Invoice OCR: Guide to Extracting Data from Invoices
Table of Contents
Invoice processing is an essential but often challenging task for businesses, as it involves managing a variety of document formats, layouts, and data structures.
Organizations routinely face hurdles such as manual data entry errors, inconsistencies in invoice formats, and delays in data extraction, all of which can negatively impact cash flow and overall operational efficiency.
The accuracy of Optical Character Recognition (OCR) plays a critical role in overcoming these challenges.
High-precision OCR not only minimizes errors in data extraction but also streamlines the processing workflow, reducing the need for manual corrections and speeding up financial reconciliations.
Accurate OCR is then fundamental to ensuring that data is reliably captured, regardless of the document’s complexity or quality.
This article focuses on contrasting the limitations of traditional OCR systems with the advanced performance of LLMWhisperer.
While conventional OCR tools often struggle with preserving document layouts and handling complex invoice elements, LLMWhisperer offers state-of-the-art solutions that significantly improve data accuracy and extraction efficiency.
The Importance of Accurate OCR for Invoice Processing
Accurate OCR is the backbone of efficient invoice management.
It addresses many challenges that businesses face when processing invoices and ensures that data extraction is both reliable and efficient.
Why Invoice OCR Accuracy Matters
In invoice processing, even minor errors can lead to significant issues.
Common problems include data misinterpretation—where numerical values, dates, or text are incorrectly recognized—and layout distortion, which can scramble the inherent structure of an invoice.
Such errors often result in incorrect financial records and delayed reconciliations, directly impacting business efficiency and operational accuracy.
These challenges underscore why reliable invoice OCR is so crucial.
Benefits of Accurate OCR
Leveraging precise OCR technology yields several key benefits.
Firstly, it significantly enhances data extraction accuracy, ensuring that every piece of information is captured correctly, regardless of variations in invoice formats or document quality.
Secondly, it accelerates processing times, reducing the need for manual data entry and subsequent corrections.
This automation streamlines workflows and enhances overall operational efficiency, making ocr invoice processing a competitive advantage for any business.
Accurate OCR is not just about reducing errors; it’s about transforming how businesses handle invoices—turning a traditionally labour-intensive process into a streamlined, reliable operation.
Introducing LLMWhisperer: The Best OCR for Invoice Processing
LLMWhisperer is an advanced OCR solution designed specifically for the complex demands of invoice processing.
Developed with cutting-edge technology, it leverages modern machine learning techniques to accurately extract data from a wide variety of invoice formats.
Positioned as a next-generation tool, LLMWhisperer excels where traditional OCR systems falter.
Its innovative approach not only improves data extraction accuracy but also ensures that the integrity and layout of documents are preserved, making it an ideal choice for modern businesses.
Unlike conventional OCR tools, LLMWhisperer is built to tackle common pitfalls such as misinterpretation of data and layout distortions.
It handles complex invoice elements with ease, ensuring that critical details are captured accurately.
By integrating advanced processing techniques, LLMWhisperer reduces manual intervention and streamlines the entire invoice management workflow, offering businesses a more reliable and efficient solution.
LLMWhisperer: Best OCR for invoice processing
Key Invoice OCR Features of LLMWhisperer
Maintaining the original structure of an invoice is crucial for ensuring data integrity during extraction.
LLMWhisperer is engineered to preserve layouts, ensuring that headers, tables, checkboxes, radio buttons, and other design elements remain intact.
This careful layout preservation is essential for understanding the contextual relationships between data elements, minimizing errors, and supporting seamless financial reconciliation.
Supported Invoice Document Formats
LLMWhisperer is designed to handle a broad range of file formats, making it an adaptable solution for diverse invoice processing needs.
Beyond file formats, LLMWhisperer excels in processing various document types critical to invoice processing:
Native PDFs: Extracts high-fidelity text from native PDF documents.
Scanned Images: Provides robust OCR for scanned documents, ensuring accuracy even with lower quality scans.
PDF Forms: Capable of detecting and accurately extracting data from PDFs that include interactive elements like checkboxes and radio buttons.
Complex Layouts: Handles documents with intricate tables, multi-column formats, and varying designs.
Photographed Invoices: Processes images of invoices captured via cameras, compensating for challenges like skew and low lighting.
Multi-lingual Invoice OCR Capability
With support for extraction in over 300 languages, LLMWhisperer ensures accurate processing of invoices regardless of the language.
This global capability is particularly advantageous for businesses with international operations, ensuring that language barriers do not compromise data quality.
Additional Features
LLMWhisperer comes with a suite of advanced features tailored to optimize invoice processing:
Advanced Modes: Choose from different operational modes—Native Text, Low Cost, High Quality, and Form—to balance speed, cost, and extraction accuracy based on your specific needs.
Below is a table summarizing the advantages of each LLMWhisperer mode:
Mode
Key Advantages
Recommended Use Cases
Native Text
– Extremely fast extraction performance- Superior layout preservation – Ideal for native text PDFs with high-density text
– Documents that are native PDFs – Use cases with minimal preprocessing needs
Low Cost
– Economical processing without sacrificing speed- Supports scanned PDFs and images – Provides very good performance in cost-sensitive scenarios
– Applications where cost is a priority – High-quality scanned PDFs and images
– Optimized for detecting interactive form elements (checkboxes, radio buttons)- AI/ML–based enhancements for accurate field extraction – Excellent line reproduction and layout preservation
– Invoices and forms with complex layouts – Documents requiring precise form element detection
Image Pre-processing: Incorporates techniques like median filtering and gaussian blur to enhance image quality before OCR, improving extraction performance.
Rotation and Skew Compensation: Automatically adjusts for misaligned or rotated documents, ensuring accurate data capture even from imperfectly scanned or photographed invoices.
Auto Repair PDFs: Features intelligent repair capabilities that correct common PDF issues, allowing for smoother processing of corrupted or non-standard files.
AI/ML Enhancements: Leverages artificial intelligence and machine learning to continually refine extraction accuracy, particularly for complex or high-entropy documents.
Together, these features make LLMWhisperer a powerful and versatile tool for invoice processing, capable of handling a wide variety of formats and document types while maintaining the highest levels of accuracy and efficiency.
Here is the GitHub repository where you will find all the codes written for this article.
LLMWhisperer: Best Invoice OCR to Extract Data from Handwritten Invoices
LLMWhisperer is available as an API that can be integrated into your existing systems to preprocess your documents before they are fed into LLMs. It can handle a variety of document types, including PDFs, images, and scanned documents.
Use Cases: LLMWhisperer Invoice OCR in Action
In the complex world of invoice processing, traditional OCR tools often struggle with a variety of document challenges.
Here, we explore six common scenarios where these limitations are most evident.
Each case demonstrates how LLMWhisperer’s advanced features—whether accessed through its interactive Playground or integrated via its API—deliver superior performance in data extraction and layout preservation.
This section highlights the practical benefits of LLMWhisperer for OCR invoice tasks, showcasing improvements in invoice OCR API integration and OCR invoice scanning accuracy.
LLMWhisperer Invoice OCR API
Before we start, let’s take a look at the Python code used for integrating with the LLMWhisperer API (version 2):
from unstract.llmwhisperer import LLMWhispererClientV2
from unstract.llmwhisperer.client_v2 import LLMWhispererClientException
import sys
# Function to process a document
def process_document(file_path):
# Initialize the client with your API key
client = LLMWhispererClientV2(base_url="https://llmwhisperer-api.us-central.unstract.com/api/v2",
api_key='<your-api-key>')
# Call the sync method with the file path
try:
result = client.whisper(
file_path=file_path,
wait_for_completion=True,
wait_timeout=200,
)
print(result['extraction']['result_text'])
except LLMWhispererClientException as e:
print(e)
# Main function
if __name__ == "__main__":
# Retrieve document name from command line arguments
if len(sys.argv) != 2:
print("Usage: python llmwhisperer.py <document>")
sys.exit(1)
# Call the function to process the document
process_document(sys.argv[1])
Don’t forget to replace with your own api_key.
You will also need to install the LLMWhisperer Python package:
pip install llmwhisperer-client
Then, execute the script with:
python llmwhisperer.py <document>
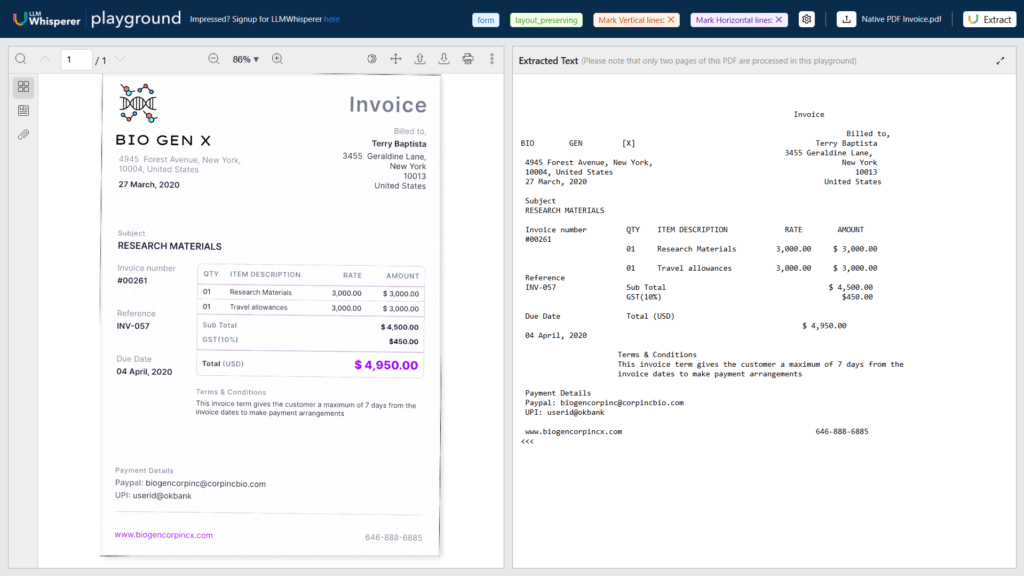
Use Case 1: Invoice OCR Processing for Native PDF Invoices
Complexity Factors
Native PDFs are inherently complex because, despite being rich in text, they often vary significantly in formatting and structure.
These documents can be created by different software tools or sourced from various origins, leading to inconsistencies in text encoding, font styles, and spatial arrangements.
For example, variations in margins, line spacing, or column alignment may cause traditional OCR systems to misinterpret where one section ends and another begins.
Additionally, the use of custom layouts, layered content, and embedded graphics further complicates the extraction process, potentially resulting in distorted headers, misplaced table data, or even omitted sections.
This variability demands an OCR solution that not only recognizes text accurately but also intelligently understands and preserves the underlying structure of the document.
This is the PDF used to demonstrate this type of document:
Let’s use the LLM Whisperer Playground to process this document:
Results
LLMWhisperer leverages advanced OCR algorithms that not only extract text with exceptional accuracy but also meticulously preserve the original document’s structure.
This means that while it converts printed or handwritten content into machine-readable text, it also maintains the spatial arrangement and formatting of key elements.
Headers, tables, footers, and other layout components are detected and replicated in the output (as seen in the screenshot), ensuring that the hierarchical and relational context of the data is retained.
This level of detail is crucial for tasks such as financial reconciliation or data analytics, where understanding the precise placement of information—like column titles in a table or section headers—can significantly enhance data interpretation and integration with existing systems.
Use Case 2: Invoice OCR Processing in Excel File Format
Challenges
Excel-based invoices frequently come with unique formatting hurdles that set them apart from standard document layouts.
These invoices may feature non-standard layouts where the data doesn’t adhere to a strict grid format, making it difficult to clearly distinguish between different sections or data fields.
Additionally, merged cells can obscure the boundaries between distinct pieces of information, causing confusion in the extraction process.
Embedded formulas, which are often used to calculate totals or other dynamic values, add another layer of complexity, as they may not be readily interpretable as plain text.
This combination of non-standard formatting, merged cells, and embedded calculations requires an OCR solution that is not only capable of accurately capturing text but also intelligently interpreting and restructuring the underlying data into a coherent, machine-readable format.
This is the document used to demonstrate this type of document:
Let’s use the LLMWhisperer API to process this document, with the previous code:
python llmwhisperer.py invoice-excel.xlsx
This is the output:
Sheet name:Blank Invoice
Magic Printers INVOICE
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
INVOICE #: 90042 DATE: 02-02-25
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
MAILING Street Address BILL│Name Roger Deakins
│ ├────────────────────────────────────────────────
INFO City, ST ZIP TO│Customer ID 894003
│ ├────────────────────────────────────────────────
│Phone: (000) 000-0000 │Street Addres12, Fywheel avenue
│ ├────────────────────────────────────────────────
│Fax: (000) 000-0000 │City, ST, ZIPFloida - 60987
│ ├────────────────────────────────────────────────
│ │Phone 678393
│ └────────────────────────────────────────────────
DESCRIPTION AMOUNT │
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬───────────────────┘
Camera large print boxes 200 │ $200
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
Camera medium pring boxes 100 │ $300
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
Camera label print large 30 │ $200
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
Camera label print large 200 │ $100
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
Camera label print small 300 │ $100
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
│
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
│
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
│
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
│
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
│
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
│
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
│
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────
SUBTOTAL │ $900
───────────────────┼────────────────────
OTHER COMMENTS │ TAX RATE │ 0.000%
────────────────────────────────────────────────────────────────── ───────────────────┼────────────────────
1. Total payment due in 30 days TAX │ $ 2.00
───────────────────┼────────────────────
2. Please include the invoice number on your check S&H │
───────────────────┼────────────────────
DISCOUNT │ $ 5.00
═══════════════════╗════════════════════
Thank You For Your Business! TOTAL │ $800
Make Make all checks payable to:
Your Company Name
[42]
Results
LLMWhisperer intelligently parses these complex structures by leveraging sophisticated algorithms that recognize and interpret the unique patterns found in spreadsheet formats.
It carefully analyzes the spatial organization of data, ensuring that even when faced with non-standard layouts, merged cells, or embedded formulas, the extracted data remains both accurate and contextually relevant.
By maintaining the relationships between rows, columns, and individual cells, LLMWhisperer preserves essential metadata such as headers, labels, and grouped data—ensuring that the logical structure of the original document is retained.
This level of precision not only enhances the quality of data extraction but also facilitates seamless integration with downstream processes like financial reporting, analytics, and automated reconciliation.
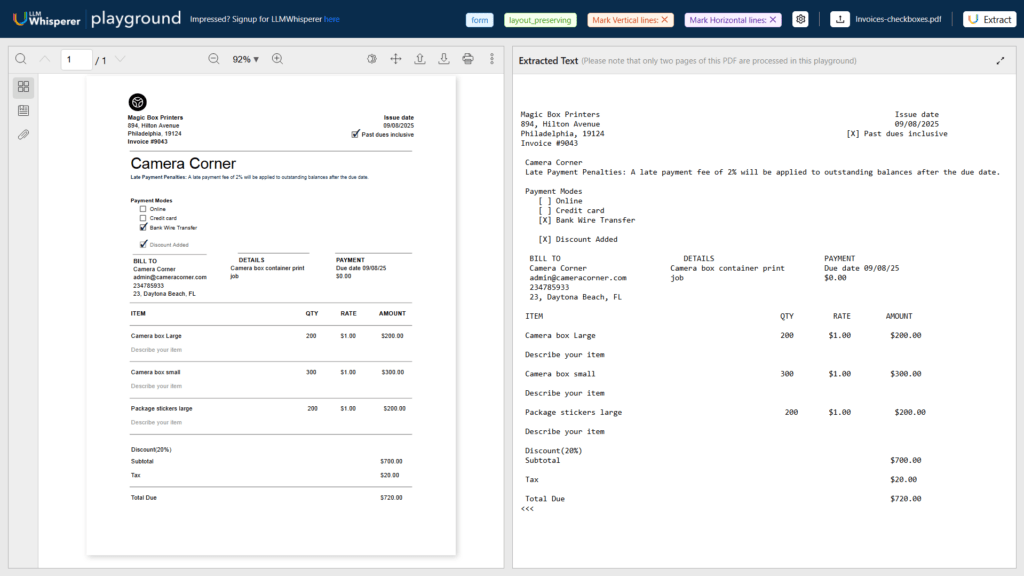
Use Case 3: Invoice OCR Processing for Checkboxes
Importance of Form Element Recognition
Invoices featuring checkboxes and other interactive form elements play a critical role in conveying user selections and approvals that directly impact decision-making processes.
Recognizing these elements accurately is essential because even a small misinterpretation—such as missing a checked box or misclassifying an empty one—can lead to significant errors in data processing and subsequent business operations.
Traditional OCR systems often struggle in this area due to their limited ability to differentiate between graphical elements and text, leading to incomplete or inaccurate data capture.
This is the PDF used as example for this type of document:
Let’s use the LLM Whisperer Playground to process this document:
Results
LLMWhisperer overcomes these challenges by employing advanced algorithms and AI/ML-based techniques specifically designed for form element detection.
This approach enables the system to precisely identify and interpret checkboxes, radio buttons, and other interactive components within an invoice.
As a result, the solution not only extracts the underlying text but also preserves the contextual integrity of the form elements, ensuring that all user inputs are accurately reflected.
This level of precision is vital for automating workflows, maintaining data integrity, and reducing the risk of manual errors in processing invoices.
Use Case 4: Invoice OCR Processing for Complex Tables
Handling Multi-row/Column Structures
Invoices that incorporate intricate tables present a significant challenge for OCR systems due to the complex spatial relationships between data points.
These tables often contain multi-row and multi-column structures, spanning across various sections with nested headers, subtotal rows, and varying cell alignments.
Traditional OCR solutions may struggle to correctly interpret these layouts, leading to issues such as misaligned columns, misplaced values, or loss of hierarchical relationships within the data.
This is the document used to demonstrate this type of document:
Let’s use the LLMWhisperer API to process this document, with the previous code:
Renewal Sales Order TM
Marketo
An Adobe Company
Customer: roger deakins,
Address: Suite 23, Bill To: Prepared By: Renee Fournier
Roger Deakins Phone:
forest avenue road
FL- 60984 Fax: +1-650-376-2332
Order Number: Q-336338
Offer Expiration: 10/28/2022
PO Number: PO Required: Yes or No Created Date:10/13/2022
Subscription Services: Marketing Automation and Analytics
Product Name Term Net Price
Select Package 12 USD 73,195.53
GRAND TOTAL: USD 73,195.53
Usage Rights
Subscription Start Date: 11/1/2022
Subscription End Date: 10/31/2023
Customer may use the Subscription Services set forth herein during the dates noted in the table(s) herein and, absent any such dates, during the
subscription term having the Subscription Start Date and Subscription End Date set forth above (each a "Subscription Term"). Customer's Usage
Rights are limited to the maximum quantities set forth below:
Select Package
Application Qty Unit Start Date End Date
Custom User Roles & Permissions 1 Each 11/1/2022 10/31/2023
API Calls 50,000 Daily API Calls 11/1/2022 10/31/2023
Lead & Account Database 200,000 Contacts 11/1/2022 10/31/2023
Custom Data Objects & Fields 2 1M Custom Object Records 11/1/2022 10/31/2023
Advanced Dynamic Content 200,000 Contacts 11/1/2022 10/31/2023
Campaign & Journey Automation 200,000 Contacts 11/1/2022 10/31/2023
Advanced Personalization 1 Each 11/1/2022 10/31/2023
Marketo Engage Users 25 Each 11/1/2022 10/31/2023
Landing Pages & Forms 1 Each 11/1/2022 10/31/2023
Audience Segmentation & Targeting 1 Each 11/1/2022 10/31/2023
Scoring, Routing & Alert 200,000 Contacts 11/1/2022 10/31/2023
Intelligent Cross-channel Nurturing 200,000 Contacts 11/1/2022 10/31/2023
Email Marketing 1 Each 11/1/2022 10/31/2023
Social Marketing 1 Each 11/1/2022 10/31/2023
Event & Webinar Marketing 1 Each 11/1/2022 10/31/2023
Marketing Calendar 25 Users 11/1/2022 10/31/2023
Search Engine Optimization 1 SEO 500-Keyword Block 11/1/2022 10/31/2023
Paid Media Targeting 1 Each 11/1/2022 10/31/2023
Campaign Reporting & Insights 1 Each 11/1/2022 10/31/2023
Attribution & ROI Dashboards 200,000 Contacts 11/1/2022 10/31/2023
Secured Domains 1 Domain 11/1/2022 10/31/2023
Sandbox Add-on 1 Each 11/1/2022 10/31/2023
Marketo, Inc., 901 Mariners Island Blvd Suite 200, San Mateo, CA, 94404, United States
Page 1 of 2
<<<
Renewal Sales Order TM
Marketo
An Adobe Company
Application Qty Unit Start Date End Date
Select Database Size 200,000 Contacts 11/1/2022 10/31/2023
Sales Insight 5 User(s) 11/1/2022 10/31/2023
Native CRM Integration (SFDC & MSD) 1 Each 11/1/2022 10/31/2023
Dynamic Chat 1 Each 11/1/2022 10/31/2023
Email MKTG - Email Deliverability 1 Each 11/1/2022 10/31/2023
Core Application - Managed Service Provider Instance 2 Each 11/1/2022 10/31/2023
Online Support 1 Each 11/1/2022 10/31/2023
Bizible Tier 2 1 Each 11/1/2022 10/31/2023
Core Application - Additional Marketo Engage Users 25 Each 11/1/2022 10/31/2023
Terms of Use
This Sales Order, together with the Marketo End User Subscription Agreement signed on 10/31/2017 constitutes the entire agreement between
Marketo and Customer governing the Services referenced above ("Agreement"), to the exclusion of all other terms. Any capitalized terms not
otherwise defined herein shall have the meanings attributed in the Agreement. The terms of this Sales Order are Marketo Confidential Information.
Subscription fees for the products listed herein will automatically increase by 8% per year on the next annual renewal. As used herein, the term
"Sales Order" is synonymous with the term "Order."
Additional Terms
Payment Frequency: Quarterly
Payment Terms: Net 30
Customer gives permission to Marketo to use Customer's name and logo for marketing efforts.
Managed Service Provider
Notwithstanding the service bureau restriction set forth in the Agreement, Marketo hereby grants to Customer the non-transferable, non-
sublicensable right during the during the Subscription Term to permit Customer employees to access and use the Services for service bureau
purposes, solely to provide such Services to Customer's clients (subject to all other usage limits and restrictions in the Agreement). The rights
and obligations of Marketo under the Agreement are to Customer only, and Customer's clients shall not be deemed a party to or a third party
beneficiary of the Agreement.
Marketo and Customer have caused this Sales Order to be signed and effective, as of the last date signed below, by their duly authorized
representatives ("Order Effective Date"). Unless otherwise set forth herein, Customer will be invoiced for the initial payment on the Subscription
Start Date. The Subscription Start Date will commence on the date listed above.
-
Marketo, Inc., 901 Mariners Island Blvd Suite 200, San Mateo, CA, 94404, United States
Page 2 of 2
<<<
Results:
LLMWhisperer addresses these challenges by utilizing advanced table recognition and layout preservation techniques.
It intelligently detects row and column boundaries, ensuring that data is extracted while maintaining the structural integrity of the original table.
Whether dealing with invoices that feature dynamic line items, itemized tax breakdowns, or multi-tiered financial summaries, LLMWhisperer accurately reconstructs the table format.
This allows for seamless integration with accounting systems, ERP software, and other data processing tools, ultimately reducing manual corrections and improving the efficiency of invoice processing workflows.
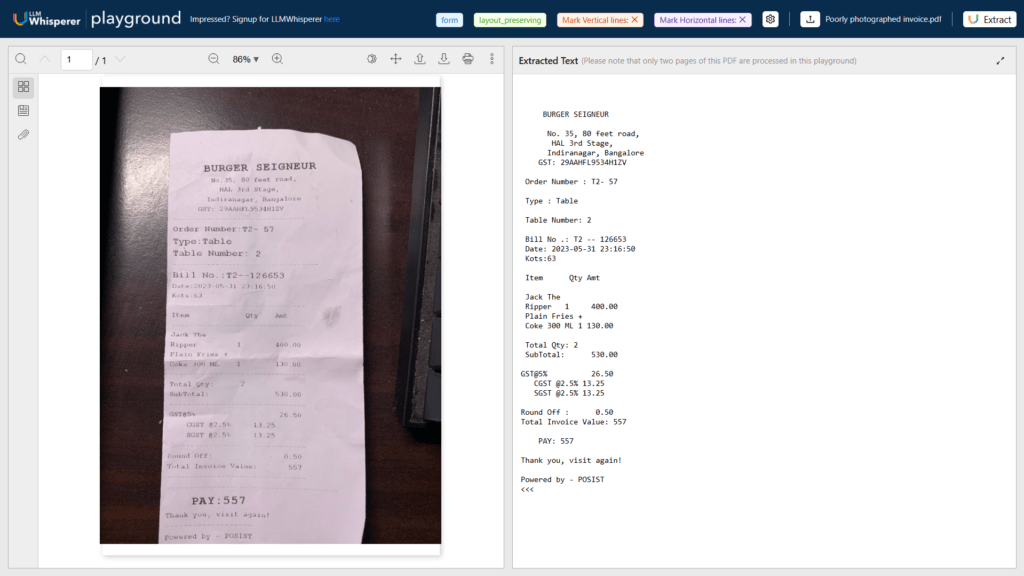
Use Case 5: Invoice OCR Processing for Poorly Photographed Invoice
Addressing Low-Quality Images
Photographed invoices introduce a range of challenges that can severely impact OCR performance, making accurate data extraction difficult.
These challenges often include skewed perspectives, where the invoice is captured at an angle rather than head-on, leading to distorted text alignment.
Low-resolution images may cause text to appear blurry or pixelated, making character recognition unreliable.
Additionally, inconsistent lighting conditions—such as shadows, glare, or uneven brightness—can obscure key details, resulting in incomplete or inaccurate data capture.
This is the PDF used as example for this type of document:
Let’s use the LLM Whisperer Playground to process this document:
Results
LLMWhisperer overcomes these issues through advanced pre-processing techniques, including automatic deskewing, noise reduction, and adaptive contrast enhancement.
By intelligently correcting distortions, sharpening text clarity, and normalizing brightness levels, LLMWhisperer significantly improves text recognition accuracy.
Furthermore, its deep learning-based OCR capabilities allow it to intelligently reconstruct missing or unclear characters, ensuring that even invoices captured in suboptimal conditions are processed with high fidelity.
This ensures businesses can rely on accurate data extraction, regardless of the quality of the original image.
Use Case 6: Invoice OCR Processing for Scanned Invoice
Traditional OCR Limitations
Scanned documents introduce several challenges that can significantly hinder the accuracy of traditional OCR tools.
One common issue is uneven lighting, where variations in brightness across the document—caused by shadows, glare, or improper scanning techniques—can obscure text and reduce recognition accuracy.
Blurry text is another frequent problem, often resulting from low-resolution scans or improper focus, making it difficult for OCR engines to differentiate between similar-looking characters.
Additionally, scanned documents may suffer from compression artifacts, faded ink, or background noise (such as watermarks or stamps), all of which can interfere with accurate text extraction.
Traditional OCR systems often struggle to preserve the original structure of the document, leading to misaligned text, lost formatting, and inaccurate data representation.
This is the document used to demonstrate this type of document:
Let’s use the LLMWhisperer API to process this document, with the previous code:
python llmwhisperer.py 'Scanned Invoice.pdf'
This is the output:
Spalding & Bros. SPALDING PLEASE REMIT TO SPALDING SALES CORP.
SION OF SPALDING SALES CORPORATION
STORE NO. FOLIO C
FAMOUS FOR ATHLETIC EQUIPMENT
INVOICE NO. S 2812
CUSTOMER'S
Sold To DATE 6/1/39 Ship To ORDER NO.
BKLYN EAGLES B B CLUB DELD TO DIRK LUNDY
EMANLEY -
ADDRESS ADDRESS
101 MONTGOMERY STREET
TOWN NEWARK, N.J. STATE TOWN STATE
TERMS:
2% CASH 10 DAYS-NET 30 DAYS- VIA
DEALER INST. GOLF PRO. ORDER TAKEN BY SALESMAN'S NAME NO,
CLASS
OF
BALE A GOODWIN TAGUER 106
ITEM QUANTITY UNIT
86 NO. DESCRIPTION OF ARTICLE ORDERED SHIPPED PRICE AMOUNT
125 BATS 9 9 EA 1 75 15 75
120 BATS 1 1 EA 1 75
-
200 BATS 6 6 EA 1 00 6 00
1 30 BATS 2 2 EA 1 40 2 80
26 30
1 50
-
#24.80-
DI
- -
SEP -
A
Form F 21 1-39-M
NO RETURN OF MERCHANDISE FROM THIS INVOICE WILL BE ACCEPTED UNLESS YOU HAVE OUR WRITTEN PERMISSION.
<<<
Results
LLMWhisperer addresses these challenges with a suite of advanced processing algorithms designed to enhance both text recognition and layout preservation in scanned documents.
Unlike traditional OCR systems that struggle with artifacts such as noise, faded text, and distortions, LLMWhisperer applies intelligent image pre-processing techniques, including noise reduction, contrast enhancement, and adaptive binarization, to optimize text clarity before extraction.
Its deep-learning-based OCR models are specifically trained to handle the complexities of scanned invoices, enabling it to recover faint or distorted characters and reconstruct missing sections with remarkable precision.
Moreover, LLMWhisperer goes beyond simple text extraction by preserving the structural elements of the document, such as tables, headers, and section boundaries, ensuring that the extracted data retains its original context.
By consistently delivering higher accuracy in recognizing and organizing financial information from scanned invoices, LLMWhisperer minimizes the need for manual corrections, streamlines invoice processing workflows, and enhances data reliability for financial reconciliation and record-keeping.
Final Thoughts
Each of these use cases highlights the transformative benefits of LLMWhisperer in addressing the limitations of traditional OCR systems.
Whether dealing with native PDFs, complex tables, checkboxes, Excel-based invoices, or low-quality scanned and photographed documents, LLMWhisperer consistently delivers superior text recognition and layout preservation.
By intelligently handling diverse invoice formats and overcoming common OCR pitfalls—such as misalignment, data loss, and form element misinterpretation—it enables businesses to extract critical financial data with precision and reliability.
By leveraging both its interactive Playground and robust API integration, organizations can seamlessly integrate LLMWhisperer into their existing workflows.
The Playground provides a user-friendly environment for testing and refining OCR outputs in real time, while the API allows for scalable automation, making high-accuracy invoice processing accessible across enterprise applications.
This dual capability empowers businesses to reduce manual intervention, accelerate financial operations, and enhance overall efficiency in invoice management.
Invoice OCR Processing: Conclusion
Accurate OCR is not just a convenience—it’s a critical component for efficient and error-free invoice processing.
By minimizing manual intervention, reducing data misinterpretation, and preserving original document layouts, high-precision OCR dramatically improves business operations and financial reconciliation.
LLMWhisperer stands out with its advanced capabilities, including robust layout preservation, multi-format support, multi-lingual extraction, and specialized modes tailored for diverse document types.
As demonstrated through the various use cases—from native PDF invoices to poorly photographed documents—LLMWhisperer consistently delivers enhanced performance, making it an invaluable tool for modern invoice management.
We encourage you to experience the transformative power of LLMWhisperer yourself. Explore its user-friendly Playground for real-time demonstrations and consider integrating its powerful API into your workflow for seamless, scalable invoice processing.
Embrace the evolution of OCR technology and take the next step towards a more efficient, accurate, and automated future in business processes.
Take LLMWhisperer for a test drive, check out our free playground.
LLMWhisperer: Best Invoice OCR to Extract Data from Handwritten Invoices
PDF forms have checkboxes and radiobuttons that can be filled out by hand by the user. These form elements are used to collect various bits of important data from them. In this repo, we will show how to extract these form elements using LLMWhisperer in a way that LLMs can understand.
What is invoice OCR, and why is its accuracy so important? Invoice OCR (Optical Character Recognition) is technology that converts different types of invoices into machine-readable text data. Its accuracy is critical because even minor errors can lead to data misinterpretation, incorrect financial records, and delayed reconciliations, directly impacting business efficiency and cash flow.
How does LLMWhisperer enhance invoice OCR accuracy compared with traditional OCR tools? LLMWhisperer utilizes advanced layout preservation, image pre-processing (deskew, denoise, and contrast enhancement), and specialized modes (Native Text, Low Cost, High Quality, and Form). These features let it capture complex tables, checkboxes, and handwritten notes with far fewer errors than legacy OCR engines that often distort layouts or miss form elements.
Which file formats and document types are supported by LLMWhisperer for invoice OCR? LLMWhisperer handles a wide range of formats—including PDF, DOCX, PPTX, XLSX, ODT, TXT, JPG, PNG, TIFF, and WEBP—and document types such as native PDFs, scanned images, photographed invoices, PDF forms, and files with complex multi-column layouts. It also supports more than 300 languages for truly global invoice OCR needs.
Can invoice OCR with LLMWhisperer manage low-quality or non-standard invoices, such as handwritten or poorly photographed documents? Yes. The High-Quality mode applies powerful image enhancement and handwriting recognition to extract data from low-resolution scans, skewed photographs, or faded text. The engine can also detect and interpret interactive elements like checkboxes and radio buttons, making it suitable for handwritten or form-based invoices.
How can businesses integrate invoice OCR into their existing workflows? Businesses can use the LLMWhisperer invoice OCR API to integrate automated invoice data extraction directly into their systems, enabling scalable, real-time invoice processing that minimizes manual intervention and enhances overall efficiency.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.