Extract Data from Healthcare, Medical, and Clinical Documents
Table of Contents
What is Data Extraction in Healthcare
Every time a patient visits a doctor, whether for routine care or complex surgery, a paper trail is created. Physicians must generate comprehensive medical records to ensure future healthcare professionals understand the patient’s condition. This information moves through the healthcare system to clinics, hospitals, or pharmacies, where more documents are generated.
Today, this medical documentation can accumulate to roughly 10k exabytes of data. Despite the increased use of digital devices and sensors, most medical records remain in physical form, highlighting the growing importance of efficient document processing.
Medical document processing or data extraction in healthcare involves extracting valuable information from these records, organizing it effectively, and making it easily accessible when needed.
These documents that need to be processed could come at any stage of the patient treatment, with the following ones appearing to be the most frequent:
Patient Records: They are written, physical, and digital records detailing a patient’s medical history, including demographics, diagnoses, treatments, and test results, maintained by healthcare providers.
Insurance Claims: These are formal requests submitted by healthcare providers to insurance companies aiming for a financial reimbursement for medical services provided to insured patients.
Lab Results: These are reports produced from medical laboratory tests providing data on a patient’s health status to assist in the most accurate diagnosis and treatment planning
Medical Prescriptions: These are mainly handwritten authorised instructions from licensed healthcare professionals that allow patients to obtain and use specific medication or therapies. These documents usually contain a stamp or signature of the professional.
Consent Forms: These are documents typically in a form format that the patients need to fill and sign, indicating that they have been informed and agree to the potential risks and benefits of undergoing a particular medical procedure
Discharge Summaries: These are documents prepared after a patient’s stay in a hospital, providing a summary of their hospitalisation along with recommendations for post-discharge care.
Doctor Notes: These are usually handwritten records by doctors or physicians documenting patient encounters, including observations, assessments, and proposed plans for treatment.
Clinical Trials: These are documented research studies assessing new treatments or medications, usually combining handwritten notes and electronic data, crucial for regulatory approvals and medical advances.
Thus, Medical Document Processing can play a crucial role in healthcare organisations by ensuring that all these different records are accurately depicted in patients’ electronic records and are easily accessible across multiple points of care. Since patients often visit different doctors, hospitals, or specialists, maintaining an updated medical profile resulted in timely and more effective treatments. Additionally, streamlining this documentation accelerates processes such as insurance claims and doctor assessments, which can be critical in some cases based on studies that consistently show that reducing the time to act significantly improves patient outcomes.
Challenges of Traditional Clinical/Medical Processing
Despite the importance of accurately capturing and storing information from different healthcare documents, this process presents significant challenges for healthcare organizations and professionals. One of the main pain points of this task is the different ways that the information can be depicted in these medical documents that are based on the stage of diagnosis or treatment of the patient may vary significantly in layout and content. More specifically, the different methods of data capture include:
Handwritten Notes: Healthcare providers have traditionally used handwritten notes to document patient histories, observations, and treatment plans. These notes may include drawings, symbols, and annotations with clinical significance.
Typed or Transcribed Text: With advancements in technology, many clinicians have shifted to typing notes directly into electronic health record (EHR) systems or using transcription services to convert dictated notes into text.
Scanned Documents: Paper-based records, including handwritten notes and printed reports, are often digitized through scanning. These scanned documents are integrated into EHR systems, preserving the original content and layout.
Medical Images: Diagnostic imaging modalities like X-rays, MRIs, and CT scans are integral to patient records. These images provide visual insights into a patient’s condition and are often accompanied by radiology reports that interpret the findings.
Annotated Images: Medical images frequently include annotations—such as arrows, labels, or highlighted regions—to emphasize specific areas of interest or concern to aid in diagnosis, treatment planning, and communication among healthcare professionals.
Figures and Diagrams: Medical records may encompass various figures, such as charts, graphs, and anatomical diagrams, to illustrate patient data trends, procedural steps, or anatomical references. These visual aids enhance understanding and provide quick references for clinicians.
Structured Data Entries: Modern EHR systems facilitate the input of structured data, including checkboxes, drop-down menus, and standardized fields, to capture specific information like vital signs, medication lists, and allergy information.
The diverse nature and complex terminology of healthcare records often cause professionals to spend significant time extracting, reformulating, and verifying data, resulting in substantial overhead costs. This time increases further when accuracy standards require peer reviews and additional checks to reduce inevitable human errors caused by repetitive, low-effort tasks.
Additionally, various stakeholders like doctors, lawyers, insurance experts, and claim examiners must access these records. As these professionals often bill hourly, poorly captured or difficult-to-access information can lead to time-consuming searches or document audits. This inefficiency increases organisational costs and potentially jeopardises patient care.
How Intelligent Document Processing Benefits Businesses (Automation)
Intelligent Document Processing (IDP) streamlines the process of information extraction of these paper-based documents to integrate them to other healthcare business processes and systems. It leverages technologies such as optical character recognition (OCR), Machine learning algorithms, and Natural Language Processing (NLP) techniques to effectively identify, extract, classify, and validate information with greater accuracy and speed than the traditional labor-intensive operations.
Traditionally, there have been various IDP pipelines tailored to different areas within the healthcare industry, with proposed solutions ranging from simpler pipelines with fewer steps to more complex ones featuring sophisticated architectures. Some of the primary technologies utilised in these solutions include:
Optical Character Recognition is the process of digitalising the information present in the physical documents (scanned or machine-generated) to make it available as a machine-readable text.
Rule-based techniques that expect hand-crafted rules and specific patterns that match the target information in the text. This allows the system to identify meaningful information from the text following these patterns and process them based on a specific rule. For example, in a simple Name Entity Recognition system, some patterns can be provided to identify all the nouns in a sentence and classify them to predefined entities/classes such as diseases or drugs based on some (grammatical /syntactical) rules.
Machine learning Models and NLP Techniques utilise statistical algorithms that use a large amount of annotated data to learn these patterns and make predictions on specific information based on these patterns. For example, an ML model can be trained to identify patterns and indications in patients’ data to predict any potential health risks to validate and enrich the retrieved information.
The automation of medical document processing offers various benefits for the healthcare industry, including improved diagnostic accuracy, quicker treatment decisions, and increased efficiency through effective storage, indexing, and organisation of information. This significantly reduces the time highly paid professionals spend processing or searching for information, lowering administrative costs and minimising human errors. Additionally, automating medical documentation enhances the work experience of healthcare employees by eliminating tedious, repetitive tasks, allowing them to focus on better patient care.
How LLMs Help in Processing Unstructured Documents
Large Language Models (LLMs), such as GPT-4, Claude, or Gemini, have significantly advanced document processing by effectively handling complex layouts across various formats, including scanned documents, handwritten notes, and digital files. Due to their self-attention mechanisms, LLMs outperform traditional NLP methods in understanding text by capturing complex contextual relationships and long-range dependencies. This feature enables them to perform:
Advanced Named Entity Recognition (NER): LLMs dynamically adapt to language variations, domain-specific terms, and ambiguous entities, leading to higher accuracy than traditional rule-based methods.
Context-Aware Relationship Extraction: LLMs leverage deep contextual embeddings to accurately interpret entity relationships beyond fixed syntactic rules, effectively managing complex or ambiguous cases.
Dynamic Context Interpretation for Ambiguous Data: LLMs use attention mechanisms to dynamically resolve ambiguity by analyzing the broader context, adapting to variations in meaning, sarcasm, and implied references.
LLMs, however, can go beyond of just an advanced data extraction tool, having the potential to significantly enhance the organisation and retrieval of extracted data by understanding context, improving classification, and ensuring data quality. Here’s how LLMs contribute to these key areas:
Semantic Search: LLMs improve search by understanding the context and intent behind queries, offering more relevant results. Unlike traditional keyword-based search methods, LLMs analyze the semantic meaning of both the query and the content, allowing for more accurate and context-aware search results.
Data Classification: LLMs can classify and tag unstructured data, making it easier to organize and retrieve. By learning from large datasets, they recognize patterns and contextual cues, enabling them to accurately categorize complex and ambiguous data without relying on predefined rules.
Standardisation: LLMs help establish data entry and storage standards to maintain quality and consistency. They adapt to various data formats and automatically align content with established standards, ensuring that data remains uniform and structured.
Validation: LLMs implement validation checks to ensure data accuracy. They can identify inconsistencies, outliers, and errors by understanding contextual relationships within the data, leading to higher accuracy and data integrity.
TL;DR
This article examines the challenges involved in processing medical and healthacre documents and demonstrates how using Large Language Models (LLMs) can enable new ways of handling healthcare documents extraction.
If you wish to skip directly to the solution section, where you can see how Unstract in action, click here.
LLMs’ Role in Processing Clinical/Medical Reports
So, LLMs can play a crucial role in improving medical document processing by significantly enhancing accuracy, efficiency, and consistency when extracting information from clinical and medical reports. Their advanced capabilities enable healthcare providers to overcome challenges associated with traditional extraction methods such as rule-based techniques.
More specifically, LLMs assist medical document processing by:
Handling Medical Terminology Variations: Accurately parsing misspellings, abbreviations, and diverse terminologies commonly found in clinical notes. They dynamically adapt to varied and evolving medical language, ensuring that subtle linguistic nuances and domain-specific terms are accurately recognized.
Managing Typographical Errors: Reliably interpret documents despite typographical errors or unconventional formatting. For example, LLMs can accurately interpret handwritten doctor’s notes or clinical prescriptions with unclear handwriting or incorrect spelling, minimizing misinterpretations and errors.
Achieving Human-Level Accuracy: Demonstrating exceptional extraction performance through advanced training on large medical datasets. For instance, a fine-tuned Llama-3.1 8B model achieved exact-match rates of 91.5% for prostate and breast reports, 72.2% for kidney reports, and 89.4% for myelodysplastic syndrome reports, indicating precision comparable to medical experts.
Interpreting Complex Medical Jargon: Effectively understanding and tagging medical acronyms and specialised terms to enhance data retrieval and analysis. LLMs provide context-aware recognition of medical jargon, simplifying the categorization and searchability of medical information across extensive databases.
By addressing these specific challenges, the integration of LLMs into medical documentation workflows substantially improves operational efficiency, reduces reliance on manual oversight, and ultimately enables healthcare professionals to dedicate more attention to patient-centered care. Additionally, the use of LLMs facilitates faster access to critical patient information, enhancing timely decision-making in clinical settings.
Brief Introduction to Unstract and How it Leverages AI in Structuring Unstructured Data
Unstract is an advanced AI-powered open-source platform designed to simplify and streamline the extraction of structured data from complex, unstructured documents. Leveraging state-of-the-art LLMs, Unstract surpasses traditional Intelligent Document Processing (IDP) and Robotic Process Automation (RPA) systems by accurately processing diverse document types and transforming them into structured, LLM-friendly formats.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
One of the key advantages of Unstract is its technology-agnostic architecture, which facilitates seamless integration with existing technology stacks. Its workflow’s component can be easily tailored to each use case, including components such as:
Text Extraction: Integrate various text extraction tools, including Unstract’s LLMWhisperer, to accurately capture and format content from diverse documents.
Embedding Models: Use proprietary or open-source embedding models from providers such as OpenAI, Azure, or HuggingFace to convert extracted information into meaningful numeric vectors.
Vector Databases: Seamlessly integrate, store, and manage embeddings efficiently in SQL or vector databases like PostgreSQL, optimizing interactions with search engines and LLMs.
LLM Providers: Deploy and test different LLM providers’ models, including OpenAI, Anthropic, Gemini Vertex, and Mistral, tailoring model performance to specific needs.
These capabilities can be found in the two main products of Unstract:
LLMWhisperer: Converts diverse and complex documents (PDF, DOC, PPT, images, etc.) into formats optimized for LLM processing. It accurately preserves layouts, extracts detailed table data, form elements, and handwritten text, making it ideal for automating business workflows. LLMWhisperer operates on a pay-as-you-go model, offering the first 100 pages free and flexible pricing.
Unstract Cloud: An open-source, no-code subscription-based platform designed to automate complex document-intensive workflows in a user-friendly interface, specifically beneficial for healthcare documents like clinical reports and patient forms. It leverages the latest in AI and Large Language Models to efficiently handle various document complexities, providing accurate structured outputs without manual intervention. Users can quickly start and build end-to-end ETL extraction projects, easily integrating Unstract Cloud into their processes.
Both products seamlessly integrate as stand-alone solutions into existing applications via API or as ETL processes, populating vector databases to build comprehensive knowledge bases for LLM-driven Chatbots.
Steps in Unstract to parse clinical/medical reports using LLMWhisperer Playground
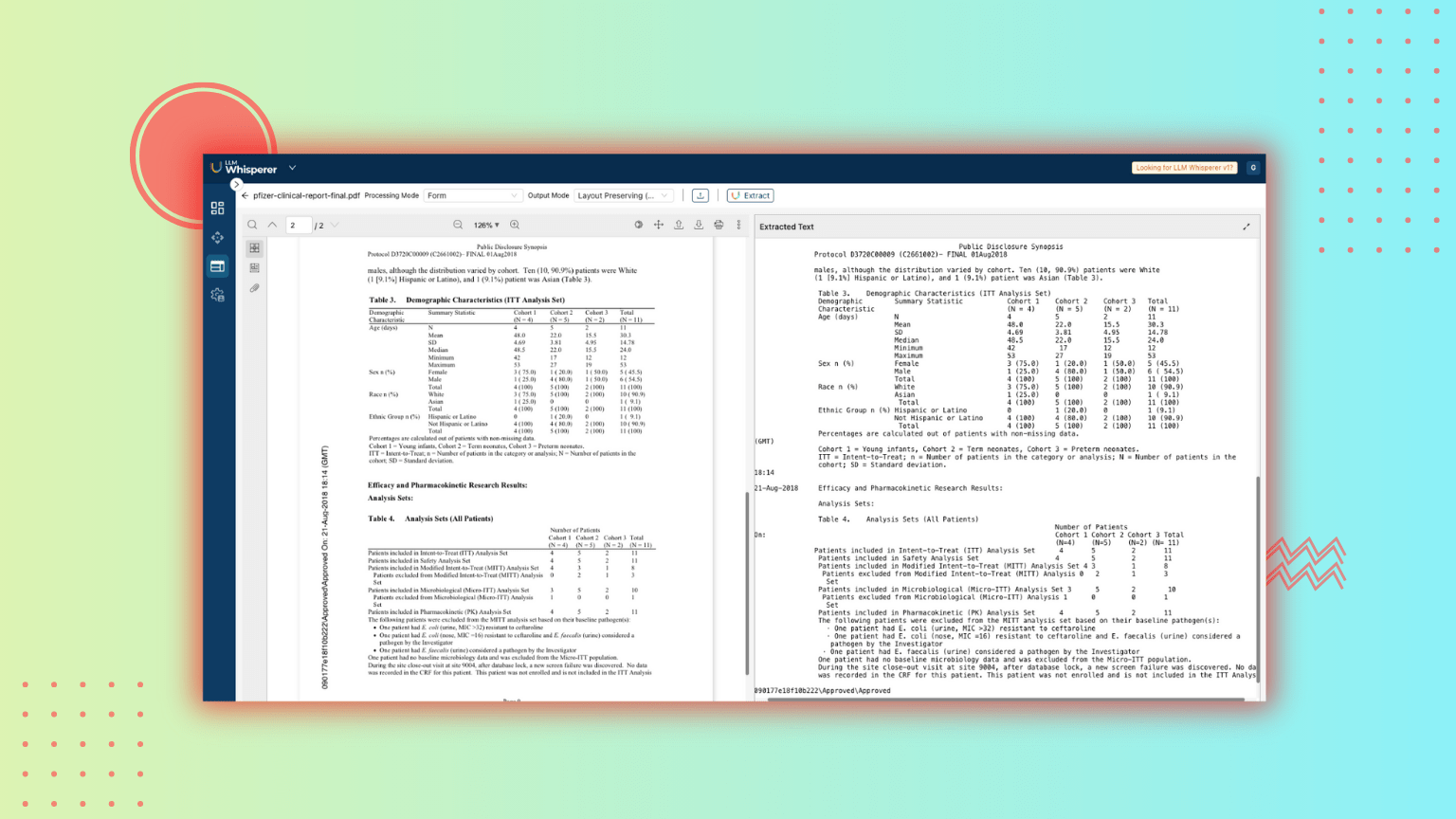
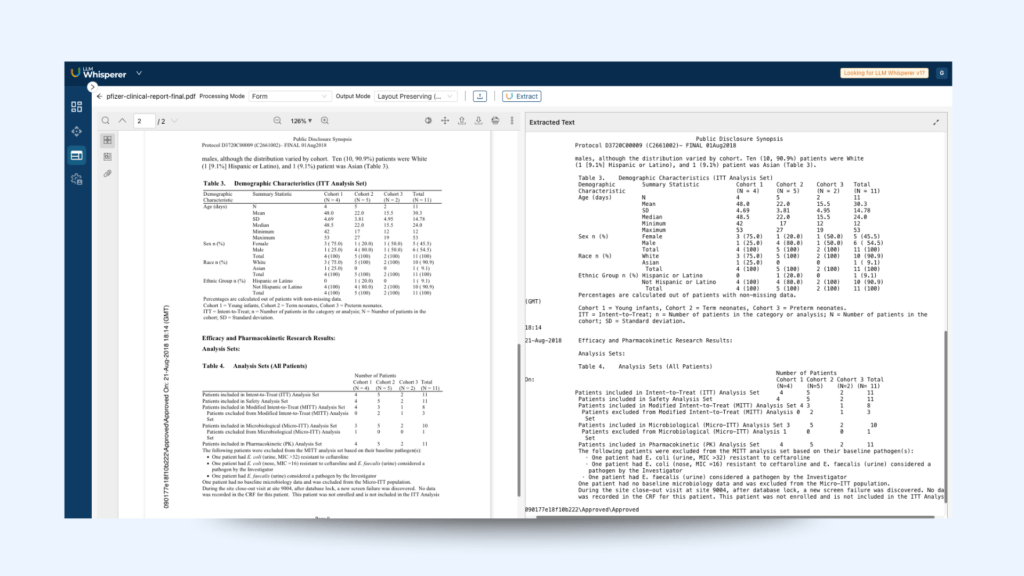
LLMWhisperer is a general-purpose PDF-to-text converter that presents data from complex documents (of different designs, layouts, complex tables, and scanned images) to LLMs in a way they can best understand. A quick and easy way to grasp all the advanced extraction capabilities of the LLMWhisperer we will use a typical clinical report generated from Pfizer on LLMWhisperer playground:
The setup of the playground is pretty straightforward and easy to use:
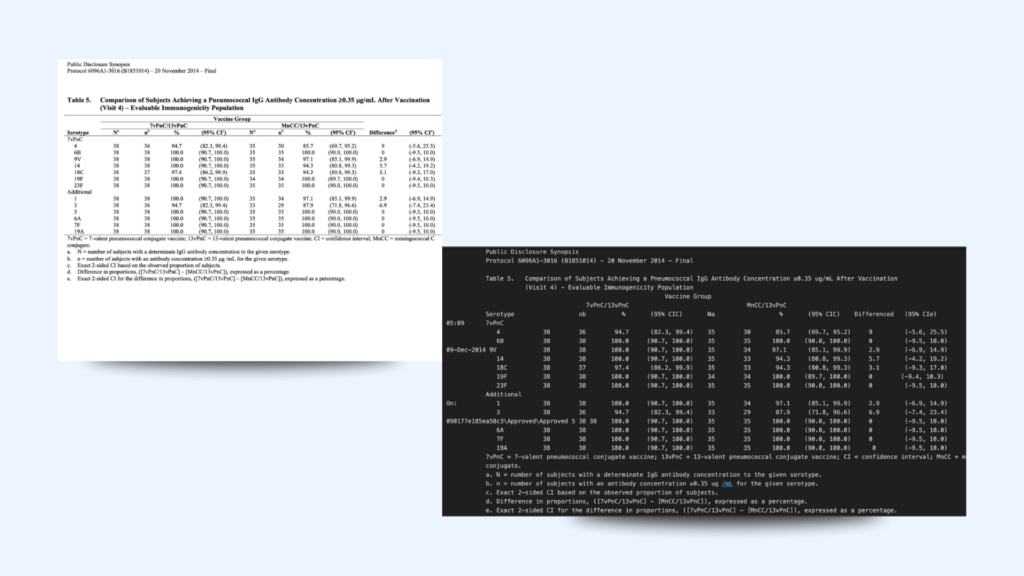
A detailed review of the results highlights the impressive accuracy of LLMWhisperer in capturing various components of clinical documents. Although this might seem straightforward, many tools designed for text extraction excel in identifying certain elements but struggle significantly with others.
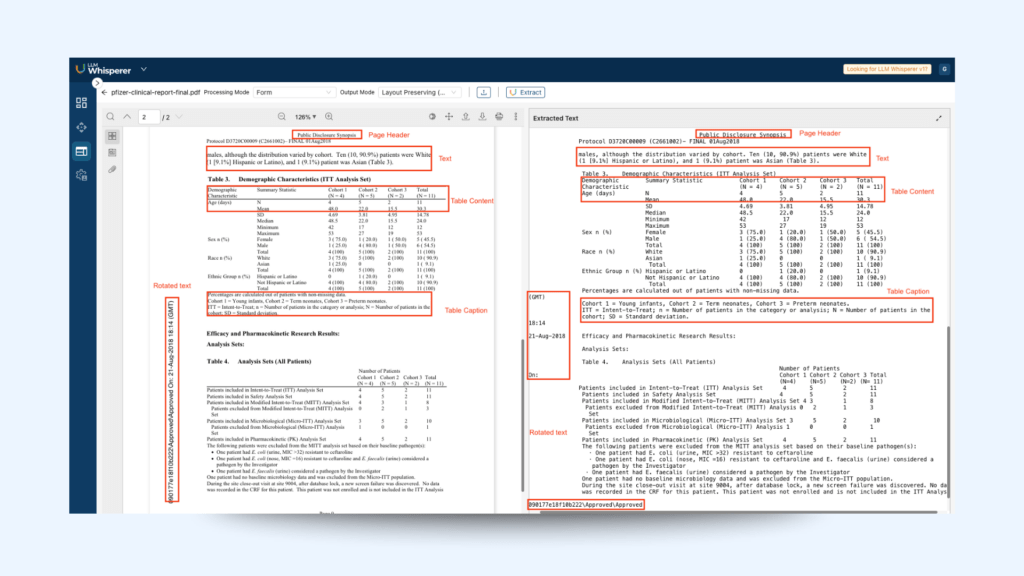
In the example below, we can identify the different components that the LLMWhisperer accurately extracted:
Page Header: Text at the top of healthcare documents, usually containing patient identification, document type, dates, or healthcare provider details.
Free text: Unstructured narrative content in healthcare documents, including clinician notes, diagnoses, treatment plans, or observations.
Table Content: Structured healthcare data arranged in rows and columns, commonly representing patient vitals, lab results, medication lists, or treatment schedules.
Table caption: Brief descriptions or titles above or below tables in healthcare documents, summarizing the purpose or contents, such as “Patient Vital Signs,” “Medication Summary,” or “Laboratory Test Results.”
Rotated text: Text oriented vertically or at an angle in healthcare documents, often found in labels, margins, or charts, used for displaying additional context, test identifiers, specimen labels, or space optimisation.
Steps in Unstract to parse clinical/medical reports using LLMWhisperer API (Postman)
LLMWhisperer also offers a programmatic approach to parsing healthcare files through its API endpoint. This capability makes it straightforward to integrate LLMWhisperer into various applications or seamlessly embed it within existing document processing workflows.
Setting up this API endpoint is again really easy and straightforward:
In LLMWhisperer:
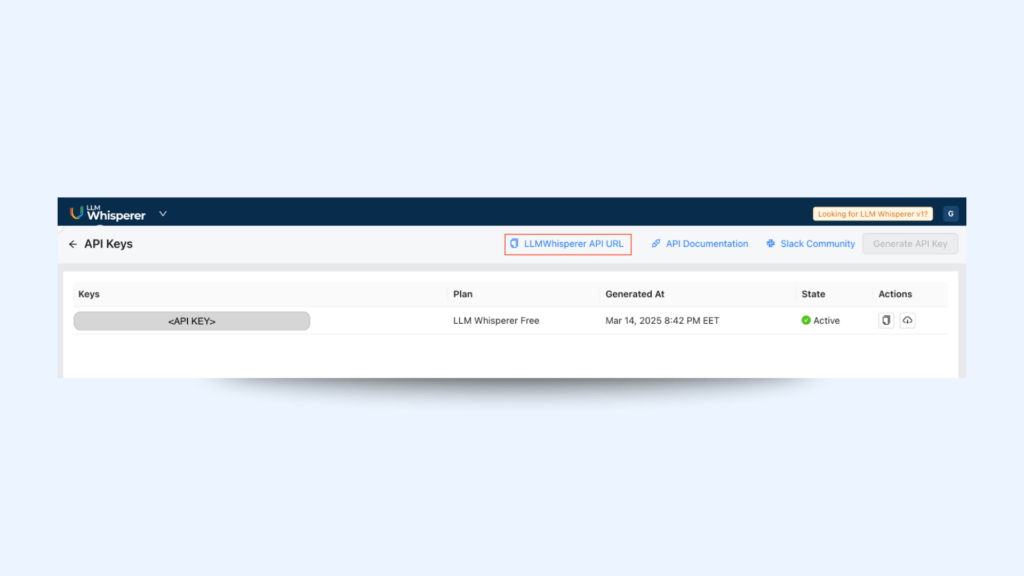
When you visit the LLMWhisperer page and successfully create your free Account, an API key is automatically generated.
Navigate to the API Keys Tab to review your LLMWhisperer plans and retrieve:
Base API URL: by clicking LLMWhisperer API URL button
API Key: Under the Keys column
Using this information, you can utilise tools like Postman to integrate with the Unstract API
In Postman
Open Postman and add a new request
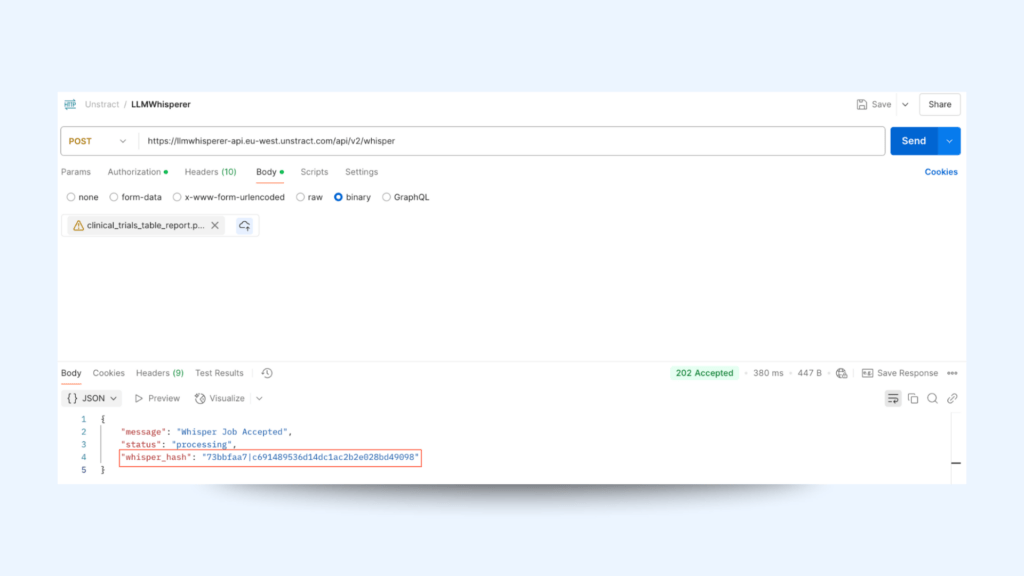
In the POST request, add the below information to use the Extraction API
Endpoint
/whisper
URL
<base-url>/whisper
Method
POST
Headers
unstract-key: <YOUR API KEY>
Body
application/octet-stream
For additional parameters to the Extraction endpoint, visit the API documentation
In the Body, select the Binary data type and upload the file from your local machine and sent the request
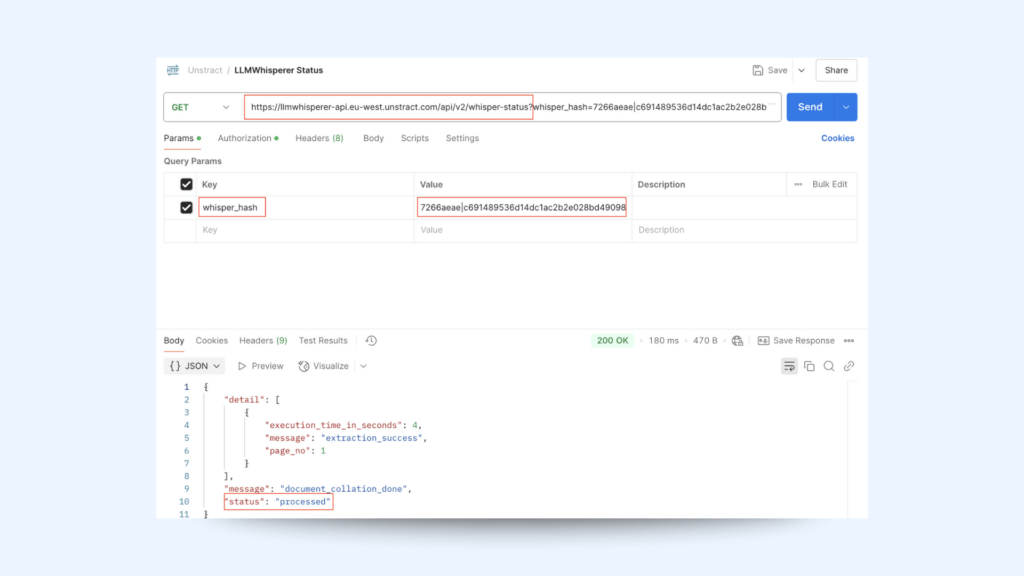
From the response of the extraction endpoint, take the whisper_hash value to see the progress of the request from the status API
Endpoint
/whisper-status
URL
<base-url>/whisper-status
Method
GET
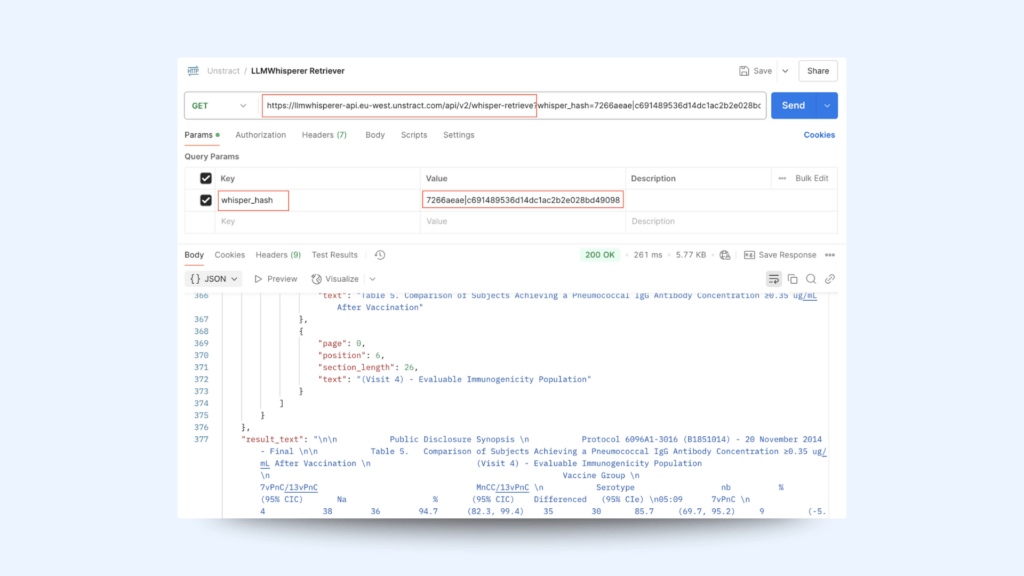
If the status is processed, you can retrieve the parsed output via the Retriever API using the same whisper_hash
Endpoint
/whisper-retrieve
URL
<base-url>/whisper-retrieve
Method
GET
From the retrieved API, we can extract the parsed output with the below format with the content of the page to be captured under the result_text item.
Steps to extract key information from clinical/medical by writing prompts via Prompt Studio
Prompt Studio is a no-code platform to extract data from unstructured documents by implementing all the components of a Retrieval Augmented Generation in a streamlined workflow.
More specifically, you can configure the:
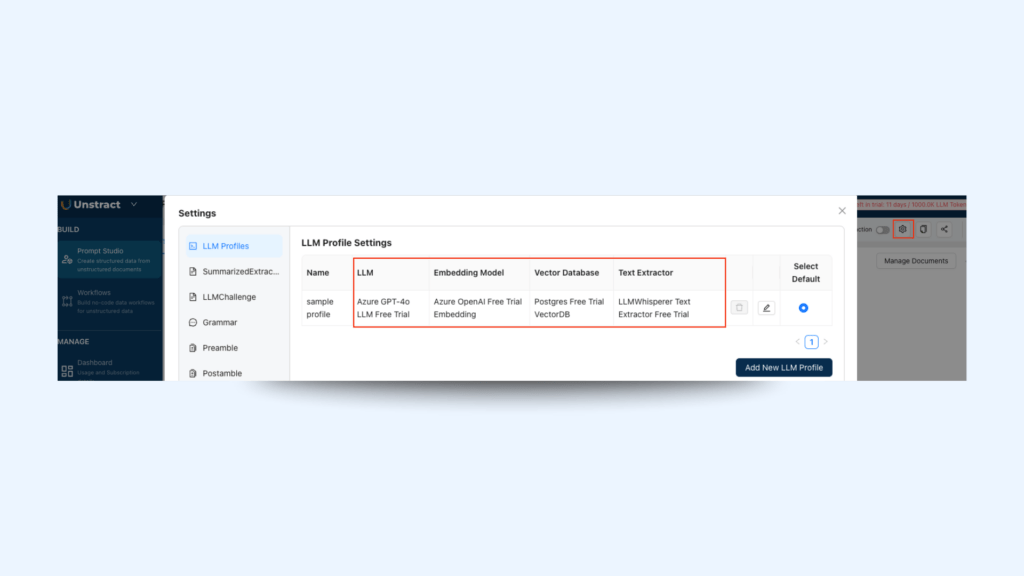
Text Extractor: To parse the healthcare document by navigating to Settings → Text Extractor (LLMWhisperer is preconfigured as a free trial)
Embedding Model: To convert the extracted information to numeric embeddings by navigating to Settings → Embedding (Azure OpenAI Free Trial Embedding preconfigured)
Vector Database: To store the information embedding and retrieve it to be used from the selected LLM by navigating to Settings → Vector DBs (Postgres Free Trial VectorDB preconfigured)
LLM Model: To generate the final response, extract data from the healthcare document by navigating to Settings → LLMs (Azure GPT-4o LLM Free Trial preconfigured)
This provides an enhanced IDE where, in one place, you can experiment with different prompts while seeing the source document to validate your results.
Let’s try it out with a Lab Test Report in the following example:
On the top right of the page, switch from LLM Whisperer to Unstract platform and select the Prompt Studio tab to create a project for this example
Select New Project on the top right, provide the name of the tool, author, and description,n and click Save
This will open a new project in Prompt Studio IDE
Verify all the components of the project by clicking the settings icon in the top right
Then, from the Prompt Studio, click Manage Documents to load the Document
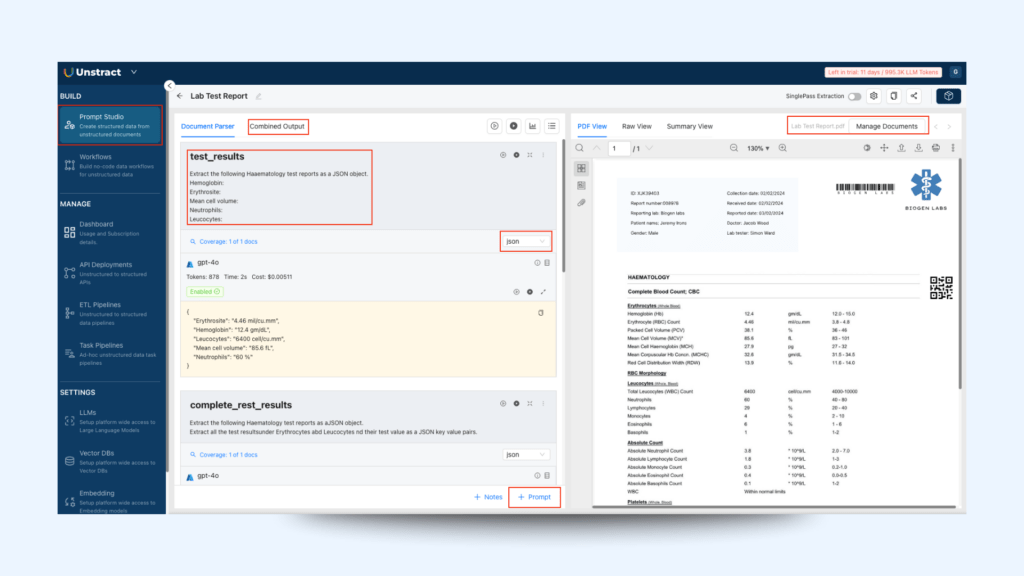
Then, in the left panel click + prompt to ask questions to the configured LLM about the document by providing:
The title of the question → patient_name
The description → What is the name of the Patient
And the output format → Text
After configuring all the questions, run them into the document
All the question results can be found in the Combined Output in the JSON format
It can be seen that this RAG system accurately captured the presented information from the Lab report by extracting both:
The complex clinical terms of the haematology domain
Precisely captured the corresponding information as logically was rendered in PDF file keeping it in key, value pairs
Generated the combined output in a JSON format that can be easily parsed and utilized in the following steps of an extended ETL process or as a knowledge base for an LLM-powered product.
Steps to extract key information from clinical/medical by writing prompts via API (Postman)
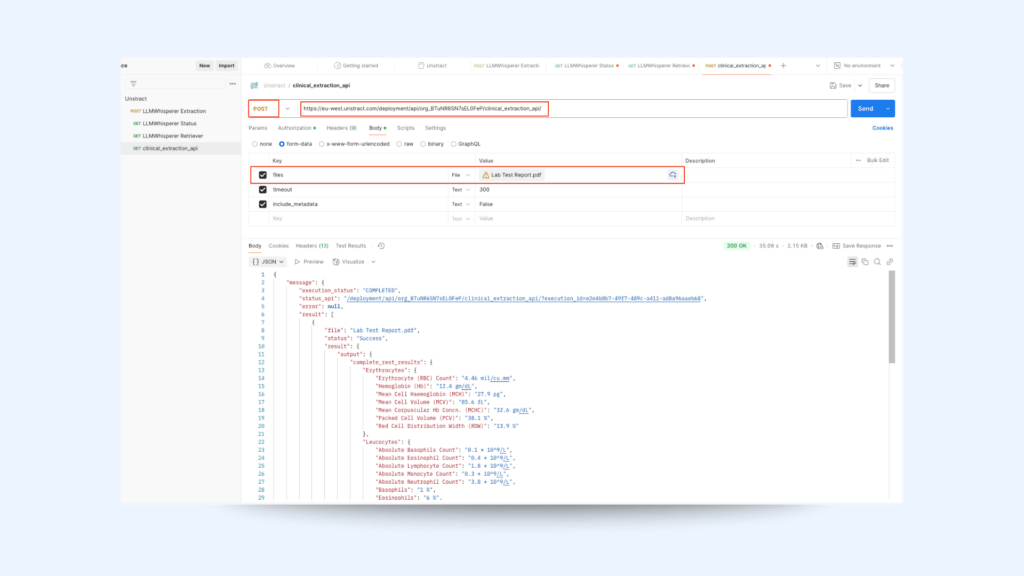
As we can see above, the results are pretty impressive for someone running an example and comparing them side by side. However, the real power of the Unstract lies in its opportunity to be integrated in any existing ETL process or data management system. So to achieve that, we can replicate this exercise and wrap all the workflow in just one API call as below:
In the Unstract Platform:
Create and refine your prompts for accurate extraction of clinical or medical data in your Prompt Studio project
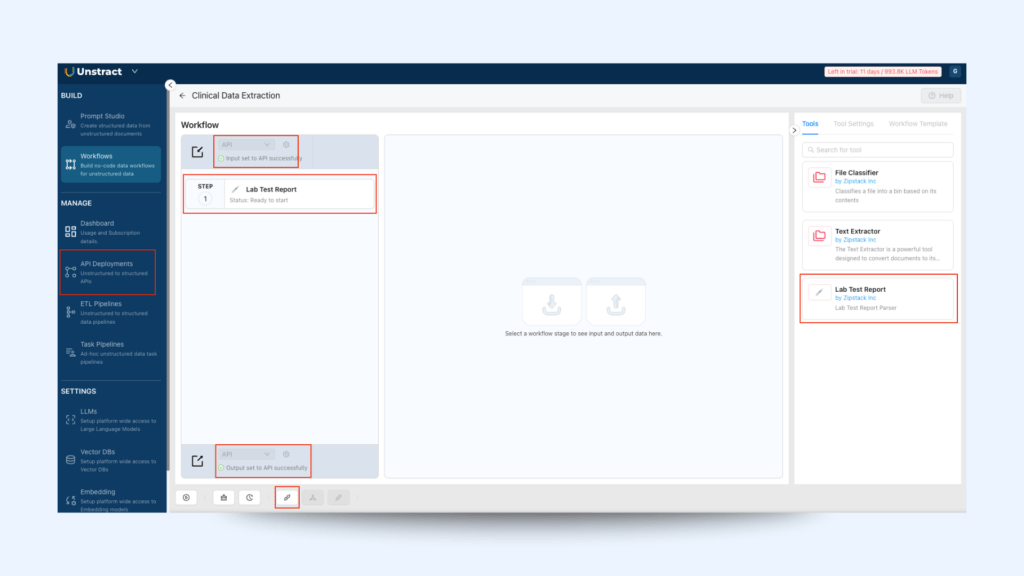
In Prompt Studio, click the ‘Export as tool’ icon in the top-right corner of your project to turn your clinical data extraction prompts into a reusable tool.
Navigate to BUILD tab→ Workflows and click + New Workflow to initiate a new workflow.
Locate your newly created clinical data extraction tool under the Tools section and drag it into the workflow setup area. Ensure the input and output formats are defined as API.
5. Navigate to MANAGE → API Deployments and click + API Deployment to deploy your workflow as an API.
Once deployed, use the provided API Endpoint link to manage your API, including generating API keys from Manage Keys or downloading a Postman collection for testing.
In Postman:
Create a new POST request in Postman and add the API Endpoint
Configure authentication by selecting the type Bearer Token and enter your API key.
Select a clinical or medical document (e.g., a clinical report PDF) in Body by selecting form-data and execute the request to test and validate your API’s functionality.
This demonstrates that we can achieve results similar to those obtained in Prompt Studio through a more programmatic approach.
Conclusion
The complexity and diversity in medical document formats and terminologies pose significant challenges to healthcare organisations, resulting in increased overhead costs, reduced efficiency, and potential risks to patient care. Manual processing of these documents often involves repetitive tasks that lead to human errors, prolonged processing times, and inefficient data retrieval, affecting various stakeholders, including doctors, lawyers, and insurance experts.
Automating medical document processing effectively addresses these issues, offering substantial benefits such as improved diagnostic accuracy, accelerated treatment decisions, reduced administrative costs, and minimised human errors. Additionally, automation enhances healthcare employees’ work experiences by eliminating tedious tasks, allowing more time for patient-focused activities.
In this context, Unstract plays a crucial role by leveraging advanced, AI-driven Large Language Models (LLMs) to accurately extract structured data from complex, unstructured documents. Unstract significantly outperforms traditional IDP methods, particularly demonstrated through tools like LLMWhisperer and Prompt Studio. These tools excel in capturing detailed clinical information from complex documents and presenting it in structured, easily integrable formats such as JSON, enabling seamless incorporation into existing ETL processes or LLM-based workflows.
Ultimately, adopting Unstract not only enhances operational efficiency and reduces costs but also unlocks new potential for streamlined, accurate, and scalable document processing across the healthcare sector and similar industries.
Unstract 101: Leveraging AI to Convert Unstructured Documents into Usable Data
Watch this webinar/demo to explore Unstract, a platform for LLM-powered unstructured data extraction. Learn how to process complex documents—like those with images, forms, and multi-layout tables—without the need for pre-training.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.