Guide to Extracting Data from PDF Form with Unstract
Table of Contents
Introduction: What is PDF Form Processing?
PDF form processing refers to the automated method of extracting, capturing, and organizing data from various types of PDF forms—whether they are fillable forms with predefined fields or scanned documents containing handwritten notes.
This process leverages advanced technologies such as OCR (Optical Character Recognition), ICR (Intelligent Character Recognition), and machine learning algorithms to convert unstructured data from PDFs into structured formats like Excel spreadsheets, JSON files, or databases.
Unlike static PDF documents, fillable PDFs allow users to input data directly into fields such as names, addresses, dates, dropdown menus, radio buttons, and checkboxes. With PDF form processing, businesses can automatically identify these fields and extract data accurately, removing the need for manual data entry.
TL;DR
This article examines the challenges involved in processing PDF documents with form fields and demonstrates how using Large Language Models (LLMs) can enable new ways of handling bank documents parsing.
PDF forms are interactive documents that contain various field types designed for data entry, such as:
Text fields: Capture basic text input like names, addresses, or emails.
Checkboxes and radio buttons: Useful for capturing multi-choice inputs.
Dropdown menus: Provide a set of pre-defined choices for users.
Signature fields: Allow users to digitally sign the document.
Unlike regular PDFs, which only display fixed content, fillable PDFs have structured fields that can be identified and extracted programmatically, streamlining the data collection process.
Extracting Data from Fillable PDF Fields: A Practical Example
Consider a job application form stored as a fillable PDF, with fields like:
First Name: Samuel
Last Name: Jhonson
Email: samuel@Jhonson.com
Phone Number: 123-456-7890
Instead of manually copying this information, PDF form processing software identifies the field labels (e.g., “First Name”) and extracts the user inputs (“Samuel “) into structured formats like Excel. This way, businesses can import hundreds of forms into their databases in minutes rather than hours.
In summary, PDF form processing provides a fast and reliable way to automate data extraction from interactive documents, reducing manual errors and ensuring data consistency across systems.
Importance of PDF Form Processing
1. Why Automating PDF Form Data Extraction is Essential for Businesses
Manual data extraction from PDF forms can be extremely time-consuming and error-prone. Organizations handling high volumes of PDF forms—such as loan applications, tax filings, medical forms, or employment applications—cannot rely solely on manual labor. This not only increases operational costs but also introduces the possibility of errors, such as missed entries or transcription mistakes. Automating the extraction process ensures that data is captured accurately, efficiently, and with minimal human intervention.
For businesses, delayed or inaccurate data can lead to missed opportunities and poor decision-making. For instance:
Banks need applicant data quickly to process loans.
Hospitals must access patient information immediately to provide timely care.
Government agencies depend on precise data for compliance and auditing purposes.
Automation helps companies stay competitive by providing real-time data that drives faster decisions and more efficient operations.
2. Benefits of Converting Data from Fillable PDFs into Structured Formats (Excel, JSON)
Automated PDF form processing transforms data into structured formats that can be easily integrated with business intelligence tools, CRMs, ERPs, and databases. Here’s how structured data formats benefit businesses:
Excel Spreadsheets: Enable users to filter, sort, and analyse data for reporting purposes.
JSON Files: Allow seamless integration with APIs and other software systems, making it easier to transfer data across platforms.
This structured approach ensures that:
Loan applications are quickly uploaded to financial systems for evaluation.
Tax documents are imported into accounting software without manual effort.
Customer data is easily managed and utilized by marketing teams for better targeting.
By automating the conversion to structured formats, companies save time and reduce errors, ensuring their operations run smoothly.
3. How PDF Form Processing Streamlines Workflows and Reduces Manual Data Entry
Manual data entry slows down business processes, creates bottlenecks, and increases the chances of mistakes. With automated PDF form processing:
Data is captured directly from PDFs without requiring employees to re-enter information.
Duplicate entries and inconsistencies are minimized, ensuring data accuracy.
Time-to-decision is reduced since data is instantly available for analysis.
For example, in a typical loan processing workflow:
The applicant submits a fillable PDF form with their details.
The automated system extracts the information and sends it to the underwriting department for assessment.
Loan officers receive the structured data within minutes, expediting the approval process.
This smooth workflow improves efficiency and productivity, allowing businesses to focus on value-adding tasks instead of tedious data entry.
Business Use Cases Across Various Industries
PDF form processing offers valuable benefits to diverse industries, each of which deals with different forms. Below are the most common PDF documents processed in various sectors and how automation enhances their workflows.
1. Insurance Forms (e.g., ACCORD Forms)
Insurance providers handle numerous forms, including policy applications, claims, and accident reports. PDF form processing allows insurers to:
Quickly extract policyholder details from filled forms.
Automatically verify claims data by cross-referencing it with policy documents.
Reduce the time required to process claims and issue payouts, improving customer satisfaction.
By automating form processing, insurers can also ensure regulatory compliance by maintaining accurate and auditable records.
2. Tax Forms (e.g., IRS 5500 Form)
Tax professionals and government agencies rely heavily on accurate data from tax forms for compliance and reporting. Automation enables:
Seamless extraction of financial information from tax filings.
Faster income verification and tax audits, reducing the workload on staff.
Automatic integration with accounting software, ensuring accurate tax calculations.
This is particularly beneficial during tax season, where hundreds of forms need to be processed quickly and accurately.
Financial institutions process loan applications that contain detailed information about applicants’ financial health. Automating PDF form processing allows lenders to:
Extract applicant data directly from submitted forms.
Evaluate creditworthiness faster by feeding data into underwriting systems.
Minimize manual labour and ensure error-free approvals.
This ensures that applicants receive faster responses, enhancing the customer experience.
4. Medical Consent Forms
Hospitals and clinics process medical consent forms, patient history forms, and insurance claims daily. Automated PDF extraction helps healthcare providers:
Import patient data into hospital management systems in real-time.
Maintain accurate medical records without manual entry.
Accelerate insurance claim processing by automatically validating patient information.
In emergencies, quick access to accurate patient data can make a significant difference in providing timely care.
5. Employment Application Forms
Human Resources (HR) departments receive numerous job applications and resumes daily. Automating form processing enables HR teams to:
Extract applicant data such as names, qualifications, and experience directly from submitted forms.
Store structured data in applicant tracking systems (ATS) for faster recruitment.
Filter and shortlist candidates efficiently, allowing recruiters to focus on interviews.
This streamlined approach speeds up the hiring process and ensures consistency in applicant data management.
6. Legal Documents and Contracts
Legal firms deal with contracts, agreements, and compliance forms, all of which require precise data extraction. PDF form processing automates:
Extraction of key clauses and personal information from legal documents.
Creation of centralized databases for managing legal data.
Verification of contract terms, ensuring compliance and consistency.
This improves the speed and accuracy of legal operations, allowing firms to meet deadlines and serve clients more effectively.
PDF form processing is transforming operations across industries by eliminating manual data entry, improving accuracy, and streamlining workflows.From loan applications and tax forms to insurance claims and employment applications, automated form processing ensures businesses can handle large volumes of data quickly and efficiently.
By adopting automated solutions, organizations unlock new levels of productivity, reduce costs, and enhance decision-making, ensuring a competitive edge in today’s data-driven world.
Challenges in PDF Form Processing
PDF forms come in a variety of types and structures, creating several challenges for organizations trying to automate their data extraction workflows. The ability to handle both structured and unstructured data is crucial for achieving accurate results. Below are the key challenges that businesses encounter when dealing with PDF forms:
1. Variety of PDF Form Types and Structures (Fillable vs. Scanned Forms)
PDF forms can be categorized into fillable forms and scanned forms. Fillable PDFs contain interactive fields where users input data directly, while scanned PDFs are digitized images of paper-based documents. Handling both types in a unified workflow poses difficulties because:
Fillable PDFs have predefined fields such as text boxes, checkboxes, and radio buttons, making extraction easier.
Scanned PDFs are often unstructured and require advanced OCR (Optical Character Recognition) to convert text from images into digital data.
Developing a hybrid pipeline that works seamlessly for both formats is essential to minimize errors and ensure consistent results.
2. Handling Unstructured or Inconsistent Data Across Different Forms
A major challenge in PDF forms processing is dealing with unstructured data, where the layout or structure of forms varies. Even similar types of forms (like loan applications) may differ slightly in field placement or naming conventions. This variability makes it challenging to extract data accurately without template-based extraction techniques. Automated systems must account for:
Changes in form designs from different institutions.
Irregular field labels or missing field identifiers.
Inconsistent formats for dates, amounts, or names.
A solution involves building flexible templates and validation rules that can adjust to variations across different forms.
3. Extracting Data from Scanned PDFs with Handwritten Notes or Poor Quality
Scanned PDFs often contain handwritten notes or signatures, especially in tax forms, medical consent forms, or legal documents. Low-quality scans with blurry text, misaligned images, or faded ink further complicate data extraction. Traditional OCR may struggle with such documents, leading to:
Incorrect text extraction or skipped content.
Misinterpretation of handwriting and special characters.
Advanced OCR engines with ICR (Intelligent Character Recognition), noise filtering, and image pre-processing techniques can help overcome these issues.
4. Managing Different Field Types (Text Fields, Checkboxes, Radio Buttons, etc.)
PDF forms contain various field types like text fields, dropdowns, checkboxes, and radio buttons. Automating extraction requires specialized algorithms capable of:
Identifying checkboxes or radio buttons and determining if they were selected.
Extracting multi-choice responses from dropdowns or lists.
Handling complex field dependencies (e.g., one field’s value impacting another).
Using field recognition algorithms ensures accurate classification of field types and improves data consistency across forms.
Benefits of Automating PDF Form Processing
Organizations that process large volumes of PDF forms—such as banks, insurance companies, and healthcare providers—gain significant advantages from automation. Here are the key benefits of automated PDF form processing:
1. Improved Accuracy and Consistency in Data Extraction
Manual data entry is prone to transcription and formatting errors, which can lead to inconsistent data across systems. Automated PDF processing reduces these errors by:
Extracting data directly from forms without human involvement.
Using validation rules to ensure that the data follows predefined formats and meets quality standards.
This results in greater accuracy and ensures data consistency across all records.
2. Faster Data Processing and Analysis
Manual processing of forms takes 10-15 minutes per document, which can stretch to hours for larger files. Automated PDF form extraction speeds up the workflow by:
Processing hundreds of forms in minutes.
Making data immediately available for analysis and reporting.
This rapid extraction allows businesses to reduce turnaround times for important processes like loan approvals, claim settlements, or customer onboarding.
3. Enhanced Compliance and Audit Readiness
Many industries, such as finance, healthcare, and government, require strict compliance with data regulations and audit requirements. Automated PDF form processing provides:
Accurate records for audits and compliance checks.
Real-time tracking of data changes through automated logs.
Data validation mechanisms to ensure that required fields are filled correctly, reducing compliance risks.
This helps organizations stay audit-ready and avoid penalties for non-compliance.
4. Seamless Integration with Existing Business Systems (ERP, CRM, etc.)
Automated PDF form processing enables businesses to integrate extracted data into their existing systems, such as:
ERPs (Enterprise Resource Planning) for financial data and resource management.
CRMs (Customer Relationship Management) for customer onboarding and marketing.
The ability to export data as JSON ensures that it can be used across different platforms, improving overall operational efficiency.
5. Scalability to Handle High Volumes of Documents
Manual form processing becomes inefficient as document volumes grow. Automated systems can scale effortlessly to handle large datasets, ensuring that businesses:
Keep up with high demand during peak times (e.g., tax season or loan campaigns).
Maintain consistent processing speeds even with thousands of forms.
This scalability ensures that businesses remain agile and responsive to customer needs.
AI-Driven PDF Form Processing
The emergence of AI and Large Language Models (LLMs) has fundamentally transformed how organizations manage unstructured data and complex PDF forms. These technologies provide unmatched efficiency, accuracy, and scalability, helping businesses automate labor-intensive document processes that were once prone to errors and delays. From loan applications to insurance claims and tax filings, the AI-powered revolution in PDF form processing is reshaping the way organizations extract, validate, and use data.
1. Introduction to AI and LLMs in Document Processing
Traditional data extraction methods depended heavily on template-based models, which worked well for structured, repetitive forms. However, as organizations began dealing with varied, unstructured, or semi-structured PDF documents, these legacy systems struggled. The introduction of AI-powered solutions and LLMs has brought new capabilities, such as:
Context-aware data extraction: AI systems can identify key information beyond fixed templates, even if the format or layout varies across documents. This eliminates the need to create custom templates for every type of form.
Understanding relationships between fields: AI-based tools comprehend how different sections of a form are interlinked, allowing for more accurate and meaningful data extraction.
Handling complex and unstructured PDFs: AI models can process everything from digital fillable PDFs to scanned handwritten forms, extracting relevant information efficiently regardless of the document structure.
For example, OpenAI’s GPT models can interpret PDF documents by understanding the text and structure, recognizing form fields (like names, dates, or checkboxes), and extracting critical insights without requiring manual inputs. This flexibility offers significant advantages over static, template-based systems.
2. How AI Enhances the Accuracy and Efficiency of Extracting Data from PDF Forms
AI-based PDF processing tools excel in both precision and speed, allowing businesses to streamline their workflows while reducing the chances of human error. Below are key areas where AI provides measurable improvements over traditional methods:
2.1 Field Recognition and Classification
AI-powered systems use advanced field recognition algorithms to accurately identify different field types, including:
Text fields for names or addresses.
Checkboxes and radio buttons for preferences or selections.
Dropdowns for categorical data such as regions or job roles.
The ability to contextually interpret fields ensures that information is accurately classified, even when field labels are ambiguous or inconsistently placed across multiple documents.
2.2 Adaptive Learning Capabilities
AI models, particularly LLMs, improve their performance over time by learning from previous extractions. This means that each time the system processes a document, it becomes better at:
Identifying new patterns or variations in forms.
Recognizing frequent errors and making adjustments to improve future extractions.
Predicting likely field placements based on historical data.
These adaptive learning capabilities ensure that the AI-based systems stay up-to-date, even as form layouts or document formats evolve.
2.3 Real-Time Error Detection and Correction
Unlike traditional systems, which require post-processing validation, AI-powered solutions automatically detect and correct errors in real-time. This is especially useful when:
Mandatory fields are left blank.
Numerical fields (like Social Security Numbers) contain invalid entries.
Fields are populated with mismatched data types (e.g., text instead of numbers).
With built-in error detection mechanisms, AI systems notify users immediately, allowing them to correct issues on the spot and ensure data accuracy from the outset.
3. Role of LLMs in Understanding Document Context, Structure, and Relationships
A significant challenge in form processing is interpreting the relationships between different fields and sections. LLMs, such as GPT-4 or OpenAI models, excel at understanding document semantics, enabling them to extract context-rich data that goes beyond individual text fields.
3.1 Loan Applications and Financial Documents
In loan applications, LLMs can:
Link income fields with expense fields to assess the applicant’s financial health.
Extract employer details, loan amounts, and interest rates from multi-page documents and summarize key data for faster decision-making.
This helps financial institutions quickly determine whether an applicant qualifies for a loan without the need for manual review.
3.2 Insurance Claims
In the insurance industry, claims processing involves extracting data from multi-page forms that often include:
Policyholder information.
Incident reports and claim amounts.
Supporting documentation, such as photographs or police reports.
LLMs not only extract key data points but also connect related information (e.g., matching policy numbers with claim details) to ensure the entire claim is processed accurately and in compliance with industry regulations.
3.3 Tax Filings and Compliance Forms
For government agencies and auditors, LLMs simplify the handling of complex tax forms like the IRS 5500. These forms contain multiple sections with intricate relationships between fields. LLMs can:
Identify and extract relevant information, such as income, deductions, and liabilities.
Ensure compliance by cross-referencing fields against regulatory requirements.
Generate summaries and reports for easier review during audits.
By preserving the structure and layout of the original forms, AI models ensure that extracted data maintains its context and relevance, enabling organizations to make informed decisions quickly.
Real-World Use Cases and Current Scenarios
Several industries have already adopted AI-powered PDF form processing to address their unique challenges. Let’s explore a few real-world scenarios where these technologies are making a difference:
1. Banking and Financial Services
Banks and financial institutions use AI-powered tools to:
Automate loan origination processes, speeding up approvals.
Extract data from account opening forms and KYC documents with minimal manual intervention.
Monitor fraud patterns by analyzing transaction histories and connecting data points across multiple forms.
2. Healthcare and Medical Administration
Hospitals and clinics use automated PDF form processing to:
Extract patient data from medical consent forms and insurance claims.
Accelerate billing workflows by identifying relevant treatment codes and charges.
Ensure compliance with healthcare regulations by validating data across multiple documents.
3. Government and Public Sector Agencies
Government agencies streamline their processes using AI-powered form extraction for:
Automating tax filing processes and ensuring compliance with tax laws.
Processing license renewals and permit applications faster.
Extracting and validating data for public assistance programs.
4. Human Resources and Recruitment
AI-powered systems in HR departments help:
Extract applicant data from employment application forms.
Automate employee onboarding processes by populating relevant systems with data from signed forms.
Manage benefit enrolment and payroll processing efficiently.
The Future of AI-Powered PDF Form Processing
The integration of LLMs into PDF form processing represents a paradigm shift for organizations dealing with high volumes of documents. With the ability to understand context, handle complex relationships, and adapt to new formats, AI-powered solutions are helping businesses achieve:
Greater operational efficiency.
Reduced processing times.
Higher data accuracy and consistency.
In the coming years, advancements in LLMs and AI algorithms will further enhance form processing, enabling systems to:
Predict missing data or autofill fields based on historical trends.
Provide real-time analytics and insights from extracted data.
Integrate seamlessly with blockchain and IoT systems for end-to-end automation.
The AI-driven revolution in PDF form processing is not just a technological shift—it’s a business imperative. Organizations that adopt AI-powered solutions will not only enhance operational efficiency but also gain a competitive advantage by streamlining workflows and unlocking new levels of productivity.
By embracing AI and LLM-powered form processing, organizations position themselves to meet the challenges of the future, thrive in a data-driven world, and unlock the full potential of their operations.
Introduction to Unstract in PDF Form Processing
In today’s fast-paced business environment, processing complex PDF forms efficiently is crucial. Unstract emerges as a groundbreaking, no-code, open-source platform, providing businesses with a powerful solution to automate PDF form processing and data extraction.
Leveraging Artificial Intelligence (AI) and Large Language Models (LLMs), Unstract simplifies the transformation of unstructured data into structured formats like JSON or Excel, reducing the manual workload and increasing accuracy. This section introduces the platform, explores its capabilities, and highlights why Unstract outshines traditional document processing tools.
Unstract is an open-source no-code LLM platform to launch APIs and ETL pipelines to structure unstructured documents. Get started with this quick guide.
Overview of Unstract and Its Capabilities
Unstract is designed to handle a variety of document types—from fillable PDF forms to scanned handwritten documents—extracting relevant data and converting it into structured formats ready for further use.
Businesses can integrateUnstract seamlessly through its API, upload documents directly, and receive clean JSON outputs with minimal human intervention. Whether it’s invoices, loan applications, tax filings, or medical forms, Unstract ensures high-quality extraction that meets enterprise needs.
Unstract:Intelligent Document Processing 2.0 (IDP 2.0) Platform Powered by Large Language Models
Key capabilities of Unstract include:
No-code environment: The platform eliminates the need for programming skills, enabling business users and technical teams to set up workflows easily.
Multi-format document handling: Supports scanned PDFs, fillable forms, images, and complex multi-column documents, making it ideal for industries like finance, healthcare, and government.
AI-powered extraction: The platform combines LLMs and OCR to extract data from even the most challenging documents, ensuring consistency and precision.
Real-time API output: Unstract converts PDFs into structured formats like JSON, facilitating smooth integration with ERP, CRM, and data management systems.
Unstract: AI powered PDF form data extraction
Unstract is a no-code LLM Platform to launch APIs and ETL Pipelines to structure unstructured documents.
How Unstract Leverages LLMs for Data Extraction
At the core of Unstract’s innovation lies its ability to harness the power LLMs. Unlike traditional form processing tools that depend on static templates, Unstract uses dynamic models capable of adapting to complex layouts. This makes it exceptionally effective at processing documents with tables, radio buttons, and checkboxes or documents containing unstructured text.
Contextual understanding:
Unstract’s LLMs analyze the semantic context of documents, extracting key elements such as dates, names, totals, and line items. This ensures that even irregularly formatted PDFs are processed with high accuracy.
Example: In an insurance claim form, the platform identifies and extracts policyholder details, claim amounts, and incident descriptions, mapping them into a structured JSON format for easy analysis.
Handling complex layouts with ease:
Unstract go beyond simple text extraction to recognize tables, checkboxes, and nested fields.
Example: In a loan application form, the platform extracts income details and matches them with expense fields to provide a comprehensive creditworthiness report.
The system also detects and extracts checkbox values and radio button selections, making it ideal for forms that rely heavily on user inputs.
Why Unstract Outperforms Traditional PDF Form Processing Tools
Unstract’s AI-powered approach offers several advantages over traditional tools, which often rely on template-based methods that can be inflexible and prone to errors when documents deviate from predefined layouts. Let’s explore how Unstract revolutionizes document processing:
Template-Free Extraction:
Traditional tools require predefined templates for each document type. If a document layout changes, the templates must be manually updated.
Unstract eliminates this need by using LLMs that dynamically interpret document structures, reducing the time and cost associated with template maintenance.
High Accuracy and Consistency:
With a combination of LLMs and OCR, Unstract ensures precision in data extraction from even the most complex multi-page PDFs.
Example: In a tax filing form, it accurately extracts financial data, even when figures are embedded within nested tables.
Faster Processing and Scalability:
Unstract can process large volumes of documents simultaneously, making it an ideal solution for businesses dealing with high data throughput.
Example: Financial institutions can automate the extraction of thousands of loan applications, reducing approval times and enhancing customer satisfaction.
Example: A logistics company can use Unstract to extract data from shipping documents, feeding the data directly into its inventory management system.
Cost and Time Efficiency:
Unstract’s no-code platform minimizes the need for technical resources, lowering operational costs. The AI automation also reduces the risk of human errors, further improving efficiency.
Use Case: Unlocking the Potential of LLMWhisperer with Unstract
Unstract integrates with LLMWhisperer, a tool designed to prepare complex documents for processing by LLMs. LLMWhisperer enhances document understanding and layout preservation, ensuring the extracted data retains its original context and structure. This makes it ideal for industries like finance, insurance, and healthcare.
LLMWhisperer document pre-processor: Get complex documents ready for LLM consumption
How LLMWhisperer Enhances PDF to JSON Conversion:
Layout Preservation: LLMWhisperer’s layout-preserving mode ensures that multi-column PDFs and tables are converted into structured JSON without losing their format.
Detection of Handwritten Notes and Annotations: The system seamlessly extracts handwritten elements and integrates them with other data fields.
Checkbox and Radio Button Recognition: Forms with checkboxes and radio buttons are processed accurately, capturing user selections for further analysis.
LLMWhisperer: Best Invoice OCR to Extract Data from PDF Forms
LLMWhisperer is available as an API that can be integrated into your existing systems to preprocess your documents before they are fed into LLMs. It can handle a variety of document types, including PDFs, images, and scanned documents.
The Future of PDF Form Processing with Unstract
Unstract’s AI-driven platform is shaping the future of automated document processing. As businesses increasingly adopt digital transformation strategies, Unstract’s scalability and flexibility ensure that they are well-equipped to handle the evolving landscape of data extraction and workflow automation.
With continuous advancements in AI, LLMs, and OCR technologies, Unstract is poised to lead the next generation of PDF form processing by:
Reducing manual intervention and improving workflow automation.
Enabling real-time analytics and decision-making through structured data outputs.
Enhancing regulatory compliance by ensuring accurate, traceable data extraction.
Unstract is transforming PDF forms processing by offering businesses an AI-powered platform that combines LLMs, OCR capabilities, and seamless integrations to deliver exceptional results. Its no-code environment, high scalability, and template-free approach make it an invaluable tool for organizations looking to streamline workflows, improve data accuracy, and reduce operational costs.
By adopting Unstract, businesses unlock new levels of productivity and efficiency, ensuring they stay ahead in a competitive, data-driven landscape. Whether it’s insurance forms, tax filings, or loan applications, Unstract provides the tools needed to handle complex PDFs with precision and speed, positioning it as the future of automated document processing.
Explore the power of Unstract today and revolutionize your PDF to JSON extraction workflows with the combined strength of AI, LLMs, and real-time API integrations.
Set up Unstract to Extract Data from PDF Forms
In this section, we walk through the setup process for Unstract and explain how LLMWhisperer plays a critical role in pre-processing data for Large Language Models (LLMs). This guide covers every step, from configuring tools to creating prompts for extracting data from digital and scanned PDFs, demonstrating the platform’s end-to-end automation capabilities.
Going Deep into LLMWhisperer and Its Role in Pre-processing Data
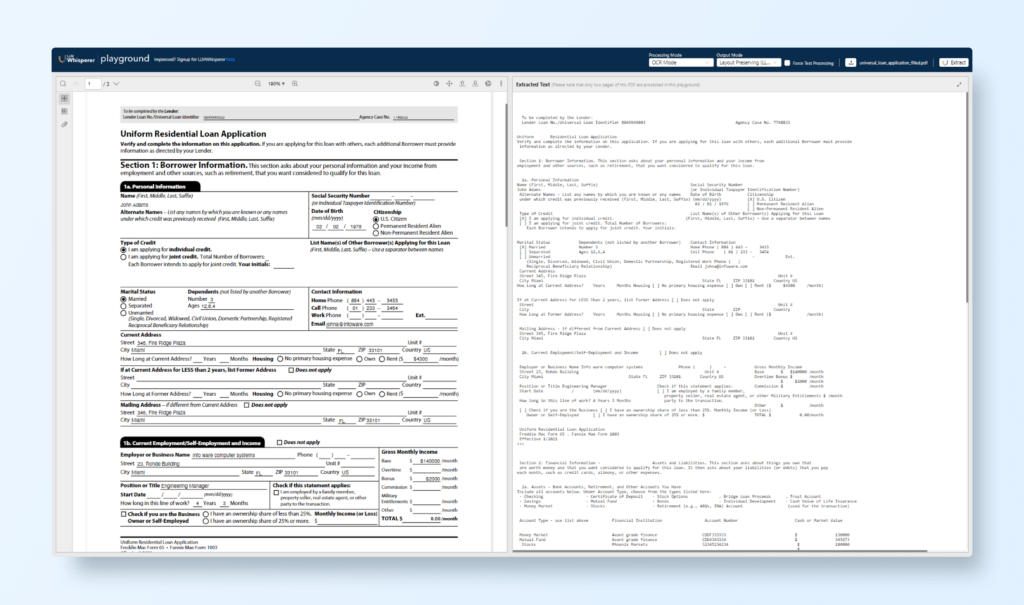
LLMWhisperer is a powerful tool that optimizes documents for LLM consumption, ensuring accurate extraction even from complex, scanned, or unstructured PDFs. Below, we delve into the key features of LLMWhisperer and how it enhances the data extraction pipeline.
What is LLMWhisperer?
LLMWhisperer acts as a pre-processing engine that transforms unstructured PDFs into LLM-friendly formats by:
Preserving Layouts: Ensuring tables, multi-column layouts, and forms retain their structure.
Automatic Mode Switching: Switching between OCR and text extraction modes based on document type (scanned vs. digital).
Checkbox and Radio Button Recognition: Detecting selections and turning them into textual data for easier analysis.
Live coding session on PDF table and form field extraction with LLMWhisperer
You can also watch this live coding webinar where we explore all the challenges involved in PDF parsing. We’ll also compare the capabilities of different PDF parsing tools to help you understand their strengths and limitations.
How LLMWhisperer Enhances LLM-Based Data Processing:
Document Layout Preservation:
LLMWhisperer maintains the original table and form structures, preserving context for LLMs to interpret data correctly.
Example: In a loan application form, LLMWhisperer can differentiate between sections for borrower details, income, and checkbox selections for loan type.
OCR Integration for Scanned PDFs:
For scanned PDFs, LLMWhisperer applies OCR technology to extract handwritten notes and low-quality text accurately.
It ensures misaligned or poorly scanned forms are still processed effectively, minimizing data loss.
Handling Checkbox and Radio Button Data:
LLMWhisperer recognizes checkboxes and radio buttons, recording their status as text (e.g., “Checked: Yes” or “Unchecked: No”).
Example: In an employment application, LLMWhisperer captures whether the applicant has opted for health benefits using checkbox prompts.
Optimizing Data for LLMs:
By reducing token usage and filtering irrelevant content, LLMWhisperer ensures that only relevant information is passed to LLMs for processing, improving efficiency and reducing costs.
Uploading and Exploring Example Documents
We demonstrate how LLMWhisperer processes two types of PDF forms—one digital and structured, and the other scanned with handwritten notes.
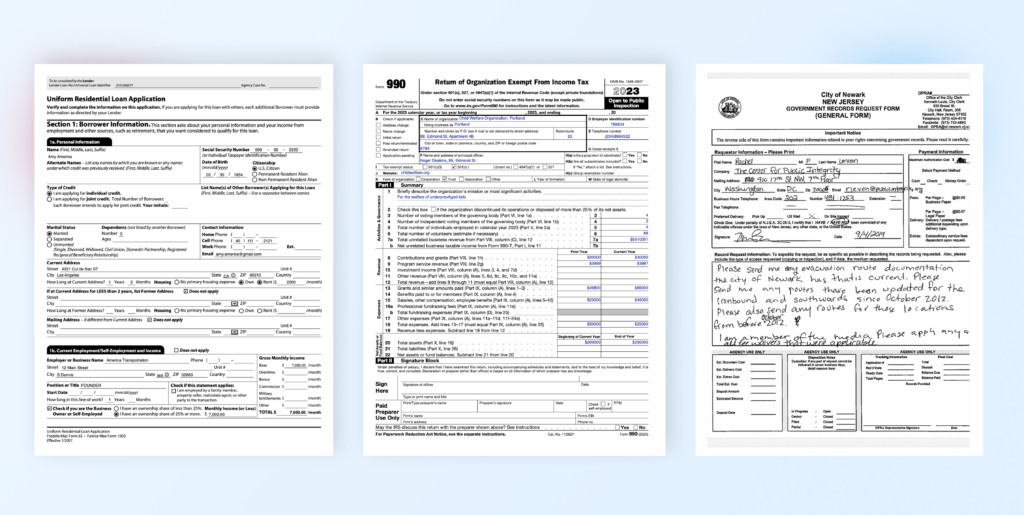
Example 1: Structured Digital PDF Form (Loan Application)
Document: A Uniform Residential Loan Application with sections for personal information, loan details, and multiple checkboxes.
Fields: Marital status, loan type, and credit options are captured through checkboxes and text fields.
LLMWhisperer Output: The form layout remains intact, and data like income details, loan preferences, and checkbox selections are accurately extracted into preserved layout format.
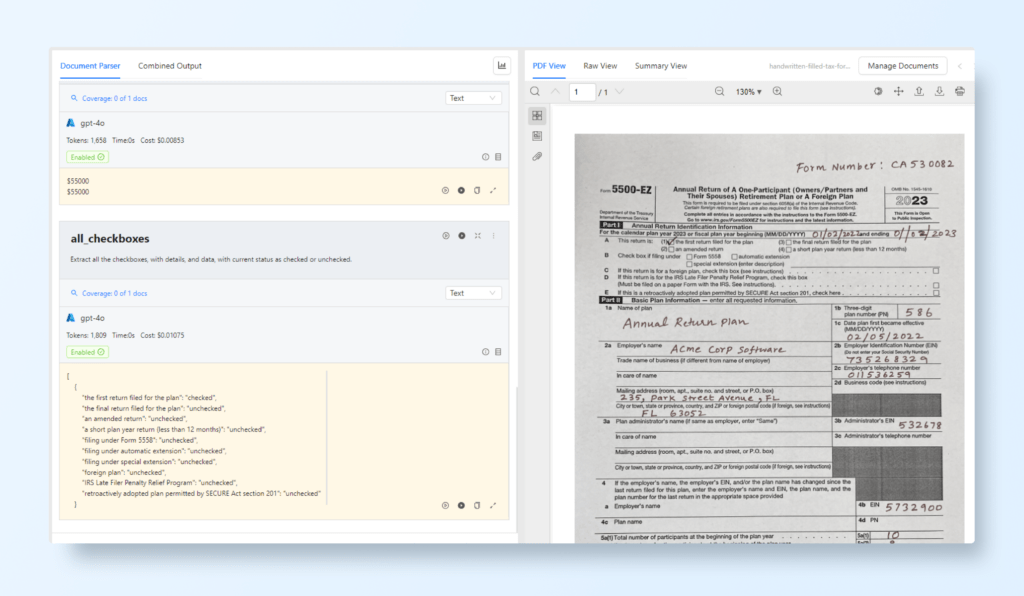
Example 2: Scanned PDF with Handwritten Notes (IRS 5500 Form)
Document: A scanned IRS Form 5500-EZ, including multiple sections with checkboxes and handwritten notes.
Fields: This form includes plan details, employer information, and participant counts.
LLMWhisperer Output: OCR extracts handwritten notes along with the checkbox states, ensuring the structured data is preserved in same layout for further use.
With LLMWhisperer, both forms are processed with the original structure preserved, and the extracted data—whether typed or handwritten—is correctly captured.
Detailed Setup Instructions for Unstract
Configuring OpenAI, Embeddings, and Vector DB
To leverage the power of LLMs and embeddings for efficient PDF form extraction, we begin by configuring these essential tools.
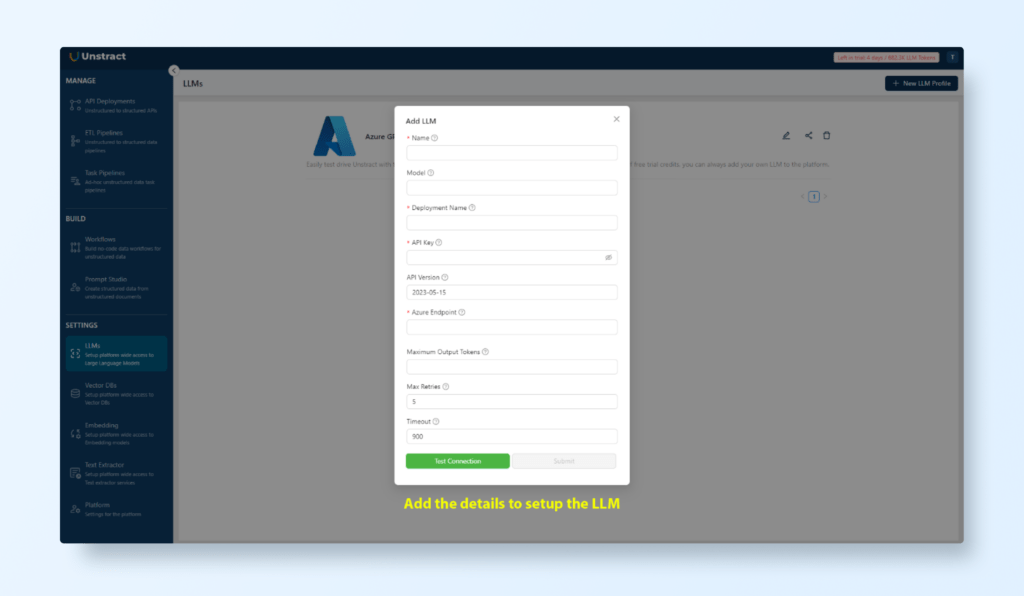
Configure OpenAI LLMs:
Log into the Unstract platform and navigate to Settings > LLM Profiles.
Add your OpenAI API key to enable the platform to process and interpret form content.
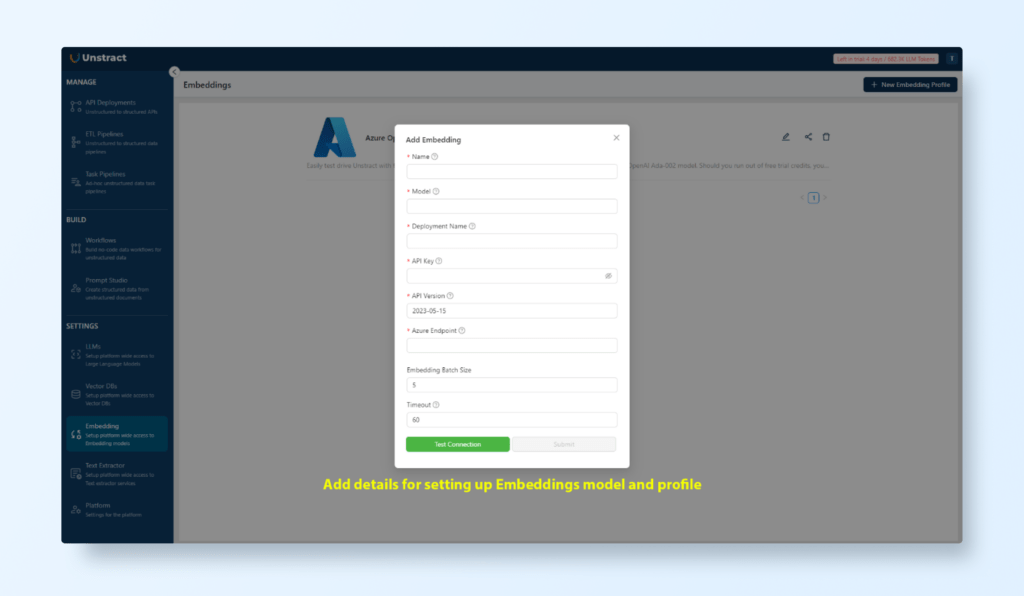
Configure Embeddings for Data Retrieval:
Navigate to Settings > Embedding Profiles.
Select OpenAI embeddings, which map text into numerical vectors, making it easier to retrieve and analyse extracted data.
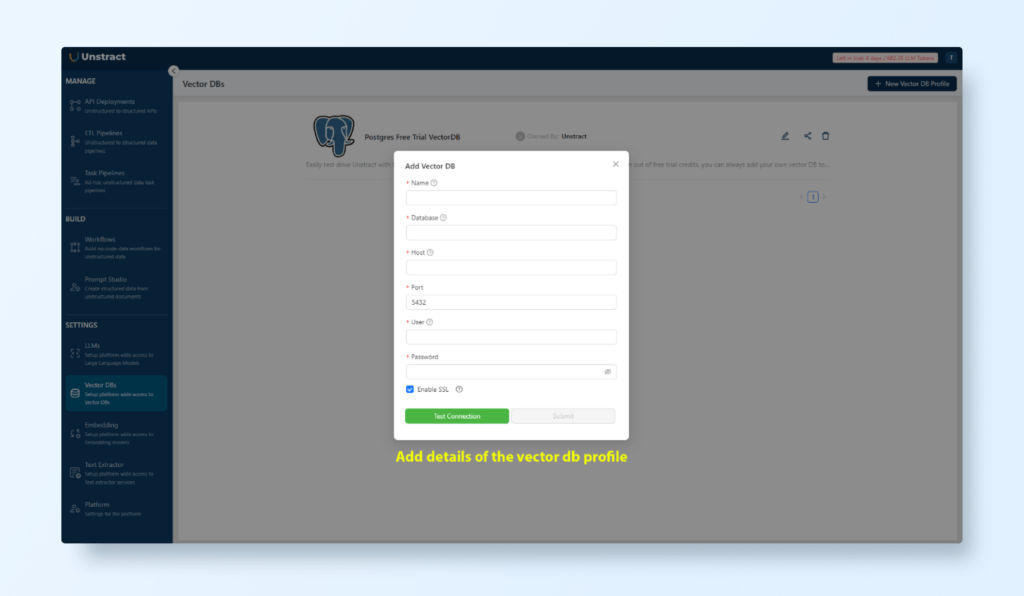
Set Up a Vector Database (Vector DB):
Go to Settings > Vector DB Profiles and configure a PostgreSQL Vector DB.
This database will store and retrieve embeddings, ensuring seamless data access and organization for future queries.
Set Up LLMWhisperer Text Extractor
Navigate to Settings > Text Extractor in Unstract.
Click on New Text Extractor.
Select LLMWhisperer and enter the API key.
Set the processing mode to OCR (for scanned bank statements) and the output mode to line-printer.
Setting Up a Prompt Studio Project for Data Extraction
The Prompt Studio in Unstract provides a no-code environment to define extraction logic and configure prompts for capturing key information from both digital PDFs and scanned forms. Below is a step-by-step guide to setting up your project.
Step-by-Step Guide to Create and Configure Prompts:
Access Prompt Studio:
Click on Prompt Studio from the left pane to open the user interface.
Create a New Project:
Click on the New Project button at the top right corner of the Prompt Studio UI.
Fill in the required details:
Tool Name: Provide a name for your tool (e.g., “Loan Application Parser”).
Author/Org Name: Enter your name or the organization’s name.
Description: Add a brief description of the tool’s functionality.
Tool Icon (Optional): You can upload an icon for your tool if desired.
Click Save to create the project.
Upload PDF Forms:
Click Manage Documents within the project interface.
Upload the sample PDF forms you wish to process by clicking on the Upload Files button.
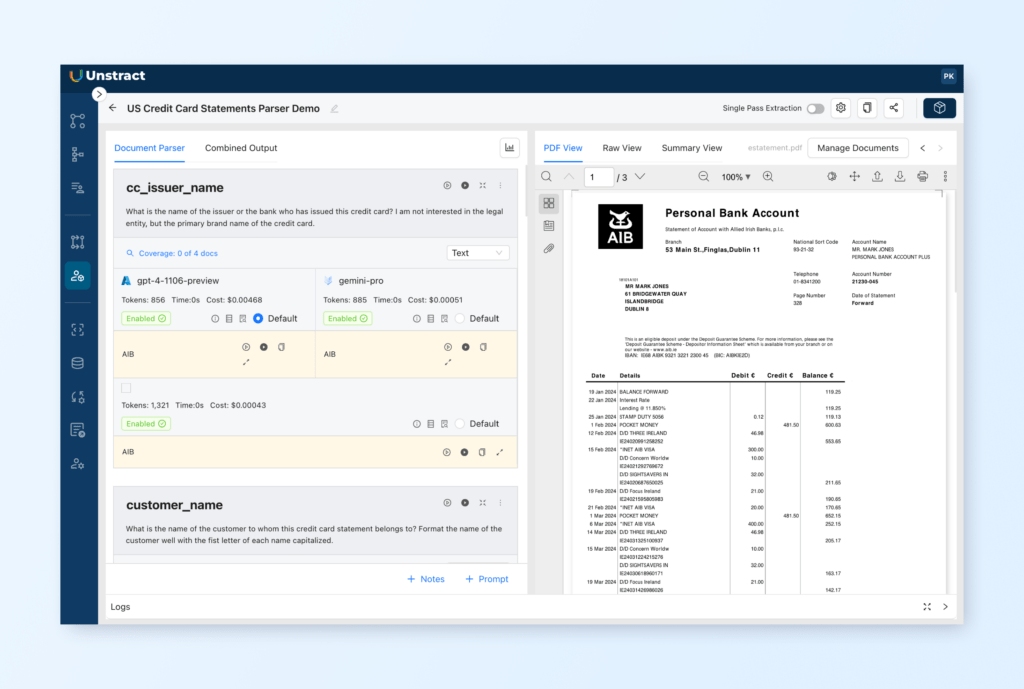
Extracting data is as easy as writing prompts
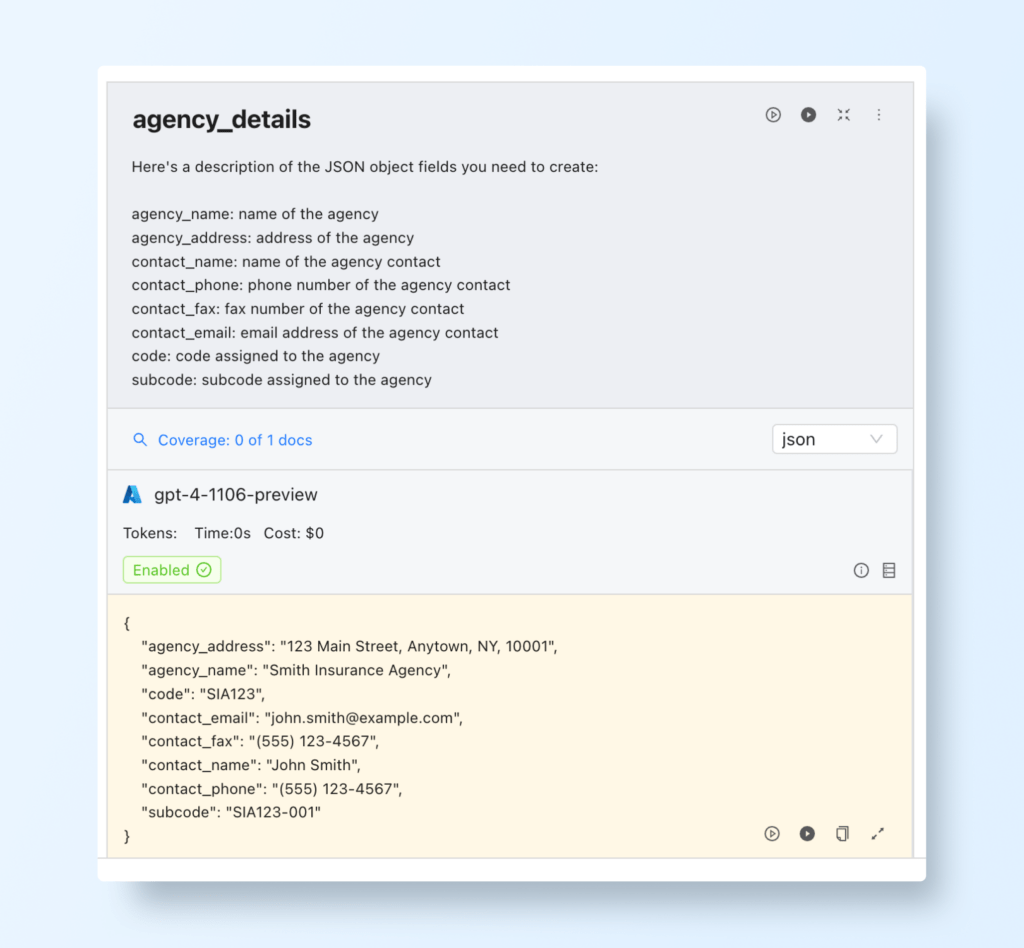
Write Custom Prompts for Key Data Extraction:
Click Add Prompts to define the fields you want to extract and add the field names accordingly.
Example Prompts and Field Names:
Prompt: “Identify and extract checkboxes related to loan type, marital status, and citizenship, including their checked/unchecked states.”
Field Name: specific_check_boxes
Prompt: “Extract all the checkboxes, with details, and data, with current status as checked or unchecked.”
Field Name: all_checkboxes
Prompt: “Retrieve the state of the ‘Primary Residence’ checkbox from the ‘Occupancy’ section of the form, along with any alternative options selected.”
Field Name: primary_residence
Test the Prompts:
Ensure that:
All fields, including text inputs, radio buttons, and checkboxes, are extracted correctly.
The results match the correct checkbox and radio button states for each field.
Scanned PDFs are processed using OCR, with handwritten notes captured accurately.
Run the Prompts:
Click the Run button to execute the prompts.
The extracted information will appear in the Output section.
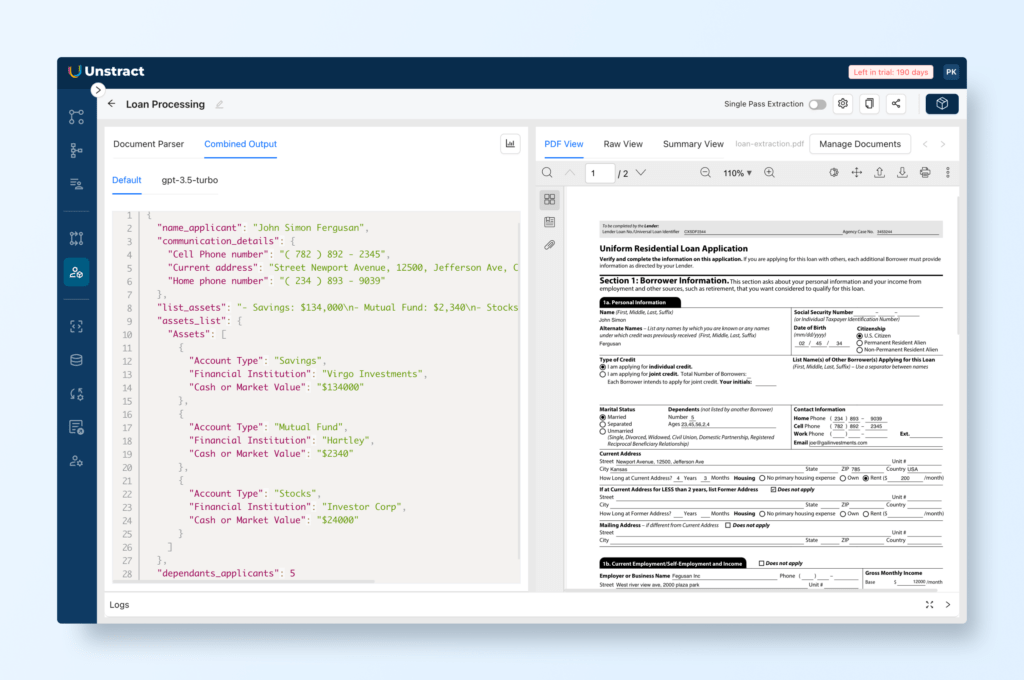
View Combined JSON Output:
To see the responses in JSON format, switch to the Combined Output tab.
This view will display the structured JSON output for all processed PDF forms.
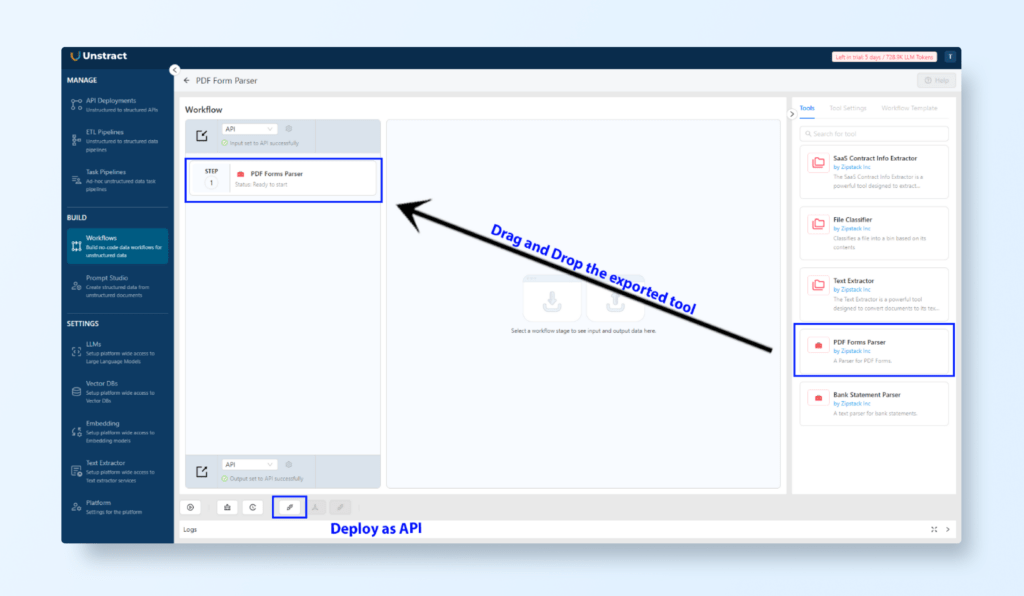
Export the Project as a Tool:
Click Export as Tool to save the project.
This exported tool can later be deployed as an API and used across multiple applications.
Deploying the PDF Extraction Workflow as an API
The final step involves deploying the extraction workflow as an API, allowing seamless integration with business systems.
Steps to Configure and Deploy the API Workflow:
Create a New Workflow:
Navigate to Workflows and click New Workflow.
Drag and drop your Prompt Studio project into the workflow builder.
Configure API Input and Output:
Set the API Input Connector to accept PDF documents.
Configure the API Output Connector to return data in JSON format.
Save the Workflow:
Provide the Display Name, Description, and API Name for the workflow.
Click Save to finalize the configuration.
Deploy the API:
Click Deploy API to activate the workflow.
A success message confirms the API is live and ready to process documents.
Accessing the API via Postman
After deploying the API, test its performance using Postman to ensure the workflow operates as expected.
Step 1: Send a POST Request in Postman
Open Postman and create a new POST request.
Paste the API URL provided by Unstract into the request field.
Add the Bearer Token in the Authorization tab to authenticate the request.
Step 2: Upload PDF Documents for Extraction
In the Body tab, select form-data and upload a PDF form (digital or scanned).
Example: Upload a general loan application PDF to validate checkbox extraction.
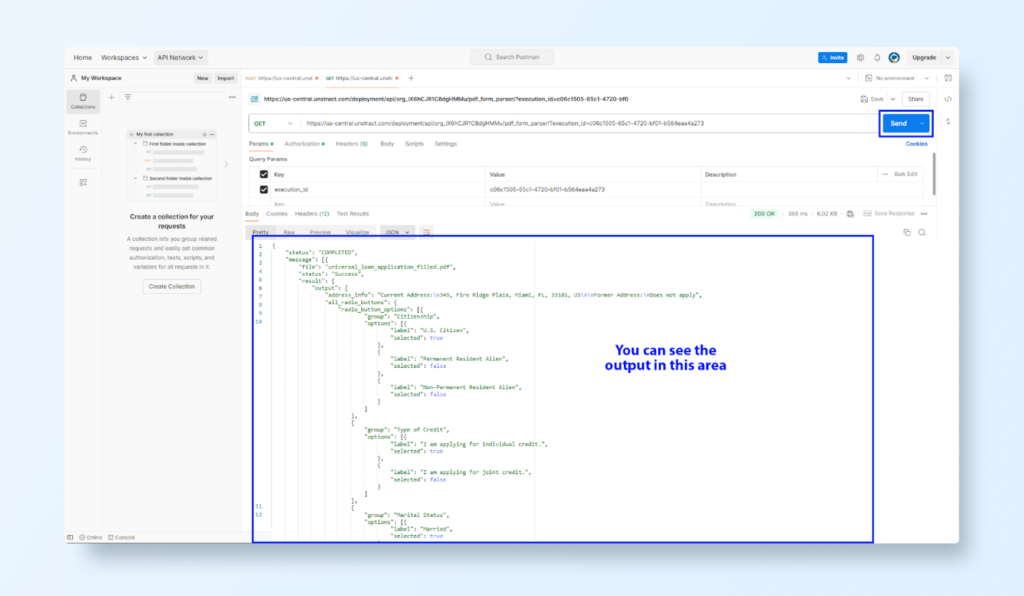
Step 3: Check the API Response
Click Send to initiate the extraction.
The API returns JSON output containing the extracted fields:
For digital PDFs: All text fields, checkboxes, and radio button values are captured accurately.
For scanned PDFs: OCR processes handwritten notes and converts them into structured data.
By following these steps, organizations can use Unstract to extract structured data from both digital and scanned PDF forms. LLMWhisperer ensures that layouts are preserved and handwritten content is accurately processed.
Deploying the workflow as an API allows businesses to integrate data extraction seamlessly into their operations, improving efficiency, scalability, and accuracy. With the power of AI and LLMs, Unstract delivers an innovative, reliable solution for managing even the most complex PDF forms.
Conclusion
The Power of Automated PDF Form Processing with Unstract
In today’s fast-paced business environment, PDF forms processing plays a pivotal role in managing data efficiently. By leveraging automated form processing software, organizations can transition from manual workflows to seamless, automated operations. Unstract simplifies the complexities of PDF forms data extraction by using advanced AI models and the LLMWhisperer tool. Whether dealing with fillable form data extraction from PDF or scanned documents, Unstract ensures that businesses can accurately extract data from PDF forms with minimal effort.
Unstract’s intelligent use of OCR form processing enables organizations to handle both digital and scanned PDFs with precision, minimizing human errors and improving productivity. The ability to extract fillable fields from PDFs and convert the output to structured formats like Excel or JSON streamlines data integration with other systems such as ERPs and CRMs.
Unlocking the Future of AI-Driven Document Automation
As businesses handle increasing volumes of documents, automated PDF form processing is becoming essential for sustainability and growth. Traditional methods struggle to keep up with the dynamic needs of modern organizations. The use of AI-powered solutions like Unstract offers a competitive edge by automating complex tasks, improving accuracy, and reducing manual data entry efforts. With Unstract, businesses can now extract data from fillable PDFs, manage OCR form processing, and deploy workflows through APIs, ensuring a seamless transition to automation.
In the coming years, AI and automated form processing software will play a pivotal role in transforming industries—from finance to healthcare—by streamlining operations, reducing turnaround times, and improving compliance. As regulations become more stringent and customers expect faster responses, adopting automated PDF form processing solutions becomes a critical business decision.
What is next? Explore Unstract’s capabilities
We are building Unstract. Unstract is a no-code platform to eliminate manual processes involving unstructured data using the power of LLMs. The entire process discussed above can be set up without writing a single line of code. And that’s only the beginning. The extraction you set up can be deployed in one click as an API or ETL pipeline.
With API deployments, you can expose an API to which you send a PDF or an image and get back structured data in JSON format. Or with an ETL deployment, you can just put files into a Google Drive, Amazon S3 bucket or choose from a variety of sources and the platform will run extractions and store the extracted data into a database or a warehouse like Snowflake automatically. Unstract is an open-source software and is available at https://github.com/Zipstack/unstract.
Sign up for our free trial if you want to try it out quickly. More information here.
How do I extract data from a PDF form with Unstract?
Unstract lets you extract data from a PDF form in just a few clicks: upload the document, write natural language prompts in Prompt Studio, and run the workflow. The platform’s LLM-powered engine identifies every text box, checkbox, and table, then returns clean JSON without any manual templates.
Will Unstract really extract fillable fields from PDF files whose layout keeps changing?
Yes. Because Unstract relies on LLM’s Intelligence rather than rigid templates, it can extract fillable fields from PDF documents even when the form version, position of labels, or order of pages varies. The model understands context, so “Applicant Name” is captured whether it sits at the top, bottom, or inside a table.
Can I extract data from a fillable PDF and export it directly to my database, CRM, or BI tool?
Absolutely. When you extract data from fillable PDF documents with Unstract, the workflow can immediately push the JSON output to Postgres, Snowflake, HubSpot, Salesforce, or any REST endpoint, letting you automate downstream reporting or analytics.
Why is Unstract’s form field extraction from PDFs more accurate than rule-based solutions?
Traditional tools rely on static coordinates; Unstract combines OCR, embeddings, and a large-language model that learns patterns across thousands of layouts. This AI-first approach delivers form field extraction from PDFs with far higher tolerance for new templates, rotated pages, and mixed content.
Does Unstract expose a simple API for PDF form data extraction at scale?
Yes. Once you publish a workflow, Unstract generates an HTTPS endpoint for PDF form data extraction. Send a POST request with one or many PDFs and receive structured JSON in seconds, allowing you to process thousands of applications, claims, or contracts concurrently.
Fillable PDF Forms Data Extraction in 2026: Related topics to explore
Engineer by trade, creator at heart, I blend Python, ML, and LLMs to push the boundaries of AI—combining deep learning and prompt engineering with a passion for storytelling. As an author of books and articles on tech, I love making complex ideas accessible and unlocking new possibilities at the intersection of code and creativity.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.