Dealing with unstructured data is one of the major hurdles in the modern data-centric world.
Unlike structured data, which fits neatly into tables, unstructured data exists in PDFs, images, videos, emails, and social media content. This variability makes it challenging to derive useful insights and incorporate such data into traditional analytical frameworks.
Unstract is a solution that extracts meaningful information from unstructured sources. Leveraging AI-powered tools, it processes documents like PDFs and converts them into structured formats. Its flexibility to connect with diverse sources and destinations makes it an ideal candidate for ETL processes.
BigQuery, Google Cloud’s scalable and serverless data warehouse, is a powerful tool for storing and analyzing the structured data generated by Unstract. It supports structured and semi-structured formats like JSON, allowing seamless integration of varied data types.
By combining Unstract’s data extraction capabilities with BigQuery’s analytical strength, this ETL pipeline unlocks the full potential of unstructured data, enabling better decision-making.
Understanding ETL for Unstructured Data
ETL, short for Extract, Transform, and Load, is a standard process used to move and prepare data for analysis. Traditionally, the process involves:
Extraction: Pulling raw data from various source systems.
Transformation: Modifying the data to meet analytical or operational requirements (e.g., cleaning, reformatting, or aggregating).
Loading: Depositing the transformed data into a target system, such as a data warehouse.
When applied to unstructured data, ETL becomes more challenging. Unlike structured data, unstructured data lacks a predefined format or schema.
ETL processes for unstructured data focus on:
Identifying and extracting significant details from raw content.
Utilizing machine learning and natural language processing (NLP) to establish structure.
Converting unstructured inputs into formats like JSON or relational schemas for further analysis.
This process ensures unstructured data, such as textual documents or multimedia files, becomes actionable and insightful for business applications.
Comparing Traditional ETL and ETL for Unstructured Data
Category
Traditional ETL(structured data)
ETL for Unstructured data
Data Format
Organized tables with rows and columns.
Various formats (PDFs, images, audio, videos, etc.).
Extraction
Straightforward querying via databases or APIs.
Advanced AI/ML methods for extraction.
Transformation
Standard tasks like joining or cleaning tables.
NLP, computer vision, embeddings for structuring.
Complexity
Well-defined schemas make it simpler.
Schema inference and contextual understanding are needed.
Storage
Fits easily into relational databases.
Fits easily into relational databases.
ETL for unstructured data demands sophisticated tools like Unstract to bridge the gap between raw, unstructured data and actionable insights.
Unstructured data comes from various sources and formats, such as:
Documents: PDFs, Word files, scanned agreements, and forms.
Images: Photos, scanned pictures, and annotated graphics.
Audio: Recorded conversations, podcasts, and voice messages.
Videos: Surveillance footage, tutorials, and vlogs.
Text: Emails, chat logs, social media posts, and blogs.
Sensor Logs: Data from IoT devices, GPS trackers, and system monitors.
Tools like Unstract simplify the process of extracting and transforming vital information from these sources, allowing their integration into platforms like BigQuery for analysis.
Unlike conventional databases hosted on physical servers, BigQuery’s serverless design eliminates infrastructure management, offering unmatched scalability and flexibility.
As a modern data warehouse, BigQuery facilitates the consolidation of structured, semi-structured, and unstructured data into a single environment.
This makes it a valuable tool for organizations seeking insights from varied datasets. Its architecture separates storage from computing resources, enabling independent scaling based on workload needs.
Key Highlights of BigQuery
Serverless Setup: No need for infrastructure management; it scales automatically based on demand.
Cost-Effective: Charges are based on storage and query usage, offering flexibility.
Semi-Structured Data Compatibility: Built-in support for JSON and similar formats ensures seamless querying without extra conversion steps.
Machine Learning Integration: BigQuery ML enables predictive analytics directly within the warehouse.
Google Cloud Ecosystem: Smooth integration with tools like Cloud Storage, Dataflow, and AI/ML products.
Data Sharing Features: Allows secure data sharing with others without duplicating datasets.
BigQuery’s ability to handle JSON and semi-structured data makes it a versatile platform for processing outputs from tools like Unstract. Its serverless framework ensures high performance and scalability for even the most demanding ETL workflows.
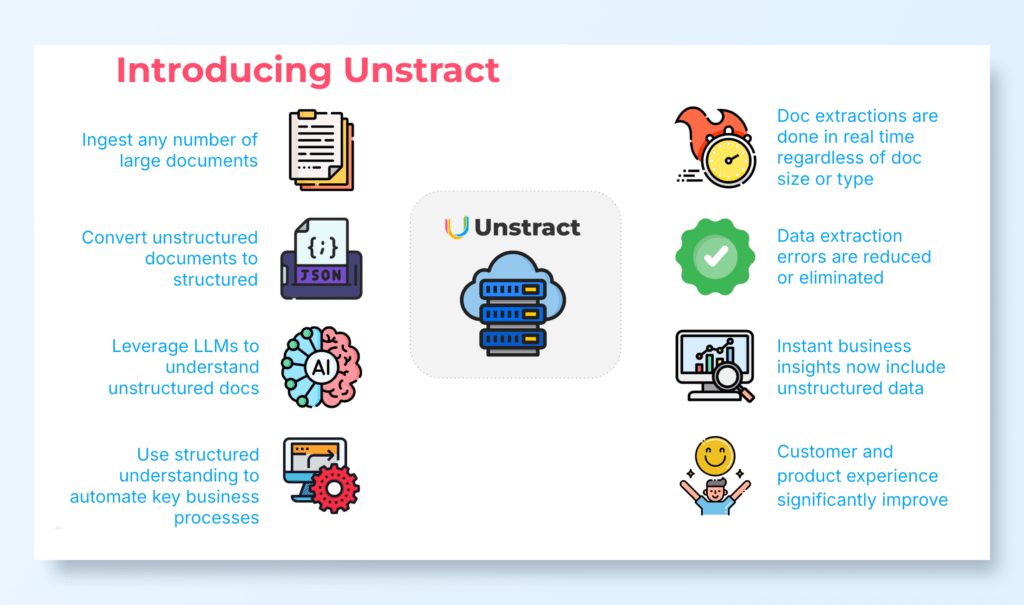
Introducing Unstract
Unstract is a solution designed to simplify the extraction of structured information from unstructured content, such as loan applications, invoices, or reports.
Unstract’s Key Features
Efficient Data Extraction:
Leverages NLP, embeddings, and LLMs to identify and extract crucial details from unstructured files.
Converts raw documents into structured formats ready for downstream analysis.
Seamless Integration:
Works effortlessly with popular platforms like BigQuery, ensuring smooth ETL workflows.
Processes data into scalable, queryable structures for comprehensive analytics.
Customizable Processes:
Tools like Prompt Studio enable users to create tailored workflows for extracting specific fields such as names, dates, and financial details.
Designed to handle growing data volumes without compromising efficiency.
Unstract’s capabilities make it an essential tool for extracting insights from unstructured data. Paired with BigQuery’s analytical power, it offers a comprehensive ETL solution.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
ETL for Unstructured Data Workflow Overview
The ETL workflow involving Unstract and BigQuery is as follows:
Unstructured PDFs in Google Drive → Unstract for Extraction → Structured Data in BigQuery
This setup demonstrates how raw, unstructured data like PDFs stored in Google Drive can be transformed into structured formats and analyzed in BigQuery.
ETL Workflow Outline
Data Collection:
Unstructured PDFs stored in sources like Google Drive are identified as the input files.
Extraction via Unstract:
Unstract fetches PDFs and extracts essential data using its AI-powered features.
Extracted details are structured in formats like JSON.
Data Transformation:
Unstract cleans, organizes, and prepares the extracted data for BigQuery.
Custom rules or field specifications can be applied during this stage.
Loading into BigQuery:
The structured data is loaded into a BigQuery dataset.
BigQuery serves as the repository for the processed data, enabling queries and visualizations.
Analysis and Insights:
Using BigQuery, analysts can perform SQL-based queries, generate reports, and visualize insights via tools like Looker Studio.
This workflow illustrates how Unstract and BigQuery collaborate to turn unstructured data into actionable insights efficiently.
Step-by-Step Guide: Setting Up the ETL Workflow
Set Up Unstract
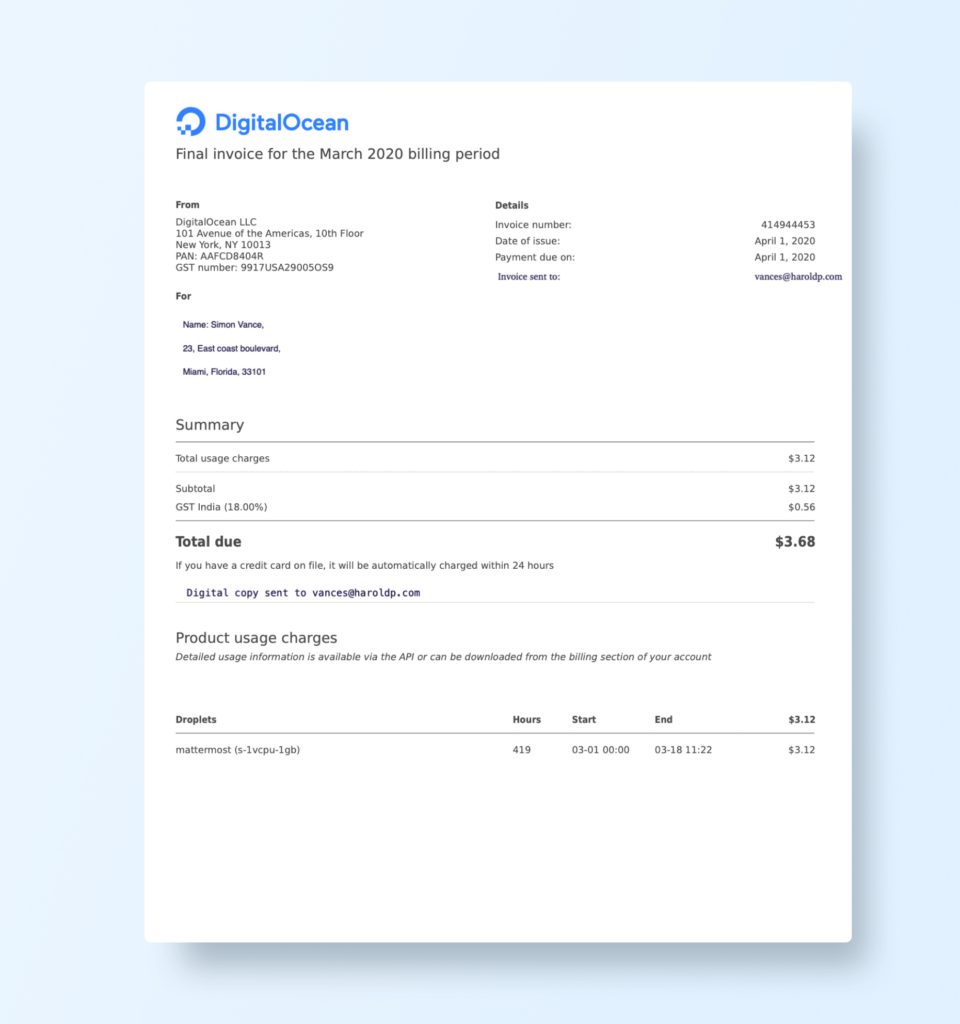
For the examples in this section, we will process invoice documents stored as PDFs. These documents may include fields such as Invoice Number, Date, Customer Details, Item Descriptions, Quantities, and Total Amounts.
The test document for extraction:
Setting Up Key Components in Unstract
Getting Started
Visit the Unstract website and create an account. Registration provides access to features like Prompt Studio and LLMWhisperer.
Upon signing up, you receive a 14-day trial with $10 in LLM tokens to begin using the platform immediately.
Configuring Components
If additional resources are needed, you can integrate your external services like LLMs, embeddings, vector databases, or text extractors via the SETTINGS menu.
Add an LLM Provider: Navigate to SETTINGS → LLMs, create a new LLM profile, and link your preferred provider (e.g., OpenAI).
Configure an Embedding Provider: Go to SETTINGS → Embedding, add a new profile, and specify your embedding provider.
Connect a Vector Database: In SETTINGS → Vector DBs, set up a new vector database profile. Set Up a Text Extractor: Access SETTINGS → Text Extractor and define a custom text extraction provider to focus on relevant invoice data.
How These Components Aid Invoice Extraction
Large Language Models (LLMs) play a crucial role in processing invoice data by identifying key details such as item descriptions, totals, and other relevant fields. Through advanced natural language processing, they can accurately extract meaningful information from text-heavy invoices, reducing manual effort and improving efficiency.
Embeddings further enhance this process by transforming the text within invoices into numerical vectors. These vectors allow for semantic similarity analysis, making it easier to identify recurring patterns, such as similar line items or descriptions, across multiple invoices.
Vector databases complement embeddings by storing these vectorized representations in an organized manner. This setup enables fast retrieval of patterns or insights, particularly useful for analyzing recurring invoice structures or identifying anomalies.
Text extractors focus on isolating and formatting specific fields like invoice dates, numbers, or customer details. By targeting these key elements, they ensure the data is clean and ready for integration into downstream systems like BigQuery for analytics and reporting.
Prompt Studio Project – Extracting Invoice Data
Unstract’s Prompt Studio allows users to create customized prompts for extracting specific fields from invoice PDFs, enabling seamless data capture across various invoice formats.
Key fields like Invoice Number, Invoice Date, Customer Name, and Billing Address can be easily identified, along with detailed line items such as Item Descriptions, Quantities, Unit Prices, and Line Totals.
By tailoring prompts to focus on these essential details, businesses can automate the transformation of unstructured invoice data into structured formats, streamlining workflows and enhancing analytics.
Setting Up Prompts in Prompt Studio
To get started, create a new project in Prompt Studio, naming it something relevant, such as “Invoice Data Extraction”.
This project will be a dedicated workspace for designing prompts tailored to your specific invoice data extraction needs.
Begin by uploading sample invoice PDFs that represent the range of formats you expect to process. These samples will help in testing and refining the prompts to ensure accurate extraction of key data points.
By carefully setting up and testing these prompts, you can create a reliable and efficient extraction workflow that accurately transforms unstructured invoice data into structured formats ready for further processing or analysis.
Note: Remember to set the output format as JSON in the prompts.
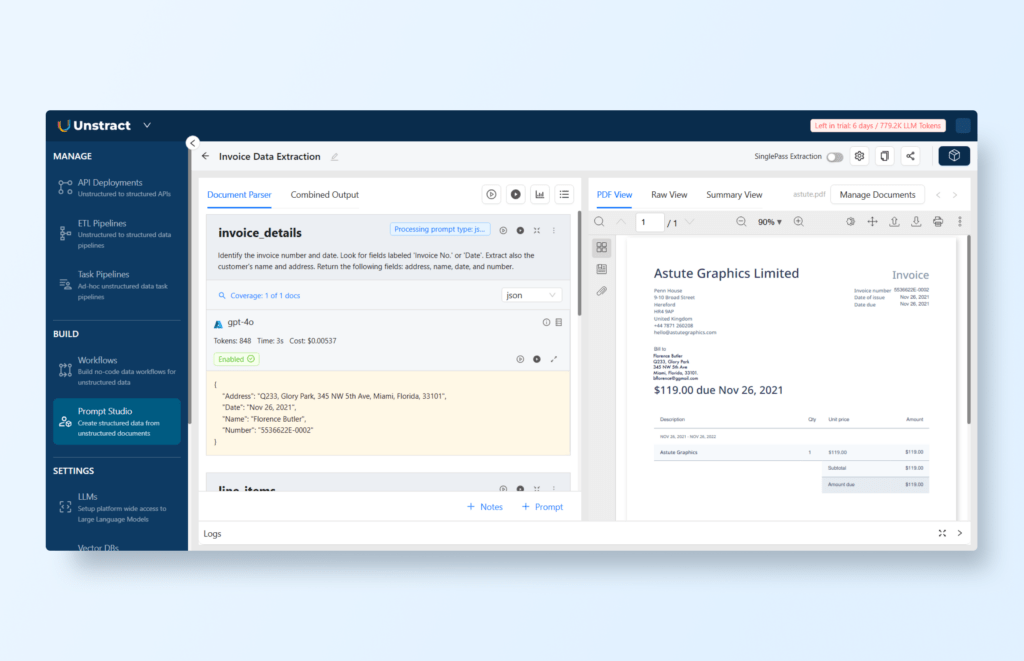
Extract Invoice Details
Prompt: “Identify the invoice number and date. Look for fields labeled ‘Invoice No.’ or ‘Date’. Extract also the customer’s name and address. Return the following fields: address, name, date, and number.”
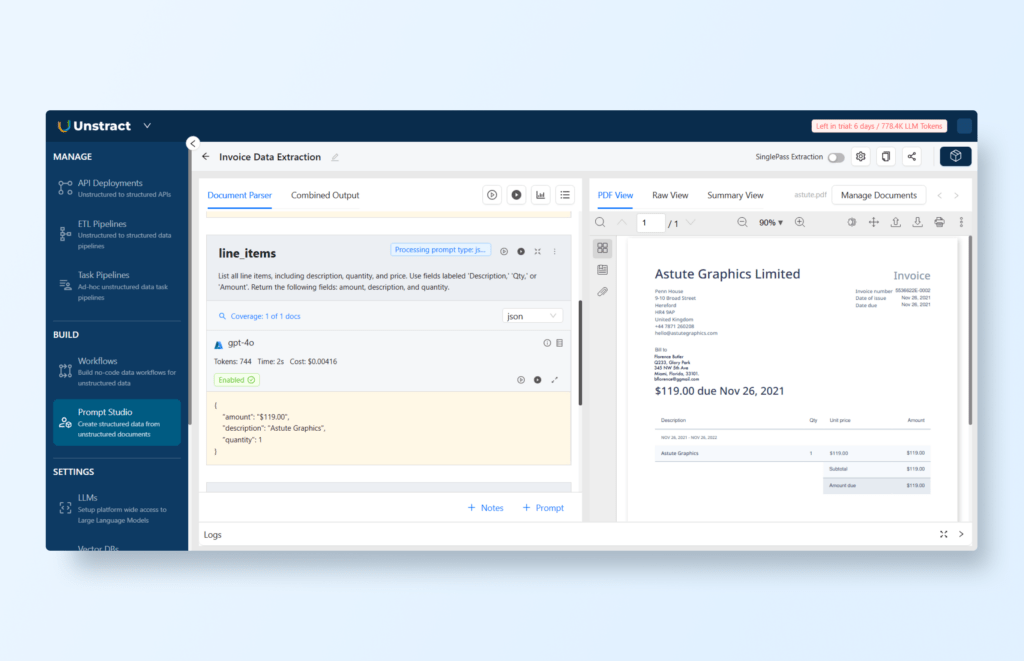
Extract Line Items
Prompt: “List all line items, including description, quantity, and price. Use fields labeled ‘Description,’ ‘Qty,’ or ‘Amount’. Return the following fields: amount, description, and quantity.”
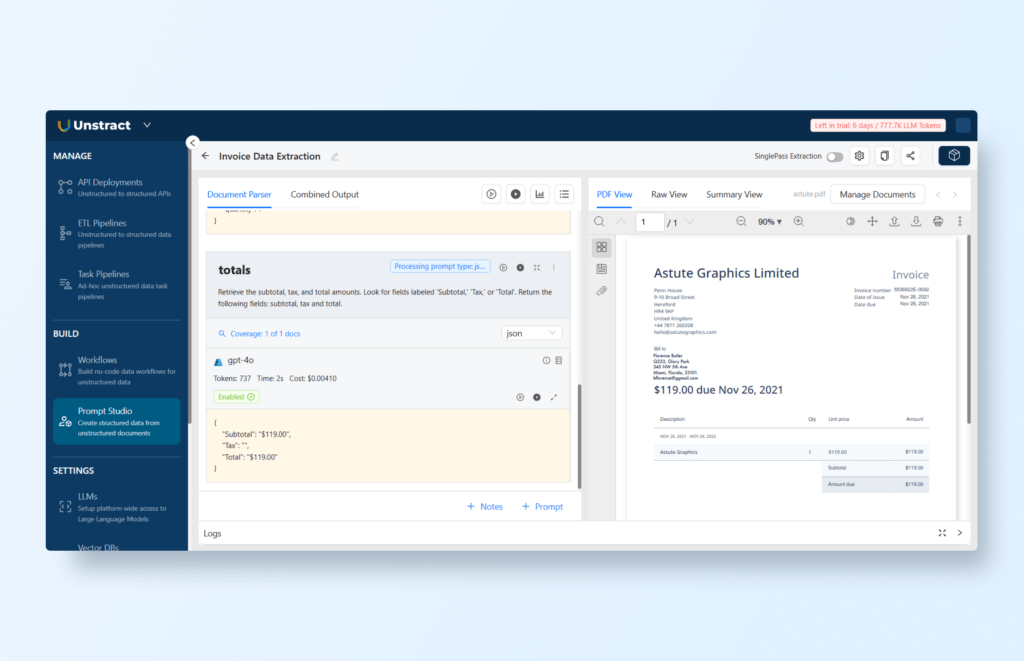
Extract Totals
Prompt: “Retrieve the subtotal, tax, and total amounts. Look for fields labeled ‘Subtotal,’ ‘Tax,’ or ‘Total’. Return the following fields: subtotal, tax and total.”
Run these prompts to extract structured JSON outputs ready for BigQuery. The combined output of the different prompts is for example:
Connect Source (Google Drive) and Destination (BigQuery)
To use Google Drive as the source for unstructured invoice PDFs and BigQuery as the destination for the processed structured data, you’ll need to create a workflow in Unstract.
Begin by converting your existing project into a reusable tool. Open your project in Prompt Studio and click the ‘Export as Tool’ button located in the top-right corner. This action will package your project into a tool that can be integrated into workflows.
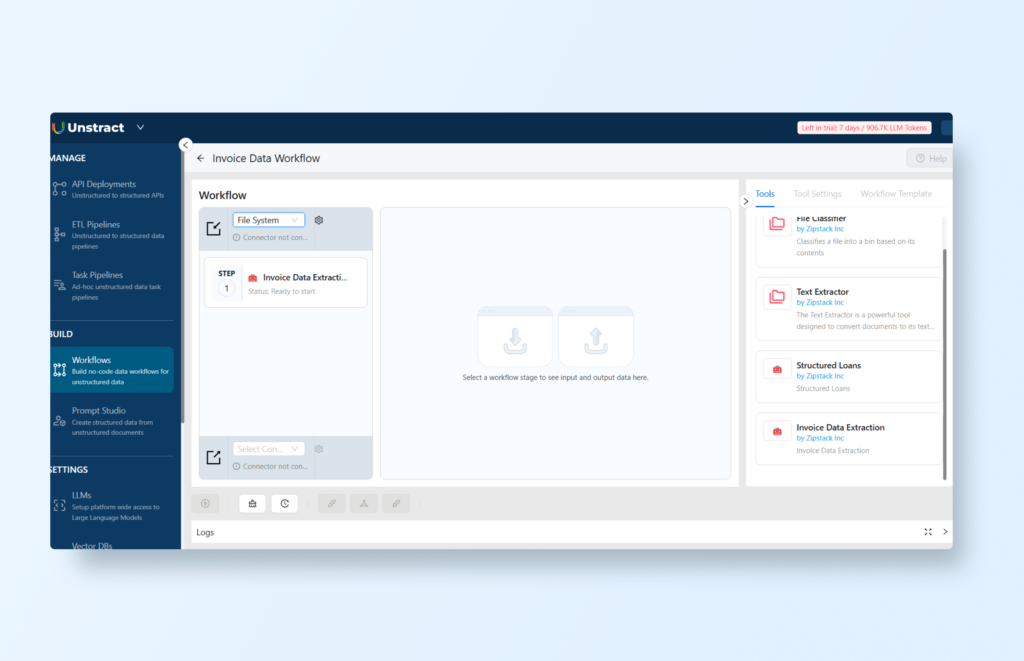
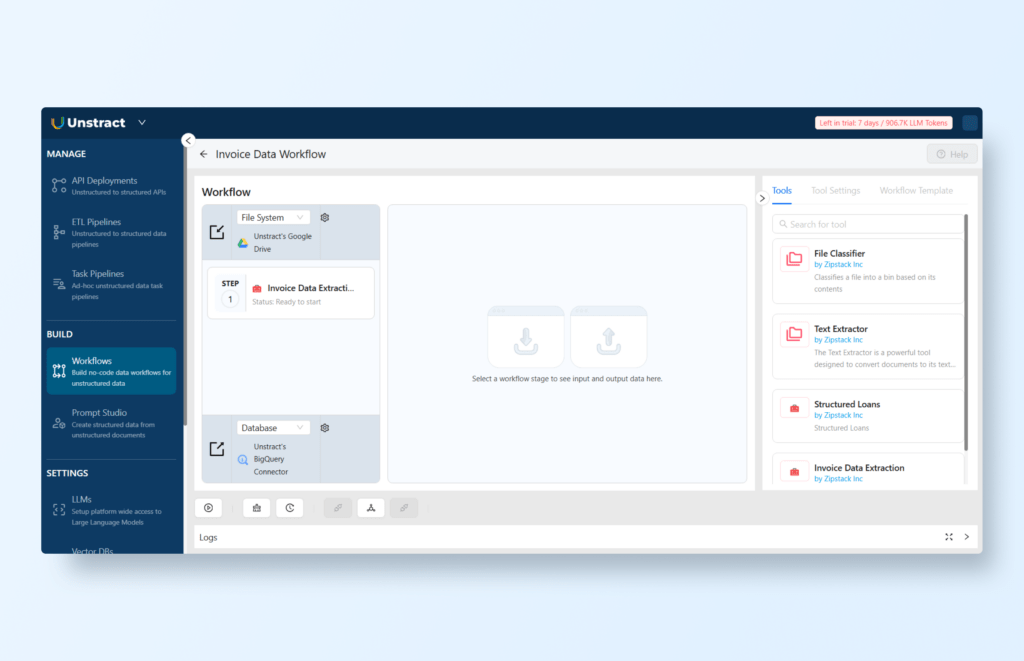
Next, navigate to the BUILD section and select Workflows. Click on ‘+ New Workflow’ to create a new workflow and assign it a meaningful name, such as “Invoice Data Workflow”. Within the Tools section on the right-hand side, locate the tool you just created (e.g., ‘Invoice Data Extraction’) and drag it into the workflow canvas on the left-hand side. This will allow you to configure how the data flows from Google Drive to BigQuery:
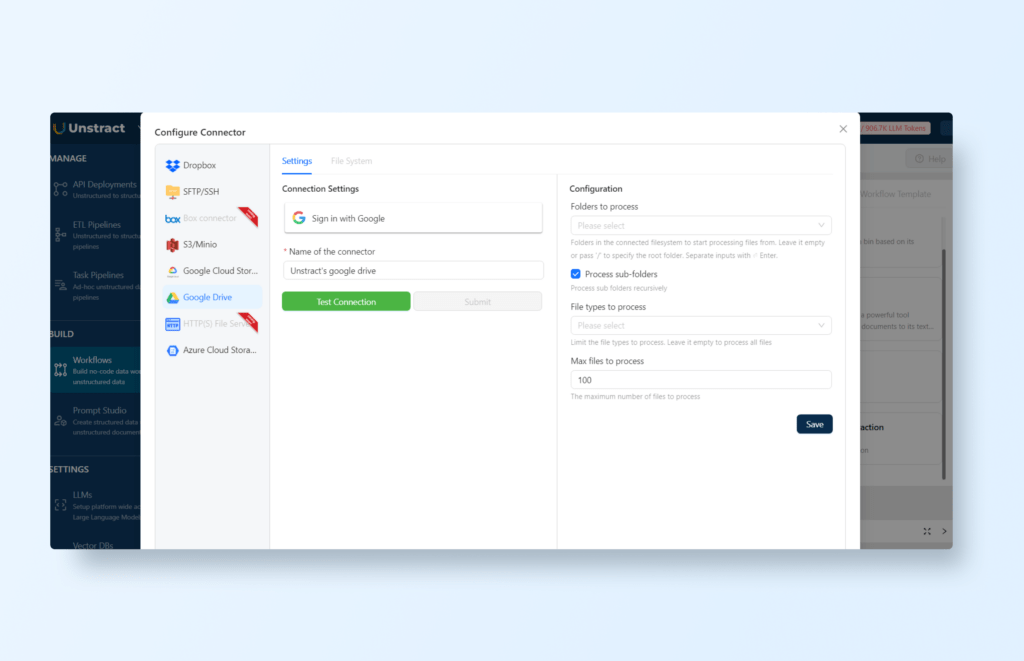
To connect Google Drive to Unstract, choose ‘File System’ from the input options, then click the gear icon to access additional settings, and select ‘Sign in with Google’:
Ensure you grant access to your Google Drive files. If necessary, you can find the documentation here.
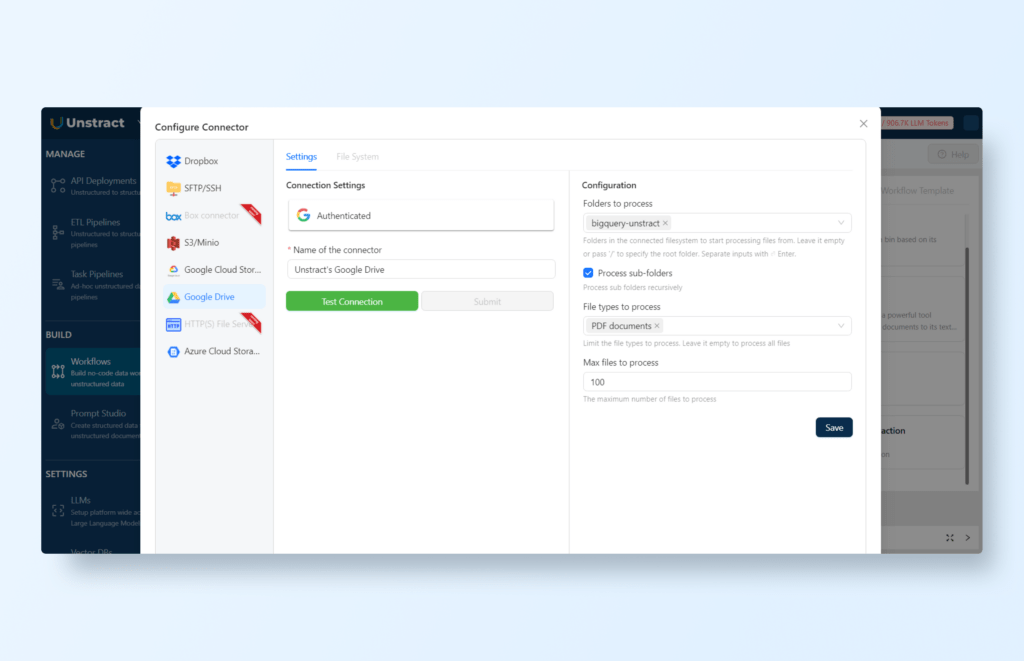
Next, choose the folder and specify the file types to be processed (in this case, PDF documents):
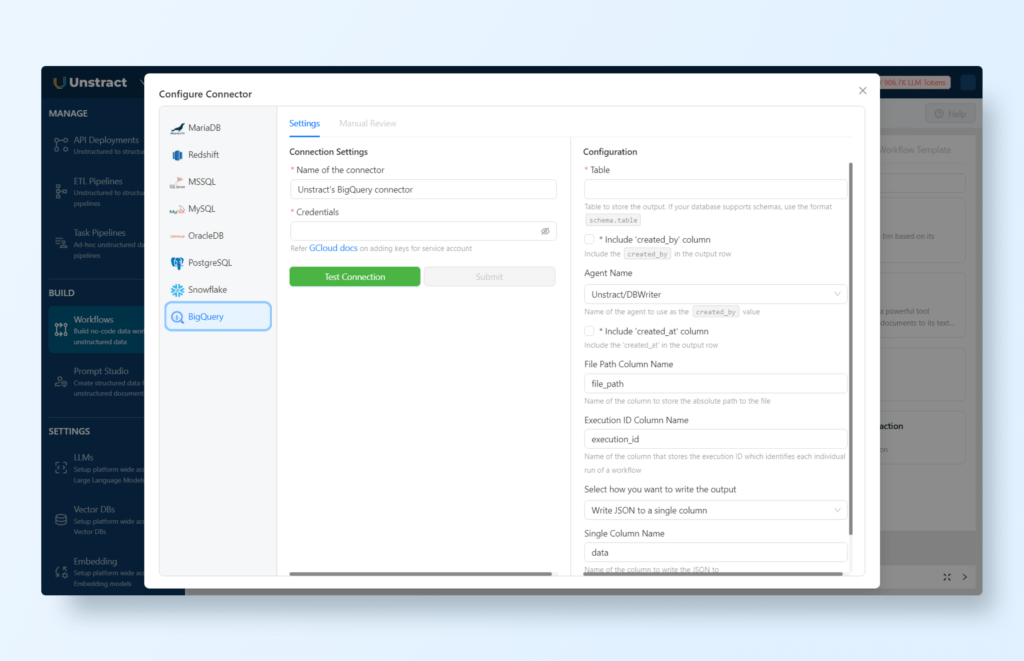
To configure BigQuery as the destination for your structured data, choose ‘Database’ from the output options. And click the gear icon to configure the BigQuery access:
For guidance on configuring your BigQuery database, you can find detailed instructions on setting up your database to connect with Unstract by referring to the documentation available here.
Note: Make sure you have a billing account set up on your BigQuery project since the integration is not possible in the free tier.
Once you have specified all the connection parameters and successfully connected to BigQuery, you are ready to process the workflow:
Run/Schedule Workflow
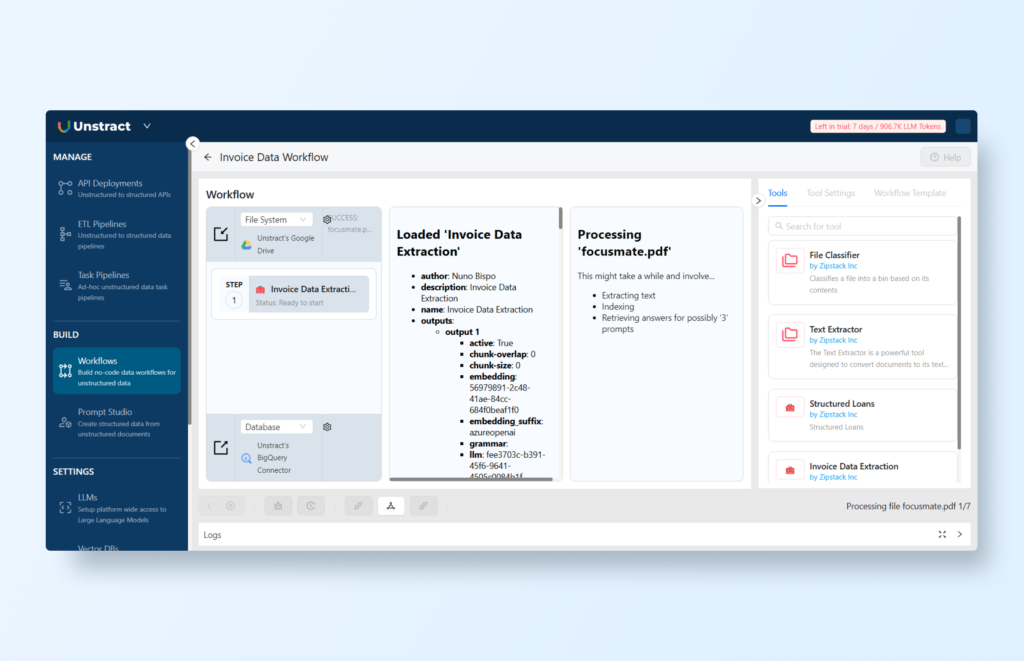
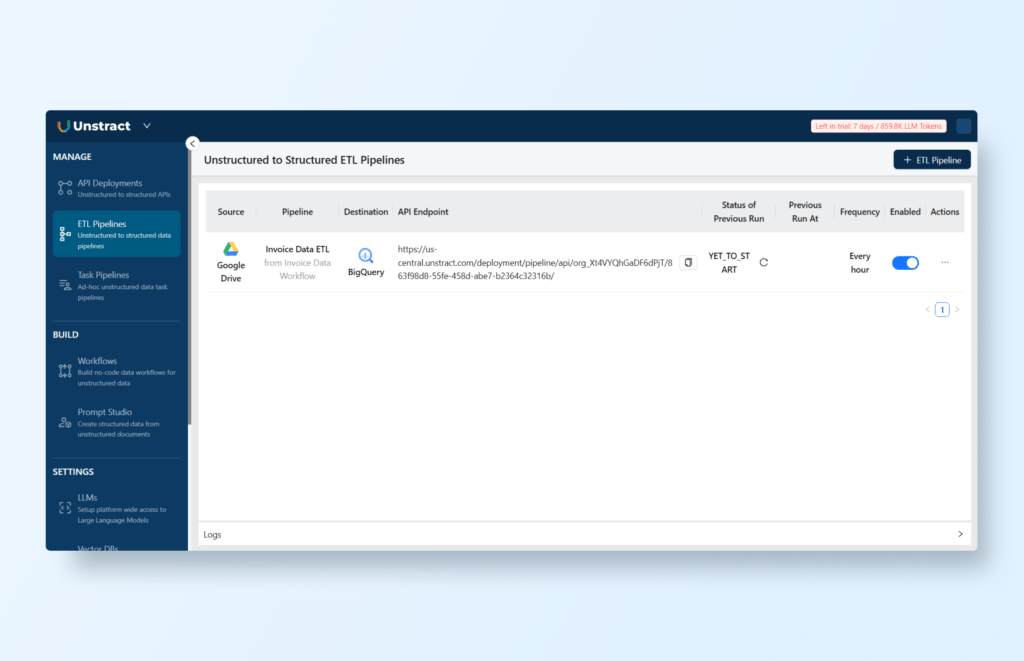
You can now run the workflow by clicking ‘Run Workflow’ icon:
The workflow will handle all files within the designated Google Drive folder; in this instance, there are 7 files to be processed.
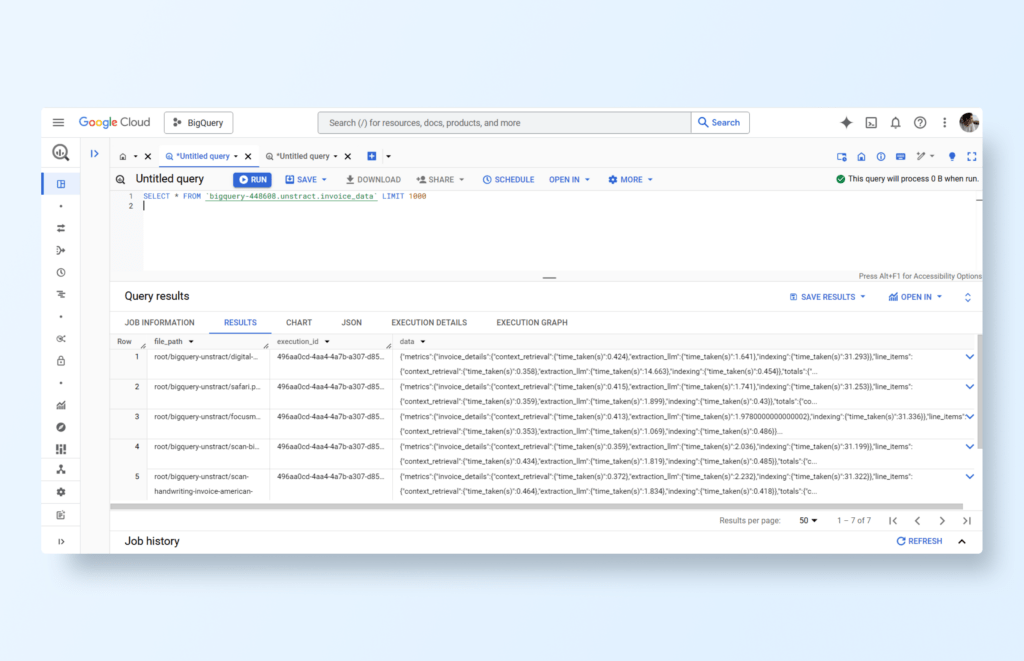
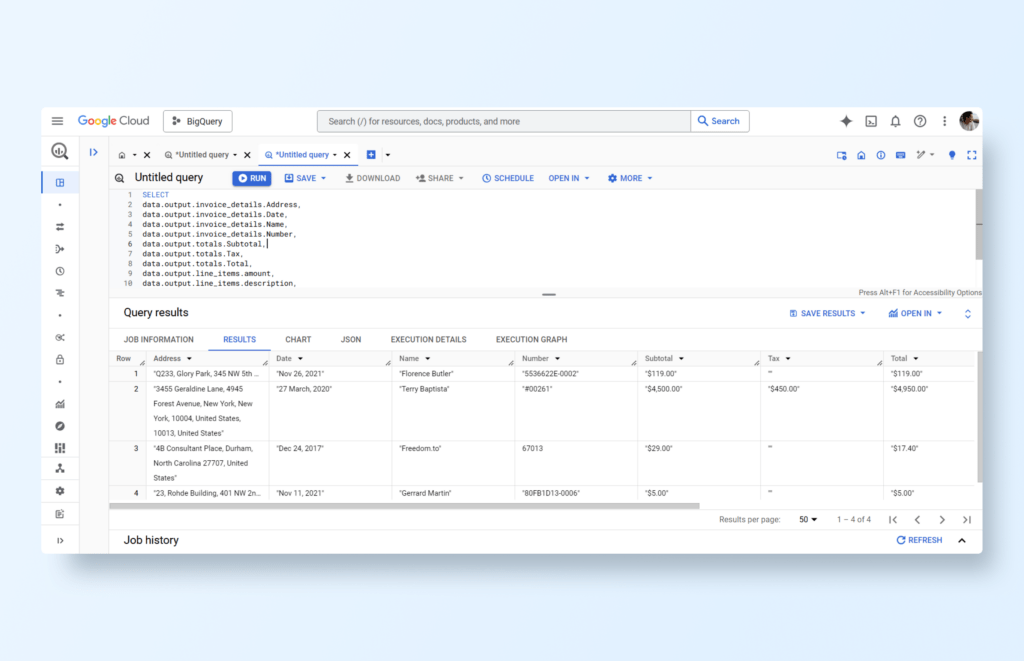
Upon completion, by verifying the BigQuery database and running an SQL query, you can observe the populated data:
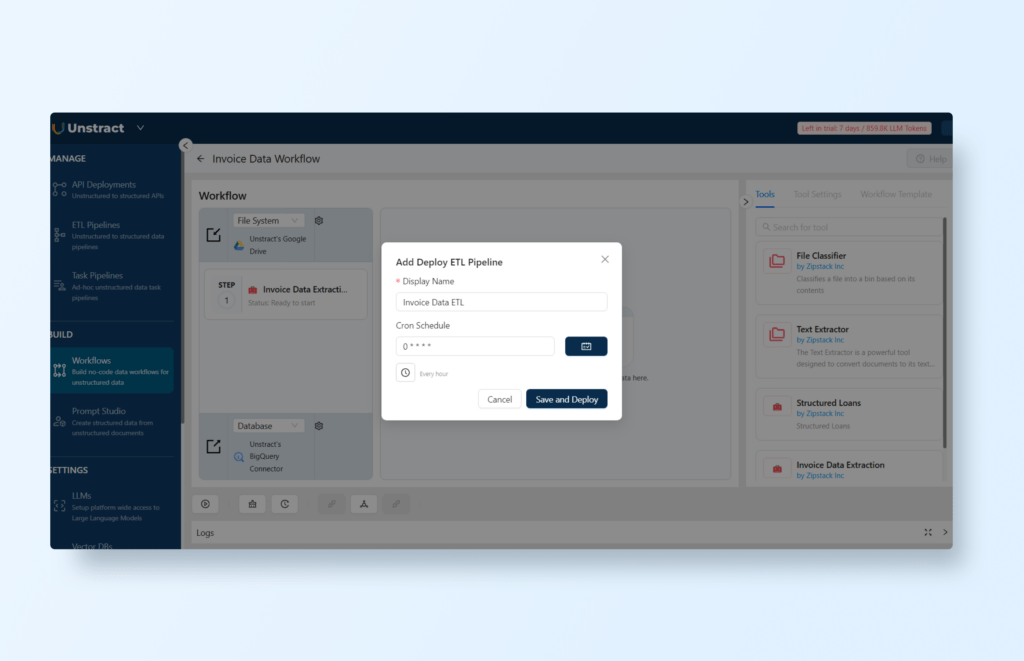
You can also schedule the workflow to run as an ETL Pipeline by clicking the ‘Deploy as ETL Pipeline’ button and defining a cron schedule:
You can check the created pipeline logs or perform actions by going to the ‘ETL Pipelines’ menu option:
Demo of Unstract for processing unstrucutred documents
In this webinar, we’ll dive deep into all the features of Unstract and guide you through setting up an ETL pipeline tailored for unstructured data extraction.
Advanced Techniques: Working with JSON in BigQuery
Unstract outputs its structured data as JSON, which is typically stored in BigQuery tables within STRING columns.
While this format retains all the structured data, querying and analyzing specific fields from these JSON objects can be challenging without flattening them into multiple columns.
Let’s take for example the JSON output of one invoice:
To make this data easier to work with, BigQuery allows you to flatten the JSON data into separate columns, enabling easy querying and analysis. Let’s assume that the structured processed data from the workflow is stored in a table called invoice_data. We can create a new table called invoice_data_json where we can store the JSON values as a single JSON column (which facilitates access to the JSON data):
CREATE OR REPLACE TABLE `invoice_data_json`
AS (
SELECT
SAFE.PARSE_JSON(data) AS data
FROM
`invoice_data`
);
With the new table in place, we can query the individual fields as JSON, like this:
In this guide, we explored how Unstract and BigQuery can be leveraged to create a seamless ETL pipeline for unstructured data. By extracting data from sources like PDFs, transforming it into structured formats, and storing it in BigQuery, organizations can unlock the value of previously untapped data.
If you want to quickly try it out, sign up for our free trial. More information here.
Unstract simplifies the complexity of working with unstructured data. It efficiently extracts and transforms content into actionable formats, providing the foundation for deeper analysis.
BigQuery complements Unstract by offering a powerful platform for data storage and analytics. Its serverless architecture, support for semi-structured data, and integration with Google Cloud services enable businesses to handle diverse datasets with ease.
Together, Unstract and BigQuery provide a robust, scalable, and future-ready solution for managing unstructured data, empowering organizations to turn raw content into actionable insights and stay ahead in a competitive data-driven landscape.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.