Processing unstructured data is one of the most significant challenges in today’s data-driven world.
Unlike structured data, which fits neatly into rows and columns, unstructured data comes in diverse formats such as PDFs, images, videos, emails, and social media posts.
This diversity makes it difficult to extract meaningful insights and integrate such data into traditional analytics workflows.
Unstract excels in extracting meaningful information from unstructured data sources. Using AI-powered components, it processes documents like PDFs and converts them into structured data. Its ability to integrate with various sources and destinations makes it an ideal choice for ETL workflows.
Snowflake, a leading cloud-based data warehouse, is perfectly suited to store and analyze Unstract’s structured output. It supports both structured and semi-structured data formats, such as JSON, enabling seamless integration of data from diverse sources.
By combining the extraction capabilities of Unstract with the storage and analytical power of Snowflake, this ETL solution enables businesses to unlock the full potential of their unstructured data, driving informed decision-making and operational efficiency.
What is ETL for Unstructured Data?
ETL stands for Extract, Transform, and Load, a process commonly used in data management to move and prepare data for analysis.
Traditionally, ETL involves:
Extracting raw data from source systems.
Transforming the data to fit analytical or operational requirements (e.g., cleaning, restructuring, or aggregating).
Loading the transformed data into a destination system, such as a database or data warehouse.
ETL becomes more complex when dealing with unstructured data. Unlike structured data (organized in rows and columns), unstructured data lacks a predefined format or schema.
ETL for unstructured data focuses on:
Identifying and extracting key information from raw data.
Using advanced techniques like machine learning and natural language processing (NLP) to derive structure.
Transforming unstructured content into a format that can be queried and analyzed, such as JSON or a relational schema.
This process enables businesses to make unstructured data, like text documents or multimedia files, actionable and valuable for decision-making.
Key Differences Between Traditional ETL for Structured Data and ETL for Unstructured Data
Aspect
Traditional ETL(structured data)
ETL for Unstructured data
Data Format
Relational (tables with rows and columns).
Diverse (PDFs, images, audio, videos, etc.).
Extraction
Simple querying from databases or APIs.
Complex extraction using AI/ML techniques.
Transformation
Standard operations like cleaning or joining tables.
NLP, computer vision, and embeddings for structuring.
Complexity
Well-defined schemas simplify the process.
Requires schema inference and contextual analysis.
Storage
Fits neatly into relational databases.
Often requires JSON, XML, or hybrid models.
ETL for unstructured data demands more advanced tools and techniques, making solutions like Unstract critical for bridging the gap between raw unstructured content and actionable structured data.
Unstructured data originates from a wide variety of sources and comes in different formats, including:
Documents: PDFs, Word documents, scanned contracts, and forms.
Images: Scanned images, photos, and annotated graphics.
Audio: Recorded phone calls, podcasts, and voice messages.
Videos: Surveillance footage, tutorials, and video logs.
Textual Data: Emails, chat logs, social media posts, and articles.
Sensor Data: Logs from IoT devices, GPS trackers, and system monitors.
These sources often contain valuable insights but require robust ETL workflows to unlock their potential.
Tools like Unstract streamline this process, enabling the extraction and transformation of key information, which can then be stored in systems like Snowflake for analysis.
What is Snowflake?
Snowflake is a modern, cloud-based data platform designed to handle a wide range of data storage, processing, and analytical needs. Unlike traditional on-premises databases, Snowflake operates entirely in the cloud, offering scalability, flexibility, and performance without the need for complex infrastructure management.
As a data warehouse, Snowflake allows businesses to consolidate structured, semi-structured, and unstructured data into a single platform, making it an essential tool for organizations aiming to derive insights from diverse data sources. Snowflake’s unique architecture decouples storage and computing, enabling users to scale resources independently based on their workload requirements.
Key features of Snowflake for unstructured data processing
Elastic Scaling: Automatically adjusts compute resources to match workload demands, ensuring high performance even for large datasets.
Pay-As-You-Go: Organizations only pay for the storage and computing resources they use, reducing costs.
Structured Data: Handles traditional relational data with rows and columns.
Semi-Structured Data: Natively supports JSON, XML, Avro, and Parquet formats. Users can query semi-structured data using SQL without the need for additional parsing or transformations.
SQL Support: Snowflake offers robust SQL capabilities, making it easy to perform complex queries and analytics.
Integration with BI Tools: Compatible with popular business intelligence tools like Tableau, Power BI, and Looker.
Data Sharing: Snowflake enables secure data sharing across accounts without the need to move or copy data.
Snowflake has evolved to provide comprehensive support for unstructured data, making it a versatile platform for diverse data types:
Unstructured Data Support: Snowflake can ingest and store unstructured data such as images, PDFs, and audio files. These files are stored in a dedicated storage layer and can be managed alongside structured data for a unified data strategy.
JSON and Semi-Structured Data Processing:
JSON files can be directly loaded into Snowflake tables, where they are stored in their native format or semi-structured column types like VARIANT.
Snowflake’s SQL functions enable users to parse, query, and extract specific fields from JSON data effortlessly.
With the FLATTEN function (or dot notation), Snowflake can transform deeply nested JSON objects into tabular structures for easier analysis.
Its ability to handle complex workflows and deliver insights from diverse datasets makes it a cornerstone of modern data architectures.
By choosing Snowflake, organizations gain a scalable and powerful platform that not only stores unstructured data but also enables advanced querying and seamless integration with modern ETL solutions.
This makes Snowflake an indispensable tool for unlocking the potential of unstructured data and transforming it into actionable insights.
Introducing Unstract
Unstract is an open-source platform engineered to streamline and automate the extraction of structured data from unstructured documents such as loan applications, invoices, and reports.
Utilizing advanced technology, Unstract transforms various document formats into actionable data, eliminating the need for manual intervention or frequent reconfiguration.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
Key Features of Unstract
Ability to Extract Structured Data from Unstructured Sources:
Unstract uses natural language processing (NLP), embeddings, and large language models (LLMs) to identify and extract meaningful information from unstructured data formats.
It converts raw content, such as loan application forms or scanned contracts, into structured, actionable data ready for analysis.
Seamless Integration with Popular Data Destinations:
Unstract connects effortlessly to leading cloud data platforms, including Snowflake, enabling seamless ETL workflows.
This integration ensures that processed data is stored in scalable, queryable formats for downstream analytics and reporting.
Customizable and Scalable Workflows:
With tools like Prompt Studio, users can create tailored prompts to extract specific fields, such as names, dates, and financial information, from unstructured sources.
Unstract is built to scale with growing data volumes, ensuring consistent performance even with large datasets.
Unstract addresses the long-standing challenge of deriving insights from unstructured data, offering a solution that is not only powerful but also user-friendly and adaptable:
Efficiency:
Traditional methods of processing unstructured data are labour-intensive, requiring manual extraction and transformation. Unstract automates these tasks, significantly reducing time and effort.
Accuracy:
By leveraging AI and machine learning, Unstract achieves high accuracy in extracting relevant data, even from complex or poorly formatted sources.
Flexibility:
With support for diverse data types and customizable workflows, Unstract caters to a wide range of industries and use cases, from financial services to healthcare and beyond.
End-to-End Solution:
When paired with platforms like Snowflake, Unstract provides a complete ETL solution for unstructured data. From ingestion to transformation and final storage, it streamlines the entire workflow, enabling businesses to focus on deriving insights rather than managing data.
Unstract’s ability to transform unstructured content into structured data, combined with its integrations and scalability, makes it a vital tool for organizations looking to harness the full potential of their unstructured data.
Demo of Unstract for processing unstrucutred documents
In this webinar, we’ll dive deep into all the features of Unstract and guide you through setting up an ETL pipeline tailored for unstructured data extraction.
The Setup: Unstructred ETL pipeline overview
The ETL workflow for processing unstructured data using Unstract and Snowflake follows this straightforward flow:
Unstructured PDFs in Google Drive → Unstract for Processing → Structured Data in Snowflake
This setup demonstrates how unstructured data, such as loan application PDFs stored in Google Drive, can be transformed into structured, queryable data stored in Snowflake.
Process Outline: From Data Ingestion to Final Storage
Data Ingestion:
The process begins with unstructured PDFs stored in a source location, such as Google Drive. These files contain raw data that needs to be extracted and structured.
Data Extraction with Unstract:
Unstract connects to Google Drive and retrieves the unstructured PDFs.
Using its AI-powered capabilities, Unstract extracts key information (e.g., names, dates of birth, and financial details) from the documents.
The extracted data is organized into a structured format, such as JSON.
Data Transformation:
Unstract transforms the extracted data by cleaning, formatting, and preparing it for storage in Snowflake.
During this step, users can define specific fields or rules to ensure the data meets business requirements.
Data Loading into Snowflake:
The structured data is then loaded into a Snowflake database.
Snowflake acts as the destination where the processed data is securely stored, and ready for querying and analysis.
Data Analysis and Visualization:
With the data in Snowflake, users can perform SQL queries, create dashboards, and generate insights using business intelligence tools.
This workflow highlights how Unstract and Snowflake work together to transform unstructured data into a valuable asset, enabling seamless integration, scalability, and actionable insights at every stage of the ETL process.
Step-by-Step Guide: Setting up the unstructured ETL workflow
Set Up Unstract
For the examples that we will work on in the next sections, we are going to use loan application PDF samples like this one:
The goal is to extract structured data from fields like Name, Date of Birth, Social Security Number and also Marital Status, Phone Number, Address as well Email ID, Monthly Income, and any others that might be necessary.
Setting Up Key Components in Unstract
Getting Started
Visit the Unstract website and create an account. The registration process is straightforward and grants you access to the platform’s features, including the Prompt Studio and LLMWhisperer tools.
Upon signing up, you will receive a 14-day trial that includes $10 in LLM tokens, allowing you to start using the account immediately.
Configuring Components
If you run out of credits or wish to add your own LLMs, embeddings, vector database, or text extractor providers, you can use the various options available in the SETTINGS menu.
To connect your OpenAI account (or other LLMs):
Navigate to SETTINGS → LLMs.
Choose ‘+ New LLM Profile’ and then select OpenAI (or your LLM of choice).
Provide your API key to complete the setup.
To add your own embedding provider:
Go to SETTINGS → Embedding.
Select ‘+ New Embedding Profile’ and follow the instructions to add your embedding provider.
To add your vector database provider:
Navigate to SETTINGS → Vector DBs.
Select ‘+ New Vector DB Profile’ and follow the instructions to add your vector database provider.
To add your own text extractor:
Go to SETTINGS → Text Extractor.
Select ‘+ New Text Extractor’ and follow the instructions to add your text extractor.
How these components help in data extraction
The OpenAI LLM (or any other LLM) is crucial for natural language processing tasks. It helps in understanding human-like text, which is essential for extracting meaningful information from unstructured data. By integrating LLMs, you can automate the process of identifying and extracting relevant data from textual content.
Embeddings convert textual data into numerical vectors that can be easily processed by machine learning algorithms. This transformation is vital for tasks like semantic search, clustering, and classification. By adding your own embedding provider, you can customize the embedding process to better suit your specific data extraction needs.
A vector database stores and manages high-dimensional vectors, making it easier to perform similarity searches and other vector-based operations. This is particularly useful for retrieving relevant information from large datasets. By integrating a vector database, you can efficiently store and query embedded data, enhancing the accuracy and speed of data extraction.
A text extractor is a tool that automatically identifies and extracts specific pieces of information from textual data. This can include names, dates, addresses, and other relevant details. By adding your own text extractor, you can tailor the extraction process to focus on the specific types of information that are most important to your use case.
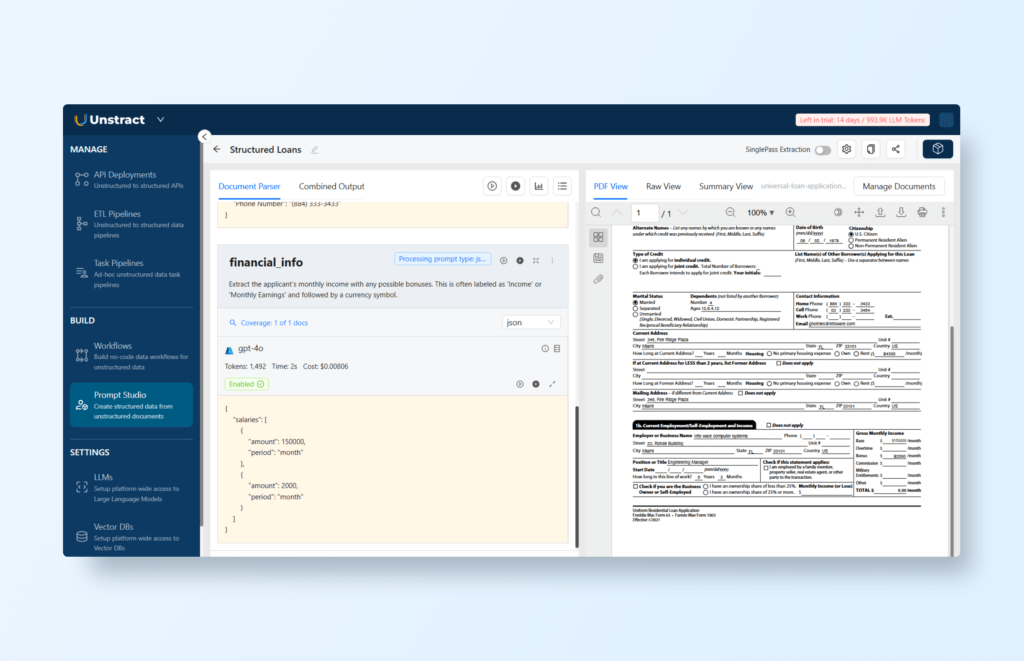
Prompt Studio Project – Extracting Key Information
Unstract’s Prompt Studio is a powerful tool that enables users to design and customize AI-driven prompts for extracting specific information from unstructured data.
In this section, we’ll focus on creating prompts to extract critical fields from loan application documents, such as personal and financial details.
The extraction of structured data from the unstructured loan application PDFs is targeting the following fields:
Personal Information: Name, Date of Birth, Social Security Number (SSN).
Navigate to the Prompt Studio interface in Unstract and create a new project specific to the loan application use case, for instance, ‘Structured Loans’.
Add the documents on which you want to test and write the prompts with ‘Manage Documents’.
Prompts are designed to instruct the AI to focus on specific information fields within the document. Below are examples of how to craft effective prompts.
Extracting Personal Information
Prompt: “Identify the applicant’s full name from the document. Look for fields labeled as ‘Name’ or phrases like ‘Applicant Name’. Extract the applicant’s Date of Birth (DoB). It is often formatted as MM/DD/YYYY or similar. Find the applicant’s Social Security Number (SSN), typically a nine-digit number formatted as XXX-XX-XXXX.”
Note: Remember to set the output format as JSON.
Running the prompt, we get the following JSON:
Output Format
The extracted data is organized into structured JSON, as mentioned. The combined output of the different prompts is for example:
By leveraging Prompt Studio’s intuitive interface and customizable options, users can extract highly specific, accurate data from unstructured documents.
This flexibility ensures that key information is captured efficiently, forming the basis for further processing and analysis in Snowflake.
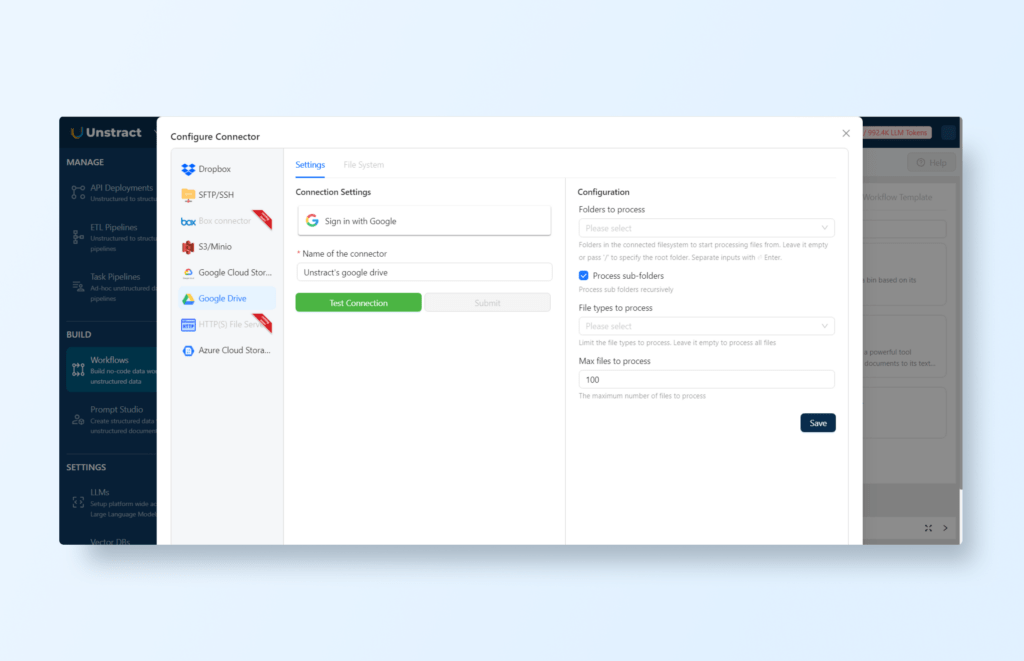
Connect Source (Google Drive) and Destination (Snowflake)
To use Google Drive as a source for the unstructured loan documents and Snowflake as a destination for the structured data, we need to create a Workflow.
But first, we need to define the existing project as a tool so it can be used in a workflow. In the Prompt Studio project, click the ‘Export as tool’ icon in the top right corner. This action will create a usable tool for your project.
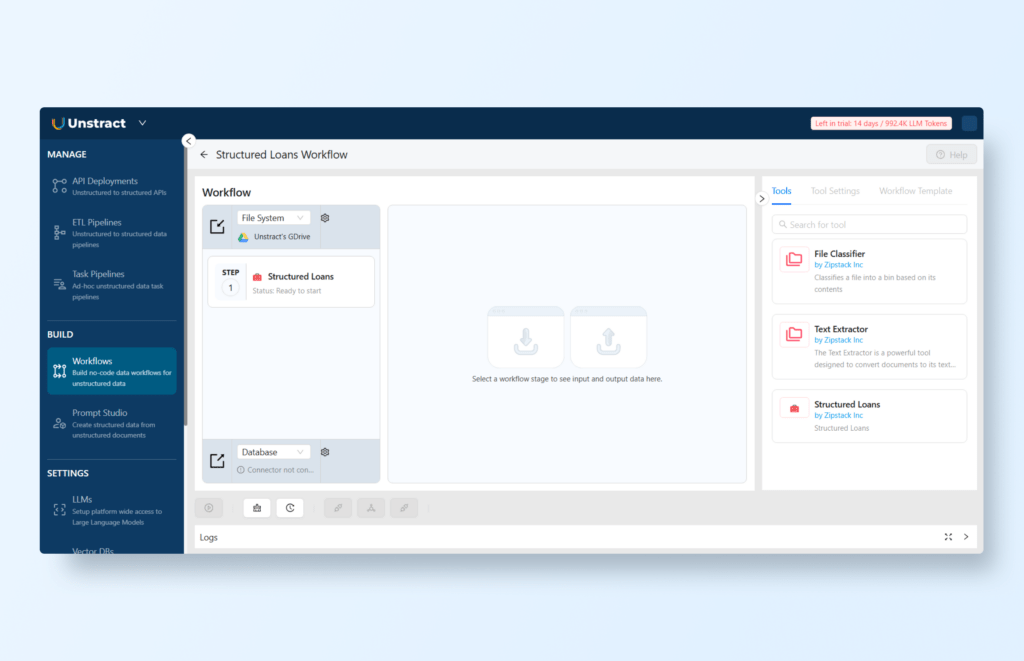
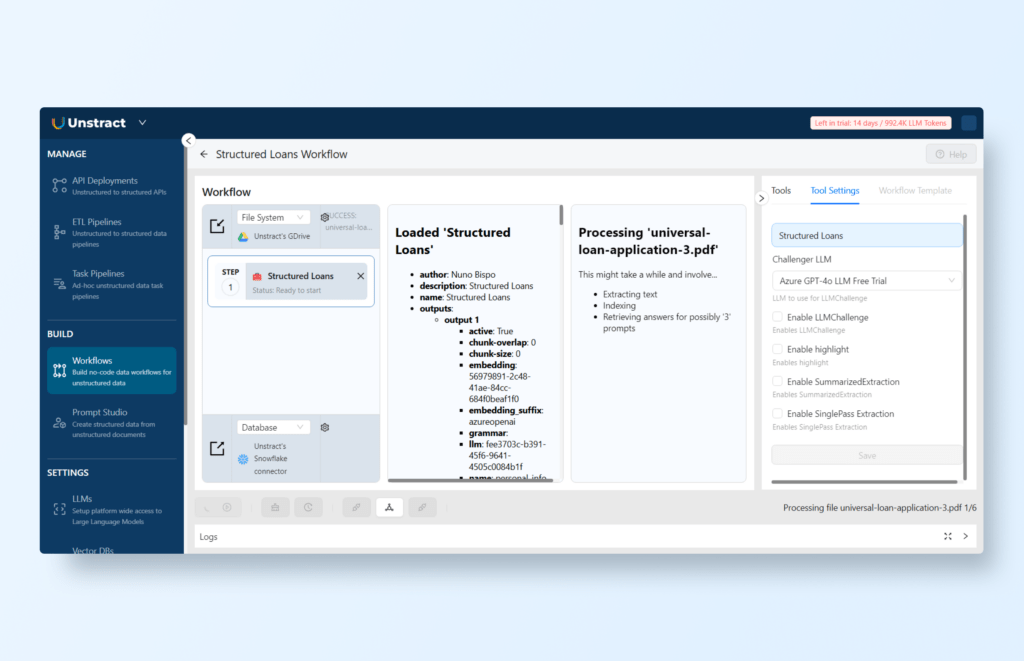
Then Navigate to BUILD → Workflows and click on ‘+ New Workflow’ to add a new workflow. You can name it for instance ‘Structured Loans Workflow’.
In the Tools section on the right-hand side, find the tool created from your project (e.g., ‘Structured Loans’) and drag and drop it into the workflow settings on the left-hand side.
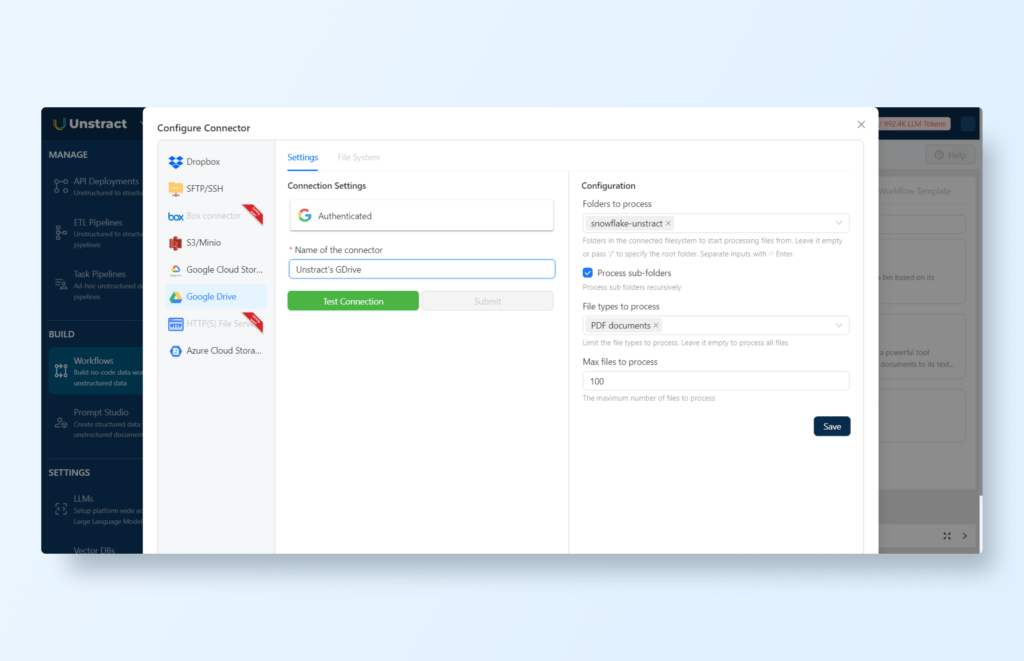
Now to link Google Drive to Unstract, select ‘File System’ on the input and click the gear icon for configuring additional settings and ‘Sign in with Google’:
Make sure to allow access to your Google Drive files. You can get the documentation here if needed.
Then select the folder and the file types to process (PDF documents in this case):
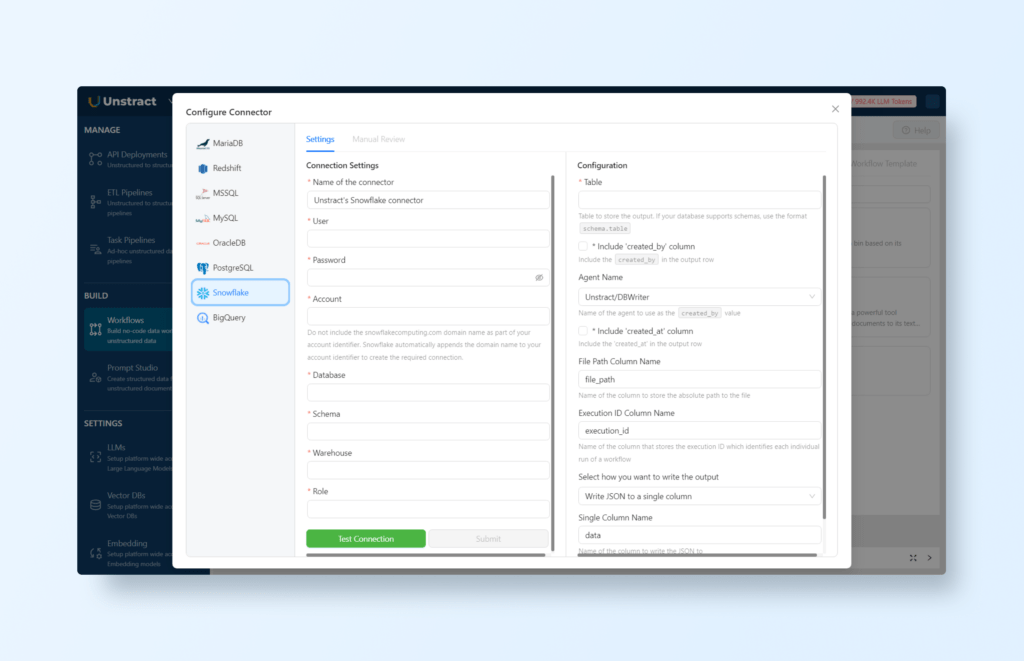
To set up Snowflake as the destination for structured data, select ‘Database’ on the output:
And click the gear icon to configure the Snowflake access:
You can find information here on how to setup your Snowflake database to be able to connect it to Unstract.
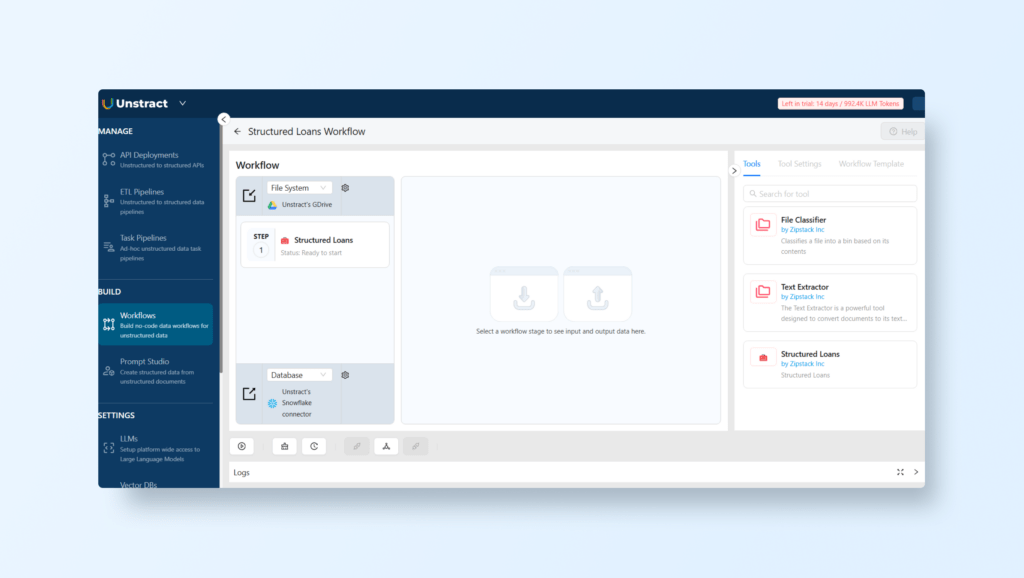
After defining all the connection parameters and connecting to Snowflake, you are now ready to process the workflow
Run/schedule unstructured ETL workflow
You can now run the workflow by clicking ‘Run Workflow’ icon:
The workflow will process all the files in the configured Google Drive folder, in this example there are 6 files to process.
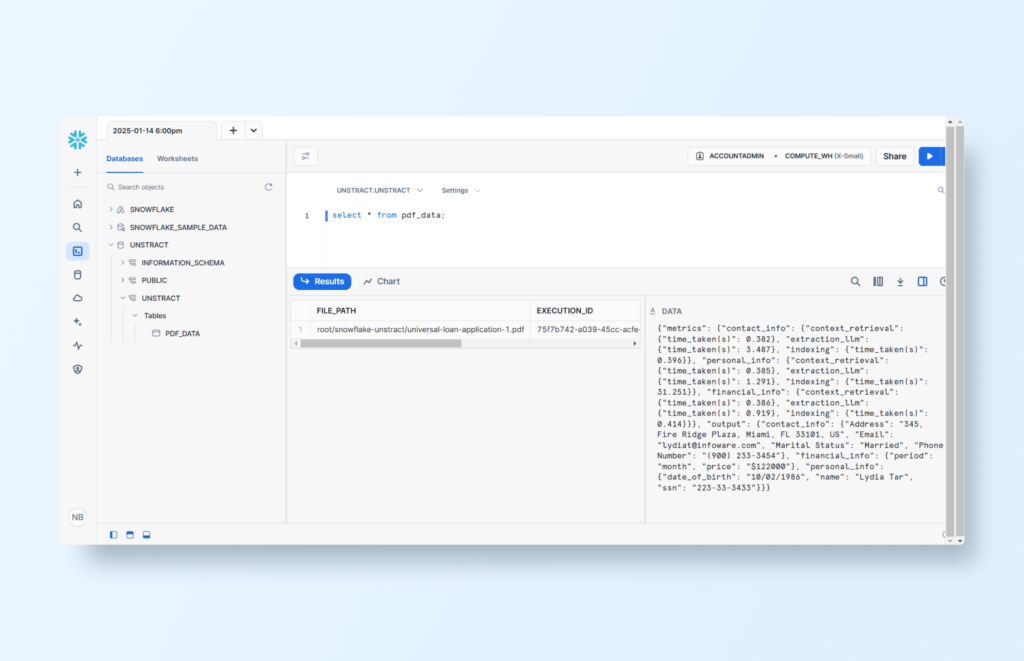
Checking after processing in the Snowflake database and executing an SQL query, we can see the data populated:
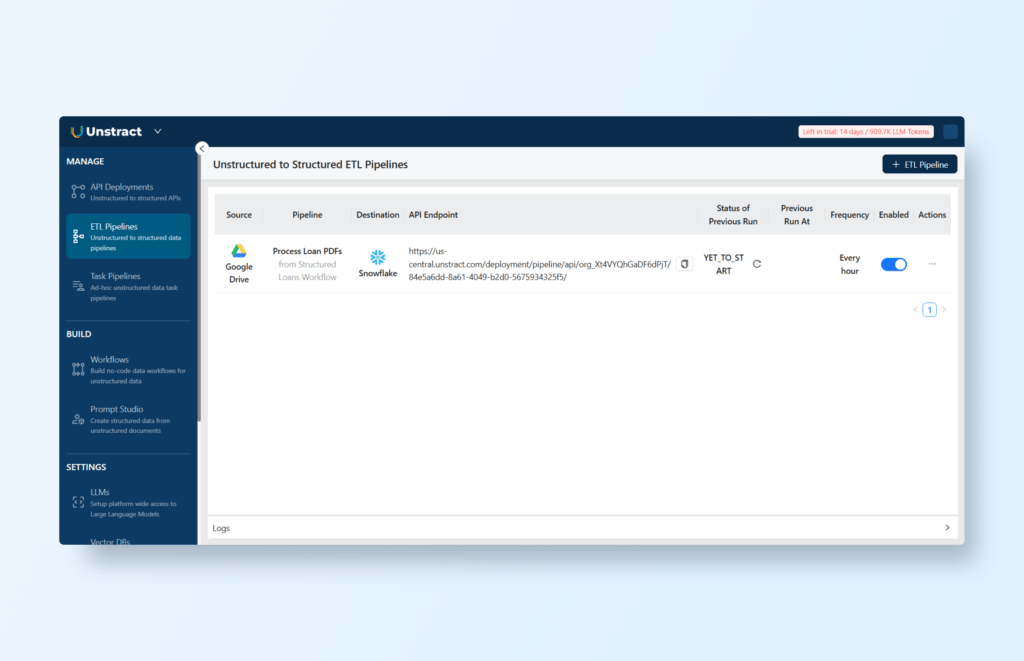
You can also schedule the workflow to run as an ETL Pipeline by clicking the ‘Deploy as ETL Pipeline’ button and defining a cron schedule:
You can check the created pipeline logs or perform actions by going to the ‘ETL Pipelines’ menu option:
Enhancements: Flattening JSON Data in Snowflake
When working with unstructured data, Unstract outputs the structured results as JSON objects.
These JSON objects are stored in Snowflake as a single column in a table, typically in a VARCHAR data type.
While this format retains all the structured data, querying and analyzing specific fields from these JSON objects can be challenging without flattening them into multiple columns.
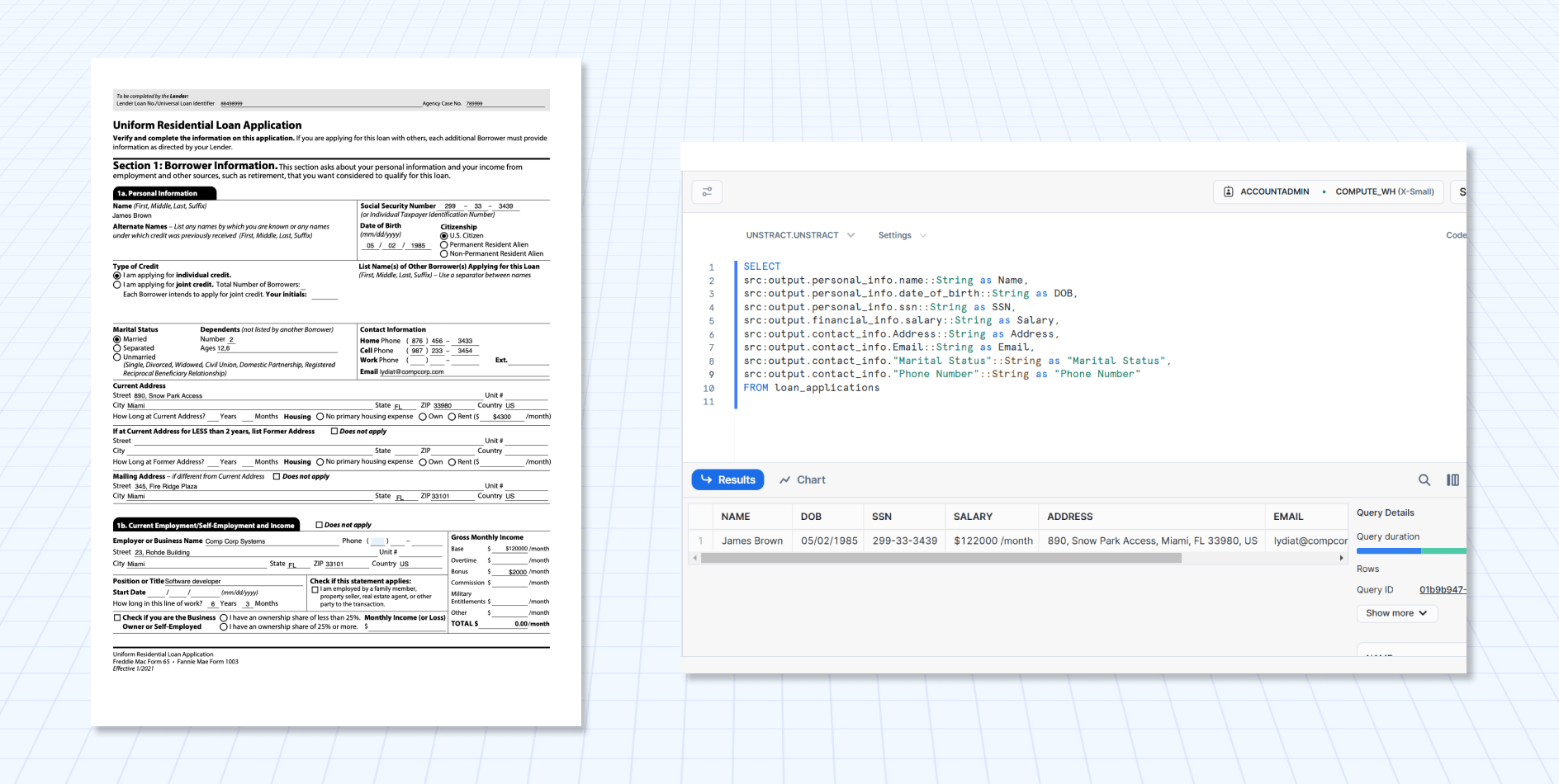
Let’s the example of the JSON output of one of the loan applications:
To make this data easier to work with, Snowflake allows you to flatten the JSON data into separate columns, enabling easy querying and analysis.
Let’s assume that the structured processed data from the workflow is stored in a table called pdf_data. We can create a new table called loan_applications where we can store the JSON as a single VARIANT column (which facilitates access to the JSON data):
CREATE OR REPLACE TABLE loan_applications
(
src variant
)
AS
SELECT PARSE_JSON(data) AS src
FROM pdf_data
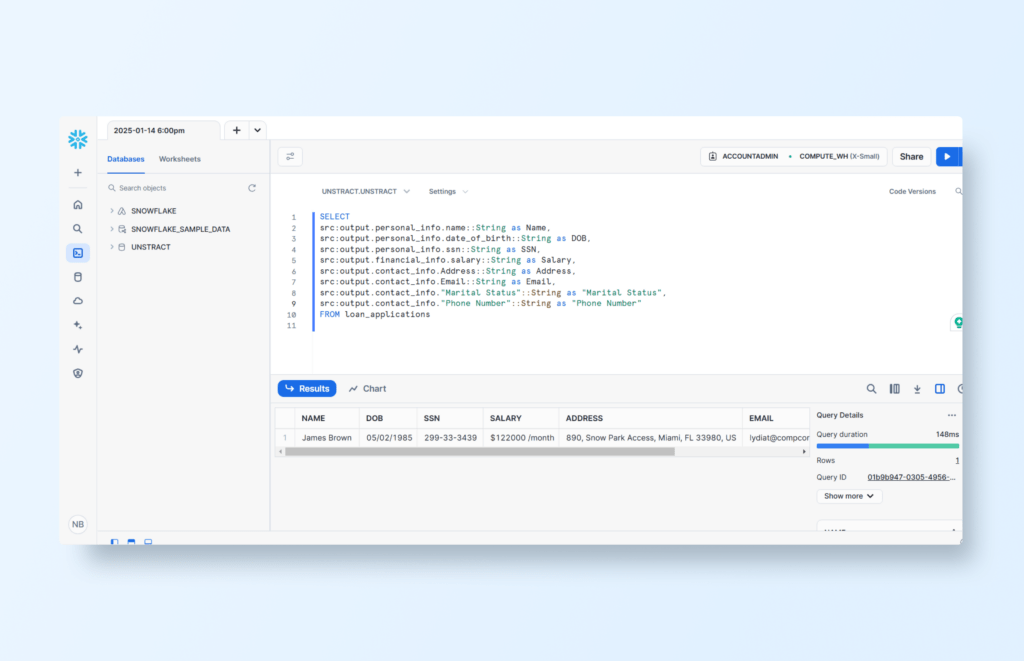
With the new table in place, we can query the individual fields using dot notation, like this:
SELECT
src:output.personal_info.name::String as Name,
src:output.personal_info.date_of_birth::String as DOB,
src:output.personal_info.ssn::String as SSN,
src:output.financial_info.salary::String as Salary,
src:output.contact_info.Address::String as Address,
src:output.contact_info.Email::String as Email,
src:output.contact_info."Marital Status"::String as "Marital Status",
src:output.contact_info."Phone Number"::String as "Phone Number"
FROM loan_applications
And we get the following result:
Conclusion
In this article, we explored how Unstract and Snowflake provide a powerful, integrated solution for managing the ETL process for unstructured data. This workflow transforms previously difficult-to-handle unstructured data, such as PDFs, into structured and analysis-ready formats stored in Snowflake.
Unstract and Snowflake offer a seamless, powerful solution for ETL workflows, especially when dealing with unstructured data. Unstract excels at extracting meaningful information from complex sources like text-heavy PDFs and images. Its prompt-driven extraction capabilities allow businesses to customize the process, ensuring that the data collected aligns with specific needs. By transforming unstructured data into a structured format, Unstract simplifies what was once a highly complex task.
If you want to quickly try it out, sign up for our free trial. More information here.
Snowflake complements this process by providing a robust and scalable platform for data storage and analysis. Its cloud-based infrastructure ensures high performance, enabling rapid querying and analytics even for large datasets. Snowflake’s native support for semi-structured data, including JSON handling makes it easier to work with data outputs from Unstract. As data volumes grow, Snowflake’s dynamic scalability ensures consistent performance, allowing businesses to adapt effortlessly to increased demands.
Together, Unstract and Snowflake deliver an integrated ETL solution that is efficient, customizable, and future-proof. The ability to automate and schedule workflows minimizes manual intervention, enhancing consistency and saving time. This seamless integration empowers organizations to unlock the value of their unstructured data, driving insights and enabling better decision-making in an increasingly data-driven world.
As businesses increasingly rely on data-driven strategies, the ability to process and analyse unstructured data is becoming essential. By leveraging Unstract and Snowflake, organizations can streamline their ETL workflows, transform unstructured data into actionable insights, and stay ahead in a data-centric world.
Unstract and Snowflake don’t just make the impossible possible—they make it efficient, scalable, and impactful.
UNSTRACT
AI Driven Document Processing
The platform purpose-built for LLM-powered unstructured data extraction. Try Playground for free. No sign-up required.
Nuno Bispo is a Senior Software Engineer with more than 15 years of experience in software development.
He has worked in various industries such as insurance, banking, and airlines, where he focused on building software using low-code platforms.
Currently, Nuno works as an Integration Architect for a major multinational corporation.
He has a degree in Computer Engineering.