Specification Grounding: The Missing Link in Vibe Coding
Table of Contents
Whether you’re creating new projects from scratch or want to speed up the development of existing, large projects, you will always want to counter one property of LLMs: their eagerness to please you, which can be, more often than not, detrimental to whatever development goal it is that you have in mind.
Tight vs loose specifications
When you sit down with a pair programmer to either develop something new or add or modify a feature in an existing application, the specification is something that is figured out in the conversation. But, depending on the complexity of the specific implementation you have in mind, it can be achieved in a couple of ways:
Front-loading specifications and removing Reasonable Ambiguity
This is where you have somehow (magically)figured out every single aspect of the implementation (new app, changes or a new feature to an existing app). You have then provided a well-defined specification to your engineer or pair programmer so they can go heads down on the keyboard and, after a period of time has passed, can deliver the implementation you wanted. For simplicity’s sake, let’s also assume that they(equally magically) deliver to you what you’ve wanted.
LLM-driven development works really well with this, but getting the spec to this level of clarity and groundedness can be a lot of effort. But there are ways to do this very efficiently, as we’ll discuss later. Remember that we’re talking about, ideally speaking, getting as close as possible to a level of detail where neither a human nor an LLM will feel there is any reasonable ambiguity for all implementation details.
Rough specifications with ongoing clarifications
In this way of working, you’ve given the engineer a rough idea of what you need, but both you and your engineer know that your specification isn’t watertight. However, in the spirit of quick iterations, your engineer begins the implementation.
Wherever she feels your inputs might add value, she pauses her work, asks you how to proceed and incorporates your inputs. This repeats until the implementation is complete. Now, following this approach when it comes to LLMs might not give you the best results. Due to how eager they are, they will themselves make various assumptions and take a path that you might not really like.
Specification Grounding and how it helps
Your first job as someone engaging in LLM-powered development is to counter their eagerness by “grounding” the LLM with specifications that are as tight as possible. Turns out, this works like magic and can be the difference between a “runaway app” that the LLM has created ,which is far from what you need, and an app that is the stuff of your dreams.
Reasonable Ambiguity
When I say “tight”, there are many ways to interpret that, so we’ll qualify that with a specification or sub-specification that doesn’t have any “reasonable ambiguity”. Since this involves natural language and a generalized field like software engineering, there is no end to how specific you can get, but taking a pragmatic approach, it’s a good approach to ask if something you’ve asked someone or an agent to do is devoid of any reasonable ambiguity.
Here, we will assume that given a specification, the developer or the LLM is able to come up with a good implementation utilizing whatever language/framework you want, following good engineering practices.
Helps with common agentic development patterns
When you utilize whatever agentic tool (Claude Code, Cursor, Windsurf) you’re using to work on a feature or fix a bug, the process is optimal only when it goes away, does its thing (while you presumably watch YouTube) and comes back with a perfect implementation as far as both functional and non-functional requirements are concerned. There is no back and forth between you and the agentic tool (no matter how many holes your specifications have). Given how eager these agentic tools are, they’re making a lot of assumptions for you, many of which you may absolutely hate.
What you then want is to take advantage of this asynchronous nature of development that the LLM-powered agentic software development tools afford you, while getting output that aligns closely with or better than what you envisioned. It is specification grounding that helps here.
The stateless nature of LLM calls
Due to how LLMs work, every API call made to them is truly stateless. The agentic tools you use are building a summarized context about your past conversations, adding in bits of code and sending it to the LLM with each call, along with your prompt. It is crucial to recognize this.
To get the results you need, you need to come up with a way to always keep the LLMs always grounded to your specifications. Fortunately, pretty much all the popular agentic development tools provide ways to do this. We will delve into this with a solid example.
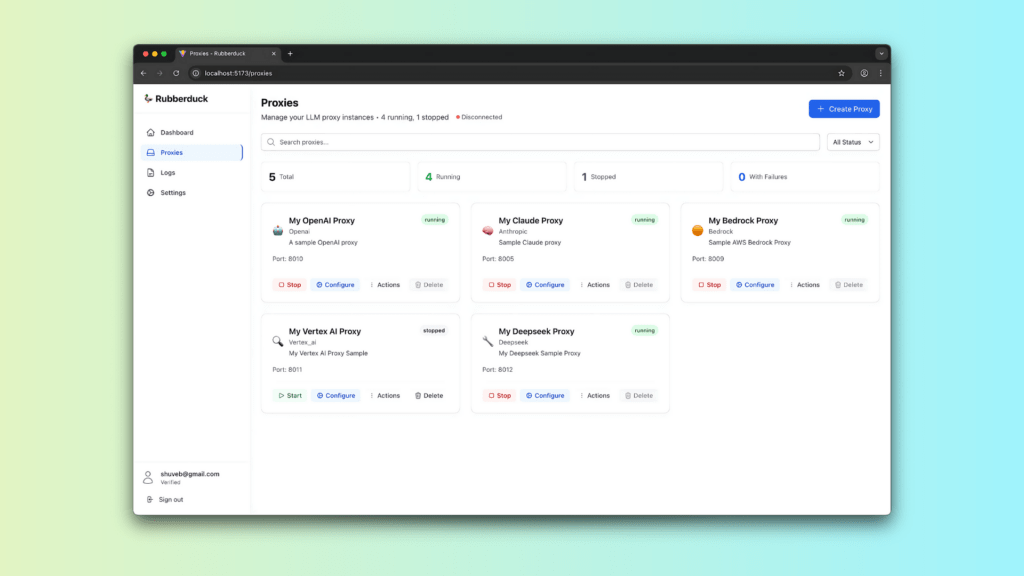
Rubberduck: A Practical Example (without ourselves writing a single line of code)
We’re developers of the open-source Unstract platform that helps turn complex documents into clean, structured JSON data accurately and efficiently. Once prompt engineering is done in Prompt Studio, our purpose-built environment for defining an extraction schema for complex documents, the project can be deployed as either an API or an ETL Pipeline. It’s critical for us to test the performance and the resilience of our API Deployments and ETL Pipelines. This means testing with hundreds, or sometimes, thousands of documents.
We wanted to ensure no regressions occurred while also testing for performance. We also needed to ensure great error handling and reporting in the face of LLM timeouts or failures. One major goal: achieving this should not be an expensive endeavor. If it was expensive, we wouldn’t do it very often, which does not help the platform. What we needed was an LLM testing gateway with the following properties:
Accurately emulate LLM providers enough for the clients to use the official LLM provider SDKs
Cache requests to save costs
Inject timeouts and errors at user-specified percentage levels
Provide a simple UI for the creation and management of LLM proxies
Provide good logging capabilities
Provide a solid testing client that can load test Rubberduck
One security-related advantage of this model of operation was that Rubberduck did not need to store LLM credentials. What the client sent, would use those credentials to make downstream LLM calls.
Let’s look at how to get great results building Rubberduck, a non-trivial LLM Testing Gateway using “vibe coding” methods.
Here are the top-level goals:
End up with a high-quality LLM Testing Gateway without writing a single line of code
Use the best technologies/toolkits available for the job, though I might not have direct experience with those toolkits (I do have experience with JS and Python, though I don’t have experience with Tailwind CSS, for example)
Ensure good test coverage
Ensure a very good UI and user experience
Leveraging LLMs to come up with the grounding specification
Very luckily for us, we can use LLMs not just to actually write the code, but to also come up with the detailed grounding specification and a detailed prompting plan that will keep the LLM on a tight leash. This will be the difference between the LLM being a bull in a china shop vs. it being a super-fast bullet train on tracks we’ve carefully laid out to our destination. We will need 3 documents to ground the LLM:
idea.md: the project idea file, which we will create by hand, from scratch.
spec.md: the specification file, which we will create in collaboration with a reasoning model with idea.md as the input.
prompt_plan.md: The actual phase-wise plans that will help the agentic coding tool create the code we need on a tight leash.
Creating the idea.md file
Let’s see how we created these files and what they contain for Rubberduck. Let’s start with idea.md, which we create by hand:
I want to build a LLM caching proxy server that emulates popular LLMs with theability to simulate failures. We will call this Rubberduck.
Features
Caching: Since this proxy server will be used to test systems that use LLMs, it should be able to cache responses from the LLMs to avoid making unnecessary requests.
LLM Emulation: The proxy server should be able to emulate popular LLMs from various providers. We will start with OpenAI, Anthropic, Azure OpenAI, AWS Bedrock, and Google Vertex AI.
Failure Simulation: The proxy server should be able to simulate failures to test the robustness of the systems that use LLMs.
Rate Limiting: The proxy server should be able to limit the number of requests per minute to avoid being rate limited by the LLMs.
Authentication: It should authenticate requests to the LLMs using the LLM keys provided in the API requests. For the proxy server itself, it should provide a flexible way for users to log in or register.
UI
The user journey looks something like this:
- User logs in with their email and password or via social login (Google, GitHub, etc). - User can create a new LLM proxy, specifying a name, description, LLM provider, and LLM model. - This creates a new LLM proxy running on a separate thread and binding to a separate port. On this port, the LLM proxy acts as a reverse proxy to the LLM API. - The user must pass the LLM key in the API request to the LLM proxy. The proxy authenticates the request and forwards it to the LLM API. - Users can configure the LLM proxy to simulate failures (on a per-proxy basis): - Timeouts - Error injection - IP allow-list / block-list - Rate limiting - The proxy caches the response from the LLM API and returns it to the user. - The user can point their system to the LLM proxy’s URL to use it in place of a direct LLM connection.
Rubberduck Settings
- Allow/disallow new user registration - Allow/disallow login via social login (Google, GitHub, etc) - Allow/disallow login via email and password - Global IP allow-list / block-list
Logging
- All requests to the LLM proxy should be logged - All responses from the LLM proxy should be logged - All errors from the LLM proxy should be logged - Logs should indicate: - Cache hits/misses - Rate limit hits/misses - IP allow/block list hits/misses - LLM cost (where available)
Implementation
- Backend: Python + FastAPI - Frontend: React + Tailwind UI - Database: SQLite - Each LLM provider will have its own modular implementation
Rubberduck Authentication
- Use FastAPI-Users for authentication - An environment variable should control whether Rubberduck allows new user registration - If not allowed, only specific email addresses or domains can register (default behavior) - Login should support: - Email + password - Social login (Google, GitHub, etc)
As you can imagine, since this was created by hand, it took a while to create. Though it can’t serve as a specification for Rubberduck, it can act as a great foundation to coax an LLM to work with us and come up with a solid specification.
Creating the spec.md file
This is a very involved step. It is the spec.md file which will contain very detailed specifications about what we want to build and so, some effort will need to be put into creating it. Luckily, we can take help from an LLM to discover blind spots in our thinking—areas we completely missed to cover in our spec.md file.
We will now create a prompt with two parts: the first, instructions to an LLM asking it to take the contents of our idea.md file and ask us yes/no style questions, so we can come up with a detailed specification for software development. Second, the contents of the idea.md file. This brilliant approach is documented by Harper Reed on his blog, and I highly recommend you read it yourself. We will be using his prompts verbatim.
To create the spec.md file, I used 4o with the following prompt:
Ask me one question at a time so we can develop a thorough, step-by-step spec for this idea. Each question should build on my previous answers, and our end goal is to have a detailed specification I can hand off to a developer. Let’s do this iteratively and dig into every relevant detail. Remember, only one question at a time.
Here’s the idea: <contents of idea.md>
4o then proceeds to ask me various questions:
I answered about 50 questions, which I felt addressed blind spots in my thinking, which were documented in idea.md. After ~50 questions, I could see that the questions started getting to a hair-splitting level and they no longer fell into my “reasonable ambiguity” category any more. This is when I issued the following prompt, asking 4o to create a spec.md for me based on our conversation so far.
Now that we’ve wrapped up the brainstorming process, can you compile our findings into a comprehensive, developer-ready specification? Include all relevant requirements, architecture choices, data handling details, error handling strategies, and a testing plan so a developer can immediately begin implementation.
It came up with this, which I saved as spec.md:
Rubberduck: Developer Specification
Overview Rubberduck is a local LLM caching reverse proxy server designed to emulate major LLM providers such as OpenAI, Anthropic, Azure OpenAI, AWS Bedrock, and Google Vertex AI. It provides caching, failure simulation, rate limiting, per-user proxy instances, and detailed logging.
Architecture - Backend: Python + FastAPI - Frontend: React + Shadcn UI - Database: SQLite - Authentication: FastAPI Users (email/password + social login via Google/GitHub) - LLM Provider Modules: Modular Python files in providers/, auto-registered - Proxy Binding: One proxy per thread, bound to a unique host port
Features
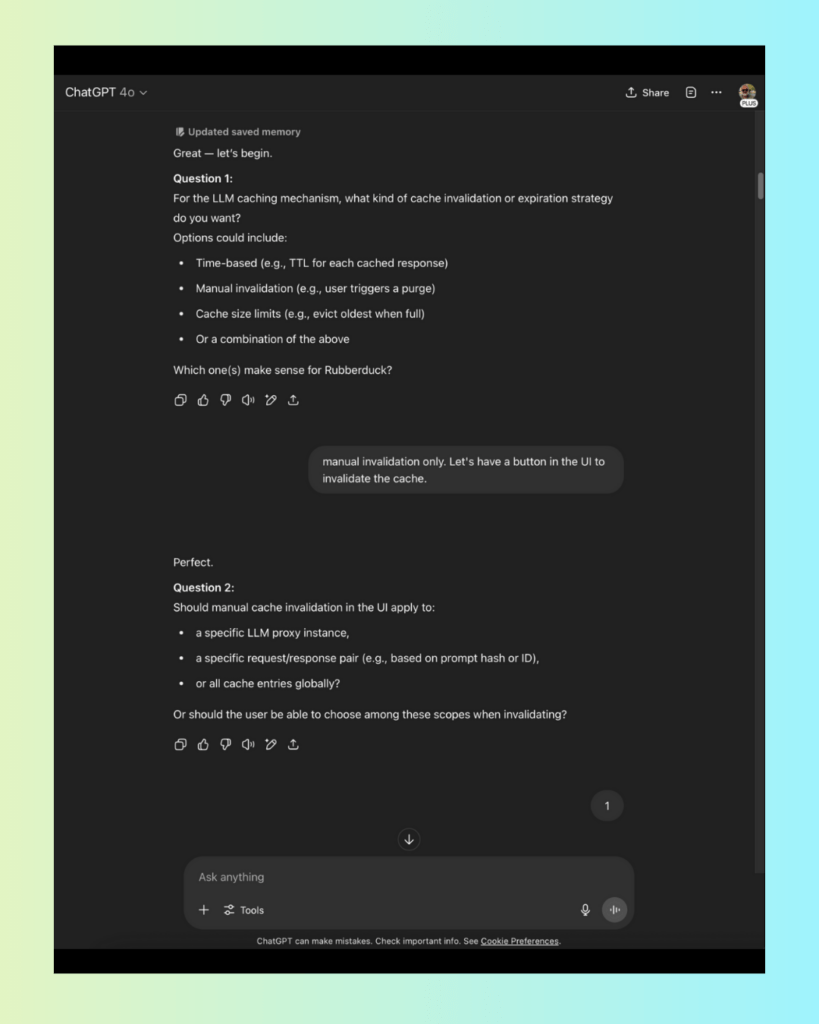
Caching - Only successful responses from upstream LLMs are cached - Cache key: hash of the normalized (sorted JSON) request body - Manual invalidation only, via UI, scoped to a single proxy instance - Cache does not interfere with upstream provider's caching headers
LLM Emulation - Emulates real request/response behavior: headers, status codes, and error formats - Passes through Authorization headers without validation - All request parameters are client-controlled - No prompt/response bodies are stored in logs
Failure Simulation - Configurable per proxy - Types: - Timeouts: Fixed delay or indefinite hang (user-defined) - Error injection: Selectable error codes (e.g., 429, 500, 400) with individual failure rates - IP allow/block list: Exact IPs, CIDR ranges, and wildcards - Rate limiting: Requests per minute (RPM) - Failures override request forwarding; failed responses are not cached
Rate Limiting - Configurable RPM per proxy instance - On limit exceeded: proxy mimics upstream LLM behavior (usually HTTP 429)
Authentication - Login via email/password and social (Google/GitHub), controlled by env vars - Email verification required - Password reset supported - No role-based permissions; all users manage their own proxies
Proxy Lifecycle - Auto-start proxy threads on app restart using DB state - UI allows: - Start / Stop - Graceful stop (waits for in-flight requests to finish) - Force stop - Ports: - Auto-assigned and stored - User-editable - Startup failure (e.g., port conflict) shown in UI
Proxy Configuration - Required fields: Name, provider, model name (display only) - Optional fields: Port number (auto-assigned if not provided), description, tags - No advanced model configs; all details expected to be in incoming requests
Data Handling - Request/response bodies never stored - API keys never stored or shown in UI - Only logs and metrics retained
Error Handling - Upstream LLM errors are transparently forwarded - Simulated failures override request - Port binding conflicts shown in UI - Email verification and reset via SendGrid (configurable)
Health Monitoring /healthz endpoint returns: - Status: 200 OK - JSON payload: app version, DB status, running proxy count
Testing Plan
Unit Tests - Caching logic and key normalization - LLM provider forwarding and response wrapping - Failure simulation paths (timeouts, errors, rate limits) - Port conflict detection and assignment
Armed with a specification that can ground the LLM well, all I needed now was a prompt plan for any agentic coding tool to execute step by step and actually create the product I had in mind. Handling that duty was Deepseek R1, a so-called reasoning model. I did try creating a prompt plan with 4o, but I felt it was wanting. This is subjective for sure, but I felt R1 did a better job, at least in this case. Here’s the prompt (thanks to Harper again!) to create the prompt plan:
Draft a detailed, step-by-step blueprint for building this project. Then, once you have a solid plan, break it down into small, iterative chunks that build on each other. Look at these chunks and then go another round to break it into small steps. Review the results and make sure that the steps are small enough to be implemented safely with strong testing, but big enough to move the project forward. Iterate until you feel that the steps are right sized for this project.
From here you should have the foundation to provide a series of prompts for a code-generation LLM that will implement each step in a test-driven manner. Prioritize best practices, incremental progress, and early testing, ensuring no big jumps in complexity at any stage. Make sure that each prompt builds on the previous prompts, and ends with wiring things together. There should be no hanging or orphaned code that isn't integrated into a previous step.
Make sure and separate each prompt section. Use markdown. Each prompt should be tagged as text using code tags. The goal is to output prompts, but context, etc is important as well.
- Each prompt builds on previous artifacts - All code paths covered by tests - No orphaned components - Integration points explicitly defined - Security checks at subsystem boundaries
Next Steps:
- Execute prompts sequentially - Validate test coverage after each step - Measure step completion time (target: <2hrs/step) - Adjust granularity based on implementation friction
Awesome! Now that we have the required documents for specification grounding of LLMs, all that is left from a setup perspective is to set up your favorite agentic coding environment with the documents we’ve generated. My tool of choice is Claude Code, but a similar methodology applies to pretty much any tool. Remember that since all these tools pretty much connect to a handful of LLMs and are primarily powered by them, it’s the methodology that matters, not the tool you’re using.
Setting up your LLM-powered development environment
I created a new GitHub repository and checked it out. I created the directory “prompting” at the root of the project and copied over idea.md, spec.md, and prompt_plan.md there. Next, I created CLAUDE.md with the following contents:
Remember that the basic idea for this project is in prompting/idea.md, the spec is in prompting/spec.md and the prompt plan, which serves as the implementation plan is in prompting/prompt_plan.md. Always read these files to get a good idea about how the implementation is to be carried out. Also, remember that after the implementation, tests need to be written and run successfully before moving on to the next step. Once a step has been implemented, always mark it as done in the prompting/prompt_plan.md file.
## Notes
- Do not start the backend or frontend servers yourself. I will run them with stdout and stderr redirected to <project_root>/backend.log and <project_root>/frontend/frontend.log. You can read these files to understand what's going on. - Whenever the user asks you to commit / push to git, always do it from the project's root directory and never commit or push without first confirming with me. - For Rubberduck, use the venv in the project root. For the testing script, use the venv at scripts/proxy_testing/. Do not use the system Python. - The Django backend listens on port 9000, while the frontend listens on port 5173.
Please note that the equivalent of CLAUDE.md in Claude Code is `.windsurfrules` for Windsurf and `.cursorrules` for Cursor. You are free to refer to other files from these files (see content above), which are loaded when the respective tool starts up. Setting these files up well, including separating them out well is important since it should make for better maintenance later on.
Remember that for each prompt you enter into these tools, details from the rules files and the contents of the files they refer to are sent to the LLM each time it’s invoked, along with your prompt and bits of code. This is critical in grounding the LLM. All our hard work so far will amount to nothing should you not set up these files well.
A new kind of development
Once Claude Code loads the CLAUDE.md as it starts, in turn it refers to the 3 files we took so much effort to create: idea.md, spec.md and prompt_plan.md. But, the really great thing now is that there’s hardly anything for us to do until the first version is made available and all phases of development marked as “done” in the prompt_plan.md file. We simply need to keep an eye on and keep prompting “OK. Implement the next step” and that’s it!
For each step it’s implementing, the LLM has full content of the idea of our app, the detailed spec, the prompt plan and even what’s been implemented so far. And precisely because of how specific and narrow we’ve made the instructions to the LLM, it creates something in a way we envisioned, rather than having to make wild assumptions that did not align with what we need.
Contrast this to a method where you issue ad-hoc prompts to the LLM, trying to explain feature by feature piecemeal.
The 5x rule
I’d be lying if I said I did not prompt anything else other than what’s exclusively in the prompt_plan.md file to bring the app to where it is now. But, 90% of the project landed in a way that I liked and that was huge. I’ve worked using this methodology in both greenfield and brownfield projects, one thing I’ve observed is that if it takes 1x time and effort for the LLM-powered agentic coding tool to complete implementing your full prompt plan, it takes 5x time and effort to bring it to a robust state in a loop of testing and fixing. You’re mainly taking care of useability and robustness in this 5x time.
Moving fast
LLMs can generate so much code so quickly, that it can be pretty daunting just to keep up. Rather than verifying the code, it might be a good idea to verify the tests. If the tests are implemented correctly and they’re working, then it implies that the code being tested is indeed working.
Setting up a timesaving feedback loop
If you are copying screenshots and browser JS console messages to the agentic coding tool, you haven’t embraced LLM-powered development in its full spirit. Using a tool like Playwright with its Playwright MCP server will let your coding agent get screenshots and JS console logs at will. You can simply include statements like “take a screenshot” and “look at the browser JS console logs” for the LLM to figure out that it needs to talk to Playwright via its MCP server to achieve those actions.
Grounding documentation
The fact that LLMs are trained on internet text that includes code and documentation and also because they have a knowledge cut-off date, they can make a lot of assumptions about using a library. They might be using it in an outdated way even though it might have installed its latest version. This might cause you to run into numerous, very nuanced and often confusing problems. Again, going with our philosophy of giving as many exact details to the LLM as possible, grounding it with the right documentation for the libraries you’re using is important. This is especially true for libraries that are relatively new or not very popular.
For this I recommend a service like Context7, which, like Playwright can also be connected to your agentic coding tool via an MCP server.
Continuing development in phases
You might have come up with a pretty detailed specification and might have even completed development, testing and tweaking. With the LLM marking all your prompt plans are done however, you might not just ride into the sunset. As more ideas brim, you might want to continue developing, now that intelligence is available on tap. To make future development easy, you might want to think of organizing your grounding files in a folder structure like this:
CLAUDE.md / windsurfrules / cursorrules / gemini.md: Your development preferences related to style, code commits, running servers, etc. Also a good place to keep information on the project layout, tech, module-wide implementation details of directory/file locations, etc.
idea.md: The idea of the project as you’d explain to an engineer (basic idea, implementation details, tech stack, features, etc). Essentially, things that don’t change with new feature / phase development.
Phase-wise directories: Create directories for different phases (prompting/phase_1, prompting/phase_2, etc) with each of those directories containing the spec.md and prompt_plan.md files.
This should allow you to create more phase-wise directories to ground the LLM. Make sure that your rules file points to the right phase of implementation.
Dealing with brownfield projects
Because LLM calls are stateless, a greenfield project is new only the first time an LLM creates it. For the very next prompt, it’s a brownfield project. All that matters is how well your project is grounded. You can ground existing projects easily with the help of LLMs themselves. Let them analyze the code and come up with the essential grounding files. Claude Code has an `/init` command that does this and creates a new CLAUDE.md file. From here, follow the steps we discussed so far to create specs and a prompt plan and take it from there.
Testing by leveraging LLMs
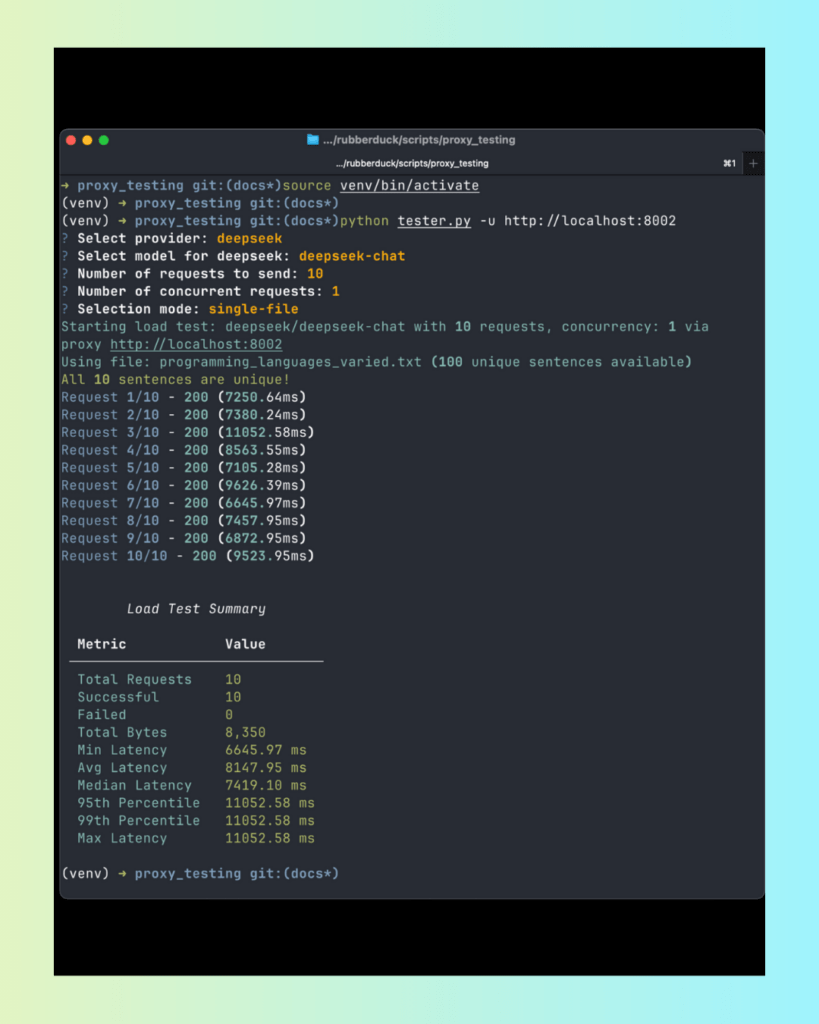
One challenge we have with testing an LLM caching proxy is that we need a way to generate data that can be random and miss the cache, but also will help us test cache hits.
The testing script in scripts/proxy_testing/tester.py is one that was vibe coded. It sends a random “fact” sentence read from a file in unstructured_data/, which the LLM will then convert into a JSON response. Here’s a list of files:
-rw-r--r--@ 1 shuveb staff 15512 6 Jun 18:24 airports_varied.txt
-rw-r--r--@ 1 shuveb staff 13633 6 Jun 18:26 blockbuster_films_varied.txt
-rw-r--r--@ 1 shuveb staff 14262 6 Jun 18:25 nobel_physics_laureates_varied.txt
-rw-r--r--@ 1 shuveb staff 13822 6 Jun 18:25 open_source_projects_varied.txt
-rw-r--r--@ 1 shuveb staff 12184 6 Jun 18:26 programming_languages_varied.txt
-rw-r--r--@ 1 shuveb staff 13663 6 Jun 18:25 space_missions_varied.txt
-rw-r--r--@ 1 shuveb staff 12021 6 Jun 18:23 tourist_spots_varied.txt
Each file consists of a prompt that can turn sentences in that file into a structured JSON. The testing tool can read from one file or all the files (depending on what the user told it to do). Each file contains 100 sentences, and there are 7 files for a total of 700 sentences, which should provide enough for us to test a proxy well. Here’s a sample of the content from the blockbuster_films_varied.txt file.
### Prompt
You will receive one descriptive snippet. Parse it and return **only** JSON that fits this schema exactly:
{
"title": "string",
"release_year": "number",
"director": "string",
"box_office_usd_billion": "number",
"genre": "string"
}
---
Jordan White's Infinity Quest hit theatres in 1994; it went on to post around 1.33 billion USD, a record for biographical films.
Robin Wilson's Eternal Echoes hit theatres in 1988; it went on to post around 2.42 billion USD, a record for fantasy films.
Directed by Dakota Miller, the 2007 blockbuster Silver Skies brought a around 2.13 billion USD worldwide, cementing its place in animation.
Silver Skies—a drama epic helmed by Dakota Garcia—premiered in 2007 and raked in 2.4 billion‑dollar haul.
Directed by Jordan Smith, the 1994 blockbuster Neon Mirage brought a 2.47 billion‑dollar haul worldwide, cementing its place in science‑fiction.
Directed by Robin Smith, the 1986 blockbuster Crimson Tide brought a 2.73 billion‑dollar haul worldwide, cementing its place in fantasy.
Directed by Jordan Johnson, the 1999 blockbuster Shadow Realm brought a around 0.84 billion USD worldwide, cementing its place in science‑fiction.
Directed by Adrian Johnson, the 2001 blockbuster Silver Skies brought a around 2.31 billion USD worldwide, cementing its place in fantasy.
Cameron Johnson's Infinity Quest hit theatres in 2021; it went on to post 2.77 billion‑dollar haul, a record for action films.
Directed by Morgan Brown, the 1989 blockbuster Eternal Echoes brought a around 1.55 billion USD worldwide, cementing its place in action.
I used GPT-4o to create these files. The tester.py testing script was also created using Claude Code.
We’re only scratching the surface
There’s so much you can do with LLM-powered software development tools. More ideas are: raising PRs with detailed comments auto-generated, PR reviews, fixing simple bugs, and raising PRs on Github by tagging agents, asking how code can be improved, asking for a security audit (both to locate vulnerable libraries and also code), etc.
Also read:
Why LLMs Are Not (Yet) the Silver Bullet for Unstructured Data Processing
There are plenty of existing methods for handling unstructured data, and many of them work quite well—especially for simpler use cases. In fact, at the lower end of the complexity spectrum, these traditional techniques are often highly accurate and cost-effective, which makes it hard for LLMs to compete given their current costs and response times. That’s why it’s important to evaluate the practicality of using LLMs, particularly when you’re working at scale.
Shuveb Hussain is the Co-founder and CEO of Unstract. Previously, he served as VP of Engineering at Freshworks, a NASDAQ-listed global SaaS company. With over two decades of experience, Shuveb has co-founded multiple internet startups and worked with companies operating at massive scale—handling petabytes of data and billions of requests per hour.