Product
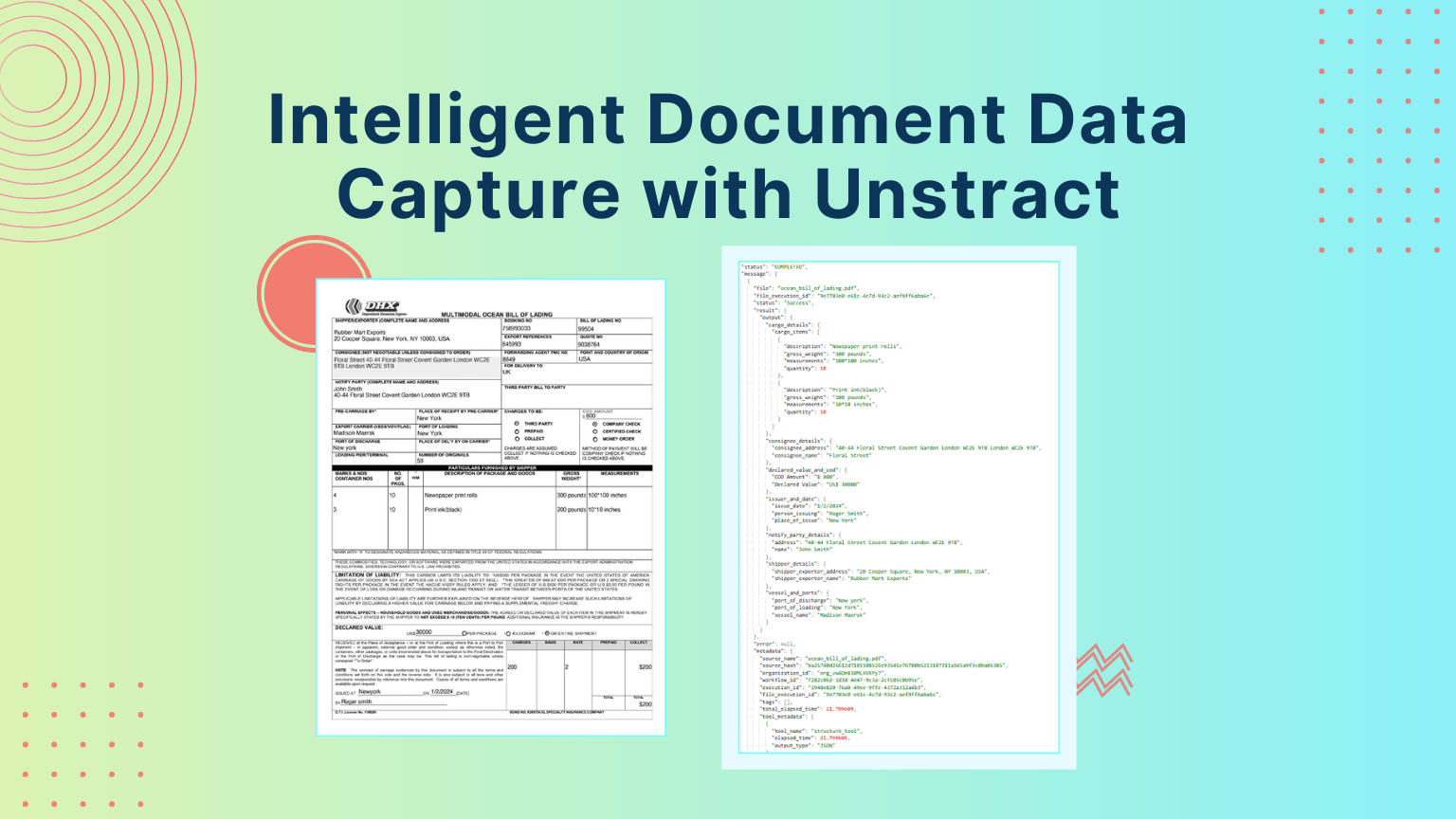
Intelligent Document Data Capture with Unstract
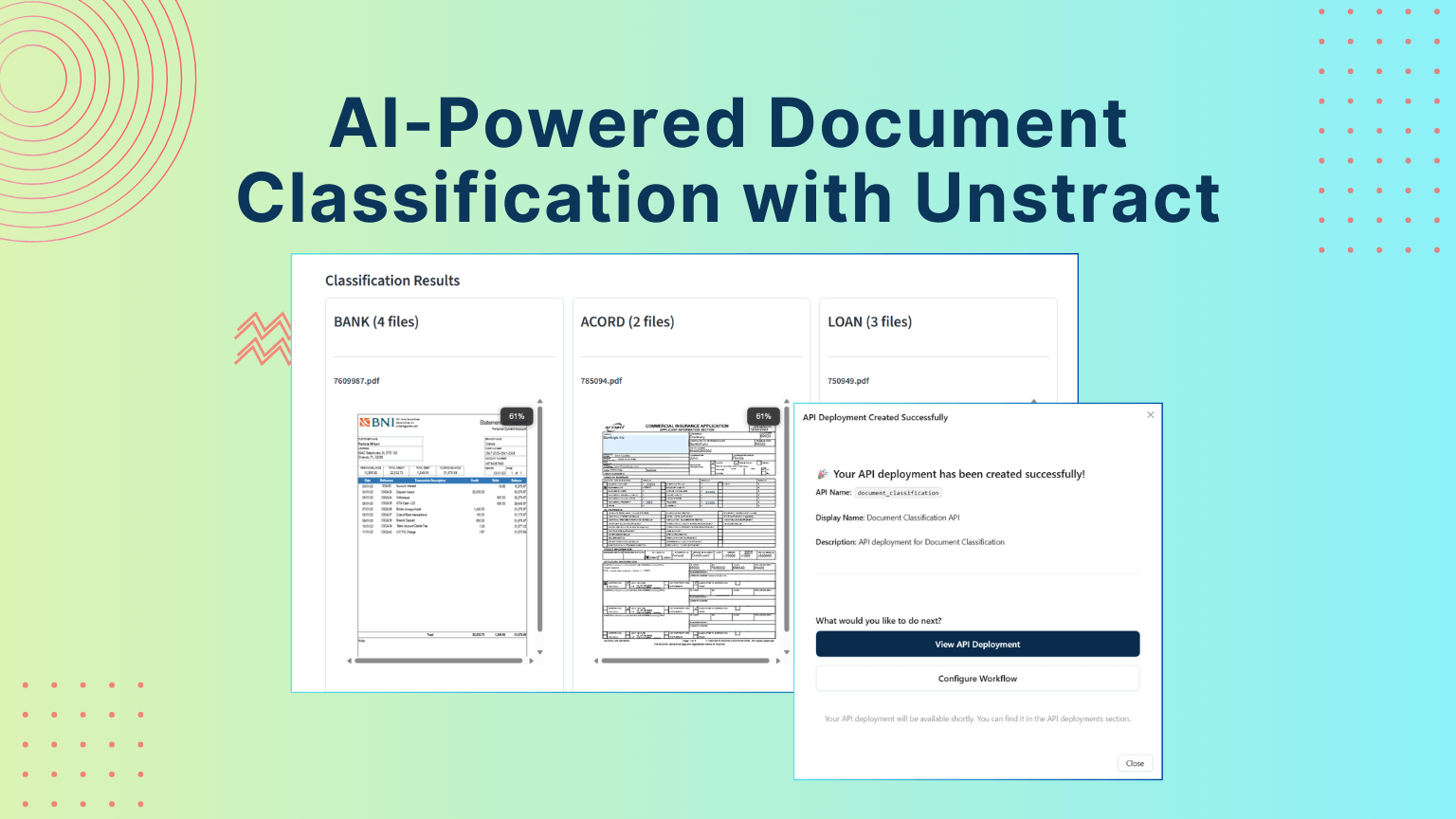
Intelligent Document Capture automates reading and extracting data from physical or digital documents, turning them into structured formats. See how Unstract and LLMWhisperer lead the way in next-gen document capture.