Documents
To determine how well LLMWhisperer performs in real-world scenarios, we applied it to the same set of sample documents seen before.
First, let’s take a look at the Python code, which uses the LLMWhisperer new V2 API:
# llmwhisperer_example.py
import sys
from unstract.llmwhisperer import LLMWhispererClientV2
from unstract.llmwhisperer.client_v2 import LLMWhispererClientException
# Define a function to process a document
def process_document(file_path):
# Provide the base URL and API key explicitly
client = LLMWhispererClientV2(base_url="https://llmwhisperer-api.us-central.unstract.com/api/v2",api_key="")
try:
# Process the document
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
)
# Print the extracted text
print(result['extraction']['result_text'])
except LLMWhispererClientException as e:
print(e)
# Main function
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python script.py <PDF file>")
sys.exit(1)
process_document(sys.argv[1])
Don’t forget to replace api_key with your own API key.
Here’s a breakdown of what the code does:
process_document(file_path): This function takes a file path as an argument and processes the document located at that path.
It initializes an LLMWhispererClientV2 object with a specified base URL and API key.
It attempts to process the document using the whisper method of the client, waiting for the completion of the process with a timeout of 200 seconds.
If successful, it prints the extracted text from the document.
If an exception occurs (specifically LLMWhispererClientException), it catches the exception and prints the error message.
You can execute the script with:
python llmwhisperer_example.py my-document.pdf
Below is a detailed evaluation of how LLMWhisperer performs on each implementation with the different sample documents.
OSHA Form (Operational Health and Health Administration)
Observation: LLMWhisperer has demonstrated exceptional capability in preserving the original layout of the OSHA form. The vertical text is rendered in its intended orientation, with no evidence of the reflow or misalignment issues observed in other OCR tools. Additionally, checkboxes are distinctly recognized and correctly marked, ensuring that both selected and unselected states are clearly identifiable.
Details: The output from LLMWhisperer mirrors the original form structure with remarkable fidelity. Every element—from form labels and data fields to the orientation of vertical text and checkboxes—is accurately captured. The preservation of vertical text is particularly noteworthy, as it maintains the spatial and contextual relationships essential for accurate data interpretation. Furthermore, the checkboxes are processed with precision, eliminating ambiguity that can arise from misinterpreted selections. This high level of accuracy minimizes the need for manual corrections and ensures that any subsequent data extraction or analysis is based on reliable and well-structured information.
Live coding session on data extraction from a scanned PDF form with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in scanned PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
FICUS BANK
4321 Random Boulevard · Somecity, ST 12340 Save this Loan Estimate to compare with your Closing Disclosure.
Loan Estimate LOAN TERM 30 years
PURPOSE Purchase
DATE ISSUED 2/15/2013 PRODUCT Fixed Rate
APPLICANTS Michael Jones and Mary Stone LOAN TYPE [X] Conventional [ ] FHA [ ] VA [ ]
123 Anywhere Street LOAN ID # 123456789
Anytown, ST 12345 RATE LOCK [ ] NO [X] YES, until 4/16/2013 at 5:00 p.m. EDT
PROPERTY 456 Somewhere Avenue Before closing, your interest rate, points, and lender credits can
Anytown, ST 12345 change unless you lock the interest rate. All other estimated
SALE PRICE $180,000 closing costs expire on 3/4/2013 at 5:00 p.m. EDT
Loan Terms Can this amount increase after closing?
Loan Amount $162,000 NO
Interest Rate 3.875% NO
Monthly Principal & Interest $761.78 NO
See Projected Payments below for your
Estimated Total Monthly Payment
Does the loan have these features?
Prepayment Penalty YES . As high as $3,240 if you pay off the loan during the
first 2 years
Balloon Payment NO
Projected Payments
Payment Calculation Years 1-7 Years 8-30
Principal & Interest $761.78 $761.78
Mortgage Insurance + 82 +
Estimated Escrow + 206 + 206
Amount can increase over time
Estimated Total
Monthly Payment $1,050 $968
This estimate includes In escrow?
[X] Property Taxes YES
Estimated Taxes, Insurance $206 YES
[X]
& Assessments Homeowner's Insurance
Amount can increase over time a month [ ] Other:
See Section G on page 2 for escrowed property costs. You must pay for other
property costs separately.
Costs at Closing
Estimated Closing Costs $8,054 Includes $5,672 in Loan Costs + $2,382 in Other Costs - $0
in Lender Credits. See page 2 for details.
Estimated Cash to Close $16,054 Includes Closing Costs. See Calculating Cash to Close on page 2 for details.
Visit www.consumerfinance.gov/mortgage-estimate for general information and tools.
LOAN ESTIMATE PAGE 1 OF 3 . LOAN ID # 123456789
<<<
LLMWhisperer Output Analysis
Observation: LLMWhisperer demonstrates outstanding performance by capturing every form element with comprehensive detail. In the output, every label—from headers to sub-sections—is present, and all corresponding values are accurately extracted. Unlike other OCR solutions that might leave gaps or omit critical fields, LLMWhisperer ensures that no element is missing, preserving the logical relationship between labels and their associated values.
Details: The output provides a complete mapping of the form, reflecting the structure and hierarchy of the original document. Each data point is not only extracted but also aligned correctly with its corresponding label. For example, financial figures, dates, and text entries are all positioned exactly as they appear on the original form. This meticulous attention to detail means that numerical data retains its formatting (such as currency symbols and decimal points) and text fields are fully captured without truncation. The spatial and contextual alignment of the extracted elements mirrors the original layout, making it easier to verify and validate the data. Furthermore, the output shows that checkboxes and other selection elements are clearly marked, providing an unambiguous representation of user inputs. This level of accuracy significantly reduces the need for any manual correction or post-processing, ensuring that the data is immediately ready for downstream applications.
The overall summary of reliability and quality status on those items of flight hardware
which have been designated for the Apollo-Saturn 201 Mission appears in Figure 3-4.
The measurement yardstick used as a base is derived from the phased program ele-
ments of NPC 500-5, "Apollo Reliability and Quality Assurance Program Plan" (2).
NPC-500-5 Engines Booster CSM
SLA
Program Elements H-1 J-2 S-IB S-IVB IU
Reliability Goals Conceptual C C C C C C
R&QA Plan Phase U I I I I C
Reliability Predictions C I C C C I
Apportionments U U I C I C
FMEA's C C C C I C
Specification Reliability Req. C C C C I C
Mission Profile Design C C C I C C
Human Eng. and Maint. Phase I C C I I U
Parts and Materials I I I I I U
Test Requirements C C C C C
Change Control C C C C C C
Critical Items Development C C C C I I
FR's and Corrective Action Phase U I C I I I
Reliability Assessments I I U U U I
MRB Fabrication C I C C I I
Configuration Control Phase C C C C C C
Program Reviews U U I I I I
Contractor Audits by Center I I I I I I
Qualification Tests C I I I I I
Qual. Status List U I C U I I
Reliability Demo. Test Ground Test I I I U U U
EI Accept. Tests Phase C C C I I I
Checkout C I I I I U
U U
Equipment Logs I I U U
Buy-Off I I U U U U
Key
C - Complete
I - Initiated
U - Status Unknown
Figure 3-4. Apollo-Saturn 201 Vehicle Reliability and Quality Program Status
3-3
<<<
LLMWhisperer Output Analysis
Observation: This document features tables that incorporate vertical text—a format that many OCR tools struggle to interpret accurately. While other solutions often rotate or misinterpret such text, LLMWhisperer successfully recognizes and maintains the vertical orientation as it appears in the original document. This capability is crucial, as vertical text typically serves as headers or key labels that define the structure and meaning of the table.
Details: The extracted table produced by LLMWhisperer retains the exact structure of the original document. The vertical text elements remain correctly oriented, preserving their spatial relationship to the corresponding data cells. This means that headers, labels, and any text presented vertically are not rotated or misplaced, ensuring that the hierarchy and categorization within the table are clear. As a result, the risk of misinterpretation or data misalignment is greatly reduced. The precise preservation of vertical text enables accurate mapping of each column and row, allowing for seamless integration of the extracted data into further processing workflows.
Key Features of LLMWhisperer Explored via Sample Documents
With the analysis of the sample documents, we tested some of the key features of LLMWhisperer:
Layout Preservation: Across all tested documents, LLMWhisperer consistently maintains the original document structure. This is crucial for workflows relying on accurate layout information for LLM-based processing.
Enhanced Parsing: The tool demonstrates an advanced understanding of complex formats, effectively differentiating between forms and tables and accurately processing vertical text.
Consistency: Regardless of the document’s complexity, LLMWhisperer delivers consistent, high-quality outputs, reducing the need for manual corrections and additional post-processing.
These evaluations clearly illustrate that LLMWhisperer not only meets but exceeds expectations in preserving document integrity and handling challenging formats, making it a standout choice for modern OCR and document parsing workflows.
Comparative Analysis: Textract vs. LLMWhisperer
Performance on Sample Test Documents
Test Document
Text Extraction Service
Observation
OSHA Form
Textract
Textract struggles with vertical text, often misinterpreting its orientation. Additionally, the tool sometimes mishandles checkboxes, leading to ambiguity in the extracted data.
LLMWhisperer
LLMWhisperer demonstrates superior handling of the OSHA form. It accurately preserves the vertical text orientation and clearly distinguishes checkboxes, ensuring that every element of the form is captured as intended.
Loan Estimate Form
Textract
When processing the Loan Estimate form, Textract occasionally misses key form elements. This incomplete extraction results in gaps where some field labels and values are not properly recognized or associated.
LLMWhisperer
LLMWhisperer excels with the Loan Estimate form by capturing all form elements with high accuracy. Its output reflects a complete and organized mapping of the form, maintaining the necessary associations between labels and their values.
Apollo Space Program Document
Textract
For the Apollo Space Program document, which includes tables with vertical text, Textract tends to reorient the vertical text into a horizontal layout. This alteration can disrupt the intended structure of the data, making it harder to interpret.
LLMWhisperer
LLMWhisperer effectively parses the Apollo document by correctly preserving the vertical orientation of text within tables. This accurate extraction maintains the integrity of the document’s original layout, ensuring that the data is both reliable and immediately usable.
In summary, while Textract delivers robust functionality for standard document processing, LLMWhisperer clearly outperforms it in scenarios involving complex layouts—particularly with vertical text and intricate form structures—making it the more reliable choice for precise and context-aware document parsing.
Textract vs. LLMWhisperer: Pricing Comparison
When evaluating OCR solutions like Textract and LLMWhisperer, pricing plays a crucial role, especially for organizations processing large volumes of documents or working with complex layouts.
Below is a detailed breakdown of their cost structures and an analysis of their cost-effectiveness:
Service
Pricing Model
Estimated Cost per 1,000 Pages
Additional Costs
Textract
Pay-as-you-go, based on pages processed
Varies by document type (e.g., plain text, forms, tables)
Extra fees for form and table analysis
LLMWhisperer
Subscription-based or pay-per-use
Generally lower for structured documents
No additional cost for layout preservation
Cost-Effectiveness Analysis
Textract: While Textract offers strong integration with AWS services, its pricing can quickly add up, particularly for complex documents containing forms, tables, or vertical text. Organizations processing large-scale document batches may find these costs significant.
LLMWhisperer: LLMWhisperer provides a more cost-effective alternative for structured documents, as it does not charge extra for maintaining layout integrity. This makes it a better choice for businesses dealing with complex document structures on a regular basis.
Best Use Cases Based on Pricing
Textract is ideal for: Organizations already embedded in the AWS ecosystem that prioritize seamless integration over cost.
LLMWhisperer is better suited for: Businesses handling high volumes of structured documents that require precise layout preservation at a predictable or lower cost.
Overall, while Textract remains a competitive solution within AWS, LLMWhisperer may offer better value for organizations needing accurate, layout-preserving OCR without excessive additional costs.
Textract vs. LLMWhisperer: Overall Evaluation
Both Textract and LLMWhisperer are powerful OCR solutions, but they excel in different areas.
While Textract offers deep integration with AWS and a solid foundation for text extraction, LLMWhisperer outperforms it in critical aspects such as layout preservation, structured data extraction, and handling of complex document formats. These advantages make LLMWhisperer the preferable Textract alternative.
Key Areas of Parity
Basic OCR Performance: Both tools effectively extract standard printed text from documents.
Scalability: Each solution is designed to handle high-volume document processing, making them viable for enterprise use.
API Availability: Both provide well-documented APIs, allowing developers to integrate them into existing workflows.
Where LLMWhisperer Provides a Significant Edge Over Textract
Layout Preservation: Unlike Textract, which often distorts tables and vertical text, LLMWhisperer accurately maintains the original document structure.
Form and Table Extraction: LLMWhisperer ensures that labels, values, and checkboxes are correctly associated, reducing errors in structured data extraction.
Vertical Text Handling: While Textract frequently misinterprets vertical text by reorienting it, LLMWhisperer retains it as intended, improving accuracy.
Cost-Effectiveness: For businesses working with structured documents, LLMWhisperer provides better value by avoiding additional fees for preserving complex layouts.
If you want to quickly take it for test drive, you can checkout our free playground.
Learn how faithfully reproducing the structure of tables and other elements by preserving the original PDF layout is crucial for better performance in LLM and RAG applications.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.