Best OCR Software in 2025 — A Tool Comparison & Evaluation Guide
Table of Contents
Introduction
Optical Character Recognition (OCR) technology has become indispensable in today’s digital landscape.
By converting various document types—such as scanned papers, PDF files, and images—into editable and searchable text, OCR software significantly enhances productivity and efficiency.
This is particularly crucial in industries that handle large volumes of documents, including finance, healthcare, legal, and education.
The effectiveness of OCR software can greatly impact workflows, data accuracy, and overall operational efficiency. As businesses increasingly rely on digital transformation, selecting the right OCR tool is more important than ever.
This article aims to provide a comprehensive overview of the best OCR software available in 2025. We will compare their features, capabilities, and performance to help you make an informed decision.
This article provides a comprehensive overview of the top OCR tools in 2025. We will compare:
OCR software is a powerful tool designed to interpret and convert different types of documents—such as scanned papers, PDF files, and images—into machine-readable text.
This technology is widely used in various applications, including data entry, archiving, document management, and digital transformation initiatives.
By converting physical or static digital documents into editable and searchable text, OCR software enables businesses to streamline workflows, improve data accessibility, and enhance overall operational efficiency.
How Does OCR Software Work?
OCR software works by analyzing the shapes and patterns of characters in document images and converting them into corresponding text characters.
The process typically involves several steps:
Image Pre-processing:
Enhancement: Improving the quality of the document image by adjusting brightness, contrast, and resolution.
Noise Reduction: Removing any unwanted artifacts or distortions that could interfere with text recognition.
Binarization: Converting the image to a binary format (black and white) to simplify the recognition process.
Character Recognition:
Segmentation: Identifying and separating individual characters, words, and lines of text within the image.
Pattern Matching: Comparing the shapes of characters in the image with a predefined set of character templates to determine the corresponding text.
Machine Learning: Utilizing advanced algorithms and neural networks to improve recognition accuracy, especially for complex or handwritten text.
Post-processing:
Error Correction: Identifying and correcting any errors in the recognized text, such as misspelled words or incorrect characters.
Formatting: Applying appropriate formatting to the text, including paragraphs, headings, and tables, to maintain the original document structure.
Validation: Verifying the accuracy of the recognized text through various checks, such as dictionary lookups and context analysis.
If your solution involves using Large Language Models(LLMs) to process and extract document data:
LLMs are powerful, but their output is as good as the input you provide. Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables.
LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they’re able to best understand it.
When selecting OCR software, it’s important to consider the following features to ensure it meets your specific needs:
Accuracy: The ability to correctly recognize and convert text, even in challenging conditions such as low-quality images, handwritten text, or complex layouts.
Language Support: Compatibility with multiple languages, including support for special characters, accents, and non-Latin text.
Speed: The processing speed, especially for large documents or high-volume workflows, to ensure efficient and timely conversion.
Ease of Integration: Ability to integrate seamlessly with other software systems, such as document management systems, enterprise resource planning (ERP) systems, and customer relationship management (CRM) platforms.
Cost: Evaluating whether the software is free or paid, and assessing its cost-effectiveness based on your specific requirements and budget.
User Interface: The ease of use and intuitiveness of the software’s interface, ensuring that users can quickly learn and effectively utilize its features.
Customization: The ability to customize the software to meet specific needs, such as adding custom dictionaries, training the OCR engine with specific fonts, or configuring workflows.
Security: Ensuring that the software provides robust security measures to protect sensitive data, including encryption, access controls, and compliance with industry standards.
Comparing Locally Runnable OCR Software
For reference, the sample documents used to test the different libraries are these:
Tesseract OCR is an open-source tool for recognizing text in images. It was first created by Hewlett-Packard and later made open-source by Google. It is known for being very accurate and flexible, which makes it one of the most popular OCR tools available.
Main Features and Capabilities:
Neural Network-Based Recognition: Tesseract 4 introduced a new OCR engine based on Long Short-Term Memory (LSTM) neural networks, which greatly improves accuracy, especially for recognizing lines of text. It still works with the older OCR engine from Tesseract 3.
Broad Language Support: Tesseract can recognize over 100 languages right out of the box, including support for Unicode (UTF-8), which covers a wide range of character sets.
Diverse Output Formats: It supports various output formats such as plain text, hOCR (HTML), PDF, TSV, ALTO, and PAGE, making it adaptable for different uses.
Image Format Compatibility: Tesseract can process various image formats including PNG, JPEG, and TIFF. However, to get the best OCR results, the quality of the input image often needs to be improved.
No Built-In GUI: Tesseract primarily operates via the command line, but there are several third-party graphical user interfaces (GUIs) available for those who prefer a visual interface.
Custom Training Capabilities: Users can train Tesseract to recognize new languages or improve their accuracy with specific fonts or handwriting styles. This makes it highly customizable for specialized OCR needs.
Installation and Setup Process
Here’s how you can install and set up Tesseract OCR using Python:
First, you need to make sure that you have the Tesseract OCR library installed, details here.
Then you can install a Python wrapper, in this case will use tesserocr, more details about the wrapper are here. For installation requirements of the wrapper, you can check the official GitHub page.
Since Tesseract OCR cannot process PDF files directly, we need to first extract the contents of the sample PDF files into images.
For this, we will use the library pypdfium2 and also the PIL library for additional image support:
pip install pillow pypdfium2
Then we can write the following code to perform the OCR from the sample documents:
import tesserocr
import pypdfium2 as pdfium
# Load a document
pdf = pdfium.PdfDocument("bill-of-sale.pdf")
# Loop over pages and render
for i in range(len(pdf)):
page = pdf[i]
image = page.render(scale=5).to_pil()
print(tesserocr.image_to_text(image))
Here’s a description of what the code does:
The script loads a PDF document named “bill-of-sale.pdf” using pdfium.PdfDocument.
It then loops over each page in the PDF:
The page is rendered as an image with a scale factor of 5 (to increase the resolution) using page.render(scale=5).to_pil(). The to_pil() method converts the rendered image to a PIL (Pillow) image object.
The tesserocr.image_to_text(image) function is used to perform OCR on the image and extract text, which is then printed to the console.
Performance Test
We tested Tesseract against the two sample documents. Here are the results:
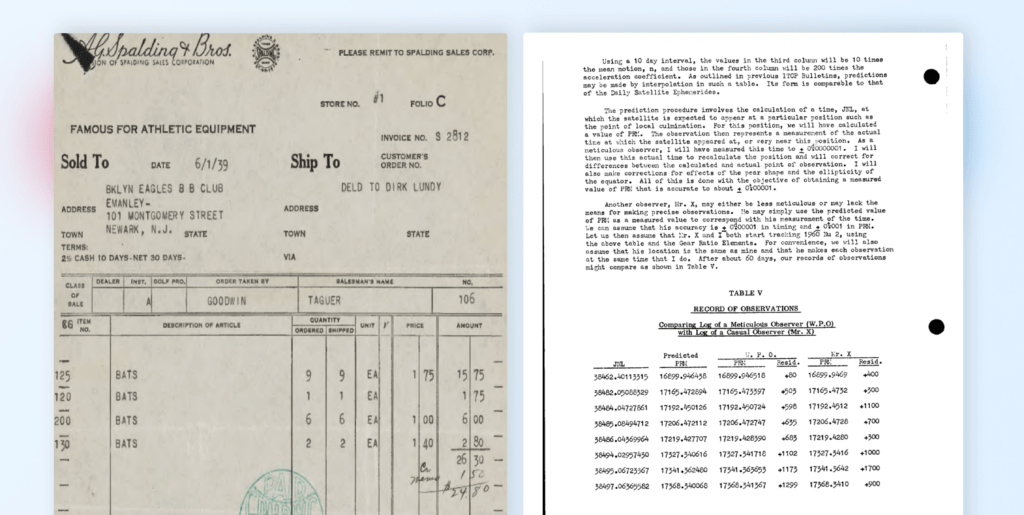
Document 1: Medium accuracy, missed several of the items lines of the bill of sale.
PION OF SPALDING SALES CORPORATION
FAMOUS FOR ATHLETIC EQUIPMENT
Sold To 6/1/39
BKLYN EAGLES 8 B CLUB
EMANLEY -
101 MONTGOMERY STREET
NEWARK, N.J.
DATE
ADDRESS
TOWN STATE
TERMS:
2% CASH [0 DAYS-NET 30 DAYS-
PLEASE REMIT TO SPALDING SALES CORP,
a oi ¢
STORE NO.
INVOICE No. S 2812
CUSTOMER'S
ORDER NO.
DELD TQ DIRK LUNDY
Ship To
ADDRESS
TOWN
VIA
Class | OEALER
Inst, |GOLF PRO,| ORDER TAKEN BY
-- -- --
NO,
SALESMAN'S NAME
OF
BALE GOODWIN
TAGUER
RB ITEM
NO DESCRIPTION OF ARTICLE
125
120
200
130
Form F 71 139-M
3 | 106
AMOUNT
QUANTITY
ORDERED | SHIPPED
15| 75
175
00
80
30
xe
bie
6
2
26
/
Y
NO RETURN OF MERCHANDISE FROM THIS INVOICE WILL BE ACCEPTED UNLESS YOU HAVE OUR WRITTEN PERMISSION.
Document 2: High accuracy, extracted almost completely the total information from the document
Using a 10 day interval, the values in the third column will be 10 times
the mean motion, n, and those in the fourth column will be 200 times the
acceleration coefficient. As outlined in vrevious I1TCP Bulletins, predictions
may ve made by interpolation in sucn a table. Its form is comparable to that
of the Daily Satellite Ephenmerides.
The prediction procedure involves the calculation of a time, JNL, at
which the satellite is expected to appear at a particular position such as
the point of local culmination. For this position, we will have calculated
a value of PRY. The observation then represents a measurement of the actual
time at which the satellite appeared at, or very near this position. As &
meticulous observer, I will have measured this time to + ofo0000001. I will
then use this actual time to recalculate the position and will correct for
differences between the calculated and actual point of observation. I will
also make corrections for effects of the pear shape and the ellipticity of
the equator. All of this is done with the objective of obtaining a measured
value of PRM that is accurate to about + 0%00001.
Another observer, Mr. X, may either be less meticulous or may lack the
means for making precise observations. l!e may simply use the predicted value
of PRM as a measured value to correspond with his measurement of the time.
Ge can assume that his accuracy is + of00001 in timing and + otoot in PRM.
Let us then assume that Mr. X and I both start tracking 1960 Nu 2, using
the above table and the Gear Ratio Elements. For convenience, we will also
assume that his location is the same as mine and that he makes each observation
at the same time that I do. After about 60 days, our records of observations
night compare as shown in Table V.
TABLE V
RECORD OF OBSERVATIONS
Comparin of a Meticulous Observer (W.P.O
with of a Casual Observer -X
Predicted Wie P.O. Kr. X
JNL PRM PRN st«éRR@SAd PRY. Resid.
58462.40113315 16699.946438 16899.946518 +80 16899.9469 +400
3848205088329 171656472894 171654473397 = 4503 1716544752 = +300
38484.04727861 17192.450126 17192450724 4598 1719264512 +1100
3848508494712 172060472112 172066472747 = +635 172064728 = +700
38486 604369964 17219427707 172194428590 4683 1721924280 +300
38494 .02957430 173272340616 175276341718 = +1102 1732723416 +1000
38495 .06723367 173410362480 = 173410565653 «+1173 --17341.5642 = +1700
38497 006365582 173684340068 173682341367 +1299 =: 1736823410 = +900
Wie can assume thet Mr. X's values of JNL will be the same as mine (in the first
column) except that they will include only five digits to the right of the
decimal.
In the above table, each "residual" column represents the difference
between the observed valuesand the predicted values, which are in the second
column. As we proceed, Mr. X and I will both plot these residuals against time,
as shown in Figure 2.
12
Paddle OCR
PaddleOCR is a free, open-source toolkit for OCR created by the PaddlePaddle community.
It’s designed to be practical and lightweight, supporting over 80 languages, which makes it very versatile for many different OCR uses.
Built on the advanced deep learning framework PaddlePaddle, it offers strong tools for training, deploying, and integrating OCR models on various platforms like servers, mobile devices, embedded systems, and IoT devices.
Key Features of PaddleOCR:
Multilingual Support: PaddleOCR can recognize over 80 languages, including complex ones like Chinese, Japanese, and Korean. This makes it a global solution for OCR needs.
Comprehensive Tools: The toolkit provides a full set of tools for OCR tasks, from labeling data and training models to compressing models and deploying them. This includes high-quality models like PP-OCR, PP-Structure, and PP-ChatOCR, which are optimized for different OCR tasks.
Deployment Flexibility: PaddleOCR is designed to be easily used on various platforms. Whether you’re working on a server, a mobile app, or an embedded system, PaddleOCR has the tools and support to integrate OCR capabilities efficiently.
Lightweight and Fast: One of the main goals of PaddleOCR is to stay lightweight and fast without losing accuracy. This makes it great for real-time applications where performance is important.
Community and Documentation: PaddleOCR has an active community behind it, offering lots of documentation and resources to help developers get started and solve problems. The project is licensed under Apache License 2.0, which encourages its wide use and contributions.
Installation and Setup Process
To install Paddle OCR, the following command can be used:
pip install paddlepaddle paddleocr
This will install Paddle OCR with CPU support. If we want to use GPU support, we can run:
pip install paddlepaddle-gpu paddleocr
Then we can write the following code:
from paddleocr import PaddleOCR, draw_ocr
import pypdfium2 as pdfium
from PIL import Image
# Load a document
pdf = pdfium.PdfDocument("bill-of-sale.pdf")
# Initialize PaddleOCR and load English model
ocr = PaddleOCR(use_angle_cls=True, lang='en')
# Loop over pages and render
for i in range(len(pdf)):
page = pdf[i]
image = page.render(scale=5).to_pil()
image.save(f'image{i}.jpg')
# OCR the image
result = ocr.ocr(f'image{i}.jpg', cls=True)
for idx in range(len(result)):
res = result[idx]
# Print the OCR result
for line in res:
print(line)
# Optionally, draw the OCR result on the image
result = result[0]
image = Image.open(f'image{i}.jpg').convert('RGB')
boxes = [line[0] for line in result]
texts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, texts, scores, font_path='C:\\\\Windows\\\\Fonts\\\\Arial.ttf')
im_show = Image.fromarray(im_show)
im_show.save(f'result{i}.jpg')
Performance Test
We tested PaddleOCR on the same two sample documents:
Document 1: High accuracy, extracted almost completely the total information from the document
Document 2: High accuracy, extracted almost completely the total information from the document
[[[553.0, 311.0], [2408.0, 298.0], [2408.0, 359.0], [554.0, 373.0]], ('Using a 10 day interval, the values in the third colurn will be 10 times', 0.9857205152511597)]
[[[434.0, 417.0], [2430.0, 403.0], [2431.0, 460.0], [434.0, 474.0]], ('acceleration coefficient. As outlined in previous ITcp Bulletins, predictions', 0.9794966578483582)]
[[[434.0, 469.0], [2404.0, 452.0], [2404.0, 513.0], [434.0, 531.0]], ('may be made by interpolation in such a table. Its form is comparable to that', 0.9822374582290649)]
[[[438.0, 517.0], [1346.0, 517.0], [1346.0, 574.0], [438.0, 574.0]], ('of the Daily Satellite Ephenerides.', 0.9848372340202332)]
[[[562.0, 632.0], [2315.0, 623.0], [2316.0, 684.0], [562.0, 693.0]], ('The prediction procedure involves the calculation of a time, JNL, at', 0.99403977394104)]
[[[438.0, 689.0], [2337.0, 675.0], [2338.0, 732.0], [439.0, 746.0]], ('which the satellite is expected to appear at a particular position such as', 0.9948274493217468)]
[[[438.0, 895.0], [2182.0, 881.0], [2183.0, 938.0], [439.0, 952.0]], ('meticulous observer, I will have measured this time to + Odoooooo1.', 0.9829939603805542)]
[[[2183.0, 886.0], [2355.0, 886.0], [2355.0, 930.0], [2183.0, 930.0]], ('I will', 0.996565580368042)]
[[[443.0, 943.0], [2342.0, 930.0], [2342.0, 991.0], [443.0, 1004.0]], ('then use this actual time to recalculate the position and will correct for', 0.9911159873008728)]
[[[447.0, 996.0], [2165.0, 987.0], [2165.0, 1044.0], [447.0, 1053.0]], ('differences between the calculated and actual point of observation..', 0.9875534176826477)]
[[[2200.0, 991.0], [2355.0, 991.0], [2355.0, 1035.0], [2200.0, 1035.0]], ('I will', 0.9729122519493103)]
[[[438.0, 1048.0], [2346.0, 1035.0], [2347.0, 1092.0], [439.0, 1105.0]], ("also make corrections for effects of' the pear shape and the ellipticity of.", 0.9852278828620911)]
[[[757.0, 1096.0], [2390.0, 1087.0], [2391.0, 1144.0], [757.0, 1153.0]], ('All of this is done with the objective of obtaining a measured', 0.9988162517547607)]
[[[452.0, 1110.0], [775.0, 1110.0], [775.0, 1153.0], [452.0, 1153.0]], ('the equator..', 0.9692018032073975)]
[[[566.0, 1250.0], [2368.0, 1237.0], [2369.0, 1298.0], [567.0, 1311.0]], ('Another observer, Mr. X, may either be less meticulous or may lack the', 0.9877793192863464)]
[[[438.0, 1303.0], [2417.0, 1289.0], [2417.0, 1346.0], [439.0, 1360.0]], ('means for making precise observations. He may simply use the predicted value', 0.9835277199745178)]
[[[438.0, 1351.0], [2337.0, 1337.0], [2338.0, 1399.0], [439.0, 1412.0]], ('of PRt as a measured value to correspond with his measurement of the time.', 0.9732710123062134)]
[[[438.0, 1403.0], [2342.0, 1390.0], [2342.0, 1447.0], [439.0, 1460.0]], ('Fhdd ut loogo+ pue 3ugngg ut loooopo+ st Ronannn sty goyn aunsse uuo a!', 0.5953871011734009)]
[[[443.0, 1452.0], [2297.0, 1443.0], [2298.0, 1500.0], [443.0, 1509.0]], ('Let us then assune that lr. X and I both start tracking 1960 Nu 2, using', 0.97115159034729)]
[[[1447.0, 1553.0], [2470.0, 1543.0], [2471.0, 1601.0], [1448.0, 1610.0]], (' mine and that he makes each observation', 0.9914621114730835)]
[[[447.0, 1566.0], [1470.0, 1557.0], [1470.0, 1601.0], [447.0, 1610.0]], ('assume that his location is the same as.', 0.9801846742630005)]
[[[443.0, 1658.0], [1328.0, 1653.0], [1328.0, 1715.0], [443.0, 1719.0]], ('might conpare as shown in Table V.', 0.9593335390090942)]
[[[1386.0, 1833.0], [1616.0, 1833.0], [1616.0, 1881.0], [1386.0, 1881.0]], ('TABLE V', 0.9975382089614868)]
[[[1142.0, 1930.0], [1846.0, 1930.0], [1846.0, 1987.0], [1142.0, 1987.0]], ('RECORD OF OBSERVATIONS', 0.9988337159156799)]
[[[925.0, 2035.0], [2085.0, 2030.0], [2085.0, 2087.0], [925.0, 2092.0]], ('Comparing Log of a Meticulous Observer (W.P.O)', 0.9923900961875916)]
[[[1045.0, 2088.0], [1965.0, 2083.0], [1966.0, 2144.0], [1045.0, 2149.0]], ('with Log of a Casual Observer (Mr. X)', 0.9935088157653809)]
[[[956.0, 2237.0], [1195.0, 2237.0], [1195.0, 2285.0], [956.0, 2285.0]], ('Predicted', 0.9988049268722534)]
[[[1492.0, 2237.0], [1704.0, 2237.0], [1704.0, 2285.0], [1492.0, 2285.0]], ('W. P. O.', 0.8736283183097839)]
[[[2054.0, 2232.0], [2191.0, 2232.0], [2191.0, 2280.0], [2054.0, 2280.0]], ('Mr. X', 0.9575027227401733)]
[[[1032.0, 2289.0], [1124.0, 2289.0], [1124.0, 2342.0], [1032.0, 2342.0]], ('PRM', 0.9898760318756104)]
[[[1974.0, 2285.0], [2063.0, 2285.0], [2063.0, 2333.0], [1974.0, 2333.0]], ('PR', 0.9861990213394165)]
[[[2225.0, 2283.0], [2382.0, 2265.0], [2388.0, 2326.0], [2231.0, 2344.0]], ('Resid.', 0.9992003440856934)]
[[[633.0, 2294.0], [717.0, 2294.0], [717.0, 2346.0], [633.0, 2346.0]], ('JNL', 0.8906293511390686)]
[[[1426.0, 2294.0], [1505.0, 2294.0], [1505.0, 2329.0], [1426.0, 2329.0]], ('PRM', 0.9811756014823914)]
[[[1690.0, 2295.0], [1848.0, 2284.0], [1852.0, 2336.0], [1694.0, 2347.0]], ('Resid.', 0.9998622536659241)]
[[[1749.0, 2368.0], [1842.0, 2368.0], [1842.0, 2421.0], [1749.0, 2421.0]], ('+80', 0.9984487891197205)]
[[[1899.0, 2359.0], [2169.0, 2359.0], [2169.0, 2421.0], [1899.0, 2421.0]], ('16899.9469', 0.9996829032897949)]
[[[2262.0, 2359.0], [2373.0, 2359.0], [2373.0, 2412.0], [2262.0, 2412.0]], ('+400', 0.9191010594367981)]
[[[505.0, 2377.0], [868.0, 2377.0], [868.0, 2434.0], [505.0, 2434.0]], ('38462.40113315', 0.9995452165603638)]
[[[934.0, 2377.0], [1248.0, 2377.0], [1248.0, 2425.0], [934.0, 2425.0]], ('16899.946438', 0.9993425011634827)]
[[[1315.0, 2373.0], [1629.0, 2373.0], [1629.0, 2421.0], [1315.0, 2421.0]], ('16899.946518', 0.9998354911804199)]
[[[1731.0, 2473.0], [1837.0, 2473.0], [1837.0, 2526.0], [1731.0, 2526.0]], ('+503', 0.9993162155151367)]
[[[1899.0, 2465.0], [2174.0, 2465.0], [2174.0, 2526.0], [1899.0, 2526.0]], ('17165.4732', 0.9999091029167175)]
[[[2267.0, 2465.0], [2377.0, 2465.0], [2377.0, 2517.0], [2267.0, 2517.0]], ('+300', 0.9997279644012451)]
[[[509.0, 2487.0], [868.0, 2487.0], [868.0, 2530.0], [509.0, 2530.0]], ('38482.05088329', 0.9956350922584534)]
[[[920.0, 2478.0], [1252.0, 2468.0], [1254.0, 2530.0], [922.0, 2540.0]], ('17165.472894', 0.9996970295906067)]
[[[1315.0, 2478.0], [1629.0, 2478.0], [1629.0, 2526.0], [1315.0, 2526.0]], ('17165.473397', 0.9995167851448059)]
[[[1731.0, 2574.0], [1842.0, 2574.0], [1842.0, 2627.0], [1731.0, 2627.0]], ('+598', 0.9998121857643127)]
[[[1899.0, 2565.0], [2178.0, 2565.0], [2178.0, 2627.0], [1899.0, 2627.0]], ('17192.4512', 0.9999018907546997)]
[[[500.0, 2579.0], [867.0, 2574.0], [868.0, 2635.0], [501.0, 2640.0]], ('38484.04727861', 0.9995495080947876)]
[[[1319.0, 2579.0], [1634.0, 2579.0], [1634.0, 2627.0], [1319.0, 2627.0]], ('17192.450724', 0.9986034035682678)]
[[[2240.0, 2570.0], [2377.0, 2570.0], [2377.0, 2618.0], [2240.0, 2618.0]], ('+1100', 0.9997634887695312)]
[[[934.0, 2583.0], [1248.0, 2583.0], [1248.0, 2631.0], [934.0, 2631.0]], ('17192.450126', 0.9997585415840149)]
[[[1319.0, 2679.0], [1629.0, 2679.0], [1629.0, 2728.0], [1319.0, 2728.0]], ('17206.472747', 0.9998332858085632)]
[[[1735.0, 2675.0], [1842.0, 2675.0], [1842.0, 2728.0], [1735.0, 2728.0]], ('+635', 0.999264121055603)]
[[[1908.0, 2675.0], [2174.0, 2675.0], [2174.0, 2723.0], [1908.0, 2723.0]], ('17206.4728', 0.9994878768920898)]
[[[2267.0, 2671.0], [2382.0, 2671.0], [2382.0, 2723.0], [2267.0, 2723.0]], ('+700', 0.9996985197067261)]
[[[500.0, 2684.0], [872.0, 2679.0], [872.0, 2741.0], [501.0, 2746.0]], ('38485.08494712', 0.9998096823692322)]
[[[939.0, 2684.0], [1253.0, 2684.0], [1253.0, 2732.0], [939.0, 2732.0]], ('17206.472112', 0.9997091889381409)]
[[[1727.0, 2761.0], [1853.0, 2774.0], [1846.0, 2839.0], [1720.0, 2827.0]], ('+683', 0.999439537525177)]
[[[1319.0, 2780.0], [1629.0, 2780.0], [1629.0, 2829.0], [1319.0, 2829.0]], ('17219.428390', 0.9997485280036926)]
[[[1904.0, 2772.0], [2178.0, 2772.0], [2178.0, 2833.0], [1904.0, 2833.0]], ('17219.4280', 0.9998974800109863)]
[[[2271.0, 2772.0], [2382.0, 2772.0], [2382.0, 2824.0], [2271.0, 2824.0]], ('+300', 0.9997367858886719)]
[[[504.0, 2785.0], [876.0, 2780.0], [877.0, 2842.0], [505.0, 2846.0]], ('38486.04369964', 0.9973931908607483)]
[[[939.0, 2789.0], [1248.0, 2789.0], [1248.0, 2837.0], [939.0, 2837.0]], ('17219.427707', 0.9997722506523132)]
[[[1898.0, 2877.0], [2181.0, 2867.0], [2183.0, 2929.0], [1901.0, 2939.0]], ('17327.3416', 0.9986153841018677)]
[[[2240.0, 2868.0], [2386.0, 2868.0], [2386.0, 2929.0], [2240.0, 2929.0]], ('+1000', 0.9997513890266418)]
[[[509.0, 2890.0], [877.0, 2890.0], [877.0, 2947.0], [509.0, 2947.0]], ('38494.02957430', 0.999668300151825)]
[[[929.0, 2886.0], [1256.0, 2876.0], [1258.0, 2938.0], [931.0, 2948.0]], ('17327.340616', 0.9951233267784119)]
[[[1319.0, 2881.0], [1634.0, 2881.0], [1634.0, 2929.0], [1319.0, 2929.0]], ('17327.341718', 0.9993224740028381)]
[[[1704.0, 2881.0], [1846.0, 2881.0], [1846.0, 2929.0], [1704.0, 2929.0]], ('+1102', 0.9996550679206848)]
[[[929.0, 2987.0], [1260.0, 2977.0], [1262.0, 3039.0], [931.0, 3048.0]], ('17341.362480', 0.9986879825592041)]
[[[1315.0, 2982.0], [1642.0, 2982.0], [1642.0, 3043.0], [1315.0, 3043.0]], ('17341.363653', 0.9986193776130676)]
[[[1704.0, 2986.0], [1842.0, 2986.0], [1842.0, 3035.0], [1704.0, 3035.0]], ('+1173', 0.9992446899414062)]
[[[1903.0, 2978.0], [2181.0, 2968.0], [2183.0, 3030.0], [1905.0, 3040.0]], ('17341.3642', 0.9991554021835327)]
[[[2245.0, 2978.0], [2382.0, 2978.0], [2382.0, 3026.0], [2245.0, 3026.0]], ('+1700', 0.9995923042297363)]
[[[509.0, 2991.0], [877.0, 2991.0], [877.0, 3048.0], [509.0, 3048.0]], ('38495.06723367', 0.9991346001625061)]
[[[1315.0, 3087.0], [1634.0, 3087.0], [1634.0, 3136.0], [1315.0, 3136.0]], ('17368.341367', 0.999509871006012)]
[[[1704.0, 3087.0], [1842.0, 3087.0], [1842.0, 3136.0], [1704.0, 3136.0]], ('+1299', 0.9989592432975769)]
[[[1908.0, 3079.0], [2178.0, 3079.0], [2178.0, 3140.0], [1908.0, 3140.0]], ('17368.3410', 0.9998946189880371)]
[[[2271.0, 3079.0], [2382.0, 3079.0], [2382.0, 3131.0], [2271.0, 3131.0]], ('006+', 0.9992048144340515)]
[[[509.0, 3096.0], [881.0, 3096.0], [881.0, 3153.0], [509.0, 3153.0]], ('38497.06365582', 0.9980858564376831)]
[[[929.0, 3092.0], [1260.0, 3082.0], [1262.0, 3144.0], [931.0, 3154.0]], ('17368.340068', 0.9978811144828796)]
[[[451.0, 3403.0], [2372.0, 3385.0], [2373.0, 3460.0], [452.0, 3478.0]], ('column) except that they will include only five digits to the right of the', 0.9924128651618958)]
[[[465.0, 3469.0], [682.0, 3469.0], [682.0, 3517.0], [465.0, 3517.0]], ('decimal.', 0.9990857243537903)]
[[[580.0, 3561.0], [2346.0, 3539.0], [2347.0, 3609.0], [581.0, 3631.0]], ('In the above table, each "residual" column represents the difference', 0.9948480129241943)]
[[[460.0, 3666.0], [2519.0, 3648.0], [2519.0, 3710.0], [461.0, 3728.0]], ('colunn. As we proceed, Mr. X and I will both plot these residuals against time,', 0.986700713634491)]
[[[460.0, 3723.0], [1014.0, 3723.0], [1014.0, 3780.0], [460.0, 3780.0]], ('as showm in Figure 2..', 0.9618627429008484)]
[[[1501.0, 3807.0], [1558.0, 3807.0], [1558.0, 3846.0], [1501.0, 3846.0]], ('12', 0.9994889497756958)]
LLMWhisperer: Best OCR to Extract Data from Handwritten Forms
Let’s see how to process challenging PDFs that contain hand-filled forms with elements like checkboxes and radiobuttons and also bad scan pages the unfriendly orientations with LLMWhisperer. LLMWhisperer is a text extraction service that specifically targets large language models (LLMs).
Comparing Cloud-Based OCR Services
Azure Document Intelligence
Azure Document Intelligence, which used to be called Azure Form Recognizer, is a cloud-based service from Microsoft Azure.
It offers advanced features for extracting text, key-value pairs, tables, and other structured data from documents.
This service is part of Azure’s AI and Cognitive Services, aimed at automating the processing and analysis of forms and documents on a large scale.
Key Features of Azure Document Intelligence:
Text Extraction and OCR: Azure Document Intelligence uses Optical Character Recognition (OCR) technology to accurately extract text from various document types like PDFs, images, and handwritten forms. It can handle both printed and cursive handwriting, making it useful for different situations.
Pre-built Models: The service provides ready-made models for specific document types, such as invoices, receipts, business cards, and ID documents. These models automatically recognize and extract relevant information, reducing the need for manual data entry.
Custom Models: Users can create custom models to recognize and extract data from documents with unique structures. This is particularly helpful for organizations working with specialized forms or documents that don’t fit standard templates.
Table Extraction: Azure Document Intelligence is excellent at extracting tables from documents, keeping the structure and relationships between cells intact. This is important for cases where tabular data needs to be imported into databases or spreadsheets.
Integration and Scalability: As a cloud service, Azure Document Intelligence can be easily integrated with other Azure services. This lets users build scalable document processing workflows and create end-to-end automation solutions with tools like Azure Logic Apps and Power Automate.
Security and Compliance: Being a Microsoft Azure service, it follows Azure’s strict security and compliance standards. This makes it suitable for handling sensitive documents and data in industries like finance, healthcare, and government.
Installation and Setup Process
First, you will need an account with Azure to retrieve your API credentials. You can sign up here and get 500 pages for free each month.
Then you can install the Python SDK with:
pip install azure-ai-documentintelligence
Now you can write the following code:
from azure.core.credentials import AzureKeyCredential
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.ai.documentintelligence.models import AnalyzeDocumentRequest
# set `<your-endpoint>` and `<your-key>` variables with the values from the Azure portal
endpoint = "<your-endpoint>"
key = "<your-key>"
def analyze_invoice():
# Create a Document Intelligence client
document_intelligence_client = DocumentIntelligenceClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
# Read PDF to bytes
with open("bill-of-sale.pdf", "rb") as f:
# Analyze the document
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-invoice", analyze_request=f, content_type="application/pdf"
)
invoices = poller.result()
print(invoices.content)
if __name__ == "__main__":
analyze_invoice()
Performance Test
Testing Azure Document Intelligence:
Document 1: High accuracy, recognized the majority of the invoice elements.
Al, Spalding & Bros.
SPALDING
PLEASE REMIT TO SPALDING SALES CORP.
SION OF SPALDING SALES CORPORATION
#1
STORE NO.
FOLIO C
FAMOUS FOR ATHLETIC EQUIPMENT
INVOICE NO.
S 2812
Sold To
6/1/39
Ship To
CUSTOMER'S
DATE
ORDER NO.
BKLYN EAGLES B B CLUB
DELD TO DIRK LUNDY
EMANLEY -
ADDRESS
101 MONTGOMERY STREET
ADDRESS
TOWN
NEWARK, N.J.
STATE
TOWN
STATE
TERMS:
2% CASH 10 DAYS-NET 30 DAYS-
VIA
CLASS
DEALER
INST.
GOLF PRO.
ORDER TAKEN BY
SALESMAN'S NAME
NO,
OF
BALE
A
GOODWIN
TAGUER
106
86
ITEM
QUANTITY
NO.
DESCRIPTION OF ARTICLE
ORDERED SHIPPED
UNIT
PRICE
AMOUNT
125
BATS
9
9
EA
1
75
15
75
120
BATS
1
1
EA
1
75
-
200
BATS
6
6
EA
1
00
6
00
1 30
BATS
2
2
EA
1
40
2
80
26
30
DI
/
50
-
$24.80
SEP 1 / 1933
-
Form F 21 1-39-M
NO RETURN OF MERCHANDISE FROM THIS INVOICE WILL BE ACCEPTED UNLESS YOU HAVE OUR WRITTEN PERMISSION.
Document 2: High accuracy, extracted the complete information from the document.
Using a 10 day interval, the values in the third column will be 10 times
the mean motion, n, and those in the fourth column will be 200 times the
acceleration coefficient. As outlined in previous ITCP Bulletins, predictions
may be made by interpolation in such a table. Its form is comparable to that
of the Daily Satellite Ephemerides.
The prediction procedure involves the calculation of a time, JNL, at
which the satellite is expected to appear at a particular position such as
the point of local culmination. For this position, we will have calculated
a value of PRM. The observation then represents a measurement of the actual
time at which the satellite appeared at, or very near this position. As a
meticulous observer, I will have measured this time to + 090000001. I will
then use this actual time to recalculate the position and will correct for
differences between the calculated and actual point of observation. I will
also make corrections for effects of the pear shape and the ellipticity of
the equator. All of this is done with the objective of obtaining a measured
value of PRM that is accurate to about + 0500001.
Another observer, Mr. X, may either be less meticulous or may lack the
means for making precise observations. He may simply use the predicted value
of PRM as a measured value to correspond with his measurement of the time.
We can assume that his accuracy is + 0900001 in timing and + 0f001 in PRM.
Let us then assume that Mr. X and I both start tracking 1960 Nu 2, using
the above table and the Gear Ratio Elements. For convenience, we will also
assume that his location is the same as mine and that he makes each observation
at the same time that I do. After about 60 days, our records of observations
might compare as shown in Table V.
TABLE V
RECORD OF OBSERVATIONS
Comparing Log of a Meticulous Observer (W. P.O)
with Log of a Casual Observer (Mr. X)
Predicted
V. P. 0.
Mr. X
JNL
PRM
PRM
Resid.
PRM
Resid.
38462.40113315
16899.946438
16899.946518
+80
16899.9469
+400
38482.05088329
17165.472894
17165.473397
+503
17165.4732
+300
38484.04727861
17192.450126
17192.450724
+598
17192.4512
+1100
38485.08494712
17206.472112
17206.472747
+635
17206.4728
+700
38486.04369964
17219.427707
17219.428390
¥683
17219.4280
+300
38494.02957430
17327.340616
17327.341718
+1102
17327.3416
+1000
38495.06723367
17341.362480
17341.363653
+1173
17341.3642
+1700
38497.06365582
17368.340068
17368.341367
+1299
17368.3410
+900
We can assume that Mr. X's values of JNL will be the same as mine (in the first
column ) except that they will include only five digits to the right of the
decimal.
In the above table, each "residual" column represents the difference
between the observed values and the predicted values, which are in the second
column. As we proceed, Mr. X and I will both plot these residuals against time,
as shown in Figure 2.
12 :selected: :selected:
Amazon Textract
Amazon Textract is a fully managed machine learning service offered by Amazon Web Services (AWS) that automatically extracts text, handwriting, and other data from scanned documents.
It goes beyond simple Optical Character Recognition (OCR) by not only identifying text but also extracting structured data like tables, forms, and fields.
This makes it particularly powerful for processing complex documents.
Key Features of Amazon Textract:
Text and Handwriting Extraction: Amazon Textract can extract both printed text and handwriting from scanned documents, including forms, invoices, receipts, and more. It supports a wide range of document formats, such as PDFs and images (PNG, JPEG, TIFF).
Form and Table Extraction: One of Textract’s standout features is its ability to detect and extract structured data from forms and tables. It not only extracts the text but also preserves the relationship between fields and data. This is crucial for accurately capturing information from complex documents.
Scalability and Integration: As a cloud-native service, Amazon Textract scales automatically to handle large volumes of documents. It can be easily integrated with other AWS services like Amazon S3 for storage, Amazon Lambda for serverless computing, and Amazon Comprehend for further text analysis. This makes it a robust component for building comprehensive document processing workflows.
Security and Compliance: Amazon Textract adheres to AWS’s rigorous security standards, including encryption of data in transit and at rest. This makes it suitable for handling sensitive and regulated information. It also complies with various industry standards such as HIPAA for healthcare data and GDPR for data protection.
Automatic Language Detection: Textract supports automatic detection of multiple languages within documents, enabling it to process documents in different languages without requiring prior specification.
Machine Learning-Based Accuracy: Unlike traditional OCR, which might struggle with complex layouts or variations in text size and alignment, Textract leverages machine learning to improve accuracy in text extraction and interpretation, particularly in documents with irregular layouts.
Installation and Setup Process
First, you will need to install the Python library to interface with AWS APIs:
pip install boto3
Then you can write the following code:
import boto3
from textractprettyprinter.t_pretty_print_expense import get_string, Textract_Expense_Pretty_Print, Pretty_Print_Table_Format
# AWS credentials
AWS_ACCESS_KEY_ID = "AKIAXBTCFDEFMHROHVGD"
AWS_SECRET_ACCESS_KEY = "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"
# Initialize Textract client
textract = boto3.Session(aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY,
region_name='eu-central-1').client('textract')
# Call Textract to extract text from the document
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': "nunobispo-text",
'Name': "bill-of-sale.pdf"
}
},
FeatureTypes=["TABLES", "FORMS"]
)
# Print the extracted text
for block in response['Blocks']:
if block['BlockType'] == 'LINE':
print('Detected text: ' + block['Text'])
elif block['BlockType'] == 'KEY_VALUE_SET' and 'KEY' in block['EntityTypes']:
print('Key: ' + block['Text'])
elif block['BlockType'] == 'TABLE':
print('Table detected:')
for relationship in block['Relationships']:
for id in relationship['Ids']:
for cell in response['Blocks']:
if cell['Id'] == id:
print('Cell text: ' + cell['Text'])
Performance Test
Testing Amazon Textract:
Document 1: Extremely accurate, especially with printed text.
Detected text: Ahspalding & Bros.
Detected text: mone
Detected text: PALDIN
Detected text: PLEASE REMIT TO SPALDING SALES CORP.
Detected text: SION OF SPALDING SALES CORPORATION
Detected text: MARK
Detected text: #1
Detected text: STORE NO.
Detected text: FOLIO C
Detected text: FAMOUS FOR ATHLETIC EQUIPMENT
Detected text: INVOICE NO. S 2812
Detected text: Sold To
Detected text: Ship To
Detected text: CUSTOMER'S
Detected text: DATE
Detected text: 6/1/39
Detected text: ORDER NO.
Detected text: BKLYN EAGLES B B CLUB
Detected text: DELD TO DIRK LUNDY
Detected text: EMANLEY-
Detected text: ADDRESS
Detected text: ADDRESS
Detected text: 101 MONTGOMERY STREET
Detected text: TOWN
Detected text: NEWARK, N.J. STATE
Detected text: TOWN
Detected text: STATE
Detected text: TERMS:
Detected text: 2% CASH 10 DAYS-NET 30 DAYS-
Detected text: VIA
Detected text: DEALER
Detected text: INST.
Detected text: GOLF PRO.
Detected text: ORDER TAKEN BY
Detected text: SALESMAN'S NAME
Detected text: CLASS
Detected text: NO,
Detected text: OF
Detected text: SALE
Detected text: A
Detected text: GOODWIN
Detected text: TAGUER
Detected text: 106
Detected text: 86
Detected text: ITEM
Detected text: QUANTITY
Detected text: DESCRIPTION OF ARTICLE
Detected text: UNIT
Detected text: y
Detected text: PRICE
Detected text: AMOUNT
Detected text: NO.
Detected text: ORDERED
Detected text: SHIPPED
Detected text: -
Detected text: 125
Detected text: BATS
Detected text: 9
Detected text: 9
Detected text: EA
Detected text: 1
Detected text: 75
Detected text: 15
Detected text: 75
Detected text: 120
Detected text: BATS
Detected text: 1
Detected text: 1
Detected text: EA
Detected text: 1
Detected text: 75
Detected text: -
Detected text: -
Detected text: 200
Detected text: BATS
Detected text: 6
Detected text: 6
Detected text: EA
Detected text: 1
Detected text: 00
Detected text: 6
Detected text: 00
Detected text: -
Detected text: -
Detected text: 130
Detected text: BATS
Detected text: 2
Detected text: 2
Detected text: EA
Detected text: 1
Detected text: 40
Detected text: 2
Detected text: 80
Detected text: -
Detected text: 26
Detected text: Cr
Detected text: 30
Detected text: -
Detected text: /
Detected text: 50
Detected text: -
Detected text: BAB
Detected text: memo
Detected text: 80
Detected text: -
Detected text: 24
Detected text: -
Detected text: -
Detected text: SEP /
Detected text: -
Detected text: -
Detected text: -
Detected text: it
Detected text: -
Detected text: Form F 21 1-39-M
Detected text: NO RETURN OF MERCHANDISE FROM THIS INVOICE WILL BE ACCEPTED UNLESS YOU HAVE OUR WRITTEN PERMISSION.
Table detected:
Document 2: Excellent table and form extraction.
Detected text: Using a 10 day interval, the values in the third column will be 10 times
Detected text: the mean motion, n, and those in the fourth column will be 200 times the
Detected text: acceleration coefficient. As outlined in previous ITCP Bulletins, predictions
Detected text: may be made by interpolation in such a table. Its form is comparable to that
Detected text: of the Daily Satellite Ephemerides.
Detected text: The prediction procedure involves the calculation of a time, JNL, at
Detected text: which the satellite is expected to appear at a particular position such as
Detected text: the point of local culmination. For this position, we will have calculated
Detected text: a value of PRM. The observation then represents a measurement of the actual
Detected text: time at which the satellite appeared at, or very near this position. As a
Detected text: meticulous observer, I will have measured this time to + 0.0000001. I will
Detected text: then use this actual time to recalculate the position and will correct for
Detected text: differences between the calculated and actual point of observation. I will
Detected text: also make corrections for effects of the pear shape and the ellipticity of
Detected text: the equator. All of this is done with the objective of obtaining a measured
Detected text: value of PRM that is accurate to about 0.00001.
Detected text: Another observer, Mr. X, may either be less meticulous or may lack the
Detected text: means for making precise observations. He may simply use the predicted value
Detected text: of PRM as a measured value to correspond with his measurement of the time.
Detected text: We can assume that his accuracy is 000001 in timing and + 0.001 in PRM.
Detected text: Let us then assume that Mr. X and I both start tracking 1960 Nu 2, using
Detected text: the above table and the Gear Ratio Elements. For convenience, we will also
Detected text: assume that his location is the same as mine and that he makes each observation
Detected text: at the same time that I do. After about 60 days, our records of observations
Detected text: might compare as shown in Table V.
Detected text: TABLE V
Detected text: RECORD OF OBSERVATIONS
Detected text: Comparing Log of a Meticulous Observer (W.P.O)
Detected text: with Log of a Casual Observer (Mr. X)
Detected text: Predicted
Detected text: V. P. O.
Detected text: Mr. X
Detected text: JNL
Detected text: PRM
Detected text: PRM
Detected text: Resid.
Detected text: PRM
Detected text: Resid.
Detected text: 38462.40113315
Detected text: 16899.946438
Detected text: 16899.946518
Detected text: +80
Detected text: 16899.9469
Detected text: +400
Detected text: 38482.05088329
Detected text: 17165.472894
Detected text: 17165.473397
Detected text: +503
Detected text: 17165.4732
Detected text: +300
Detected text: 38484.04727861
Detected text: 17192.450126
Detected text: 17192.450724
Detected text: +598
Detected text: 17192.4512
Detected text: +1100
Detected text: 38485.08494712
Detected text: 17206.472112
Detected text: 17206.472747
Detected text: +635
Detected text: 17206.4728
Detected text: +700
Detected text: 38486.04369964
Detected text: 17219.427707
Detected text: 17219.428390
Detected text: +683
Detected text: 17219.4280
Detected text: +300
Detected text: 38494.02957430
Detected text: 17327.340616
Detected text: 17327.341718
Detected text: +1102
Detected text: 17327.3416
Detected text: +1000
Detected text: 38495.06723367
Detected text: 17341.362480
Detected text: 17341.363653
Detected text: +1173
Detected text: 17341.3642
Detected text: +1700
Detected text: 38497.06365582
Detected text: 17368.340068
Detected text: 17368.341367
Detected text: +1299
Detected text: 17368.3410
Detected text: +900
Detected text: We can assume that Mr. X's values of JNL will be the same as mine (in the first
Detected text: column) except that they will include only five digits to the right of the
Detected text: decimal.
Detected text: In the above table, each "residual" column represents the difference
Detected text: between the observed values and the predicted values, which are in the second
Detected text: column. As we proceed, Mr. X and I will both plot these residuals against time,
Detected text: as shown in Figure 2.
Detected text: 12
It keeps the structure of the document so the LLM can process it accurately. It can switch between text extraction and OCR ( Optical Character Recognition) modes automatically, depending on the type of document, and it can handle even poorly scanned or misaligned documents.
Key Features
Key features of LLMWhisperer include:
Automatic Mode Switching: It can easily switch between extracting text and using OCR based on the type of document, making sure it gets the best results from both digital text and scanned images.
Layout Preservation: LLMWhisperer keeps the original layout of documents when it extracts text. This is important for keeping the context and accuracy when the data is used by large language models.
Checkbox and Radio Button Recognition: It accurately identifies and converts checkboxes and radio buttons from forms into a text format that language models can easily understand, making it better for processing form-based data.
Document Preprocessing: The tool has advanced options for preprocessing documents, like applying filters and adjusting image settings. This helps improve the quality of text extraction, especially from poorly scanned documents.
Structured Data Output: LLMWhisperer can produce structured data outputs, like JSON, making it easier to use the extracted information in other systems and workflows.
SaaS and On-Premise Deployment: It offers flexible deployment options, including a fully managed online service and an on-premise version for handling sensitive data securely.
Learn how faithfully reproducing the structure of tables and other elements by preserving the original PDF layout is crucial for better performance in LLM and RAG applications.
LLMWhisperer: Best OCR for PDF Checkbox Extraction
PDF forms have checkboxes and radiobuttons that can be filled out by the user. These form elements are used to collect data from the user. In this video, we will show how to extract these form elements using LLMWhisperer in a way that LLMs can understand.
Installation and Setup Process
To use LLMWhisperer, you need to install the llmwhisperer-client package and obtain an API key from the LLMWhisperer website.
Follow these steps to get started:
Sign Up for an API Key: Visit the LLMWhisperer website and sign up for an account. You will receive an API key that you need to use in your code. Install the LLMWhisperer Client: Use pip to install the llmwhisperer-client package.
pip install llmwhisperer-client
Then you can write the following code:
from unstract.llmwhisperer.client import LLMWhispererClient
# Initialize the client with your API key
client = LLMWhispererClient(base_url="<https://llmwhisperer-api.unstract.com/v1>", api_key='<YOUR_API_KEY>')
# Extract tables from the PDF
result = client.whisper(file_path="bill-of-sale.pdf")
extracted_text = result["extracted_text"]
print(extracted_text)
Performance Test
Testing LLMWhisperer on the two documents:
Document 1: Exceptional accuracy, especially with complex layouts and handwritten text.
Al, Spalding Bros. SPALDING PLEASE REMIT TO SPALDING SALES CORP.
SION OF SPALDING SALES CORPORATION MARK
#1
STORE NO. FOLIO C
FAMOUS FOR ATHLETIC EQUIPMENT
INVOICE NO. S 2812
CUSTOMER'S
Sold To DATE 6/1/39 Ship To ORDER NO.
BKLYN EAGLES B B CLUB DELD TO DIRK LUNDY
EMANLEY -
ADDRESS ADDRESS
101 MONTGOMERY STREET
TOWN NEWARK, N.J. STATE TOWN STATE
TERMS:
2% CASH TO DAYS-NET 30 DAYS- VIA
DEALER INST. GOLF PRO. ORDER TAKEN BY SALESMAN'S NAME NO,
CLASS
OF
BALE A GOODWIN TAGUER 106
ITEM QUANTITY
86 NO. DESCRIPTION OF ARTICLE ORDERED SHIPPED UNIT PRICE AMOUNT
125 BATS 9 9 EA 1 75 15 75
-
120 BATS 1 1 EA 1 75
-
200 BATS 6 6 EA 1 00 6 00
1 40
1 30 BATS 2 2 EA 2 80
26 30
150
-
80-
-
SEP / / 1933
Form F 21 1-39-M
NO RETURN OF MERCHANDISE FROM THIS INVOICE WILL BE ACCEPTED UNLESS YOU HAVE OUR WRITTEN PERMISSION.
<<<
Document 2: Superior structured data extraction compared to other tools.
Using a 10 day interval, the values in the third column will be 10 times
the mean motion, n, and those in the fourth column will be 200 times the
acceleration coefficient. As outlined in previous ITCP Bulletins, predictions
may be made by interpolation in such a table. Its form is comparable to that
of the Daily Satellite Ephemerides.
The prediction procedure involves the calculation of a time, JNL, at
which the satellite is expected to appear at a particular position such as
the point of local culmination. For this position, we will have calculated
a value of PRM. The observation then represents a measurement of the actual
time at which the satellite appeared at, or very near this position. As a
meticulous observer, I will have measured this time to + 090000001. I will
then use this actual time to recalculate the position and will correct for
differences between the calculated and actual point of observation. I will
also make corrections for effects of the pear shape and the ellipticity of
the equator. All of this is done with the objective of obtaining a measured
value of PRM that is accurate to about + 0500001.
Another observer, Mr. X, may either be less meticulous or may lack the
means for making precise observations. He may simply use the predicted value
of PRM as a measured value to correspond with his measurement of the time.
We can assume that his accuracy is + 0900001 in timing and + 0f001 in PRM.
Let us then assume that Mr. X and I both start tracking 1960 Nu 2, using
the above table and the Gear Ratio Elements. For convenience, we will also
assume that his location is the same as mine and that he makes each observation
at the same time that I do. After about 60 days, our records of observations
might compare as shown in Table V.
TABLE V
RECORD OF OBSERVATIONS
Comparing Log of a Meticulous Observer (W.P.O)
with Log of a Casual Observer (Mr. [X] X)
Predicted W. P. O. Mr. X
JNL PRM PRM Resid. PRM Resid.
38462.40113315 16899.946438 16899.946518 +80 16899.9469 +400
38482.05088329 17165.472894 17165.473397 +503 17165.4732 +300
38484.04727861 17192.450126 17192.450724 +598 17192.4512 +1100
38485.08494712 17206.472112 17206.472747 +635 17206.4728 +700
38486.04369964 17219.427707 17219.428390 +683 17219.4280 +300
38494.02957430 17327.340616 17327.341718 +1102 17327.3416 +1000
38495.06723367 17341.362480 17341.363653 +1173 17341.3642 +1700
38497.06365582 17368.340068 17368.341367 +1299 17368.3410 +900
We can assume that Mr. X's values of JNL will be the same as mine (in the first
column ) except that they will include only five digits to the right of the
decimal.
In the above table, each "residual" column represents the difference
between the observed values and the predicted values, which are in the second
column. As we proceed, Mr. X and I will both plot these residuals against time,
as shown in Figure 2.
12
<<<
Best OCR Software: Comparison of Main Features, Capabilities, and Precision
In this section, we will compare the four OCR tools—Tesseract, PaddleOCR, Azure Document Intelligence, and Amazon Textract—along with LLMWhisperer. We’ll focus on their main features, abilities, accuracy, and overall performance.
Feature
Tesseract
PaddleOCR
Azure Document Intelligence
Amazon Textract
LLMWhisperer
Accuracy
High
Very High
Very High
Extremely High
Superior
Language Support
100+
80+
Multi-language
Multi-language
Multi-language
Complex Layouts Handling
Moderate
High
Very High
Very High
Superior
Structured Data Extraction
Low
Moderate
Very High
Extremely High
Superior
Deployment Flexibility
High (Local)
High (Local)
High (Cloud)
High (Cloud)
High (Cloud)
Ease of Use
Moderate
Easy
Easy
Moderate
Easy
Cost
Free
Free
Paid
Paid
Paid
Custom Training
Yes
Yes
Yes
No
Yes
Integration
Moderate
High
High
High
High
Security and Compliance
N/A
N/A
High
High
High
Evaluating the Best OCR Software: Analysis of Performance Tests
When evaluating these tools against the sample documents, several factors come into play, including their ability to accurately extract text, handle complex layouts, and maintain the structure of the document.
Tesseract OCR:
Strengths:
Tesseract performs well with clean, high-quality images and provides solid accuracy for straightforward text recognition tasks.
It supports a wide range of languages and allows for custom training to improve recognition.
Weaknesses:
It struggles with complex layouts and handwritten text, which can result in lower accuracy and missed data in such cases.
PaddleOCR:
Strengths:
PaddleOCR excels in recognizing text in multi-language documents and handles complex layouts better than Tesseract.
It is also lightweight and fast, making it suitable for real-time applications.
Weaknesses:
While it performs well, its structured data extraction capabilities are less advanced compared to cloud-based services like Azure Document Intelligence and Amazon Textract.
Azure Document Intelligence:
Strengths:
Azure Document Intelligence offers excellent accuracy and handles structured data extraction extremely well, especially in documents with tables and forms.
Its pre-built models simplify the extraction process for common document types.
Weaknesses:
As a cloud-based service, it requires a paid subscription, and its performance is dependent on internet connectivity.
Amazon Textract:
Strengths:
Textract is highly accurate, particularly with complex documents and forms.
It excels in structured data extraction and is well-integrated with other AWS services, making it a powerful tool for large-scale document processing.
Weaknesses:
Similar to Azure, it is a paid service and requires integration into the AWS ecosystem, which might be a barrier for some users.
LLMWhisperer:
Strengths:
LLMWhisperer stands out with its ability to handle complex layouts, extract structured data with superior accuracy, and maintain the original document structure.
It is particularly effective for documents that combine various types of content, such as text, images, and forms.
Weaknesses:
Being a new entrant, it might have limited community support compared to more established tools.
It is also a paid service.
Choosing the Right OCR Tool: Aligning with Your Project Needs
In summary, the best OCR tool depends on your specific needs:
Tesseract is ideal for those who need a free, highly customizable tool for simple OCR tasks.
PaddleOCR is a great choice for users who require a lightweight, fast, and highly accurate OCR solution with support for multiple languages.
Azure Document Intelligence and Amazon Textract are top choices for businesses that need advanced structured data extraction and can afford a cloud-based, paid solution.
LLMWhisperer is recommended for those who need superior accuracy and the ability to handle complex documents with various content types.
Ultimately, the choice of OCR tool should align with the specific requirements of your projects, whether it’s cost-effectiveness, accuracy, language support, or the ability to process complex document layouts.
For the curious. Who are we, and why are we writing about OCR?
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
LLMWhisperer is a document-to-text converter(best ocr). Prep data from complex documents for use in Large Language Models. LLMs are powerful, but their output is as good as the input you provide. Documents can be a mess: widely varying formats and encodings, scans of images, numbered sections, and complex tables.
Extracting data from these documents and blindly feeding it to LLMs is not a good recipe for reliable results. LLMWhisperer is a technology that presents data from complex documents to LLMs in a way they can best understand.
If you want to take it for a test drive quickly, you can check out our free playground.
What criteria should I use to identify the best OCR software for my organization? Focus on ten factors highlighted in the article: accuracy, multi-language support, complex-layout handling, structured data extraction, deployment flexibility, ease of use, cost, custom training options, integration capability, and security/compliance. Weigh these against your document types (invoices, forms, scientific papers, etc.) and your budget.
What is the best OCR software for handling complex layouts and handwritten forms in 2025? Based on the performance tests, LLMWhisperer is highlighted as providing superior accuracy for complex documents, including those with handwritten text and challenging layouts like the sample bill of sale, outperforming other tools in this specific category.
Which best OCR software offers both on-premise and cloud-based deployment options in 2025? Several top contenders for the best OCR software provide both deployment options. LLMWhisperer, for example, offers flexible deployment as a Software-as-a-Service (SaaS) or on-premise, making it suitable for organizations with strict security requirements.
What deployment models do the best OCR software options support in 2025? You have three broad choices:
Local/offline (Tesseract, PaddleOCR) – full control, no recurring fees, but more maintenance.
Cloud APIs (Azure Document Intelligence, Amazon Textract) – scalable and managed, paid per page.
Hybrid/SaaS or on-prem (LLMWhisperer) – hosted service for ease of use plus an optional on-prem version when data residency or privacy demands it.
How does LLMWhisperer position itself as the best OCR software for large-language-model (AI) workflows? The best OCR software, like LLMWhisperer, can detect and extract form elements such as checkboxes and radio buttons, converting them into formats that are easily interpreted by AI or LLM workflows. This is especially useful for automating data entry from scanned forms and PDF documents.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms. Currently, Nuno works as an Integration Architect for a major multinational corporation. He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
We do not use cookies of this type.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
We do not use cookies of this type.
Analytics cookies help website owners to understand how visitors interact with websites by collecting and reporting information anonymously.
We do not use cookies of this type.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.
We do not use cookies of this type.
Unclassified cookies are cookies that we are in the process of classifying, together with the providers of individual cookies.