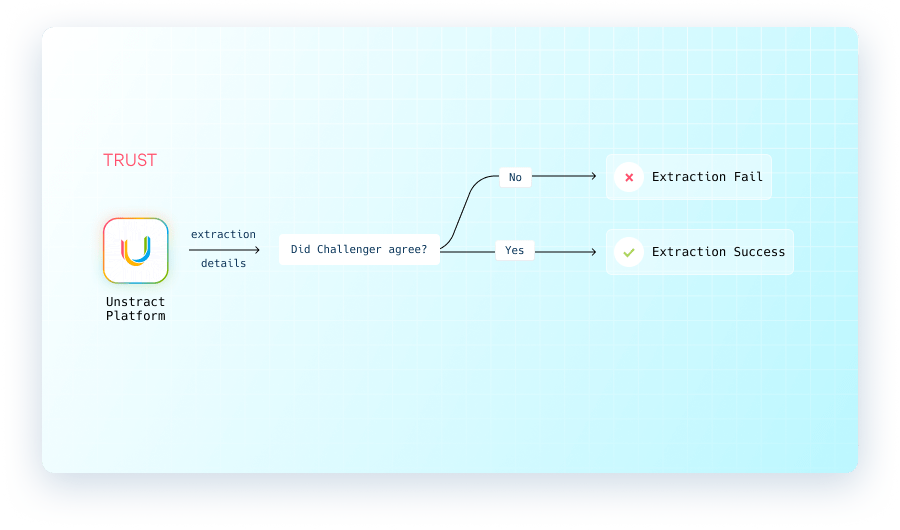
Two LLMs run your prompts in parallel: an extractor and a challenger. Get an output only if both agree—NULL if not. Configure any combination: OpenAI + Claude, Azure GPT + Vertex + more!
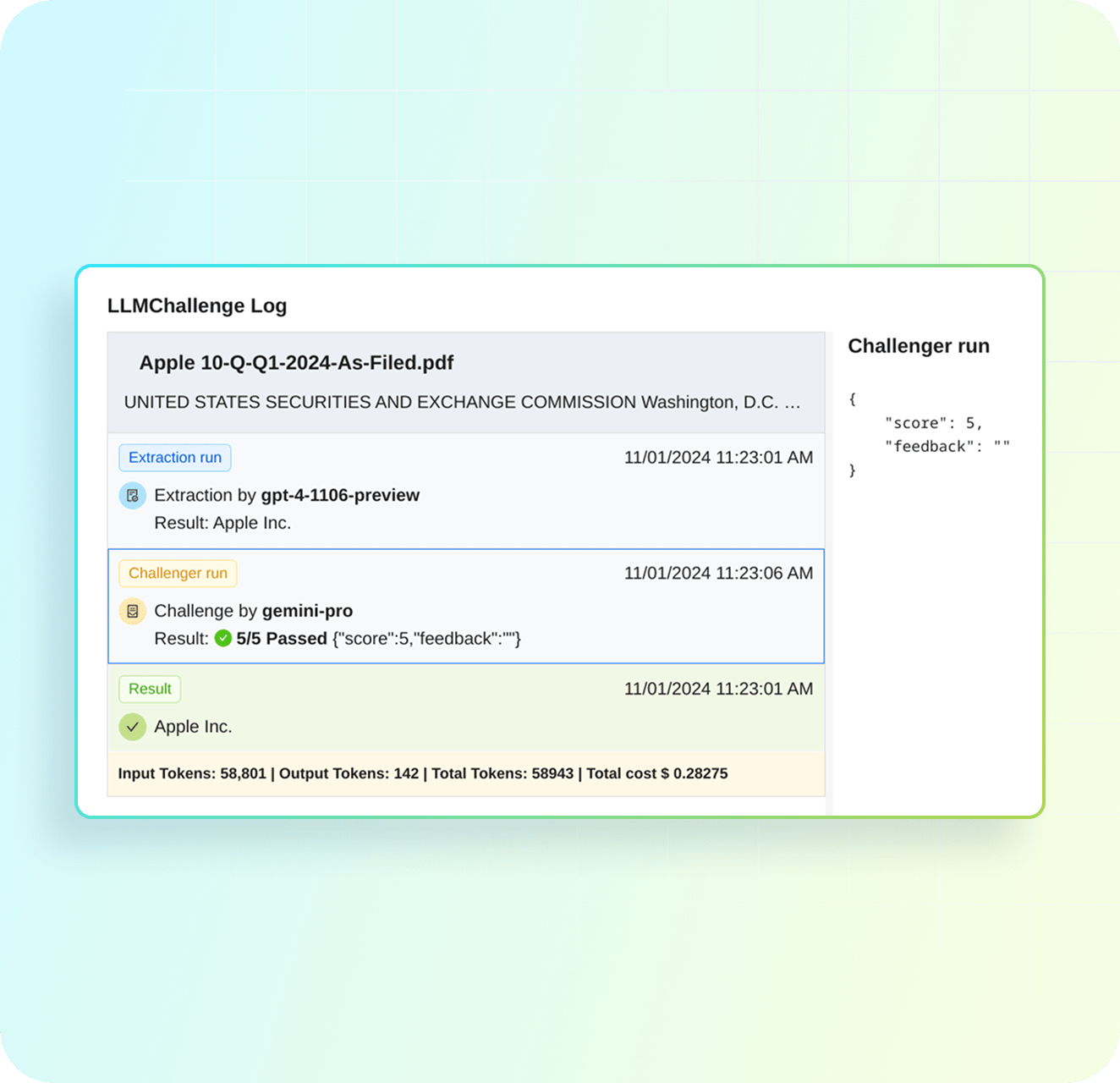
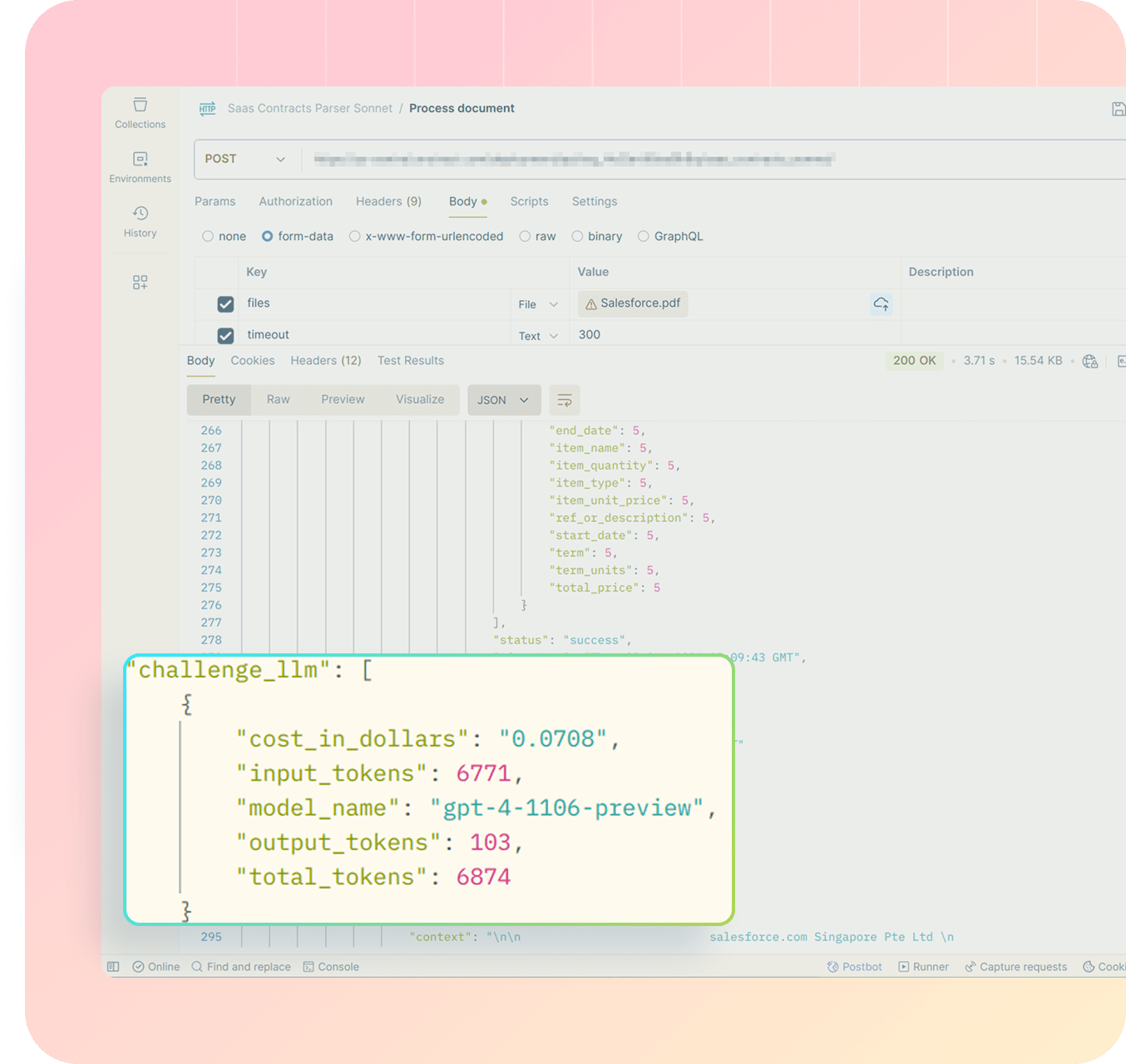
Track, debug & optimize with extraction metadata
Get drilled-down insights by running the metadata for every extraction. Track token costs, view challenger confidence scores, or debug outputs after deployment.
Verify outputs with two LLMs
Two LLMs run your prompts in parallel: an extractor and a challenger. Get an output only if both agree—NULL if not. Configure any combination: OpenAI + Claude, Azure GPT + Vertex + more!
Get drilled-down insights by running the metadata for every extraction. Track token costs, view challenger confidence scores, or debug outputs after deployment.
Unstract lets us turn a wide range of document formats into clean, structured data with low integration effort and without compromising on enterprise-grade controls. Its high extraction accuracy paired with clear highlight-based validation speeds up our process a lot!
Results you can count on
Production-Grade Data Integrity
Improved Automation Scaling
Reduced Manual Oversight
FAQs
Which LLM combinations work best?
We recommend pairing LLMs from different providers. Popular combinations: OpenAI GPT-4 + Google Gemini Pro, Anthropic Claude + Cohere, OpenAI + Anthropic.
What happens when LLMs disagree?
The field returns NULL.
How long does consensus take?
Typically adds 2-5 seconds to extraction time. For financial and legal documents, accuracy trumps speed.
Can I use the same LLM model for both extraction and challenging?
Technically yes, but you shouldn’t! Using the same model (or even models from the same provider) defeats the purpose because they tend to make similar mistakes. Provider diversity is key to catching different error patterns.
What’s the difference between a NULL and an empty field?
Important distinction: NULL means “we couldn’t reach consensus.” Empty means “we agreed this field has no value.”
Can I see the challenge metadata for debugging?
Yes. The full conversation log is available via API for every extraction. You can see why the LLMs disagreed and the confidence score given by the challenger LLM.